
您是否遇到过这样的问题?大语言模型回答答非所问,或者直接在胡说八道。这种情况一般是因为大语言模型产生了幻觉。在开发和实际应用中,幻觉问题是一个常见且严重的问题,因为幻觉的存在,会导致回答的可信度大大降低。
幻觉出现的原因通常是模型对于某些特定领域或最新信息缺乏了解的情况下,而RAG(Retrieval-Augmented Generation)技术通过结合检索和生成的方法来增强模型处理知识密集型任务的能力,能够有效减少模型幻觉的发生。
RAG和GraphRAG的原理介绍

首先,我们要先来了解一下RAG和GraphRAG:
什么是RAG?
RAG的全称叫作Retrieval-Augmented Generation,直译为“检索增强生成”。是一种连接外部数据源以增强大语言模型(LLM)输出质量的技术。这种技术帮助 LLM 访问私有数据或特定领域的数据,并解决幻觉问题。
一个基本的 RAG 通常集成了一个向量数据库和一个 LLM,其中向量数据库存储并检索与用户查询相关的上下文信息,LLM 根据检索到的上下文生成答案。
简单理解就是:模型生成回答时,不是自己直接生成,而是先去查一下知识库,再进行生成。
一个传统基本的RAG通常会按照以下步骤回答问题:
检索:根据用户的查询内容,从外挂知识库获取相关信息。
增强:将用户的查询内容和检索到的相关知识一起嵌入到一个预设的提示词模板中。
生成:将经过检索增强的提示词内容输入到大语言模型(LLM)中,以此生成所需的输出。
缺点:由于RAG中,AI只拿到了部分数据,无法看到全局,因此传统RAG劣势也是很明显的,就是断章取义。
什么是GraphRAG?
GraphRAG是微软提出的一种新式RAG技术,通过结合知识图谱(KGs)来增强 RAG,旨在提高大型语言模型(LLMs)在处理复杂知识密集型任务时的性能。它通过构建知识图谱,利用图结构数据来增强信息检索和生成过程,从而提供更准确、更丰富的回答。
简单理解就是:在数据输入阶段,用AI对数据进行了图谱化处理,让AI去理解数据,建立数据语义的关联,使检索精度大大提高。
GraphRAG的本质,是在原有的数据基础上,用AI创造新的数据。
GraphRAG的流程一般分成两个阶段:索引、查询。
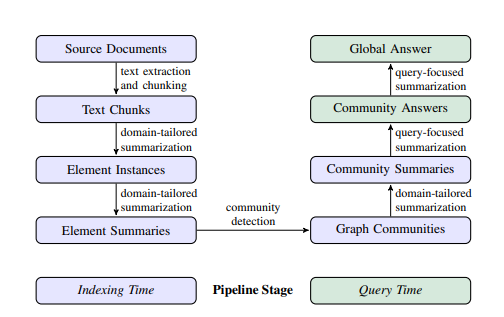
其中第一阶段索引又可以分为四个关键步骤:
文本单元分割(Text Unit Segmentation):整个输入语料库被划分为多个文本单元(文本块)。这些文本块是最小的可分析单元,可以是段落、句子或其他逻辑单元。通过将长文档分割成较小的文本块,我们可以提取并保留有关输入数据的更详细信息。
提取 Entity、关系(Relationship)和 Claim:GraphRAG 使用 LLM 识别并提取每个文本单元中的所有Entity(人名、地点、组织等)、Entity 之间的关系以及文本中表达的关键 Claim。我们将使用这些提取的信息构建初始知识图谱。
层次聚类:GraphRAG 使用 Leiden 技术对初始知识图谱执行分层聚类。Leiden 是一种 community 检测算法,能够有效地发现图中的 community 结构。每个聚类中的 Entity 被分配到不同的 community,以便进行更深入的分析。
生成Community 摘要:GraphRAG 使用自下而上的方法为每个 community 及其中的重要部分生成摘要。这些摘要包括 Community 内的主要 Entity、Entity的关系和关键 Claim。这一步为整个数据集提供了概览,并为后续查询提供了有用的上下文信息。
在查询阶段,GraphRAG 有两种不同的查询工作流程,针对不同类型的查询进行了优化:
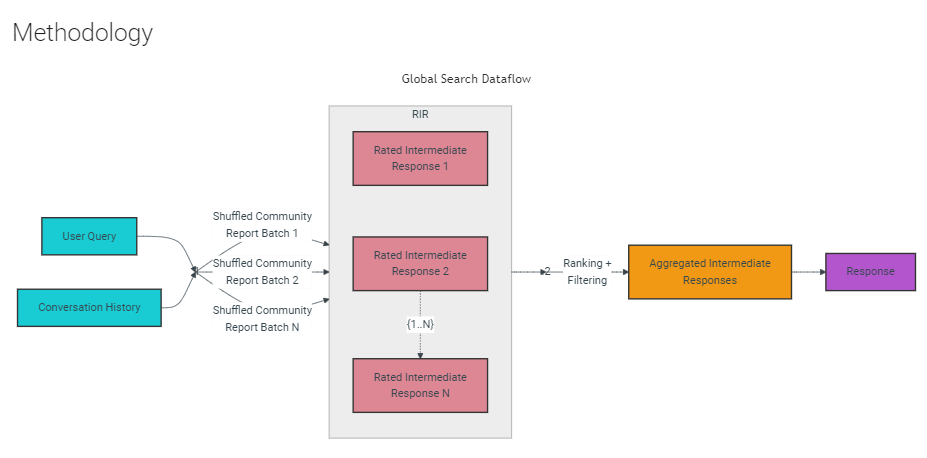
全局搜索:通过利用 Community 摘要,对涉及整个数据语料库的整体性问题进行推理。
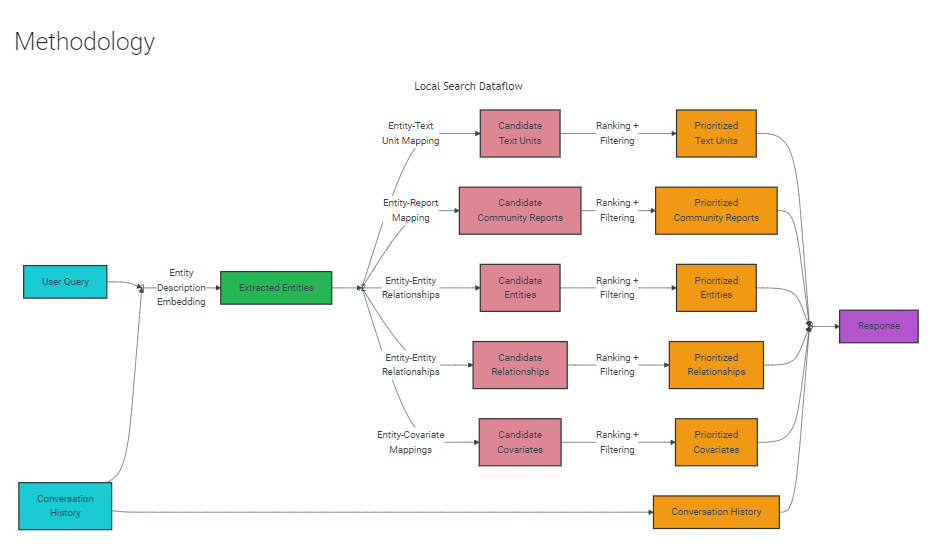
本地搜索:通过扩展到特定 Entity 的邻居和相关概念,对特定 Entity 进行推理。
缺点:GraphRAG的缺点第一是比较贵,因为在数据录入的过程中,需要AI进行处理,一定会产生AI的费用。第二就是比传统RAG要慢,因为检索图谱的过程会复杂很多。
总的来说,选择RAG还是GraphRAG取决于具体的应用场景和需求,GraphRAG提供了更强的知识处理能力,但RAG可能在速度和成本上更具优势。
那么!Yuki今天将为不同需求的读者朋友们展示如何一键部署302上的知识库机器人。
302.AI一键部署知识库机器人
搭建GraphRAG应用通常涉及从基础开始构建知识图谱、集成图神经网络和生成模型,以及进行必要的微调,以适应特定的应用场景,这个过程需要深入的技术知识和大量的开发时间。
而我们302.AI目前已独家提供GraphRAG的知识库接入和API接入,代码基于Nano-GraphRAG开发,更加轻量化,用户只需进行简单的配置即可快速部署,能够大大降低了技术门槛和部署时间。
另外,302.AI的知识库机器人提供了两种模式:传统RAG和GraphRAG,用户可以根据需求去选择:
为了直观对比RAG和GraphRAG的区别,Yuki做了一个小实验:在302.AI的知识库机器人中导入相同的文章数据集,选择同样的模型,并对相同的问题进行提问。
实验中导入知识库中的文章来自国家统计局的《2023年城镇单位就业人员年平均工资情况》:https://www.stats.gov.cn/sj/zxfb/202405/t20240520_1950434.html
数据需要按照传统RAG和GraphRAG两种模式分别导入,两种模式的操作方式基本相同,接下来Yuki以传统RAG为例讲述一下具体操作步骤:
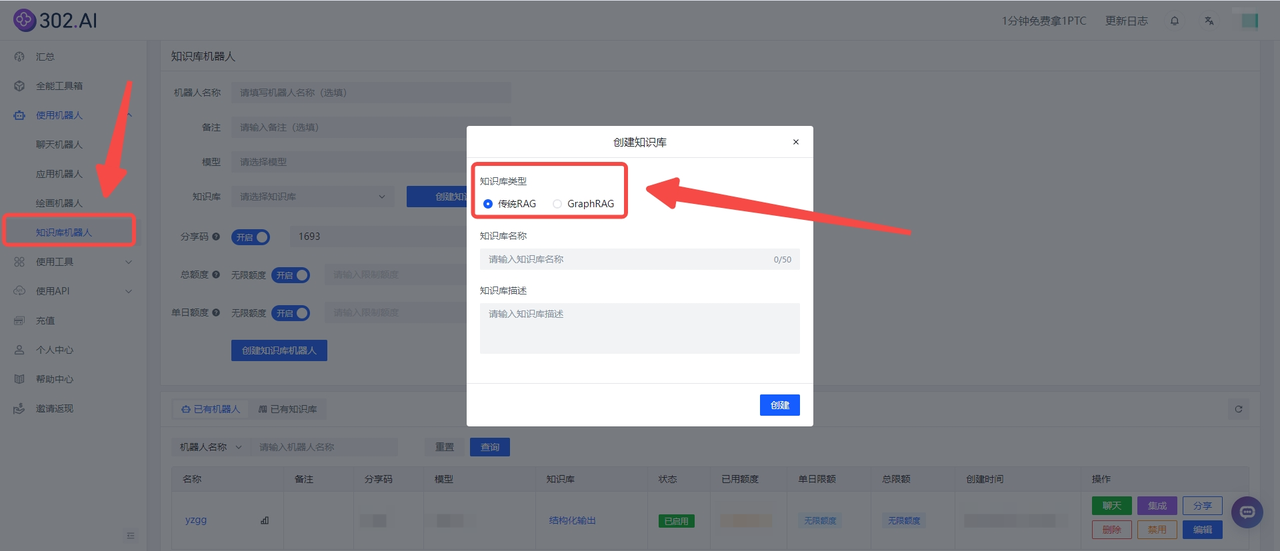
首先点击创建知识库——选择知识库类型:
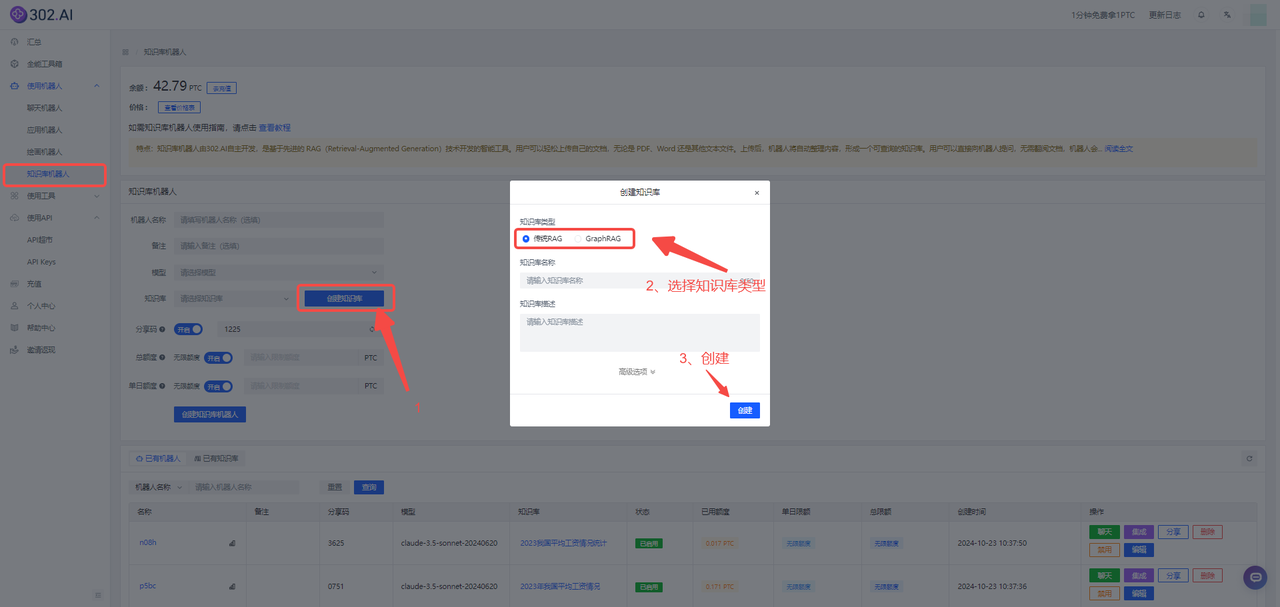
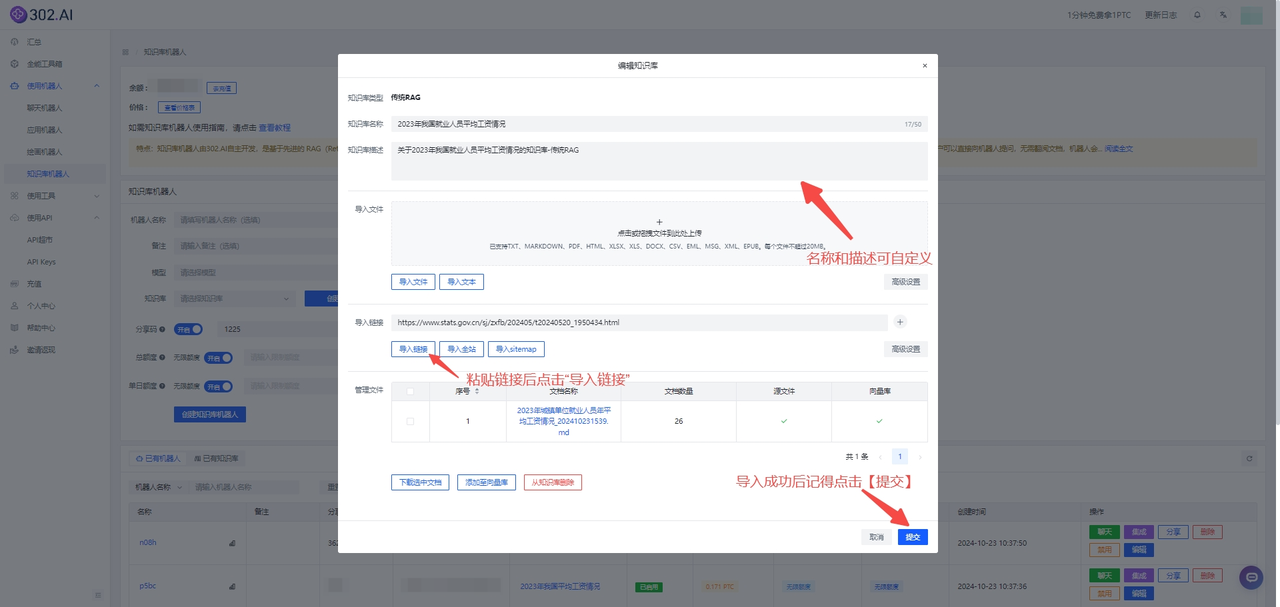
把上述链接粘贴在【导入链接】框中,并点击【导入链接】按钮,等待片刻后会有导入成功提示,页面中也会显示绿色“√”,最后点击【提交】即可。
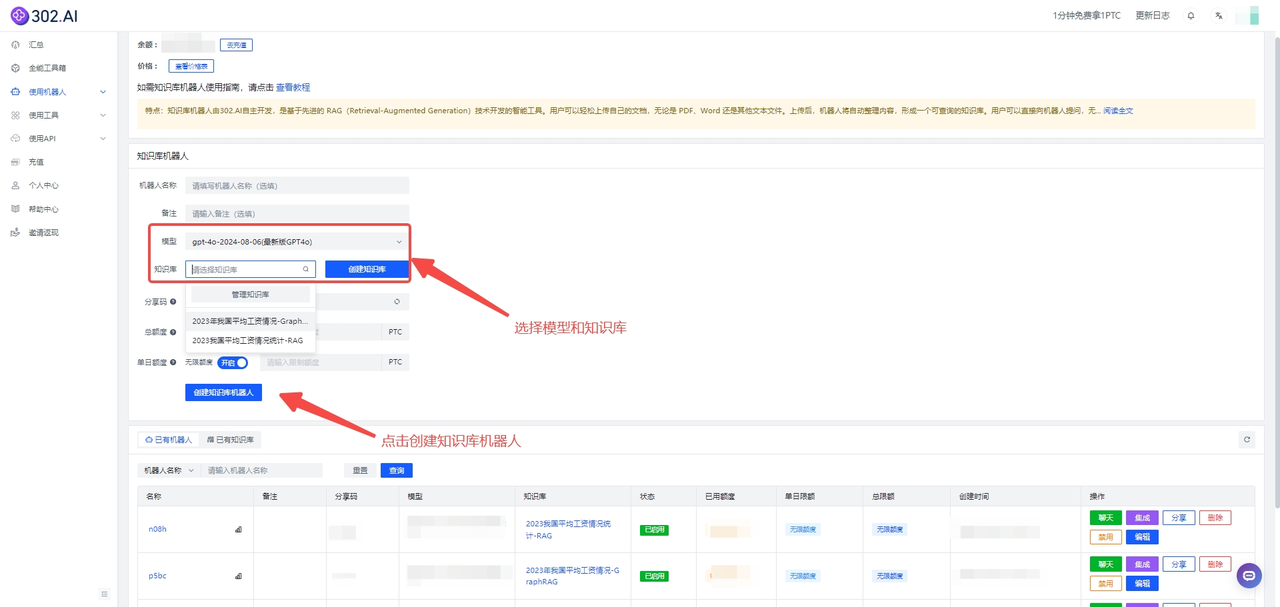
创建知识库成功后,选择模型和知识库后点击【创建知识库机器人】即可进入:
首先提出问题一:2023年全国城镇私营单位就业人员年平均工资是多少?
RAG的回答:
GraphRAG回答如下:
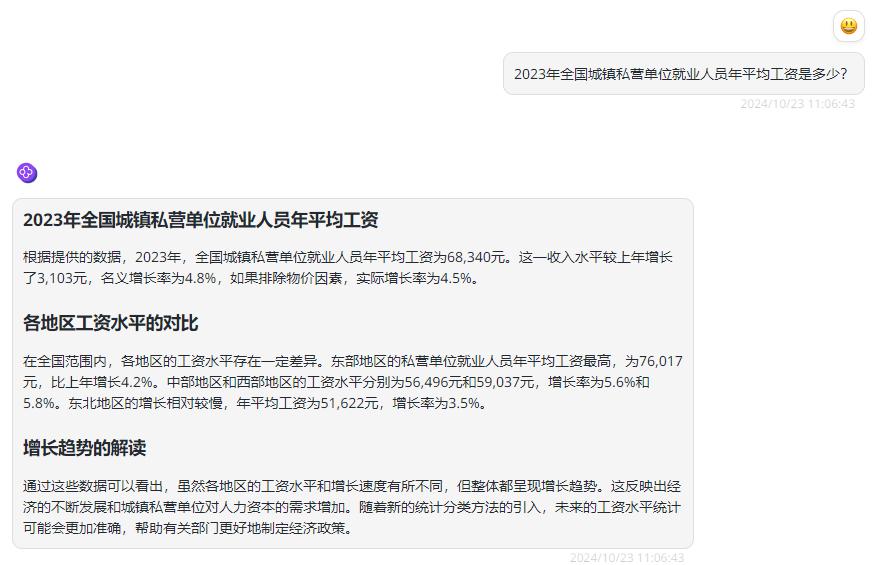
这一问题非常具象,在导入的知识库里面是有明确答案的,RAG能够找到含有这一答案的分块,然后给出正确回答。而GraphRAG的回答结构化地组织数据全面、系统地总结数据集中的主题和关系,极大地增强了回答的全面性和多样性。
再提出问题二:2023年全国城镇非私营单位和城镇私营单位中就业人员年平均工资为负增速的行业有哪些?
RAG的回答:
GraphRAG回答如下:
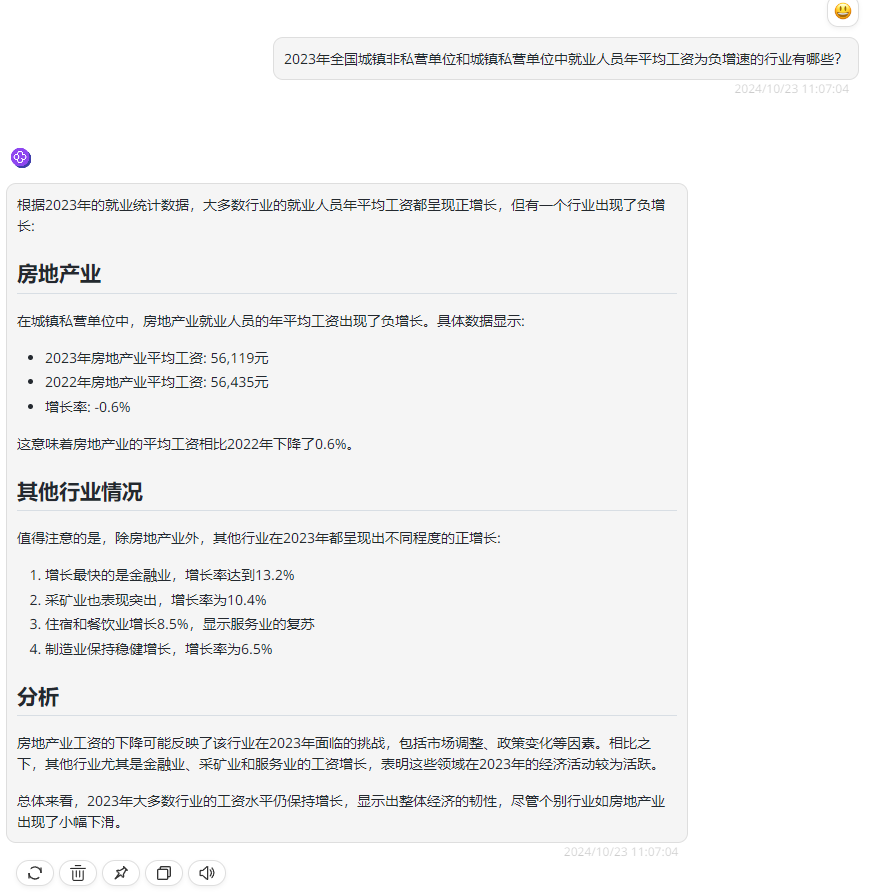
问题二是一个全局性的问题,想要回答这个问题,需要把知识库中所有行业的就业人员平均工资都结合分析才可以进行回答,而从上述回答中可以看到RAG方法对于这些全局性问题往往无法提供准确的答案,因为这些问题涉及整个数据集,传统的RAG只生成与问题语义相似的文本片段的答案,而不是从所有输入文本中提取答案。
相比之下,GraphRAG通过考虑所有输入文本构建的图索引,能够更有效地回答这类问题,相当于提前整理好这个信息和他们之间的关系、分类。
通过这个实验,我们可以观察到两种方法在处理信息和生成回答时的不同表现,GraphRAG能够进行更深层、更细致与上下文感知的检索,而传统RAG主要依赖于文本块的相似匹配。GraphRAG更适合处理统计性、总结性、概要性的查询,而传统RAG在处理这类问题时可能不够全面。
RAG和GraphRAG作为一种强大的知识增强工具,正逐渐成为各行各业智能化升级的关键因素。而302.AI平台通过其高效的一键部署功能,不仅大幅降低了技术的应用门槛,还极大地提升了部署效率和用户体验,让GraphRAG这一强大的知识增强工具得以迅速融入各类业务场景,无论是科研探索、企业决策支持,还是日常信息处理,都能轻松应对!
展望未来,302.AI平台将持续为用户提供更加优质、全面、深入的智能化服务,让更多用户享受到智能化带来的便捷与高效。
参考文章:
https://help.302.ai/docs/zhi-shi-ku-de-yuan-li
https://mp.weixin.qq.com/s/9P0yel8EsEsPNeeCTZ5GTA
https://microsoft.github.io/graphrag
https://zhuanlan.zhihu.com/p/708393911
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

Comments(2)
Fantastic site. Plenty of helpful info here. I’m sending it to several buddies ans additionally sharing in delicious. And obviously, thank you in your sweat!
I’m typically to blogging and i actually admire your content. The article has really peaks my interest. I am going to bookmark your site and preserve checking for new information.