


AI到底能不能看懂火星文差评!看看哪个模型表现更好!
大家都知道,在《歌手2024》播出的时候,13.8和13.11哪个大的问题难倒了不少AI模型。而最近,AI模型迎来了新一轮考验来了,起因是这样的,为了防止外国人通过翻译软件看懂原意,一些中国人在海外订酒店吃亏后,用火星文提醒同胞不要再来,而这些帖子被截图搬运到了国内的社交媒体平台后很快就火了,引发了不少网友的讨论,火星避雷帖比如是这样的:
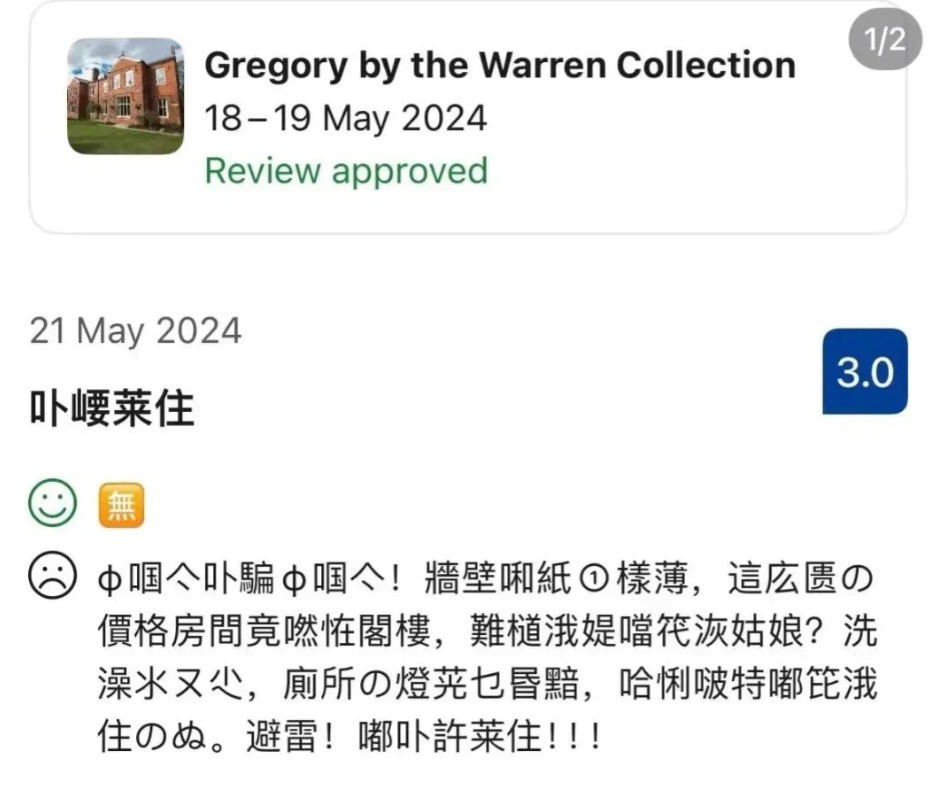
![]()
还有这样的:
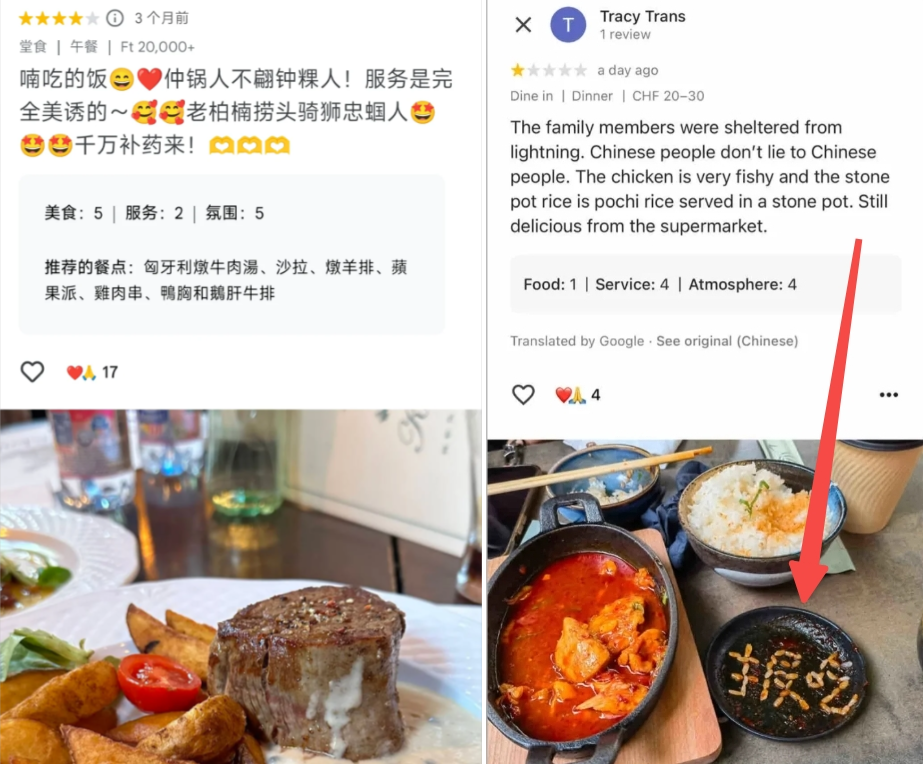
![]()
甚至有网友在评论区无奈表示:“国人都有些看不懂了”。
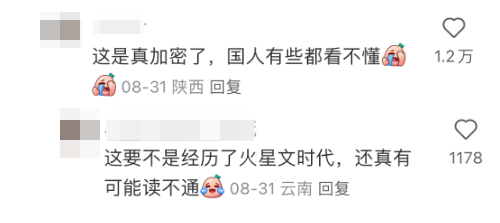
![]()
还有网友尝试将帖子翻译再翻译,发现如果站在外国商家的角度,这是绝对是看不懂的:

![]()
这加密程度显然是够了。然而,自从火星避雷帖火起来后,就有国外网友尝试用GPT-4o模型去解密这一段火星文,结果到底怎么样呢?别急,小编今天就带大家实测一下各大模型到底能不能读懂火星文。
为了直观对比各模型的回答,小编选择了302.AI的模型竞技场去进行测试,302.AI的模型竞技场集成了多种主流AI模型,用户可以按需勾选不同的模型同时对同一个问题进行回答,省去了逐个模型注册登录的繁琐流程,方便的同时还能更直观对比不同模型的答案,而且提供按需付费的服务方式,用户可以根据实际用量来支付费用,没有月费或捆绑套餐。
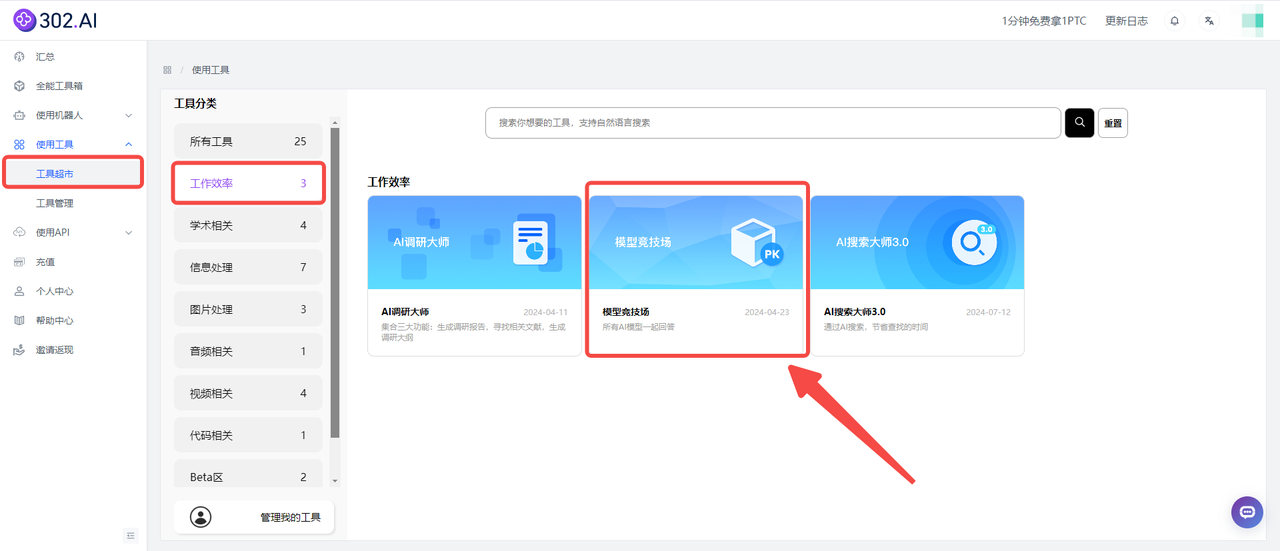
![]()
小编接下来勾选七个模型进行测试,分别是o1-preview、GPT-4o、Claude-3.5-sonnet、Qwen-Max、ERNIE-4.0-Tubro、Step-2-16k、Spark Ultra:
![]()
接下来输入提问:
以下是加密后的酒店点评文字,请完整解密还原:
“卟崾莱住”
“ф啯亽卟騙ф啯亽!牆壁啝紙①樣薄,這庅匮の價格房間竟嘫恠閣樓,難檤涐媞噹笩洃姑娘?洗澡氺ㄡ尐,廁所の燈茪乜昬黯,哈悧啵特嘟笓涐住のぬ。避雷!嘟卟許莱住!!!”
正确的翻译是这样的:
“不要来住”
“中国人不骗中国人!墙壁和纸一样薄,这么贵的价格房间竟然在阁楼,难道我是当代灰姑娘?洗澡水又少,厕所的灯光也昏暗,哈利波特都比我住的好。避雷!都不许来住!!!”
首先看下“草莓”o1-preview和GPT-4o的表现,两个模型分别都有一点小瑕疵在“难道我是当代灰姑娘”这句话上面:

![]()
再来是小编抱以厚望的Claude-3.5-sonnet,解密正确了80%的内容,主要的错误出现在第一句“中国人不骗中国人”还有小细节“灯光”解密成了“灯泡”,但是Claude在最后总结的几点都是正确的:
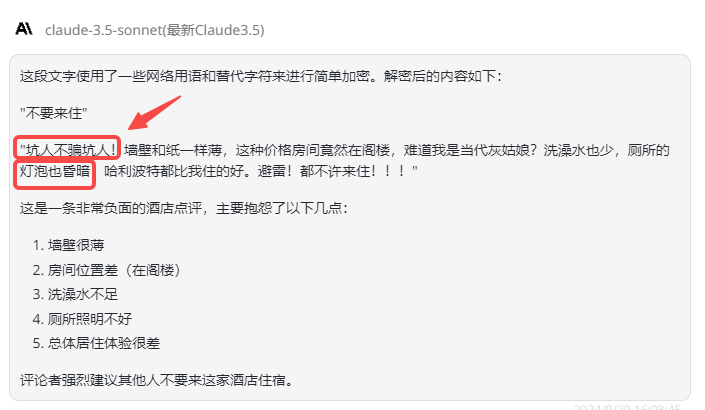
![]()
再来是国内模型,首先是Qwen-Max和Spark Ultra模型,和以上的模型差不多,主要出现在“中国人不骗中国人”以及“难道我是当代灰姑娘”这两句话上:
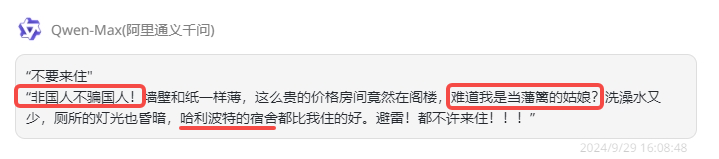
![]()

![]()
紧接着是ERNIE-4.0-Tubro,文心一言在进行一番分析后,将“中国人不骗中国人”直接爆改成“俄罗斯人不骗俄罗斯人”,“灰姑娘”变成了“白姑娘”:

![]()
最后是表现非常出色的Step-2-16k,回答里找不出一点瑕疵,同时也是本次测试中唯一一个完全正确的模型:

![]()
通过本次测试可以判断AI模型是否能够识别和理解非常规的字符组合,而Step-2-16k模型的表现确实令人瞩目,其余六个模型在细节上或多或少都存在一些瑕疵。
想要准确解读火星文的含义,AI模型不仅需要强大的语言文本处理能力,还要对火星文这种特定的网络文化有一定的理解。总之,AI模型对火星文的破解,展示了人工智能在语言处理方面的进步,随着AI的发展,我们期待AI能够在处理全球多种语言和文化现象方面发挥更大的作用。
参考文章:
https://twitter.com/dotey/status/1835910802072592794
https://mp.weixin.qq.com/s/-ruGnlbFLd4Df7RKi_QuRQ
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
