
2月25日凌晨,Anthropic发布了首款混合推理模型——Claude 3.7 Sonnet。
Claude 3.7 Sonnet 能够在标准模式(Normal) 下既提供近乎即时的响应,也可以也能切换到扩展思考模式(Extended),进行详细的逐步推理。
![]()
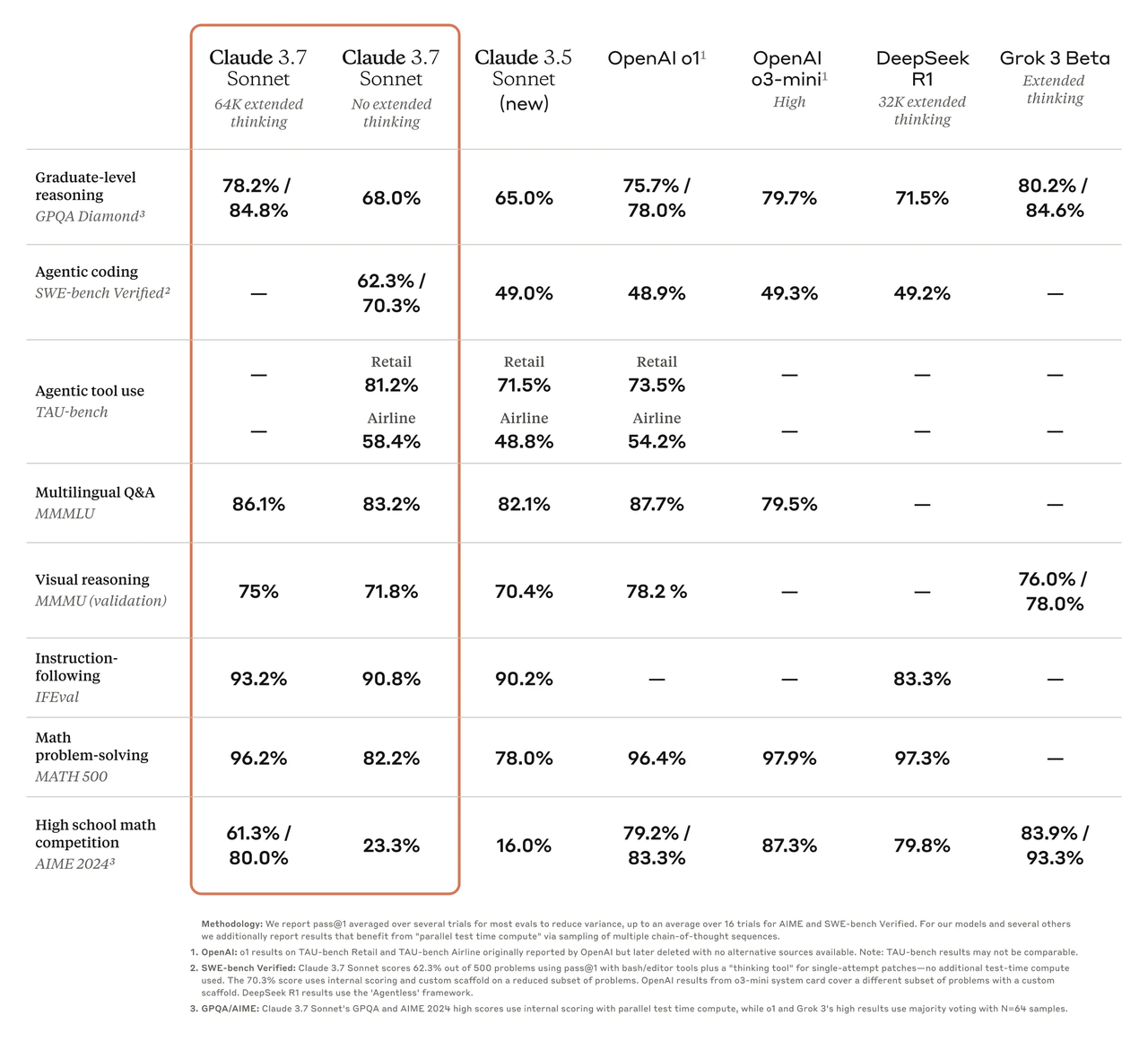
在扩展思考模式的加持下,Claude 3.7 Sonnet 在数学、物理、指令遵循、编码等方面获得了额外的提升:
![]()
(Anthropic官方提供的基准测评结果)
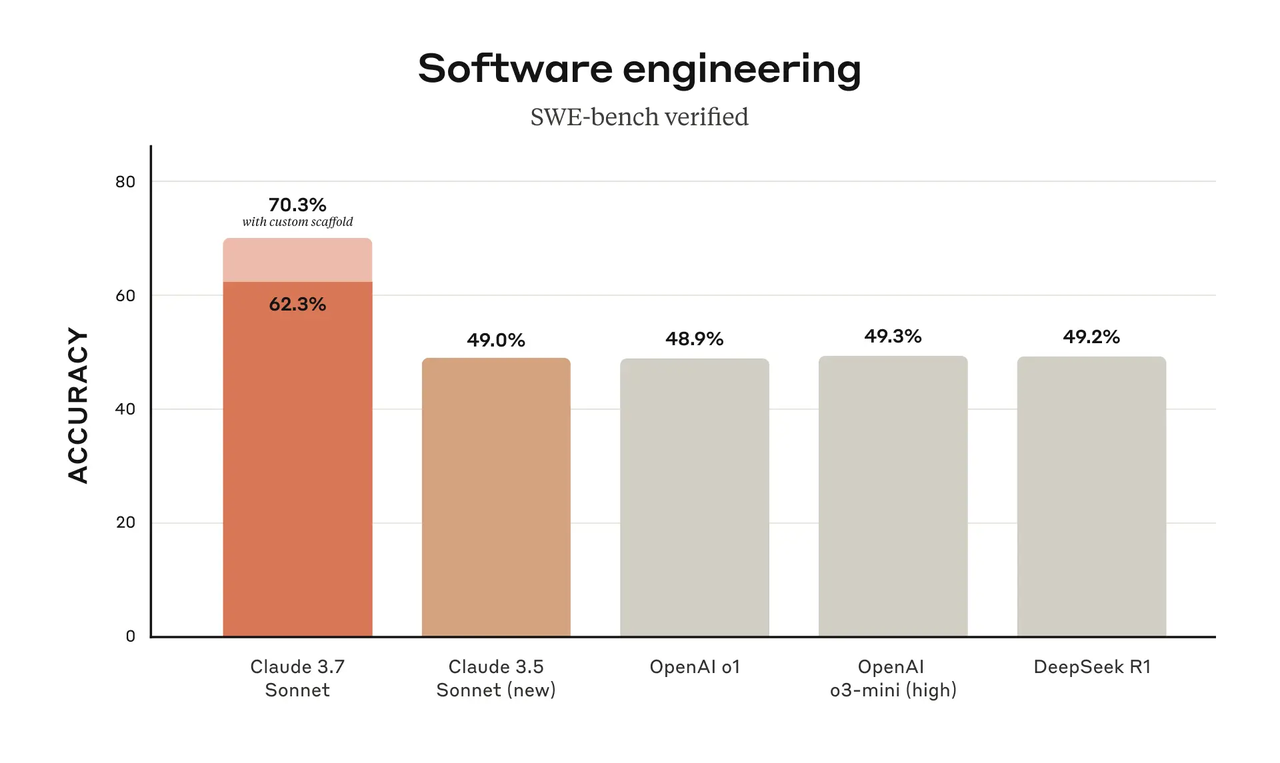
作为AI编程领域的传统强者,Claude系列再次实现突破:Claude 3.7 Sonnet 在SWE-bench测试中取得了70.3%的准确率,较前代Claude 3.5 Sonnet有了显著的性能提升,并以绝对优势超越了OpenAI的o1、o3-mini等模型。
![]()
Claude 3.7 Sonnet模型实测
下面我们将通过一系列实测对比,深入探究模型的实际效果。
对比模型有Claude 3.7 Sonnet(非推理模式)、o3-mini、DeepSeek-R1
(claude推理模式正在紧锣密鼓地适配中,所以这次没有参与实测)
一、逻辑测试
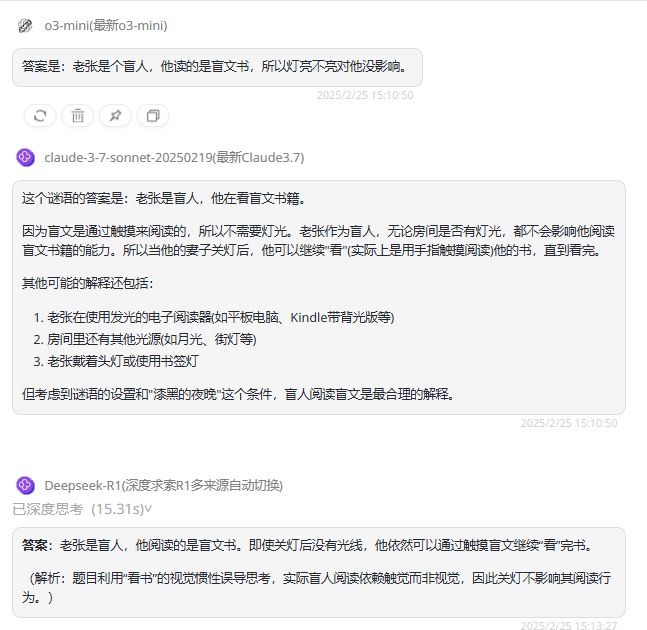
提示词:漆黑的夜晚,老张在家看书,看着看着,他的妻子说:“太晚了,关灯睡觉吧。”就把灯关了,可老张理也不理继续看书,还一直把书看完了,这是怎么回事?
考察点:首先简单测试一下模型的逻辑推理能力和常识理解能力。
o3-mini:回答正确。
Claude 3.7 Sonnet:回答正确,同时还给出了更多可能的解释。
DeepSeek-R1:回答正确,同时分析了题目的陷阱。
![]()
逻辑实测排名:Claude 3.7 Sonnet=o3-mini=DeepSeek-R1
二、编程测试
以下编程测试分为编程正确性检验和编程效果对比两部分内容。
编程正确性检验测试会借助编程学习平台出题,在模型生成代码后复制粘贴到平台检验是否通过。
编程效果测试会让模型编程生成可预览的效果,从而进行对比,使用到的是工具是302.AI聊天机器人的Artifacts功能。
编程正确性检验
1、python-中等难度
提示词:

![]()
o3-mini:检验不通过,代码有误。
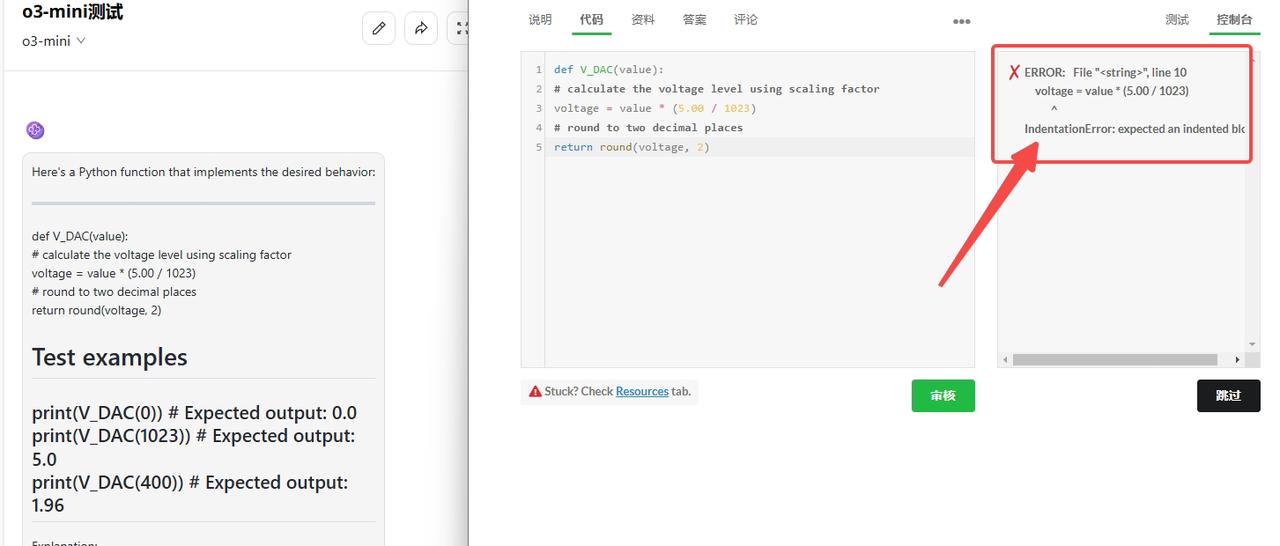
![]()
Claude 3.7 Sonnet:检验通过。
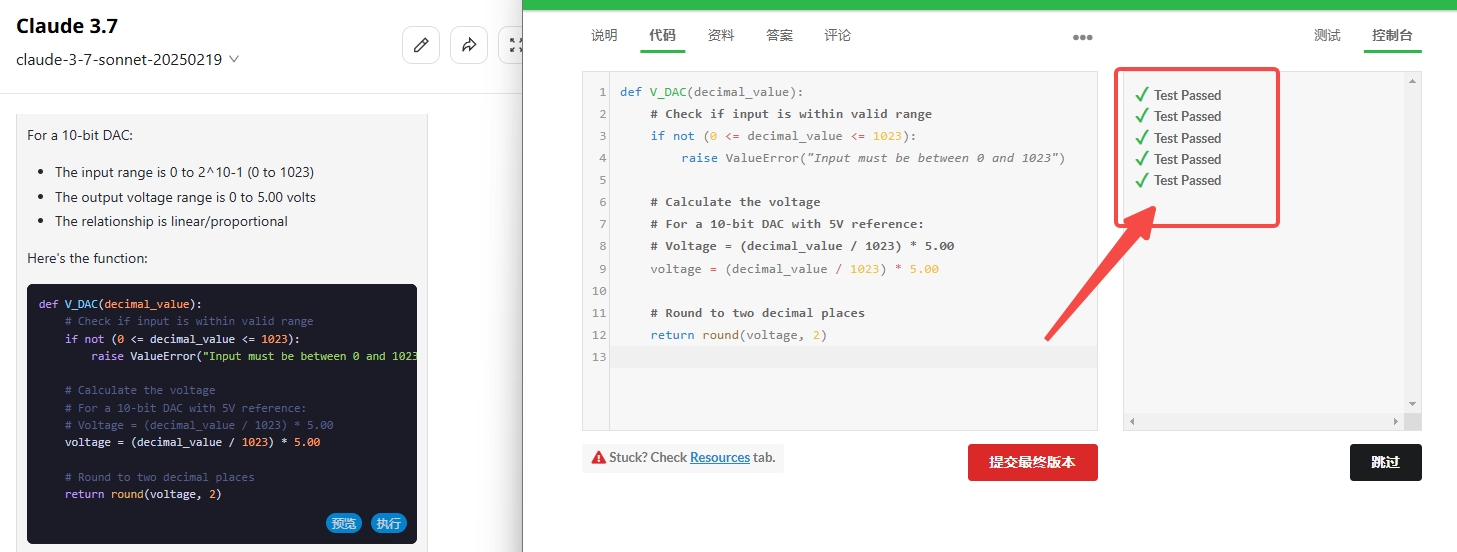
![]()
DeepSeek-R1:检验通过。
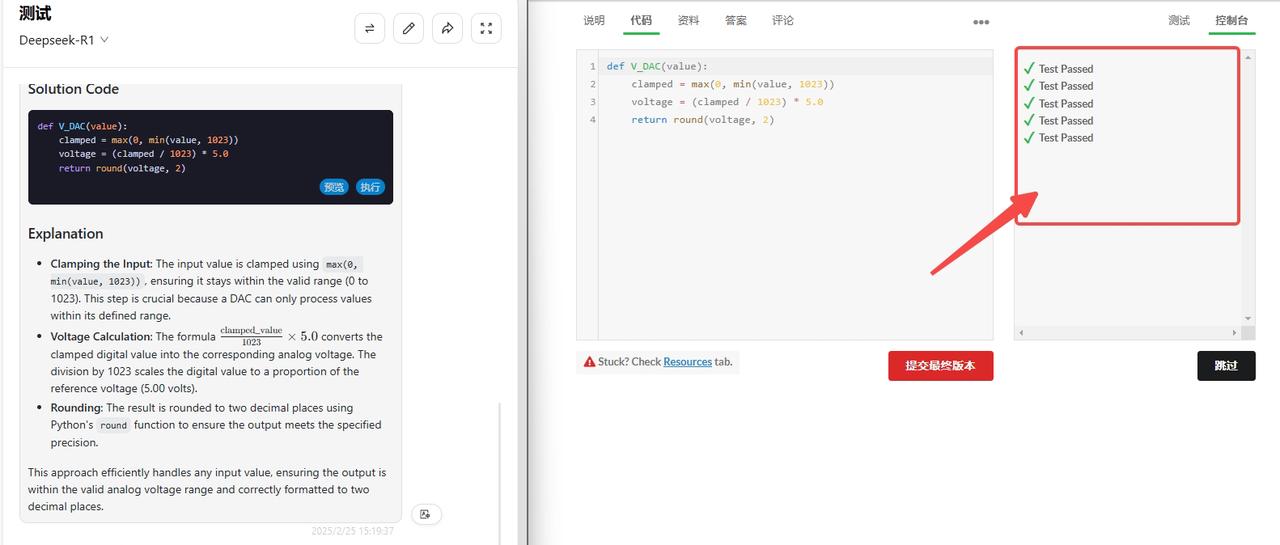
![]()
2、python-困难难度
提示词:

![]()
o3-mini:检验不通过。
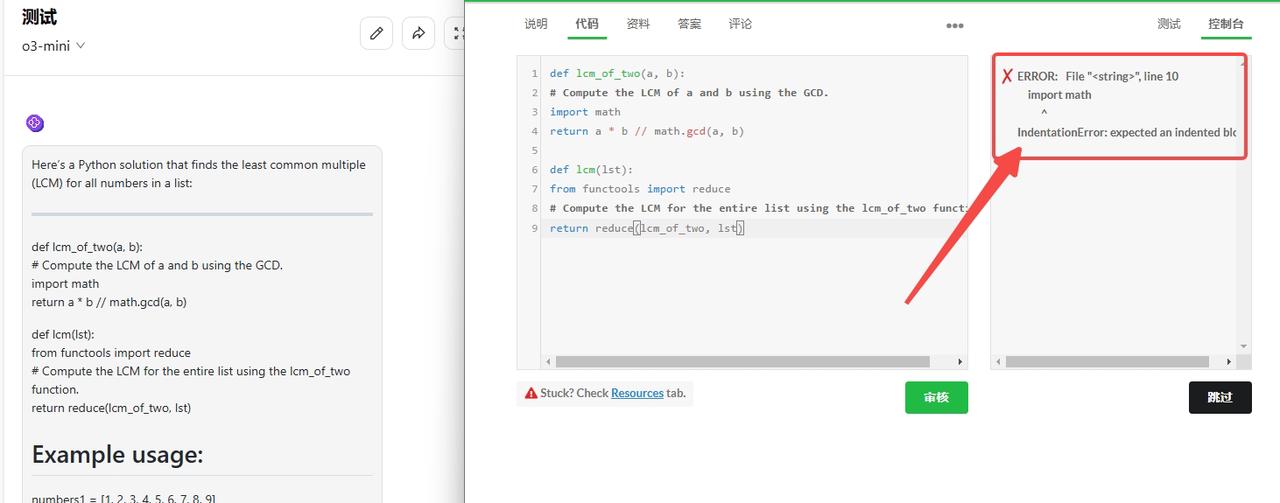
![]()
Claude 3.7 Sonnet:代码检验通过。
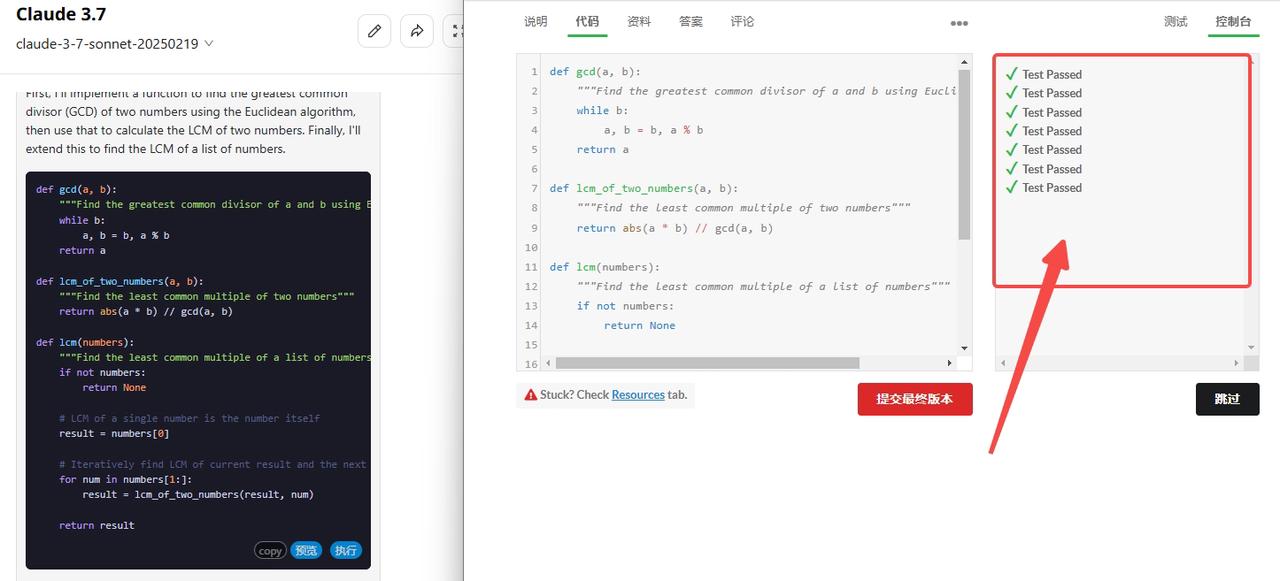
![]()
DeepSeek-R1:代码检验未完全通过。
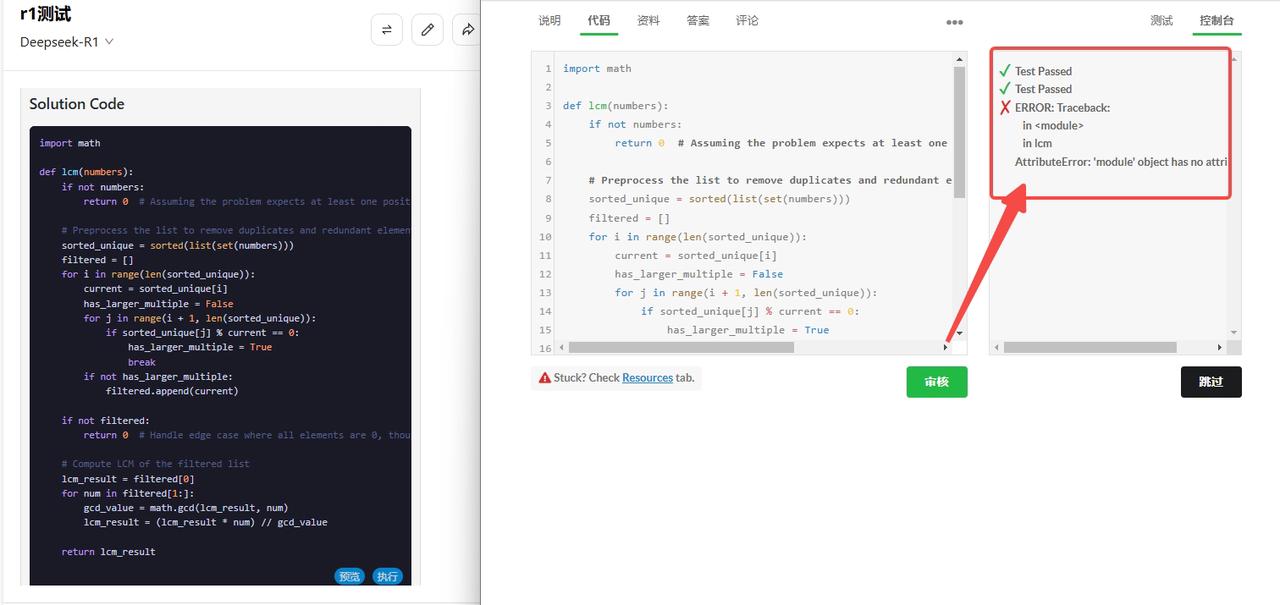
![]()
两次编程检测综合排名:Claude 3.7 Sonnet>DeepSeek-R1>o3-mini
编程效果对比:
提示词:请帮我创建一个类似马里奥的游戏,可直接预览
考察点:通过简单的提示词,考察模型是否能够结合创意、逻辑生成具有实际应用价值的游戏效果。
o3-mini:完成度较低,仅为30%。 虽然角色能够执行基本的跳跃操作,但整体功能有限。金币、障碍物、实时分数等关键元素均未实现,缺乏完整的游戏机制。
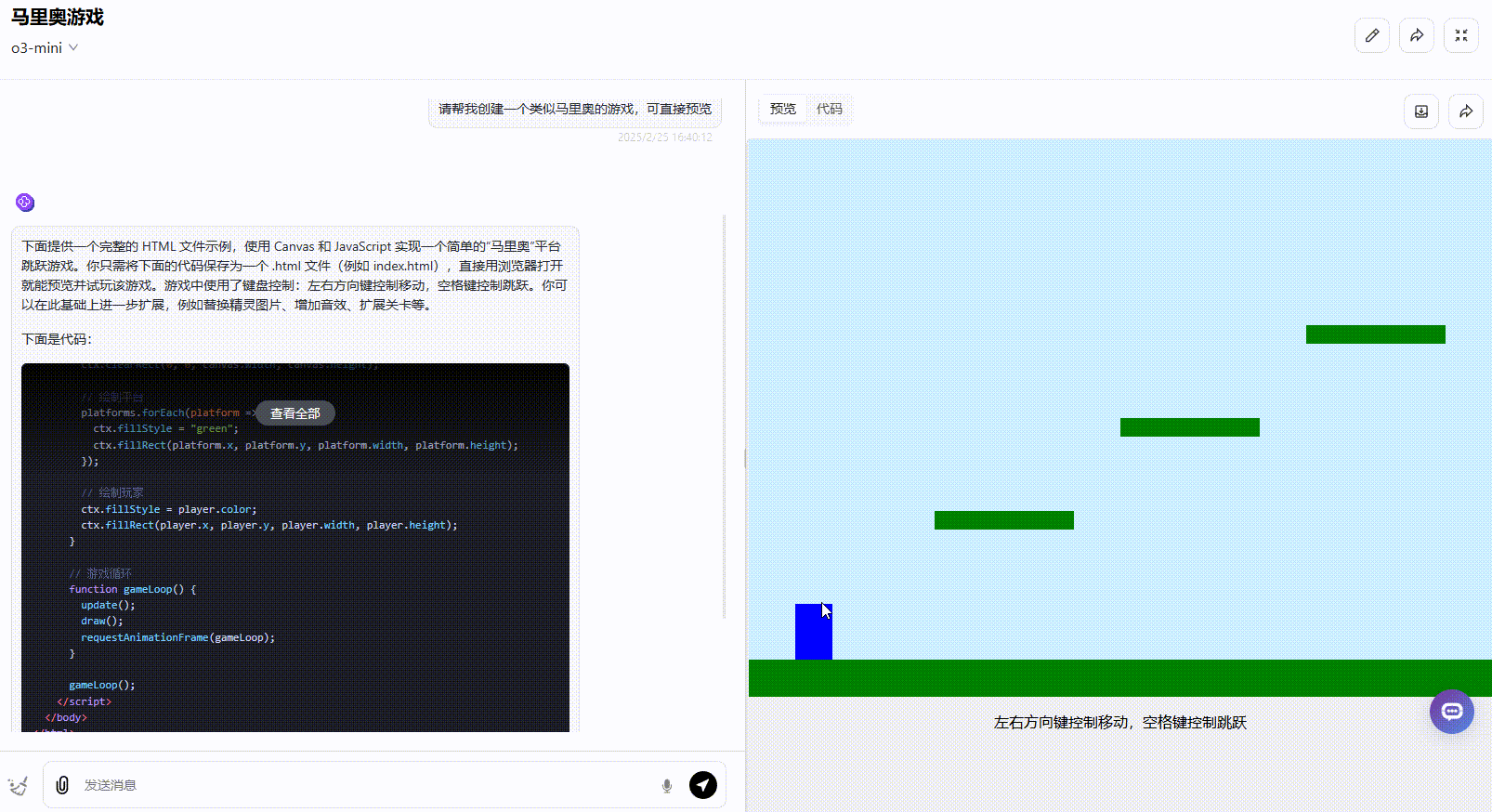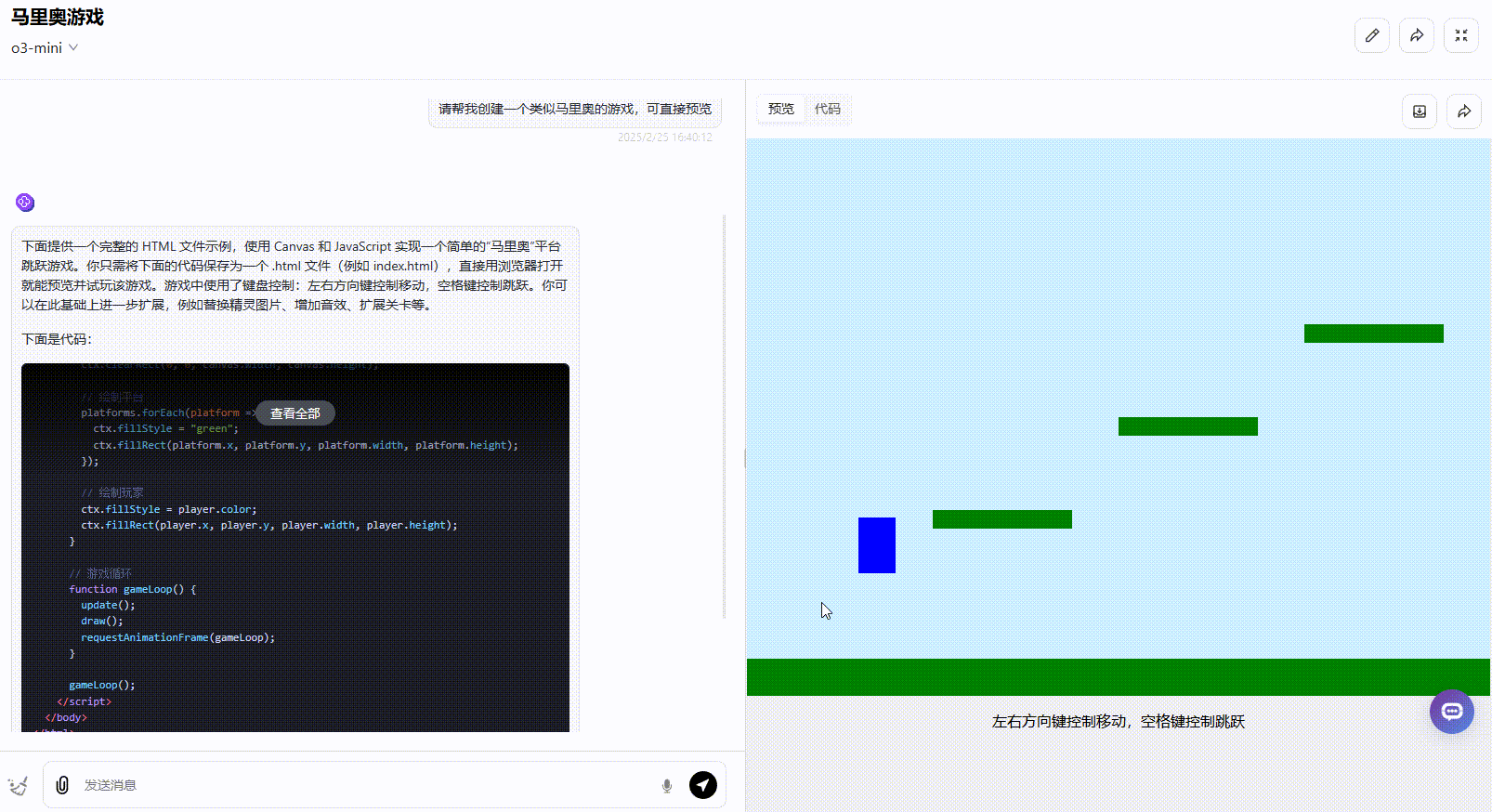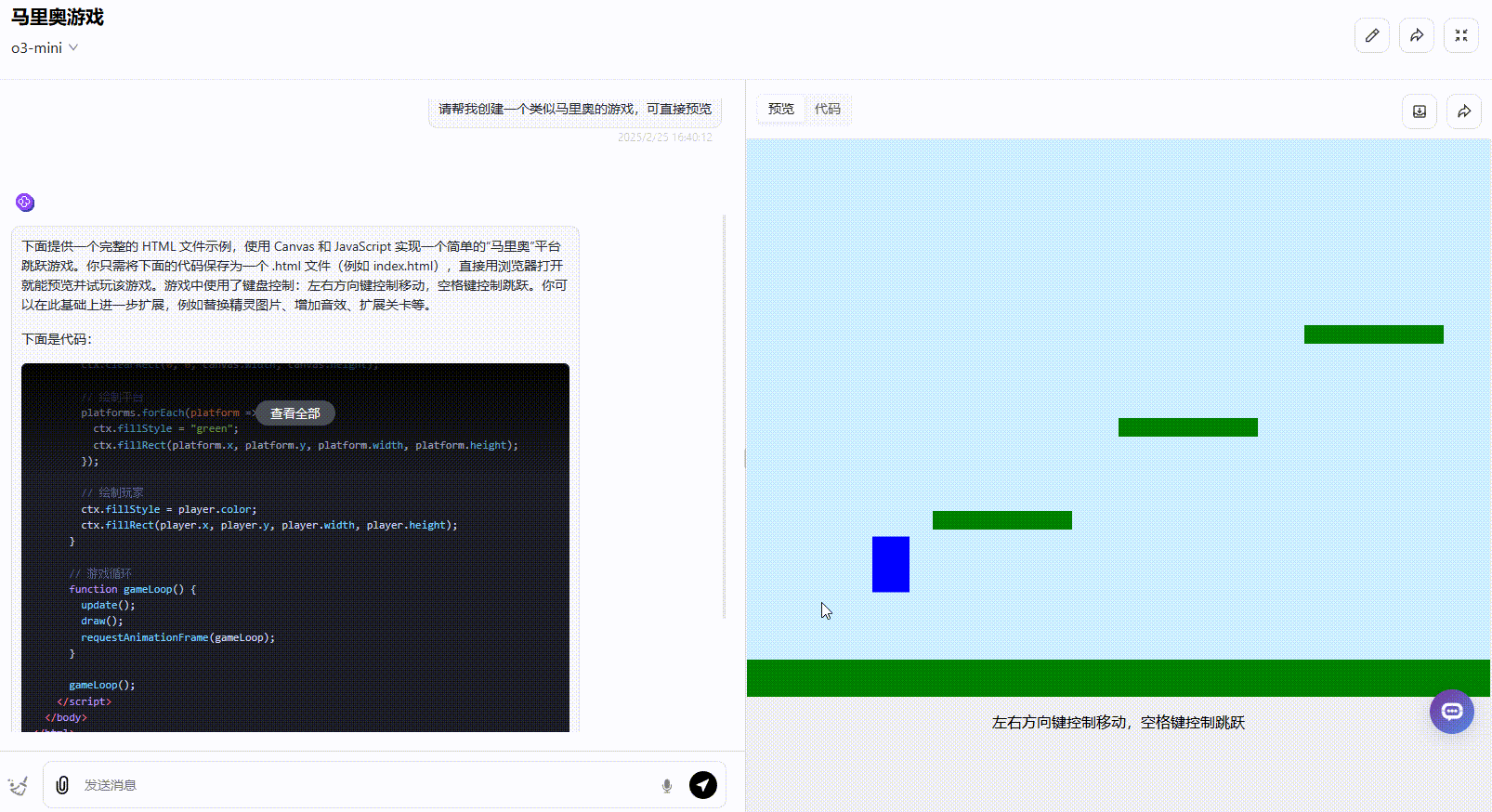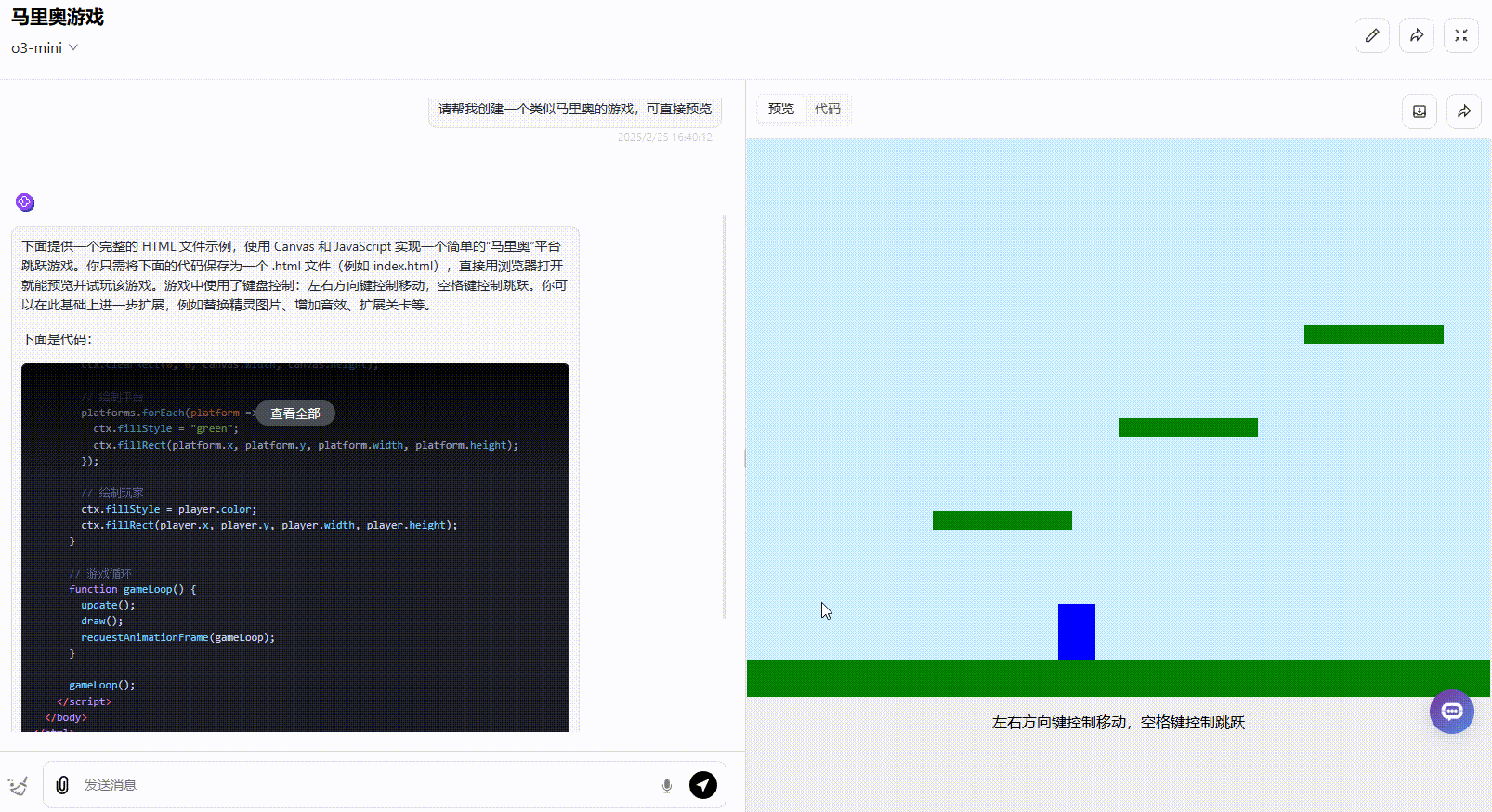
![]()
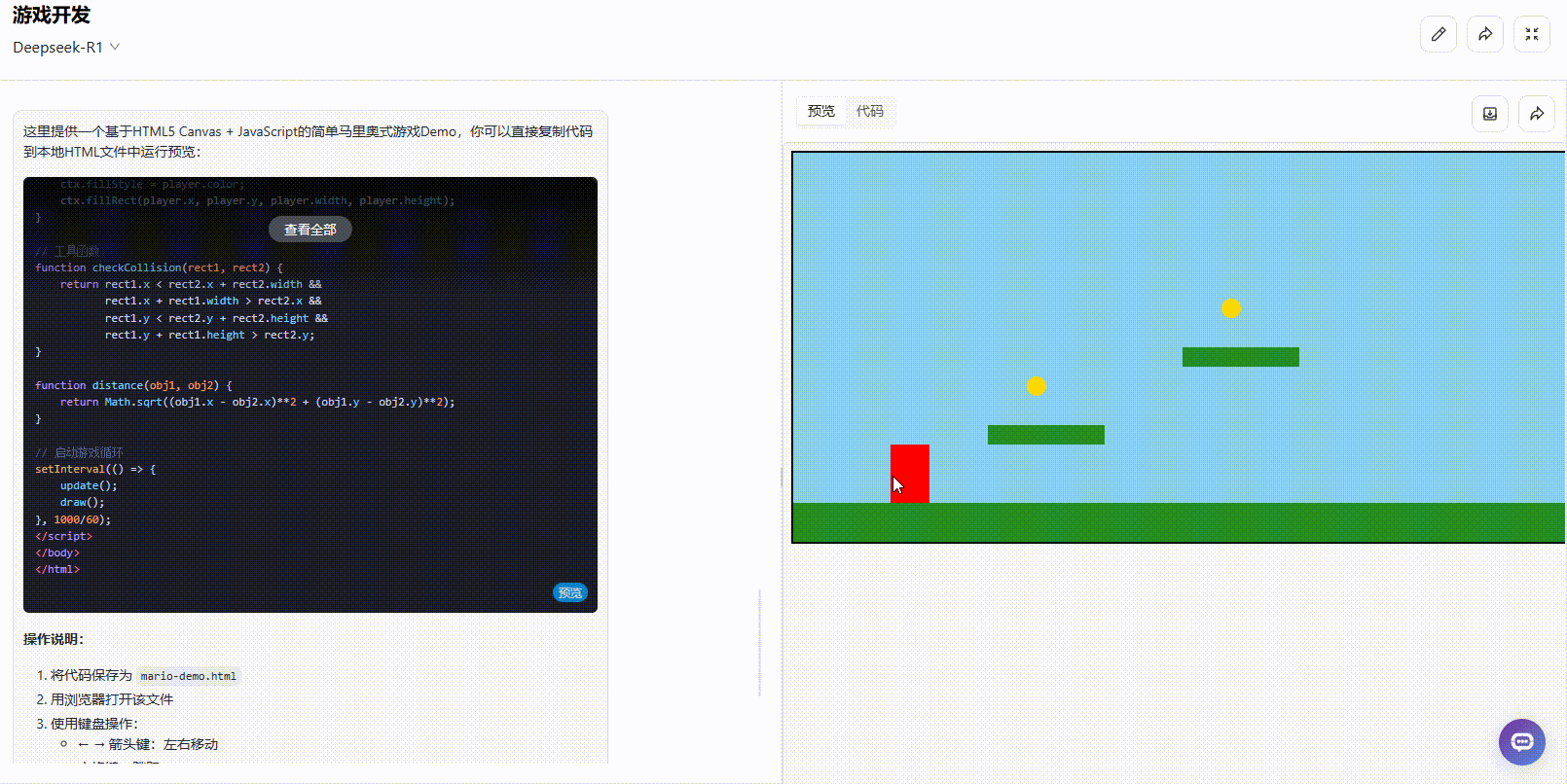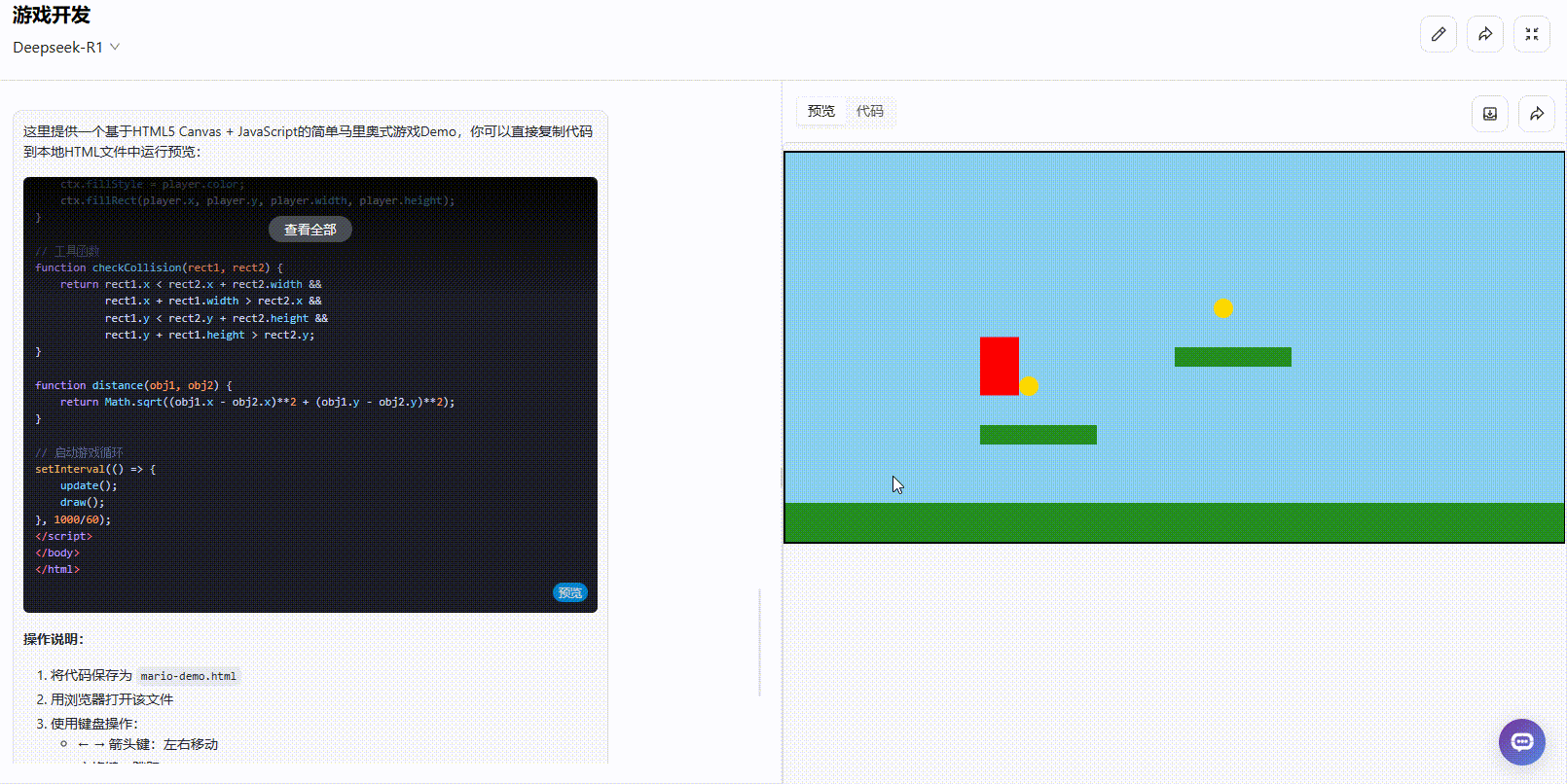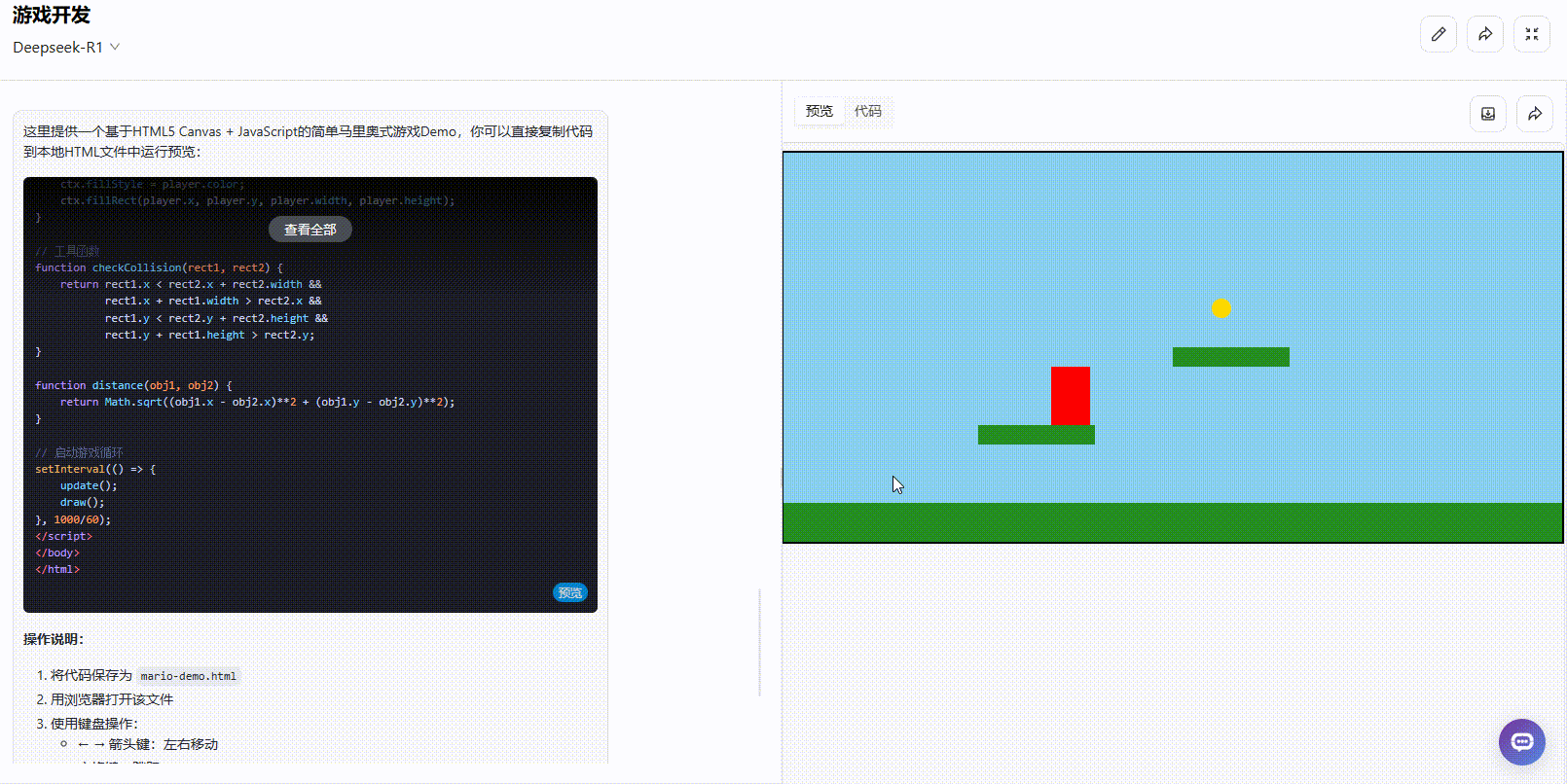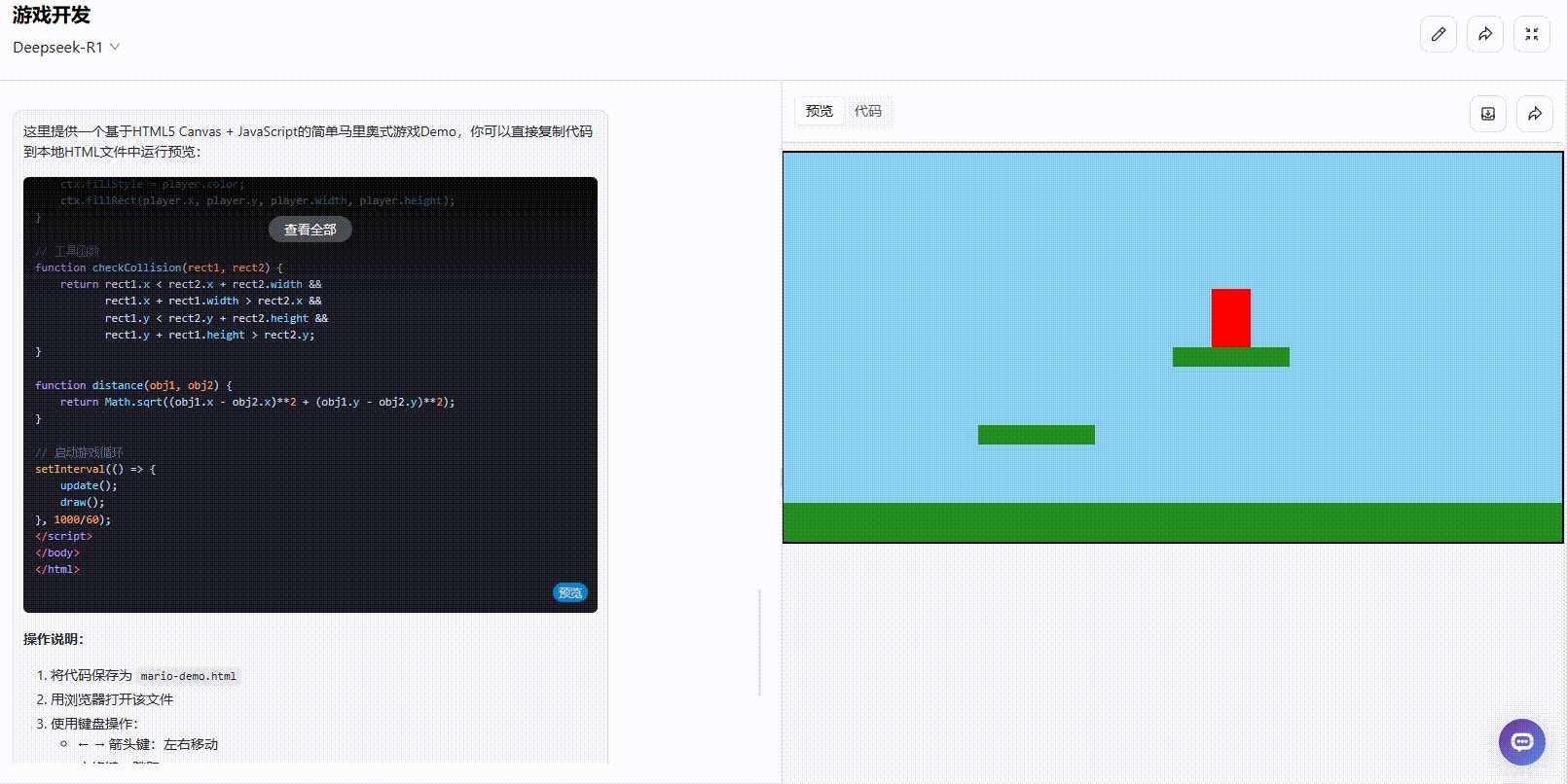
Claude 3.7 Sonnet:效果基本完整,完成度较高。 游戏具备了金币、障碍物、实时分数等核心元素,还设置了敌人角色,增加了游戏的挑战性。整体体验较为完整,基本满足了类似马里奥游戏的核心玩法。

![]()
DeepSeek-R1:完成度约45%,部分功能缺失。 角色能够正常移动和跳跃,且具备了金币收集机制,但实时分数和操作说明等重要功能尚未完善。整体仍需进一步补充和完善。
![]()
编程效果排名:Claude 3.7 Sonnet>DeepSeek-R1>o3-mini
模型实测总结:
通过以上对比实测,能够初步得出以下结论:
(1)在逻辑任务中表现排名:Claude 3.7 Sonnet=o3-mini=DeepSeek-R1
在逻辑任务的测试中,三个不同的模型都表现出色,能够准确地回答所有提出的问题。输出的结果答案中,Claude 3.7 Sonnet给出了更多的可能性,相较于其他模型回答可能会更加全面。
(2)编程检测方面表现排名:Claude 3.7 Sonnet>DeepSeek-R1>o3-mini
两种难度的编程测试中,Claude 3.7 Sonnet均通过了检验,这进一步表明Claude 3.7 Sonnet在编程能力和解决复杂问题上的能力十分出色。
(3)在编程效果方面表现排名:Claude 3.7 Sonnet>DeepSeek-R1>o3-mini
在游戏效果生成方面,Claude 3.7 Sonnet的表现同样令人瞩目。它能够通过简单的提示词,生成一个接近完整且符合用户需求的效果。
通过一些简单的实际测试,我们可以清晰地发现Claude 3.7 Sonnet在编程方面展现出了非常出色的能力。无论是编程的准确性,还是在效果生成方面,Claude 3.7 Sonnet都能够为用户提供更加优质和高效的体验。总之,Claude 3.7 Sonnet值得广大程序员和开发者去关注与尝试。
在302.AI上使用Claude 3.7 sonnet模型
302.AI的聊天机器人和API超市均上线了 Claude 3.7 sonnet模型,并提供按需付费的服务方式,企业和个人用户可按需灵活选用。
1、使用模型对话
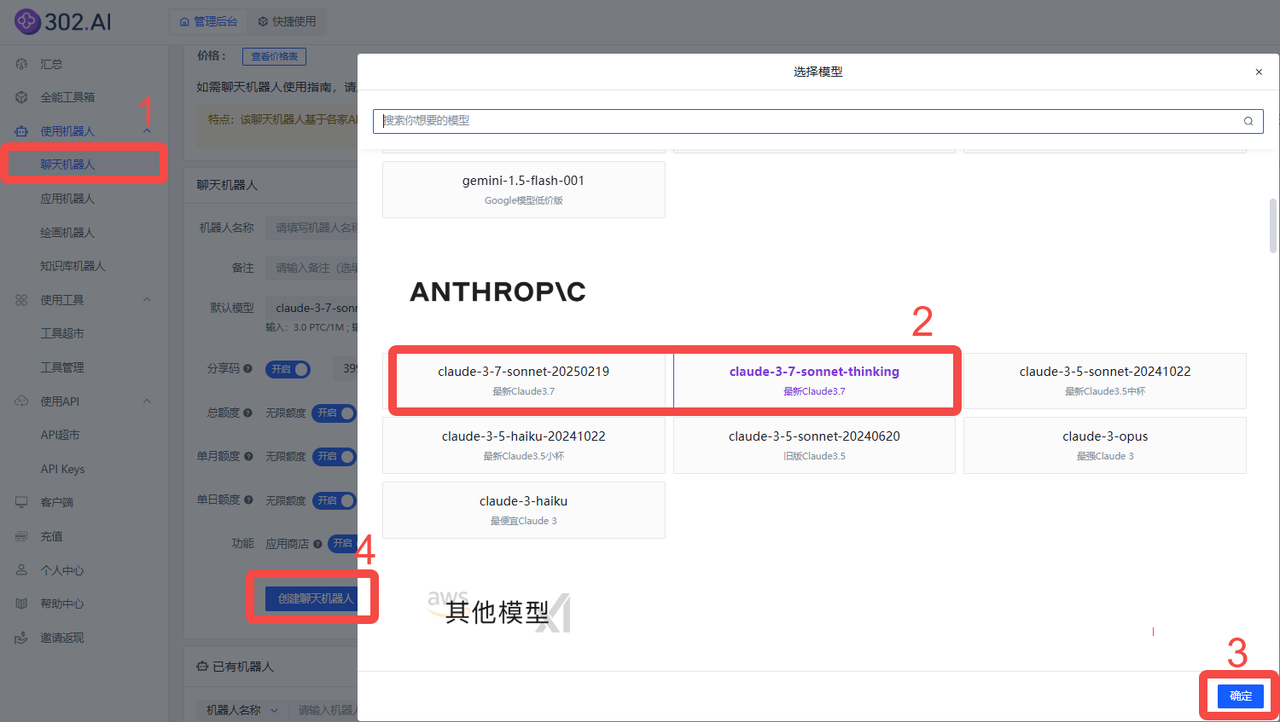
依次点击使用机器人→聊天机器人→ 模型→claude-3-7-sonnet→ 创建聊天机器人;
2、使用模型API
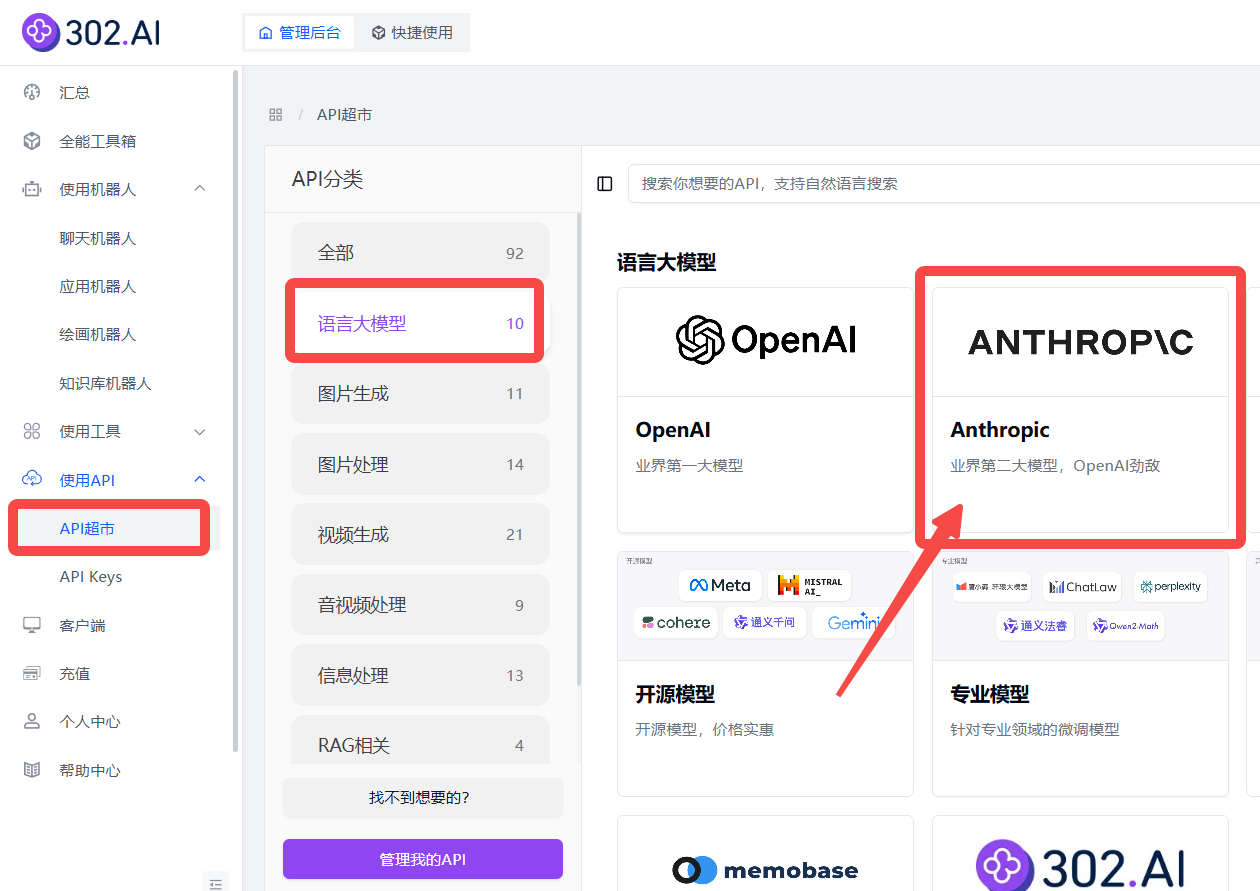
企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发。
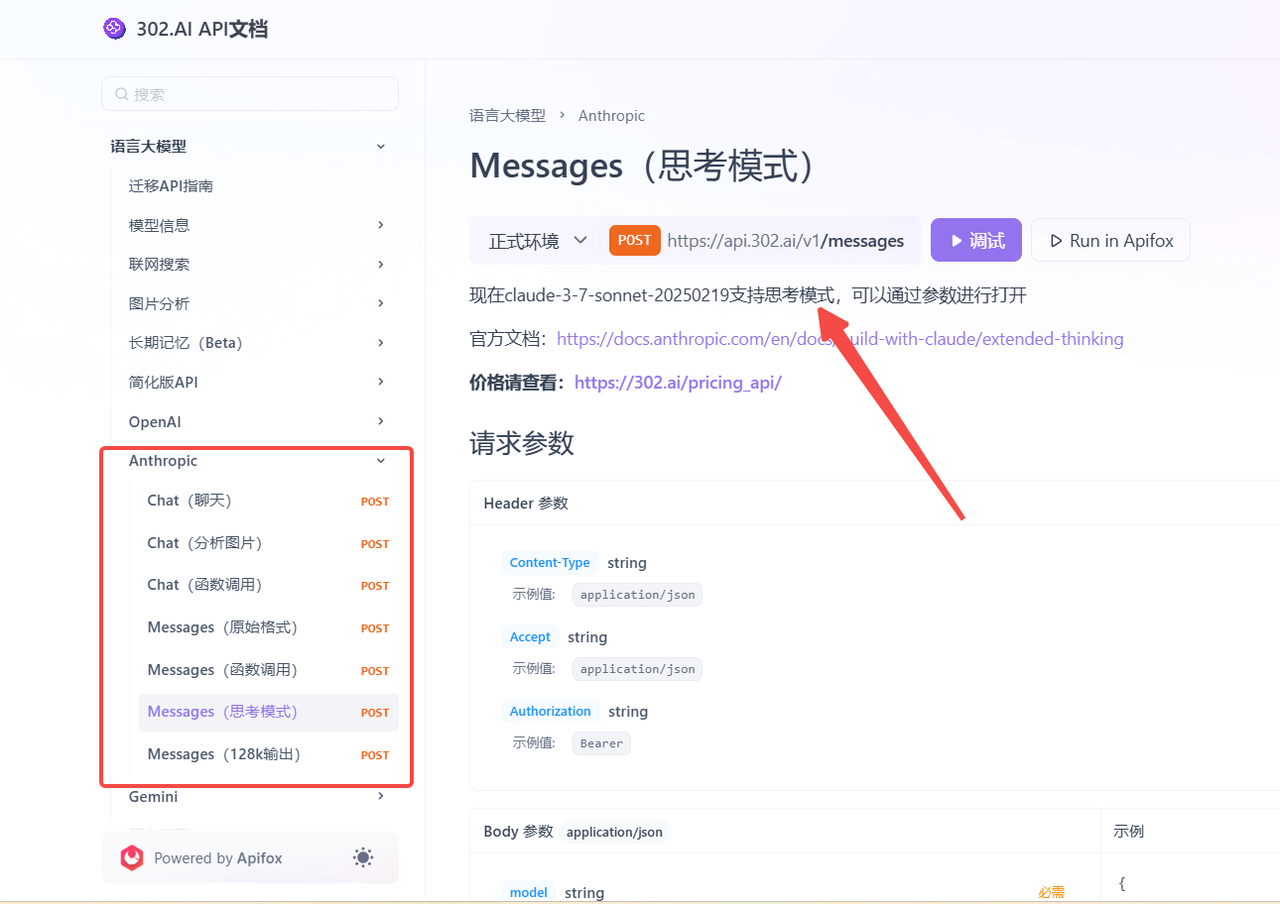
相关文档:使用API→API超市→语言大模型→Anthropic→查看文档;
可通过参数打开思考模式:
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(11)
I think you have noted some very interesting points, thanks for the post.
What i don’t realize is if truth be told how you are no longer really much more neatly-appreciated than you may be now. You’re very intelligent. You know therefore considerably when it comes to this topic, made me in my opinion imagine it from so many varied angles. Its like women and men are not interested unless it is one thing to accomplish with Lady gaga! Your individual stuffs nice. All the time maintain it up!
You made some nice points there. I looked on the internet for the subject matter and found most people will consent with your blog.
Sweet website , super pattern, very clean and use genial.
Excellent read, I just passed this onto a friend who was doing a little research on that. And he actually bought me lunch since I found it for him smile Thus let me rephrase that: Thank you for lunch!
Good day I am so excited I found your website, I really found you by accident, while I was researching on Google for something else, Regardless I am here now and would just like to say cheers for a incredible post and a all round entertaining blog (I also love the theme/design), I don’t have time to browse it all at the minute but I have saved it and also included your RSS feeds, so when I have time I will be back to read a lot more, Please do keep up the awesome job.
You have brought up a very good details, thankyou for the post.
Its such as you read my thoughts! You seem to understand so much approximately this, like you wrote the e book in it or something. I feel that you simply can do with a few to power the message house a bit, however instead of that, that is excellent blog. An excellent read. I will definitely be back.
As I website possessor I believe the content material here is rattling fantastic , appreciate it for your efforts. You should keep it up forever! Good Luck.
I got what you intend, thanks for putting up.Woh I am glad to find this website through google. “Being intelligent is not a felony, but most societies evaluate it as at least a misdemeanor.” by Lazarus Long.
I’ve been absent for some time, but now I remember why I used to love this website. Thank you, I’ll try and check back more often. How frequently you update your website?