


时隔gemini-exp-1114发布仅一周,谷歌DeepMind在11月21日再次发布实验AI模型gemini-exp-1121。根据官方介绍,gemini-exp-1121在编码、推理和视觉能力都有提升。

![]()
在gemini-exp-1121发布之后,它迅速赢得了Arena榜单的冠军宝座,根据测评结果显示,除了风格控制外,其他方面都位于第一。
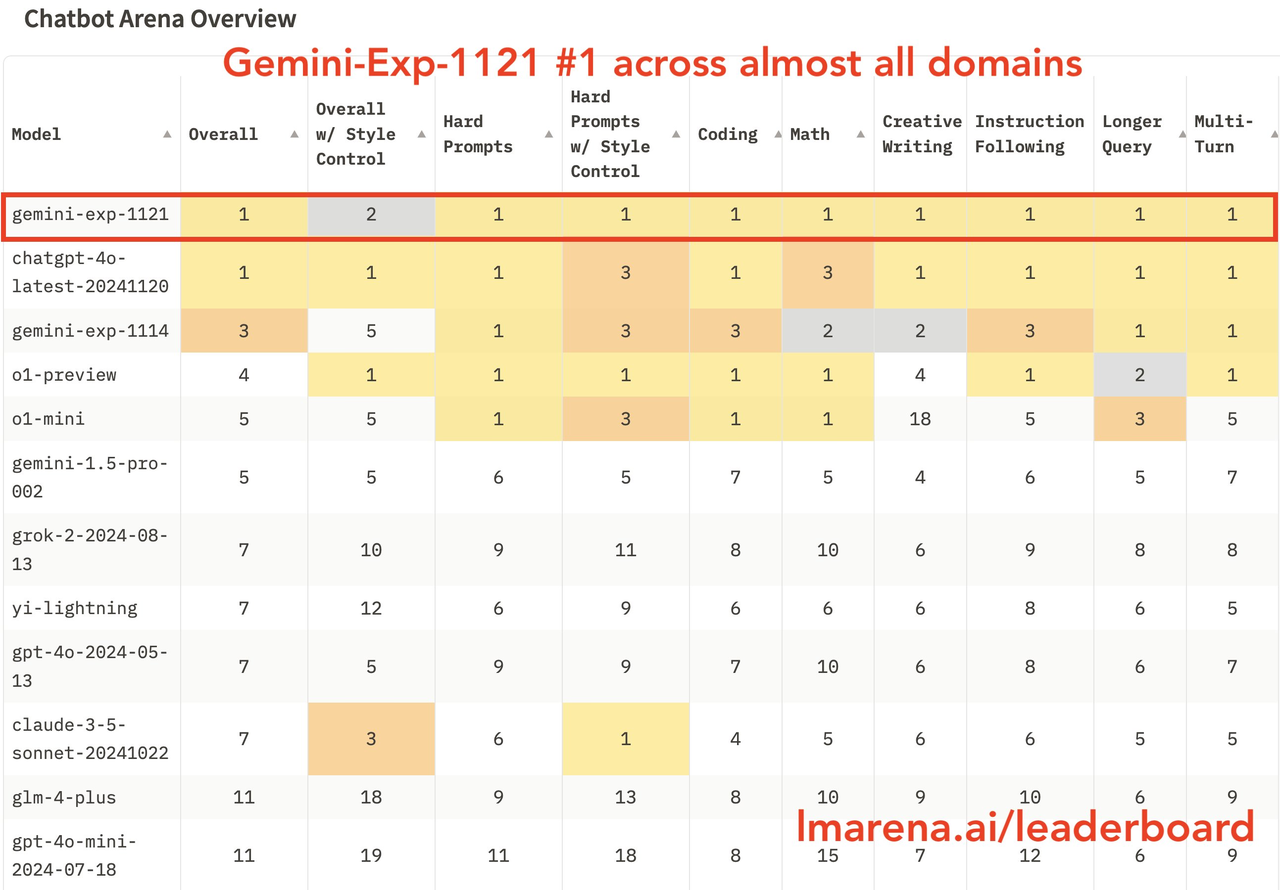
![]()
但在发布gemini-exp-1121模型后,立即有网友发出灵魂拷问:
“为什么不直接发布gemini-exp-1121,而是要先发布gemini-exp-1114呢?”
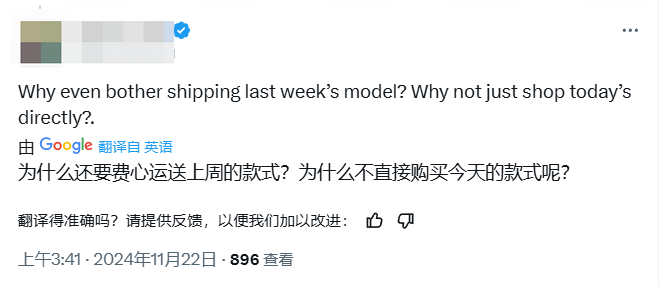
![]()
这或许也是大家心中疑惑的问题!要知道,就在gemini-exp-1121发布的前一天,OpenAI刚刚推出了GPT-4o的更新版本GPT-4o-2024-11-20,这一时间节点的巧合,让人不得不怀疑DeepMind是否有意在等待OpenAI的更新,以便在此之后再推出他们的模型。
而上周我们在进行grok-vision-beta视觉能力实测的时候,选择了gemini-exp-1121作为实测对比,竟意外发现了gemini-exp-1121视觉方面能力非常出色。今天,我们将通过302.AI进一步实测gemini-exp-1121逻辑推理以及编程方面的能力。
(PS:附上grok-vision-beta视觉能力实测链接:https://mp.weixin.qq.com/s/tuUBTvb7b5w0h378ntbuZA)
> 在302.AI上使用gemini-exp-1121
首先,我们先看看如何在302.AI上获得gemini-exp-1121模型:
【聊天机器人】
1、进入302.AI,点击“使用机器人”——“聊天机器人”——选择“模型”——在Gemini分类中找到“gemini-exp-1121”。
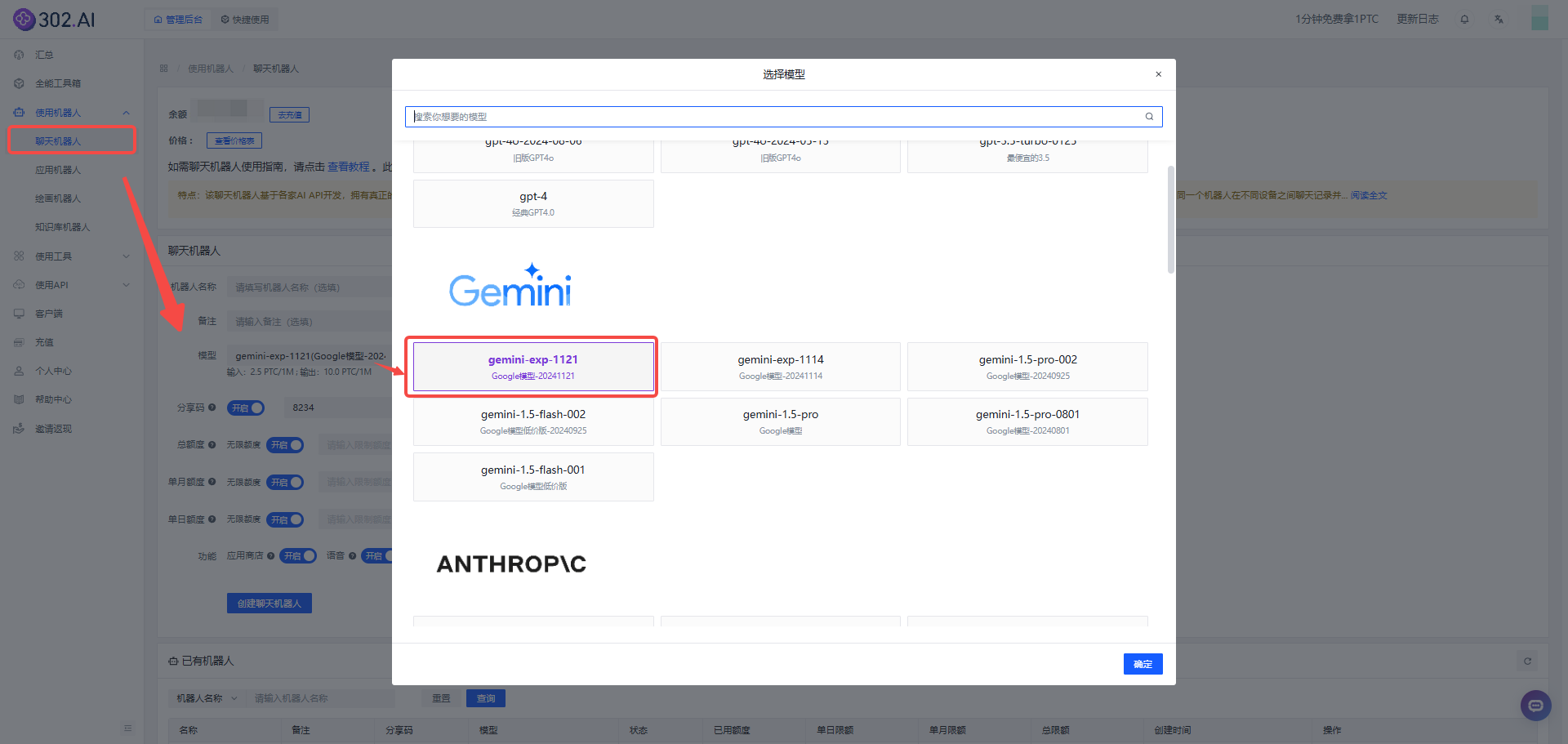
![]()
2、进入聊天机器人后点击页面左下角的设置——可以打开实时预览功能:
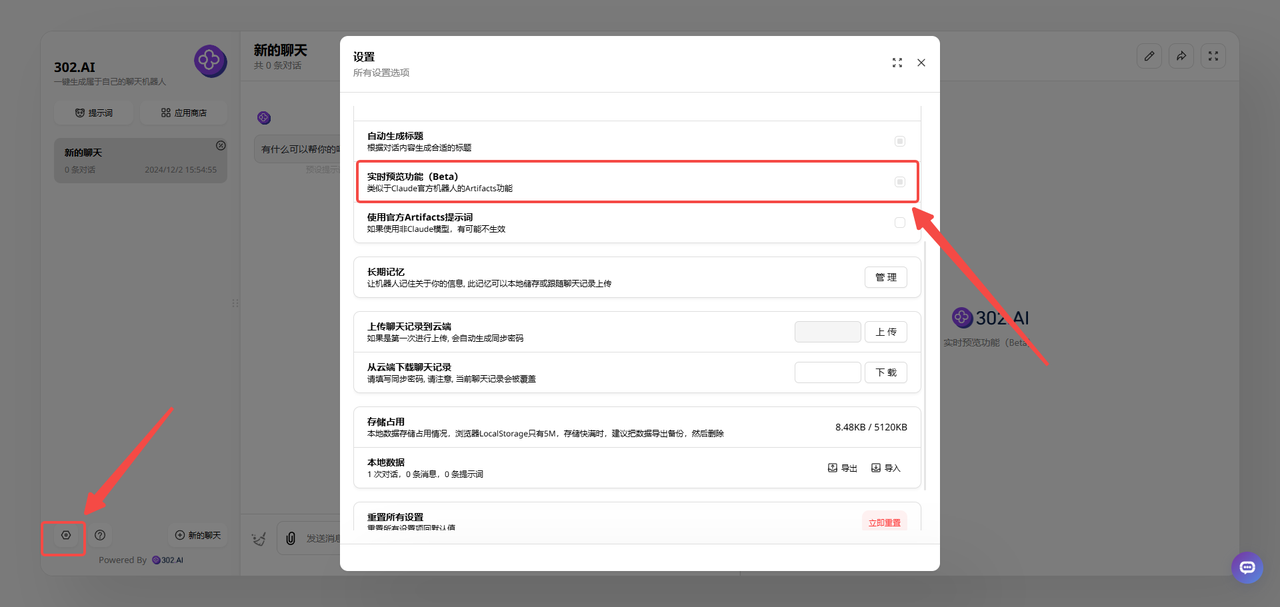
![]()
【API超市】
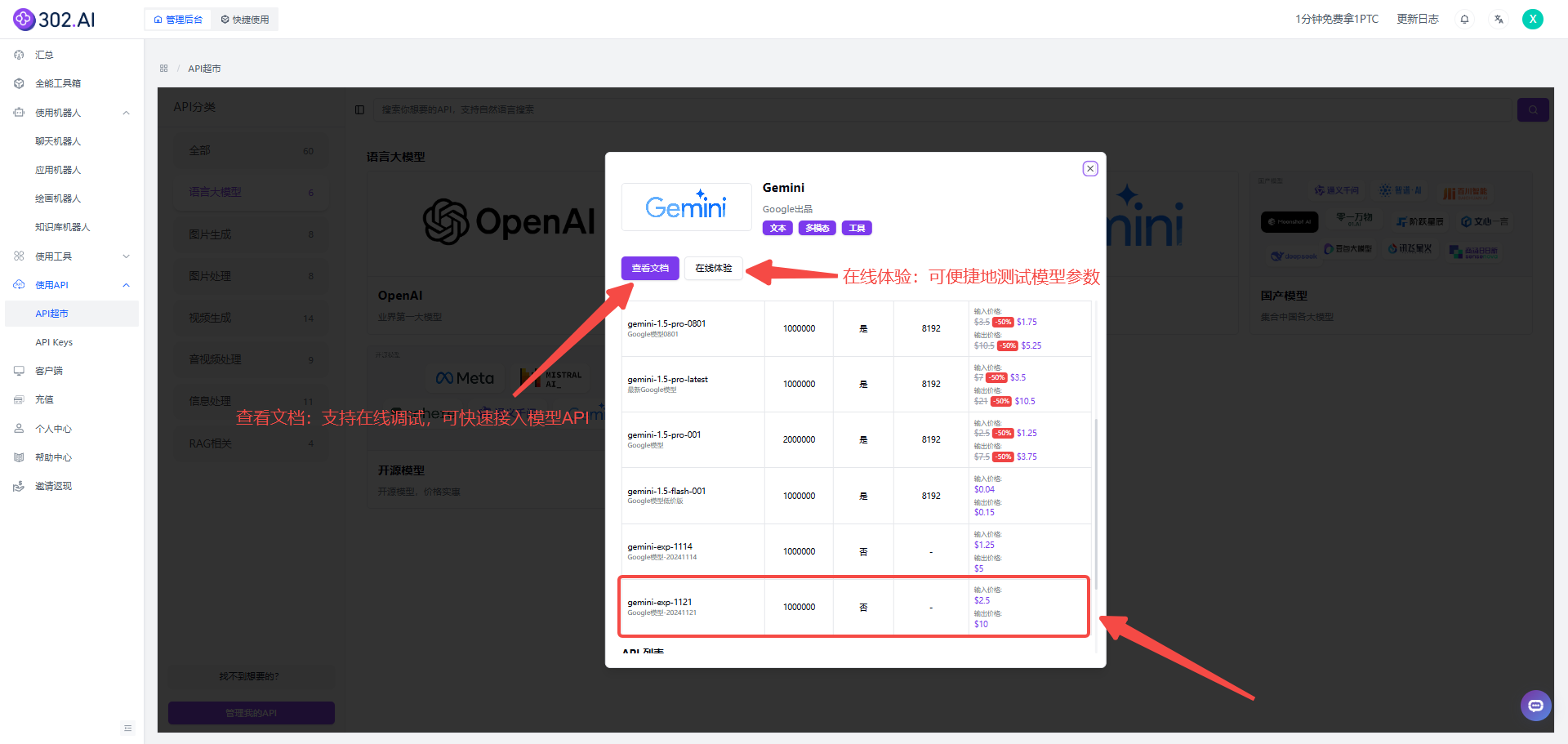
1、点击“使用API”——“API超市”——“语言大模型”——选择“Gemini”。

![]()
2、选择“Gemini”可以看到列表中已经提供了gemini-exp-1121模型的API,可以根据需求选择“查看文档”或者“在线体验”功能进一步使用。
![]()
> gemini-exp-1121实测对比
气氛已经烘托到这了,那接下来我们实测就选择gemini-exp-1114、gpt-4o-2024-11-20、gemini-exp-1121这三个模型,主要测试逻辑推理、编程等方面的表现。
数学理解测试:
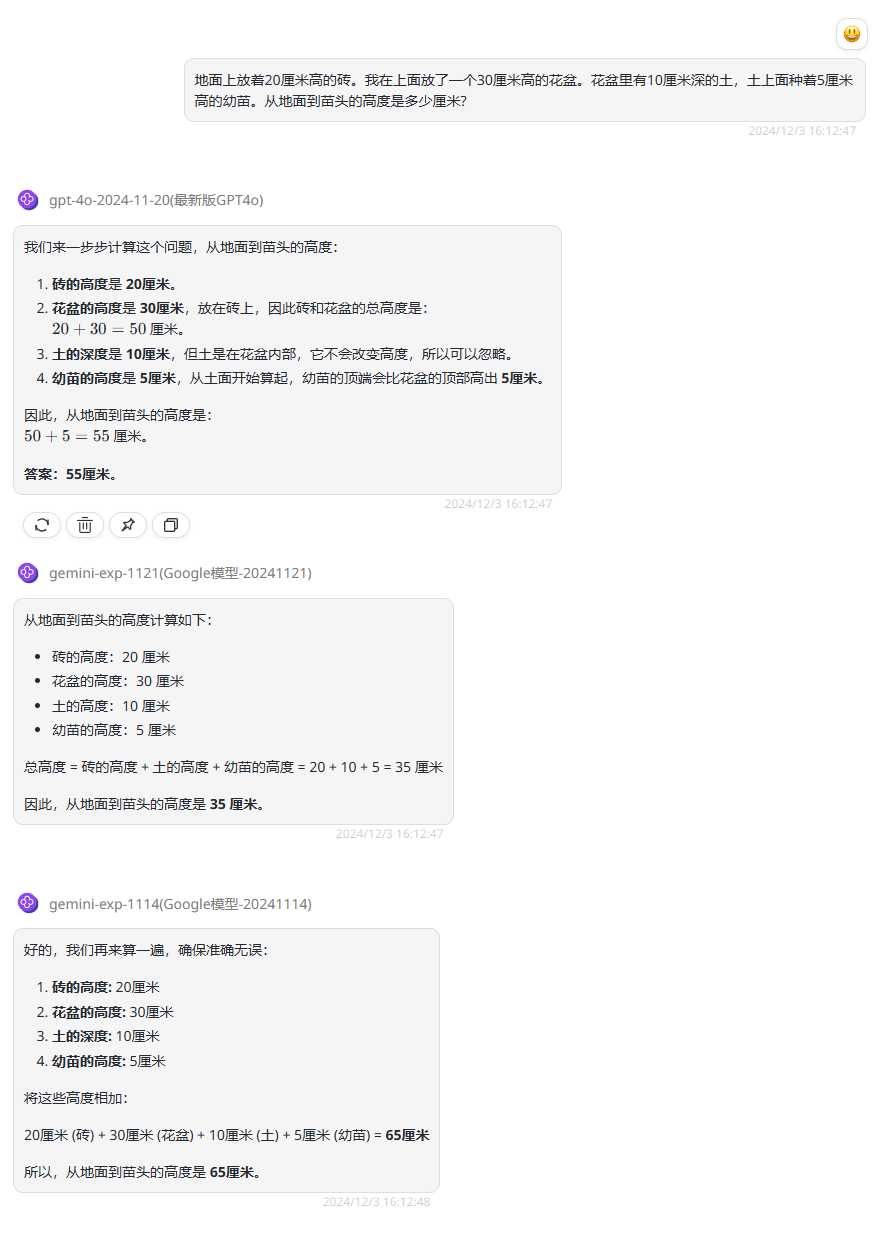
提示词:地面上放着20厘米高的砖。我在上面放了一个30厘米高的花盆。花盆里有10厘米深的土,土上面种着5厘米高的幼苗。从地面到苗头的高度是多少厘米?
分析:首先这一题目的正确答案是35厘米,看下个模型的答案:
gpt-4o-2024-11-20:分析对了一半,最终回答错误
gemini-exp-1121:思路清晰,回答正确。
gemini-exp-1114:并未理解题目,回答错误。
![]()
逻辑推理测试:
提示词:

![]()
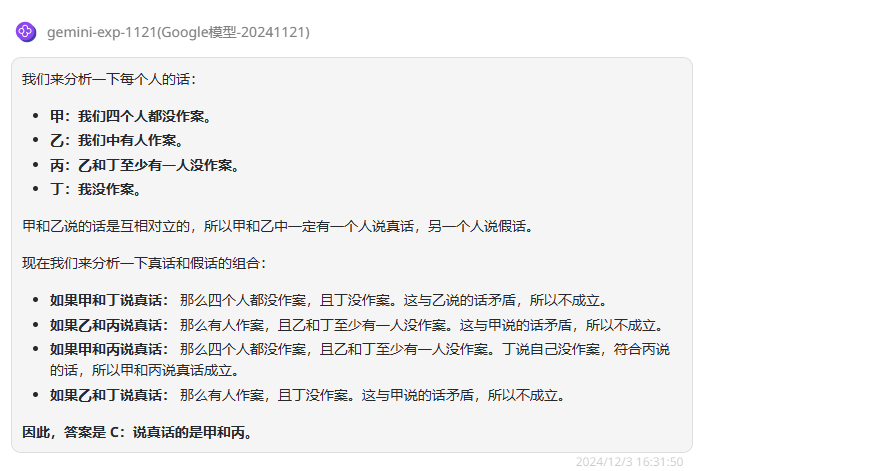
分析:这是一道经典的逻辑推理测试题,来看下三个模型的回答。
gpt-4o-2024-11-20:分析正确,整体篇幅较长,回答正确。

![]()
gemini-exp-1121:分析错误,回答错误。
![]()
gemini-exp-1114:分析正确且清晰,回答正确。

![]()
编程测试:
使用工具:302.AI的聊天机器人——Artifacts功能;
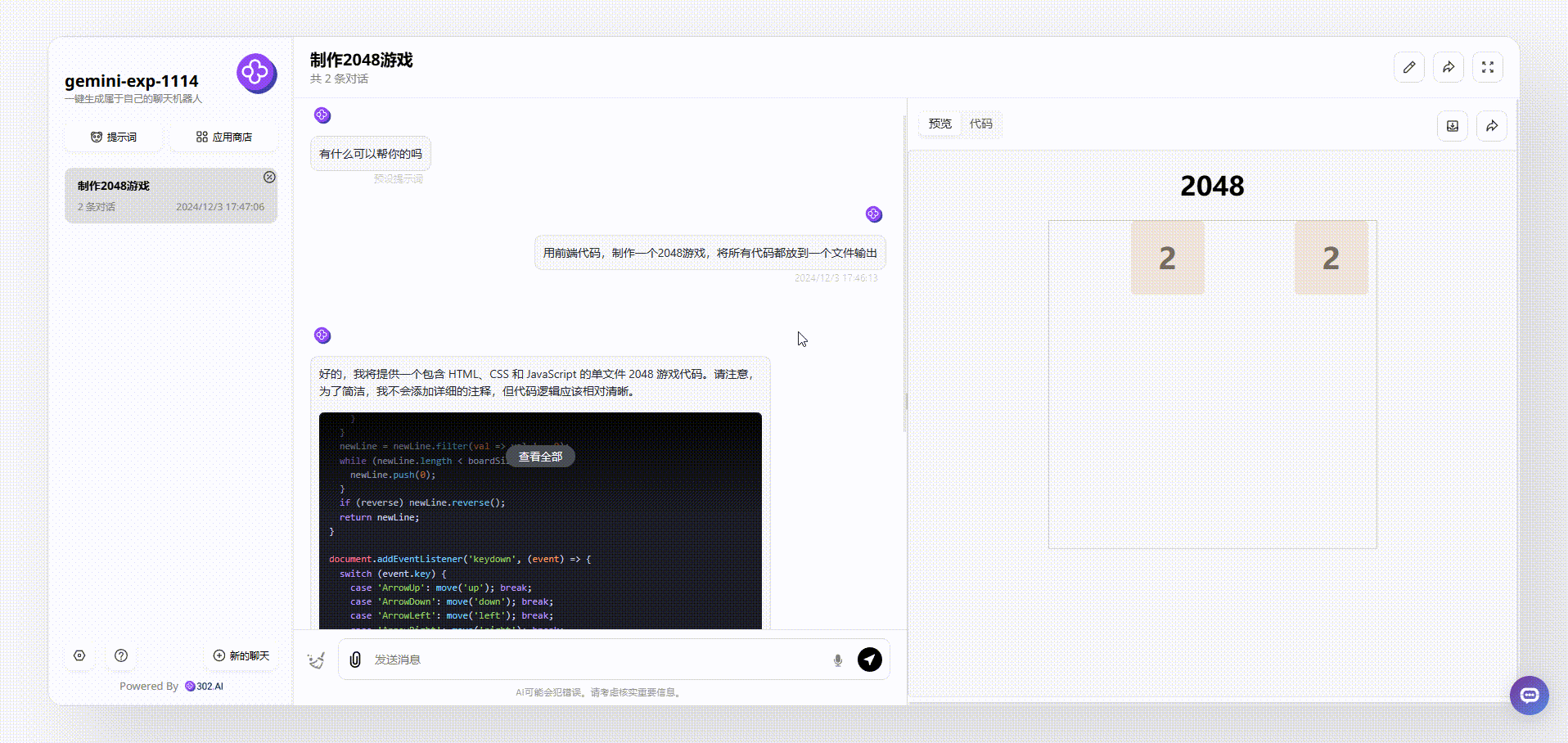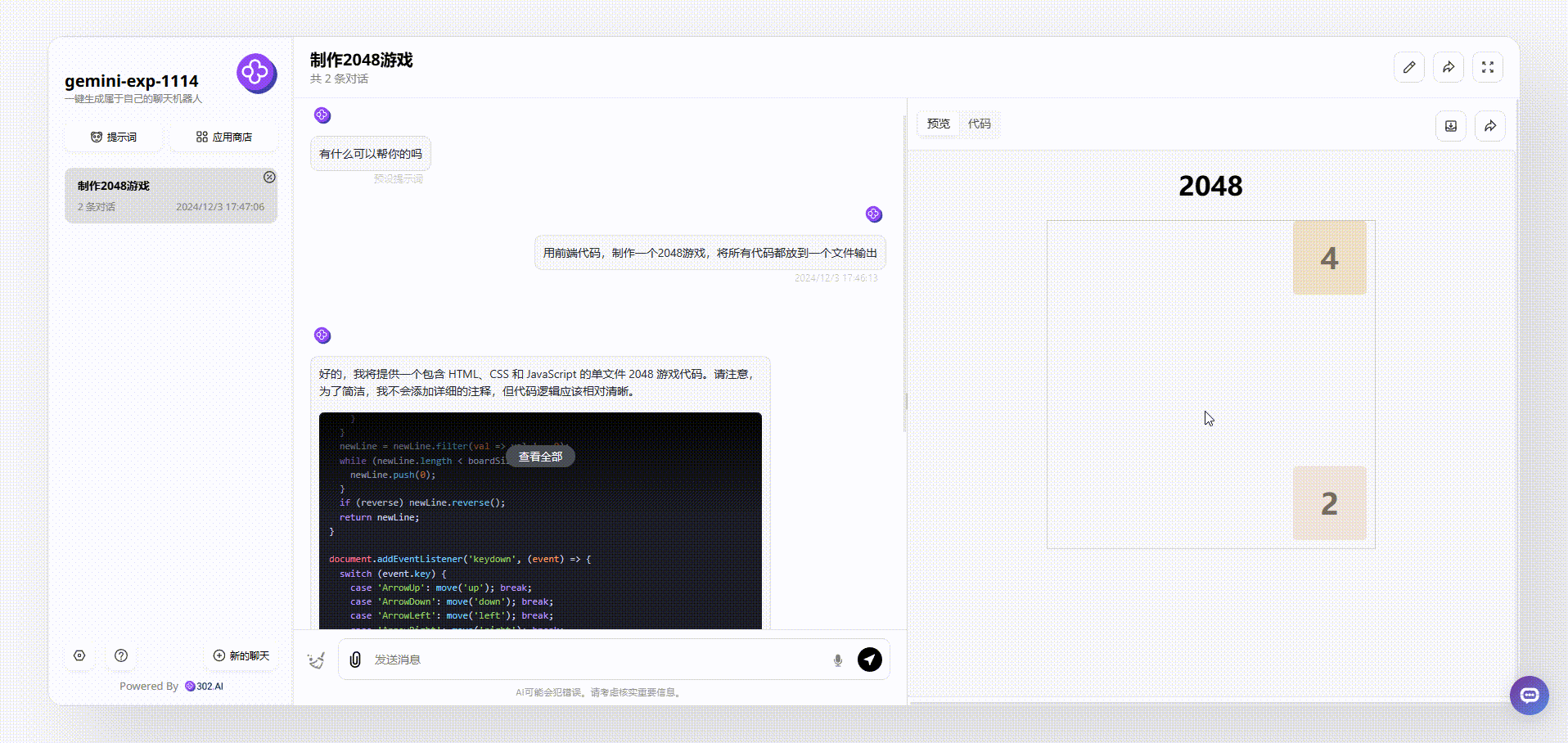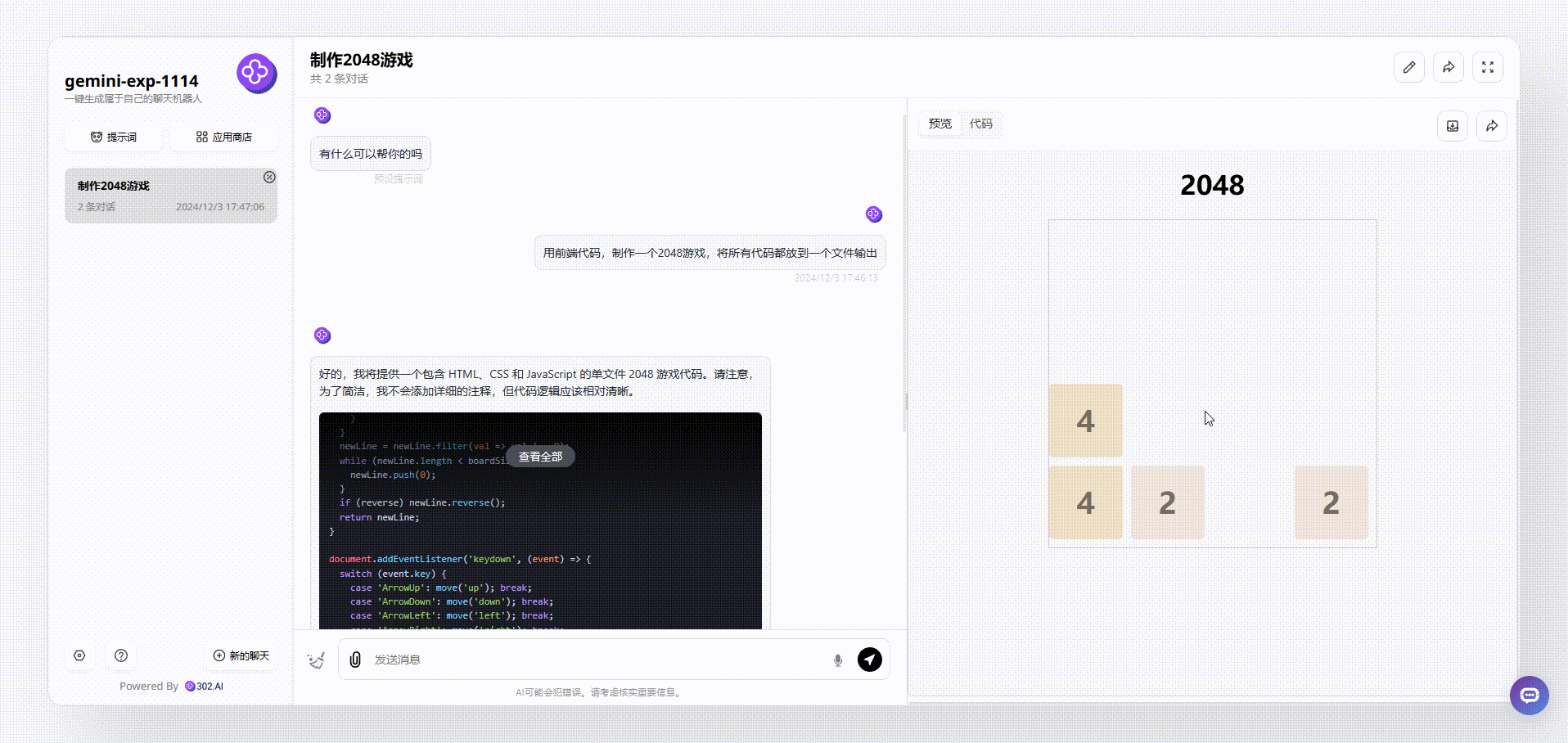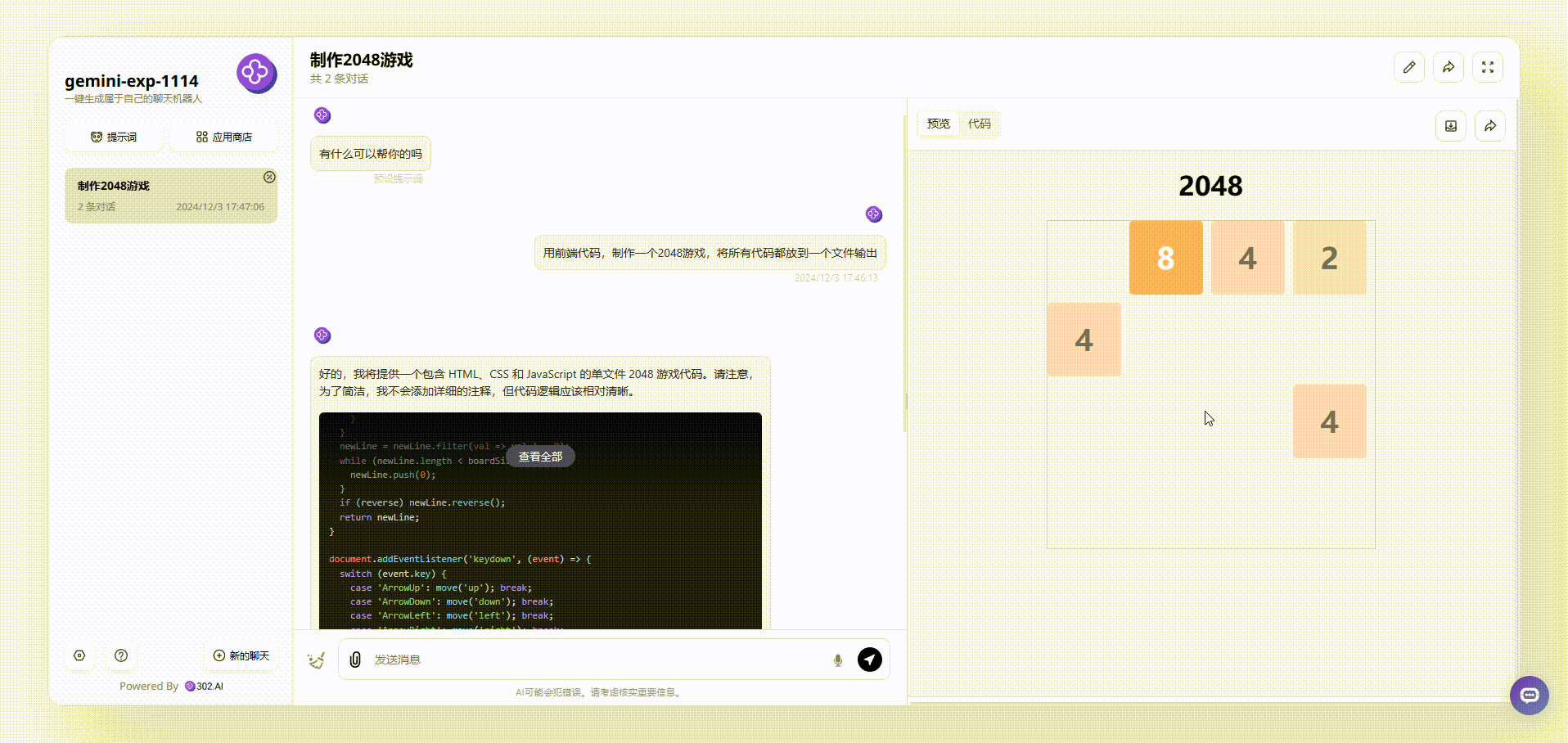
提示词:用前端代码,制作一个2048游戏,将所有代码都放到一个文件输出
gemini-exp-1114:生成的效果能够通过键盘方向键进行游戏,但页面美观性和完整性稍有欠缺。
![]()
gemini-exp-1121:同样提示词下,gemini-exp-1121生成的效果仅仅只能看,无论是使用鼠标还是键盘都不能操作游戏,且没有开始游戏按钮。
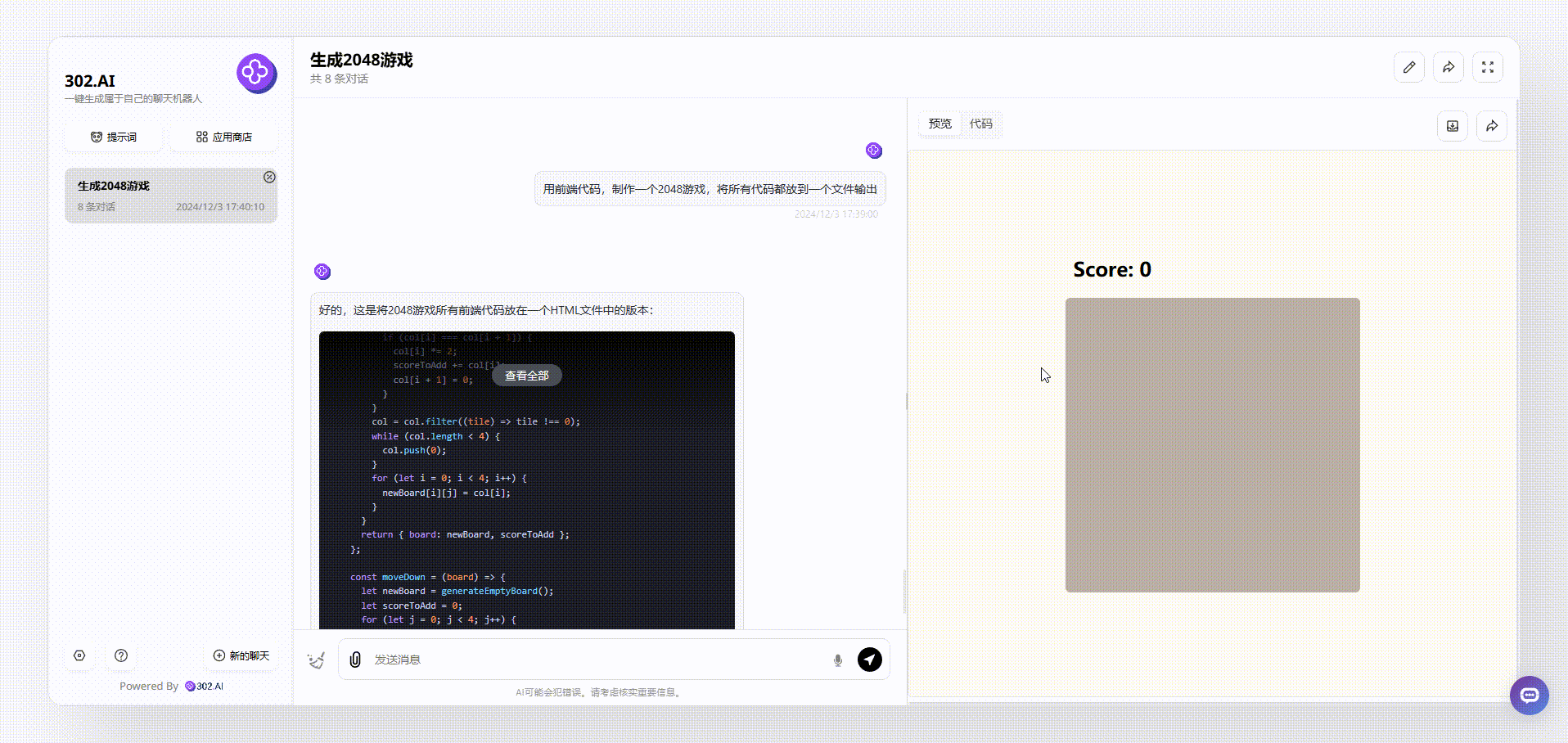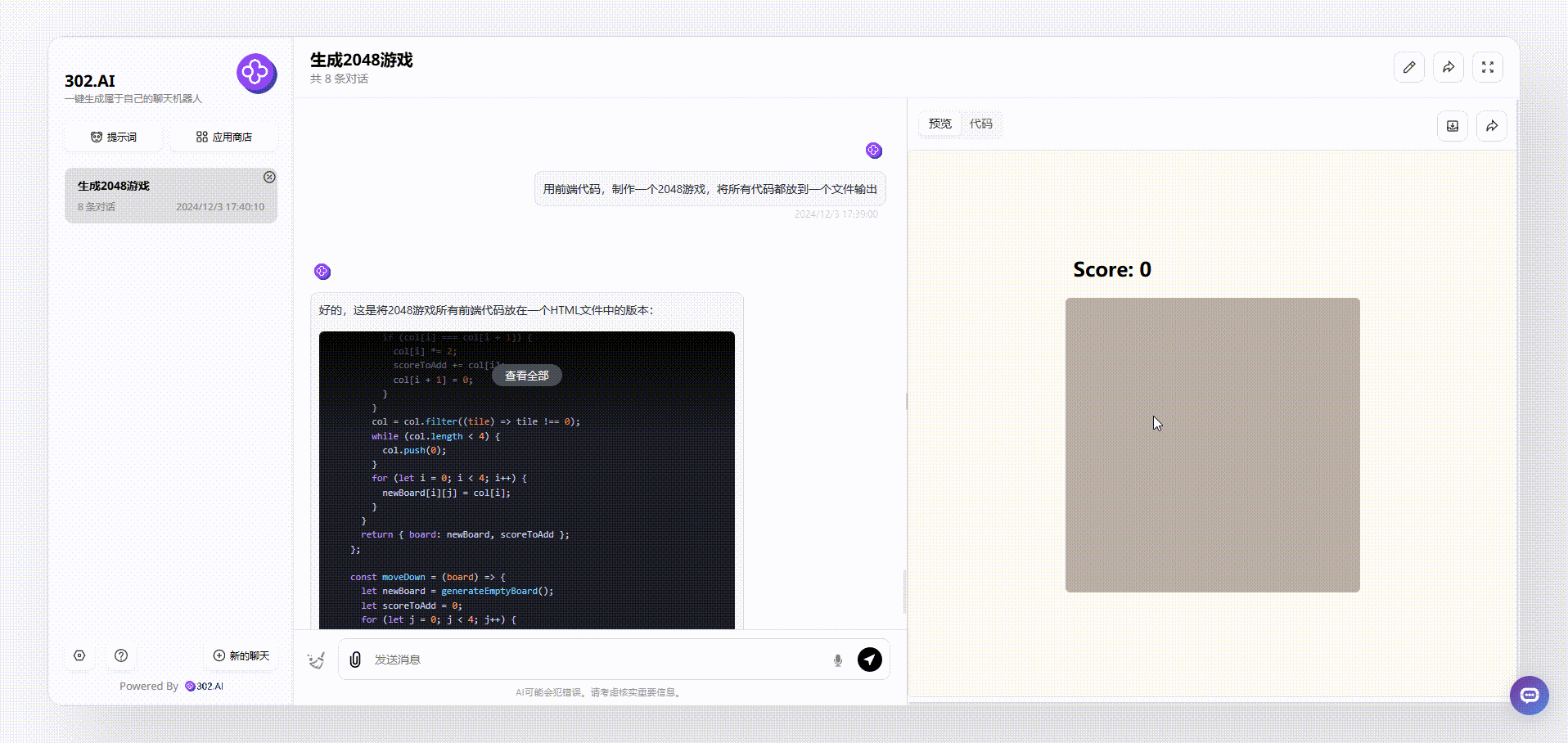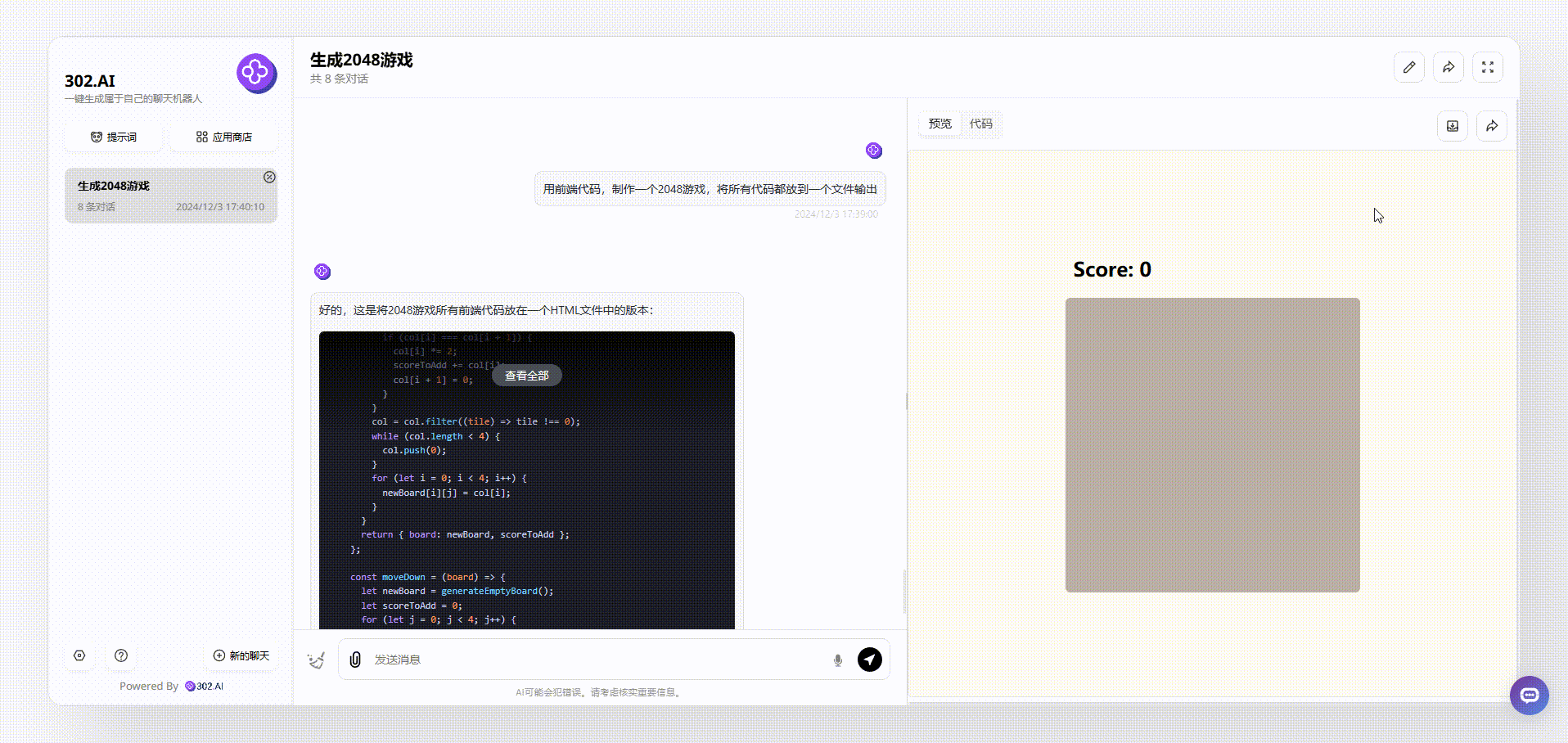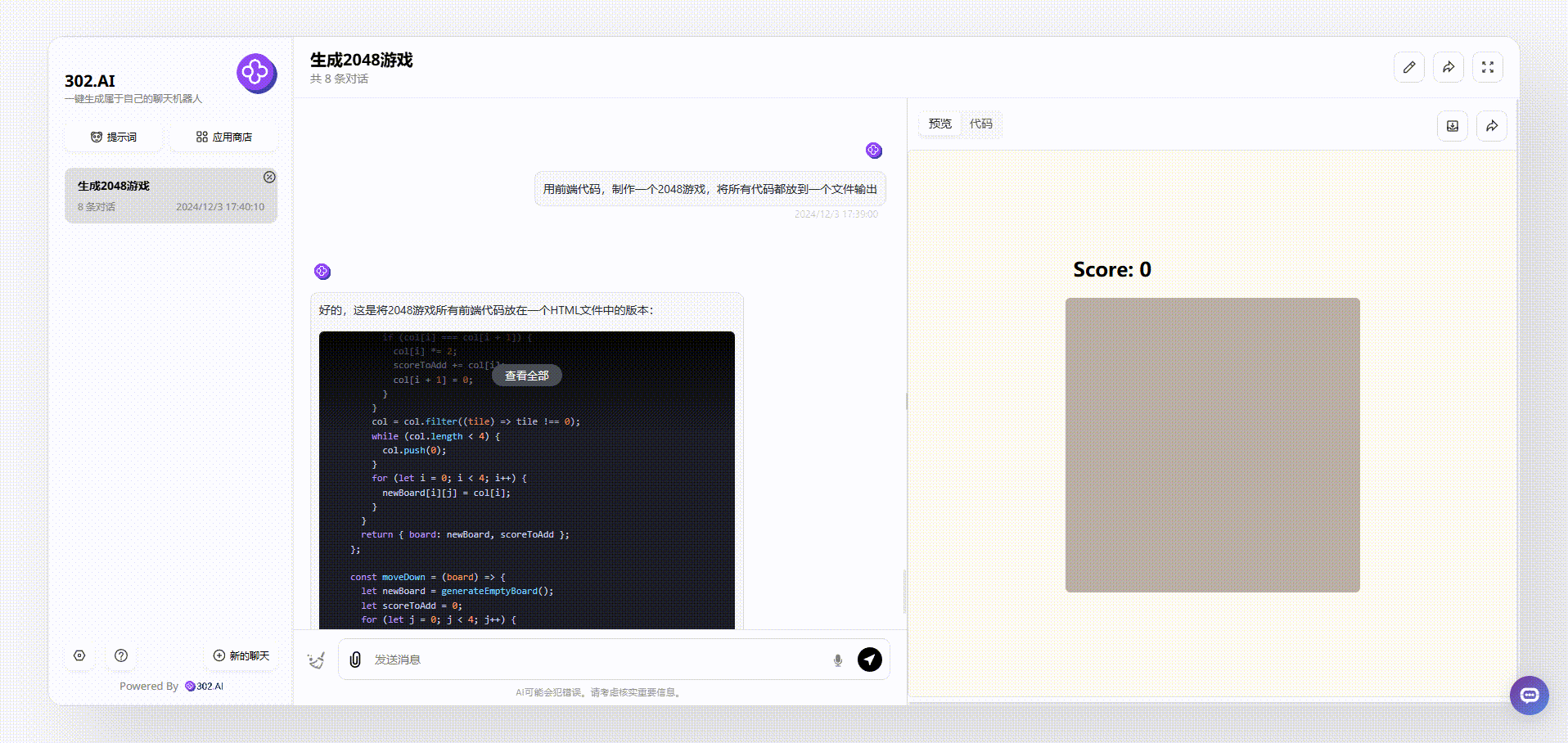
![]()
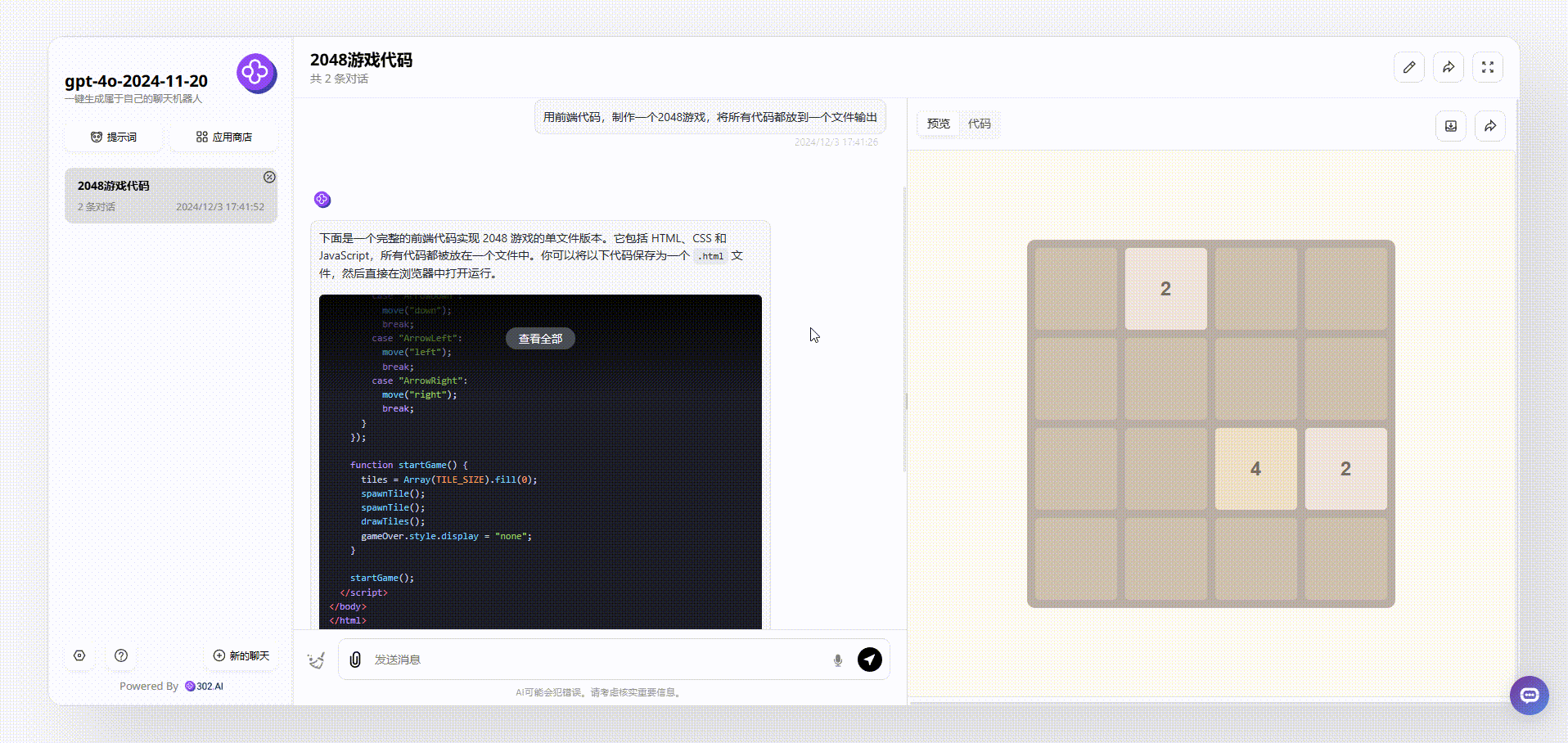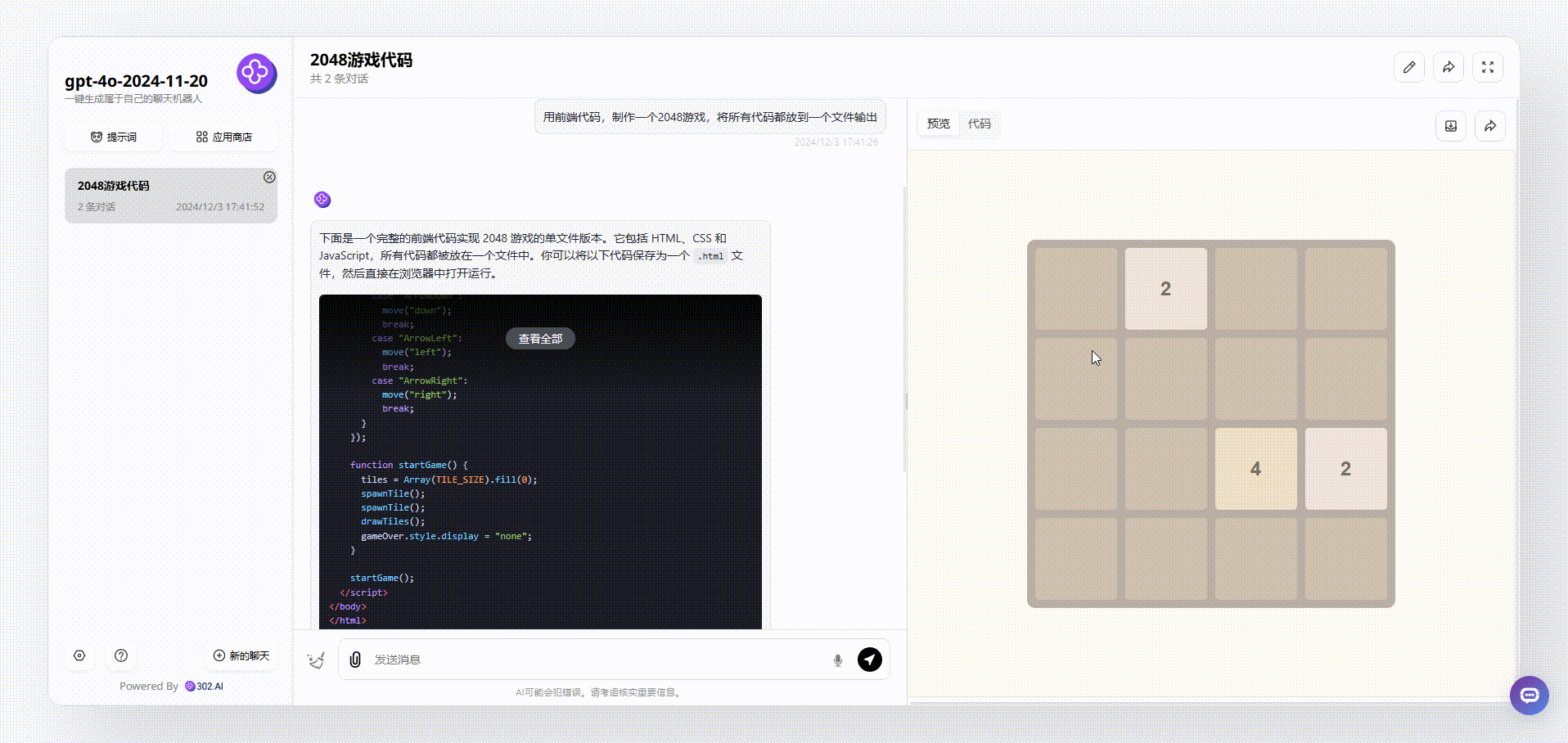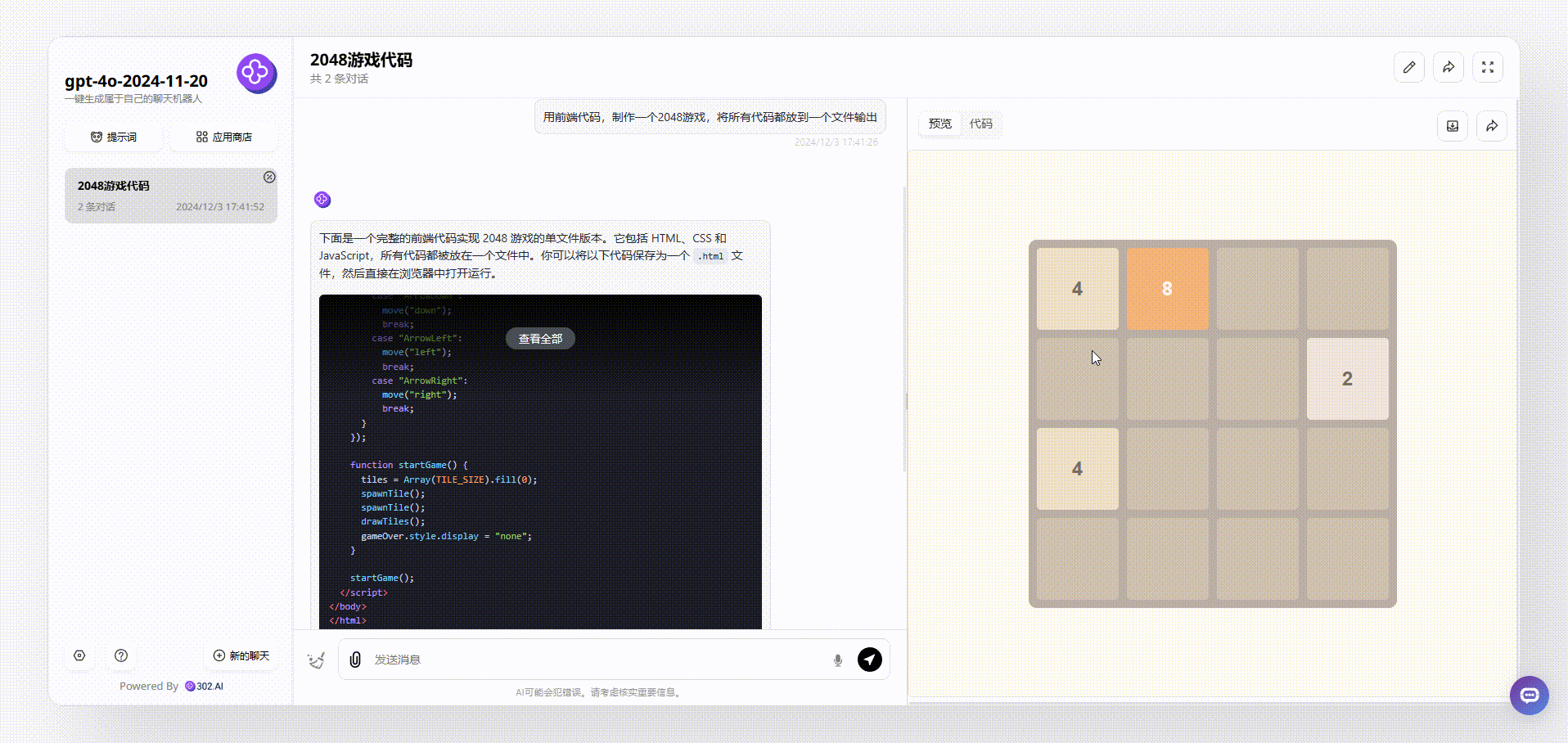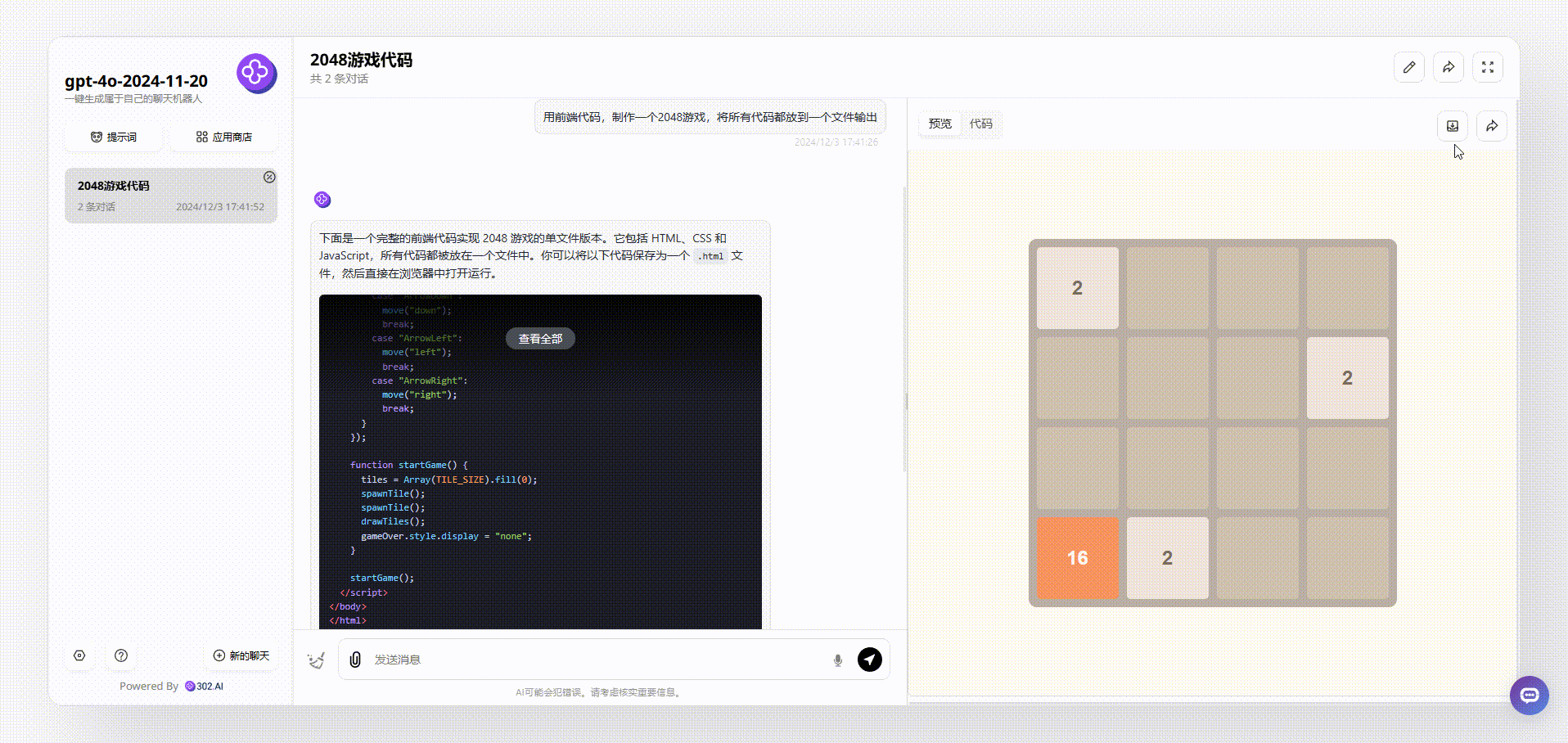
gpt-4o-2024-11-20:最后gpt-4o-2024-11-20生成的效果具备了美观性,且能够使用键盘操作,但是美中不足是完整性还有欠缺,缺少了得分提示、开始结束等。
![]()
o1-preview:最后,看下生成效果比较好的o1-preview,整个游戏非常完整,具备开始游戏等按钮、还有记录得分板块,同时还具有操作性。

![]()
> 总结
通过以上实测可以初步得出以下结论:
数学理解测试:在数学测试中,只有gemini-exp-1121模型真正理解题目并给出正确答案,其余的模型只是对数据进行简单累加,并未能够理解并分析题目的具体情境。
逻辑推理测试:在逻辑测试中,gemini-exp-1114的表现比gemini-exp-1121更好,不仅逻辑清晰,分析的答案易理解,而且给出了正确的答案。
编程测试:对于简单的游戏生成,gemini-exp-1121的表现未能令人满意,生成的效果仅为静态界面,不具备操作性。
综上所述,虽然gemini-exp-1121在各个测试中展现出不同程度的优势,但仍有改进的空间。尤其是在编程能力方面,模型需要进一步优化生成代码的质量和复杂性。但令人不解的是,在逻辑测试和编程测试中,前一版本的表现明显比gemini-exp-1121更好,难道是前一版本的算法更加优化?但无论是gemini-exp-1121还是gemini-exp-1114,都仅为实验性模型,我们可以持续关注Google,看看后续是否对模型有改进。
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(8)
Yay google is my queen aided me to find this great site! .
Thank you for some other informative blog. The place else could I am getting that type of information written in such a perfect approach? I’ve a undertaking that I am just now working on, and I have been at the look out for such info.
Excellent weblog here! Additionally your website lots up fast! What web host are you the usage of? Can I get your associate link in your host? I desire my web site loaded up as fast as yours lol
I’ve been browsing online more than 3 hours today, yet I never found any interesting article like yours. It is pretty worth enough for me. In my view, if all webmasters and bloggers made good content as you did, the internet will be much more useful than ever before.
I am happy that I observed this site, precisely the right information that I was searching for! .
Please let me know if you’re looking for a article author for your site. You have some really good posts and I feel I would be a good asset. If you ever want to take some of the load off, I’d absolutely love to write some material for your blog in exchange for a link back to mine. Please send me an email if interested. Kudos!
Nice post. I was checking continuously this blog and I am impressed! Extremely helpful info specifically the last part :) I care for such info a lot. I was seeking this particular information for a long time. Thank you and good luck.
I want reading and I think this website got some genuinely utilitarian stuff on it! .