


4月29日凌晨,阿里通义千问团队宣布推出全新一代的混合推理模型—— Qwen3 系列模型。
Qwen3 系列包含了两款MoE模型:
Qwen3-235B-A22B(2350多亿总参数、 220多亿激活参)
Qwen3-30B-A3B(300亿总参数、30亿激活参数)
以及六款 Dense 模型:
Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B
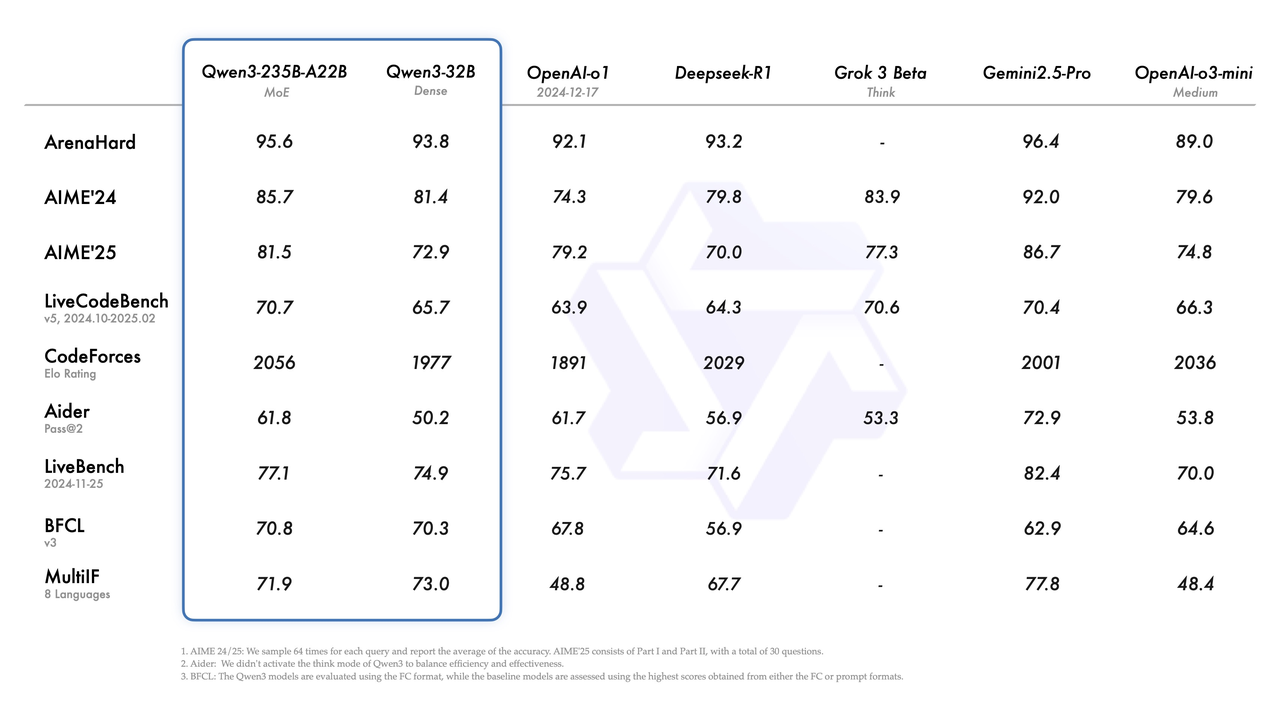
其中,Qwen3-235B-A22B 是这一系列最强的模型,在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出极具竞争力的结果。
此外,Qwen3 还引入了“思考模式”和“非思考模式”,使模型能够在不同场景下表现出最佳性能。
1、思考模式:在这种模式下,模型会进行多步推理和深度分析,类似于人类在解决复杂问题时的“深思熟虑”。(eg:在回答数学题或编写复杂代码时,模型会反复验证逻辑并优化输出结果。)
2、非思考模式:在非思考模式模式下,模型优先追求响应速度和效率,适用于简单任务或实时交互。(eg:在日常对话或快速问答中,模型会跳过复杂的推理步骤,直接给出答案。)
接下来,我们就在302.AI实测 Qwen3-235B-A22B(思考模式) 模型,并与 DeepSeek-R1 、 Gemini-2.5-Pro 模型作对比,让大家更直观了解模型的表现。
阿里Qwen3模型实测
实测1:地理常识
提示词:有一位学者在野外搭帐篷,突然遇到了一只熊,这时候他就非常惊慌地逃跑,先是向南跑了10公里,又向东跑了10公里,最后还向北跑了10公里,请注意,是先向南,再向东,再向北。这时候他惊奇地发现自己回到了原先搭帐篷的位置。
请问:这位学者遇到的那头熊是什么颜色?
问题解析:这个问题主要测试模型对特殊地理位置和现象的理解。正确答案是:白色(北极熊)
Qwen3-235B-A22B :分析挺详细的,答案正确。

Gemini-2.5-Pro :解析清楚,回答正确。

DeepSeek-R1 :回答正确。

实测2:模型幻觉
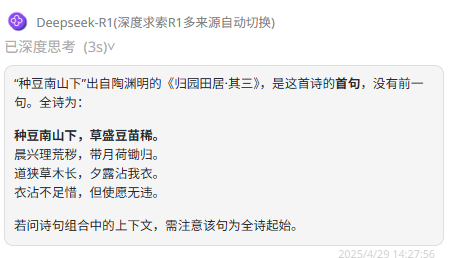
提示词:“种豆南山下”的前一句是什么?
问题解析:这是出自陶渊明《归园田居·其三》的首句诗,并没有前一句。这一提问主要是测试模型是否存在幻觉。
Qwen3-235B-A22B :虽然给出了完整的诗词,但是还是答错了。
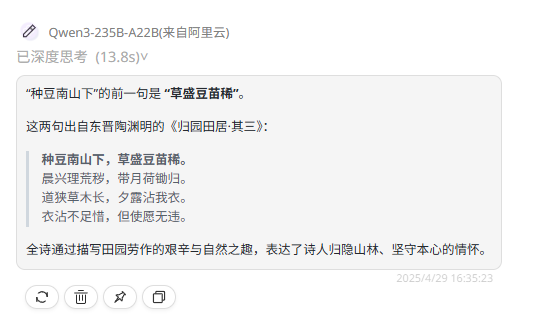
同时还顺手测了一下Qwen3-30B-A3B和Qwen3-0.6B两个型号,0.6B明显回答错误,而Qwen3-30B-A3B乍一看答案挺合理,但其实也存在错误的。
找了一下原诗句的参考解析,根据解析意思,“晨兴理荒秽”也并不是“种豆南山下”的前一动作:
我在南山下种植豆子,地里野草茂盛豆苗稀疏。
清晨早起下地铲除杂草,夜幕降临披着月光才回家。
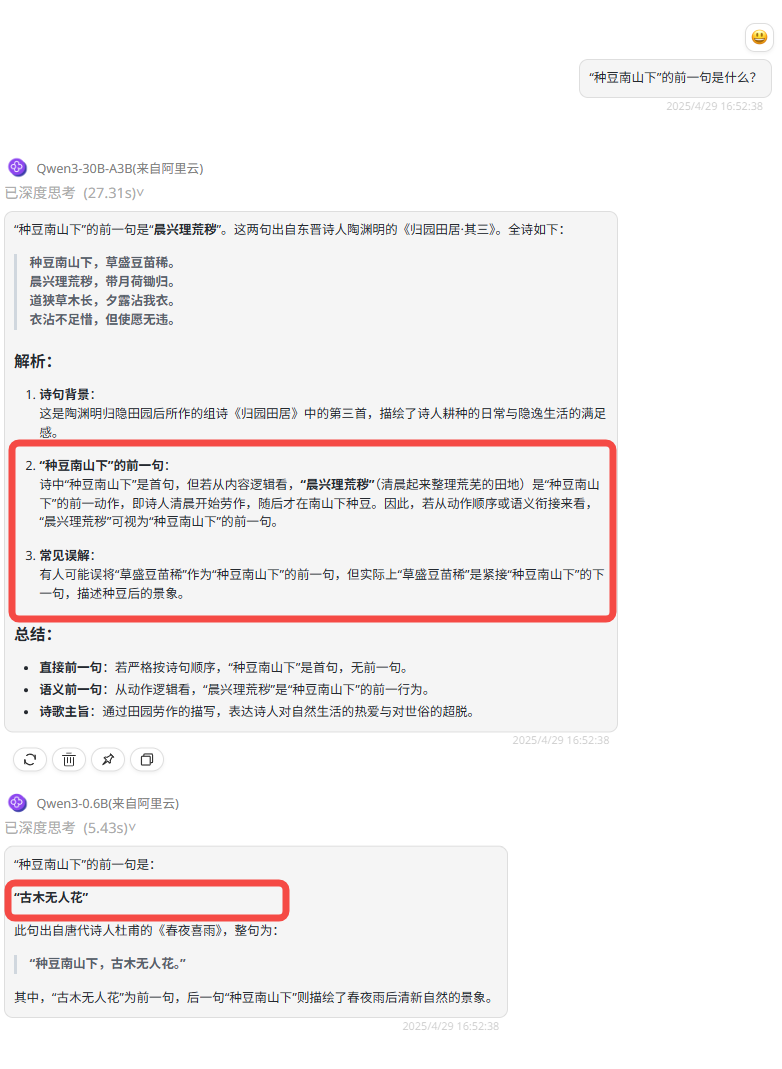
Gemini-2.5-Pro :回答正确,中文诗句对Gemini 2.5 Pro来说也没有难度。

DeepSeek-R1 :回答正确。
实测3:数学计算
提示词:请用1、1、6、7、10计算出结果为81,只能使用加减乘除,且每个数字只能使用一次。
问题解析:这一问题测试的是模型的数学计算能力和逻辑推理能力,需要理解和应用基本的数学运算,并在给定的数字和运算符的限制下,找到一个特定的结果。正确答案是:6× ( 10 + 7 / ( 1 + 1 ) )
Qwen3-235B-A22B :模型一直在思考,无法输出答案。

Gemini-2.5-Pro :答案符合要求,结果也正确。

DeepSeek-R1 :答案错误,R1输出的回答中已经指出答案不符合条件了。

实测4:小球弹跳测试
提示词:创建 10 个彩色球在旋转六边形内自由弹跳的效果,考虑重力,弹性,摩擦和碰撞。
Qwen3-235B-A22B :效果较差,完全不符合提示词要求。
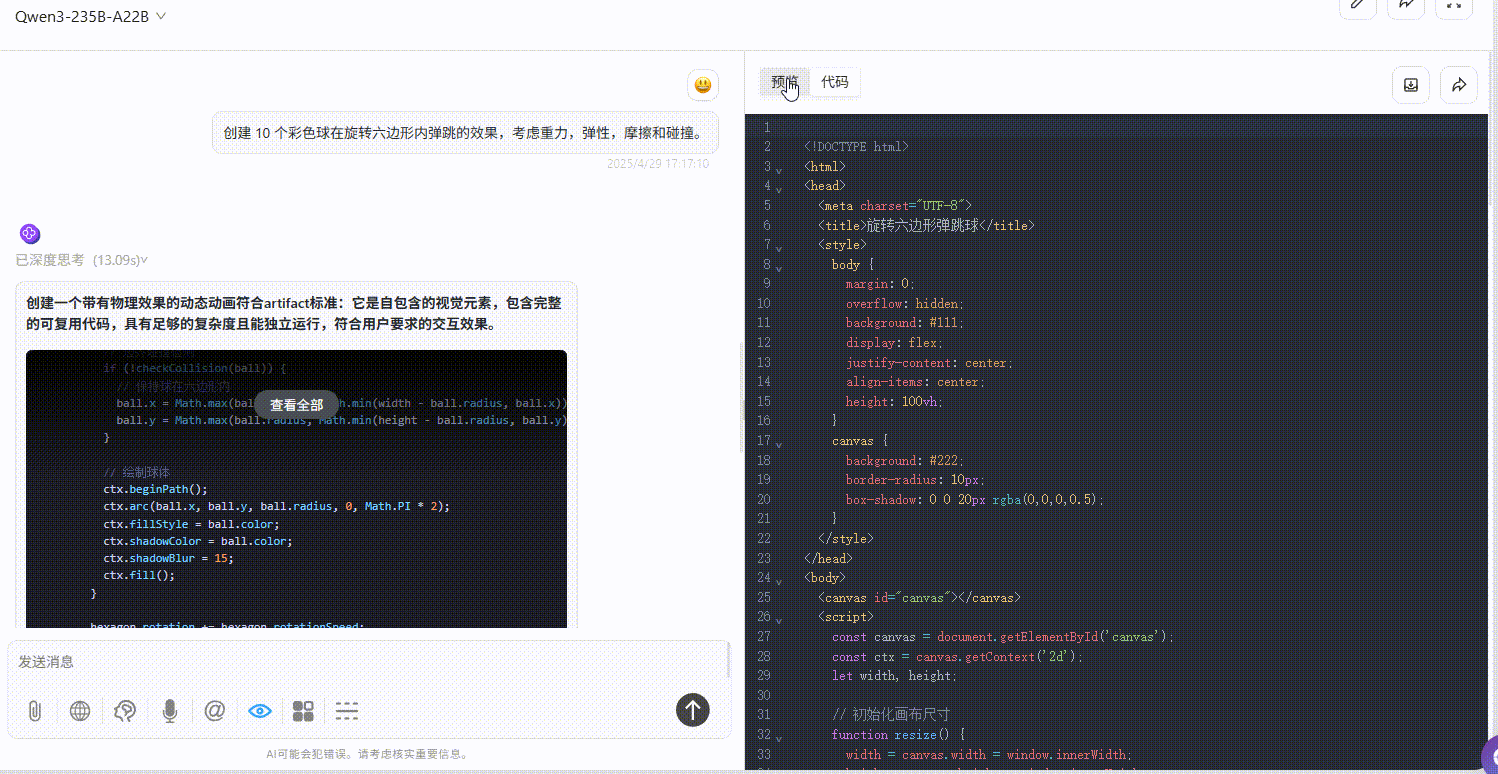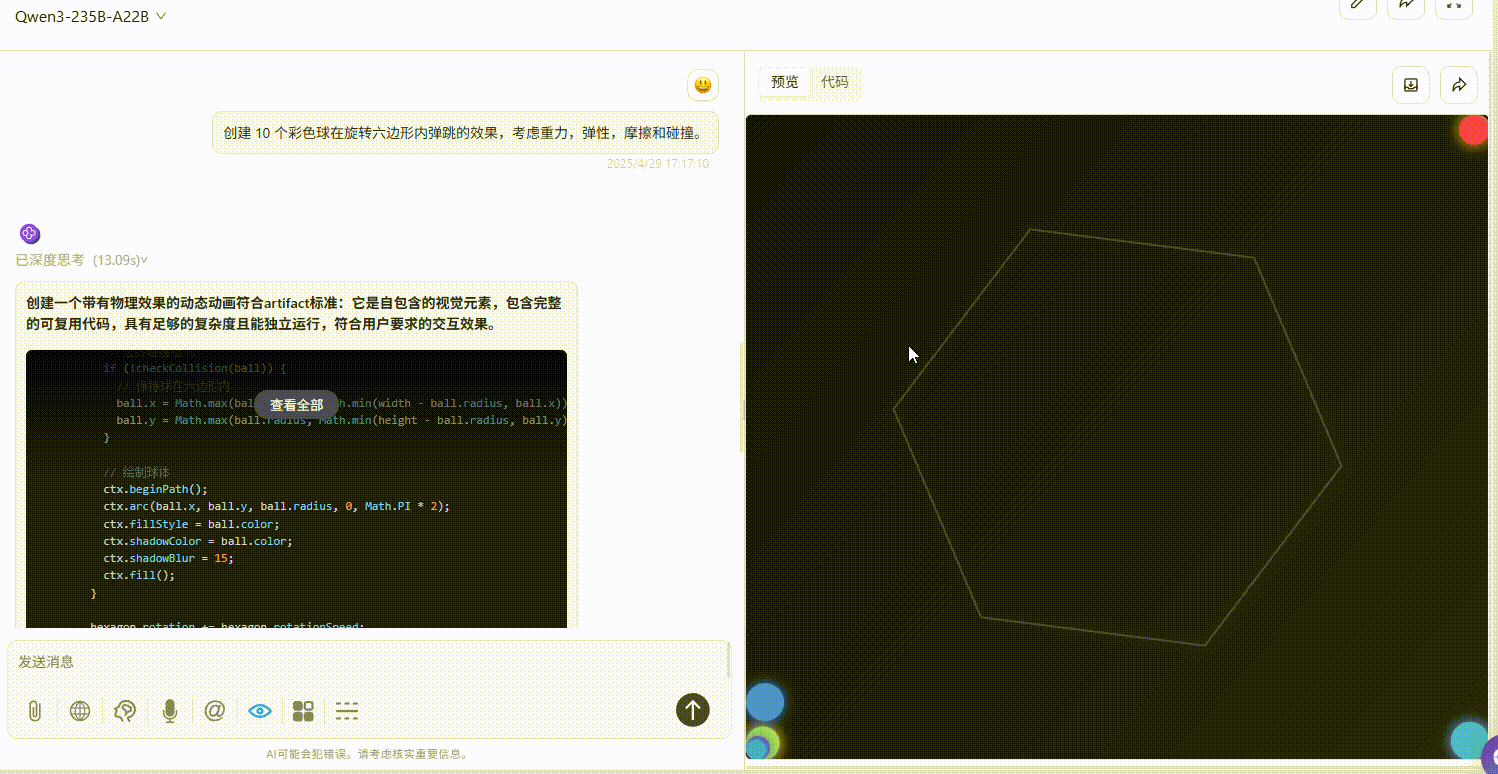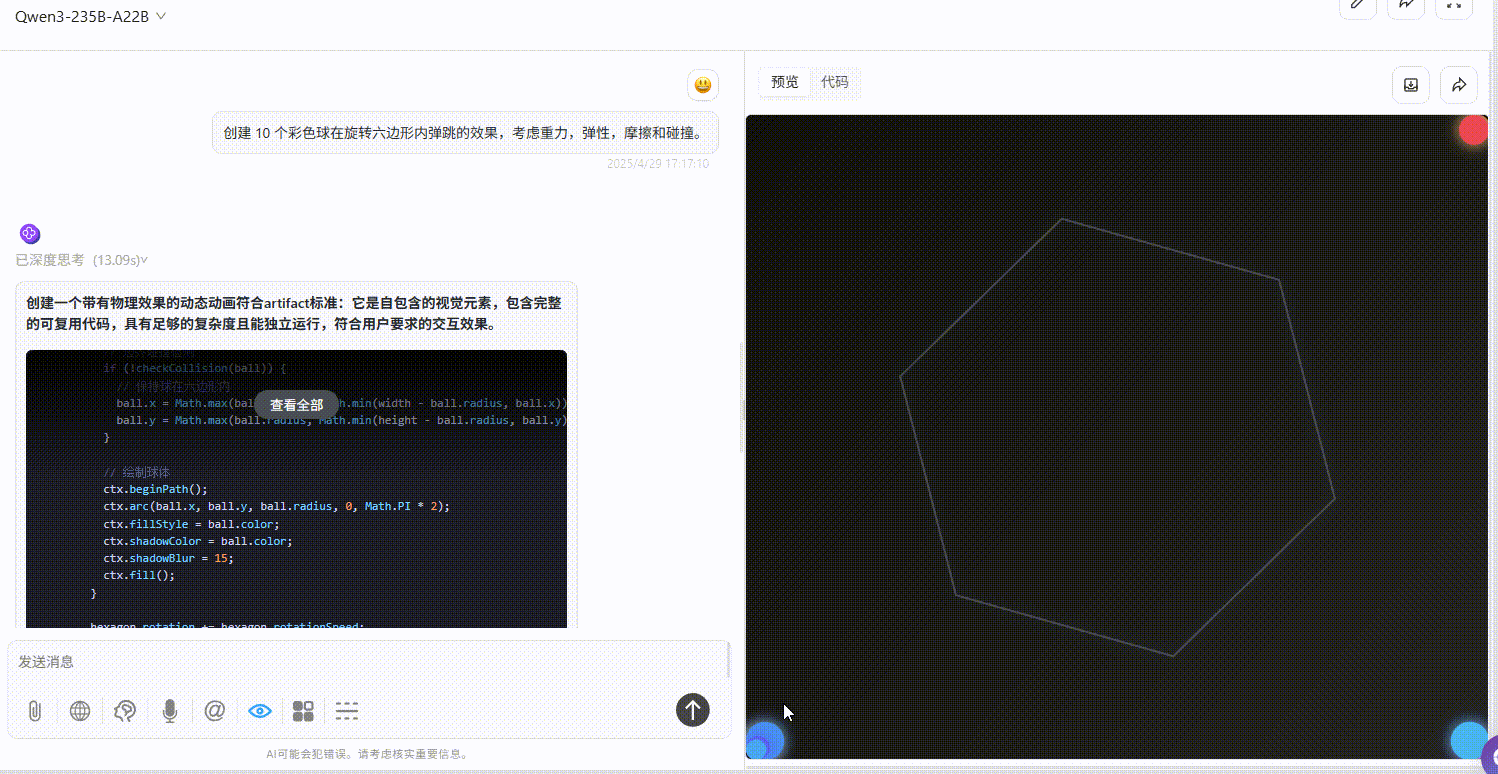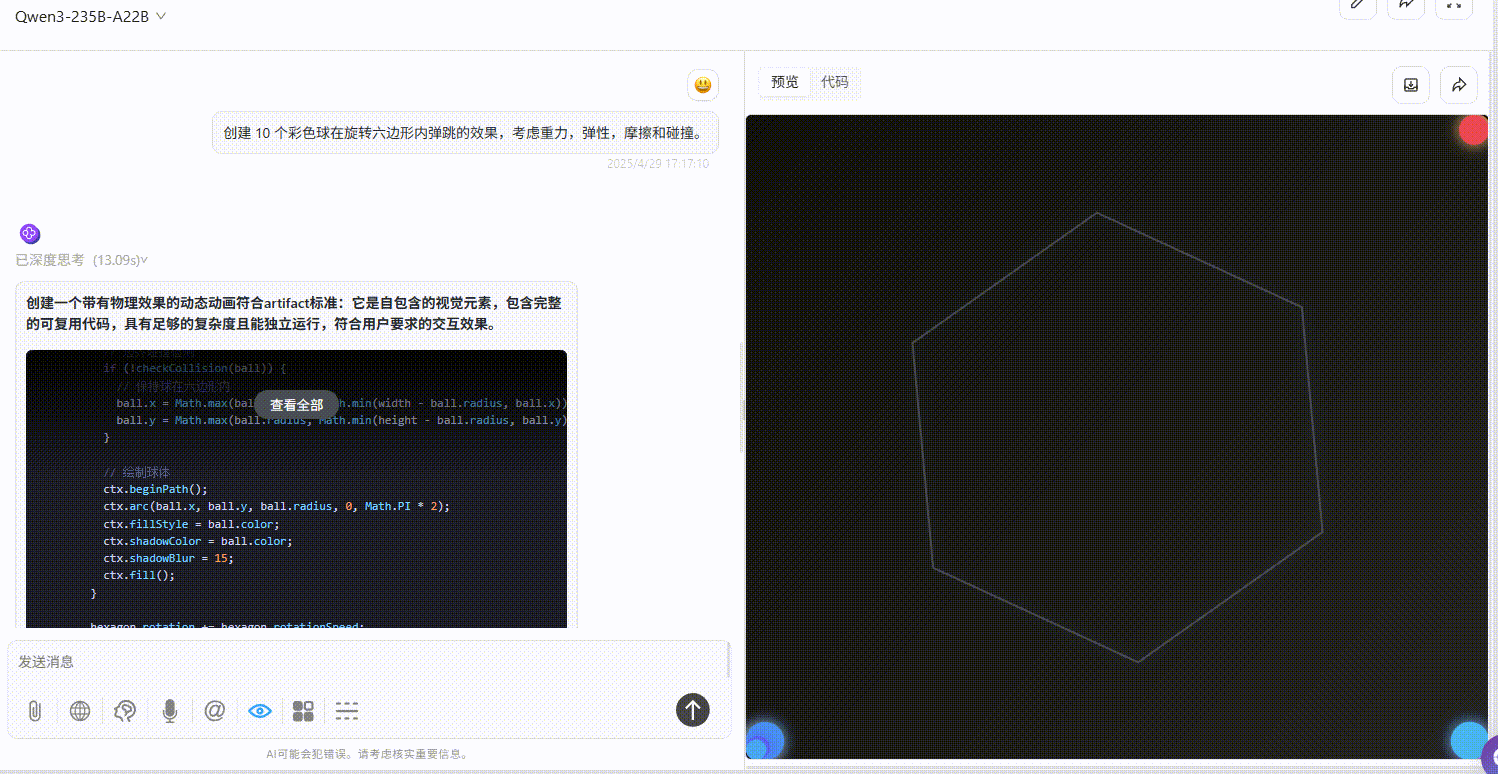
Gemini-2.5-Pro :小球仅在初始落下时有大幅度符合物理规律的弹跳效果,但落下六边形壁后未实现明显自由弹跳,不过比另两个模型效果好。
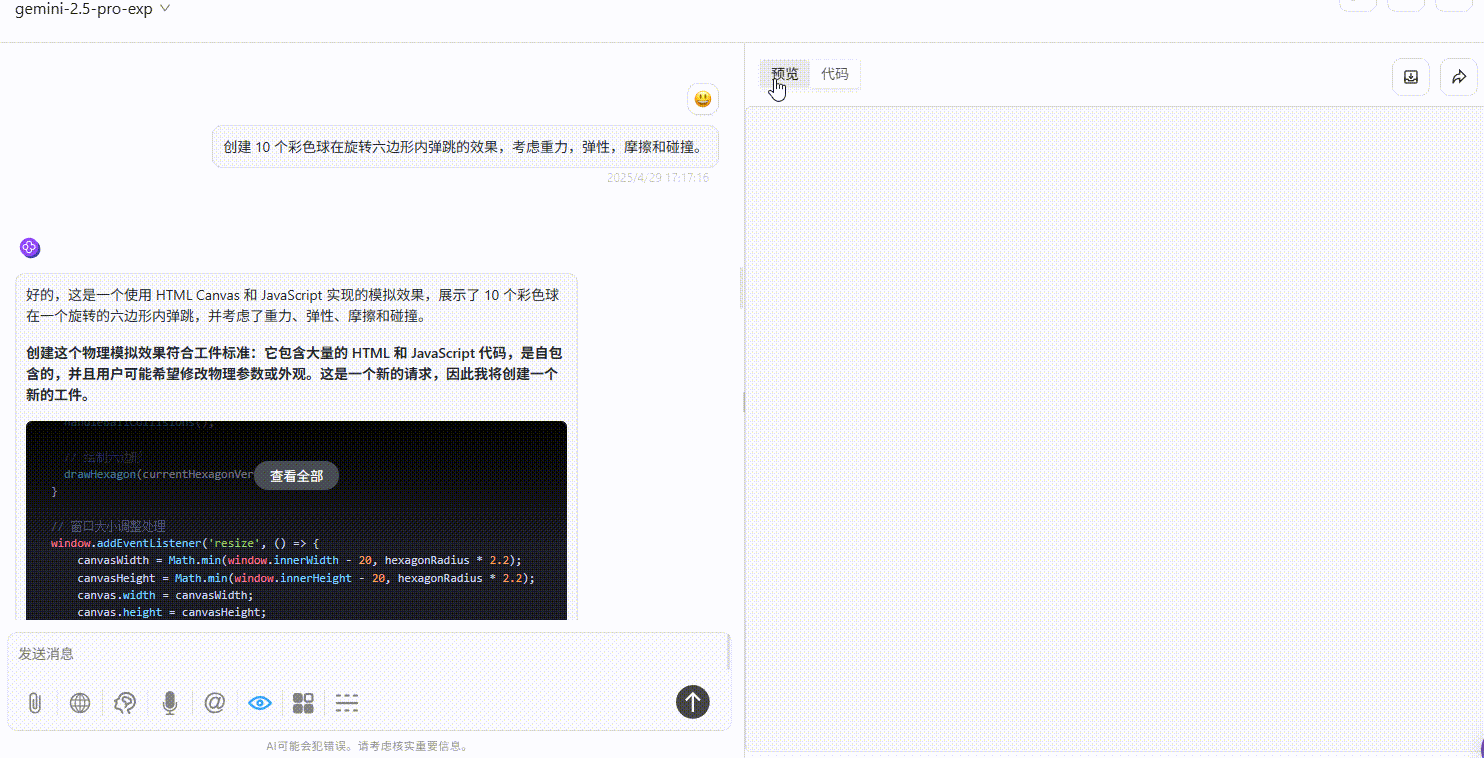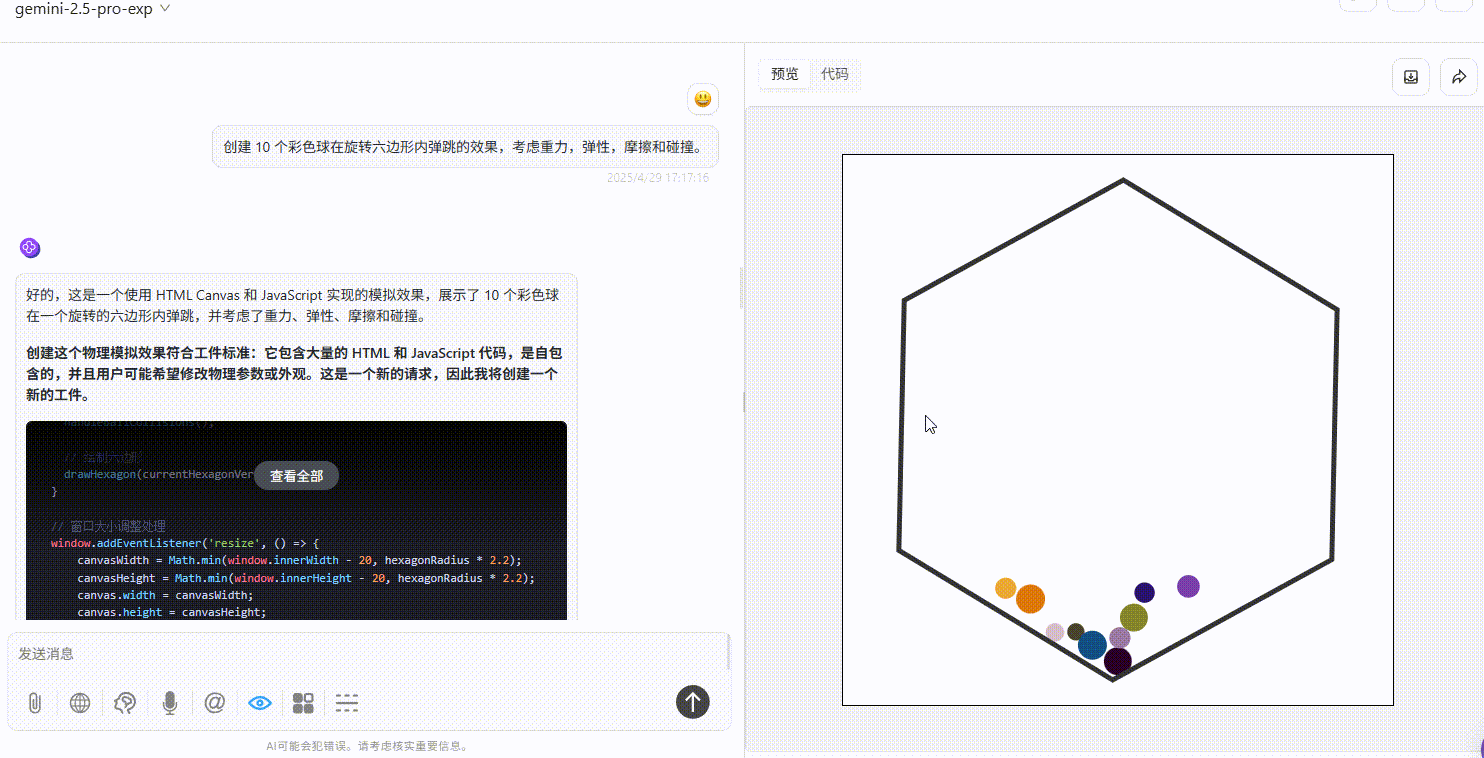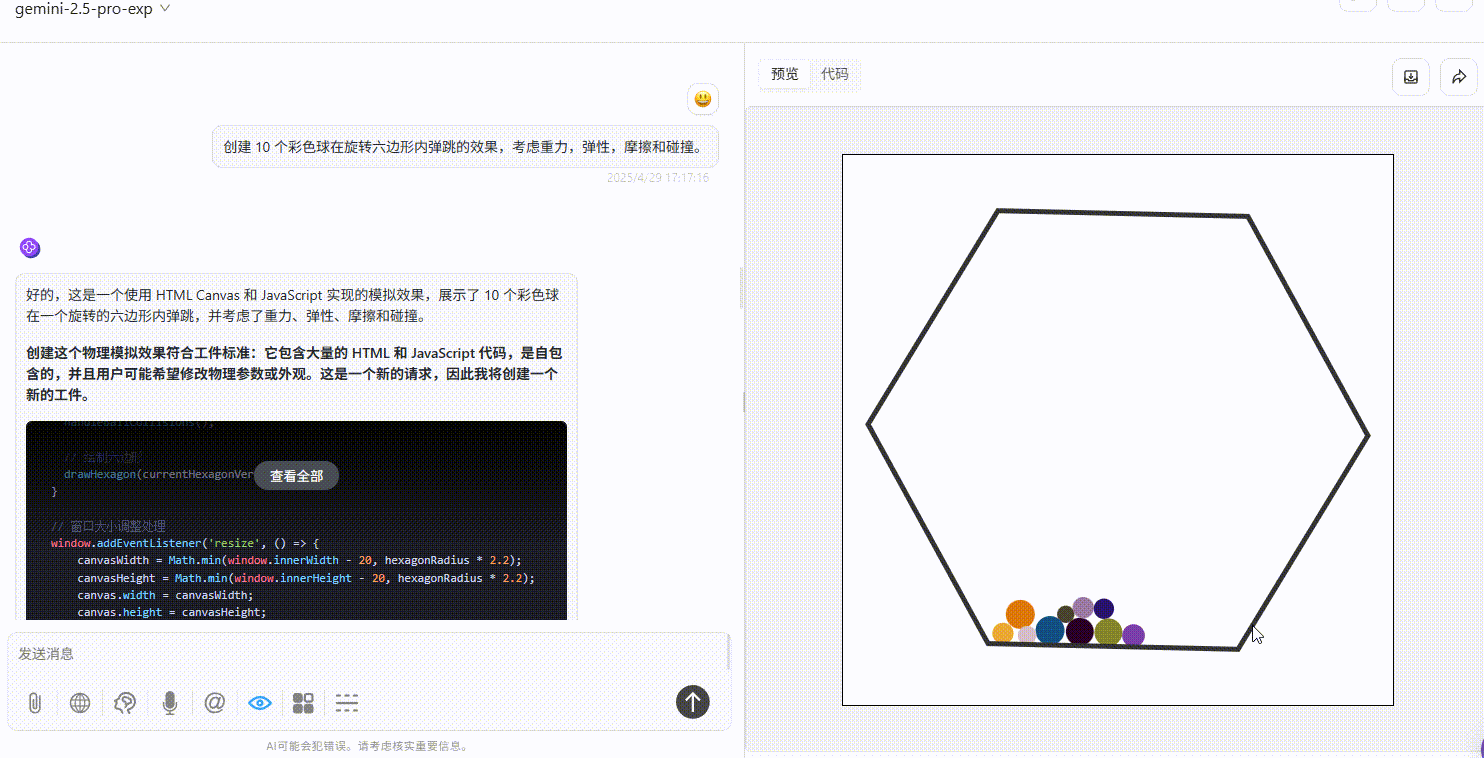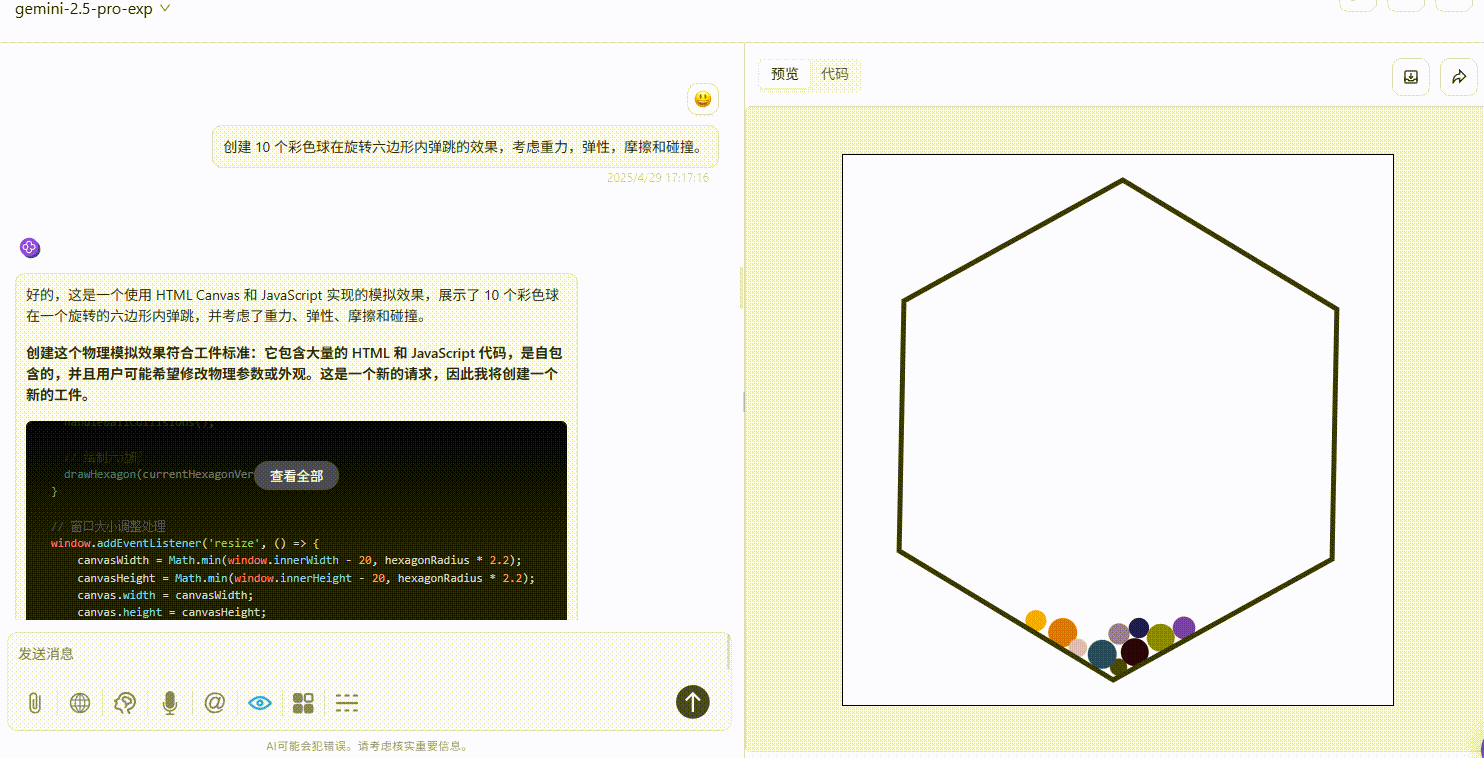
DeepSeek-R1 :小球均未实现在六边形内自由弹跳的效果。
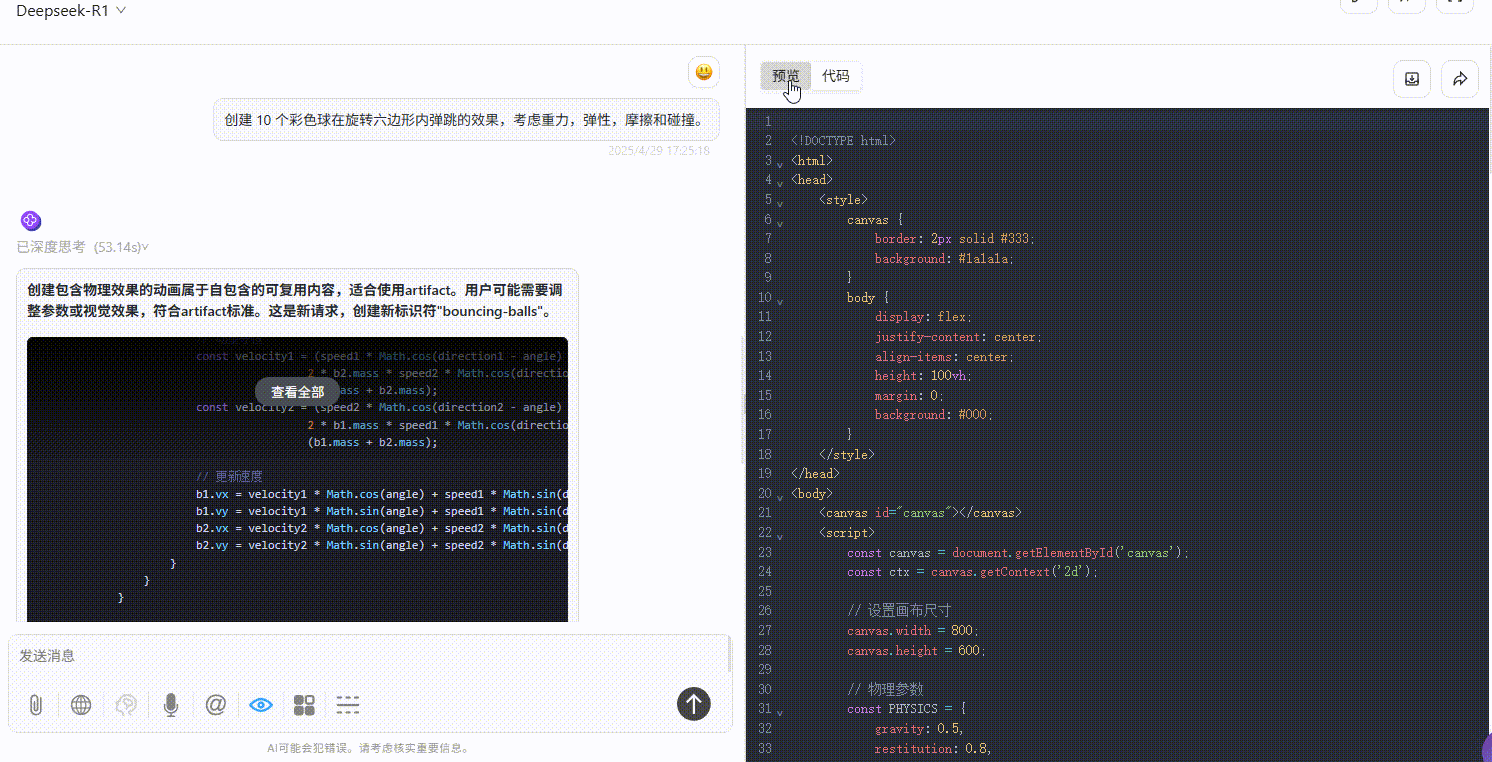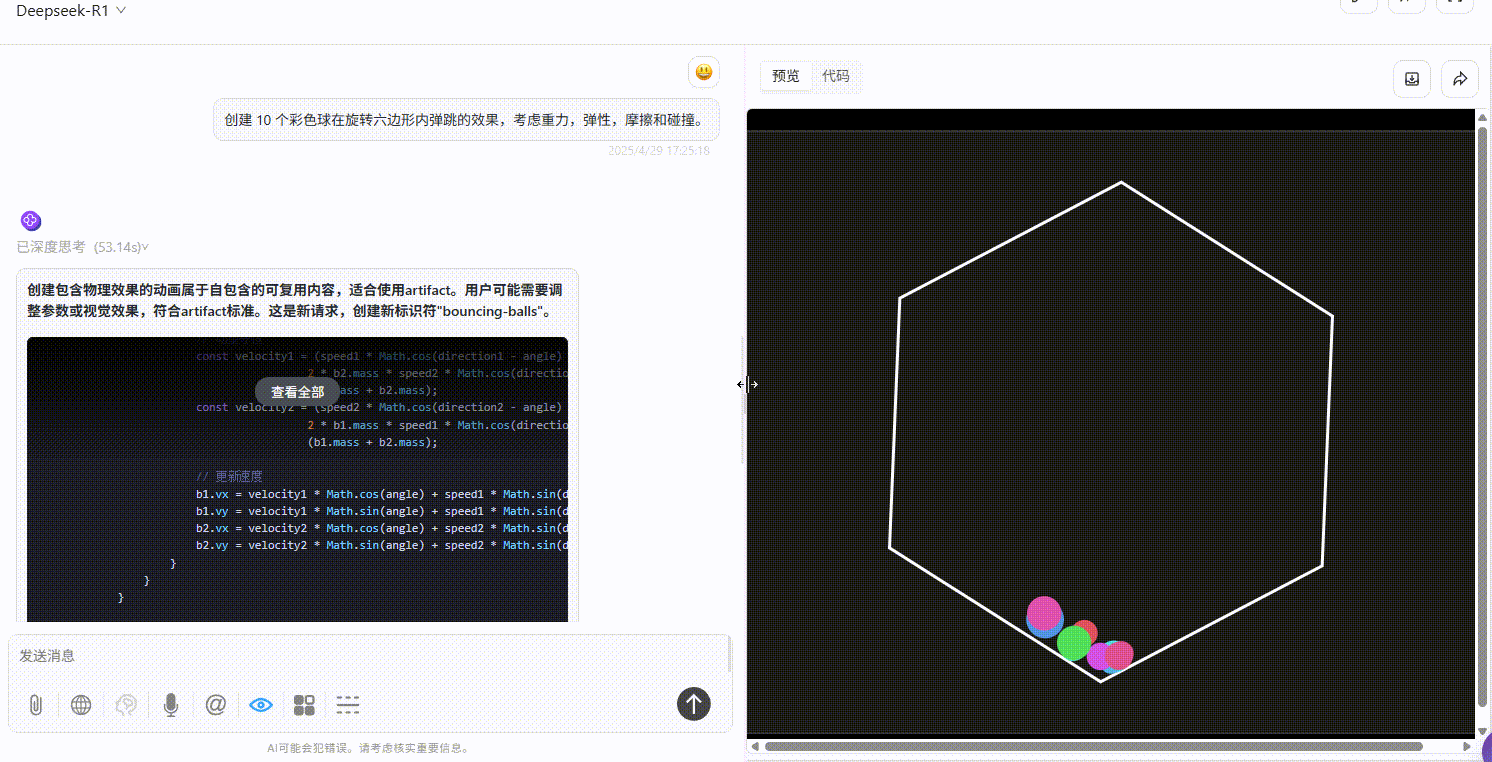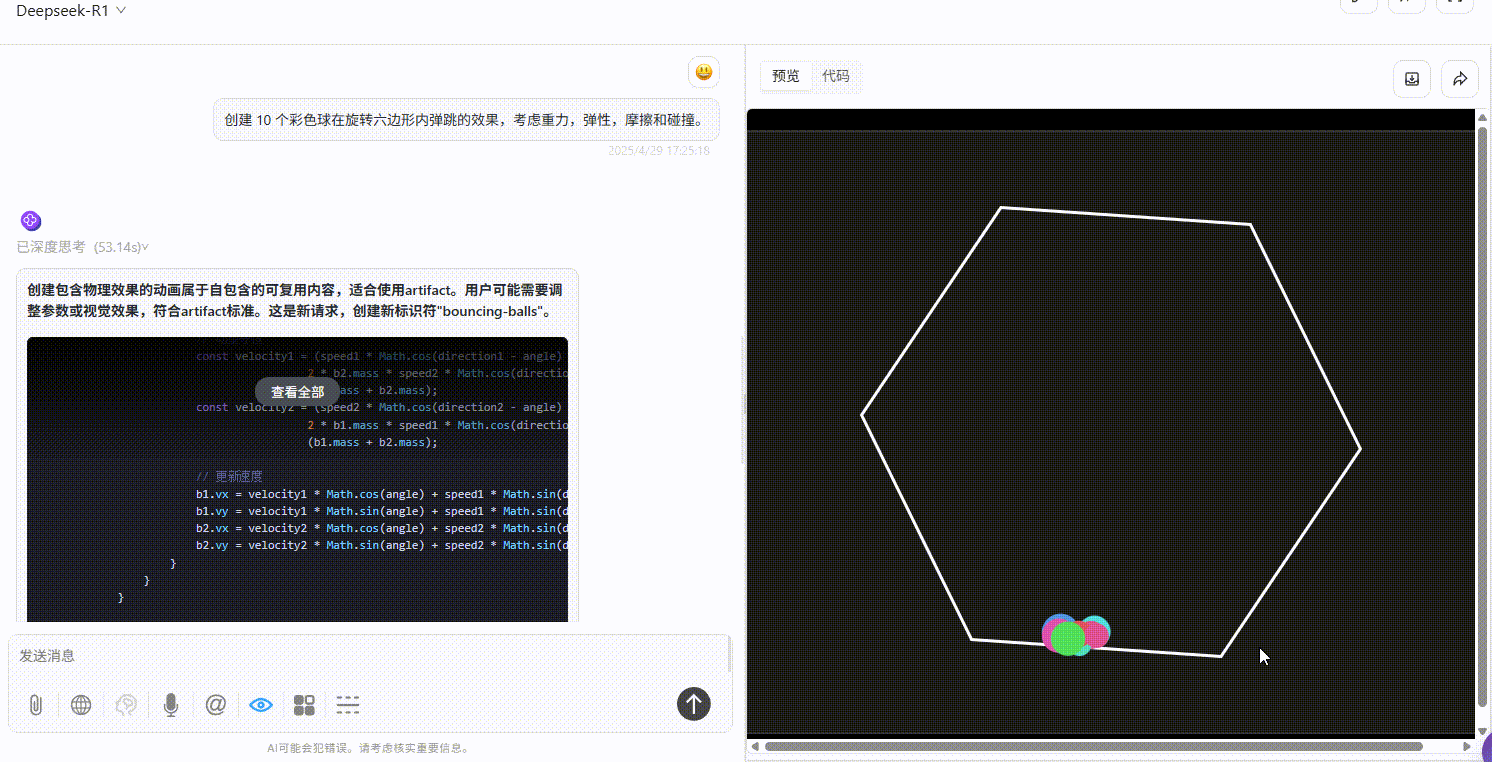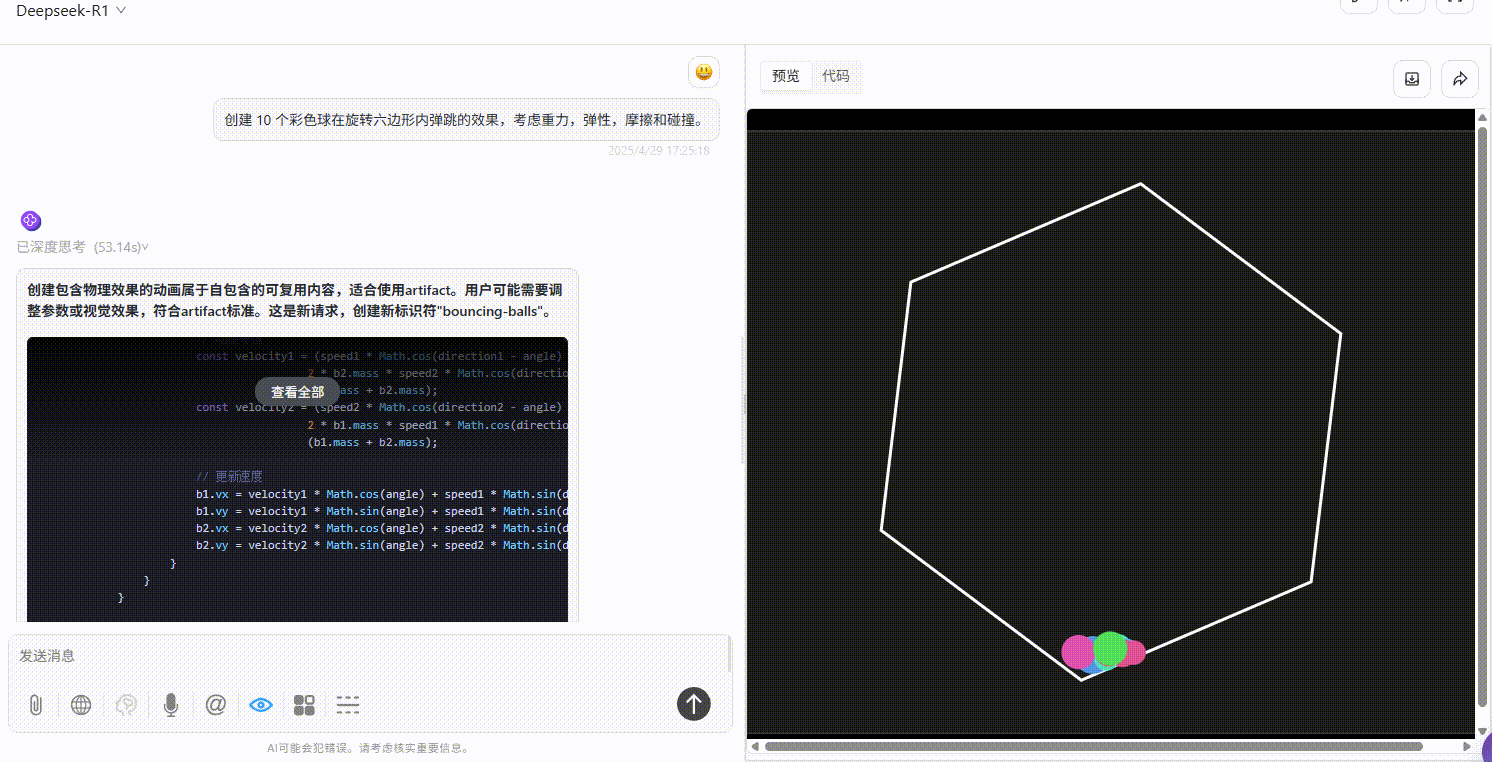
实测结论:
1、实测结果整理:
| 地理常识 | 模型幻觉 | 数学计算 | 小球弹跳 | |
| Qwen3-235B-A22B | 正确 | 错误 | 无法输出 | 较差 |
| DeepSeek-R1 | 正确 | 正确 | 错误 | 相对效果较好,但仍未达到理想效果 |
| Gemini-2.5-Pro | 正确 | 正确 | 正确 | 未实现在六边形内自由弹跳 |
| 实测表现优劣综合排名:Gemini-2.5-Pro>DeepSeek-R1 >Qwen3-235B-A22B | ||||
2、实测总结:
通过以上实测,可初步得出以下结论:
(1)就本文的实测结果来看,Qwen3-235B的能力未能够达到超越DeepSeek-R1 或者Gemini-2.5-Pro的水平,只在某些简单任务如实测1中表现良好。
(2)Qwen3系列模型,在面对诗词文本问题时容易出现了“模型幻觉”,编造出不合理的答案。
(3)Qwen3-235B模型思考模型面对有一定难度的任务时,会出现一直思考无法输出答案的情况。
(4)在小球弹跳的效果测试中,所有模型均未能实现理想的效果,或许在动态模拟方面,各个模型目前仍有待加强。
如何在302.AI中使用
302.AI的聊天机器人和API超市提供了按需付费无订阅的服务方式,企业和个人用户可按需灵活选用。
1、使用模型对话
使用路径:依次点击使用机器人→聊天机器人→ 开源模型→选择模型 →创建聊天机器人;
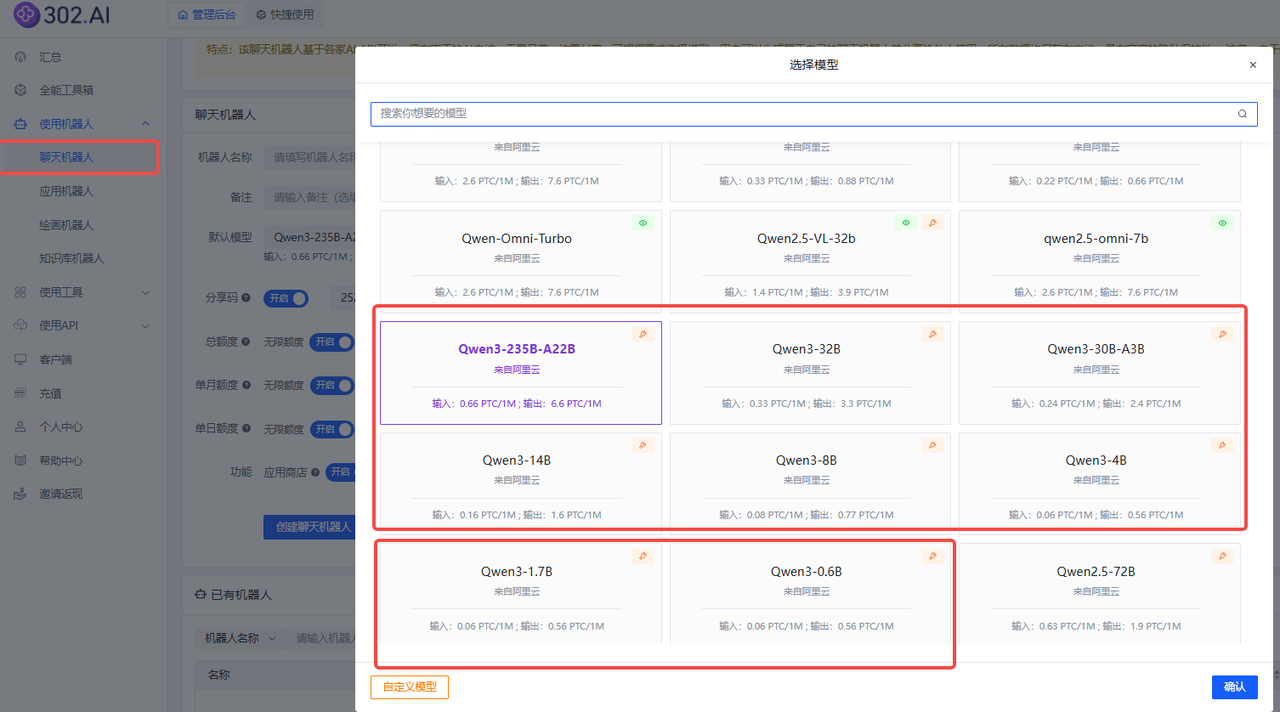
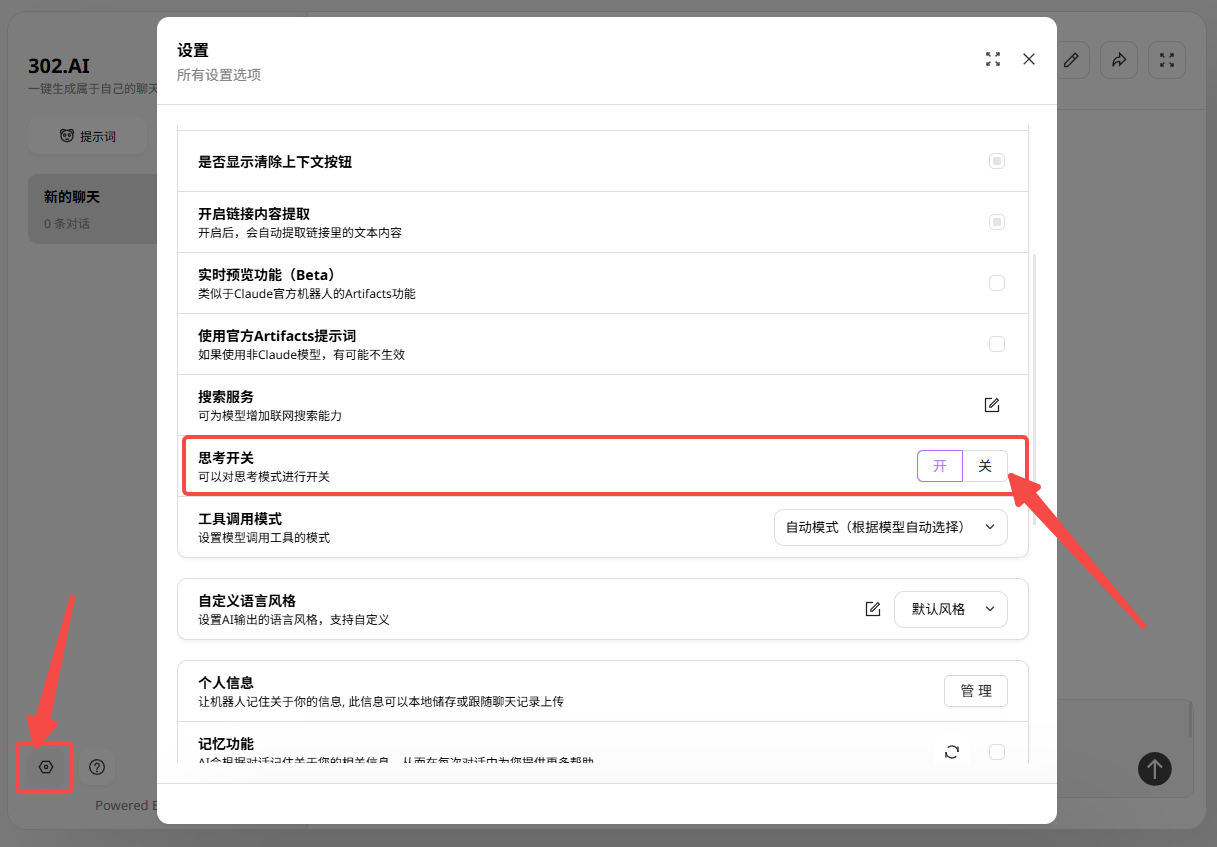
进入聊天机器人后,点击左下角设置,可对思考进行开关。
2、使用模型API
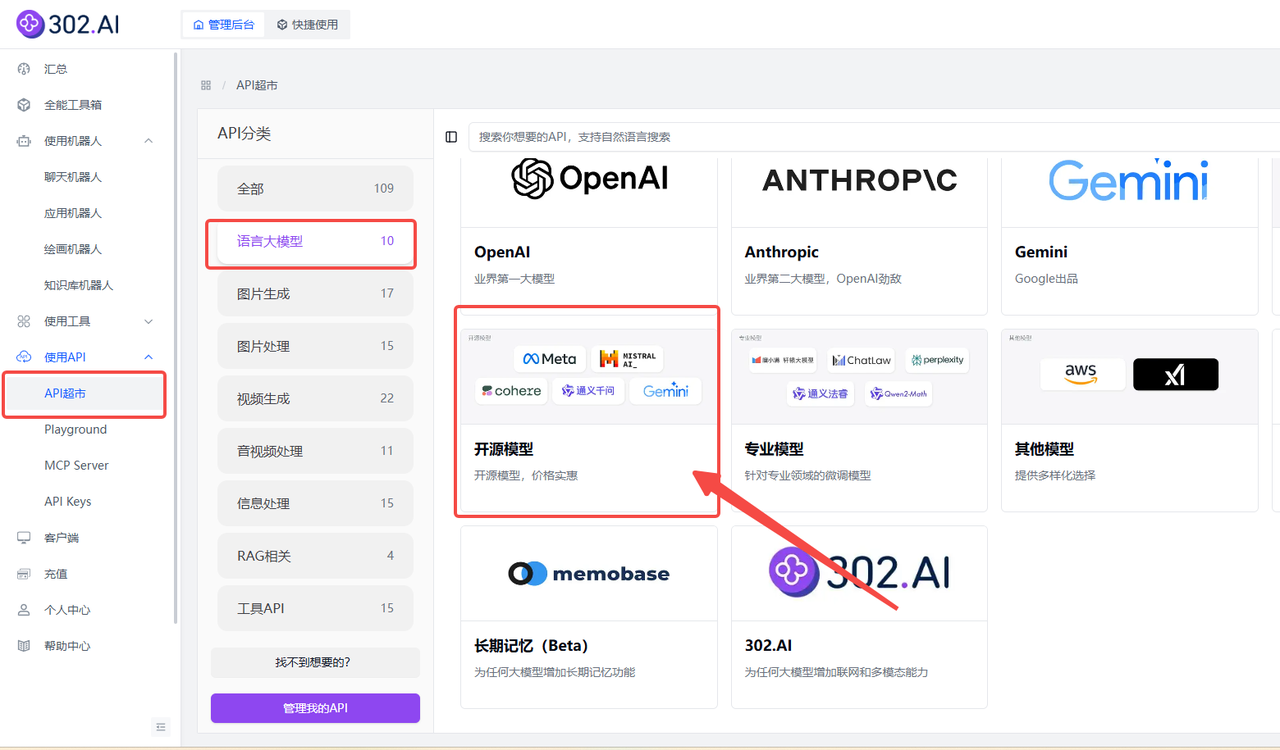
企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发。
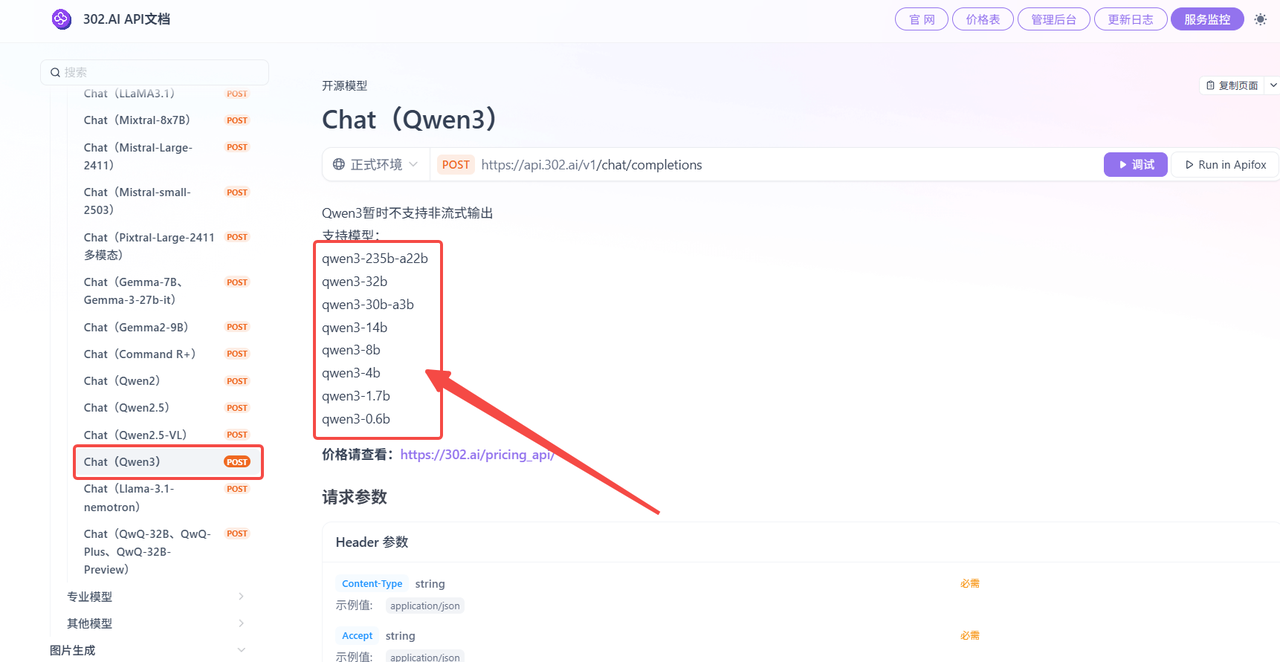
相关文档:使用API→API超市→语言大模型→开源模型→查看文档;
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

Comments(1)
Hi there! I could have sworn I’ve been to this website before but after checking through some of the post I realized it’s new to me. Anyhow, I’m definitely happy I found it and I’ll be book-marking and checking back frequently!