


11中旬,生数科技推出了最新AI视频生成模型Vidu 1.5版本,并声称这一版本模型为“全球首个支持多主体一致性的大模型”。
先简单理解下多主体一致性的意思,多主体一致性即多个主体如人物、物体、场景等,在不同场景、不同镜头下的形象、特征和行为都是连贯和一致的。更简单地说,就是视频里的每个角色或物体在不同时间和不同地点都能保持他们的特征和行为,使得整个视频看起来流畅自然,没有突兀的变化。
据了解,Vidu 1.5的多主体参考实是一种上下文记忆。模型将多张图片作为输入并理解,把多主体、多特征之间的关系作为上下文进行记忆和关联。Vidu 1.5 支持用户上传1至3张参考图片,并通过模型生成多主体间的交互及主体与场景的无缝融合。
> 在302.AI上使用
【API超市】
为了满足用户的需求,302.AI也接入了Vidu模型。有需要的企业可以通过302.AI的API超市获得这一模型的API,从而快速集成该模型并自行开发产品。
以下是在API超市获得Vidu模型的方法:
1、进入302.AI的客户端后,点击“API超市”,在分类中选择“视频生成”,最后点击“Vidu”。

![]()
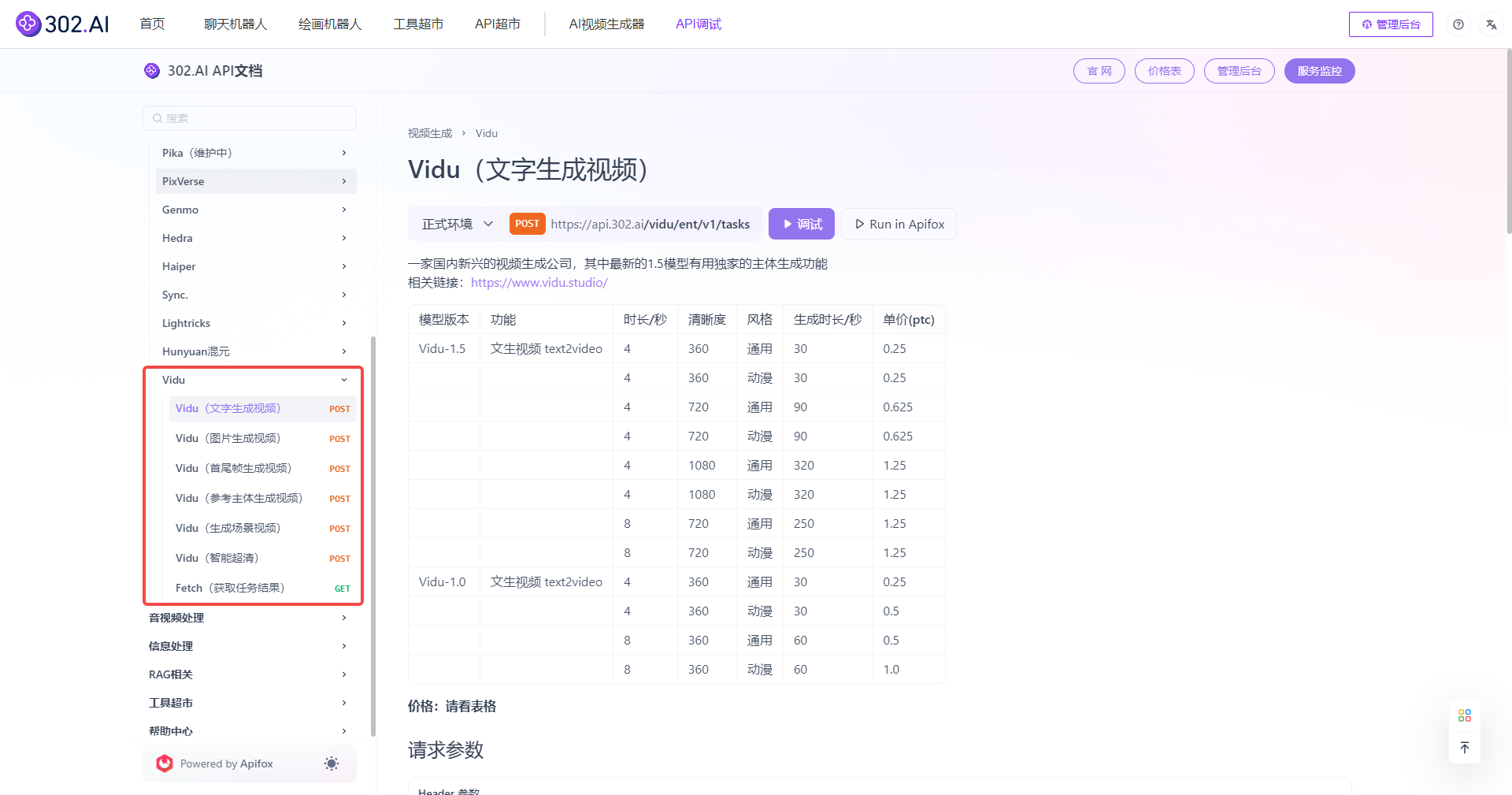
2、点击“查看文档”进入后,可以看到已经提供了“Vidu”模型的API,并涵盖了不同风格、功能、版本。此外,302.AI的API超市还支持在线调试,开发者可以直接对API进行实时测试和调试,大大节省时间和精力。
![]()
【AI视频生成器】
用户还可以通过302.AI的AI视频生成器直接使用这一模型。302.AI提供按需付费的服务方式,无需订阅,无月费捆绑套餐,更加灵活。
目前,302.AI的AI视频生成器已经开源,用户可以根据需求对这一工具进行二次开发。
开源链接:https://github.com/302ai/302_video_generator/blob/main/README_zh.md
以下是通过302.AI的AI视频生成器使用Vidu模型的详细步骤:
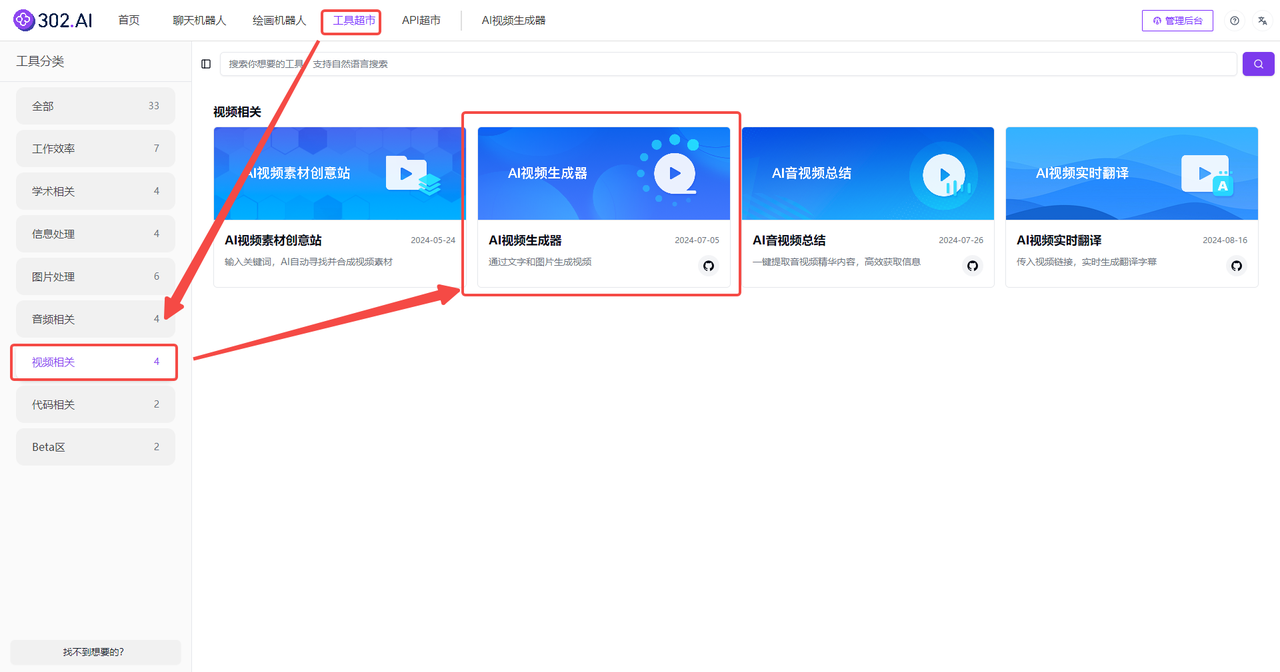
1、创建工具:登录302.AI客户端后,在页面上方的菜单栏中点击“工具超市”,在分类中选择“视频相关”,最后点击“AI视频生成器”。
![]()
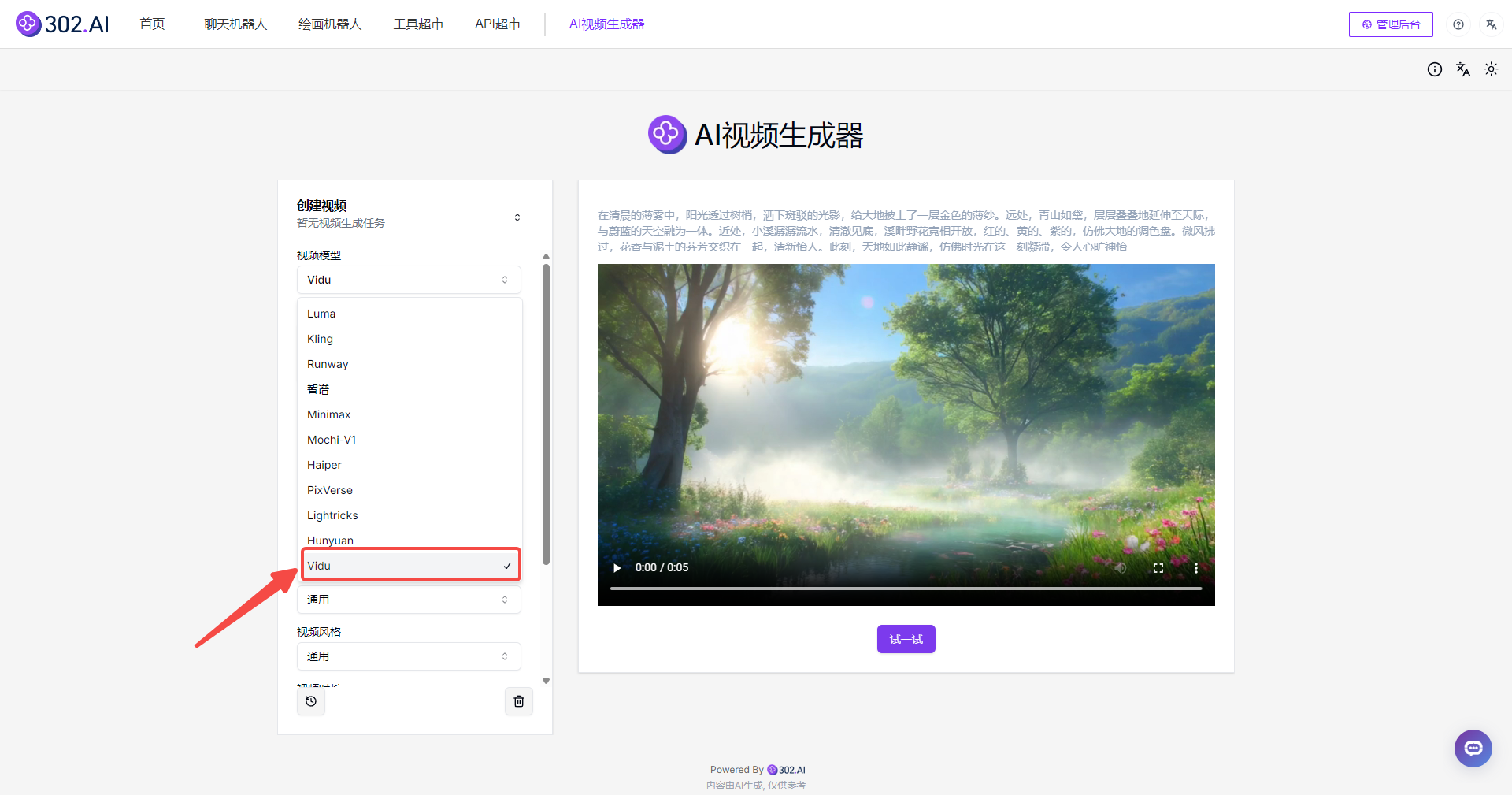
2、选择模型:进入工具后,首先我们可以看到302.AI的AI视频生成器提供了多种视频模型,我们这里选择的视频模型是“Vidu”。
![]()
3、选择视频类型:选择完模型后,我们需要选择视频类型,视频类型分为以下三种:
(1)通用:和一般的视频模型相似,可以输入一段文本,生成视频,也可以输入首帧和尾帧图片以及对应的文本描述生成视频;此外,这一视频类型支持通用风格以及动漫风格;
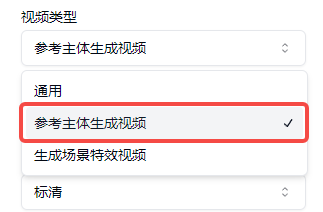
(2)参考主体生成视频:包含单主体和多主体生成,单主体即是上传单个主体不同角度的图片,多主体则是上传人、物、景等不同主体的图片,融合生成视频。
(3)生成场景特效视频:这一视频类型是可以上传图片后结合场景效果使用的,比如提供的场景效果有:拥抱、亲吻、圣诞老人送礼等。
今天给大家展示的是多主体生成效果,所以我们选择的风格类型是”参考主体生成视频“
![]()
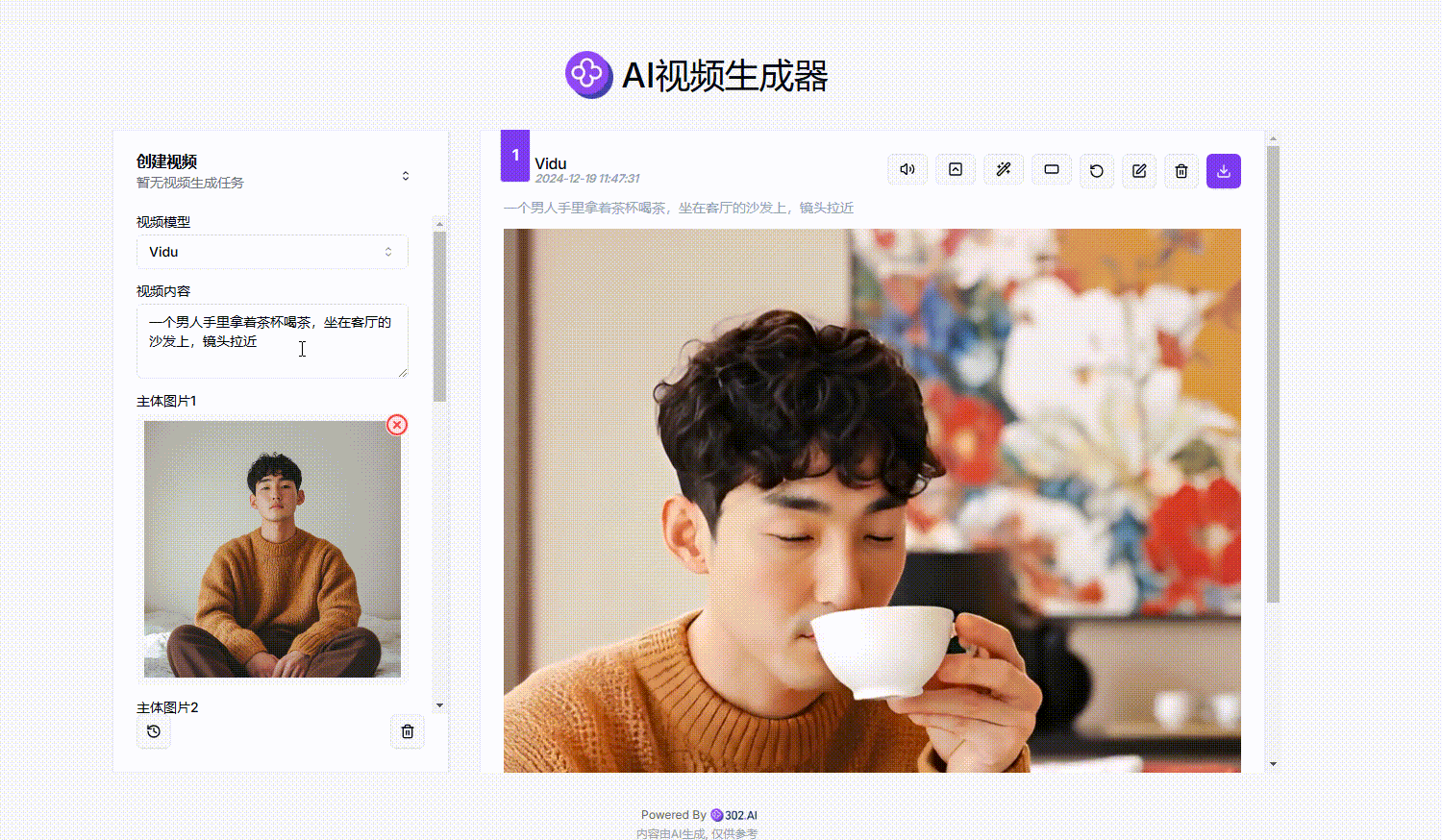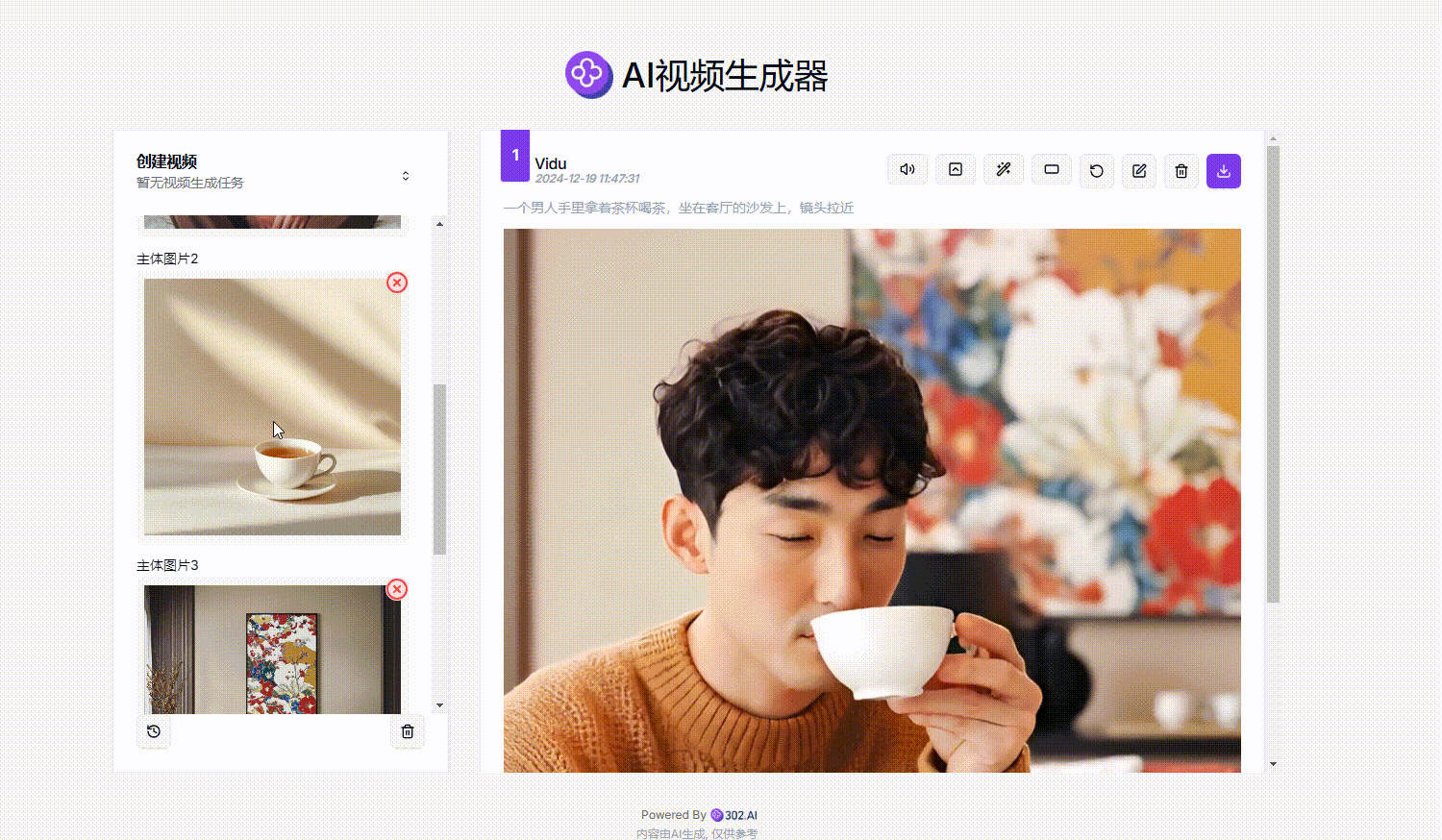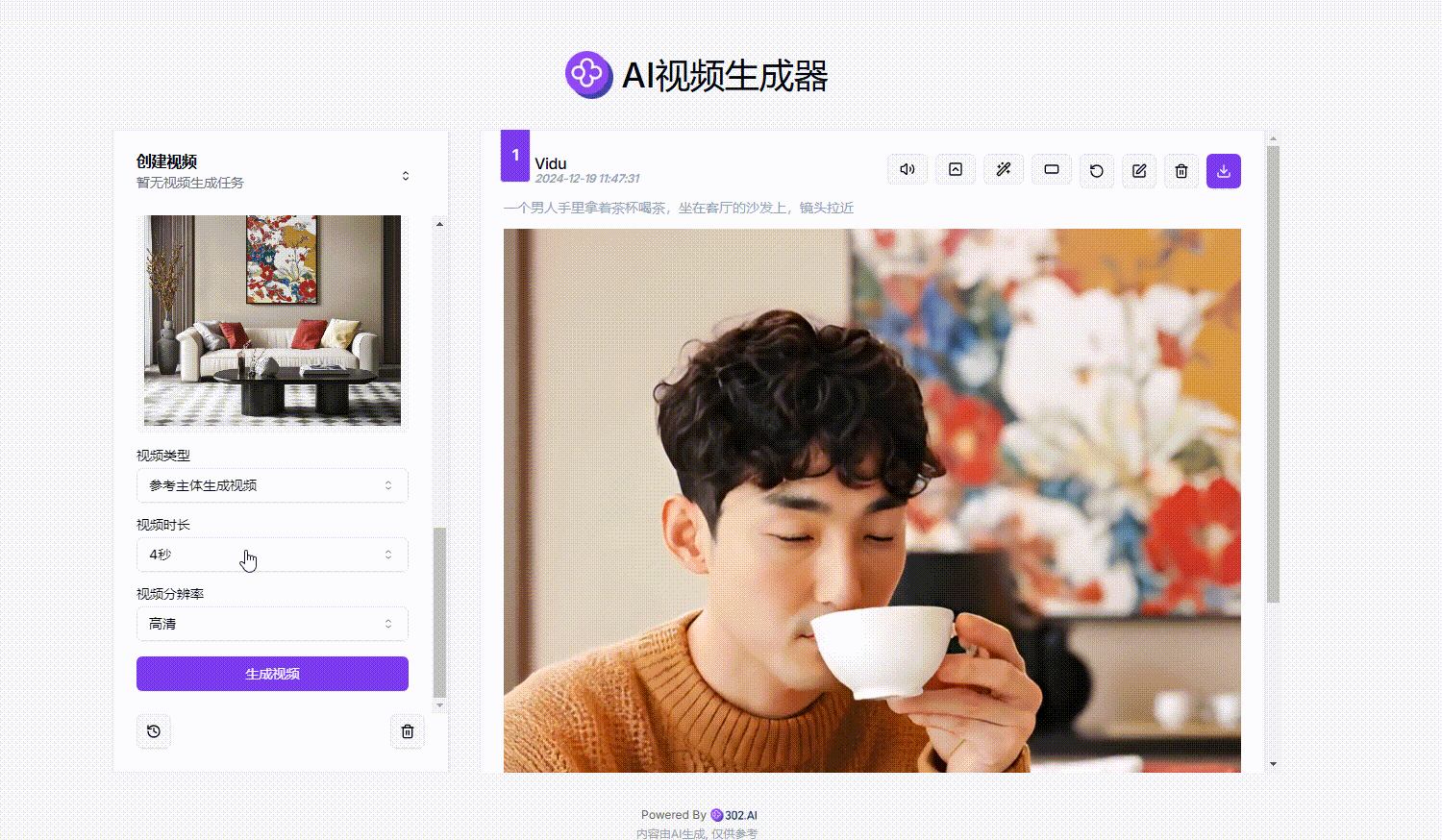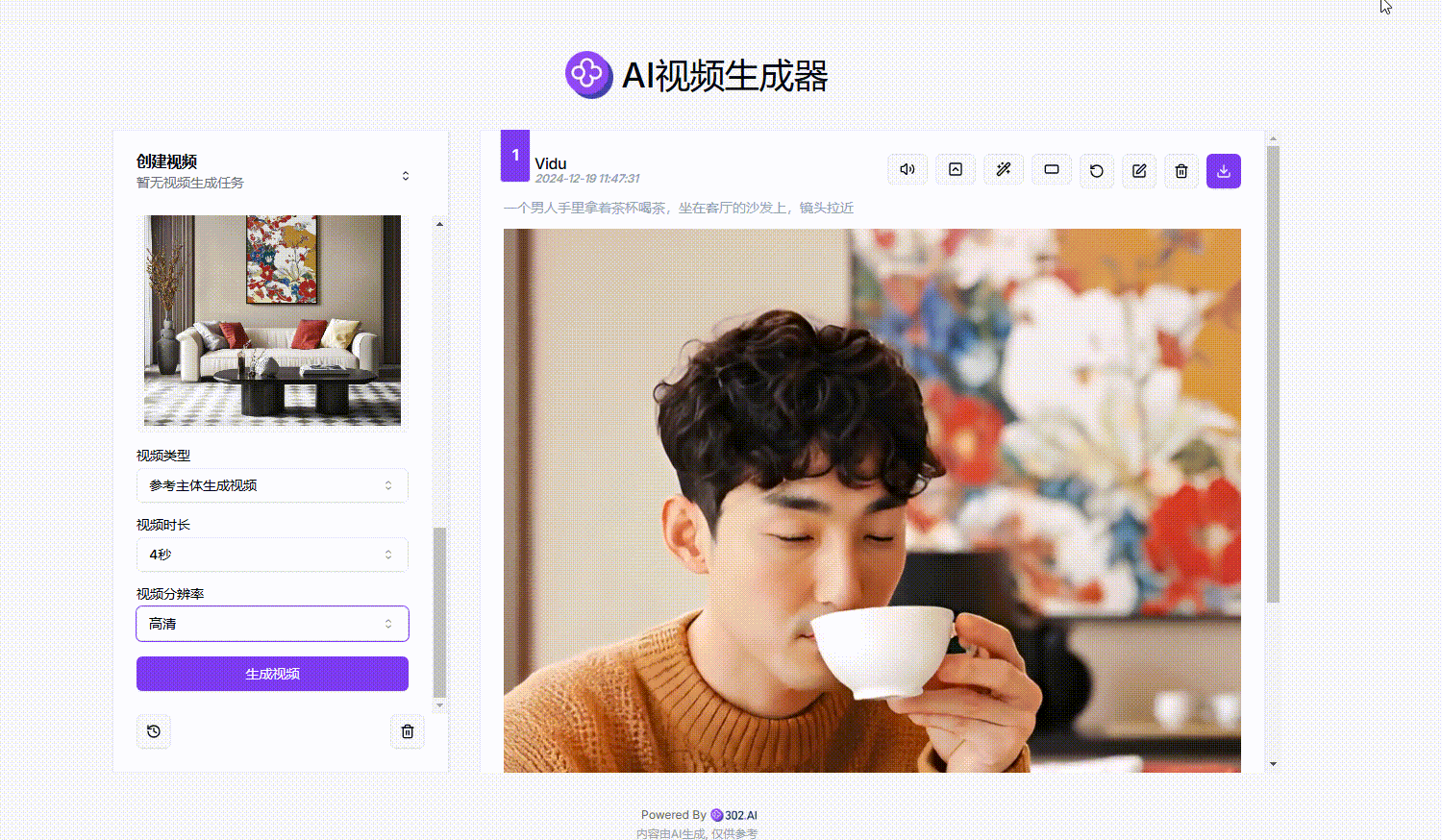
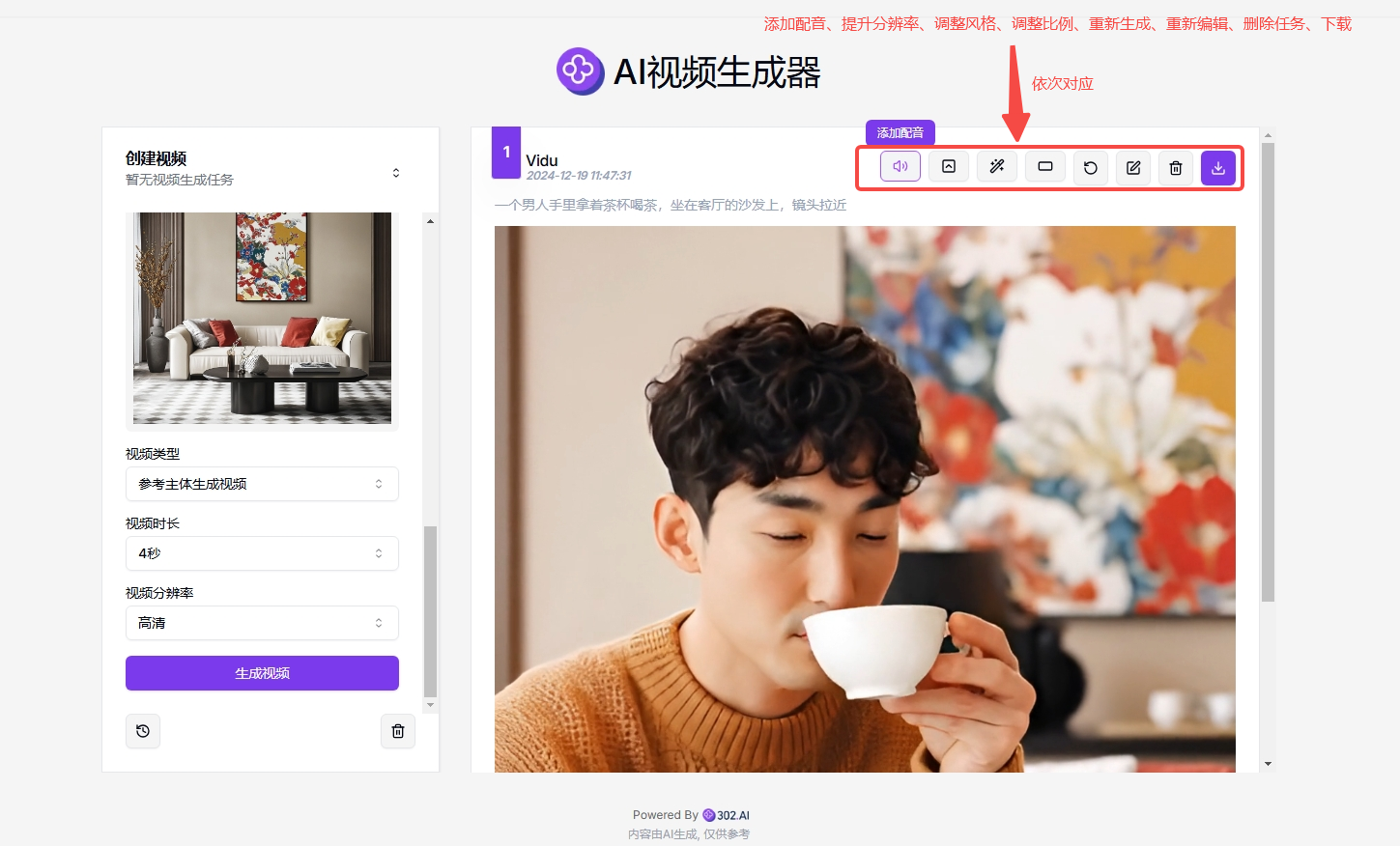
4、上传图片并输入提示词:接下来需要上传三张不同主体的照片作为参考,并输入提示词,然后选择视频时长以及分辨率,最后点击“生成视频”,选择视频比例后等待页面右侧生成视频效果。
参考提示词:一个男人手里拿着茶杯喝茶,坐在客厅的沙发上,镜头拉近
(这里亲测按照人+物+景的顺序上传,视频生成效果会更好)
![]()
5、进一步操作视频:生成后的视频可以进一步操作,比如给视频配音、调整视频分辨率、调整比例、下载等。
![]()
> 效果展示
下面来看下生成的效果:
(以下主体参考图片以及视频均由302.AI生成)
效果一:多主体生成
主体参考照片:

![]()
视频生成效果:
效果二:场景特效生成
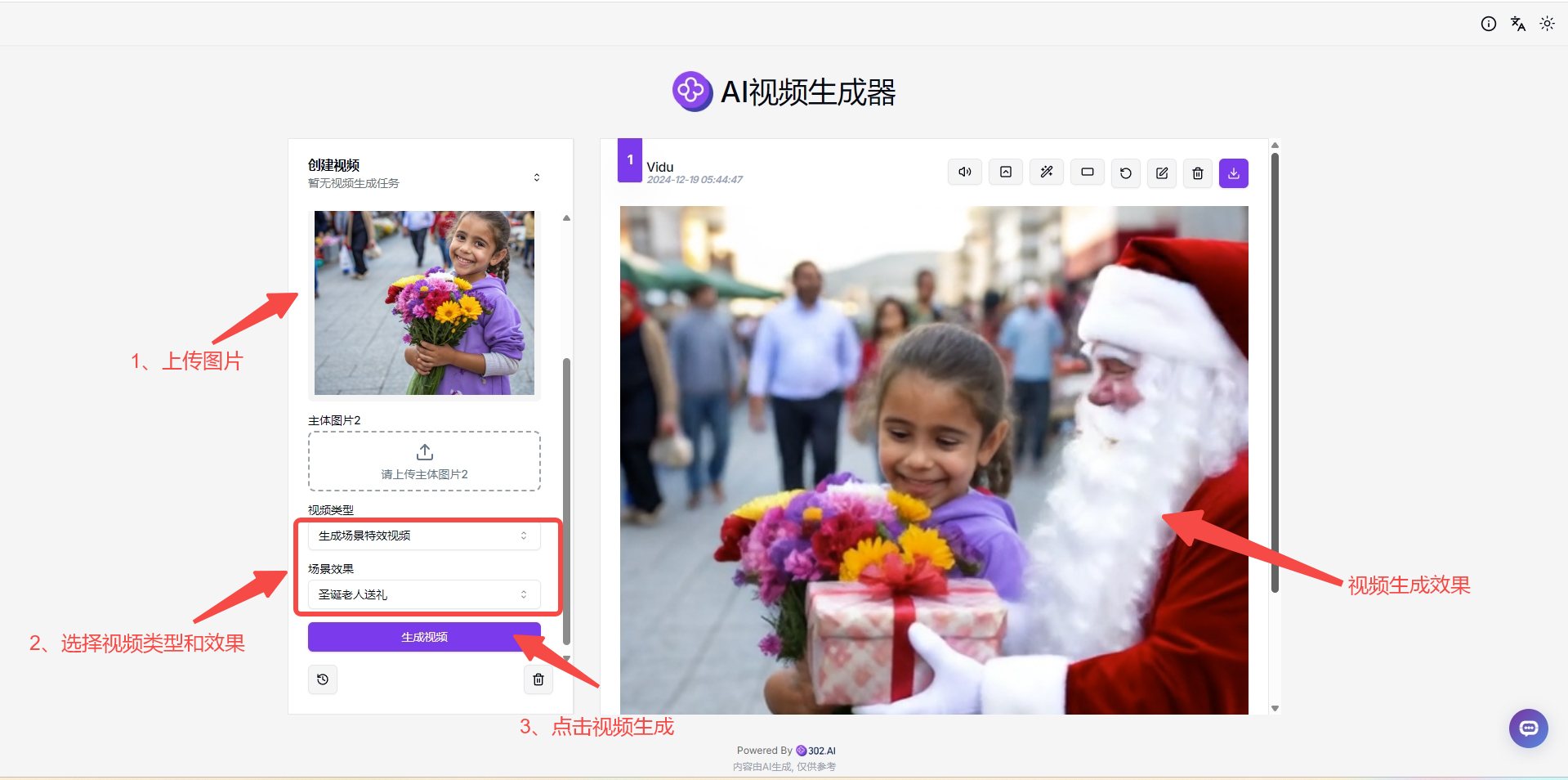
![]()
主体参考照片:

![]()
视频生成效果:
> 总结
Vidu 1.5版本除了在多主体一致性方面的突破,根据官方介绍,其在生成质量、语义理解等方面也都有了提升。这些改进使得Vidu 1.5的应用场景更加广泛。具体来说,Vidu 1.5能够支持包括社交媒体互动玩法的双人拥抱、与圣诞老人拥抱等多种有趣效果的生成。这种功能不仅增强了用户在社交平台上的互动体验,同时也带来了更多创新的表达方式。此外,Vidu 1.5还适用于虚拟IP的日常互动宣传内容制作等。
尽管Vidu 1.5在多个方面取得了进展,AI视频模型的市场竞争依然非常激烈。各大公司和团队都在不断努力推出更加先进的技术和应用,以满足用户需求并引领行业发展。我们或许可以期待在视频生成领域能够见证更多创新性的突破!
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(9)
What i don’t realize is actually how you’re no longer actually much more smartly-appreciated than you may be right now. You are so intelligent. You realize thus considerably on the subject of this matter, made me in my opinion consider it from so many various angles. Its like men and women aren’t fascinated until it¦s something to do with Woman gaga! Your personal stuffs nice. At all times maintain it up!
Excellent website you have here but I was wanting to know if you knew of any message boards that cover the same topics talked about in this article? I’d really love to be a part of community where I can get opinions from other knowledgeable individuals that share the same interest. If you have any suggestions, please let me know. Bless you!
Some genuinely excellent blog posts on this website, thanks for contribution. “Such evil deeds could religion prompt.” by Lucretius.
I conceive this internet site has got very great indited subject material posts.
Howdy! Would you mind if I share your blog with my zynga group? There’s a lot of people that I think would really enjoy your content. Please let me know. Thanks
It’s in reality a great and useful piece of information. I am happy that you just shared this helpful information with us. Please keep us up to date like this. Thanks for sharing.
Great post. I was checking continuously this weblog and I am impressed! Very useful information specifically the remaining part :) I take care of such info much. I used to be seeking this particular info for a very lengthy time. Thank you and best of luck.
This design is incredible! You certainly know how to keep a reader entertained. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Wonderful job. I really loved what you had to say, and more than that, how you presented it. Too cool!
What i do not understood is if truth be told how you are now not actually a lot more well-preferred than you may be right now. You’re so intelligent. You understand therefore considerably on the subject of this matter, produced me in my view imagine it from so many numerous angles. Its like women and men aren’t involved except it?¦s one thing to do with Lady gaga! Your personal stuffs great. Always care for it up!