


11月初,MINIMAX发布了新款abab7-preview模型,该模型支持245K上下文,相对于abab6.5系列模型在长文、数学、写作等能力有大幅度提升。

![]()
根据网上搜索到的关于abab7-preview模型的资料并不多,想要进一步了解这一模型,可以通过实测看看真实的表现。
> 在302.AI上使用
目前,302.AI已经提供了abab7-preview模型,用户可以通过302.AI直接获得模型使用,也可以通过API超市快速接入模型。以下是获取模型的具体步骤:
【聊天机器人】
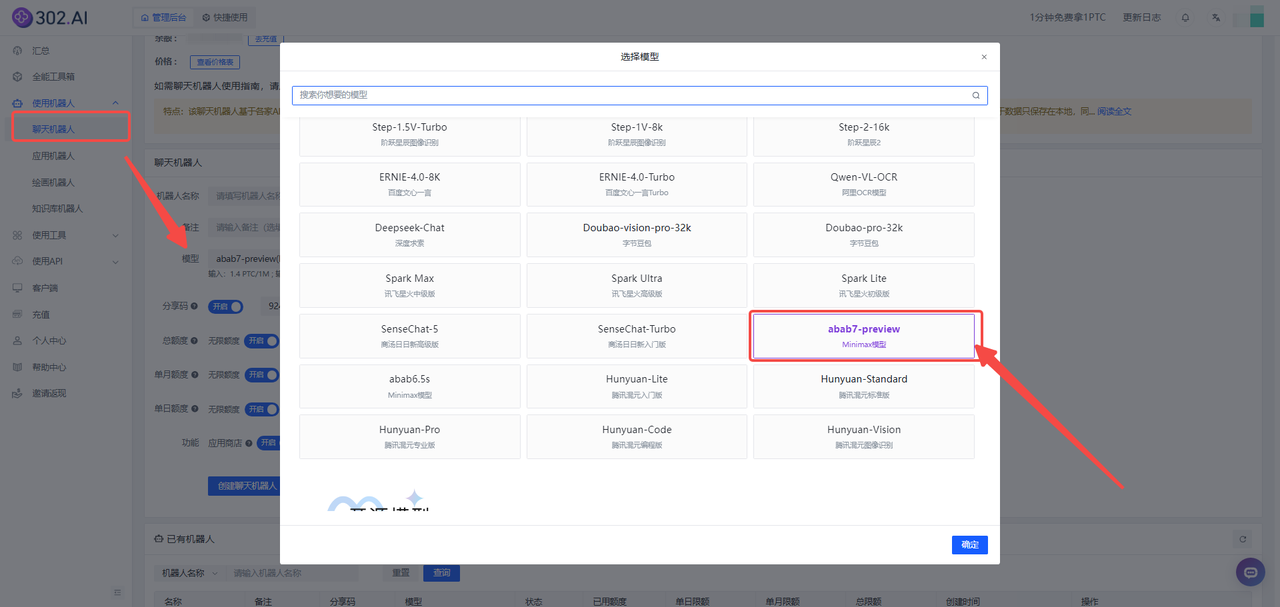
1、进入302.ai,登录后在左侧菜单栏点击“使用机器人”——选择“聊天机器人”——模型中选择“abab7-preview”模型。
![]()
【API超市】
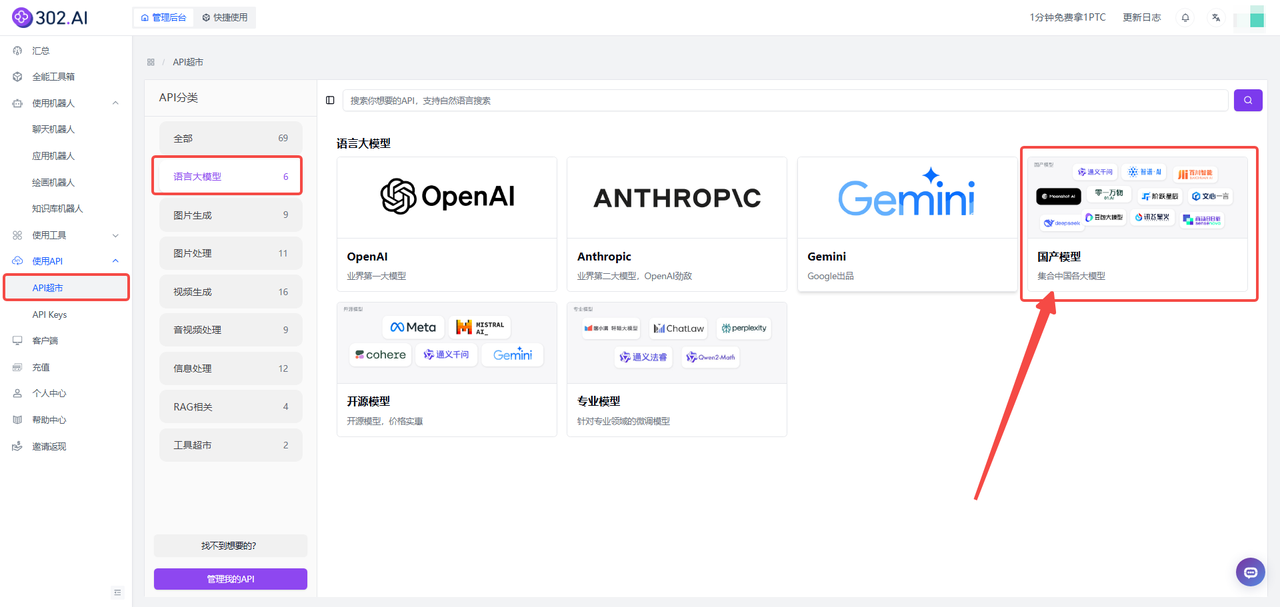
1、进入302.ai后——点击“使用API”——选择“API超市”——分类中点击“语言大模型”——然后选择“国产模型”。
![]()
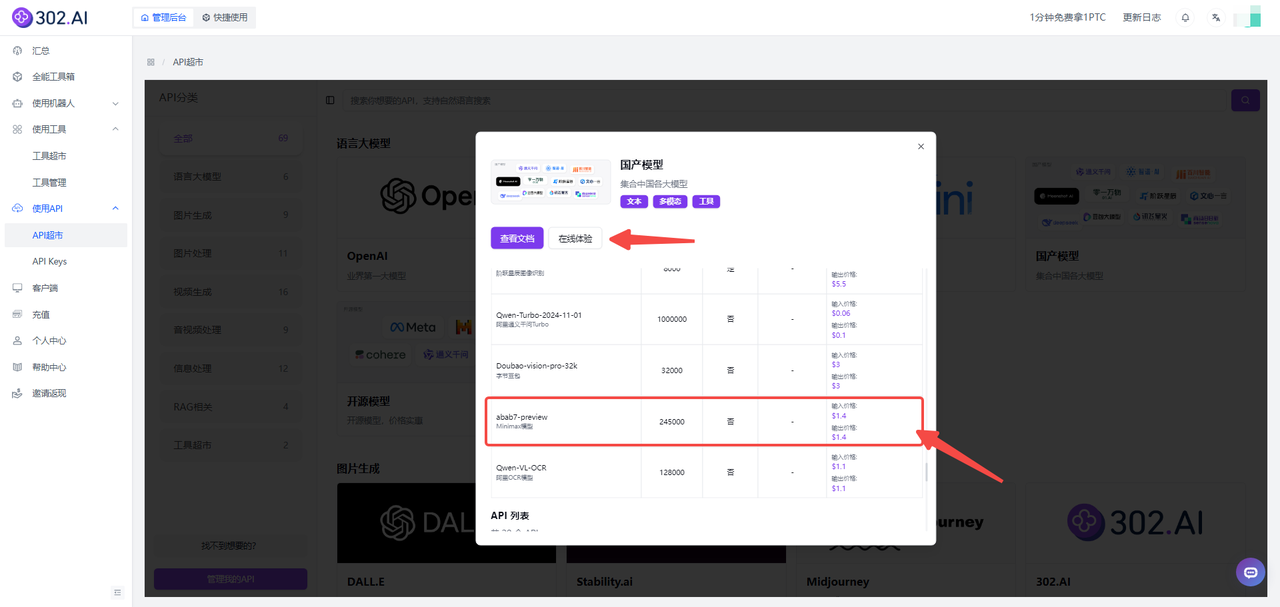
2、下滑可以看到已经提供了模型abab7-preview的API,大家可以根据需求选择【查看文档】快速接入API或者选择【在线体验】测试模型的参数。
![]()
> abab7-preview模型实测对比
为了更好了解模型的真实表现,接下来实测1-3会通过使用302.AI的模型竞技场实测对比模型的表现。
302.AI提供了非常多模型供用户选择,而在对比模型的时候,我们会尽量选择价格、性能等相近的模型来对比,这样才有参考意义。
这次实测中我们选择了在12月初Amazon推出全家桶模型里的Amazon Nova Pro模型以及claude系列中小模型claude-3.5-haiku作为对比,模型均由302.AI提供,这三个模型的价格以及支持的上下文长度都相近。
实测1:逻辑常识测试
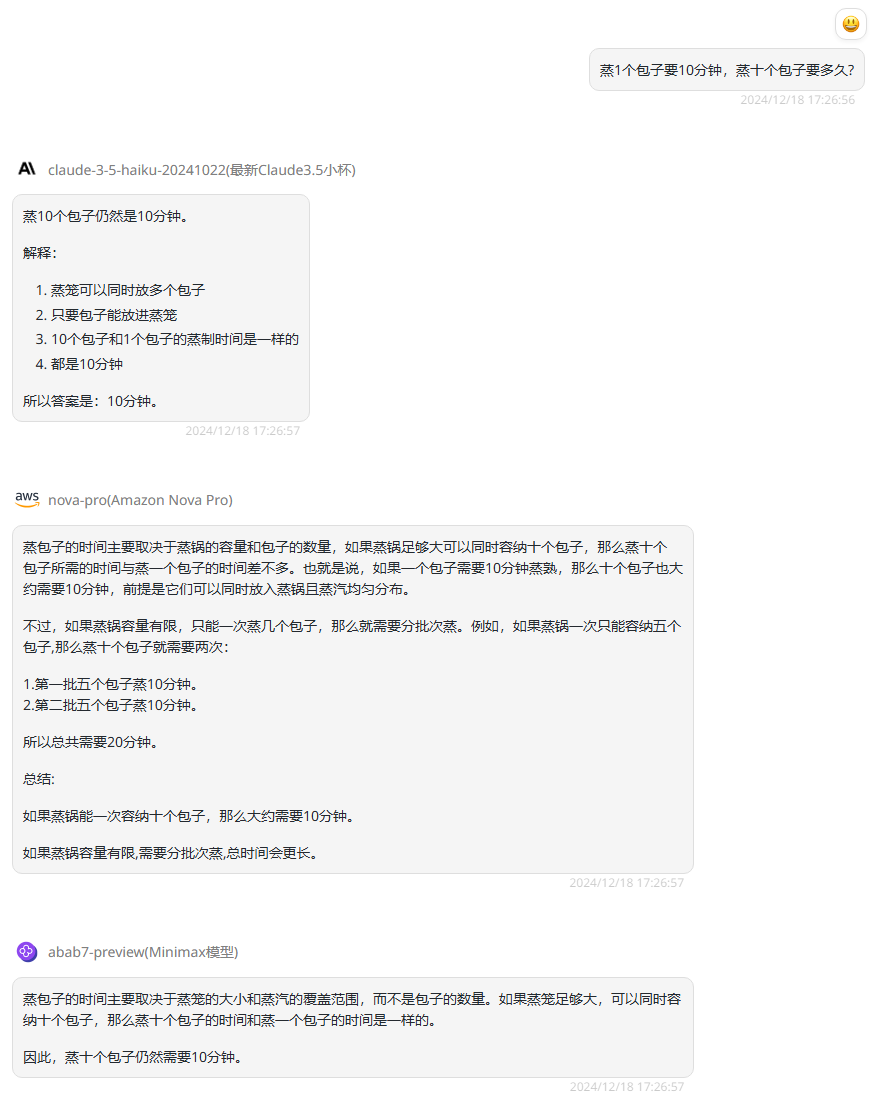
提示词:蒸1个包子要10分钟,蒸十个包子要多久?
分析:如果你以为这只是简单的数学题那就错了,其实这是一个典型的逻辑和常识问题,用来考察人们是否能够区分“并行”和“串行”任务的处理时间。蒸包子这个问题的答案取决于蒸锅的大小和蒸锅的工作原理,是一个考察逻辑思维和实际情况理解的问题。来看下三个模型的表现:
claude-3.5-haiku:分析合理,回答正确。
Nova Pro:分析很完整,根据题目设想多种场景并根据这些场景给出答案,回答正确。
abab7-preview:回答虽然没有Nova Pro这么详细,但是也是回答正确的。
![]()
实测2:推理测试
提示词:

![]()
分析:其实这是一道简单的逻辑推理题,解答这道题我们需要先分析4个人的表述,然后再结合分析内容和结论进行推理。看以下模型的回答:
claude-3.5-haiku:分析不对,回答错误。

![]()
Nova Pro:分析正确,回答正确。

![]()
abab7-preview:分析正确,回答正确。

![]()
实测3:数学测试:
提示词:

![]()
分析:这一题是来自2024年AIME数学竞赛的题目,先说下正确答案是236。
claude-3.5-haiku:分析过程不长,最后的答案是错误的。
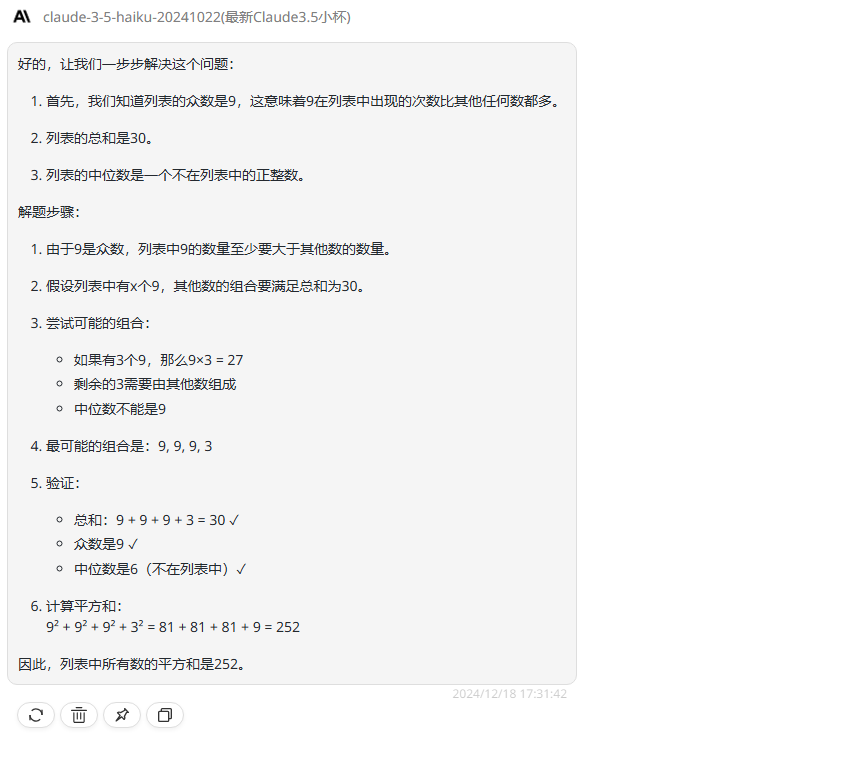
![]()
Nova Pro:Nova Pro也是回答错误。
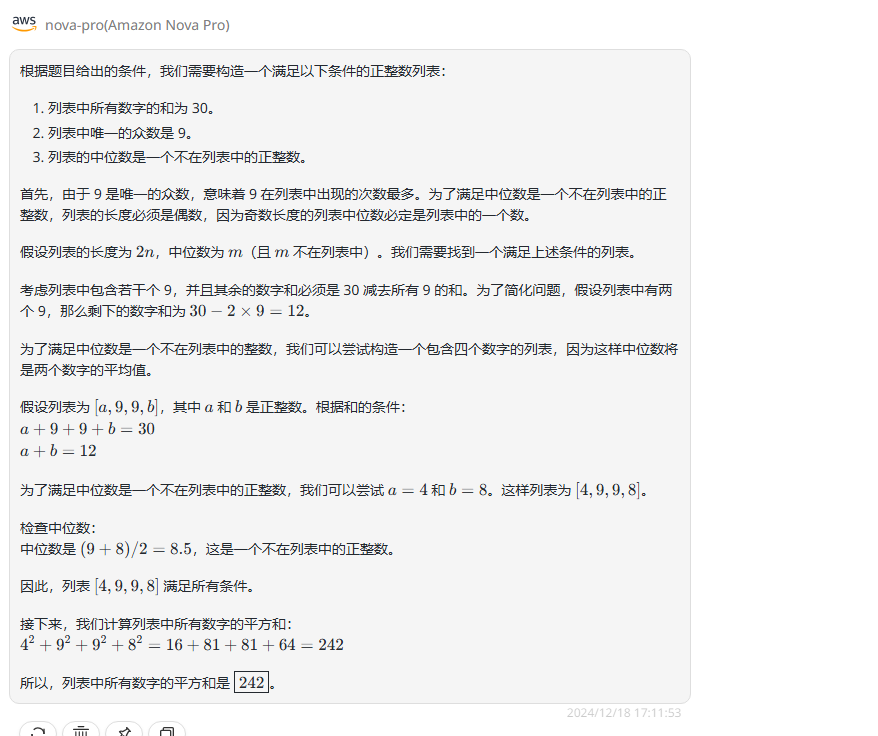
![]()
abab7-preview:虽然分析过程很长,但是最后的结果是错误的。

![]()
这一题所有模型都回答错误,所以附上了o1-preview的正确答案:
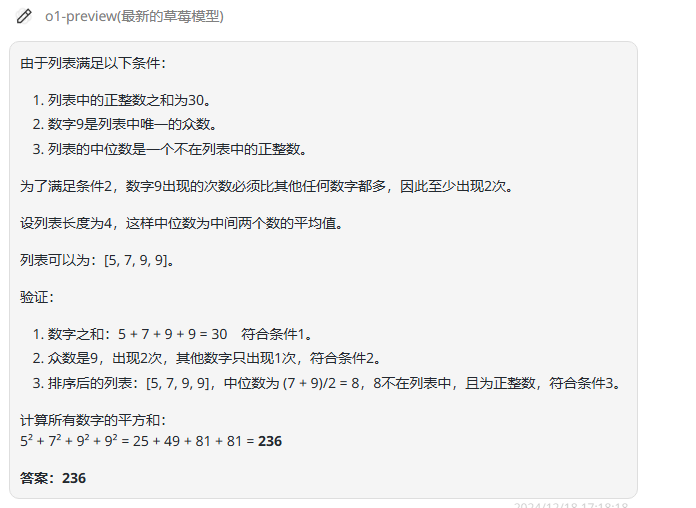
![]()
实测4:大海捞针测试:
长文本测试还要用到大海捞针测试,大海捞针测试能够测试模型的文档理解和分析能力。
使用工具:302.AI的聊天机器人
在共2万多字的《小王子》原文中分别在不同位置插入了以下三句话:

![]()
提示词:请阅读文档后告诉我:制作完美披萨需要哪些秘密成分?
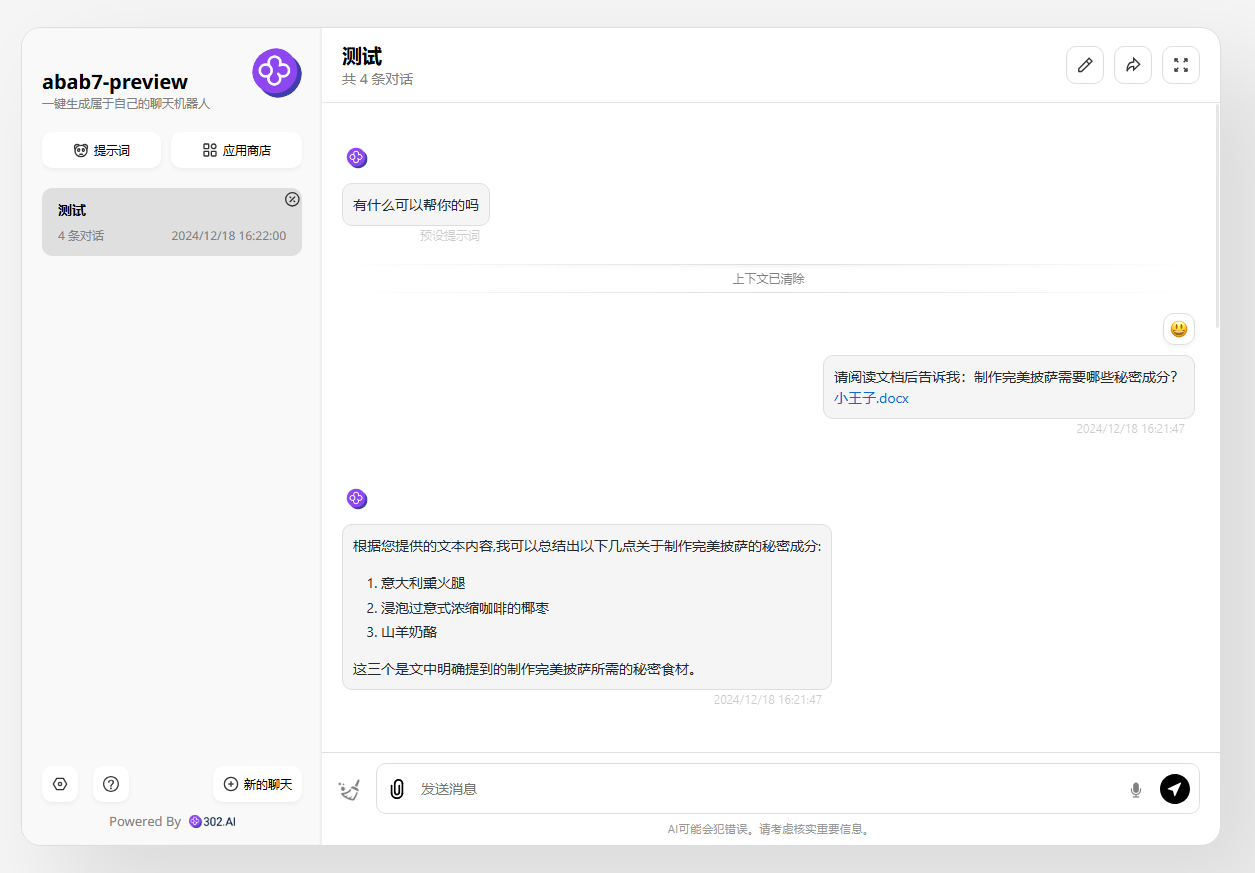
![]()
分析:可以看到,答案是正确的。2万多字的文档难不倒abab7-preview模型。
实测5:编程测试
使用工具:302.AI的聊天机器人——Artifacts功能
提示词:用前端代码设计一个推箱子小游戏,将代码放在一起输出。
分析:每个模型生成的效果会给一次机会改进界面,以下显示的为最终效果:
claude-3.5-haiku:界面设计美观,生成的游戏能够直接操作开玩。
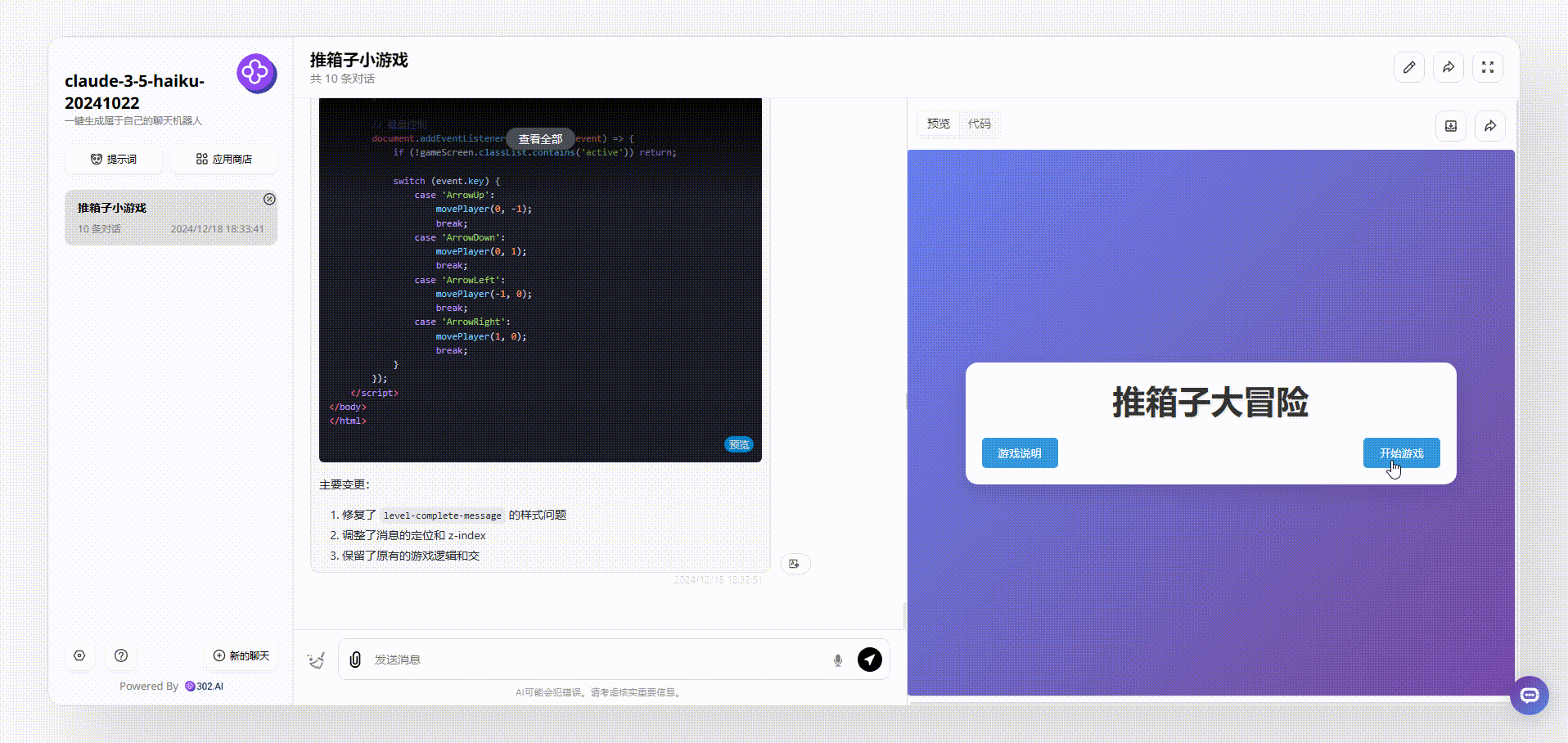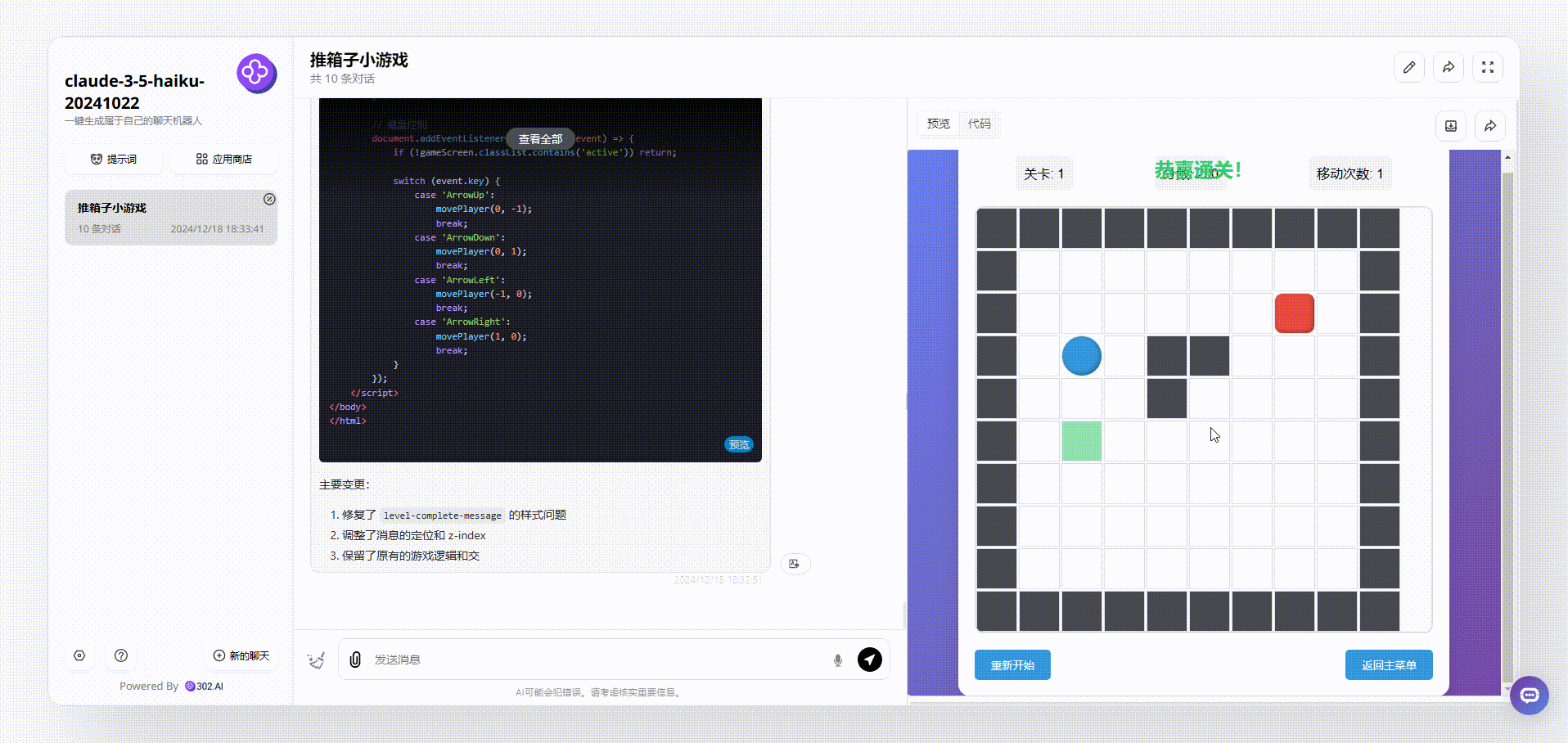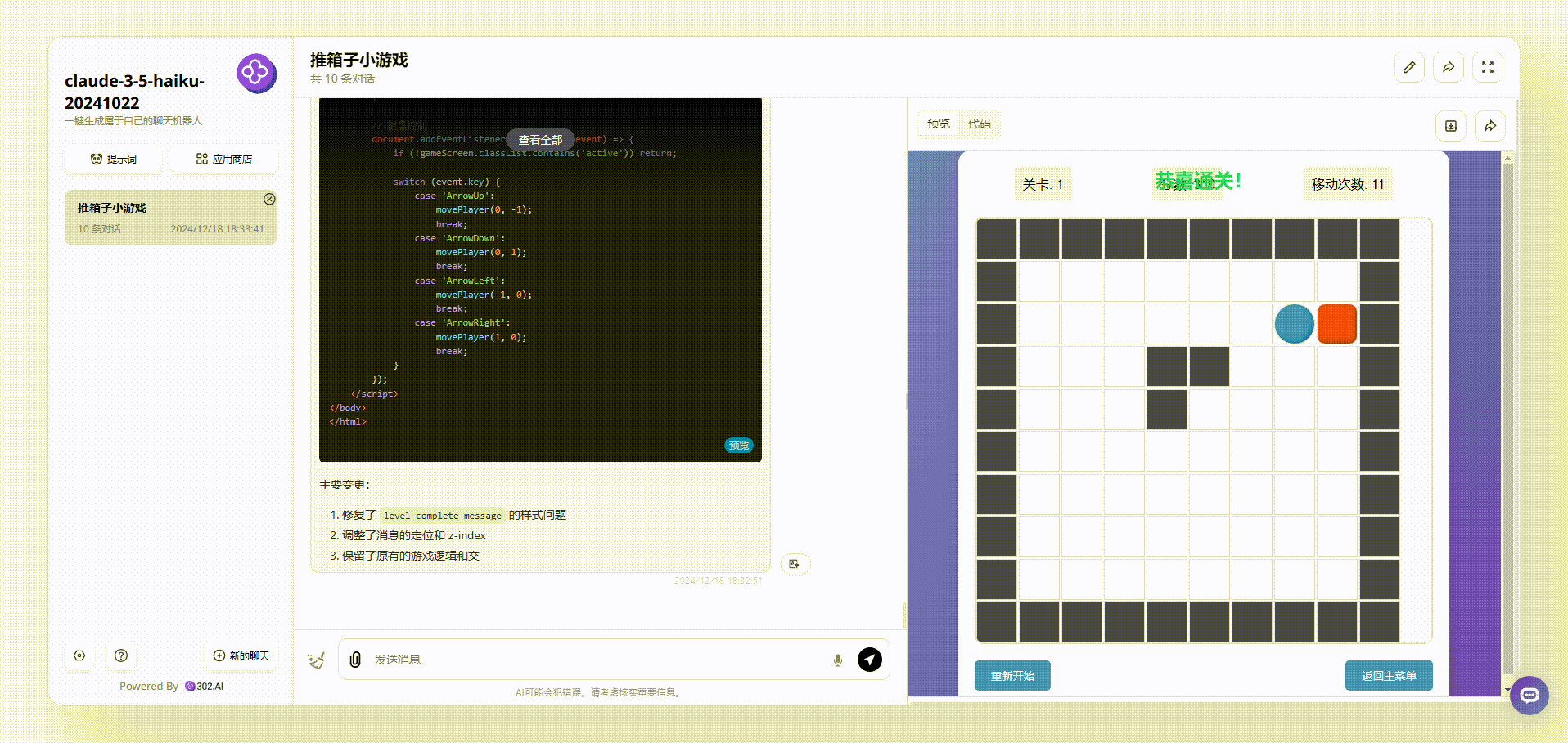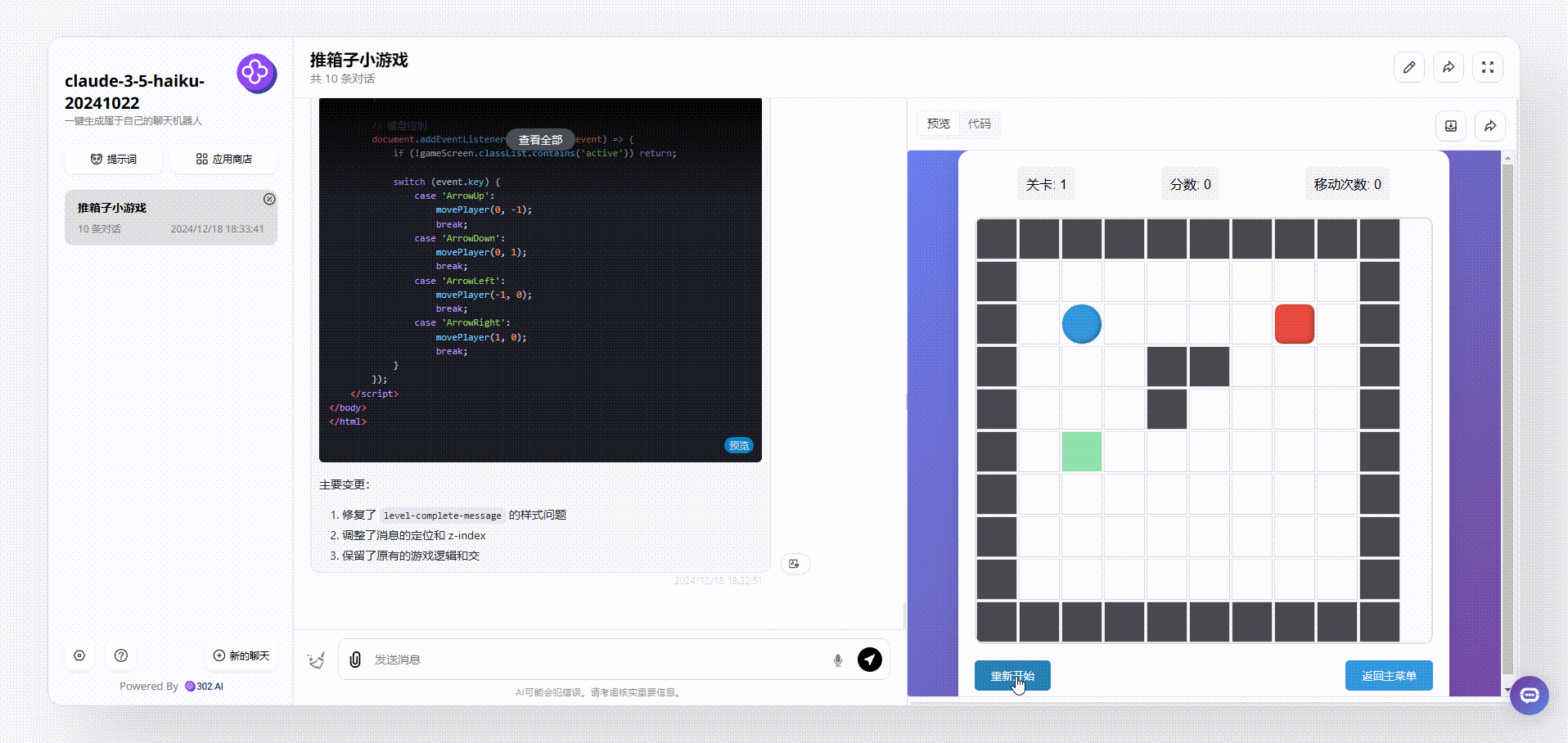
![]()
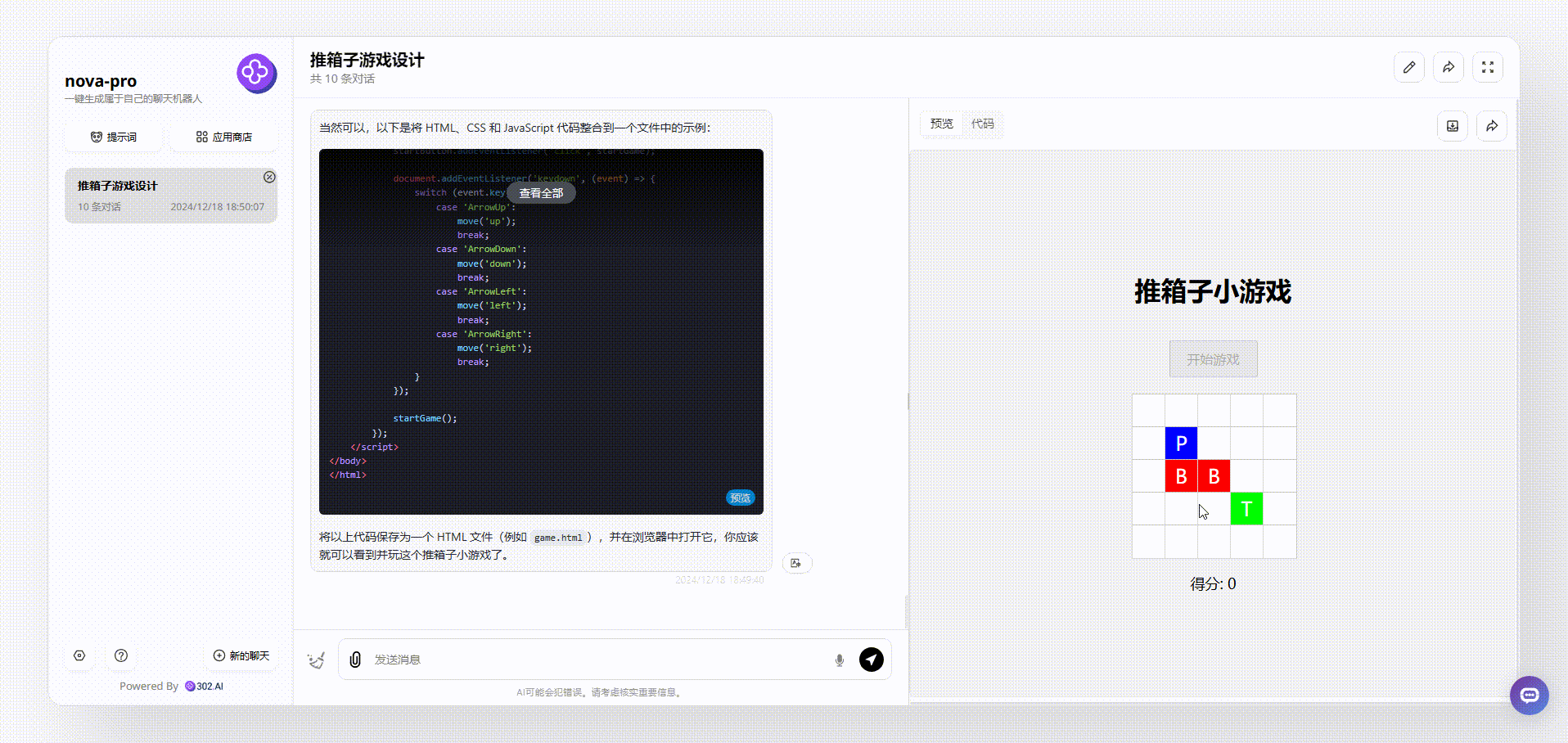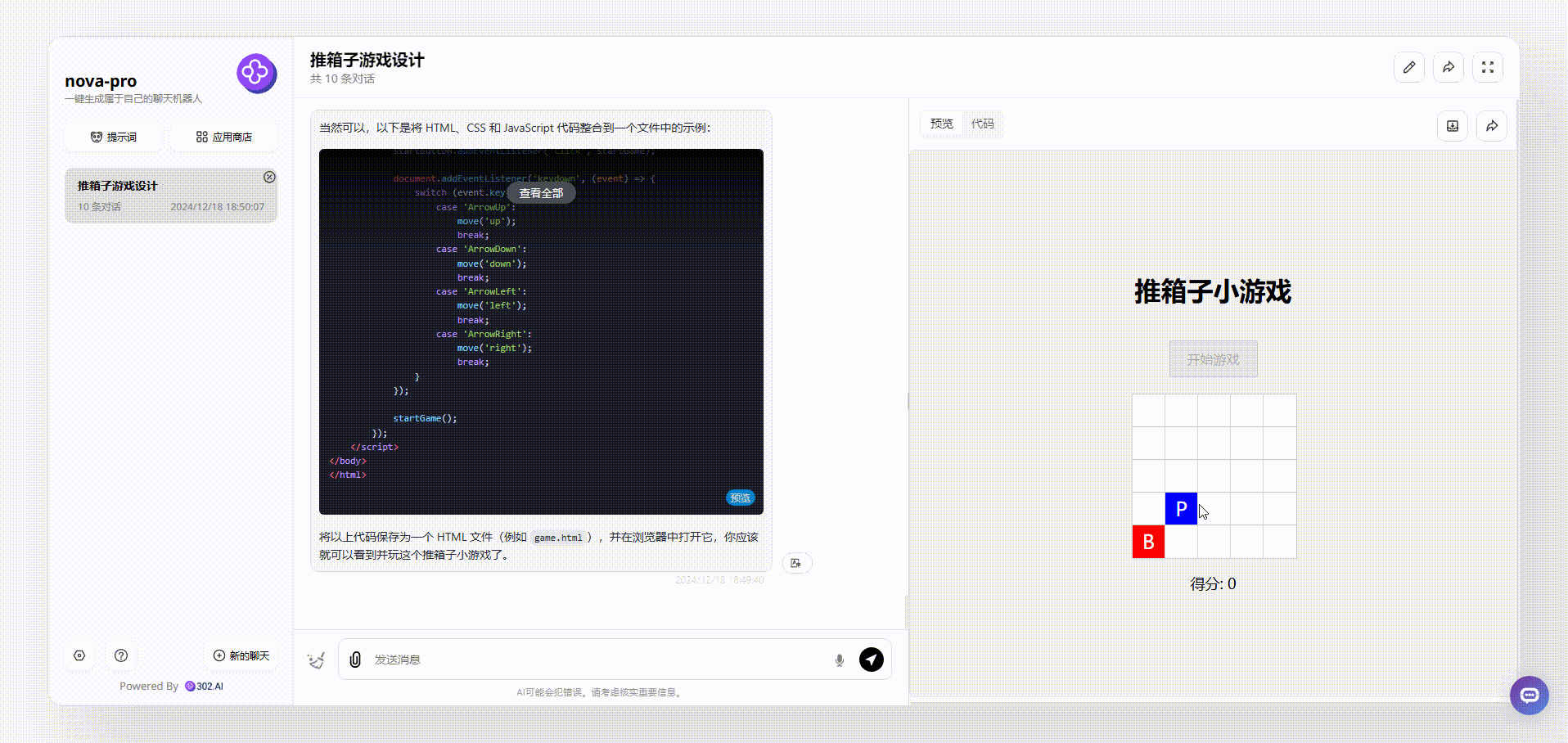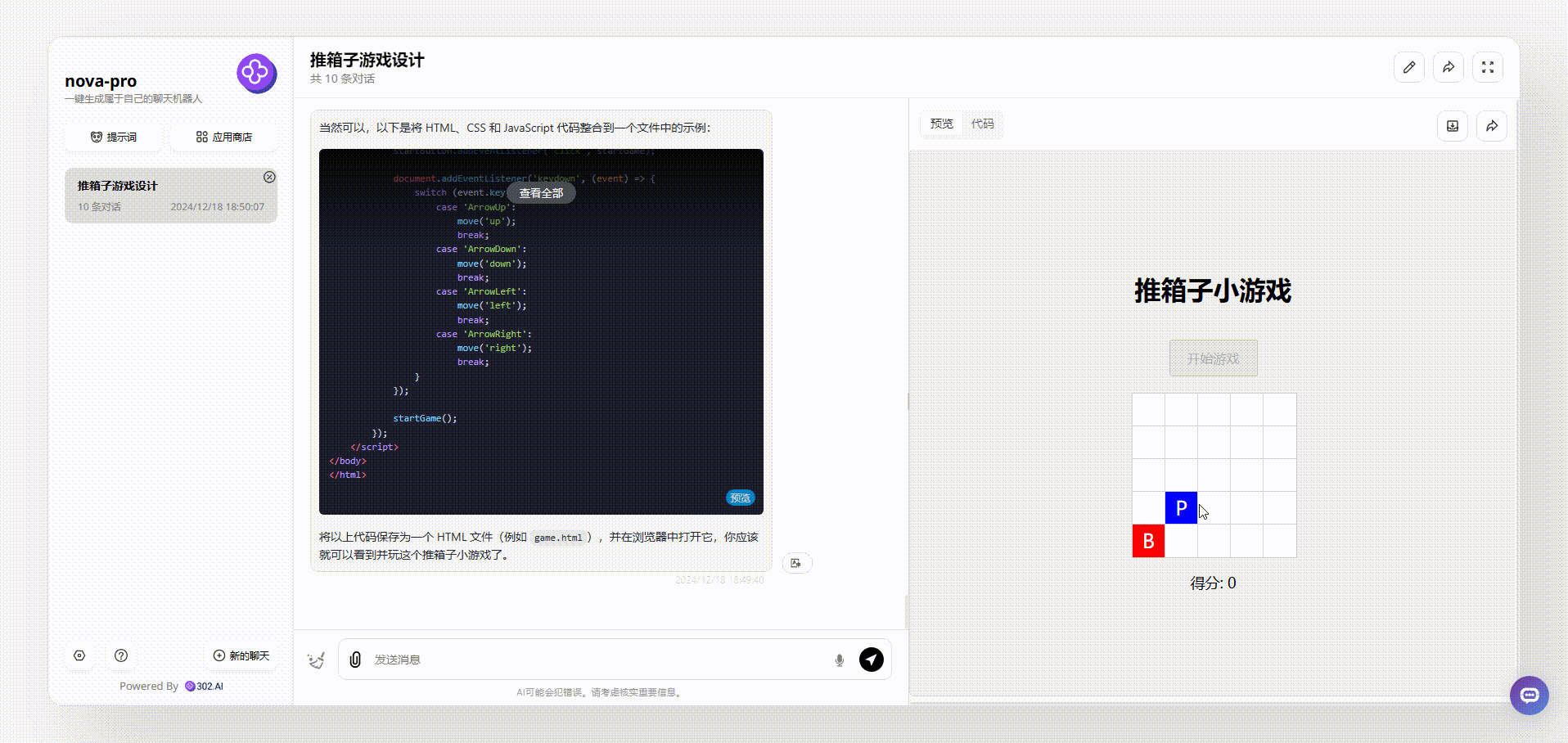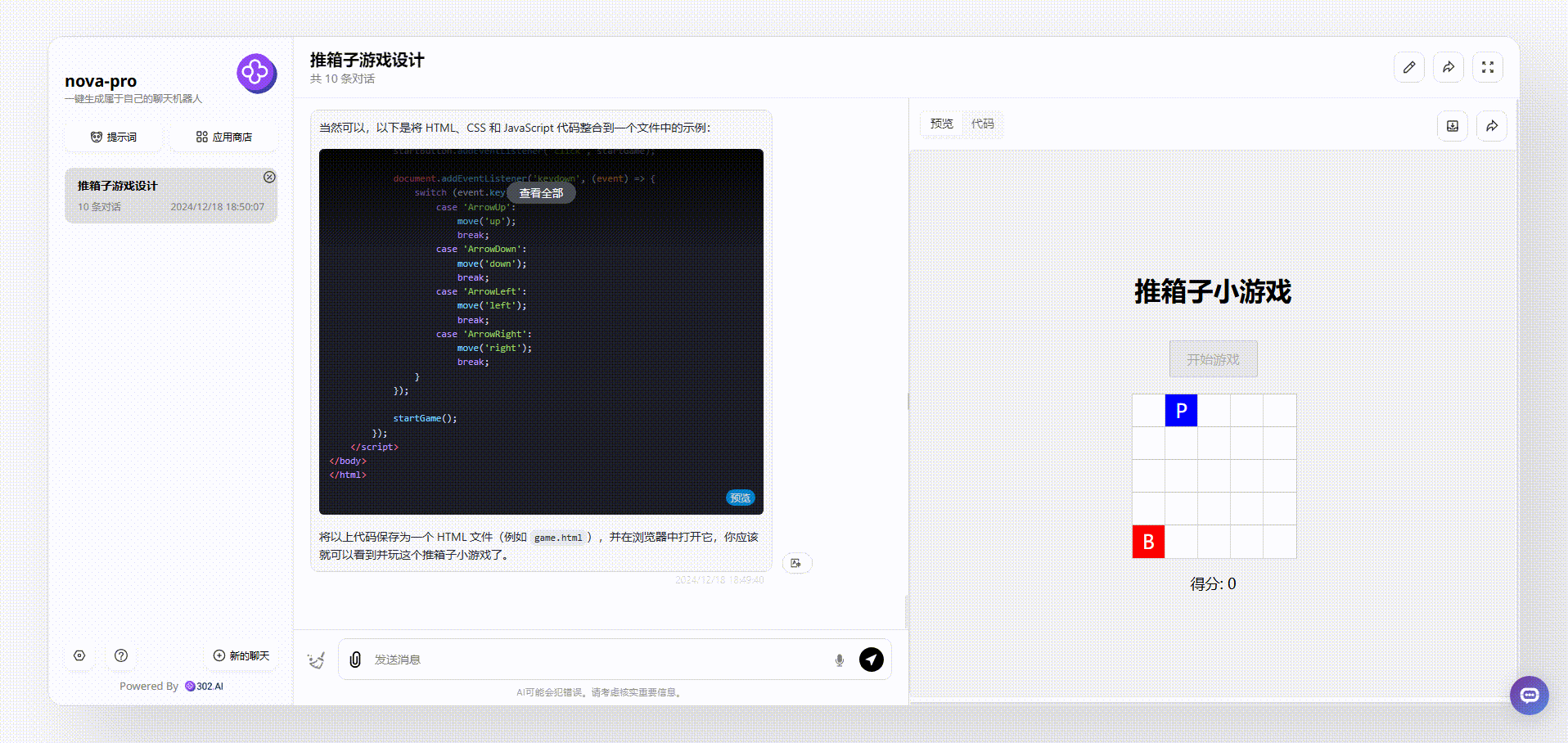
Nova Pro:生成的界面比较简陋,虽然能够操作,但是可以发现得分等板块并不会根据游戏操作而实时变化的,总体来说不够完整。
![]()
abab7-preview:界面设计还算美观,但展示的为静止界面,游戏无法操作。
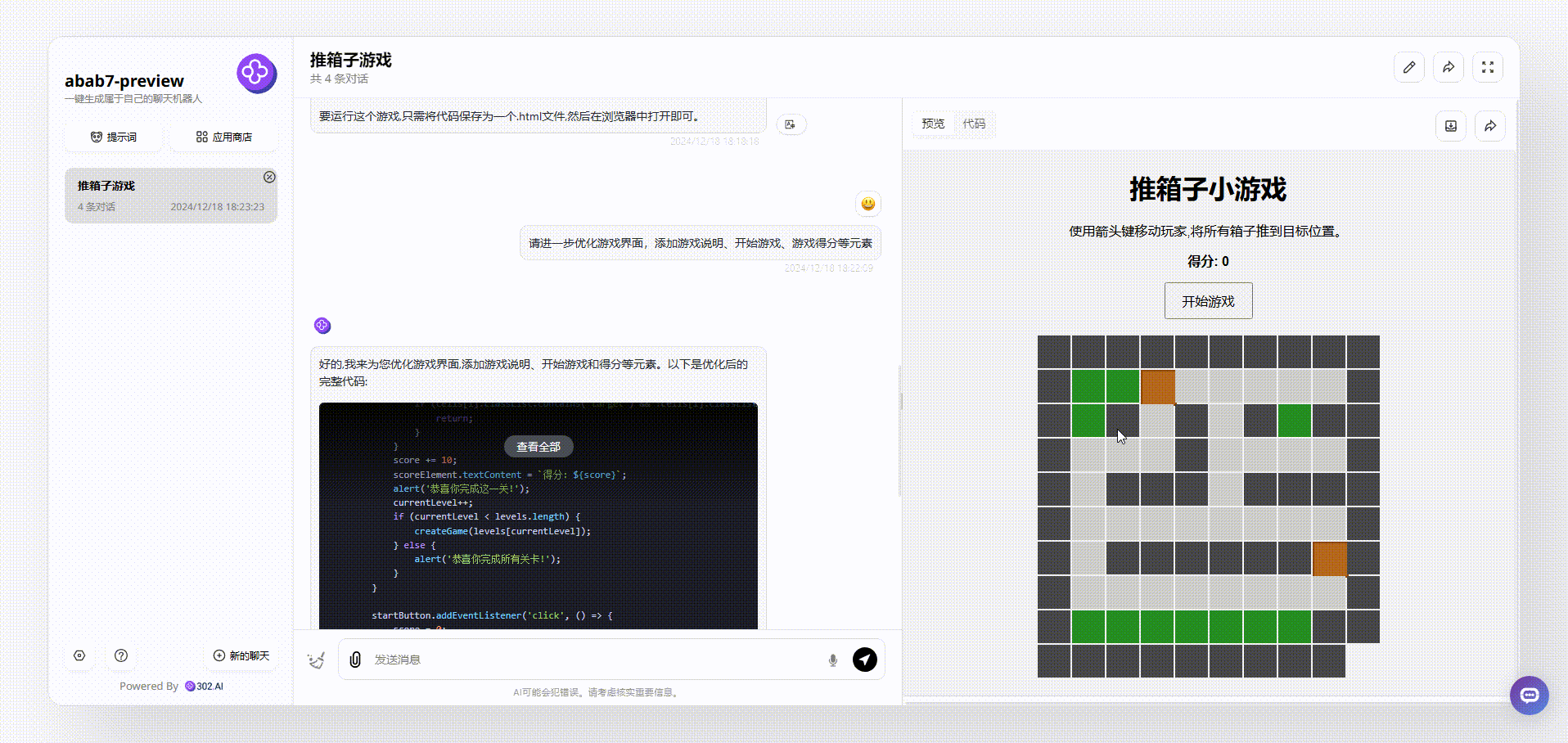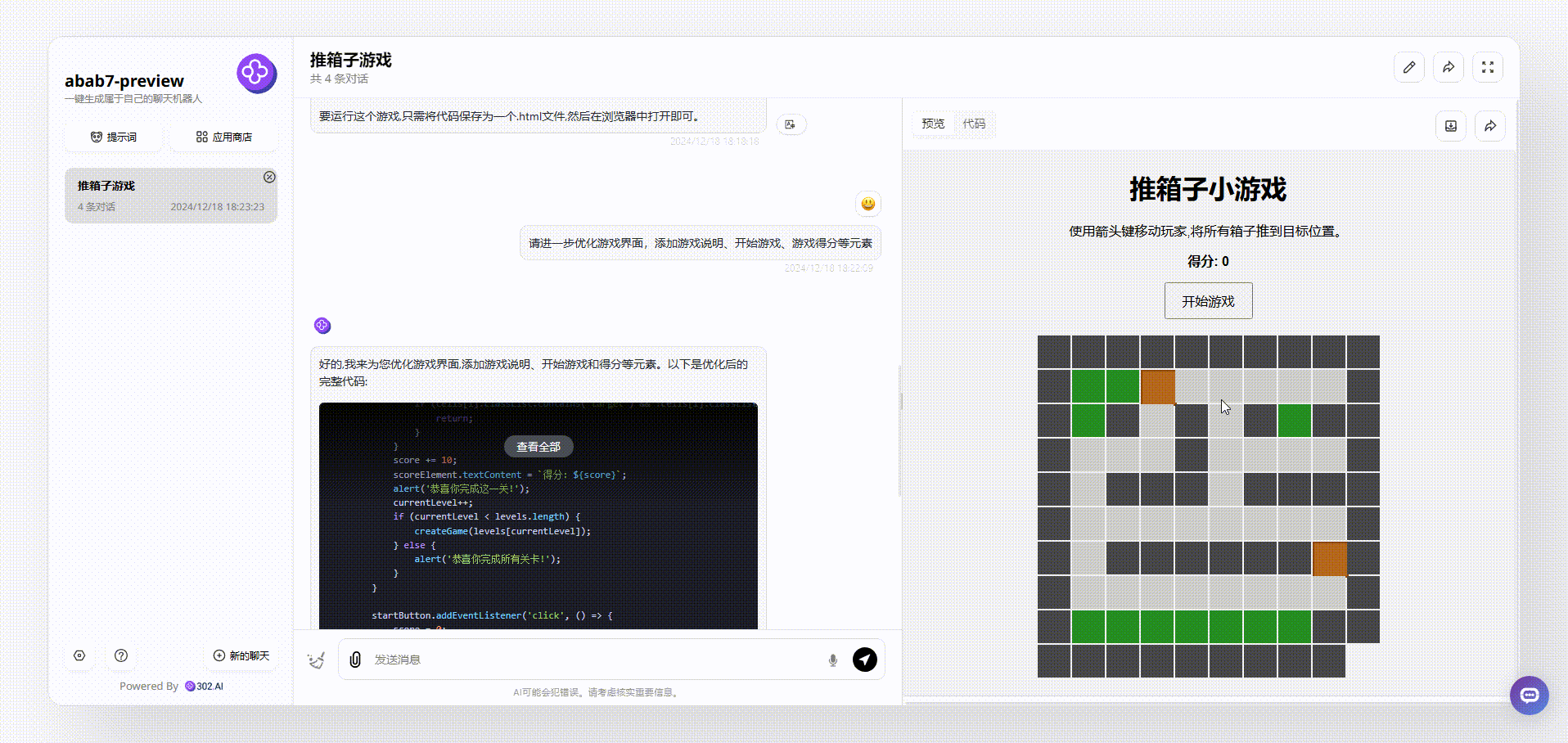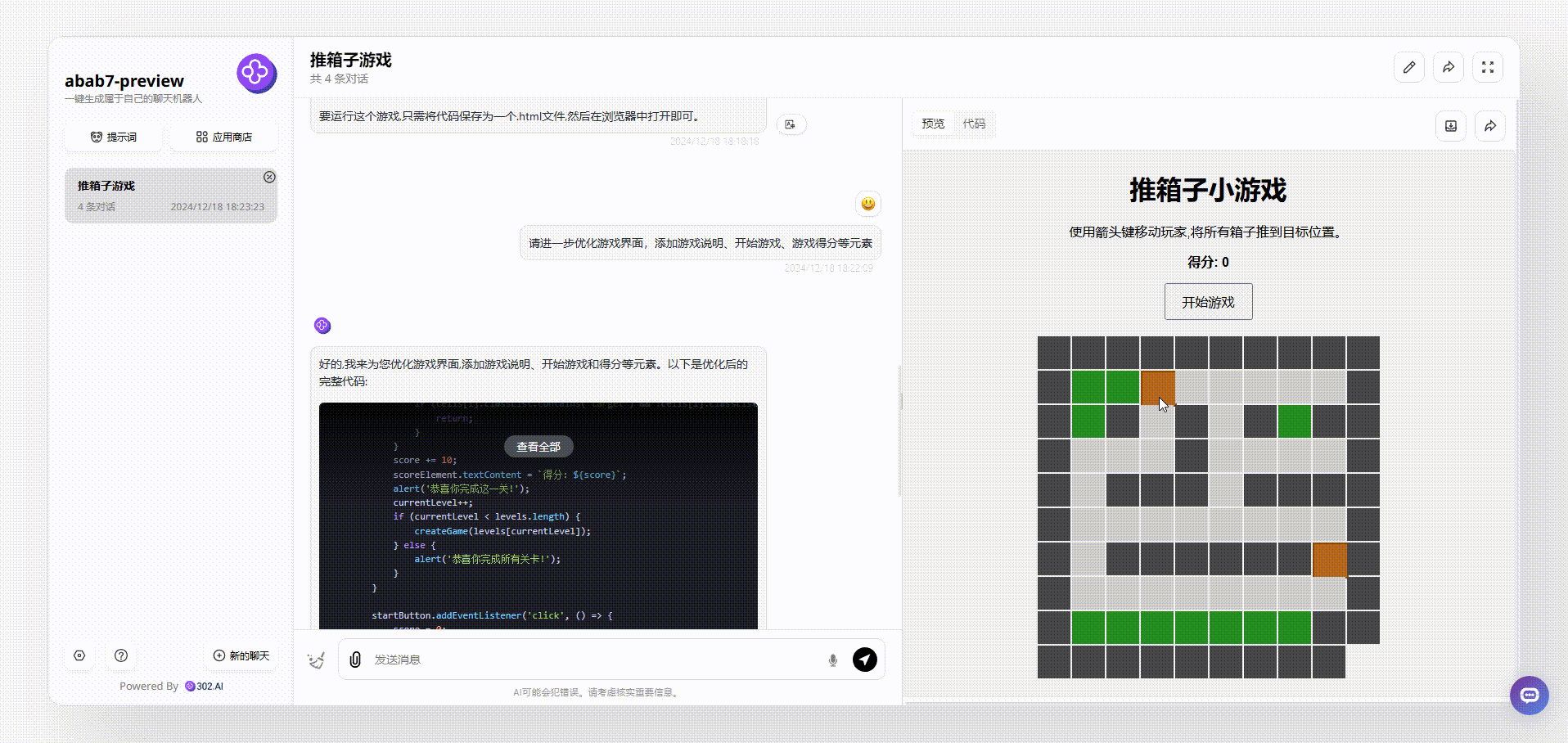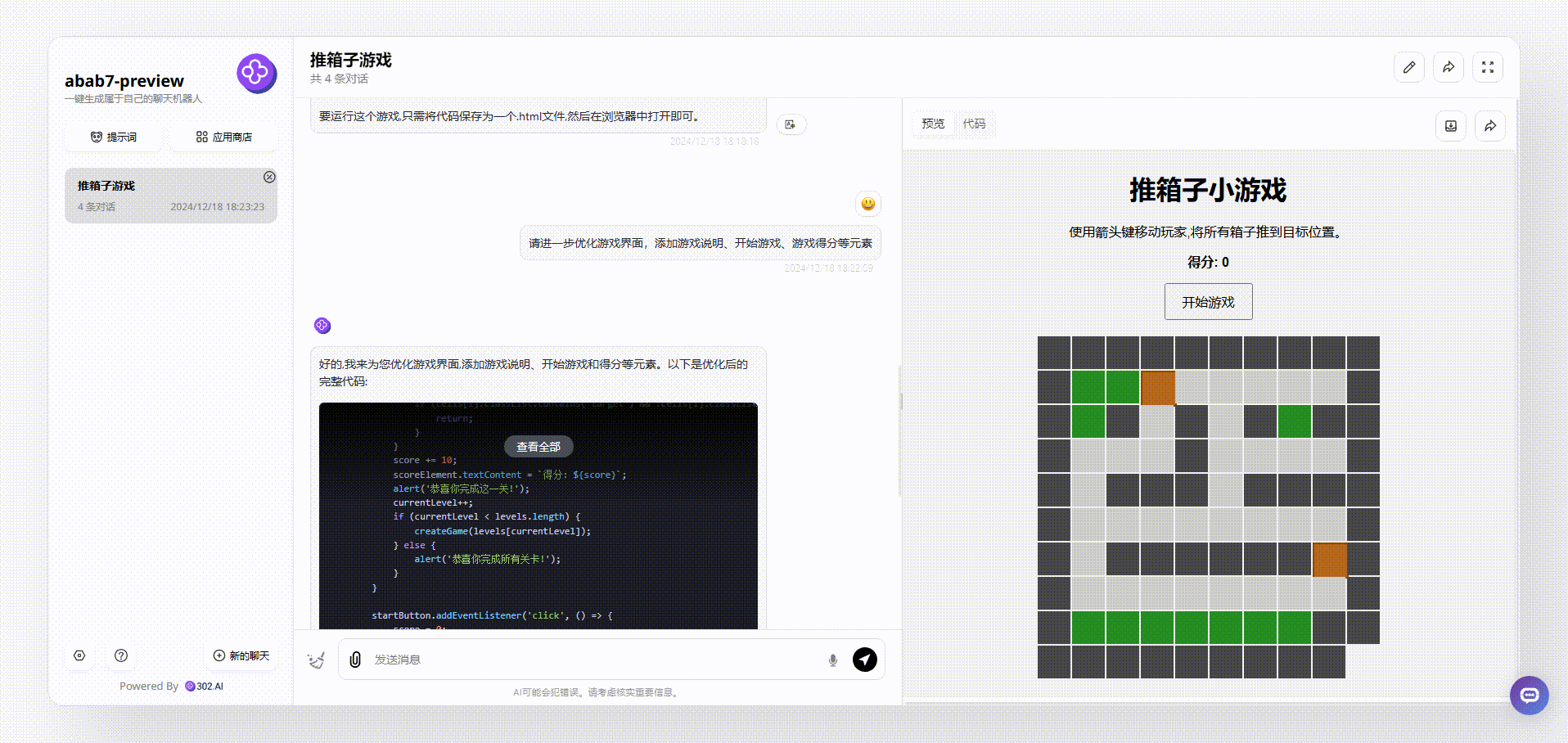
![]()
> 总结
通过以上实测,可以初步得出以下结论:
逻辑常识测试:对于逻辑常识问题,三个模型的都能合理进行分析,但是分析最完整的模型不是abab7-preview,而是Nova Pro。
推理测试:面对逻辑推理能力测试,abab7-preview在回答的准确性和分析的深度上表现还不错。
数学测试:对于难度较高的数学题目abab7-preview在内的三个实测模型存在明显的不足。
长文本测试:而在长文本大海捞针测试中,abab7-preview能够快速而准确地从大量信息中提取出关键内容,显示出其在处理复杂文本方面的不错表现。
编程测试:在编程测试中,abab7-preview虽然生成的界面美观度还不错,但是游戏无法操作,编程能力不足。
总的来说,abab7-preview作为国产模型,性价比还是挺高的,以上实测除了编程和数学测试的,其余测试表现都比claude-3.5-haiku更好,而且abab7-preview适合用于各种应用场景,包括但不限于长文本理解、复杂推理和逻辑分析等。根据MINIMAX官方表示,abab7正式版本目前在紧急筹备中,我们可以持续关注看看!
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(1)
Appreciate it for this post, I am a big big fan of this website would like to keep updated.