


5月29日,沉寂许久了的 Black Forest Labs (黑森林实验室) 通过官网发布了可用于生成和编辑图像的全新模型:FLUX.1 Kontext 系列,该系列模型能够同时使用文本和图像进行提示,并无缝地提取和修改视觉概念,从而生成全新、连贯的渲染效果。

FLUX.1 Kontext 系列分为以下版本:
- FLUX.1 Kontext [Pro] – 快速迭代图像编辑的先驱
- FLUX.1 Kontext [max] – 高速高效,性能最大化,显著提升了快速一致性和排版生成能力,实现了高度一致的编辑体验
根据官方介绍,FLUX.1 Kontext系列模型提升的核心功能包括:
角色一致性:引入「流匹配(Flow-Matching)+ 全局-局部上下文编码器」,在多个场景和环境中保留图像的独特元素,例如图片中的参考字符或对象。
风格参考:在文本提示的指导下,生成新颖的场景,同时保留参考图像的独特风格。
本地编辑:支持局部掩膜、分层指令和权重调节,让用户像使用 Photoshop 图层一样“点对点”修改,而非整幅重绘。
交互速度:以最小的延迟对图像生成和编辑进行迭代,比同规格扩散系竞品普遍的 30–40 s 最高快约 10 倍。

(在人物一致性上,FLUX获得了广泛赞誉)
很显然,Black Forest Labs 推出 FLUX.1 Kontext 就是直接对标GPT-4o的图片编辑功能。
302.AI团队紧跟市场动向,第一时间接入了 FLUX.1 Kontext 系列模型的API,并对其展开与 GPT-Image-1 模型的实测对比。
I. FLUX.1 Kontext 系列 vs. GPT-Image-1 图像编辑实测
模型基本信息
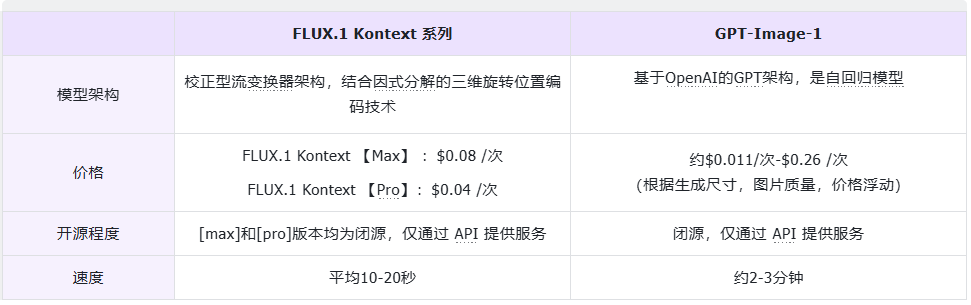
测评目标:
(1)在性能与成本的双重考量下,评估 FLUX.1 Kontext 系列相较于GPT-Image-1,是否具备更显著的性价比优势,在“快、稳、准”三个评测维度下,输出质量能否匹敌价格更高的对手。
(2)针对 FLUX.1 Kontext [Pro] 与 [Max] 版本,其定价与性能表现是否呈正相关。
*GPT-Image-1默认选择高质量画质。另:以下实测均取自模型第一次生成效果,具备随机性,仅供参考。
1、换装测试
提示词:Change the costume of the doll. Change a chunky, hand-knitted sweater in a cream or oatmeal color, paired with a classic plaid scarf. For the lower body, corduroy trousers would be perfect, with a pair of fluffy snow boots on its feet. If possible, add a miniature hand-warmer or a tiny cup of “hot cocoa” in its hand.
(参考翻译:更换娃娃的服装。换成一件厚实的奶油色或燕麦色的手工针织毛衣,搭配一条经典的格子围巾。下半身可以选择灯芯绒裤子,脚上再穿一双毛茸茸的雪地靴。如果可能的话,在他的手上放一个迷你暖手器或一小杯热可可。)

效果对比:
GPT-Image-1:毛衣颜色生成准确,围巾,杯子的颜色搭配合理,整体画面的光影写实感强,环境背景细节保留一致。但还是人物一致性的老问题:Labubu的眼睛,眉毛乃至标志性的牙齿都被进行了替换。
FLUX.1 Kontext [Pro]:整体效果满意,细节上还有能够提升的点比如雪地靴的毛茸茸质感未见体现,但Labubu的五官,动作都能够保持一致性。
FLUX.1 Kontext [Max]:整体效果满意。在保持人物一致性的基础上,准确还原了提示词中所有换装的要求,效果自然,具有美感。但出现了和GPT类似的问题,有“自主”改图的情况:Labubu面部周围的轮廓由毛发变为了帽子。

2、背景生成+局部替换
提示词:Place the model on the street of Tokyo. Night scene. Tokyo Tower in the background. Cars on the road. Replace the model’s blue bucket hat into a red baseball hat. Replace the black trousers into a blue denim jeans.
(参考翻译:让模特置身于东京的街道,夜景。背景能看到东京塔。汽车行驶在路上。将模特的蓝色桶帽换成红色棒球帽。把黑色的裤子换成蓝色的牛仔裤。)

效果对比:
GPT-Image-1:场景生成较准确,但东京塔有略微扭曲变形。画面景深过渡准确,尤其是人物面光的质感好。服饰根据提示词要求更换正确。T恤印花中的字母识别最为准确。但人物一致性的老问题依然存在,细节上如模特脖子上的黑痣未保留。
FLUX.1 Kontext[Pro]:根据提示词要求,背景及服饰生成正确,画面景深,光影表现合理,模特脖子上的黑痣准确还原,人物动作自然。但T恤印花中的字母出现涂抹现象。
FLUX.1 Kontext[Max]:和Pro版本表现基本一致,包括画面构图,整体光影表现以及人物一致性。明显的短板仍是对于字母识别的准确性。

3、文本替换+颜色转换
提示词:Transform the main text “AI” into “302.AI”, with glittering golden metal art style. Transform the text ” EFFICIENCY REDEFINED” into “Let AI Find the Answers For All Your Needs”. Change the main color blue into purple (#8e47f1).
(参考翻译:将正文“AI”转换为“302.AI”,表现为金光闪闪的金属艺术风格。将文本“EFFICIENCY REDEFINED”替换为“Let AI Find the Answers For All Your Needs”。将主色调蓝色改为紫色(#8e47f1)。)

效果对比:
GPT-Image-1:整体表现最佳,准确还原了提示词的所有要求。字体特效美观,为了防止遮挡机器人元素,主动将AI两个字母的字号缩小,排版合理。但两个机器人的细节均发生了变动。
FLUX.1 Kontext[Pro]:提示词理解有误,要求将主色调蓝色替换,仅替换了长文本的颜色。字体特效美观度较差,文字遮挡画面元素(虽然还调整了透明度),未能主动调整排版。人物一致性保留。
FLUX.1 Kontext[Max]:文字特效效果较佳,对长文本进行了合理排版,但颜色转换失败。人物一致性保留。

4、背景人物消除
提示词:Eliminate all the soldiers in the background
(参考翻译:消除背景中的所有士兵)

效果对比:
GPT-Image-1:背景人物消除成功,景深过渡自然。但整体色温发生变化,由冷色调变成了暖色调,人物五官,表情均发生了改变。
FLUX.1 Kontext[Pro]:效果最差。提示词理解失败,消除了主体人物。
FLUX.1 Kontext[Max]:整体表现最佳,背景人物消除干净,过渡自然,图片的整体色温氛围未发生改变。主体人物的五官、表情均保持了一致性,细节上的雪花也都得以保留。

5、风格迁移
提示词:Maintain the original style of the picture and create a new work: a small alley in the south of the Yangtze River in the early morning, just washed by the rain. A kite was coiled around an electric pole. A bamboo basket was hung under the eaves. The teahouse at the end of the alley had just opened, and warm light was shining from inside.
(参考翻译:保持画面原有风格,创作新作品:清晨江南的小巷子,刚被雨水冲刷过。风筝盘绕在电线杆上。屋檐下挂着一个竹篮。胡同尽头的茶馆刚刚开门,暖暖的灯光从里面照进来。)

效果对比:
GPT-Image-1:整体表现最佳,提示词中的“风筝、竹篮、茶馆、暖灯”等细节元素均有生成,构图合理且具有美感,提示词遵循准确性高。整体水墨画风格能够还原,唯一偏差在于整体色调与原画相比,提升了对比度,整体氛围更暗。
FLUX.1 Kontext[Pro]:画面风格保持了一致性,但提示词遵循不够准确,风筝,竹篮,茶馆的表现都不够明显。
FLUX.1 Kontext[Max]:整体效果与Pro版本接近,画面风格进行了还原,但提示词遵循不够准确,作品中风筝是挂在了屋檐边而非盘绕在电线杆上,茶馆的属性也并未具象化体现。

6、多图融合
提示词:The woman, wearing a black top and a white dress, is standing at the entrance of the banquet hall
(参考翻译:一位女士穿着黑色上装与白色裙子,站在宴会厅入口处。)

效果对比:
GPT-Image-1:整体表现最佳,背景生成正确,突出了宴会厅的场景,但人物与背景的过渡稍显生硬。白色裙子在融合后细节处发生了变化(腰带扣消失)。人物一致性问题存在。
FLUX.1 Kontext[Pro]:场景的主题性不够突出,但人物背景过渡柔和自然。人物和裙子的一致性准确保留。
FLUX.1 Kontext[Max]:与Pro版本的整体场景色调基本一致,人物&裙子一致性准确,但莫名其妙生成了第二个人。

II. 实测总结
1、实测结果整理:
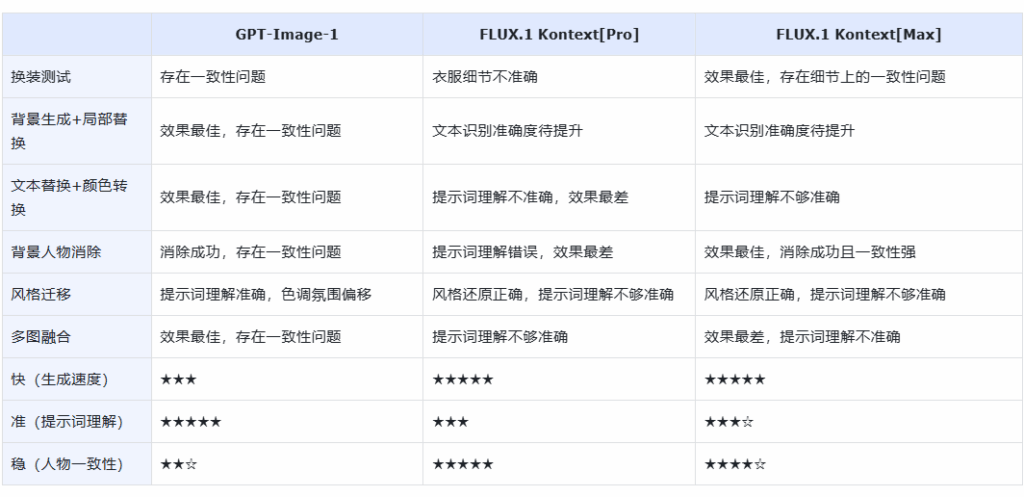
2、实测结论:
基于以上实测结果,可初步得出以下结论:
(1)在一致性问题上,FLUX.1 Kontext 系列完胜 GPT-Image-1,确实是目前模型中最强。GPT-Image-1 生成的作品有着自己明显的“美学理解”,除了老生常谈的人物一致性问题,画面的色调饱和度亮度也都会发生一定的偏移,是锦上添花还是弄巧成拙,具有很强的不可控性。
(2)FLUX.1 Kontext [Pro] 与 [Max] 版本,其定价与性能表现并非完全正相关,FLUX.1 Kontext[Pro] 价格更低,但在角色一致性、细节保留方面反而更佳;FLUX.1 Kontext[Max] 和GPT-Image-1一样,偶尔会出现“无中生有、自主改图”的现象。
(3)对于提示词的理解,FLUX.1 Kontext 系列距离GPT-Image-1还有着可见的差距。用户明确表达的需求,如何用更准确的角度,更具美感的方式来体现,就是体现模型功底的时刻。如果不在意人物一致性的前提下,我们推荐用户使用GPT-Image-1,用于生图的参考对比。
(4)综合成本和以上实测表现,如果保持人物一致性是刚需(如批量生成同一人物的系列图),FLUX.1 Kontext [Pro] 有着极具性价比的价格(不到GPT-Image-1 1/4的价格),最快的生成速度。而提示词理解准确度欠缺的问题可以通过对提示词进行调整优化来解决,这套方案是我们建议大多用户进行尝试体验的选择。
🎁Bonus:
Replicate官方出品:FLUX.1 Kontext使用说明与提示词技巧
III. 如何在302.AI上使用:
302.AI提供按需付费无订阅的服务模式,用户可以根据自身业务需求灵活选择使用。
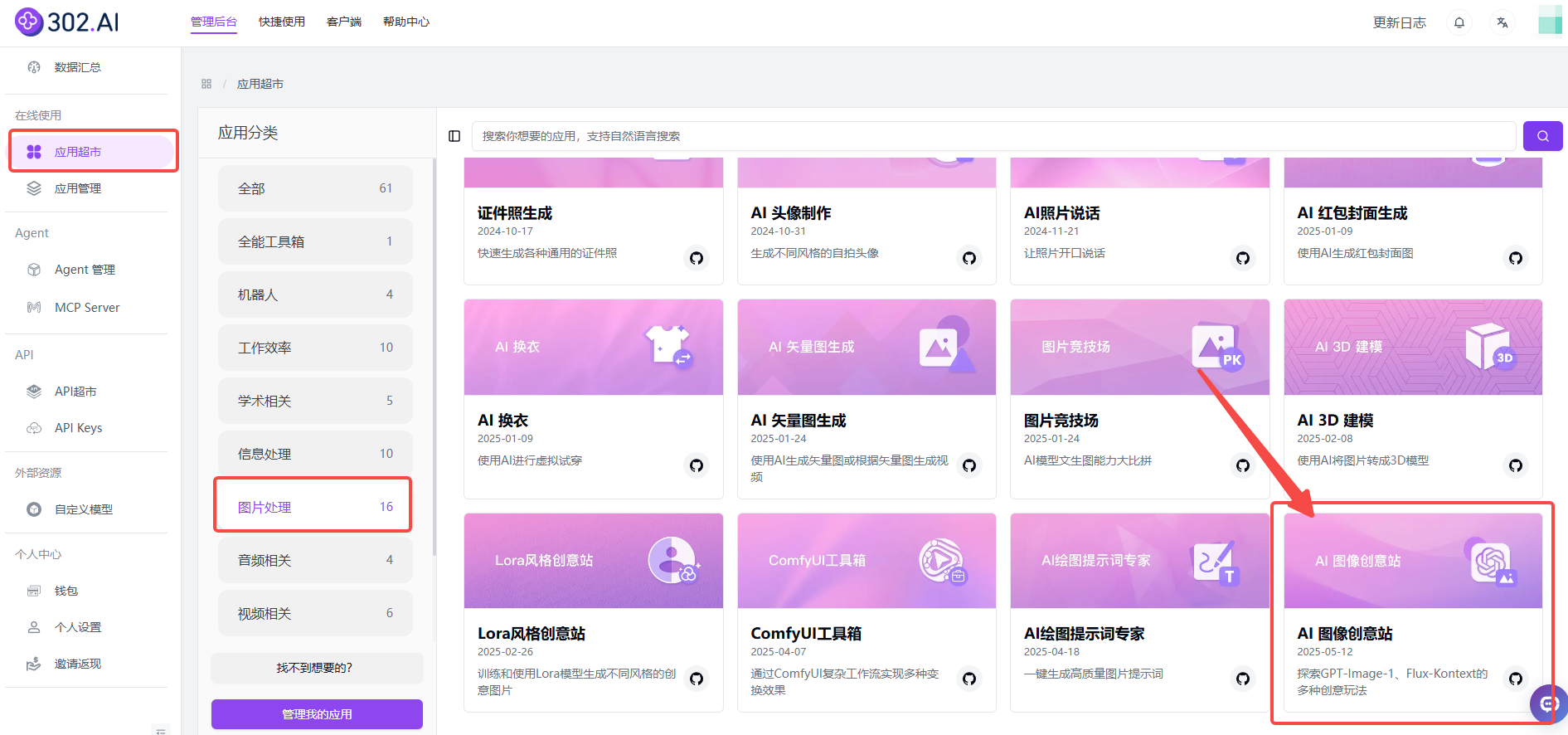
1、在应用中使用
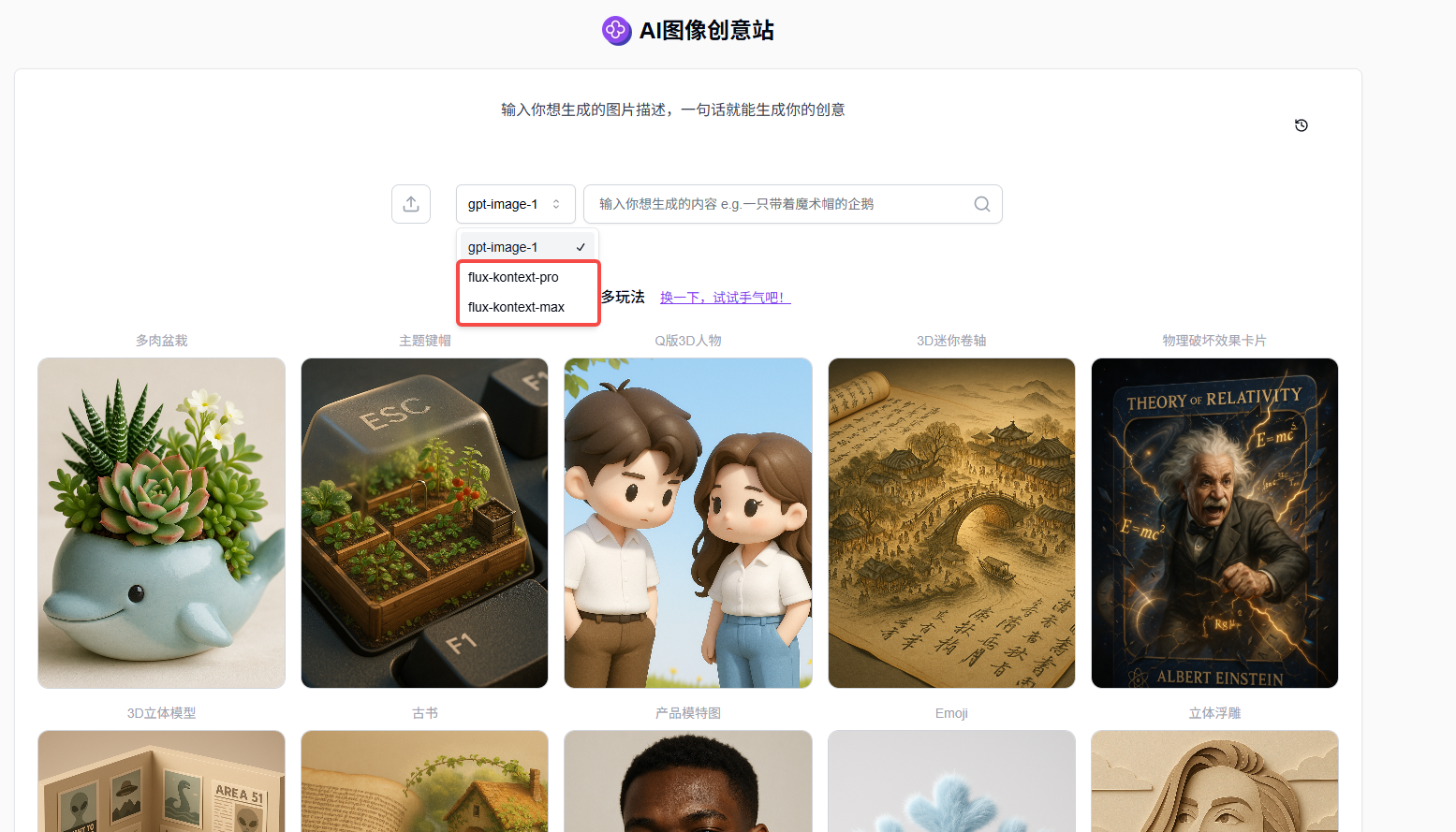
(1)在线使用→ 应用超市→ 图片处理→ AI 图像创意站→创建。
(2)选择模型FLUX-Kontext-Pro/FLUX-Kontext-Max后,可直接输入提示词进行文生图,也可以上传图片并输入提示词在线编辑图片。
(3)此外,AI 图像创意站除了支持基础生图,还提供了超60种风格模板,用户可选择模板直接生成作品。
2、获得模型API
【图片生成】
相关文档:API→API超市→图片生成→ flux→查看文档;
【图片编辑】
相关文档:API→API超市→图片处理→ Black Forest Labs→查看文档;


想体验 FLUX.1 Kontext 系列模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
