
I. 2025年上半年多模态大模型评测与推荐:洞悉前沿,智选未来


2025 年上半程,多模态大模型又一次把“看图回答”这件事做到了难以想象的高度。谷歌在 I/O 上抛出的 Gemini-2.5 系列率先给外界打了样:Pro 型号在多项推理基准夺冠,Elo 得分刷新纪录;而 Flash 则把一次图文推理的平均延迟压进 500 ms 并新增视频输入通道。Anthropic 紧随其后,Claude Sonnet 4 的 05-14 版本在代码与长文本双基准上与 Gemini 平分秋色。OpenAI 低调更新的 o3 虽未公布参数,却在 60% 以上准确率的三大编码测试里悉数上榜,展示了对图像-文本混合推理的硬实力。
国内战场同样硝烟滚滚:字节的 Doubao-Seed-1.6-thinking 聚焦“极速响应”,面向移动端推理;阿里的 QvQ-Max 则用一体化视觉编码器让表格、配图同屏问答成为日常;阶跃星辰发布的 Step-R1-V-mini 把 70 亿参数塞进工作站,智谱 GLM-4V-Plus 则把多模态上下文延伸到 60 页 PPT。它们共同勾画了一个从“跑分”走向“端云协同、场景落地”的新周期:速度、成本与长上下文三足鼎立,API-SaaS 完整链路逐渐成型。
302.AI 基准实验室的这期横评,选择了以上八款2025上半年度最具代表性的多模态模型,统一以“图片+问题”这一高频交互范式,对其理解深度、推理准确率与响应时延展开全流程实测,为开发者与产品经理提供真正可落地的选择推荐参考。
Ⅱ. 模型测评
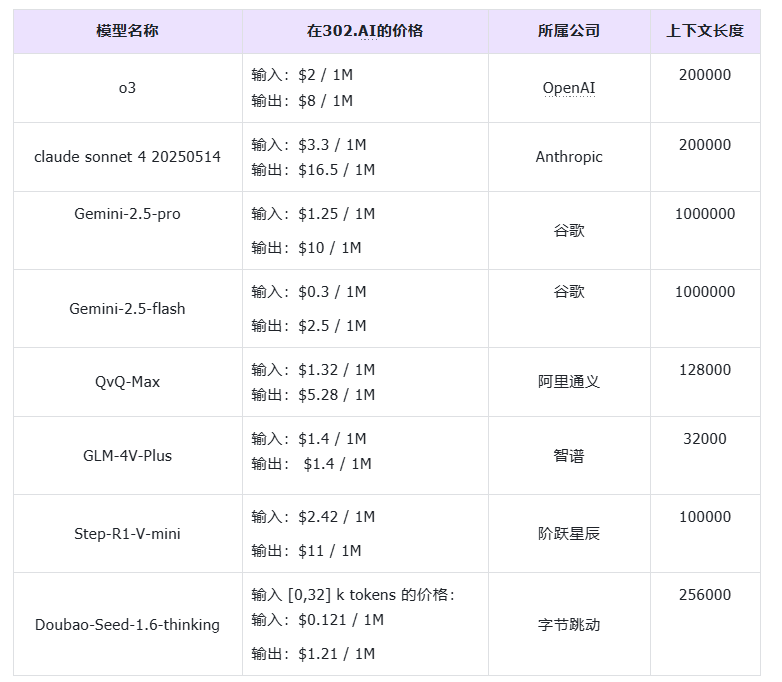
1、参与测评的模型基本信息
2、测评工具:
以下测评使用的工具为302.AI的模型竞技场,实测取自模型第一输出结果,仅供参考。
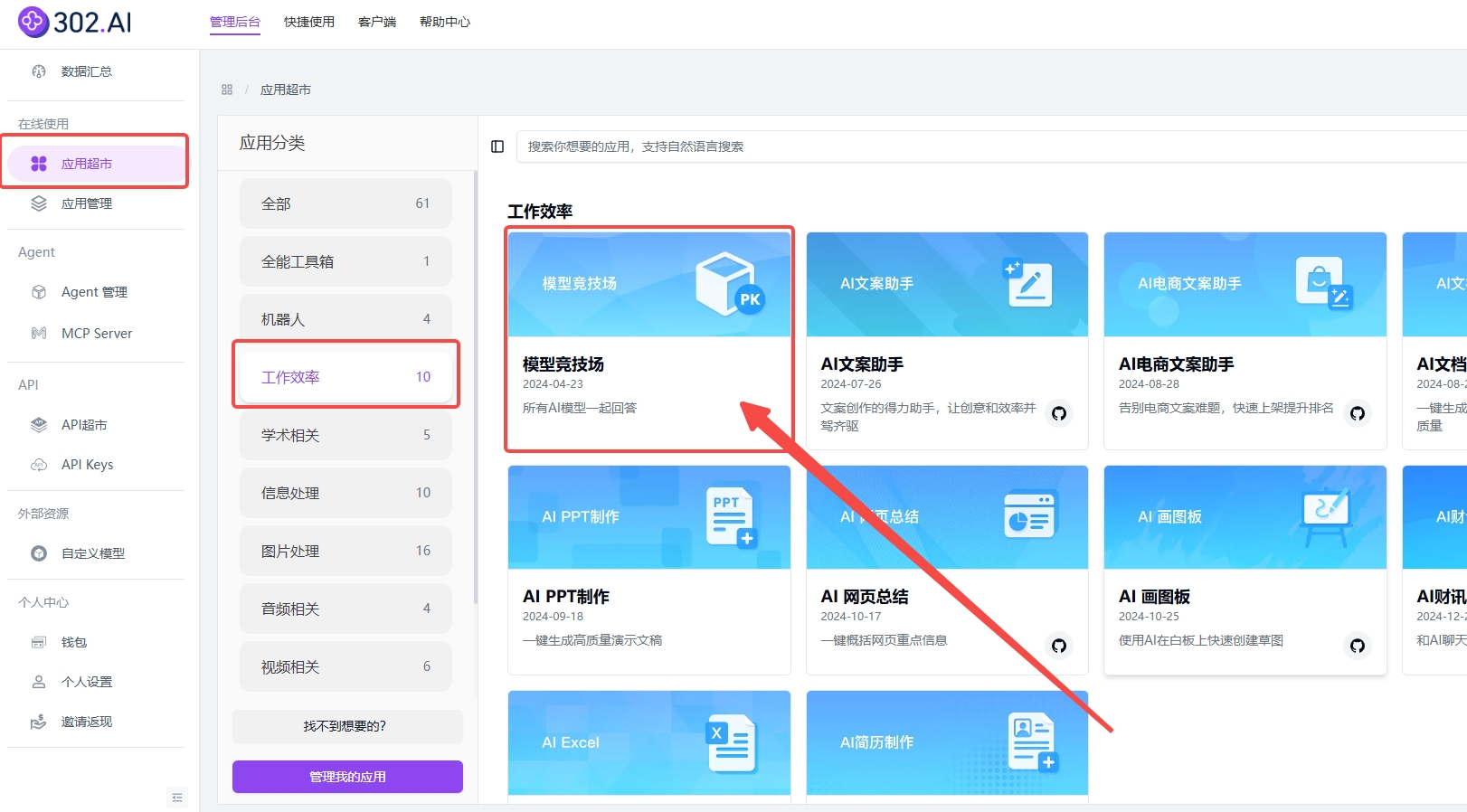
模型竞技场使用步骤:
(1)登录进入302.AI→在线使用→应用超市→工作效率→模型竞技场→【创建】;
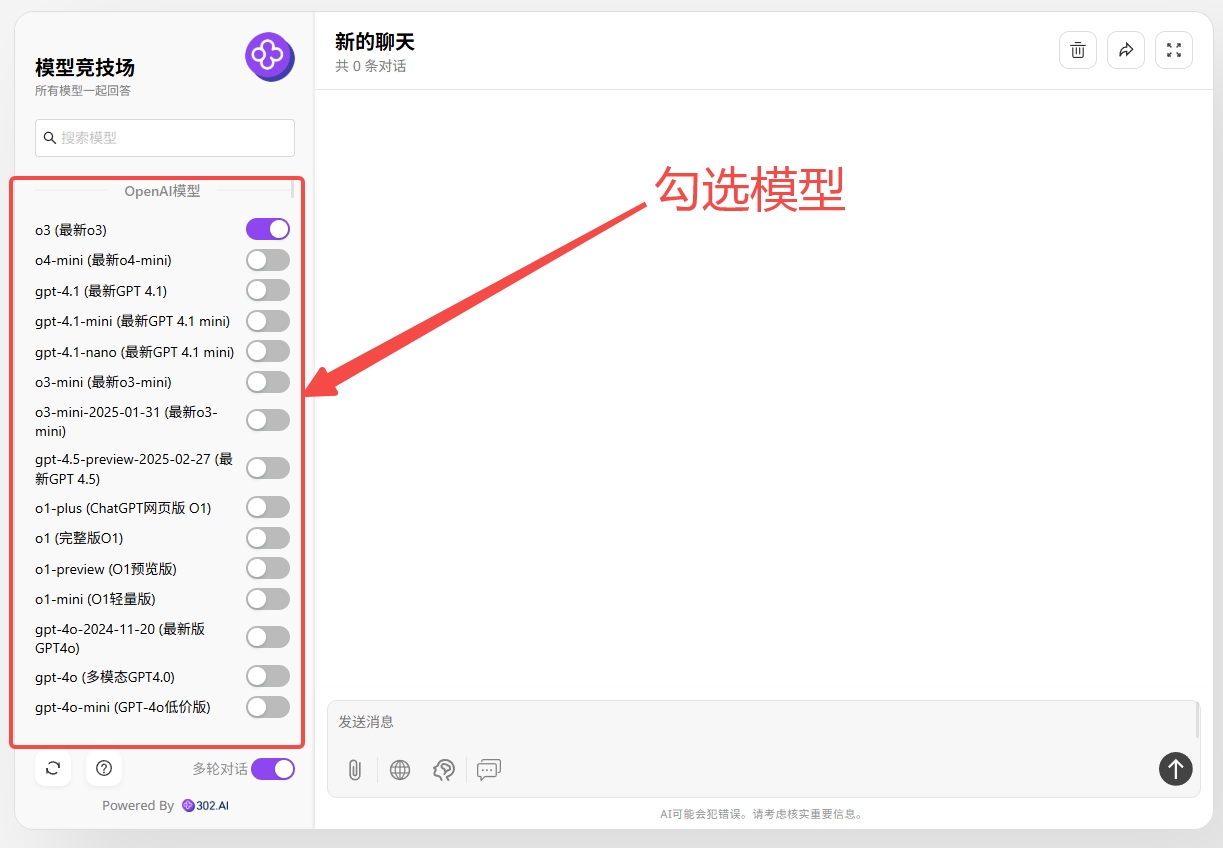
(2)勾选所需模型,发送提示词即可开启使用。模型竞技场中可对比多个模型的回答,非常直观。
3、测评案例:
测评案例整体遵循着从简单到复杂的测试逻辑。
测评摘要:
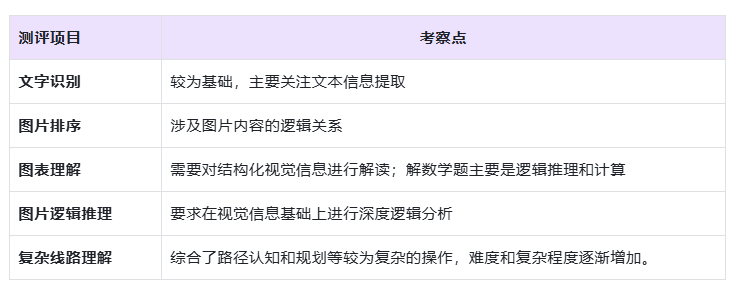
(1)文字识别:
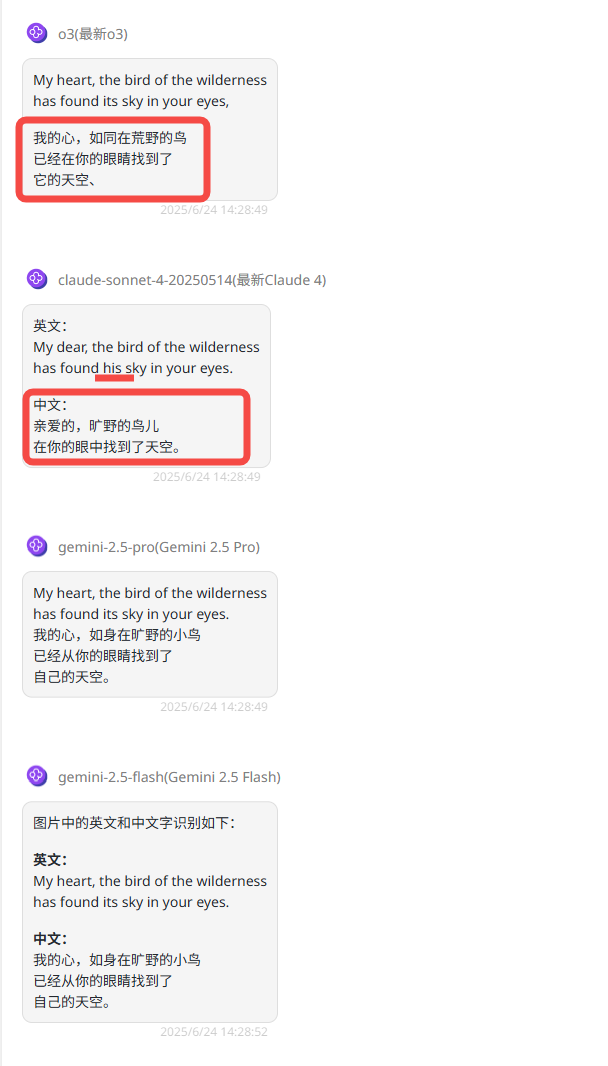
提示词:请不要加入自己的思考,直接识别出图片中的英文和中文字。
(图源网络)

题目解析:测试模型是否能够准确提取文本信息,针对识别书籍扫描件中的文字、街边招牌的文字等,是多模态模型处理文本输入的基础功能测试。
正确答案:
My heart, the bird of the wilderness has found its sky in your eyes.
我的心,如身在旷野的小鸟
已经从你的眼睛找到了
自己的天空。
o3:英文正确,中文识别不准确。
claude sonnet 4:中英文识别均不完全准确。
Gemini-2.5-pro:中英文均准确。
Gemini-2.5-flash:中英文均准确。
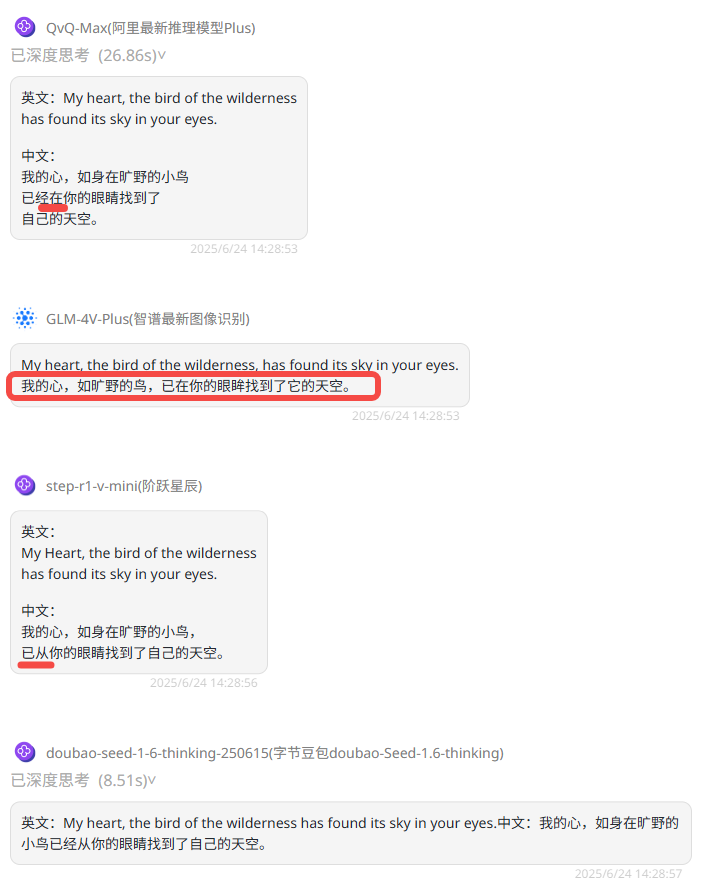
QvQ-Max:英文准确,中文识别部分细节不准确。
GLM-4V-Plus:英文准确,中文识别部分细节不准确。
Step-R1-V-mini: 英文正确,中文识别不准确。
Doubao-Seed-1.6-thinking: 中英文均准确。
(2)图片排序:
提示词:请根据图片中显示的场景,将最有可能发生的事件按顺序排列。
(图源网络)
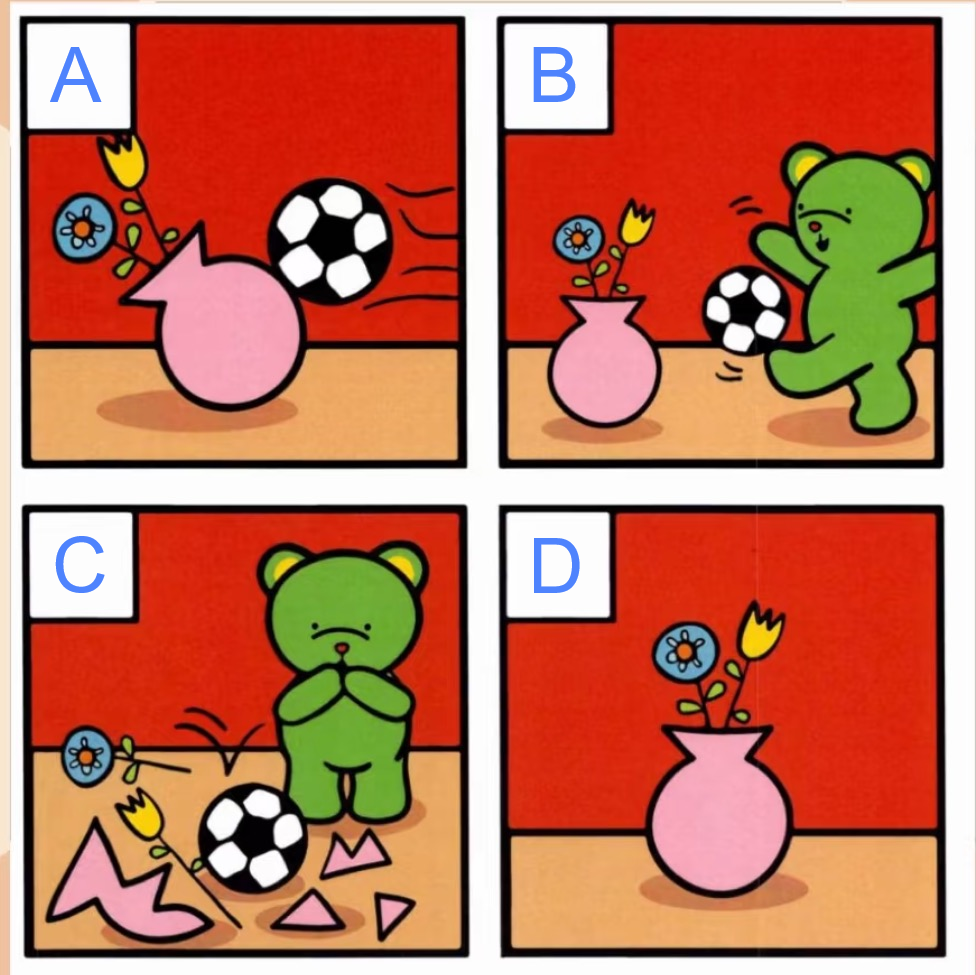
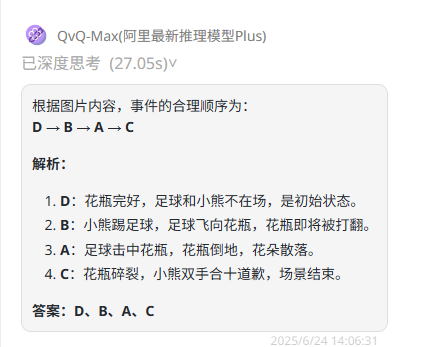
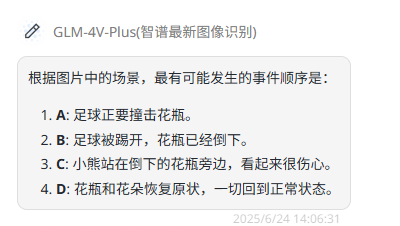
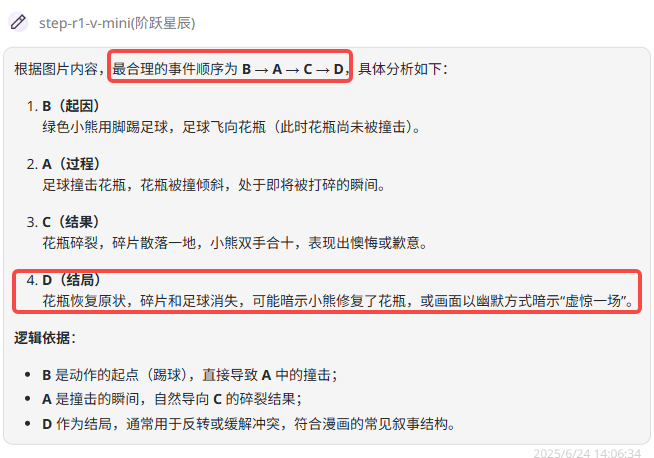
题目解析:着重于考察模型对图片内容的语义理解和逻辑关系把握,属于基础的逻辑测试。正确答案:D→B→A→C
o3:解释和答案均正确。

claude sonnet 4:答案错误,解释逻辑不通。
Gemini-2.5-pro:描述和答案均正确
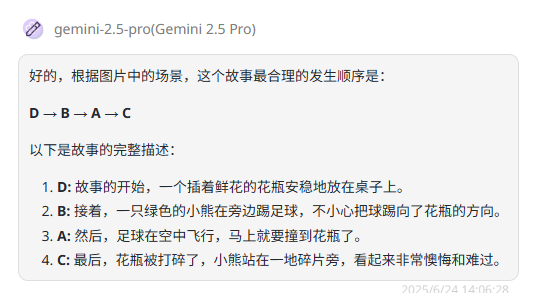
Gemini-2.5-flash:描述和答案均正确

QvQ-Max:描述和答案均正确
GLM-4V-Plus:完全错误。
Step-R1-V-mini:逻辑不够合理,答案错误。
Doubao-Seed-1.6-thinking:解析得非常逻辑化且内容详实,答案正确。

(3)图表理解:
提示词:请阅读图片并告诉我,2025年广东省高考人数为多少,占全国高考人数的百分之几?
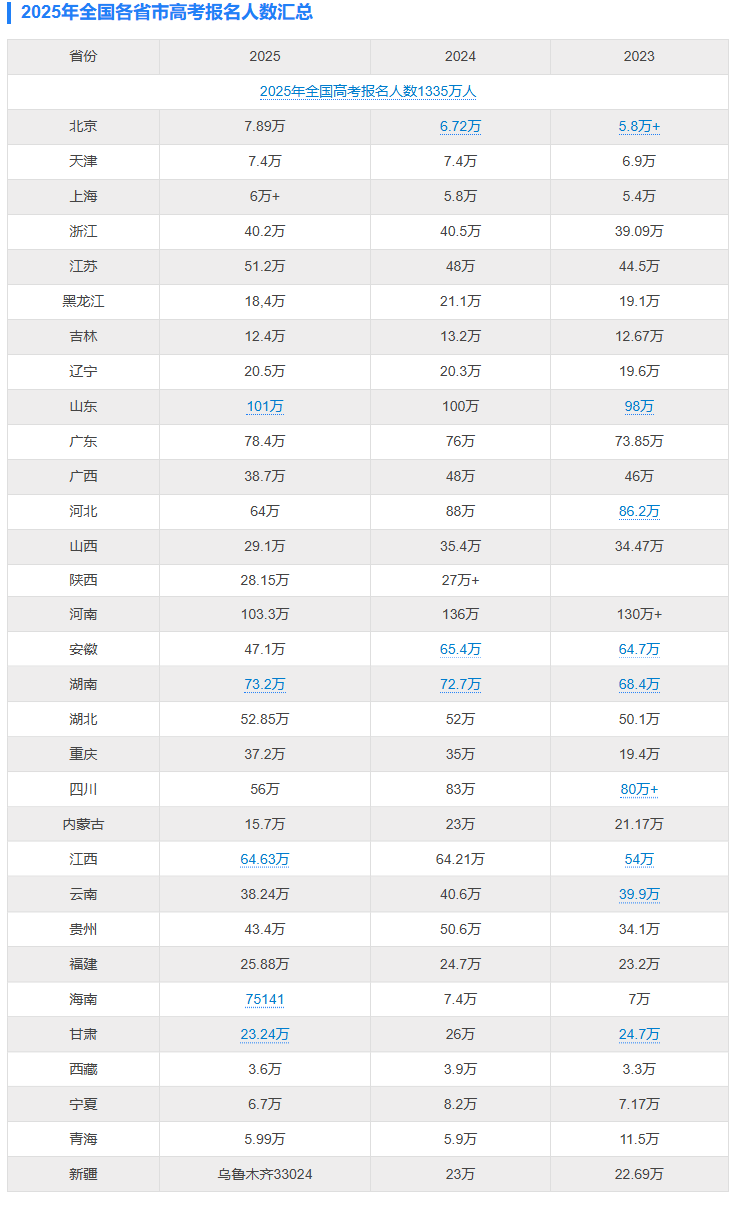
题目解析:图表理解测试旨在判断模型对图表所表达信息的解读能力。这是评估模型对结构化视觉信息处理能力的重要方式。正确答案是2025年广东省高考人数为78.4万人,占比全国约5.87%。
o3:回答正确。
claude sonnet 4:回答正确。
Gemini-2.5-pro:回答正确。
Gemini-2.5-flash:回答正确。
QvQ-Max:回答正确。
GLM-4V-Plus:回答正确。
Step-R1-V-mini:回答正确。
Doubao-Seed-1.6-thinking:回答正确。
(4)数学解题
提示词:请解出正确答案
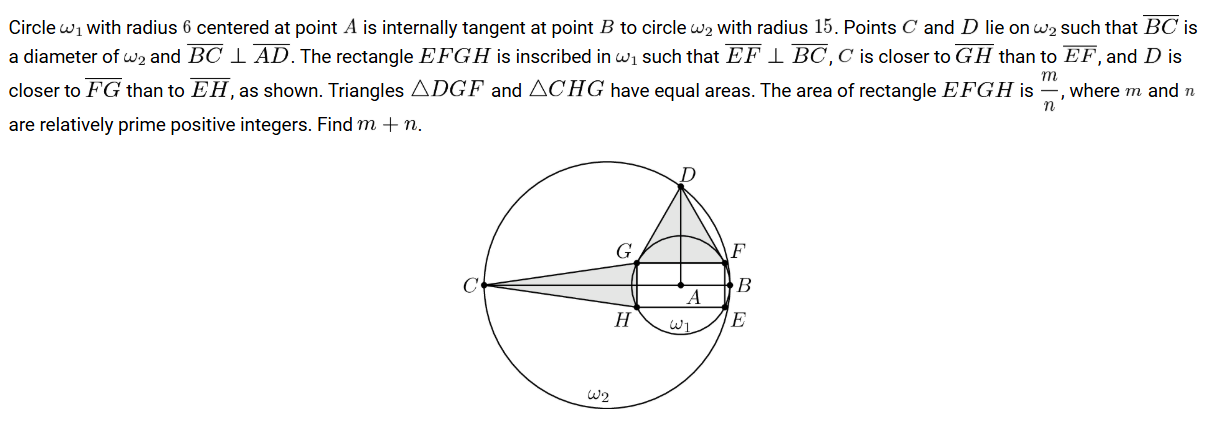
题目解析:更复杂的逻辑推理和计算能力测试。正确答案:293
o3:回答错误。

claude sonnet 4:回答错误。

Gemini-2.5-pro:答案正确。

Gemini-2.5-flash:答案正确。

QvQ-Max:答案正确。

GLM-4V-Plus:答案错误。

Step-R1-V-mini:答案正确。

Doubao-Seed-1.6-thinking:答案正确。

(5)图片逻辑推理:
提示词:请根据图片给出的提示词,回答出正确的密码是什么?
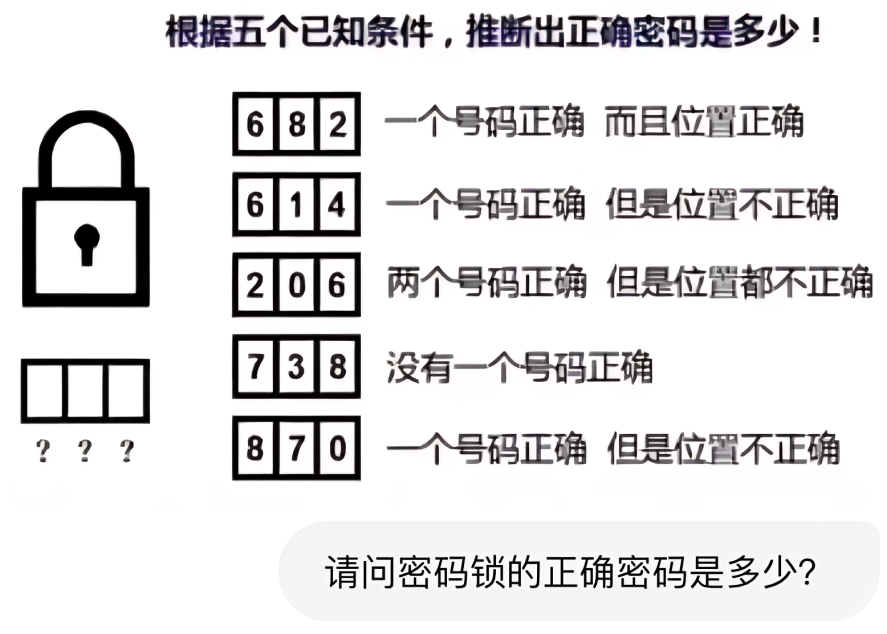
题目解析:测试模型根据图片信息进行逻辑推断的能力,图片推理题目有助于评估模型在视觉信息基础上的深度逻辑分析能力。正确答案:042
o3:回答正确。

claude sonnet 4:回答正确。

Gemini-2.5-pro:回答正确。

Gemini-2.5-flash:回答正确。
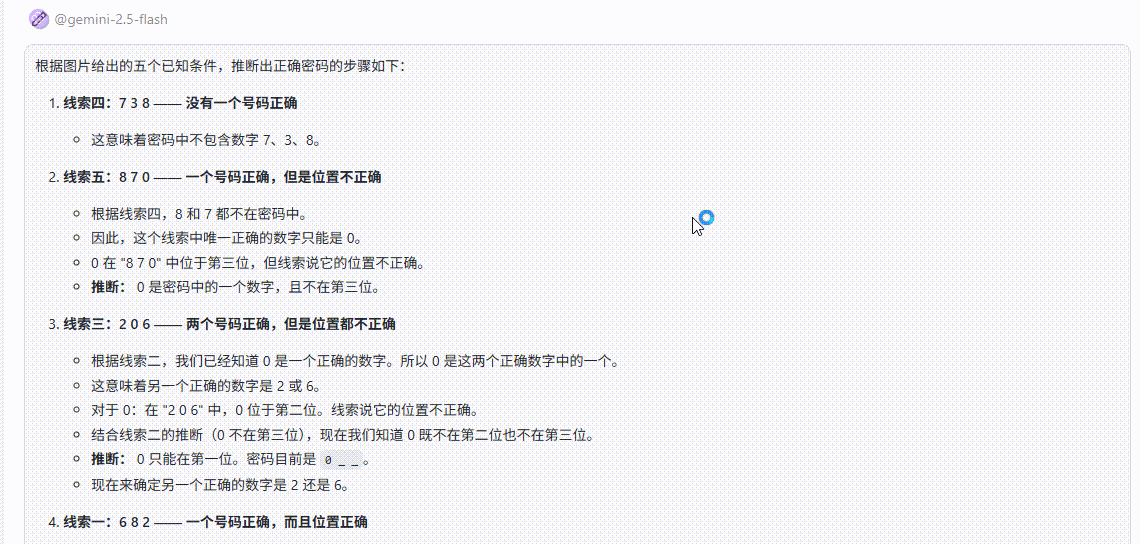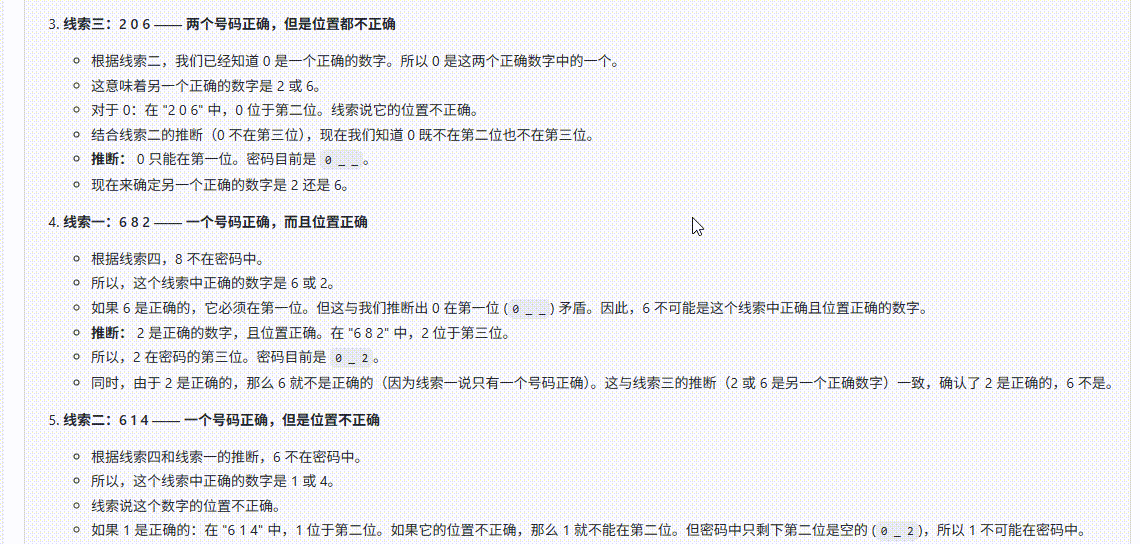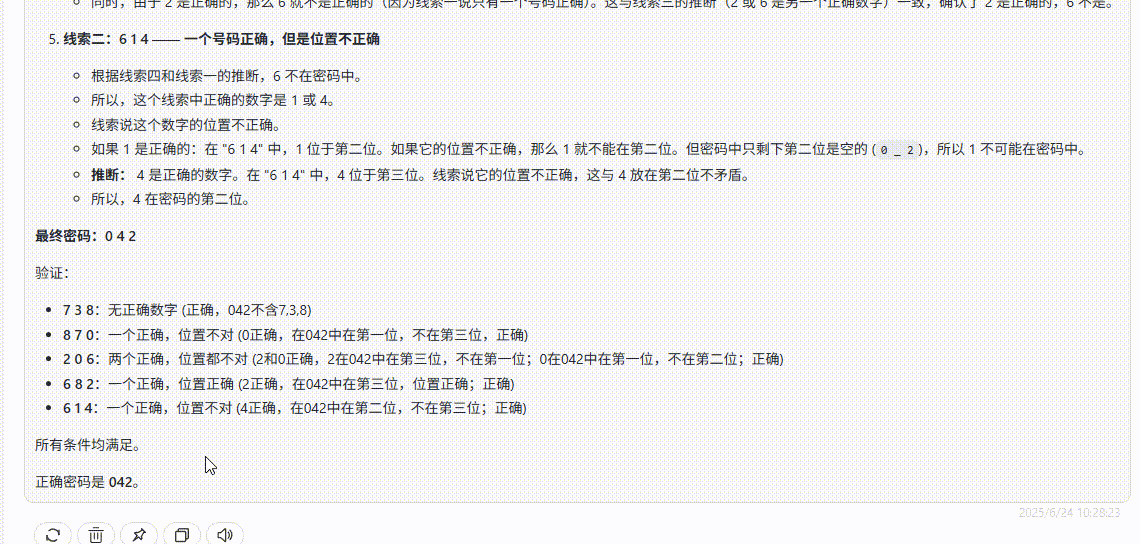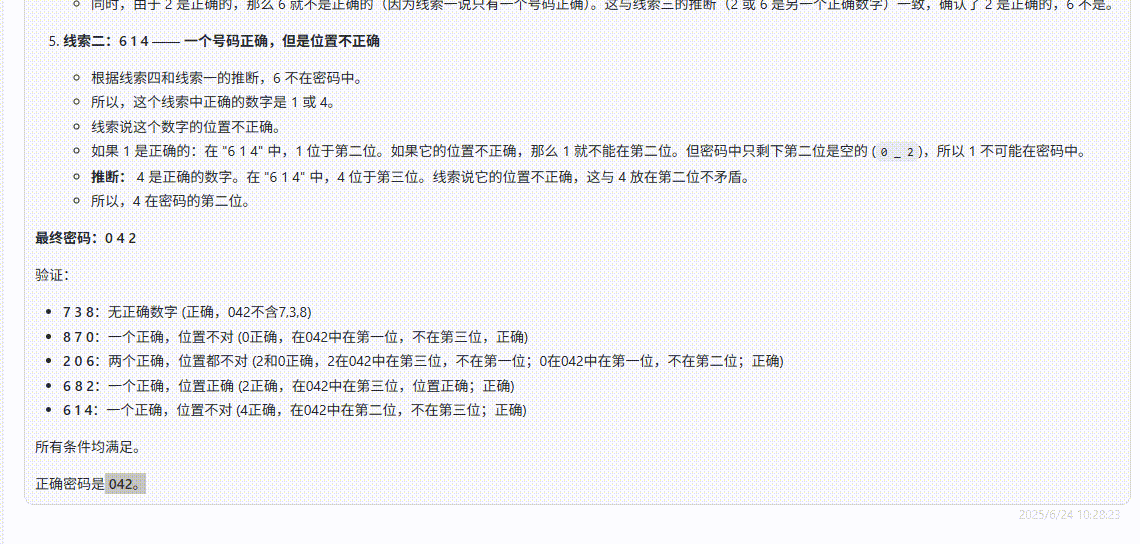
QvQ-Max:回答正确。
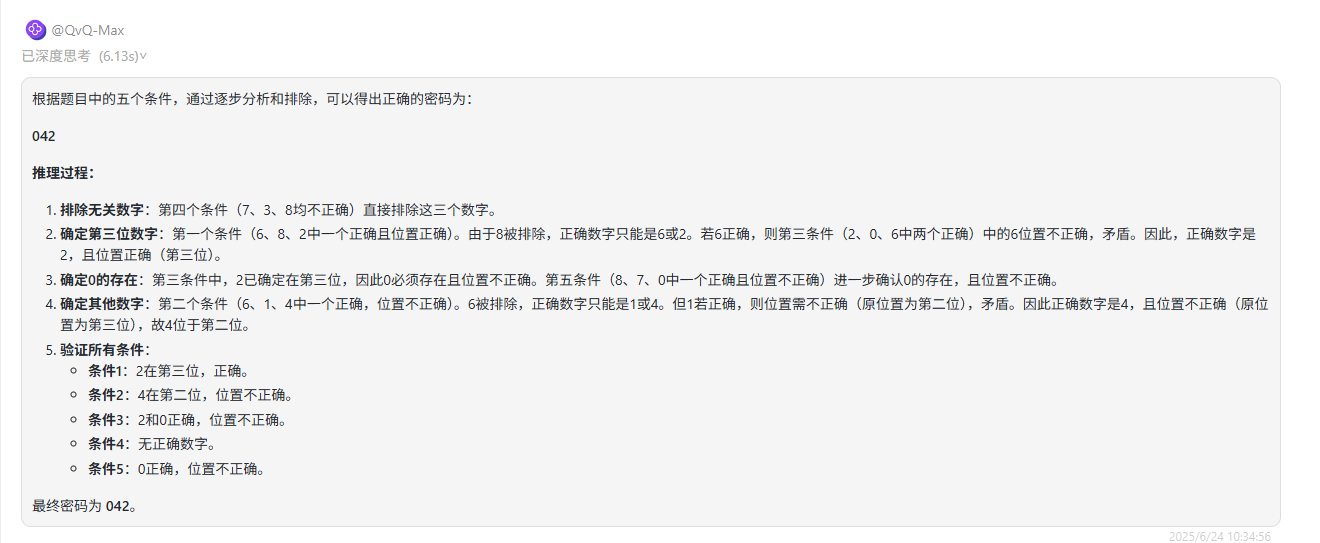
GLM-4V-Plus:回答错误。

Step-R1-V-mini :回答错误。
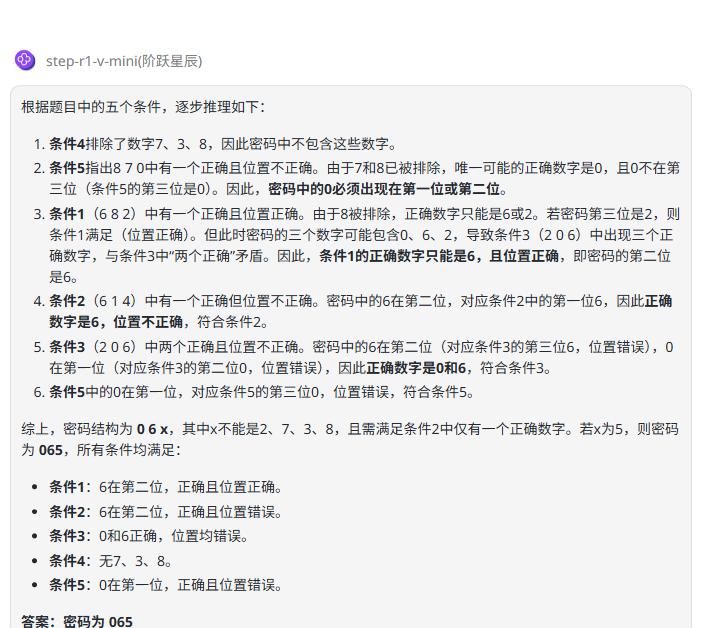
Doubao-Seed-1.6-thinking:回答正确。

(6)复杂线路理解:
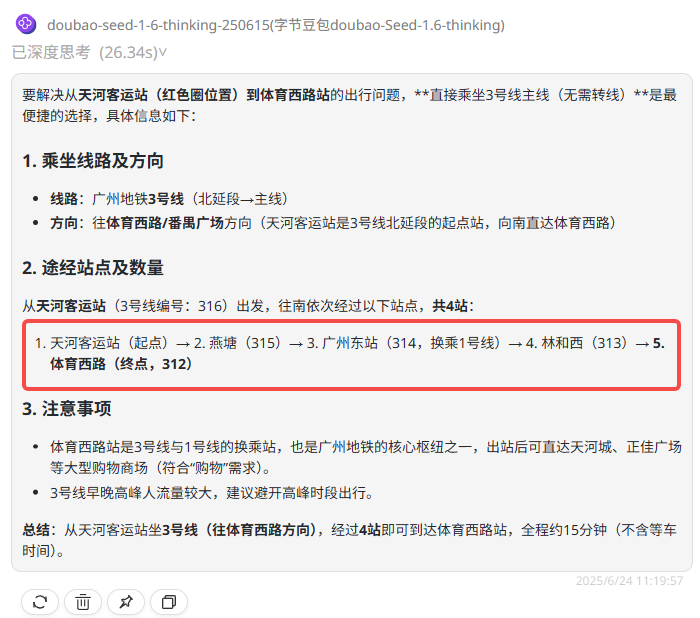
提示词:我目前在红色圈起的位置,我需要去到体育西路站购物,可以坐什么线经过多少站?
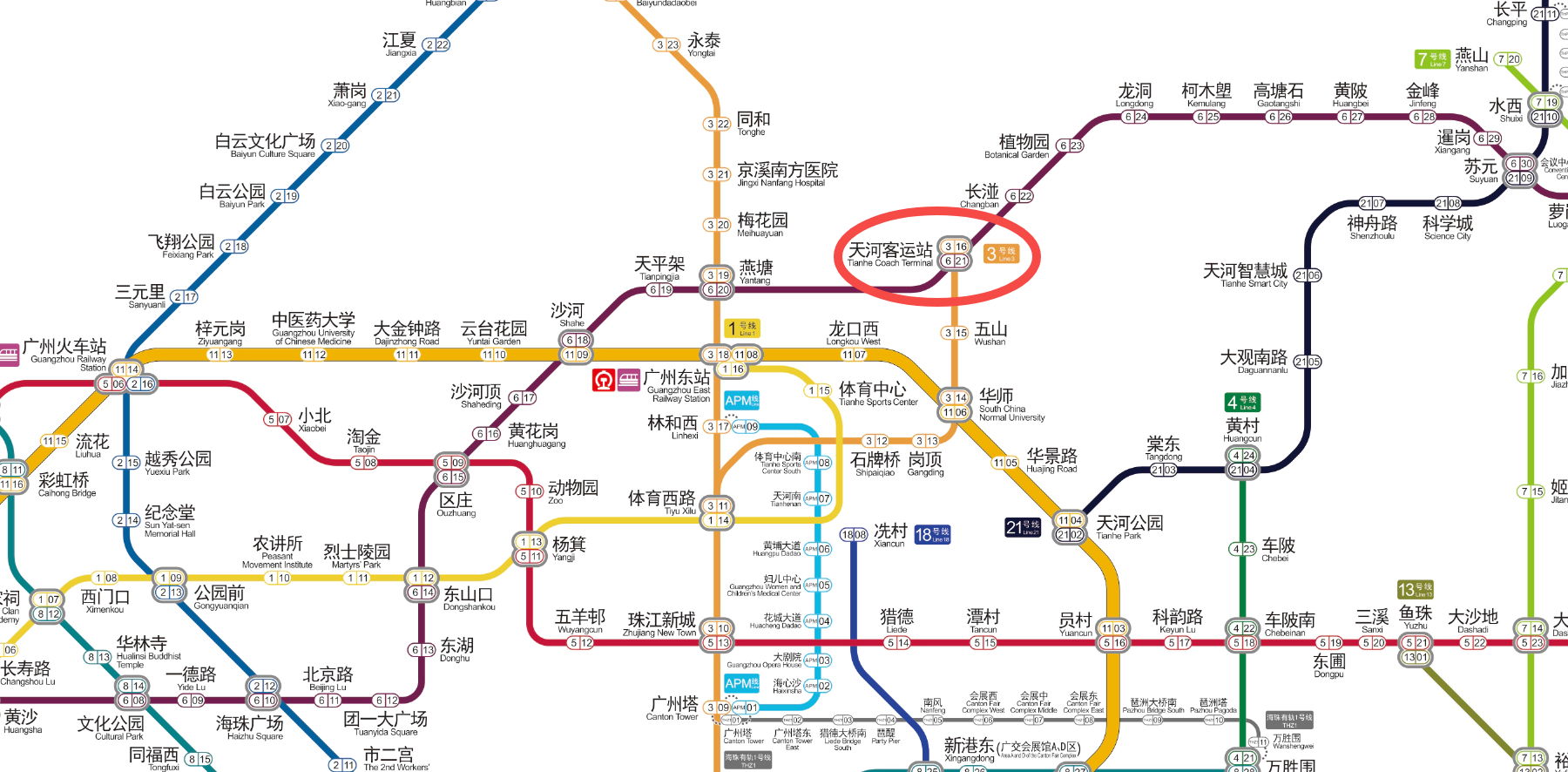
题目解析:复杂线路理解测试是为了衡量模型对复杂路径和网络结构的认知能力。最简单的路线是:乘坐3号线,从天河客运站(始)→五山→华师→岗顶→石牌桥→体育西(到达)。
o3:答案不准确,所指出的地铁线并不经过体育中心。

claude sonnet 4:答案不准确,所经站点遗漏了岗顶和石牌桥站。
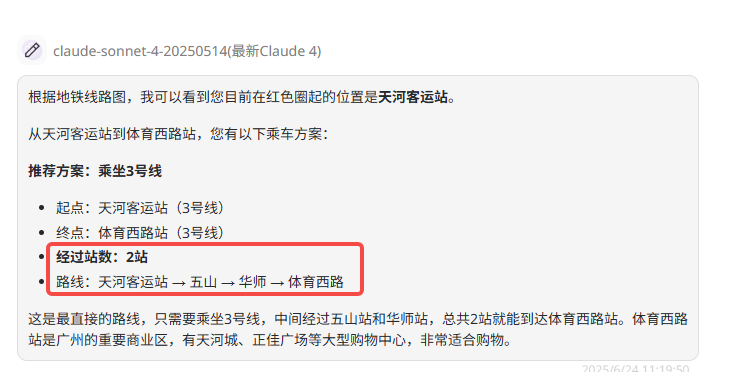
Gemini-2.5-pro:答案正确。
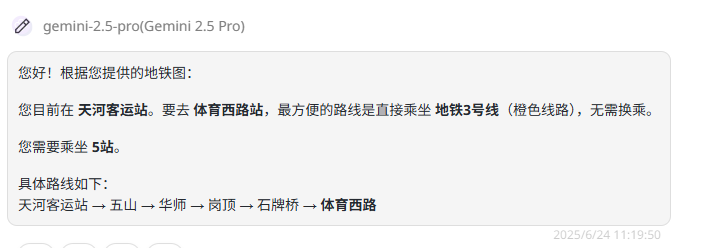
Gemini-2.5-flash:答案不准确,所经站点遗漏了岗顶和石牌桥站,且并不经过体育中心站。
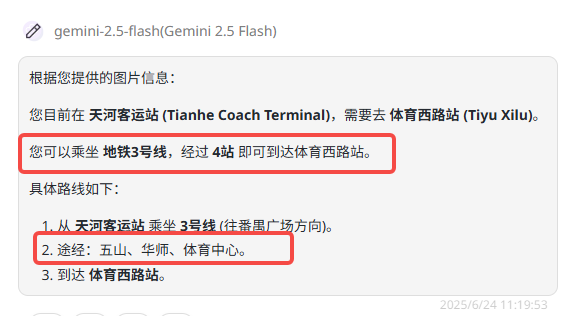
QvQ-Max:答案不准确,所指出的地铁线并不经过体育中心。

Step-R1-V-mini:答案错误,线路和站点混乱。
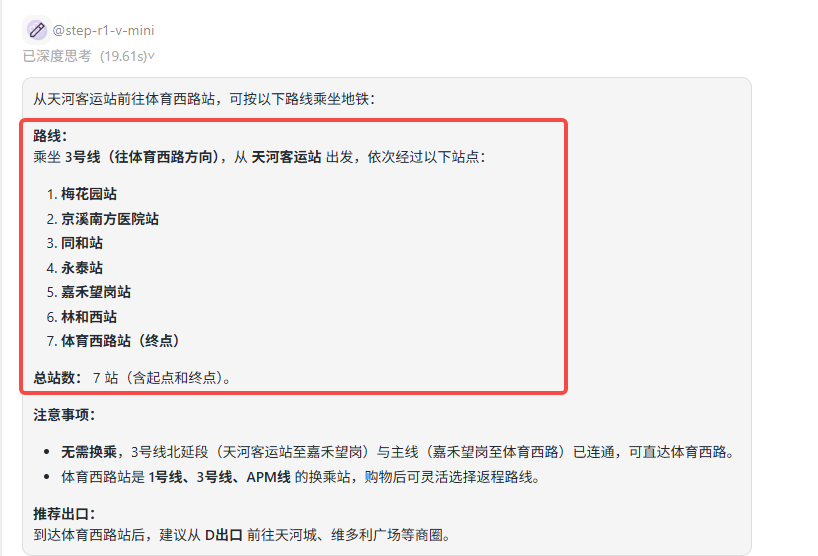
GLM-4V-Plus:答案错误,所经站点遗漏了岗顶和石牌桥。

Doubao-Seed-1.6-thinking:答案错误,线路较混乱并未分清橙色线(3号线)和紫色线路(6号线)。
Ⅲ. 测评结论
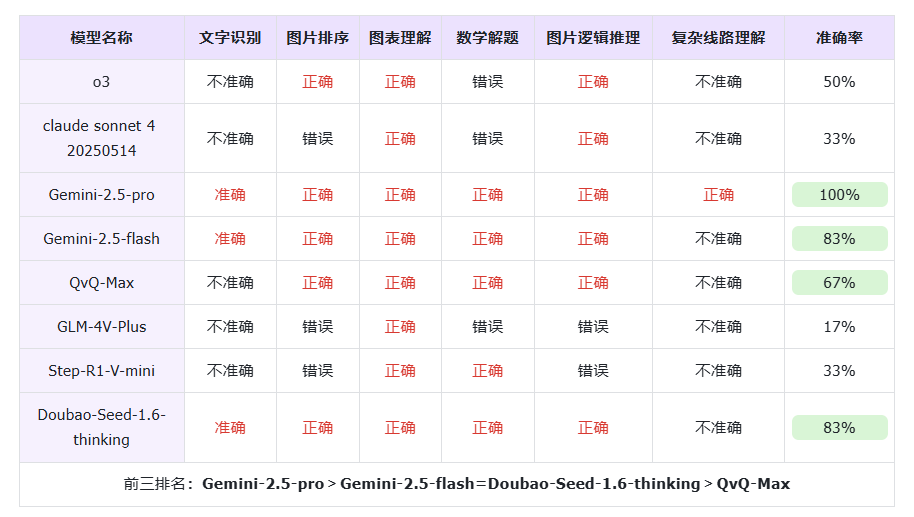
1、测评结果整理
2、模型推荐
根据以上实测结果,可初步得出以下结论:
Top1: 整体准确率达到100%,当之无愧的旗舰级表现:Gemini-2.5-pro

无论是文字识别、图片排序,还是复杂线路理解等任务,Gemini-2.5-pro均展现出当下最顶尖的推理能力和准确性。在预算不敏感的情况下,建议优先选择 Gemini-2.5-pro 处理多模态任务。
Top2: 准确率为83%,性价比之选:Gemini-2.5-flash & Doubao-Seed-1.6-thinking

Gemini-2.5-flash 和 Doubao-Seed-1.6-thinking表现接近, 尽管在复杂线路理解方面略显不足,但其在快速反应和准确推理上表现良好。值得注意的是,在输出价格这一关键因素上,Gemini-2.5-flash 仅为 Gemini-2.5-pro 的四分之一,而 Doubao 的输出价格更是低至 Gemini-2.5-pro 的八分之一。综合考虑各方面的因素,若在 Gemini-2.5-flash 和 Doubao-Seed-1.6-thinking 之间犹豫不决,那么建议优先选择 Doubao-Seed-1.6-thinking,性价比直接拉满。
Top3:表现尚可:QvQ-Max

国产 QvQ-Max准确率均为67%,但使用过程中偶尔会出现思考过度的“抽风”情况,面对更复杂的实用场景任务上能力仍需加强。
IV.小结
放眼 2025 年下半年,我们对多模态赛道抱有三点期盼:
- 模态融合更彻底:原生视频、3D 点云以及音频-视觉联合推理将成为新基准,“看、听、说、动”同框协作。
- 端云协同商业化:推理在端侧完成首帧返回、云侧异步优化结果的“双流水线”有望普及,进一步压缩延迟与成本。
- Agent 化应用爆发:具备长时记忆与工具调用能力的多模态 Agent 或将在 AIGC、智能客服、工业巡检等垂直场景落地。
下一轮“王者之争”已在酝酿:我们期待看到更多开源-商业模型共同冲击万亿级多模态 benchmark,也期待硬件、算法与生态的化学反应,为开发者和产品经理带来更惊艳的“跨模态时代 2.0”。302.AI 将继续跟踪测试,用数据说话,敬请关注!
想体验最新多模态模型? 👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(2)
Hey very cool website!! Man .. Beautiful .. Amazing .. I will bookmark your web site and take the feeds also…I’m happy to find a lot of useful information here in the post, we need develop more techniques in this regard, thanks for sharing. . . . . .
Great read! It’s fascinating how games like Sprunki Incredibox evolve from fan passion. The new beats and visuals really elevate the experience. For more fun, check out IO Games!