


北京时间 7 月 28 日,智谱发布了新一代旗舰模型 GLM-4.5 ,根据 Hugging Face 上的介绍,GLM -4.5 系列模型是专为 Agent 设计的基础模型。GLM-4.5 拥有 3550 亿个总参数,其中 320 亿个活跃参数;而 GLM-4.5-Air 则采用更紧凑的设计,拥有 1060 亿个总参数,其中 120 亿个活跃参数。GLM-4.5 模型统一了推理、编码和智能代理功能,以满足智能代理应用的复杂需求。GLM-4.5 和 GLM-4.5-Air 都是混合推理模型,提供两种模式:用于复杂推理和工具使用的思维模式,以及用于立即响应的非思维模式。

目前该模型在 Hugging Face 上开源后已登顶。
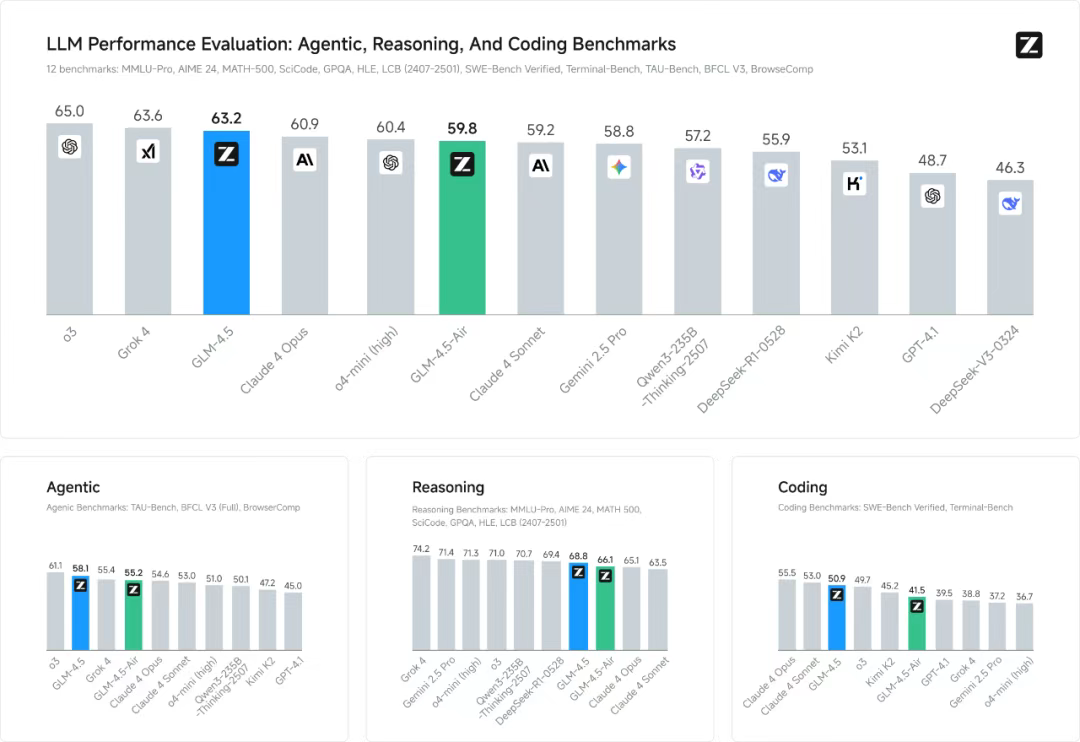
智谱官方还对 12 项行业标准基准进行了全面评估,结果表明 GLM-4.5 性能卓越,得分高达 63.2 分,在所有专有和开源模型中位居第三。值得一提的是,GLM-4.5-Air 的得分高达 59.8 分,在保持卓越效率的同时,也展现出极具竞争力的成绩。
302.AI 第一时间接入了 GLM-4.5 系列模型,今天我们将围绕 GLM-4.5 模型展开对比测评,以便帮助大家更好地了解该模型的性能。
I. GLM-4.5 系列模型实测对比
各模型在 302.AI 的价格及所支持的上下文长度:
| 参与对比测评的模型 | 输入 | 输出 | 上下文长度 |
| GLM-4.5 | 0.15 $/1M | 0.58 $/1M | 128000 |
| o3 | 2 $/1M | 8 $/1M | 200000 |
| Grok 4 | 3 $/ 1M | 15 $/ 1M | 256000 |
| DeepSeek-R1 | 0.6 $/ 1M | 2.3 $/1M tokens | 128000 |
| Gemini 2.5 pro | 1.25 $/ 1M | 10 $/ 1M tokens | 1000000 |
实测 1:语境逻辑
提示词:明天的前天,是昨天的后天吗?
题目解析:明天的前天就是相对于今天的昨天,昨天的后天相当于今天的明天,今天的昨天不等于今天的明天,也就是相差两天
GLM-4.5:回答正确,解析合理且完整,加入了举例论证。

o3:回答错误。

Grok 4:回答正确。

DeepSeek-R1:回答正确,解析合理。

Gemini 2.5 pro :回答正确,解析合理。

实测 2:逻辑推理
某仓库失窃,四个保管员因涉嫌而被传讯。四个人的供述如下:
甲:我们四人都没作案; 乙:我们中有人作案
丙:乙和丁至少有一个没作案; 丁:我没作案
如果四个人中有两人说的是真话,有两个人说的是假话,则( )断定成立。
A. 说真话的是甲和丙
B. 说真话的是乙和丙
C. 说真话的是乙和丁
D. 说真话的是丙和丁
答案:B
GLM-4.5:回答正确,分步剖析推导出结果,逻辑严谨。

o3:回答正确,推理过程使用了符号化陈述。

Grok 4:回答正确,推理清晰。

DeepSeek-R1:回答正确,推理清晰。

Gemini 2.5 pro :回答正确,推理清晰。

实测 3:模型幻觉
提示词:请给出 5 个英文单词,每个单词必须刚好包含 3 个字母 e
GLM-4.5:回答正确,选取了常用词汇的例子。

o3:回答正确。
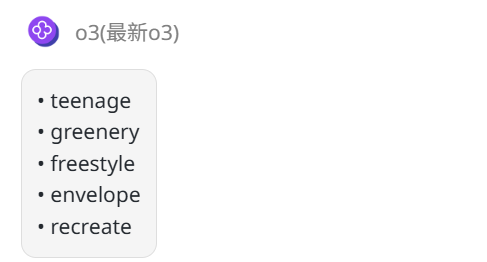
Grok 4:回答正确,思路清晰。

DeepSeek-R1:回答正确。

Gemini 2.5 pro :回答错误,5 个单词中有 2 个单词(Referee,Preference)是有四个字母 e。

实测 4:前端编程能力
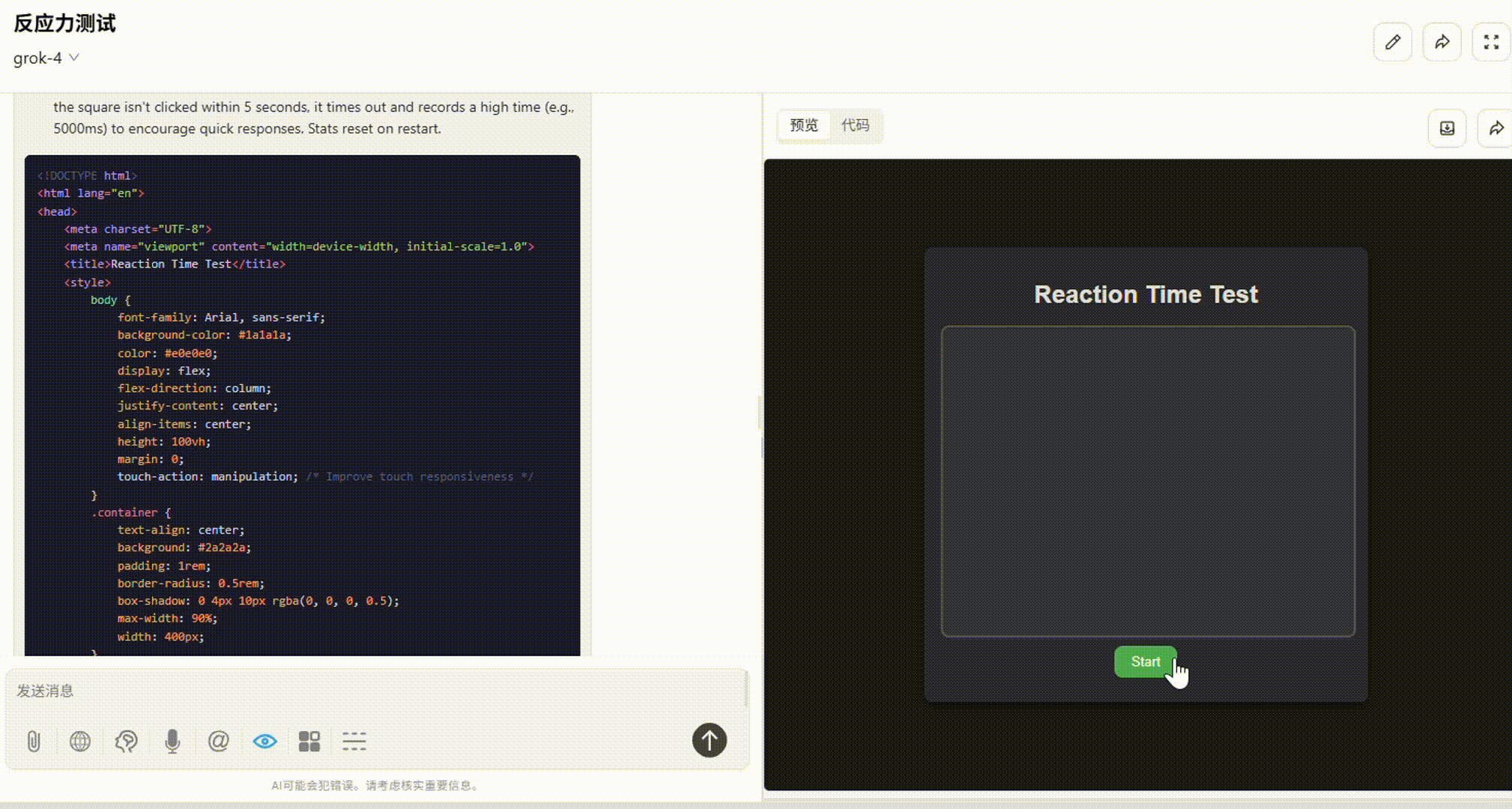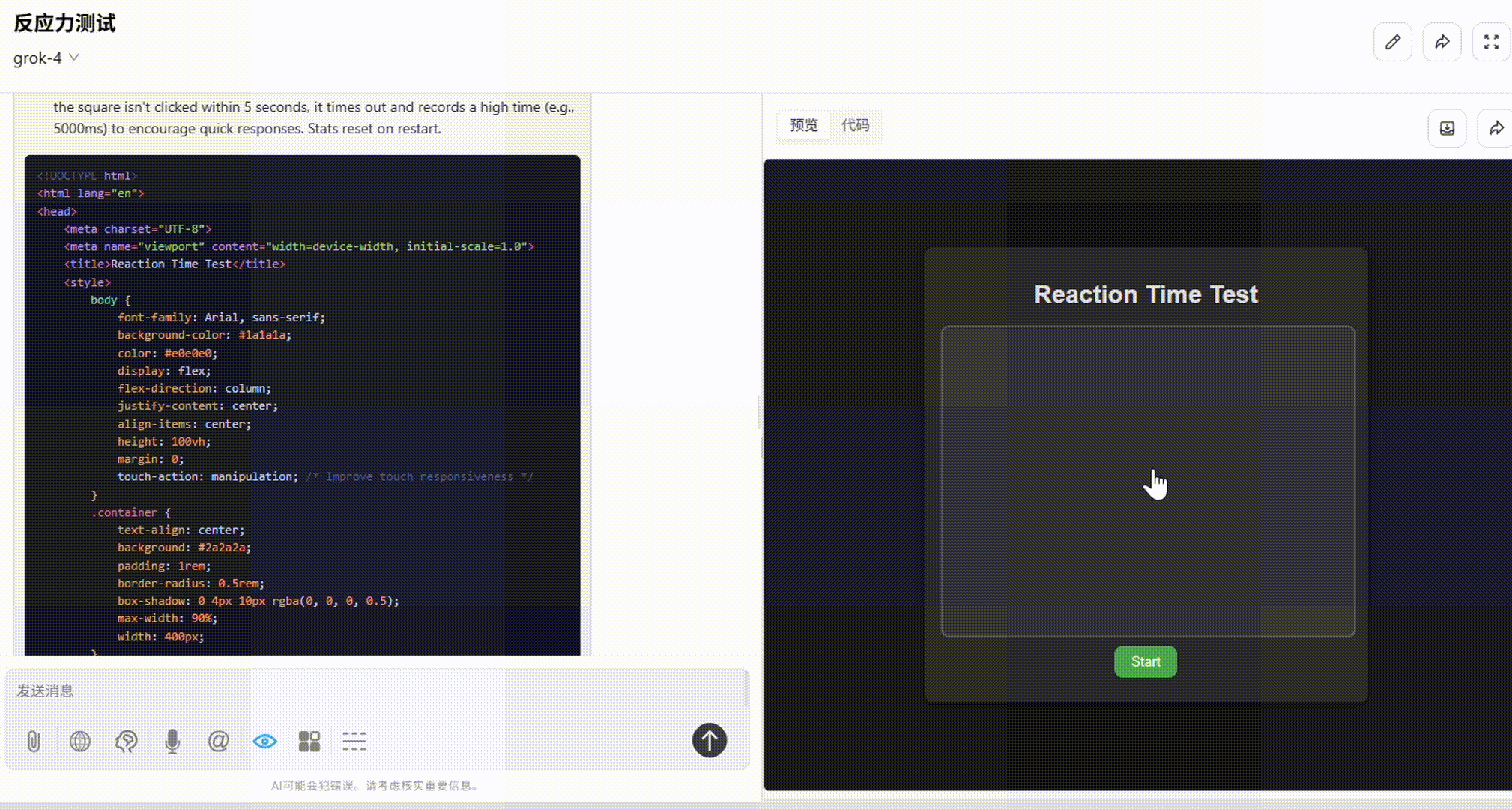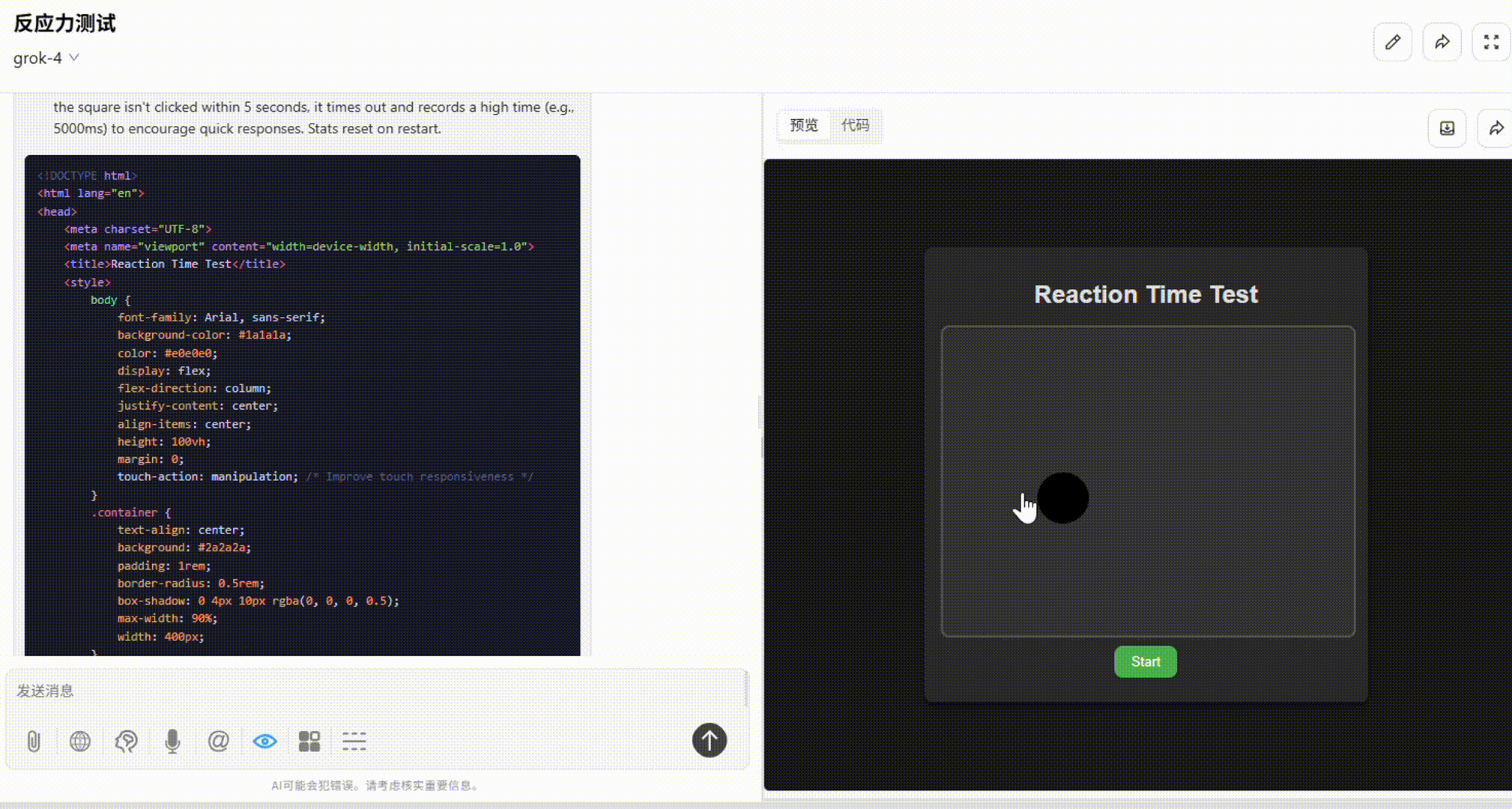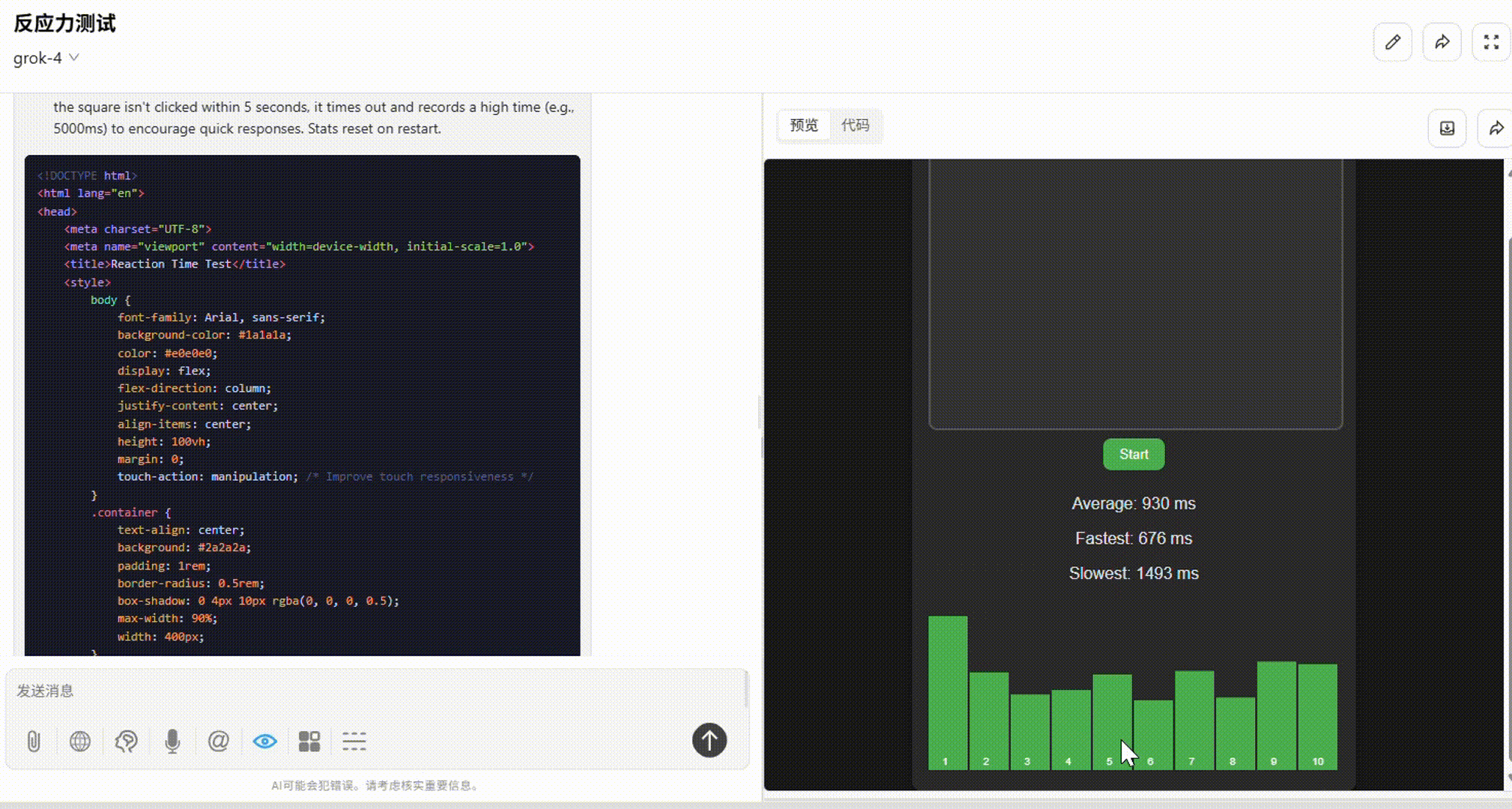
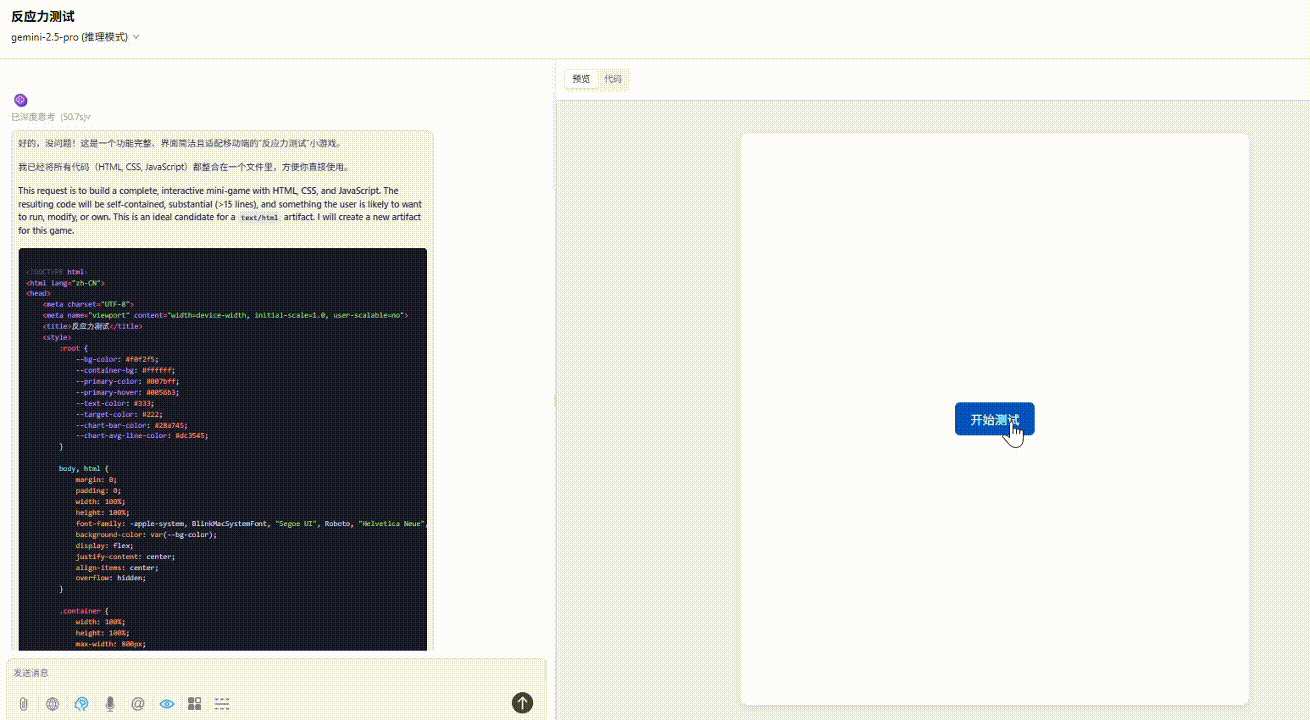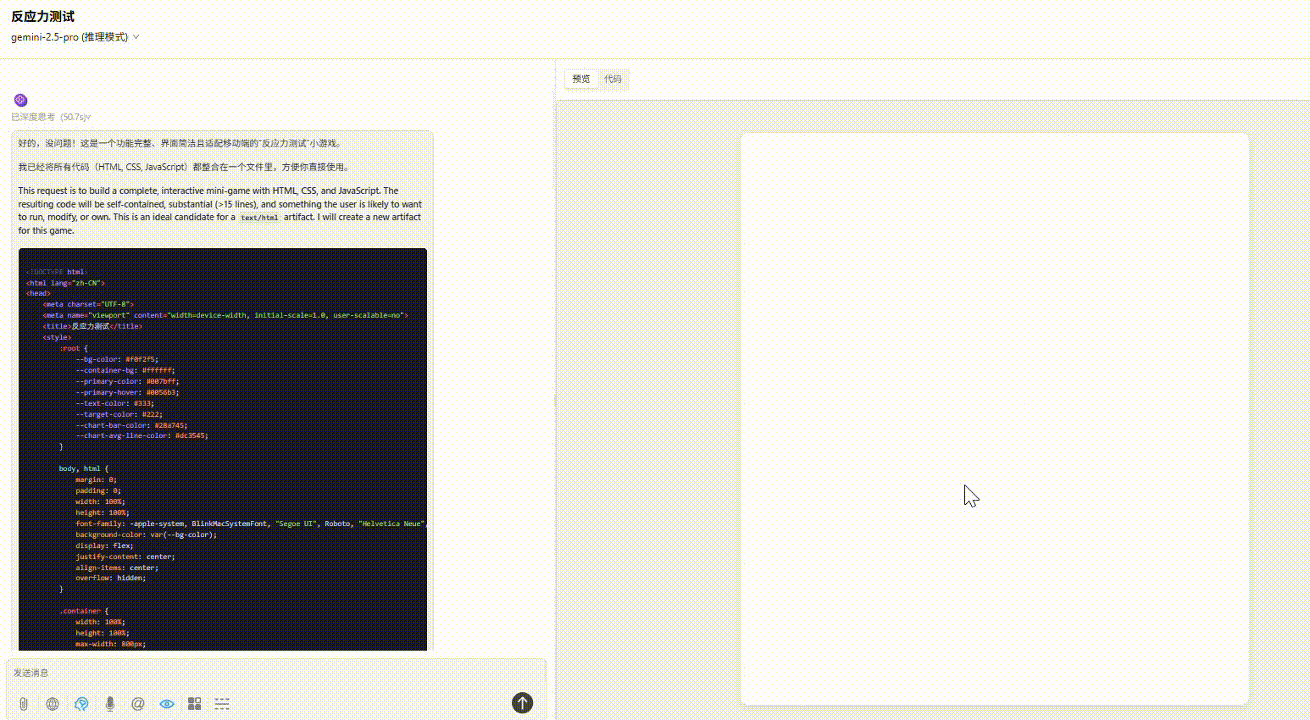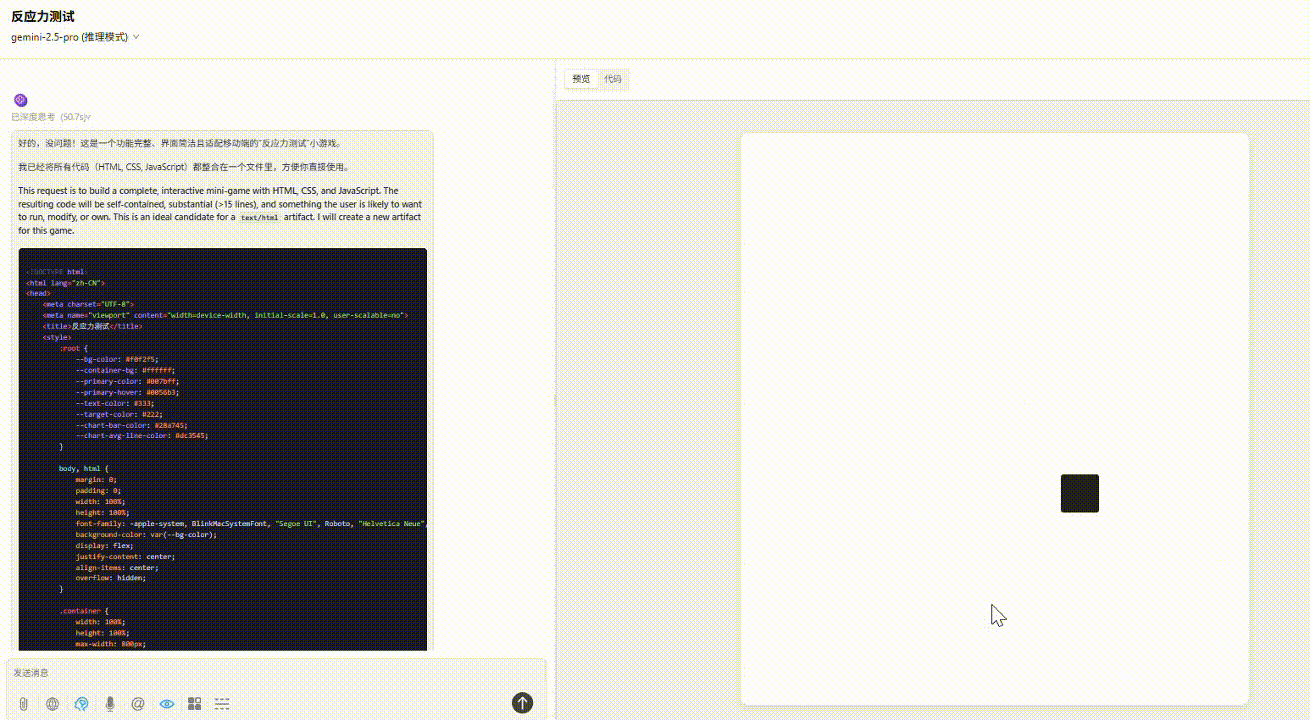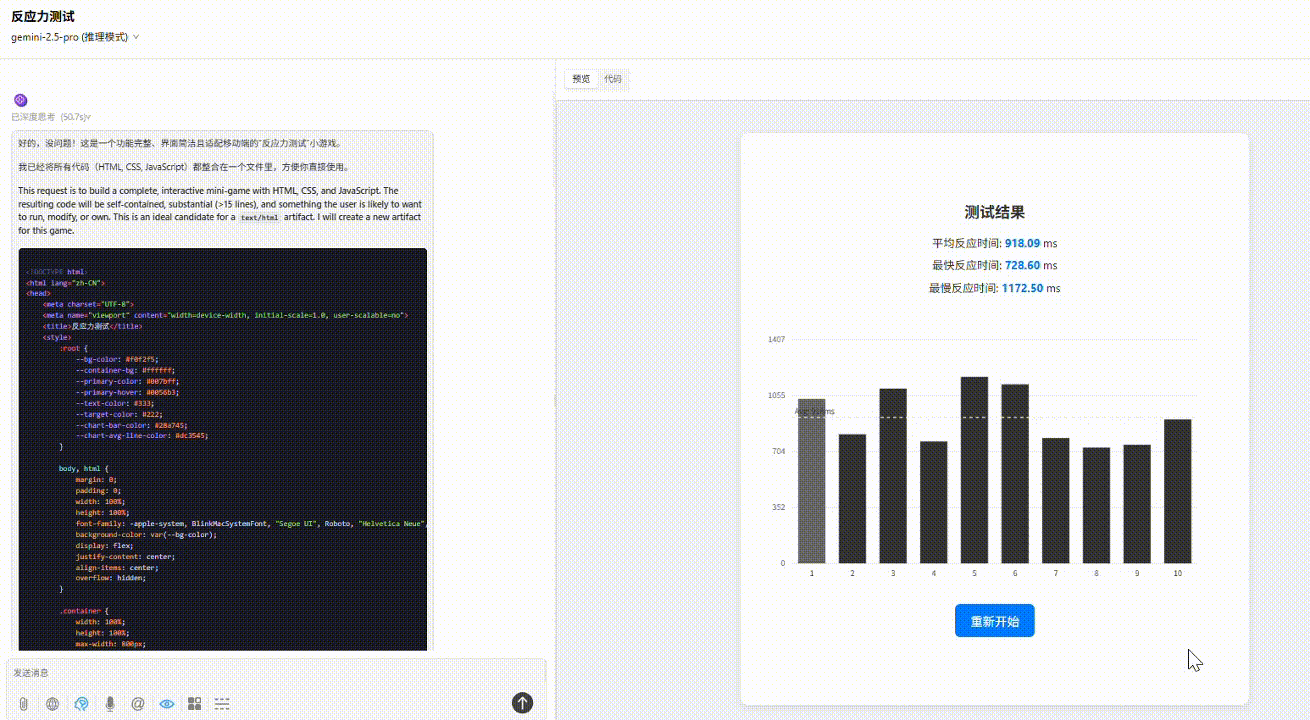
提示词:请用 HTML/CSS/JS 实现一个“反应力测试小游戏”:画面上有一个小黑块随机出现,你需要用鼠标点击它,越快越好,系统会记录你的反应时间。连续 10 次后给出统计数据:平均反应时间、最快/最慢一次、反应偏差图表。界面简洁,响应迅速。
GLM-4.5:界面简洁易用,点击小黑块响应迅速,操作较流畅,且实时显示了上次反应时间。但缺失游戏结束后数据统计的板块,不够完整。
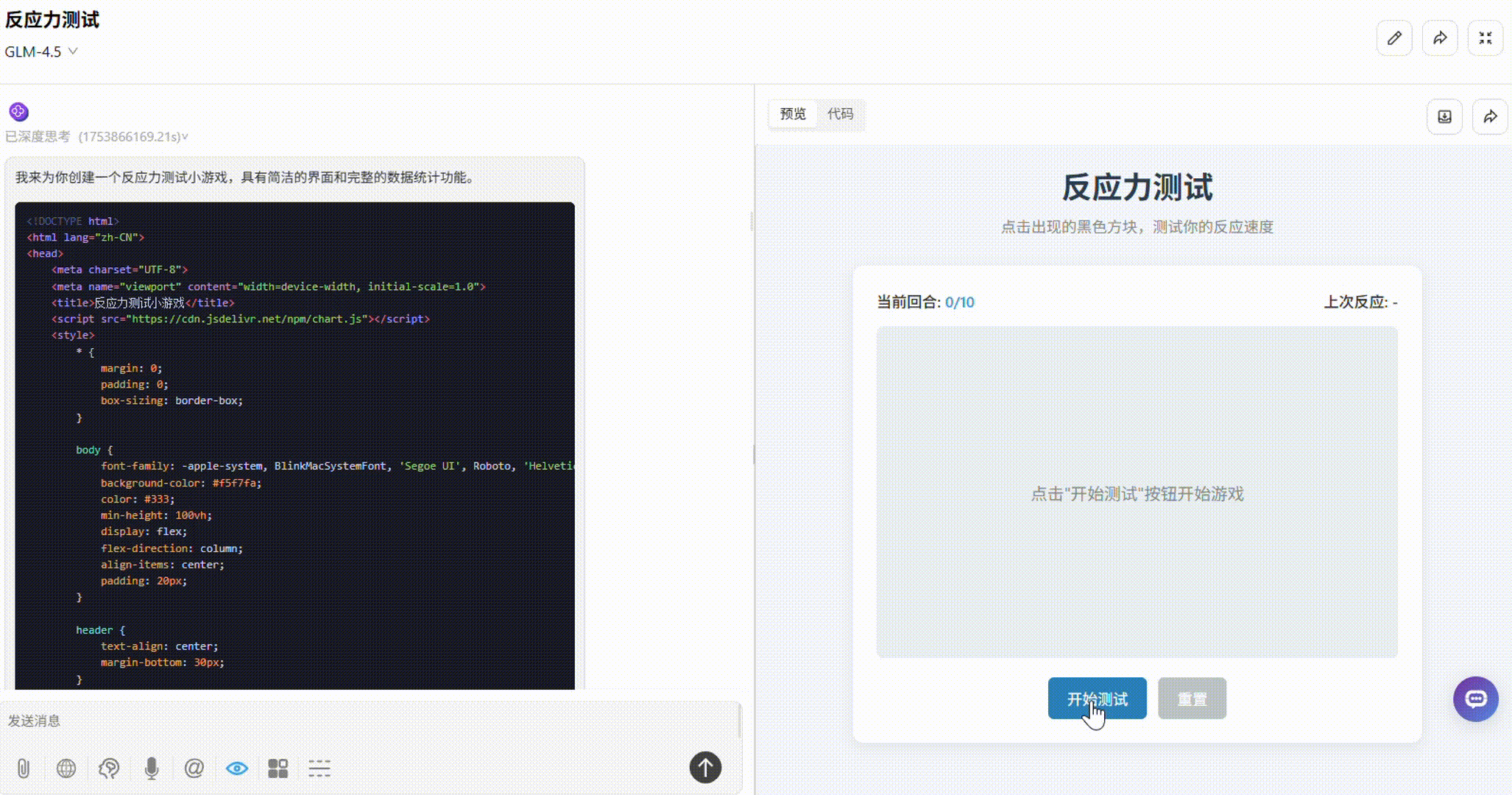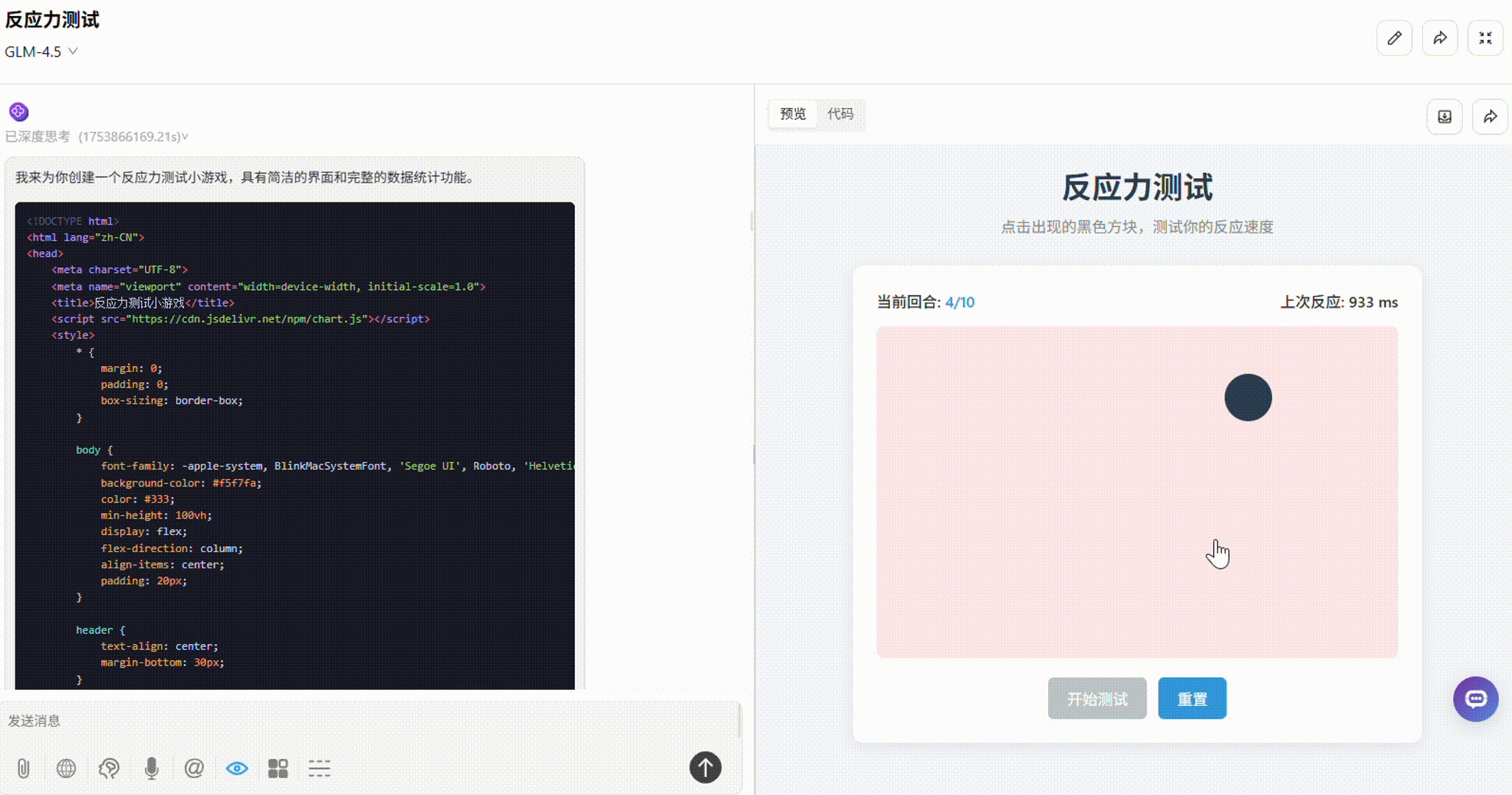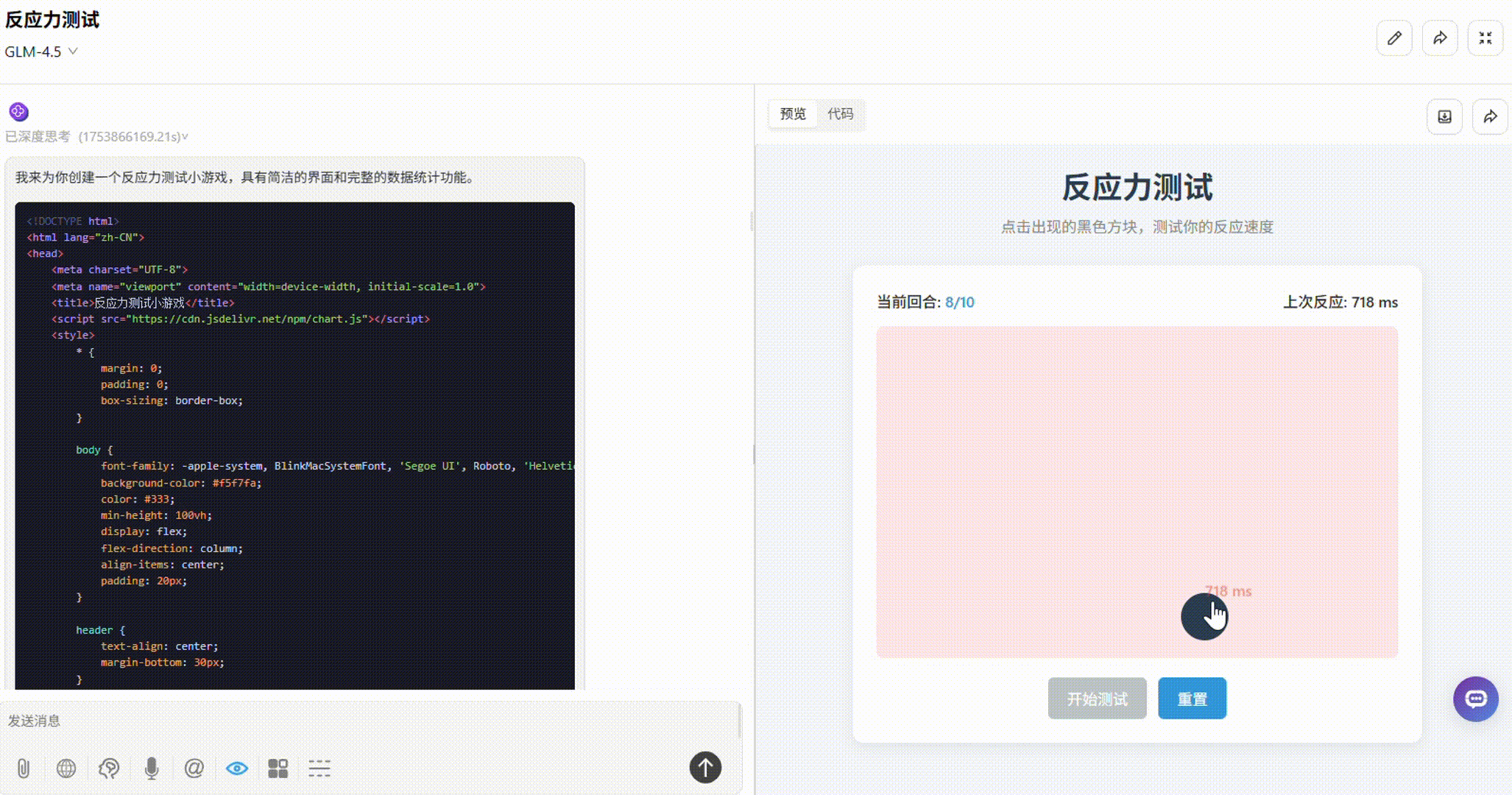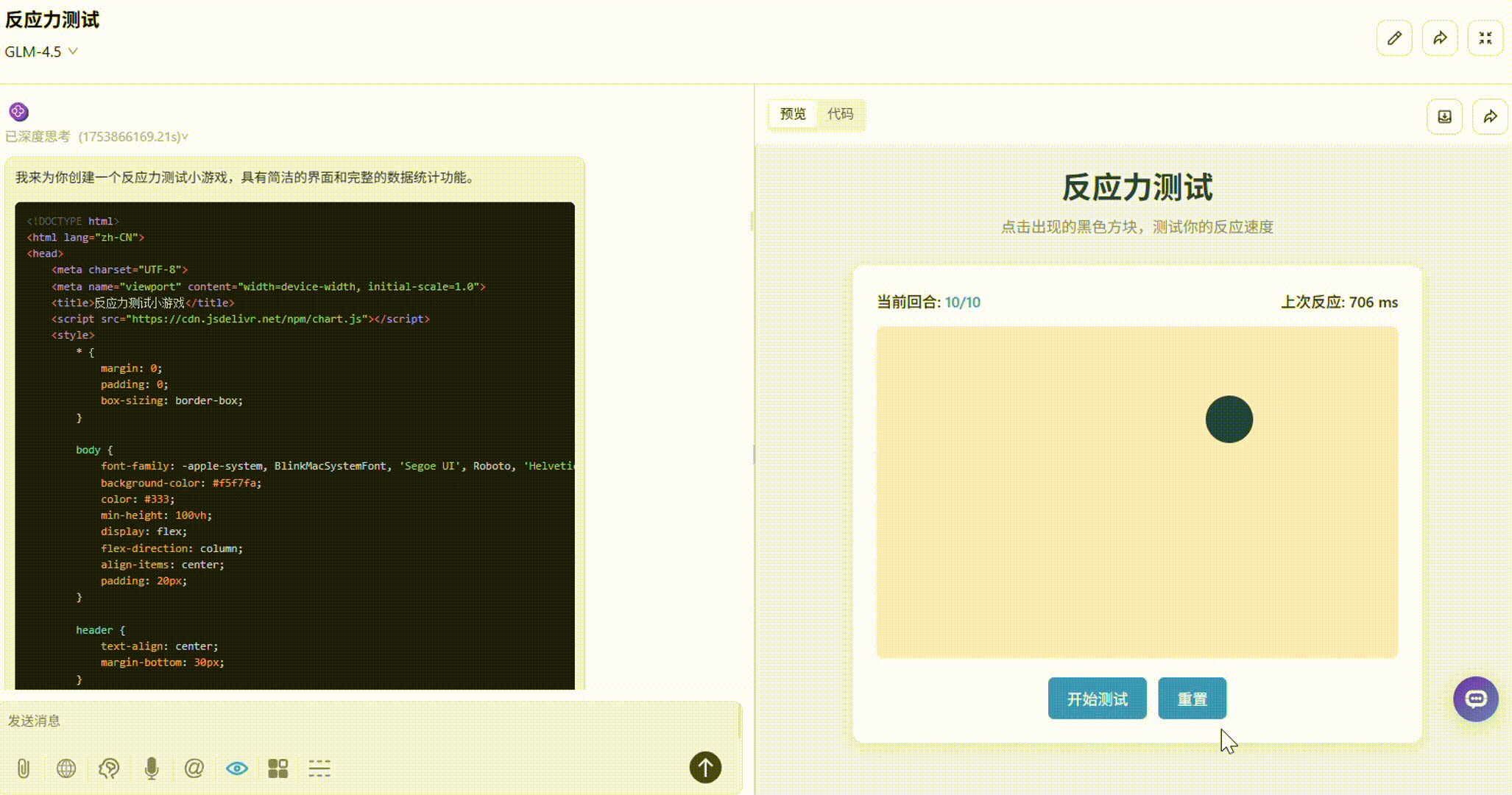
o3:整体一般。板块布局不够合理,部分小黑块超出了框外。有平均反应时间、最快/最慢一次统计,但显示方式不够直观。

Grok 4:整体不错。布局合理,点击响应流畅,最后显示的统计数据和图表完整无误。缺陷在于配色较深,弱化了小黑块的显示。
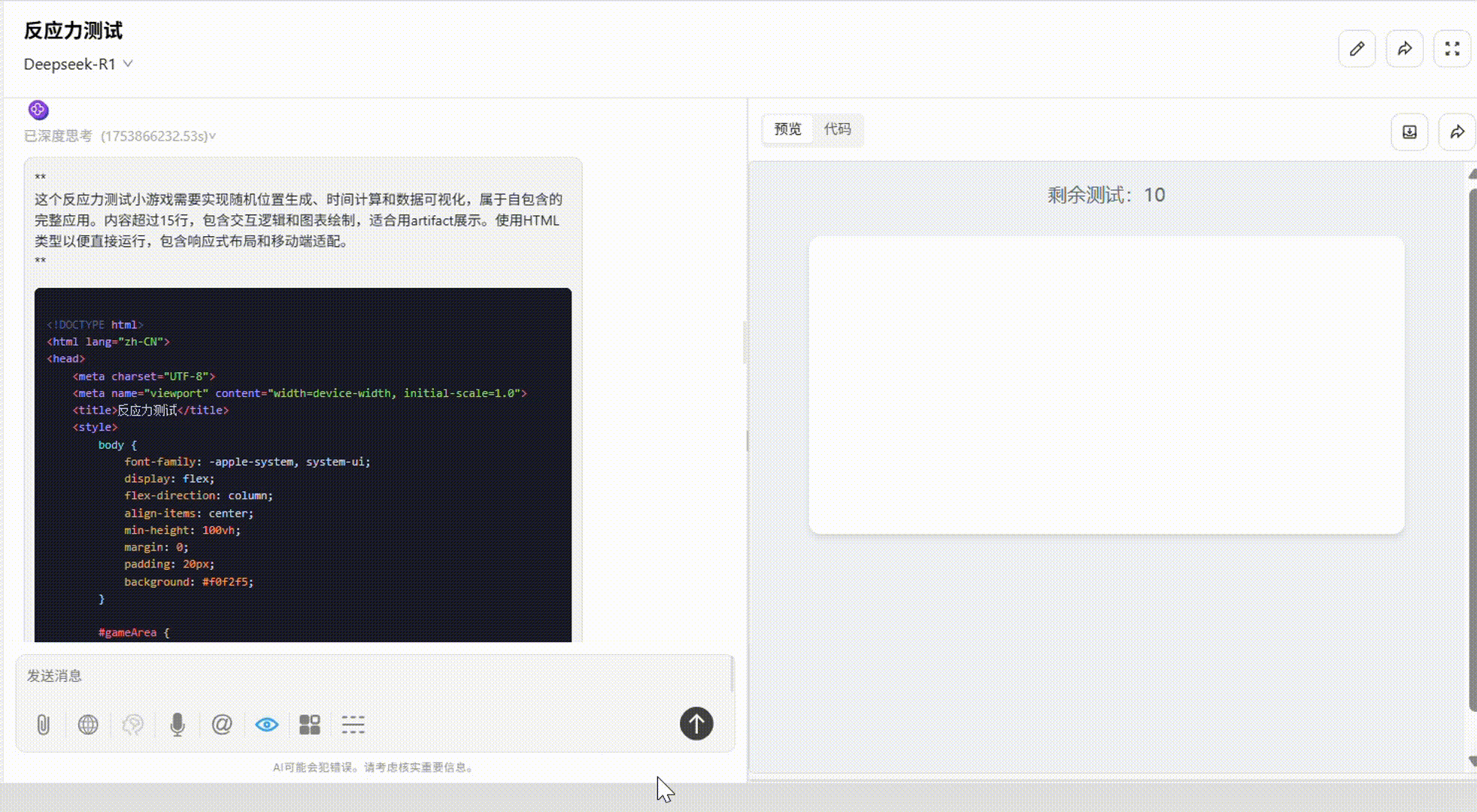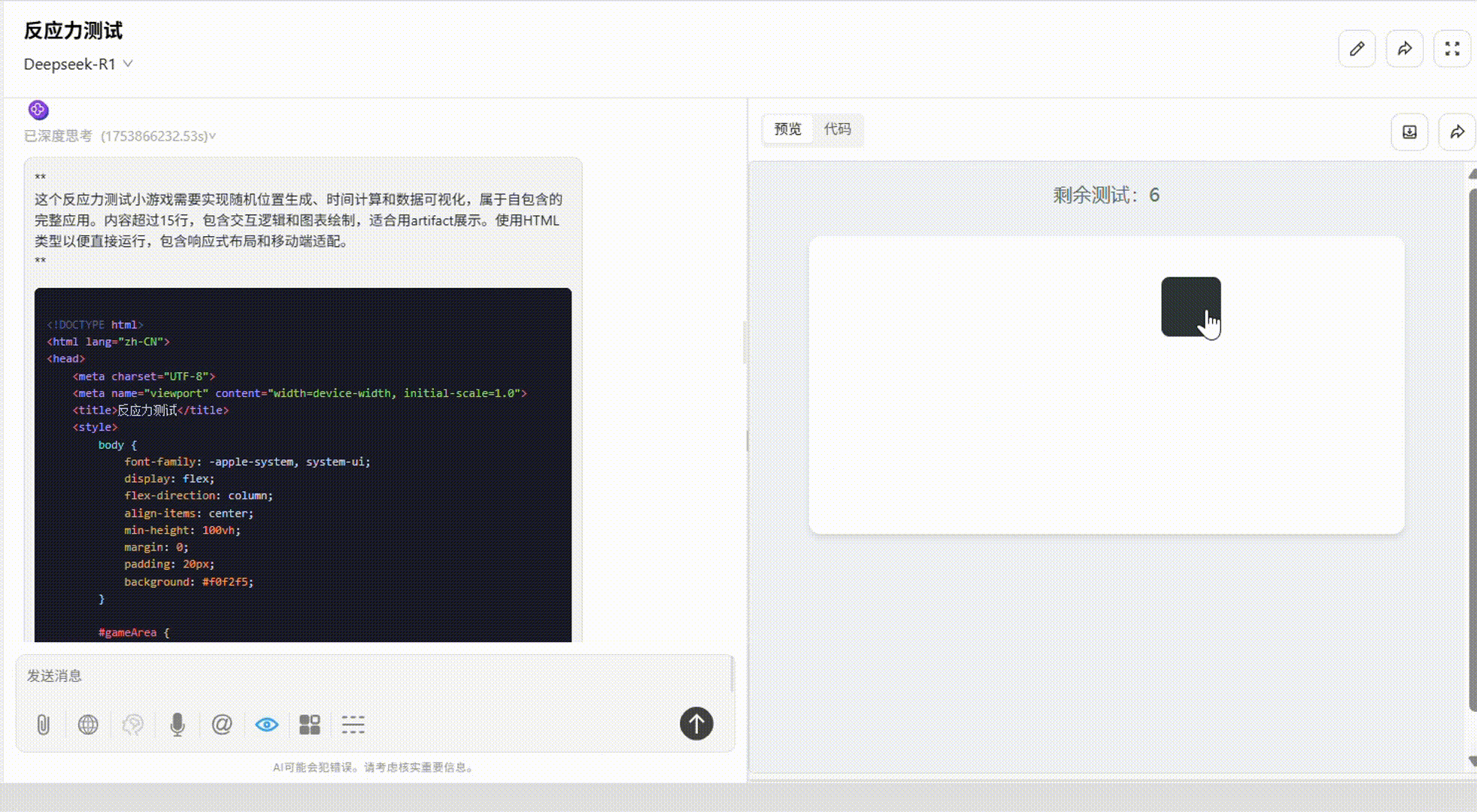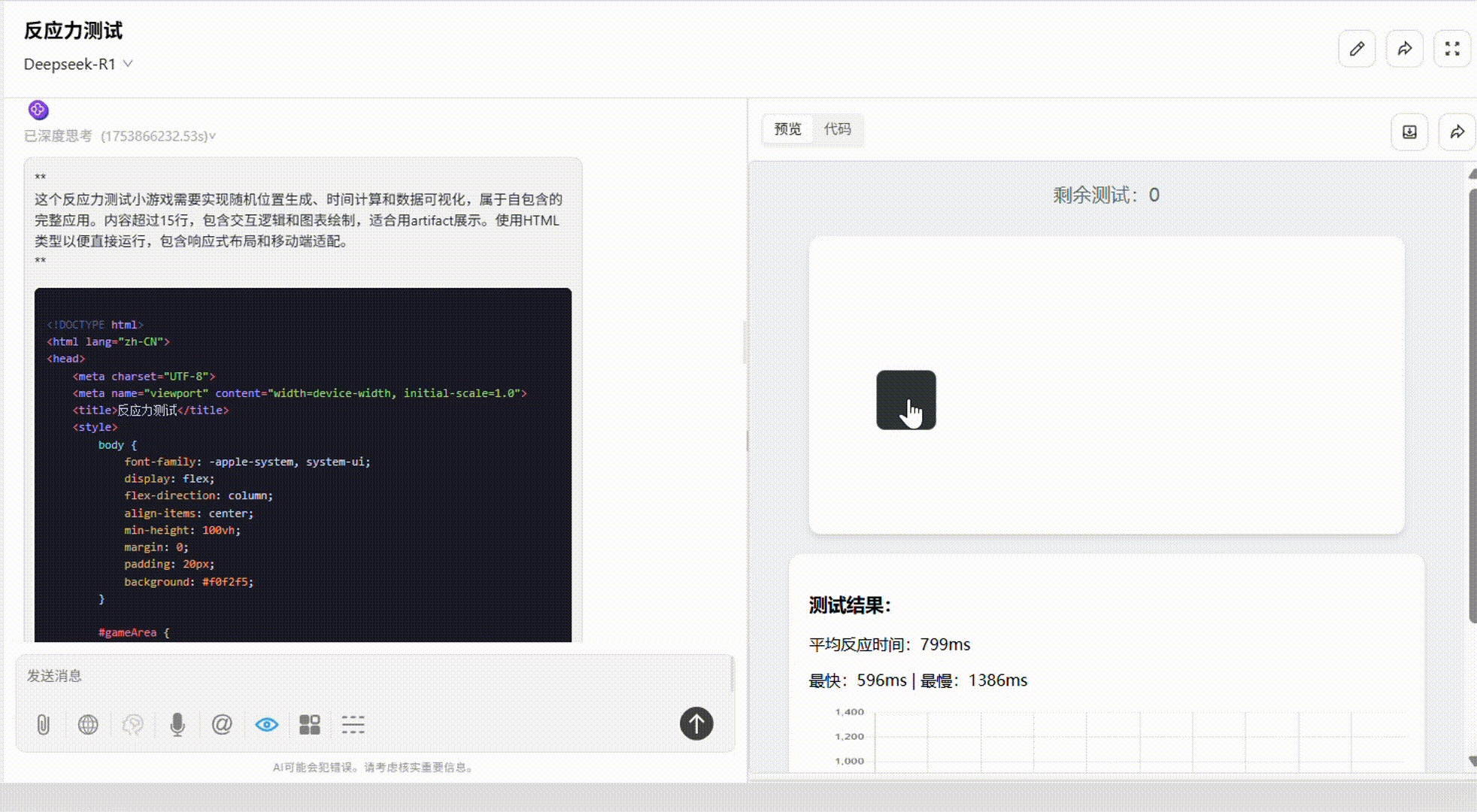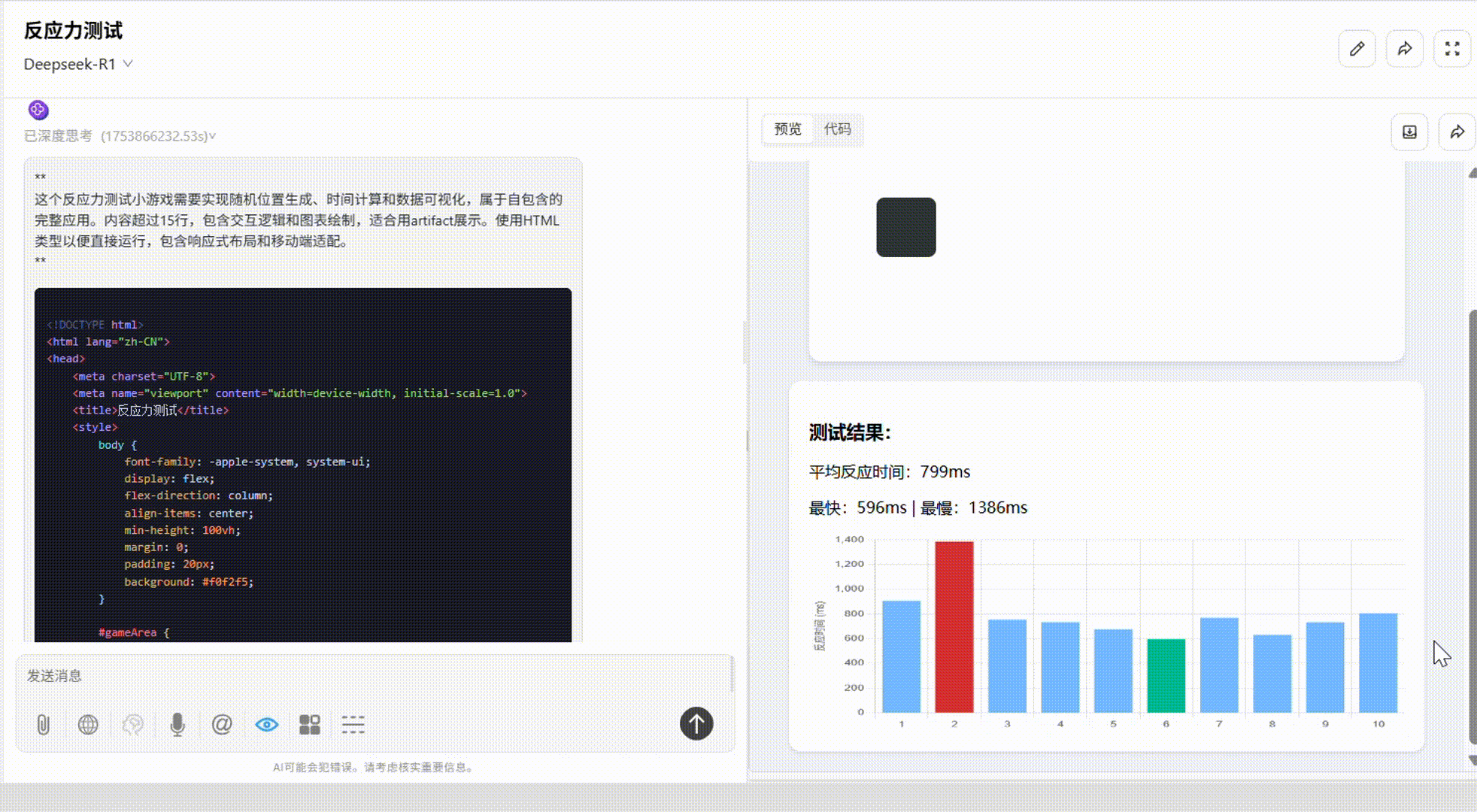
DeepSeek-R1:整体较出色。配色优秀,游戏结束后出现的统计图表根据反应速度而呈现不同颜色,使得结果更为直观。唯一不足是缺少了开始和重置键。
Gemini 2.5 pro :表现最佳。功能完整,配色、布局贴合要求。游戏结束后的数据统计表显示了平均值参考线,整体来看效果最好。
II. GLM-4.5 系列模型实测总结

1、实测结果整理:
评测标准:
- ★(不可用):代码完全无法执行或存在错误导致功能缺失
- ★★(明显缺陷):基础功能可运行但存在明显 bug,或核心功能未实现
- ★★★(基本实现):主要功能可用,但欠缺部分功能,或 UI/UX 需优化
- ★★★★(完整实现):功能完整实现,代码规范,交互流畅,达到预期效果
- ★★★★★(卓越实现):功能表现超出预期,包含创新性实现或优化
| 语境逻辑 | 逻辑推理 | 模型幻觉 | 前端编程能力 | |
| GLM-4.5 | ✔️ | ✔️ | ✔️ | ★★★ |
| o3 | ❌ | ✔️ | ✔️ | ★★★ |
| Grok 4 | ✔️ | ✔️ | ✔️ | ★★★★ |
| DeepSeek-R1 | ✔️ | ✔️ | ✔️ | ★★★★ |
| Gemini 2.5 pro | ✔️ | ✔️ | ❌ | ★★★★★ |
2、实测结论:
基于以上实测结果,可初步得出以下结论:
(1)GLM-4.5 在语境逻辑、逻辑推理和模型幻觉测试中整体表现出色,展现出强大的综合能力,与其官方报告中多项关键评估指标的卓越表现一致。尤其在逻辑推理任务中,其分步剖析和严谨推导的能力优于部分竞品,能系统性拆解复杂问题,通过数学推导和因果分析确保结论的准确性。这种在多步推理连贯性和结论可验证性上明显优势,使其能够适用于科研辅助、法律解析等深度逻辑分析场景。
(2)在前端编程测试中,GLM-4.5 实现了基础功能,界面简洁且响应迅速,但缺失数据统计模块,完整度明显逊色于 Gemini 2.5 pro 和 DeepSeek-R1。这种功能完整度上的差距,在一定程度上影响了其在数据密集型项目中的实用价值。若后续能针对实际需求和使用场景优化细节,将能够显著提升产品的实用性和用户体验。
(3)对比输入输出价格,GLM-4.5 展现出显著的成本优势,其定价明显低于 o3、Grok 4 等同类竞品。特别是在处理大规模应用场景时,这种价格差异会带来可观的成本节约。对企业用户和开发者而言,这意味着能以更低成本获取优质 AI 服务。特别是在需要频繁调用 API、处理大量文本数据的应用场景中,如智能客服、内容生成、数据分析等领域,GLM-4.5 都是一个极具吸引力的选择。
总体来看,GLM-4.5 系列在开源大模型领域中展现出了颇具竞争力的性能优势,尤其适合需要高逻辑性与成本敏感的应用,但仍需针对具体场景细化功能适配,方能充分发挥其技术优势。
III. 如何在302.AI上使用:
302.AI 提供按需付费无订阅的服务模式,用户可以根据自身业务需求灵活选择使用。
1、聊天机器人中使用
步骤指引 :在线使用→应用超市→机器人→聊天机器人;
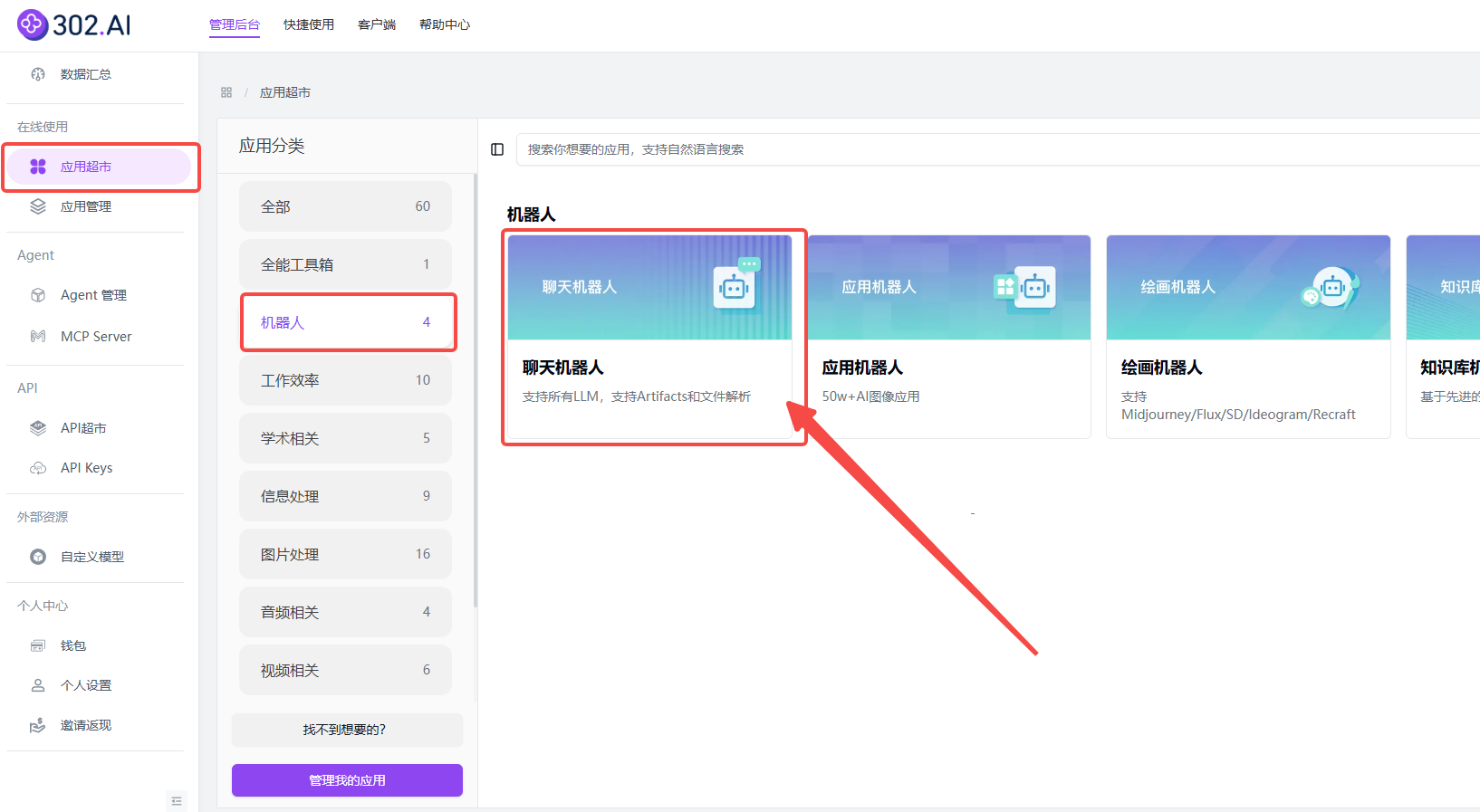
使用搜索框搜索“GLM-4.5”→确定→创建;
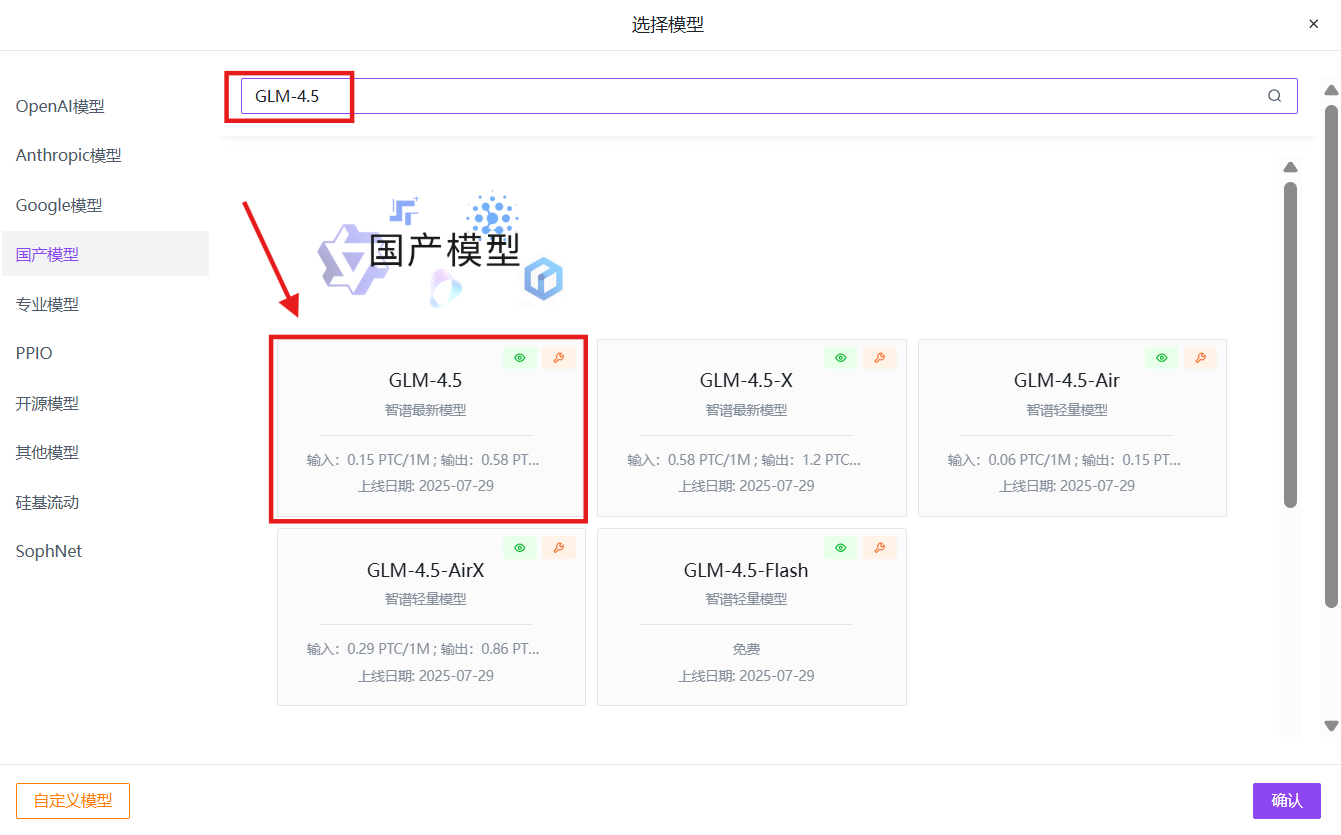
2、使用模型 API
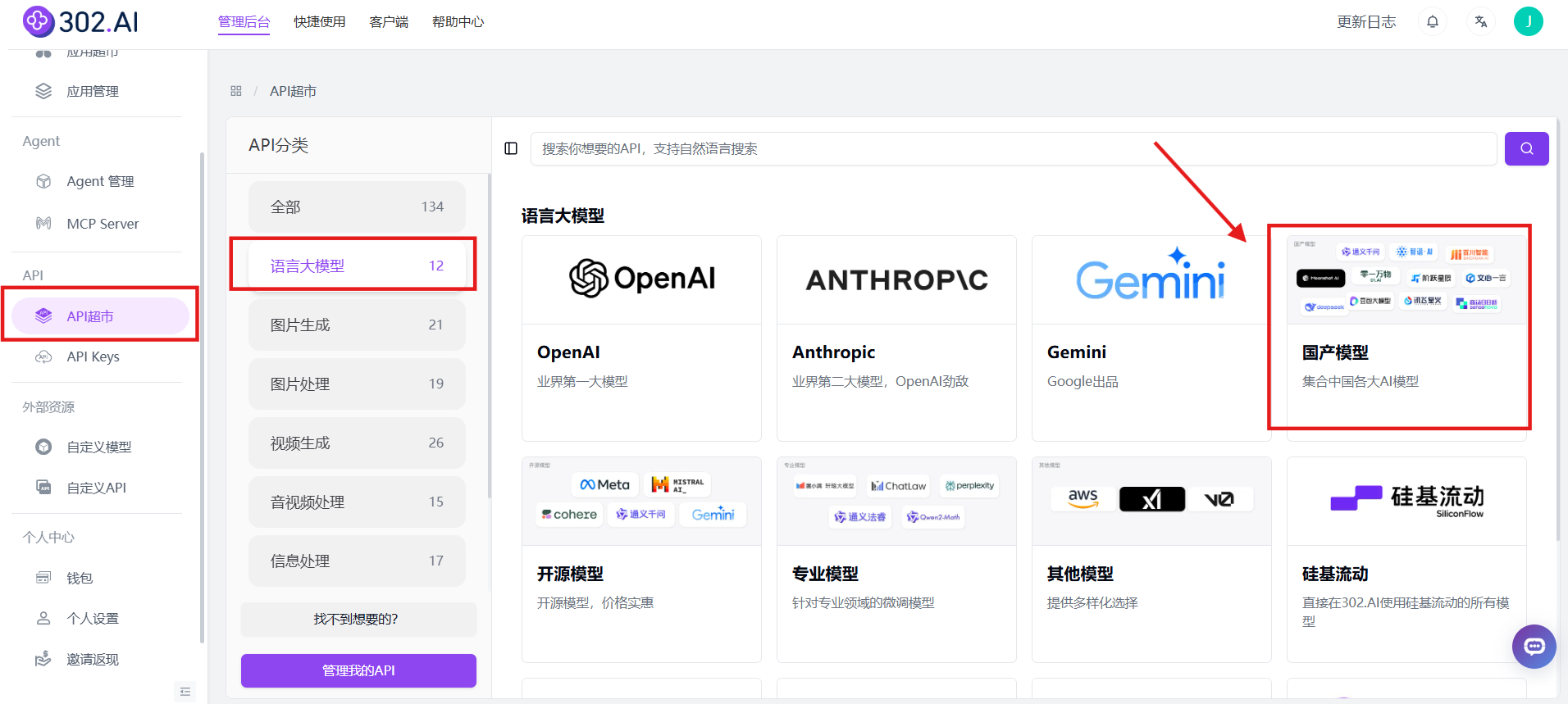
相关文档:API→API超市→语言大模型→国产模型→查看文档;
API 名称:glm-4.5
想体验 GLM-4.5 模型? 👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(1)
[…] 这个月是国产模型爆发月。K2 / GLM-4.5 / Step-3 / Qwen-2507,无论是编程能力、Agent […]