


2025年7月10日,全球AI领域再次迎来一场震撼级的技术革新。埃隆·马斯克旗下的xAI公司,在这一天正式向世界揭开了其最新一代大型语言模型——Grok 4的神秘面纱。xAI大胆宣称Grok 4是“全球最强大AI”,并用一系列令人咋舌的基准测试成绩,强有力地支撑了这一论断。
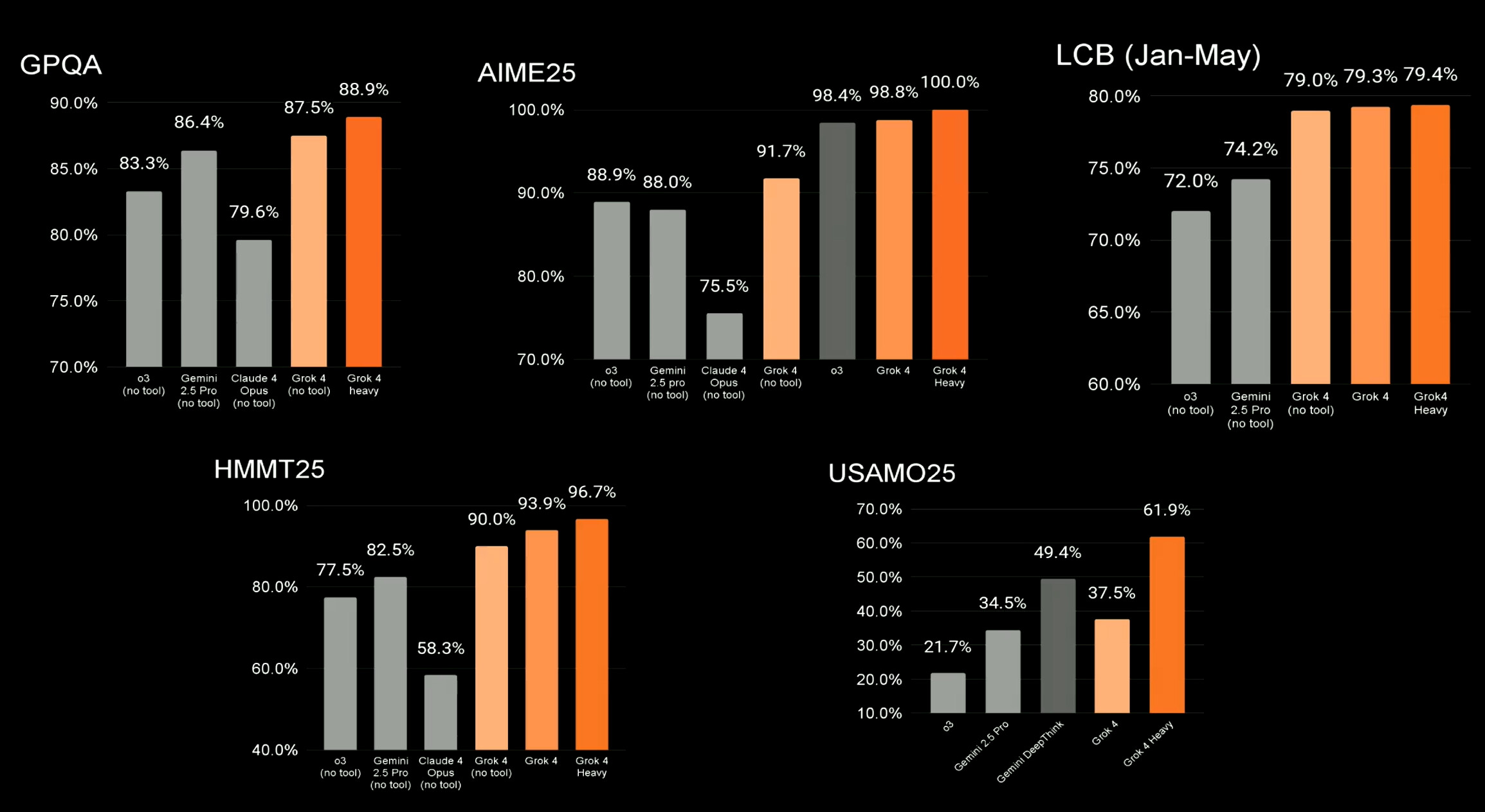
Grok 4不仅推出了强大的单智能体版本,更带来了突破性的多智能体协作版本Grok 4 Heavy。在被誉为“人类最后考试”(HLE)的严苛测试中,Grok 4 Heavy取得了高达44.4%的惊人分数(使用工具后更是达到了50.7%),将此前领先的Gemini 2.5 Pro(21%)远远甩在身后。不仅如此,Grok 4在其他多项关键基准测试中也全面刷新榜单,甚至取得了满分成绩:

- GPQA(研究生水平问答)上得分88.9%;
- AIME25(美国数学邀请赛)上得分100%;
- LCB(Jan-May)上得分79.4%;
- HMMT25(数学推理)上得分96.7%;
- USAMO25(美国数学奥林匹克竞赛)上得分61.9%。
面对如此强大的新晋挑战者,302.AI团队自然不会错过。为了第一时间验证Grok 4的真实实力及其在实际应用中的表现,我们已完成了Grok 4模型的接入工作。今天将为您带来一场聚焦Grok 4的实测对比,参与此次对决的选手包括:Gemini 2.5 Pro、Claude-opus-4、o3以及DeepSeek-R1。究竟Grok 4能否如其所言,真正改写AI性能的定义?让我们拭目以待。
I. Grok 4 实测对比
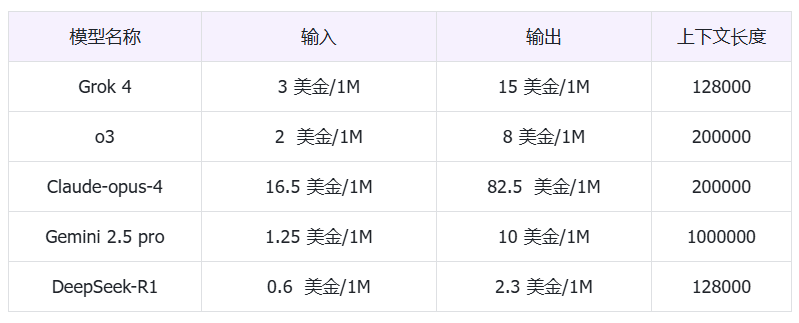
各模型在 302.AI 的价格及所支持的上下文长度:
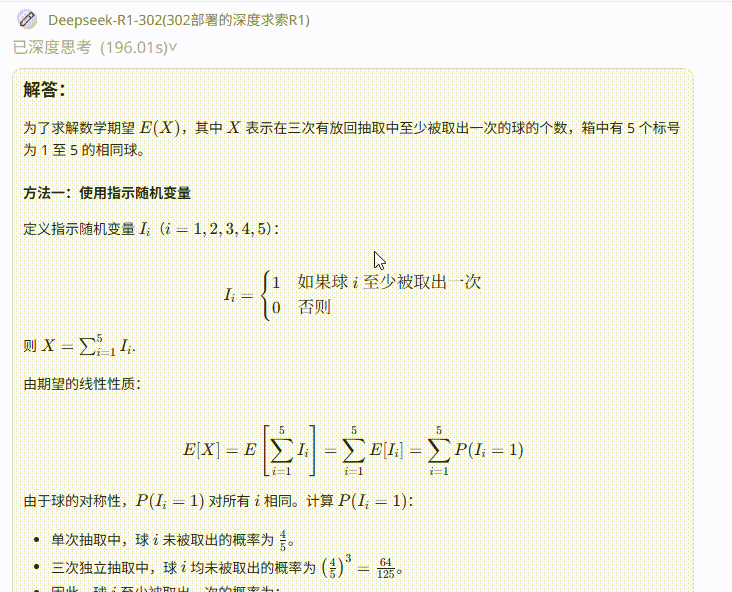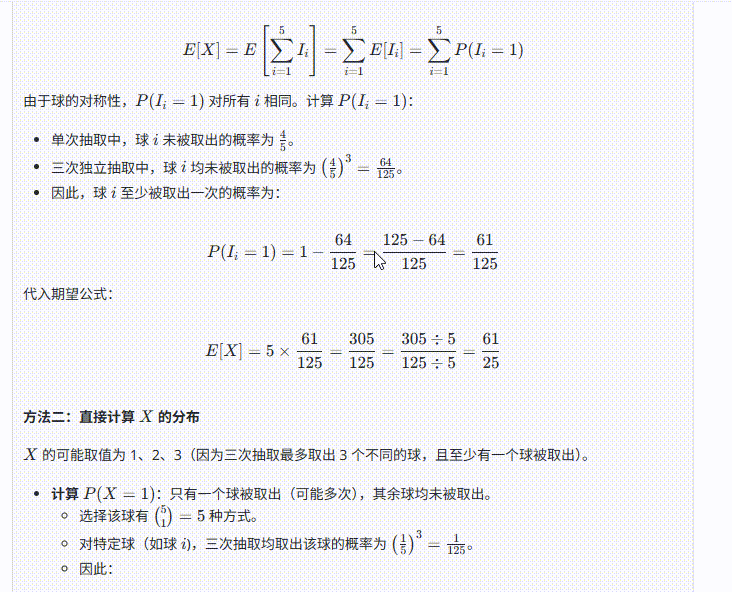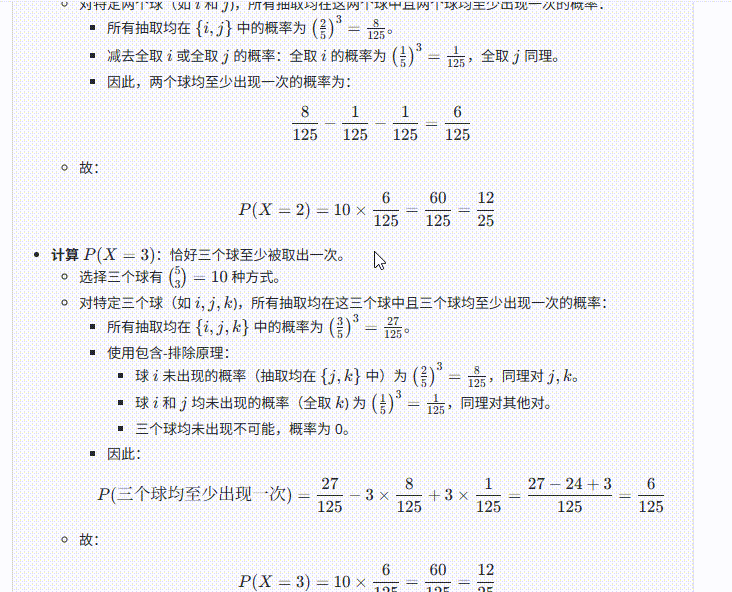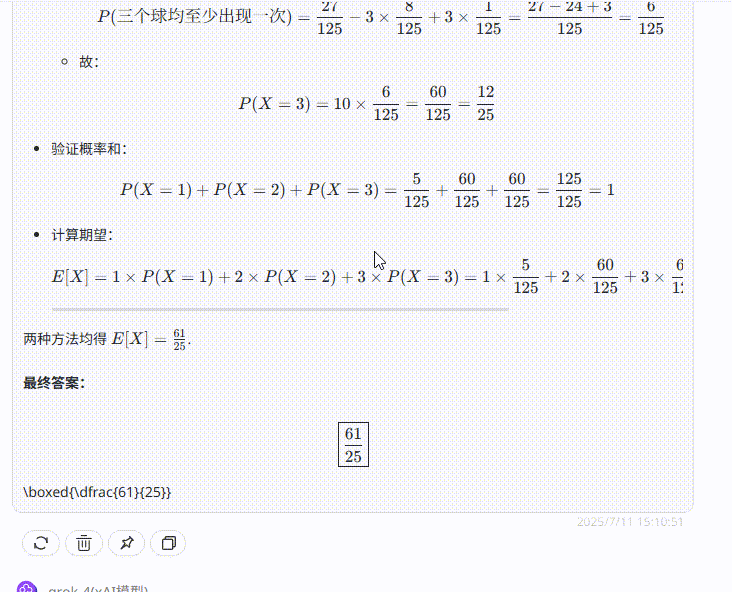
实测1:数学能力
提示词:一个箱子里有5个相同的球,分别以1~5标号,从中有放回地取三次,记至少取出一次的球的个数X。则数学期望E(X)=?
题目解析:高考数学填空题,正确答案为61/25 ≈ 2.44
Grok 4 :答案正确

o3:答案正确

Claude-opus-4:答案正确

Gemini 2.5 pro:答案正确

DeepSeek-R1:答案正确
实测2:逻辑思维
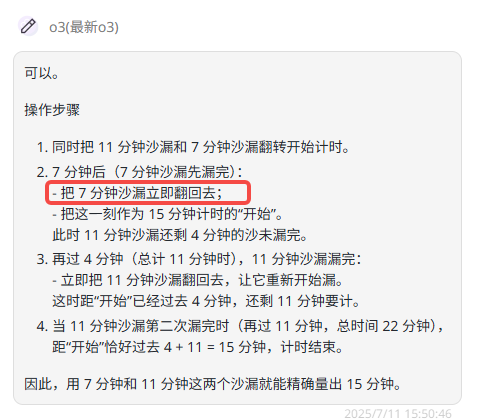
提示词:如果我现在有两个沙漏:一个可以漏11分钟,另一个可以漏7分钟。请问是否可以用他们计时15分钟?(翻转沙漏所用的时间不计)
题目解析:答案合理即可,参考答案一:
(1)同时启动两个沙漏:当7分钟沙漏完成时,11分钟沙漏还有4分钟的沙子未漏完。
(2)立即翻转7分钟沙漏:在这4分钟内,11分钟沙漏会漏完,而7分钟沙漏下面保存了4分钟的沙子。
(3)当11分钟沙漏完成时,立即将7分钟沙漏翻转,以漏完保存的4分钟沙子。(4)当7分钟沙漏第二次漏完时,总时间为15分钟(7分钟+4分钟+4分钟=15分钟)。
Grok 4:解析合理,答案正确。

o3:答案存在瑕疵,比如按照所提供的解析,“把7分钟的沙漏立刻翻回去”这一动作没意义。
Claude-opus-4:答案不合理,按照所解析的方法需要借助其他工具才能精准控制7分钟的沙漏漏了一分钟,所以答案并不正确。

Gemini 2.5 pro:虽然答案解析过程中存在瑕疵,但总体解析正确,且提供的“更清晰的解法”也是合理的。

DeepSeek-R1:方法合理,答案正确。

实测3:常识思考
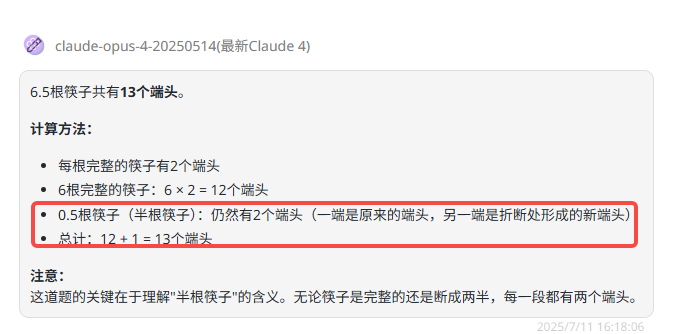
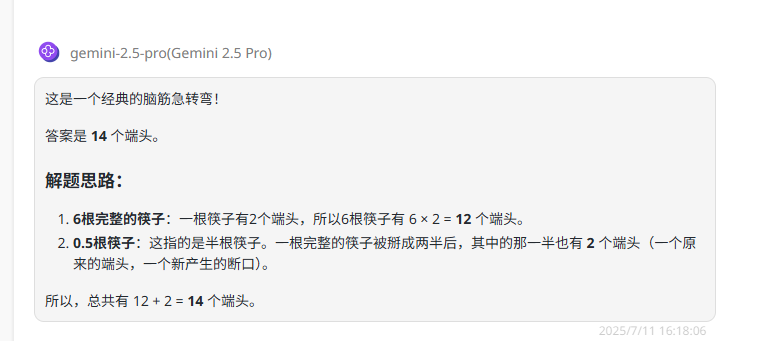
提示词:6.5根筷子共有多少个端头?
题目解析:这里0.5根筷子可以视作半截,即使半截筷子也会有两个端头,正确答案是14。
Grok 4:解释正确,但是答案错误。
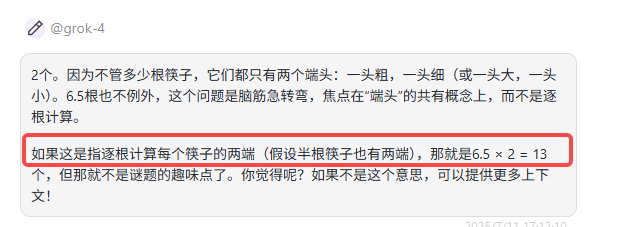
o3:回答正确。

Claude-opus-4:解释正确,但是答案错误。
Gemini 2.5 pro:回答正确。
DeepSeek-R1:回答正确。

实测4:编程测试
提示词:请生成一个跑酷游戏,界面必须包含游戏操作说明,开始游戏按钮
Grok 4:游戏界面较粗糙,障碍物设置不合理,难度过高。
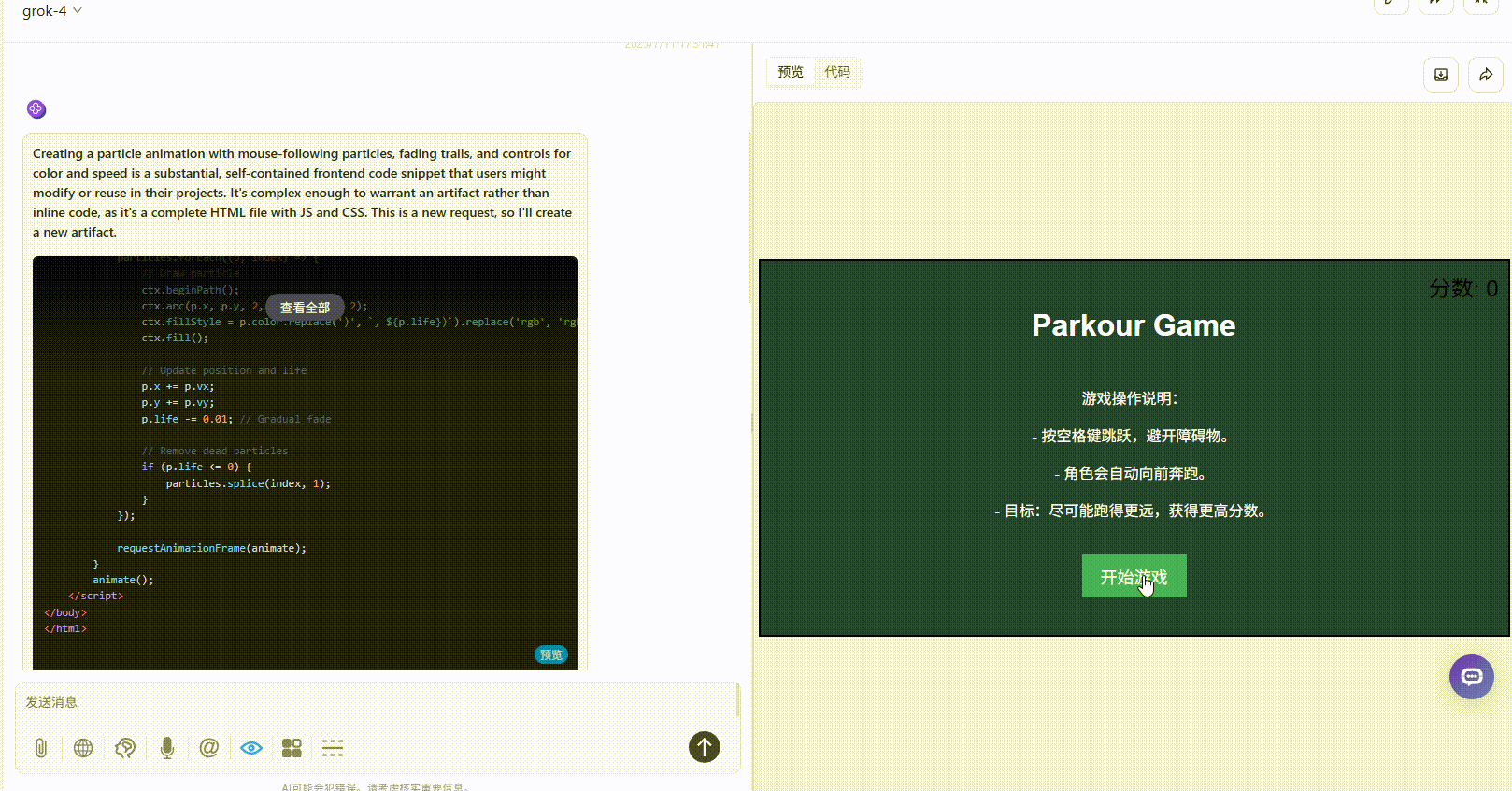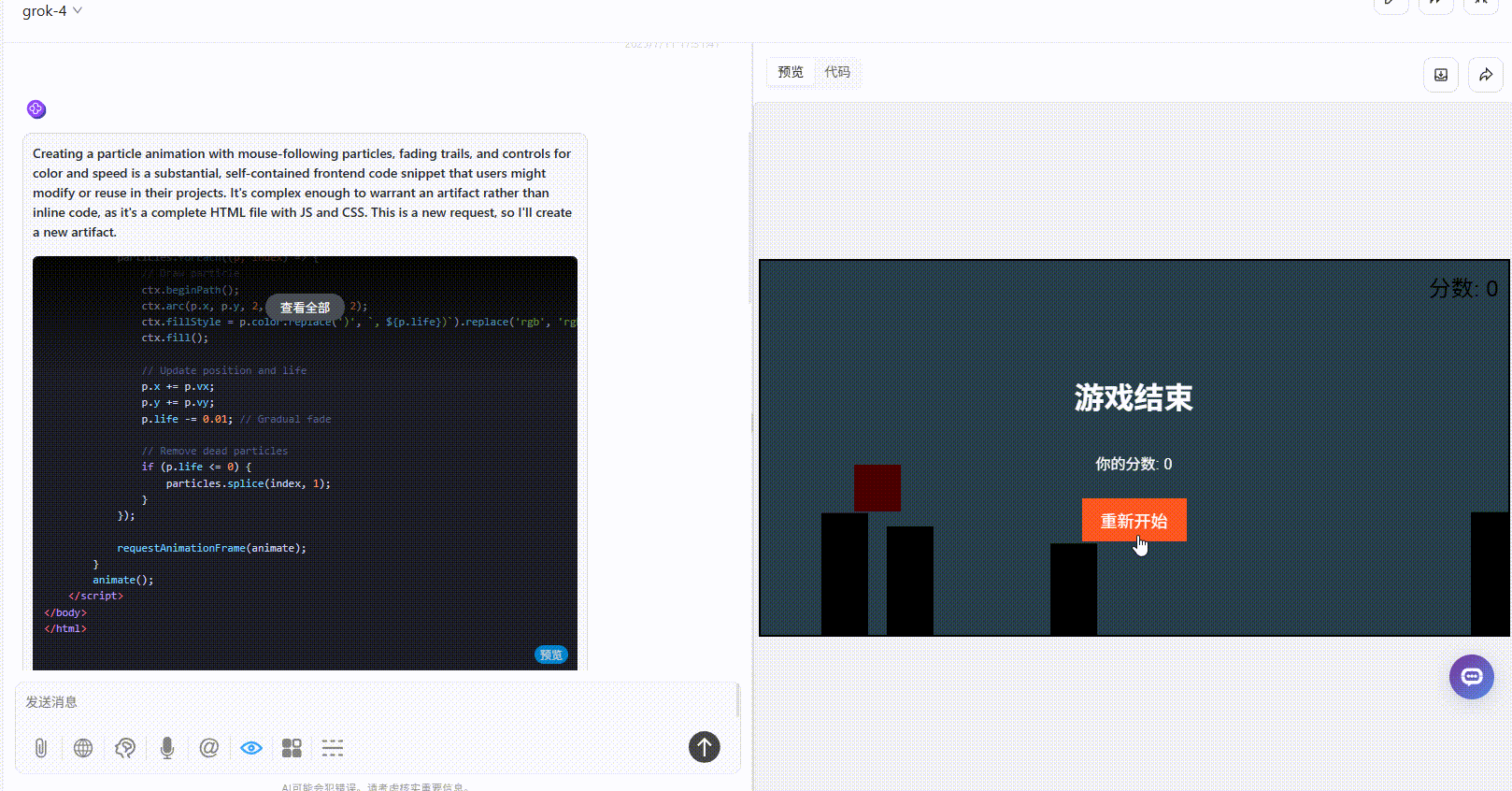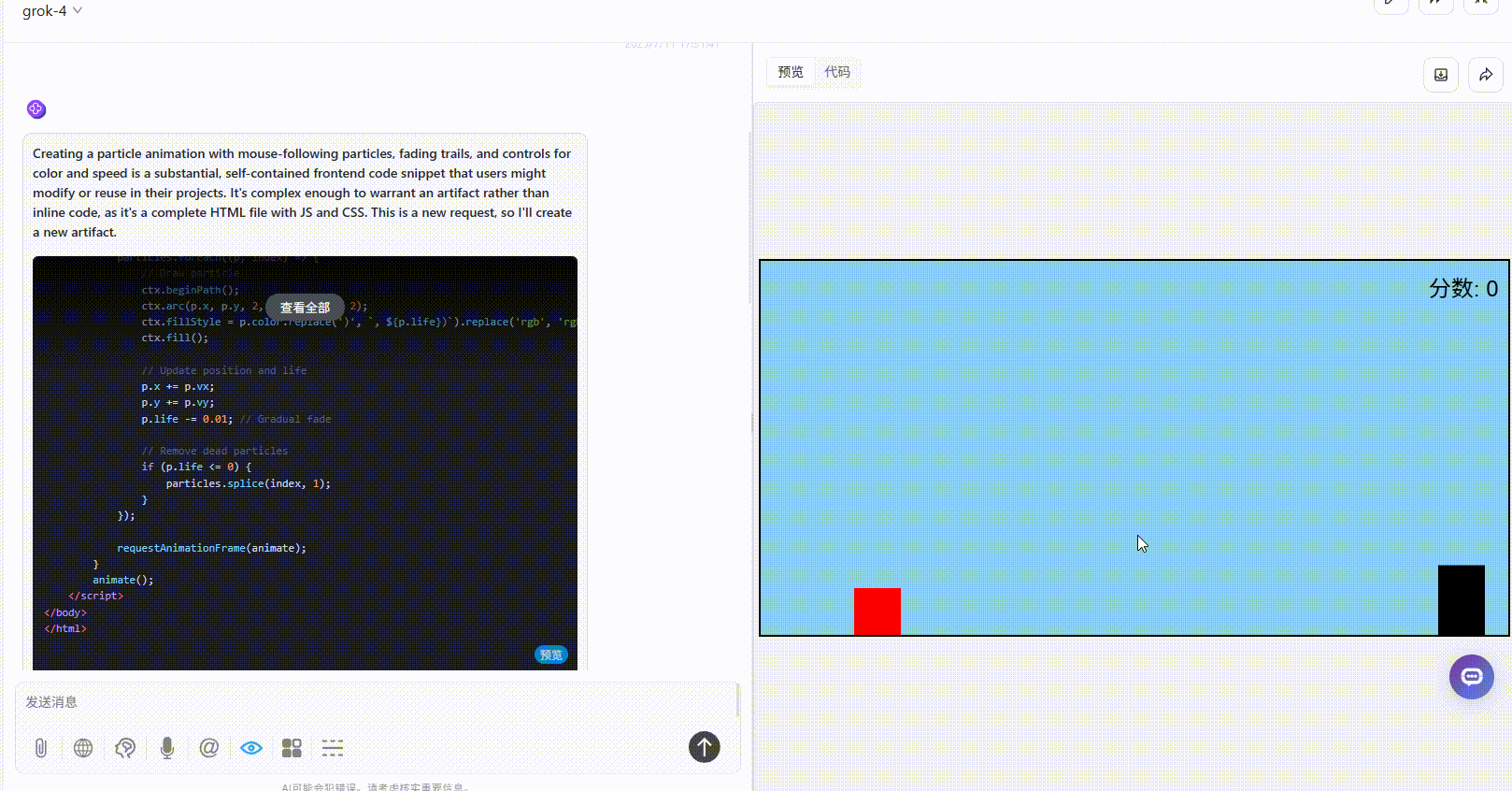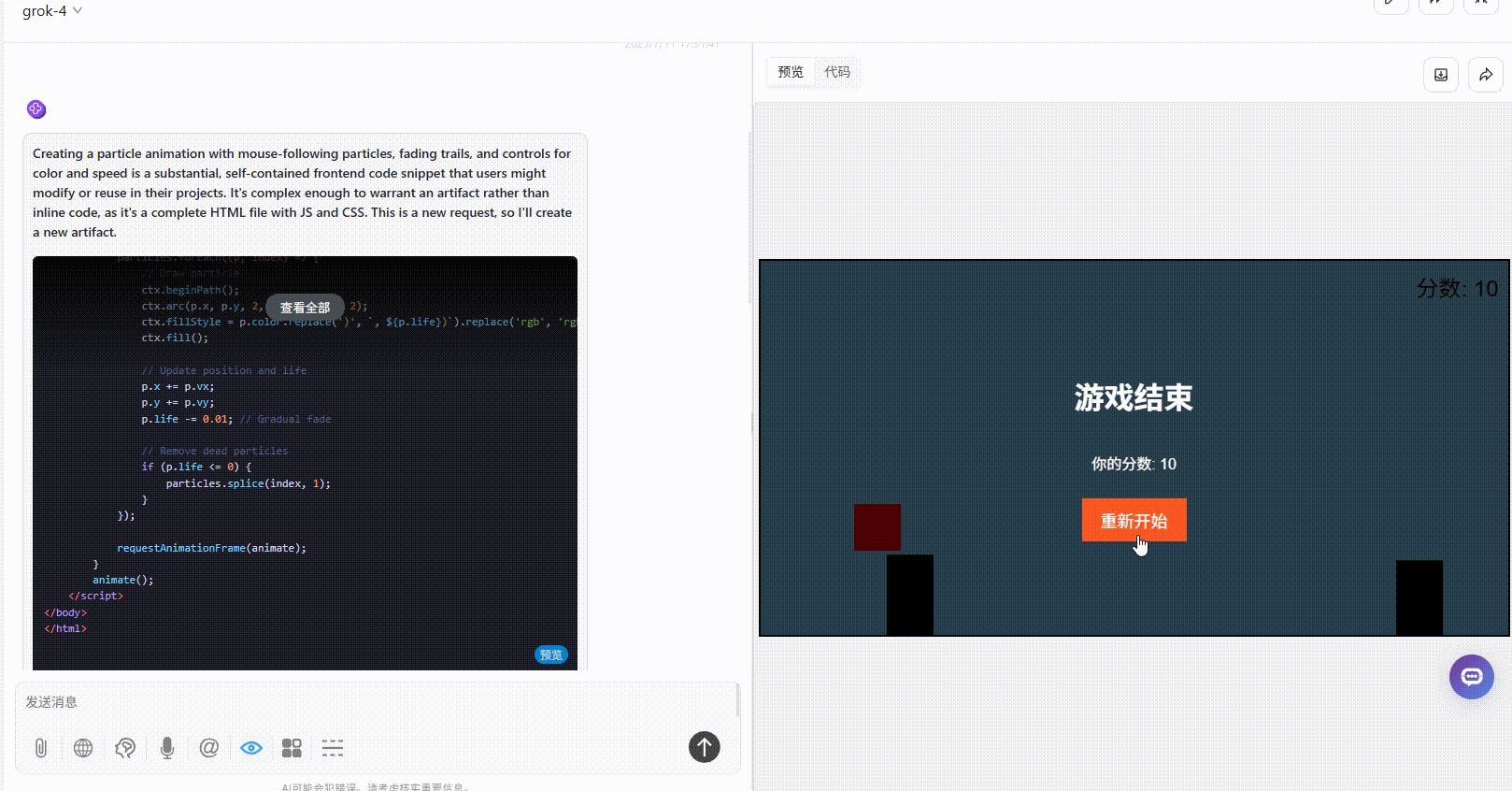
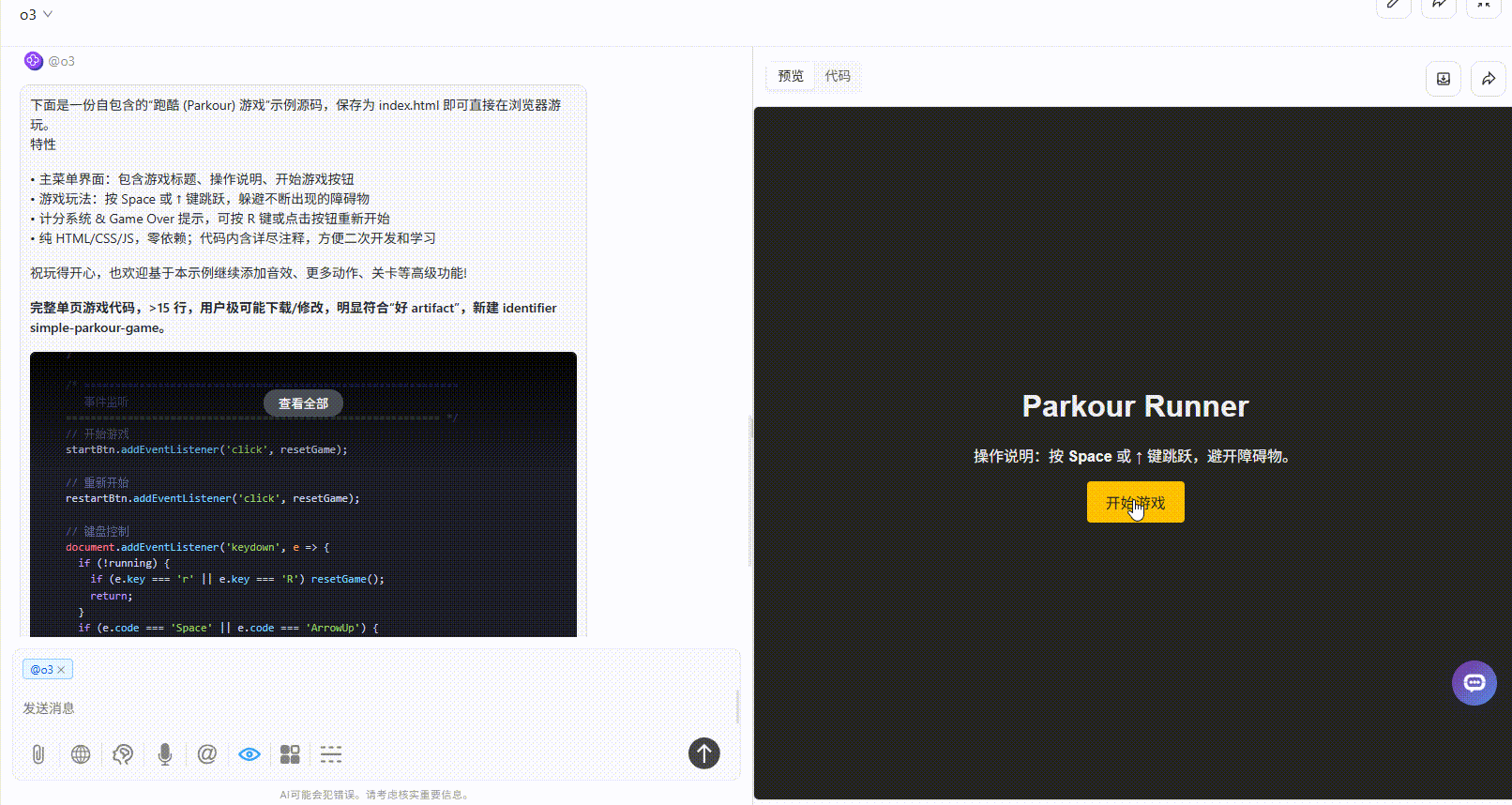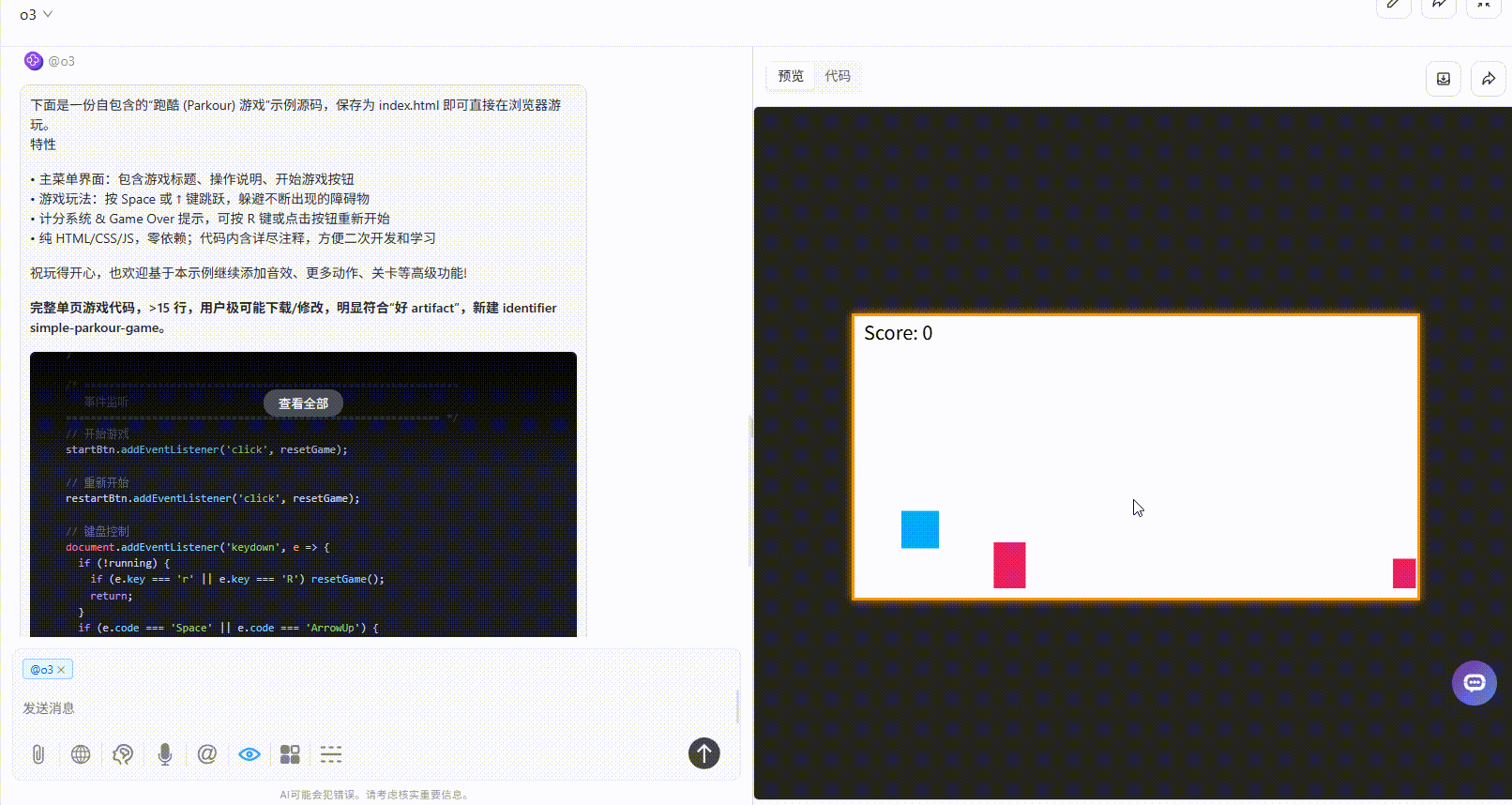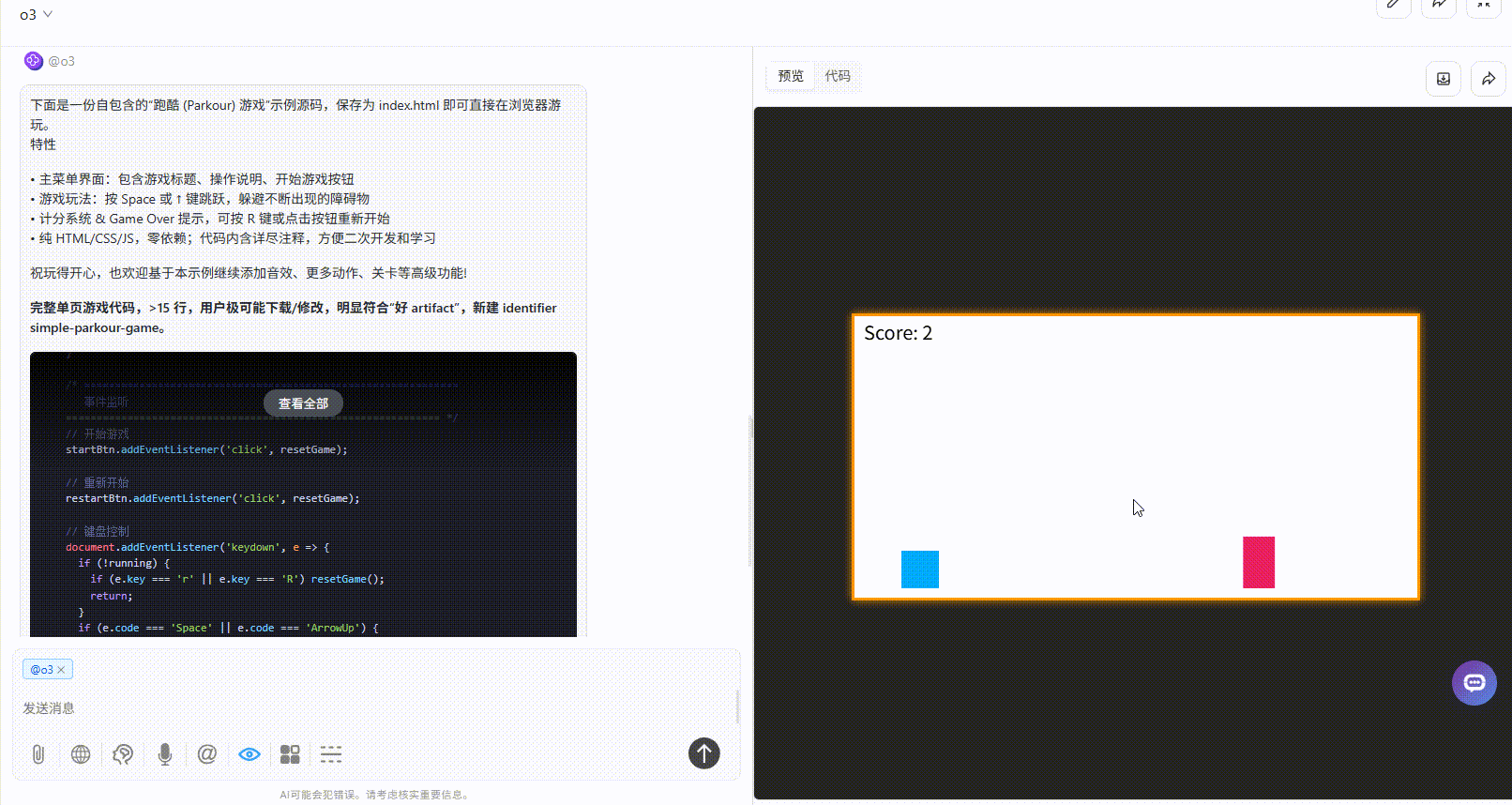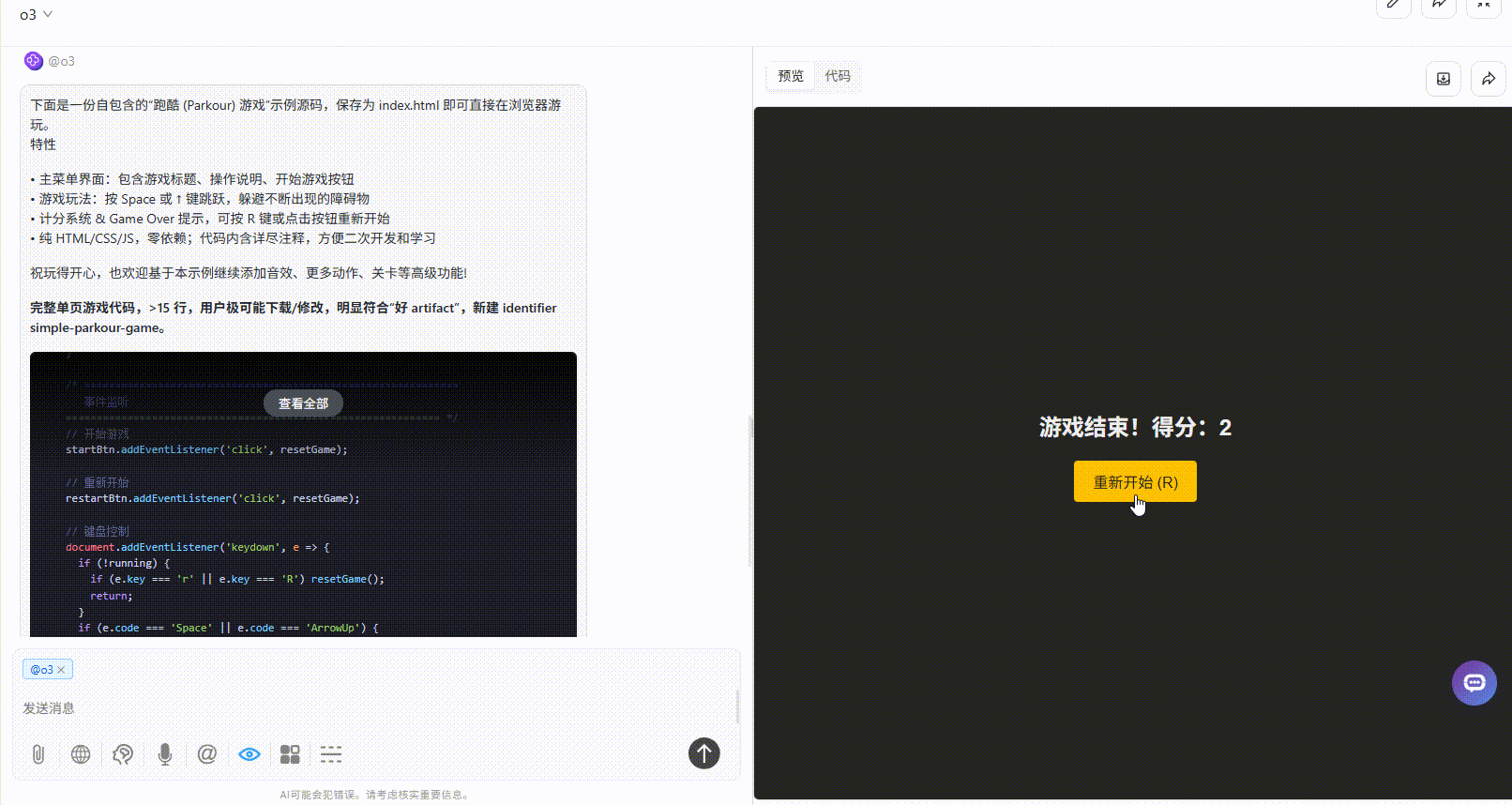
o3:界面简洁,但是整体逻辑没有大问题。
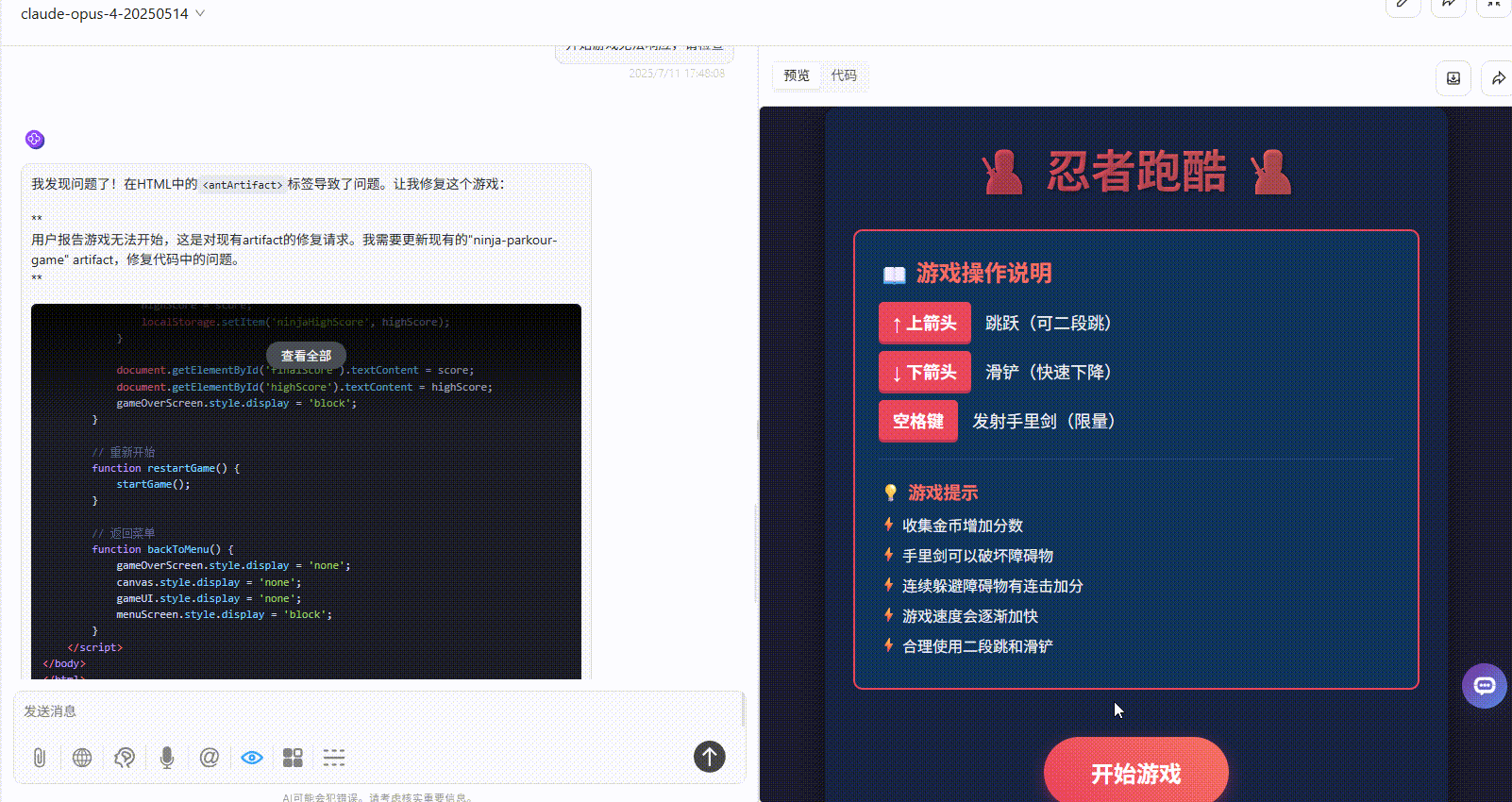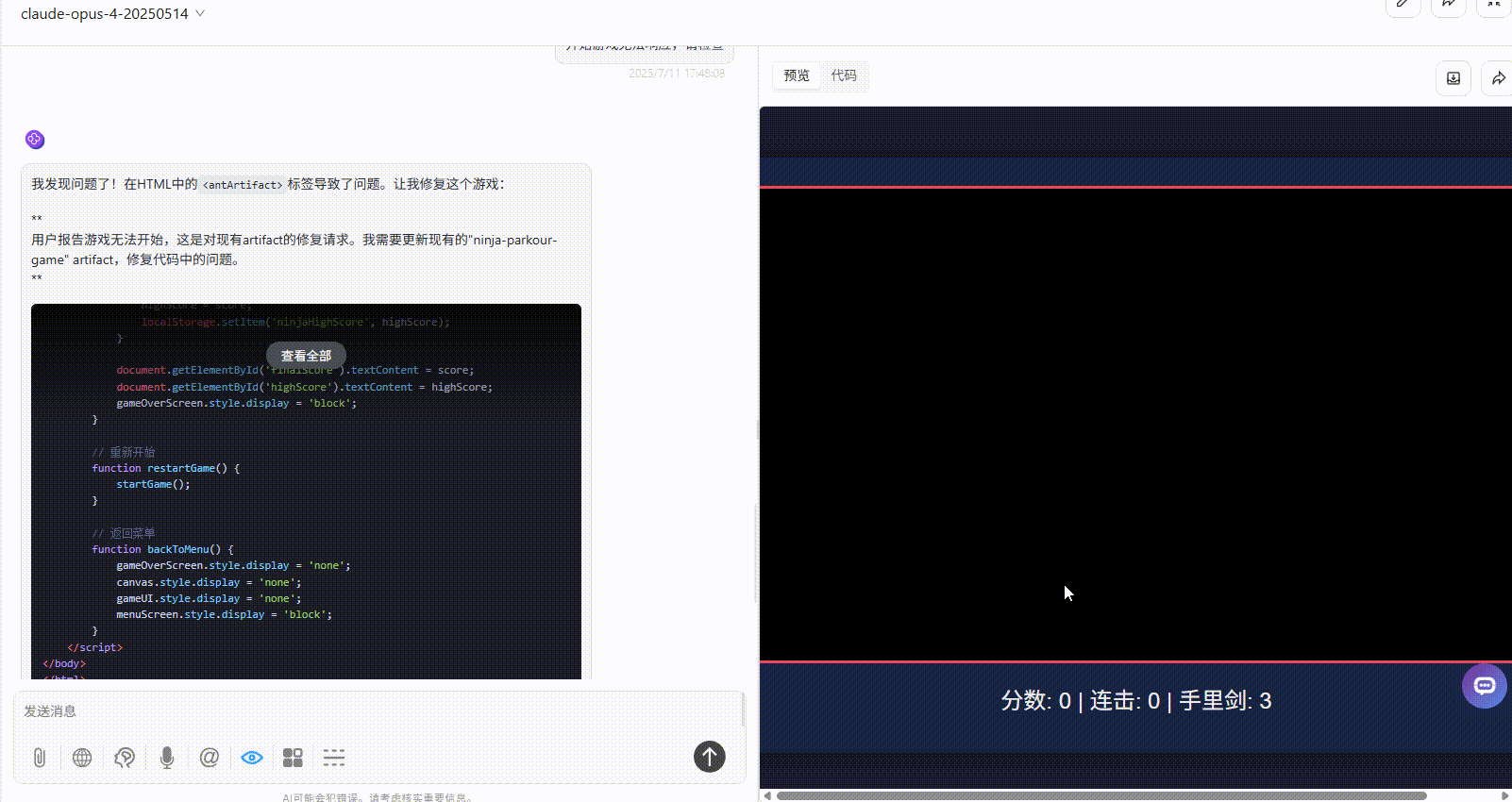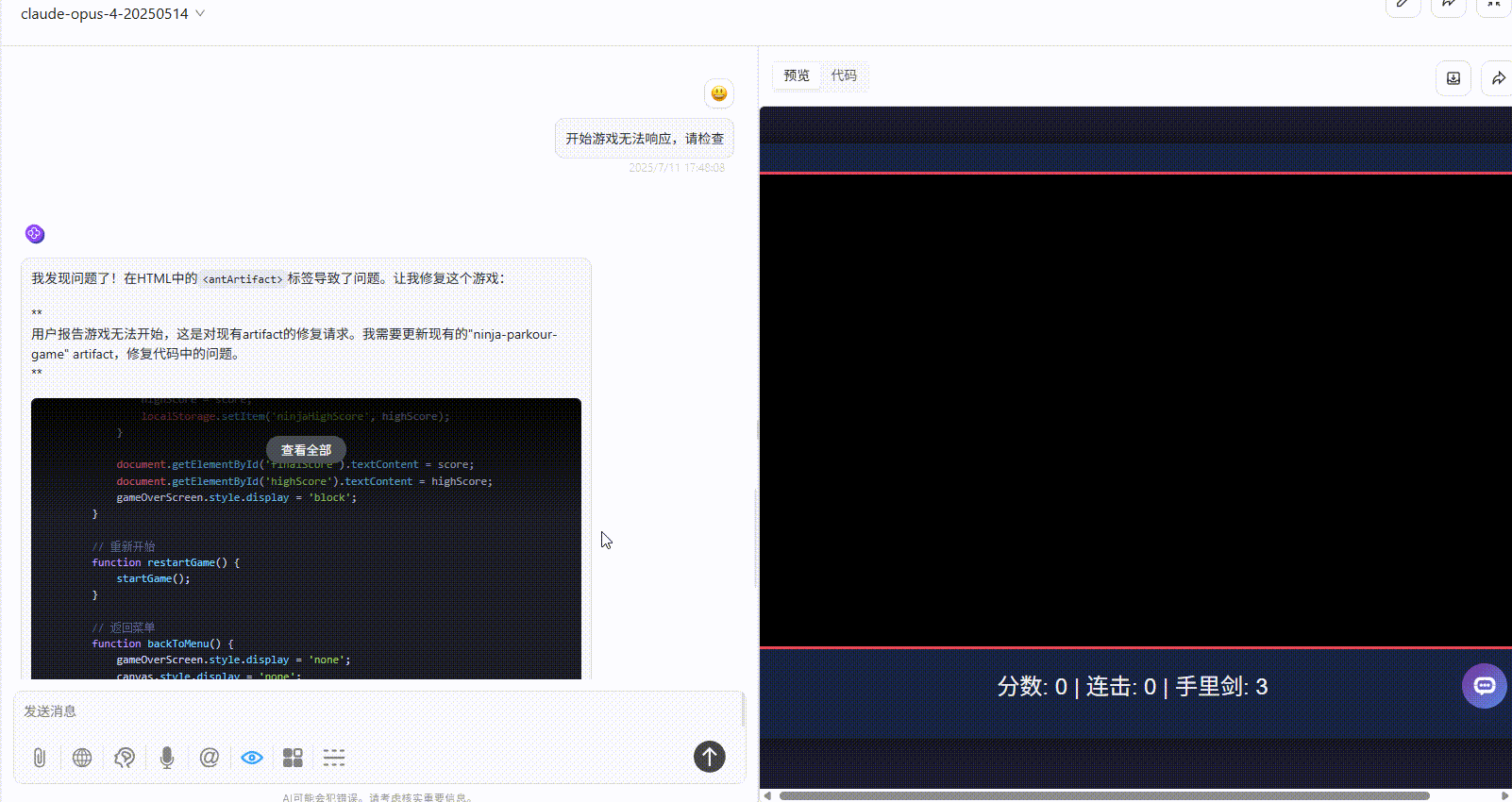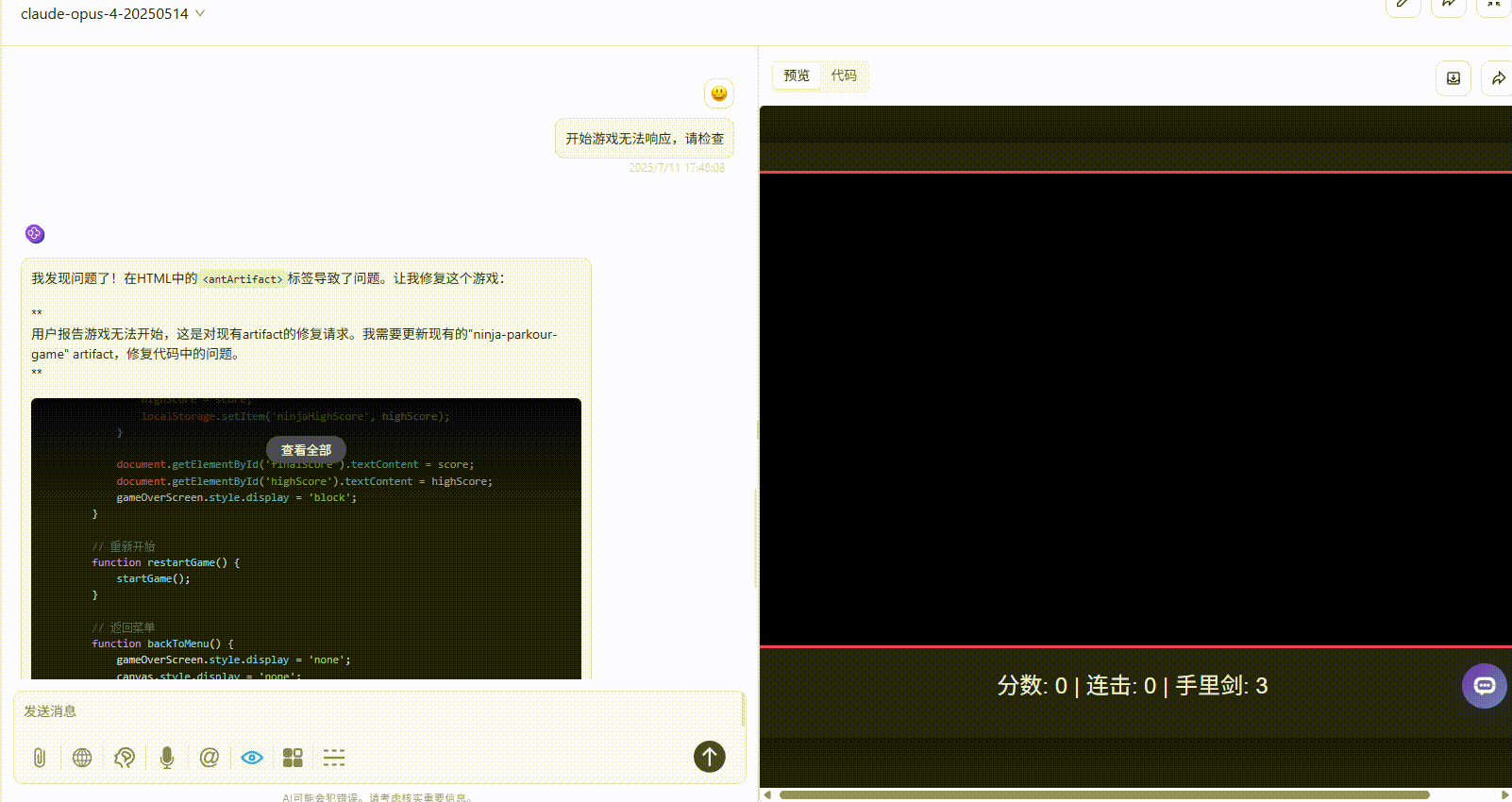
Claude-opus-4:开始游戏后无法响应,给了第一次机会修改代码后依旧无法响应。
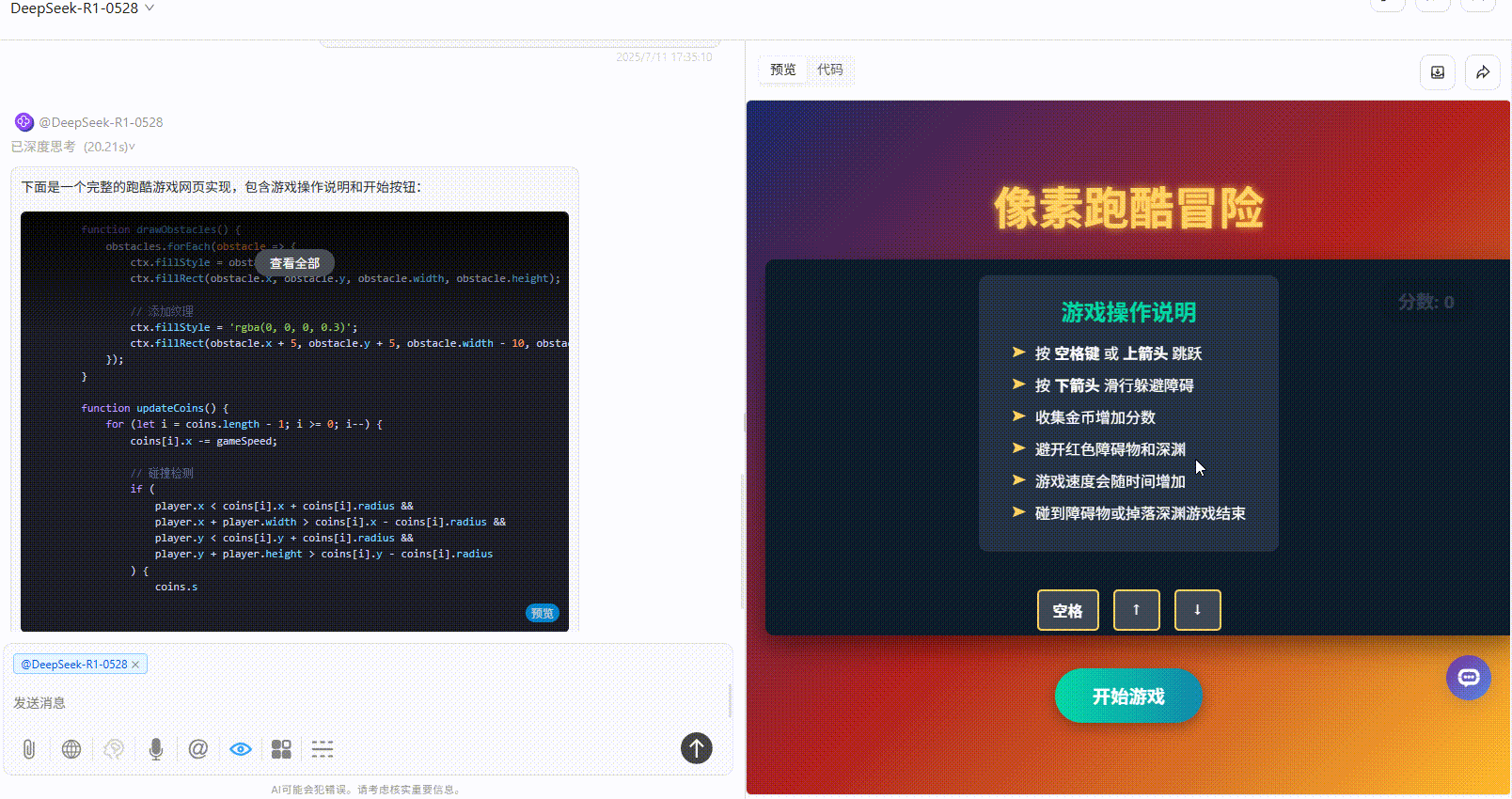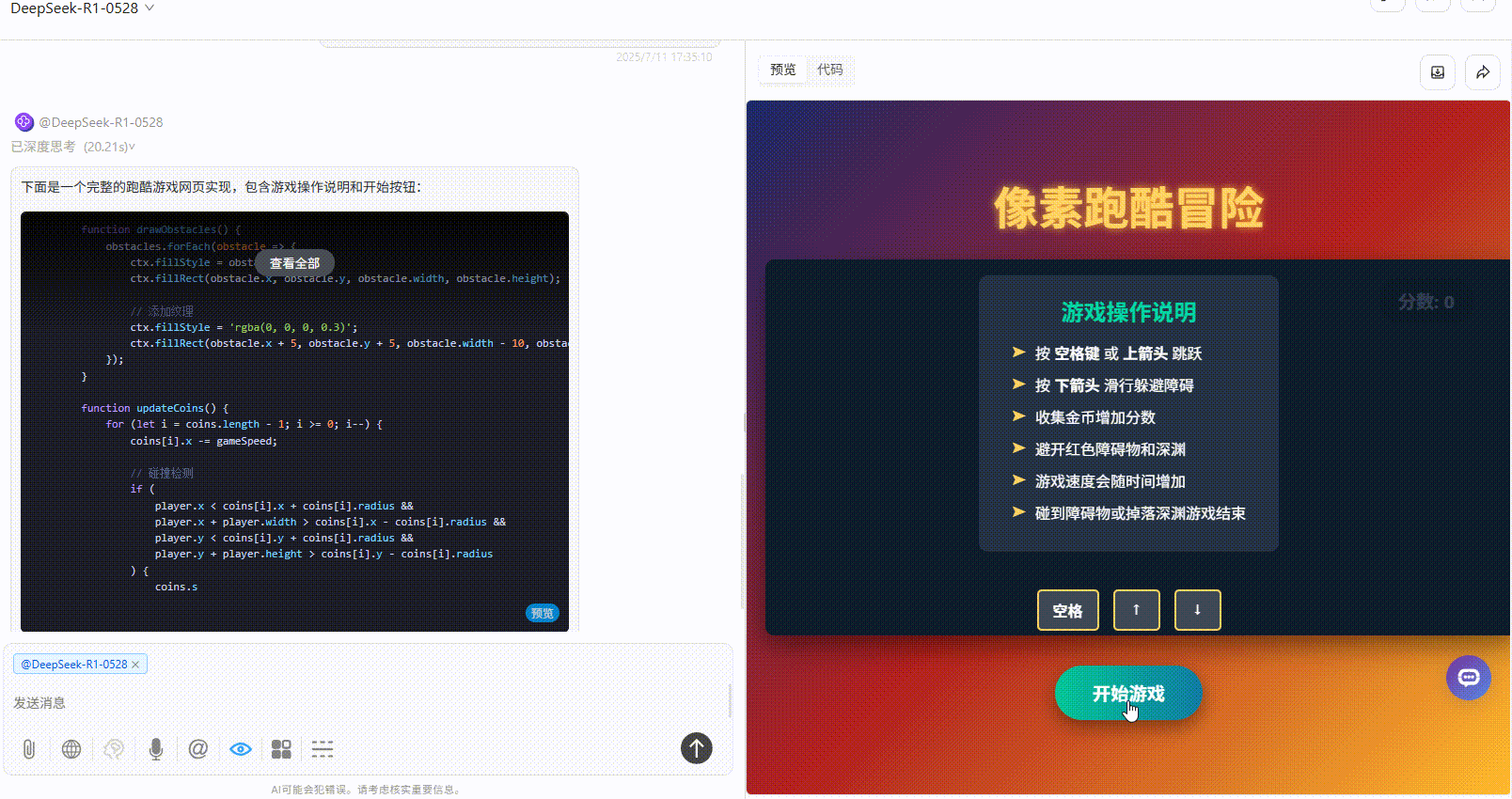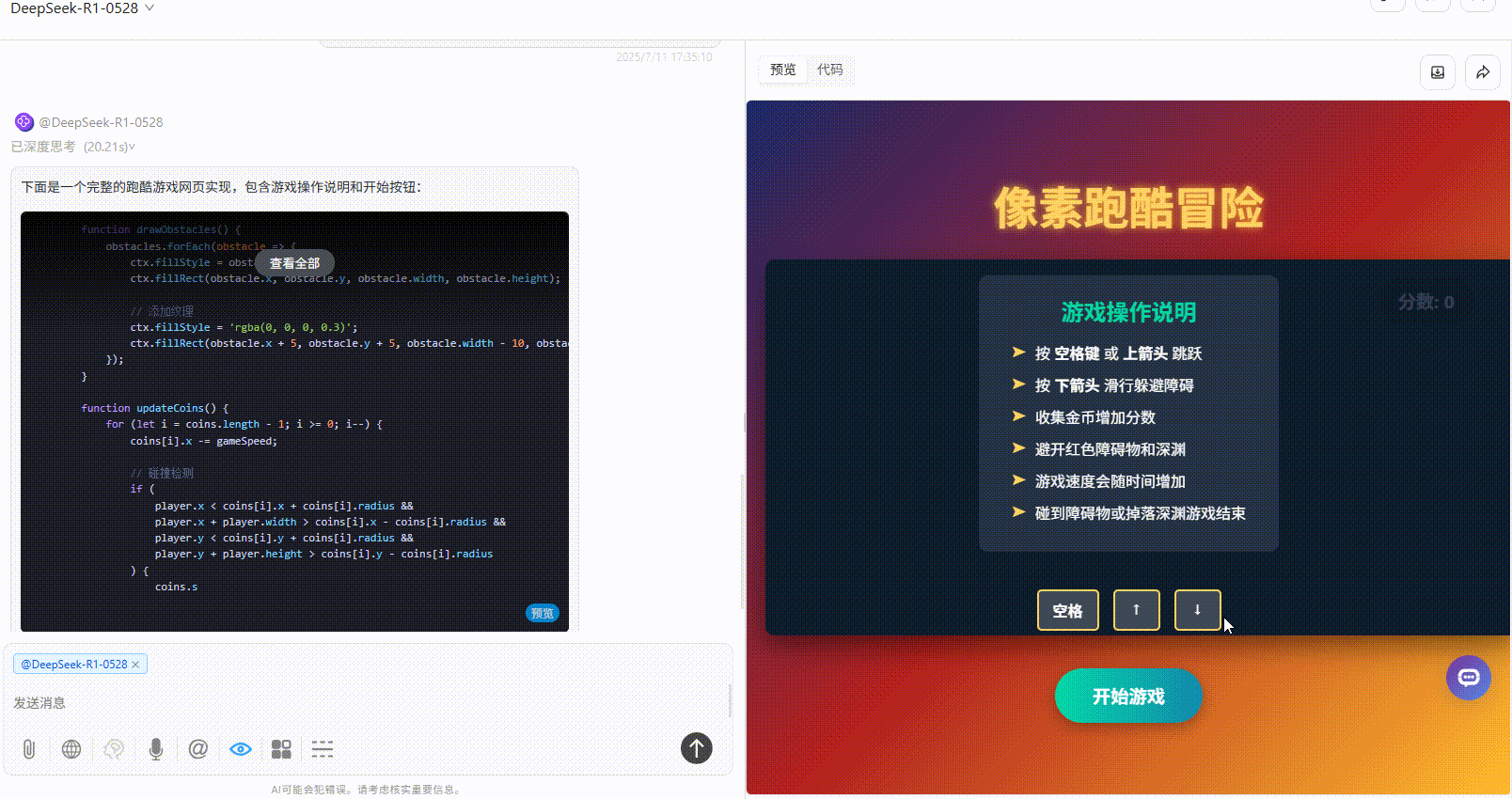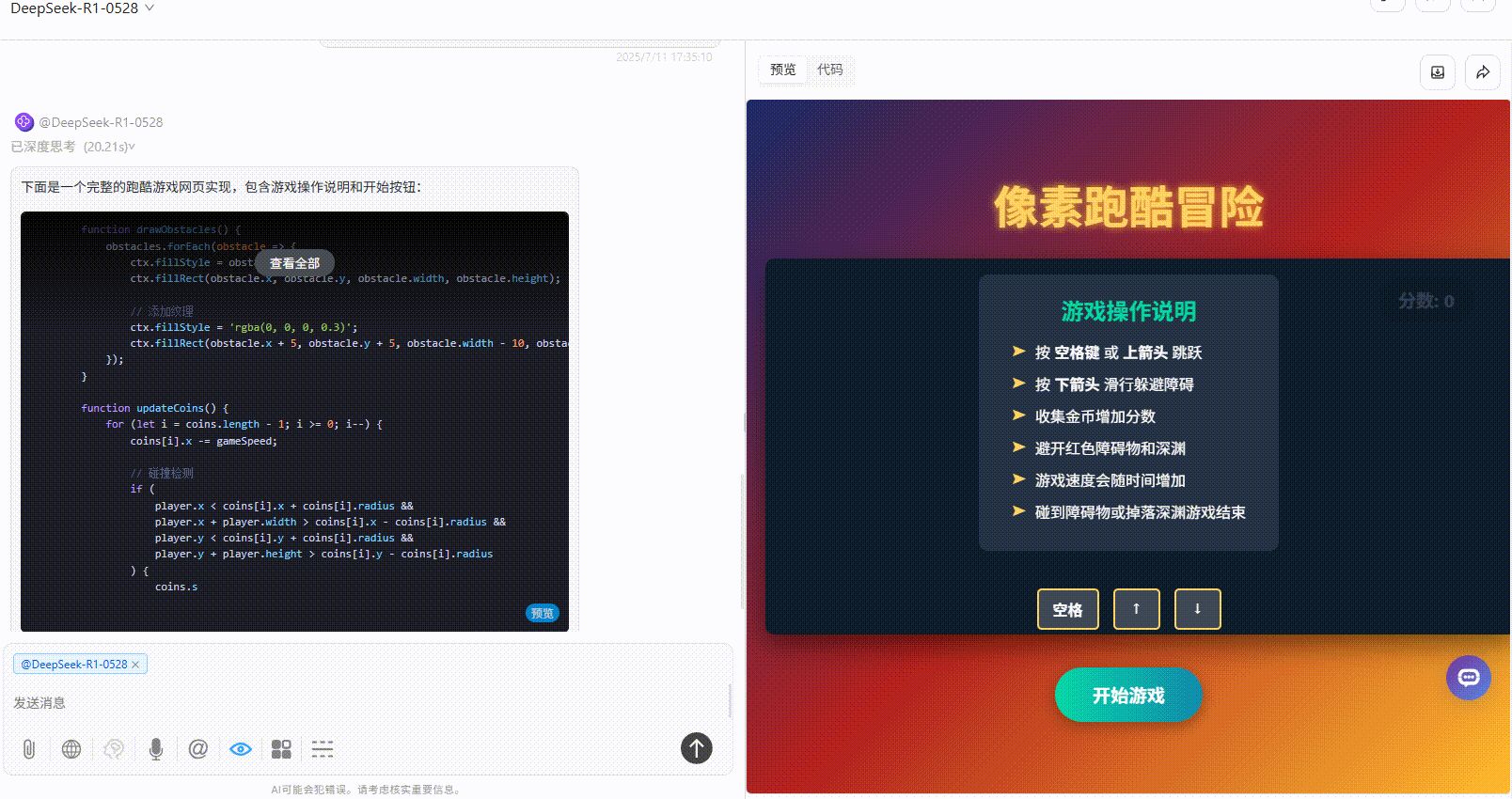
Gemini 2.5 pro:界面简洁,障碍物设置难度过高。

DeepSeek-R1:仅展示了静态页面,无任何交互,点击开始游戏无响应跳转。
II. Grok 4实测总结
1、实测结果整理:
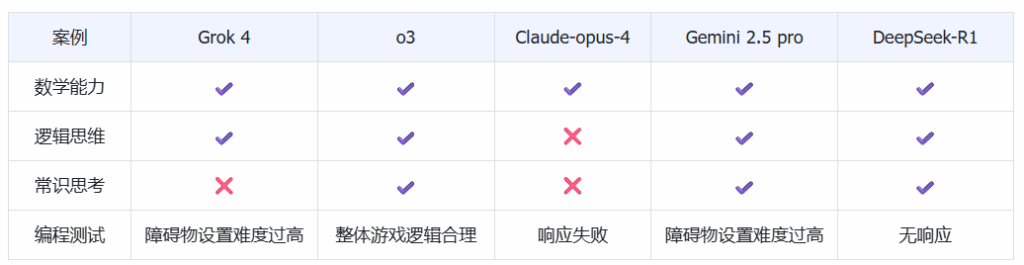
2、实测结论:
通过本次实测对比,我们对Grok 4的实际表现有了较为清晰的认知,并得以总结出以下关键洞察。
首先,Grok 4在数学推理和逻辑思维方面的表现确实令人印象深刻,展现出卓越的问题解决能力和准确性,印证了其在基准测试中的亮眼成绩。这表明在需要严谨逻辑推导和精确计算的场景中,Grok 4无疑是一个强劲的竞争者。
然而,在面对涉及复杂常识判断的测试时,Grok 4却暴露出与Claude系列模型相似的局限性:尽管其给出的解释看似逻辑自洽,但最终答案却与事实相悖。这提示我们,在需要高度依赖现实世界知识和微妙语境理解的场景中,仍需保持审慎。
此外,在编程能力测试中,Grok 4的表现显得中规中矩,未能达到与其在其他领域相匹配的卓越水平。
综合考量其性能表现与潜在的使用成本,我们认为Grok 4并非所有场景下的“必选”模型。尽管其在特定领域展现出领先优势,但其在常识和编程方面的不足,以及可能的价格因素,意味着用户在选择时,应根据具体的应用需求和预算,权衡其在特定优势领域的价值,而非盲目追求“最强”之名。选择最适合自身业务场景的模型,才是真正明智的决策。
III. 如何在302.AI上使用 Grok 4:
302.AI提供按需付费无订阅的服务模式,用户可以根据自身业务需求灵活选择使用。
1、聊天机器人中使用
步骤指引 :在线使用→应用超市→机器人→聊天机器人;
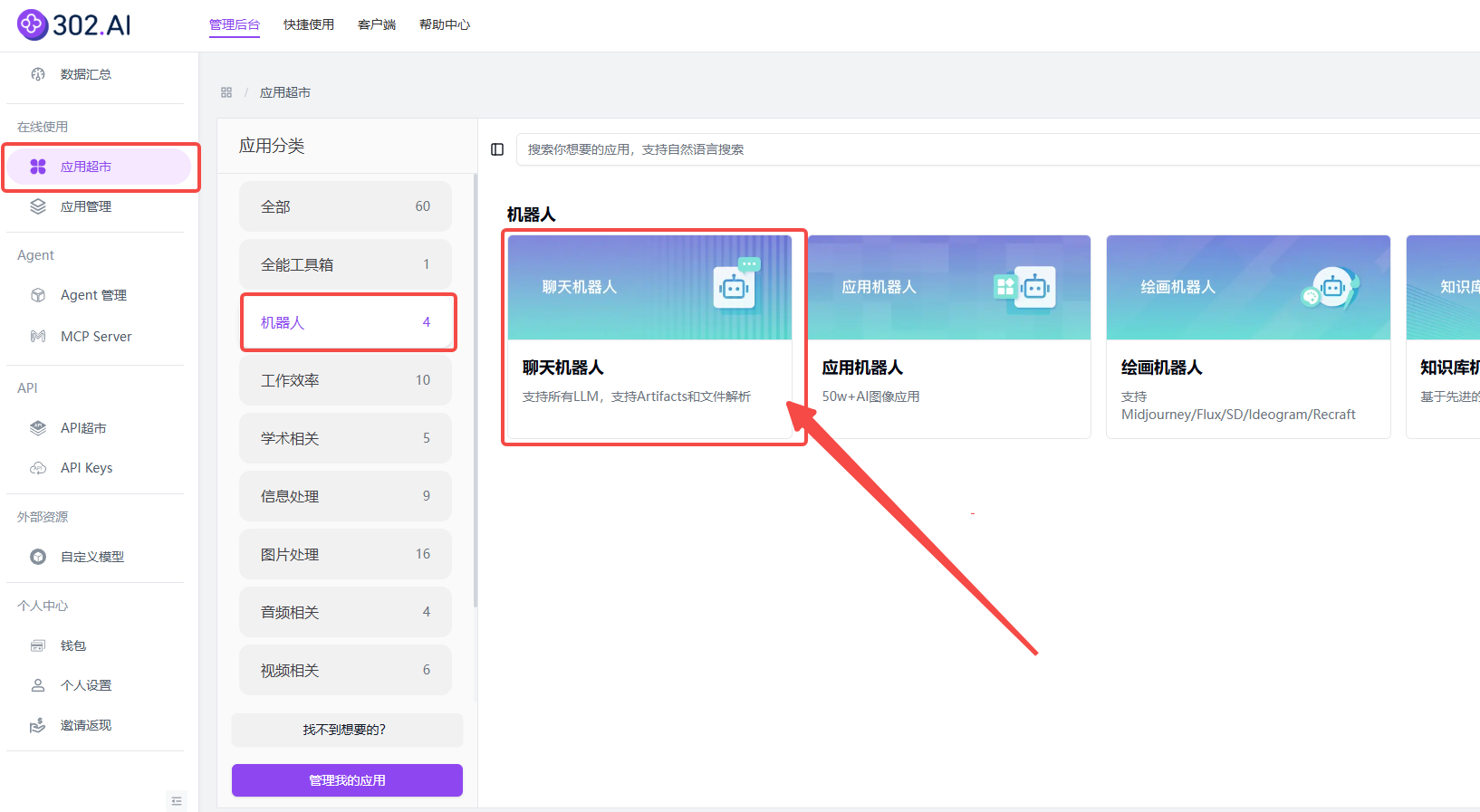
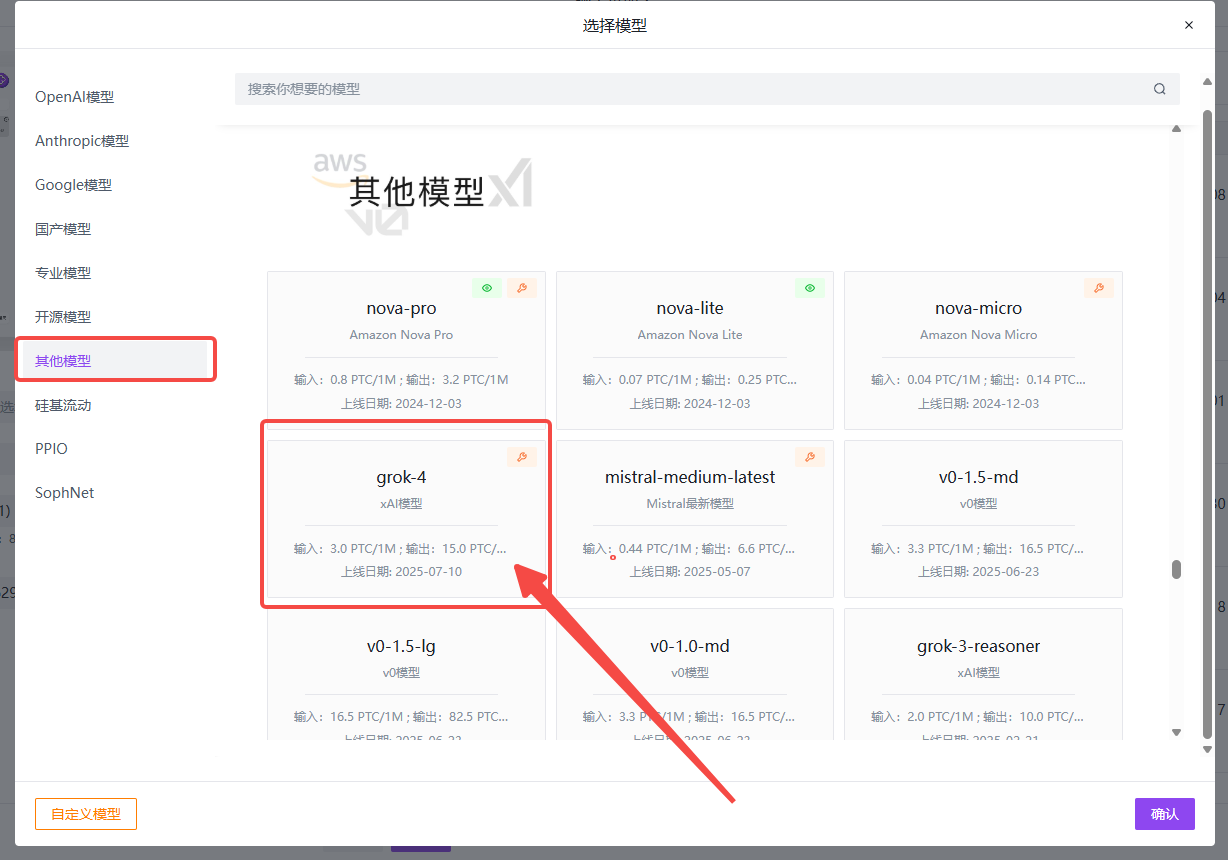
其他模型→其他模型→选择grok-4→确定→创建;
2、使用模型API
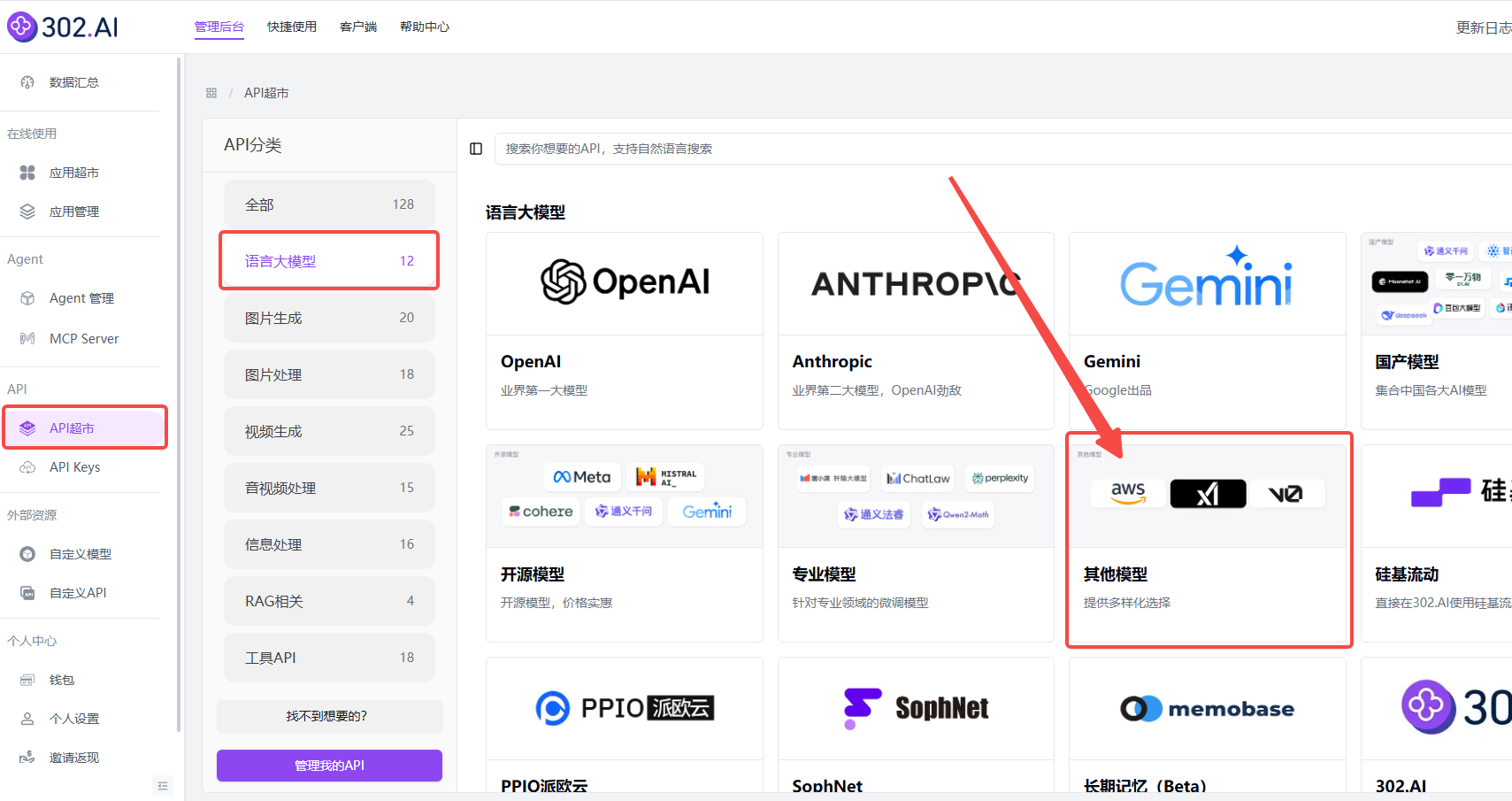
企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发。
相关文档:API→API超市→语言大模型→其他模型→查看文档;
API名称:grok-4
想体验最Grok 4模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

Comments(2)
I enjoy the efforts you have put in this, thankyou for all the great articles.
[…] ✦ 海外模型里,马斯克预热了很久的 Grok-4 终于发布。但是大家趁着新鲜体验了一下以后,就没有以后了。 […]