


在文档数字化的进程中,我们始终面临一个核心难题:如何让机器真正“理解”一份结构复杂的文档——无论是布满合并单元格的财务报表、公式交织的学术论文,还是版式迥异的商业合同。传统的 OCR 工具往往在此折戟,留下需要大量人工校对的数据残片,反而加重处理负担。
尽管目前行业在文档解析领域已有显著突破,从识别准确率到语义解构深度,模型能力仍在持续提升。可面对层出不穷的解析工具,如何判断谁才是“语义理解”的王者?谁又是“格式还原”的专家?我们亟需厘清不同工具的性能边界与应用场景,才能做出更贴合实际需求的技术选型。
为此,本篇专题测评 302.AI 将选取六款具有代表性的 AI 解析工具与模型:Mistral OCR, Markitdown, Jina Reader, MinerU,Doc2X 以及近期由小红书团队(Rednote HiLab)开源的 SOTA 级多语言文档解析大模型 Dots.OCR,从解析精度、复杂元素处理、输出结构化程度等多个关键维度开展对比评测,旨在拆解其真实能力、明确适用场景,为您的决策提供一份具有参考意义的选型指南。
I. 关于文档解析

1.1 什么是文档解析
很多人一听“文档解析”(Document Parsing)这词,下意识以为就是 OCR,光学字符识别,是不是把图识出来、转成文字就行了?
Too young too simple.
OCR 是你小时候抄黑板,文档解析是你写论文交报告。如果你正在做企业自动化、流程上云、数据归档这些活,那你最需要的不是识字机器,而是真正能“理解”文档的智能模式。
说白了,文档解析的本质,不是让机器看见文字,而是让它理解你想要的信息是什么。
OCR 解决的是“你这张图上写了什么”,而文档解析要回答的是“这张图的重点信息是什么,它们之间有什么结构逻辑”。它像是 AI 版的文秘,能自动从图像、PDF、拍照中提取出关键信息,并做成你能直接塞进数据库、系统、或者下一轮审批流程的结构化数据。
举个栗子:OCR 识别出“税额:¥5,231.00”,文档解析自动告诉你“这是第三栏的增值税小计”。 拆分出文本信息内的含义、标签和位置,就是解析干的事。
1.2 文档解析主要的应用场景
你可能以为文档解析只是个“高级 OCR”,但它其实是许多行业过自动化关口的核心环节。
以下是几个非常典型的应用场景:
- 发票管理:识别发票号码、金额、企业编码,自动入账;
- 合同审核:自动提取合同要素、截止日期、甲乙双方义务;
- 银行开户资料审查:针对扫描的业务表单,自动识别身份证、授权书内容;
- 医疗单据处理:结构化病历、诊断单、费用单据,便于医保报销自动化;
- 金融风控:提取并分析信用报告、收入证明、担保文件等。
这些看似琐碎的任务,一旦上升到数万/百万级的文档处理量,没有智能解析,不仅效率堪忧,错误更会堆成山。
1.3 文档解析的核心流程
Step 1:图像预处理(识别前的准备)
去噪点、裁剪边缘、矫正图像歪斜,让后面的 OCR “看得准”。这就像给镜头上油+调整焦距。
Step 2:OCR识别(眼睛)
把图像中每一个字符识别出来,形成无结构的文字流。到这一步,机器知道“你写了什么”。
Step 3:信息定位与结构分析(大脑)
这是文档解析的灵魂:通过 NLP 技术分析文本内容,识别实体、关系和语义信息,判断出哪些是标题、哪些是关键字段、甚至哪些是空值。
Step 4:字段抽取与标签化(摘要员)
提取所有必要信息 —— 比如“客户名称”、“发票金额”,然后打上业务标签,以 JSON、XML、表格等方式结构化输出。
Step 5:写入系统 / 进一步调度
数据被整理好,就能推送进业务系统、业务流程管理、归档系统中,进入“用得上的”阶段。
文档解析这事儿,十年前就有人尝试了,但谁也没想到它会在 AI+企业服务真正成熟之后变成产业拐点。就像 RPA(机器人流程自动化)要了解人类流程一样,文档解析就是 AI 开始理解信息、让数据“跑”起来的第一步。伴随着多模态大模型、IDP 平台、RAG 框架一起发展,它很可能是接下来数字化自动化大战中的关键词之一。
II. 实测文档解析模型&工具基本信息
| 模型名称 | 输入格式 | 输出格式 | 302.AI内的价格 |
| Mistral OCR | Markdown | $0.002/页 | |
| Dots.OCR | JPG、PNG、PDF | JSON、Text | $1/1M |
| MinerU | PDF、DOCX、PPTX、XLSX、TXT、网页URL | JSON、DOCX、Text、Markdown | $0.001/页 |
| Doc2X | PDF、DOCX、PPTX、XLSX、JPG、PNG、TIFF | DOCX、Text、Markdown | $0.005/页 |
| Jina Reader | 网页URL | Markdown | $0.05/1M |
| Markitdown | 除常见文档,图片,网页格式外,还支持wav,mp3等格式的音频文件 | Markdown | $0.01/1M |
评测使用工具:302.AI 的 API 超市→在线调试功能
III. 测评案例
- Jina Reader 适用于网页内容爬取,不支持处理扫描件等类型,复杂排版内容提取效果有限,因此只参与案例4测评。
- Markitdown 支持多种格式转md格式,但效果取决于文档质量和配置,只参与案例4测评。
- 以下附件以截图形式展示,实际测试均为PDF格式文件。
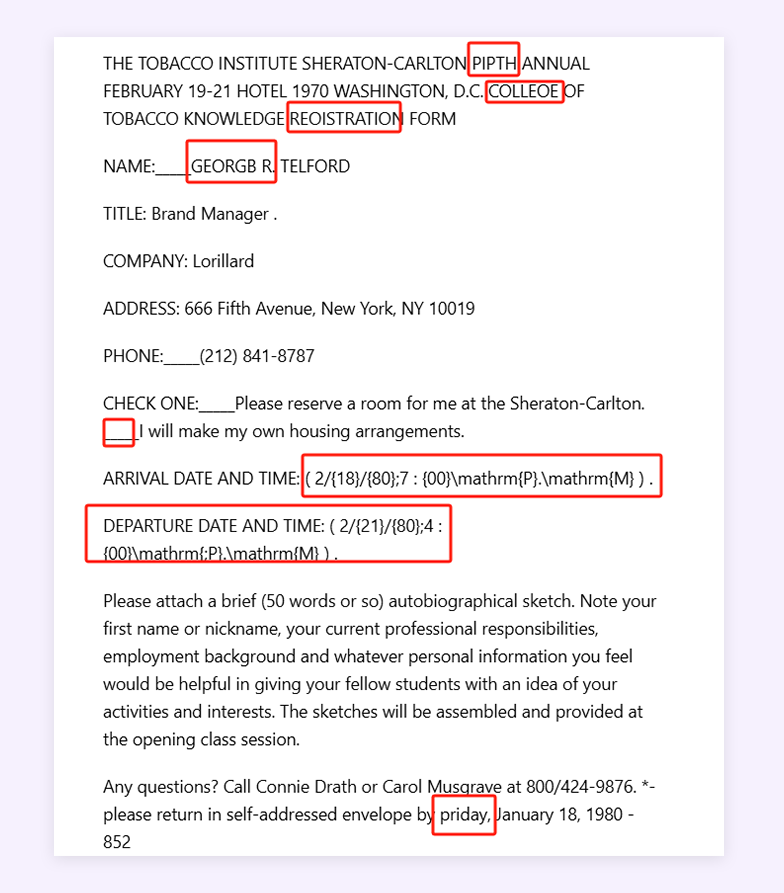
案例 1:模糊合同信息

Mistral OCR:一处识别错误;排版格式清晰易读。

Dots.OCR:信息准确;任务信息部分的分行格式,标题部分黑体可进一步优化。

MinerU:页头信息未识别录入,以图片形式保留;其余部分信息准确。

Doc2X:多处单词识别错误;时间格式存在问题。
案例 2:复杂公式

Mistral OCR:内容识别准确,解题步骤对应的分数未录入体现。

Dots.OCR:信息齐全,正确,排版格式合理。

MinerU:内容识别准确,解题步骤对应分数未录入体现。

Doc2X:得分/评阅人位置不准确;解题步骤对应分数未录入体现。

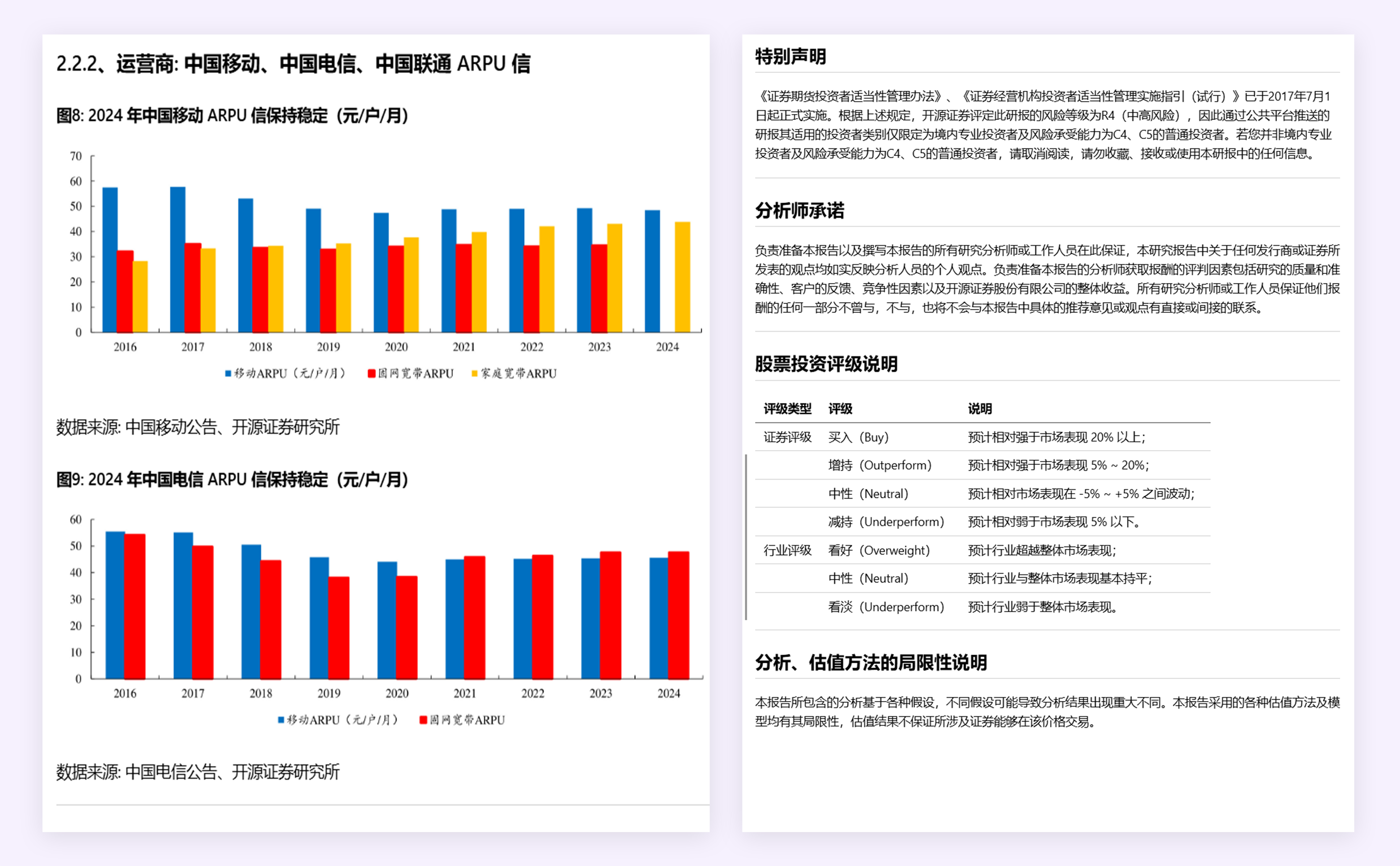
案例 3:表格/图表

Mistral OCR:信息自动提炼排版,提高了阅读效率,但存在图表和部分信息遗漏。
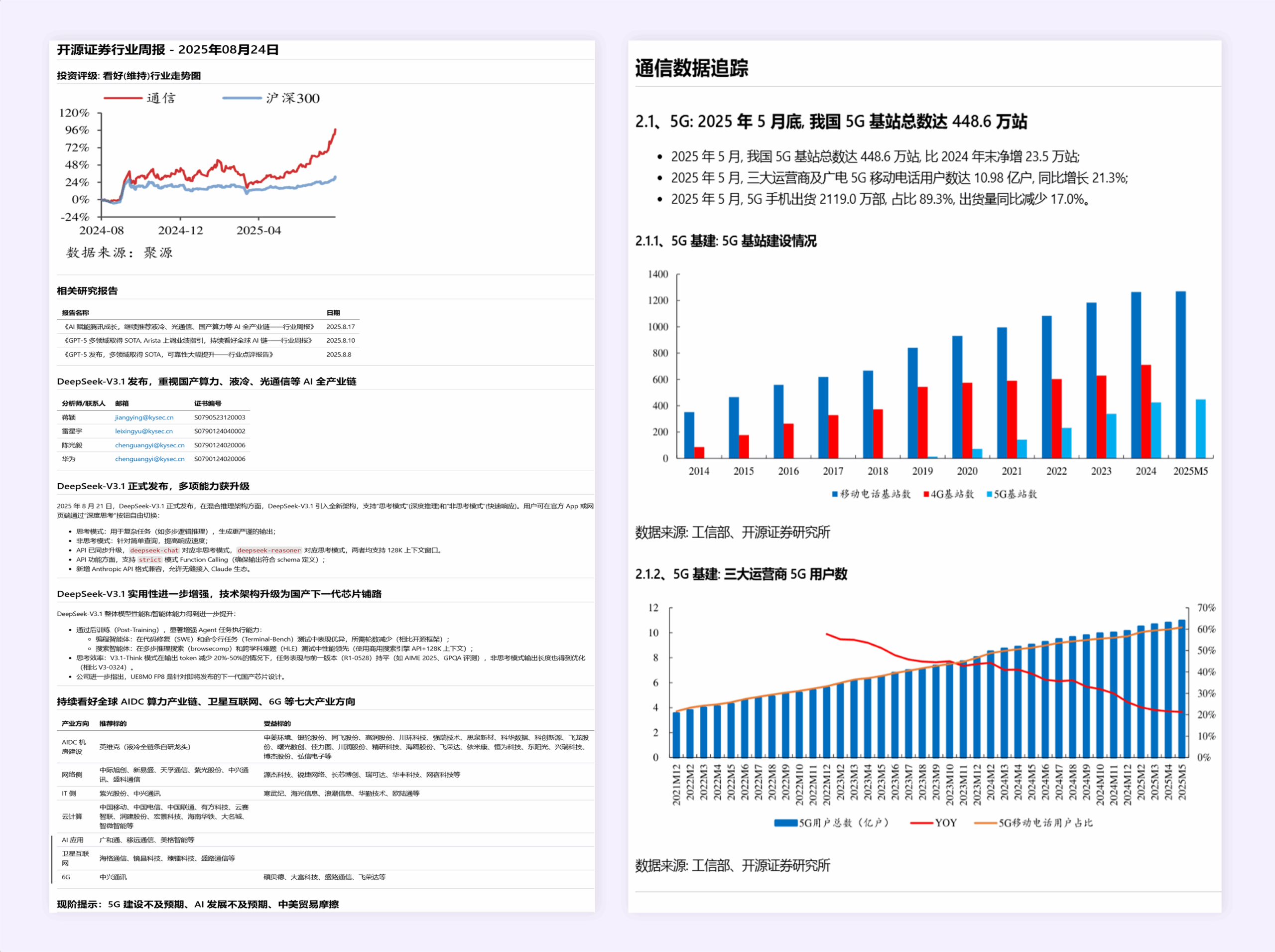
Dots.OCR:文本,图表信息准确;布局排版合理。
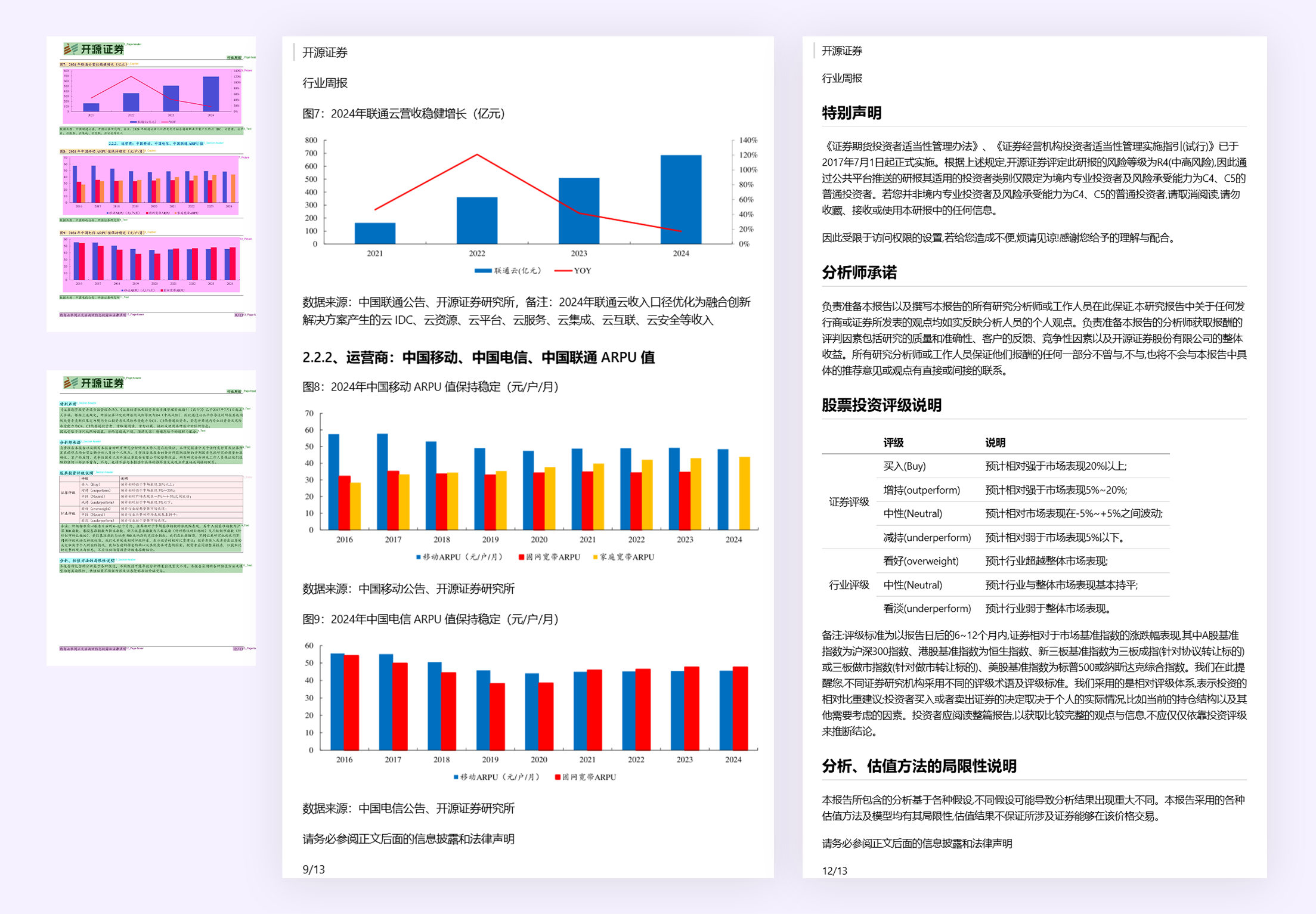
MinerU:文本,图表信息准确;布局排版合理。
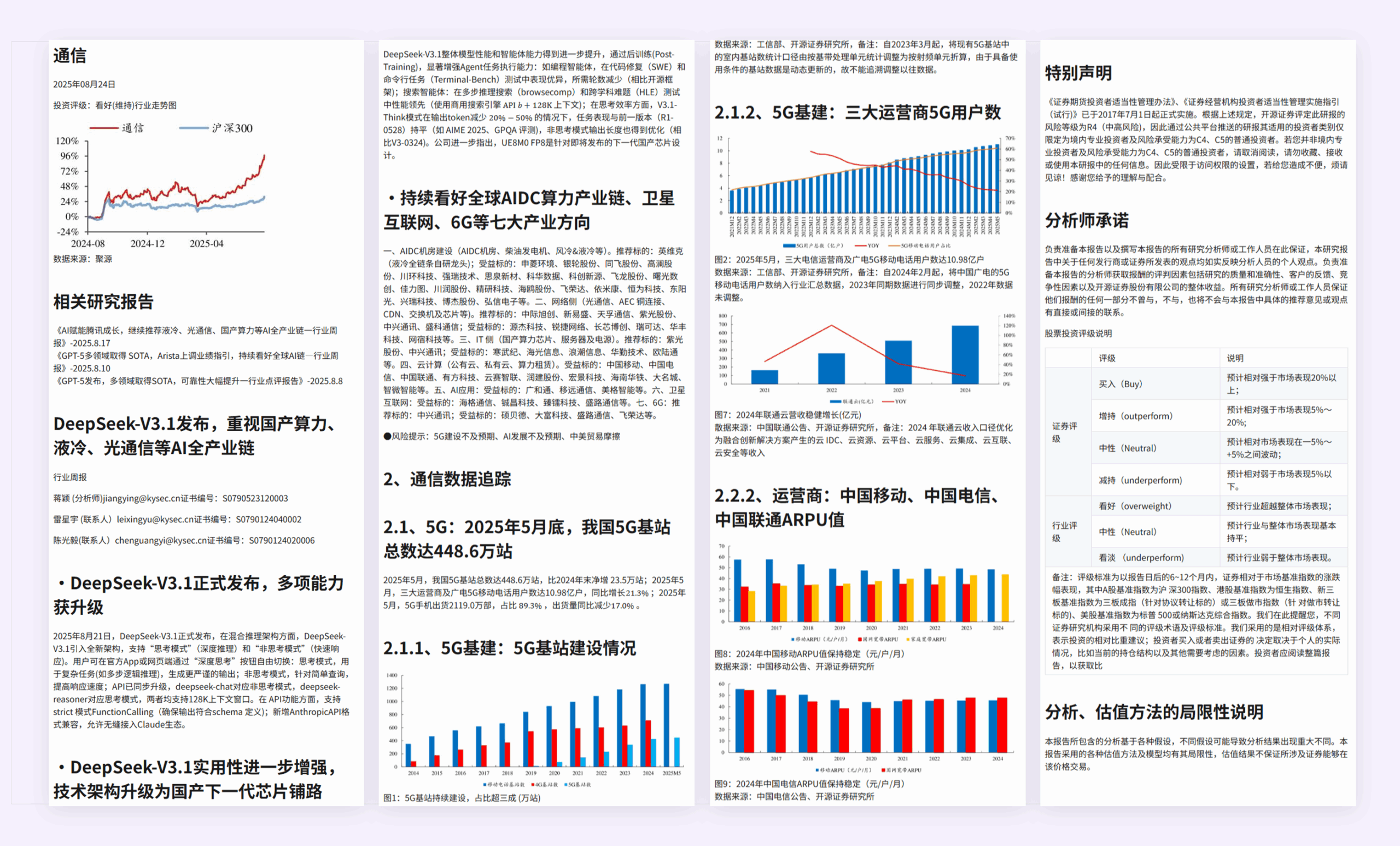
Doc2X:文本,图表信息准确;布局排版合理。

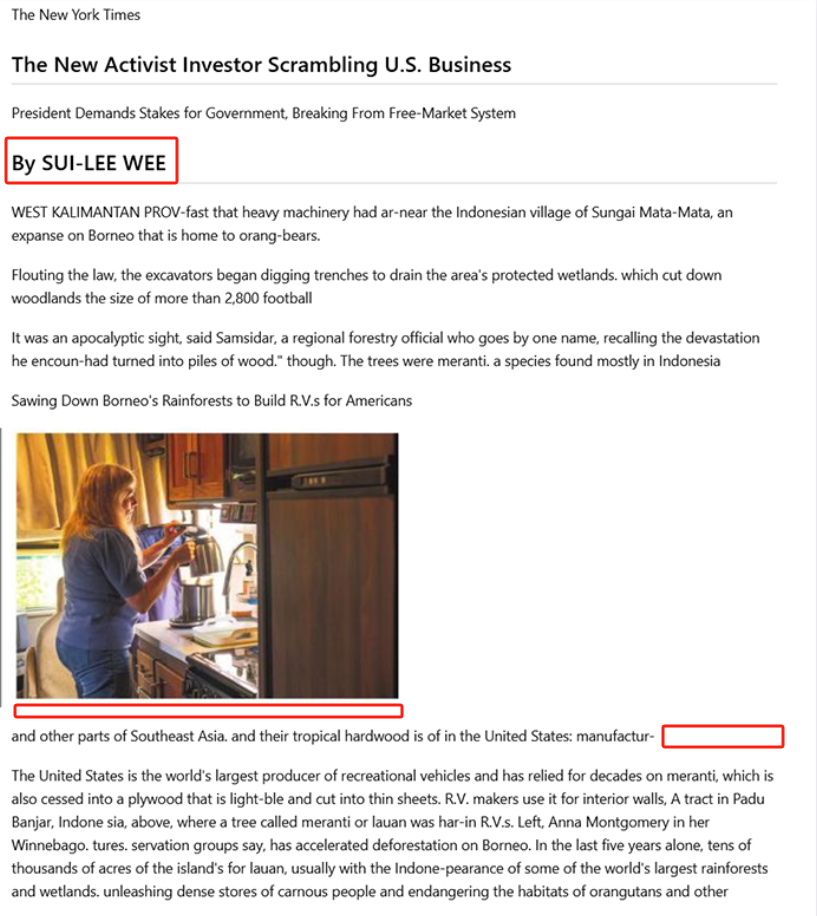
案例 4:图文阅读顺序+英语

Mistral OCR:只读取了部分信息,未能识别完整文档。

Dots.OCR:图片收录齐全;文章标题-内容-插图有不匹配问题;细节文本内容识别有出现错误;排版如文章标题有优化空间。

- 部分文字识别错误:


- 标题识别后仍以断句形式展示,并未整合成为一句完整标题:


MinerU:文字层级混乱,部分内容录入有缺漏或不符合阅读顺序。
- 标题与正文层级字号混乱:


Doc2X:主图未收录;文章与作者,插图出现对应错误;正文内容中有漏识别现象;插图对应的小字描述内容未进行识别。

- 《Sawing Down Borneo’s Rainforests to Build R.V.s for Americans》对应作者应为 SUI-LEE WEE:

Jina Reader:仅提取文字部分,文章录入顺序不符合正常阅读顺序,文本内容中出现乱码。
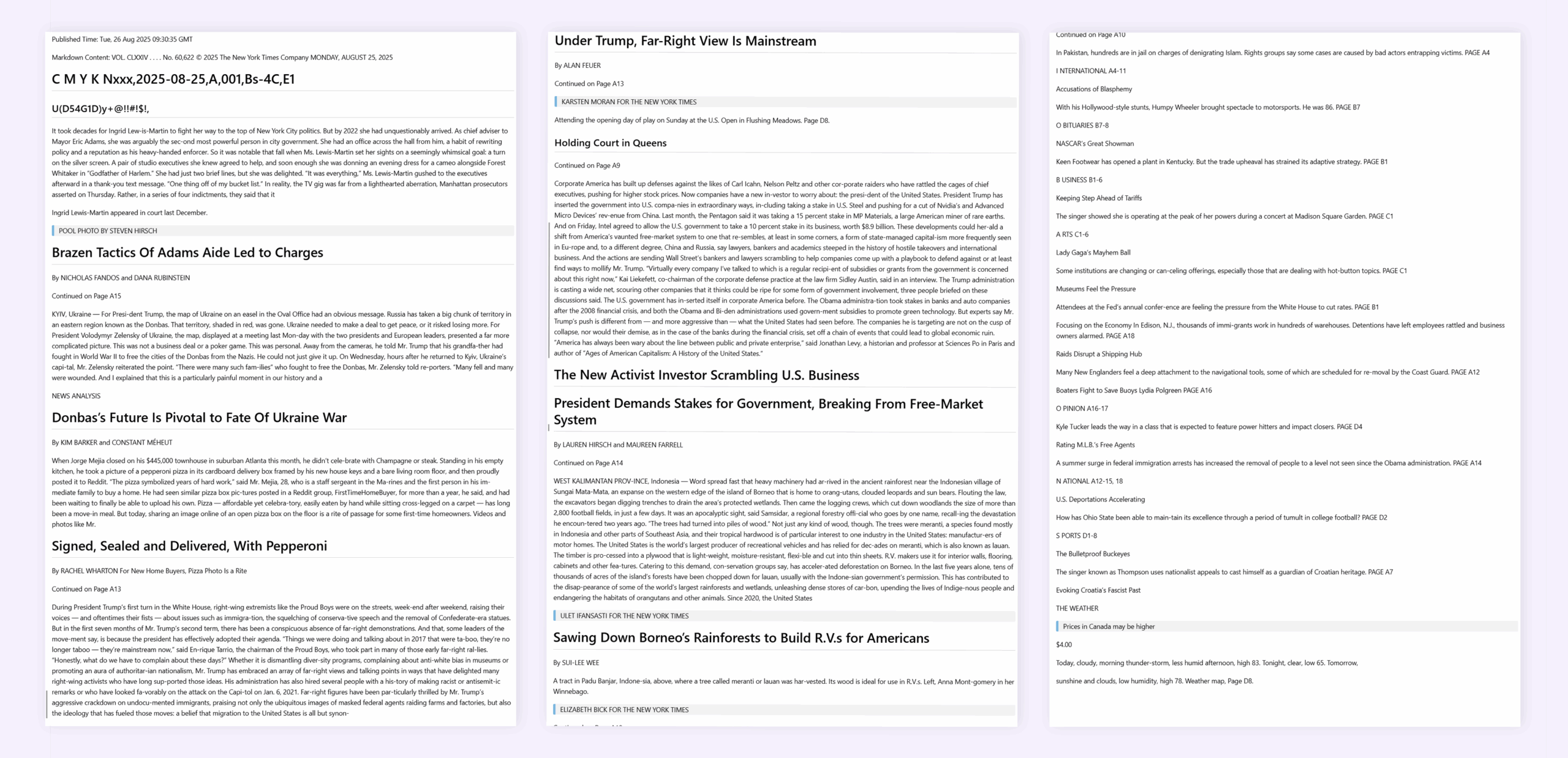
Markitdown:仅简单提取文字,未能区分板块导致不符合正常阅读顺序。

Ⅳ. 六款AI文档解析模型/工具实测结论
1. 实测结果整理:
| 模型名称 | 模糊信息 | 复杂公式 | 表格/图表 | 阅读顺序/内容完整度 |
| Mistral OCR | ★★★★ | ★★★★ | ★★★ | ★ |
| Dots.OCR | ★★★★ | ★★★★★ | ★★★★★ | ★★★ |
| MinerU | ★★ | ★★★★ | ★★★★★ | ★★★ |
| Doc2X | ★ | ★★★ | ★★★★★ | ★★★ |
| Jina Reader | N/A | N/A | N/A | ★ |
| Markitdown | N/A | N/A | N/A | ★ |
2. 实测结论
根据六款模型/工具的性能侧重和案例表现,可对其功能特点和适用场景做出如下总结:
| 模型名称 | 功能特点 | 适用场景 |
| Mistral OCR | 表格、公式、媒体等复杂元素处理,擅长多模态文档理解、关键信息提取与结构化输出特定复杂文档的处理精度仍有优化空间 | 企业级文档数字化(金融、法律合同、审查文件)科研论文与学术文献处理多语言国际业务文档处理 |
| Dots.OCR | 统一架构处理布局检测、文本、表格、公式识别,多语言支持(100种,含低资源语言),强阅读顺序理解轻量化,排版优质,准确率较高 | 多语言混合文档、扫描件、学术文档快速部署和运行的需求场景 |
| MinerU | 支持多模态文档解析,输出保持相对完整的原始格式,语意连贯性强复杂表格行/列识别、小语种OCR字符识别精度欠缺 | 学术材料、文献数据提取;企业文档管理(合同与技术文档数字化)、教材与试卷数字化为LLM提供高质量训练数据 |
| Doc2X | 快速提取(500页/分钟),高精度图表识别,跨页表格智能合并更专注于PDF/图片转Word,通用性相较其他多模态模型略有侧重 | 教育科技(教材、讲义、试卷数字化)知识库搭建(与FastGPT等平台集成)与科研文献处理 |
| Jina Reader | 专精网页内容提取,去除广告与干扰信息 | 网页内容抓取和净化、SEO优化、知识库提取为LLM准备网页训练数据 |
| Markitdown | 支持多种文件格式,主攻内容转md格式输出侧重语义结构在md中的保留,不适用于高保真文档转换, | 企业知识库与RAG系统构建内容聚合与摘要(音视频要点提炼) |
综合以上模型/工具在不同类型文档中的实测表现来看,当前AI文档解析工具的技术形态,已经从“有没有”进入“好不好”的阶段,呈现出明显的多元化与精细化分工的趋势。随着模型架构、理解机制以及后处理策略的不断优化,各家工具开始围绕不同任务场景各展所长,没有哪个能一把梭哈全场,也还没有各方面都达到完美的“全能王者”。换句话说:并不是工具不够强,而是复杂场景目前还没法靠“一招鲜走天下”。
造成这种差异的本质,一方面源于不同模型的设计逻辑和训练重点——有的更擅长结构文档的语义抽取,有的专攻表格识别或图文混排的还原能力;另一方面,也取决于用户对部署路径(如云端智能调用 vs. 本地私有化适配)和成本策略的取舍。
进一步看,目前各产品之间的分水岭多集中在三个关键维度:
对复杂元素的处理能力:特别是图表、跨页表格、公式、批注等非标准结构内容,能识别准确是基础,能还原得格式排版合理,易读是更高要求;
输出的结构化程度:是否支持按字段清洗、标签打点、支持JSON/XML等灵活嵌套输出,决定了解析结果能不能无缝衔接到下游流程;
精度的稳定性与泛化能力:用官方的demo能跑得飞起,但一换文档样式就抓瞎,那很可能暴露出训练数据量的不足。
此外,性价比与部署方式也是绕不过去的实际考量。有的模型按量计费,适合轻量化场景;有的支持私有部署,放在银行、律所、政务等高敏单位安全等级上显得更稳。
所以我们针对选型的建议是:别急着找“全能,最好”。在文档解析这条技术密集型赛道,目前最可操作的策略是明确刚需场景,通过测试反馈判断候选工具在关键指标上的表现,尤其是对结构复杂文档的解构还原能力、输出规整度与真实可用度。
V. 如何在 302.AI 上使用
302.AI 提供按需付费无订阅的服务模式,用户可以根据自身业务需求灵活选择使用。
获取模型API
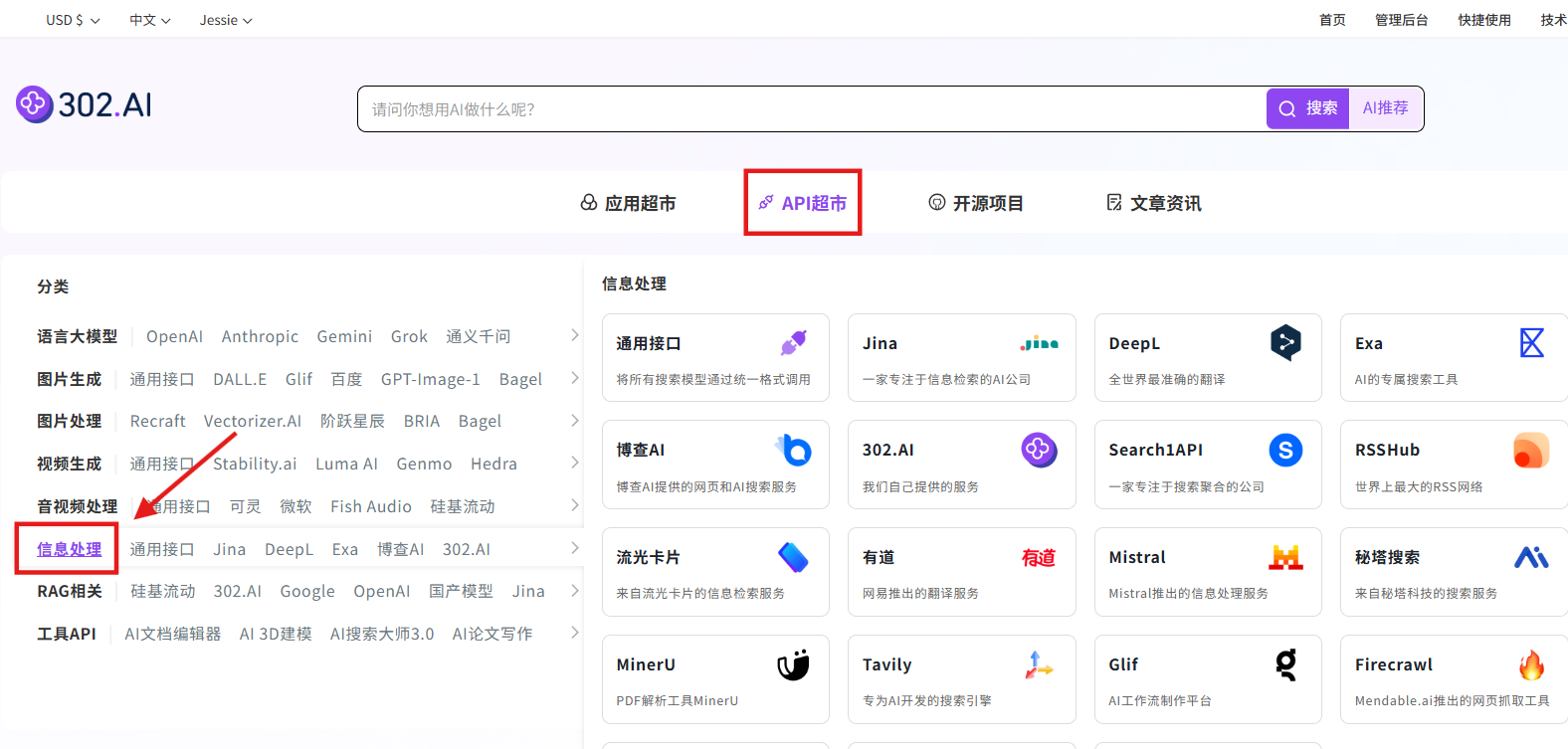
相关文档:API→API超市→信息处理→选择模型→查看文档;
可选模型:Mistral,Markitdown,Jina Reader,Dots.OCR,MinerU,Doc2X
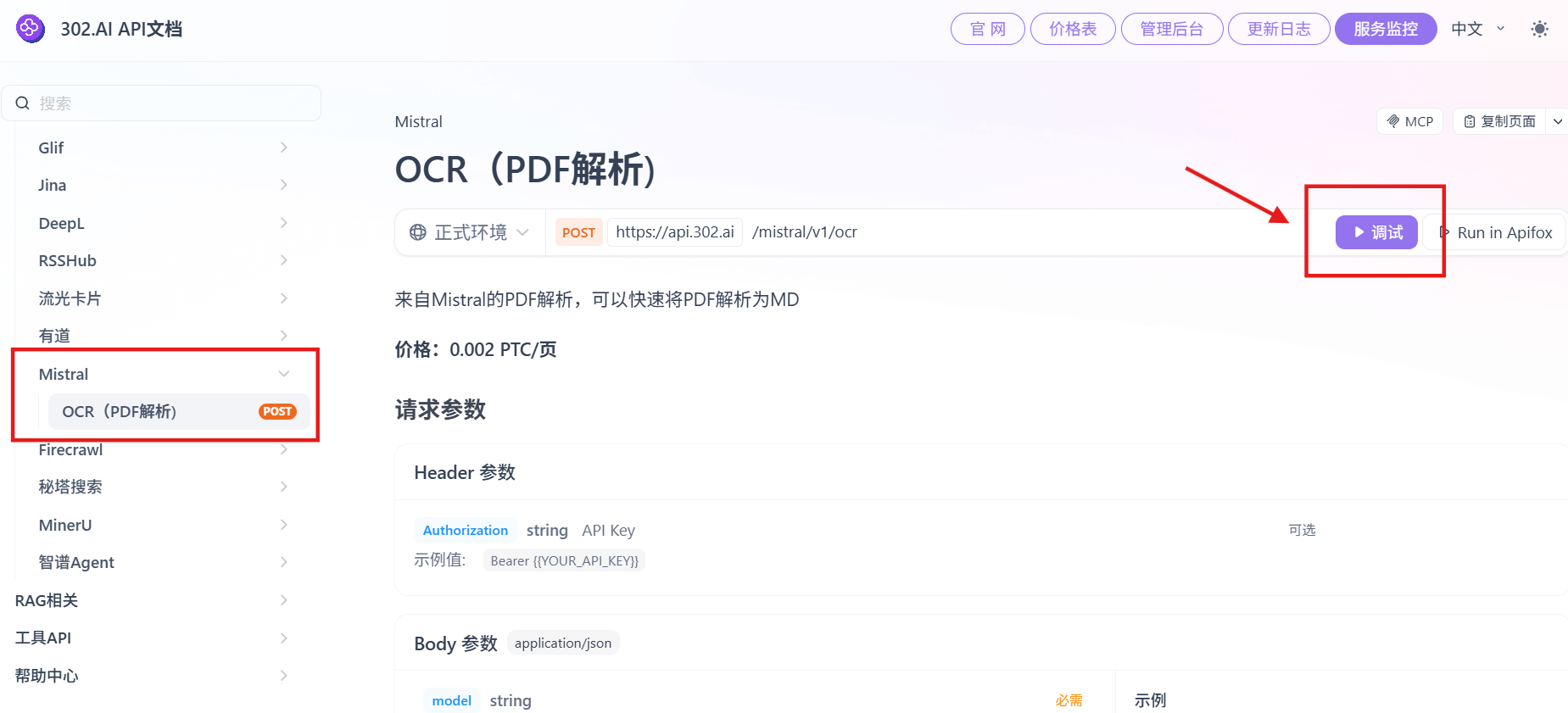
点击【调试】在线调用 API(以 Mistral OCR 为例)
想体验 AI 文档解析模型/工具?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
