
距 Claude Sonnet 4 问鼎业界编程翘楚五个月后,Anthropic 再度官宣发布其 Claude 家族轻量级新作——Claude Haiku 4.5,并宣称该模型在编码性能上已媲美 Sonnet 4,而价格仅为后者的三分之一,速度更是提升一倍以上,堪称一款极具竞争力的 Sonnet 4 平替。
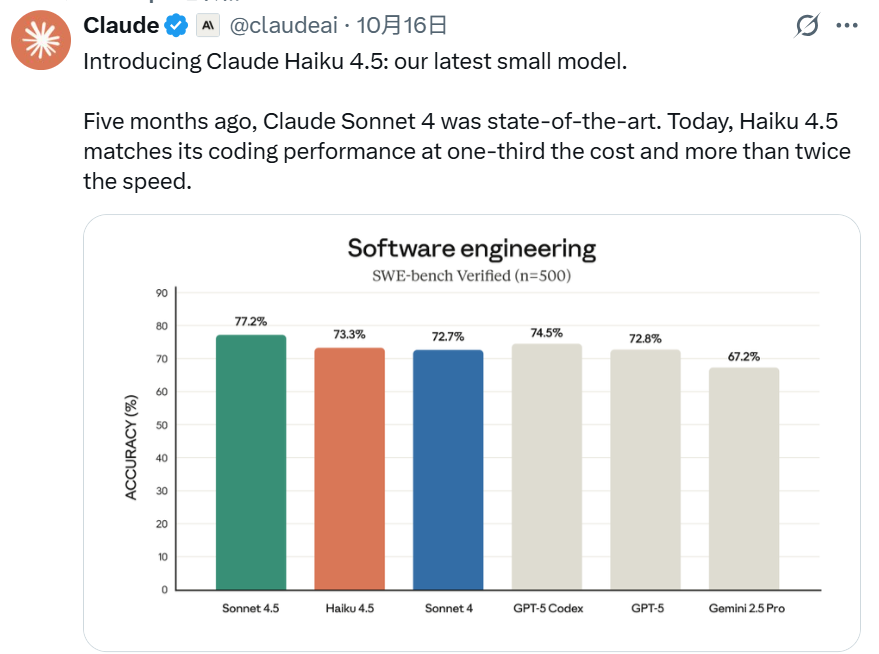

Anthropic 官方抛出的数据也直观地力证了 Haiku 4.5 的性能实力。在用于衡量 AI 编码能力的测试集 SWE-bench Verified 上,Haiku 4.5 就取得了 73.3% 的成绩,甚至小幅领先了 Sonnet 4。而在电脑操控、多智能体协作与代理编程等场景中,其表现也与 Sonnet 4 基本持平。同时,模型保持 200K token 上下文窗口,单次响应可生成多达 64K token,显现出轻量模型同样具备旗舰级的编程能力。
目前,Haiku 4.5 已全球上线,而其核心优势也是旗帜鲜明:定价为输入每百万 token 1 美元、输出每百万 token 5 美元,真正实现更低价格、更快速度,有望成为 Claude 产品线的新一代性价比天花板。
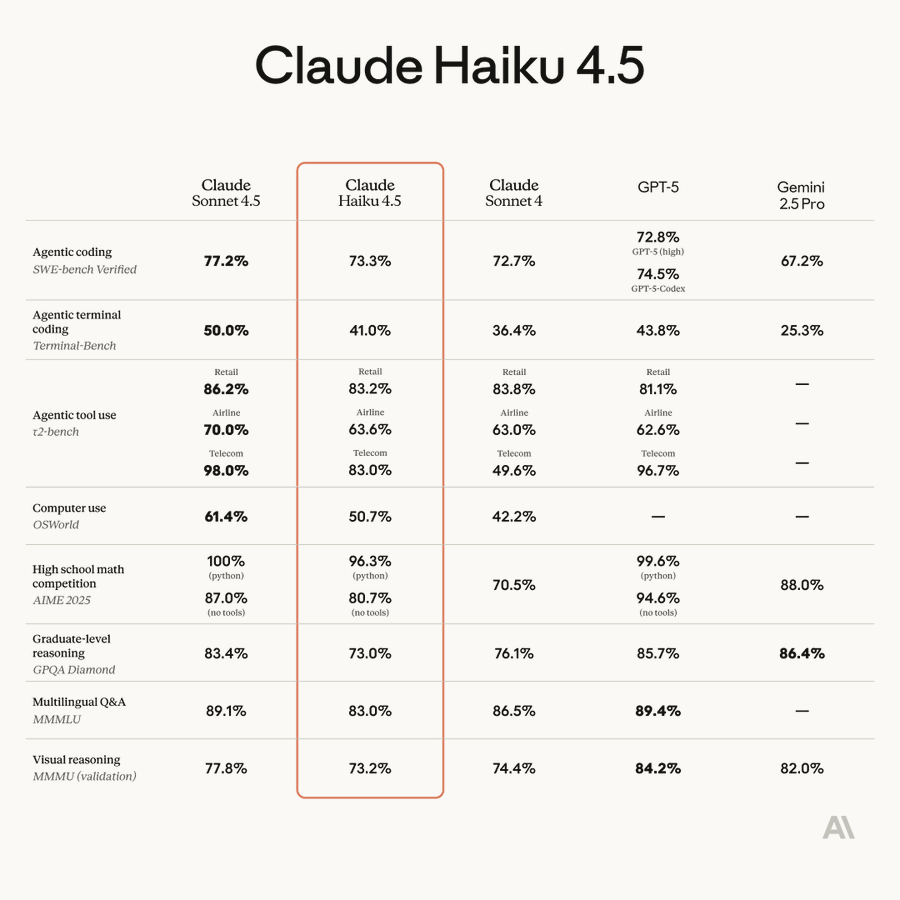
302.AI 也已第一时间接入了 Claude Haiku 4.5 模型 API,本期评测将使用 Gemini 2.5 Pro 及 GPT-5 这两款顶尖模型,与 Haiku 4.5 展开多维度实测,清晰呈现其性能定位与竞争优势。
I. 实测模型基本信息
(1)各实测模型在 302.AI 的价格:
| 参与对比测评的模型 | 说明 | 输入价格 | 输出价格 | 上下文长度 |
| claude-haiku-4-5 | $1/ 1M tokens | $5/ 1M tokens | 200000 | |
| gemini-2.5-pro | 输入/输出 ≤200K tokens | $1.25/ 1M tokens | $10/ 1M tokens | 1000000 |
| 输入/输出 >200K tokens | $2.5/ 1M tokens | $15/ 1M tokens | ||
| gpt-5 | $1.25/ 1M tokens | $10/ 1M tokens | 400000 |
(2)测评目的:
本评测侧重模型对逻辑,数学,编程,人类直觉,多模态等问题的测试,非专业前沿领域的权威测试。旨在观察对比模型的进化趋势,提供选型参考。
(3)测评方法:
本次测评使用302.AI收录的题库进行独立测试。3款模型分别就逻辑与数学(共10题),人类直觉(共7题),编程模拟(共6题),以及多模态推理(共20题)进行案例测试,对应记分规则取最终结果,下文选取代表性案例进行展示。
💡记分规则:
- 逻辑与数学、人类直觉、编程模拟类测试按满分10分记分,设定对应扣分标准,最终取每轮得分的平均值。
- 多模态类测试只记录输出答案对错,最终统计正确率。
(4)测评工具:
302.AI 的API超市→在线使用
(5)测评结果:
- 逻辑与数学测试结果(总题数:10)
| 测评对象 | 平均分 |
| claude-haiku-4-5 | 9.70 |
| gemini-2.5-pro | 9.20 |
| gpt-5 | 9.10 |
- 人类直觉结果(总题数:7)
| 测评对象 | 平均分 |
| claude-haiku-4-5 | 9.86 |
| gemini-2.5-pro | 9.57 |
| gpt-5 | 9.00 |
- 编程模拟测试结果(总题数:6)
| 测评对象 | 平均分 |
| claude-haiku-4-5 | 9.83 |
| gemini-2.5-pro | 8.67 |
| gpt-5 | 7.67 |
- 多模态能力测试结果(总题数:20)
| 测评对象 | 答对题数 | 正确率 |
| claude-haiku-4-5 | 14 | 70% |
| gemini-2.5-pro | 17 | 85% |
| gpt-5 | 15 | 75% |
- 测评结果总览:
| 测评对象 | 逻辑与数学 | 人类直觉 | 编程模拟 | 多模态(按正确率) | 加权总分 |
| claude-haiku-4-5 | 9.70 | 9.86 | 9.83 | 70% | 36.39 |
| gemini-2.5-pro | 9.20 | 9.57 | 8.67 | 85% | 35.94 |
| gpt-5 | 9.10 | 9.00 | 7.67 | 75% | 33.27 |
Ⅱ. 实测案例
案例 1:逻辑与数学
Claude Haiku 4.5 在逻辑推理与数学解题类测试中表现出较佳稳定性,擅长多步推导,步骤完整,结构严密。虽然整体输出内容相对冗长,但逻辑推理环环紧扣,保证绝对严谨性。
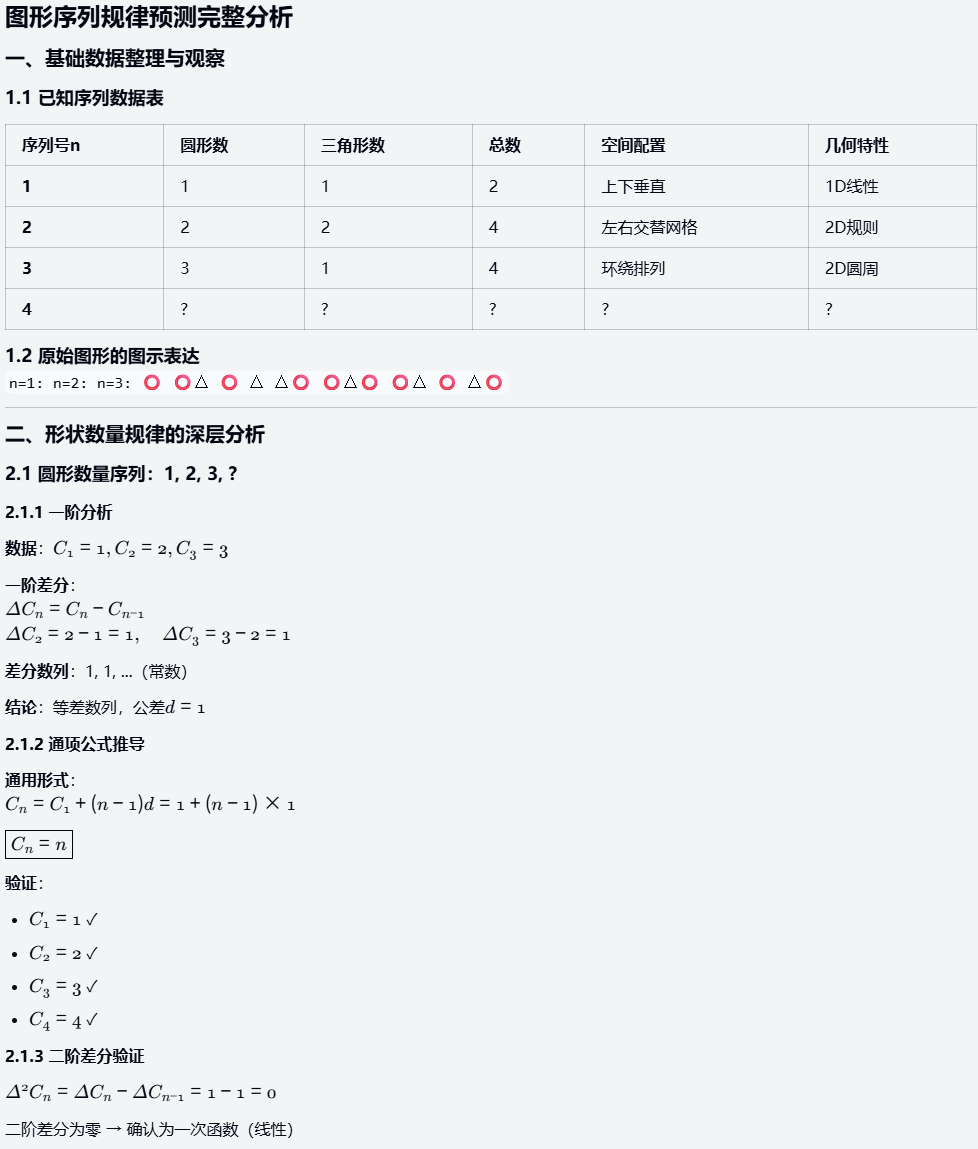
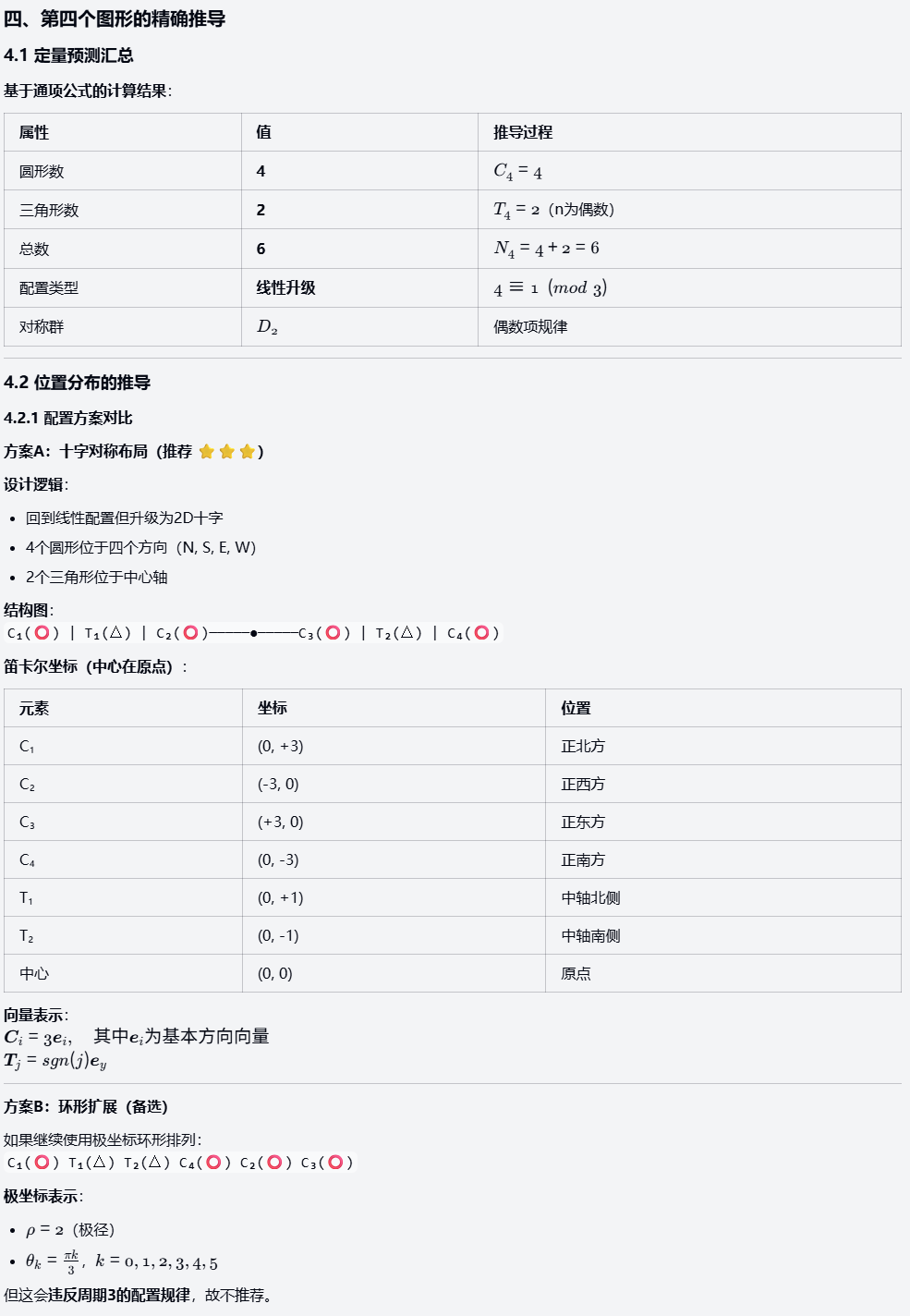
案例:观察以下图形序列:第一个图形有1个圆形在上方和1个三角形在下方;第二个有2个圆形在左侧和2个三角形在右侧,位置交替;第三个有3个圆形环绕1个三角形。请预测第四个图形的精确组成,包括形状数量、位置分布,并用数学公式(如n阶序列)证明规律(必须解释递增模式和位置变换逻辑)。
Claude Haiku 4.5:
对比其他两组模型,Haiku 4.5 擅用列表和数学公式举证,输出了完整步骤、多角度分析和位置变换逻辑(配置周期性、对称性等)。
Gemini 2.5 Pro:
Gemini 的在此题的推导有步骤和解释,包括位置变换逻辑,规律基本正确,但位置预测仅部分正确,并不精确。
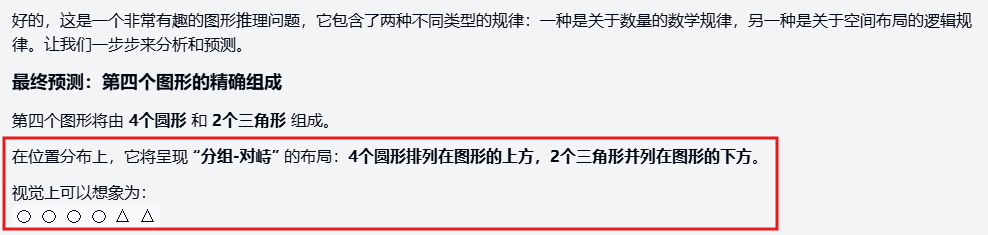
推导有步骤和解释,包括规则列出和逐验证,但规律错误。
- 数量错误(预测4个圆形和4个三角形,但标准为4个圆形和2个三角形)
- 位置错误(预测分侧布局,左侧三角形、右侧圆形,但标准为圆形在四角、三角形在中心交叠)。

案例 2:人类直觉测试
Claude Haiku 4.5 在包括旅游规划、笔记整理、健康管理、投资决策等一系列人类直觉测试中输出质量优于其他两组模型,表现在多角度全方位的具体分析,以及更加系统化和结构化的输出。
案例:职业规划:模糊职业转向:当前工作“稳定但乏味”,兴趣模糊为“创意相关,如写作或设计”,预算“有限”,时间“半年准备”。请步步设计转向计划:技能评估、学习路径、求职策略,并解释这个计划如何匹配个人成长,不允许忽略市场风险如经济 downturn。
Claude Haiku 4.5:
提供非常详细的步骤,包括诊断、路径选择、学习计划、求职策略等,步骤完整。有专门的风险评估部分,包括经济下行、AI替代等风险,加分点在于兴趣量化深,使用自我诊断问卷和表格进行显式量化。
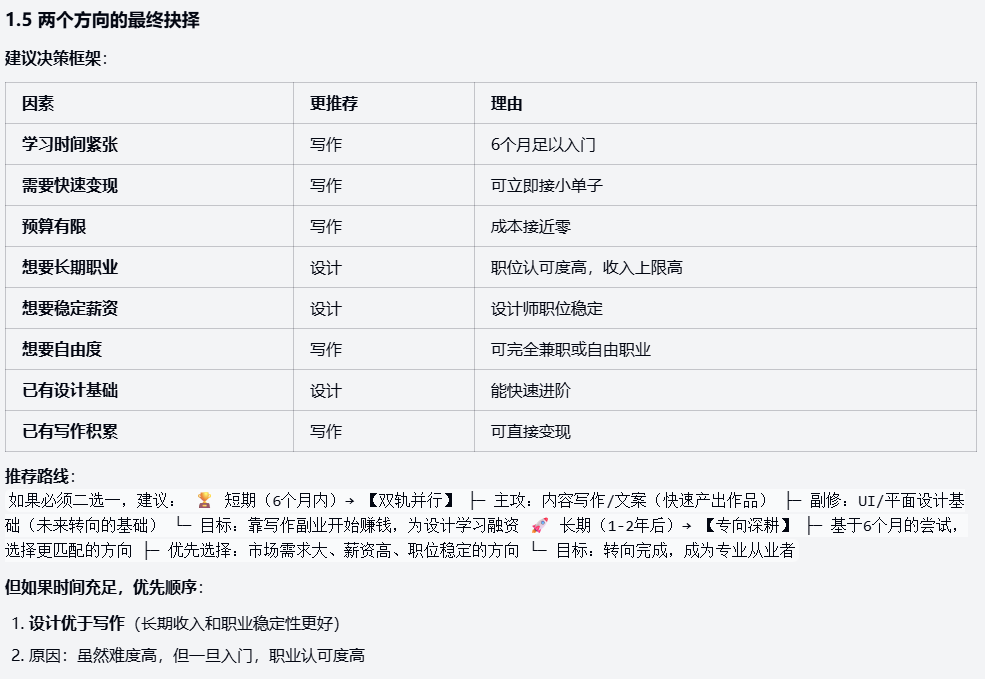

Gemini 2.5 Pro:
输出了清晰的分阶段计划,但是在风险分析中仅提到经济下行、AI替代,未提及家庭因素或中年转向。

GPT-5:
提供详细步骤,包括技能评估、学习路径、作品集构建、求职策略等。然而兴趣量化较浅,仅通过“双路径小实验”测试,未使用问卷或矩阵进行深度量化。

案例 3:多模态视觉推理
Claude Haiku 4.5 在细粒度感知、逻辑推理、科学与数学等多项多模态视觉推理任务中表现逊于其他两组模型,在抽取题型的实测任务中正确率仅达 70%,尤其在看图推理类实例中表现不佳。
案例:
What is the referee doing in the image? A: Blowing the whistle B: Talking to the players C: Watching the match from the sideline D: Scoring the goal 正确答案:C

Claude Haiku 4.5:
模型只识别了画面中的主体人物(身着黑西装男子),并根据其肢体动作误选了B。实际上画面左侧手持黄旗的人物才是裁判。
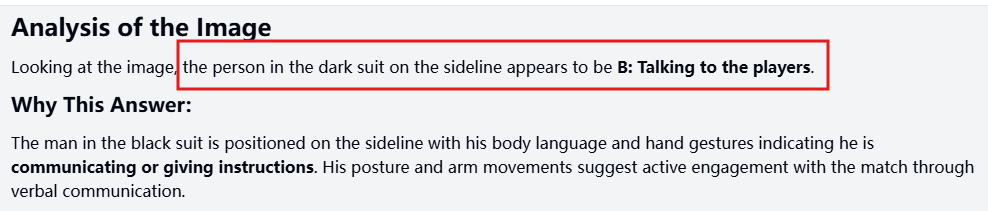
Gemini 2.5 Pro:识别正确。

GPT-5:识别正确。

不过,Haiku 4.5 在细粒度感知题型中达到了全部正确,例如以下要求识别建筑遮阳棚颜色的实测中,只有 Haiku 4.5 正确将其识别为黑色,另外两组模型均错误识别为棕色。

Claude Haiku 4.5:
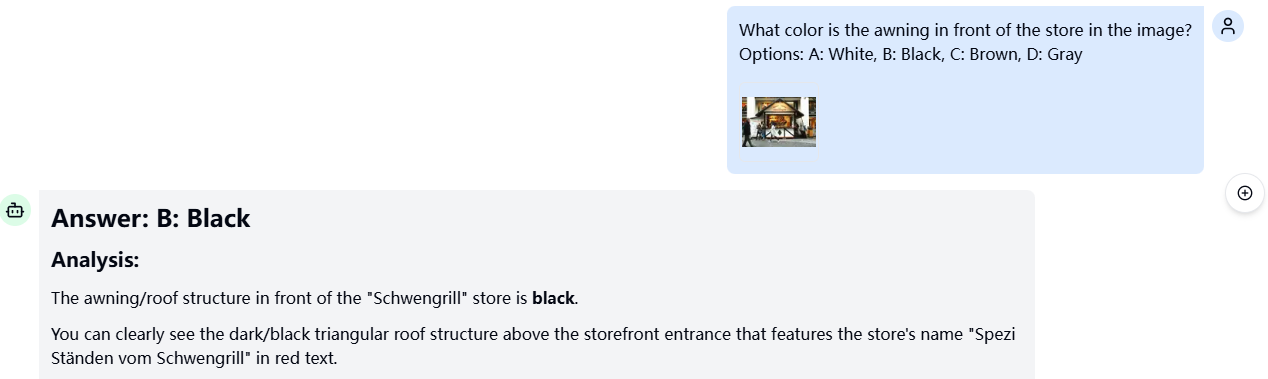
Gemini 2.5 Pro/GPT-5:


案例 4:编程模拟
在编程与模拟类任务中,Haiku 4.5 以较高的输出水准和优秀的稳定性领先于其他两组模型,见长于对任务的多角度分析、代码实现完整度以及出色的理论解释。
案例:
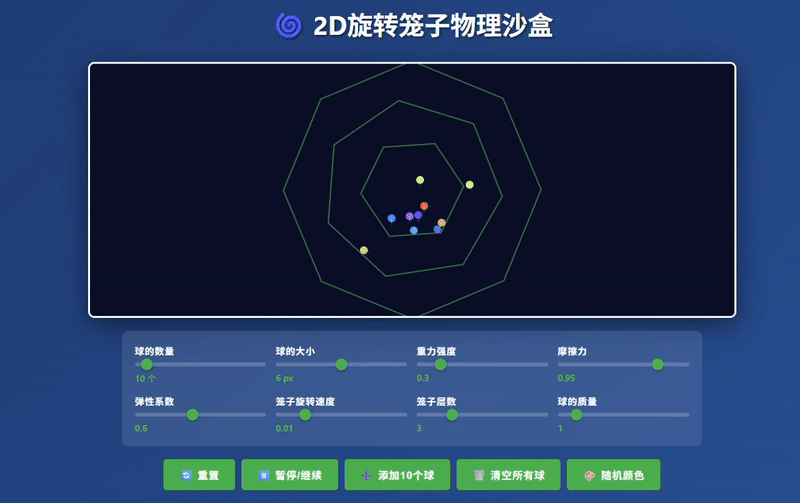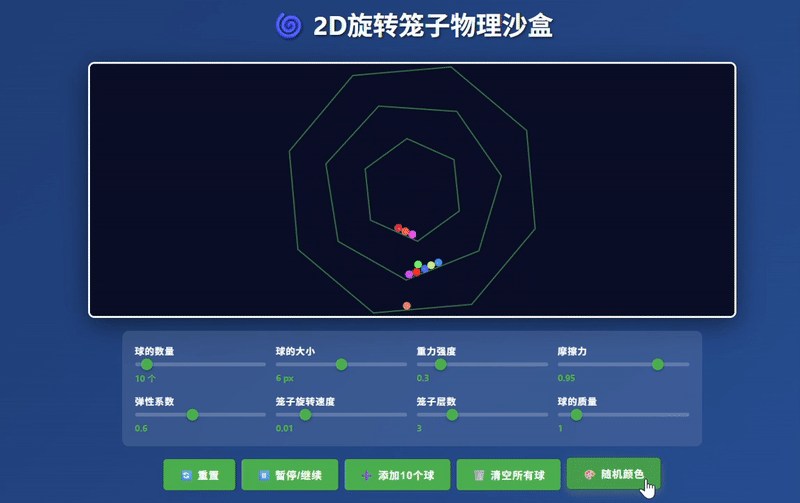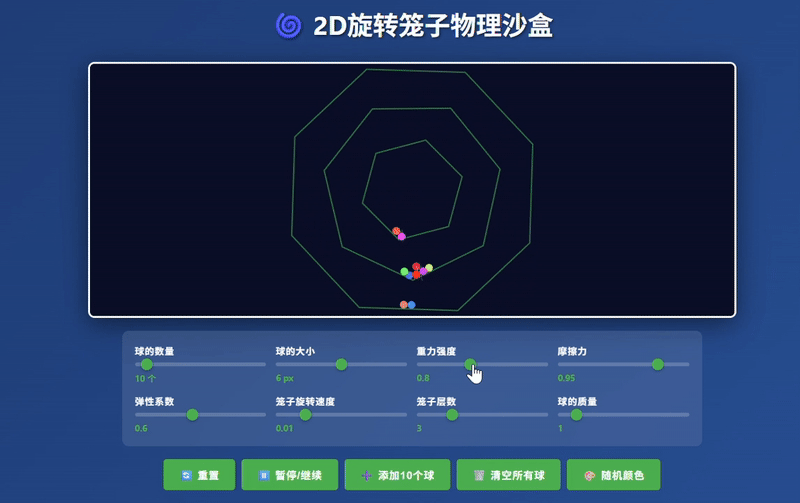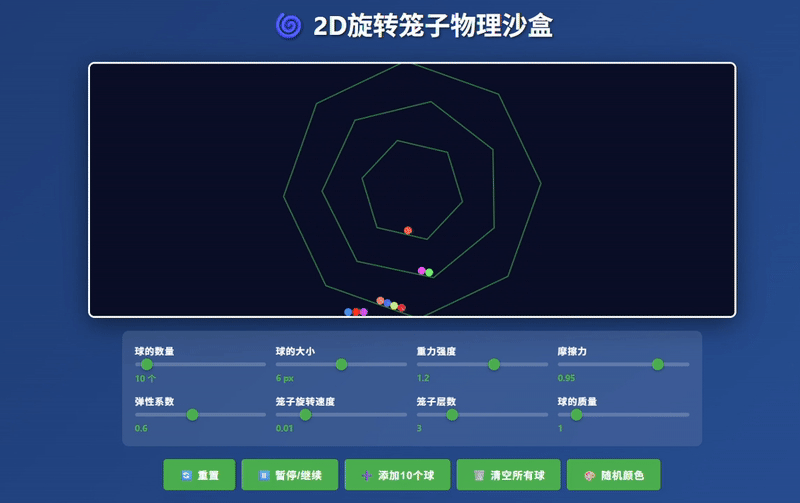
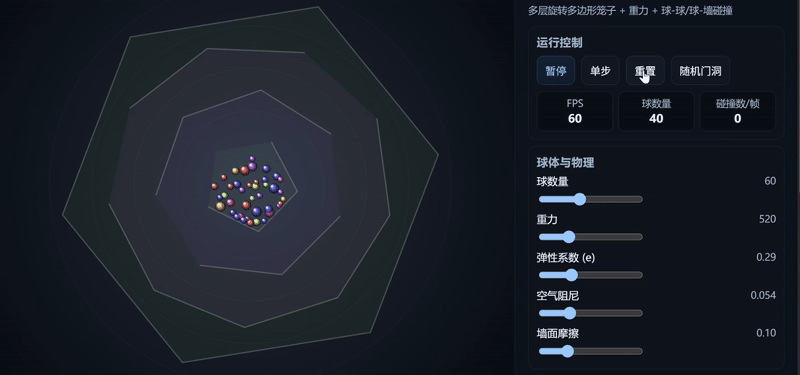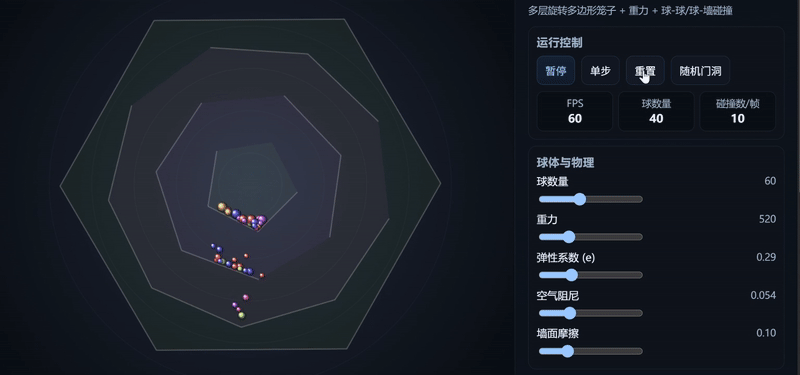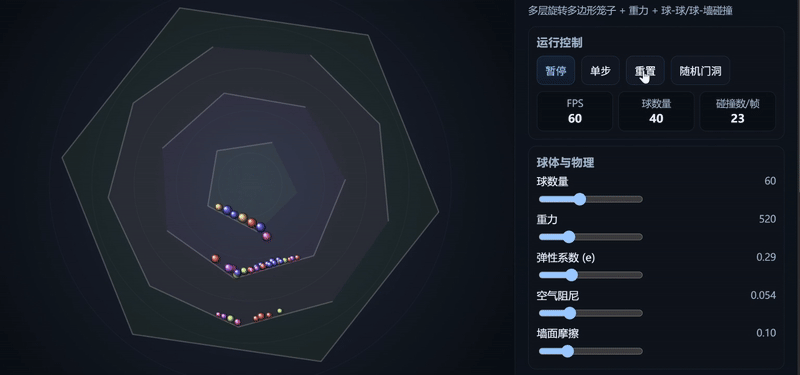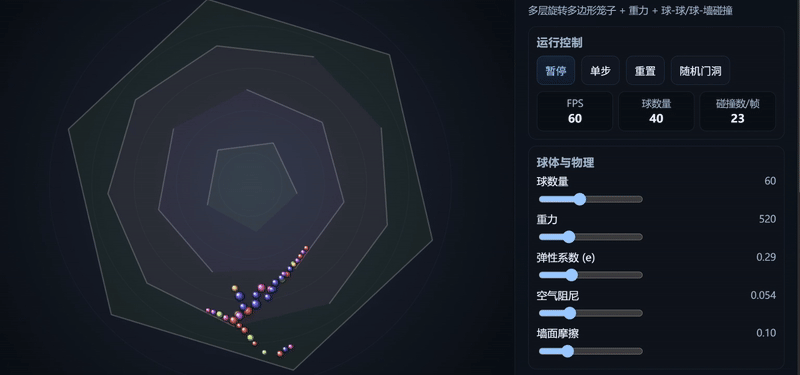
想象一个二维世界,像是一个复杂的万花筒。在这个世界里,有多个层层嵌套的多边形“笼子”。这些笼子以不同的速度和方向持续旋转。在最内层的笼子里,有许多小球。这些小球受到重力、与笼子壁的碰撞以及彼此之间的碰撞影响,在旋转的迷宫中穿行。
你的任务是创建这个二维物理沙盒的模拟器,最终在一个HTML文件内交付所有代码。
Claude Haiku 4.5:生成了相对完整的模拟器界面,小球运动符合物理规律,控制响应效果较佳。
Gemini 2.5 Pro:运动轨迹平滑,整体视觉更直观,但部分小球运动不符合物理规律,且未额外生成模拟器操作台。

GPT-5:生成了相对完整的模拟器界面,小球运动符合物理规律,但整体UI比例略失调,且小球大小不一,视觉效果不够直观。
III. Claude Haiku 4.5 实测结论

综合多维度的性能实测与深入对比,Claude Haiku 4.5 展现出其作为“轻量级旗舰”也算是打出了旗帜鲜明的特征:在编码、逻辑推理与复杂任务规划等核心领域表现卓越,成本与速度优势显著,确实是可作为其前代超强模型 Sonnet 4 的平替选择。其能力图谱十分清晰:
- 编码与编程模拟能力稳居第一梯队:在 SWE-bench 测试集上持平 Sonnet 4 的成绩在本次实测中得到印证。无论是处理复杂的物理沙盒模拟,还是进行严谨的代码生成,Haiku 4.5 均能提供步骤完整、逻辑严密且实现度高的解决方案,其稳定性与输出完整性甚至优于 Gemini 2.5 Pro 与 GPT-5,无疑是延续了 Claude 系列模型在编程领域的霸主地位。
- 逻辑推理与复杂任务处理能力突出:在逻辑数学与人类直觉测试中,Haiku 4.5 凭借其多角度、系统化的分析框架,以及环环相扣的严密推导,取得了实测案例中的均值最高分。无论是解决图形序列的数学规律,还是制定详尽的职业转型计划,它都能提供结构清晰、考量周全的答案,尤其在风险评估和量化分析方面的全方位输出,表现出超越同级模型的深度。
- 多模态能力呈现“喜忧参半”的局面:这是 Haiku 4.5 目前在实测中出现的最主要短板。在需要整体场景理解的视觉推理任务中,其识别准确率仅为 70%,确实落后于 Gemini 2.5 Pro 和 GPT-5。然而,在细粒度感知(如颜色识别)这类任务上,它又展现出了独特的优势,说明其视觉能力在某些特定维度上依然可圈可点。
- 性价比构成其最核心的竞争优势:在核心性能媲美甚至部分小幅超越 Sonnet 4 的同时,其输入/输出价格仅为后者的三分之一,速度还提升一倍以上。与同为顶级模型的 Gemini 2.5 Pro 和 GPT-5 相比,Haiku 4.5 在价格上同样具备明显优势,真正做到了“更低的成本,毫不妥协的性能”。
总而言之, Claude Haiku 4.5 精准地锚定了“高性能、低成本”的定位。它并非在所有领域都全面碾压对手,但在其擅长的逻辑、编程与结构化任务上,提供了当前 Claude 系列模型中无出其右的性价比。对于寻求旗舰级编程能力同时又高度关注预算与效率的开发者与企业用户而言,Claude Haiku 4.5 无疑是一款极具吸引力和竞争力的战略级选择。其出现也可以证明,大模型的高性能与普惠性,可以并行不悖,且势必成为未来主流。
Ⅳ. 如何在 302.AI 上使用
1. 聊天机器人中使用
步骤指引 :应用超市→机器人→聊天机器人→立即体验
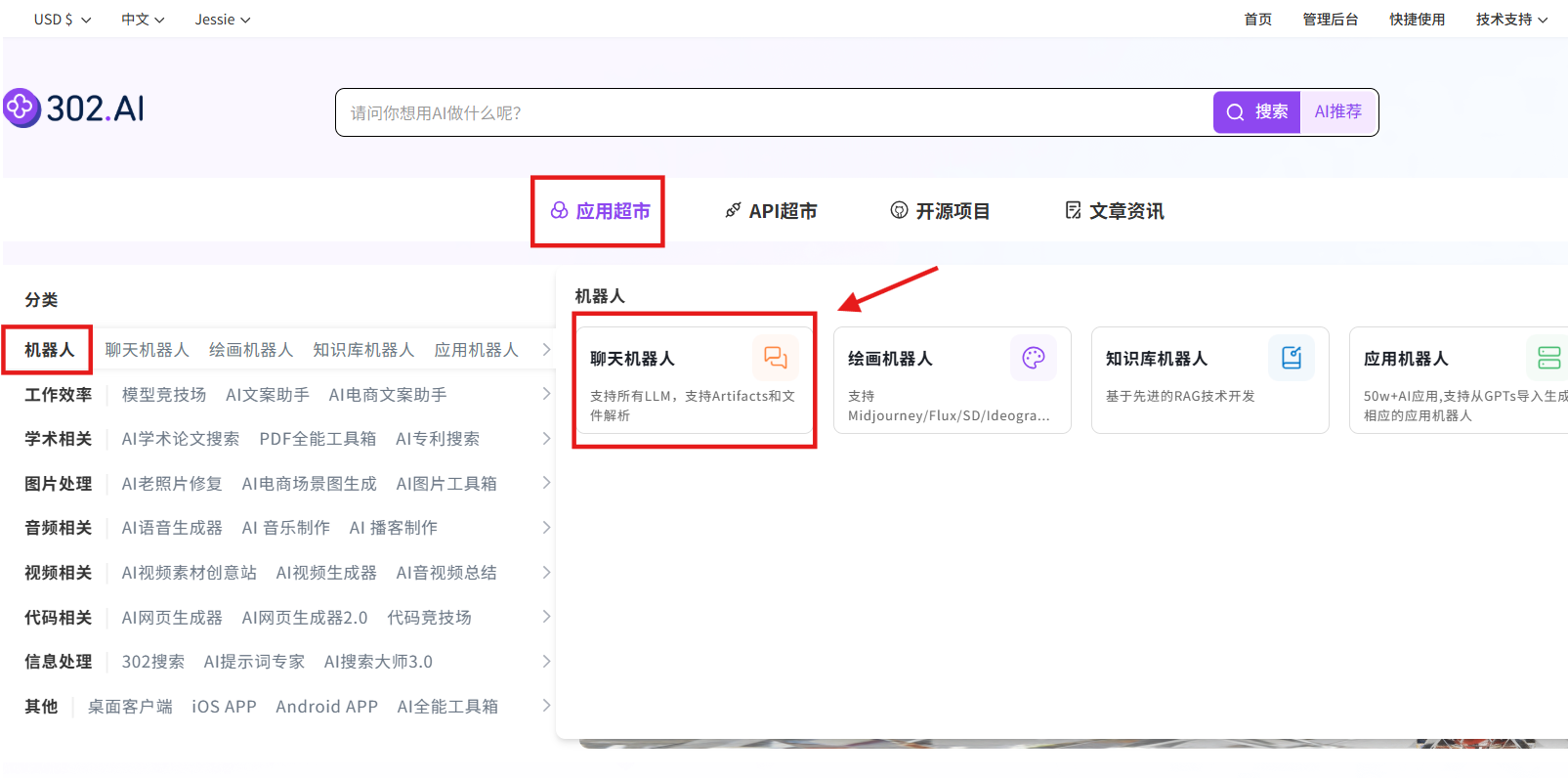
选择模型:Anthropic→claude-haiku-4-5→确认→创建
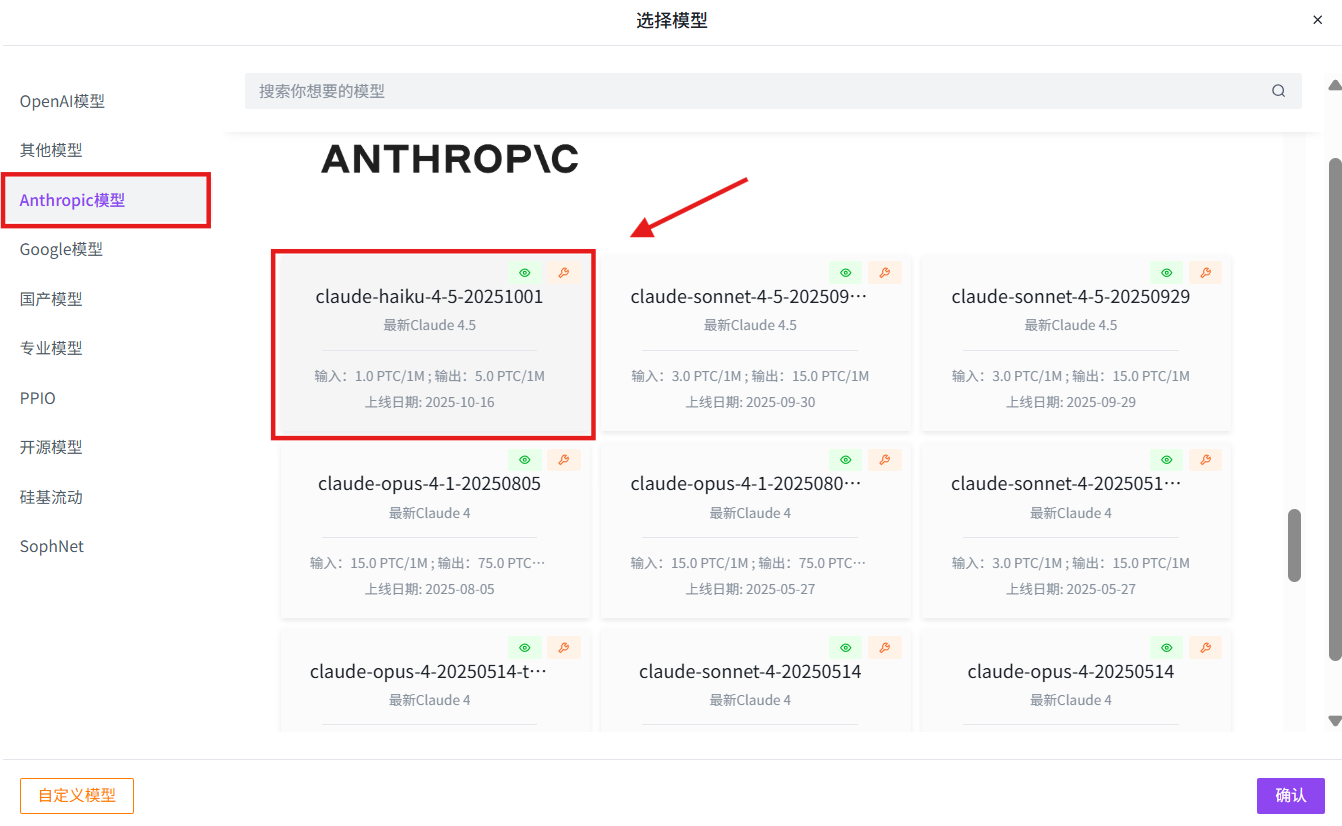
2. 使用模型 API
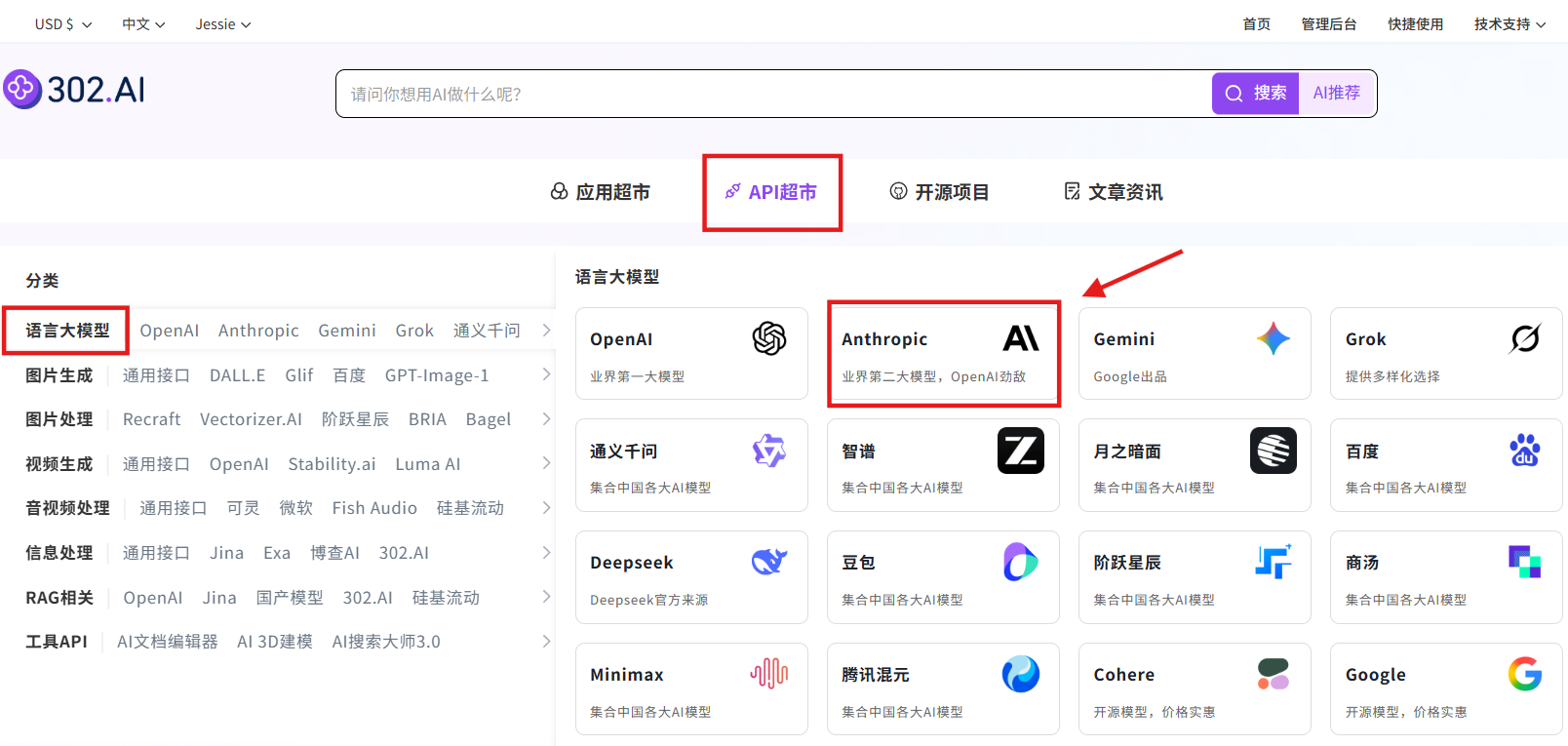
步骤指引:API超市→语言大模型→Anthropic→claude-haiku-4-5
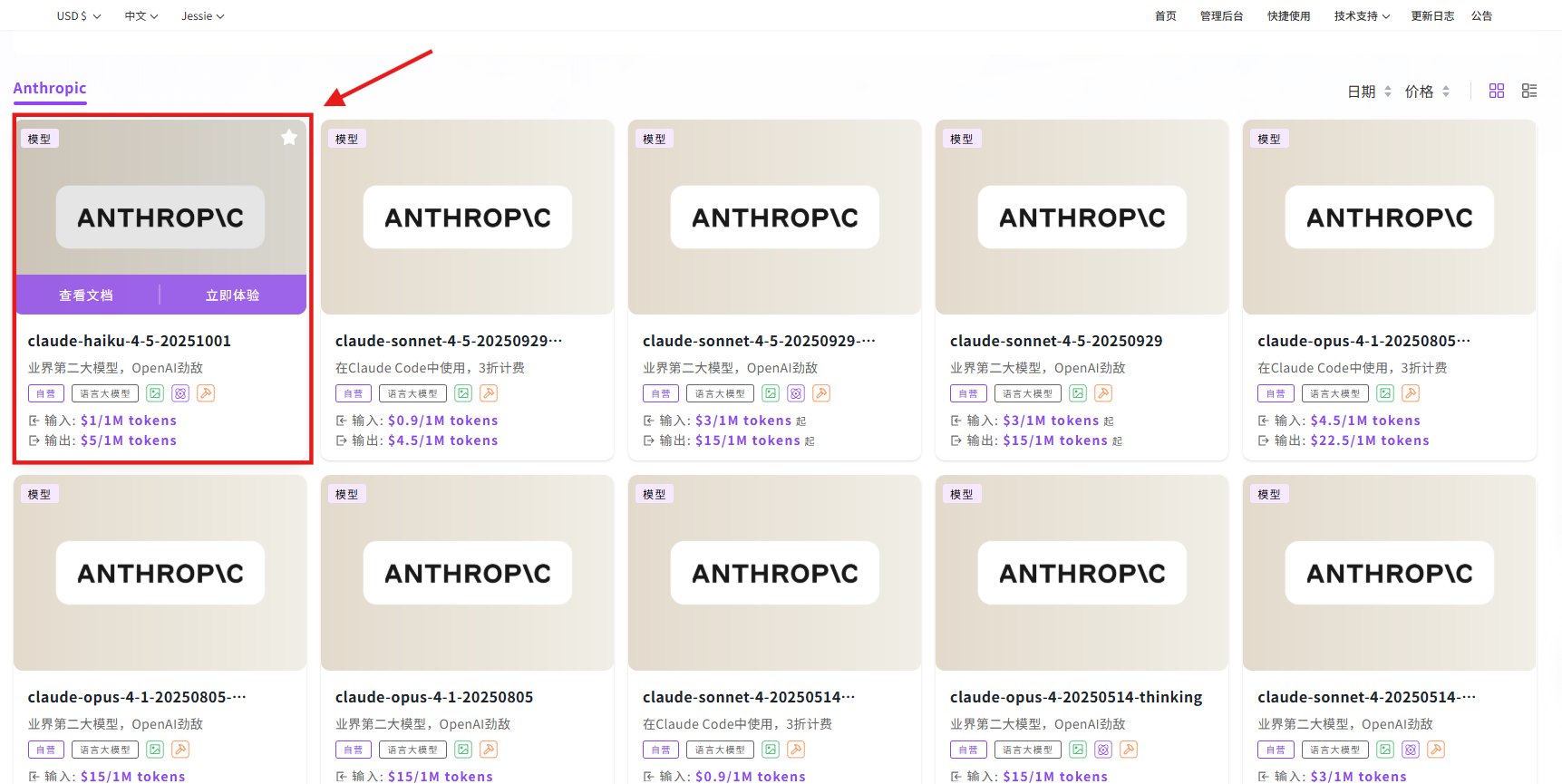
点击【立即体验】在线调用 API
想即刻体验 Claude Haiku 4.5 模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
