
今年十一国庆可谓是大模型界尤为热闹的一个行业节点。就在假期前夕的 9 月 30 日,Anthropic 与智谱先后发布 Claude Sonnet 4.5 与 GLM-4.6。而二者的升级方向都十分默契地指向同一关键战场——编程能力。
前有 Anthropic 高调宣称 Claude Sonnet 4.5 是迄今为止最强大的编程模型,后有 GLM-4.6 在 HuggingFace 与 LMArena 强势问鼎开源模型榜第一。国产与海外大模型在性能边界上的正面角逐,开源与闭源间无声的较量,在这个国庆正式拉开帷幕。
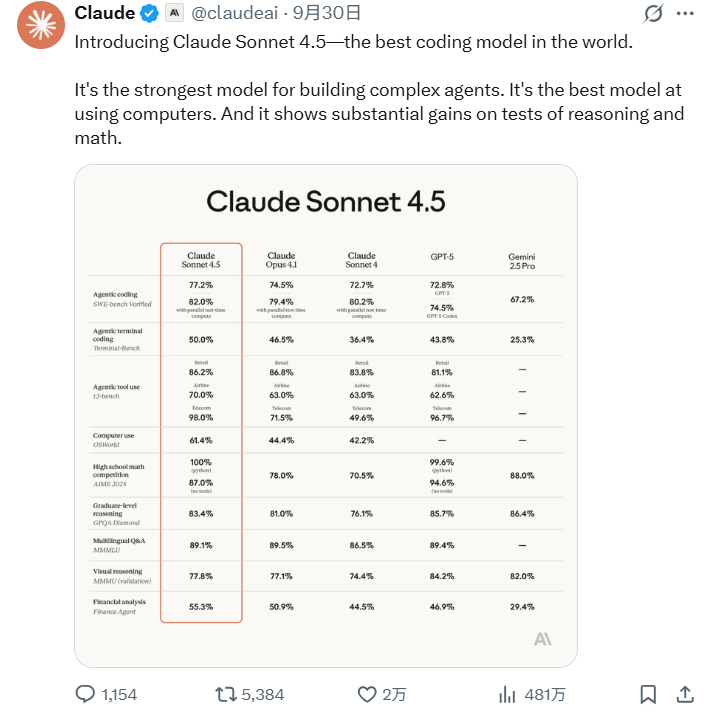

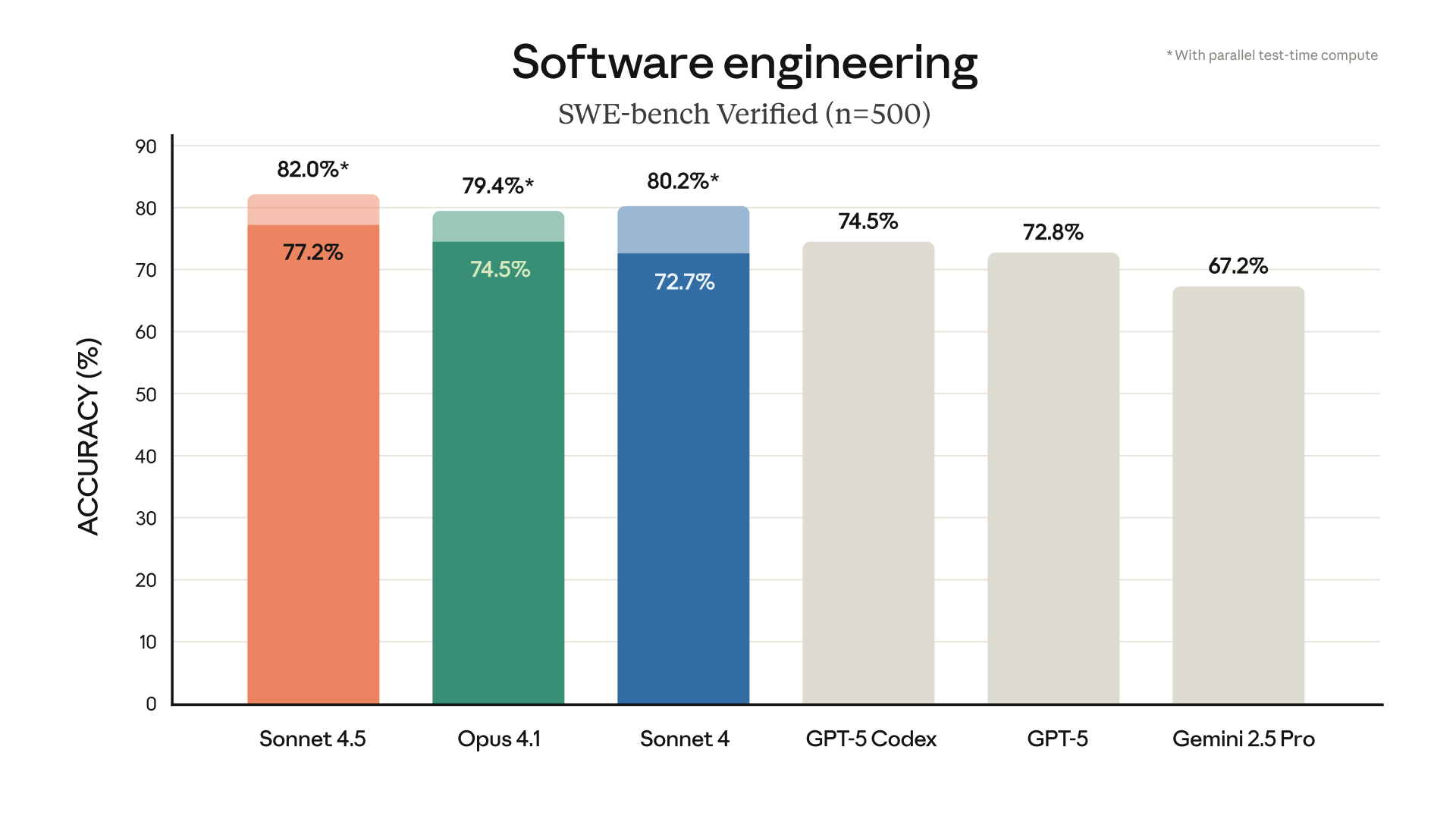
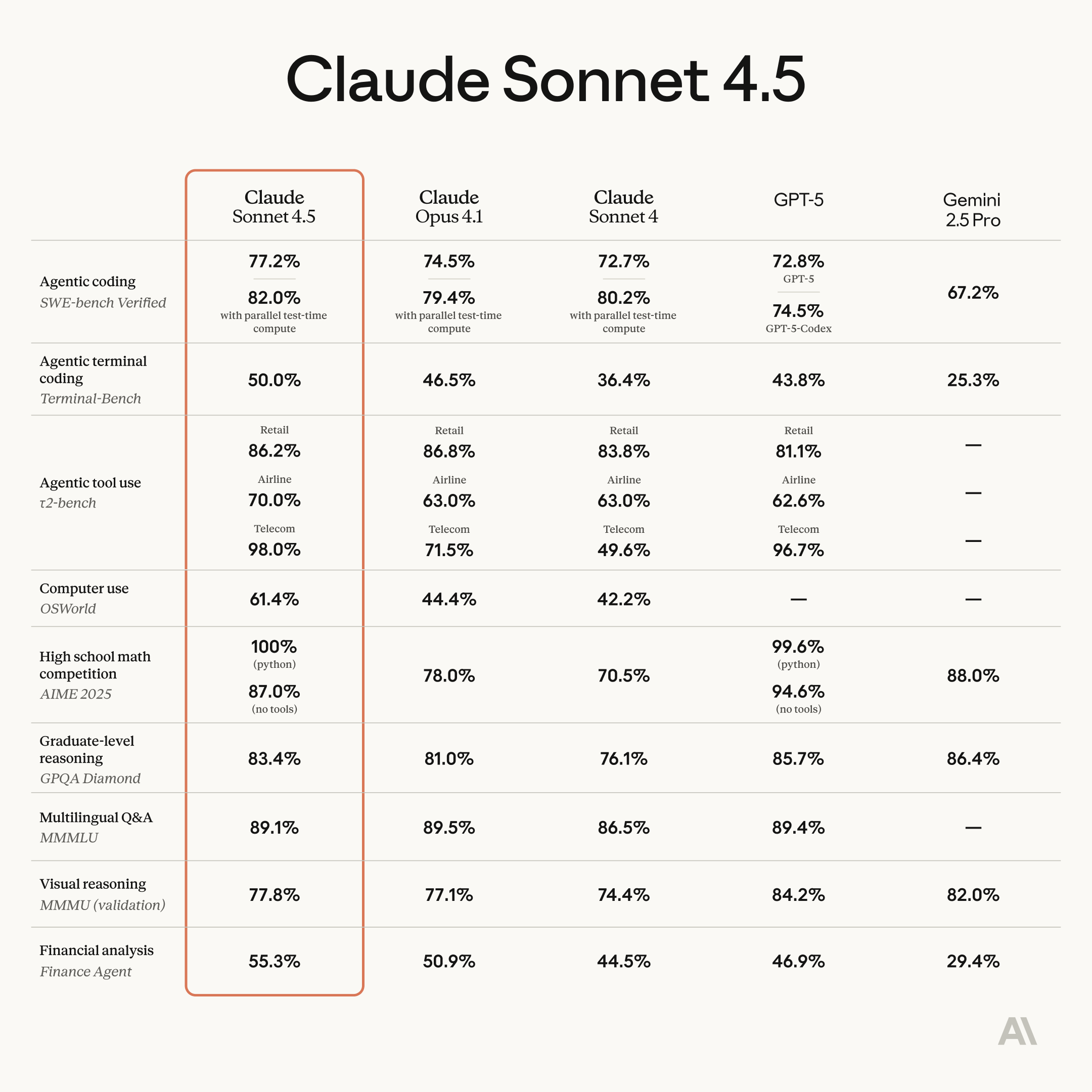
根据 Anthropic 官方数据,Claude Sonnet 4.5 在软件工程基准测试 SWE-bench Verified 上取得了业界领先的成绩,超越了包括 GPT-5、Gemini 2.5 Pro 在内的多个同类模型。在测试 AI 模型实际计算机任务能力的 OSWorld 基准中,Sonnet 4.5 也以 61.4% 的得分领先,远超四个月前的 42.2%。
模型在编程能力上呈现两大亮点:
- 超长持续工作能力:在复杂的多步骤任务中能够保持超过 30 小时的专注度,表现出超长连续工作的耐力;
- 强大的代码理解与执行能力:在多步推理与代码库理解方面进步显著,尤其擅长复杂 Bug 修复与跨代码库任务。
此外,本次更新“加量不加价”,Sonnet 4.5 与 Sonnet 4 定价一致,输入 3美元/百万token,输出 15美元/百万token。配合提示词缓存最高可节省 90% 成本。
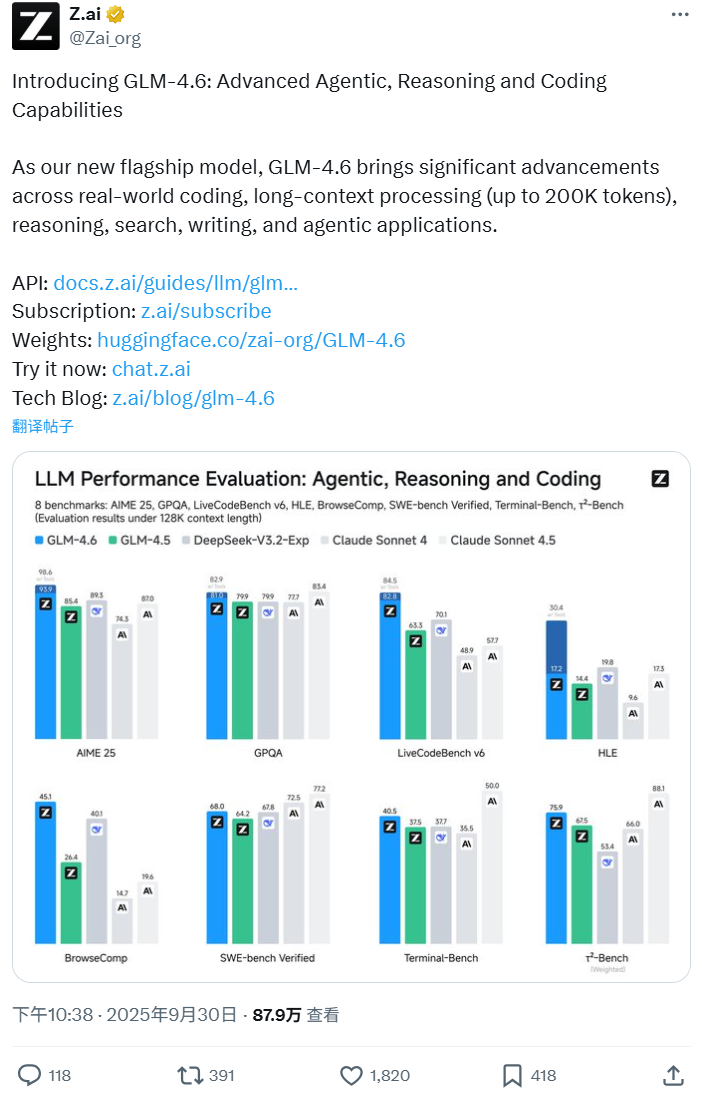
同样,智谱 GLM-4.6 的数据表现也毫不逊色。在 Claude Code 环境下的 74 个真实场景编程任务测试中,GLM-4.6 的 Agentic Coding 能力较前一版本跃升 27%,性能比肩 Claude Sonnet 4,也优于其他国产模型,达到国内编程效果最强模型。其核心优势包括:
- 高级编码能力:代码性能对齐 Claude Sonnet 4,成为国内已知效果最佳的 Agentic Coding 模型;
- 上下文窗口扩展:从 128K 提升至 200K,全面增强推理、搜索、写作与智能体应用能力;
- 硬件适配优化:适配寒武纪、摩尔线程等国产芯片,效率大大提升。
不光是效率提升,在成本方面,GLM-4.6 平均 token 消耗较 GLM-4.5 节省了 30% 以上,为同类模型中最低。
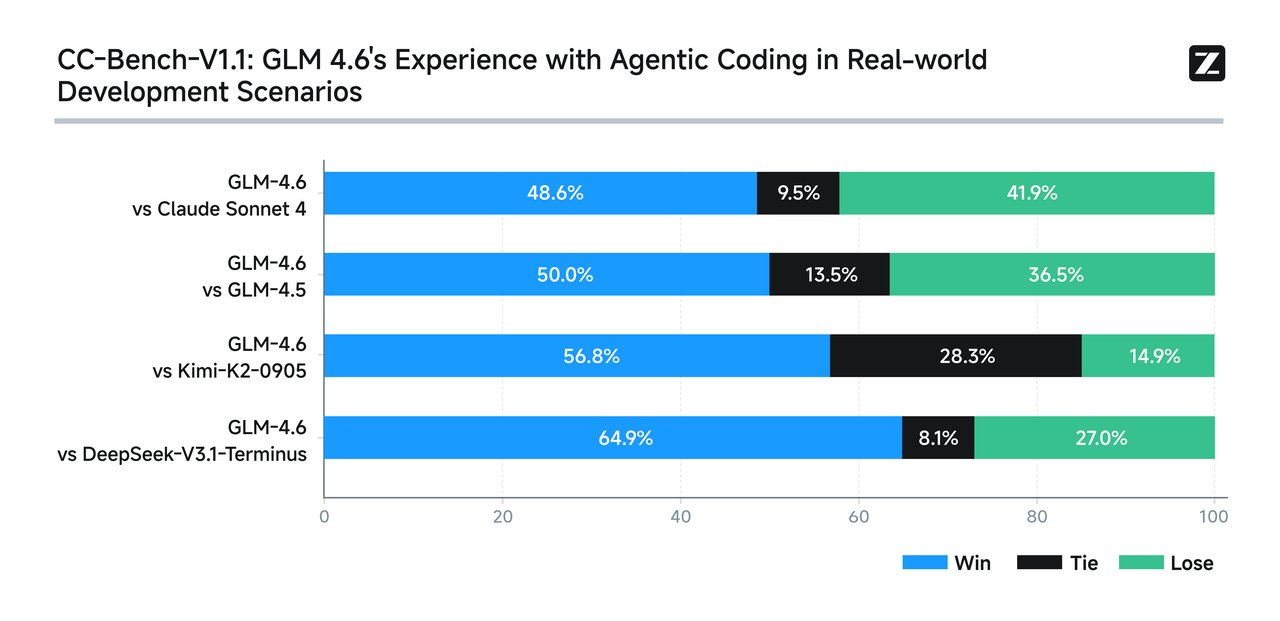
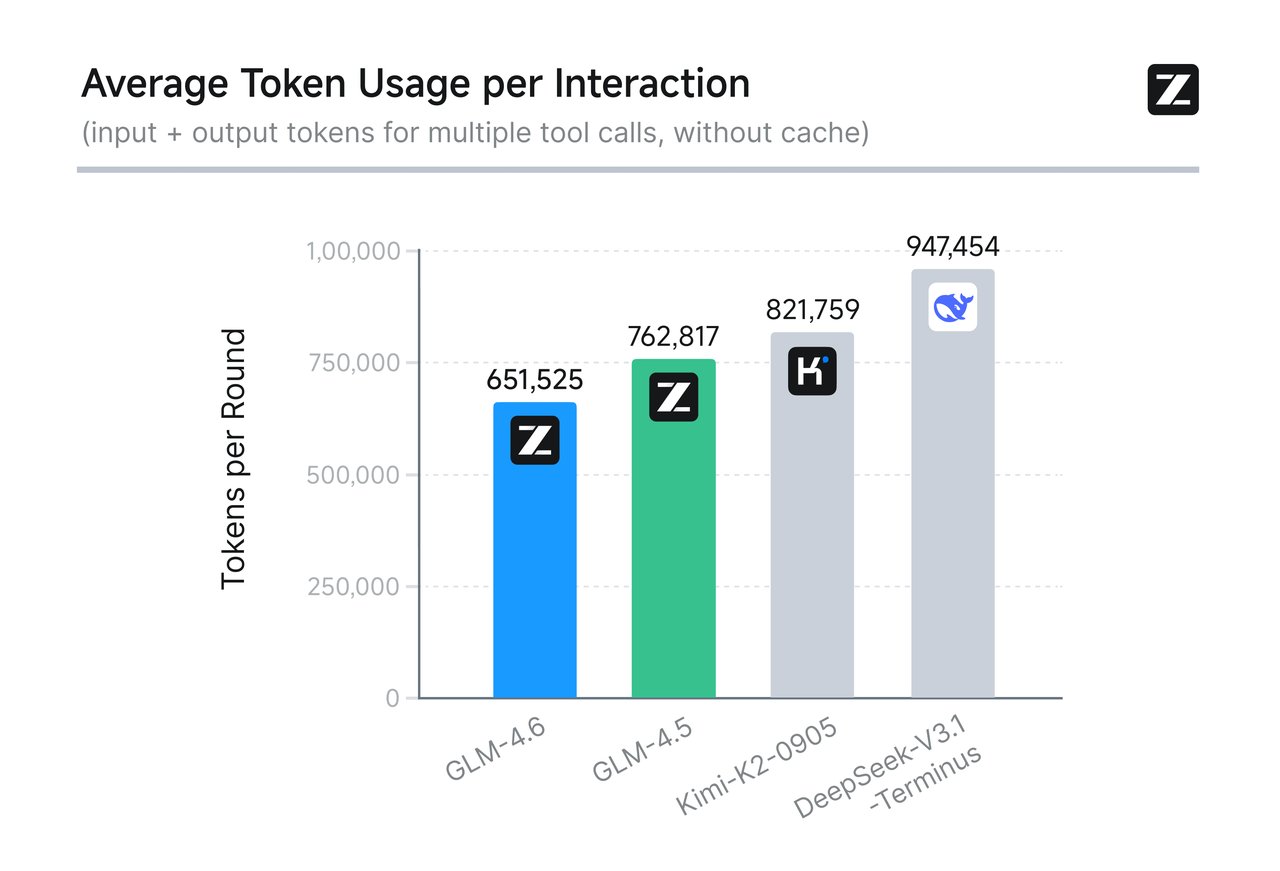
性能报告显示 GLM-4.6 编程能力已将国产模型与全球顶尖水平的差距缩至毫厘之间。仅需付出约 1/7 的成本,即可体验接近 Claude Sonnet 4 级别的编程辅助能力。那么,GLM-4.6 在实际场景中能否真正发挥出这样的性价比优势?而迭代登场、号称“全球最强编程模型”的 Claude Sonnet 4.5,又是否能稳守其领先地位?
目前,302.AI 已接入 GLM-4.6 与 Claude Sonnet 4.5 模型。本期评测将基于真实任务场景,从多个维度对二者的实际表现展开对比实测。
I. 实测模型基本信息
| 参与对比测评的模型 | 说明 | 输入价格 | 输出价格 | 上下文长度 |
| claude-sonnet-4-5 | ≤ 200K input tokens | $3/ 1M tokens | $15/ 1M tokens | 200000 |
| glm-4.6 | 输入长度[32k, 200k] | $0.572/ 1M tokens | $2.29/ 1M tokens | 200000 |
Ⅱ. 实测案例
实测 1:复杂逻辑推理
提示词:在[1,100]之间猜数字。
规则如下:
1、如果猜的小了,会提示猜的小了。
2、如果猜的大了,只会提示对错,不会提示大小。
3、如果有一次猜的大了,以后猜的无论大小,都只会提示错误,不会提示大小。
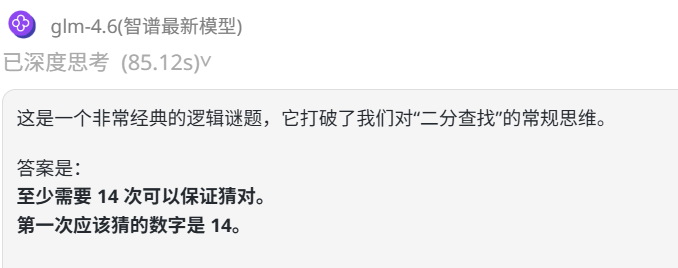
问:至少几次可以保证猜对数字?第一次应该猜哪个数字? 答案:至少14次可以猜对数字,第一次应该猜14
Claude Sonnet 4.5:回答错误
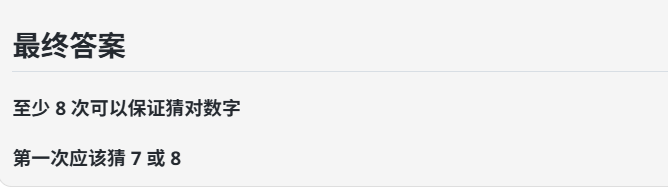

GLM-4.6:回答正确

实测 2:交互动画
提示词:请创建一个具有流体笔触效果的交互式绘画板。笔触应能模拟类似墨水在水中的扩散、混合效果,而不仅仅是简单的线条。
一、功能与交互要求
- 基本画布:提供一个全屏或大区域的画布作为绘画区域。
- 流体笔触模拟:鼠标移动时,并非绘制单一像素或线段。而是在鼠标当前位置持续生成微小的、半透明的圆形“粒子”。这些粒子在生成后,应向四周随机扩散,并逐渐淡化消失,共同构成一条具有扩散边缘和纹理的笔触。
- 颜色混合:提供至少3种基础颜色(如红、蓝、黄)供用户选择。当不同颜色的笔触重叠时,它们应进行颜色的Alpha混合,模拟出颜料相互渗透的效果。
- 交互控制:提供一个“清空画布”的按钮;提供一个滑块,用于实时调整笔触的“扩散强度”或“流体质感”。
二、技术实现要求
- 性能优先:必须使用 requestAnimationFrame 进行粒子动画循环。粒子总数需要有上限管理,当粒子数量过多时,应自动移除已完全透明的粒子,防止内存泄漏和性能下降。
- 现代代码:使用ES6+语法,代码模块化,注释清晰。
- 视觉流畅:动画应保持60fps的流畅度,无明显卡顿。
三、交付物
- 一个独立的、可直接运行的 index.html 文件。
Claude Sonnet 4.5:

GLM-4.6:

| 测评对象 | Claude Sonnet 4.5 | GLM-4.6 |
| 功能交互完整性 | ★★★ | ★★★★★ |
| UI/UX效果 | ★★★★ | ★★★★★ |
| 细节逻辑 | ★★ | ★★★★★ |
| 简评 | GLM-4.6完胜。Claude 4.5的笔触略显生硬,在画布上的晕染效果不明显,且并未实现逐渐淡化和消失,画笔颜色也存在问题,蓝色和紫色,黄色和橙色太过近似,较难区分。细节部分,工具栏显示的画面粒子数量也不合理;相比之下,GLM-4.6则完整实现了提示词要求,笔触晕染自然,粒子数量会随着操作合理地累加或减少,整体视觉观感也更佳。 | |
实测 3:网页设计
提示词:为一款名为 “Serene” 的冥想与正念应用设计官方网站。
一、核心目标:
清晰传达应用的价值,引导用户下载 App。
二、页面结构要求:
- 英雄区: 温馨、平静的背景图片或短视频。应用的 Logo、核心标语(例如“在喧嚣中找到你的宁静”)、简短介绍,以及两个非常显眼的按钮:“在 App Store 下载”和“在 Google Play 获取”。旁边放一个手机模型(mockup)展示应用主界面。
- 功能介绍区: 采用“Z”字形布局(图片在左、文字在右,下一行则文字在左、图片在右),分点介绍3个核心功能(如“引导式冥想”、“助眠故事”、“情绪追踪”)。
- 用户证言区: 引用几位用户的真实好评,并附上他们的头像和名字。
- 常见问题 (FAQ) 区: 使用手风琴(Accordion)组件,用户可以点击问题展开答案。
- 页脚: 包含下载链接、社交媒体、隐私政策和服务条款。
三、设计与交互风格:
- 风格: 干净、平和、值得信赖。使用柔和的色彩(如淡蓝色、米色),圆角元素和友好的无衬线字体。
- 交互: 页面滚动流畅,功能介绍区的元素在进入视口时有轻微的动画效果。手风琴展开/收起时有平滑的过渡动画。
四、技术挑战/加分项:
英雄区的手机模型可以实现一个微妙的动画,例如每隔几秒自动切换展示的应用截图。
请在一个 HTML 文件内实现所有 HTML、CSS 和 JavaScript 代码。
Claude Sonnet 4.5:

GLM-4.6:

| 测评对象 | Claude Sonnet 4.5 | GLM-4.6 |
| 功能完整性 | ★★★★★ | ★★★★ |
| UI/UX效果 | ★★★★★ | ★★★★ |
| 细节逻辑 | ★★★★★ | ★★★★ |
| 简评 | Claude4.5完胜。从页面完整度到细节罗列都几乎达到一个成熟网页的标准,配图和文案细节也质量极高。GLM-4.6的UI/UX美观度明显弱于Claude4.5,部分组件对齐方式略杂乱,类似于实现了一个大体框架而非视觉精美的完整网页。 | |
实测 4:小游戏制作
提示词:
请你作为一个前端专家,创建一个名为“星际炮台防御”的网页小游戏。
使用 Canvas 绘制一个处于屏幕底部中央的固定炮台;炮台的炮管需实时朝向鼠标指针的方向;通过点击鼠标左键来从炮管位置发射子弹。
游戏开始后,屏幕上方会随机位置、随机速度生成下落的目标(例如不同颜色或大小的圆形);子弹的运动轨迹为直线。
目标是操控炮台发射子弹,在目标到达屏幕底部之前将其击中并摧毁;子弹与目标需要有明确的碰撞判定,击中后目标和子弹都消失。
每成功击中一个目标,屏幕顶部的分数会增加(可根据目标大小或速度给予不同分数);随着分数的提高,目标生成的速度和下落的速度会逐渐加快,以增加游戏难度。
如果任何一个目标成功触及屏幕底部,则游戏结束,并显示最终得分。
请在一个 HTML 文件内实现所有 HTML、CSS 和 JavaScript 代码。
Claude Sonnet 4.5:

GLM-4.6:
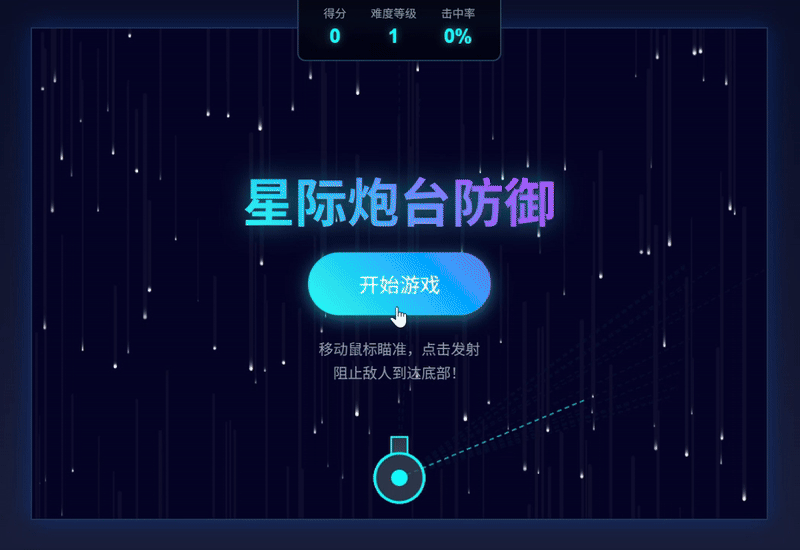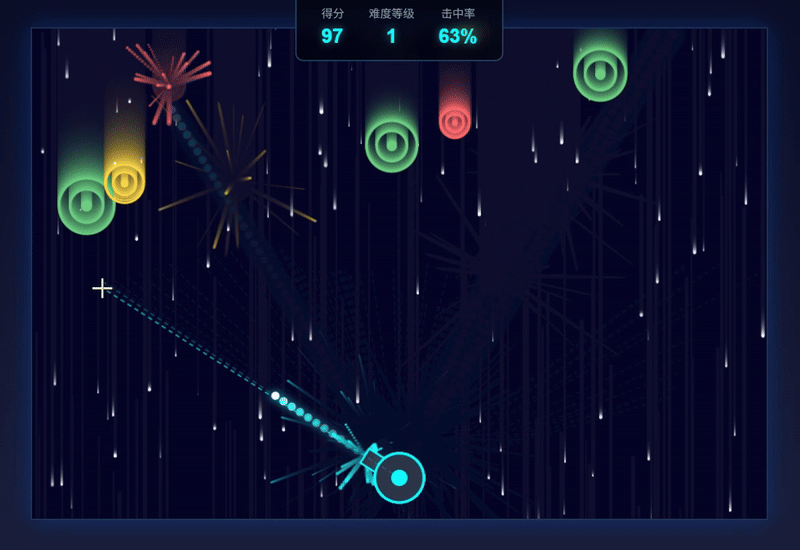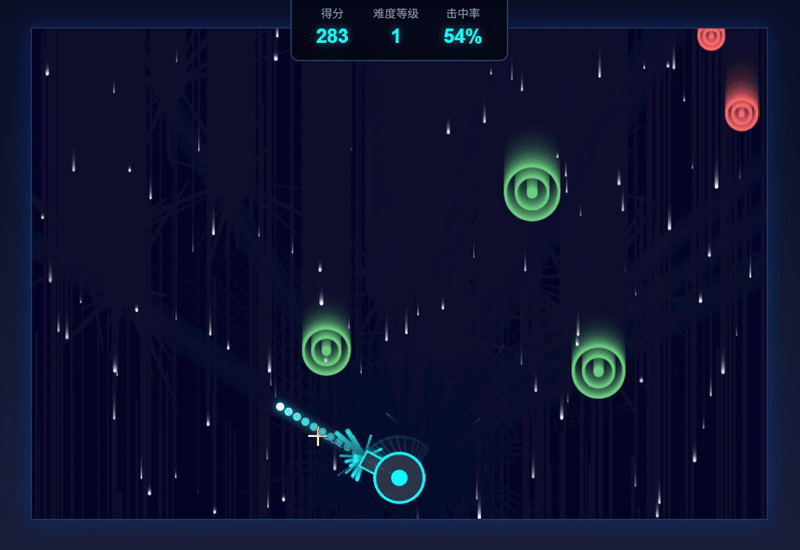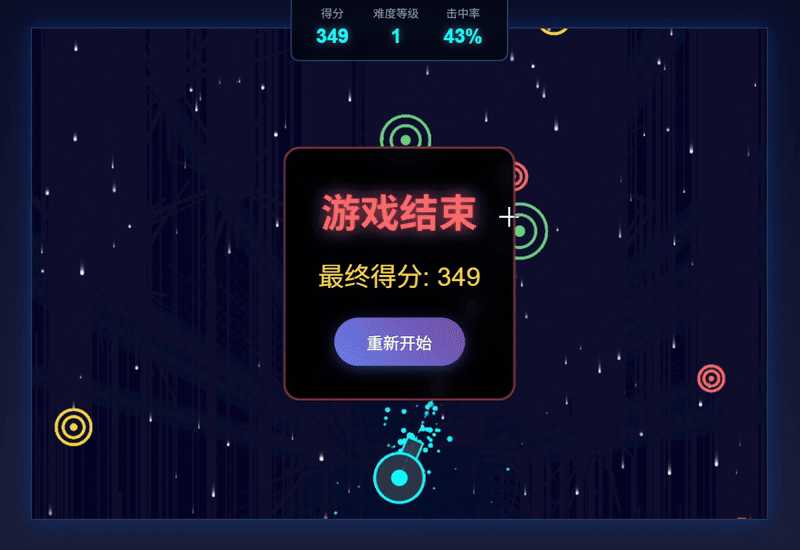
| 测评对象 | Claude Sonnet 4.5 | GLM-4.6 |
| 功能完整性 | ★★★★ | ★★★★★ |
| UI/UX效果 | ★★★★ | ★★★★ |
| 可玩性 | ★★★★ | ★★★★★ |
| 简评 | GLM-4.6略胜。两个模型都完整达成了提示词要求,GLM-4.6胜在有开始游戏的界面显示,以及增添了难度等级和击中率的细节显示。虽然从元素设计和击中效果来看,Claude4.5的整体性更强,但GLM-4.6以更高的操纵灵敏度和爆破式的击中效果呈现出了更佳的可玩性。 | |
实测 5:操作系统原型
提示词:请创建一个名为 WebOS Lite 的可交互浏览器操作系统原型,模拟现代操作系统的核心体验,包含多个功能应用程序和桌面环境,最终在一个HTML文件内交付所有代码。
Claude Sonnet 4.5:

GLM-4.6:

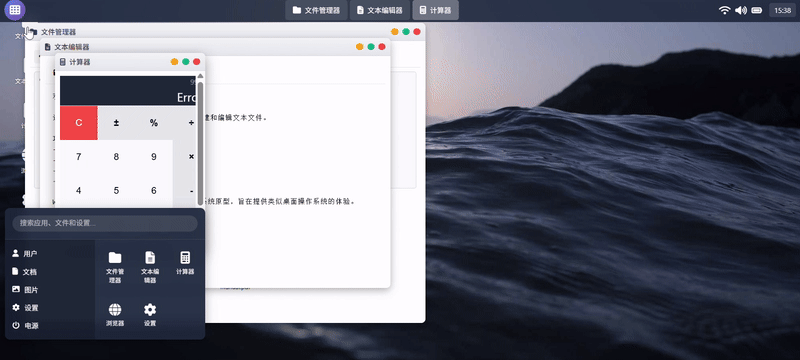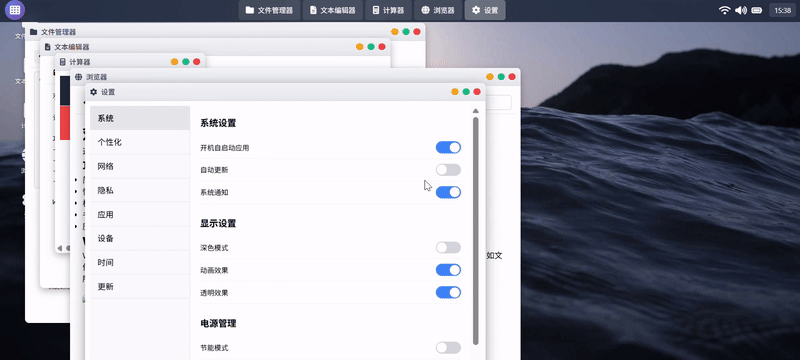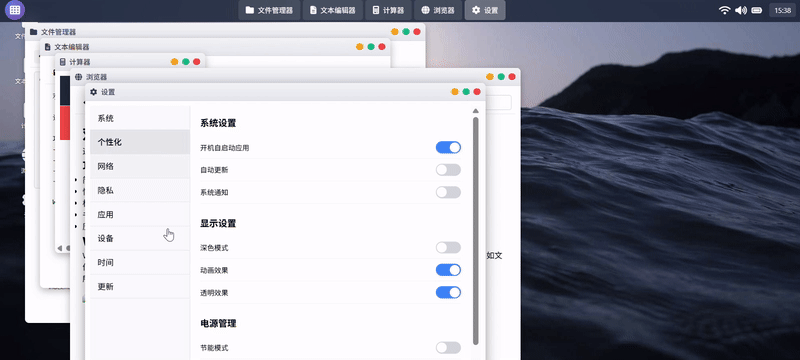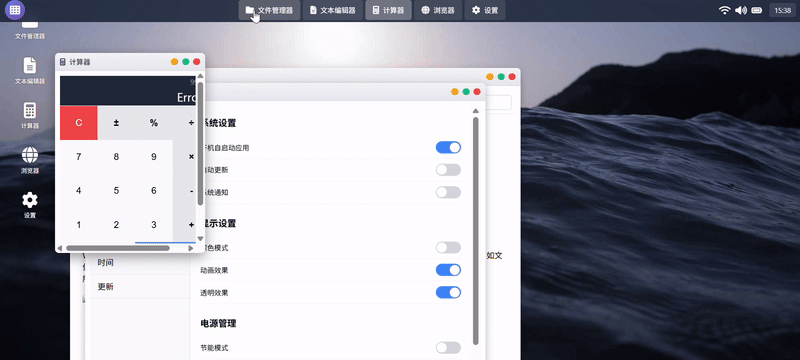
| 测评对象 | Claude Sonnet 4.5 | GLM-4.6 |
| 功能完整性 | ★★★ | ★★★★ |
| UI/UX效果 | ★★★★ | ★★★★ |
| 细节逻辑 | ★★★ | ★★★★★ |
| 可用性 | ★★★★ | ★★★ |
| 简评 | GLM-4.6胜。在不做过多限制的简单提示词要求下,GLM-4.6自由发挥的交付结果更为完整,细节还原(如启动界面、顶部菜单栏、状态栏等)部分更为全面。Claude4.5的系统功能构建略显单薄,虽交互流畅度更佳,但部分功能(如壁纸更换)也并未响应。 | |
III. GLM-4.6 与 Claude Sonnet 4.5实测结论

综合版本特性与实际测评结果来看,GLM-4.6 与 Claude Sonnet 4.5 这一对“编程双雄”之间的较量,并非简单的孰强孰弱,而是各有所长、各显其能,展现出鲜明的差异化优势。
在复杂推理这一大模型迭代中最核心的进化方向之一上,GLM-4.6 在准确性与稳定性方面表现更为突出。它能够敏锐捕捉提示词背后的隐藏逻辑,并精准输出标准答案,尤其在考验模型“硬实力”的压力测试中,展现出对复杂逻辑问题的可靠处理能力。相较之下,Claude Sonnet 4.5 在推理环节的表现略显波动,这也进一步凸显了 GLM-4.6 在需要高度可靠性的底层逻辑与复杂问题解决场景中所实现的突破。
回归到二者竞争最为激烈的代码能力层面,多轮测试下来,GLM-4.6 的表现丝毫不逊于 Claude Sonnet 4.5,“国内最强编程”的头衔并非徒有虚名。无论是系统架构思维、功能丰富度,还是交互实现的完整度,GLM-4.6 均展现出与顶尖闭源模型比肩的交付水准。尤其在粒子模拟、难度递增机制与系统细节处理上,其工程实现能力与创新性更胜一筹。更值得一提的是,GLM-4.6 在理解用户意图方面取得显著进步——例如在交互动画设计中,它能准确理解“笔触要有晕染效果”、“粒子要合理累加”等表述背后所指向的自然流畅的视觉交互目标,从而超越单纯的代码执行者角色,向更具感知力的协作伙伴迈进。
而 Claude Sonnet 4.5 则擅长代码结构优化,其生成的代码在可读性与组织架构上更显专业。在高端网页设计与 UI/UX 细节打磨方面,它展现出强大的表现力——无论是视觉美感、文案编排、动画细腻度,还是整体页面成熟度,均能高度还原商业级交付标准。在处理复杂前端交互与界面细节时,Claude 显示出更深层次的理解与执行力,尤其适合对产品级设计有高要求的场景。
总体来看,Claude Sonnet 4.5 的演化路径更偏向追求设计水准与用户体验的“代码美学大师”,而 GLM-4.6 则更似一位务实的“全能工程师”或“编程助手”。若项目追求视觉惊艳、代码优雅的展示型效果,且预算充裕,Claude 仍是理想之选;而若任务涉及严谨逻辑、复杂交互与系统架构,需兼顾功能完整与高度可靠,GLM-4.6 则展现出更强的综合实力与交付保障。
此外,在至关重要的性价比维度上,GLM-4.6 的优势显而易见。以约 1/7 的成本,在多数核心编程场景中获得接近甚至部分超越 Claude Sonnet 4.5 的体验,这对广大开发者与企业而言无疑具备强大吸引力。这不仅体现了国产顶尖模型在技术上的奋力追赶,更在让前沿技术好用且用得起的路径上迈出关键一步。
因此,对于开发者而言,最终选择仍应回归项目本身的需求侧重:如果追求极致的视觉效果和代码品味,且预算充足,Claude Sonnet 4.5 仍是一个华丽的标杆;若更看重任务精准实现、功能完整与成本效益,GLM-4.6 无疑是可靠且明智的选择。在编程大模型赛道逐渐进入分庭抗礼的当下,这场对决没有唯一的胜者,却让每一位开发者,成为了真正的赢家。
Ⅳ. 如何在 302.AI 上使用
以 GLM-4.6 为例
1. 聊天机器人中使用
步骤指引 :应用超市→机器人→聊天机器人→立即体验
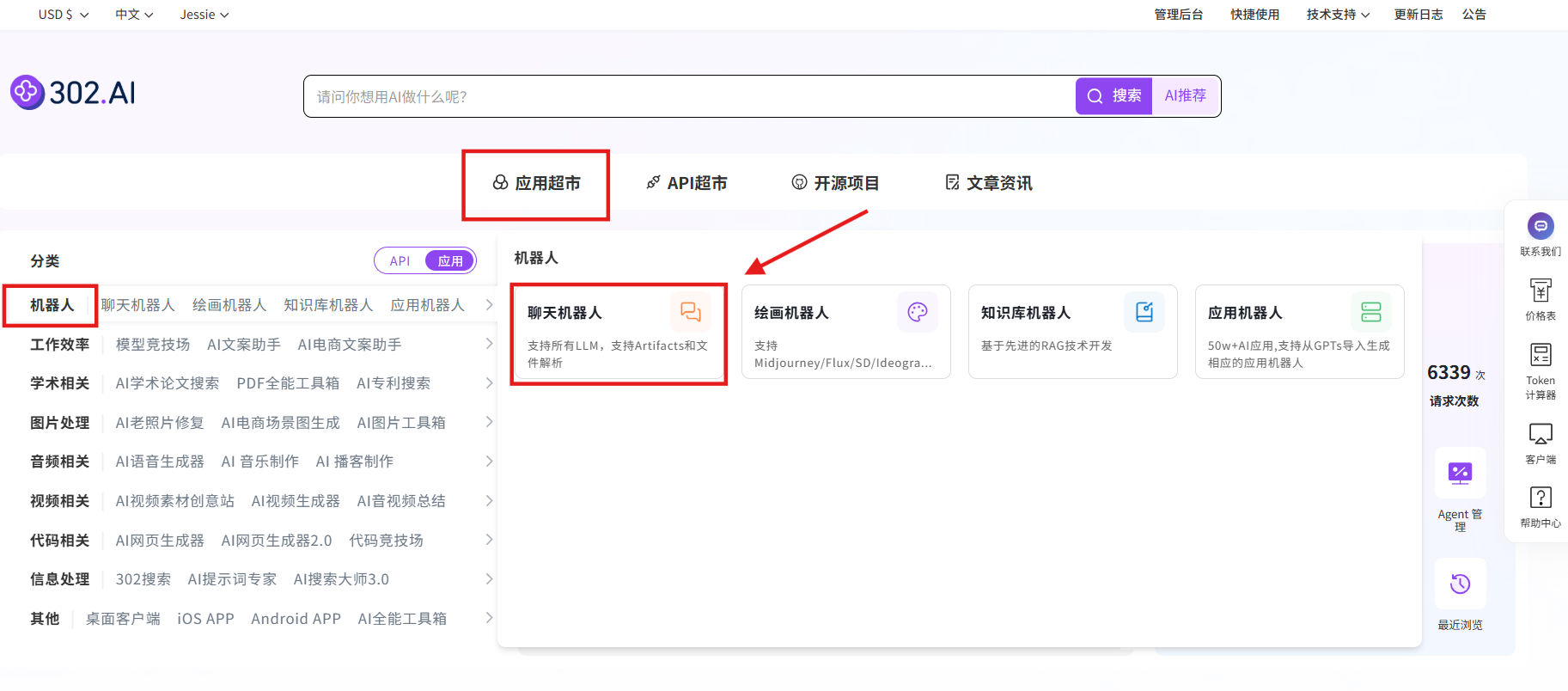
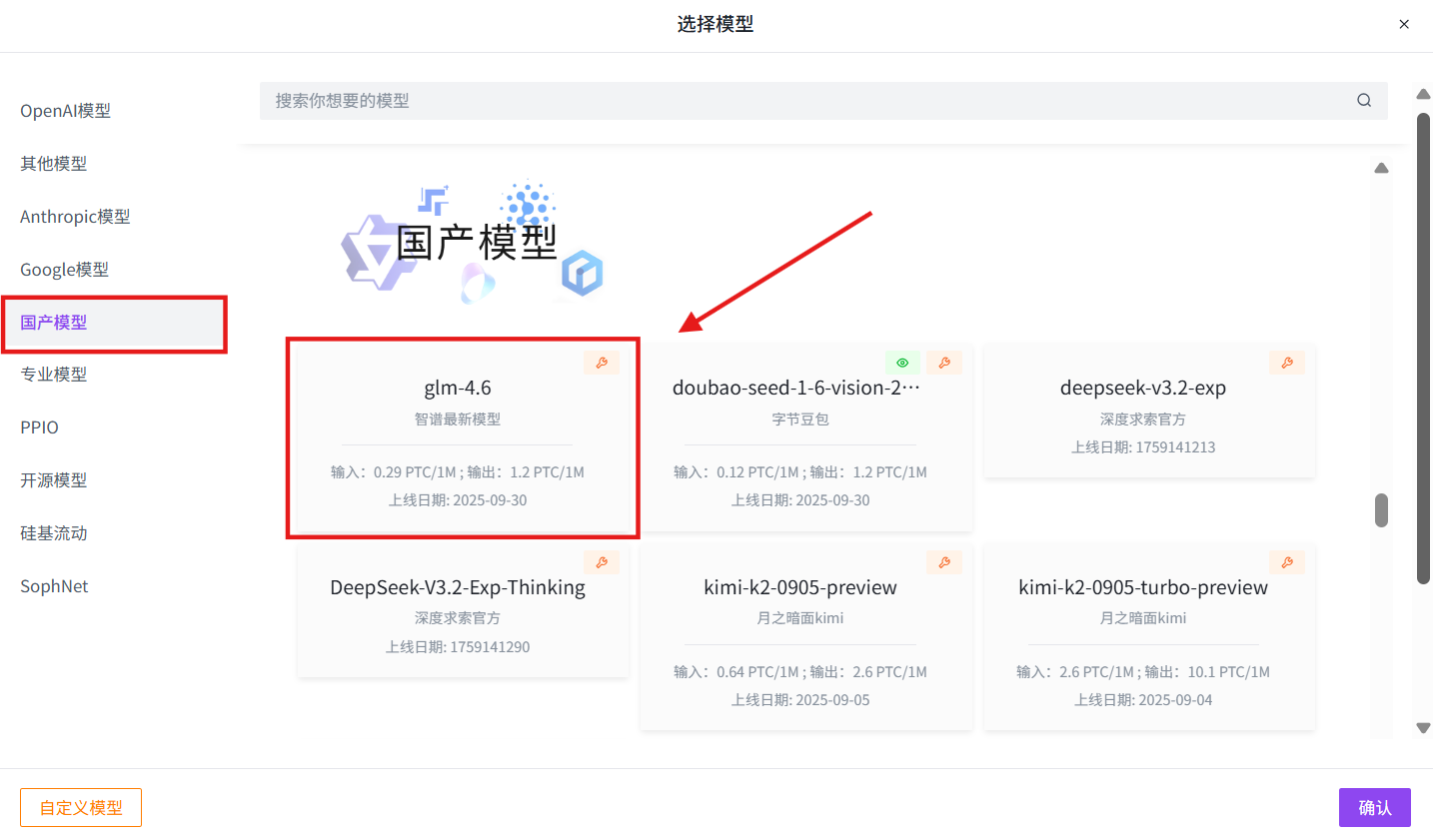
选择模型:国产模型→glm-4.6→确认→创建
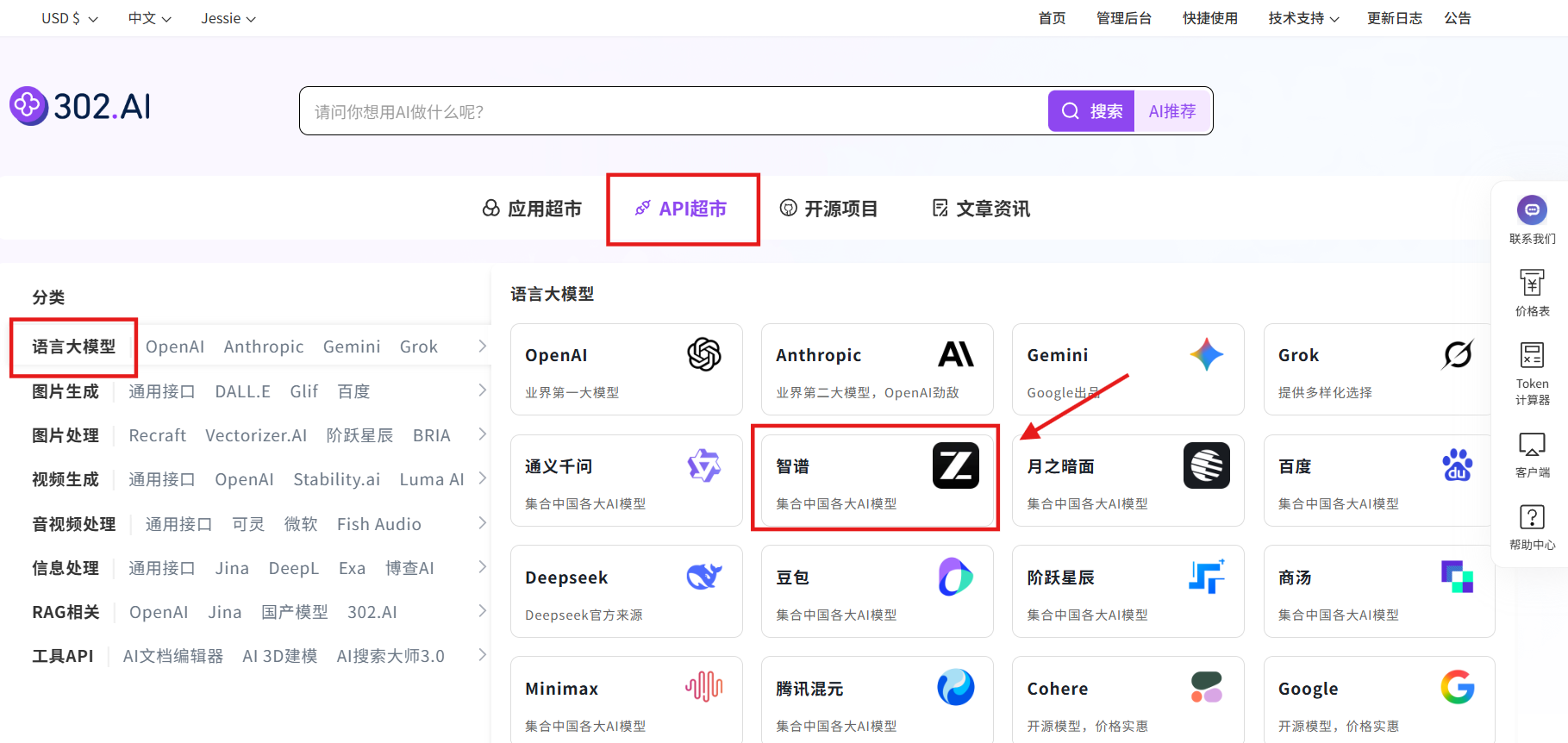
2. 使用模型 API
步骤指引:API超市→语言大模型→智谱→glm-4.6→查看文档
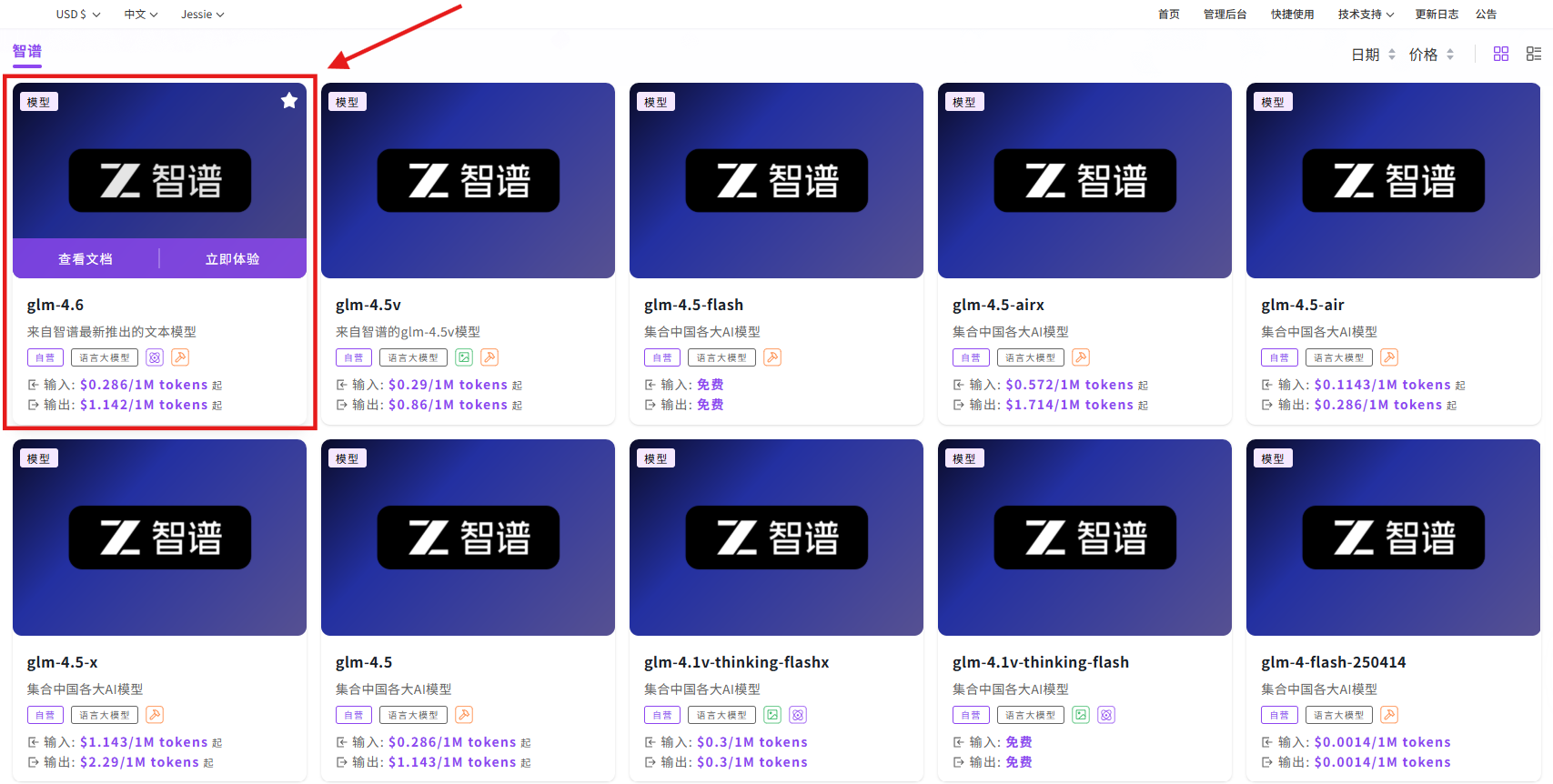
点击【调试】在线调用 API
想即刻体验 GLM-4.6 和 Claude Sonnet 4.5 模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
