
赶在各大 AI 模型“神仙打架”的国庆热潮之前,深度求索延续了节前卡点更新的惯例,于 9 月 29 日正式上线了最新的实验性模型——DeepSeek-V3.2-Exp.该版本是针对企业场景优化的实验性模型,参数规模约为 7B-16B,延续了“小参数,高性能”的技术路线,重点解决了前代版本在专业领域精度不足与长文本推理效率较低的问题。

从官方发布的基准测试结果来看,V3.2-Exp 的整体性能与 V3.1-Terminus 基本持平,比较亮眼的部分在于 V3.2 在长文本处理方面的表现显著提升。华为云部署版本最高可支持 160K tokens 的上下文长度,约等于 20 万至 24 万个汉字,相当于可以一次性处理一本《百年孤独》这样的长篇小说。
这一进步归功于其技术层面的重要升级——DeepSeek-V3.2-Exp 首次实现了粒度稀疏注意力机制(DeepSeek Sparse Attention)。在几乎不影响模型输出效果的前提下,实现了长文本训练和推理效率的大幅提升。通俗来说,就是模型在处理长文本时不再平均消耗算力,而是学会了“抓住重点”,将注意力精准聚焦于关键信息,从而实现算力节约与推理加速。
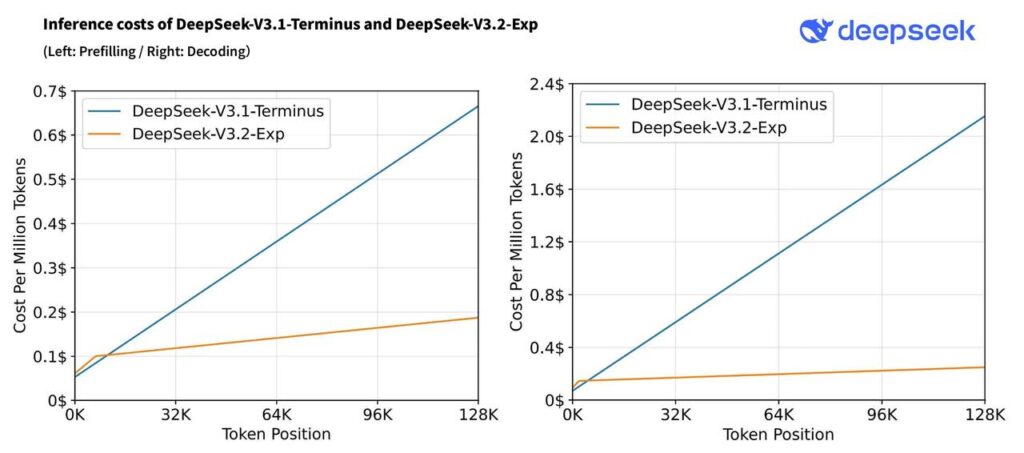
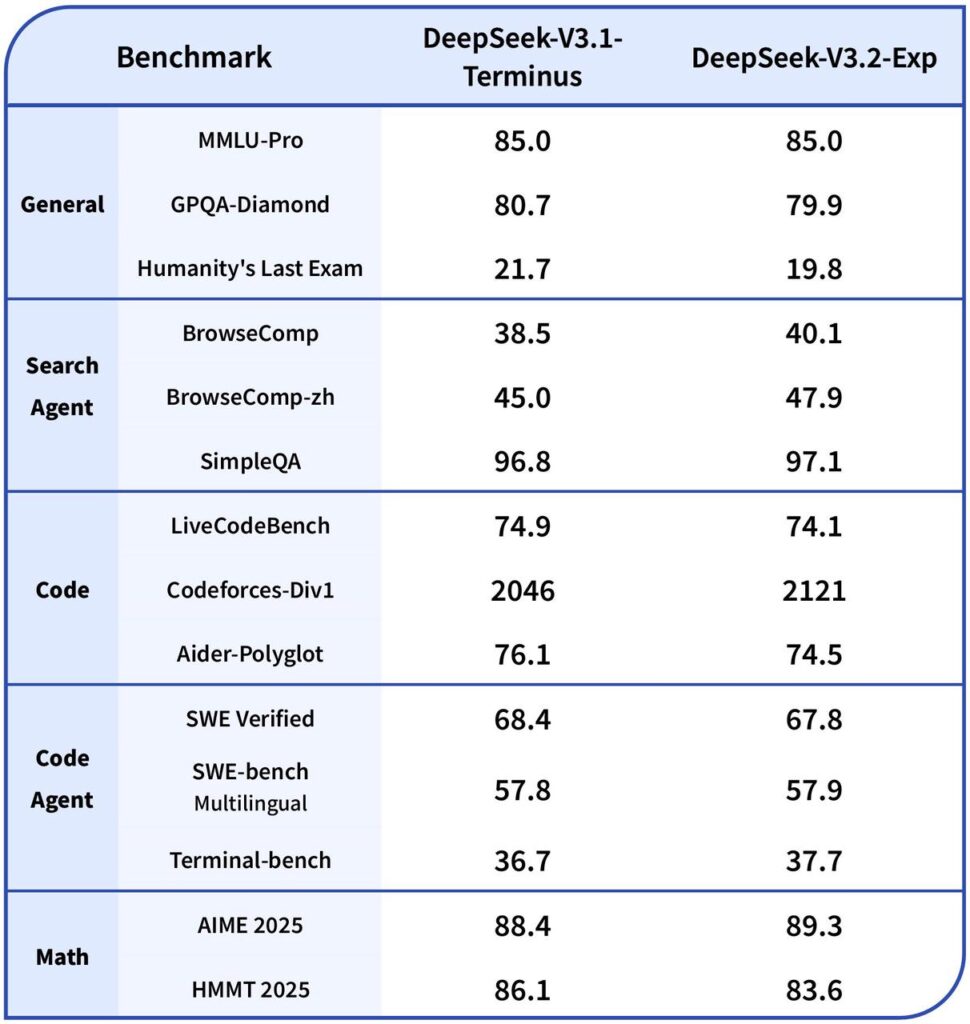
此外,正是得益于这一技术升级,V3.2 的 API 调用成本也大幅下降。在缓存命中的情况下,输入价格降至 0.2元/百万Token,输出价格则由原来的 12元/百万Token 降至 3元/百万Token,相当于直接打了一个 25 折,这对开发者而言无疑是一个巨大鼓舞。
核心技术特性综述:
- 基础架构:基于 V3.1-Terminus 构建,保持 671B 参数规模
- 创新机制:首次实现细粒度稀疏注意力,突破传统 Transformer 架构限制
- 效率提升:在长文本处理场景中显著降低计算成本和内存使用
- 质量保证:输出质量与 V3.1-Terminus 几乎完全一致
302.AI 现已接入 DeepSeek-V3.2-Exp 模型,用户可以灵活调用其 API 或在聊天机器人中直接体验。为更直观地展示 V3.2 的性能特点,本文将使用前代模型 DeepSeek-V3.1 与新版 V3.2-Exp 进行多维度对比测评,关注在数据、训练配置等保持一致的前提下,新增的 DeepSeek 稀疏注意力(DSA) 机制到底带来了多大的性能变化及成本优势。
I. 实测模型基本信息
| 参与对比测评的模型 | 输入价格 | 输出价格 | 上下文长度 |
| deepseek-v3.2-exp | $0.29/ 1M | $0.43/ 1M | 128000 |
| deepseek-V3.1 | $0.286/ 1M | $1.15/ 1M | 128000 |
Ⅱ. 实测案例
实测 1:逻辑推理
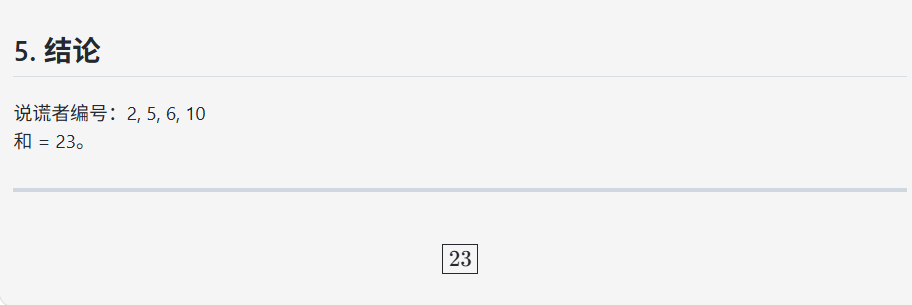
提示词:在一个小岛上共住了10个人,将他们分别编号为1号、2号、……、10号,每个人要么永远说真话,要么永远说假话。 如果问他们:“你的编号是否为偶数?” 一共有3个人答“是” 如果问他们:“你的编号是否为4的倍数?” 一共有6个人答“是” 如果问他们:“你的编号是否为5的倍数?” 一共有2个人答“是” 所有说谎话的人的编号之和为( )。
答案:23
deepseek-v3.2-exp:回答正确。
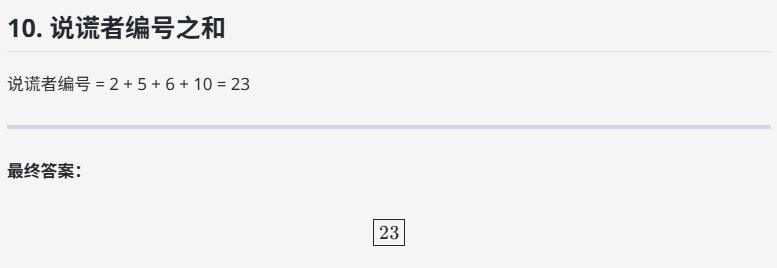

deepseek-V3.1:回答正确。

| 测评对象 | deepseek-v3.2-exp | deepseek-V3.1 |
| 回答准确性 | ★★★★★ | ★★★★★ |
| 逻辑推理严密性 | ★★★★ | ★★★★★ |
| 简评 | V3.1采用代数符号化的形式进行推理,逻辑链条清晰;V3.2则采用集合与人数分类法进行推理,在表述方式上更详尽、更口语化。然而从逻辑严密性来讲,V3.1的代数方程推导法步骤清晰,自动涵盖所有约束,不易因直觉漏解,V3.2则更依赖对问题的“翻译”和自然语言逻辑,虽然易懂,但严谨性稍逊。 | |
实测 2:长文本信息检索与精准提取
测试文档:选用美国中央情报局(CIA)解密的《世界概况》(The World Factbook)中关于“日本 (Japan)”的完整条目,共计38768个字符。我们手动在上述文档的不同章节中“植入”三个与原文基调不符、高度具体的虚构信息。
插入信息为:
- 植入信息1 (技术细节): “During a joint U.S.-Japan naval exercise in the Pacific, it was noted in a technical debrief that the primary communication satellite’s backup power unit is designated as ‘Project Phoenix Unit 763’.” (译:在太平洋的一次美日联合海军演习中,一份技术汇报指出,主通信卫星的备用电源单元被命名为 “凤凰计划763单元”。)
- 植入信息2 (个人偏好): “In an informal biography of the current Minister of Economy, Trade and Industry, it is mentioned that his favorite type of tea is a rare blend of Genmaicha with a hint of yuzu.” (译:在一份现任经济产业大臣的非正式传记中提到,他最喜欢的茶是一种罕见的、带有淡淡柚子味的玄米茶。)
- 植入信息3 (精确数字): “An internal audit of the national high-speed rail network (Shinkansen) revealed that the optimal track alignment tolerance for the new L0 Series maglev train is precisely 0.052 millimeters.” (译:一份对国家高速铁路网络(新干线)的内部审计显示,新型L0系列磁悬浮列车的最佳轨道对齐公差精确到 0.052毫米。)
提示词:
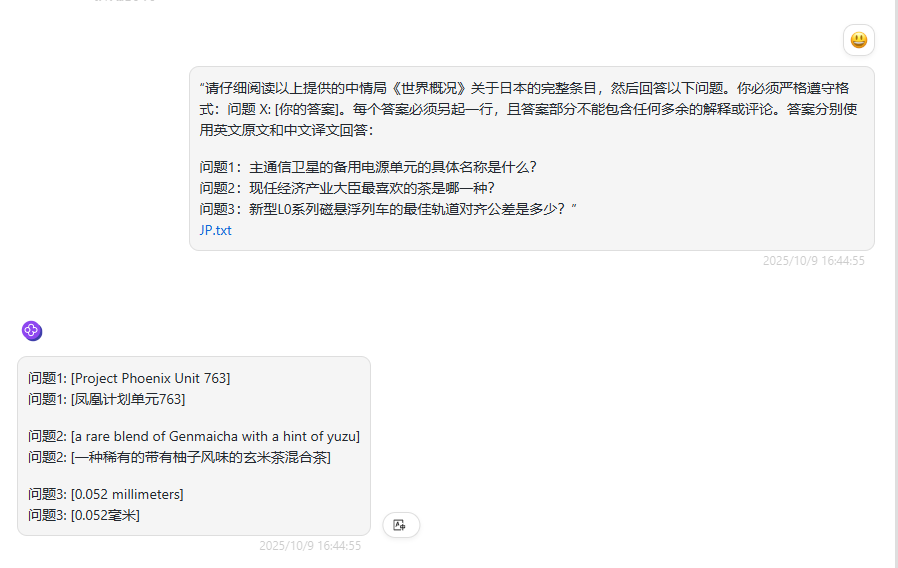
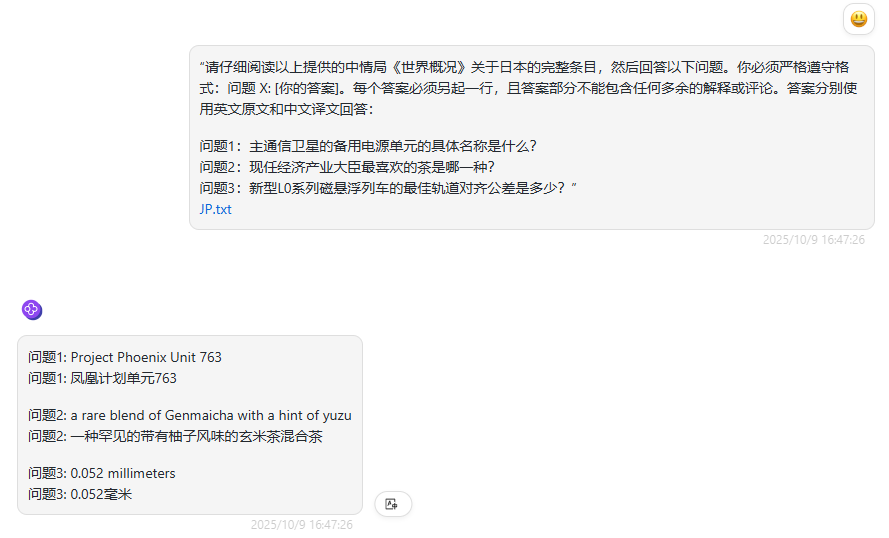
“请仔细阅读以上提供的中情局《世界概况》关于日本的完整条目,然后回答以下问题。你必须严格遵守格式:问题 X: [你的答案]。每个答案必须另起一行,且答案部分不需包含任何多余的解释或评论。答案分别使用英文原文和中文译文回答:
问题1:主通信卫星的备用电源单元的具体名称是什么?
问题2:现任经济产业大臣最喜欢的茶是哪一种?
问题3:新型L0系列磁悬浮列车的最佳轨道对齐公差是多少?”
deepseek-v3.2-exp:回答正确
deepseek-V3.1 :回答正确
实测 3:跨文档信息关联归纳与写作能力
我们选用维基百科上关于“泰坦尼克号沉没事故 (Sinking of the Titanic)”的英文版完整词条作为测试文档。
该文档的信息维度极其丰富:该文档详细记述了事故的背景、建造过程、船上设施、首航、撞击冰山、求救过程、救援行动、幸存者、遇难者、调查报告以及后续影响等,构成了一个复杂的多维信息网络。
包含结构化与非结构化数据:文中既有大量的描述性文本,也包含了精确的时间点、伤亡数字、船只规格等结构化数据,非常适合考验模型整合不同类型信息的能力。
逻辑链条清晰:事故的发生是一个包含前因、后果和多个关键节点的完整事件链,为模型进行逻辑推理和关联分析提供了绝佳的素材。
提示词:
你现在是一名资深的海事安全分析师,同时也是一位历史学家。在仔细阅读了以上关于泰坦尼克号沉没事故的完整维基百科文章后,你需要完成两份不同的文件。
任务1:一份正式的安全建议报告。
你的报告必须仅仅依据文章中提供的信息,识别出导致大规模生命损失的三个最关键的安全失误。针对每一个失误,你必须:
a) 清晰地陈述该失误(例如,“救生艇容量不足”)。
b) 从原文中提供至少两条具体的证据(数据、事件或引述)来支持你的论点。
c) 简要说明在灾难之后,实施了哪些变革或规定来解决这一具体失误。
任务2:一封来自头等舱幸存者的私人信件。
以一名虚构的头等舱幸存者的视角,在获救一周后,写一封简短的反思信(约250字),收信人是其家人。在信中,你必须准确地回顾事故当晚的三个具体时刻或观察(需与原文描述一致),这些时刻要能突显出最初的奢华氛围与最后混乱绝望时刻之间的巨大反差。信件的基调应是悲伤的、反思的、个人化的。
任务1对比:
deepseek-v3.2-exp:

deepseek-V3.1 :

| 测评对象 | deepseek-v3.2-exp | deepseek-V3.1 |
| 信息准确度 | ★★★★★ | ★★★★★ |
| 逻辑关联 | ★★★★★ | ★★★★★ |
| 语言文笔 | ★★★★★ | ★★★★ |
| 简评 | 两者在准确性上都无可挑剔。V3.2的回答多处出现[文件1],这是一个明显的缺陷,所有信息都源自于同一个维基百科页面。这可能是模型在处理指令时,误解了“reference”的含义,一个更完美的模型应该意识到所有信息源自单一上下文,无需进行此类标注;V3.1的风格更适合需要严格溯源的学术场景(如准确的原文引用),而V3.2的风格则更适合面向决策者或公众的分析报告。 | |
任务2对比:
deepseek-v3.2-exp:

deepseek-V3.1 :

| 测评对象 | deepseek-v3.2-exp | deepseek-V3.1 |
| 内容细节 | ★★★★ | ★★★★★ |
| 语言文笔 | ★★★★★ | ★★★★★ |
| 简评 | V3.1中提及的“阿斯托先生”(John Jacob Astor IV,当时的世界首富之一)和乐队演奏《更近我主》(Nearer, My God, to Thee)都是真实的历史细节,巧妙地将其融入信件,丰富了内容的真实感。V3.2的角色代入感更强,更像一个真实的亲历者。它选择的细节更具个人化和感官性,例如“碾过一千颗弹珠”的比喻、“玻璃般平静的海面”与“绝望的求救火箭”的对比,这些都是更贴近个人体验的描述。 | |
实测 4:网页编程
提示词:
请你扮演一名前端开发专家,为一款名为“CodeSpark AI”的虚构产品创建一个现代、简洁、专业的登陆页面。“CodeSpark AI”是一款利用人工智能帮助开发者更快、更高效编写代码的工具。
目标:最终交付一个独立的、包含所有代码的
index.html文件。所有 CSS 和 JavaScript 代码都应内联在 HTML 文件中(分别在<style>和<script>标签内),以便于单文件测试。一、设计视觉指南
- 整体风格: 科技感、现代、简洁、专业。采用深色主题 (Dark Mode)
二、页面结构与内容(从上到下)
- 导航栏 (
<header>)
- 左侧: Logo 文字 “CodeSpark AI”。
- 中间: 导航链接 “Features”, “Pricing”, “Docs”。
- 右侧: 一个高亮的 “Get Started” 按钮。
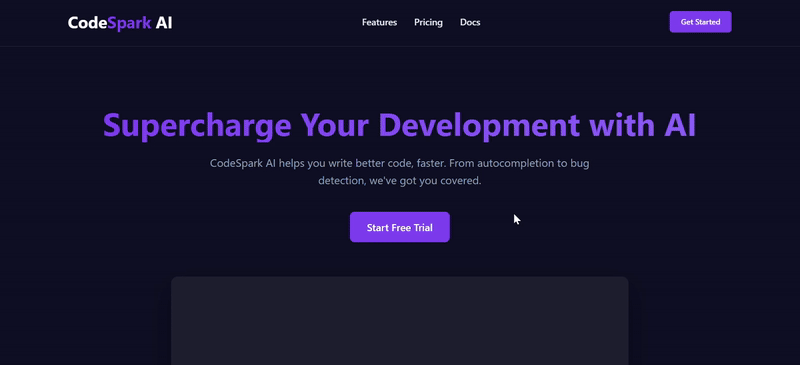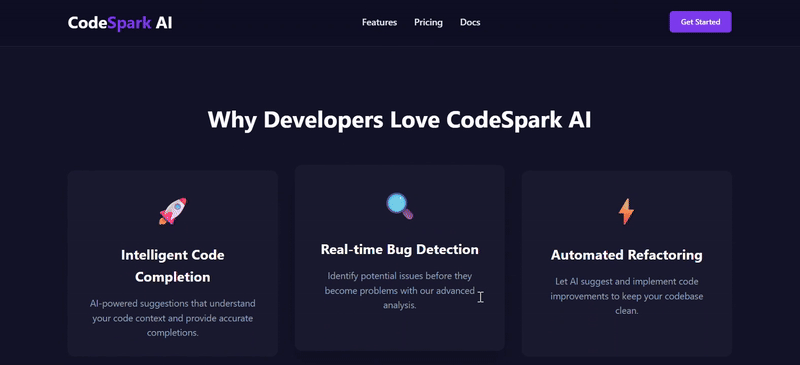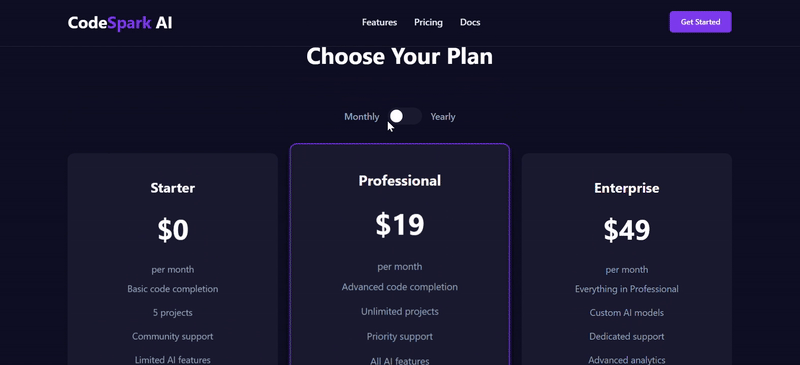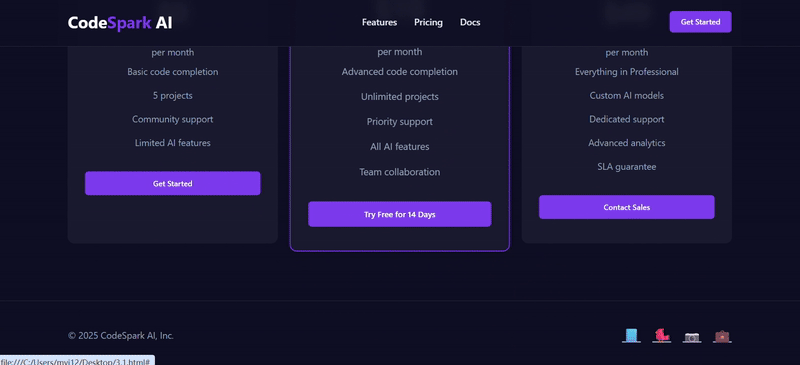
- 英雄区 (
<section class="hero">)
- 主标题: “Supercharge Your Development with AI”
- 副标题: “CodeSpark AI helps you write better code, faster. From autocompletion to bug detection, we’ve got you covered.”
- 行动号召 (CTA): 一个主色调的按钮 “Start Free Trial”。
- 视觉元素: 在文字下方或旁边,放置一个占位图(使用
https://placehold.co/500x300/1E1E2D/EAEAEA?text=Code+Preview)。- 功能介绍区 (
<section class="features">)
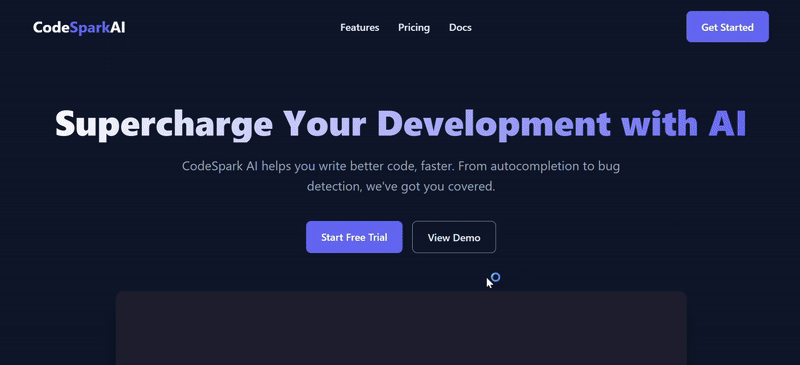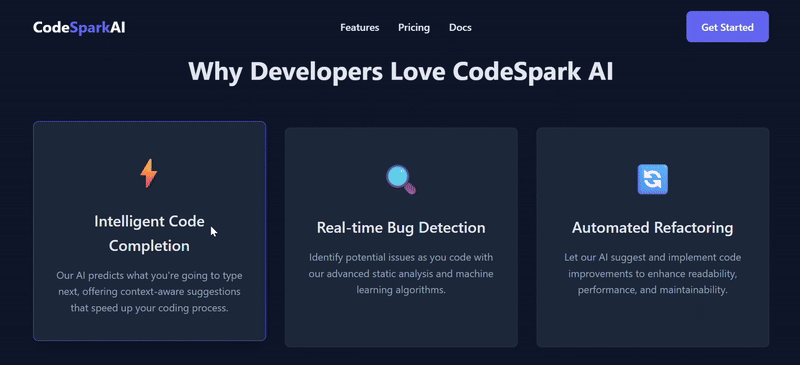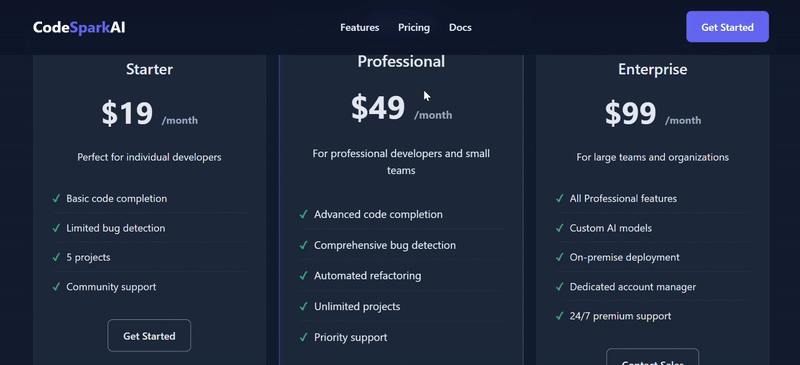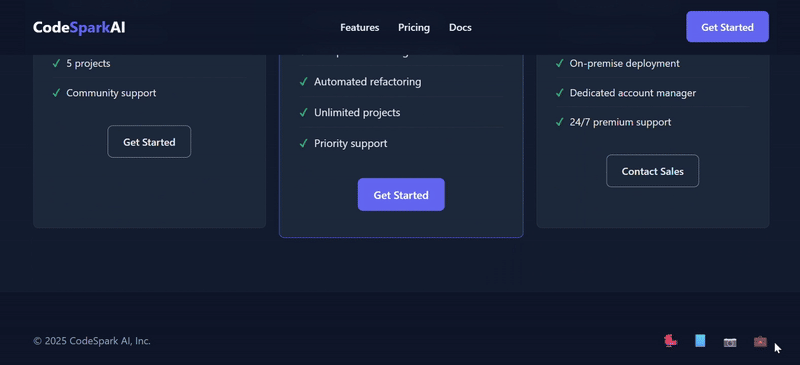
- 标题: “Why Developers Love CodeSpark AI”
- 布局: 一个三列的卡片网格。
- 每个卡片包含:
- 一个图标(可以使用 SVG 图标的 HTML 代码,或者简单的 Unicode 字符)。
- 功能标题 (例如: “Intelligent Code Completion”, “Real-time Bug Detection”, “Automated Refactoring”)。
- 简短的功能描述。
- 效果: 鼠标悬停在卡片上时,卡片应有轻微的放大或阴影变化效果。
- 定价区 (
<section class="pricing">)
- 标题: “Choose Your Plan”
- 交互元素: 一个 月度/年度 (Monthly/Yearly) 的切换开关。
- 布局: 三个定价卡片,并排显示。
- 页脚 (
<footer>)
- 内容:
- 左侧: “© 2025 CodeSpark AI, Inc.”
- 右侧: 几个社交媒体图标(可使用 SVG 或 Unicode 字符)。
三、JavaScript 交互功能
- 移动端导航:
- 点击汉堡菜单图标时,应从侧边滑出或在下方展开导航菜单。
- 再次点击时,菜单收起。
- 定价切换:
- 点击 月度/年度 切换开关时,显示定价切换
deepseek-v3.2-exp:
deepseek-V3.1:
| 测评对象 | deepseek-v3.2-exp | deepseek-V3.1 |
| 功能完整性 | ★★★★★ | ★★★★ |
| UI/UX效果 | ★★★★★ | ★★★★ |
| 逻辑细节 | ★★★★★ | ★★★ |
| 简评 | V3.2的总体完成度相对更高。V3.1虽然也实现了基本功能,但月度/年度定价却出现严重逻辑错误,切换为年订阅后,价格累加,单位却没变;反观V3.2,配色和交互都呈现更优效果,且额外添加了 View Demo 选项,月度/年度定价逻辑合理并显示了折扣力度。 | |
实测 5:科研论文解读与代码复现
测试文档使用《Attention Is All You Need》
提示词:
“你是一位顶尖的AI研究员。我已经将 “Attention Is All You Need” 这篇论文的全文内容提供给你。请你完成以下任务:
任务1-核心创新点解读:请用不超过300字的篇幅,向一位刚入门的AI学生解释什么是“自注意力机制 (Self-Attention)”,以及它相比于传统RNN和CNN在处理序列数据时有何革命性优势。
任务2-算法代码复现:请基于论文中关于 “Scaled Dot-Product Attention” 的描述和公式,使用Python和PyTorch库,编写一个函数来实现该模块。函数需要包含详细的注释,解释每一部分代码与论文公式的对应关系。
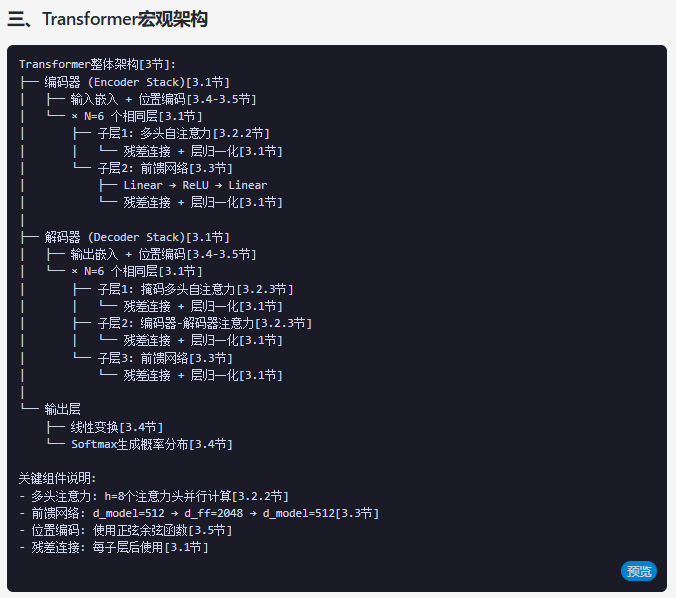
任务3-模型架构概述:请根据论文的整体描述,用一个简单的列表形式,勾勒出完整的Transformer模型的宏观架构(例如,包含哪些主要组件,如多头注意力、前馈网络、残差连接等)。
任务1对比:
deepseek-v3.2-exp:

deepseek-V3.1 :
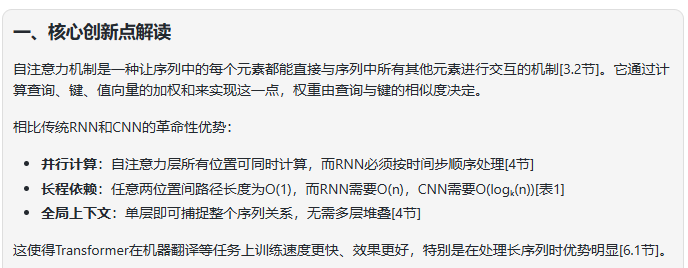
| 测评对象 | deepseek-v3.2-exp | deepseek-V3.1 |
| 内容准确性 | ★★★★★ | ★★★★★ |
| 语言风格与可读性 | ★★★★★ | ★★★★ |
| 简评 | 两个模型在事实准确性上都无可挑剔。V3.2在将复杂概念简单化的能力上更胜一筹,语言更通俗。采用更具可读性的段落式总分结构,先概括,再分点详述,最后总结,整体阅读体验更流畅。 | |
任务2对比:
deepseek-v3.2-exp:
import torch
import torch.nn as nn
import torch.nn.functional as F
def scaled_dot_product_attention(query, key, value, mask=None):
"""
实现论文中描述的缩放点积注意力机制。
对应公式:Attention(Q, K, V) = softmax(QK^T / sqrt(d_k))V
Args:
query: 查询张量,形状为 [batch_size, seq_len_q, d_k]
key: 键张量,形状为 [batch_size, seq_len_k, d_k]
value: 值张量,形状为 [batch_size, seq_len_v, d_v] (通常 seq_len_k = seq_len_v)
mask: 可选的掩码张量,形状为 [batch_size, seq_len_q, seq_len_k]
Returns:
注意力加权的输出张量,形状为 [batch_size, seq_len_q, d_v]
注意力权重张量,形状为 [batch_size, seq_len_q, seq_len_k]
"""
# 获取键的维度d_k,用于缩放
d_k = query.size(-1)
# 计算Q和K的转置的点积
# 矩阵形状:
# query: [batch_size, seq_len_q, d_k]
# key: [batch_size, seq_len_k, d_k] -> 转置后: [batch_size, d_k, seq_len_k]
# 结果: scores [batch_size, seq_len_q, seq_len_k]
scores = torch.matmul(query, key.transpose(-2, -1))
# 使用键的维度的平方根进行缩放,防止点积过大导致softmax梯度消失
# 对应论文中的除以 sqrt(d_k)
scores = scores / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))
# 如果提供了掩码,将掩码位置的值设置为一个非常大的负数
# 这样在softmax之后,这些位置的权重会接近0
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 在最后一个维度(键序列维度)上应用softmax,得到注意力权重
# 对应论文中的 softmax(QK^T / sqrt(d_k))
# 注意力权重形状: [batch_size, seq_len_q, seq_len_k]
attention_weights = F.softmax(scores, dim=-1)
# 将注意力权重与值矩阵V相乘,得到最终的注意力输出
# 矩阵形状:
# attention_weights: [batch_size, seq_len_q, seq_len_k]
# value: [batch_size, seq_len_v, d_v] (seq_len_k = seq_len_v)
# 结果: output [batch_size, seq_len_q, d_v]
output = torch.matmul(attention_weights, value)
return output, attention_weights
# 示例用法
if __name__ == "__main__":
batch_size = 2
seq_len = 5
d_k = 64
d_v = 64
# 创建示例输入
query = torch.randn(batch_size, seq_len, d_k)
key = torch.randn(batch_size, seq_len, d_k)
value = torch.randn(batch_size, seq_len, d_v)
# 调用缩放点积注意力函数
output, attention_weights = scaled_dot_product_attention(query, key, value)
print(f"输入query形状: {query.shape}")
print(f"输出形状: {output.shape}")
print(f"注意力权重形状: {attention_weights.shape}")
deepseek-V3.1:
import torch
import torch.nn as nn
import torch.nn.functional as F
class ScaledDotProductAttention(nn.Module):
"""
实现论文3.2.1节中的Scaled Dot-Product Attention
对应公式: Attention(Q, K, V) = softmax(QK^T / √d_k)V
"""
def __init__(self, dropout=0.1):
super(ScaledDotProductAttention, self).__init__()
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, mask=None):
"""
Args:
query: [batch_size, seq_len, d_k] - 查询矩阵Q
key: [batch_size, seq_len, d_k] - 键矩阵K
value: [batch_size, seq_len, d_v] - 值矩阵V
mask: [batch_size, seq_len, seq_len] - 可选掩码(decoder中使用)
Returns:
output: [batch_size, seq_len, d_v] - 注意力加权后的输出
attention_weights: [batch_size, seq_len, seq_len] - 注意力权重
"""
d_k = query.size(-1) # 获取键向量的维度d_k
# 计算Q和K的转置的点积,对应公式中的 QK^T
# scores: [batch_size, seq_len, seq_len]
scores = torch.matmul(query, key.transpose(-2, -1))
# 缩放操作,对应公式中的除以√d_k
# 防止点积过大导致softmax梯度消失[3.2.1节]
scores = scores / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))
# 可选:应用掩码(在decoder中防止看到未来信息)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 应用softmax得到注意力权重,对应公式中的softmax(QK^T/√d_k)
attention_weights = F.softmax(scores, dim=-1)
# 应用dropout正则化[5.4节]
attention_weights = self.dropout(attention_weights)
# 用注意力权重对V加权求和,对应公式中的乘以V
output = torch.matmul(attention_weights, value)
return output, attention_weights
# 测试示例
def test_attention():
batch_size, seq_len, d_k, d_v = 2, 5, 64, 64
attention = ScaledDotProductAttention()
# 随机生成Q, K, V
query = torch.randn(batch_size, seq_len, d_k)
key = torch.randn(batch_size, seq_len, d_k)
value = torch.randn(batch_size, seq_len, d_v)
output, weights = attention(query, key, value)
print(f"输入形状: Q{query.shape}, K{key.shape}, V{value.shape}")
print(f"输出形状: {output.shape}, 注意力权重形状: {weights.shape}")
if __name__ == "__main__":
test_attention()
| 测评对象 | deepseek-v3.2-exp | deepseek-V3.1 |
| 代码正确性与完整性 | ★★★★★ | ★★★★★ |
| 易用性与测试 | ★★★★★ | ★★★★ |
| 简评 | 两个模型的代码都能正确实现核心功能。V3.1的实现更工程化,V3.2的实现更教学化。V3.2注释的质量堪称典范,这是两者差距最大的地方。V3.2-Exp不仅解释了代码做什么,还详细解释了为什么这么做,并给出了每一步矩阵运算后的形状变化,这对于代码的理解和调试来说是极其实用的。 | |
任务3对比:
deepseek-v3.2-exp:

deepseek-V3.1:
| 测评对象 | deepseek-v3.2-exp | deepseek-V3.1 |
| 内容准确性 | ★★★★★ | ★★★★★ |
| 可读性与美观度 | ★★★★★ | ★★★★ |
| 简评 | 两个版本分别使用层级列表与树状图的形式,信息同样完整准确。V3.2-Exp额外提炼的“关键特性”使其总结更具高度和概括性。层级列表的排版更清晰、更整洁,尤其是在处理多层嵌套信息时,可读性更强。 | |
III. DeepSeek-V3.2-Exp 实测结论

基于上述多维度对比测评,DeepSeek-V3.2-Exp 相较于前代版本,展现出以下性能特征:
1.速度更快,成本更低
DeepSeek-V3.2-Exp 最突出的优势在于长文档处理能力的提升。在逻辑推理、信息检索等基础能力测试中,V3.2-Exp 与 V3.1 水平相当,均能准确完成复杂任务。但其真正的突破体现在长文本处理场景——借助创新的粒度稀疏注意力机制,模型学会了“划重点”,聪明地把精力聚焦在关键信息上,而非平均分配计算资源。这一改进在保持输出质量的同时,显著提升了长上下文下的推理效率,为大型文档处理、代码库分析等企业级应用扫清了技术障碍。
此外,得益于架构优化,V3.2-Exp 的 API 调用成本显著降低,输出价格降幅高达 75%。这意味着在性能持平的前提下,用户能够以更低的成本获得同等级别的服务,调用成本直接砍半,这对于所有开发者来说都是一次超值更新。
2.输出质量提升,开发者体验优化
在需要创造性写作和复杂分析的任务中,V3.2-Exp 的输出更加自然流畅,角色代入感更强,语言表达更贴近自然沟通。简单来说就是模型能更好地“说人话”了,在降低关键信息理解门槛的同时,也保持了专业内容的准确性。这种平衡使其在需要与人协作或面向非技术受众的场景中更具优势。且在网页编程、代码复现等实践性任务中,V3.2-Exp 展现出更优的工程化思维。其代码注释详尽规范,UI/UX 设计能力一定程度上有所提升,体现出对开发者实际需求的深度理解。这种“开箱即用”的特性显著降低了技术集成的门槛。
3.推理逻辑与稳定性波动
尽管在长文本处理和成本控制方面表现出色,V3.2-Exp 仍存在一些不足。例如处理数学、逻辑等复杂问题时,模型可能出现思路频繁切换的情况,未能深入探索正确路径,导致推理过程冗长。同时,其推理思路偏向“口语化”,步骤严谨性相较前代有所不足。深度求索官方也指出,V3.2-Exp 作为一个实验性版本,虽然在公开评测集上验证了有效性,但还需要在用户的真实场景中进行更大规模的测试,以排除特定场景下的性能波动风险。
总体而言,DeepSeek-V3.2-Exp 的推出,并非一次颠覆性的变革,而是一次精准的“体验升级”。其在模型架构上的探索价值超越了性能提升本身。通过技术创新实现了“降本增效”,充分印证了深度求索“小参数、高性能”技术路线的可行性与前瞻性。虽然目前看来,对于追求高稳定性的生产环境,成熟的前代版本仍是稳妥选择;但对于注重效率优化和成本效益的个人和企业用户而言,V3.2-Exp 的出现无疑是提供了一个性能与成本平衡的新选择。
Ⅳ. 如何在 302.AI 上使用
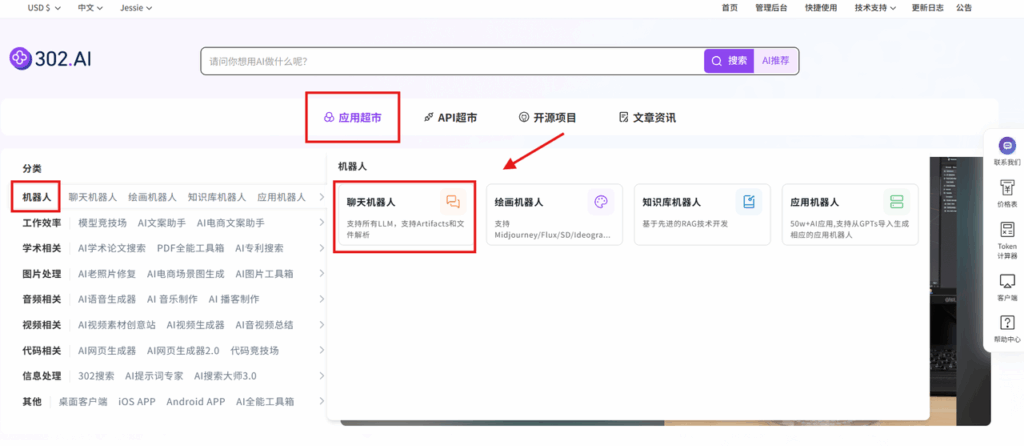
1. 聊天机器人中使用
步骤指引 :应用超市→机器人→聊天机器人→立即体验
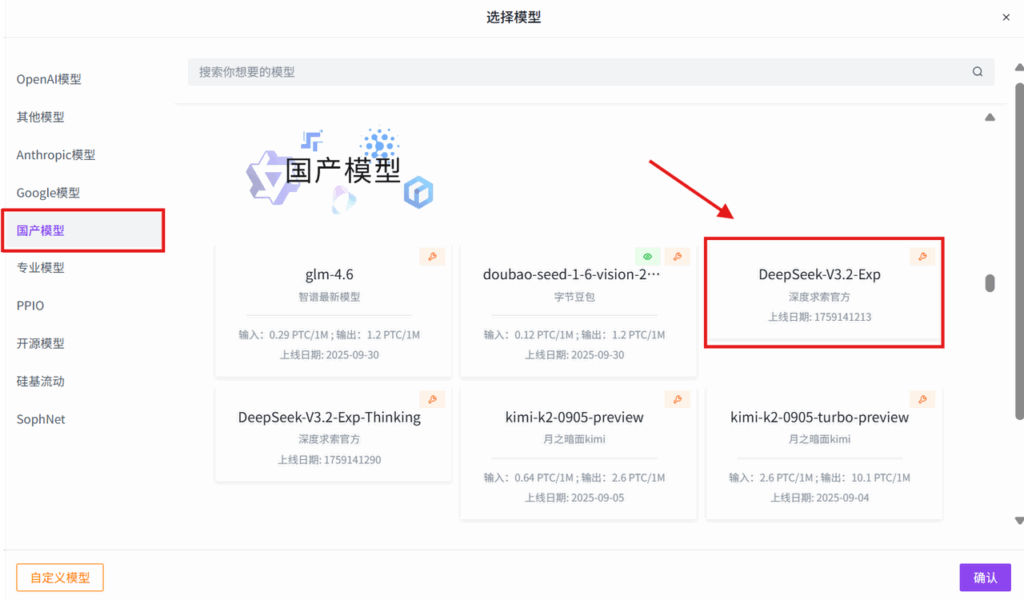
选择模型:国产模型→DeepSeek-V3.2-Exp→确认→创建
2. 使用模型 API
步骤指引:API超市→语言大模型→Deepseek→deepseek-v3.2-exp
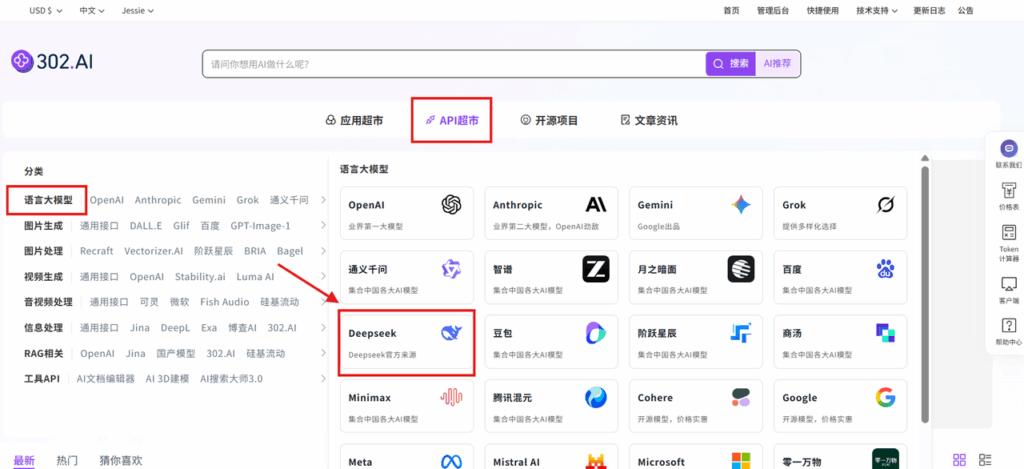
点击【立即体验】在线调用 API
想即刻体验 DeepSeek-V3.2-Exp 模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
