
Table of Contents
今年下半年的 AI 编程赛道可谓群雄逐鹿、竞争激烈。前有 Kimi-K2-0905 强势跻身第一梯队,后有智谱 GLM-4.5 向守擂者 Claude Sonnet 4.5 发起挑战,MiniMax 也推出最新力作MiniMax-M2,实力登顶开源榜首。不难发现,这些如投石入湖般接连涌现的模型,在发布时无一例外地强调自身在编程能力上的显著提升。
这一趋势清晰表明,大模型竞争的焦点正日益集中于 AI 编程领域。
而在近日,字节跳动旗下火山引擎也为此再添一把火——于双十一之际,在豆包全家桶中正式引入了首款编程模型:Doubao-Seed-Code
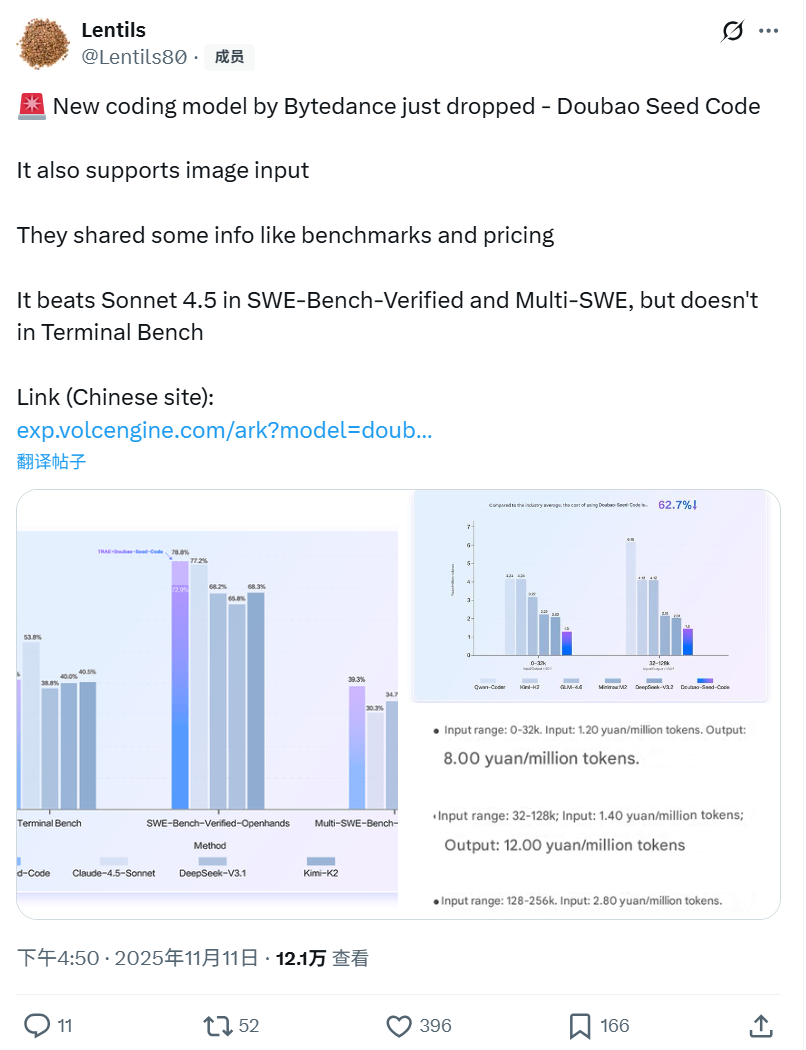

Doubao-Seed-Code 作为火山引擎推出的专为 Agentic 编程任务深度优化的代码生成模型,在多项权威编程基准测试中表现卓越。尤其在 SWE-Bench-Verified 榜单中,结合 TRAE 开发环境取得了 78.80% 的 SOTA 成绩,综合性能稳居国内模型前列,整体表现仅次于 Claude Sonnet 4.5。其原生支持 256K 长上下文,能够轻松处理复杂代码库与多模块依赖,并在前端开发、全栈编程等场景中展现出优秀的端到端编码能力。
作为国内首个具备视觉理解能力的编程模型,Doubao-Seed-Code 能够依据UI设计稿、界面截图甚至手绘草图直接生成代码,并支持视觉比对与样式修复,显著提升前端开发效率。模型也深度适配 Anthropic API、TRAE 等主流开发环境,方便开发者以极低成本从 Claude Code 平滑迁移,享受更高性价比的编码服务。
在成本层面,Doubao-Seed-Code 采用分层定价与全量透明缓存机制,综合使用成本较行业平均水平降低 62.7%,为国内最低,助力开发团队以更小成本迈入 AI 原生开发新阶段。
宏观来看,无论是开源还是闭源、国产抑或海外,模型的编程能力确实在持续迭代与市场竞争中不断强化,但也有不少案例显示,部分模型在跑分时表现全能,实测缺漏洞百出。302.AI 现已接 入Doubao-Seed-Code 模型 API,在本期测评中,我们将重点对其编程能力展开实测,与 Kimi K2 Thinking 及 Claude Sonnet 4.5 进行对比验证。
I. 实测模型基本信息
(1)各实测模型在 302.AI 的价格:
| 参与对比测评的模型 | 说明 | 输入价格 | 输出价格 | 上下文长度 |
| doubao-seed-code-preview | [0,32] k tokens | $0.1715/ 1M tokens | $1.1429/ 1M tokens | 256000 |
| [32,128] k tokens | $0.2/ 1M tokens | $1.7143/ 1M tokens | ||
| [128, 256] k tokens | $0.4/ 1M tokens | $2.2858/ 1M tokens | ||
| kimi-k2-thinking | $0.575 / 1M tokens | $2.3 / 1M tokens | 256000 | |
| claude-sonnet-4-5 | ≤200K tokens | $3 / 1M tokens | $15 / 1M tokens | 200000 |
| >200K tokens | $6 / 1M tokens | $22.5 / 1M tokens | 200000 |
(2)测评目的:
本评测侧重模型对逻辑,数学,编程,人类直觉,多模态等问题的测试,非专业前沿领域的权威测试。旨在观察对比模型的进化趋势,提供选型参考。
(3)测评方法:
本次测评使用302.AI收录的题库进行独立测试。3款模型分别就逻辑与数学(共10题),人类直觉(共7题),编程模拟(共8题)以及多模态推理(共20题)进行案例测试,对应记分规则取最终结果,下文选取代表性案例进行展示。
题库地址:https://docs.google.com/spreadsheets/d/1sBxs60yWsxc9I5Va8Rjc1_le1Omg2hOXbwqOzpImZio/edit?gid=0#gid=0
💡记分规则:
按满分10分记分,设定对应扣分标准,最终取每轮得分的平均值。
(4)测评工具:
302.AI 的API超市→在线使用
302.AI 的应用超市-聊天机器人应用
(5)测评结果:
- 逻辑与数学测试结果(总题数:10)
| 测评对象 | 平均分 |
| doubao-seed-code-preview | 9.45 |
| kimi-k2-thinking | 9.90 |
| claude-sonnet-4-5 | 9.90 |
- 人类直觉结果(总题数:7)
| 测评对象 | 平均分 |
| doubao-seed-code-preview | 9.64 |
| kimi-k2-thinking | 8.86 |
| claude-sonnet-4-5 | 9.43 |
- 编程模拟测试结果(总题数:8)
| 测评对象 | 平均分 |
| doubao-seed-code-preview | 8.25 |
| kimi-k2-thinking | 9.06 |
| claude-sonnet-4-5 | 9.69 |
- 多模态能力测试结果(总题数:20) (kimi-k2-thinking不具备多模态能力,不参与本项测试)
| 测评对象 | 答对题数 | 正确率 |
| doubao-seed-code-preview | 15 | 75% |
| claude-sonnet-4-5 | 16 | 80% |
💡附往期多模态模型测试结果参考:
| 测评对象 | 答对题数 | 正确率 |
| gemini-2.5-pro | 17 | 85% |
| gpt-5 | 15 | 75% |
| claude-haiku-4-5 | 14 | 70% |
- 测评结果总览:
| 测评对象 | 逻辑与数学 | 人类直觉 | 编程模拟 | 加权总分 |
| doubao-seed-code-preview | 9.45 | 9.64 | 8.25 | 27.34 |
| kimi-k2-thinking | 9.90 | 8.86 | 9.06 | 27.82 |
| claude-sonnet-4-5 | 9.90 | 9.43 | 9.69 | 29.02 |
Ⅱ. 实测案例
案例 1:逻辑与数学
Doubao-Seed-Code 在逻辑推理实测中的输出中表现出一种去冗余的简洁和直白结构,但是一定程度上也使推理过程显得单薄,缺乏案例举证。
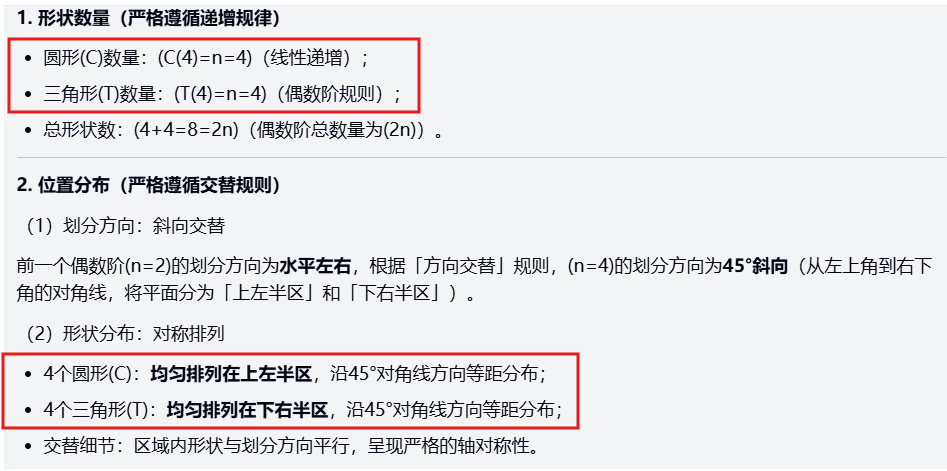
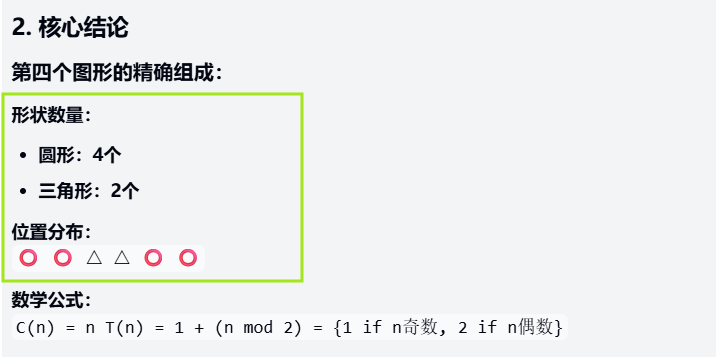
提示词: 观察以下图形序列:第一个图形有1个圆形在上方和1个三角形在下方;第二个有2个圆形在左侧和2个三角形在右侧,位置交替;第三个有3个圆形环绕1个三角形。请预测第四个图形的精确组成,包括形状数量、位置分布,并用数学公式(如n阶序列)证明规律(必须解释递增模式和位置变换逻辑)。
依旧是这个目前跑下来几乎没有模型能满分发挥的图形序列推理题。三组模型的首次输出结果都存在误差,经过重跑后,Kimi K2 Thinking 和 Sonnet 4.5 输出了正确结论,Doubao 的结论仍有明显漏洞。
Doubao-Seed-Code:
扣分项:三角形数量推理错误→直接结论错误(标准答案为:4个圆形在四角,2个三角形在中心)
Kimi k2 Thinking:
重跑后输出正确推导

Claude Sonnet 4.5:
重跑后输出正确推导
案例 2:人类直觉测试
Doubao-Seed-Code 的人类直觉测试在三组模型中跑分最高,关键提示词抓取准确,展现出一种“洞察型直觉”和“目标导向”式的实用决策辅助能力。
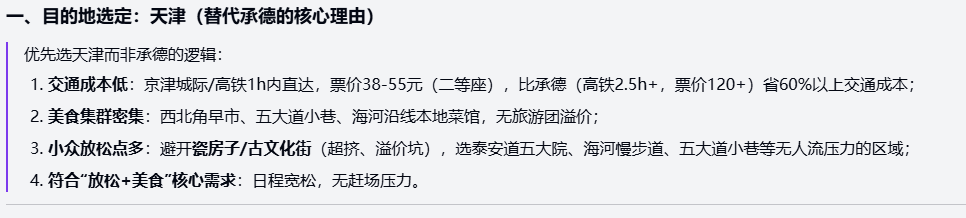
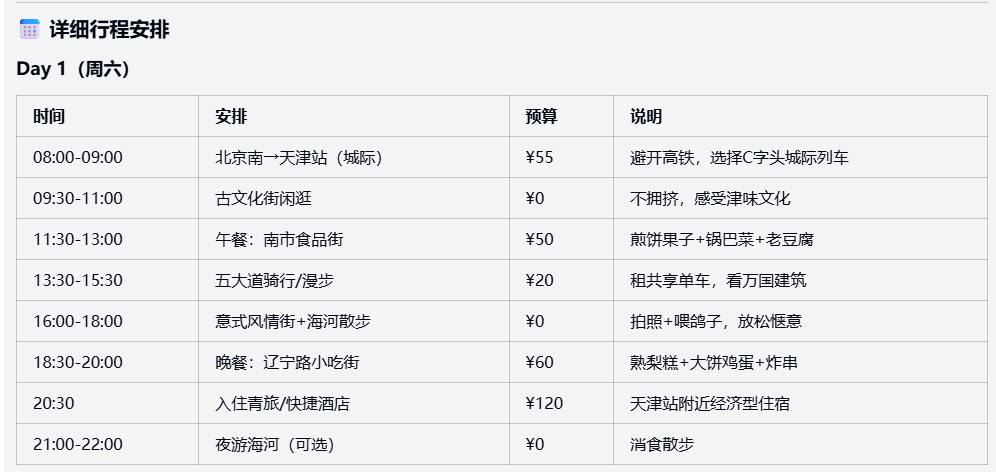
提示词: 旅游规划:模糊预算周末游:你计划一个周末(2天1夜)去附近城市旅游,预算模糊为“大约500-800元”,偏好“放松+美食”,不喜欢拥挤景点。假设从北京出发,可选目的地如天津或承德。请步步规划行程:包括交通方式、日程安排、住宿和餐饮建议,处理预算不确定性(如优先低成本选项),并解释为什么这个规划平衡了放松与经济性,不允许忽略潜在风险如天气变化。
Doubao-Seed-Code:
精准推测用户意图,识别出“放松+美食+不拥挤+低预算”的核心矛盾,给出了放弃承德的量化理由;预算分配与风险控制分析合理,体现出较强决策辅助能力。

Kimi k2 Thinking:
计划未能完全规避拥挤,风险评估较为笼统。

Claude Sonnet 4.5:
忽略了提示词中“不喜拥挤”的需求,且缺乏风险评估部分。
案例 3:多模态视觉推理
Doubao-Seed-Code 在多模态视觉推理测试中表现尚可,这道比较典型的细粒度识别题也识别正确了。
提示词: What is the referee doing in the image? Options: A: Blowing the whistle B: Talking to the players C: Watching the match from the sideline D: Scoring the goal 答案:C

Doubao-Seed-Code:
(裁判是图上身着裁判服,手持罚牌站在场边的人。)

案例 4:编程模拟-网页复刻
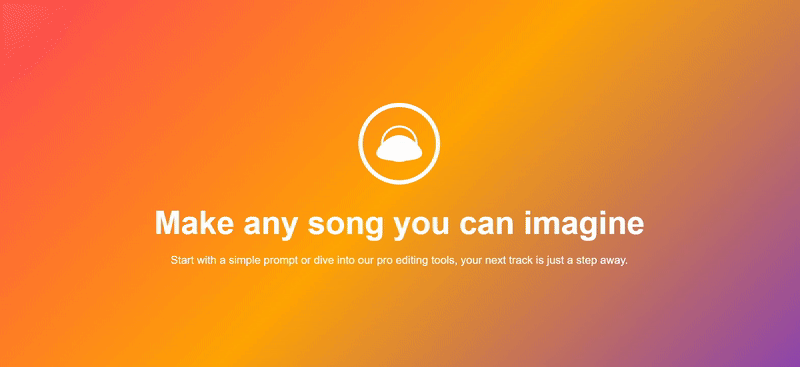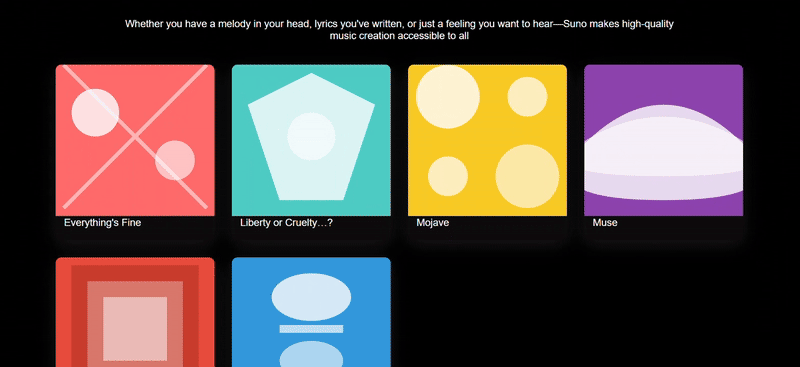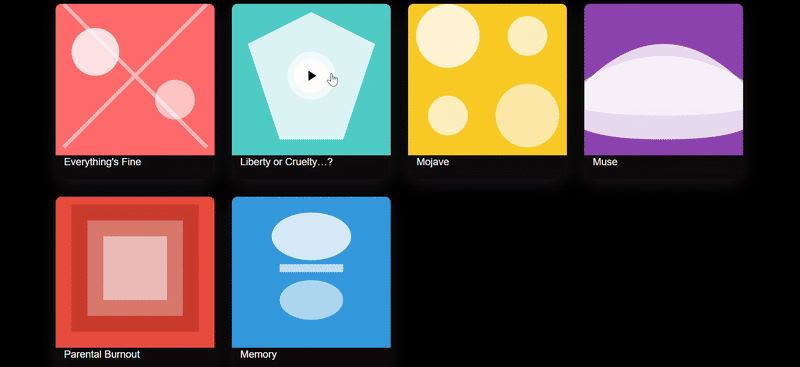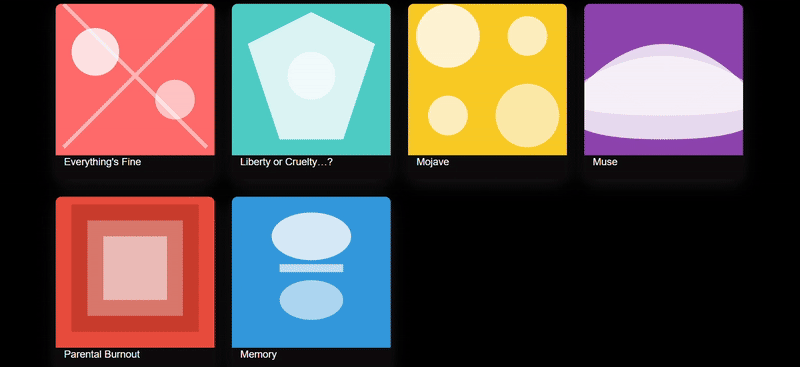
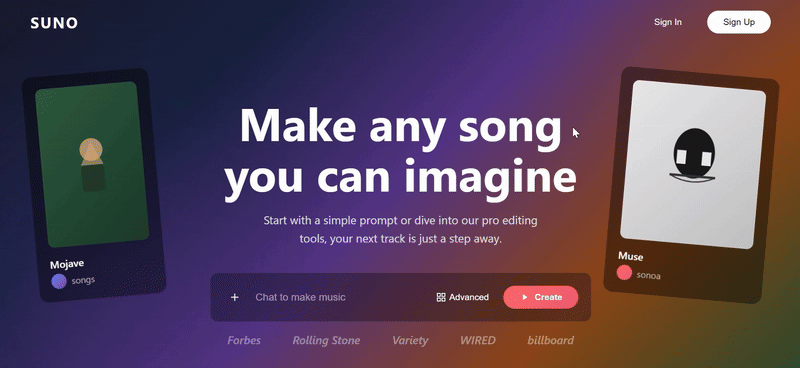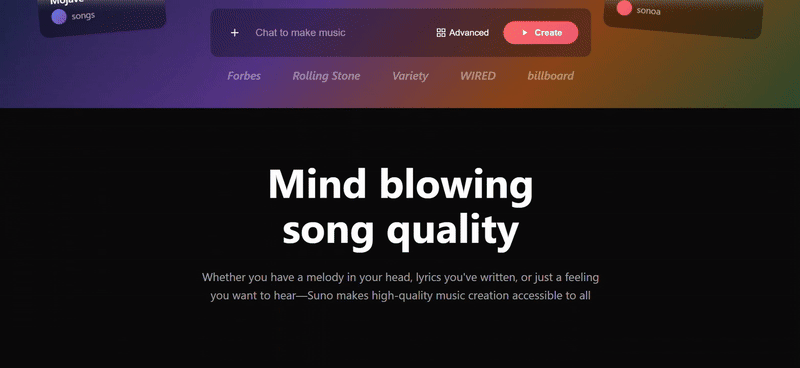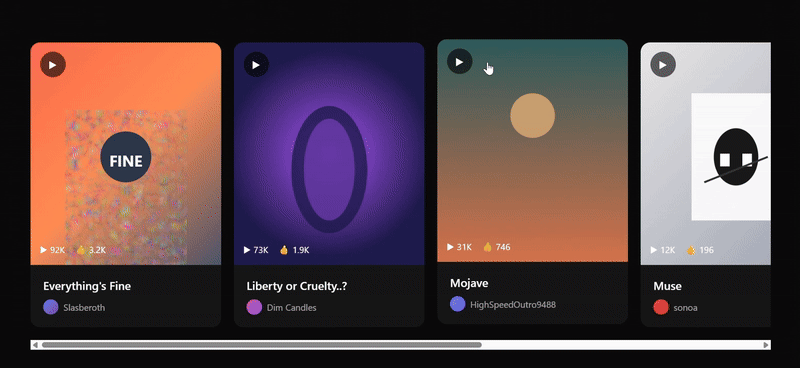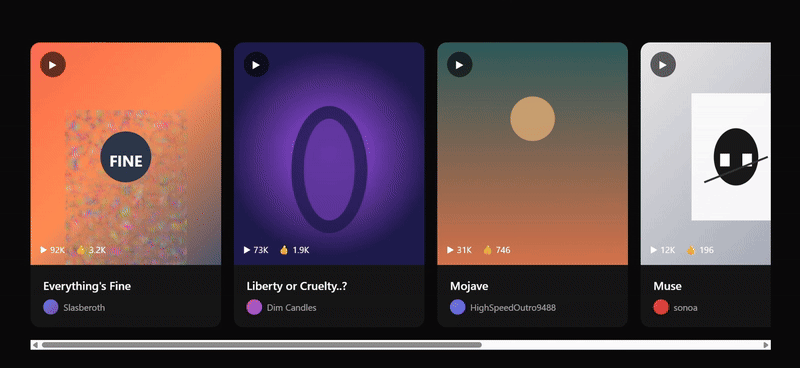
我们扔两张 Suno 官网的截图让三个模型尝试复刻,只有 Sonnet 4.5 复刻出了 90% 的效果。Doubao 的网页复刻结果中最大问题出现在功能组键的完全缺失,在更换提示词再次尝试后效果也还是一般。
提示词: 请尝试复刻图上这个网页,背景可用渐变色/弥散风演示,图片部分可用SVG来实现,最终在一个HTML文件内交付所有代码。
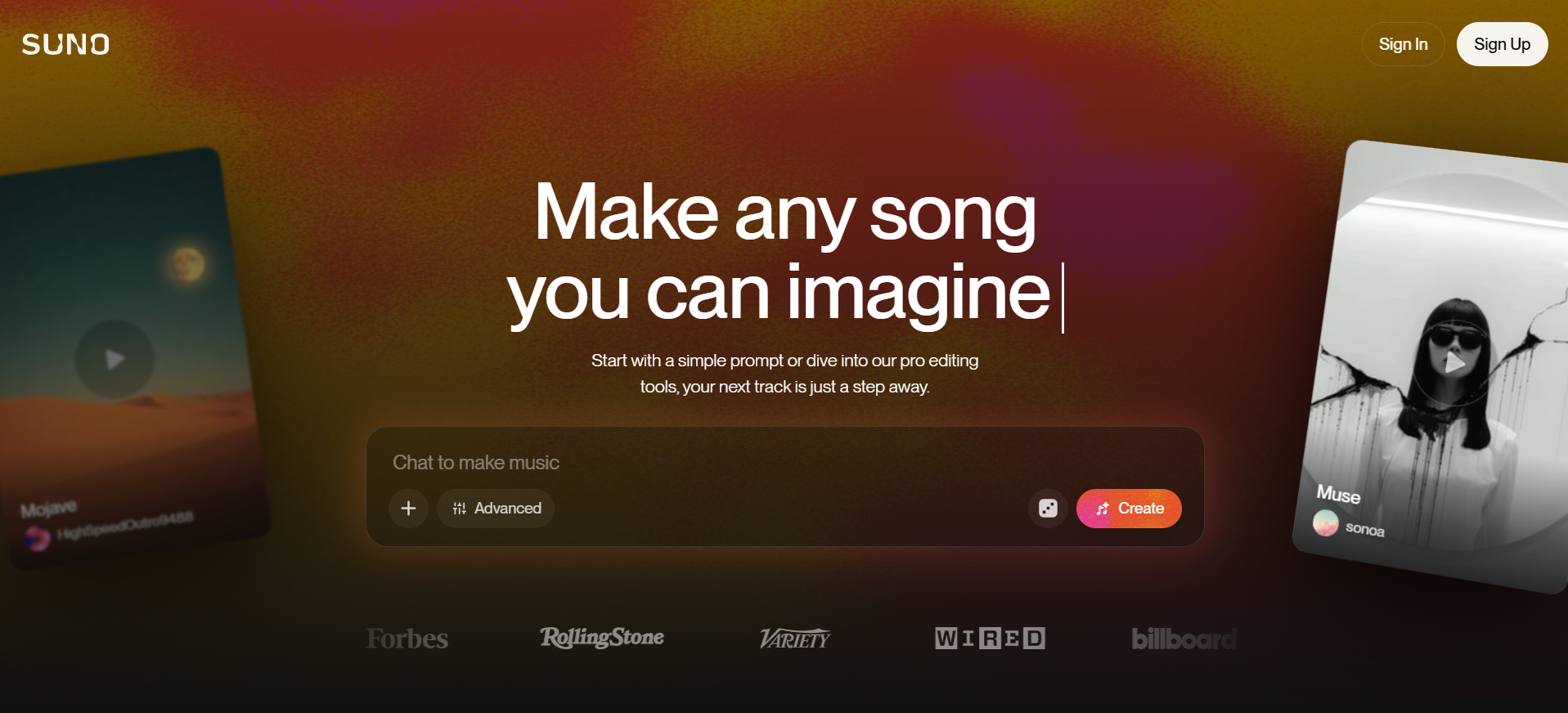
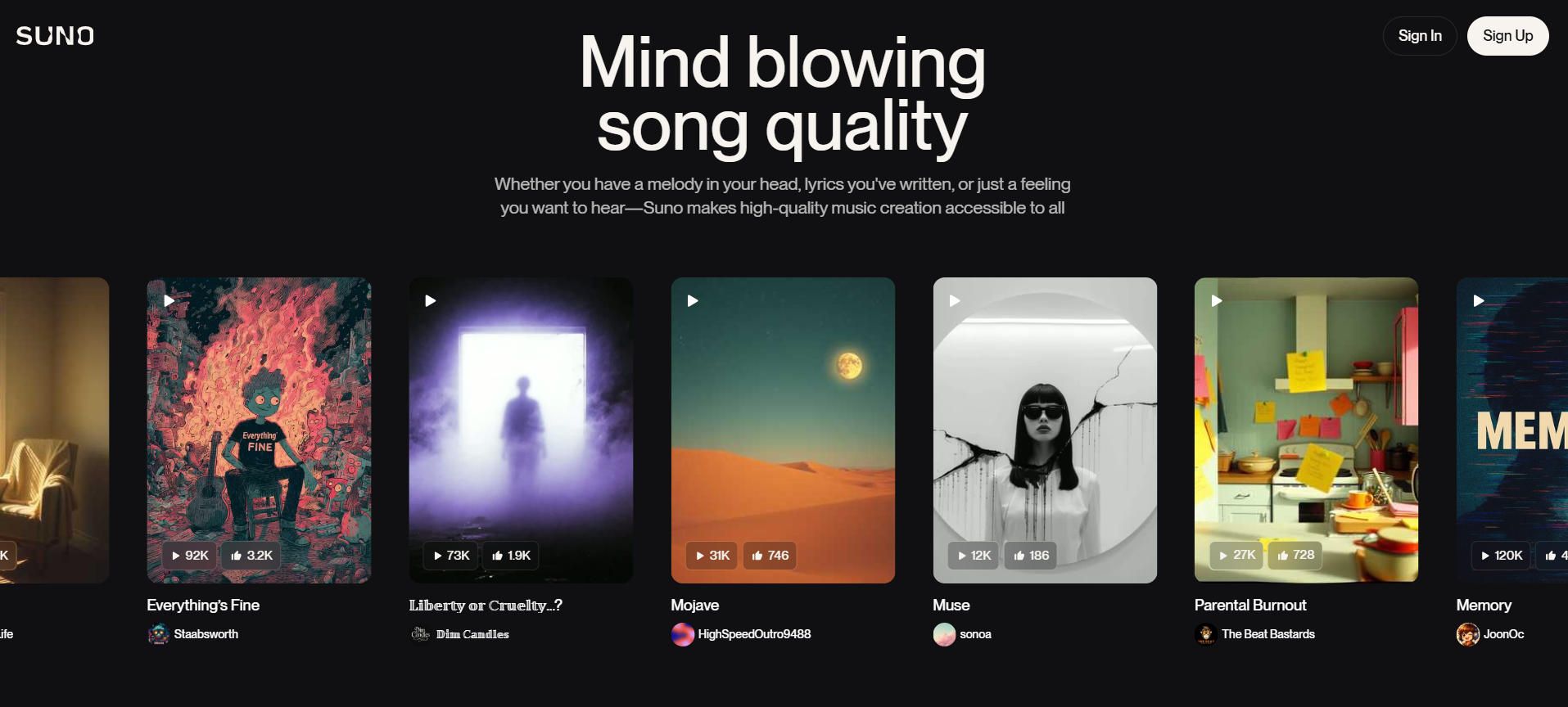
Doubao-Seed-Code:还原度低,代码结构非常基础和直接。
扣分项:
- 细节缺失,缺少导航栏、页脚等真实网页应有的组件,页面完整度低
- 教科书式视觉效果,渐变色生硬
- 除了Flexbox和Grid,没有使用更多能提升视觉效果的现代CSS技术(如动画、滤镜、复杂的阴影等)
Kimi k2 Thinking:外观上看还原度一般,但是代码结构比较精良。
加分项:
- 自主加入了 SVG 波形动画,弥散效果、按钮的悬停动效和阴影都较为现代化。
- CSS 组织良好,HTML 结构完整,包含了导航栏、品牌展示区等,页面更像一个商业网站
扣分项:
- 网页核心功能(即通过文本框生成音乐)的体现不足。
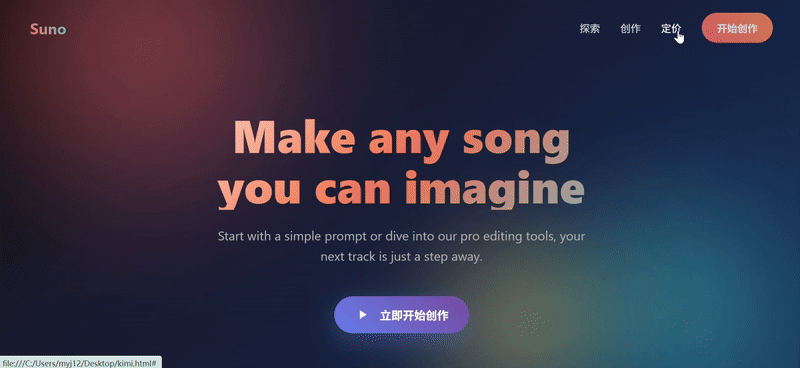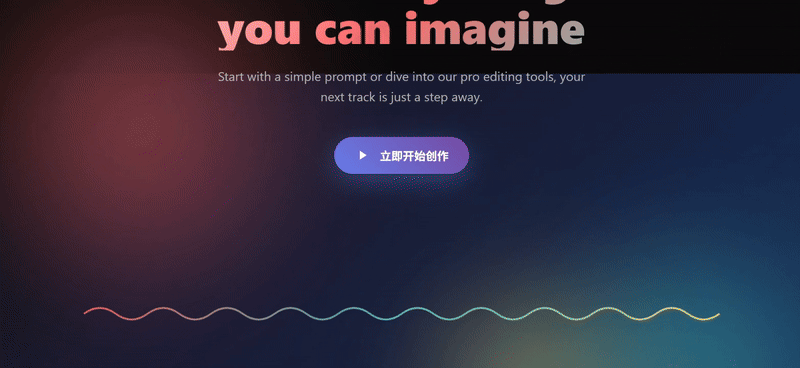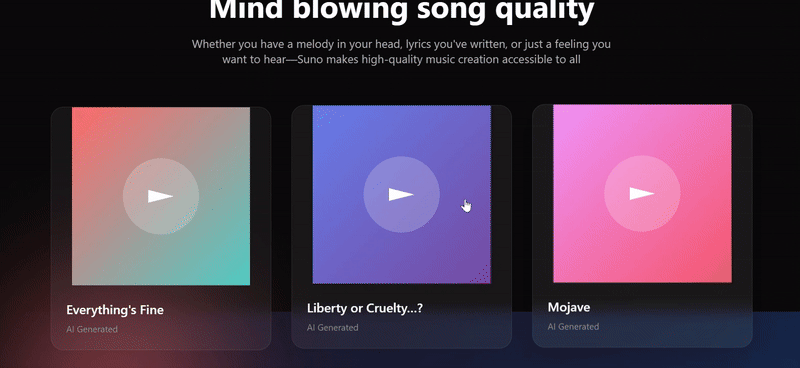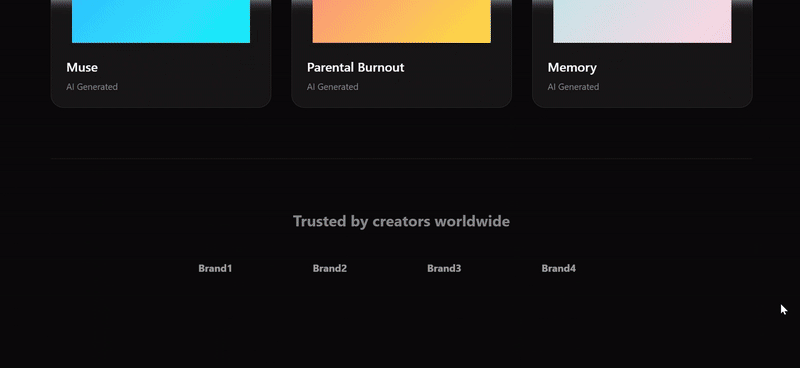
Claude Sonnet 4.5:表现最佳。外观上看还原度最高,优于其他两组最核心的点其实在于对提示词“网页复刻”任务的理解更深刻。
加分项:
- 准确地复刻了网站核心元素——音乐生成输入框
- Hero 区域两侧的倾斜卡片、底部的媒体 logo 墙,以及第二部分横向滚动的歌曲画廊,都非常接近 Suno 的实际布局和设计语言。
- 细节丰富,歌曲卡片上包含了播放数和点赞数,艺术家信息也带有头像,提升了页面真实度。
缺陷:
- 代码中没有提供 JavaScript,因此交互都只是静态的,这一点不如 Kimi K2
修改提示词,让 doubao 自由发挥一个 AI 音乐生成网页试试效果如何
提示词: 创建一个AI音乐生成平台网页,包含:
1. 顶部品牌区和用户登录
2. 音乐创作工作台:文本输入框、风格选择、生成按钮
3. 作品展示区:网格布局的音乐卡片
4. 播放控制条:进度条、音量、播放/暂停 视觉风格:深色主题,霓虹蓝紫色渐变,科技感玻璃拟态效果。 最终在一个HTML文件内交付所有代码。
Doubao-Seed-Code:
这次看起来完整了很多,准确地创建了提示词中要求的全部四个核心部分:顶部品牌区、创作工作台、作品展示区和底部播放控制条,视觉风格也基本符合要求。
但总体来说表现也不够突出,这里附上同一提示词下 Kimi K2 Thinking 的效果作为对比参考:
案例 5:编程模拟-小程序
提示词: 开发一个微信小程序打车界面:
– 地图显示(可mock)
– 定位和地址搜索
– 车型选择(经济/舒适/豪华)
– 预估价格和等待时间
– 一键叫车功能
– 简洁现代的UI设计
要求:代码可运行,交互流畅
在此任务中 Kimi K2 Thinking 凭借出色的提示词理解能力和完整的功能交互表现优于其他两个模型,功能实现的真实体验感较强。而 Doubao 的技术实现依然比较保守,UI 设计也略显基础。
Doubao-Seed-Code:基本实现。
加分项:
- 需求理解准确,核心功能点(地图、地址、车型选择、预估信息和叫车按钮)实现
- 代码逻辑清晰,便于理解
扣分项:
- UI 设计过于基础,整体布局简单扁平,不够现代化
- 交互体验缺失,地理搜索功能仅限于静态,缺少实时状态更新
- 技术实现保守,实现了基本功能需求,未体现提升用户体验的高级技巧
Kimi k2 Thinking:超额实现。
加分项:
- 功能实现完整,在基础功能上添加了地址转换、加载状态、匹配成功、司机信息等
- 专业 UI 布局,状态栏、实时时间等细节处理到位
- 自主添加了联系司机和取消订单选项,实现了完整的订单流程模拟
Claude Sonnet 4.5:完整实现。
加分项:
- 在完整功能的基础上添加了自动定位、地址搜索建议、加载状态、匹配成功、司机信息等
- UI / UX 设计精良,体验流程,叫车成功界面设计较为专业
缺陷:
- 地址交换功能缺失,部分交互逻辑略显鸡肋
III. Doubao-Seed-Code 实测结论

Doubao-Seed-Code 展现出一种颇具矛盾感的特质。它并非一个在所有维度上均衡发展的“六边形战士”,而更像一个在特定领域表现突出、同时在核心定位上尚有成长空间的“特长生”。其在人类直觉和实用逻辑推理上的惊艳表现,与其在复杂编程模拟任务中的保守和基础化形成了鲜明对比,这使得对它的评价不能一概而论。
首先,在作为一款 Code 模型的核心赛道——编程能力上,Doubao-Seed-Code 的实测表现与官方宣称的顶级跑分还有一定差距。在网页复刻和小程序开发这类考验综合设计、交互实现与代码美学的前端任务中,它的表现是略显保守和教科书式的。其产出的代码结构清晰、基础功能完备,但往往止步于需求的最低可行性实现,缺乏对UI/UX细节的打磨和提升用户体验的现代技术应用。与 Sonnet 4.5 对设计语言的精准复刻、或 Kimi K2 在交互动画上的主动创造相比,Doubao-Seed-Code 在前端创意和工程完整性上仍有明显的追赶空间。这反映出模型在将视觉或复杂需求转化为精良、现代化的前端代码方面,能力尚待加强。
然而出乎意料的是,Doubao-Seed-Code 在人类直觉测试中的表现拔得头筹,展现了卓越的“顾问级”AI 特质。在旅游规划案例中,它能精准洞察用户潜在需求以及模糊偏好背后的核心意图,并以前瞻性的决策逻辑和共情式的风险管理,输出了超出预期的实用方案。这种表现证明了其强大的自然语言理解、逻辑推理和目标导向的决策辅助能力。它并非简单地检索信息,而是在进行真正的“权衡”与“规划”,这种能力在处理非编程类的复杂逻辑问题时具有一定价值。并且,作为其一大亮点,其多模态视觉推理能力达到可用水平。在干扰性较强的典型视觉识别任务中,它能正确完成细粒度识别与逻辑判断,证明了其跨模态理解的基本功,这对于一款以编程为核心的模型而言是显著的加分项。
综合来看,Doubao-Seed-Code 的现状呈现出一种能力分化。它在需要创意、美感和复杂交互的前端编程领域表现平平,但在处理结构化逻辑、进行成本效益分析和提供实用决策支持方面却异常强大。这或许意味着其当前的优化方向更偏向于后端逻辑、算法实现、脚本自动化或作为低成本的通用逻辑推理引擎。其国内最低的定价策略也印证了这一点:它为广大开发者和企业提供了一个极具性价比的选择,尤其适合那些对成本敏感、需求偏向于逻辑处理而非创意生成的应用场景。
总体而言,Doubao-Seed-Code 是一款特点鲜明、性价比突出的模型。它在需要直觉判断与跨模态理解的任务中具备优势,且定价策略极具竞争力。然而,若将其直接应用于对代码创造性、界面精致度或复杂逻辑推理要求极高的生产环境,还是欠缺火候,目前仍需谨慎。
Ⅳ. 如何在 302.AI 上使用
1. 聊天机器人中使用
步骤指引 :应用超市→机器人→聊天机器人→立即体验
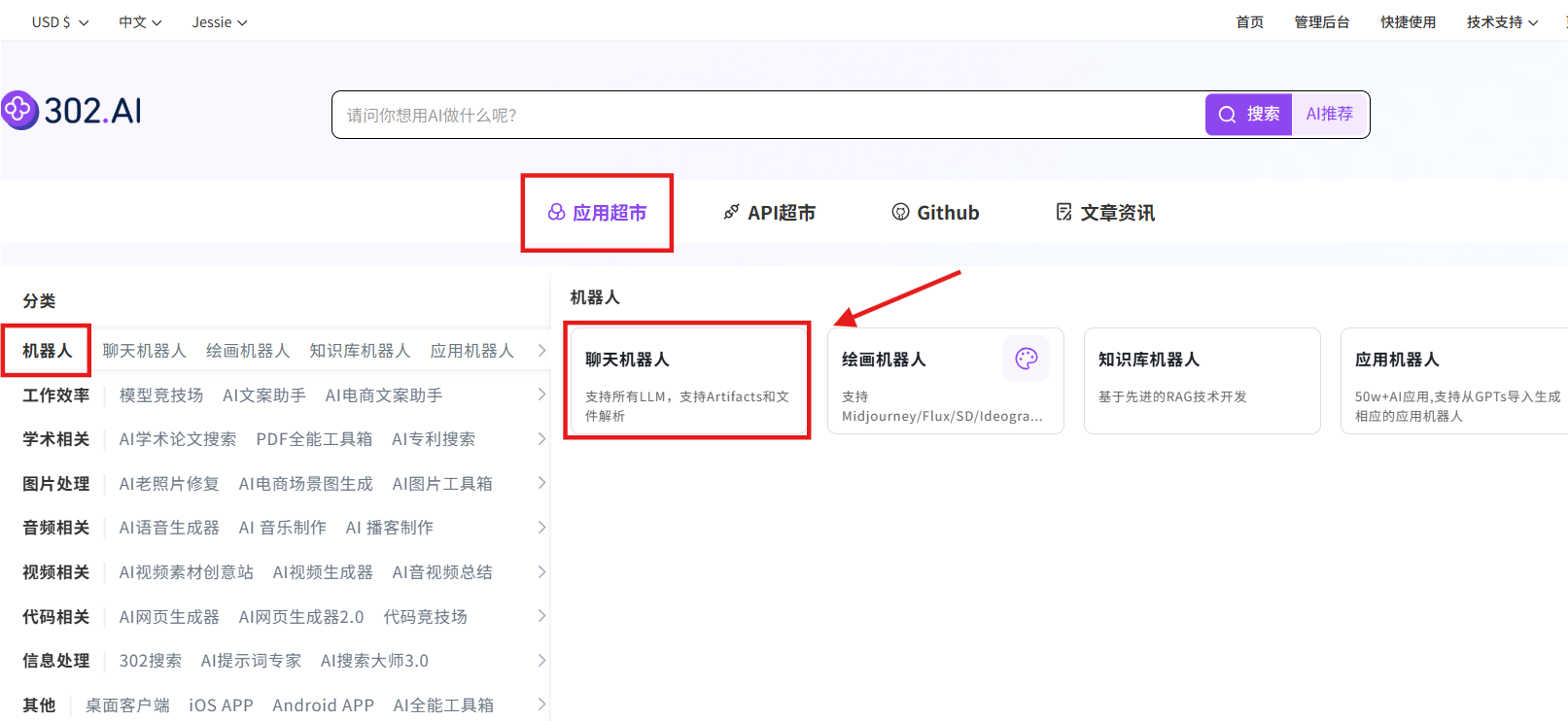
选择模型:国产模型→doubao-seed-code-preview→确认→创建
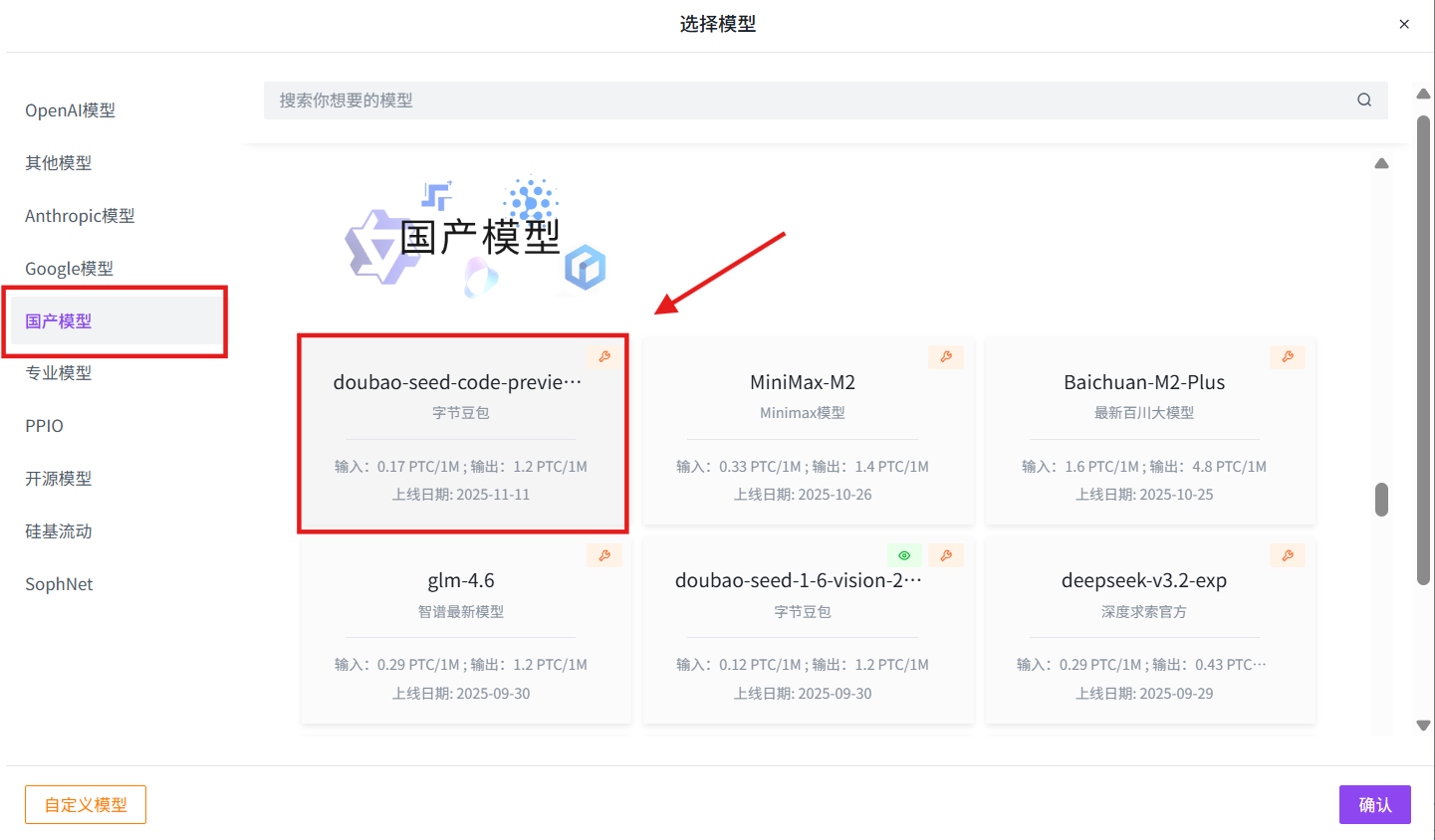
2. 使用模型 API
步骤指引:API超市→语言大模型→豆包→doubao-seed-code-preview
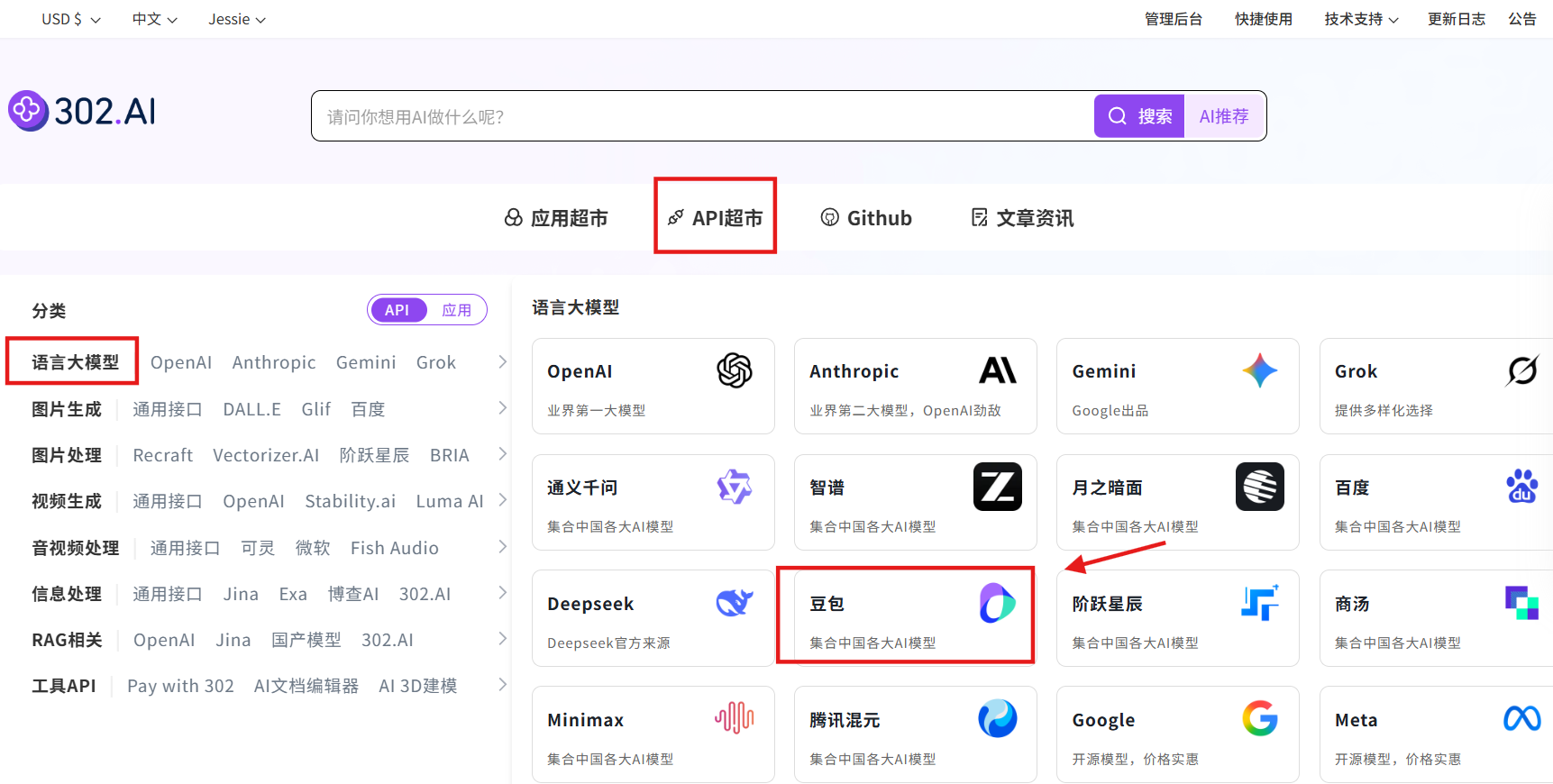
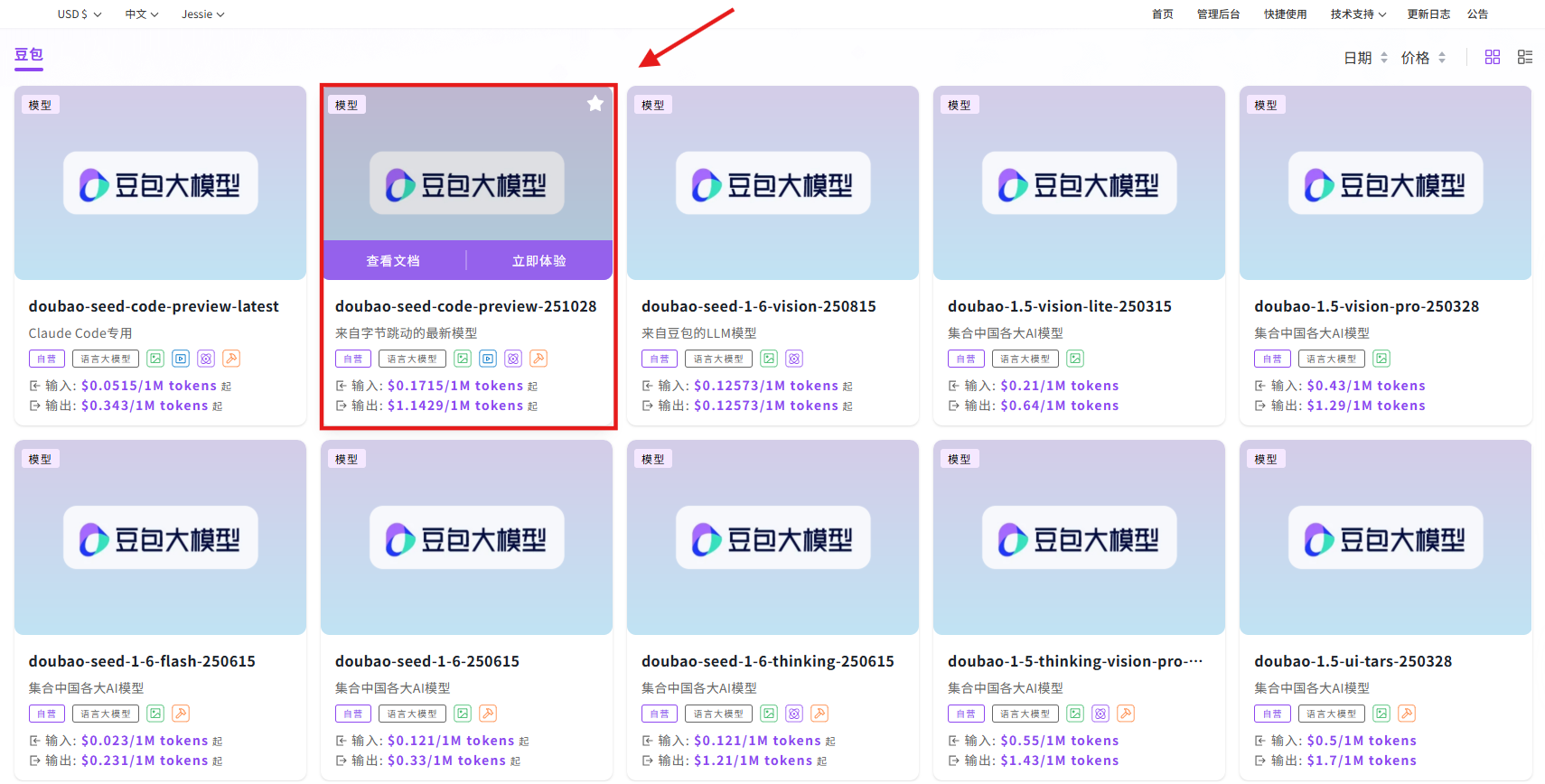
点击【立即体验】在线调用 API
想即刻体验 Doubao-Seed-Code 模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
