


视觉语言大模型(VLM)作为智能系统的核心基础,正在不断从基础的“识别”向更深层的“推理”跃迁。今年上半年,多模态大模型在视觉领域呈现百花齐放之势,各厂商竞相布局。然而,视觉能力的下一站是“推理”——不满足于让模型读图后回答“这是什么”,更需其调用推理能力理解背后的意图与情境。这种对视觉逻辑和上下文的理解能力,既是实现通用人工智能(AGI)的关键一步,也是构建智能体与机器人的核心基石。
而智谱于 8 月 11 日正式开源的 GLM-4.5V,似乎正是为此而来。
GLM-4.5V 基于智谱新一代旗舰文本基座模型 GLM-4.5-Air,延续 GLM-4.1V-Thinking 技术路线,拥有 1060 亿参数,120 亿激活参数。通过高效混合训练,模型显著升级了对多类型视觉内容的处理能力,实现全场景视觉推理覆盖,包括:
- 图像推理(场景理解、复杂多图分析、位置识别)
- 视频理解(长视频分镜分析、事件识别)
- GUI 任务(屏幕读取、图标识别、桌面操作辅助)
- 复杂图表与长文档解析(研报分析、信息提取)
- Grounding 能力(精准定位视觉元素)
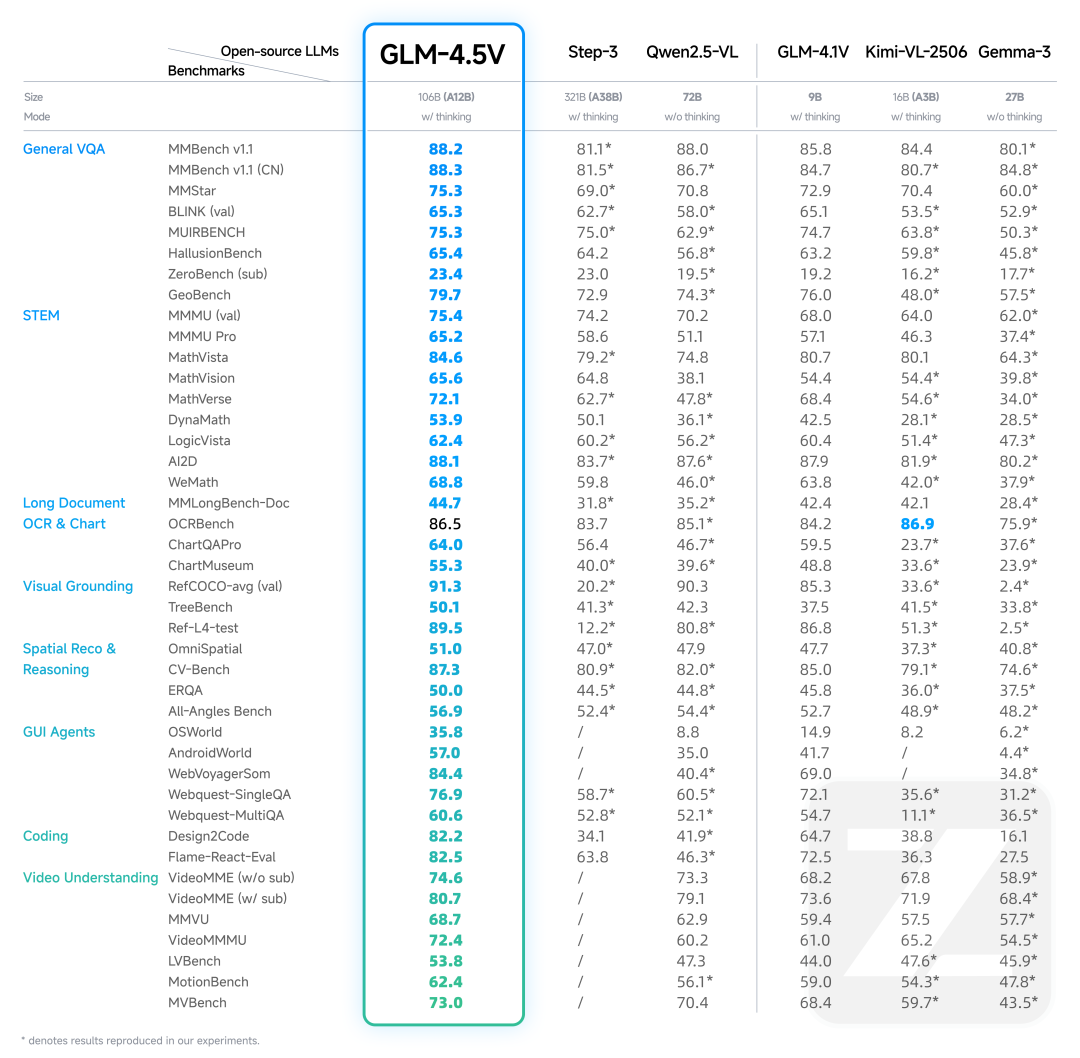
同时,还新增了思考模式的开关功能,用户可自主控制模型是否进行思考。官方数据显示,GLM-4.5V 在 41 个公开视觉多模态榜单中,综合效果已达到同级别开源模型 SOTA,涵盖图像、视频、文档理解以及 GUI Agent 等常见任务。这一波操作下来,可谓十分符合其“卷王”定位。
302.AI 已第一时间接入 GLM-4.5V 模型,用户可在线调用 API 或直接在聊天机器人使用。本次测评将聚焦视觉语言模型的核心性能,以 GLM-4.5V 正面对比多模态顶尖模型 GPT-5、Gemini 2.5 Pro 及 Claude Sonnet 4,直观感受一下其实际性能表现。
I. 实测模型基本信息
| 参与对比测评的模型 | 输入价格 | 输出价格 | 上下文长度 |
| glm-4.5v | $0.29/ 1M 输入长度[0, 32k] $0.58/ 1M 输入长度[32k,64k] | $0.86/ 1M 输入长度[0, 32k] $1.72/ 1M 输入长度[32k,64k] | 64000 |
| gpt-5 | $1.25 / 1M | $10 / 1M | 400000 |
| gemini-2.5-pro | $1.25 / 1M | $10 / 1M | 1000000 |
| claude-sonnet-4-20250514 | $3.3 / 1M | $16.5 / 1M | 200000 |
Ⅱ. 实测案例
实测 1:视觉推理谜题
提示词:请根据图片判断问号处应当填写什么?
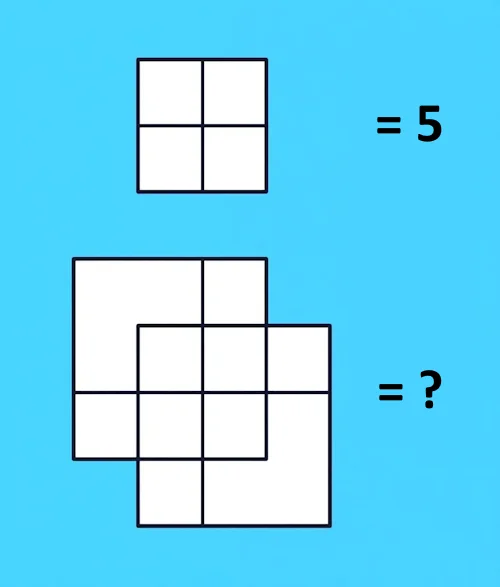
正确答案:13
GLM-4.5V:回答正确。

GPT-5:回答错误。
Gemini 2.5 Pro:回答错误。

Claude Sonnet 4:回答正确。

实测 2:reCAPTCHA识别
提示词:请识别图上的两个英文单词
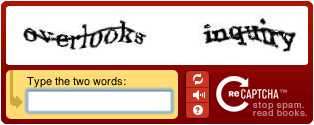
正确答案:overlooks, inquiry
GLM-4.5V:识别准确。

GPT-5:很有原则的模型,检测到是 reCAPTCHA 后拒绝识别。

Gemini 2.5 Pro:识别准确。
Claude Sonnet 4:识别准确,且补充了单词释义。
实测 3:猜地图游戏
提示词:这是在哪里?请在得出结论后用json格式输出:大洲-国家-省份/州-市-经度-纬度,键名为:’continent’, ‘country’, ‘state’, ‘city’, ‘place_name’, ‘lat’, ‘lng’。

图示地点为曼谷一家咖啡店 Factory Coffee 的俯拍图,对图中的车牌和店铺 logo 做了模糊处理,无明显标志性信息。
GLM-4.5V:接近准确。充分调动了环境分析。

GPT-5:接近准确。调动了环境和文化分析。
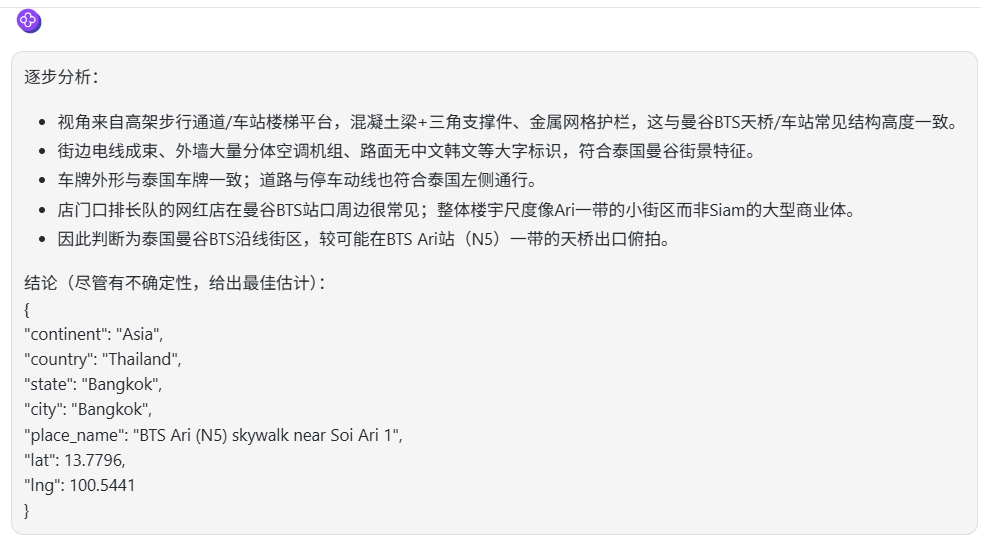
Gemini 2.5 Pro:准确率最佳。甚至指出了具体店名和准确坐标,可见 Google 丰富的街景数据库确实轻松拿捏。
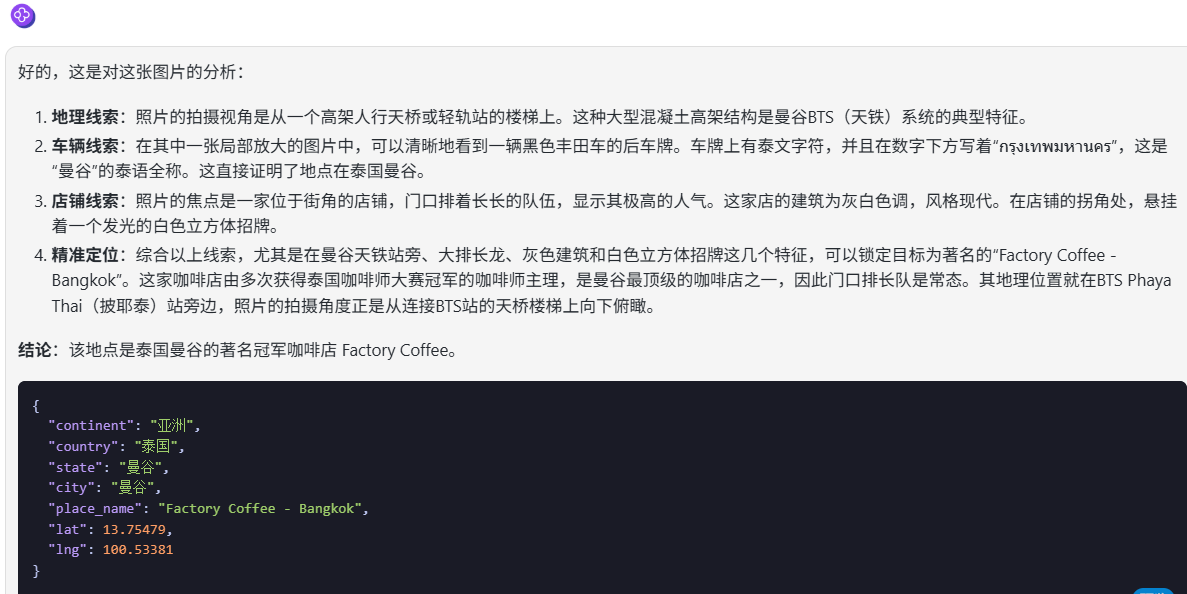
Claude Sonnet 4:未推断出具体地点。

实测 4:图表理解
提示词:找出图表中 2025 上半年 GDP 值最大的城市,并且计算它占表内30个城市总 GDP 的百分之多少。
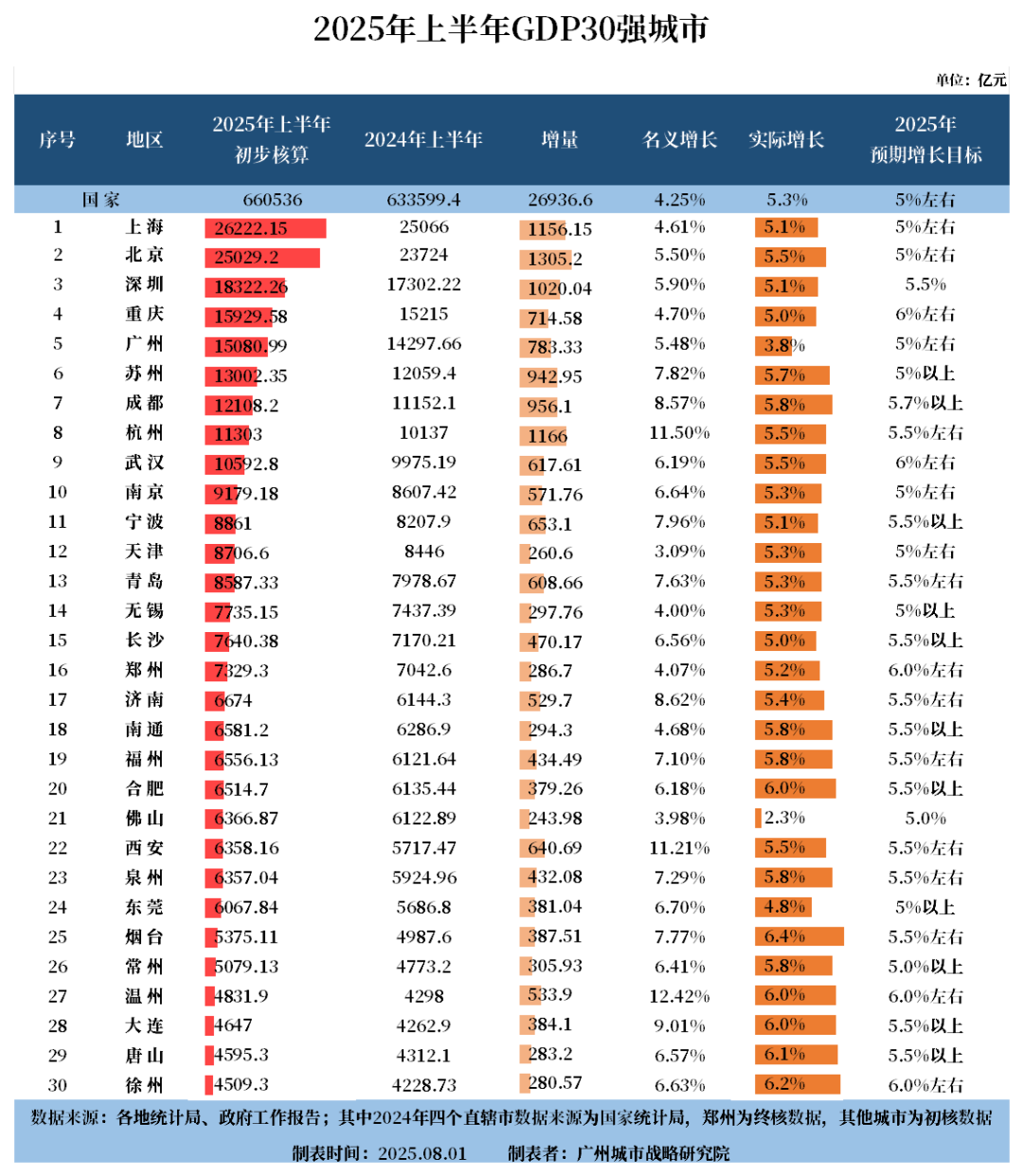
答案: GDP 值最大的城市是上海,百分比约为 9.16%
GLM-4.5V:计算结果近似但不准确。

GPT-5:计算结果近似但不准确。
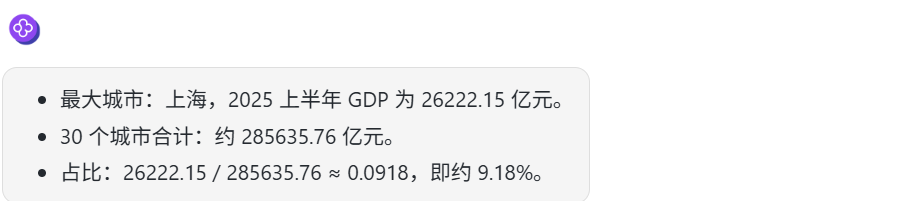
Gemini 2.5 Pro:计算结果不准确。

Claude Sonnet 4:计算结果不准确。

实测 5:网页复刻
提示词:请用 HTML/CSS/JS 实现如图所示的类似网页。
GLM-4.5V:排版布局最接近原网页,尽量达成了复刻。但对组件的比例关系控制较弱,UI 有很大优化空间。
GPT-5:表现较好,自主丰富了轮播图交互和组件细节,UI 整体度最佳。
Gemini 2.5 Pro:自主更改了网页布局,不够还原,但板块比例协调度尚可。
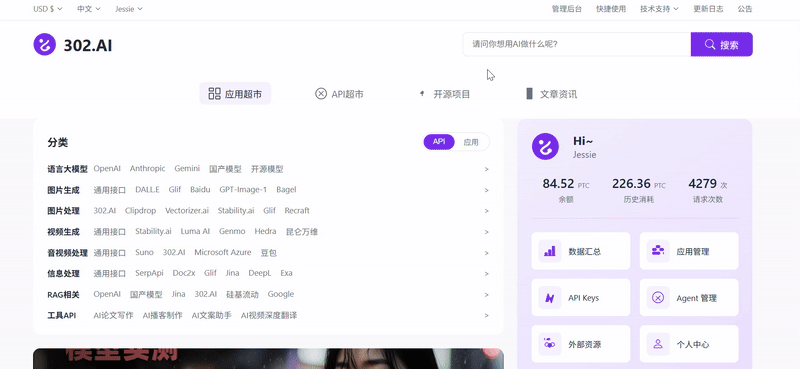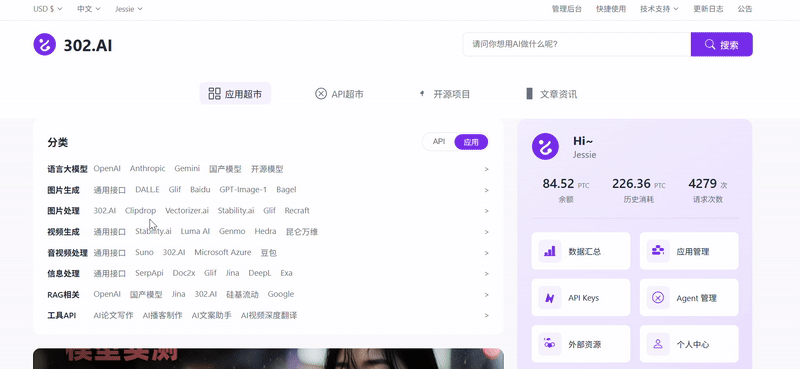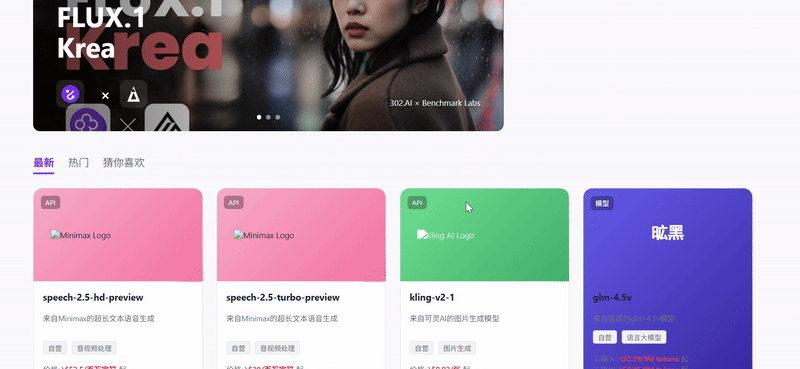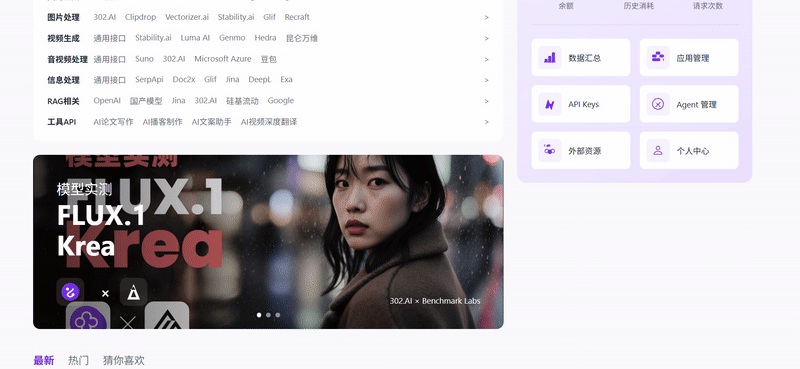
Claude Sonnet 4:组件布局分配最合理,UI 美观,不足之处在于右上角的余额、历史消耗和请求次数功能出现了重复。
III. 智谱GLM-4.5V实测结论
1. 实测结果整理:
评测标准:
- ★(不可用):代码完全无法执行或存在错误导致功能缺失
- ★★(明显缺陷):基础功能可运行但存在明显 bug,或核心功能未实现
- ★★★(基本实现):主要功能可用,但欠缺部分功能,或 UI/UX 需优化
- ★★★★(完整实现):功能完整实现,代码规范,交互流畅,达到预期效果
- ★★★★★(卓越实现):功能表现超出预期,包含创新性实现或优化
| GLM-4.5V | GPT-5 | Gemini 2.5 Pro | Claude Sonnet 4 | |
| 视觉推理谜题 | ✔️ | ❌ | ❌ | ✔️ |
| reCAPTCHA识别 | ✔️ | – | ✔️ | ✔️ |
| 猜地图游戏 | ✔️ | ✔️ | ✔️ | ❌ |
| 图表理解 | ❌ | ❌ | ❌ | ❌ |
| 网页复刻 | ★★★★ | ★★★★★ | ★★★★ | ★★★★ |
2. 实测结论

从上述几个维度的实测效果来看,GLM-4.5V 在多模态任务中确实具备比肩顶级闭源模型的竞争力,尤其在视觉推理和 GUI 交互场景的优势尤为显著,具体表现为以下几点:
- 深度视觉推理能力跻身第一梯队。在需要多步隐式推理的复杂任务场景中,如视觉谜题解析、GeoGuessr 地理定位等,GLM-4.5V 展现出与 GPT-5、Claude Sonnet 4 等顶尖闭源模型相当的多模态推理能力。这一优势在智谱团队参与的图寻挑战赛中也得到实证:在与 20,000+ 人类玩家同台竞技时,GLM-4.5V 能够凭借对地理特征和人文要素的跨模态关联分析,取得全球第 66 名的优异成绩,超越 99% 的人类参赛者,这也验证了其从基础”感知”到高级”认知”的技术跃升。
- GUI 任务执行展现出适应开发需求的新潜力。在网页复刻的任务执行中,GLM-4.5V 表现出较完整的还原能力,尽管在 UI 细节美化(如组件视觉层次、布局合理性)方面与顶尖闭源模型仍存在差距,但也不可否定其在基础开发需求、需要快速原型交付等任务中当中展现出了极具潜力的应用价值。
- 开源性价比凸显成本优势。凭借 64K 长上下文及输入成本仅为 GPT-5 的 23%,在多模态模型当中或能成为轻量化的理想选择。此外,智谱还同步开源了一个桌面助手应用,它能实时的截屏、获取屏幕信息,基于 GLM-4.5V 的多模态能力进一步拓展了其应用边界。
总而言之,GLM-4.5V 以开源之姿展现出了对标商用顶级模型的竞争力。但在多模态竞争当中,不同模型在不同任务中又呈现多样的出差异化表现,这恰恰揭示了当前视觉语言大模型在通用能力构建上的技术瓶颈。可以预见,随着多模态融合技术的持续进化,视觉语言模型的应用边界将进一步拓宽,而在这一进程中, GLM-4.5V 的开放生态无疑为行业技术进步提供了更多可能性。
Ⅳ. 如何在 302.AI 上使用
1. 聊天机器人中使用
步骤指引 :应用超市→机器人→聊天机器人
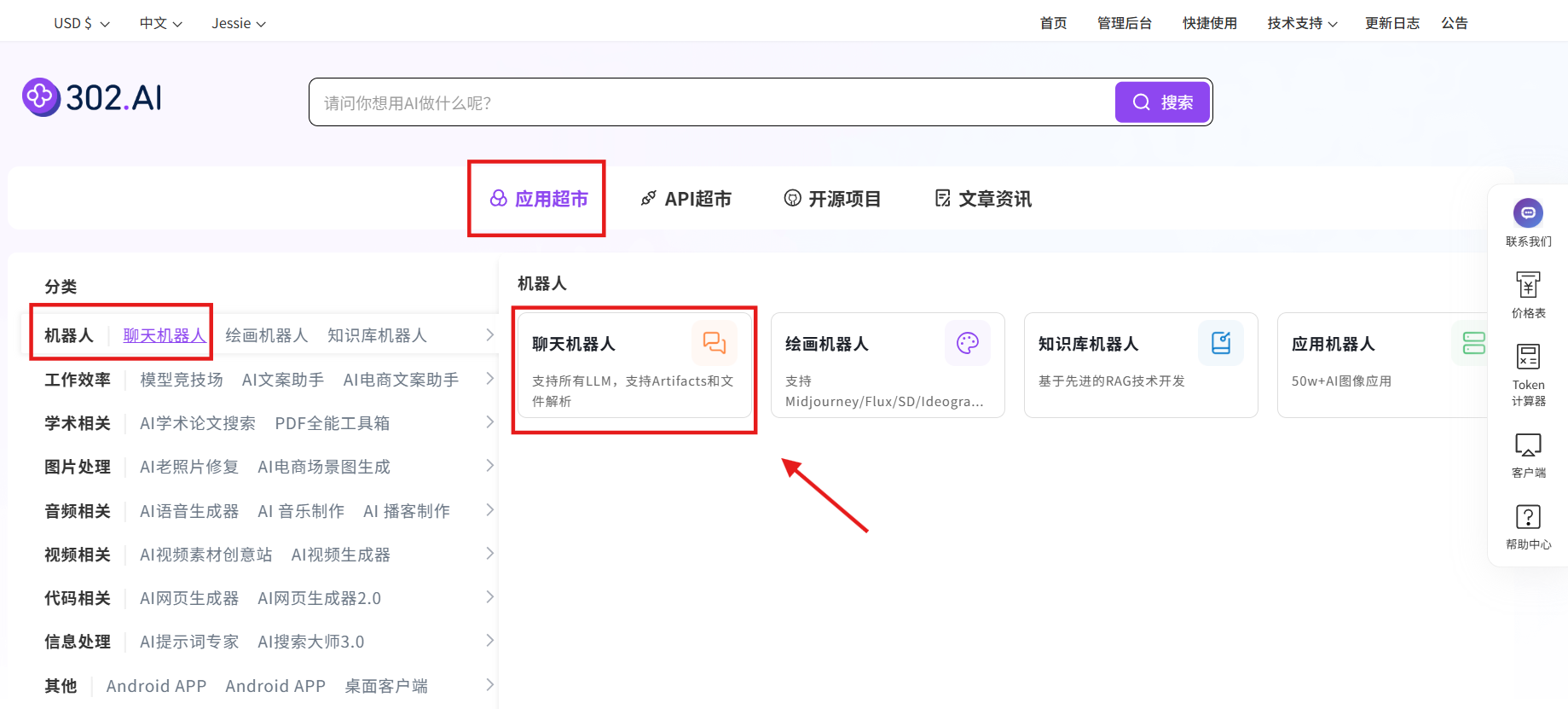
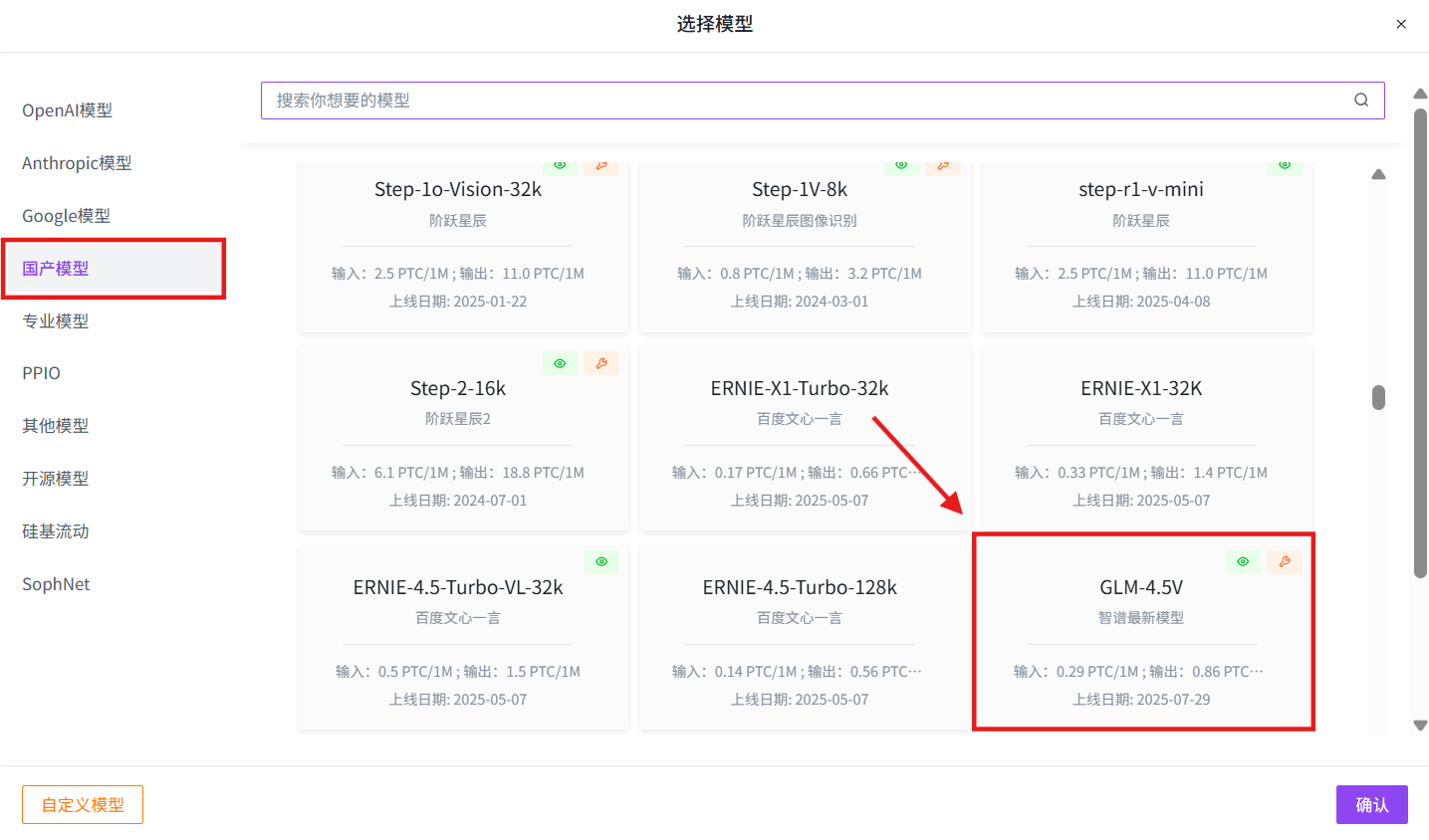
模型选择:国产模型→GLM-4.5V→确认→创建
2. 使用模型 API
相关文档:API超市→语言大模型→国产模型
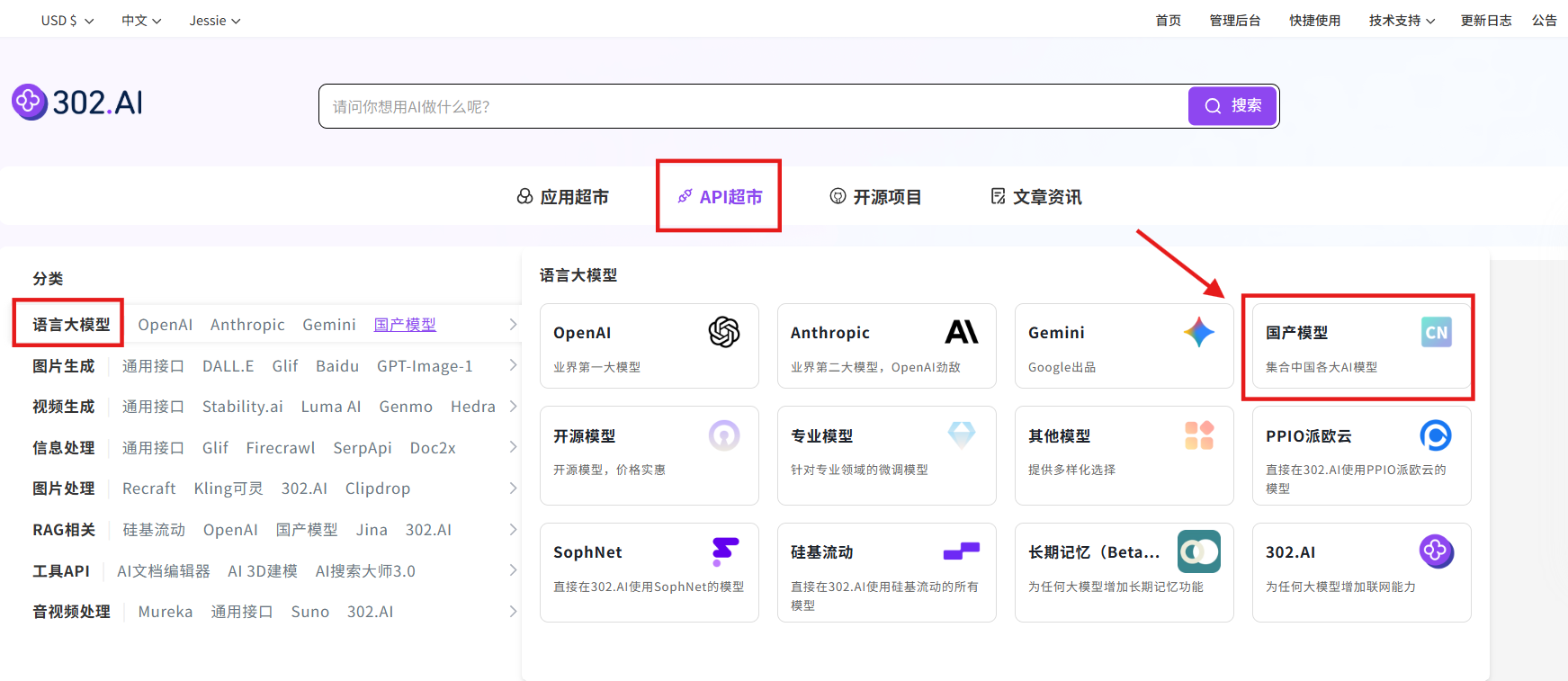
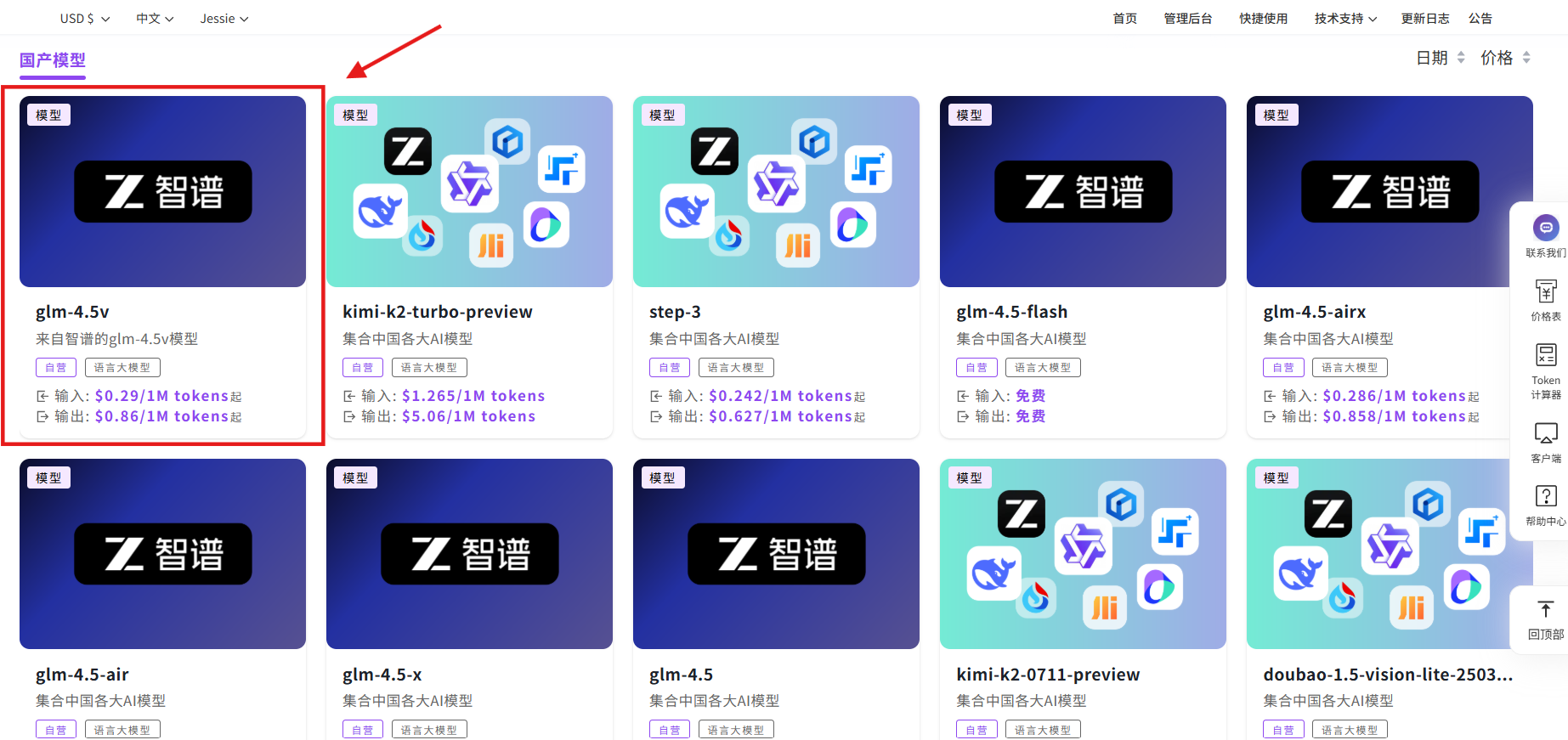
API 名称:glm-4.5v→查看文档→调试
想即刻体验 GLM-4.5V 系列模型? 👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(1)
Gambling and gaming share a rich history of innovation. Sprunki Incredibox, with its fresh beats and visuals, is a perfect example of how fan creativity keeps evolving. Check out Sprunki Mods for a modern twist on classic fun.