
Table of Contents
说实话,到了 2025 年底这个节点,大家对 AI 的感觉可能都有点“疲惫”了。过去这两年,各家大厂像疯了一样堆参数、拼算力,动不动就是参数翻倍,但日常任务用起来的感觉却大同小异。这种“卷算力”的游戏,多少已经到了边际效应递减的时刻。
但就在昨晚(北京时间11月18日),谷歌如果不声不响地扔出了 Gemini 3.0,这潭死水可能还真就被搅活了。
很多人的记忆可能还停留在今年 3 月,当时 Gemini 2.5 Pro 横空出世,在 Arena 榜单上把 Grok-3 和 GPT-4 甩开了整整 40 分,宣告谷歌从追赶者变成了领跑者。如果你以为那已经是终局,那就太小看硅谷的技术迭代速度了,蛰伏下蹲都是为了跳得更高。
这次发布的 Gemini 3.0,本质上不仅一次简单的升级,而是一次彻底的“换脑”。
谷歌这次不再执着于把模型做得更大,而是把重点放在了更深。根据流出的技术文档,Gemini 3.0 对底层架构进行了重构,极大概率采用了改进型的 MoE(混合专家)架构,并引入了被称为“System 2”的深度思维模式。现在的 Gemini 3.0 学会了深度思考,在回答你那些复杂的逻辑题和长篇代码任务之前,会先在内部进行多步推理和规划。
302.AI 已在第一时间接入了Gemini 3.0 Pro的API,并开放限时免费体验通道,本期基准实验室通过原创题库实测一探究竟:这究竟是版本的常规迭代,还是一场真正重塑生产力的技术革命?
I. Gemini版本发展史


前传:整合与统一 (2023年4月)
在 Gemini 诞生之前,Google 内部有 Google Brain 和 DeepMind 两个顶级 AI 实验室。为了应对 OpenAI (ChatGPT) 的冲击,Google 将两者合并成立 Google DeepMind,目标很明确:打造一个能超越 GPT-4 的下一代原生多模态模型,项目代号即为 Gemini。
第一阶段:Gemini 1.0 —— 原生多模态的诞生
发布时间: 2023年12月
核心特色:
原生多模态 (Native Multimodal): 不同于其他模型是“文本模型+视觉外挂”,Gemini 从训练之初就是用图像、视频、音频和文本混合训练的。Google 终于拿出了能与 GPT-4 掰手腕的产品,证明了自己还在牌桌上。
市场反响:
发布时的鸭子演示视频被指经过剪辑和加速,引发了信任危机。此外,早期版本在人物图像生成上出现了过度政治正确的舆论风波,导致图像生成功能一度暂停,整体而言只是在追赶 OpenAI 的步伐。
第二阶段:Gemini 1.5 —— 长文本与效率的革命
发布时间: 2024年2月 (Pro), 2024年5月 (Flash)
核心特色:
百万级上下文。这是 Gemini 的“成名之战”。1.5 Pro 首发支持 100万(后升级至200万)token,能一次性吃透几十本书、整个代码库或长视频。MoE 架构 (混合专家): 大幅提升了效率。
Gemini 1.5 Flash: 推出了“轻量级、低延迟、极低成本”的 Flash 版本,迅速成为开发者API的首选,性价比极高。
市场反响:
长文本能力在当时是“降维打击”,OpenAI 当时的主力模型仅支持 128k。开发者和企业用户开始大量迁移到 Gemini 用来分析在大文件。 Google 找到了区别于 GPT 系列的杀手锏——超长上下文和高性价比。
第三阶段:Gemini 2.0 —— 实时交互与代理雏形
发布时间: 2024年末 – 2025年初
核心特色:
实时多模态 (Multimodal Live): 极低的延迟,支持像真人一样打断、插话的语音视频交互,直接对标 GPT-4o。
Project Astra 落地: 增强了模型对物理世界的理解通过摄像头看世界),记忆力和情境感知能力大幅提升。
Thinking Mode (早期): 开始尝试引入类似 o1 的思维链技术,但尚未完全成熟。
市场反响:
这一代模型主要完善了用户体验(尤其是语音助手体验),Gemini app 深度整合进 Android 系统,逐渐取代了 Google Assistant。重点在于让 AI 变得好用、实时,并融入 Google 的产品全家桶。
第四阶段:Gemini 2.5 —— 编程霸主与智能体爆发
发布时间: 2025年5月 (Google I/O 2025)
在 2.0 版本发布半年后,面对竞争对手(如 Anthropic 的 Claude 3.5/4 系列)在编程和逻辑上的强力挑战,Google 推出了这个“中期改款”版本。
核心特色:
代码能力的巅峰 : Gemini 2.5 Pro 专门针对编程进行了大规模强化。它不仅能写代码,还能深入理解复杂的 Repo 结构,支持全库重构。在当时的 SWE-bench 上,它首次超越了 Claude 3.5 Sonnet,成为程序员的首选。
智能体能力: 这是 Google 真正将“AI 助手”转变为“AI 代理”的一代。2.5 版本引入了更强的Grounding with Google Search(搜索落地)和工具调用能力,能够更稳定地执行买票、订座、操作 API 等多步任务。
更强的 Flash 模型: Gemini 2.5 Flash 将“速度与智力”的平衡做到了极致,以极低的成本提供了接近 GPT-4 Turbo 的智力,成为当时商业 API 调用的性价比之王。
市场反响:
开发者社区对 2.5 版本评价极高,因为它“听得懂人话,干得对活”,2.5 的出现成功帮助 Google 夺回了开发者生态的口碑。
第五阶段:Gemini 3.0 —— 逻辑推理与AGI曙光 (当前版本)
发布时间: 2025年11月
核心特色:
System 2 推理能力: 3.0 Pro 并非单纯的语言预测,而是具备了深度思考和自我反思能力。在数学、代码、科学推理上实现了质的飞跃(如 AIME 满分)。
攻克 LLM 顽疾: 在 ARC-AGI(视觉逻辑)和 SimpleQA(事实准确性)上取得了突破性高分,大幅解决了“幻觉”和“不懂变通”的问题。
Agentic UI (屏幕智能): 模型不仅能看懂图片,还能精确理解电脑/手机屏幕UI,具备了代替人类操作软件的能力。
市场反响:
业界普遍认为这是 Google 重回铁王座 的一代。不仅在跑分上全面碾压对手,更重要的是在“逻辑推理”这一 AI 皇冠上的明珠上取得了领先。Gemini 3.0 标志着 Google 不再是追赶者,而是定义了 2026 年 AI 的新标准。
附Google Gemini 历代模型规格与定价汇总表:
| 版本型号 | 发布时间 | 参数量 (估算) | 上下文窗口 (Context) | 输入价格 (Input / 1M) | 输出价格 (Output / 1M) | 核心定位 |
| Gemini 1.0 Pro | 2023.12 | 中等 MoE | 32k | $0.50 | $1.50 | 初代通用模型,价格亲民 |
| Gemini 1.5 Pro | 2024.02 | ~600B (稀疏 MoE) | 2M | $3.50 | $10.50 | 长文本霸主,首个两百万窗口 |
| Gemini 2.0 Pro | 2024.12 | 中大型 MoE | 2M | $1.25 | $5.00 | 交互优化,延迟极低,价格略有下调 |
| Gemini 2.5 Pro | 2025.05 | 针对代码微调 | 4M | $2.50 | $15.00 | 编程特化,工具调用能力强,合理溢价 |
| Gemini 3.0 Pro | 2025.11 | 未知 (超大规模 MoE) | 10M | $4.00 | $18.00 | SOTA 旗舰,含思维链推理成本,价格较高 |
II. 实测模型基础信息
(1)各实测模型在 302.AI 的价格:
| 参与对比测评的模型 | 说明 | 输入价格 | 输出价格 | 上下文长度 |
| gemini-3-pro-preview | 输入/输出 <= 200K tokens费用 | $2 / 1M tokens | $12 / 1M tokens | 1000000 |
| 输入/输出> 200K tokens费用 | $4 / 1M tokens | $18 / 1M tokens | 1000000 | |
| gemini-2.5-pro | 输入/输出 <= 200K tokens费用 | $1.25 / 1M tokens | $10 / 1M tokens | 1000000 |
| 输入/输出> 200K tokens费用 | $2.5 / 1M tokens | $15 / 1M tokens | 1000000 | |
| gpt-5.1 | $1.25 / 1M tokens | $10 / 1M tokens | 400000 | |
| claude-sonnet-4-5 | 输入/输出 ≤200K tokens | $3 / 1M tokens | $15 / 1M tokens | 200000 |
| 输入/输出 >200K tokens | $6 / 1M tokens | $22.5 / 1M tokens | 1000000 |
(2)测评目的:
本评测侧重模型对逻辑,数学,编程,人类直觉,多模态等问题的测试,非专业前沿领域的权威测试。旨在观察对比模型的进化趋势,提供选型参考。
(3)测评方法:
本次测评使用302.AI收录的题库进行独立测试。3款模型分别就逻辑与数学(共10题),人类直觉(共7题),编程模拟(共9题),多模态(共20题进行案例测试,对应记分规则取最终结果,下文选取代表性案例进行展示。
题库地址:https://docs.google.com/spreadsheets/d/1sBxs60yWsxc9I5Va8Rjc1_le1Omg2hOXbwqOzpImZio/edit?gid=0#gid=0
💡记分规则:
按满分10分记分,设定对应扣分标准,最终取每轮得分的平均值。
(4)测评工具:
302.AI 的API超市→在线使用
III. 测评榜单排名汇总
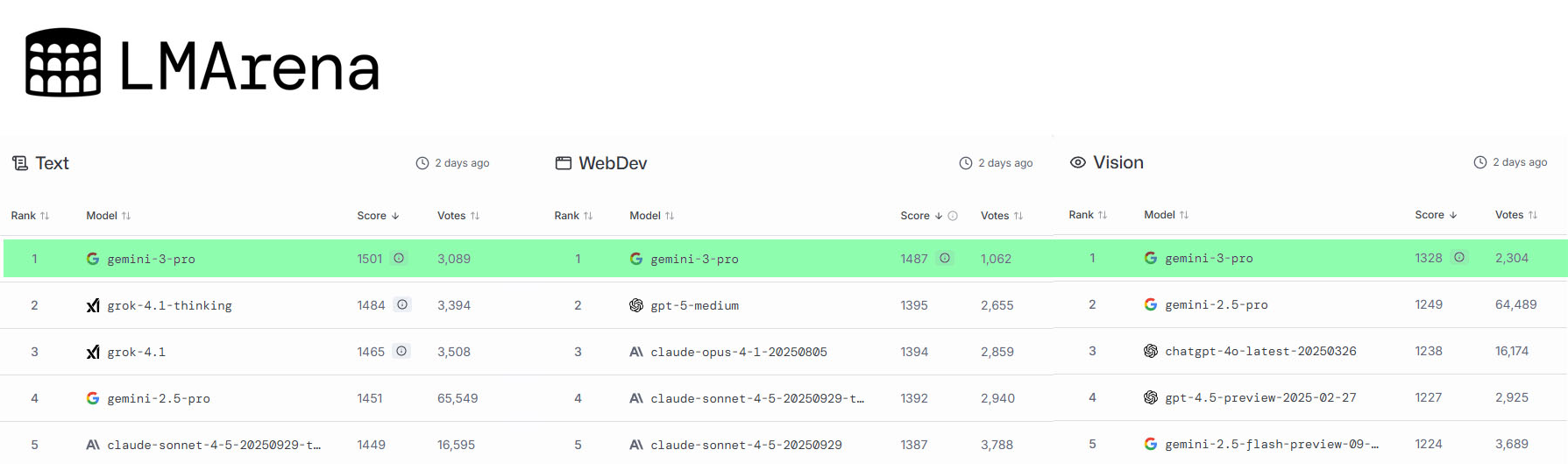
LMArena:
在Text,WebDev,Vision三个榜单均排名第一
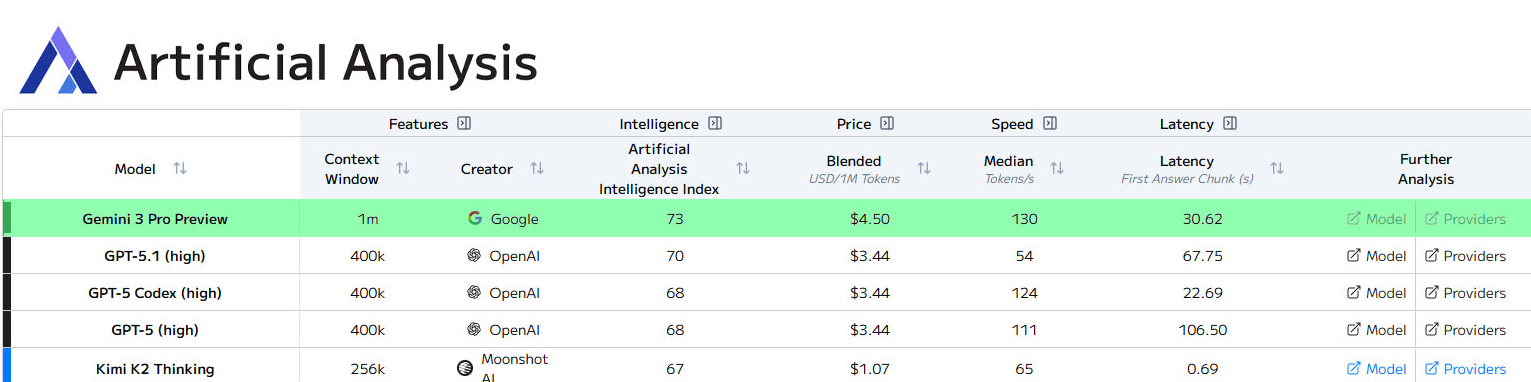
Artificial Analysis:
总榜第一
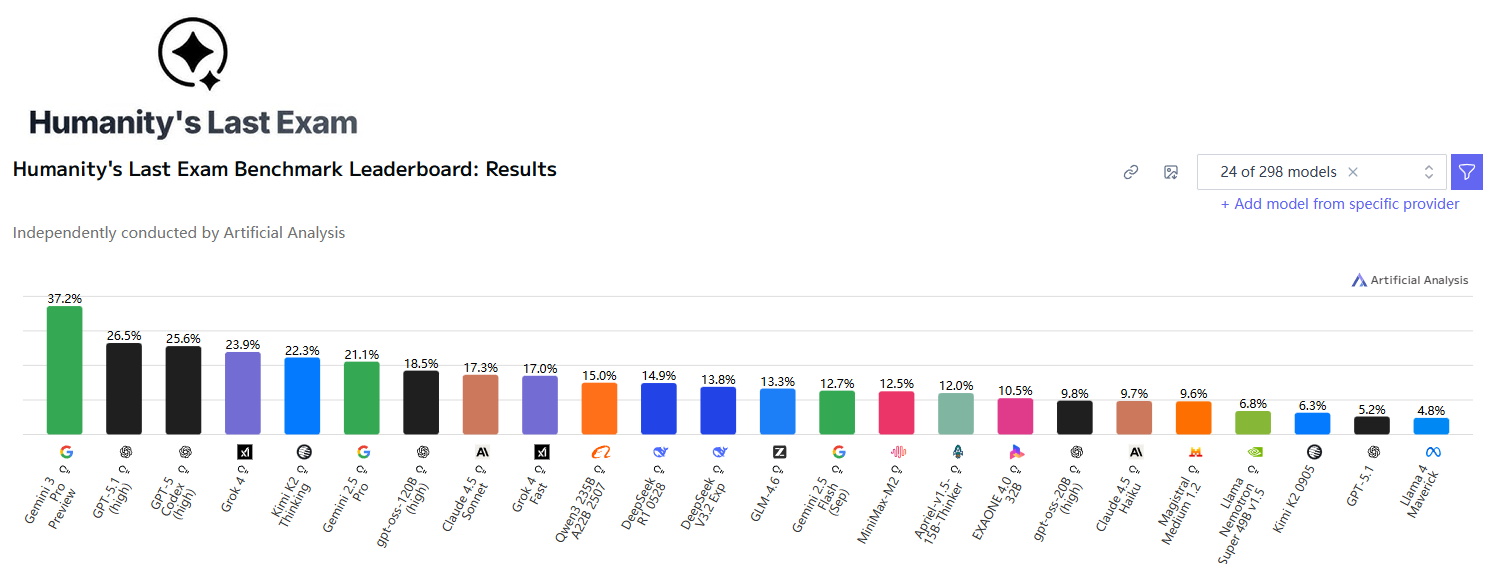
Humanity’s Last Exam(人类最后的考试):
得分: 37.2% (无工具),45.8% (配合搜索和代码执行)。该测试旨在评估AI解决人类尚未解决或极难问题的能力,Gemini 3 Pro在此项上大幅领先对手。
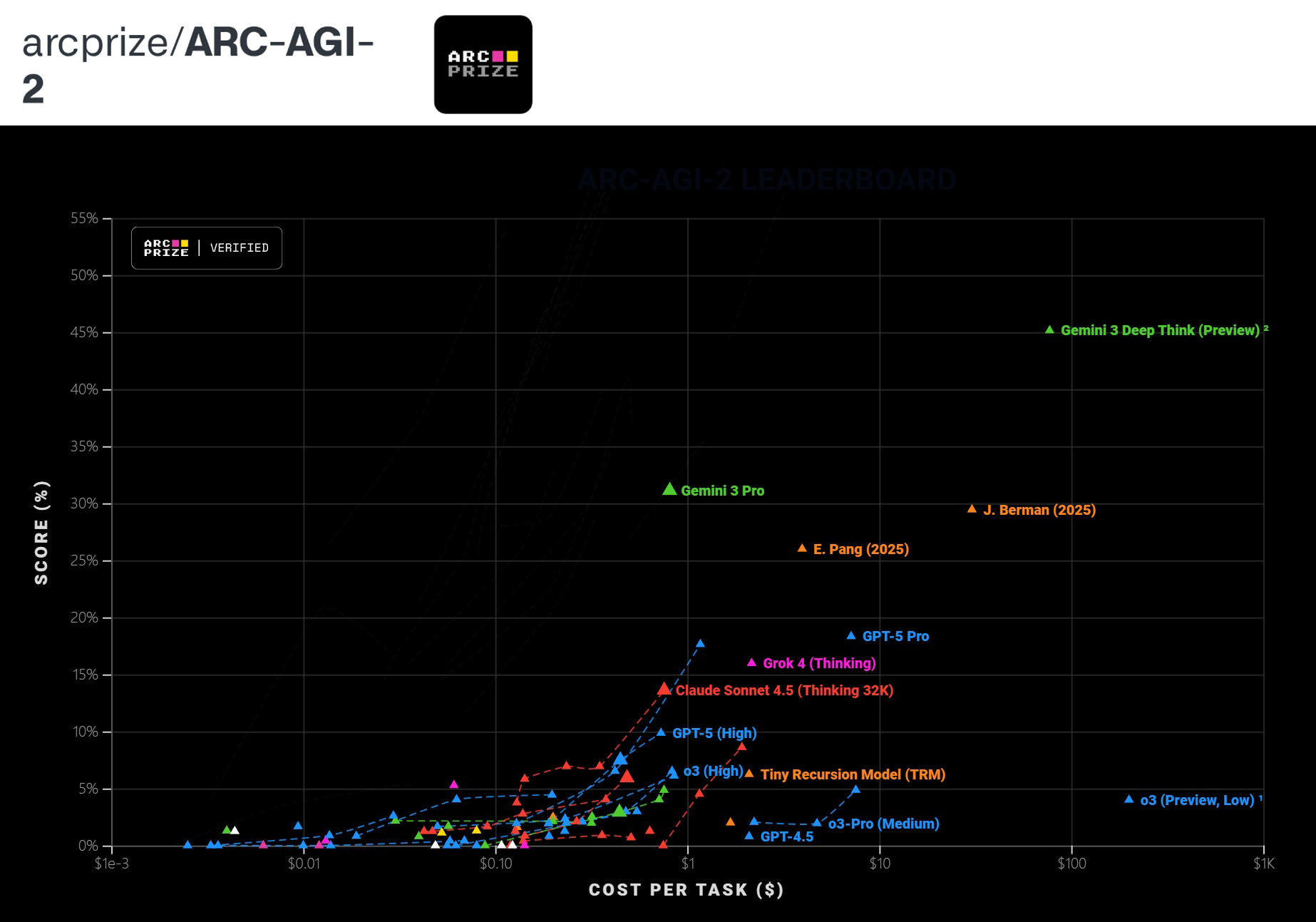
ARC-AGI-2 (视觉逻辑推理):
得分: 31%,Deep Think模式下45%. 这通常是LLM的短板,Gemini 3 Pro相比其他对手有着巨幅提升,显示出更强的通用智能潜力。
302.AI原创题库测试结果:
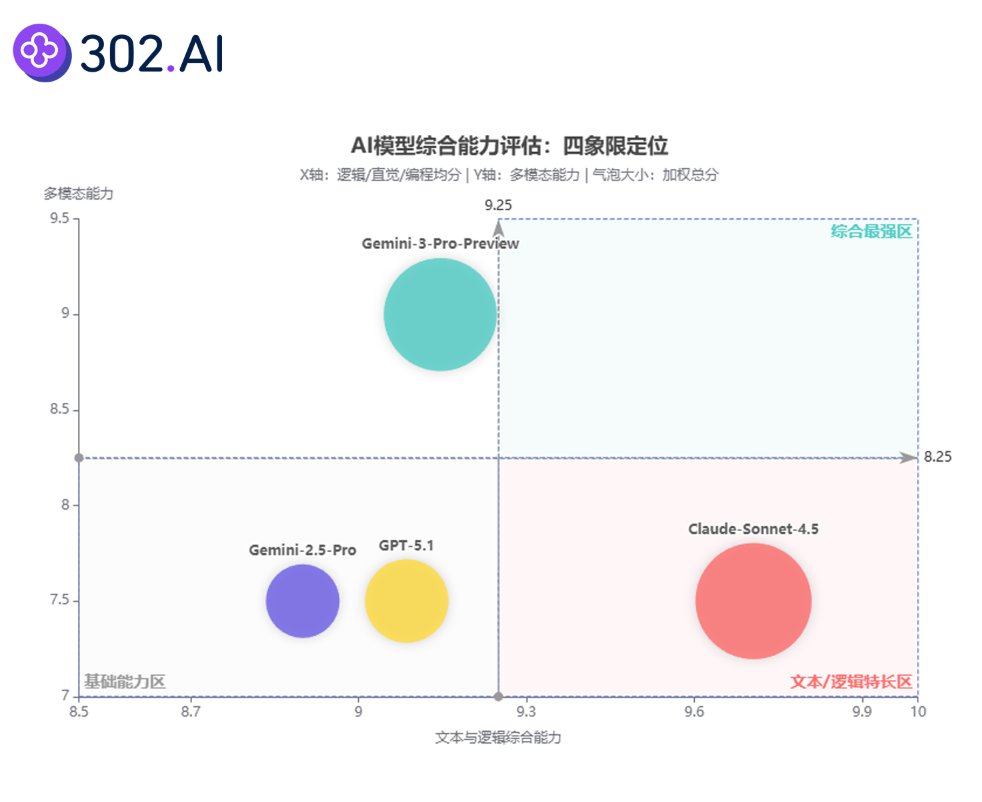
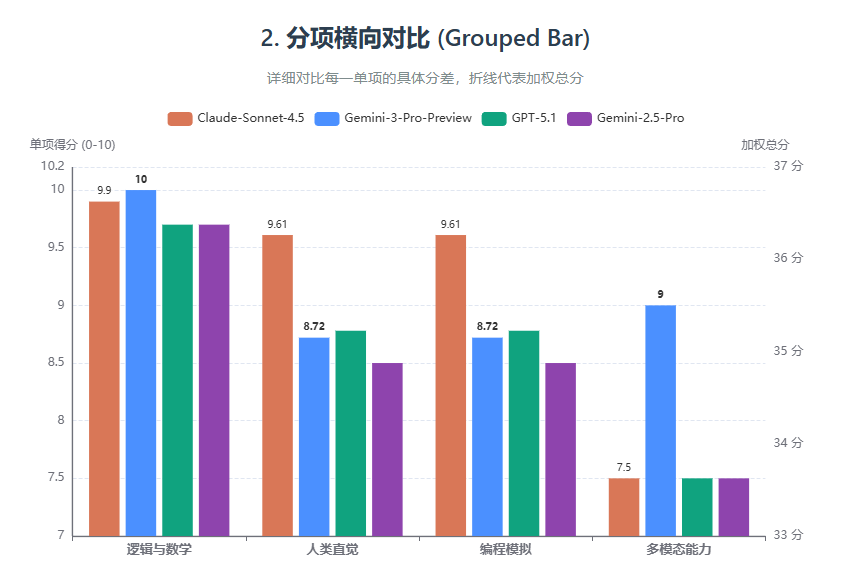
测评结果总览:
| 测评对象 | 逻辑与数学(10题) | 人类直觉(7题) | 编程模拟(9题) | 多模态能力(20题) | 加权总分 |
| claude-sonnet-4-5 | 9.90 | 9.61 | 9.61 | 7.5 | 36.62 |
| gemini-3-pro-preview | 10.00 | 8.72 | 8.72 | 9 | 36.44 |
| gpt-5.1 | 9.70 | 8.78 | 8.78 | 7.5 | 34.76 |
| gemini-2.5-pro | 9.70 | 8.50 | 8.50 | 7.5 | 34.2 |
IV. 实测案例
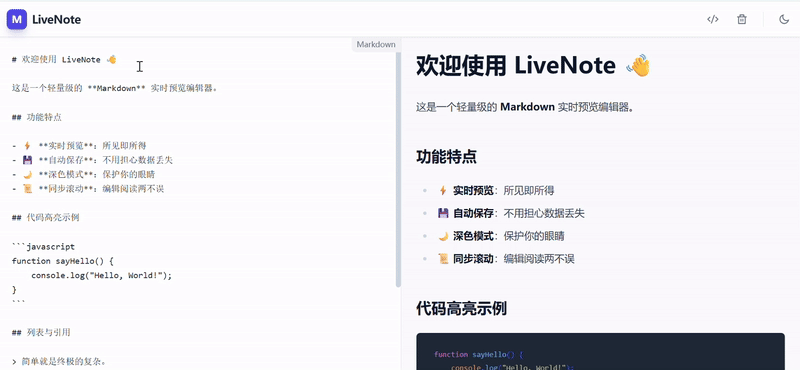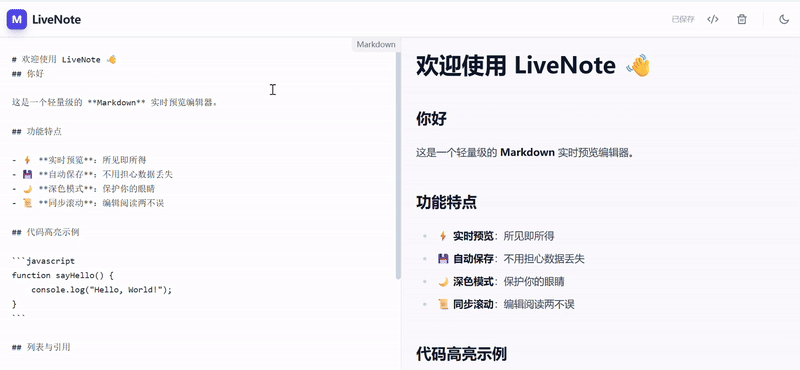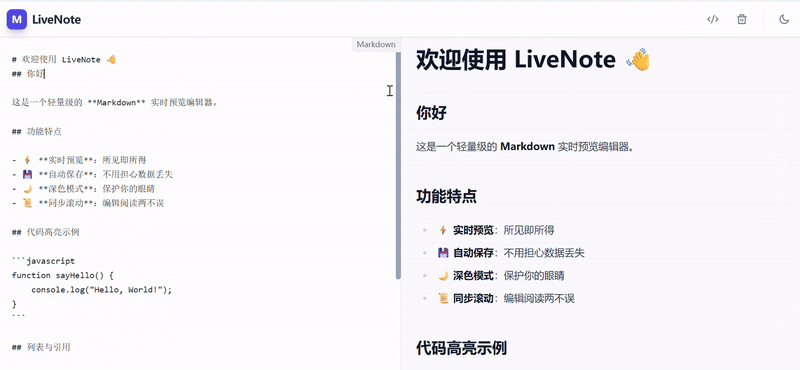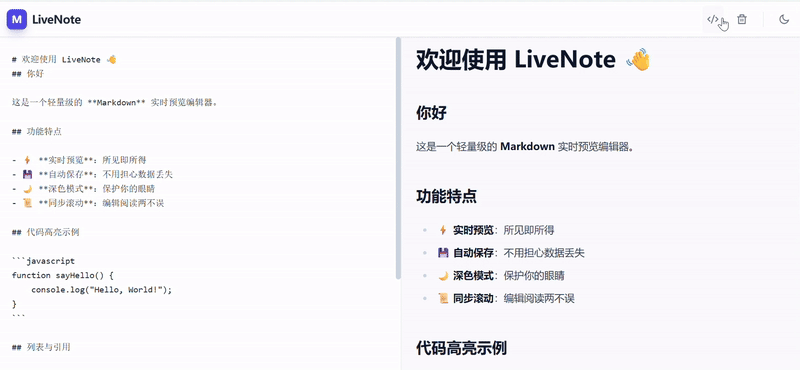
案例 1:编程模拟-Markdown笔记应用
提示词:创建一个功能性的、双栏实时预览的Markdown笔记应用,最终在一个HTML文件内交付所有代码。
Gemini 3 Pro 输出的效果在功能完整度、代码质量和可用性上都较 2.5 有了很大提升,实现了一个完整可用的 Markdown 编辑器。
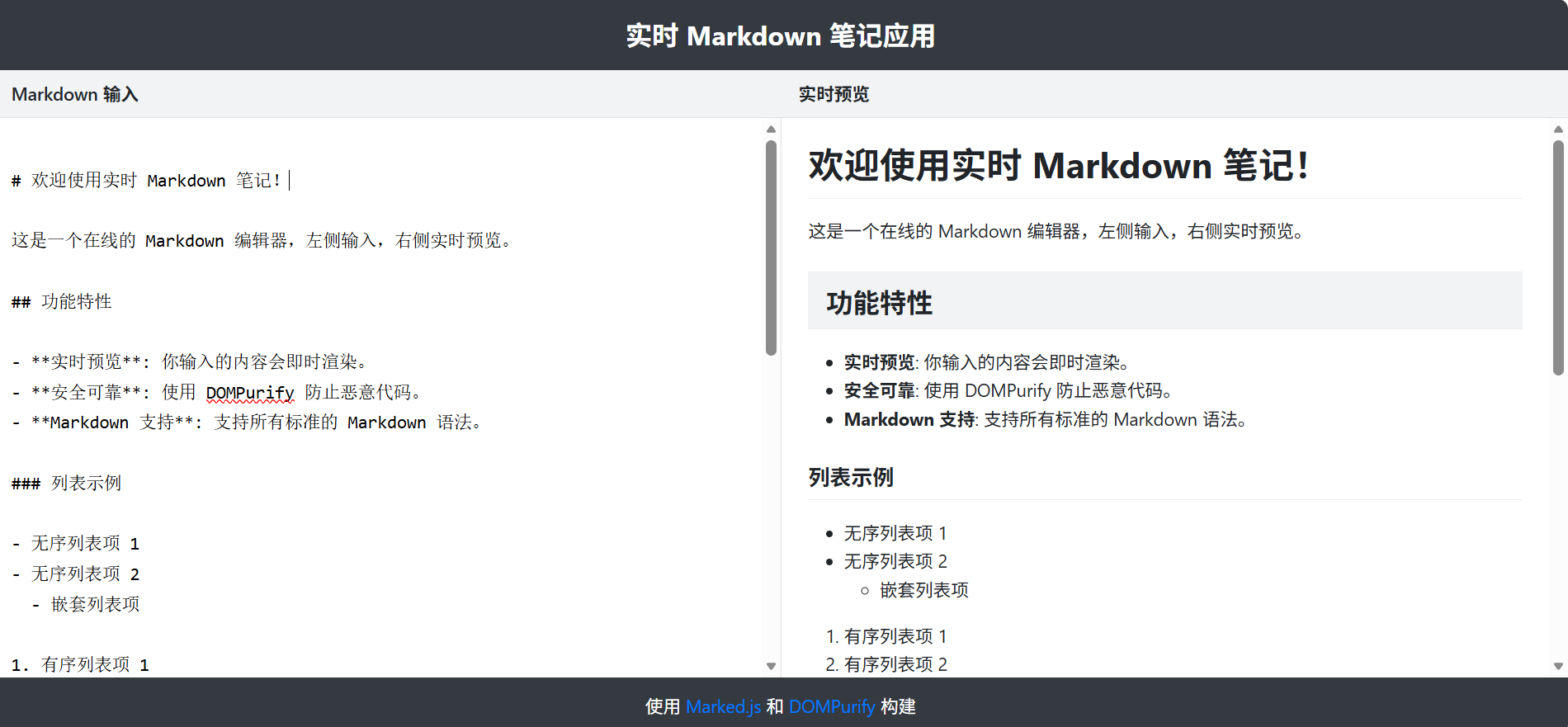
Gemini 2.5 Pro 输出参考:
案例 2:编程模拟-网页复刻
提示词: 请尝试复刻图上这个网页,背景可用渐变色/弥散风演示,图片部分可用SVG来实现,最终在一个HTML文件内交付所有代码。
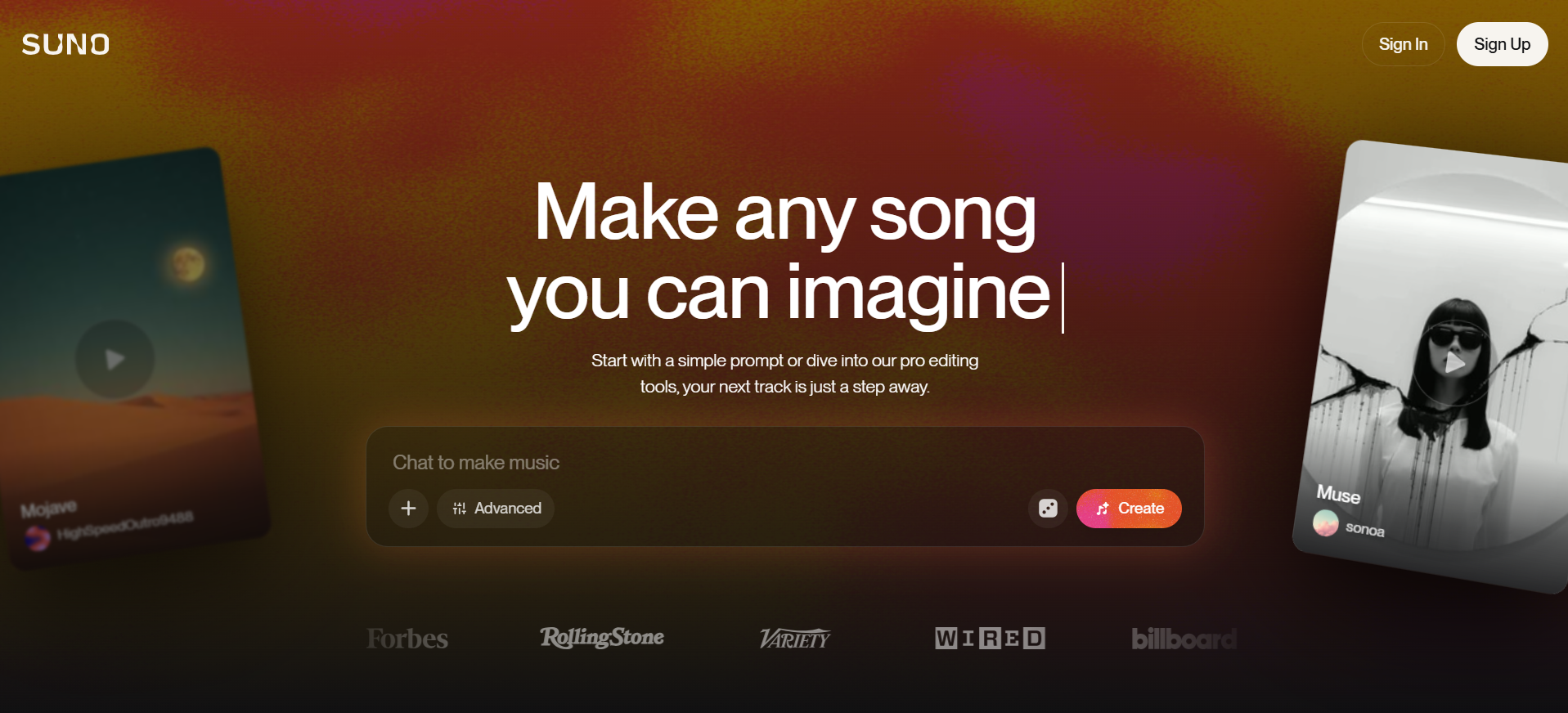
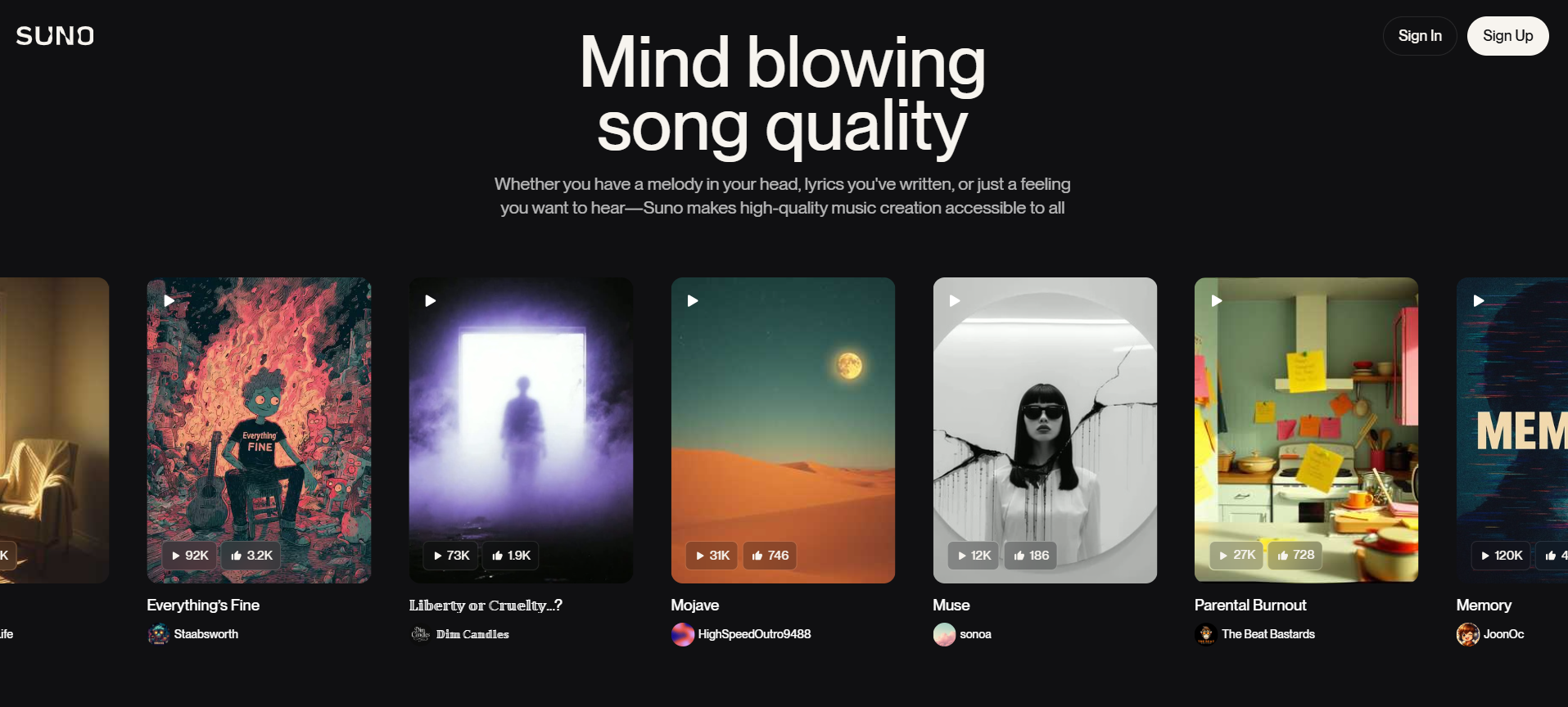
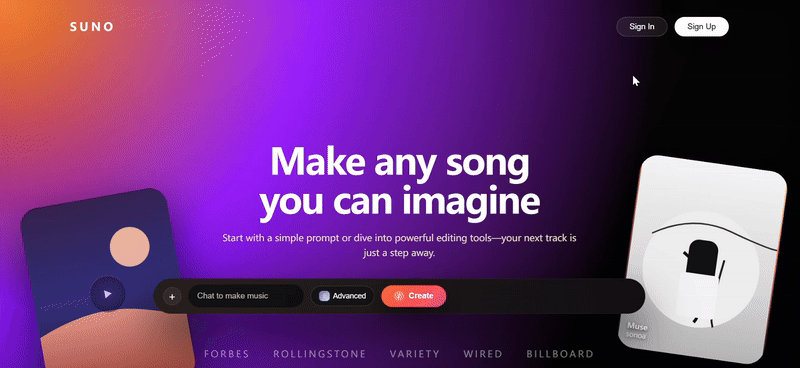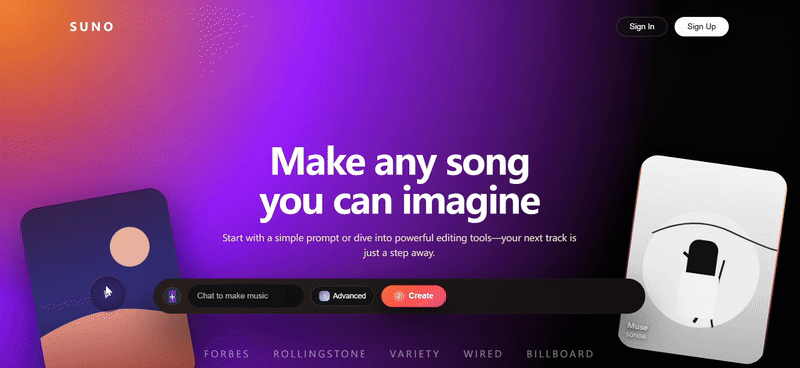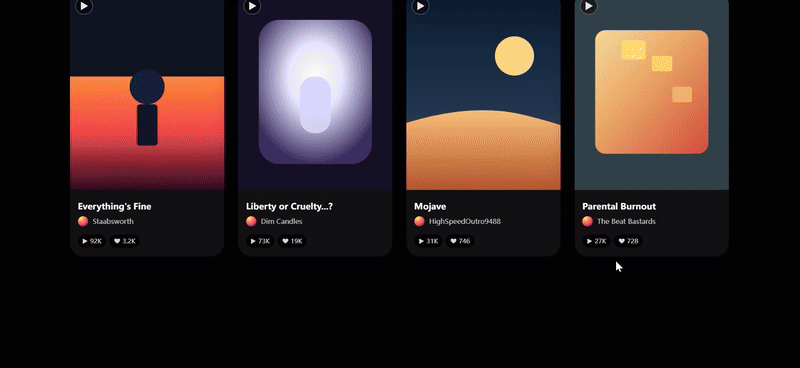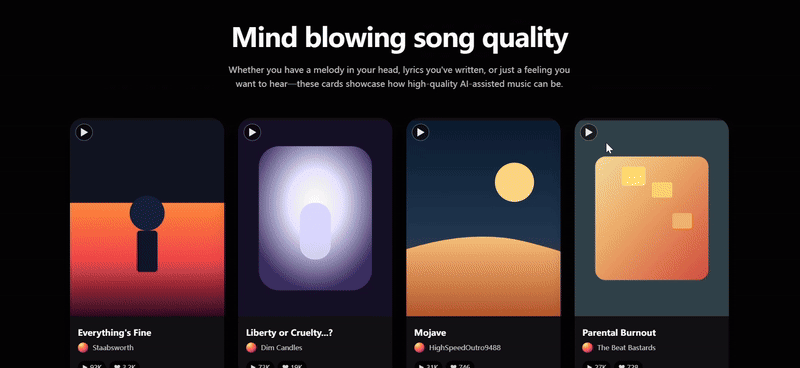
我们尝试让 Gemini 3 Pro 也复刻一遍 Suno 的网页
直观看上去效果不错,在浮动卡片和特色卡片中广泛使用 SVG,风格基调还原得比较精准,原版网页上的基本功能按键也几乎都具备了。
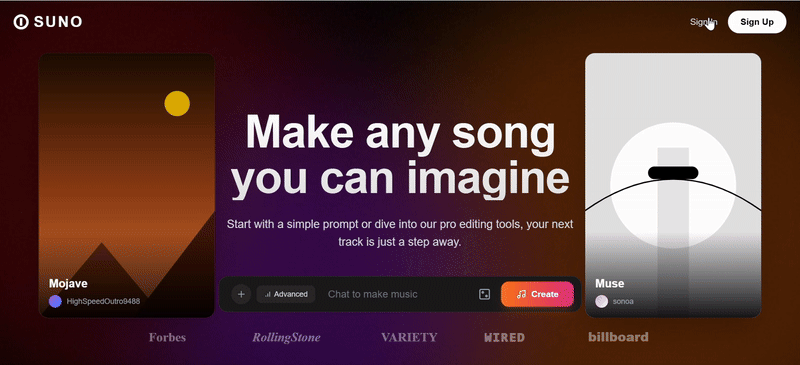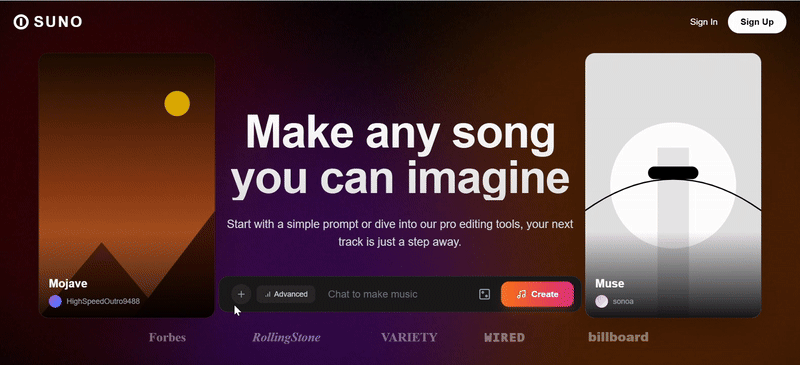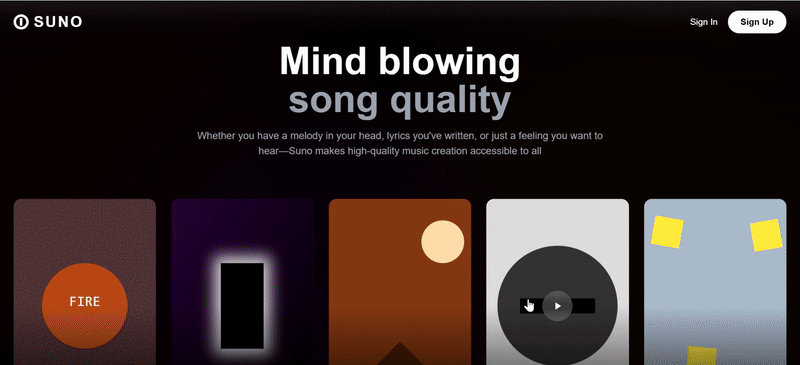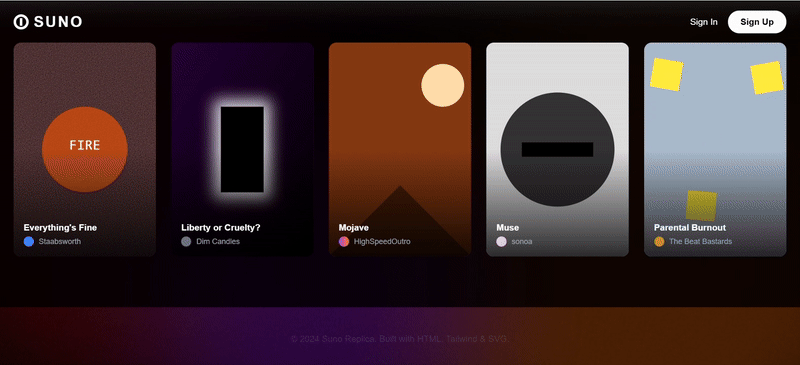
与 Claude Sonnet 4.5 的优秀案例相比,只存在微弱差距(例如布局还原度、卡片数据标注等细节问题)
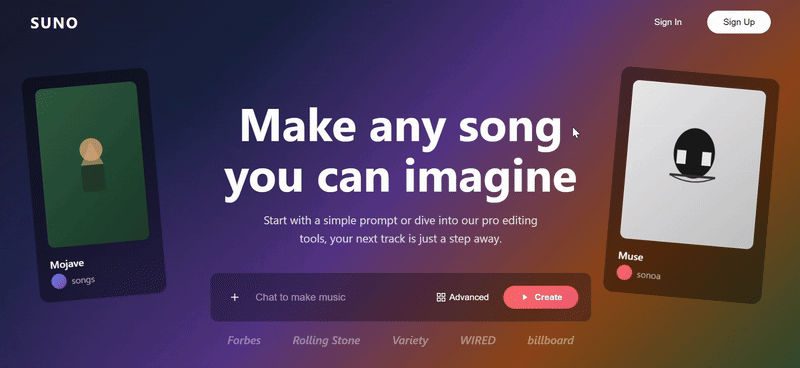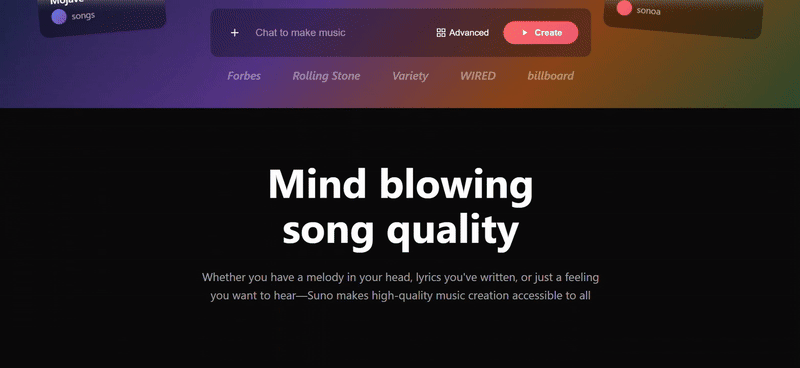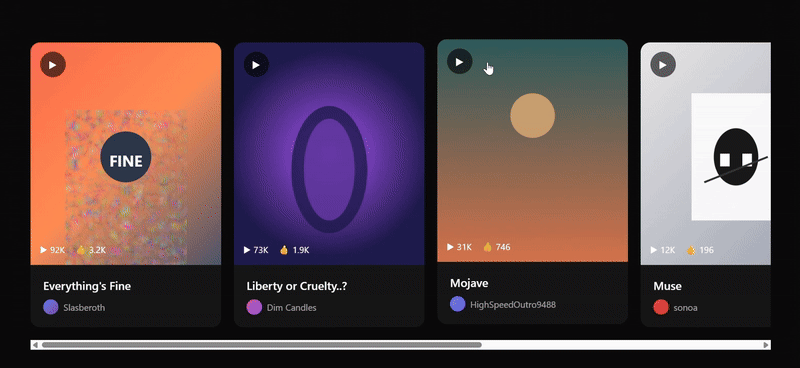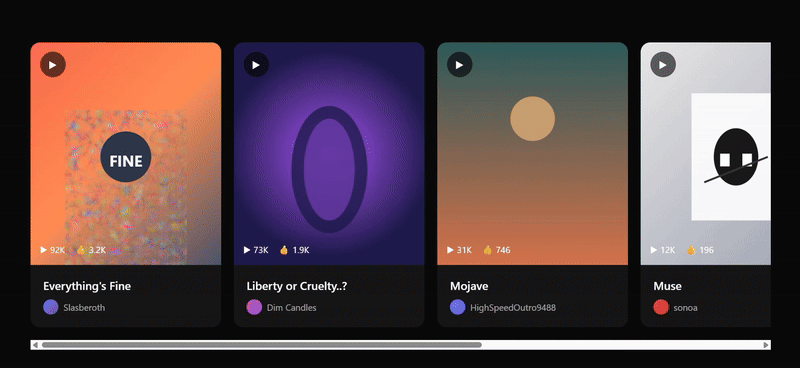
再来看看 GPT-5.1 的输出,布局莫名有点错位,交互状态不够完整。
案例 3:编程模拟-小程序
提示词: 开发一个微信小程序打车界面:
– 地图显示(可mock)
– 定位和地址搜索
– 车型选择(经济/舒适/豪华)
– 预估价格和等待时间
– 一键叫车功能
– 简洁现代的UI设计
要求:代码可运行,交互流畅
让 Gemini 3 Pro 尝试模拟做一个打车小程序
单从视觉上看是有点以假乱真的意思。用 Leaflet 实现了逼真的地图效果,以及右上角模拟的小程序菜单键和退出键,整个界面非常接近一款真实的小程序。
而且在交互上,地图的缩放和线路显示,以及点击打车后的加载响应,都非常细节。
对比 GPT-5.1 的输出,同样是比较完整的细节呈现,但比较核心的硬伤就是选择位置时缺乏下拉列表,缺少真实的地址搜索建议。
案例 4:编程模拟-404页面
据说 Gemini 3 Pro 很擅长“氛围编程”,即只需输入简短描述和核心需求,用感性描述代替详细需求文档就能生成符合预期的代码。
提示词:做一个让用户不会感觉到乏味的404错误页面。
Gemini 3 Pro 生成了一个“失重空间” 404 互动界面,出色地捕捉到“不乏味”这个核心需求,且自主添加了彩蛋。


进一步提出需求:把它替换成一个外卖网站的 404 加载页,Gemini 3 Pro 也能秒 get 你的意思

V. Gemini 3 Pro 实测结论

经过多维度的密集实测,是时候上结论了:Gemini 3 Pro 绝非只是一次常规的性能优化。
在经历了两年的参数竞赛后,我们似乎已经对“GPT-4.5级”,“性能提升30%”这些宣传话术感到麻木了。Gemini 3 Pro 这次的升级,可谓是带来了完全不一样的感觉。不再只是单纯地变得更博学,而是模型更聪明。如果说以往的模型都是通过海量的数据训练来积累各种解题套路,那么 Gemini 3 Pro 则不满足于直接抛出结果,而是会先停顿思考,这一点在逻辑推理测试和多模态测试当中尽数体现。得益于在 ARC-AGI(视觉逻辑)和 SimpleQA(事实准确性)上取得的突破性提升,模型幻觉大幅降低,这也使得模型很难会再陷入逻辑陷阱,从而输出更准确的回答。其在实际测试中碾压性的高分证明了“System 2”的深度思维模式并不是空话。
Gemini 3 Pro 在编程测试中的表现,并非达到了全面的能力跃迁,而是呈现出一种能力分化。在前端与UI工程领域,Gemini 3 Pro 的代码生成表现非常抢眼,几乎可以算是一个“成品”缔造专家。譬如案例 1 的 Markdown 编辑器构建,相比起 2.5 Pro,3.0 Pro 输出了更为成熟的、成品级的效果;此外,其架构意识令人印象深刻,例如在案例 3 小程序设计中的表现,不再只是传统模型表现出来的简单的 UI 组件堆砌,而是构建了一个完整的应用架构——近乎逼真的地图、状态管理和用户交互流程,其交付的完整度和交互细节,使对手的产出看起来像半成品。
然而其在算法理论编程测试中的发挥又暴露出不稳定性,面对复杂的递归优化、动态规划或图论证明,它依然会陷入推导深度不足的困境,表现出更类似于“辅助角色”的局限。
在一系列实测体验中,Gemini 3 Pro 展示出的最具颠覆性的体验,在于它理解了开发者的“感性需求”,即所谓 Vibe Coding. 当你说“做一个让用户不会感觉到乏味的 404 页面”时,传统模型可能会给你一堆动画效果代码,往往需要尽可能详尽地需求描述文档以及多次经历多次重跑,才能得到达到预期效果的输出。但 Gemini 3 Pro 表现出了强大的“氛围编程”能力,帮助用户将想法落地为产品。这种从功能需求到体验需求的跨越,意味着可以使用自然语义直接描述产品需求,省略了冗杂的技术需求文档,就像在与一位创意十足的工作伙伴共事,这体现出了我们与 AI 协作方式所发生的根本性转变——从指令与执行转变为对话与共创。
必须承认,Gemini 3 Pro 的出现释放出一个信号:单纯堆参数、卷算力的时代快要结束了,当模型开始从比拼上下文长度和推理速度的量变指标跨越到具备思维质量的质变指标,模型的迭代就不再只是单纯的版本迭代,而是技术路线的根本分歧。Google 显然选择了更艰巨的那条路:不再满足于速度,而是追求思考深度。
VI. 如何在 302.AI 上使用
1. 聊天机器人中使用
步骤指引 :应用超市→机器人→聊天机器人→立即体验
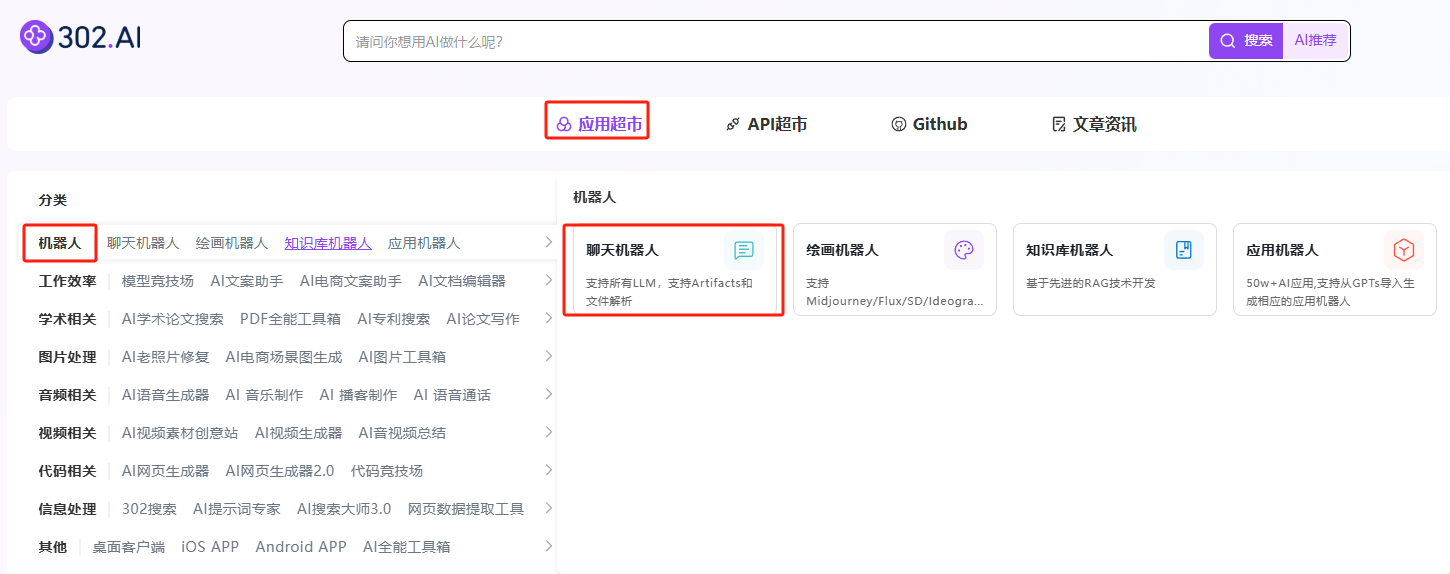
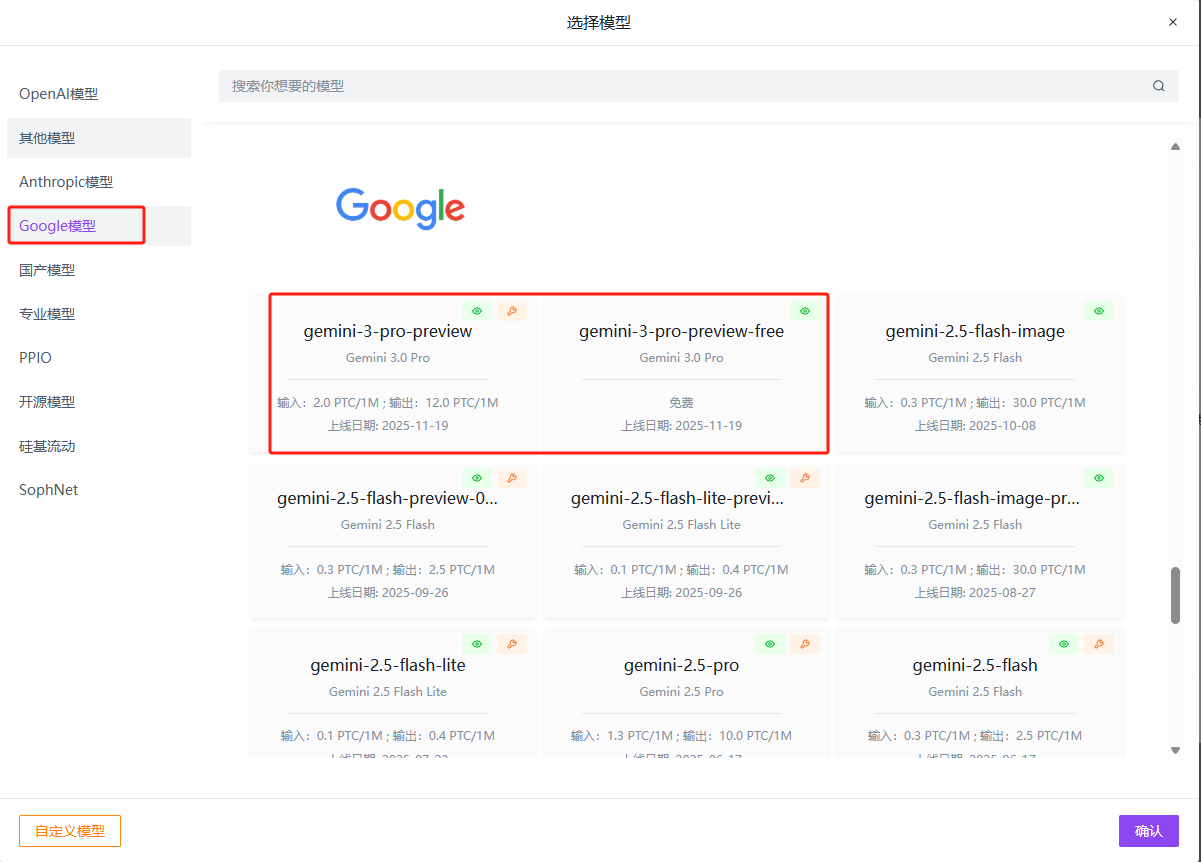
选择模型:Google模型→gemini-3-pro-preview→确认→创建
2. 使用模型 API
步骤指引:API超市→语言大模型→Gemini→gemini-3-pro-preview
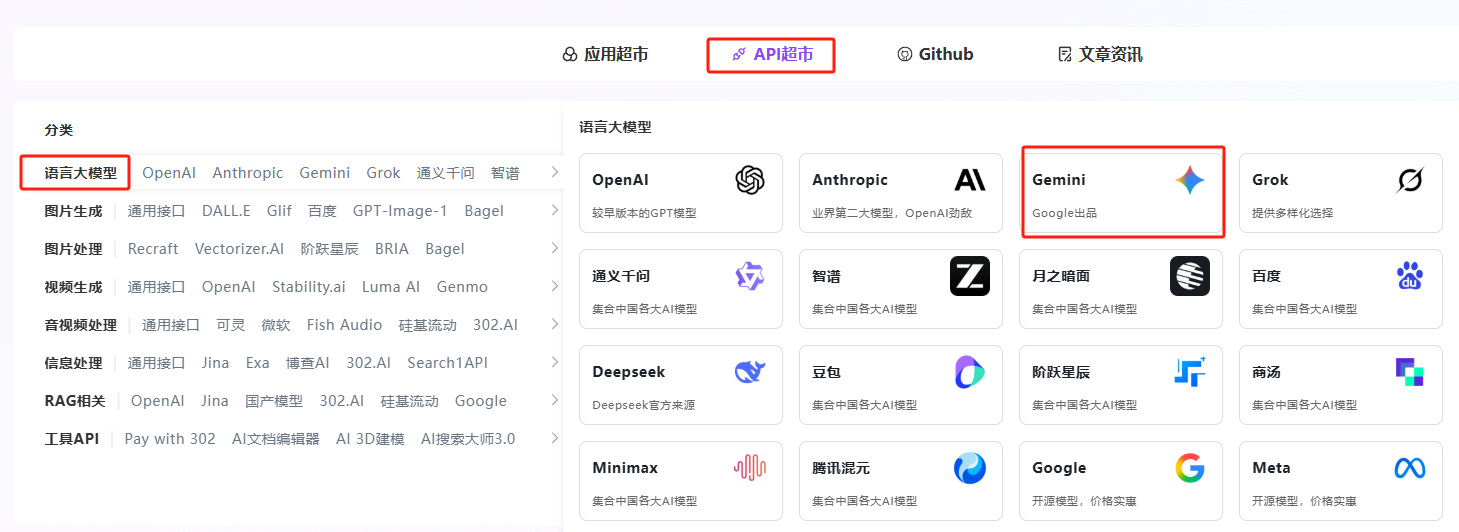
点击【立即体验】在线调用 API
想即刻体验 Gemini 3 Pro 模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
