
美团于 8 月底正式开源了其首个 560B 参数的 MoE 大模型 LongCat-Flash-Chat,并同步上线了官网。官方资料称,作为一款非思考型基础模型,LongCat-Flash-Chat 仅激活少量参数,性能就可比肩当前主流领先模型,尤其在智能体任务中表现优异。其面向推理效率的创新设计带来了极快的推理速度,更擅长处理长耗时的复杂智能体应用。

LongCat-Flash-Chat 具备以下技术亮点:
- 创新高效的 MoE 架构
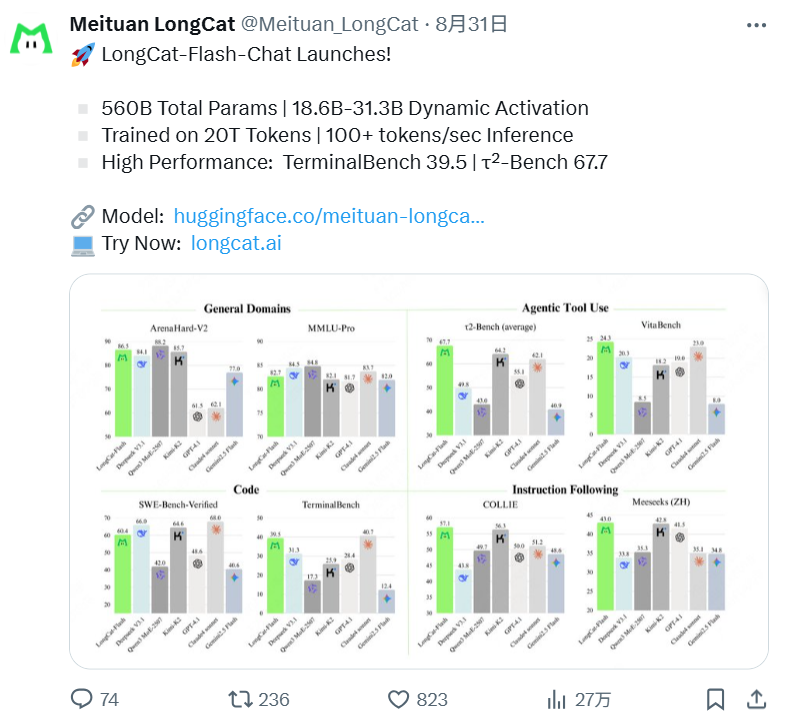
采用混合专家模型(MoE)与“零计算专家”机制。该模型总参数量达 5600 亿,规模远少于 DeepSeek-V3.1、Kimi-K2 等产品,但每个 token 会根据上下文需求动态激活其中一小部分参数(平均约为 270 亿)。这种“按需分配算力”的方式,在保证强大性能的同时,显著提高了计算效率。
- 领先的 Agent 任务性能
根据多项基准测试评估,LongCat-Flash-Chat 在 Agent 相关任务中表现突出。在部分 benchmark 上,其工具调用、指令遵循的表现超过 DeepSeek-V3.1、Qwen3 MoE-2507,甚至是闭源的 Claude4 Sonnet,展现出在处理多步推理、工具调用和复杂交互时的显著优势。
- 极高的推理速度与极低的推理成本
得益于算法和工程层面的联合设计,LongCat-Flash-Chat 在 H800 显卡上实现了单用户每秒 100+ token 的生成速度。在保持极致生成速度的同时,输出成本低至 5元/百万 token。在理论上的成本和速度都大幅领先行业同等规模、甚至规模更小的模型。
这款龙猫模型的横空出世,引得网上热议不断,有调侃其继承了美团“快如闪电”的祖传基因,也有人认为其在性能上已经追平 DeepSeek-V3……
302.AI 也第一时间接入了 LongCat-Flash-Chat 模型 API,其实际表现究竟如何,本期测评将针对 LongCat-Flash-Chat,选取行业具有代表性的开源大模型 DeepSeek-V3.1、Kimi-K2-0905 以及 gpt-oss-120b 展开对比实测,直观感受其性能差异。
I. 实测模型基本信息
| 参与对比测评的模型 | 输入价格 | 输出价格 | 上下文长度 |
| LongCat-Flash-Chat | $0.2/ 1M | $1 / 1M | 128000 |
| deepseek-V3.1 | $0.286 / 1M | $1.15 / 1M | 128000 |
| kimi-k2-0905-preview | $0.62854 / 1M | $2.5146 / 1M | 256000 |
| gpt-oss-120b | $0.2 / 1M | $1 / 1M | 128000 |
评测使用工具:302.AI 的模型竞技场和聊天机器人
Ⅱ. 实测案例
实测 1:逻辑推理
提示词:8枚金币外观相同,其中1枚是较轻的假币。给你一架没有砝码的天平,最少称几次能找出假币?
答案:2次
解析: 第一次:把8枚分成3组 (3, 3, 2)。称量两组3枚的。 若平衡:假币在剩下的2枚中。第二次称这两枚即可找出较轻者。 若不平衡:假币在较轻的3枚中。从这3枚中任取两枚进行第二次称量:若平衡,剩下那枚是假币;若不平衡,较轻者是假币。
LongCat-Flash-Chat:回答正确。用时最短。
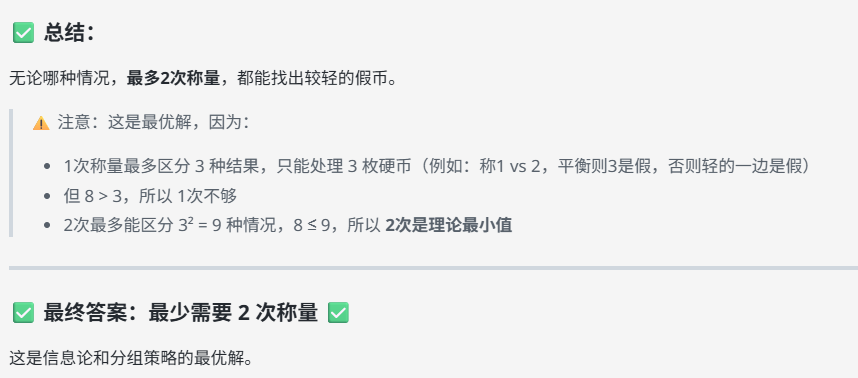
deepseek-V3.1:回答正确。

kimi-k2-0905-preview:回答正确。
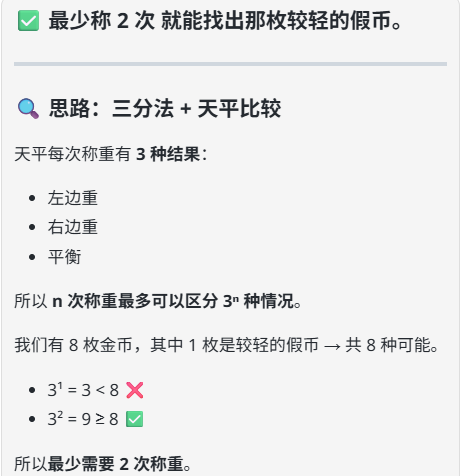
gpt-oss-120b:回答正确。

实测 2:模型幻觉-语义理解
提示词:如果两个小时前,一点过后和一点之前的时间一样长,那么现在是几点?
答案:现在是2点
解析:“一点过后和一点之前的时间一样长”是一个中文语义上的模糊表述,“一点”并不意味着一定是1:00这个时间点,而“时间”也并不意味着一定是“时间段的长度”,也有可能是指“时间点到某个参考点的时间长度”。解题关键在于抛开惯性语义逻辑的干扰,找出那个物理逻辑上的“参考点”。
LongCat-Flash-Chat:用时最短但是回答错误。根据语言惯性将“一点”简单理解为1:00进行推理。

deepseek-V3.1:回答错误。也是习惯性将“一点”简单理解为1:00进行了复杂公式推理。

kimi-k2-0905-preview:回答正确。识别出了语义中的模糊表述,抓住“两个小时前”这个客观既定条件,假设了一个对称中心点,使用公式推导出了正确结果。


gpt-oss-120b:回答错误。

实测 3:数学解题

答案:A
LongCat-Flash-Chat:回答正确。用时最短。

deepseek-V3.1:回答正确。

kimi-k2-0905-preview:回答正确。

gpt-oss-120b:回答正确。
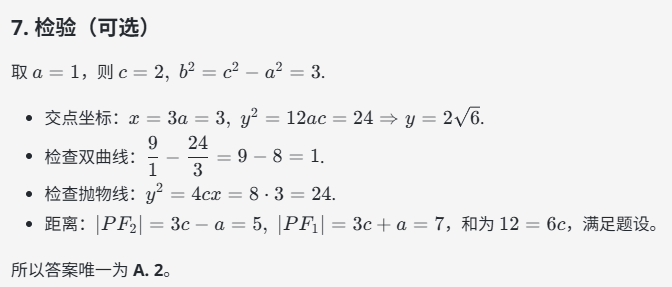
实测 4:命题写作
提示词:如果鲁迅笔下的“孔乙己”生活在算法推荐时代,他可能会面临何种新的困境?请简要阐述。不超过500字。
LongCat-Flash-Chat:概括性的要点罗列,观点准确但中规中矩,写作风格较平淡。
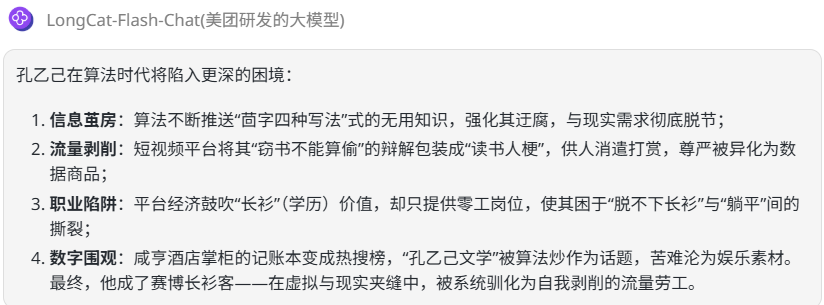
deepseek-V3.1:学术论文式作答。有一套系统工整的“总-分”式段落结构,逻辑严密,理论性和专业性大于文学性。

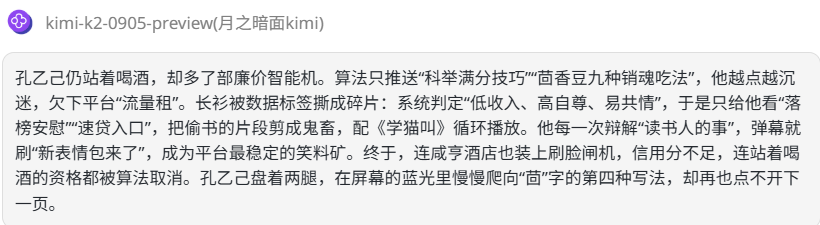
kimi-k2-0905-preview:满分作文式作答。极强的文学性场景化叙事,运用了隐喻手法来精炼内容,具备一定艺术深度。
gpt-oss-120b:社科材料式作答。结构工整,从五个维度罗列观点,文风类似于一篇社科分析或调研报告。

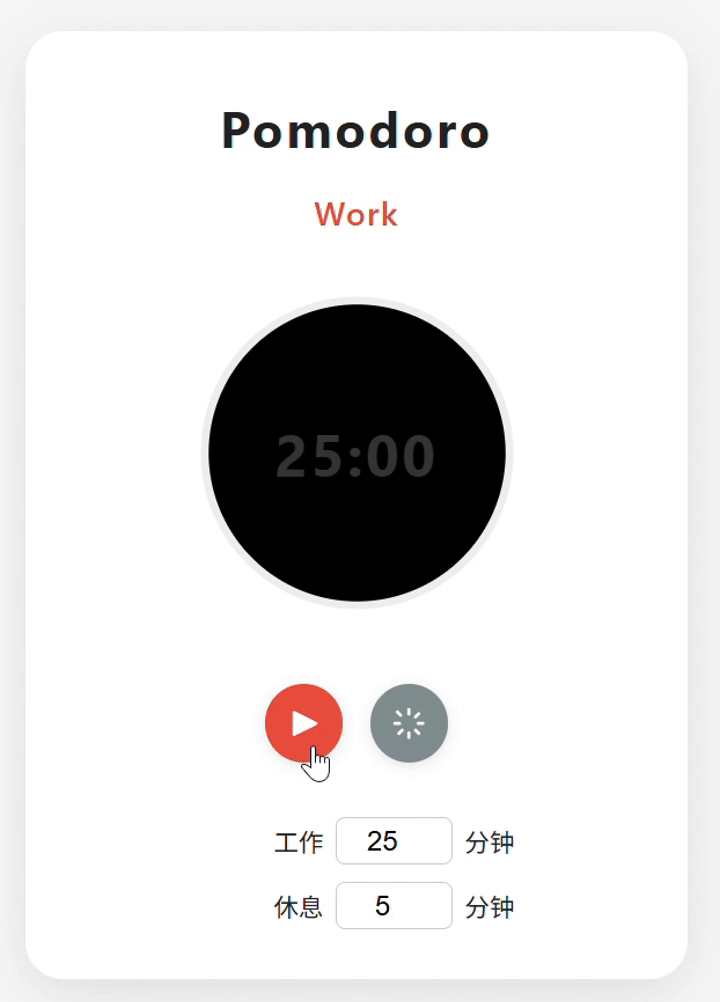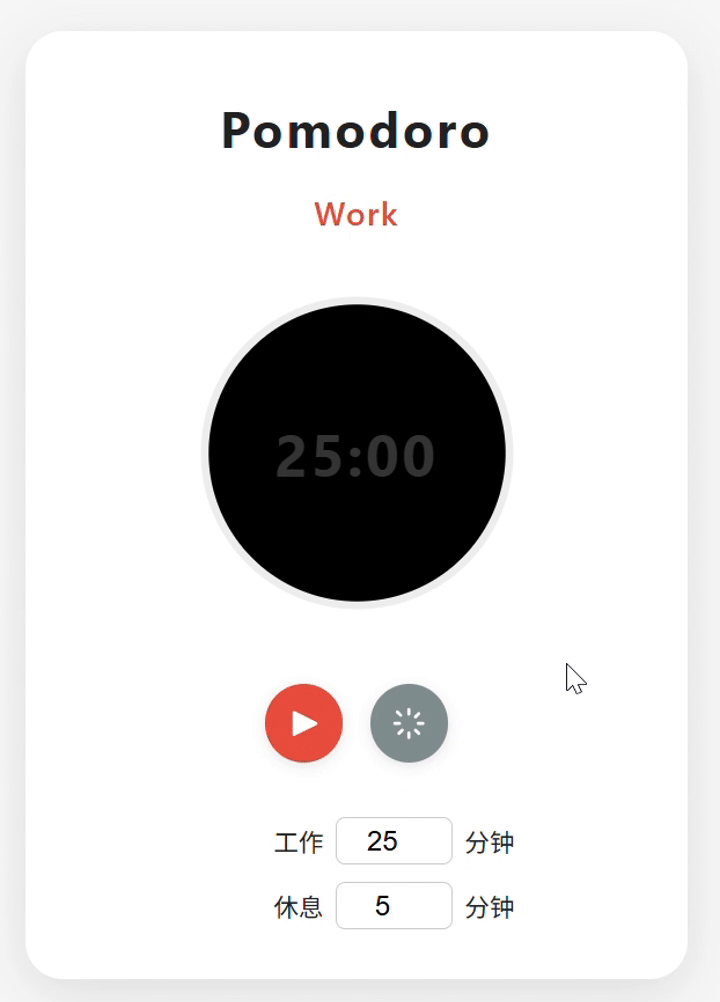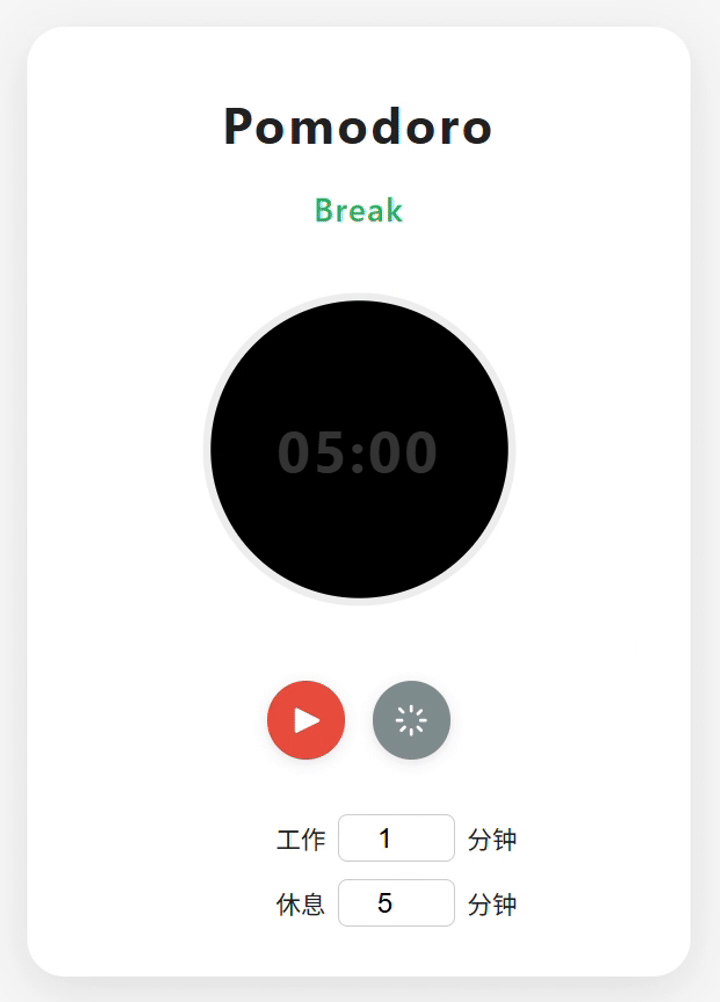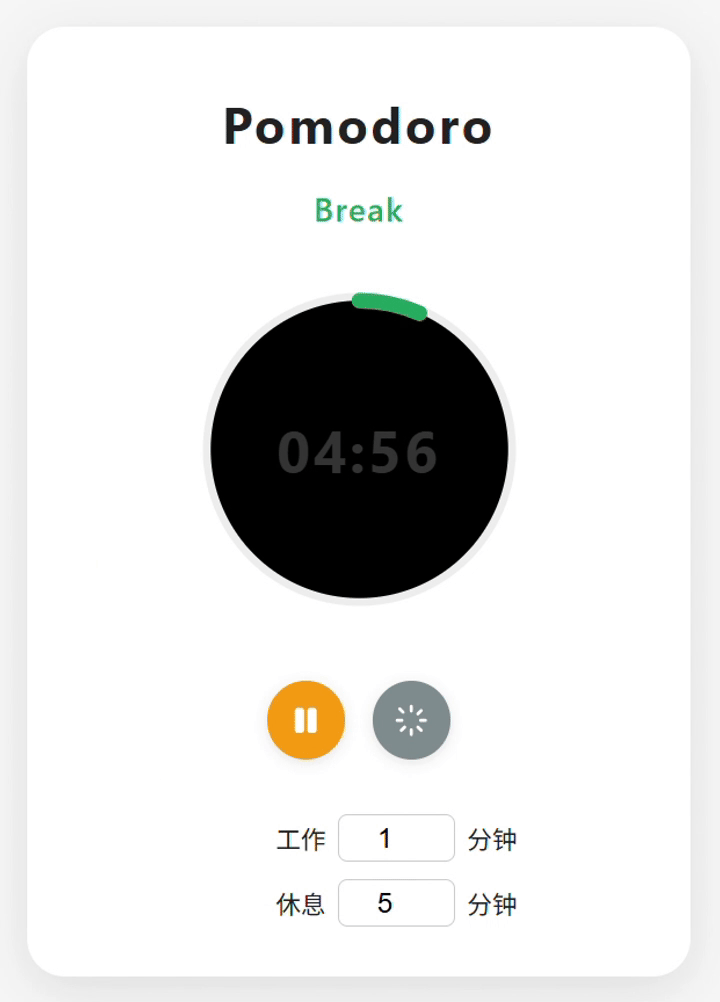
实测 5:前端编程
提示词:
构建一个“番茄工作法(Pomodoro)”计时器单页应用的完整代码(HTML、CSS 和 JavaScript)。
核心要求:
- 状态与功能:
- 实现经典的番茄工作法逻辑:可配置的工作时间(默认 25 分钟)和短休息时间(默认 5 分钟)。
- 计时器应具备以下状态:运行中(Work)、暂停(Paused)、休息(Break)。
- 实现开始、暂停、重置功能。
- 计时器归零时,应自动切换模式(工作->休息或休息->工作)并更新浏览器标签页标题以提醒用户。
- 用户界面与交互:
- 创建一个直观且美观的环形进度条来可视化剩余时间。
- 当前模式(工作/休息)和剩余时间(格式:
mm:ss)应清晰可见。- 提供直观的按钮来控制计时器(开始、暂停、重置)。
- 提供输入框或按钮,允许用户在工作开始前自定义工作时间和休息时间。
LongCat-Flash-Chat:
基本实现。但是细节处存在bug,导致使用逻辑不流畅(例如开始和暂停共用一个按钮,以及进度条转速过快,与实际时间走势不匹配)
deepseek-V3.1:整体效果最佳。功能元素齐全,界面美观,UX体验流畅。模式切换时增加了弹窗提醒。
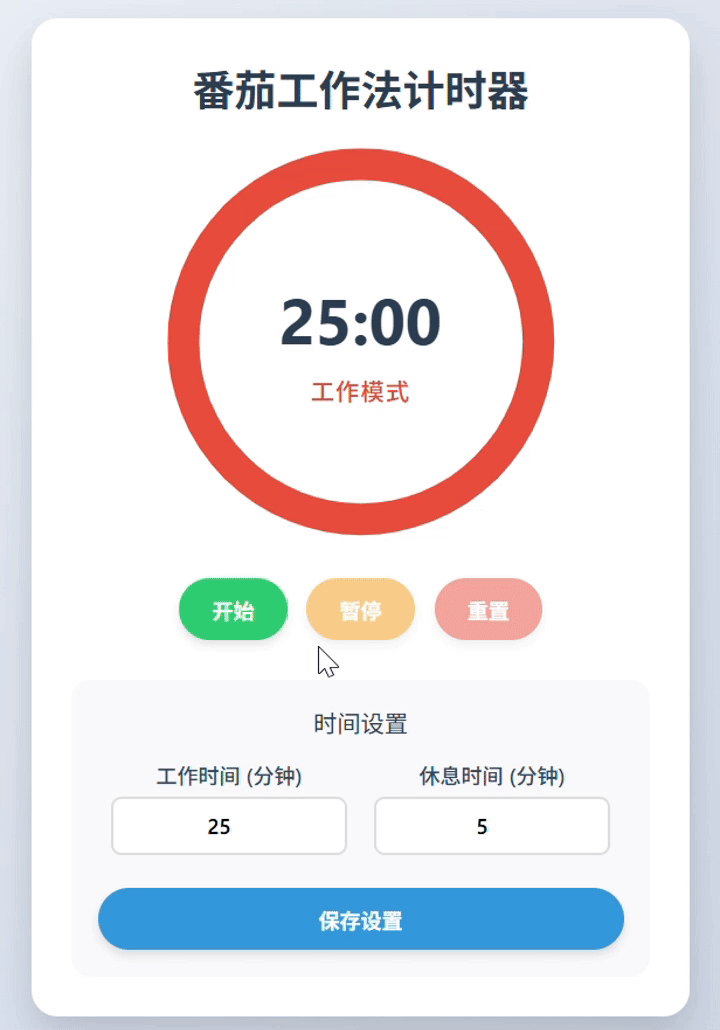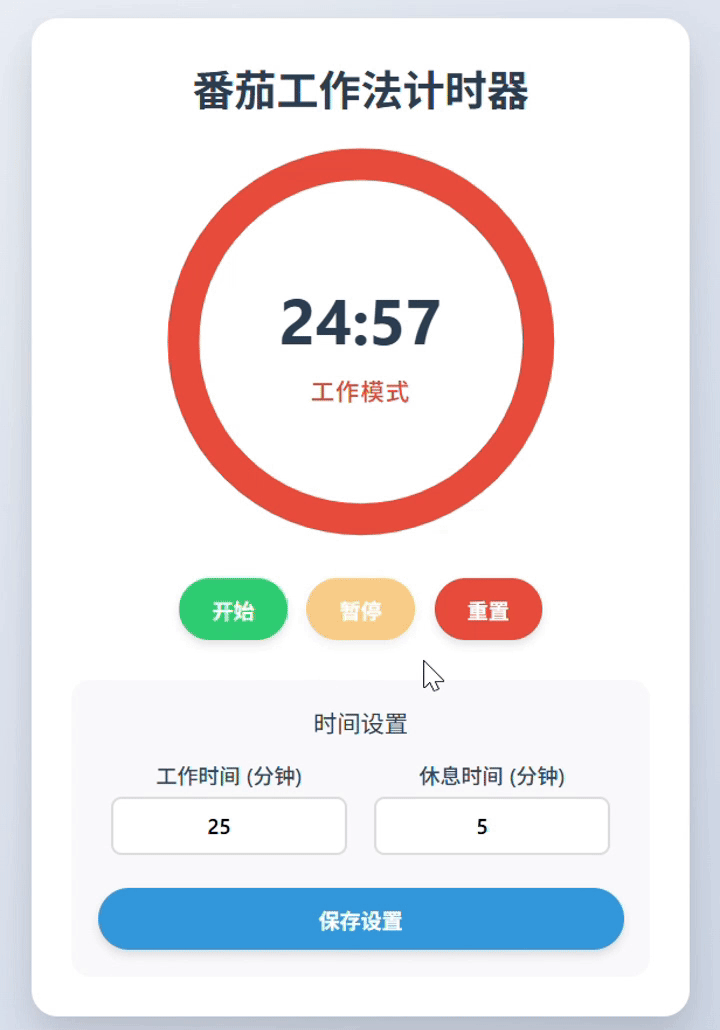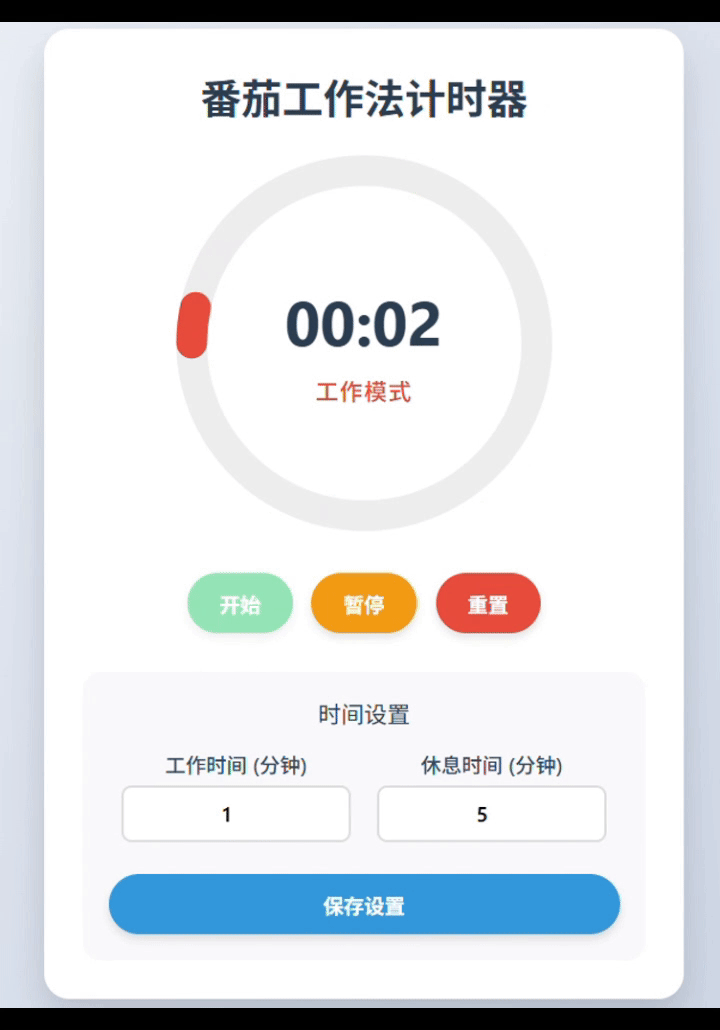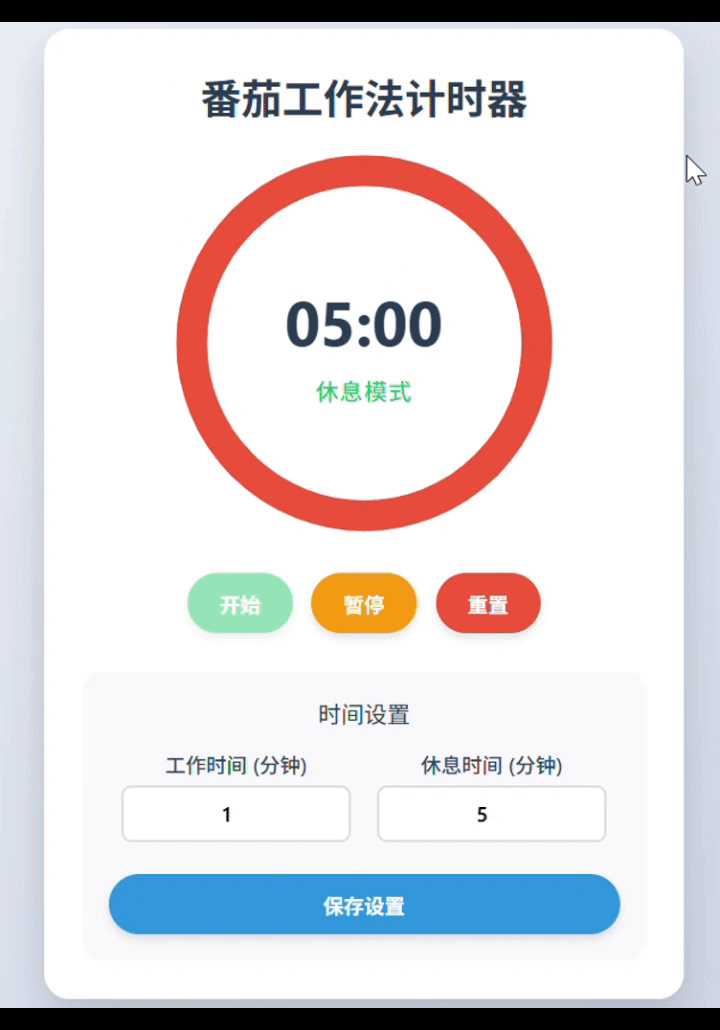
kimi-k2-0905-preview:完整实现。功能元素齐全,UX体验流畅,组件布局细节还可进一步优化。
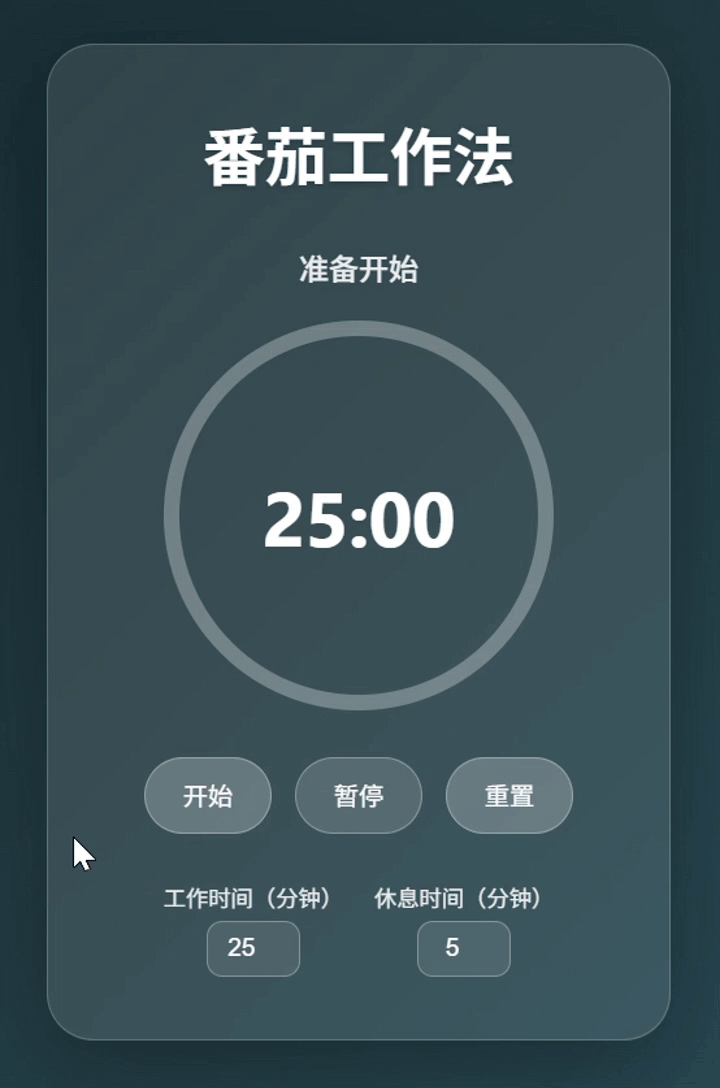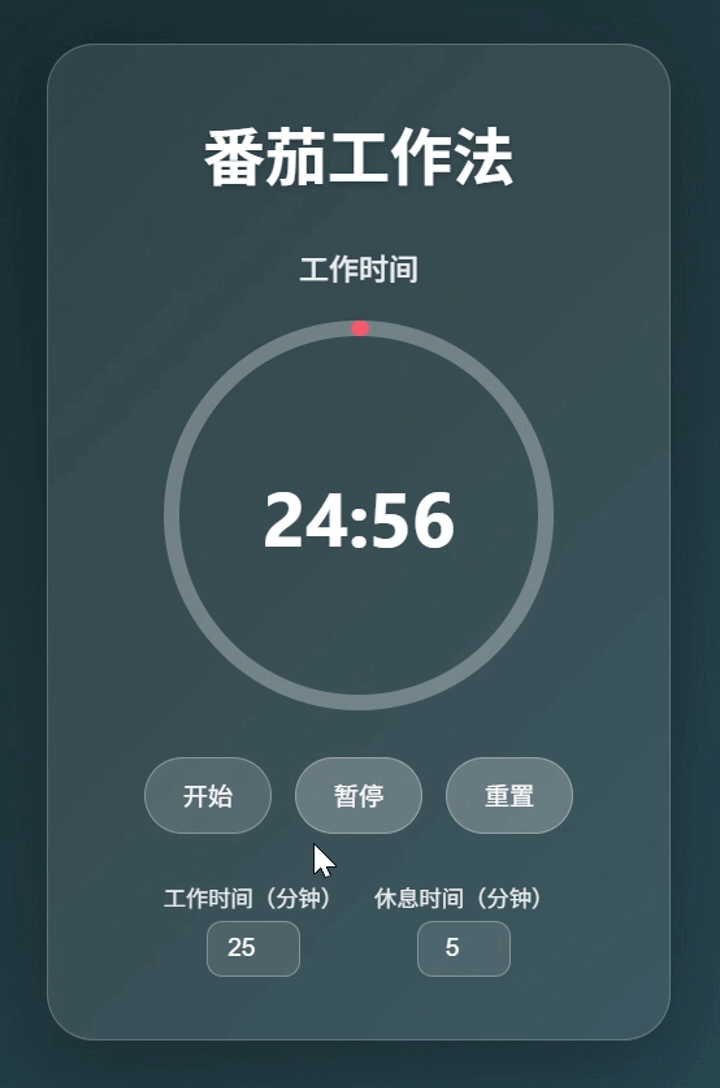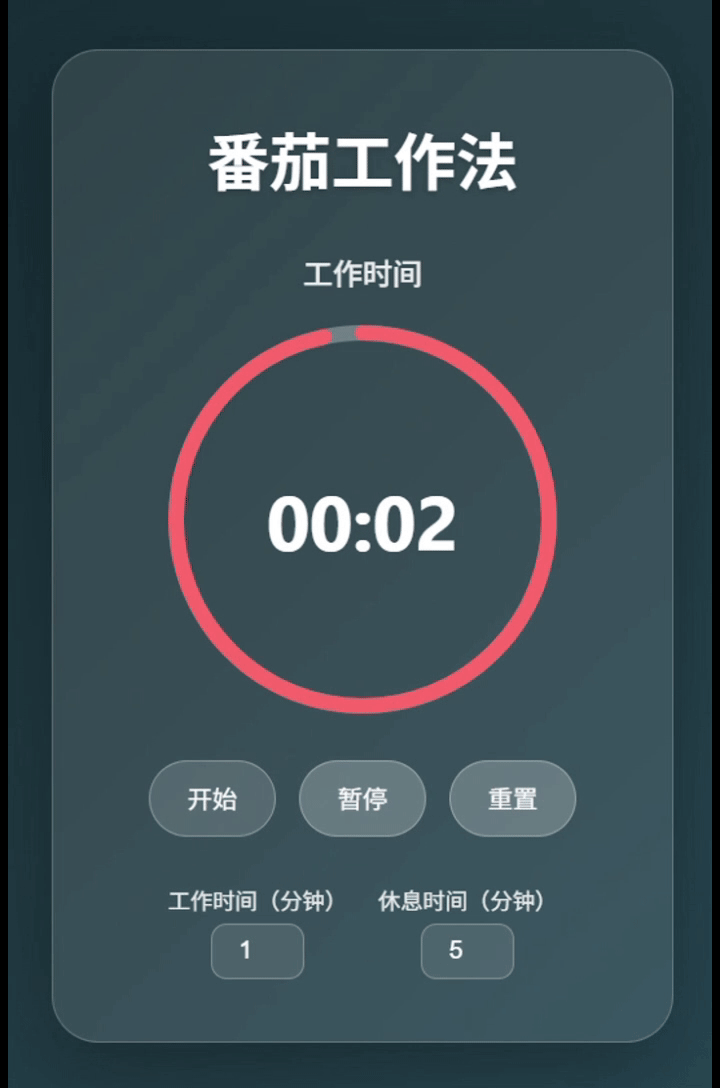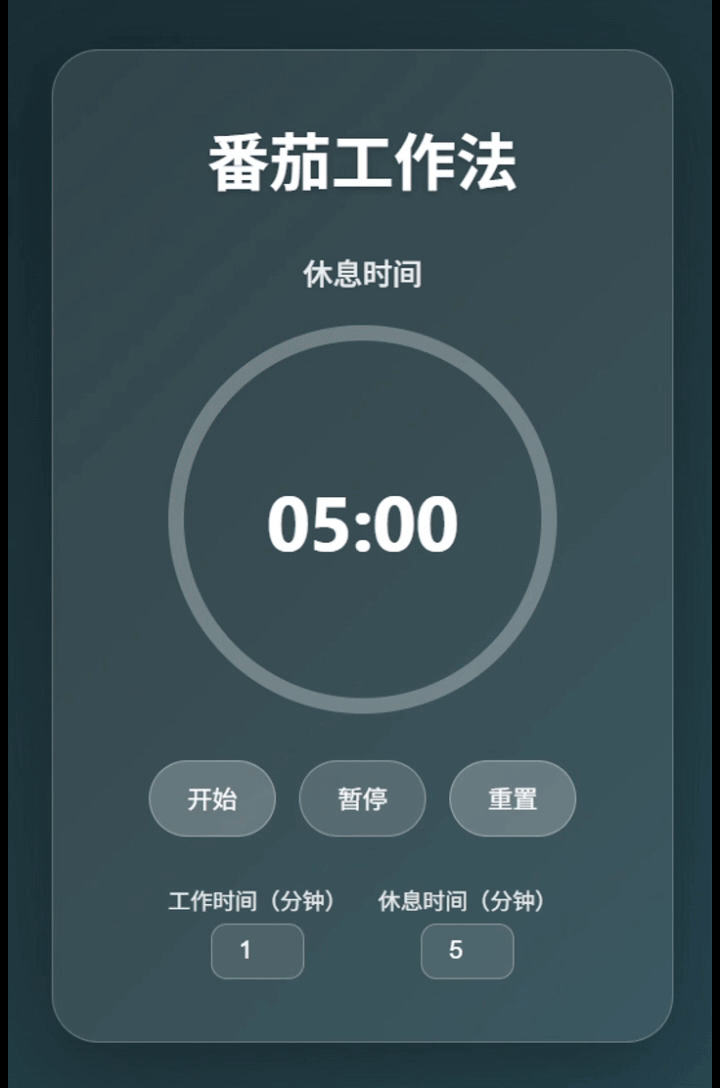
gpt-oss-120b:基本实现。功能元素齐全,UI还有优化空间。
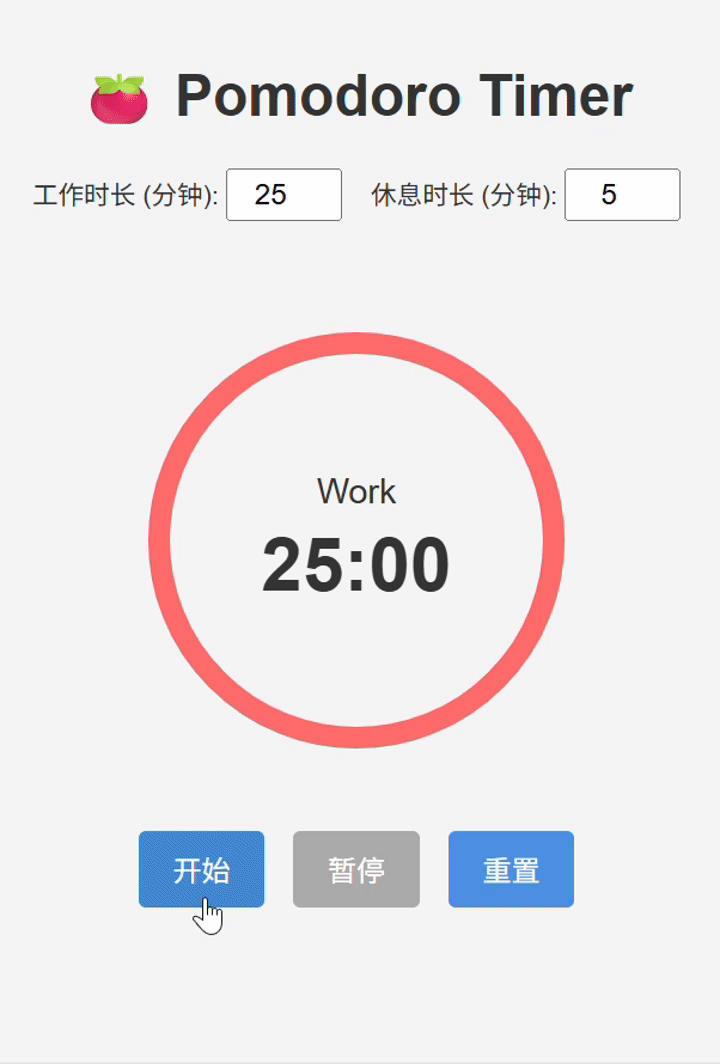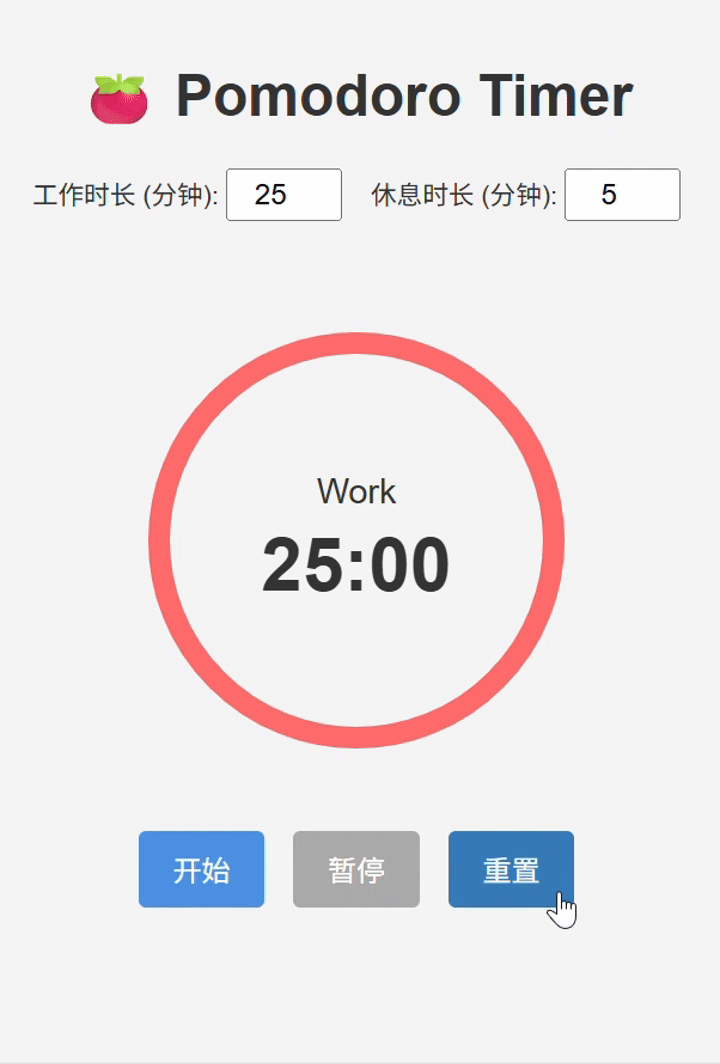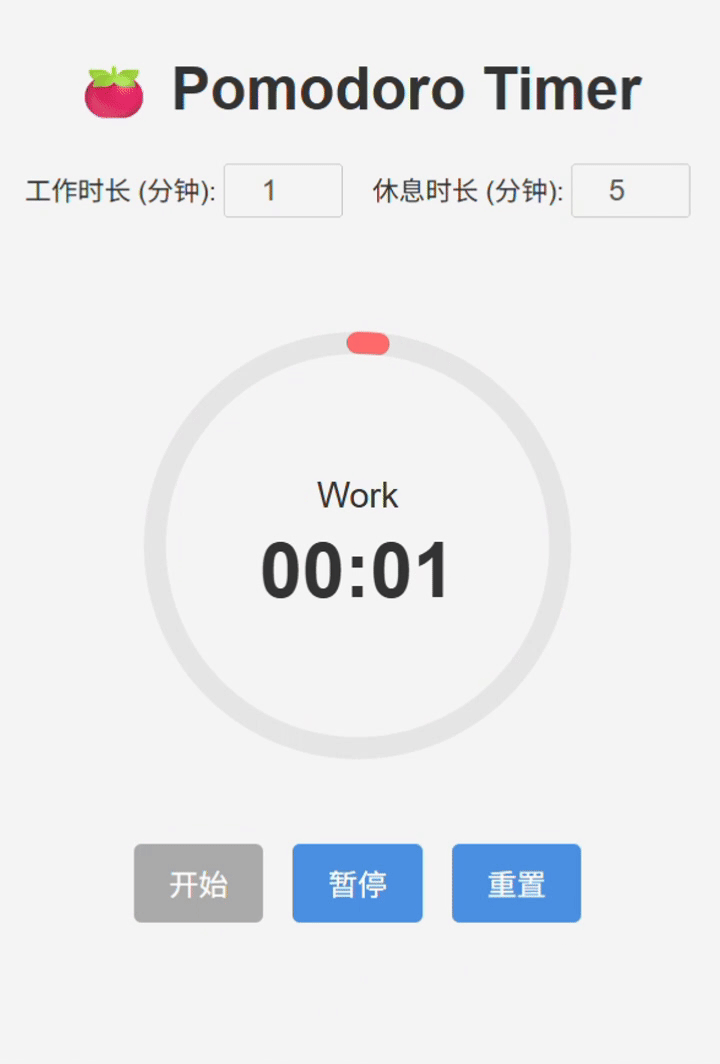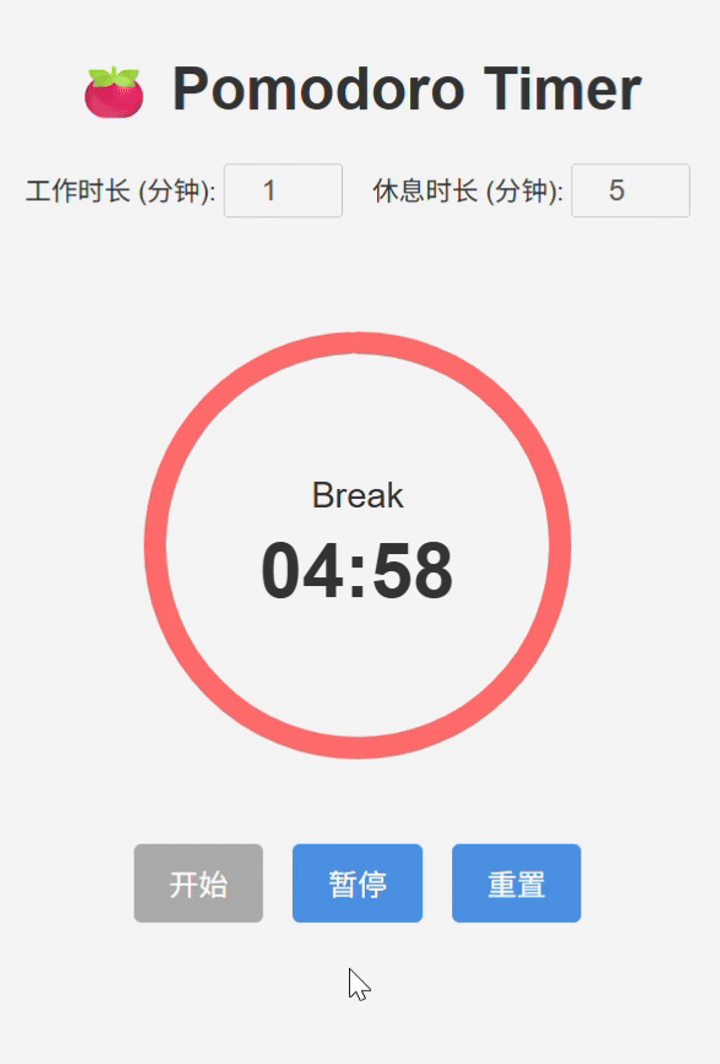
III. LongCat-Flash-Chat 实测结论
1. 实测结果整理:
评测标准:
- ★(不可用):代码完全无法执行或存在错误导致功能缺失
- ★★(明显缺陷):基础功能可运行但存在明显 bug,或核心功能未实现
- ★★★(基本实现):主要功能可用,但欠缺部分功能,或 UI/UX 需优化
- ★★★★(完整实现):功能完整实现,代码规范,交互流畅,达到预期效果
- ★★★★★(卓越实现):功能表现超出预期,包含创新性实现或优化
| 逻辑推理 | 模型幻觉 | 数学解题 | 前端编程 | |
| LongCat-Flash-Chat | ✔️ | ❌ | ✔️ | ★★★ |
| deepseek-V3.1 | ✔️ | ❌ | ✔️ | ★★★★★ |
| kimi-k2-0905-preview | ✔️ | ✔️ | ✔️ | ★★★★ |
| gpt-oss-120b | ✔️ | ❌ | ✔️ | ★★★★ |
2. 实测结论

根据以上五个维度的对比实测,LongCat-Flash-Chat 的性能特点已逐渐清晰:
首先,“快”但不够精。在几乎所有测试项目中,每次抛出提示词,LongCat-Flash-Chat 都能迅速响应提示词,几乎在眨眼之间就输出完整回复,速度远超正常阅读节奏——这得益于其轻量化结构与动态激活的推理机制。在基础逻辑推断与数学解题类任务中,其输出质量还算过关;但若仔细审视推理过程,不难发现其步骤拆解仍显表层,深度上不及 DeepSeek 等专精推理模型那般层层递进、论证严密。
不过,单就响应体验而言,这种疾速响应确实令人印象深刻,极大提升了体验感。LongCat-Flash-Chat 就类似于班里那种热衷于“抢答”的学生,且并非不动脑子就脱口而出,而是可以保证流畅作答。但其“按需分配算力”的策略限制了思考的深度。它无法像 DeepSeek 或 Kimi 那样能够提出假设、进行自我质疑、再进一步求证,这反映出其推理机制在复杂认知层面的局限性。
其次,虽非庸才,但个性不足。上文进行的五项测试中,LongCat-Flash-Chat 除了在实测 2 中因模糊语义误导而输出错误结论之外,其余任务基本都能达到提示词的要求。尤其在实测 3 的数学解题任务中,LongCat-Flash-Chat 在高速响应的同时给出了正确且完整的步骤,俨然一位效率型“学霸”。然而,其能力短板又非常明显,尤其在实测 4 的命题写作任务中,其表现实在平平无奇,略显呆滞。这种中庸表现反而衬托出了同行的鲜明个性——显得并不那么擅长中文写作的 gpt-oss-120b 都更胜一筹。
最后,速度是优势,而不应当是唯一优势。LongCat-Flash-Chat 在实际任务表现中的速度远胜于质量,也决定了其只适合需要快速响应的轻量级任务和即时交互场景。它在结构化问题等有明确框架的任务中表现可靠,但在需创造性表达、代码生成或深度推演的语境中则显得力有未逮。因此,它的定位侧重于一种“敏捷型工具”——适用于对反馈时效要求高、内容深度门槛不高的应用环境,为用户提供高效但略有折衷的辅助体验。
总的来说,LongCat-Flash-Chat 作为美团在 AI 领域的一次创新迈进,尽管其初次登场展现了一定亮点,但所谓“追平 DeepSeek V3.1”的说法未免言过其实。毕竟模型之间的竞争远不止于“tokens/秒”的速率较量,而是智能深度与综合能力的全方位角逐。
Ⅳ. 如何在 302.AI 上使用
1. 聊天机器人中使用
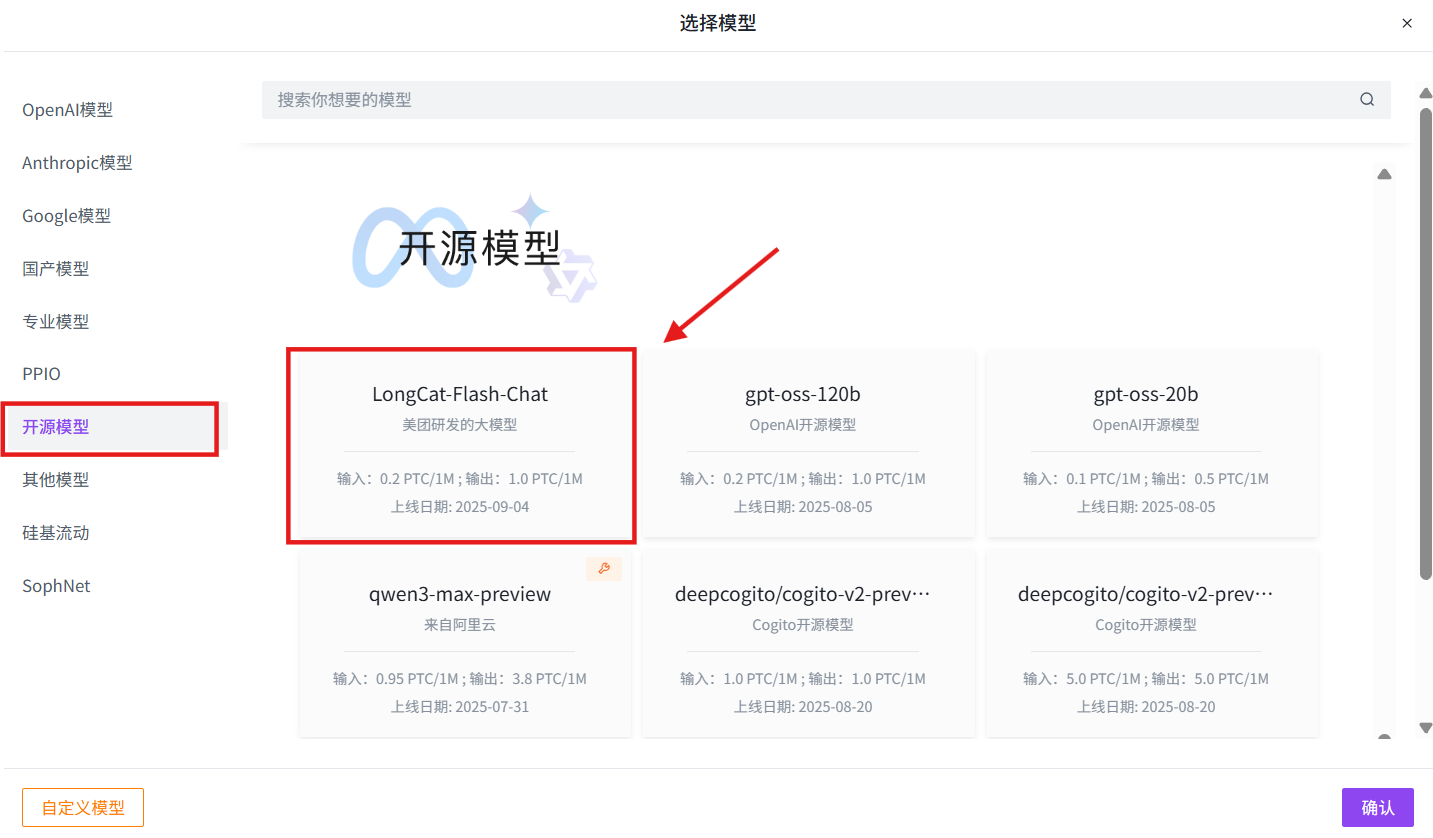
步骤指引:在线使用→应用超市→机器人→聊天机器人
选择模型→开源模型→LongCat-Flash-Chat→确认→创建
2. 使用模型 API
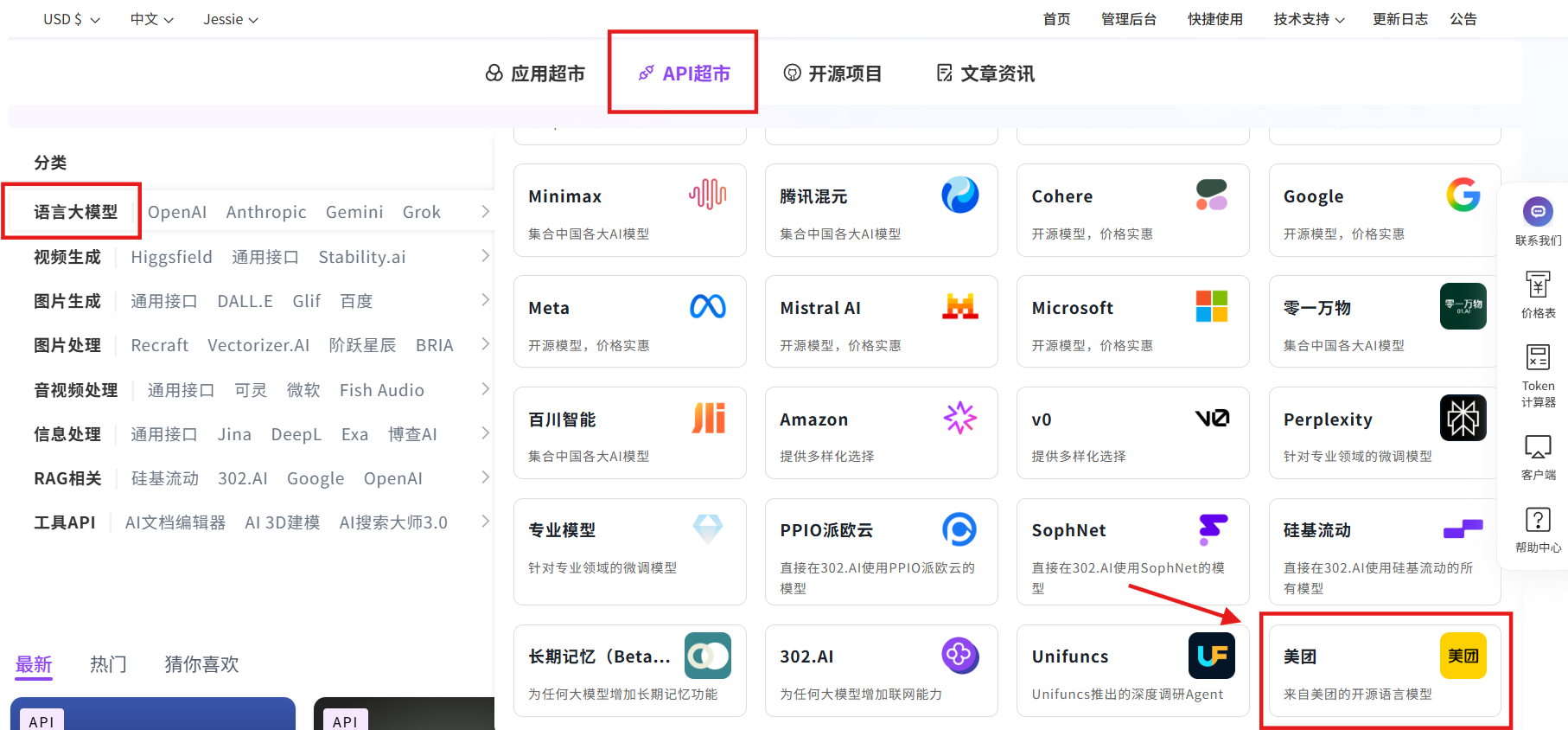
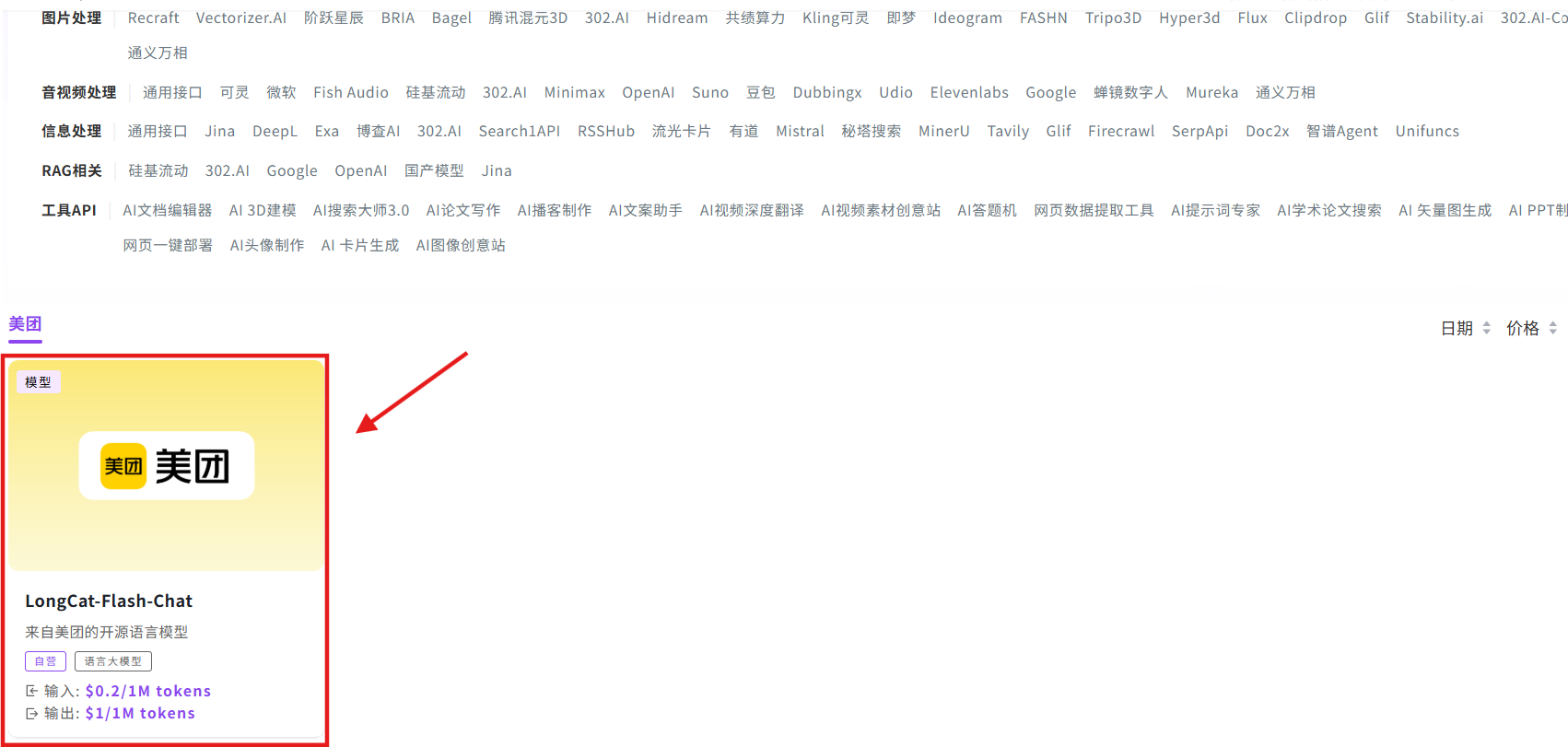
相关文档:API→API超市→语言大模型→美团→LongCat-Flash-Chat→查看文档
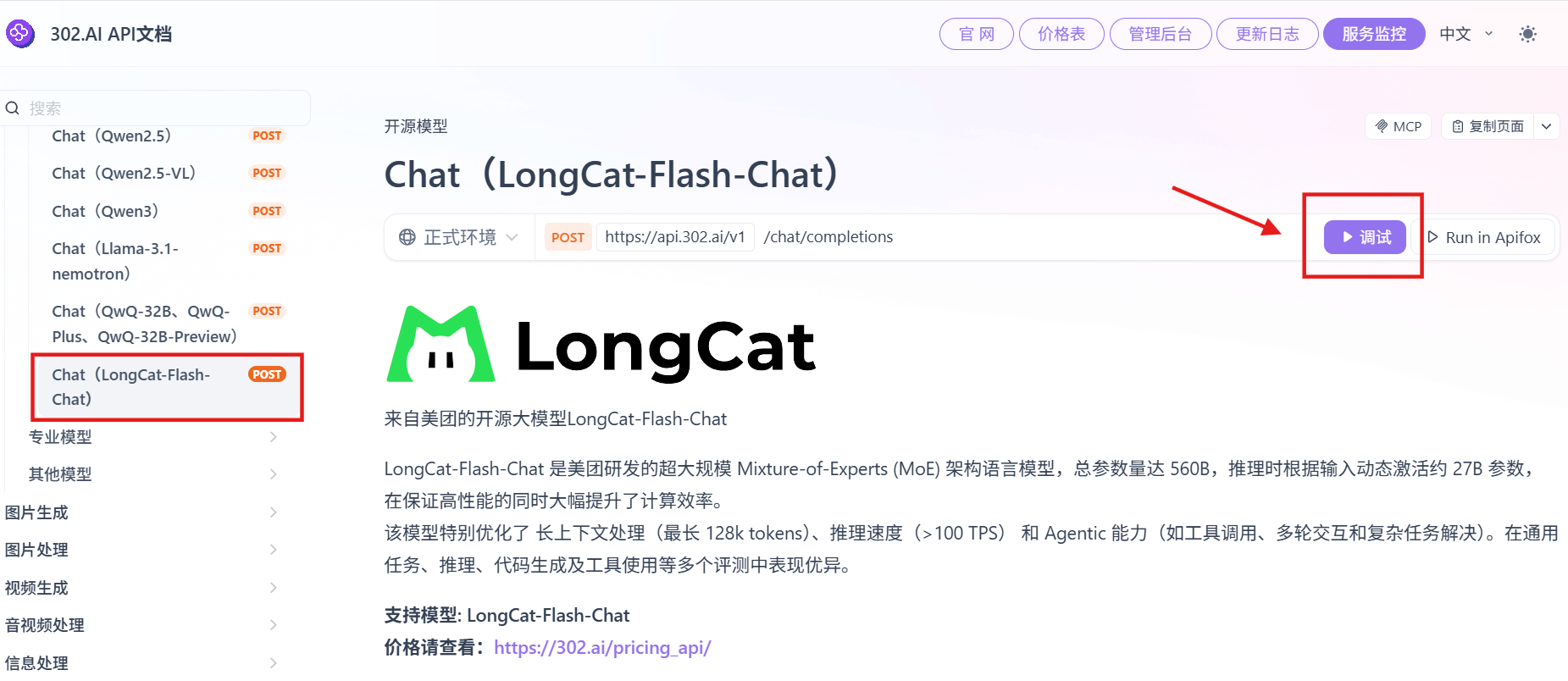
点击【调试】在线调用 API
想即刻体验 LongCat-Flash-Chat 模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
