
Table of Contents
在当前多模态 AI 已逐步攻克视觉与复杂逻辑推理的背景下,语音识别系统对于口音、噪声等变量所表现出的脆弱性,依然是该领域一个亟待攻克的核心挑战。当 AI 能看图、能推理,为何听懂一段带口音的对话依然如此之难?
这是所有开发者和用户共同的痛点。在语音转文字(STT)领域,我们似乎总面临一种“技术悖论”:模型能力在纸面上飞速进步,但在真实的会议室、嘈杂的街头、充满口音的访谈中,它们仍无法避免错漏百出,产生似是而非的“胡诌”文本。语音识别技术实用化道路上的核心瓶颈,依然顽固地集中在几点:复杂声学环境下的降噪能力、对各类口音和方言的精准捕捉、中英混杂语料的无缝切换,以及不可忽视的“性价比”平衡——我们是否必须为 1% 的准确率提升,支付翻倍的成本?面对市场上从开源翘楚到商业新贵的众多选择,为特定应用场景甄选最优技术路线,已演变为一个复杂的评估与决策过程。
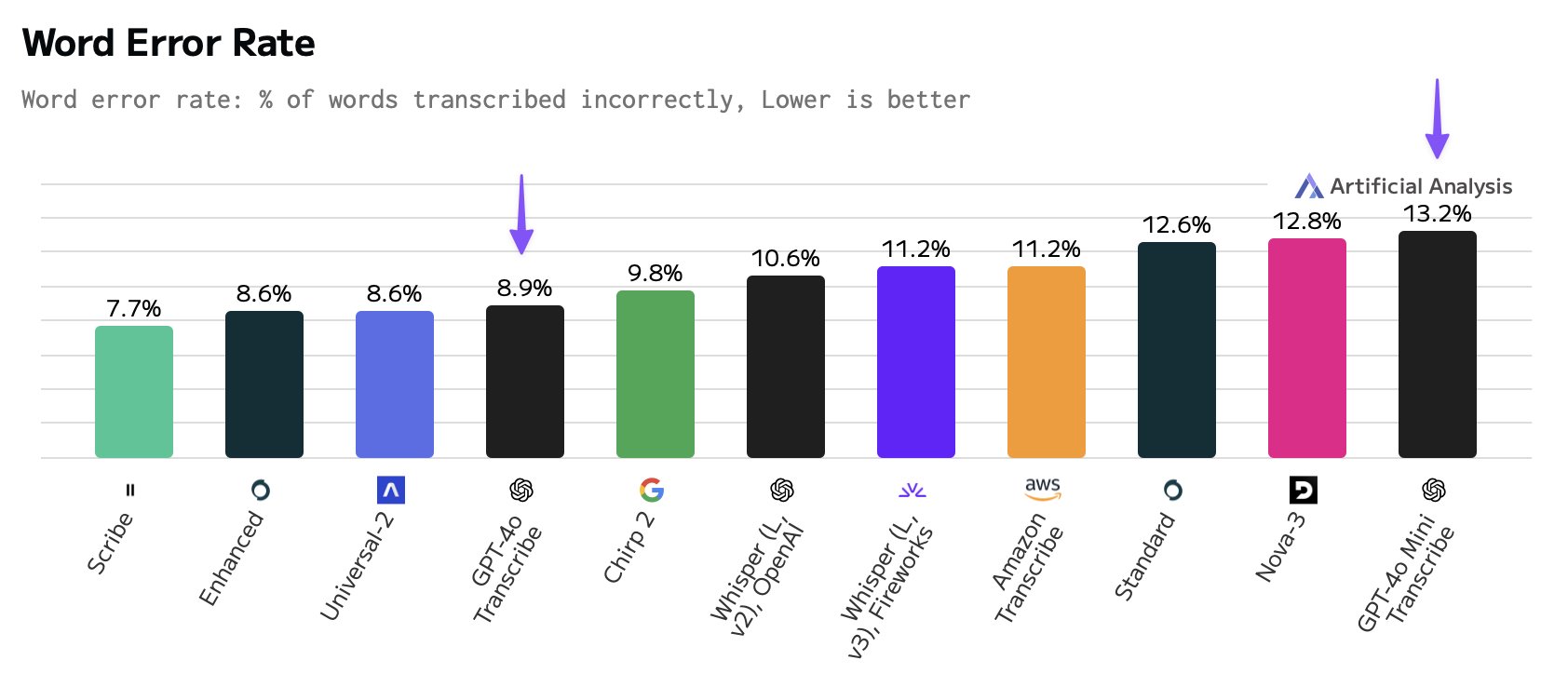

在现有的技术解决方案中,OpenAI 基于 GPT-4o 架构的语音转文本模型系列,于 3 月发布的新一代语音转文本模型系列,依据功能与定价进一步细分:
- gpt-4o-transcribe 被官方定位为原有 Whisper 模型的升级版本,在词语错误率、语言识别和准确性方面较 Whisper 都有很大提升,并增强了对噪音环境和多语言的处理能力。
- gpt-4o-mini-transcribe 则是前者的小参数版本,提供了更侧重成本效益的选项,在保留大部分核心功能的同时,价格约为旗舰模型的一半。
- 此外,该系列还包含了具备说话角色区分功能的模型(如 gpt-4o-transcribe-diarize),旨在满足多人对话场景下的自动角色分离需求。
让我们将选择权交还给数据。 本文 302.AI 将聚焦于来自 OpenAI 的 STT 模型 gpt-4o-transcribe,以及在语音合成领域同样竞争力十足的 ElevenLabs Scribe 和 Whisper 模型,展开多场景实测对比。
I. 实测模型基本信息
(1)各实测模型在 302.AI 的价格:
| 模型名称 | 价格 |
| gpt-4o-transcribe | 输入 $6 / 1M tokens输出 $10 / 1M tokens |
| WhisperX | $0.002/分钟 |
| elevenlabs-scribe_v1 | $0.01 / 分钟 |
(2)测评目的:
旨在客观评估实测模型在语音转文本生成中的识别准确性、抗干扰性和语境理解等能力。
(3)测评方法:
各案例均使用同一视频素材进行生成,且均取第一次生成结果,评测结果仅供参考。
- 案例中标红部分为有误/可优化的部分
- 案例中紫色部分为优秀
(3)测评工具:
302.AI→API超市→在线调试功能
Ⅱ. 测评案例
案例 1:噪音环境场景
准确文本:我现在处在的位置是福州连江县苔菉镇的北茭村。那么这个北茭村呢是位于整个黄岐半岛最靠近东部沿海的一个突出位置,所以每当台风来袭的时候这里都是一个值得非常特别要需要注意的一个地方。那么现在呢我们站在这个地方可以感觉到这里的风势和雨势在逐渐地增强。那么今天在三个小时内我们已经观测到整个这个苔菉镇的最大风力是达到了12级以上,因为强风啊我们可以看到我们身旁的这样的一个海堤上的监控探头的这个铁杆子也在风中不停地晃动并且晃动的幅度还是比较大的。
考察点:
- 持续噪音与模糊人声的转译准确度
- 具体地标名的识别能力
- 部分模糊信息的抗干扰纠错能力

| 测评对象 | gpt-4o-transcribe | WhisperX | elevenlabs-scribe_v1 |
|---|---|---|---|
| 信息完整度 | ★★★★★ | ★★★★★ | ★★★★★ |
| 文本准确性 | ★★★★ | ★★★ | ★★★★ |
| 特定地理名称识别 | ★★ | ★★ | ★ |
| 简评 | gpt-4o-transcribe表现较佳。虽三个模型都未能精准识别语音中的地理名称,但是识别完整度都还不错。就信息传达的视角来看,gpt识别后的文本虽未规范使用“的地得”,但没有太大影响信息的可读性;Elevenlabs虽用词准确规范,但将“黄岐半岛”错误识别为“黄芪半岛”属实极大降低了信息准确度;而WhisperX最大的缺陷在于1:1复刻了原声中的语气助词,且未做断句处理,使得信息可读性大打折扣。 | ||
案例 2:快速语流
准确文本:
Never givin’ me a break, this block
will take and make somebody great hip-hop!
Create and then obliterate spit box, distraught,
feelin’ like you finna break, Biscoffs (chyeah!)
Killed it, the faster rhyme did,
keepin’ it rough with aggression, the ASIN9NE kid (chyeah!)
Take everything down to your last rhyme biz,
an overcomer, a winner and master N9ne is
考察点:
- 快速语流节奏和非标准发音下的识别准确度
- 短促单词捕捉能力
- 非正式与创新词汇识别度

| 测评对象 | gpt-4o-transcribe | WhisperX | elevenlabs-scribe_v1 |
|---|---|---|---|
| 歌词完整度 | ★ | ★★★★★ | ★★★★★ |
| 文本准确性 | ★ | ★★★ | ★★★★ |
| 非正式词汇识别 | ★ | ★★ | ★★★★ |
| 简评 | Elevenlabs表现最佳。不仅完整识别出歌词,还识别到了每一句加入的Ad-libs,甚至最后一句中出现的歌手名“N9ne”也精准还原,不过不足之处也表现在部分词汇未能准确识别。WhisperX识别的歌词完整度尚可,也是词汇不够准确的问题;而gpt表现就彻底拉跨,仅识别到了的一句歌词。 | ||
案例 3:复杂信息与专业术语
准确文本: This is without question our best iPhone lineup ever. All the new models will start with 256GB of storage. iPhone 17 starts at $799, keeping the same great price. iPhone Air starts at $999. And iPhone 17 Pro starts at $1099, the same great price as last year’s 256GB iPhone 16 Pro. And for the first time, a 2TB configuration is available on iPhone 17 Pro Max. And the iPhone lineup starts at just $599 with iPhone 16E. Pre-orders for all new models start this Friday and they will be available starting September 19th.
考察点:
- 1.25倍速人声识别准确度
- 高密度信息、机型、数字单位组合识别后的文本格式可读性

| 测评对象 | gpt-4o-transcribe | WhisperX | elevenlabs-scribe_v1 |
|---|---|---|---|
| 信息完整度 | ★★★★★ | ★★★★★ | ★★★★★ |
| 文本准确性 | ★★★★★ | ★★★★★ | ★★★★ |
| 数字/符号识别 | ★★★★ | ★★★★★ | ★★★★ |
| 简评 | WhisperX表现略优。除了Elvenlabs有一处识别错误之外,三个模型均完整准确地还原了人声信息。而WhisperX表现优于其他两个模型的点在于将“gigabytes”“terabyte”这样的口语化表述转换为了更具易读性的“GB”“TB”。 | ||
案例 4:特定方言对话
准确文本: “余樂天,可唔可以搞搞你个头发啊?法律界中都未见过咁嘅发型㗎。”
“なんだよ! 你知唔知邊個係木村拓哉㗎?”
“他现在已经过时了。”
考察点:
- 多语言与粤语方言识别能力
- 语气词功能与文化语境理解

| 测评对象 | gpt-4o-transcribe | WhisperX | elevenlabs-scribe_v1 |
|---|---|---|---|
| 信息完整度 | ★ | ★★★★★ | ★★★★★ |
| 文本准确性 | ★★ | ★★★★ | ★★ |
| 语气词识别 | ★ | ★★ | ★★ |
| 简评 | WhisperX表现略优。虽然识别准确性与原句确实有偏差,不过大体意思得到正确传达,且是唯一一个识别到主人公名字的。gpt仍未能完整识别,仅识别到其中一句原声;Elevenlabs识别的结果中误差较多。很遗憾三组模型都没有抓取到原句中“なんだよ”这句日语。 | ||
案例 5:中英双语
准确文本:全年的普通话也在这个节目说了,这个比赛呢,看到很多很多不同的talent。我经常说这个这条路是很长很长的,因为这个不是一个race,也不是一个sprint,是一个marathon. So, I hope that we will see each other again very soon, 谢谢!
考察点:
- 中英双语格式保留程度
- “非标准”口音识别准确度

| 测评对象 | gpt-4o-transcribe | WhisperX | elevenlabs-scribe_v1 |
|---|---|---|---|
| 信息完整度 | ★★★★★ | ★★★★★ | ★★★★★ |
| 文本准确性 | ★★★★★ | ★★★ | ★★★★★ |
| 双语保留 | ★★★ | ★★★★★ | ★★★★★ |
| 简评 | Elevenlabs表现略优。主要在于三组模型都准确识别了原声的情况下,Evenlabs较好地保留了中文和英文的完整形式;WhisperX出现一处识别错误以及还是未做自动断句;gpt则把句中部分英文转换为中文输出了。 | ||
III. 三款主流STT语音转文字模型实测结论

本次横评透过五个不同应用场景,对三款 STT 模型进行了相关压力测试。整体而言,当前顶尖的语音识别技术已在标准化、高信息密度的场景中展现出卓越的可用性,但在应对极端声学环境与复杂语言现象时,各模型仍呈现出清晰的能力边界与不同的性能取舍。
从实测结果可以看出,目前 STT 模型的核心发展路径,正从单纯追求准确率转向在稳健性、成本与场景覆盖度之间寻求最佳平衡。在如极端天气报道、高密度信息汇总等背景噪声可控、语言结构规范的场景下,以 gpt-4o-transcribe 为代表的顶尖模型已能提供接近直接商用的语音转文本质量,准确捕获譬如“北茭村”、“2TB 配置”等关键实体与数字信息。这表明 STT 技术在处理主流任务需求上正日益成熟。然而,技术瓶颈在长尾挑战中依然显著。面对譬如案例 2 当中的快语速 Rap 节奏冲击、以及案例 4 的地方语言与多语言混杂等文化语境,三组模型均出现不同程度的性能短板。这揭示出现阶段的技术在应对高度模糊、非标准的声学与语言信号时,其深层次的语义理解与上下文推理能力仍有待突破。
纵观各模型的实测表现,不同模型在性能上呈现出清晰的能力阶梯与市场分层。从信息完整度和基础准确率来看,gpt-4o-transcribe 和 WhisperX 在绝大多数案例中均能较好地还原原始语音内容,尤其是在标准环境和专业术语场景下,信息传达几乎无漏失。但在极端噪音、非标准发音、方言混杂等场景中,模型表现开始分化,尤其是地理名称、专有名词和创新词汇的识别准确度,成为判断模型能力上限的关键指标。elevenlabs-scribe_v1 则倾向于在快速语流、歌词识别及中英混合语境下展现出更高的稳定性。它不仅能够完整捕捉歌词、ad-libs,还能较好地保留原声中的中英双语格式,提升了信息的真实还原度和文化语境的保留。这一优势使其在内容创作、媒体转写等需要高度原文还原的场景下有广阔应用前景。但与此同时,elevenlabs-scribe_v1 在地理专有名词、复杂方言识别等方面仍存在明显短板,其对中文语境下的细微差异处理,尚不及 WhisperX 和 gpt-4o-transcribe。
归根结底,本次测评揭示了一个核心趋势:STT 技术已整体迈入高度实用化阶段,足以稳健支撑大多数商业和消费级应用。
对于用户而言,技术选型的逻辑因此变得清晰:是追求极致精准还是能够接受在边缘场景上的一定容错率,实则对应的是不同性价比的方案。 因此无需过分纠结于模型在极端场景下的个别失败,而应聚焦于其在你最频繁、最核心的应用场景中的综合表现与成本效益。
Ⅳ. 如何在 302.AI 上使用
302.AI 提供按需付费无订阅的服务模式,用户可以根据自身业务需求灵活选择使用。
使用模型 API
以 gpt-4o-transcribe 为例
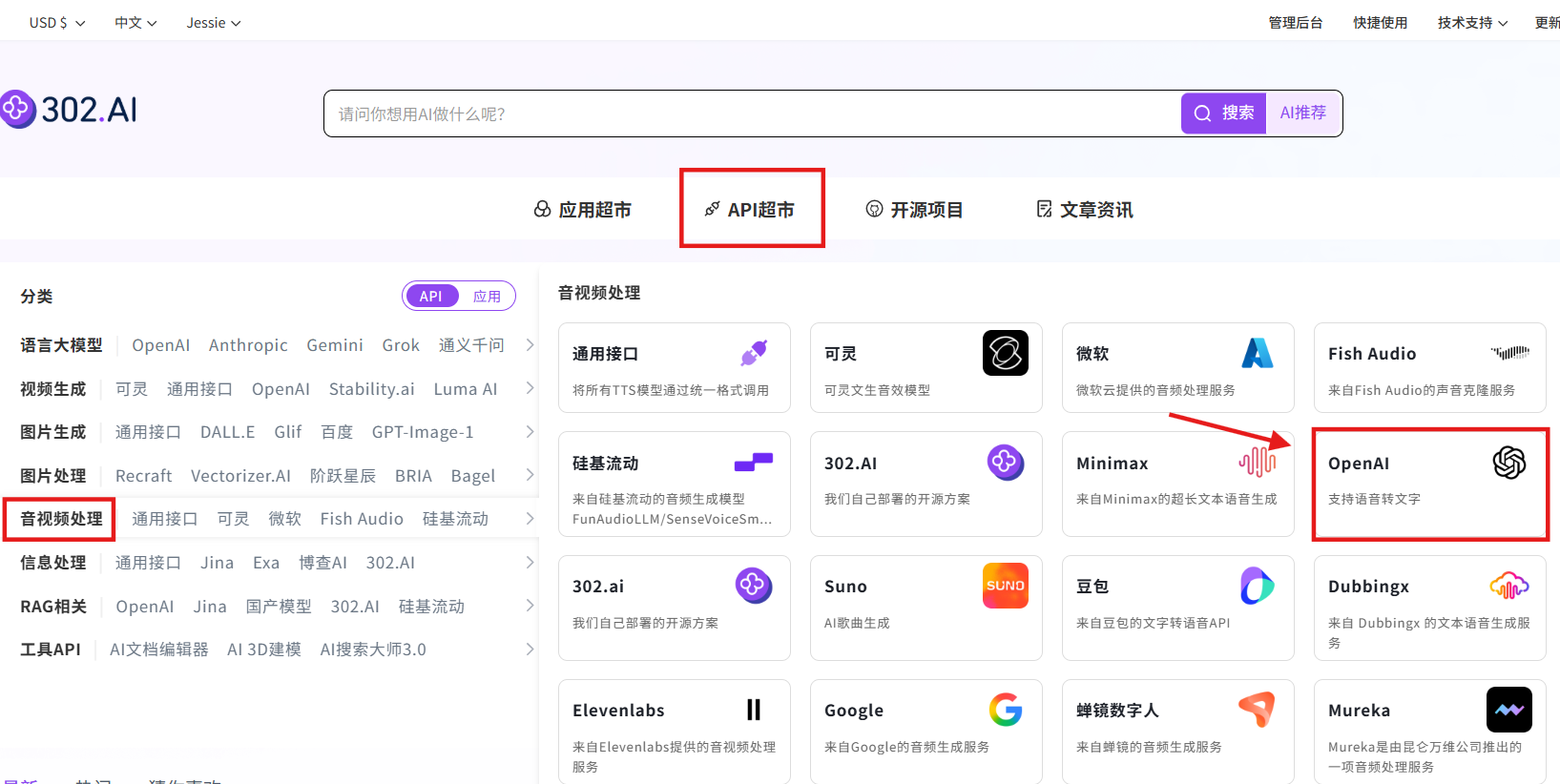
步骤指引:API超市→音视频处理→OpenAI→gpt-4o-transcribe
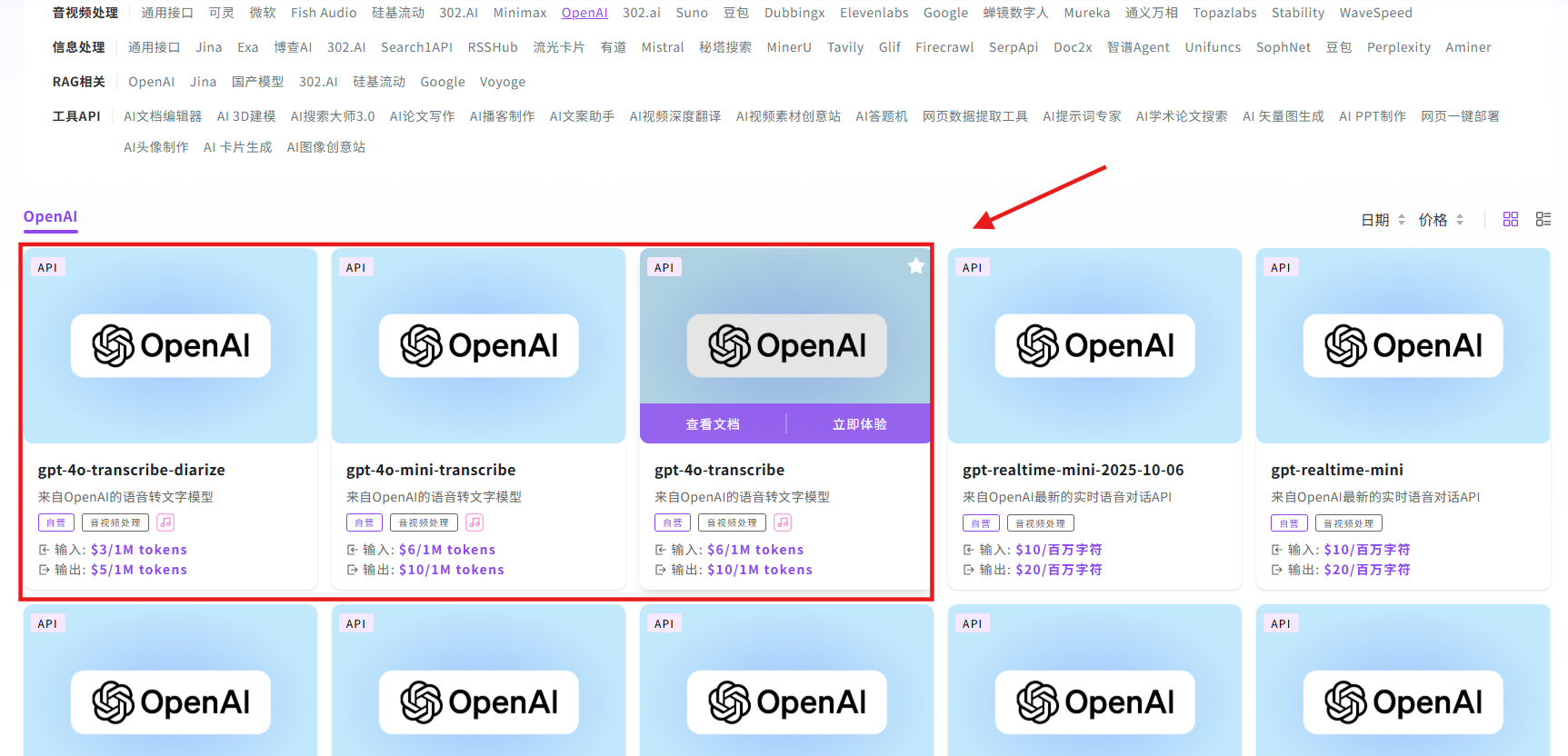
点击【立即体验】在线调用 API
想即刻体验 STT 模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
