
在开始这篇万字长文前,可以先看两则我刚剪的短视频,配乐均来自本篇评测中生成的 AI 音乐案例,能对目前的 AI 音乐质量有个直接的认知。相信我若不说明,能一耳朵辨别出这是 AI 音乐的人,恐怕寥寥无几。
放眼今天的 AIGC 版图,图像/视频领域早已卷得飞起,这周刚被万千用户追捧的 SOTA 模型很可能下周就被新的竞品完爆,潮起又潮落。然而当我们把视线挪到 AI 音乐模型,却不像其他板块那样杀到红眼,甚至中文的相关评测也不多见。简单来说,AI 音乐模型有以下三个制约难点:
1.音乐的复杂性
AI 模型擅长识别模式(Pattern Recognition),做有结构的东西。从文字中的句法,图像中的像素分布,到表单里的数据,只要能分解、能打标签、能归纳的就能学习。但音乐的魅力恰恰在于那些打破模式的“意外”与“言外之意”,节奏是时间线,旋律是抽象序列,和声是复杂堆叠,音色切换更是层层嵌套。更别提你要考虑复调、调式、情绪走向。
此外,歌曲的层级结构,比如第一段主歌的和弦进行,可能会在结尾处再次出现并产生呼应,带来一种呼应的满足感。这种跨越数分钟的结构性关联,对目前主流AI模型(如 Transformer)的“注意力窗口”构成了巨大挑战。AI 很容易“忘记”几分钟前发生了什么,导致生成的音乐结构松散,缺乏逻辑,动辄数十分钟的交响乐章更是一座大山。
2.训练数据的缺乏
图像开源有 COCO、LAION,文本领域有着维基百科 + Reddit 各大社区 + 标签数据,但音乐呢?成体系的开源数据只有少数,比如 Lakh Cleaned Dataset(MIDI 为主),要么太干净太单调,要么太粗糙没用处;更多可用素材,像是 YouTube,Spotify 以及各大音乐公司的音乐、影视原声,动不动就碰版权的红线。大模型若是没听过 Mozart、K-pop、Psytrance、大张伟,它如何精确地理解各个风格并进行创造?
3.评判标准的主观性
图像模型可以靠“像不像”,“糊不糊”来一眼评判高下,文本模型的任务完成度也能根据用户自身的逻辑和审美予以快速判断。但 AI 生成的音乐,你说它好听,我说它太老土,以什么标准来客观地判个对错?10多年来海量的抖音神曲一边被诟病低质,一边动辄亿次级别的传播,这样的音乐质量是高是低?评价标准一旦浮动,模型训练的奖励方向就很难定调。
刚好前几日,Minimax 发布了新一代音乐模型 MiniMax Music 1.5,生成音乐时长升至 4 分钟,并具备四大新突破:强控制力、人声自然饱满、乐器层次丰富、歌曲结构清晰。
302.AI 已在第一时间接入了 MiniMax Music 1.5 模型的 API。作为一名音乐爱好者,笔者刚好趁此机会来横评对比下目前市场上头部的音乐模型,捋一下这个赛道的发展成果。测试的模型包括广为人知的Suno,Elevenlabs以及同样来自中国,昆仑万维的mureka-7(目前已更新至 7.5 版本,但还未开放 API 服务),为用户选择提供选型参考。
I. AI音乐模型发展概况
1.1 AI音乐简史:从算法和声到灵魂交响


第一阶段:奠基与探索 (2023年之前)
在生成式AI浪潮席卷全球之前,AI与音乐的结合更多停留在学术研究和辅助创作层面。早在2019年,行业报告便已开始深入分析AI硬件发展、推理成本估算以及相关专利趋势,为后续的技术爆发奠定了理论与算力的基础。这一时期的AI音乐,更多是基于规则和算法的“音乐生成”,例如自动谱写和弦、编排简单的MIDI旋律,或对现有音乐进行风格分析。它们具备一定的音乐性,但缺乏灵魂、情感和高质量的音频保真度,离生成一首完整的、可供人欣赏的歌曲还有很长的距离。
第二阶段:生成式革命与“完整歌曲”的诞生 (2024年)
2024年是AI音乐发展史上具有里程碑意义的一年,其标志是能够生成包含人声、歌词和多乐器编曲的“完整歌曲”模型的出现。
- Suno的破局:2024年初,以Suno为代表的新一代音乐生成大模型开始进入公众视野,其深度发展历程标志着AI音乐正式从“片段”走向“整体”。用户只需输入简单的文本提示,即可在短时间内生成一首结构完整、风格多样的歌曲,这一突破极大地降低了音乐创作的门槛。
- 巨头入局与市场升温:Suno的成功迅速点燃了市场。各大科技公司纷纷将触角伸向音乐行业,例如Meta在2024年末推出的MusicGen模型,同样可以根据文本生成音乐,标志着AI音乐生成进入了巨头竞争的时代。
第三阶段:品质飞跃与商业化前夜 (2025年至今)
进入2025年,AI音乐模型的发展重点从能否生成转向了生成得有多好,在时长、可控性和音乐性等维度上实现了质的飞跃。
- 模型迭代加速,架构持续创新:各大厂商进入了军备竞赛式的迭代周期。例如,昆仑万维旗下的Mureka模型在2025年7月便发布了其V7版本,并引入了MusicCoT等区别于传统Next Token预测的先进架构,旨在提升音乐的逻辑性和结构感。
- 音乐时长与品质的双重突破:本次MiniMax发布的新一代音乐生成模型Music 1.5在行业内引起了巨大反响,因为它生成的音乐不仅颇具感染力,且时长达到了惊人的4分钟,相较于上一代模型有了长足的进步。这标志着AI已经有能力生成符合主流音乐工业标准的、长度完整的单曲。
- 可控性与编曲能力的精进:新一代模型不再是简单的“开盲盒”,而是在控制精度和编曲表现上展现出更高的专业度。用户可以更精细地控制风格、情绪、乐器配比乃至段落结构,AI的身份正在从一个“黑箱创作者”转变为一个可供专业人士驾驭的生产力工具。
1.2 AI音乐用户画像:什么人在用AI音乐模型?
我们可以借鉴用户研究中的经典框架,从“资历”(对音乐/技术的专业程度)和“参与度”(使用AI音乐的深度与频率)两个维度,将AI音乐的用户划分为三个核心群体。
- 社交表达者与轻度创作者 (低资历,高参与度)
这是由AIGC浪潮催生的最广泛的基础用户群体,他们将AI音乐视为一种低门槛的自我表达工具和社交货币。
- 核心特征:以年轻用户为主,活跃于短视频、社交媒体等平台。他们不关心模型的技术细节,利用AI音乐快速生成个性化的BGM、为自己的Vlog配乐,甚至创作病毒式传播的“神曲”。他们的参与度极高,是AI音乐内容生态的主要贡献者。
- 深层需求:他们的核心诉求是“表达”而非“完美”。他们追求的是生成速度、趣味性和易于分享。AI音乐模型对他们而言,是一个能将脑中闪现的灵感(“赛博朋克风的古筝曲”)迅速变为现实的“魔法棒”。
- 专业音乐人与效率追求者 (高资历,低参与度)
这个群体由专业的音乐制作人、作曲家和独立音乐人构成。他们使用AI音乐并非为了取代创作,而是将其作为激发灵感、提升效率的“超级助手”。
- 核心特征:他们拥有深厚的音乐理论知识和制作技能。他们使用AI音乐时,参与度可能表现为“低频”,但每次使用都带有极强的目的性。
- 深层需求:他们需要的是高度可控性。例如,他们可能用AI快速生成一个和弦进行或一段鼓点作为创作起点,或是利用AI分离音轨、进行音频超分等。对他们而言,AI是工具箱中的一件利器,而非全自动的生产线。
- 企业级用户与品牌策略师 (高资历,高参与度)
这是AI音乐在B端的商业化核心用户,他们利用AI音乐进行数据驱动的品牌营销和商业内容生产。
- 核心特征:包括广告公司、品牌方、游戏工作室、MCN机构等。他们将音乐视为一种商业资产,需要对其进行精细化管理和分析。
- 深层需求:他们的需求是“精准”和“合规”。例如,通过AI音乐分析技术,他们可以解构品牌的音乐选择,对情绪、流派、个性、目标受众等元素进行量化分析,确保广告配乐与品牌形象高度契合。同时,AI生成音乐也能高效地解决商用音乐的版权问题。
1.3 AI音乐模型的两大核心创作模式
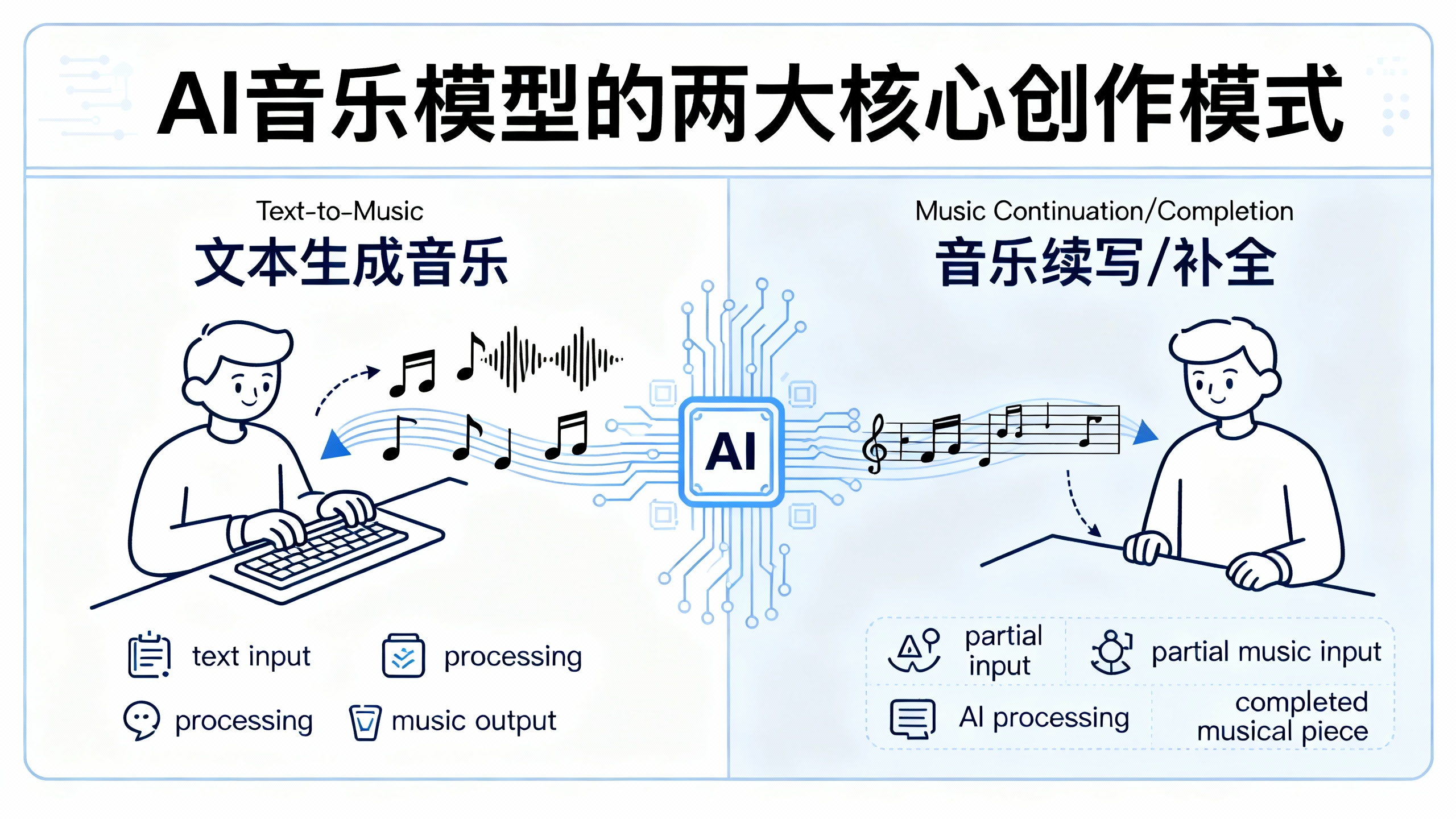
与文生图领域的“文生图”、“图生图”类似,当前的AI音乐模型也已发展出两大主流创作模式,它们分别满足了从“无”到“有”的灵感迸发和从“有”到“优”的精细打磨两种核心需求。
模式一:文本到音乐 (Text-to-Music) – 灵感的即时变现
这是当前最主流、最基础的创作路径,用户通过自然语言提示词(Prompt)来引导模型进行从零开始的完整创作。这一模式的核心优势在于其极低的门槛和近乎无限的创意空间。
- 路径详解:用户输入一段描述性的文字,模型则会利用其深度神经网络架构,模仿人类作曲家的思维方式,自动创作出全新的旋律乃至完整的曲目。提示词可以非常简单,如“一首悲伤的钢琴曲”,也可以极为复杂和专业,如“一段140BPM的四四拍Techno,使用经典的Roland TR-909鼓机音色,搭配一个深沉的sub-bass,氛围要带有2000年代柏林的冷峻工业感”。
- 技术支撑:这一模式的成熟,得益于扩散模型(Diffusion Models)与Transformer架构的技术突破,它们有效解决了过去在长序列生成、音质保真度和结构连贯性上的核心痛点。
- 代表平台与功能:
- Suno:作为早期探索者,Suno通过其强大的提示词理解能力,能够生成包含人声和歌词的完整歌曲,极大地推动了这一模式的普及。
模式二:音乐/音频到音乐 (Music/Audio-to-Music) – 创意的延续与再创作
这一模式更接近传统音乐制作中的“采样”、“改编”和“续写”,它允许用户提供一个现有的音频片段作为创作的起点或参考,赋予了AI音乐更强的互动性和可编辑性。
- 路径详解:用户上传一段旋律、一段鼓点、一段人声哼唱,甚至是环境音效,AI模型则会在此基础上进行分析、理解,并根据用户的进一步指令进行续写、扩写或风格转换。
- 应用场景与价值:
- 灵感续写:当创作者脑中只有一个动机片段时,可以将其录制下来,让AI帮助发展成完整的主歌或副歌。
- 结构化编排:平台如Udio允许用户精细地指定音乐的引子(Intro)和尾声(Outro),然后以此为“锚点”,向前或向后延伸,生成结构更长、更完整的作品。这极大地增强了用户对歌曲整体布局的掌控力。
- 风格迁移:类似于“图生图”中的风格转换,用户可以上传一段古典音乐片段,并要求AI用电子舞曲的风格对其进行重新编排。
II. 实测模型基本信息
(1)各实测模型在 302.AI 的价格:
| 模型名称 | 302.AI内的价格 |
| MiniMax Music 1.5 | $0.05/次 |
| 昆仑万维 Mureka-7 | $0.05/次 |
| Suno 4.6 | $0.1/次 |
| Elevenlabs | $0.05/次 |
(2)测评备注:测评作者非音乐专业背景出身,因此仅结合个人审美经验,从个人听感出发进行评价,不会从乐理角度进行学术性分析。
(3)测评目标:
评估各模型生成音乐的综合质量,包括音乐风格准确度、人声/乐器音色真实感、提示词遵循度以及音乐完整度。
(4)测评工具:
各模型均使用 302.AI 的 API 超市→在线调试功能
(5)测评方法:
各案例均使用统一的英文提示词进行生成,取第一次生成结果。
提示词撰写方法:明确音乐风格,人声要求,歌曲主题。不撰写具体歌词,均由 AI 进行生成,不对歌词进行质量评判。评测结果仅供参考。
III. 测评案例
案例 1:Pop流行-中文女声
提示词:
Style: A dreamy, slow-pace Pop ballad, **in Mandarin Chinese**.
Artist Style: In the style of Chinese artists like Faye Wong (王菲) or Joanna Wang (王若琳).
Song Narrative: The song is a quiet reflection on a bird navigating a rainstorm, sung by a female vocalist. The lyrics should be gentle and poetic.
风格: 梦幻感的慢板流行抒情曲,用普通话演唱。
艺人风格: 类似中国艺人王菲或王若琳的风格。
歌曲叙事: 这首歌由一位女歌手演唱,是一段关于一只小鸟在暴雨中穿行的宁静沉思,歌词应轻柔且富有诗意。
MiniMax Music 1.5
mureka-7
Suno
Elevenlabs
| 测评点 | MiniMax Music 1.5 | mureka-7 | Suno | Elevenlabs |
| 生成模式 | 提示词直接生成 | 1.根据提示词生成歌词 2.根据歌词生成歌曲 | 提示词直接生成 | 提示词直接生成 |
| 风格准确度 | ★★★★ | ★★★ | ★★★★ | ★★★ |
| 人声听感 | ★★★★ | ★★★ | ★★★★ | ★★ |
| 旋律听感 | ★★★ | ★★★ | ★★★★ | ★★ |
| 简评 | Suno较佳。Minimax的人声自然细腻,具有爆发力;编曲结构完整,但伴奏乐器(钢琴,鼓)有非常明显的MIDI数码感,听感廉价;mureka-7的配乐乐器最为丰富,律动好,但人声的高音/假声部分太多,听感累,多处旋律走向也比较怪异;Suno的人声干净,富有磁性,听感好,唱腔有运用假声,转音技巧,缺点在于整首歌旋律略显平淡,缺乏动听的副歌高潮段落。Elevenlabs更类似于单纯的词和曲堆叠,未能形成一个完整作品,且 | |||
案例 2:Hiphop-Memphis-英文男声
提示词:
Genre: Epic & Orchestral Memphis Rap / Trap
Mood & Atmosphere: Dark, menacing, and triumphant. The feeling of a king surveying his empire from a rain-swept skyscraper. Gritty and powerful, yet grand and cinematic.
Vocals: A solo male rapper with a deep, raspy, and powerful voice. His delivery should be aggressive, confident, and rhythmic, with a clear, commanding flow. The style should be reminiscent of classic Memphis Rap artists like Three 6 Mafia or modern artists like Freddie Dredd.
Instrumentation & Production:
- Rhythm (The Core): Dominated by a hard-hitting, distorted 808 bass that shakes the room. The drum pattern should be classic trap-style: rapid-fire hi-hats, a hard, punchy snare, and a simple, powerful kick drum.
- Orchestral Elements (The Grandeur): Layer a powerful, cinematic brass section (horns, trumpets, trombones) playing a majestic, triumphant fanfare melody. This should contrast with the dark 808s to create an epic feel. Add some subtle, dramatic string pads in the background for texture.
- Melody/Hook: A simple, dark, and repetitive synth melody or a haunting piano loop, typical of Memphis Rap.
- Tempo: Mid-tempo, around 130-145 BPM.
Chorus (The Hook):
The chorus must be extremely catchy, anthemic, and easy to chant along to. It should feature a simple, repetitive lyrical phrase and a strong, memorable rhythm that makes you want to nod your head. The rapper’s energy should peak here, making it the most powerful part of the song.
音乐流派: 史诗感 & 管弦乐版孟菲斯说唱 / Trap
情绪与氛围: 黑暗、险恶,同时又充满胜利的凯旋感。如同王者伫立在被暴雨冲刷的摩天楼之巅,俯瞰自己的帝国。风格粗粝、强劲,却又不失宏大与电影感。
人声: 男声独唱Rapper,嗓音深沉、沙哑且充满力量。他的说唱递进方式应充满攻击性、自信且富有节奏感,flow(说唱节奏)清晰、霸气。风格应让人联想到经典孟菲斯说唱艺人如 Three 6 Mafia 或现代艺人如 Freddie Dredd。
乐器与制作:
- 节奏(核心): 由一击即中的、带有失真效果的808贝斯主导,其低频足以撼动整个房间。鼓点应为经典的Trap风格:快速密集的踩镲(hi-hats),一个强硬、有冲击力的军鼓,以及简约而有力的底鼓。
- 管弦乐元素(宏大感): 叠加一层强大、富有电影感的铜管乐组(圆号、小号、长号),演奏一段雄伟、凯旋的号角式旋律。这应与黑暗的808形成鲜明对比,营造出史诗般的氛围。在背景中加入一些不易察觉但富有戏剧性的弦乐铺底,以增加质感。
- 旋律/记忆点: 一段简约、黑暗且重复的合成器旋律,或是一段萦绕不绝的钢琴循环段落,均为孟菲斯说唱的典型特征。
- 速度(Tempo): 中速,大约在 130-145 BPM(每分钟节拍数)之间。
副歌(记忆点/Hook): 副歌必须极其洗脑、如同圣歌般恢宏,并且易于跟随吟唱。它应包含一段简约、重复的歌词短语,以及一个强劲、令人难忘的节奏,让你情不-自禁地跟着点头。Rapper的能量应在此处达到顶峰,使其成为整首歌最 powerful 的部分。
MiniMax Music 1.5
mureka-7
Suno
Elevenlabs
| 测评点 | MiniMax Music 1.5 | mureka-7 | Suno | Elevenlabs |
| 风格准确度 | ★★ | ★★★ | ★★★★★ | ★★★★ |
| 人声听感 | ★★★ | ★★★ | ★★★★★ | ★★★★★ |
| 旋律听感 | ★★★ | ★★★ | ★★★★ | ★★★★ |
| 简评 | Suno最佳。只要你听过揽佬,那你就感受过孟菲斯说唱的精髓:伴奏有黑暗,深沉感,配合慢悠悠的人声歌词,念经一般但魔性上头。MiniMax完全没用管乐元素,人声flow也不符合该说唱风格;Mureka问题类似,配乐乐器和人声演唱方式准确度欠佳;Suno从开篇第一秒就展示出伴奏的黑暗,史诗感,配合正确的人声flow,风格正确。问题还是在于缺乏爆发的高潮段落,简单说就是情绪不够“顶”。Elevenlabs接近Suno质量,风格准确,但洗脑的Hook都未做到。 | |||
案例 3:K-Pop-英文女团
提示词:
Style: K-Pop (Teen Crush & Y2K Revival). Features a hard-hitting electronic beat, infectious synth melodies, powerful yet sweet vocals, and sharp rhythmic delivery. Production blends crisp trap drums, retro video game sounds, and airy pop harmonies for a stylish and energetic vibe.
Artist Style: A blend of (G)I-DLE’s charismatic vocal tone, TWICE’s blend of romantic sweetness and cool vibe, and NewJeans’ laid-back Y2K aesthetic.
Song Narrative: A girl group song that emphasizes self-expression and a declaration of individuality, blending sweet and cool atmospheres in perfect harmony. With a Y2K retro-futuristic vibe, it showcases a trendy and confident attitude in response to outside doubts.
音乐风格: K-Pop (Teen Crush 少女酷帅风 & Y2K 复古回潮)。以强有力的电子节拍、极具感染力的合成器旋律、有力又不失甜美的唱腔,以及干脆利落的节奏演绎为特色。制作上融合了清脆的Trap鼓点、复古电玩音效和空灵的流行和声,营造出时髦且充满活力的氛围。
艺人风格: 融合了 (G)I-DLE 那种充满克里斯马魅力的音色,TWICE 那种浪漫甜美与酷帅氛围的结合,以及 NewJeans 那种慵懒随性的Y2K美学。
歌曲叙事: 一首强调自我表达和个性宣言的女团歌曲,将甜美与酷帅的氛围完美和谐地融为一体。歌曲带有Y2K复古未来主义的氛围,旨在展现一种新潮、自信的态度,以回应外界的质疑。
MiniMax Music 1.5
mureka-7
Suno
Elevenlabs
| 测评点 | MiniMax Music 1.5 | mureka-7 | Suno | Elevenlabs |
| 风格准确度 | ★★★★ | ★★★★ | ★★★★ | ★★★★ |
| 人声听感 | ★★★ | ★★★ | ★★★★ | ★★★ |
| 旋律听感 | ★★★ | ★★★★ | ★★★★★ | ★★★ |
| 简评 | Suno较佳。呈现出一首比较典型的女团舞曲,和声和音效的添加有效还原了kpop精髓,旋律抓耳,chorus记忆点强,整体具有连贯性;mureka的呈现也较为完整,不足之处在于人声高音部分暴露出AI感;MiniMax弱在的没有intro,直接进人声略显唐突,人声的音色搭配也落差较大,并且beat过于基础,用力过猛但却缺乏活力,时长也最短;Elevenlabs的作品完整度较高,但整体人声是同一个音色,更像是一首solo,表现力弱于其他三组。 | |||
案例 4:Psychedelic Electronic-日文
提示词:
Style: A hypnotic and atmospheric Psychedelic Electronic track, in Japanese. It features pulsing analog synth basslines, shimmering arpeggios and ethereal vocal pads. The production is spacious and washed in reverb and delay, creating an immersive, trance-like state.
Campanella.
Artist Style: Evokes iconic Japanese electronic acts like Cornelius or Yellow Magic Orchestra, with a modern experimental edge akin to Wednesday Campanella.
Song Narrative: The song is a surreal, nocturnal journey through the neon-lit streets of Tokyo. The lyrics, poetic and abstract, depict a protagonist’s introspective search for connection amidst the city’s overwhelming digital haze, viewing the rain-slicked streets and flickering screens through a dreamlike, psychedelic lens. The mood is lonely, futuristic, yet filled with a sense of wonder.
音乐风格: 一首催眠般的、富有氛围感的日文迷幻电子乐曲。以脉动的模拟合成器贝斯线、闪烁的琶音和空灵的人声铺底为特色。制作上空间感十足,并浸染着大量的混响和延迟效果,营造出一种沉浸式的、恍惚的状态。
艺人风格: 让人联想到日本标志性的电子音乐人如 Cornelius (小山田圭吾) 或 Yellow Magic Orchestra (YMO),同时又具备类似于 水曜日のカンパネラ (Wednesday Campanella) 的现代实验性。
歌曲叙事: 这首歌是一趟超现实的、穿行于霓虹闪烁的东京街头的夜间旅程。歌词富有诗意且抽象,描绘了主角在令人窒息的城市数字迷雾中,内省地寻求着连接。他/她透过一个梦幻般的迷幻视角,观察着被雨水打湿的光滑街道和闪烁的屏幕。歌曲的基调是孤独的、未来主义的,但又充满了奇妙之感。
MiniMax Music 1.5
mureka-7
Suno
Elevenlabs
| 测评点 | MiniMax Music 1.5 | mureka-7 | Suno 4.6 | Elevenlabs |
| 风格准确度 | ★★ | ★★★ | ★★★★★ | ★★★★ |
| 人声听感 | ★★★ | ★★★★ | ★★★★ | ★★ |
| 旋律听感 | ★★ | ★★★★ | ★★★★★ | ★★★★ |
| 简评 | Suno最佳。混响出色,琶音创造出流畅的迷幻音效。人声不会喧宾夺主,强化了编曲的主体性。且节奏和音量遵循渐进式结构,制造情绪起伏;mureka逊色在未抓住迷幻电子音乐最重要的空间感和氛围设计,人声未做混响处理,略显干燥。而MiniMax更是偏题甚远,大白嗓+基本0混响,听感差,时长又是最短;Elevenlabs的编曲颇具递进感,不过其人声处理效果近似虚拟歌姬,使整个曲风走向更接近电子舞曲。 | |||
案例 5:Postrock-器乐摇滚/后摇-无人声
提示词:
Genre: Post-Rock / Instrumental Rock
Mood & Atmosphere: Expansive, hopeful, and deeply immersive. The feeling of soaring over vast mountain ranges or driving down an open coastal highway at sunrise. It should evoke a sense of freedom, wonder, and profound connection with nature. Perfect as a soundtrack for epic nature documentaries, travel montages, or adventure films.
Key Constraint:Crucially, this track must be purely instrumental with absolutely no vocals.
音乐流派: 后摇 / 器乐摇滚
情绪与氛围: 广阔、充满希望且深度沉浸。如同在日出时分,飞越广袤的山脉,或沿着开阔的海岸公路驰骋的感觉。它应能唤起一种自由、奇妙以及与大自然深度联结的情感。完美契合史诗级自然纪录片、旅行Vlog剪辑或探险电影的配乐需求。
关键约束:这首曲子必须是纯器乐,不包含任何人声。
MiniMax Music 1.5
由于歌词为必填参数,无法创建生成纯音乐。

mureka-7
Suno
Elevenlabs
| 测评点 | MiniMax Music 1.5 | mureka-7 | Suno 4.6 | Elevenlabs |
| 风格准确度 | N/A | ★★★★★ | ★★★★★ | ★★★★ |
| 乐器听感 | N/A | ★★★★ | ★★★★★ | ★★★★ |
| 旋律听感 | N/A | ★★★★★ | ★★★★★ | ★★★★ |
| 简评 | Suno略胜。三款模型都对后摇风格理解准确,均由电吉他作为主乐器引领着旋律走向,有着后摇经典的“渐强式”结构,动机旋律也都堪称悦耳,不会有走向怪异的段落。从吉他的音色,鼓的力度和节奏型,Suno这首会更金属风格,强劲有力,前奏和结尾的处理也更具完整性。几首作品都达到了提示词要求的“”契合史诗级自然纪录片、旅行Vlog剪辑或探险电影的配乐需求。 | |||
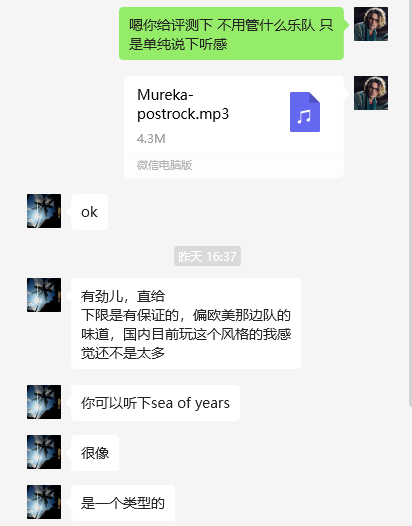
我甚至用其中的一首完全骗过了一位后摇乐迷朋友,也认可他的观点,“下限是有保证的”。
Ⅳ. 2025年AI音乐模型实测结论

在对涵盖大众流行到垂直细分流派、覆盖男女声及纯器乐的五则案例进行深度横评后,我们得以一窥当前AI音乐赛道的真实图景。不同于图像与视频领域头部模型间神仙打架、有来有回的焦灼战况,AI音乐的赛场呈现格局依然清晰:Suno,目前仍是横贯中西、难觅对手的唯一王者,在此次评测的全部五则案例中均拔得头筹。
与此同时,以Mureka v7,Minimax Music为代表的中国模型也展现出不容小觑的实力,表现令人眼前一亮。这种感觉,恰如我上半年评测字节跳动Seedream 3.0对阵Midjourney v7时的体验:在指令的理解准确度和生成稳定性上,国产模型已做得足够出色,但在最为主观,私人化的美学层面,棋差一着,而这恰恰是顶尖与优秀之间的差异。
基于本次评测,我们分别从AIGC爱好者和专业从业者的视角,得出以下三个核心结论:
- “相对成熟”的可用性:在创作者乐园与专业录音棚之间分割
AI音乐的可用度已达到一个“相对成熟”的临界点——其成熟与否,完全取决于使用场景。
- 对于广大的AIGC爱好者与内容创作者而言,这无疑是一个黄金时代。无论是为自己的虚拟数字人/偶像打造专属单曲,还是视频创作者寻求高贴合度的定制配乐,AI音乐模型已能出色地将自然语言指令转化为完成度颇高的音乐成品。创作的民主化,在这里体现得淋漓尽致。
- 然而,一旦转向专业领域的严苛需求,这层“成熟”的窗户纸便一捅即破。目前AI生成的成品,无论从音色的质感、弹奏/演唱的技法细节、编曲的丰富层次,乃至最终音频的保真度上,都与录音棚级别的“交付标准”存在着清晰可见的差距。这“最后一公里”的品质鸿沟,是AI音乐从“玩具”迈向“工具”必须跨越的门槛。
- “华彩段落”的价值:在完整乐章与灵感火花之间的权衡
从纯粹的音乐性出发,本次测试生成的20首曲目中,大约只有4-5首能让我在结构完整度和艺术感染力上产生听完整曲的意愿。但这是否意味着其余的作品都是无用的“废品”?答案是否定的。
这些看似不完整的曲目中,往往也有着悦耳的“华彩段落”(Highlight Reel)。这对当今以短视频和广告为主导的“注意力经济”而言,是完全足够,甚至是完美匹配的。毕竟,一个15秒的视频只需要一段5秒的高光旋律即可引爆传播。
而对于专业从业者,这更是一座取之不尽的灵感富矿。AI模型可以化身为一个不知疲倦的灵感马喽,以极低的成本快速生成海量Demo。用户不再需要耗费数小时去捕捉一个动机,而是可以在AI生成的“旋律碎片”中淘金。也许AI谱写的一段5秒旋律,就能成为一首年度金曲的起点。
- 创作的未来:从“指令生成”到“深度互动”的进化
当前,AI音乐的创作门槛已降至历史最低点,一句自然语言即可开启一段音乐旅程。但这仅仅是开始。下一步的进化,将是创作方式与玩法的深度拓展。
我们已经看到,“哼唱成曲”(Hum-to-Song)的功能正成为头部模型的标配(除Udio外,Mureka 7.5版本也已实现),用户与AI的互动变得更加直观和个人化。
而我个人最期待的,是真正成熟的“风格迁移”(Style Transfer)功能。想象一下这样的工作流:上传任意一首音乐,指定一个全新的音乐风格,便能即时获得一首保留原曲旋律动机、但风格焕然一新的作品。例如,为了制作一个像素风的视频,可以将一首当下最火的流行金曲,通过AI一键重制为8-bit风格的电子乐。这毫无疑问将对传统冗长的工作流,进行一次颠覆性的压缩。
总而言之,AI音乐模型已经具备较高的实用性:它为业余爱好者打开了通往音乐殿堂的大门,也为专业人士提供了无限的灵感利器。随着版本的迭代,相信它和图/视频领域一样,不再仅仅是关于“生成”,更是关于“编辑”与“再创作”的无限可能。
最后,欢迎转发本文给音乐爱好者或专业从业人员一起锐评,选出你心中最佳的AI音乐模型。
V. 如何在 302.AI 上使用
302.AI 提供按需付费无订阅的服务模式,用户可以根据自身业务需求灵活选择使用。
使用模型 API,以Minimax Music 1.5为例
相关文档:API→API超市→音视频处理→Minimax→music-1.5→查看文档;
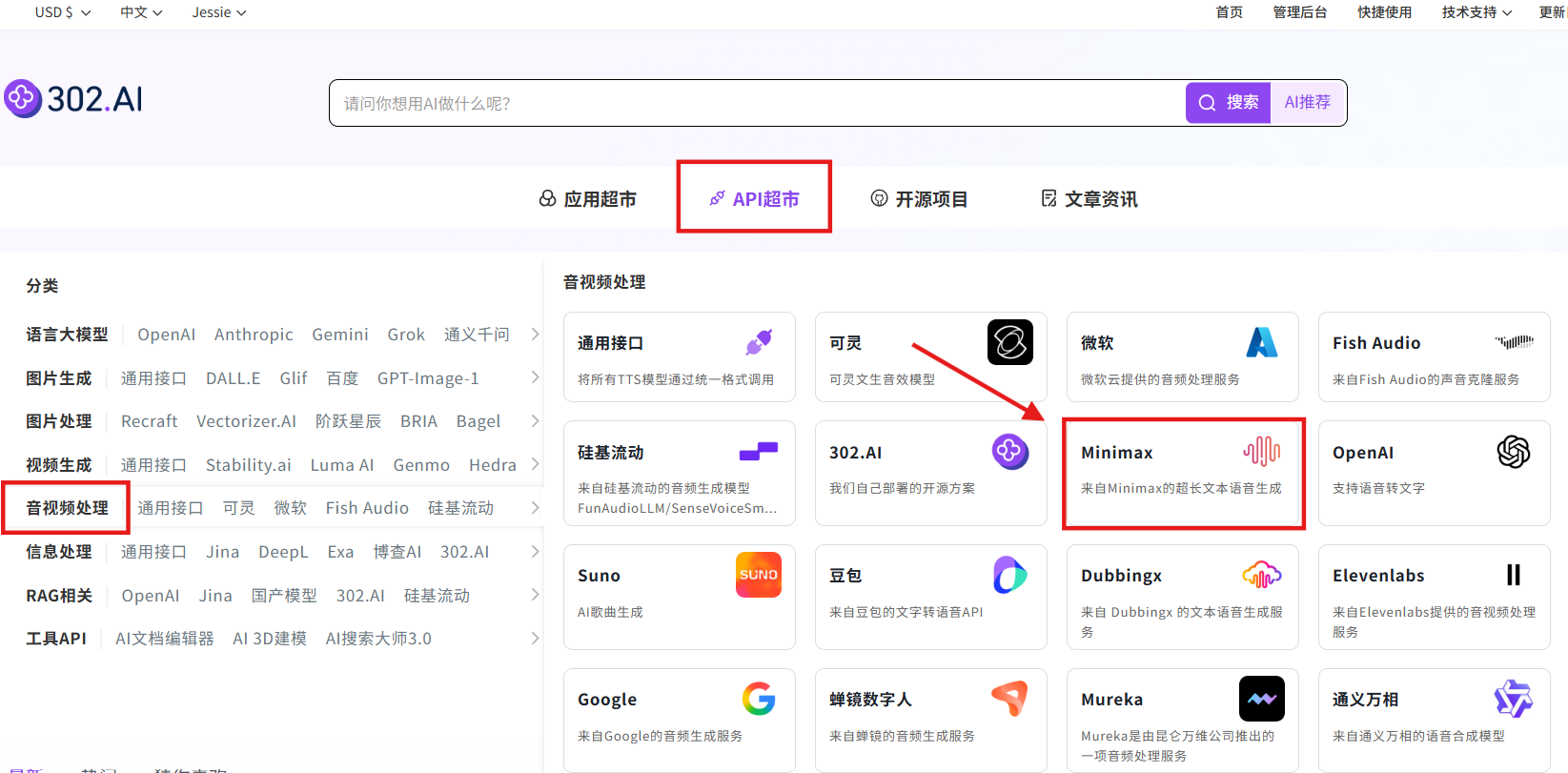
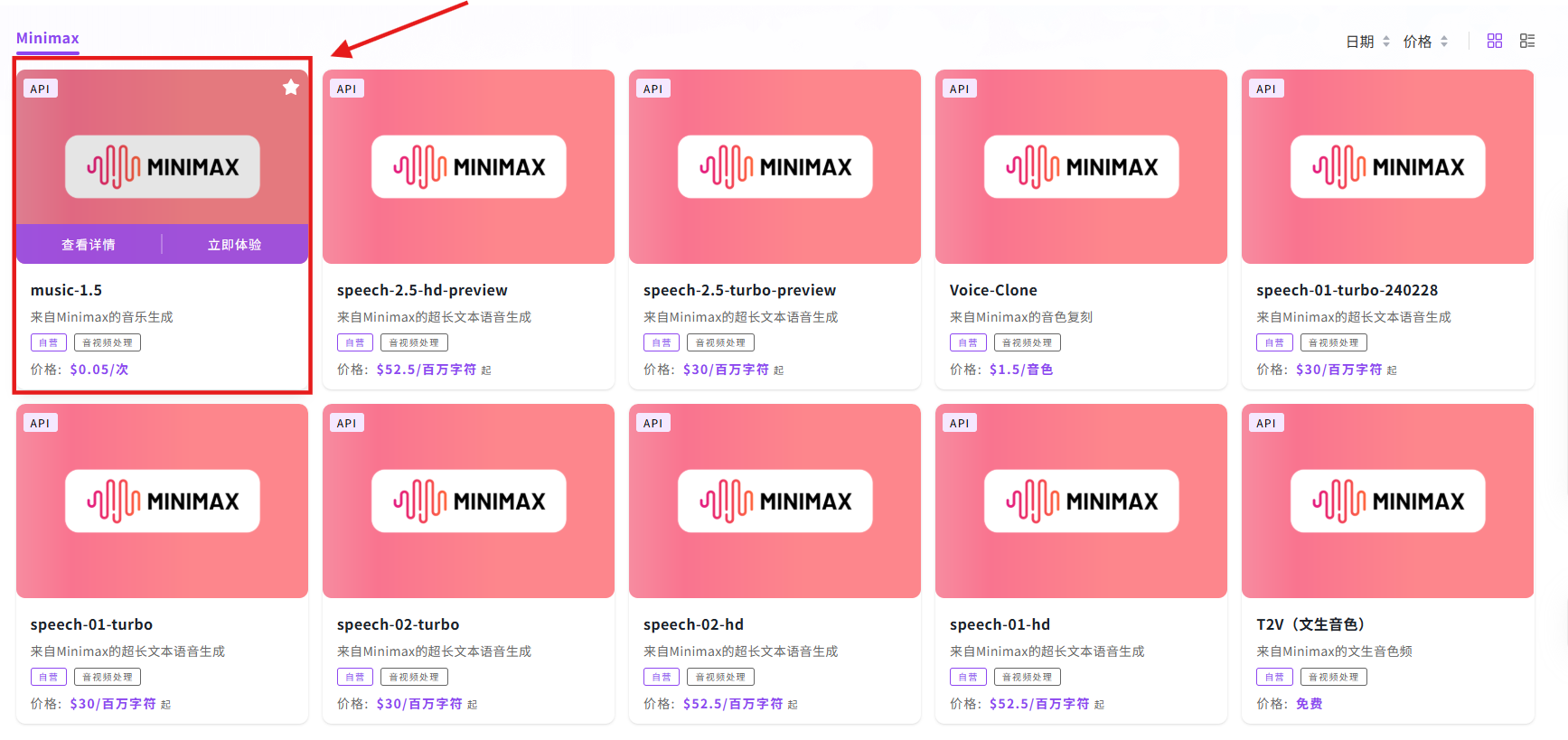
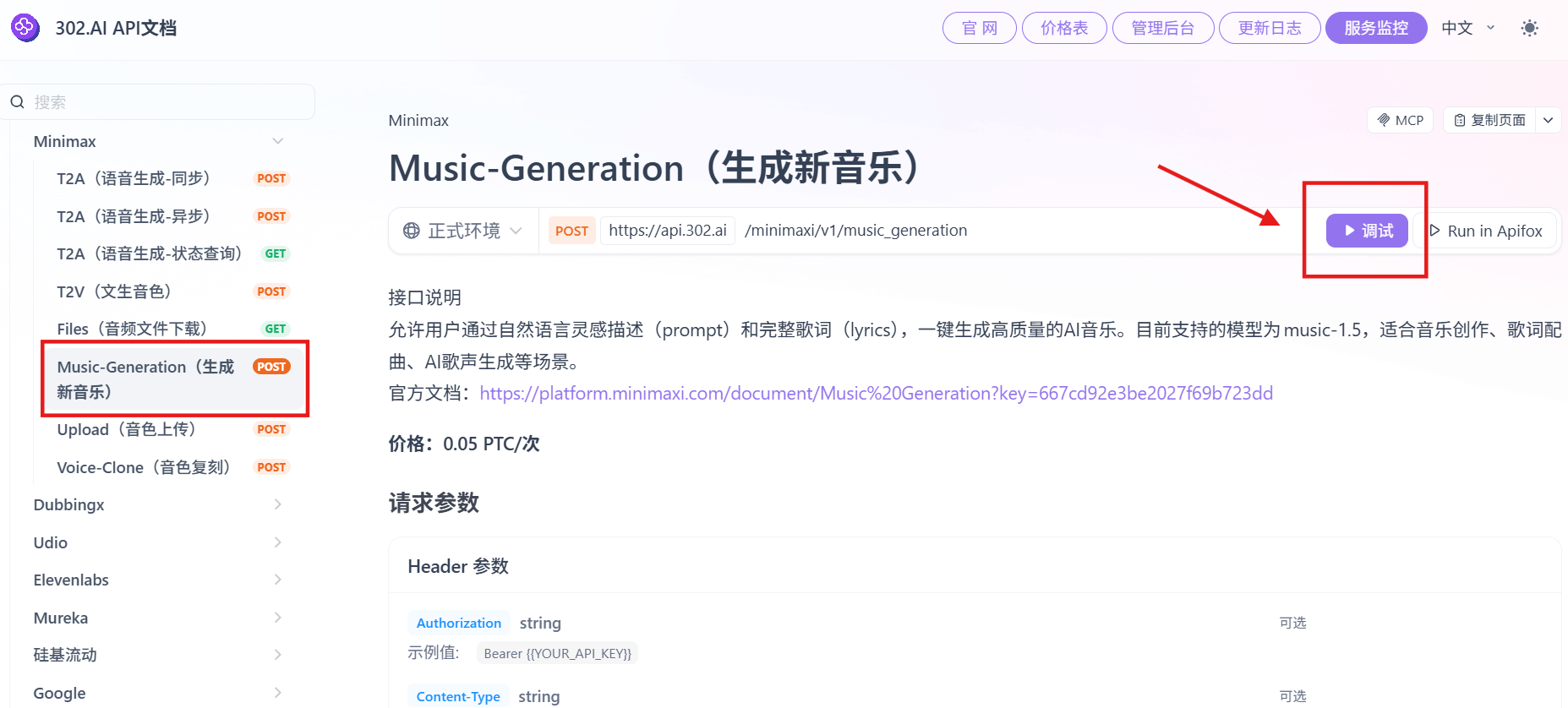
点击【调试】在线调用 API,根据提示词格式要求进行撰写
想体验中外各大音乐AI模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
