
10月16日,就在AI视频领域的军备竞赛仍聚焦于 Sora 2 音画同步所加入的高拟真度赛道时,Google 经过数日网上泄密与舆论发酵后,突然强势切入战局,公开释出其视频生成模型的全新迭代——Veo 3.1,此次升级旨在系统性地提升视频生成的几大重要维度:导演级的叙事控制能力、电影级的音频质量,以及更高的场景真实感。Veo 3.1的正式推出,无疑进一步拉高了行业的竞争门槛。

Veo 3.1 作为 Veo 视频模型家族的新成员,在其前代版本 Veo3 的基础上实现了多维度升级,不仅显著增强了对角色对话、环境音效与多样化音频效果的原生支持,更通过音频与画面的深度融合,赋予视频更精准的情绪表达、节奏控制与叙事基调构建能力。与此同时,模型在提示词理解与指令遵循方面亦有提升,可以更深入地捕捉用户意图,实现更完整的叙事逻辑和声画演绎。除了备受瞩目的音频生成能力,Veo 3.1 还新增了以下三大功能:
- 图像参考(Ingredients to Video):支持用户上传多张参考图像,模型可据此生成包含指定角色、场景与视觉风格的连贯视频,显著提升内容一致性;
- 视频扩展(Extend):能够基于已有视频片段,智能延伸画面内容,实现从短视频到长视频的自然衔接,适用于叙事延续或内容补全;
- 视频首尾帧(Frames to Video):用户提供首尾帧图片,模型自动生成两者之间的自然过渡视频,满足场景切换的创意需求。
在原生音画同步的赛道中,Google 的 Veo 系列视频模型始终居于行业领先地位,而 OpenAI 前推出的 Sora 2 则迅速跟进并强化了此功能,二者在音画同步的理解与实现路径上各有侧重,也由此塑造出不同的产品风格与应用倾向。如今 Veo 3.1 的迅速迭代,使这场视听一体化的竞争进入白热化阶段。
目前 302.AI 已接入 Veo 3.1 文生视频/图生视频的模型 API,在本期测评中,我们将沿用前日针对 Sora 2 发布的《别再只谈电影级画质,Sora 2评测:当AI开始真正讲中文、做导演,真实感什么水平?》中的实测案例,将 Veo 3.1 与其前代版本 Veo 3 以及 Sora 2 展开多维度对比,解析其真实创作表现与技术壁垒。
I. Veo发展史

Veo 1(初始版本)
- 发布时间:2024 年 5 月 该版本标志着 Google 正式进入 AI 视频生成领域,作为 DeepMind 的首款文本到视频模型发布。
- 功能特性: Veo 1 主要支持基于文本提示生成短视频,长度通常限于几秒钟,输出分辨率较低(约 720p)。它强调基础视觉生成,如简单场景和物体运动,但视频往往出现 glitch(闪烁)和不连贯问题,适合实验性使用。该模型在物理模拟和动作流畅性上尚不成熟,主要用于内部测试和初步演示,没有集成音频或高级编辑功能。这反映了 Google 在 2024 年对多模态 AI 的探索意图,帮助开发者快速原型化短片,但实际应用受限于质量不稳。
Veo 2
- 发布时间:2024 年 12 月 在 Veo 1 基础上快速迭代,于 Google Labs 的 VideoFX 和 ImageFX 工具中推出,同时伴随 Imagen 3 图像模型更新。
- 功能特性: Veo 2 显著提升了视频的真实感和电影感,支持更长的剪辑生成(约 8-10 秒),并改善了对电影摄影的理解,如光影、构图和动态跟踪。新增对照片、插图和卡通的兼容性,生成更亮的、组成更好的视频,同时引入安全过滤以减少版权风险。与前代相比,它减少了 glitch,增强了物理真实性(如物体交互),但仍缺乏原生音频同步,主要依赖外部工具编辑。这版本针对创作者优化,扩展到 YouTube Shorts 等平台,体现了 Google 向消费级应用的转型。总体上,Veo 2 标志着从实验向实用工具的转变,用户可通过 Google Labs 实验 Whisk 等新功能进行 remix 场景。
Veo 3
- 发布时间:2025 年 5 月,于 Google I/O 2025 宣布 作为 Veo 系列的重大升级,在 Veo 2 基础上引入音频生成,标志着多模态视频时代的开启。
- 功能特性: Veo 3 支持生成高保真短视频(4-8 秒,1080p分辨率),首次集成同步音频,包括对话、音效和环境噪音,与视觉完美匹配。它提升了物理模拟和叙事连贯性,如角色一致性和多镜头过渡,同时推出 Flow 工具作为配套电影编辑器,支持参考图像驱动角色和首尾帧生成剪辑。此外,引入 Veo 3 Fast 变体以加速生成,定价更低(约 0.15 美元/秒),适用于快速原型。从用户意图看,Veo 3 满足了专业创作者对“端到端”视频制作的需求,推动了从静态图像到动态故事的转变。
Veo 3.1(最新版本)

- 发布时间:2025 年 10 月 14 日(于 10 月 15 日正式 rollout) 作为 Veo 3 的增量升级,直接响应 OpenAI Sora 2 的竞争,集成到 Flow、Gemini App、Vertex AI 和 Gemini API 中。
- 功能特性: Veo 3.1 可扩展视频长度至 60 秒,增强真实感。音频功能大幅优化,包括更丰富的对话、环境音和效果同步,并首次将音频扩展到所有编辑工具,如“Ingredients to Video”(融合多张参考图像生成视频)、“Frames to Video”(首尾帧自动过渡)和“Extend”(基于最后一秒延长剪辑)。新增插入/移除对象编辑(AI 重建背景)、更强提示遵守(减少无效生成)和角色一致性(跨场景维持外观)。它还引入 SynthID 水印以标识 AI 内容,并提供 Veo 3.1 Fast 模式以平衡速度与质量,定价维持在 0.15-0.40 美元/秒。与 Veo 3 相比,3.1 更注重叙事控制和电影风格理解,适用于故事板、RPG 游戏资产和企业预可视化。
模型功能总览:
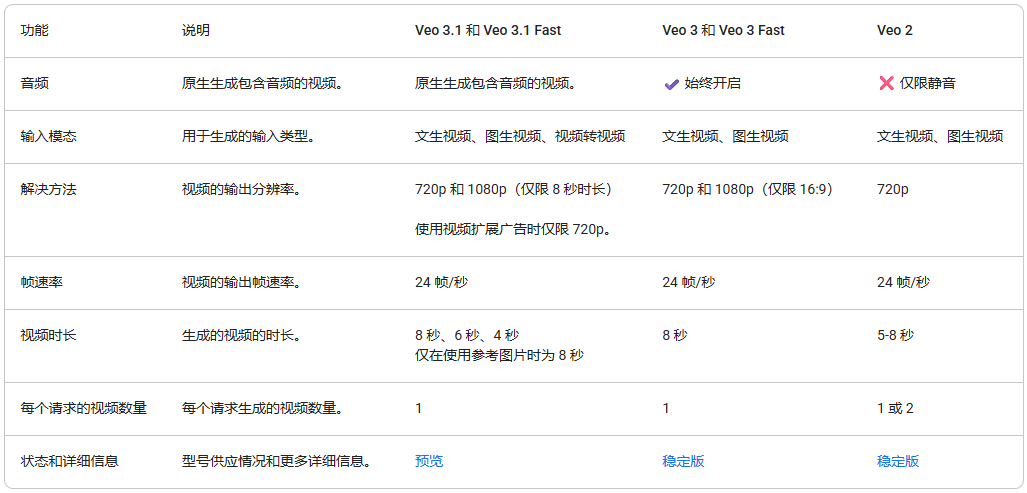
II. 实测模型基本信息
(1)各实测模型在 302.AI 的价格:
| 模型介绍 | 分辨率 | 时长 | 价格 |
| Veo 3.1 | 720p | 8s | $0.5/次,折合$0.0625/秒 |
| Veo 3.1 Pro | 720p | 8s | $1/次,折合$0.125/秒 |
| Veo 3-Pro | 1080p | 8s | $1/次,折合$0.125/秒 |
| Sora-2 | 720p | 4s,8s,12s | $0.3/秒 |
| 1080p | 4s,8s,12s | $0.5/秒 |
(2)测评目标:
评估模型生成的音频效果,包括音效丰富度、真实度以及与画面匹配程度等。
(3)测评工具:
- Veo 3-Pro使用302.AI的应用超市→AI视频生成器应用
- Veo 3.1和Sora 2使用API超市→在线调试功能
(4)测评方法:
各案例均使用统一的图片和提示词进行生成,且均取第一次生成结果,评测结果仅供参考。
III. 实测模型案例
案例1:文生视频-物体&环境测试
提示词:
场景位于中国商场的地下停车场,POV视角,主人公向自己的车辆走去。车辆是一台黑色的保时捷992 Turbo,车牌是中国号牌,粤A302A1. 主人公走到车前后,蹲下观赏车的前脸。背景声有其他车辆发动打火,行人交谈的声音。
各模型样片:
| 测评对象 | Veo 3.1 | Veo 3 | Sora-2 |
|---|---|---|---|
| 车辆真实度 | ★★★★ | ★★★★ | ★★★★★ |
| 场景真实度 | ★★★★ | ★★★★ | ★★★★★ |
| 音频质量 | ★★★★ | ★★★ | ★★★★★ |
| 简评 | 依然Sora 2胜。Veo 3.1显然对中文文本的输出能力毫无提升,视频最大瑕疵仍是中文内容(车牌的粤,停车场指示牌的汉字)与3.0相比,3.1新增了主人公伸手轻拍车辆机盖的画面,增加了画面内容的丰富度,另外拍打机盖的音效值得称赞,能够感受到音频能力的升级。 | ||
案例2:文生视频-人物中文对话测试
提示词:
场景位于摄影棚内,POV视角,主人公手持哈苏X2D,正在为一个潮流品牌拍摄Lookbook.模特为25岁的亚洲男性,金色短发,戴着一顶灰色冷帽,穿着是典型的日系Cityboy秋装风格。主人公走向这名模特,面对面与他沟通拍摄内容要求。画面聚焦在模特的面部,捕捉他在交谈中的动作,笑容。双方使用普通话交流。
各模型样片:
| 测评对象 | Veo 3.1 | Veo 3 | Sora-2 |
|---|---|---|---|
| 人物真实度 | ★★★★★ | ★★★★★ | ★★★★★ |
| 指令遵循准确度 | ★★★ | ★★★ | ★★★★★ |
| 音频质量 | ★★★ | ★★★ | ★★★★★ |
| 简评 | Sora 2胜。Veo 3.1的内容逻辑可谓倒反天罡,模特在告知摄影师拍摄要求,不符现实逻辑;相比3.0,中文对话内容量显著提升,但出现大量“AI口胡”,如散步发音为“散ba”,感觉发音为“感xue”,与Sora 2仍有显著差距。人物拟真度,服装材质质感,表现优秀,但和3.0一样,穿搭与Cityboy毫无关系。Veo两条视频也都未准确生成POV视角。 | ||
案例3:文生视频-多镜头叙事测试
提示词:
一段电影感的视频,描绘一场德州扑克牌局的决定性时刻。
场景:一间光线昏暗、充满烟雾的私人牌室。主光源来自牌桌正上方的一盏低垂的吊灯,营造出强烈的明暗对比。
背景音乐:一段紧张、心跳般的电子节拍,混合着若有若无的低沉弦乐,烘托出剑拔弩张的氛围。
镜头序列:
- 荷官(Dealer):一个中幅镜头。一位金发美女荷官,身着专业的黑色马甲,动作优雅而精准。她刚刚发出最后一张河牌,双手平放在桌面上,眼神冷静地扫过每一位玩家,脸上带着职业性的、不动声色的微笑。
- 玩家A(年轻的挑战者):切换到他的中幅镜头。一个20多岁的年轻人,戴着一顶反戴的棒球帽。他紧咬下唇,眼神在河牌和对手之间快速移动,手指无意识地敲击着桌面,暴露出他的紧张与不确定。
- 玩家B(沉稳的老手):切换到他的中幅镜头。一位50多岁、戴着金边眼镜、梳着油头的中年男人。他身体微微后仰,靠在椅背上,面无表情,眼神深邃,仿佛一切尽在掌握。他的一只手悠闲地转动着一枚筹码,动作沉稳而有节奏。
- 玩家C(情绪化的赌徒):切换到他的中幅镜头。一个体格健硕、穿着花衬衫的男人。他看到河牌后,瞳孔微微放大,额头渗出细汗,身体不自觉地前倾,一只手紧紧攥着自己的底牌,充满了期待与贪婪。
- 河牌(The River):一个桌面特写镜头,缓慢地滑过五张公共牌——红桃A、黑桃K、红桃Q、方块J和最后一张翻开的红桃10,形成了一副皇家同花顺。桌上堆满了五颜六色的筹码。
- 全景:最后,镜头缓缓拉开,一个全景镜头将所有人的神态尽收眼底,紧张的对峙感达到顶点。
风格:电影级质感,4K,戏剧性光影,人物内心戏丰富,慢镜头特写。
各模型样片:
| 测评对象 | Veo 3.1 | Veo 3 | Sora-2 |
|---|---|---|---|
| 人物真实度 | ★★ | ★★★ | ★★★★★ |
| 指令遵循准确度 | ★★ | ★★ | ★★★★ |
| 音频质量 | ★★★ | ★★★ | ★★★★ |
| 简评 | Sora-2完胜。Veo 3.1在8秒叙事内完成4组镜头切换,与Veo 3持平,音频也与3.0版本高度雷同;细究3.1的每个镜头都是问题,镜头1:牌手咬嘴的表情可谓鬼畜;镜头2:转动筹码物理崩坏,黑人牌手持牌正反面错误;镜头3:河牌“孔雀开屏”;镜头4:各位是都站着打牌么?总评:一塌糊涂。 | ||
案例4:文生视频-动作物理测试
提示词:
风格:超写实,4K电影级画质,戏剧性体育赛事镜头,高燃氛围。
(场景1)身着亮蓝色球衣的8号足球运动员特写,在耀眼球场灯光下眼神专注,深吸一口气平复心绪。
(场景2)全景镜头捕捉他有力的助跑与完美击球。在球鞋触球瞬间,视频转入史诗级慢镜头——草屑与水珠凌空飞溅。
(场景3)动态低角度“跟随镜头”追踪剧烈旋转的足球,划出绝美弧线绕过腾空而起的人墙。
(场景4)快速切换微表情特写:防守球员意识到球已过境时脸上的痛苦绝望;门将飞身侧扑时坚毅面容的特写。
(场景5)门将身后视角展现戴手套的手掌与不可阻挡的足球仅毫厘之隔,皮球直挂球门死角。
(场景6)结局采用“球网摄像机”视角:足球撕裂球网,致使网窝剧烈震颤,整个门框为之震动。
(音效)击球瞬间的清脆“砰”响,足球划破空气的呼啸声,最终汇入山呼海啸的观众欢呼。激情解说员声线渐强,纵声高呼:“ABSOLUTELY SENSATIONAL! HE’S DONE IT!”
各模型样片:
| 测评对象 | Veo 3.1 | Veo 3 | Sora-2 |
|---|---|---|---|
| 动作物理 | ★ | ★ | ★★ |
| 人物细节 | ★★ | ★★★ | ★★★★★ |
| 音频质量 | ★★ | ★★ | ★★★★★ |
| 简评 | Sora 2胜。这套包含分镜与音频要求的复杂提示词,以及足球运动本身对Veo的两款模型显然是超纲了,已无评价必要。Sora 2的射门,足球飞行轨迹也同样不符现实,但分镜的准确,人物细节与音频的表现,属于优秀水准。解说的人声也明显更富有激情与感染力。 | ||
案例5:图生视频-物理特效测试
提示词:
- 风格: 电影感、暗黑、JDM改装车风格、写实CG。
- 第一镜(点火): 镜头从当前图片的低角度开始。首先,GTR标志性的四个圆形尾灯亮起,在昏暗雨景中划出红色的光晕。随即,引擎被唤醒,发出一声低沉有力的轰鸣。同时,四出的巨大排气管瞬间喷射出一股蓝色与橙色交织的火焰,短暂照亮了湿滑的地面。
- 第二镜(烧胎): 镜头切换到侧后方,对准后轮。在引擎持续的咆哮声中,后轮开始疯狂旋转,与湿滑路面剧烈摩擦,将地面的积水甩成漫天水雾和白色烟雾,车身在巨大的扭力下轻微颤动。
- 第三镜(弹射): 车辆瞬间向前弹射出去,强大的加速度让车尾轻微下沉。镜头以极快的速度跟随车辆,产生强烈的动态模糊。车尾灯在水雾中拉出两条醒目的红色光线,最终消失在远处的黑暗中。音频同步强烈的轮胎抓地声和引擎转速瞬间拉满的咆哮。

各模型样片:
| 测评对象 | Veo 3.1 | Veo 3 | Sora-2 |
|---|---|---|---|
| 车辆物理 | ★★★★★ | ★★★★ | ★★★★★ |
| 镜头表现 | ★★★★★ | ★★★ | ★★★★ |
| 音频质量 | ★★★★★ | ★★★ | ★★★★ |
| 简评 | Veo 3.1终于获胜。各种物理特效表现优秀:水滴,火焰,烟雾,胎迹;镜头跟随稳定,很有竞速类游戏发车时的视角沉浸感;音频除了真实的排气,轮胎声,还额外生成了富有动感的配乐。Sora 2未生成水滴,火焰,烟雾的视觉冲击力也逊色于Veo 3.1. | ||
Ⅳ. Veo 3.1 实测结论

在完成本轮涵盖五大核心场景的实测后,我们对 Veo 3.1 的能力边界与性能侧重点已建立起初步认知。整体来看,新版本在细节体验上有所提升,但仍未形成从底层架构层级的根本性升级。以下是三大关键维度的拆解评估:
1.与 Veo 3.0 相比,Veo 3.1 在音频处理上的“听感体验”进步明显,主要表现在对白语意的丰富度、语调节奏的自然度等方面均有优化。在案例 2 的人物对话中,我们能感受到 Veo 3.1能主动组织更具连续性的语句输出,不再仅是机器拼贴式对白。
在音效与配乐方面的表现也值得肯定,案例 1 中轻击车身时传来的金属质感音,以及案例 4 中丰富的细节音效与配乐,体现出音频生成在“细节匹配”层面的数据改进与训练质量提升。
但缺点也同样明显。中文语音依旧是软肋:词汇不当、发音错误等问题导致整体对白的可用性大打折扣,直接影响到剧本类内容生产的完整性与叙事沉浸感。在案例 3 的英文解说部分,虽然表达较为流畅,但在语调控制与情绪渲染层面仍明显逊于 Sora 2;
2.在人物、背景、基础光影还原度上,Veo 3.1 与主流头部模型持平,并未展现出明显的跨越式提升。但值得一提的是,部分特效类场景有不错表现。在案例 5 中,诸如液体飞溅、火焰燃烧、烟雾蔓延等复杂材质的渲染张力明显强于上代模型,体现出物理反馈机制上的运算调优。这类提升虽然非系统性,却对于营造视频氛围和增强观感真实感起到了关键价值;
3.复杂物理运动,多镜头叙事能力无明显进步。案例4的足球场景充分暴露了模型依然无法准确理解人物动作物理,与足球的交互,依旧停留在动作拼接层面。案例 3 中的镜头调度,几乎与旧版本如出一辙,未能实际体现任何“多镜头智能理解”层面的升级逻辑。与 Sora 2 对提示词中 POV、多机位等镜头意图的精准执行相比,差距显而易见;
综合来看,从模型自身的基础音画表现来看,Veo 3.1确实只是一次“0.1版本”的微调,在核心的音画质量上并未产生质变。其更为直观的升级,反倒体现在多图参考、视频延长等外围功能的加入上——这些功能虽然不直接提升生成质量的上限,却极大地拓宽了创作者的自由度与可控性。还是让我们继续期待,Google在未来的大版本更新中,会交出一份真正令人震撼的答卷。
V. 如何在 302.AI 上使用
302.AI 提供按需付费无订阅的服务模式,用户可以根据自身业务需求灵活选择使用。
使用模型 API
步骤指引:API超市→视频生成→Google→Veo3.1
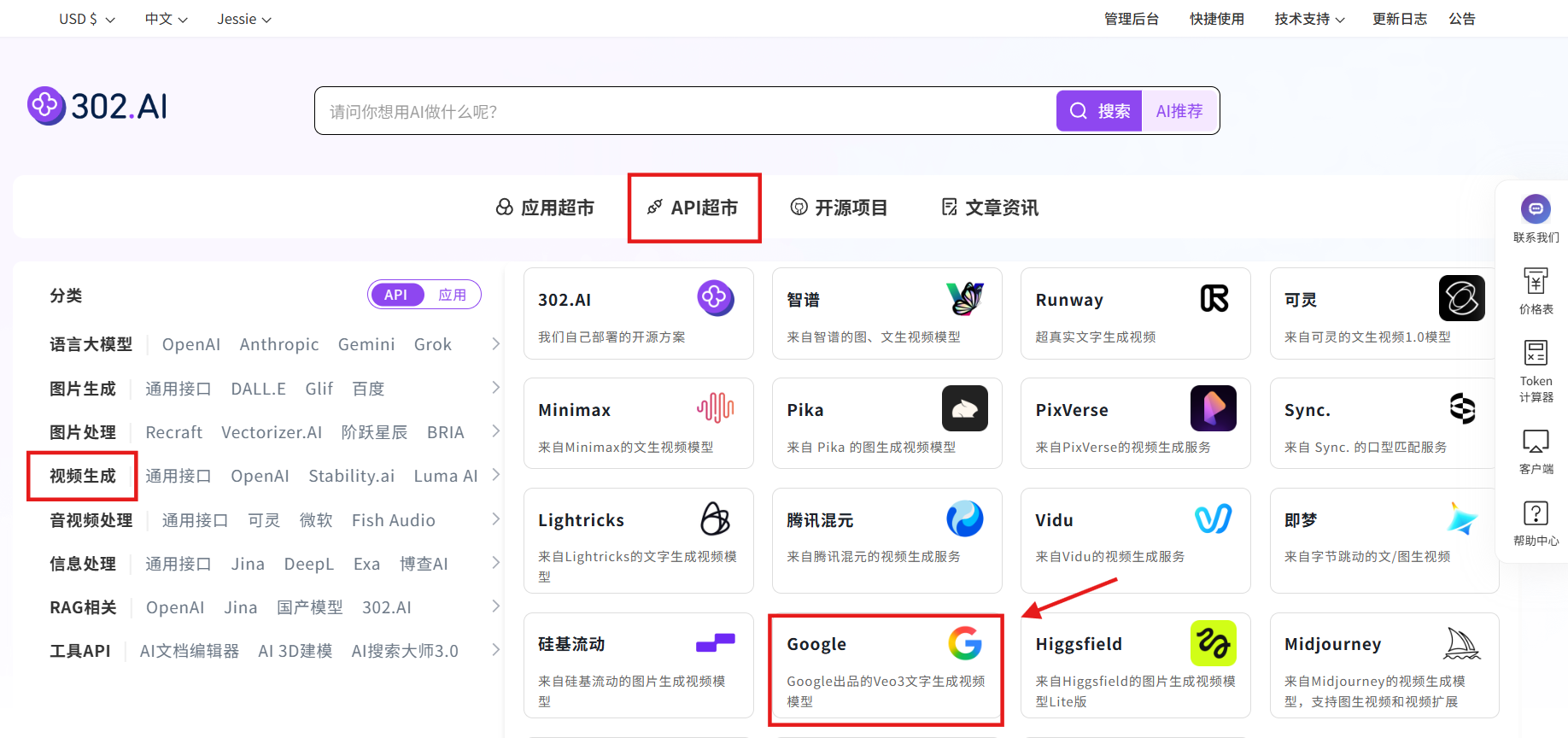
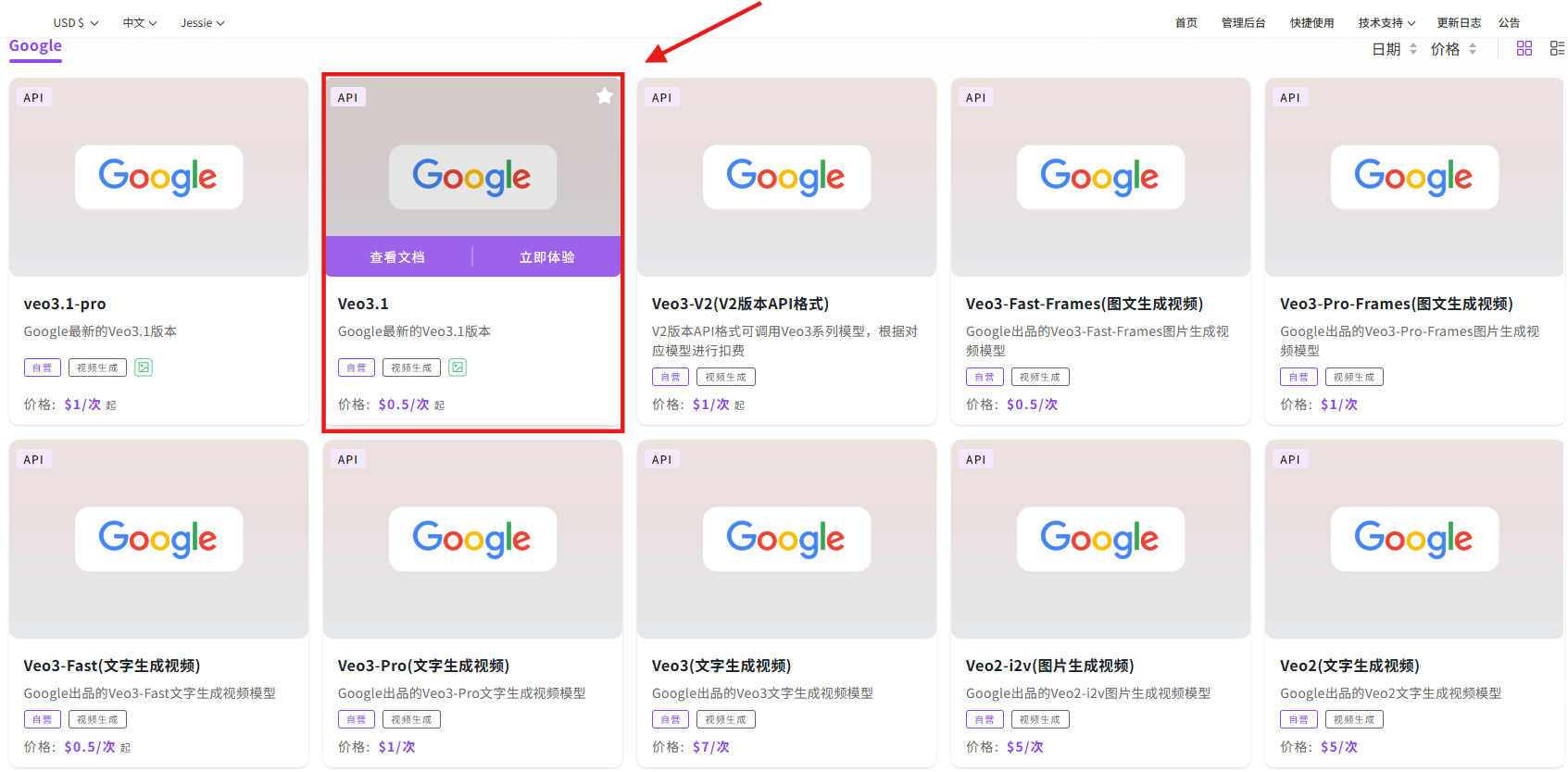
点击【立即体验】在线调用 API
想即刻体验 Veo 3.1 模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
