
仅靠一张图片就能制作电影?通义万相于 9 月 19 日开源了其角色动画驱动模型 Wan2.2-Animate —— 一款能够实现一键迁移角色动态的强大模型。其核心能力就是把人物角色的动作、神态,精准迁移到任意角色身上,从而实现让一张静态图复刻任何视频里的动作,主演任何视频里的场景。

AI 视频生成技术普及以来,如何让作品中的角色动态叙事更完整、更真实,这一直是每个 AIGC 创作者的痛点所在。数字人生成模型实现了角色开口说话,图生视频模型则让角色可以在固定场景中简单地“动起来”。然而在改善角色面部表情自然度、以及提升角色与环境融合度方面,现有技术仍存在很多亟需填补的空白。
是否存在一种模型,能够突破传统角色动画的技术瓶颈,省去繁琐的后期合成步骤,直接生成人、声、画、景高度统一的动态影像?
Wan2.2-Animate 的出现,能否补全 AI 视频生成领域中电影叙事的一块重要拼图呢?

302.AI 已第一时间接入了 Wan2.2-Animate 系列模型 API,本期文章将围绕模型的核心亮点,结合多个玩法案例为大家展示 Wan2.2-Animate 的实际应用效果。
I. Wan2.2-Animate 模型基本信息
(1)模型基本信息
Wan-Animate 构建于 Wan-I2V 之上,采用统一的模型架构,通过改进输入范式,将参考图像输入、时间帧引导以及环境信息(用于双模式兼容)统一到一种通用的符号表示中。该模型将“图生动作”(Move)与“视频换人”(Mix)两种模式统一为一种共同的符号表示。也就是说,这是一个可实现角色动画与角色替换的统一框架。且模型能根据输入条件自动切换生成模式,无需训练两个独立模型,这大大提升了开发效率和资源利用率。
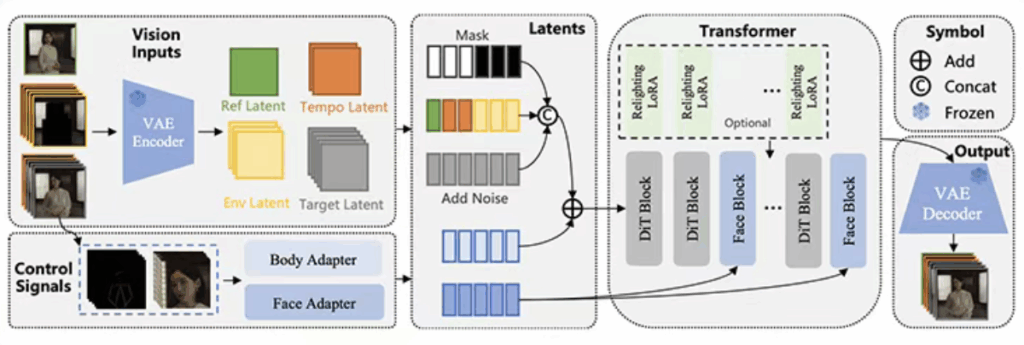
(2)性能亮点
- 精准的表情与肢体控制:通过双路径控制实现精准动作与表情迁移,身体运动采用空间对齐的骨骼信号(如 VitPose 提取的 2D 骨架)直接注入噪声向量,确保动作准确;面部表情则通过原始人脸图像编码与时序交叉注意力机制,完美保留微妙表情细节。
- 重塑真实光影,无缝替换角色:Mix 模式通过专用的 Relighting LoRA 模块,智能学习并应用目标视频的光照与色调,使迁移角色能无缝、自然地融入原有场景,并原生支持包含复杂运镜的视频,实现电影级的融合效果。
- 可定制化开源:开源了完整的动作重定向技术栈,包含从驱动视频中提取动作模板的处理代码,以及将模板应用于角色图片生成最终视频的推理代码。
(3)素材限制
- 参考图片要求:
- 格式限制:JPG、JPEG、PNG、BMP、WEBP
- 尺寸限制:图像的宽度和高度各自都必须在[200,4096]像素范围内,宽高比在1:3至3:1范围内。
- 大小限制:不超过5MB
- 参考视频要求:
- 格式限制:MP4、AVI、MOV
- 尺寸限制:宽高200-2048像素,宽高比1:3至3:1
- 大小限制:不超过200MB
- 时长限制:不小于2s且不大于30s
(4) 模型在302.AI的价格
| 模型名称 | 302.AI内的价格 |
| wan2.2-animate-move | • wan-std:$0.07/秒(基础演示、轻需求) • wan-pro:$0.1/秒(专业制作、高质量) |
| wan2.2-animate-mix | • wan-std:$0.105/秒(基础演示、轻需求) • wan-pro:$0.15/秒(专业制作、高质量) |
Ⅱ. 一个架构,两种玩法
Wan2.2-Animate 作为业内首个专注于人物角色驱动的开源模型,支持两项核心功能——角色动画和角色替换。它可以让一张静态角色图复刻任何视频里的动作、主演任何视频里的场景。
模式 1:图生动作(Move)
此模式支持输入一张角色图片+一段动作参考视频,模型会精确复刻视频中角色的表情、动作,将之迁移到图片角色上,生成一段高保真的角色动画。即成片视频的场景环境会基于图片来生成。
适用于舞蹈、高难度肢体动作、影视剧表演艺术等动态复刻场景。

模式 2:视频换人(Mix)
此模式支持输入一张角色图片+一段视频,模型能无缝替换视频角色,不仅精准复刻其动作表情,更能智能重塑光照与色彩,达成毫无违和感的电影级融合。即成片视频的场景环境会基于视频来生成。
适用于剧情魔改、角色混搭、影视后期处理换人等复杂场景。

III. 案例演示
*以下案例均使用 wan-pro 版本生成
案例 1:Move模型测试-表情动作
图片素材:Emma Watson

成片:
评分:★★★★★
简评:成片较好地保持了艾玛的外貌特征和背景环境,面部表情衔接自然,无论是说话口型、神态变化、手部动作都与原视频保持高度同步。细节在于人物头发会随身体晃动幅度而随之晃动,并且投射在面部的阴影也会随之变化,符合物理规律。唯一不足在于成片无法达到实拍视频的流畅度,例如手部快速晃动时会出现虚影。
案例 2:Move模型测试-单人舞蹈
图片素材:寡姐

成片:
评分:★★★★★
简评:成片效果较佳,能在人物头部动作变化时保持斯嘉丽的五官不崩,人物动态和舞蹈幅度也达到基本复刻了原版的程度;值得一提的细节是:服装在保持原貌的同时能够跟随舞蹈动作出现自然褶皱和光影变化,以及人物脖颈处的肌肉变化比较自然真实。此外,头发摆动除了无可避免地出现轻微虚影外,依然能够精准复刻原版的运动轨迹,整体效果佳。
案例 3:Mix模型测试-视频换人-整体人物
图片素材:星爷

评分:★★★★
简评:星爷的造型得以准确还原,神态动作与Jimmy保持高度一致。细节上,领口边缘的黑色缝线,西装口袋上的刺绣,乃至头顶翘起的发梢,在动态呈现中都做到了“自然”,“逼真”。最大的破绽在于原视频中的麦克风不翼而飞,导致星爷左手虽然呈握持状,但空然无物。另一点体现模型特点的是能很干净地消除本处于人物前方的字幕,不会出现残留痕迹,好评。
案例 4:Mix模型测试-视频换人-仅换脸
图片素材:郭德纲


灵感来源于著名的《开原DJ》系列。up主:袁大艺
成片:
评分:★
简评:翻车案例。1.该模型没有对应的参数,无法实现仅换脸的精准需求,模型仍会按照参考图中出现的部分衣服细节进行扩展生成;2.人物五官还原度差,看不出一点郭老师的特征;3.头顶的半拉耳机,暴露了模型对于物体的识别和处理还存在短板。
Ⅳ. Wan2.2-Animate测评结论

四个案例测下来,Wan2.2-Animate 这代模型的表现可以总结成一句话:它离“靠谱商用”已经不远了,但从“可控精品”还有一段路要走。
我们先说好的一面。
在前三个案例中,无论是艾玛的细腻面部与光影同步,斯嘉丽舞蹈的动作连贯与服饰动态,还是星爷动态神态还原得一板一眼——Wan2.2 有本事把静态的人物形象盘活,不仅是面部五官还原得像,连人物的衣褶、发丝、投影细节都在动,有那么几帧,你真会以为这是换了演员的真人片段。
这就是“动画模型上桌”的标志:它不是在画“会动的 GIF”,而是在做“能演戏的数码替身”,在动作表情上已经做到了逐帧还原。
更厉害的一点,它在一些看似边角料的细节上也处理得相当成熟,比如字幕擦除、背景还原、光影匹配,几乎找不到明显残幅痕迹。这些细节不是炫技,而是真在为落地打基础。
但我们也不回避问题。
第4个案例很有代表性:在没有更细致的参数限定下,全自动一键生成的模式会导致不可控因素的产生。上面提到的人物准确性,细节擦除都遭遇了翻车问题,本质就是——稳定性上目前还不能达到100%可控。这个问题谈不上致命的bug,算是阶段性门槛,但对出品成片率有实打实的影响。期待后续版本能够增加更多自定义参数配置,如设定仅替换人物面部等局部修改功能,让用户能对画面元素进行更细致的控制。
总结一句话,如果你是短视频创作者,想做动作复刻、踩点舞蹈、角色互换,那 Wan2.2-Animate 确实是目前足够方便,有出片能力的选择;但如果你是影视级内容创作者,要想让 AI 替你拍出一个无懈可击的商业级视频,你最好还是多留一个后期打磨的预算。
V. 如何在 302.AI 上使用
302.AI 提供按需付费无订阅的服务模式,用户可以根据自身业务需求灵活选择使用。
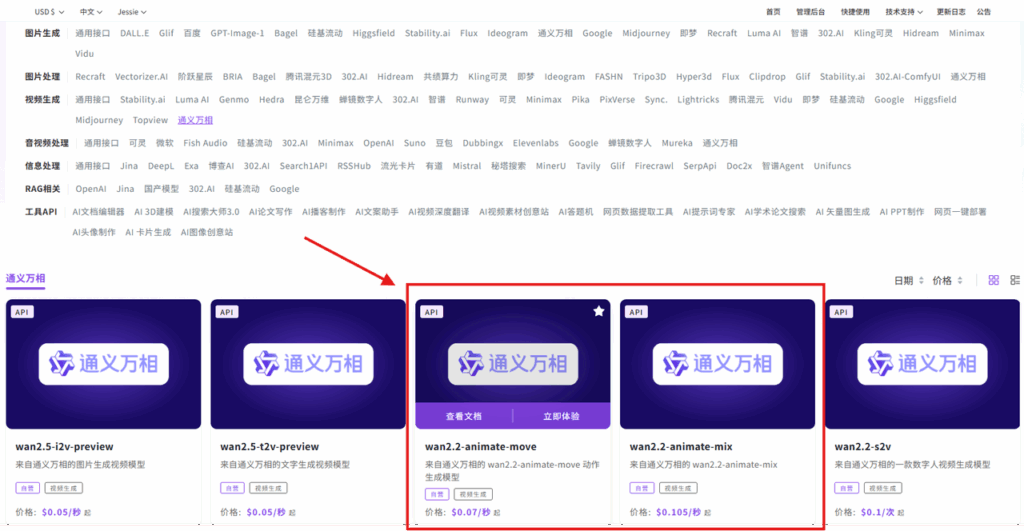
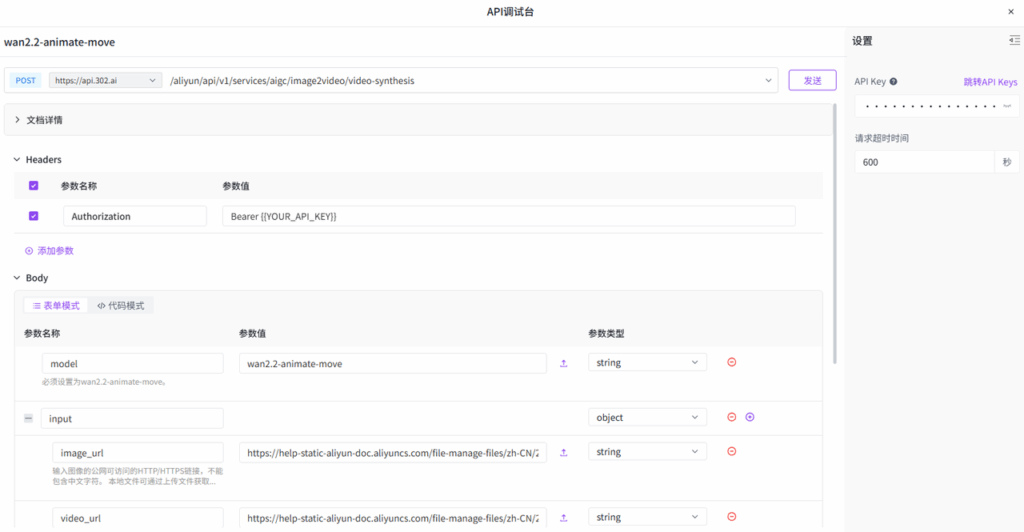
使用模型 API
相关文档:API→API超市→视频生成→通义万相→wan2.2-animate-move/wan2.2-animate-mix
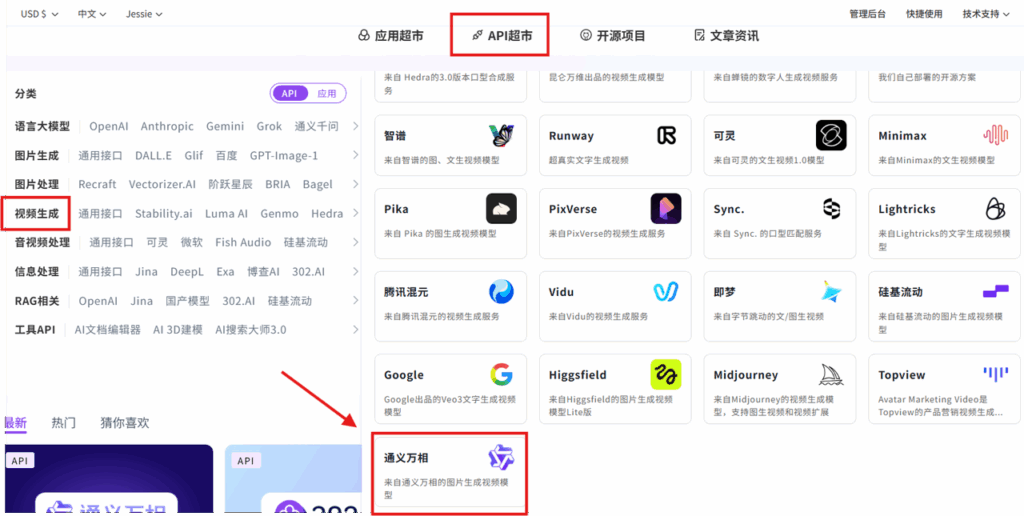
点击【立即体验】在线调用 API
想马上体验 Wan2.2-Animate 系列模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
