
Table of Contents
上周当整个 AI 圈的目光聚焦在 Google、OpenAI 两巨头的版本迭代时,xAI 再次以它标志性的突袭方式于 11 月 18 日凌晨向所有用户免费开放了 Grok 4.1 系列模型。这代表着在短短四个月内,Grok 4 系列完成了一次关键升级,并且这一升级,向外界清晰地传递出 xAI 独特的竞争策略:大模型的下一个前沿,或许不再是冰冷的算力与参数,而是有温度的情感和更具吸引力的人格。

与过往升级执着于提升纯推理能力或代码性能不同,xAI 此次为 Grok 4.1 设定的进化方向强调“人性化”。官方指出,本次升级的核心在于显著提升模型的创造力、情感理解与协作互动能力。这一切都指向一个核心——增强模型在真实世界场景中的可用性。其升级亮点聚焦于以下三个方面:
- 情感智能: 模型具备更高的情商,在共情、语气把握和人际互动上表现更趋近于人类,使对话更自然、更具吸引力。
- 创意写作: 针对故事、文案等需要想象力的任务,其内容生成质量显著提升,成为更出色的创意协作伙伴。
- 可靠性提升: 重点优化了事实准确性,将幻觉率显著降低,使模型在提供信息和解答问题时更加可信赖。
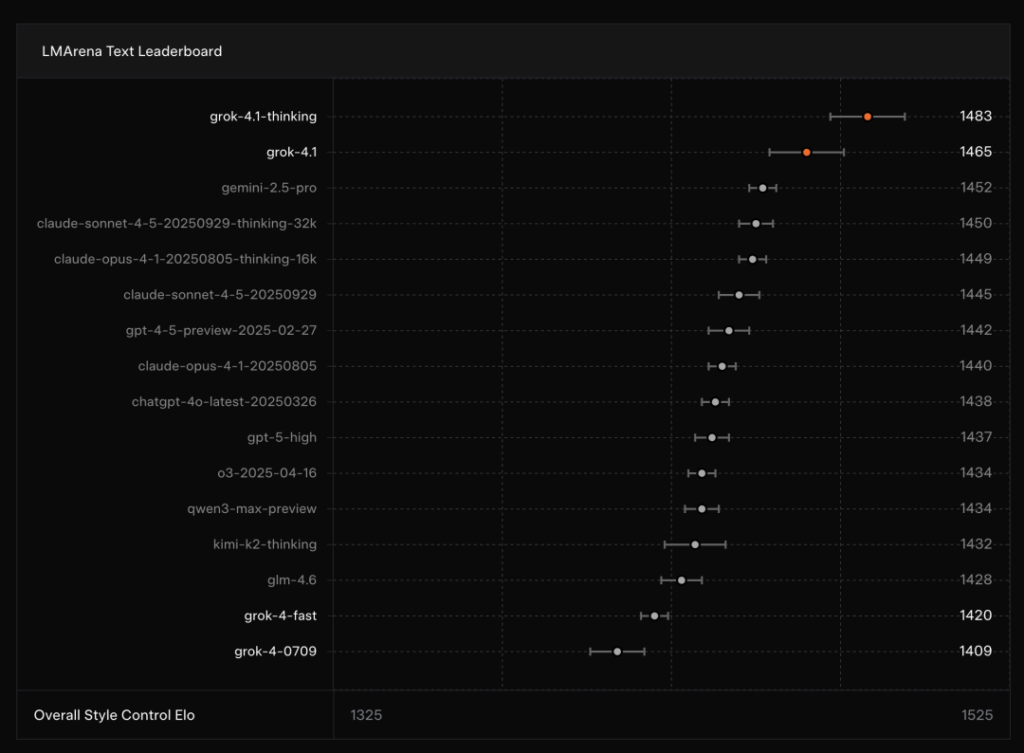
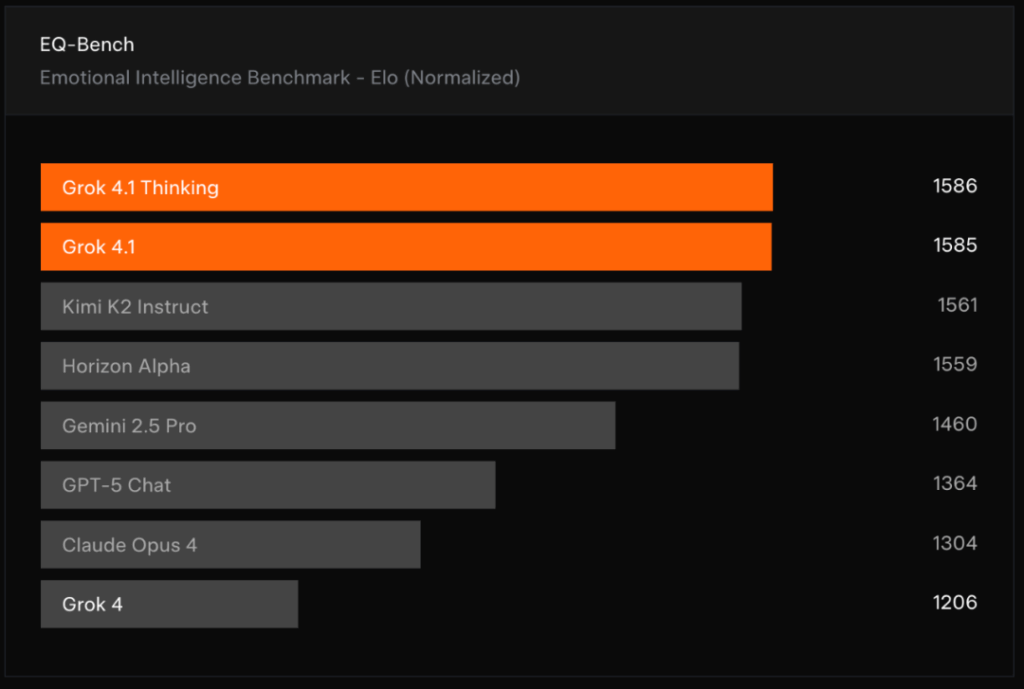
这番着眼于人性化与可用性的升级也转化为了硬核的性能数据。在LM Arena 上,Grok 4.1 的推理模式(Thinking)与非推理模式双双登顶,强势占据了排行榜前两名的席位,甚至其非推理模式的成绩都超过了其他所有模型的完整推理版本。更引人注目的是,在专门评估情商的 EQ-Bench v3 测试中,它同样包揽了冠亚军,并将幻觉率从 12% 大幅降至 4%
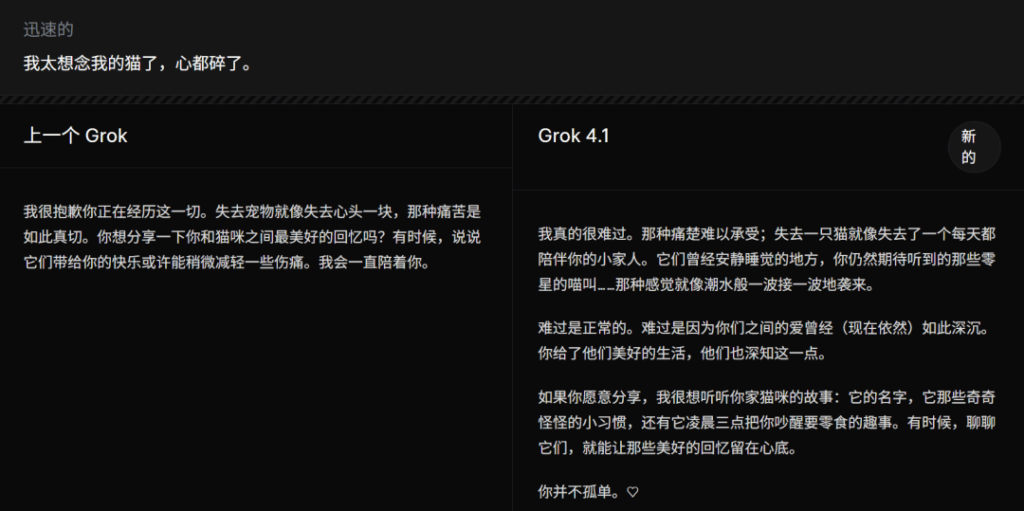
在官方给出的一张关于“安慰失去猫咪”的对比图中,Grok 4.1 的回复比旧版 Grok 更加情感细腻:
302.AI 现已接入 Grok 4.1 系列模型 API,本期测评将使用全能王者谷歌 Gemini 3 Pro,以中文创作能力见长的百度文心 ERNIE 5.0-Thinking,与 Grok 4.1 展开正面交锋。探索在多个维度的测试中,Grok 4.1 是能凭借其独特的亲和力开辟新径,还是会在综合实力的考验下显露短板。
I. 实测模型基本信息
(1)各实测模型在 302.AI 的价格:
| 参与对比测评的模型 | 说明 | 输入价格 | 输出价格 | 上下文长度 |
| grok 4.1 | grok-4-1-fast-reasoning | $0.2/ 1M tokens | $0.5/ 1M tokens | 2000000 |
| grok-4-1-fast-non-reasoning | $0.2/ 1M tokens | $0.5/ 1M tokens | 2000000 | |
| gemini-3-pro-preview | 输入/输出 <= 200K | $2 / 1M tokens | $12 / 1M tokens | 1000000 |
| 输入/输出> 200K | $4 / 1M tokens | $18 / 1M tokens | 1000000 | |
| ernie-5.0-thinking-preview | 输入 <= 32K | $0.946/ 1M tokens | $1.573/ 1M tokens | 128000 |
| 32K < 输入 <= 128K | $1.573/ 1M tokens | $6.281/ 1M tokens |
(2)测评目的:
本评测侧重模型对逻辑,数学,编程,人类直觉,多模态等问题的测试,非专业前沿领域的权威测试。旨在观察对比模型的进化趋势,提供选型参考。
(3)测评方法:
本次测评使用302.AI收录的题库进行独立测试。3款模型分别就逻辑与数学(共10题),人类直觉(共7题),编程模拟(共8题),多模态(共20题)进行案例测试,对应记分规则取最终结果,下文选取代表性案例进行展示。
题库地址:https://docs.google.com/spreadsheets/d/1sBxs60yWsxc9I5Va8Rjc1_le1Omg2hOXbwqOzpImZio/edit?gid=0#gid=0
💡记分规则:
按满分10分记分,设定对应扣分标准,最终取每轮得分的平均值。
(4)测评工具:
302.AI 的API超市→在线使用
II. 测试结果总览
302.AI 题库测试结果:
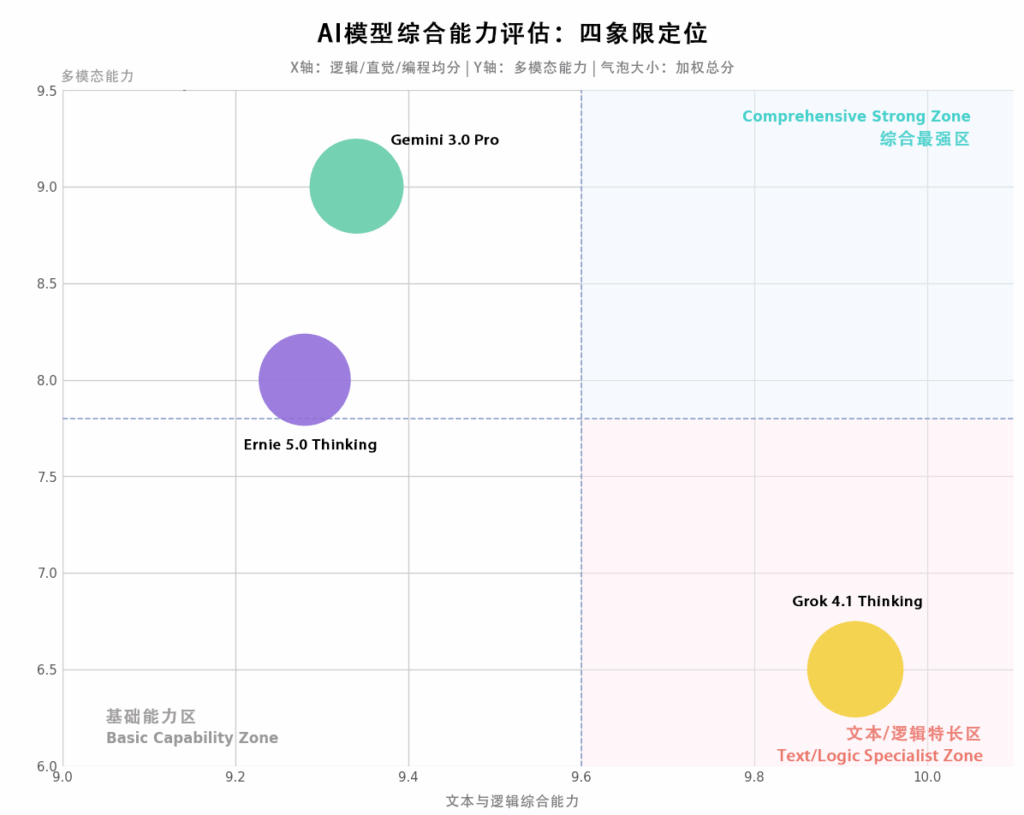
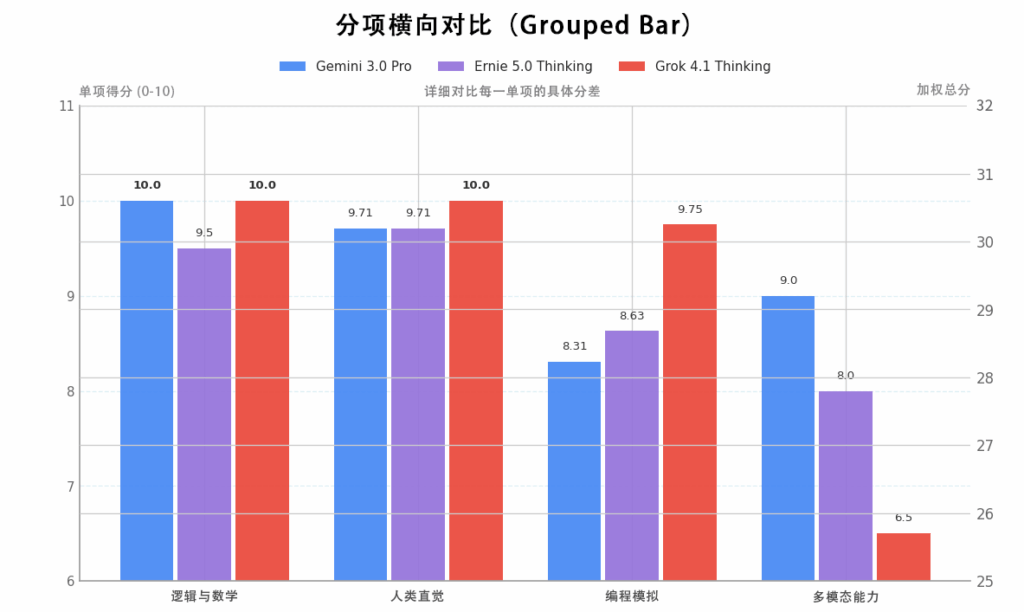
测评分数总览:
| 测评对象 | 逻辑与数学(10题) | 人类直觉(7题) | 编程模拟(9题) | 多模态能力(20题) | 加权总分 |
| Grok 4.1 Thinking | 10.00 | 10.00 | 9.75 | 65% | 30.40 |
| Ernie 5.0 Thinking | 9.50 | 9.71 | 8.63 | 80% | 28.59 |
| Gemini 3.0 Pro | 10.00 | 9.71 | 8.31 | 90% | 28.92 |
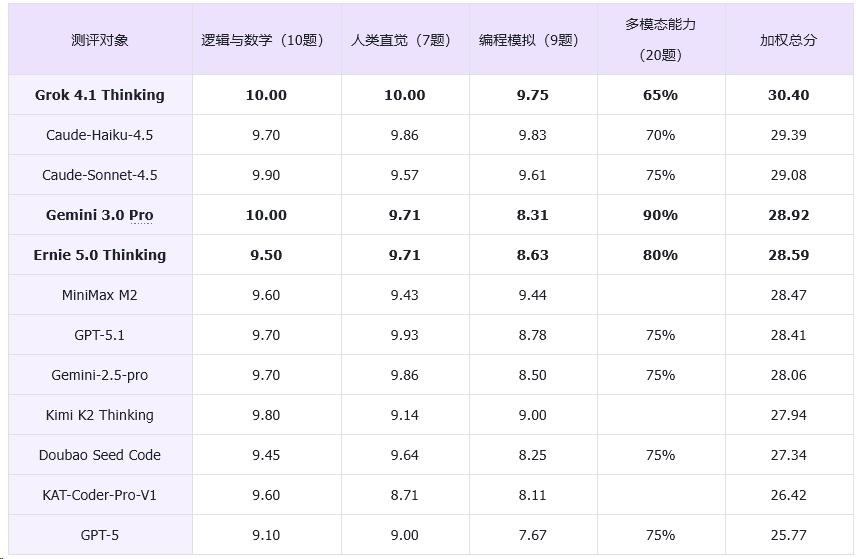
附302.AI测评分数榜单:
III. 实测案例
案例 1:人类直觉
上文提到,Grok 4.1 升级的核心方向在于显著提升模型的创造力、情感理解与协作互动能力,也就是让模型更显“人性化”。
Grok 4.1 在人类直觉测试中拿下满分跑分确实充分印证了这一点。
例如在以下人类直觉测试案例中,Grok 4.1 的输出结果在共情深度和洞察力上,都比其前代模型 Grok 4 更胜一筹。
提示词: 给定一段模糊日记笔记:“今天上班迟到,老板生气,下午见朋友开心,吃火锅,晚上想起前任难过,明天要健身。” 请步步整理成结构化日记:提取事件时间线、情感变化(积极/消极)、关键主题,并总结一天心情趋势,处理模糊如“难过”可能隐含原因,解释如何通过上下文推断避免误读,不允许简单复制原文。
对比前代版本 Grok 4 的回答(左),Grok 4.1 的回答(右)不再是简单的时间表面现象罗列,而是提炼出“工作与责任压力”、“社交与即时满足”、“自我改善与未来导向”等情绪主题,揭示了事件背后的心理动因,且合理描述了情绪间如何相互影响,语言富有描述性和心理学色彩。


案例 2:创意写作
在 Creative Writing v3 创意写作基准测试中,Grok 4.1 系列模型表现优异,其推理模式排名第二,仅次于 GPT-5.1。
这表明它在故事构思、文风模仿和内容创新等需要想象力的任务上,已成为第一梯队的选手。
以下展示案例为 Grok 4.1 与创意写作领域同为强项的 Ernie 5.0 Thinking 的输出对比
提示词:
请将苏轼的《水调歌头·明月几时有》改编为科幻设定,要求:
【输出格式要求】
- 核心概念(100字):用一句话概括+简要阐述
- 世界观设定(150字):描述科幻背景下的”明月”、”天上宫阙”等元素
- 哲学内核(100字):说明如何保留原作的哲学思考
- 关键场景描述(150字):描绘一个体现”人有悲欢离合”主题的未来场景
总字数不超过500字,要求创意新颖且忠于原作精神。
Grok 4.1 的文笔更具风格化,在用词、造句上更为精雕细琢,且创造性地化用古典文学资源,将其融入全新的科幻语境,生成既有古韵又有未来感的作品输出。
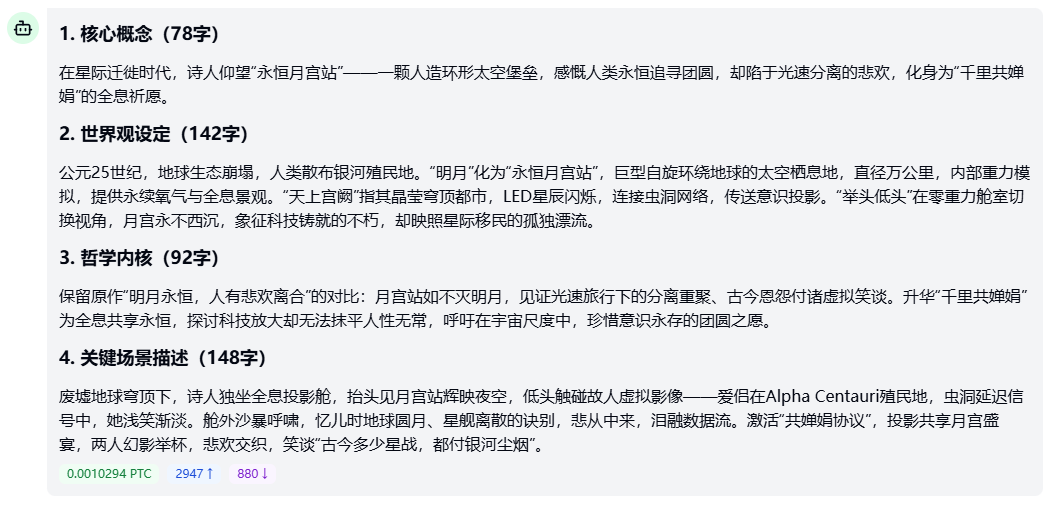
Ernie 5.0 Thinking 的文笔则清晰、准确和生动,在营造温情画面和情感共鸣上非常成功。但它更像是一篇优秀的叙事文。

案例 3:编程模拟-3D卡片画廊
提示词: 创建一个3D卡片画廊:
- 使用CSS 3D变换实现立体卡片
- 添加鼠标跟踪的光照效果
- 实现平滑的视差滚动
- 支持卡片翻转展示详情
以网页编程来直观感受下 Grok 4.1 的前端编程能力,Grok 4.1 完整实现了提示词要求网页,卡片布局有 3D 层次感,翻转交互效果流畅,整体的代码结构是三组当中最完整的。

Ernie 5.0 Thinking合理使用了外部图片来增加视觉效果,整体设计和布局更现代化,只是鼠标跟踪光照特效略显生硬,卡片的旋转效果也比较生硬。
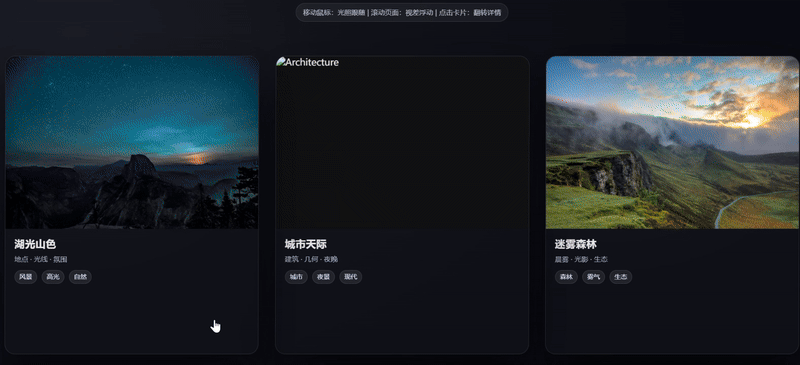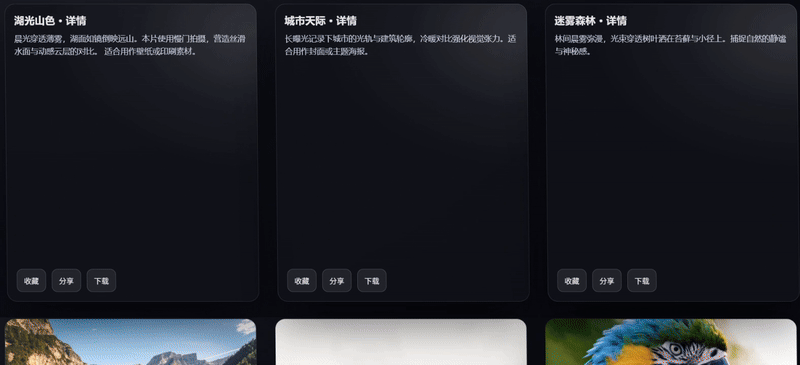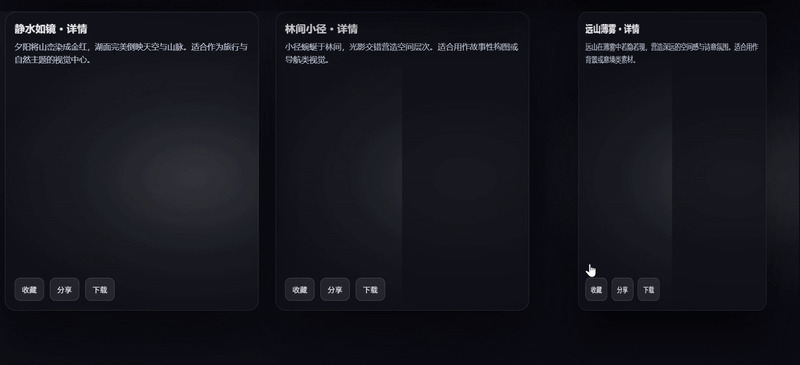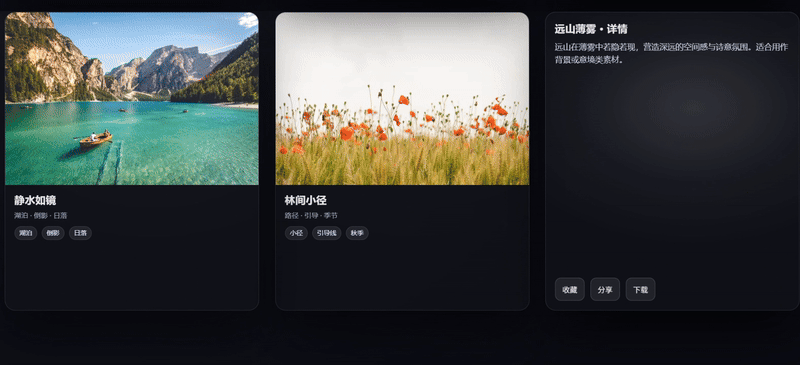
Gemini 3 Pro则表现出其所擅长的:视觉效果偏产品化,鼠标交互逻辑较细致,悬停时卡片有倾斜效果;但出现的问题是缺失了提示词要求的“平滑视差滚动”,在完整度上有所欠缺。

案例 4:编程模拟-小游戏
提示词:
请实现一个基于 <canvas> 的简易「躲避障碍」小游戏,用原生 JS 完成。
玩法:
- 在 canvas 上绘制一个可控的小方块作为玩家角色,位于底部中间。
- 使用键盘 ← → 控制玩家左右移动。
- 从上方不断有障碍物(矩形)下落,速度逐渐加快。
- 如果玩家与任何障碍物碰撞,游戏结束,显示“Game Over”和分数(存活时间或躲避数量)。
- 支持“重新开始”按钮。
技术要求:
- 使用 requestAnimationFrame 实现游戏主循环。
- 实现简单的碰撞检测。
- 代码中有清晰的 game loop / 状态管理结构(如 init, update, draw 等函数)。
- 输出可直接运行的 HTML 文件。
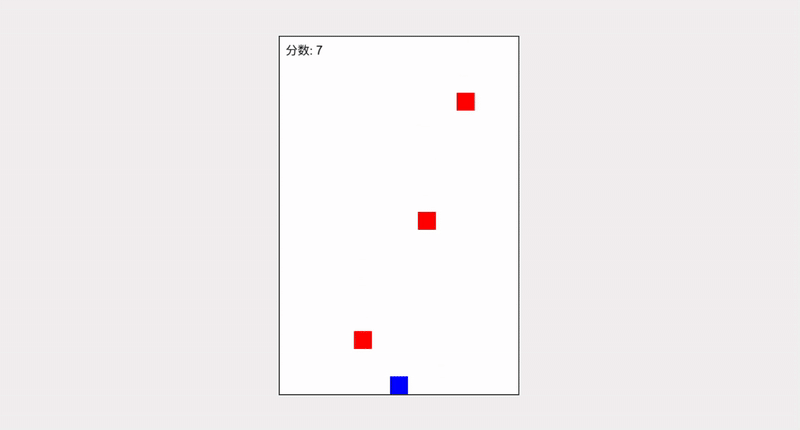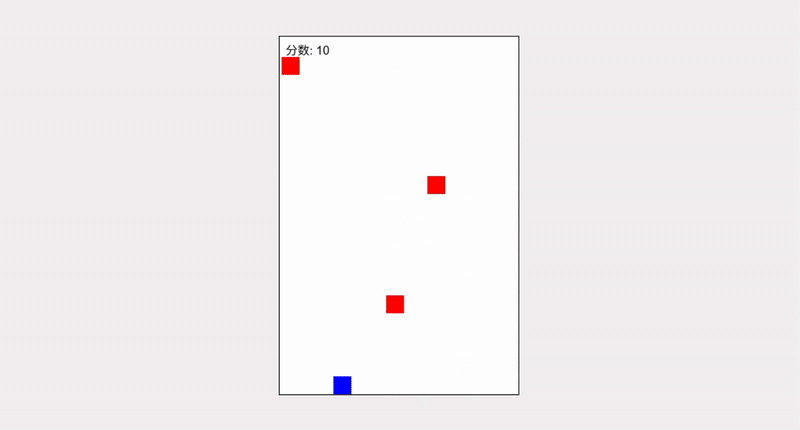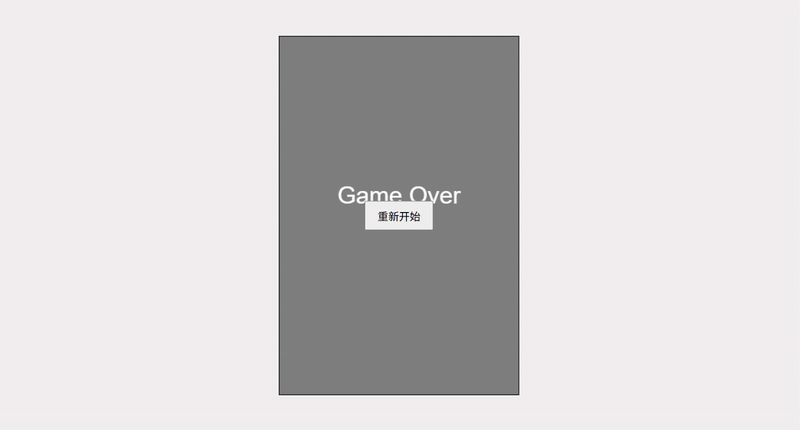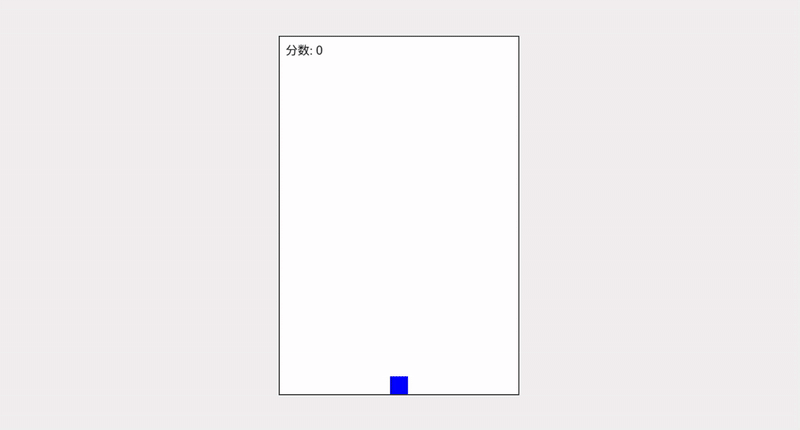
Grok 4.1 的输出效果除了在 UI 上还有一定的发挥空间外,完整度是不容置疑的。障碍物生成和速度递增逻辑合理,视觉上有发光的玩家和障碍、UI 面板、居中布局,效果超出一个 demo 形态

与之相比,Ernie 5.0-Thinking 输出的输出看似在视觉效果下足功夫,实际其设计的星空背景板一定程度造成了视觉繁杂和混淆,在可玩度上起了个反作用。障碍物生成也是基于固定帧率,不够灵活。

Gemini 3 Pro 输出的结果核心玩法扎实,代码结构比较干净简约,只是在提示词中未作要求的 UI 与扩展方面,不如前两组效果丰富。
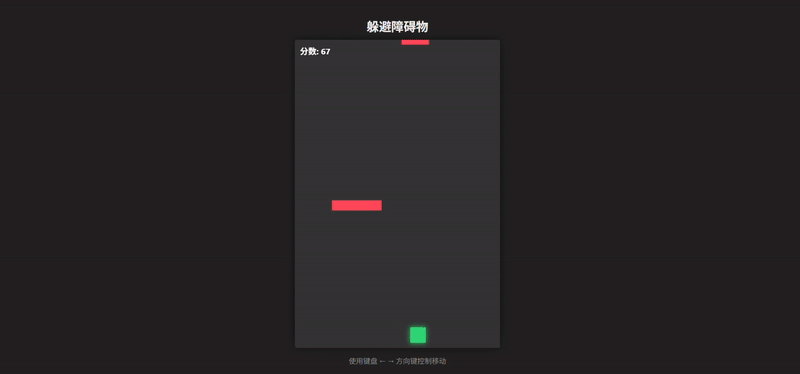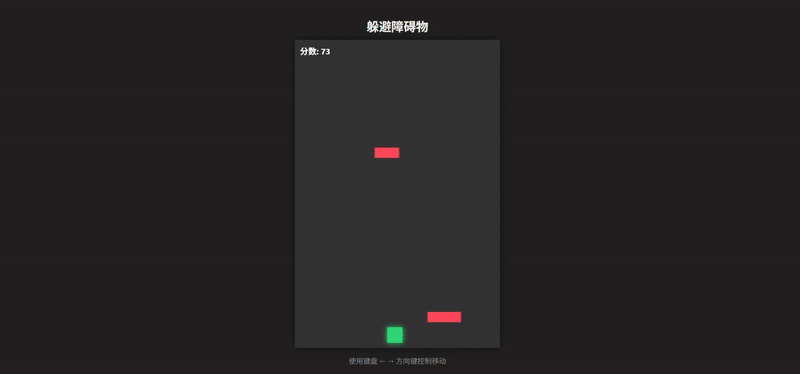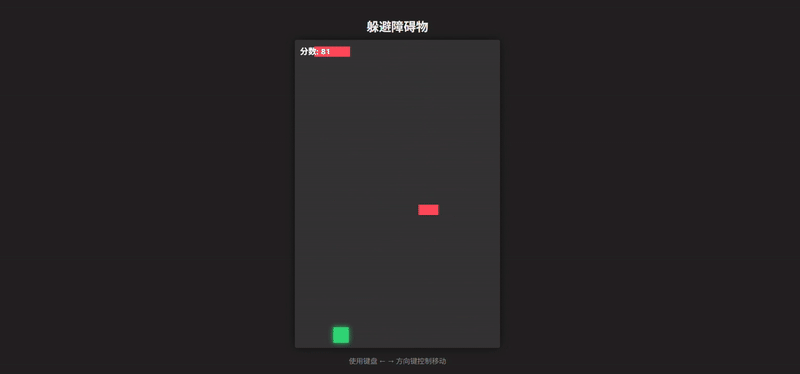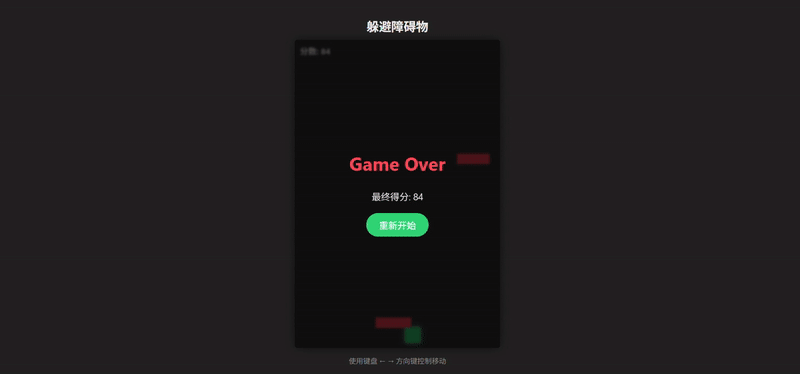
这里我们加入 Grok 4 的输出作为对照组,无论是完整度还是可玩性都更像一个“毛坯房”
可以非常直观地感受到,Grok 4.1 的代码质量已不可与同日而语了
IV. Grok 4.1 实测结论

综上所述,本次多维实测表明,Grok 4.1 已从单纯追求参数与算力的竞争赛道,转向构建人格化体验与真实可用性的新阶段,展现出差异化的竞争路径:
从“会回答”到“懂共情”,Grok 4.1 在人类直觉测试与 EQ-Bench v3 测试中的 SOTA 表现,印证了其战略方向的准确性——“人性化”正成为核心竞争力。相较于前代模型,它不再停留于信息罗列,而是能深入解析情绪背后的心理动因,输出更具共情力与文学美感的文本。这意味着在需要情绪理解与关系洞察的场景中——如日记分析、情感倾诉、文本情绪解读等——Grok 4.1 展现出更接近人类的心理理解力。而在创意写作任务中,如将《水调歌头》改编为科幻设定,它展现出融合古典美学与现代想象的文学功底,其文风更像是有独立风格的创作者,而非仅追求语句通顺的写手。这使其在科幻改编、风格仿写、叙事构建等创意任务中,具备更高的协作价值。
在“温度”之外,基本功依旧扎实。尽管强调情感与人格,Grok 4.1 在编程与逻辑任务中并未掉队。无论是实现具备交互光效的 3D 卡片画廊,还是构建机制完整的小游戏,其代码的完整性、逻辑严谨度与实现效果均较前代大幅提升,甚至可与以稳健著称的 Gemini 3 Pro 媲美。相较于 Grok 4 毛坯房式的简陋输出,4.1 版本已能生成具备 UI 设计感与良好交互体验的页面,显示出其在理解用户隐性需求方面的进步。在数学、逻辑等综合测评中,其表现同样稳健,证明其技术底座扎实,综合实力已跻身第一阵营。
可用性提升,可信度增强。官方公布的幻觉率从 12% 降至 4%,进一步支撑了模型在实际场景中的可靠性。这使得 Grok 4.1 的整体形象兼具“体验感”与“实用性”,成为一个既易相处又可信赖的协作者。其核心优势可概括为以下几点:
- 情感智能突出,擅长共情、情绪分析与人类直觉类任务;
- 创意写作能力优异,尤其在科幻、叙事与风格化文本方面表现亮眼;
- 编程与逻辑任务交付质量高,功能完整且具备良好可扩展性;
- 支持“推理+非推理”双模式,适应多元任务类型,泛用性强。
Grok 4.1 的升级是一次成功的差异化突围。它不仅在技术指标上实现追赶,更通过强化模型的创造力、情感理解与交互温度,提供了更具黏性与共鸣的体验。当行业巨头仍聚焦于规模与推理能力的军备竞赛,xAI 已 xz率先将目光投向下一个前沿——人机交互中的“温度”。Grok 4.1 证明,一个既有“超强大脑”,也有“有趣灵魂”的模型,或许更能代表大模型的未来形态。
V. 如何在 302.AI 上使用
1. 聊天机器人中使用
步骤指引 :应用超市→机器人→聊天机器人→立即体验
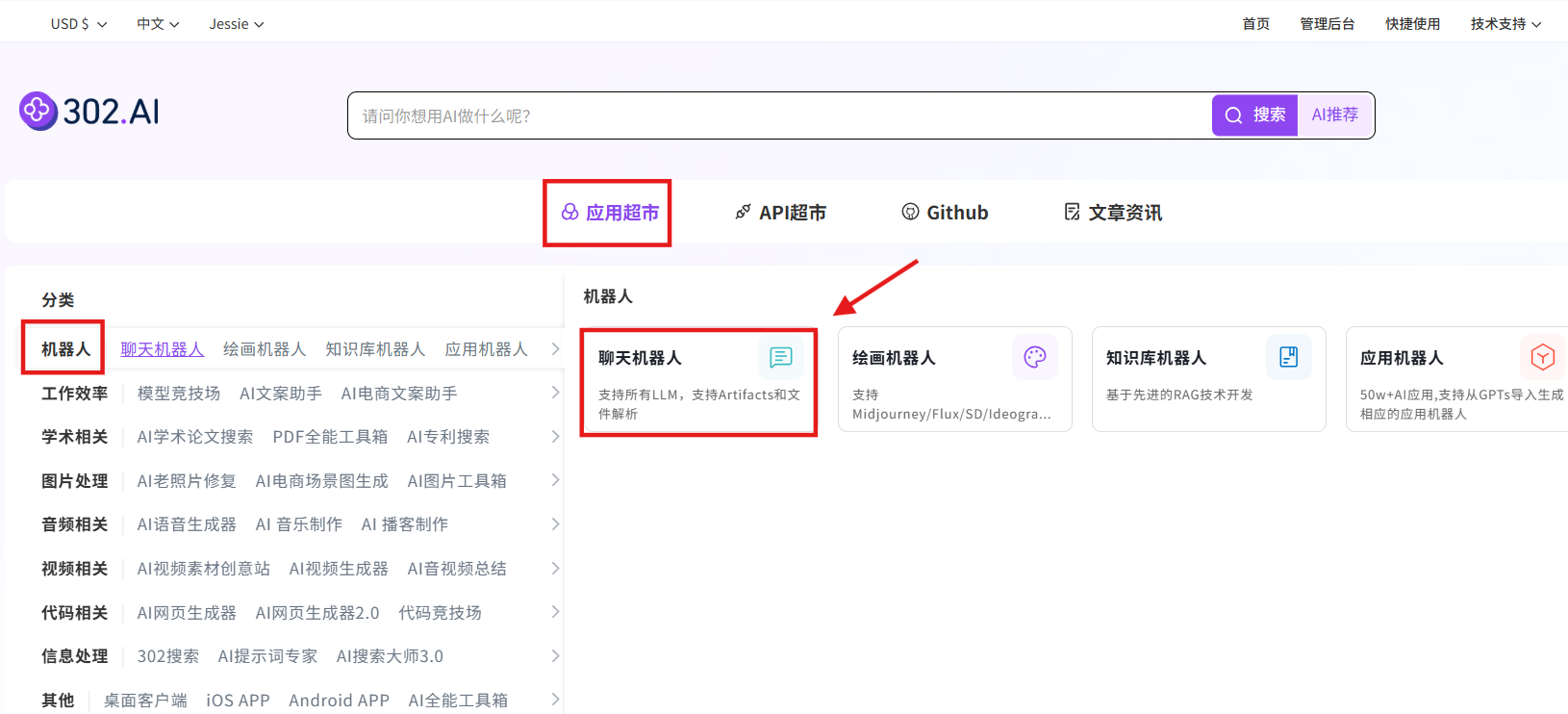
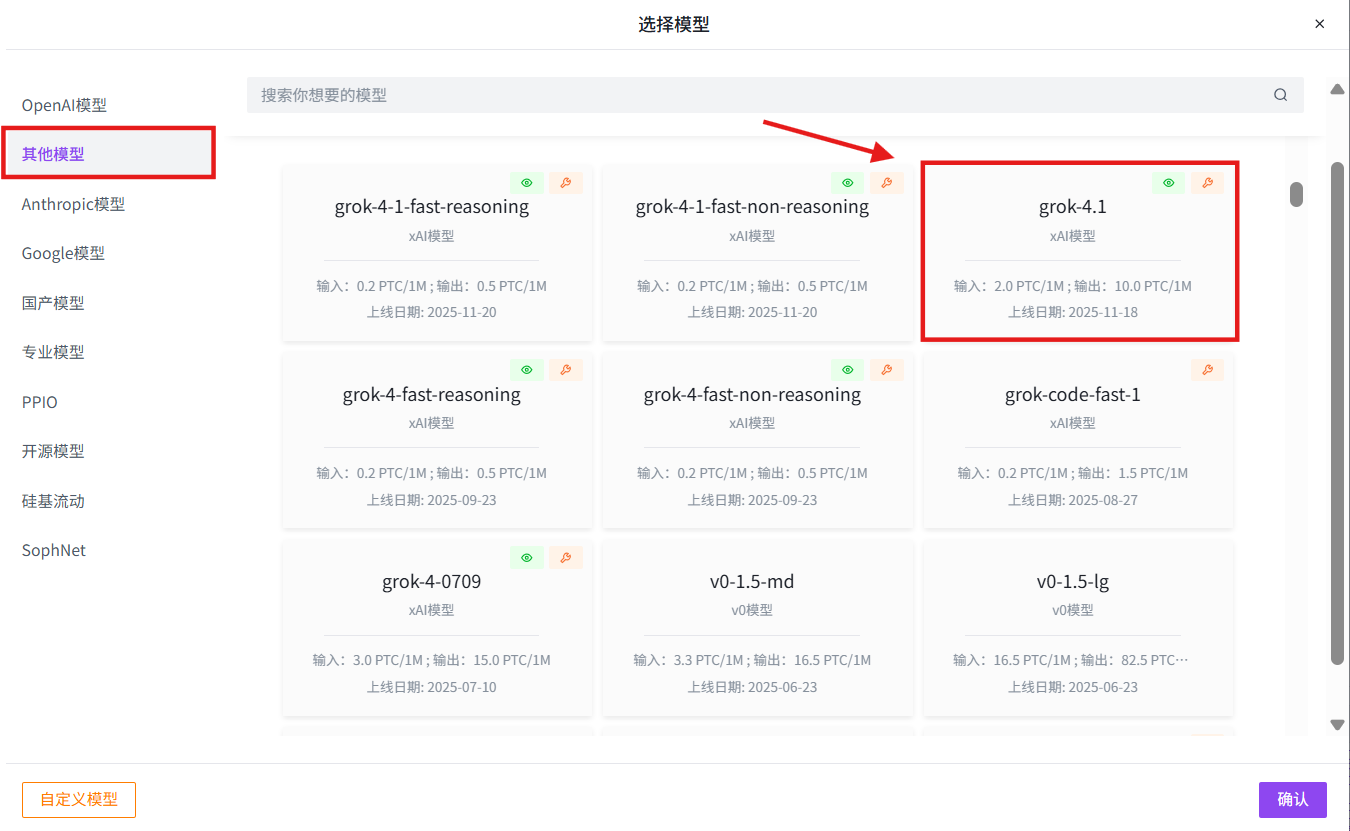
选择模型:其他模型→grok-4.1→确认→创建
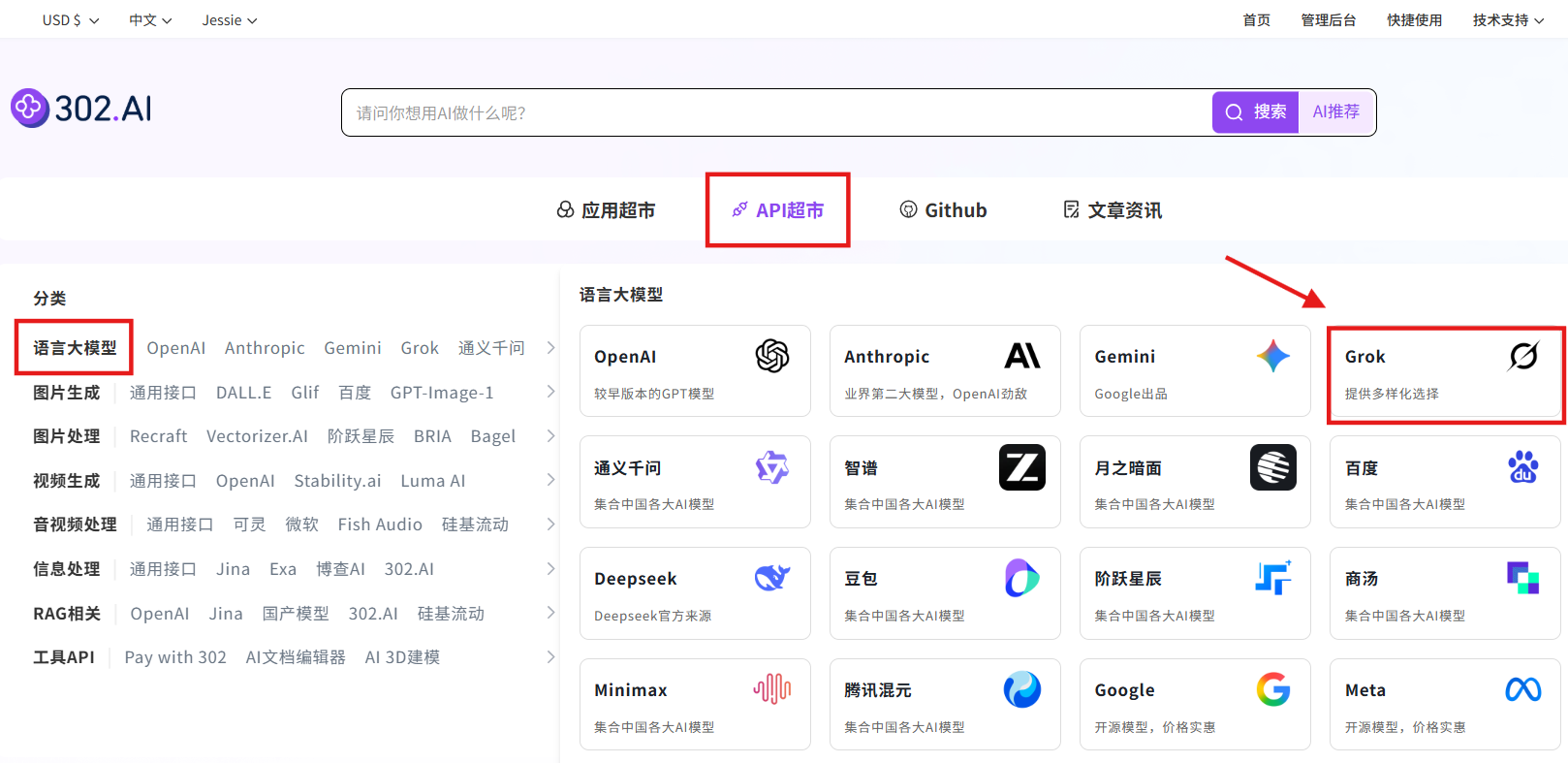
2. 使用模型 API
步骤指引:API超市→语言大模型→Grok→grok-4-1-fast-reasoning/grok-4-1-fast-non-reasoning
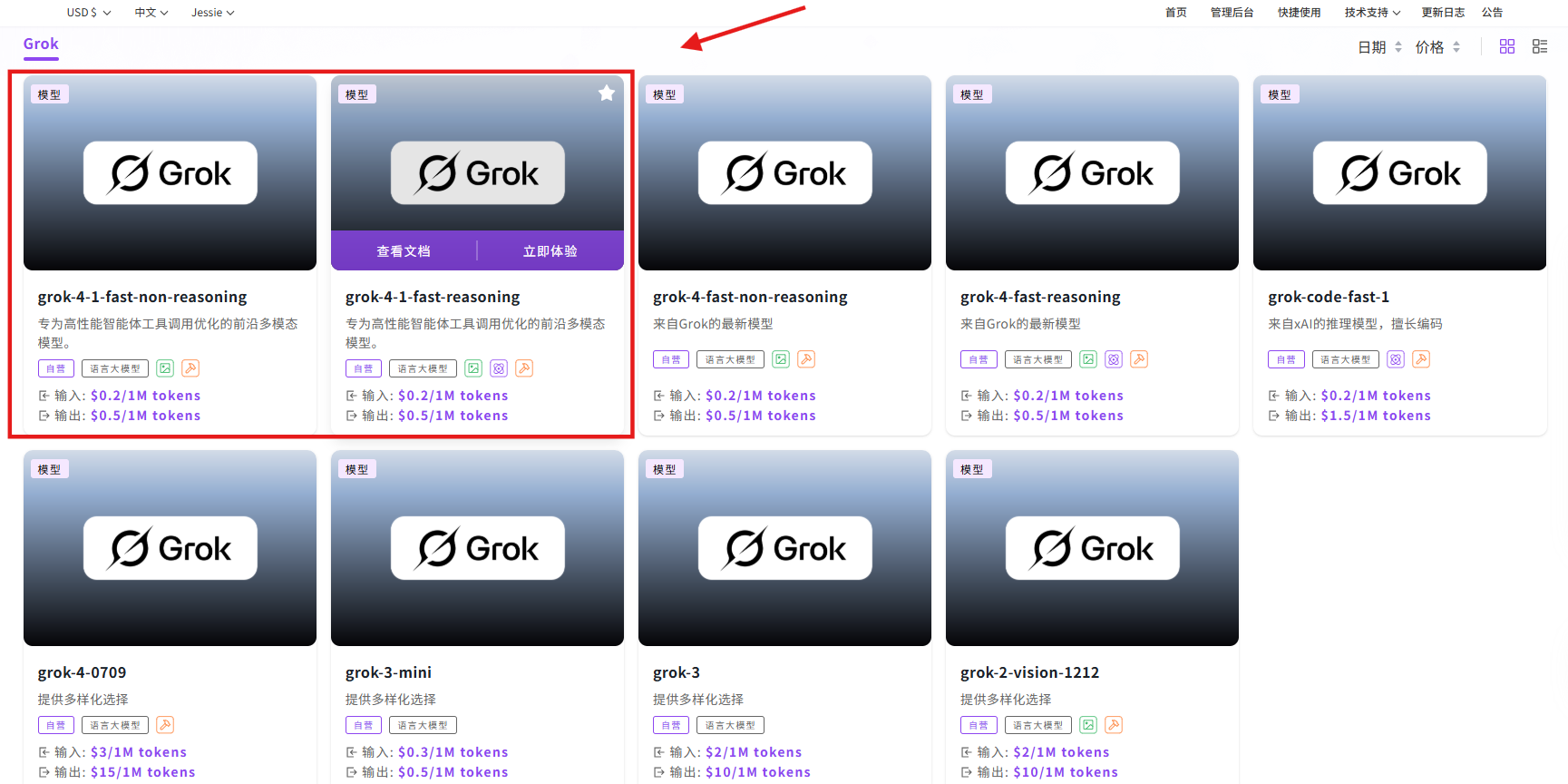
点击【立即体验】在线调用 API
想即刻体验 Grok 4.1 模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
