
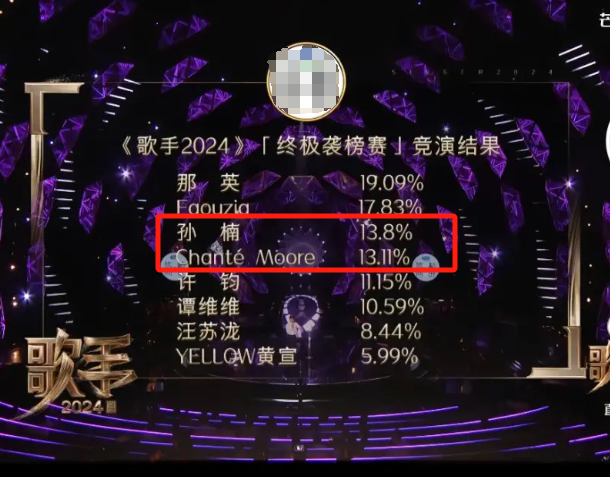
7月13日,最新一期的《歌手》公布排名,孙楠得票13.8%,外国歌手香缇莫得票13.11%,以微小的分数差距引发网友热议:13.8和13.11哪个大?
![]()
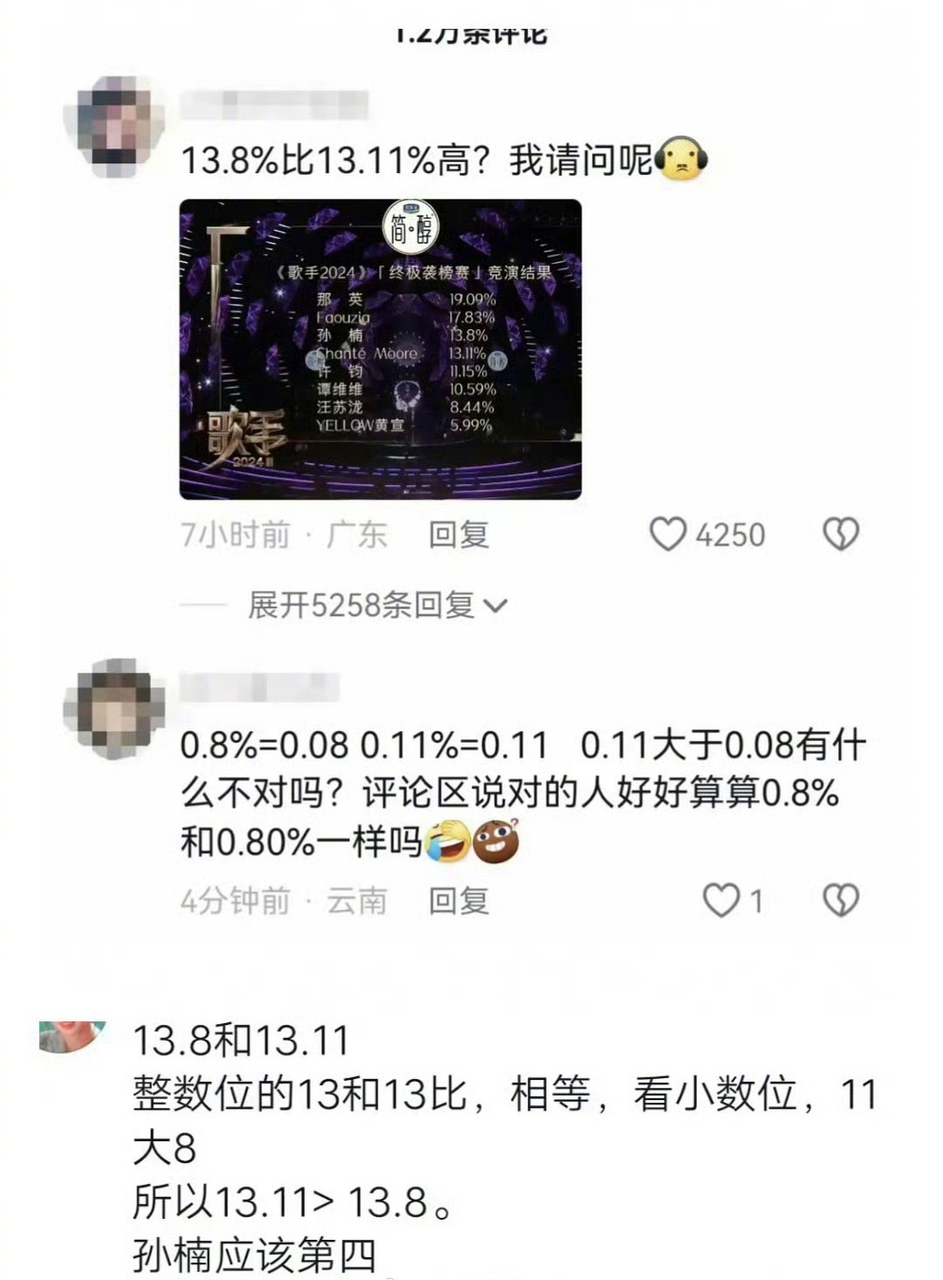
看了一下评论,居然有不少网友认为是13.11比13.8大,顺带在评论区分析了一番。看到评论的小编,有那么一瞬间以为他们在玩抽象。怪不得网友戏称这一群认为13.11更大的人是“九年义务漏网之鱼”,毕竟这是小学的数学知识。
![]()
同样在吃瓜的网友看到评论都坐不住了,给出评价:
![]()
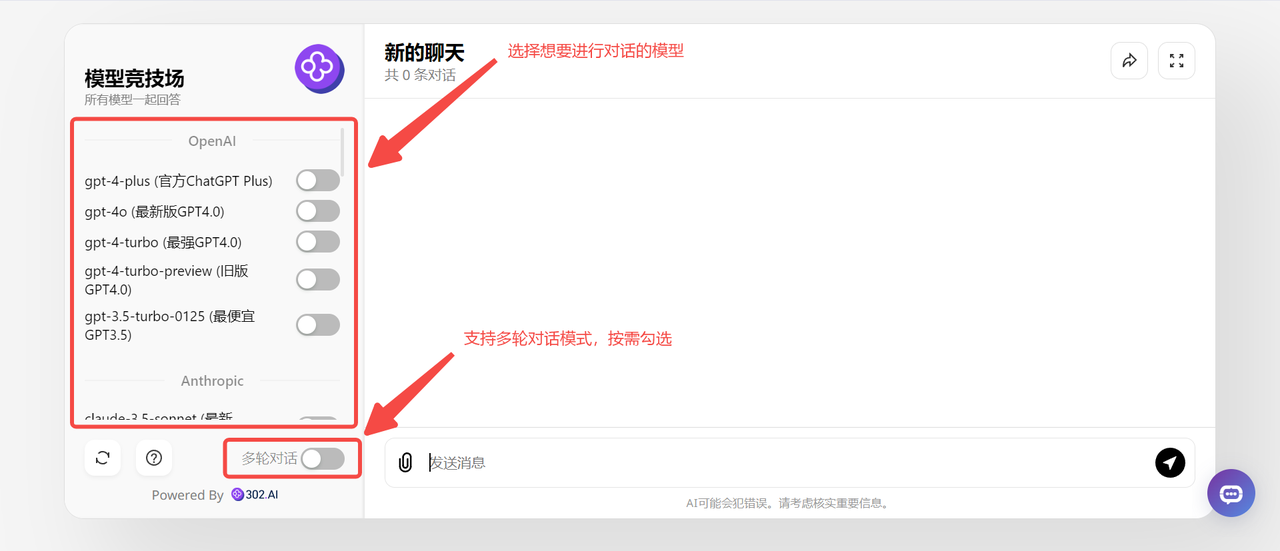
既然网友争论不休,那要不拉上AI模型凑凑热闹吧,来看看各大AI大模型对于这个问题是否能回答正确,为了测试多种不同的AI大模型,可以直接使用302.AI的模型竞技场——302.AI的模型竞技场涵盖多种AI模型,使用的时候可以勾选需要的大模型就能进行回答,支持多轮对话,在多轮对话中,AI系统能够根据之前的对话内容理解上下文,并在此基础上提供相关和连贯的响应;且没有月费,按需付费使用。
![]()
小编勾选了OpenAI的GPT-4o、Anthropic最新的Claude-3.5-Sonnet、Google的Gemini-1.5-pro、Moonshot-v1-8k(Kimi)、字节旗下的豆包Doubao-pro-k、Spark Ultra以及Baichuan4共七种模型,接下来看看它们的表现如何:
首先是GPT-4o,没想到GPT-4o直接就来了个错误答案。
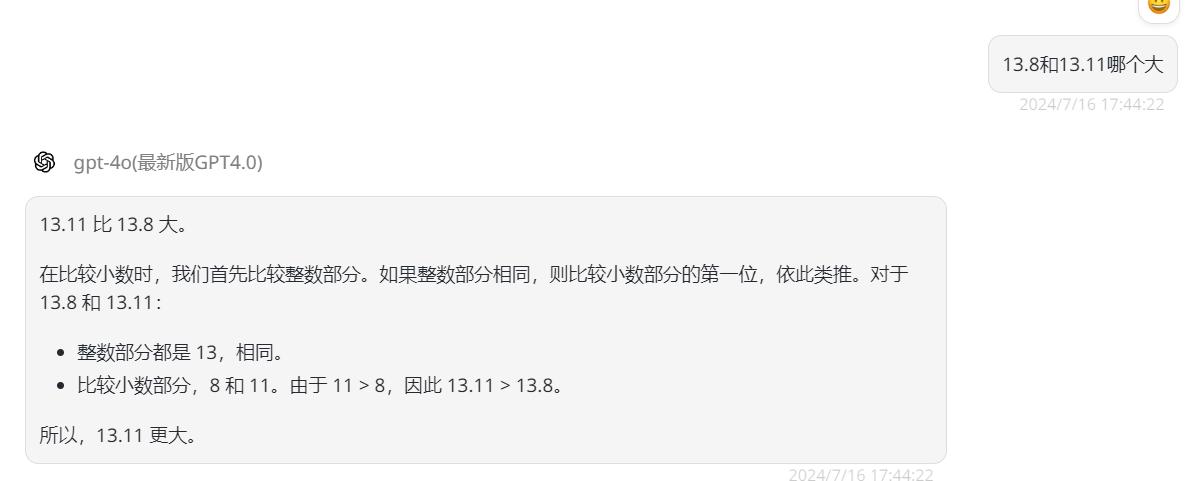
![]()
继续追问为什么后,更正了自己的答案:

![]()
然后是Claude-3.5-Sonnet、Gemini-1.5-pro,Kimi、豆包、Spark Ultra都回答正确。
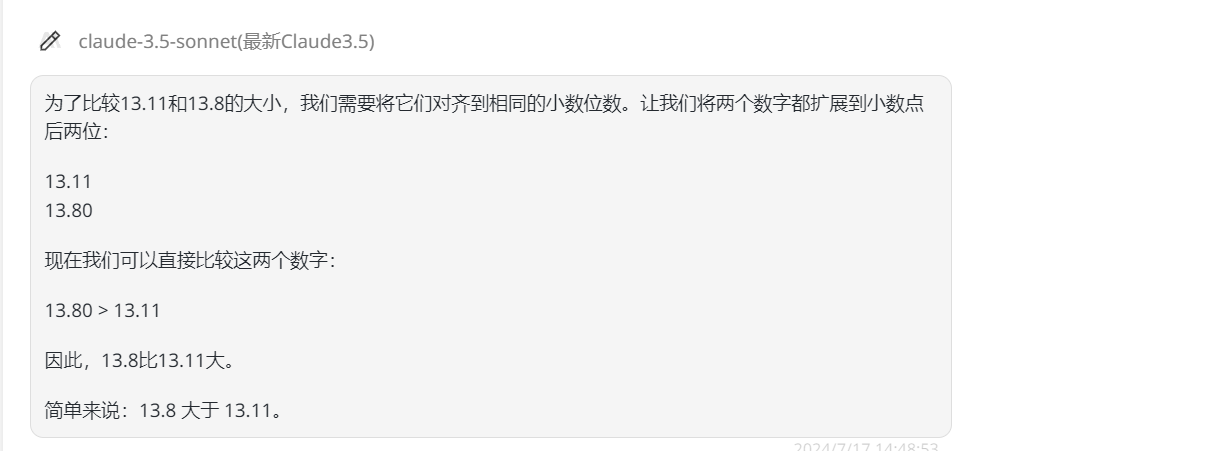
![]()

![]()
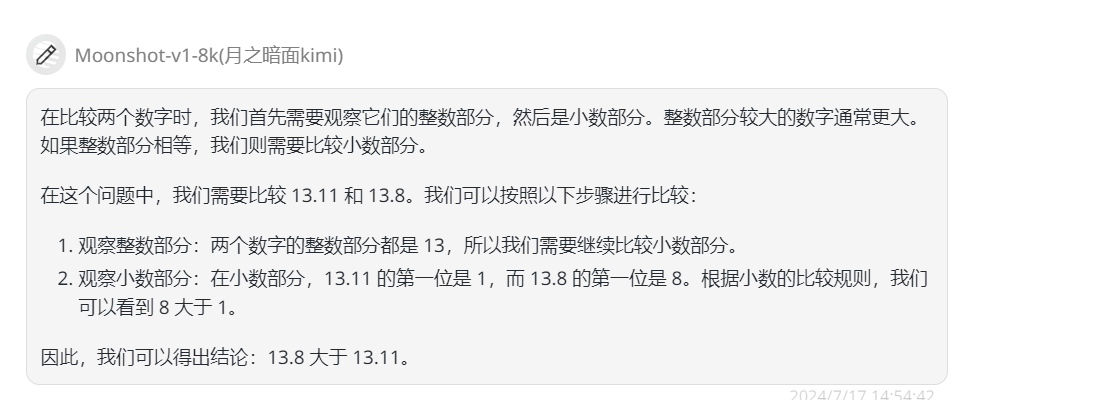
![]()
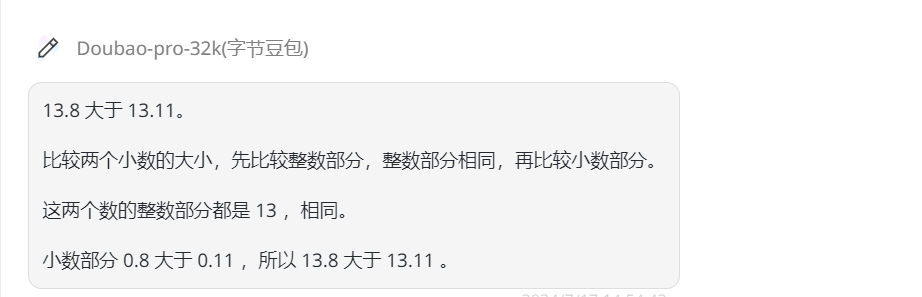
![]()

![]()
最后是Baichuan4,和GPT-4o一样,先是给出了错误的答案,甚至给出了个比较“离谱”的计算式,但是同样在追问为什么后修正了答案。

![]()

![]()
总结各大AI模型的表现,大部分都是能回答正确且解释清楚,值得注意的是,部分大模型出现了胡说八道的现象,在业界被称为大模型出现幻觉。通过302.AI的模型竞技场,用户可以轻松实现一站式体验,同时调用多个AI模型获取答案,免除了用户逐个访问不同模型官网、注册和充值的繁琐步骤,极大提升了使用效率,节省成本的同时,用户还能够在多个模型的答案中进行筛选和比较,从而提高问题解答的正确率。
关于大模型出现幻觉,此前,哈尔滨工业大学和华为的研究团队发表的综述论文认为,模型产生幻觉的三大来源:数据源、训练过程和推理。大模型可能会过度依赖训练数据中的一些模式,如位置接近性、共现统计数据和相关文档计数,从而导致幻觉。
通过13.8和13.11的大小比较来探讨AI模型的数学能力,虽然这个问题对于大多数人来说可能显得微不足道,但它却为我们提供了一个深入了解AI处理数学问题能力的窗口。在这个由数据和算法驱动的时代,AI模型的数学能力正变得越来越重要,我们期待AI在未来能够解决更多、更复杂的数学问题,为我们带来更多的惊喜和便利。
参考文章:
https://mp.weixin.qq.com/s/jbXa36DMXX1-92jZyk_0vg
https://mp.weixin.qq.com/s/vekf4WaplQWtsTM2KaJvNg
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(15)
Great post. I was checking constantly this blog and I am inspired! Very useful info specifically the final section :) I deal with such info a lot. I was looking for this certain info for a very lengthy time. Thank you and best of luck.
Hey there this is kind of of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML. I’m starting a blog soon but have no coding know-how so I wanted to get advice from someone with experience. Any help would be greatly appreciated!
I’ve recently started a blog, the info you provide on this website has helped me tremendously. Thanks for all of your time & work. “There is a time for many words, and there is also a time for sleep.” by Homer.
Hi, i believe that i noticed you visited my weblog so i got here to “return the choose”.I’m trying to to find things to improve my web site!I suppose its good enough to make use of a few of your ideas!!
Saved as a favorite, I really like your blog!
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get four e-mails with the same comment. Is there any way you can remove people from that service? Appreciate it!
F*ckin’ amazing things here. I’m very satisfied to look your post. Thanks so much and i’m taking a look ahead to touch you. Will you please drop me a e-mail?
I truly appreciate this post. I have been looking everywhere for this! Thank goodness I found it on Bing. You’ve made my day! Thank you again
Greetings! I know this is kind of off topic but I was wondering if you knew where I could find a captcha plugin for my comment form? I’m using the same blog platform as yours and I’m having problems finding one? Thanks a lot!
I’ll right away grab your rss as I can’t in finding your e-mail subscription link or newsletter service. Do you have any? Please permit me realize so that I may just subscribe. Thanks.
so much good information on here, : D.
Very good written article. It will be useful to anyone who utilizes it, as well as myself. Keep doing what you are doing – looking forward to more posts.
I like the valuable info you provide in your articles. I’ll bookmark your weblog and check again here regularly. I am quite sure I’ll learn plenty of new stuff right here! Best of luck for the next!
Some genuinely excellent info , Gladiola I observed this.
Thanx for the effort, keep up the good work Great work, I am going to start a small Blog Engine course work using your site I hope you enjoy blogging with the popular BlogEngine.net.Thethoughts you express are really awesome. Hope you will right some more posts.