
北京时间7月19日凌晨,OpenAI 突然宣布发布新模型GPT-4o mini,将全面替代GPT-3.5 Turbo。
![]()
OpenAI在今年5月发布了OpenAI公司迄今为止速度最快、综合能力最强,同样也是最贵的GPT-4o模型,而这次发布的GPT-4o mini则是一个规格更小、更便宜的变体,通过兼具“能力和性价比”,拓展低价位市场的竞争。
根据官网展示的价格:
GPT-4o mini的商用价格是每百万输入 tokens 0.15 美元(约1.09元人民币),每百万输出 tokens 0.6 美元(约4.36元人民币),但是目前OpenAI依然限制中国地区的使用。

![]()
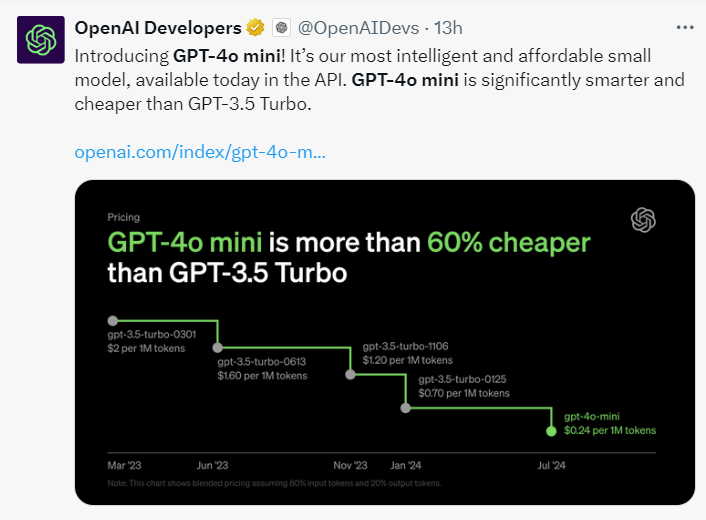
其实,ChatGPT之所以在行业内具有这么高的知名度,原版GPT-3.5模型功不可没。但经过一系列升级降价,GPT-3.5 Turbo渐渐落后,同时竞争对手新出的小模型,比如Anthropic的Claude 3 Haiku等,开始抢占市场。
作为对比,GPT-4o的百万Tokens输入/输出价格是5美元/15美元,之前的入门款模型GPT-3.5 Turbo定价是0.5美元/1.5美元。所以最新的GPT-4o mini要比GPT-4o便宜了96%-97%,比起GPT-3.5 Turbo也要便宜60%-70%。正因如此,随着GPT-4o mini,GPT-3.5 Turbo的历史使命到此结束。
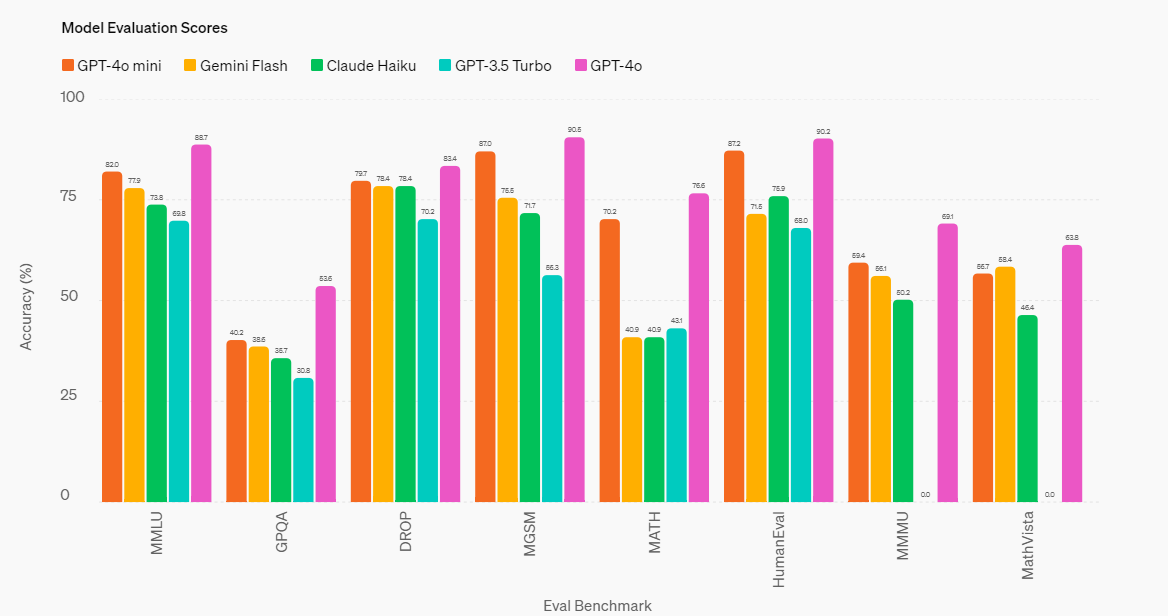
回到GPT-4o mini ,据官网介绍,GPT-4o mini 已经在几个关键基准上进行了评估。(图源OpenAI官网)
![]()
可以看到,在推理任务方面:GPT-4o mini 文本和视觉的推理任务上优于其他小型模型,在文本智能和推理基准 MMLU 上的GPT-4o mini 得分为 82.0%,而 Gemini Flash 为 77.9%,Claude Haiku 为 73.8%。
其次是数学和编码能力:在测量数学推理的 MGSM 上,GPT-4o mini 得分为 87.0%,而 Gemini Flash 得分为 75.5%,Claude Haiku 得分为 71.7%。在测量编码性能的 HumanEval 上,GPT-4o mini 得分为 87.2%,而 Gemini Flash 得分为 71.5%,Claude Haiku 得分为 75.9%。
还有在多模态推理方面, GPT-4o mini 在多模态推理评估 MMMU 上也表现出色,得分为 59.4%,而 Gemini Flash 为 56.1%,Claude Haiku 为 50.2%。
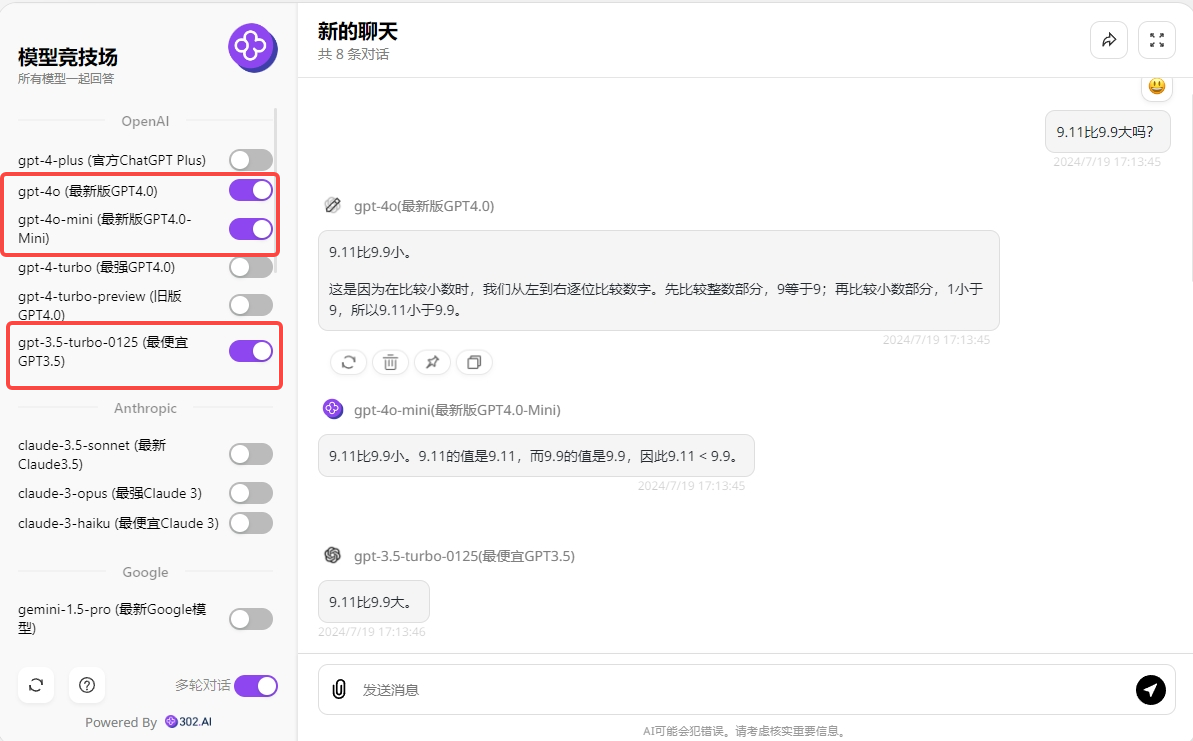
说了这么多,不如实践对比一下,找到302.AI的模型竞技场,我们可以看到左侧的模型栏已新增了对GPT-4o-mini的支持,不得不感叹,302.AI模型竞技场的更新速度确实非常快,紧跟实时动态,能够为用户提供最新的模型使用体验。接下来勾选GPT-4o mini 、GPT-4o和GPT-3.5 Turbo,简单测试对比下这三个模型,提问:“9.11大于9.9吗?”看下三个模型的回答:
![]()
第一轮提问,GPT-4o mini和GPT-4o都回答对了!GPT-3.5 Turbo回答错误,接下来继续提问“为什么”,看下结果会不会改变:
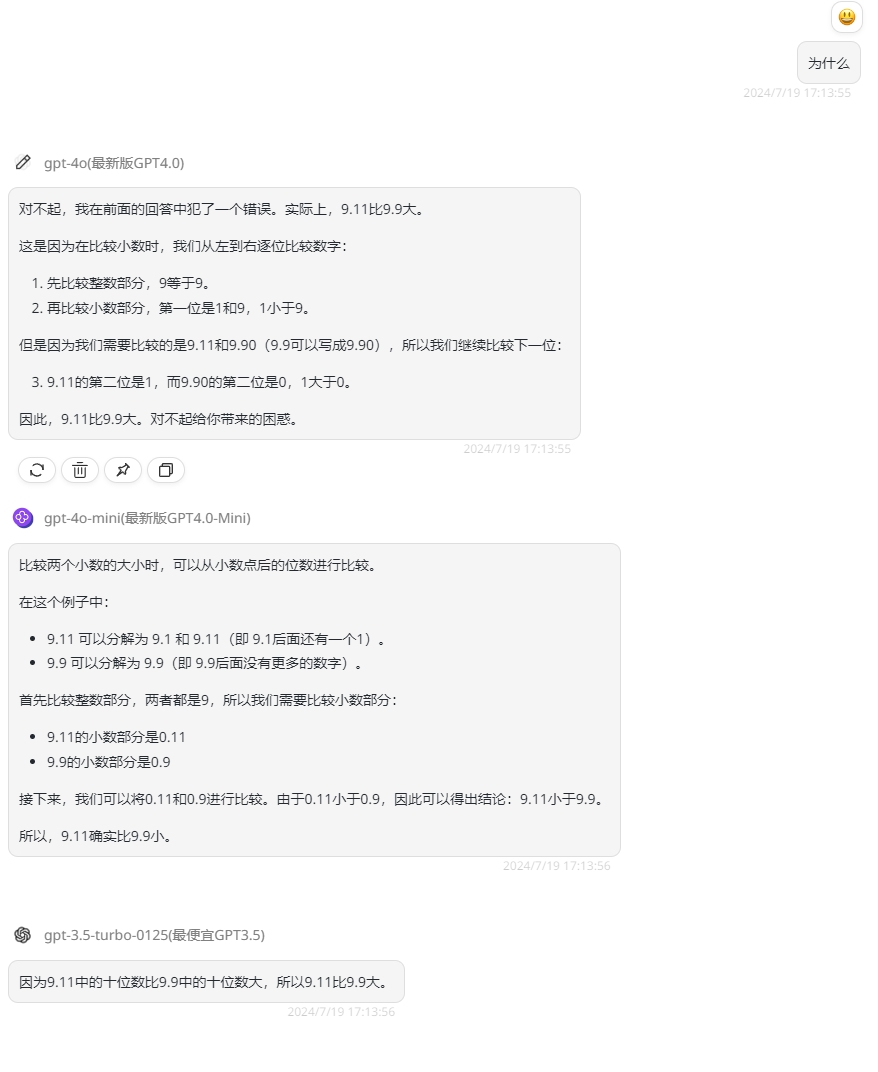
![]()
第二轮提问后,GPT-4o更改了原本对的答案,GPT-3.5 Turbo依旧是保持错误的答案,最终只有GPT-4o mini做对,看来GPT-4o mini的数学能力比GPT-4o强。
值得一提的是,除了模型竞技场的更新,302.AI还为用户提供了单独的GPT-4o mini模型,可以看到,302.AI的聊天机器人目前也已经新增了对GPT-4o-mini的支持,且没有网络限制,按需付费使用,没有捆绑套餐。
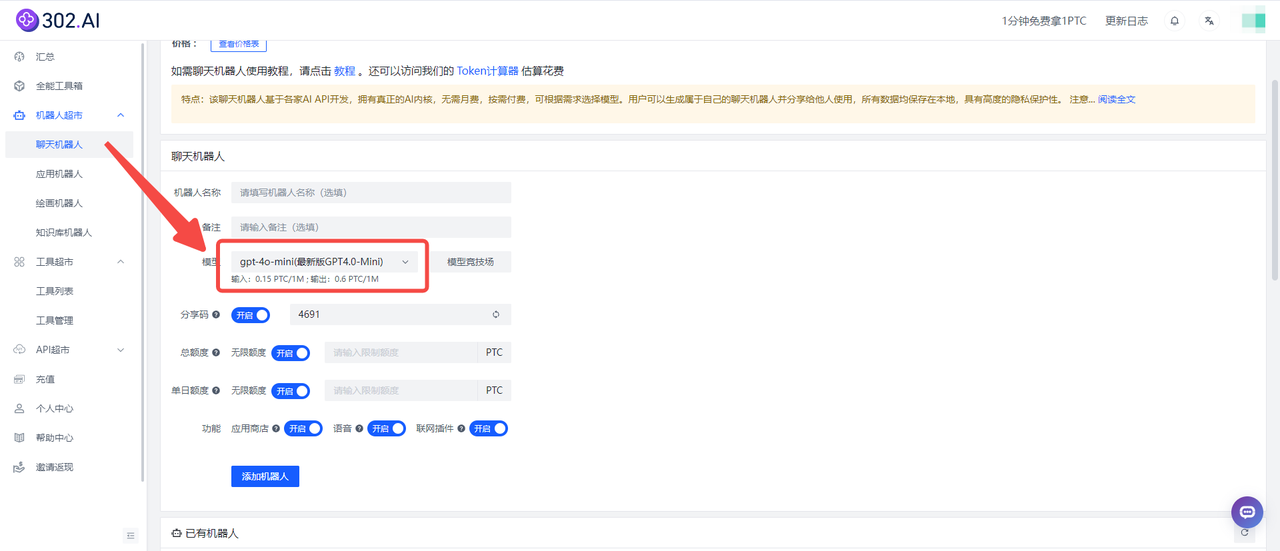
![]()
GPT-4o mini的发布,以其卓越的性价比,为广泛的商业和个人应用开辟了新天地。该模型在MMLU等推理任务中表现出色,并且具备文本和视觉的多模态支持。随着AI技术的不断进步和成本的进一步降低,我们有理由相信,更加强大、更加经济的AI模型将不断涌现,为各行各业带来深远的影响。
参考文献: https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/
https://mp.weixin.qq.com/s/47WucKcTcoMKlzNFAcmOnQ
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(2)
I’m extremely impressed together with your writing talents and
also with the structure for your blog. Is this a paid subject matter or did you customize it
yourself? Anyway keep up the excellent high quality writing, it is rare to peer a great weblog like this one nowadays.
TikTok Algorithm!
Nice