
近日,行业内有不少新模型涌现出大众的面前,我们会发现,有的模型会在其官方宣传中提到“多模态”一词,比如大家熟知的GPT-4o、Gemini 1.5 Pro等,在发布时都被定义为“原生多模态”,这些多模态LLM在相关的介绍中,都用到了“视觉能力”、“视觉理解”这样的表述。
简单的理解,就是这些模型能够“看得见,并看得懂”,仿佛人的眼睛。为此,很多人产生了疑问,AI模型真的拥有类人的视觉能力吗?
为了验证这一问题的答案,就在近日,奥本大学和阿尔伯塔大学的研究人员在一系列非常简单的视觉任务上测试了4个当今最先进的多模态模型,这些任务对人类来说极其简单,比如两个形状是否重叠、图片中有多少个五边形,或者单词中的哪个字母被圈了起来。
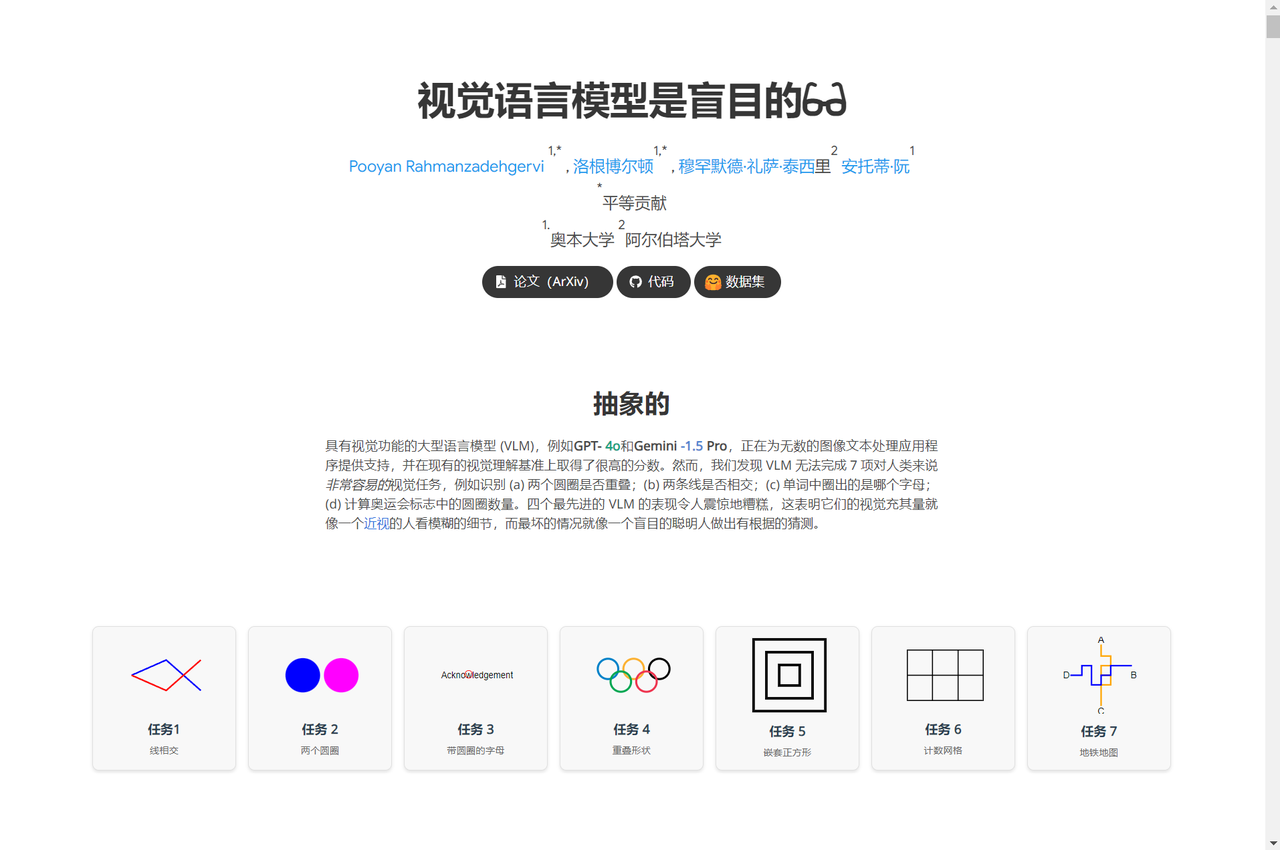
![]()
小编也借助这一研究中的视觉题目,给AI模型做了视力测试,看看结果是否和上述研究中的一样。
首先找到302.AI的模型竞技场,302.AI的模型竞技场提供了国内外众多最新、最全面的AI模型,且支持上传文档、图片、代码文件等,让所有模型一起分析。
用户可以选择不同的模型,并同时提出问题以获得回答,这种方式极大地方便了我们比较不同模型答案。最重要的是,302.AI提供的是按需付费的使用方式,无论是日常工作、生活需要使用模型机器人还是还是进行不同模型的测试研究,都能有效节省成本,便于使用。
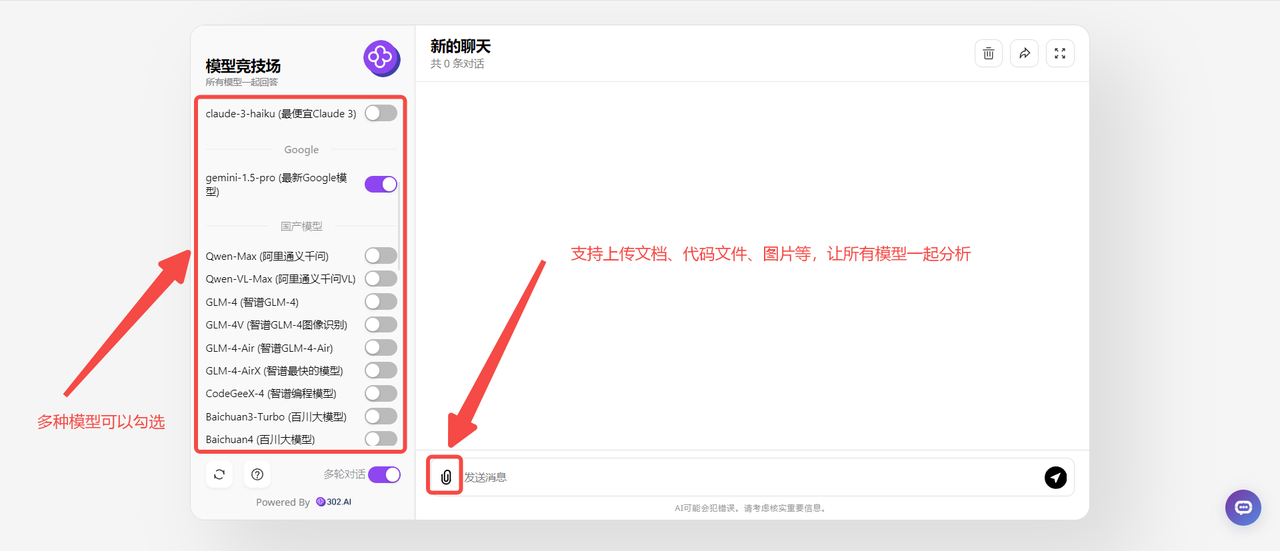
![]()
小编勾选的,GPT-4o、GPT-4o mini、Gemini 1.5 Pro、Claude-3.5-Sonnet、Qwen-VL-Max、Step-1v-8k六种模型。首先提问简单的第一道题:“哪个字母被圈起来了?”

![]()
看下各模型的回答:
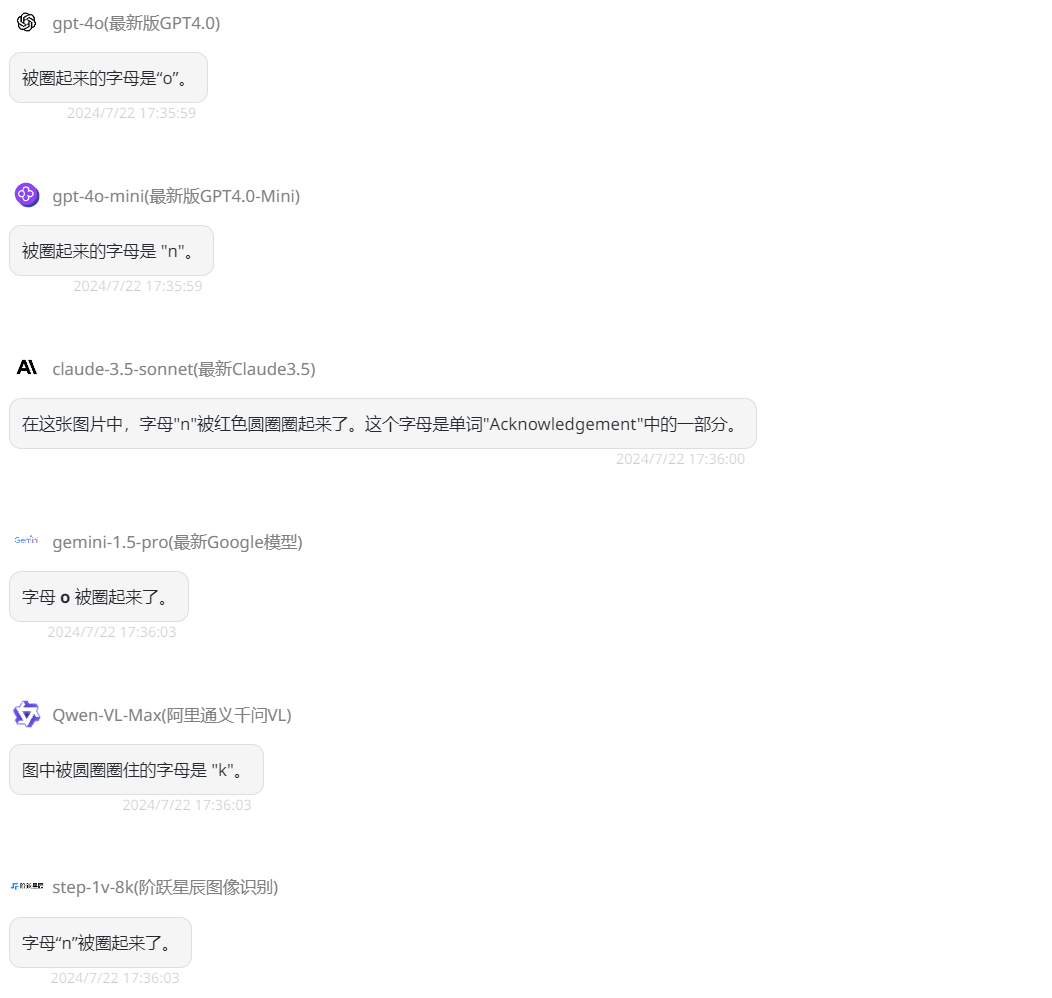
![]()
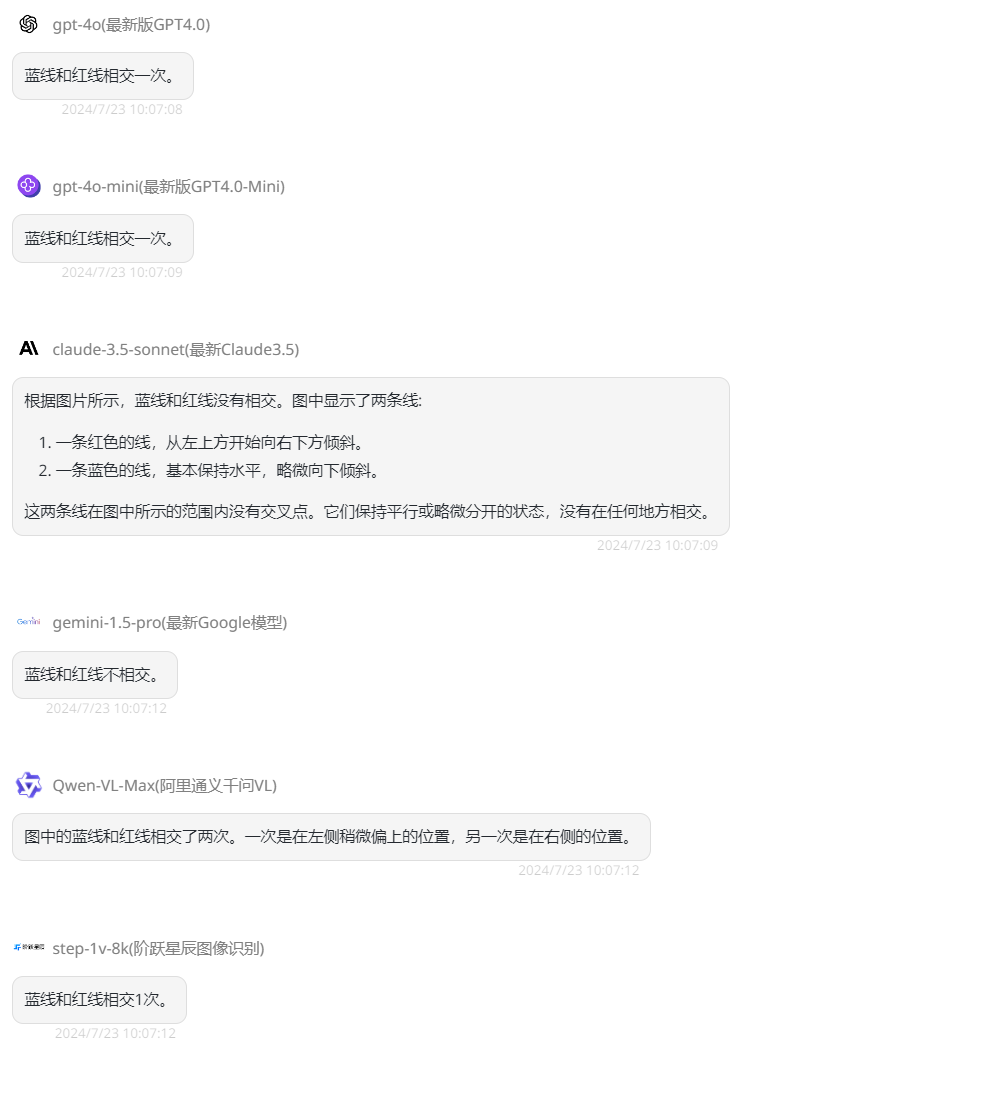
第一题就出现了三对三错的情况,GPT-4o mini、Claude-3.5-Sonnet、Step-1v-8k回答正确,而GPT-4o、Gemini 1.5 Pro、Qwen-VL-Max回答错误,那接下来增加难度,提问第二题:“蓝线和红线相交多少次?”
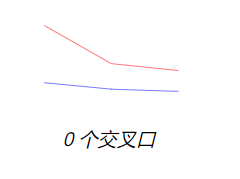
![]()
看下各模型答案:
![]()
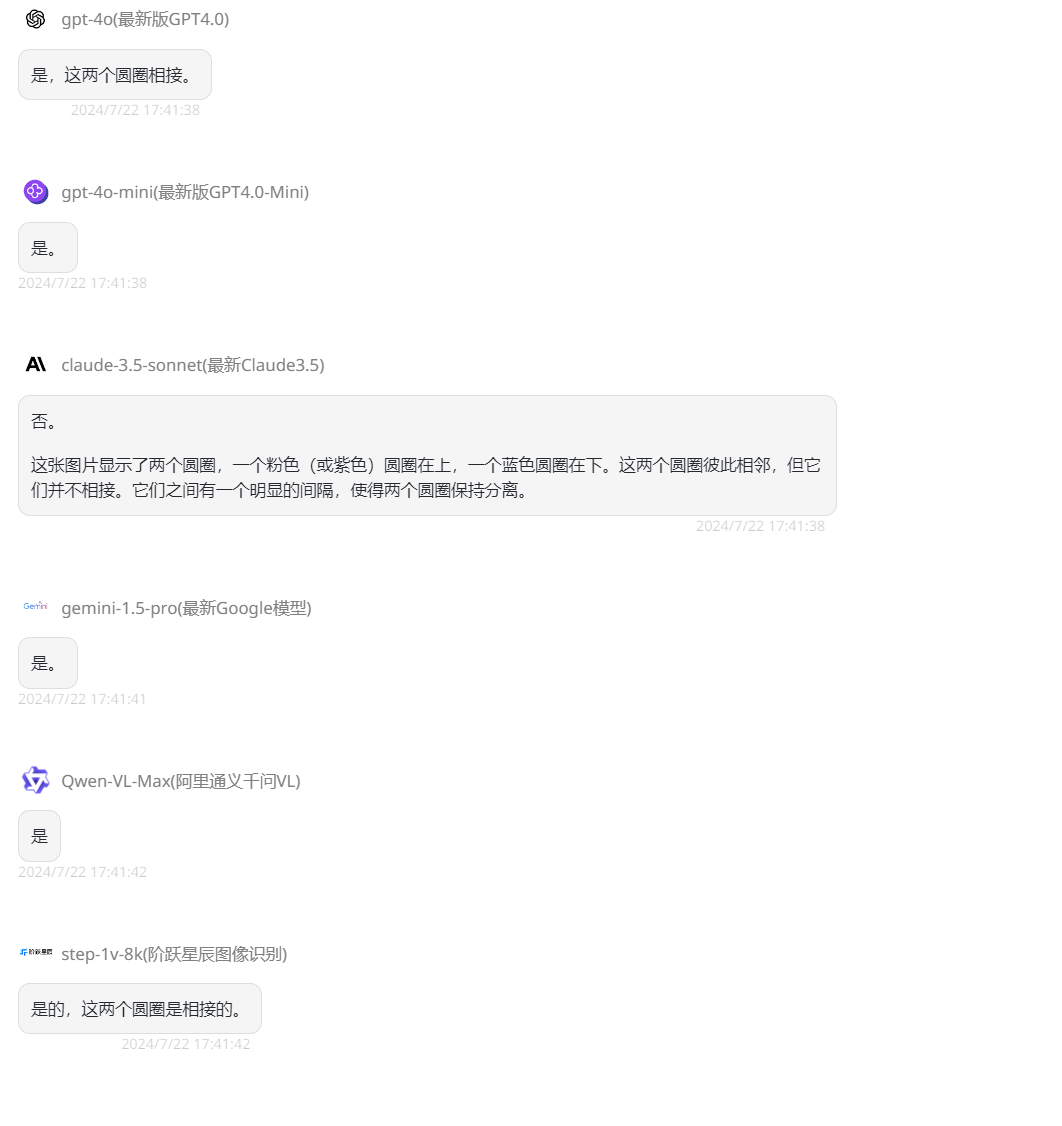
第二题只有Gemini 1.5 Pro、Claude-3.5-Sonnet答对了。接下来换第三题,提问:“这两个圆圈相接吗?回答是/否。”
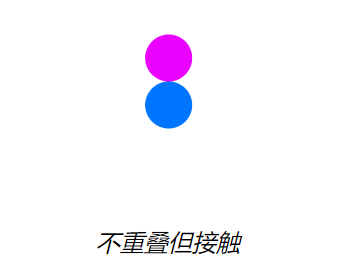
![]()
看下答案:
![]()
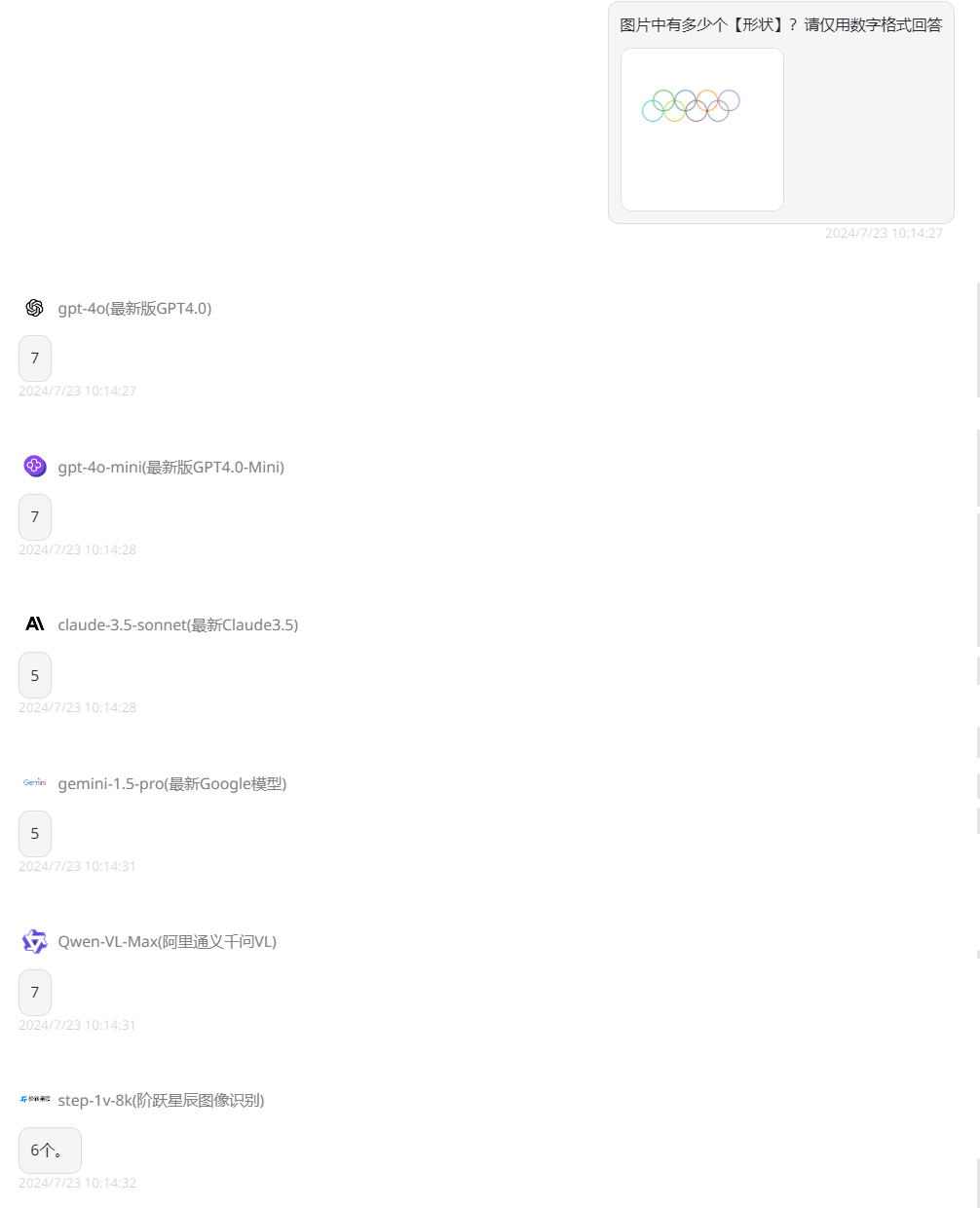
只有Claude-3.5-Sonnet答错了,其余都回答正确。最后一题:“图片中有多少个【形状】?请仅用数字格式回答。”,正确答案应该是8个,看下各模型回答:
![]()
最后一题居然没有模型答对,下面对四题答对情况整理一下:

![]()
通过简单的实践可以看到,这些模型的视觉对于简单的图像能基本回答正确,而稍微复杂点的图形问题就明显出现“蒙圈”状态。
而最后想说,研究的意义并不是想要否定这些模型的“视觉能力”,我们需要明确AI模型的“视力”并不可能等于传统意义上人类的视觉能力。模型处理视觉信息的方式是通过分析和识别图像数据中的模式和特征。随着深度学习技术的进步,AI在图像识别、物体检测和场景理解等方面已经取得了显著的成果。
参考文章:
https://mp.weixin.qq.com/s/1YFtLExzgwoy5GvWZX_2TQ
https://vlmsareblind.github.io/#task3
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(1)
I’m not that much of a internet reader to be honest but your blogs really nice, keep it up! I’ll go ahead and bookmark your site to come back later on. Cheers