


7月6日,可灵网页版正式上线并且宣布了该网页端集成了文生图、文生视频相关能力,同时提供了一些新功能,如更加清晰的高画质版视频、首尾帧控制、镜头控制等全新编辑能力。
而在可灵网页版上线的前两天,快手发布了Live-portrait初始版本的推理代码和模型模型。此外,LivePortrait的官方网站也在同一天上线。
Live-portrait能够将静态照片转化为逼真的动态视频,通过智能算法控制眼睛和嘴唇的动作,生成生动的效果,突破传统动画制作的难题。上传自己的照片,并选择不同的动作和表情,就能生成具有高度真实感和细腻表情变化的动态人像。
简单粗暴的理解就是,表情的“移花接木”,Live-portrait能够让一张面无表情或者只有简单表情的照片动起来,例如在Live-portrait的功能下,各大艺术作品中的人物也被“唤醒”了。

(图源302.AI的API超市)
自从Live-portrait技术推出后,就迅速成为了热门话题。连HuggingFace的首席战略官Thomas Wolf也在社交媒体上分享了自己使用Live-portrait功能后的作品。
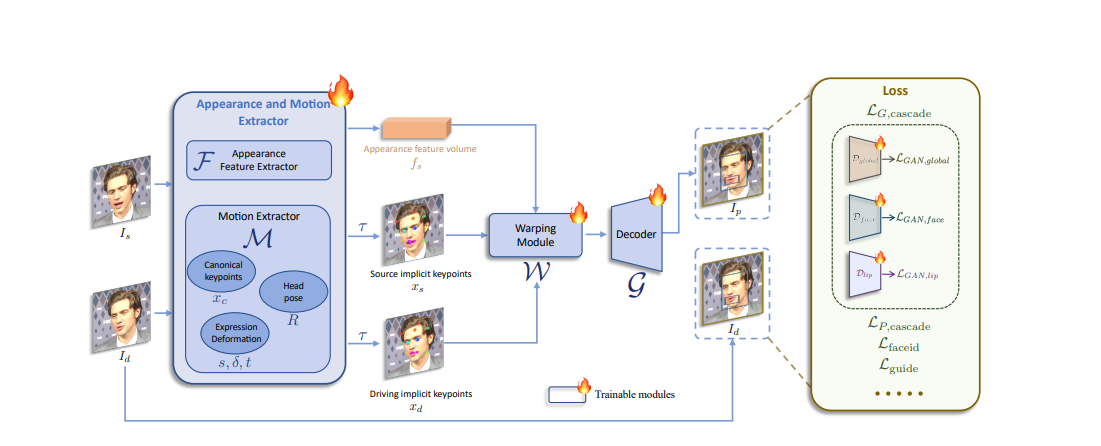
Live-Portrait为什么这么火?先来看下它的方法介绍:LivePortrait的模型训练分为两阶段。第一阶段为基础模型训练,第二阶段为贴合和重定向模块训练。
在第一阶段模型训练中,LivePortrait对基于隐式点的框架,如Face vid2vid,做了一系列改进,包括:高质量训练数据收集、视频-图像混合训练、升级的网络结构、更灵活的动作变换建模、关键点引导的隐式关键点优化、级联损失函数。第一阶段的所有模块为从头训练,总的训练优化函数 (Lbase) 为以上损失项的加权和。
而第二阶段,贴合和重定向模块训练,考虑到实际需求,LivePortrait设计了一个贴合模块、眼部重定向模块和嘴部重定向模块。当参考人像被裁切时,驱动后的人像会从裁图空间被反贴回原始图像空间,贴合模块的加入是为了避免反贴过程中出现像素错位,比如肩膀区域。
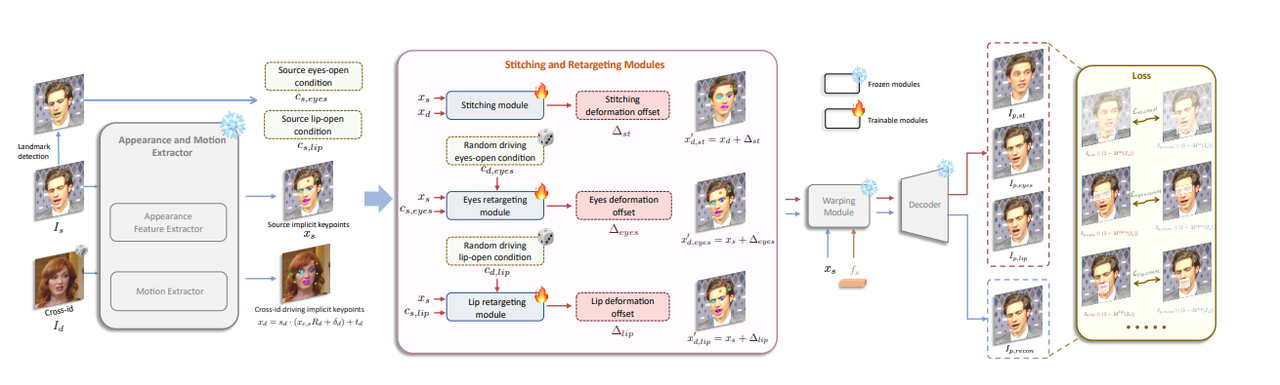
眼部重定向模块旨在解决跨身份驱动时眼睛闭合不完全的问题,尤其是当眼睛小的人像驱动眼睛大的人像时。嘴部重定向模块的设计思想类似于眼部重定向模块,它通过将参考图片的嘴部驱动为闭合状态来规范输入,从而更好地进行驱动。
接下来,为了更好理解,一起来看下Live-Portrait的实际效果展示。除了文章上面提到的单一的图像生成,对于多人合照,也可以实现“表情转移”:

如果仅把目光局限在人物上,那就错了!因为除了能将人物的静态照片转化为动态视频,动物也可以:

除了人像照片,给定一段人像视频,比如舞蹈视频,Live-Portrait也可以用驱动视频对头部区域进行动作编辑,看下效果:

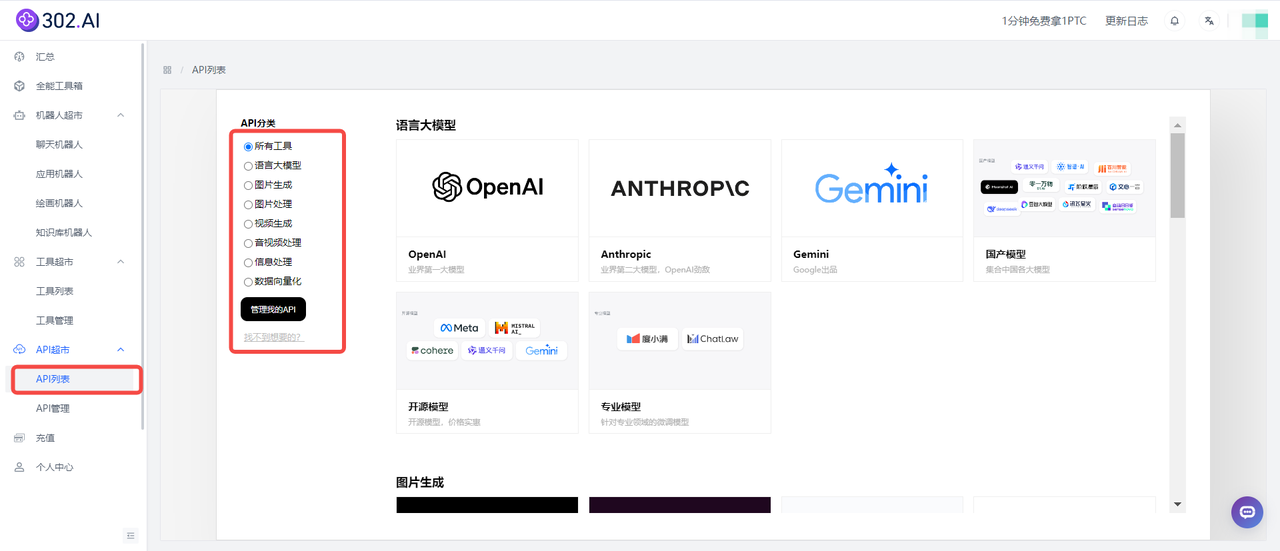
虽然Live-Portrait是一款开源模型,但是如果用户想要使用,需要在下载好模型后,设置开发环境、安装必要的软件,还需要如足够的内存和高性能的GPU等一系列繁琐的步骤。然而,302.AI提供了一个更为便捷的解决方案,首先进入302.AI官网后找到API超市,在API分类选择【视频生成】,点击302.AI;
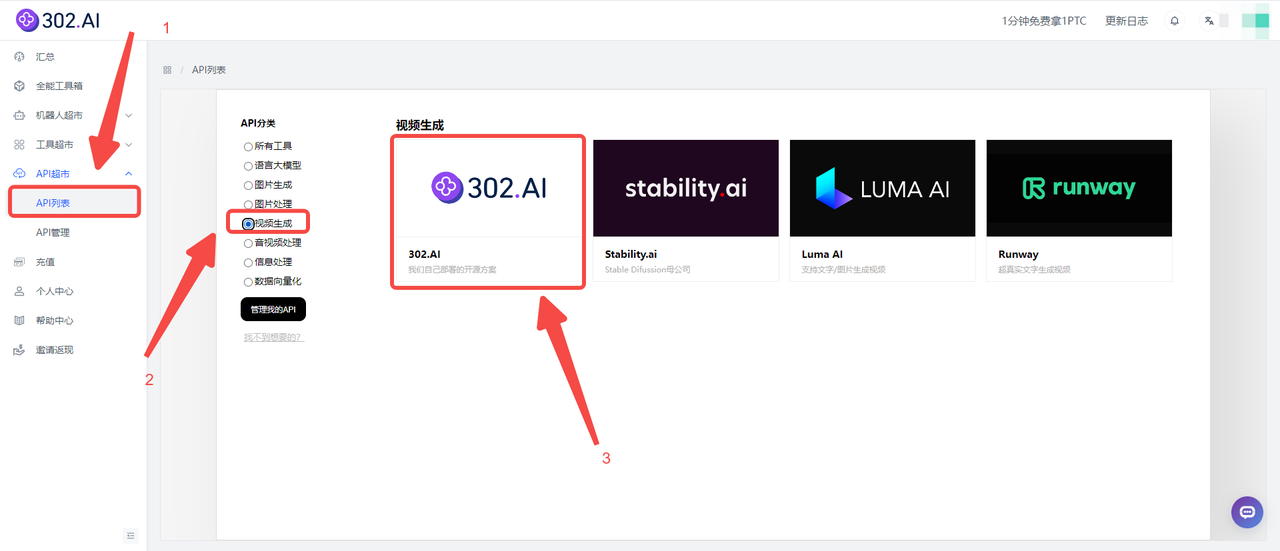
只需要找到302.AI的API超市提供的Live-Portrait的API,可以省去大量配置和安装的步骤,支持在线调试,快速接入Live-Portrait模型。重要的是,302.AI提供按需付费的方式,且无捆绑套餐。
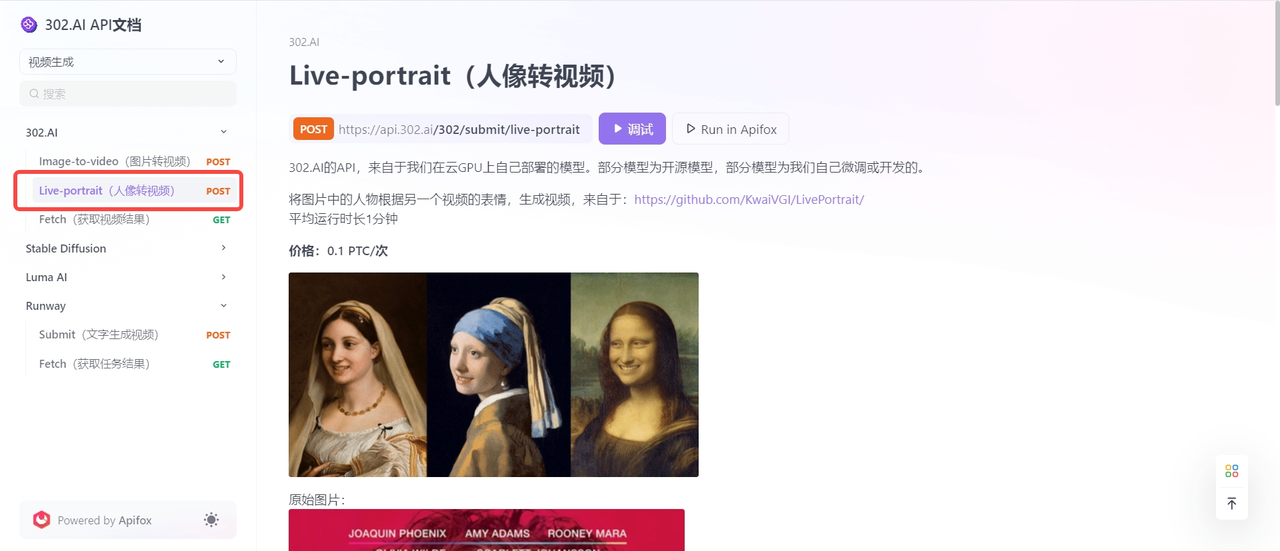
让我们一起看看通过302.AI的API超市实现的Live-Portrait技术成果:

原图(来源于302.AI的API超市)

效果图(来源于302.AI的API超市)
302.AI的API超市分类明晰,会实时更新市面上AI模型的API,不需要自己找模型,不需要配置环境,不需要部署,即使是小白用户也能轻松打开并立即使用。
参考文章:https://mp.weixin.qq.com/s/b_7N4KaY8El4JeD1lorodQ
在探索Live-portrait技术,将静态人像转换为动态视频的旅途中,我们见证了技术的巨大潜力,正如我们已经看到的那些通过Live-portrait动起来的艺术画像,每一个成功的转换都让人感受到时间的力量和科技的魅力。未来,随着技术的进步和应用的深入,我们期待看到更多曾经静默的面孔走入我们的世界,以全新的方式诉说他们的故事。
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
