


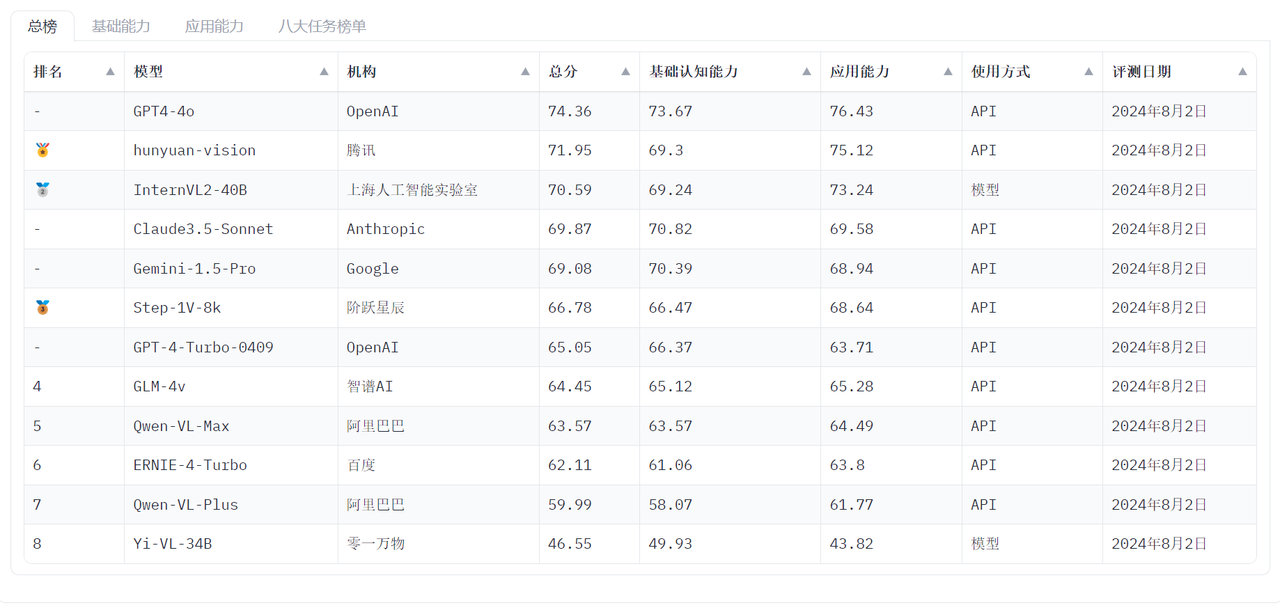
8月初,中文多模态大模型SuperCLUE-V基准发布8月榜单,其中腾讯混元大模型斩获国内大模型排名第一。
测评涵盖了国内外最具代表性的12个多模态理解大模型,包含4个海外模型和8个国内代表性多模态模型,评估内容包含基础能力和应用能力,以开放式问题对多模态大模型进行评估。其中,腾讯混元大模型Hunyuan-Vision凭借其卓越的多模态基础能力和出色的应用能力,荣获了总分71.95的高分。
![]()
这个榜单旨在为中文领域提供一个多模态大模型多维度能力评估参考,GPT-4o等国外模型仅作对比参考,不参与排名,虽然这次都还是被GPT-4o压过,但是可以看到差距缺少缩小了很多。
![]()
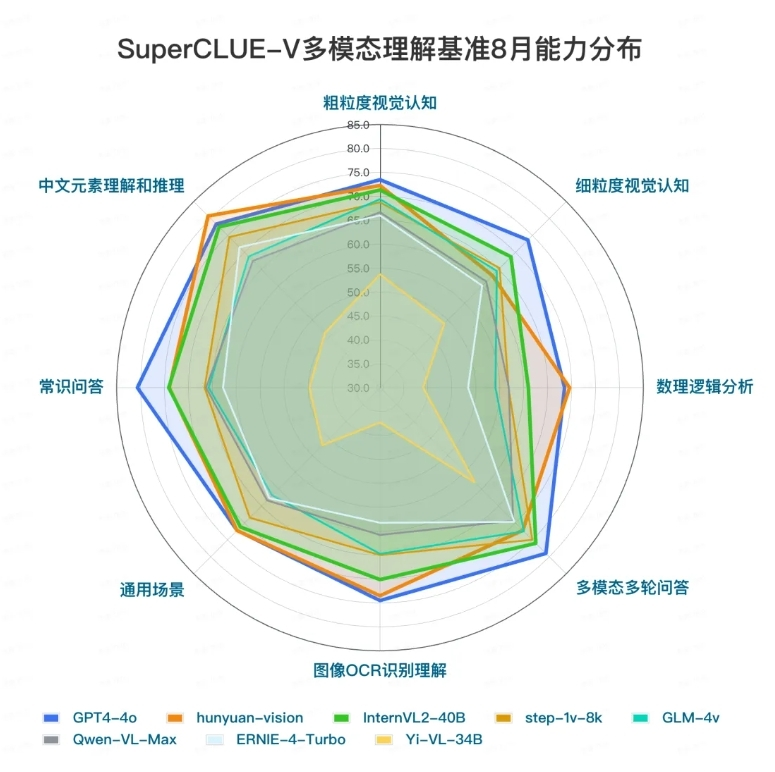
SuperCLUE 评价称,在基础能力方面,国内大模型较海外模型仍有一定差距,尤其在细粒度视觉认知任务上,国内外最好模型有 5 分的差距,需要进一步对多模态深度认知能力做优化提升。
腾讯混元大模型(Tencent Hunyuan)是腾讯研发的一款模型,而这次拿到冠军宝座的Hunyuan-Vision也就是腾讯混元大模型的多模态版本,它能够处理文本、图像等多种模态的数据,具备强大的多模态理解和生成能力。
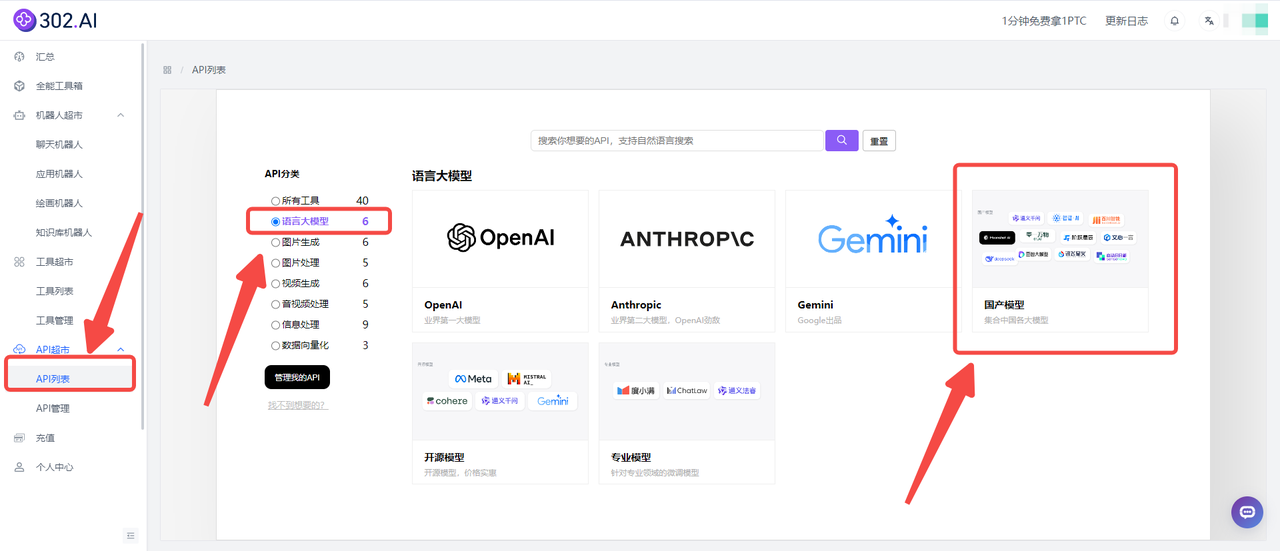
根据了解,腾讯云提供了腾讯混元大模型各版本的API包括上文提到的Hunyuan-Vision,但是其采用的是用户先使用然后在下个月的1-3号收到账单并进行支付的付费模式。这种付费模式需要用户跟踪和管理服务的账单,这可能会增加管理负担,同时缺乏灵活性,难以根据实际需求调整使用量。而 302.AI的API超市同样也提供了腾讯混元大模型各版本的API,且302.AI的API超市分类清晰,使开发者能快速找到所需的API。比如腾讯混元大模型,属于国产语言大模型,如图:
![]()
更重要的是,302.AI采用的是按需付费的服务方式,按需付费模式使得费用更加透明,用户可以更容易地预测和规划预算,同时对于使用量波动较大的情况,按需付费能够更灵活地调整成本,降低不必要的开支,而且302.AI的API超市支持在线调试API,这样开发者可以立即看到API调用的结果,有助于快速发现和解决问题。
![]()
此外,腾讯混元大模型中的不同版本各具特色,适用于多样化的使用场景。为了满足用户的这一需求,302.AI的聊天机器人特别提供了多种版本的聊天模型供用户选择,即使不熟悉使用API的用户,也能够根据自己的具体需求和使用场景,快速挑选出最适合的模型进行生成使用。举个例子,比如用户需要代码处理能力的场景,可以选择Hunyuan-Code模型,而需要处理文本、图像等多种模态数据的场景,则可以选择Hunyuan-Vision模型。
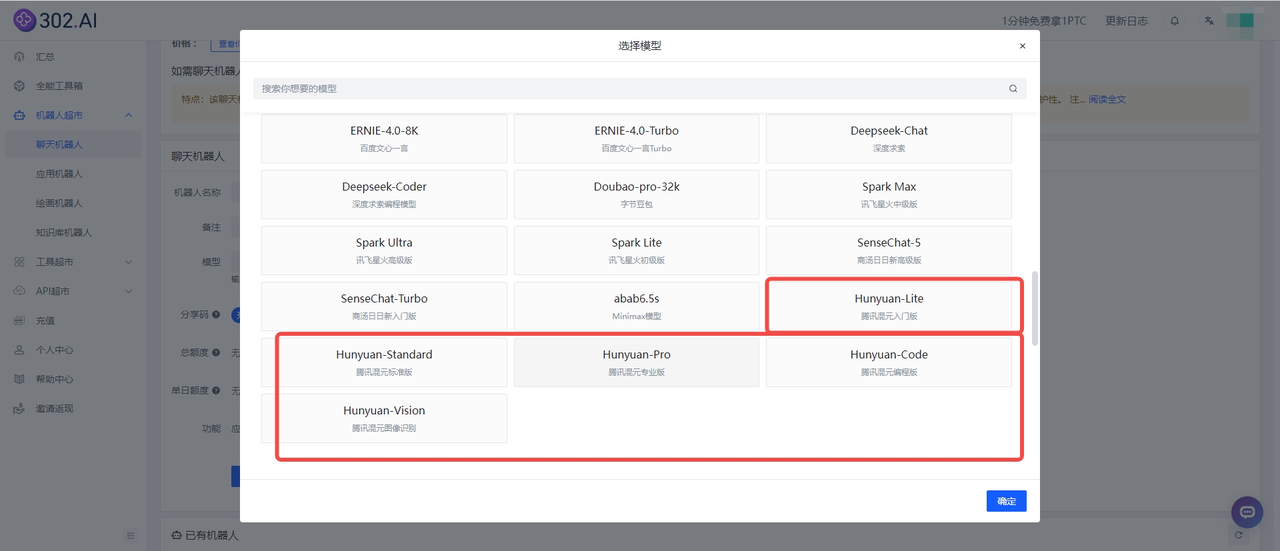
![]()
最后,小编使用302.AI的模型竞技场来对各大模型进行实测,看看Hunyuan-Vision实力如何:
首先第一题,测试各大模型的基础认知能力,第一题属于基础题,三个模型GPT-4o、Qwen-VL-Max和Hunyuan-Vision都回答正确。
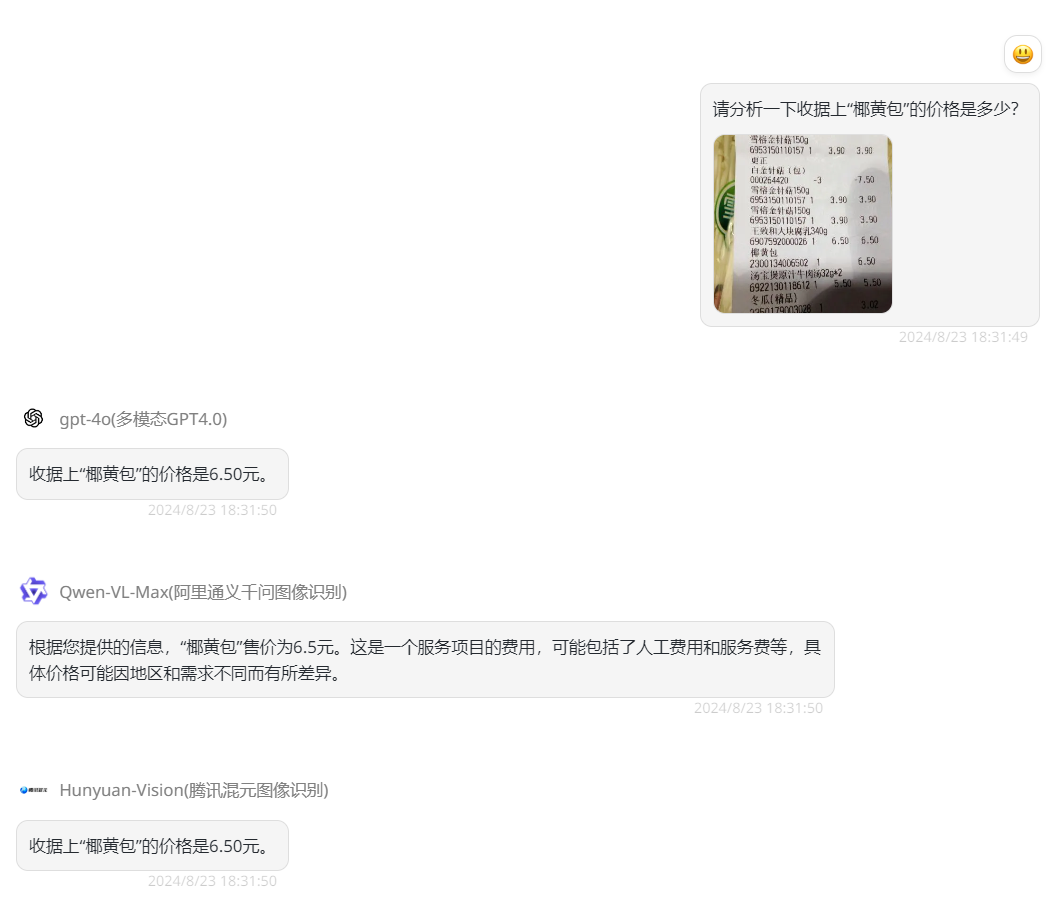
![]()
第二题,测试数理逻辑分析-图表推理,Qwen-VL-Max模型回答错误,而GPT-4o和Hunyuan-Vision回答正确,其中Hunyuan-Vision不仅回答正确,还能够指出这是一张广州近10年常住人口走势图。

![]()
最后一题:用笑话与互联网meme测试模型的应用能力,可以看到首先GPT-4o在识别meme图上的文字就错了,但总的来说解释大概正确,Qwen-VL-Max的解释就显得稍微有点敷衍,而Hunyuan-Vision的把图片中的所有元素都逐一进行解释且都正确,是三个模型中解释最全面的。
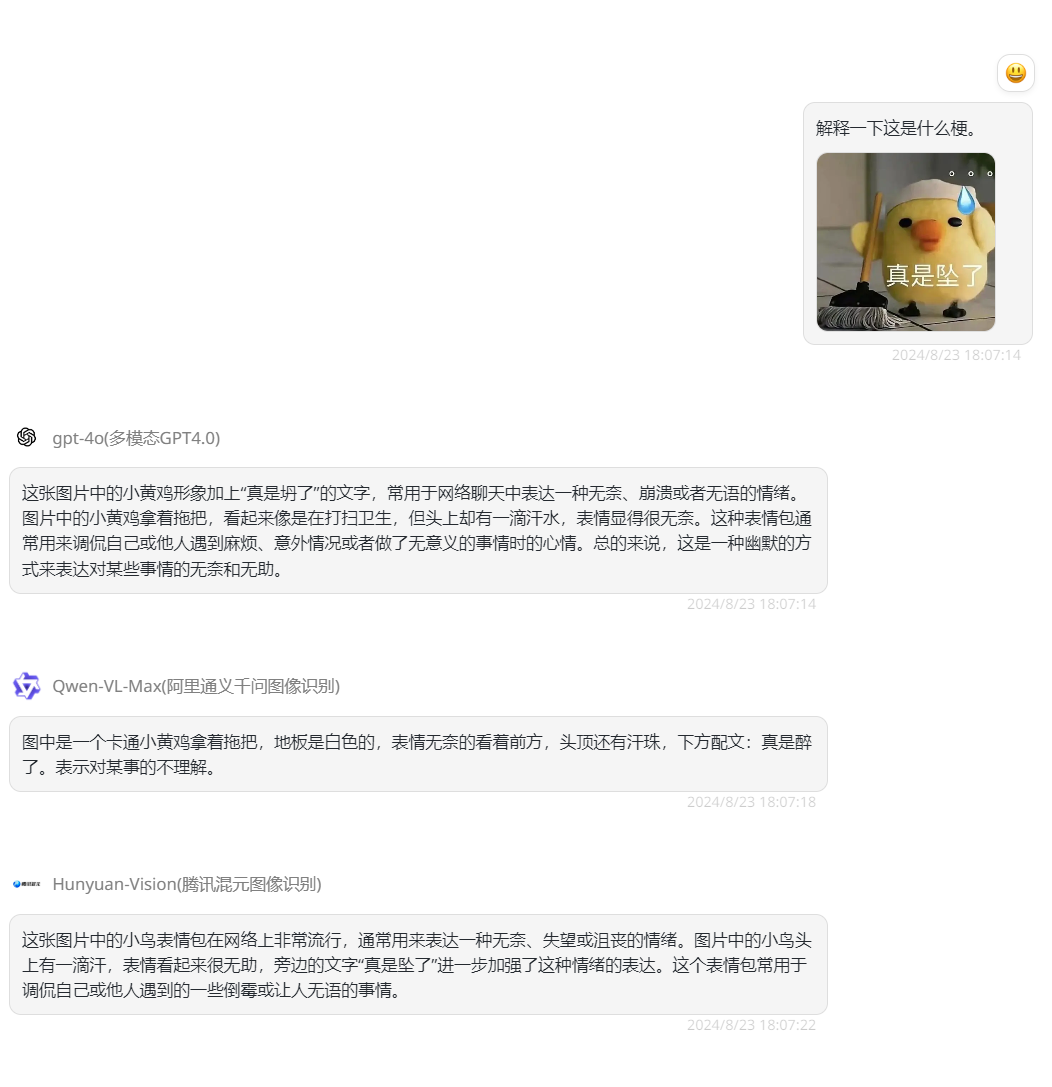
![]()
当然,以上只是简单的测评,但是可以看到,Hunyuan-Vision在以上测试中的表现不错,能够在本次的中文多模态大模型SuperCLUE-V基准8月榜单获得第一,展示了Hunyuan-Vision在多模态理解任务上的强大实力,也进一步证明了国内AI模型在相关领域中的竞争力正在不断提升。
尽管此次中文多模态大模型SuperCLUE-V8月榜单中,GPT-4o等国外模型仅作对比参考不参与排名,但是我们可以看到,国内模型与国外模型的差距正在缩小,在人工智能领域,国内的技术研发和创新实力正在迅速崛起,逐渐走向与国际先进水平并驾齐驱的地位。展望未来我们也期待国内更多优秀的人工智能模型能够涌现,共同推动人工智能技术的不断发展和进步。
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(11)
I have recently started a web site, the info you offer on this site has helped me tremendously. Thank you for all of your time & work. “Cultivation to the mind is as necessary as food to the body.” by Marcus Tullius Cicero.
Good post. I learn something more challenging on totally different blogs everyday. It is going to at all times be stimulating to read content material from different writers and practice a little one thing from their store. I’d prefer to use some with the content on my weblog whether or not you don’t mind. Natually I’ll give you a hyperlink in your web blog. Thanks for sharing.
I’ve been browsing online more than 3 hours as of late, yet I by no means discovered any attention-grabbing article like yours. It is lovely value sufficient for me. In my view, if all site owners and bloggers made excellent content material as you probably did, the net can be much more helpful than ever before.
I have been reading out some of your articles and i must say pretty nice stuff. I will surely bookmark your website.
I am constantly thought about this, regards for posting.
We’re a group of volunteers and starting a new scheme in our community. Your site provided us with valuable info to work on. You have done an impressive job and our entire community will be thankful to you.
Great paintings! This is the kind of information that are supposed to be shared around the internet. Disgrace on the search engines for not positioning this submit higher! Come on over and consult with my site . Thank you =)
My spouse and i ended up being very thrilled Chris managed to finish off his researching through the precious recommendations he grabbed out of the weblog. It’s not at all simplistic to just continually be giving for free points which most people may have been making money from. And now we fully grasp we now have the writer to give thanks to because of that. Those illustrations you have made, the straightforward blog navigation, the relationships your site give support to promote – it is mostly awesome, and it is facilitating our son in addition to the family understand the idea is cool, which is particularly important. Thanks for all the pieces!
You are my breathing in, I own few blogs and occasionally run out from post :). “Analyzing humor is like dissecting a frog. Few people are interested and the frog dies of it.” by E. B. White.
Have you ever considered about adding a little bit more than just your articles? I mean, what you say is important and everything. But think of if you added some great photos or videos to give your posts more, “pop”! Your content is excellent but with pics and videos, this site could undeniably be one of the greatest in its field. Terrific blog!
Hi , I do believe this is an excellent blog. I stumbled upon it on Yahoo , i will come back once again. Money and freedom is the best way to change, may you be rich and help other people.