


8月29日,智谱AI在KDD国际数据挖掘与知识发现大会上发布了新一代基座模型,包括语言模型GLM-4-Plus、图像/视频理解模型GLM-4V-Plus等。
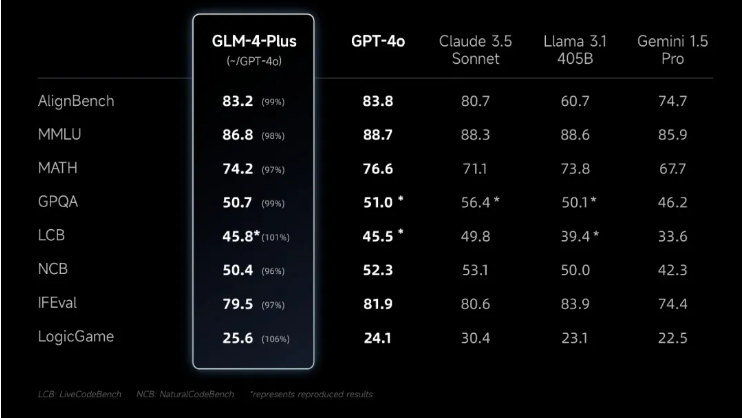
GLM-4-Plus 基座模型,通过多种方式构造出了海量高质量数据,并利用 PPO等多项技术,有效提升了模型推理、指令遵循等方面的表现,能够更好地反映人类偏好。据官方称,GLM-4-Plus在各项指标上,做到与 GPT-4o 等第一梯队模型持平。另外,还采用更精准的长短文本数据混合策略,增强了模型在长文本推理方面的表现。
![]()
此外,基于CogVLM系列模型上的研究经验,智谱研发了同时具备高质量图像理解和视频理解能力的多模态模型 GLM-4V-Plus,GLM-4V-Plus 除了能理解并分析复杂的视频内容外,同时还具备超强的时间感知能力。

![]()
据官方消息称,GLM-4-Plus即将在清言APP上线体验,但是这个【即将】的具体时间还不明确,而且有些用户会认为,为了体验一个模型而花费时间搜索下载一个应用程序,不仅耗费时间还占用手机空间。为此,小编提供一个更为便捷的方式,无需下载任何应用程序,用户可以直接进入302.AI的官网找到302.AI的聊天机器人使用GLM-4-Plus,目前,302.AI的聊天机器人不仅更新了GLM-4-Plus模式,还同步上线了GLM-4V-Plus模型,用户无需下载任何APP,也不必掌握API的使用方法,即可轻松体验。
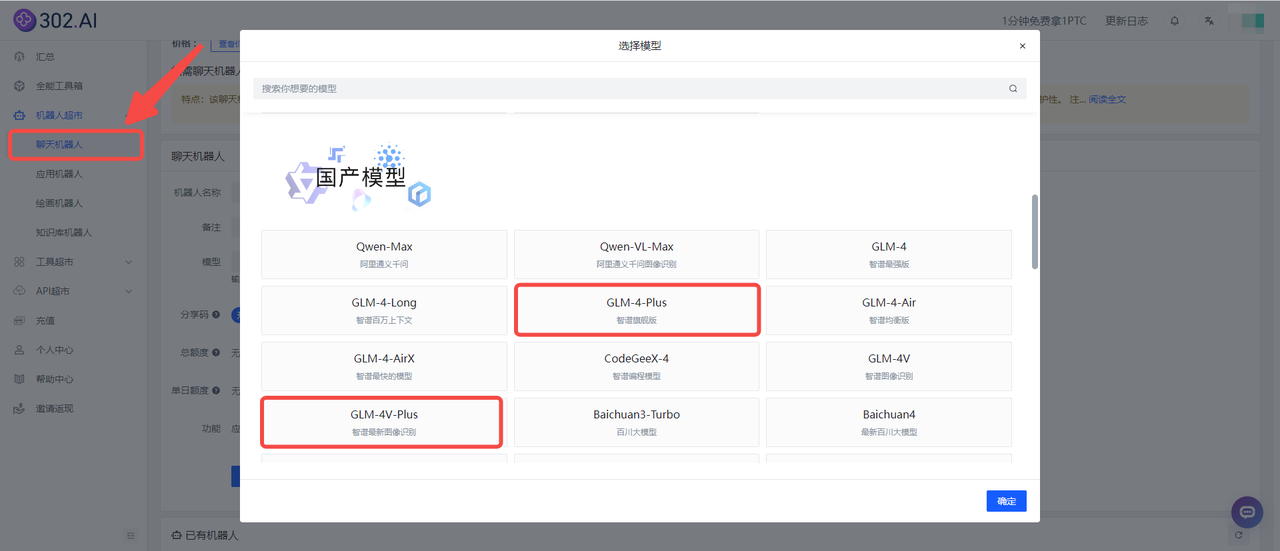
![]()
302.AI提供按需付费的服务方式,聊天机器人还可以在高级设置里开启机器人显示消耗,让用户能够实时掌握聊天机器人的使用情况,从而更精确控制费用支出,更灵活控制预算。
接下来,小编就带大家抢先试用下GLM-4-Plus模型:
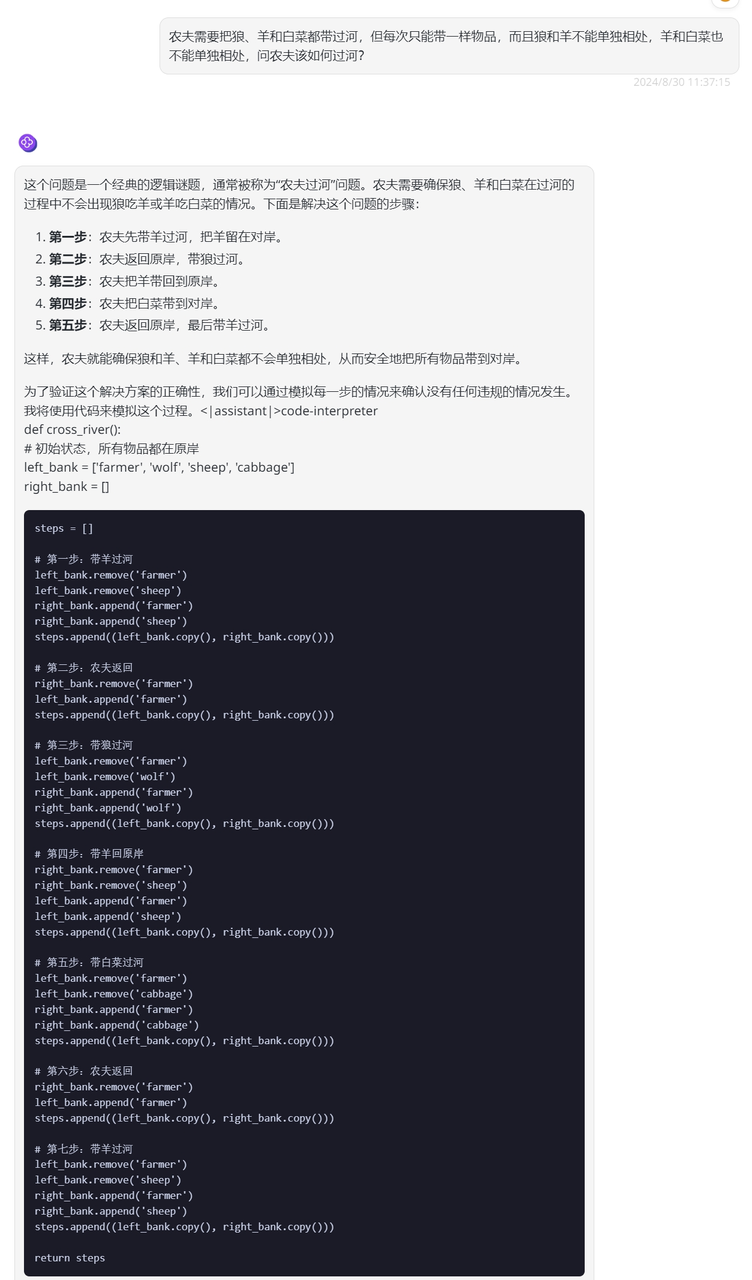
用经典农夫过河问题测试一下GLM-4-Plus的推理能力,从以下的结果来看,GLM-4-Plus不仅回答正确,甚至还给出了代码模拟这一过程从而检查结果是否正确,小编表示,仿佛看到了读书时代学霸同学做题的情景:
![]()
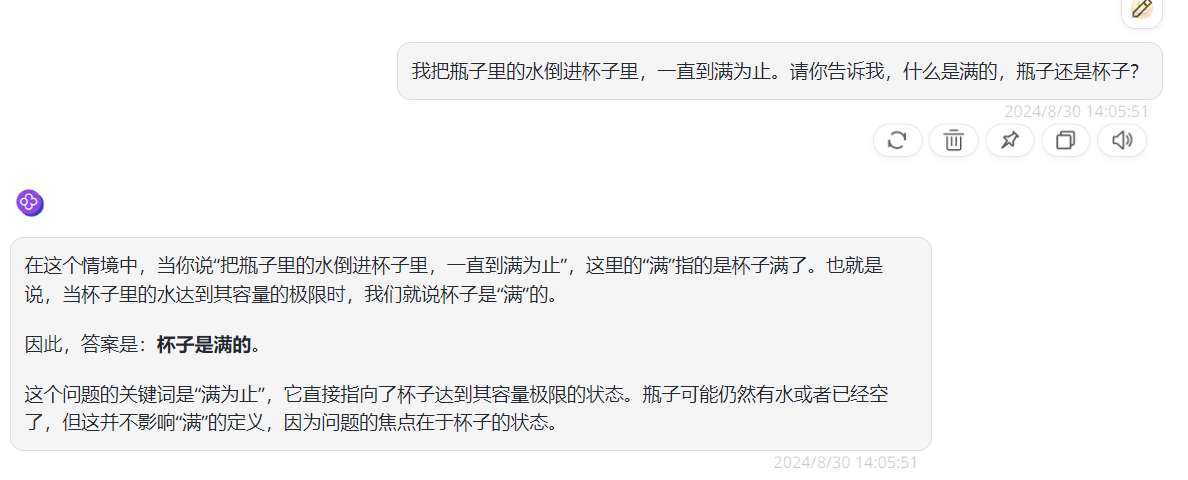
再来测试一下GLM-4-Plus语言理解能力,如下图提出杯子和瓶子的相关问题,看下模型能否准确理解人类语言的含义和上下文,根据结果可以看到,GLM-4-Plus的回答是正确,没有被绕晕,可以说在语言理解方面表现也是不错的。
![]()
接下来再简单测试一下GLM-4v-Plus的图片理解能力,上传一张网络搞笑图片让模型分析下笑点。
从回答结果来看,小编觉得这个解释有点过于简略,好像解释了但又好像没有解释(就比如我问为什么要吃饭,你回答因为到吃饭时间了):

![]()
而同样的问题,提问GPT-4o,得到的回答先是介绍了整个图片中所有的元素,连包装上的文字都能清楚解释,还有形状结构都有提到,最后介绍完所有有关物品后再回答好笑的地方。

![]()
总的来说,通过以上简单的测试,GLM-4-Plus模型在推理能力、语言理解方面的能力都有明显的提升,而GLM-4v-Plus在图片理解方面还有比较大的上升空间。
除此之外,302.AI的API超市的【国产模型】分类区也已经上线了GLM-4-Plus和GLM-4V-Plus的API,同样是按需付费,且支持在线调试,不仅提高了开发效率,还能够降低开发成本。
众所周知,智谱AI是一家成立于2019年的人工智能公司,由清华大学计算机系技术成果转化而来,目前已经成为国内AI大模型领域的领军企业之一。智谱AI发布的GLM-4-Plus和GLM-4V-Plus模型,无论是从技术创新还是应用实践,都展现出了不错的能力,而GLM-4V-Plus更是国内首个通用图像&视频理解模型,未来,希望智谱将继续发挥其在人工智能领域的优势,为用户带来更多惊喜和价值。
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(1)
There are some fascinating closing dates on this article however I don’t know if I see all of them middle to heart. There may be some validity but I’ll take maintain opinion till I look into it further. Good article , thanks and we wish more! Added to FeedBurner as properly