


9月6日,AI写作初创公司HyperWrite发布了Reflection-Llama-3.1-70B模型。该模型基于Meta的Llama 3.1-70B Instruct,并使用原始的 Llama Chat 格式,确保了与现有工具和 pipeline 的兼容性。
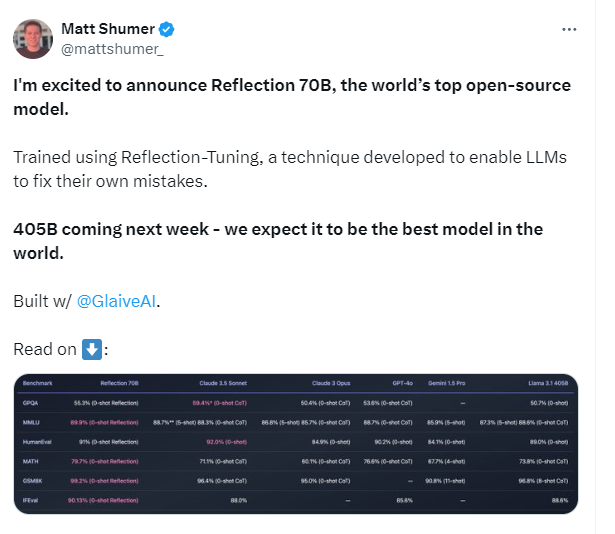
在发布当天,HyperWrite 公司的 CEO Matt Shumer 在社交媒体平台发文表示,Reflection-70B(即Reflection-Llama-3.1-70B) 是“世界上最顶级的开源 AI 模型”,还宣称Reflection 70B 甚至可以与顶级闭源模型(Claude 3.5 Sonnet、GPT-4o)相媲美,并表示Reflection-Llama-3.1-70B每项基准测试上都超过了 GPT-4o,还击败了 405B 的 Llama 3.1。
![]()
除通用能力之外,Reflection-Llama-3.1-70B最大的亮点是“错误识别和错误纠正”:由于其自我反思和纠错的能力,Reflection-Llama-3.1-70B 在需要高精度和低错误率的任务中表现尤为出色。
凭借如此惊艳成绩,Reflection-Llama-3.1-70B一推出便被冠以开源大模型新王的称号。令人意外的是,该模型是仅仅由HyperWrite CEO Matt Shumer 和 Glaive AI 创始人 Sahil Chaudhary两人花了 3 周时间完成的。
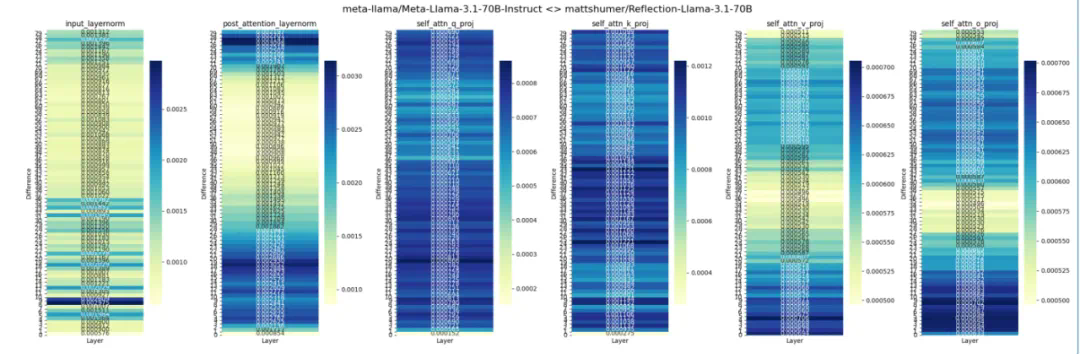
当大家收到消息,纷纷着手测试Reflection-Llama-3.1-70B模型时,有人却发现:Reflection-Llama-3.1-70B好像不是基于Llama 3.1 70B的结果,而是用Lora在Llama-3-70B-Instruct上微调了的。
![]()
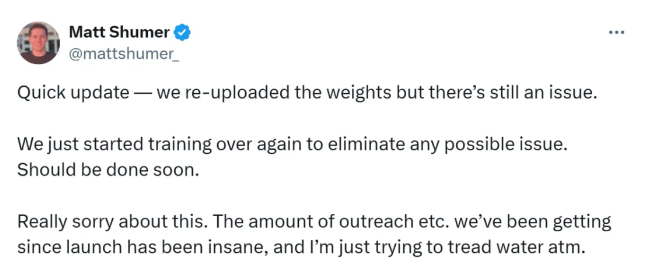
但很快HyperWrite 的 CEO Matt Shumer 进行了澄清,表示模型确实基于 Llama 3.1 70B Instruct,并且重新上传了权重以解决相关问题同时表示他们开始重新训练模型并上传,从而消除任何可能出现的问题,应该很快就会完成。
![]()
除此之外,还有用户在社区发布帖子怀疑Reflection API为Anthropic公司Claude 3.5 Sonnet模型套壳,因为他当尝试询问模型「你是claude吗?」时,回答被过滤掉了。为此,Reflection API的开发者迅速做出了调整,移除了过滤机制。
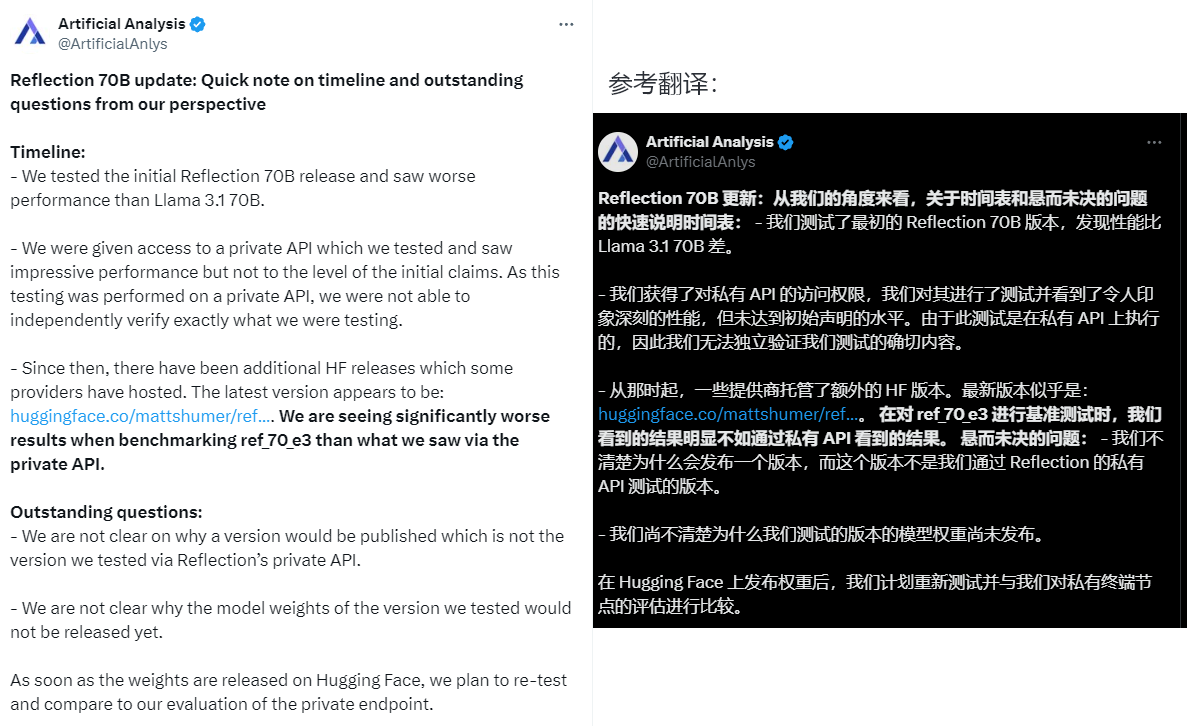
不仅如此,Artificial Analysis也对Reflection-Llama-3.1-70B进行了独立评估测试,结果显示Reflection-Llama-3.1-70B的 MMLU 得分仅与 Llama 3 70B 相同,并且明显低于 Llama 3.1 70B。而就在今天上午,Artificial Analysis官方发布了最新关于Reflection-Llama-3.1-70B的帖子,表示他们获得了私有API访问权限,并对其进行测试虽然结果还不错,但是仍没有达到初始声明的水平:
![]()
尽管争议不断,但是还有很多人想上手测试一下Reflection-Llama-3.1-70B模型,毕竟实践出真知。然而,目前Reflection-Llama-3.1-70B演示网站已经因为CPU不足崩溃了,如果不熟悉使用API的用户,想要快速试用测试Reflection-Llama-3.1-70B模型,可以选择 302.AI的聊天机器人,目前已经更新了Reflection-Llama-3.1-70B模型,而且302.AI提供按需付费的服务方式,无月费和捆绑套餐。
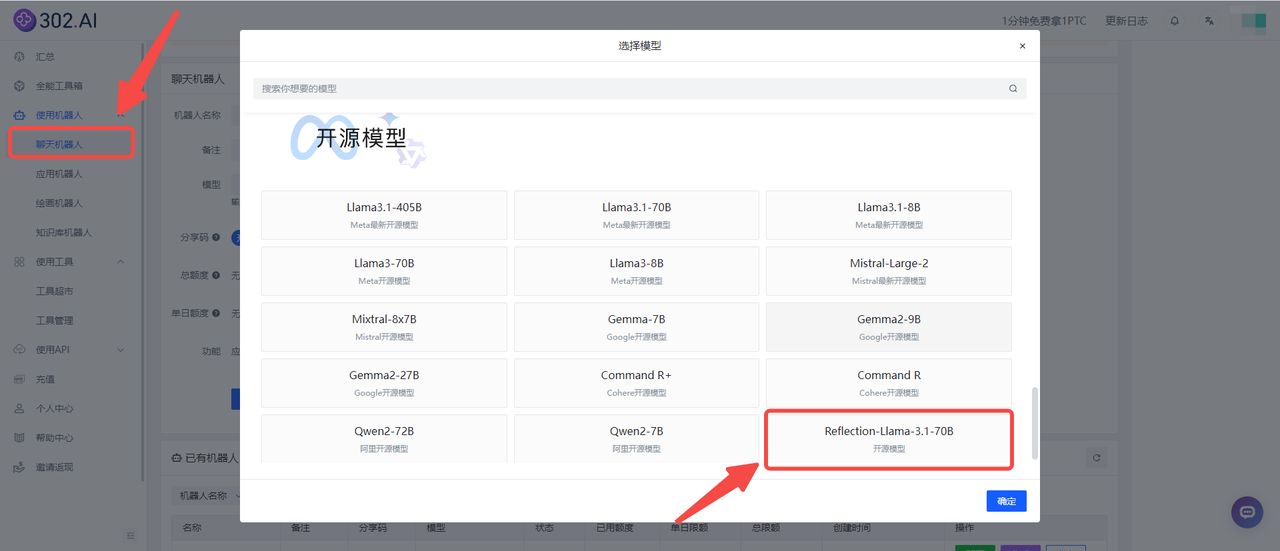
![]()
小编首先对官方示例中的问题“9.9和9.11哪个大”进行了测试,发现Reflection-Llama-3.1-70B模型确实能够正确回答。然而,当小编继续提出“9.8和9.11哪个大”的问题时,模型的回答却出人意料,难不成该模型只能算对一道题目?另外,Reflection-Llama-3.1-70B还有一个明显的问题,当使用中文提问,该模型却仍然是用英文来回答,除非在提问后面打上“请用中文回答”,模型才切换到中文回答。
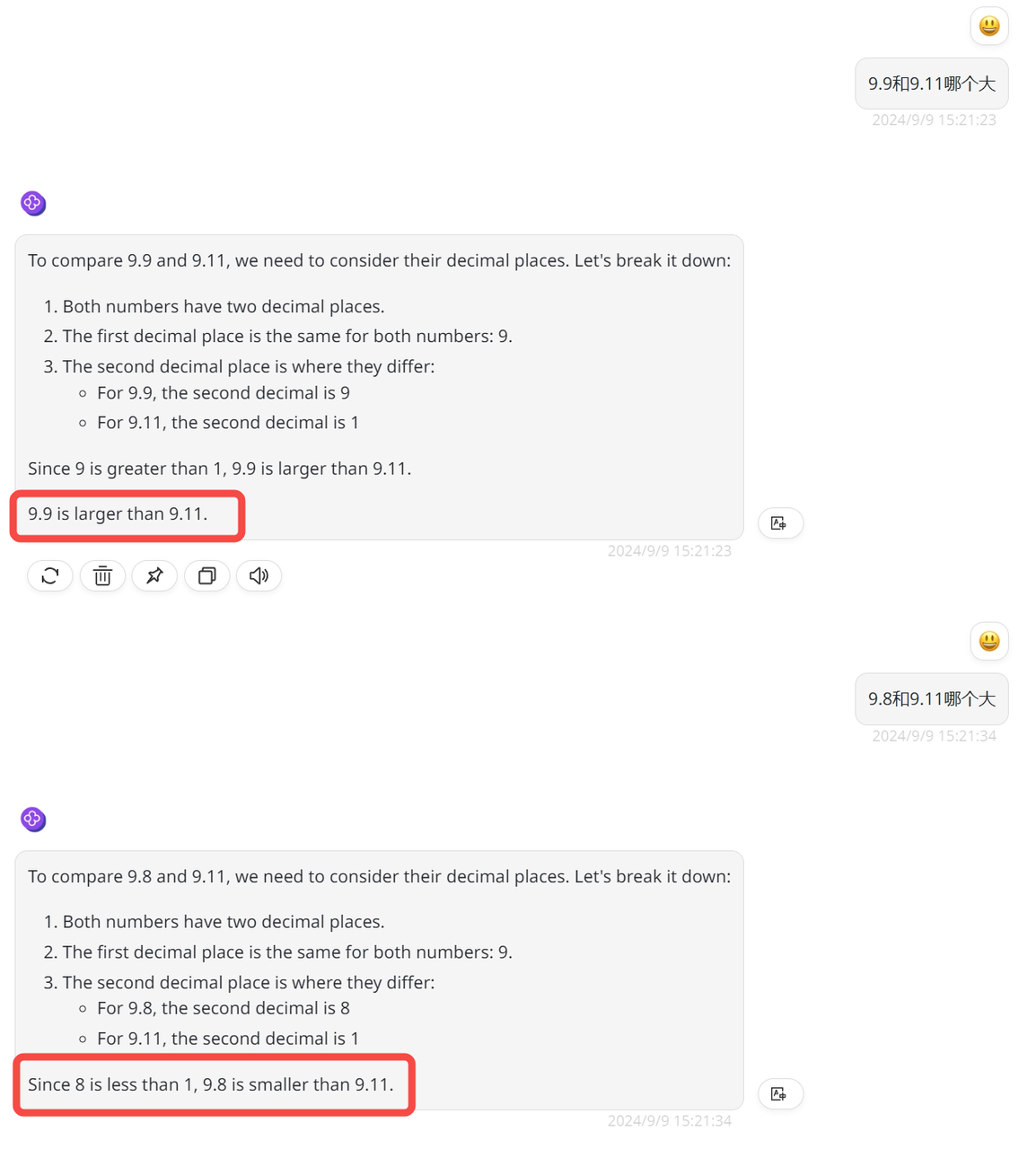
![]()
而面对关于杯子和硬币的问题的时候,的确看到Reflection-Llama-3.1-70B模型的回答中的错误识别和错误纠正能力,它会反思自己的答案,但其实仔细看它的回答,在前半部分的回答分析中实际上并没有出现什么错误:
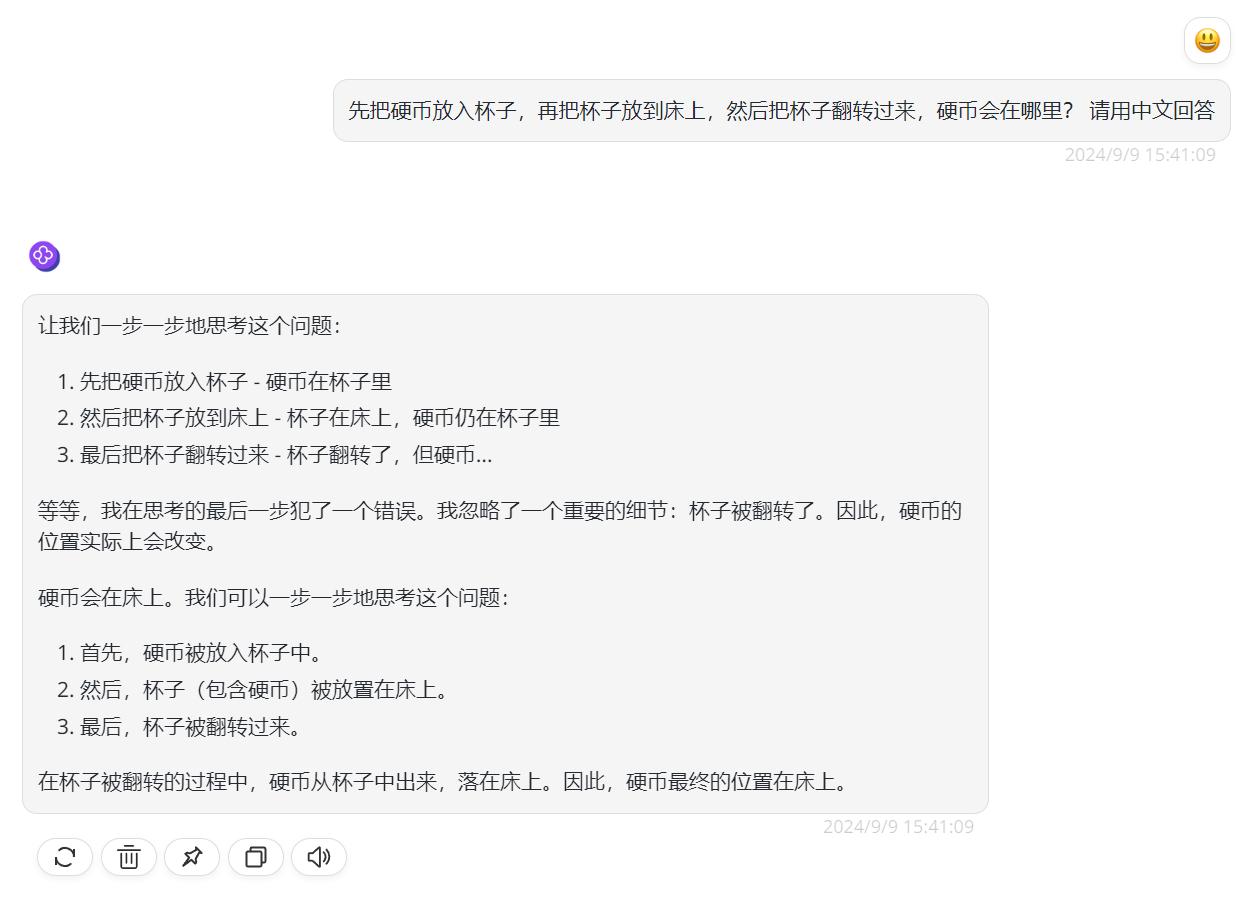
![]()
然而,在面对弱智吧的问题“我想配个6000多的电脑,大概要多少钱?”时,Reflection-Llama-3.1-70B模型并未给出预期中的答案。这个问题的答案其实就在题目里——既然已经明确了预算为“6000多”,那么答案自然不言而喻。

![]()
对于想要快速上手并微调Reflection-Llama-3.1-70B模型的用户,302.AI的API超市提供了一个便捷的解决方案。用户可以直接通过302.AI的API超市获取Reflection-Llama-3.1-70B的API接口,而且302.AI提供按需付费的服务方式,这样不仅简化了技术门槛,还使得用户可以根据自己的实际需求和预算,轻松地进行模型的微调和应用。
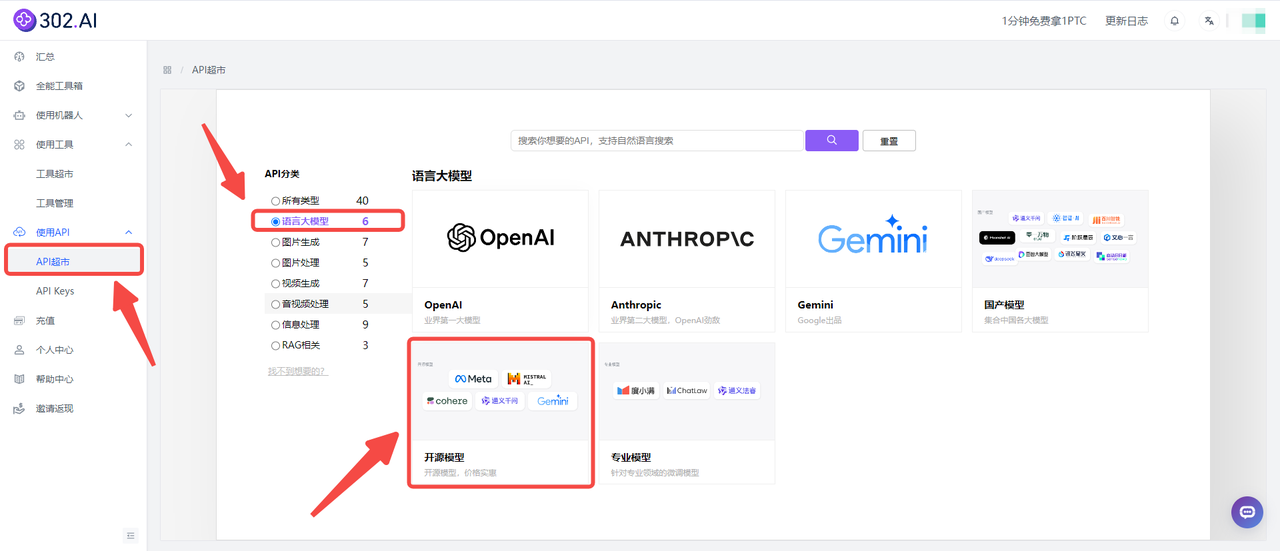
![]()
而且,302.AI的API超市支持在线调试,开发者可以快速集成和使用API服务,并提供详细的API文档,帮助开发者快速上手,提高效率,减少在使用API时出现的错误。目前Reflection-Llama-3.1-70B已经开始重新训练,如果后续训练完成后推出新版本,302.AI也会同步更新。
![]()
最后,根据媒体消息,Reflection-Llama-3.1-70B的两位开发者表示将会在本周发布Reflection-Llama-3.1-70B的技术报告。
面对围绕Reflection-Llama-3.1-70B模型的种种争议,小编认为不必急于做出结论。不妨先“让子弹飞一会儿”,在这个快速发展的领域,每一次的技术迭代和每一次的公众讨论都是推动行业向前发展的重要力量,让我们以开放的心态,观察并等待HyperWrite接下来的动向。
参考文章:
https://www.jiqizhixin.com/articles/2024-09-08-8
https://mp.weixin.qq.com/s/XBc1codHx7eandyPd7Tnig
https://mp.weixin.qq.com/s/80tgme9Dxz3zk41dqw-EEw
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(1)
Can I just say what a relief to find someone who actually knows what theyre talking about on the internet. You definitely know how to bring an issue to light and make it important. More people need to read this and understand this side of the story. I cant believe youre not more popular because you definitely have the gift.