


在人工智能领域,知识库机器人已经成为推动智能化发展的重要力量。它们能够高效地处理海量信息,为用户提供精准、及时的知识服务。今天,我们将一起揭开知识库机器人的神秘面纱,探讨知识库机器人的原理。

什么是RAG?
知识库的整套技术在学术界有一个专业名词,叫RAG,即Retrieval-Augmented Generation,翻译成中文就是检索信息增强,是一种将信息检索机制与AI模型结合的创新方法。
RAG还有一个通俗的叫法,叫外挂知识库。外挂的含义就是,和AI大模型是分离的。如果不分离,那就是模型微调了,又是另外一回事了。
RAG的原理
RAG的原理其实很简单,就是模型生成回答时,不是自己直接生成,而是先去查一下知识库,再进行生成。通俗的来说,就是开卷考试(RAG)和闭卷考试(直接生成)的差别。
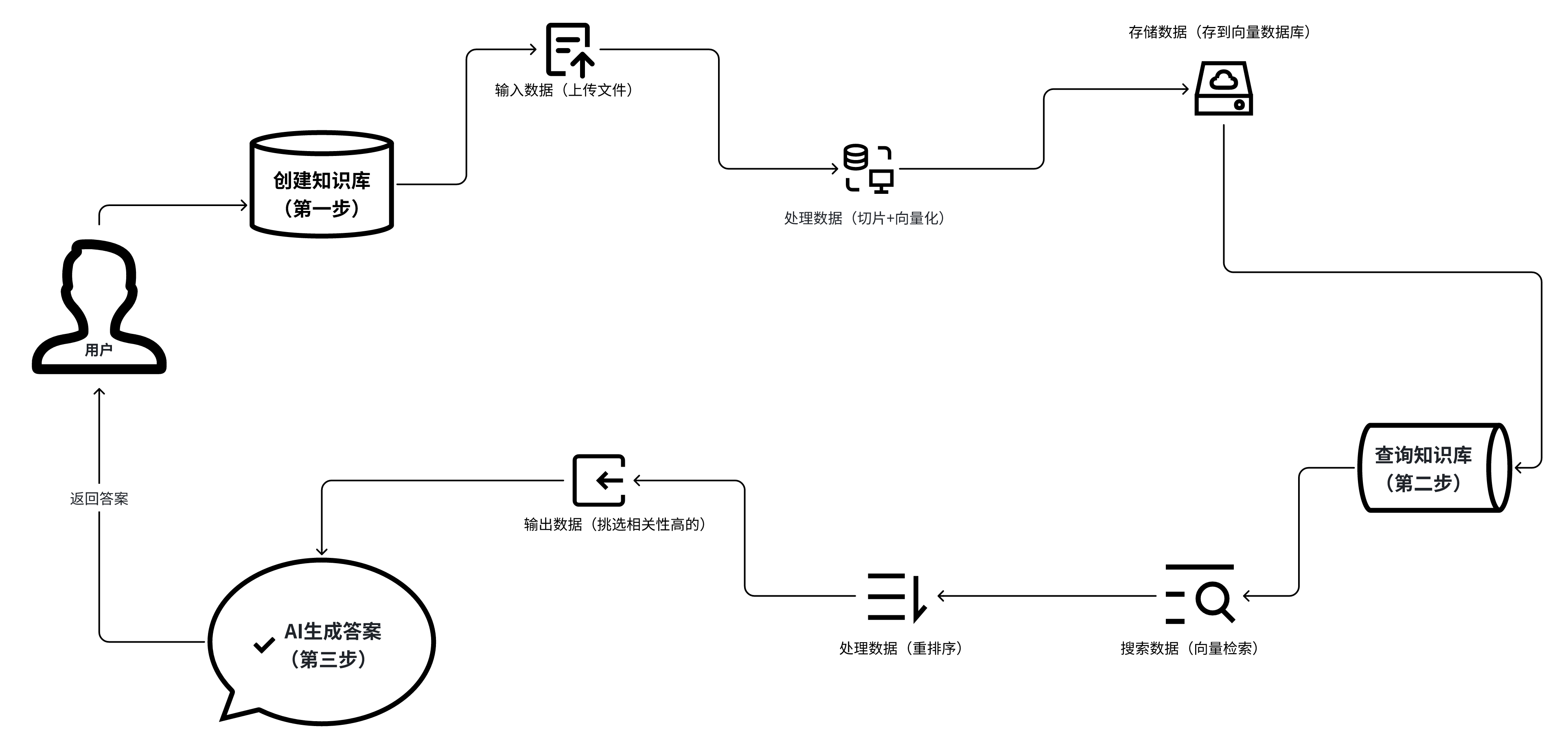
从流程上来说,绝大多数RAG可以分为这3步:
1、创建知识库
(1)输入数据(上传文件)
(2)处理数据(切片+向量化)
(3)存储数据(存到向量数据库)
2、查询知识库
(1)搜索数据(向量检索)
(2)处理数据(重排序)
(3)输出数据(挑选相关性高的)
3、AI生成答案
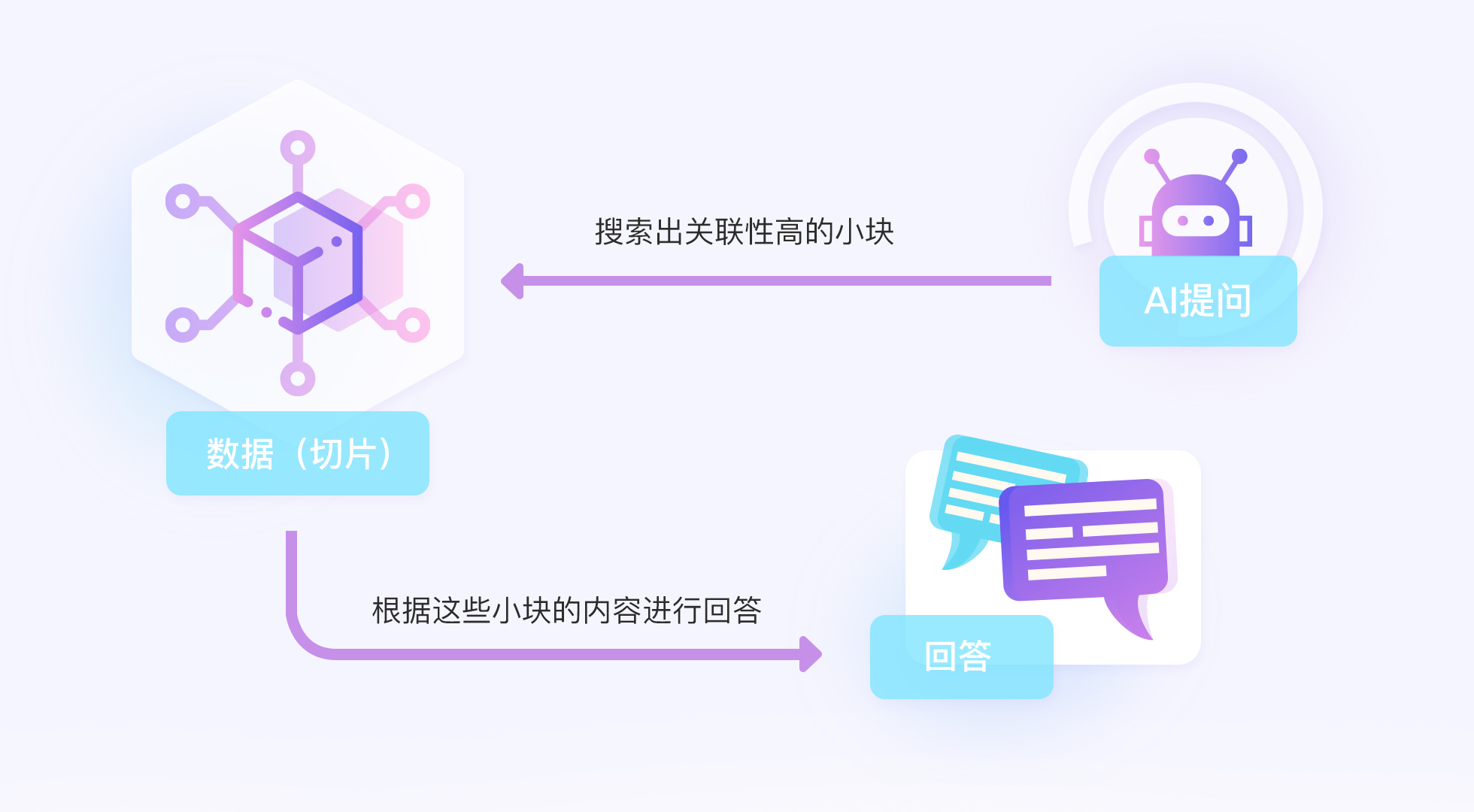
通俗的来说,就是将一个巨大的数据,切成很多小块,当AI进行问答时,搜索出关联性高的小块,根据这些小块的内容进行回答。这样的好处就是:AI不需要处理大量的数据,只需要处理很少量的数据就可以了,提高了速度,降低了成本。
但是劣势也是很明显的,就是断章取义。由于AI只拿到了部分数据,无法看到全局,所以这是RAG的天然劣势。
RAG的关键
RAG的本质就是断章取义,那么怎么断,怎么取,就决定回答的质量,在整个过程中,AI的作用其实是很小的。关键是在第一和第二步中,也就是数据处理和数据检索。
‘’数据处理的关键是如何切片,302.AI提供了非常丰富的切片设置,具体可以看这一篇文章:如何进行切片优化
数据检索的关键是如何找到关联性大的内容,302.AI采用了双重检索的机制,先使用向量检索粗检索,再用重排序算法(rerank)精检索,最后输出到大模型,大大提高了精度。
GraphRAG
GraphRAG是微软提出的一种新式的RAG技术,原理就是在数据输入阶段,用AI对数据进行了图谱化处理,让AI去理解数据,建立数据语义的关联,使检索精度大大提高。
GraphRAG的本质,是在原有的数据基础上,用AI创造了新的数据。这种新的数据是通过构建知识图谱来实现的,这不仅有助于更好地组织和存储信息,还能使AI在进行检索时能够更智能地识别和推理数据之间的关系。这种方法有效地提升了信息检索的准确性和效率,使得系统在处理复杂查询时表现得更加出色。此外,GraphRAG的图谱化处理还可以帮助发现数据中的隐藏模式和趋势,从而为用户提供更深刻的洞察和决策支持。
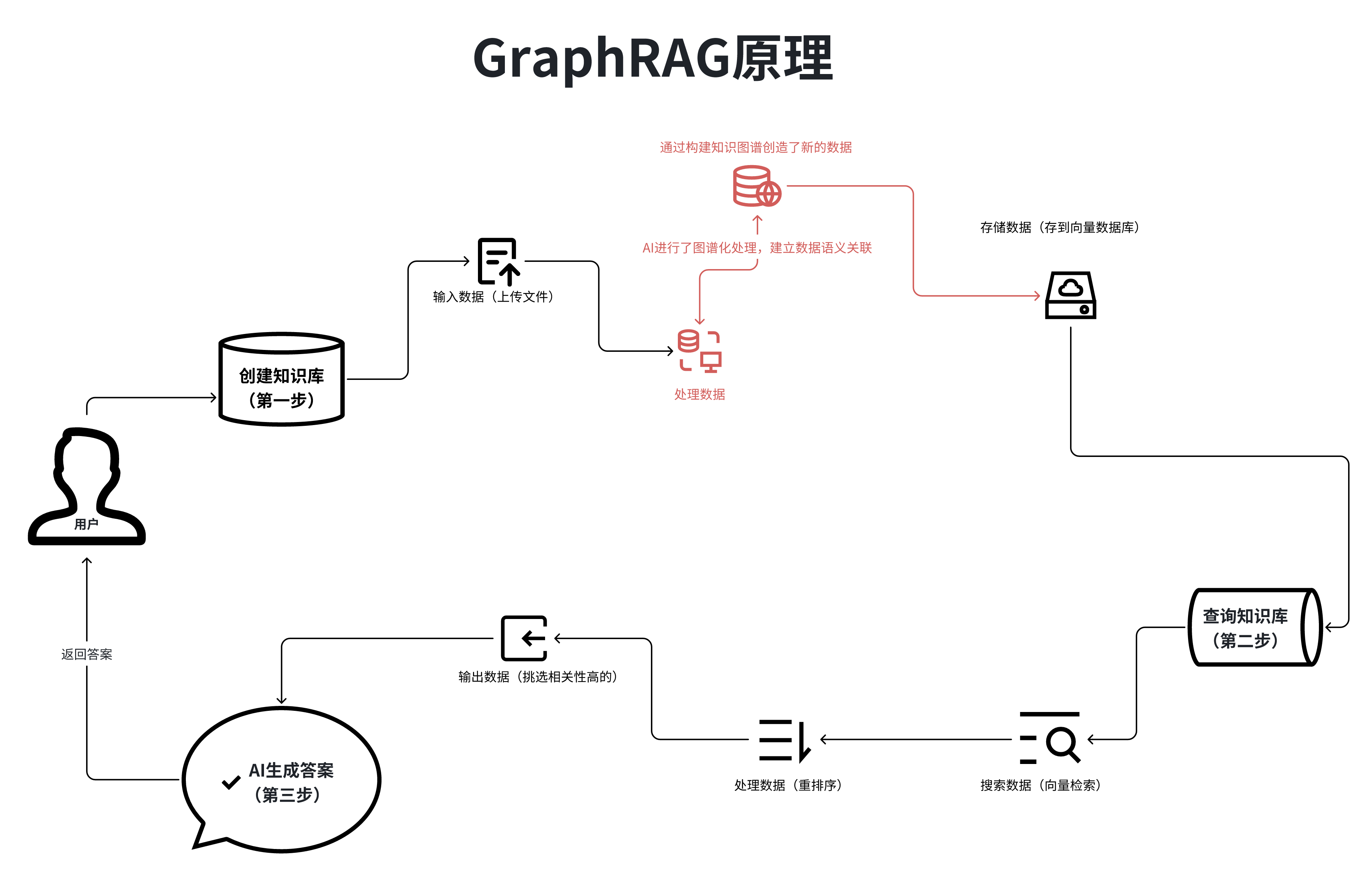
GraphRAG也不是没有缺点的,第一就是会比较贵,因为在数据录入的过程中,需要AI进行处理,一定会产生AI的费用。第二就是比传统RAG要慢,因为检索图谱的过程会复杂很多。
302.AI现已独家提供GraphRAG的知识库接入和API接入,代码基于Nano-GraphRAG开发,更加轻量化。
知识库的原理就是AI先查询再回答。那么如何查询到关联性高的片段,就是知识库最核心的部分。302.AI提供了2种模式:传统RAG和GraphRAG,可以根据需求去选择,下面将简单展示一下如何使用302.AI的知识库机器人:
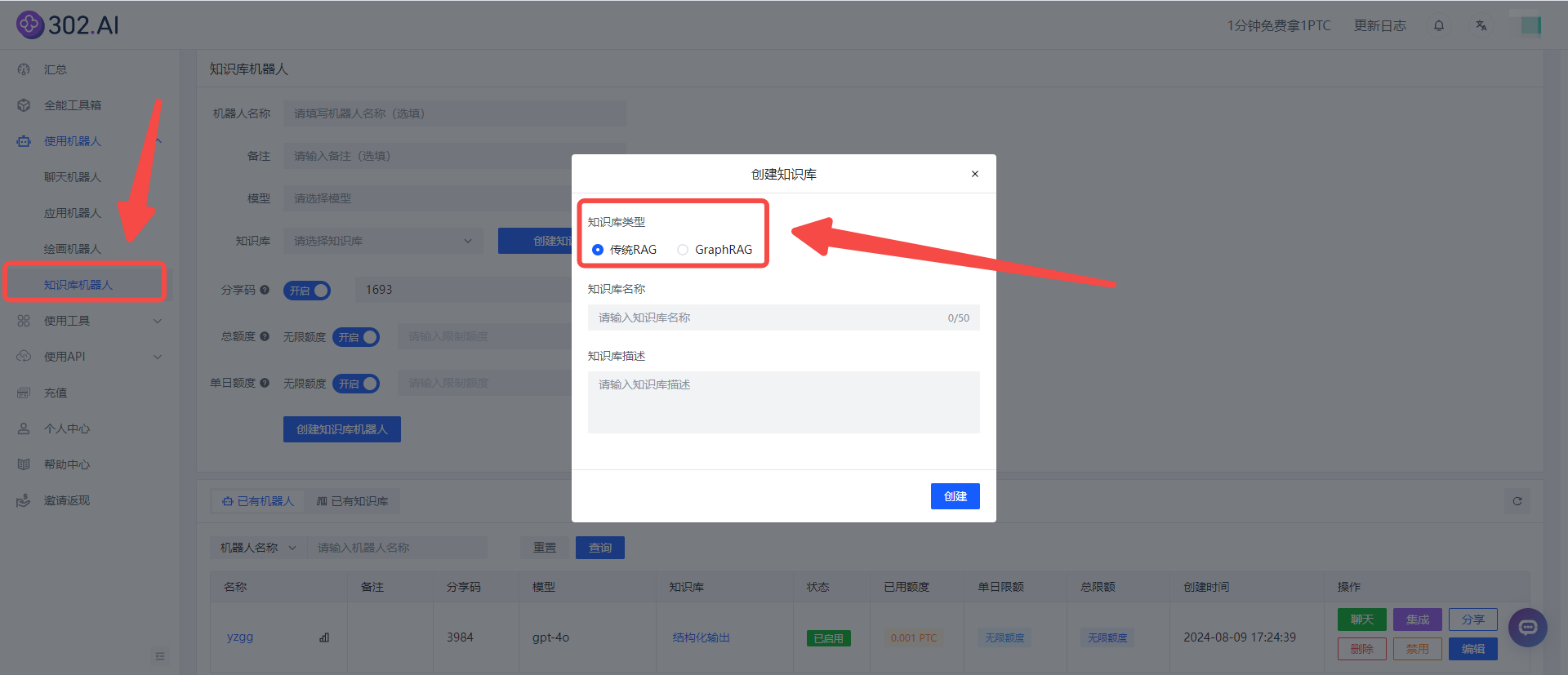
选择好后填写知识库名称和描述进入编辑知识库页面(不填会自动生成),选择【导入文档】或是复制【链接】进行导入数据(下面以GraphRAG为例):
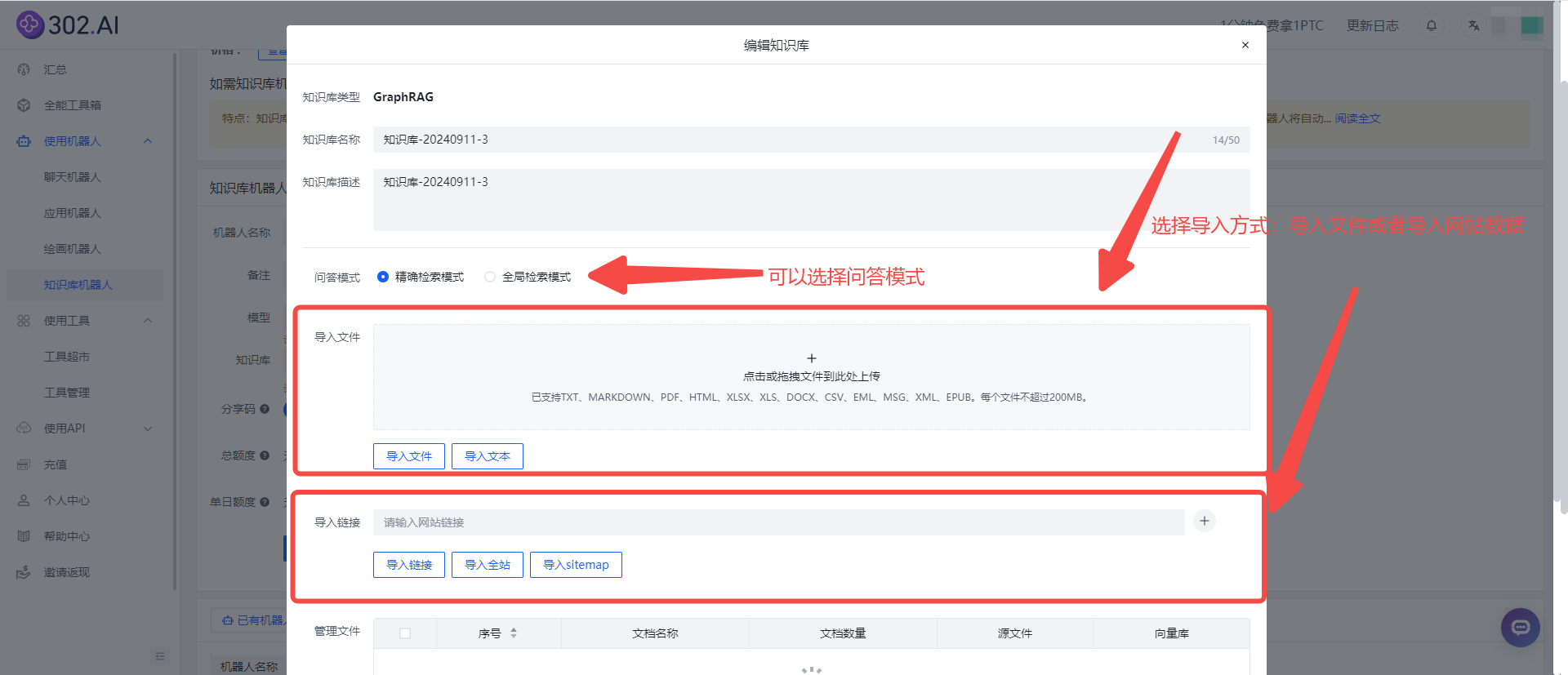
导入成功后表明知识库已经建立完成,接下来就是要选择模型及刚刚新建的知识库,目前提供了国内外多种模型选择,可满足不同任务和领域的需求。
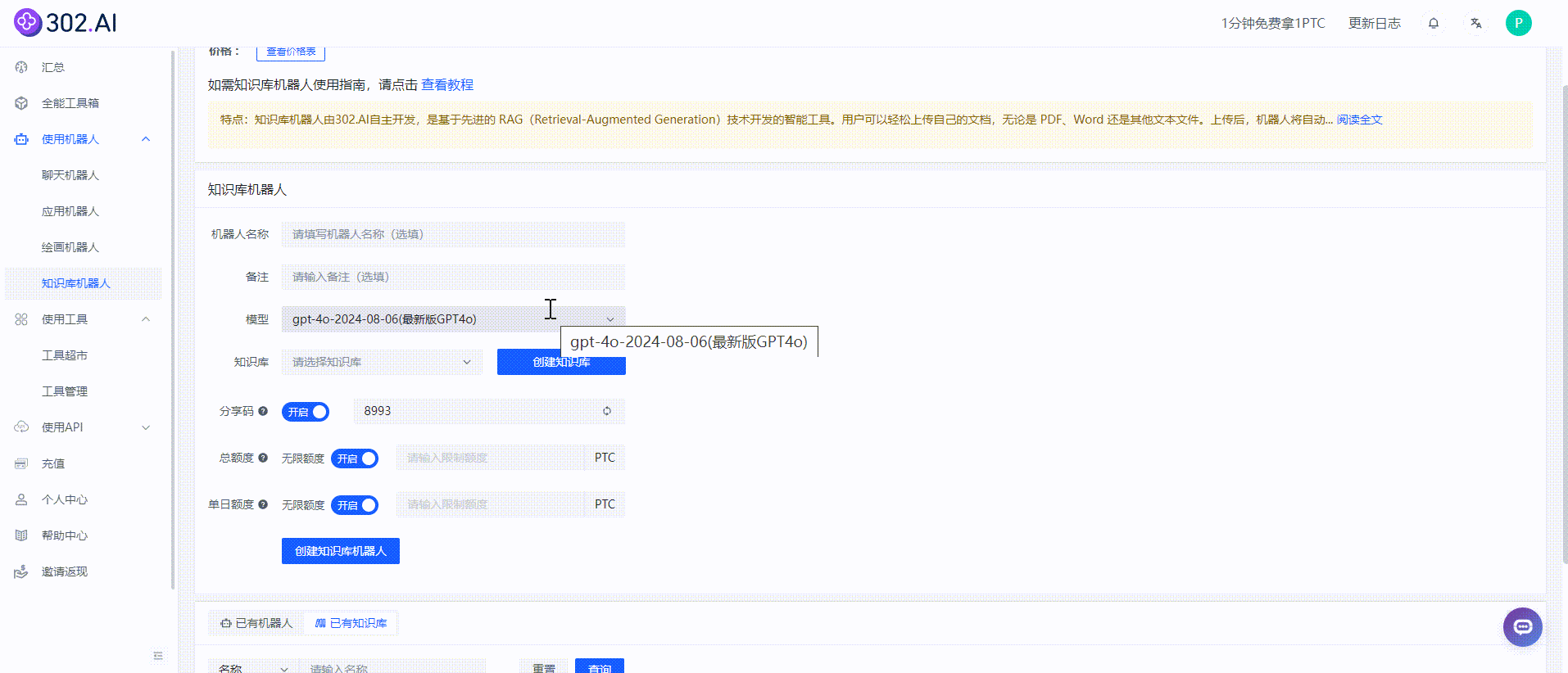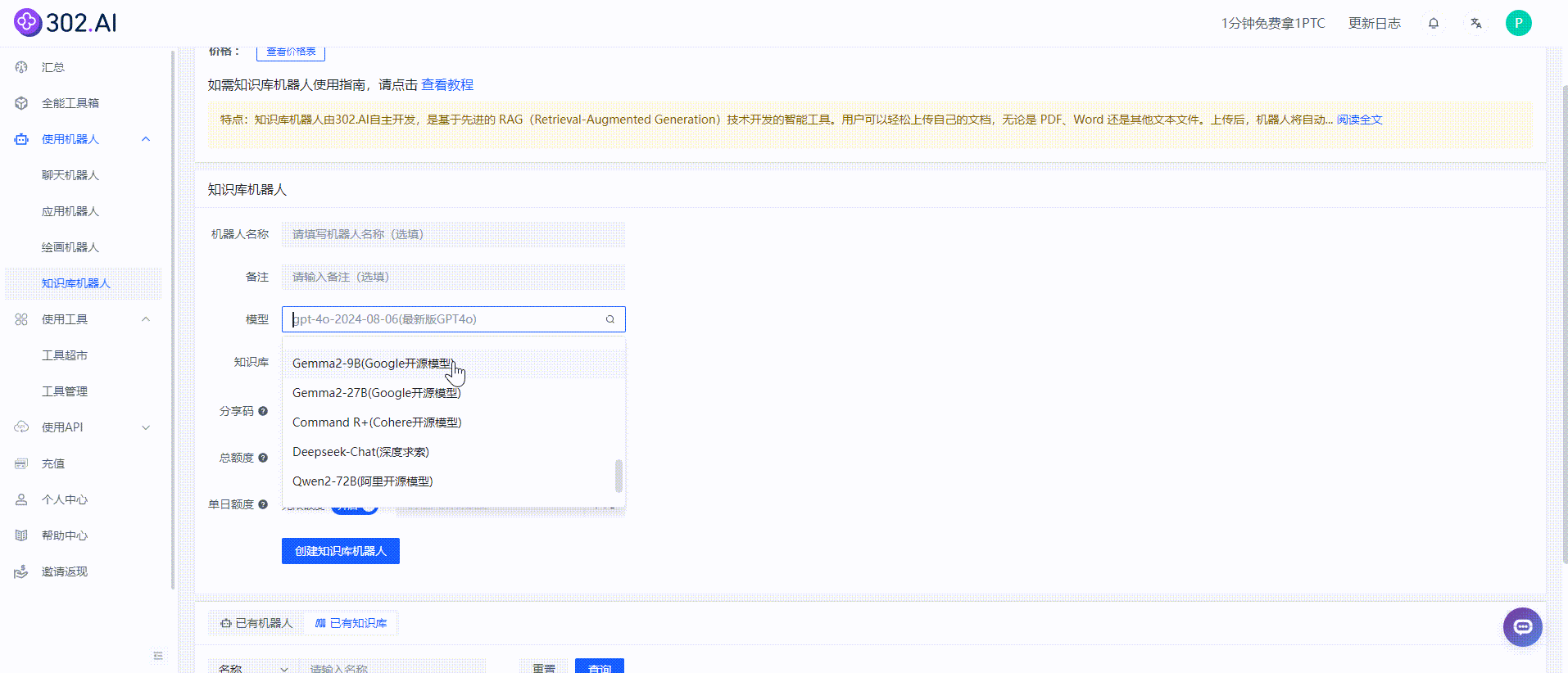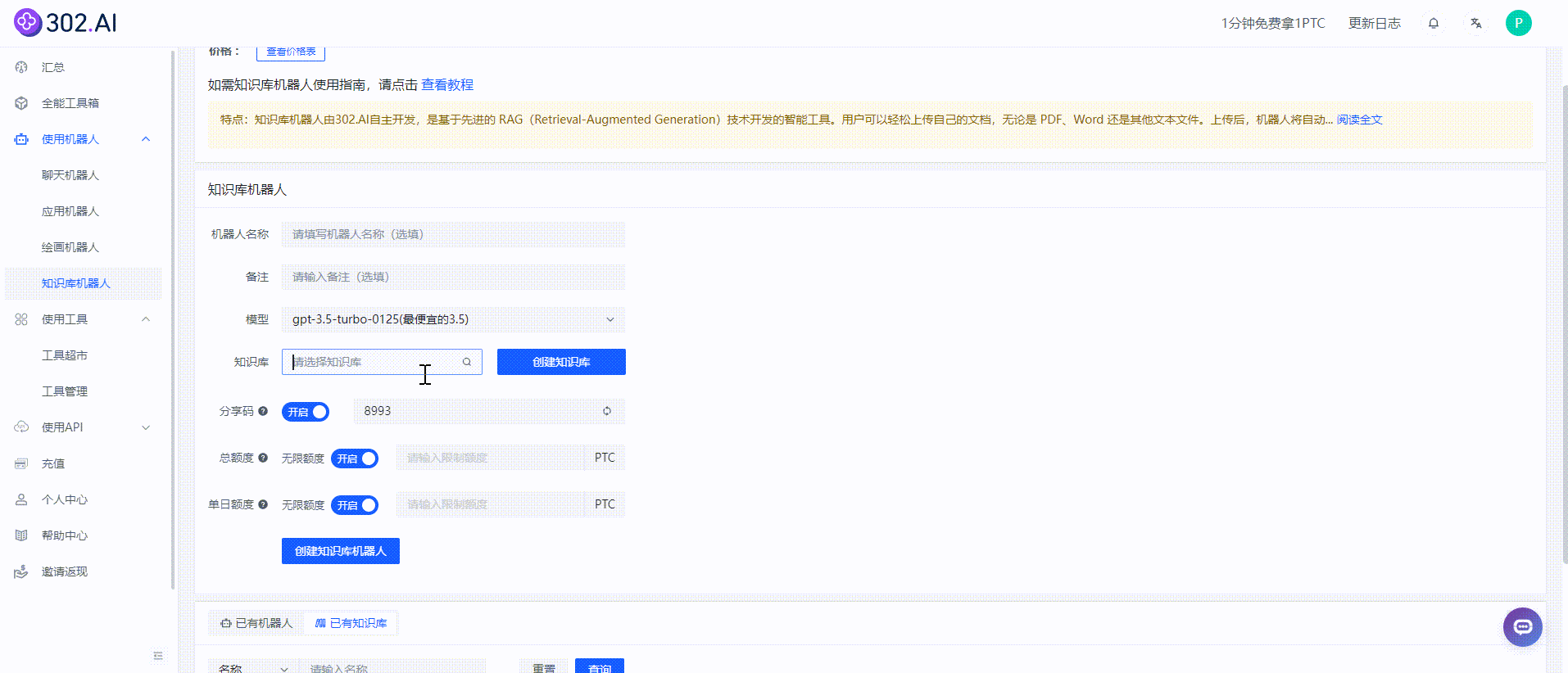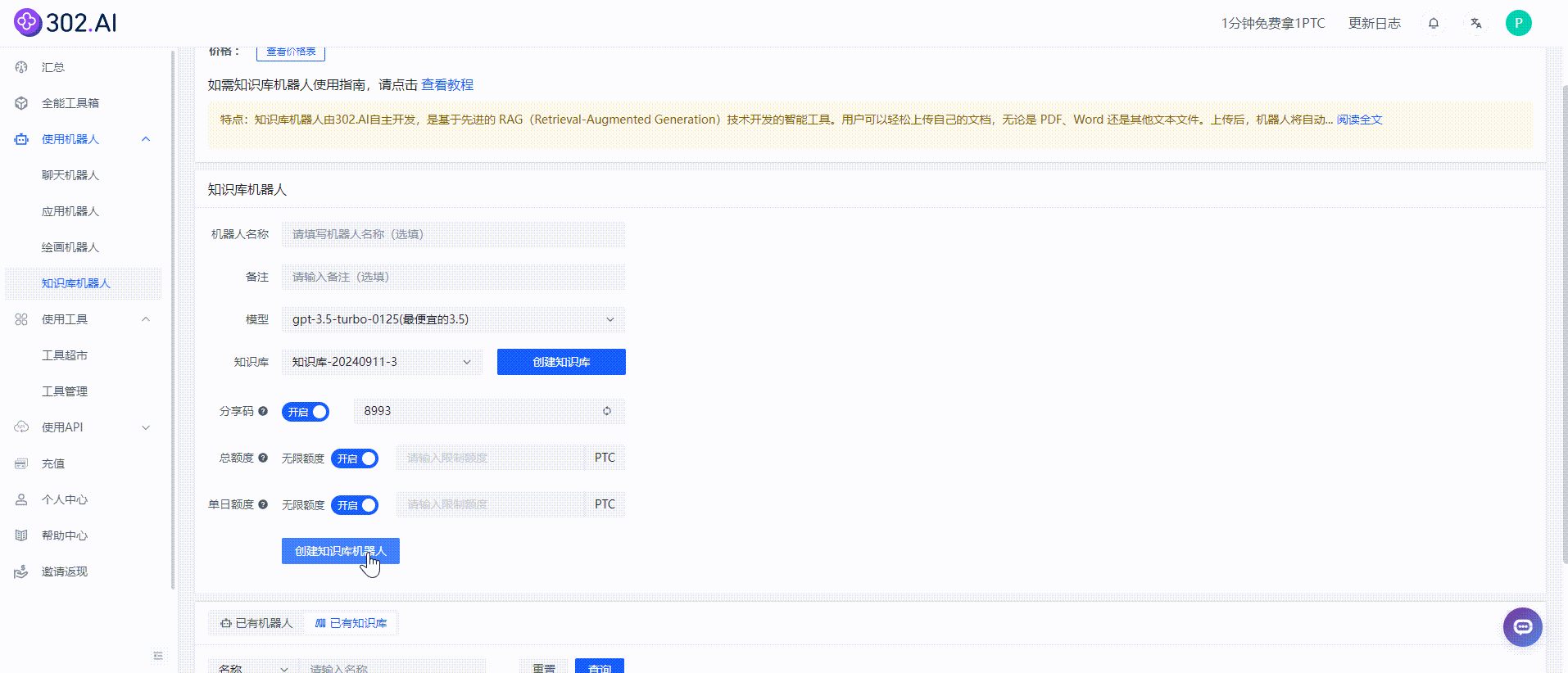
知识库机器人创建成功后会直接跳转进入聊天界面,这样就可以向知识库机器人进行提问啦!
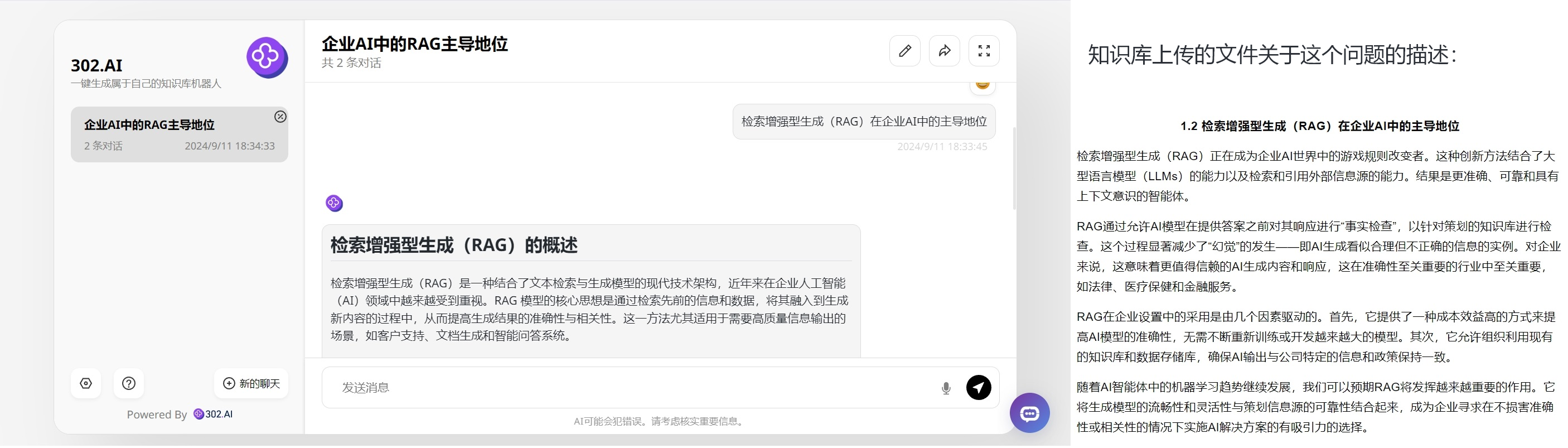
希望通过本文对RAG和GraphRAG的解析,能让读者更好地理解知识库机器人背后的强大技术支撑。随着人工智能技术的不断进步,知识库机器人将在更多领域发挥巨大潜力,同时,我们也期待看到更多创新性的应用场景涌现,让知识库机器人更好地服务于人类社会,推动知识的传播与进步。
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(2)
I was recommended this web site by way of my cousin. I’m not positive whether this publish is written via him as nobody else understand such specified approximately my difficulty. You are incredible! Thank you!
You made some decent points there. I looked on the web for the issue and located most individuals will go together with with your website.