


10月17日,英伟达(Nvidia)开源了微调后的Llama3.1——Llama-3.1-Nemotron-70B-Instruct。
Llama-3.1-Nemotron-70B-Instruct 是 NVIDIA 使用私有数据集微调后的Llama3.1,旨在提高 LLM 生成的响应对用户查询的帮助性。
![]()
根据官方Tech Report,Llama-3.1-Nemotron-70B-Instruct采用了人类反馈强化学习(RLHF)方法,特别是 REINFORCE 算法,这使得模型在理解和执行指令方面表现出色。它还采用了一种创新的混合训练方法,巧妙地将 Bradley-Terry 和 Regression 奖励模型结合在一起。
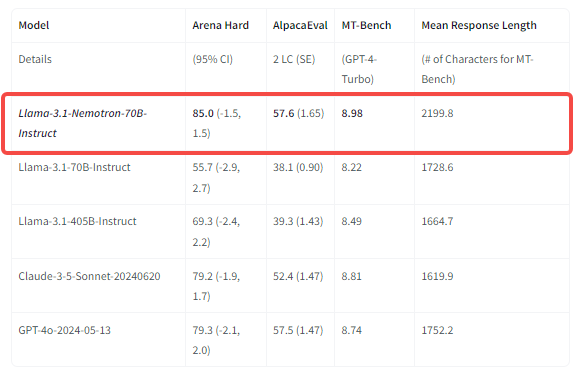
这一模型在多个基准测试中表现出色,例如在 Arena Hard 上得分为 85.0,在 AlpacaEval 2 LC 上得分为 57.6,在 GPT-4-Turbo MT-Bench 上得分为 8.98,截至 2024 年 10 月 1 日,在这些基准测试中表现最佳,超越了 GPT-4o 和 Claude 3.5 Sonnet 等模型:
![]()
理论和数据固然重要,但更重要的是实际应用中的表示,既然都在说Llama-3.1-Nemotron-70B-Instruct超越了GPT-4o和Claude 3.5 Sonnet模型,抱着“看热闹不嫌事大”的态度,接下来,Yuki将通过302.AI的模型竞技场测试对比一下和其他闭源模型的真实表现。
302.AI的模型竞技场集成多种AI模型,用户可以选择多个模型同时回答问题,能够更直观、清晰地对比不同模型的表现,而且302.AI提供了按需付费的使用方式,用户无需担心月费和捆绑套餐,使得付费更加灵活和经济。
在302.AI上使用Llama3.1
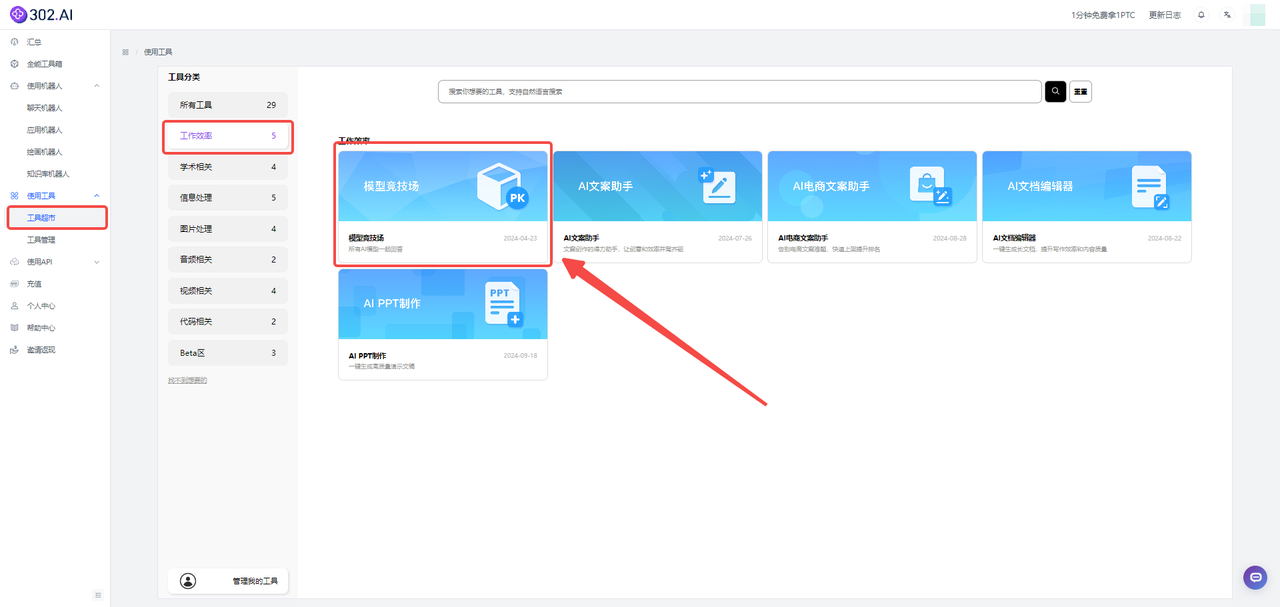
首先,我们进入302.AI的工具超市——工作效率——模型竞技场:
![]()
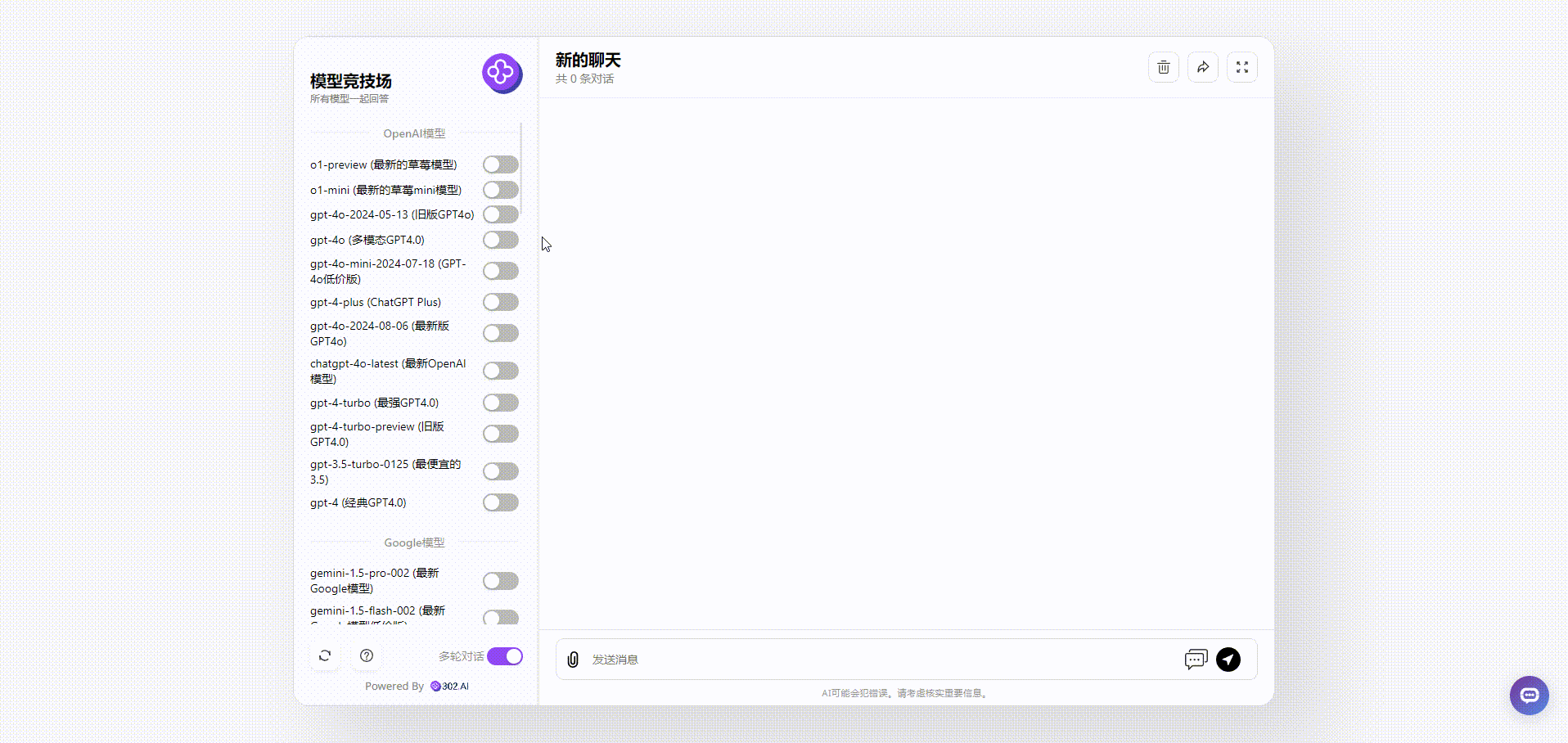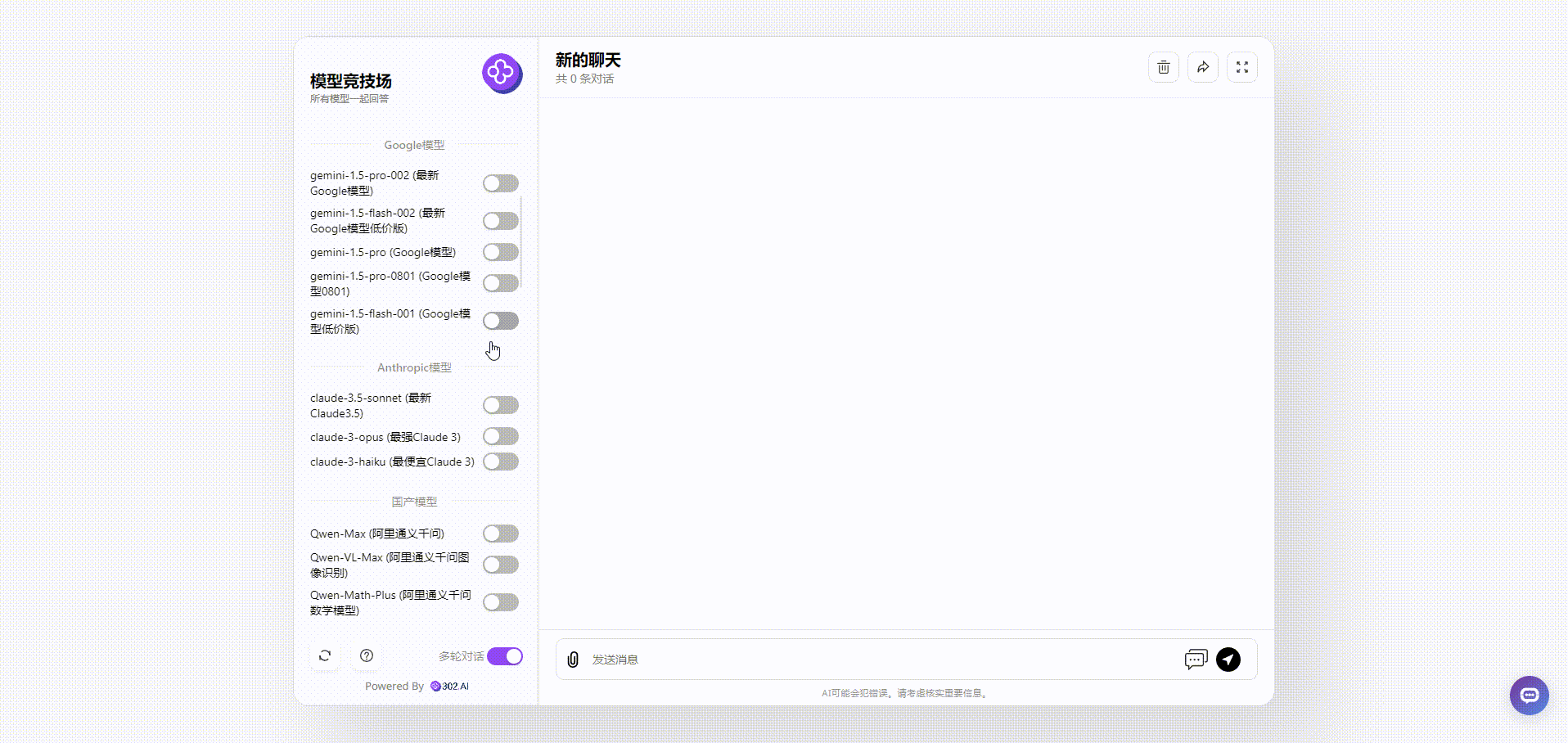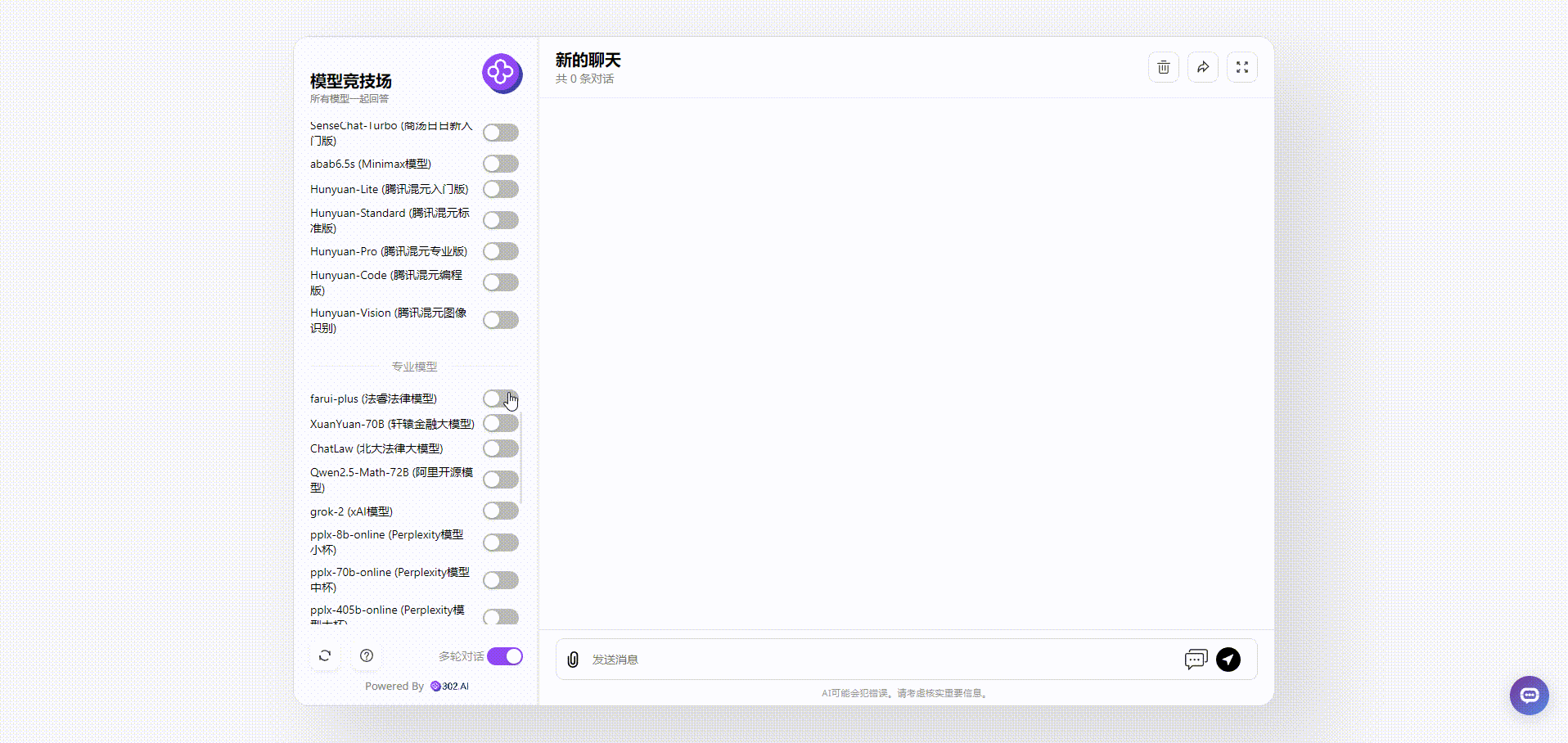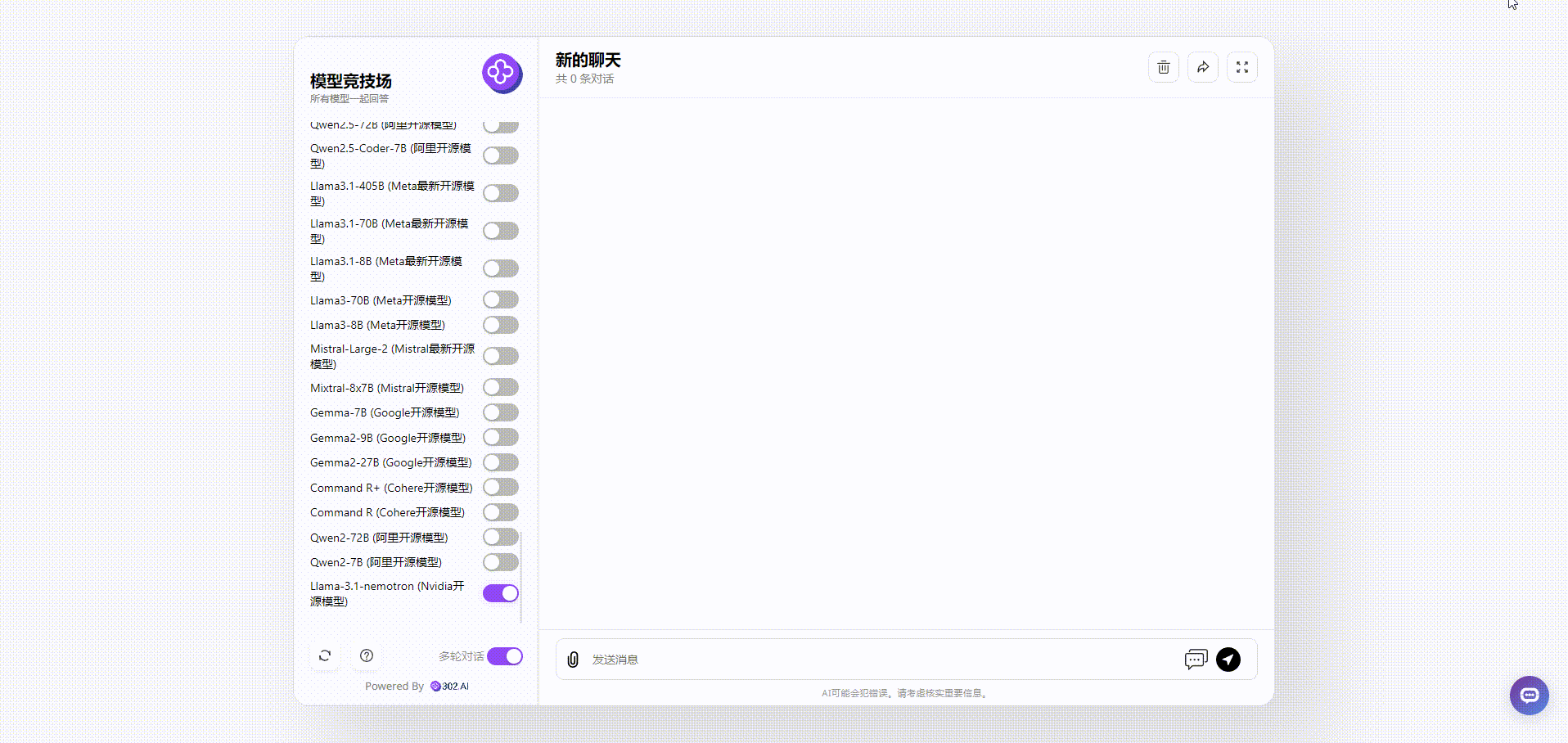
进入模型竞技场后,按需勾选模型,可以看到302.AI已经更新了“Llama-3.1-nemotron (Nvidia开源模型)”即是上文提到的Llama-3.1-Nemotron-70B-Instruct,按照Yuki的需求,一共勾选了四个模型,分别是:o1-preview、GPT-4o、Claude 3.5 Sonnet和Llama-3.1-nemotron (Nvidia开源模型):
![]()
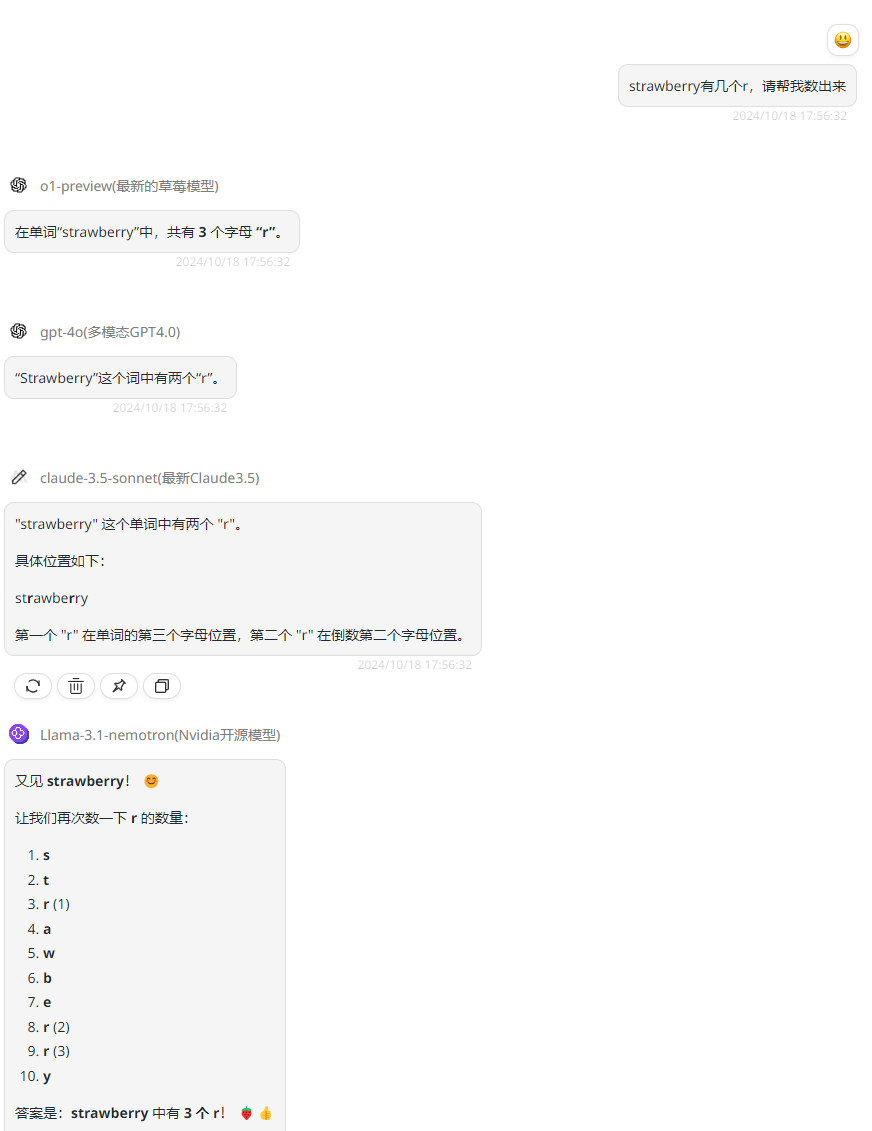
先测试一下官方给出的草莓问题,从结果来看,只有Llama-3.1-Nemotron-70B-Instruct和o1-preview回答正确,不过Llama-3.1-Nemotron-70B-Instruct更详细的数了出来:
![]()
再来测试一个“煮鸡蛋和煎饼问题”:
题目:煮1个鸡蛋需要5分钟,煎一块饼的一面需要3分钟,饼需要翻面两次才能熟。煮锅和煎锅可以同时开火,煎锅一次最多只能放两块饼,那么我想要煮3个鸡蛋和3块饼,最快一共需要几分钟?
看下在这一问题上三个模型的表现怎么样:
先给大家看看标准答案,来自老朋友GPT-4o,其实这道题的难点在于题目问的是“最快需要几分钟”,这考验了对时间最优化的理解和计算,可以看到GPT-4o的回答给出了最优最详细的方案:
![]()
再来看看Claude 3.5 Sonnet,虽然懂得把3个鸡蛋放一起煮,但是在煎饼的时候并没有找到真正的最优方法,只是照常规的方式按顺序进行煎饼:

![]()
o1-preview的答案虽然很长很详细,但还是错的:

![]()
最后是今天的主角Llama-3.1-Nemotron-70B-Instruct,Llama-3.1-Nemotron-70B-Instruct给出的答案有点难理解,整个逻辑有点绕,按照回答前部分的内容,即使第二轮开始时第一轮已经结束,花费的时间也是18分钟,不知道9分钟是如何得来的: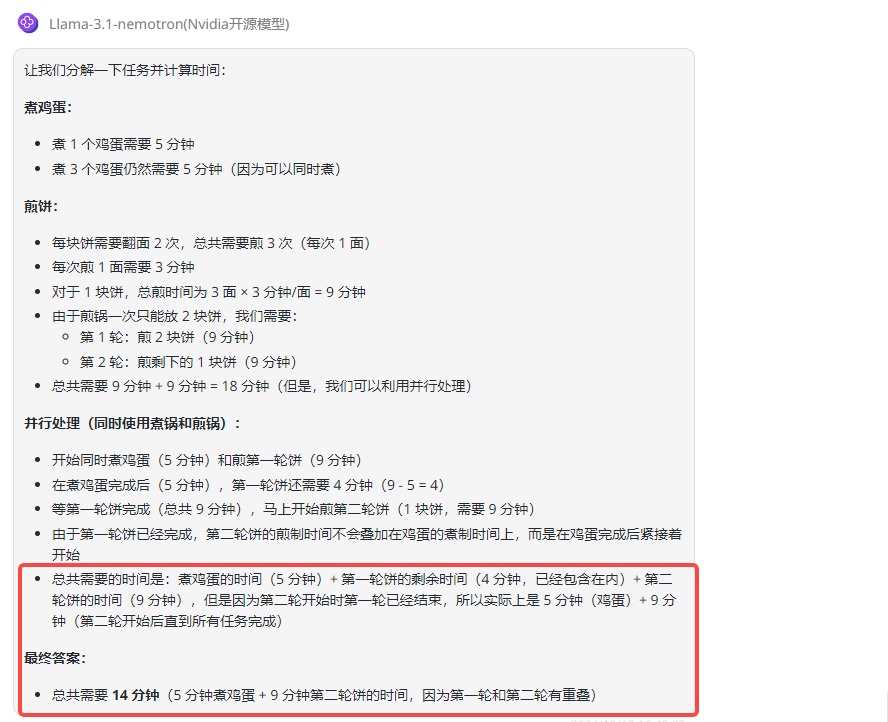
![]()
最后,在302.AI的API超市中也同步更新了Llama-3.1-Nemotron-70B-Instruct的API,用户可以快速快速理解和集成API,支持在线调试,能够节省时间并提高了工作效率:
![]()
![]()
虽然Llama-3.1-Nemotron-70B-Instruct在一些基准测试中表现出色,但在特定实际应用场景中的优化和表现似乎还有比较大的改进空间。具体而言,在这类时序优化问题上,该模型在逻辑推理能力和回答准确性方面可能仍不如GPT-4o那么成熟。尽管如此,Llama-3.1-Nemotron-70B-Instruct的出现,展示了高质量的私有数据微调潜力。
展望未来,我们302.AI会持续更新更多最新、最强的模型,致力于满足用户日益增长的需求和期待,欢迎大家来302.AI体验!
参考文章:
https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Instruct https://mp.weixin.qq.com/s/ebJkBkGAn8QS-_xVK__MMw
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
