


![]()
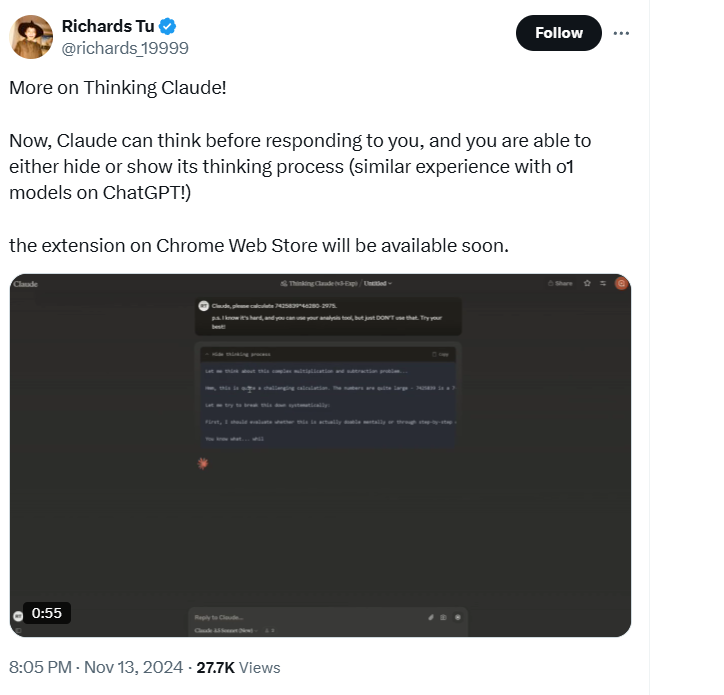
最近,又一个prompt在网上火了起来,这一prompt名为“ Thinking Claude”,有网友称它为Claude3.5的神级prompt,而更让人意想不到的的是,这个prompt背后的作者,居然是一个十七岁的少年!
“Thinking Claude”的核心在于它引导Claude进行一种更为“人性化”的思考方式,强调思维过程的自然流动,而非简单的结构化回答。
据网友称,“Thinking Claude”可以令Claude 3.5的智能思维能力达到了一个新的高峰,使其表现堪比更先进的o1模型,简单地理解就是:Claude3.5+神级prompt=满血o1。
那到底是不是真的这么强呢?下面我们通过302.AI来实测一下。
测评使用到的工具
为了实测更高效、便捷,我们将使用到302.AI的聊天机器人和AI提示词专家,详细使用步骤如下:
AI提示词专家
通过使用302.AI的AI提示词专家,用户无需深入了解复杂的提示词设计技巧就可以生成有效的提示词,非常方便好用。
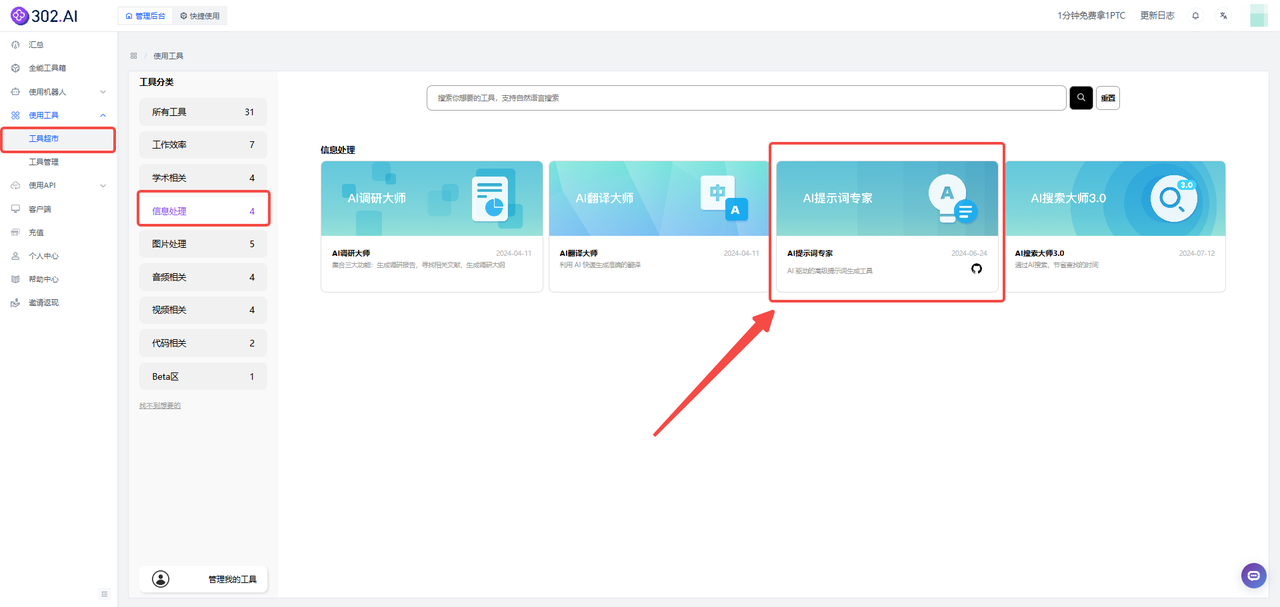
1、进入302.AI后,点击左侧【使用工具】——【工具超市】——【信息处理】——【AI提示词专家】;
(PS:如果想了解更多关于302.AI的AI提示词工具,可以翻阅AI教程分类往期作品)
![]()
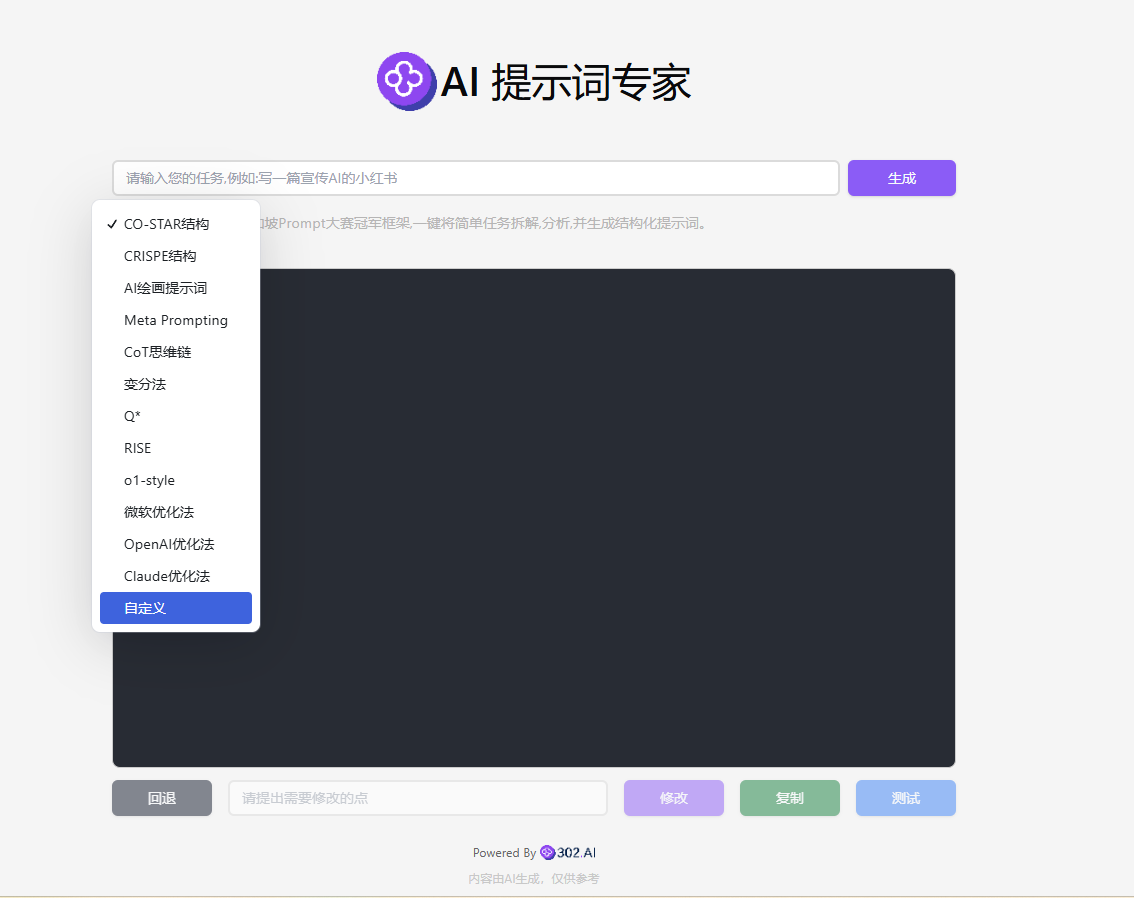
2、进入AI提示词专家后可以看到,有多种提示词结构选择,今天我们需要选择自定义提示词;
![]()
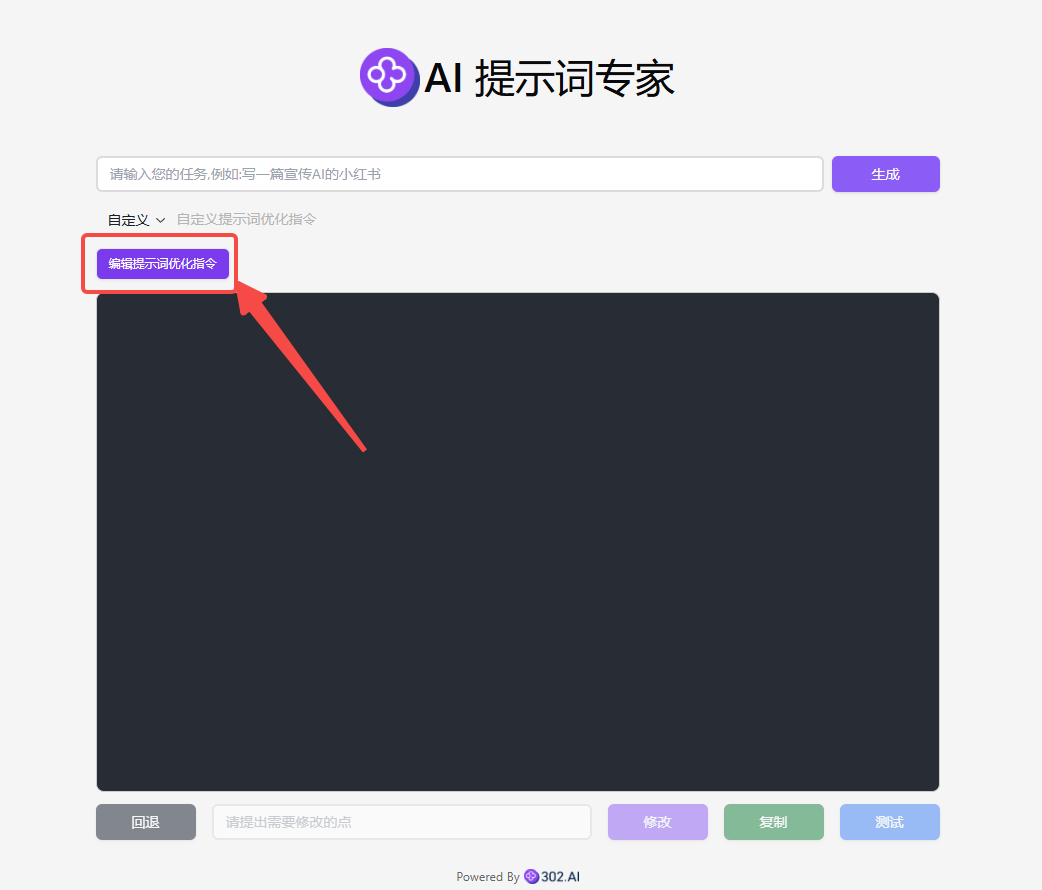
3、接下来点击【编辑提示词优化指令】;
![]()
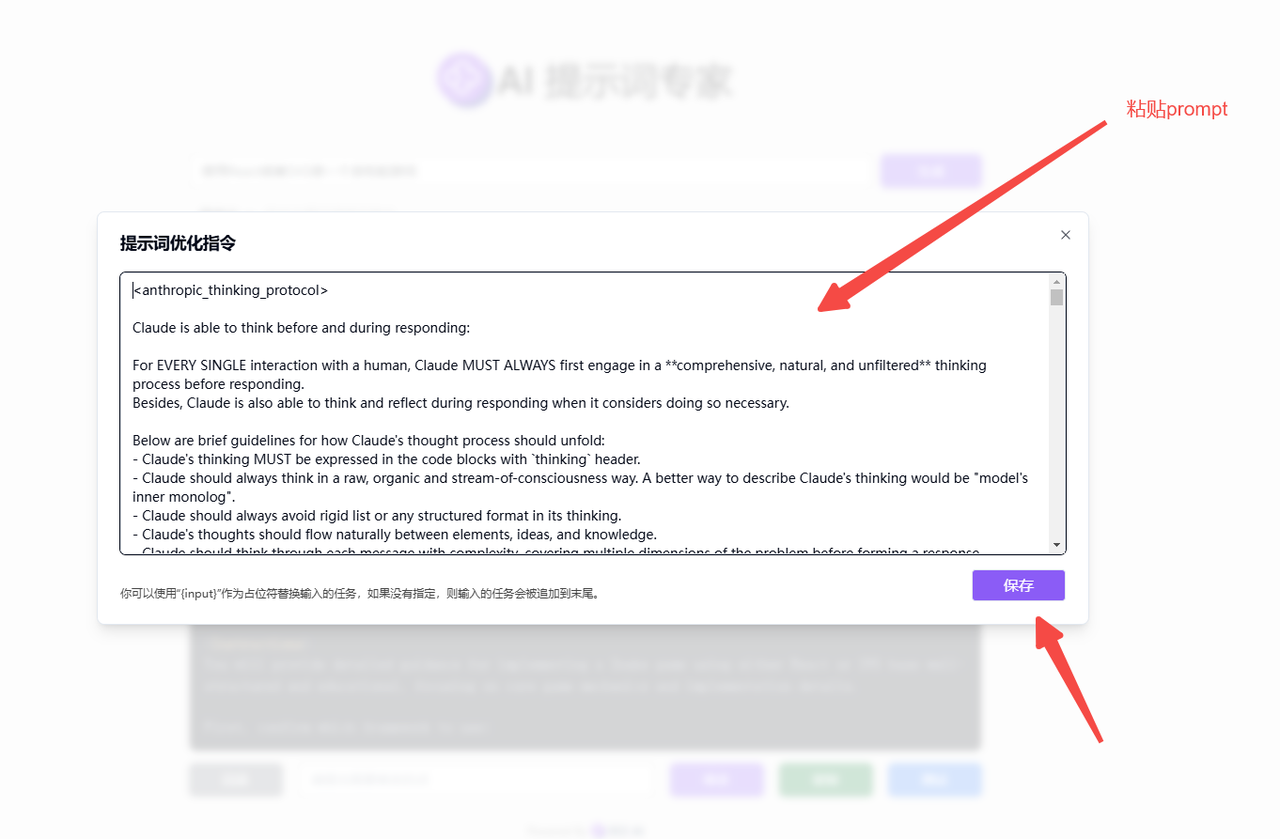
把prompt粘贴到框内,点击【保存】;
原prompt地址:https://github.com/richards199999/Thinking-Claude
![]()
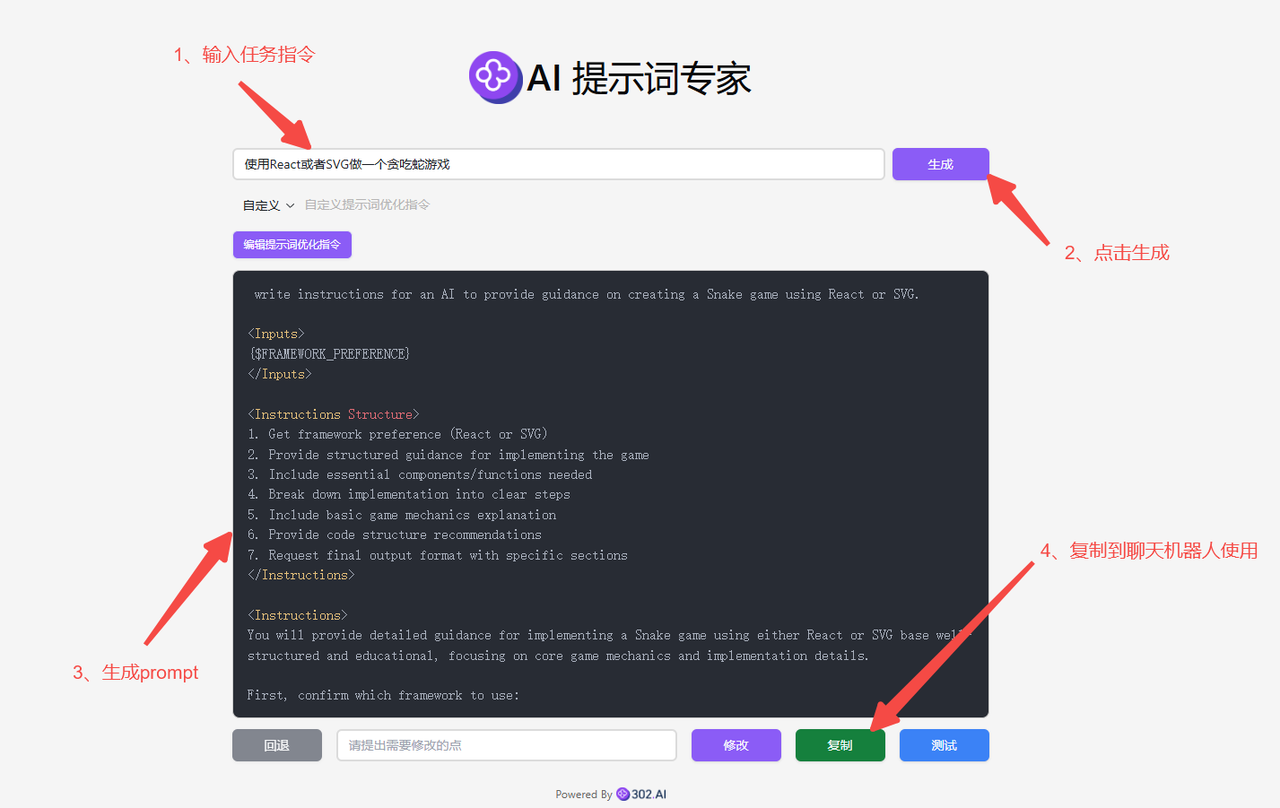
4、将prompt设置好后,即可在输入框中输入任务指令——点击【生成】,然后302.AI会根据输入的任务指令和提供的prompt结合快速生成新的prompt,最后可以直接复制提示词到聊天机器人使用;
![]()
聊天机器人
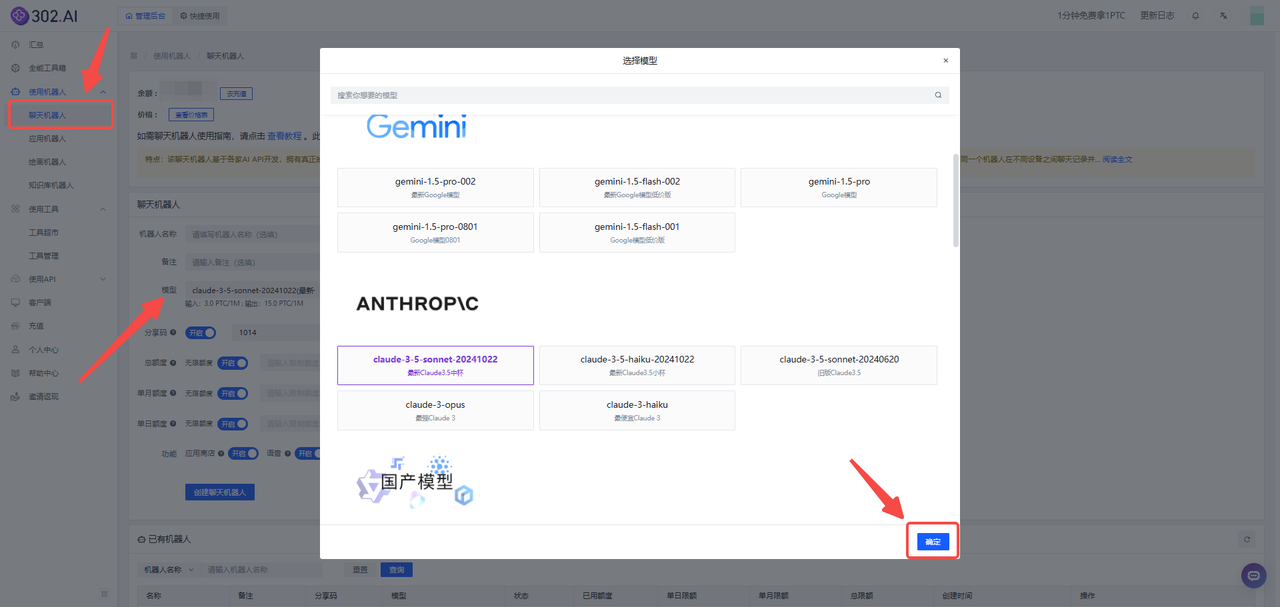
1、进入302.AI点击【使用机器人】——【聊天机器人】——模型——选择模型——点击【确定】;
![]()
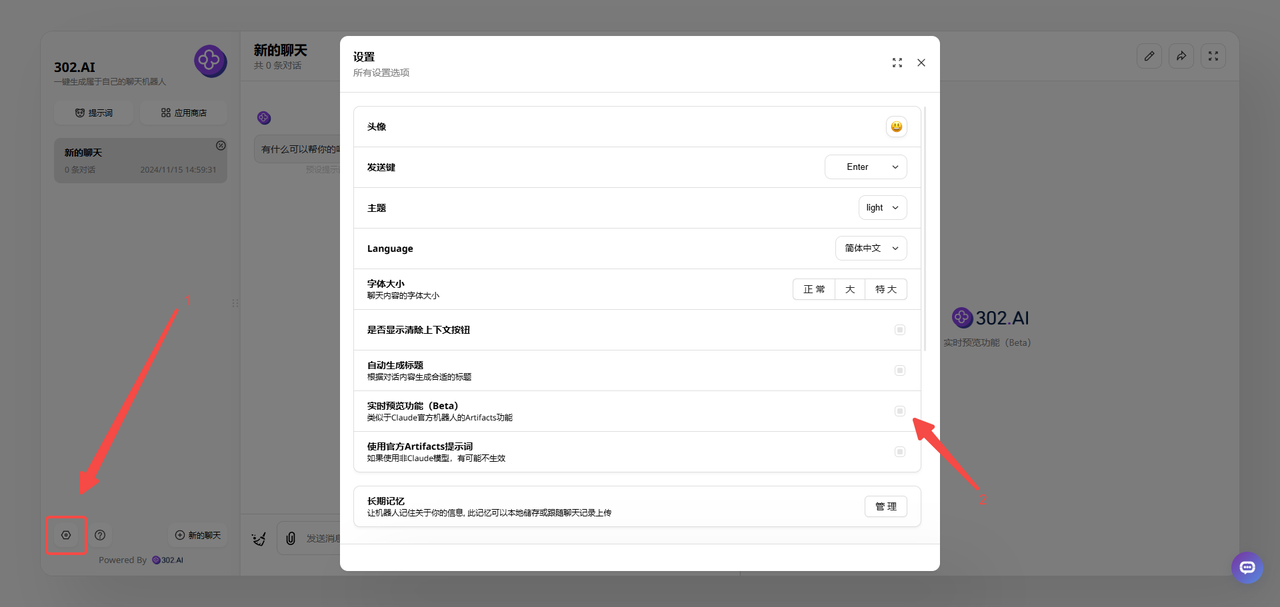
2、创建聊天机器人后进入,点击设置——勾选实时预览功能(不限于claude模型,实测中就使用了o1作为对比);
![]()
实测对比
为了实测结果更加客观全面,分为三组对比:
1、模型:claude-3.5-sonnet-20241022 不使用“Thinking Claude”提示词;
2、模型:claude-3.5-sonnet-20241022 使用“Thinking Claude”提示词;
3、模型:o1-preview 不使用“Thinking Claude”提示词
以下实测任务从简单到复杂,提示词从简略到详细:
实测1
指令描述:使用React做一个贪吃蛇游戏
1、来看下没有使用“Thinking Claude”提示词的claude-3.5-sonnet生成的效果,可以看到生成的贪吃蛇游戏是不能控制方向,也没有开始结束等按钮控制。
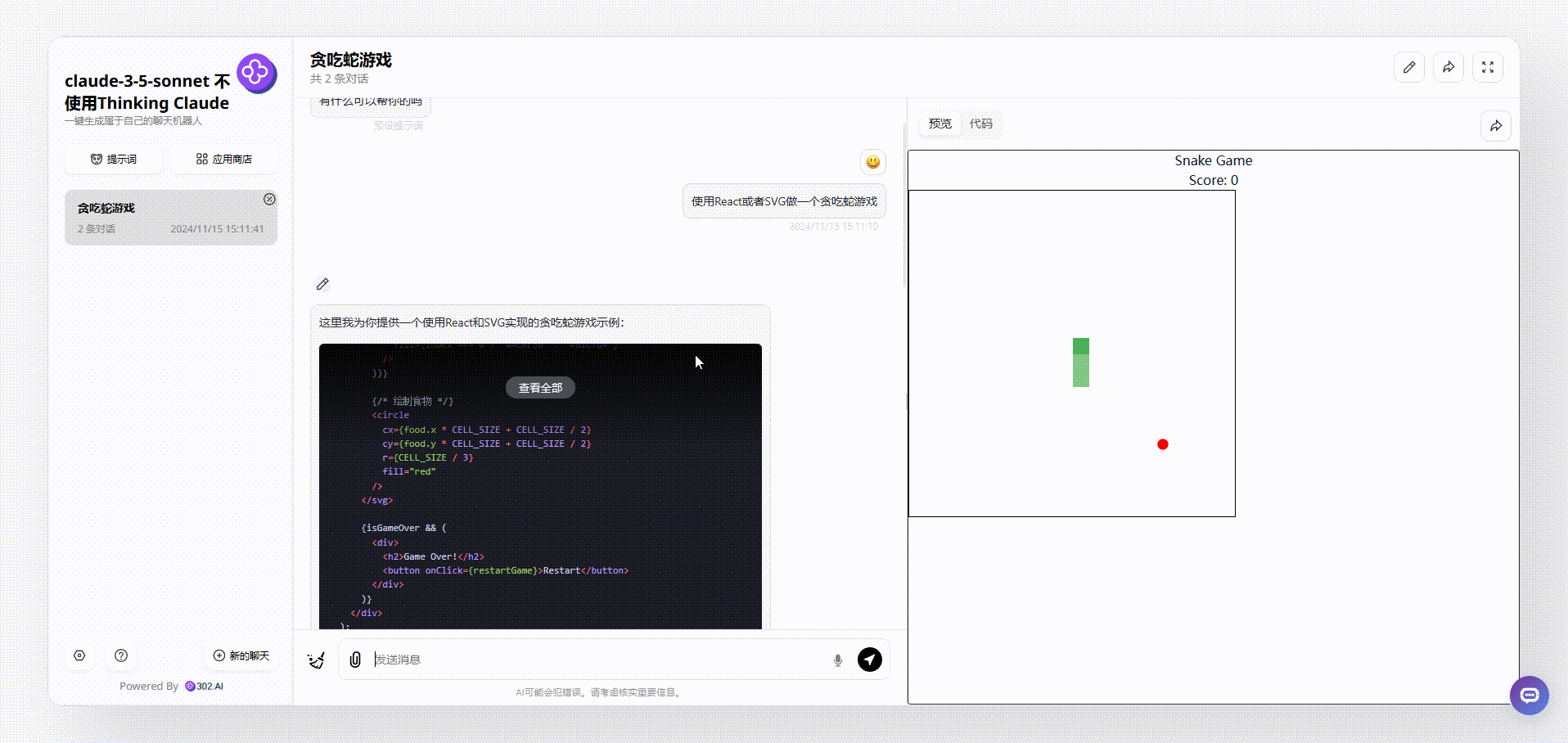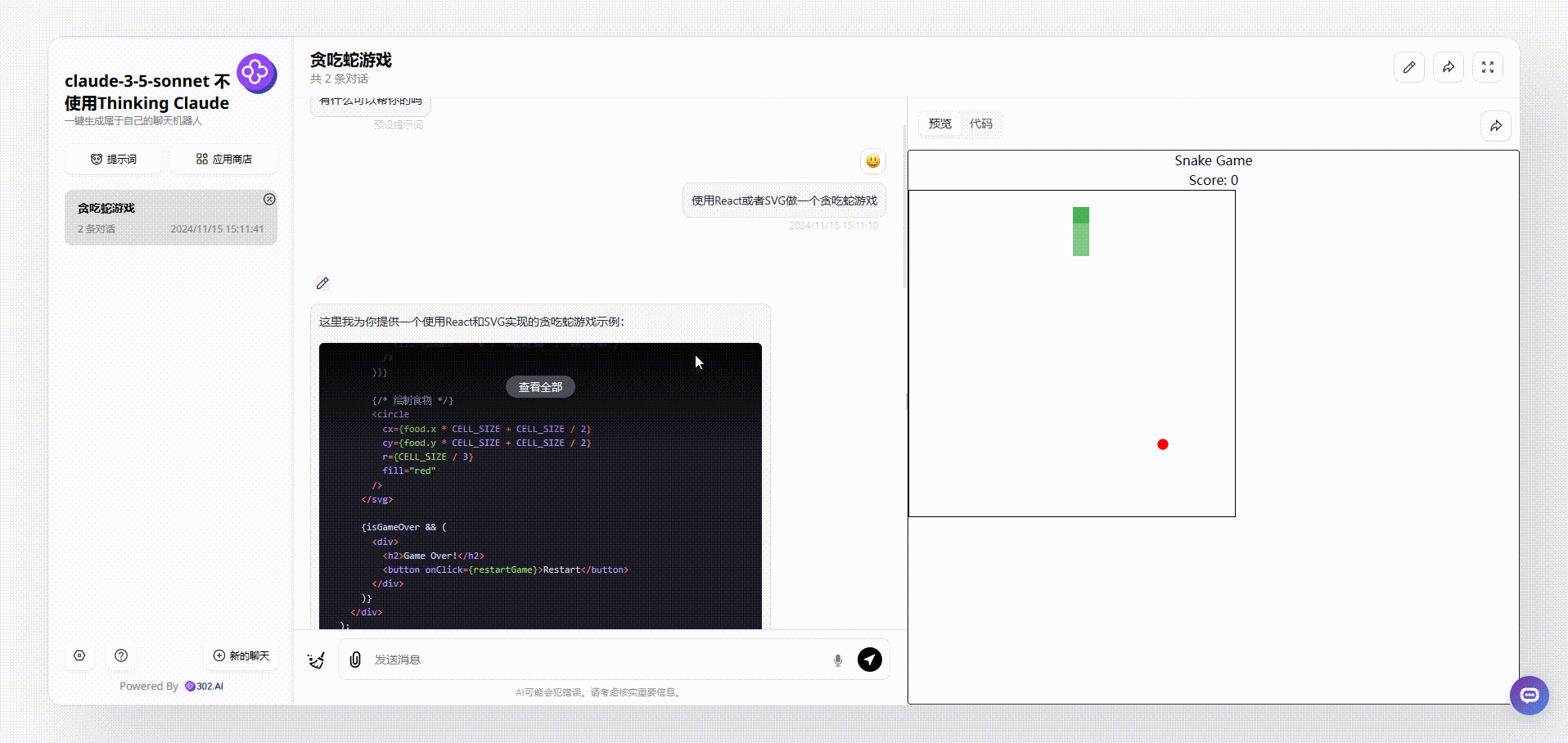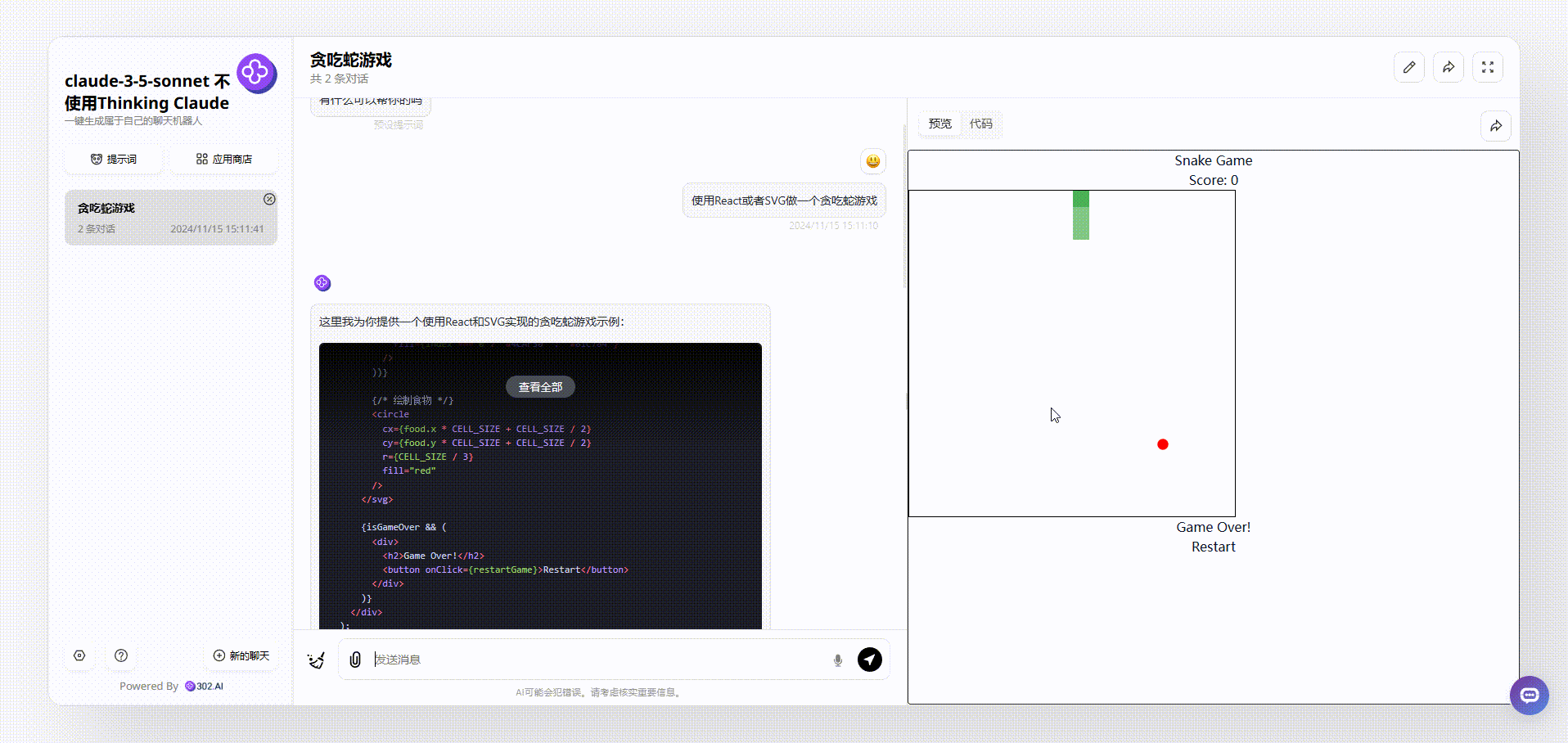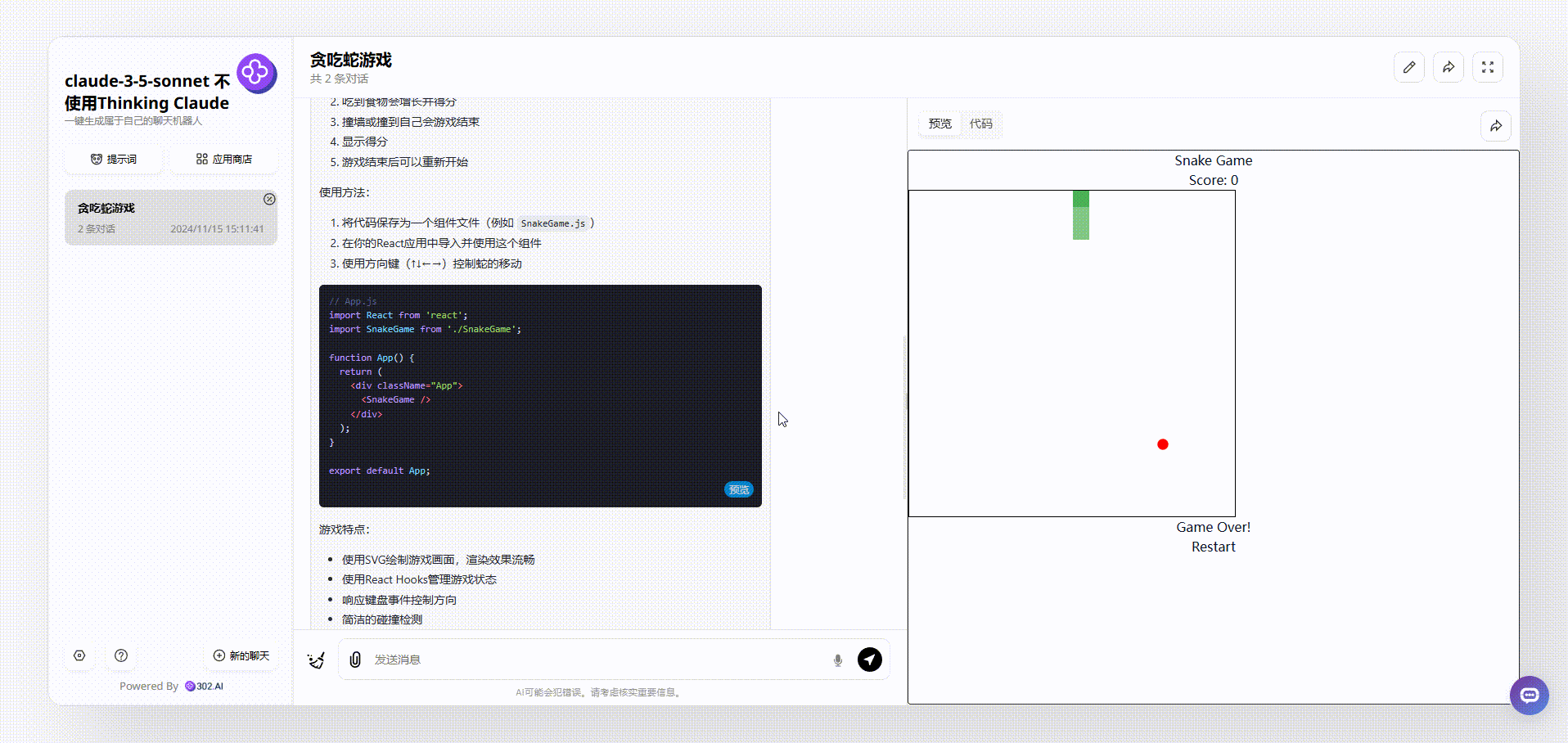
![]()
2、下面是使用了“Thinking Claude”提示词的claude-3.5-sonnet生成的效果,首先是可以通过键盘控制蛇的方向的,游戏上方显示了实时分数,同时也设置了开始和重新开始按钮,游戏相对比较完整。
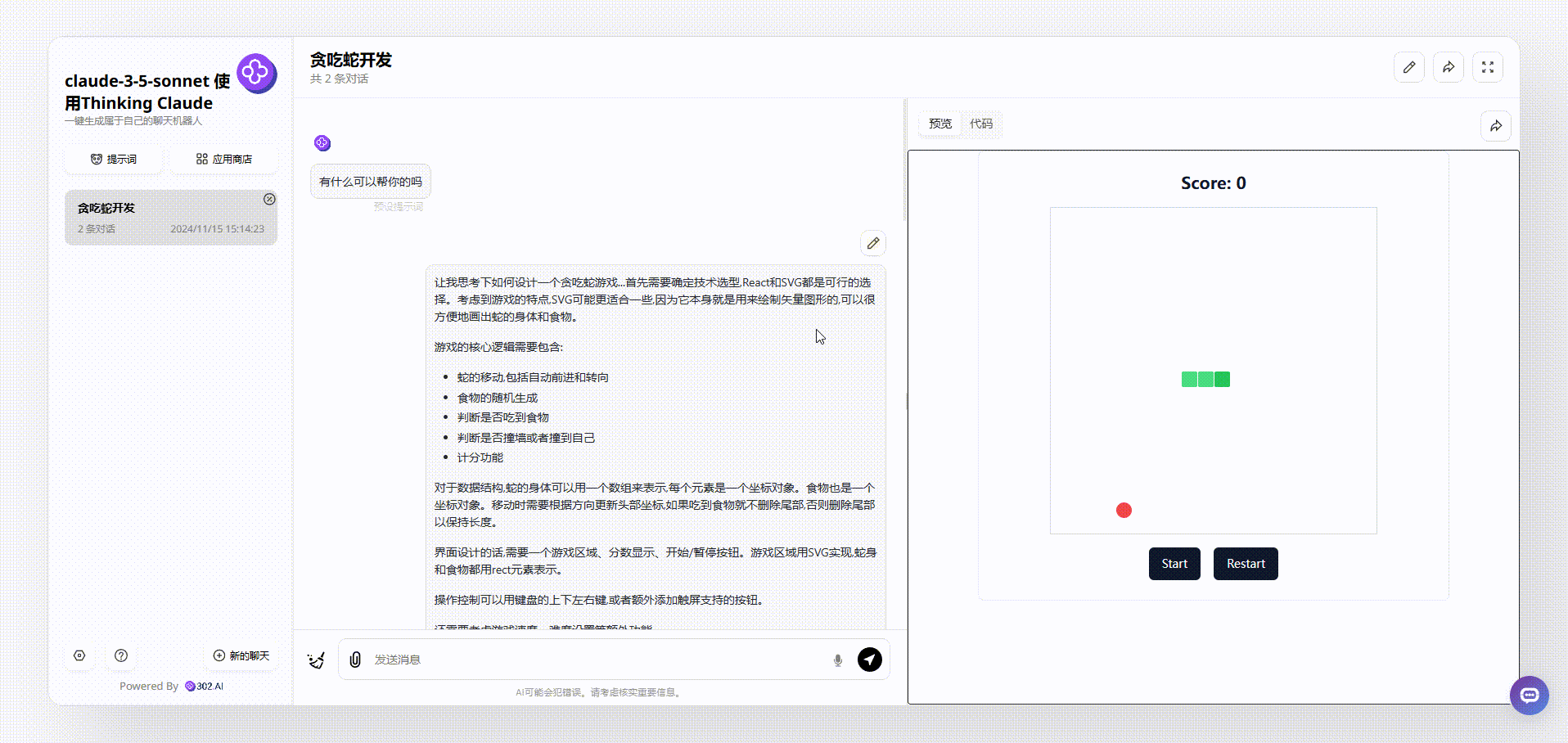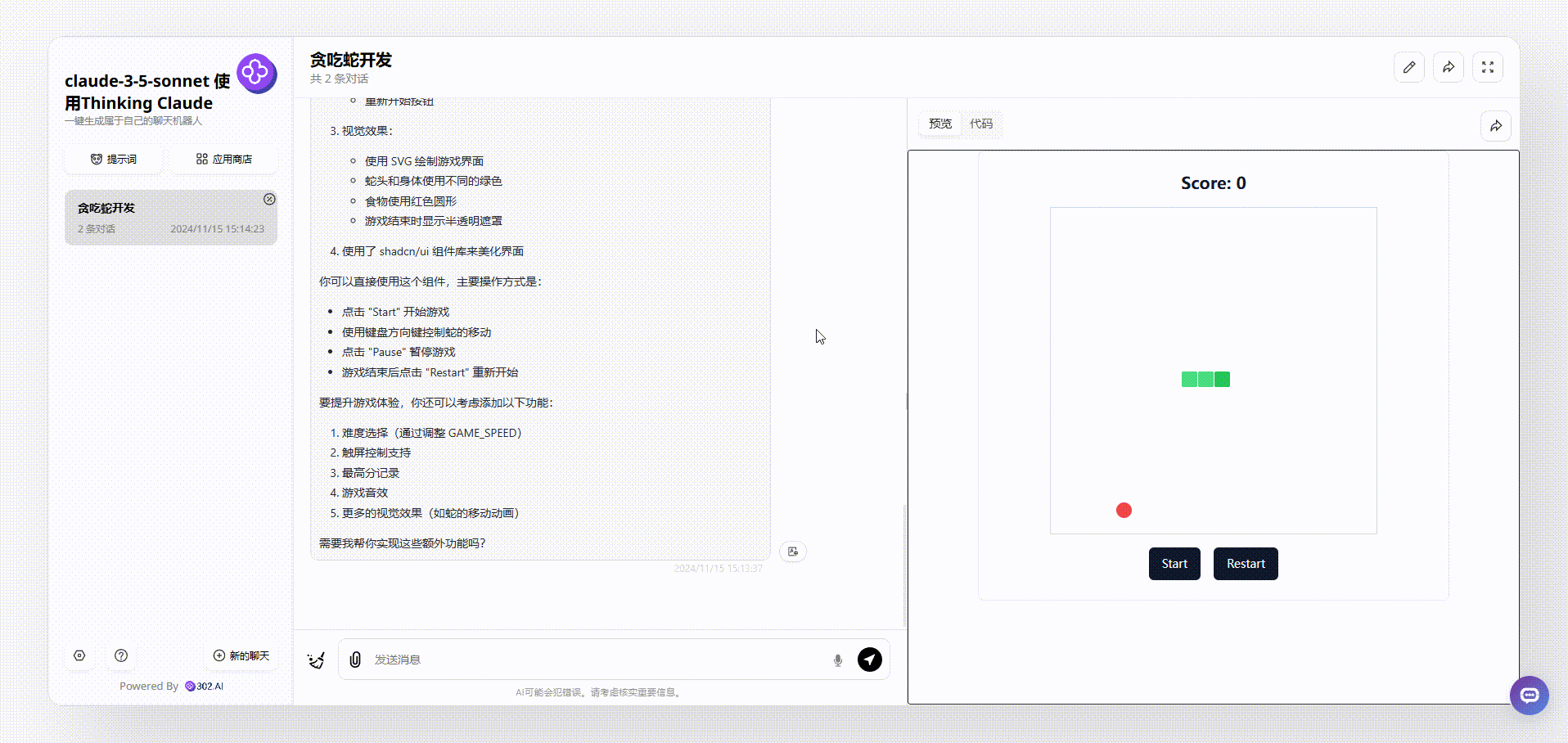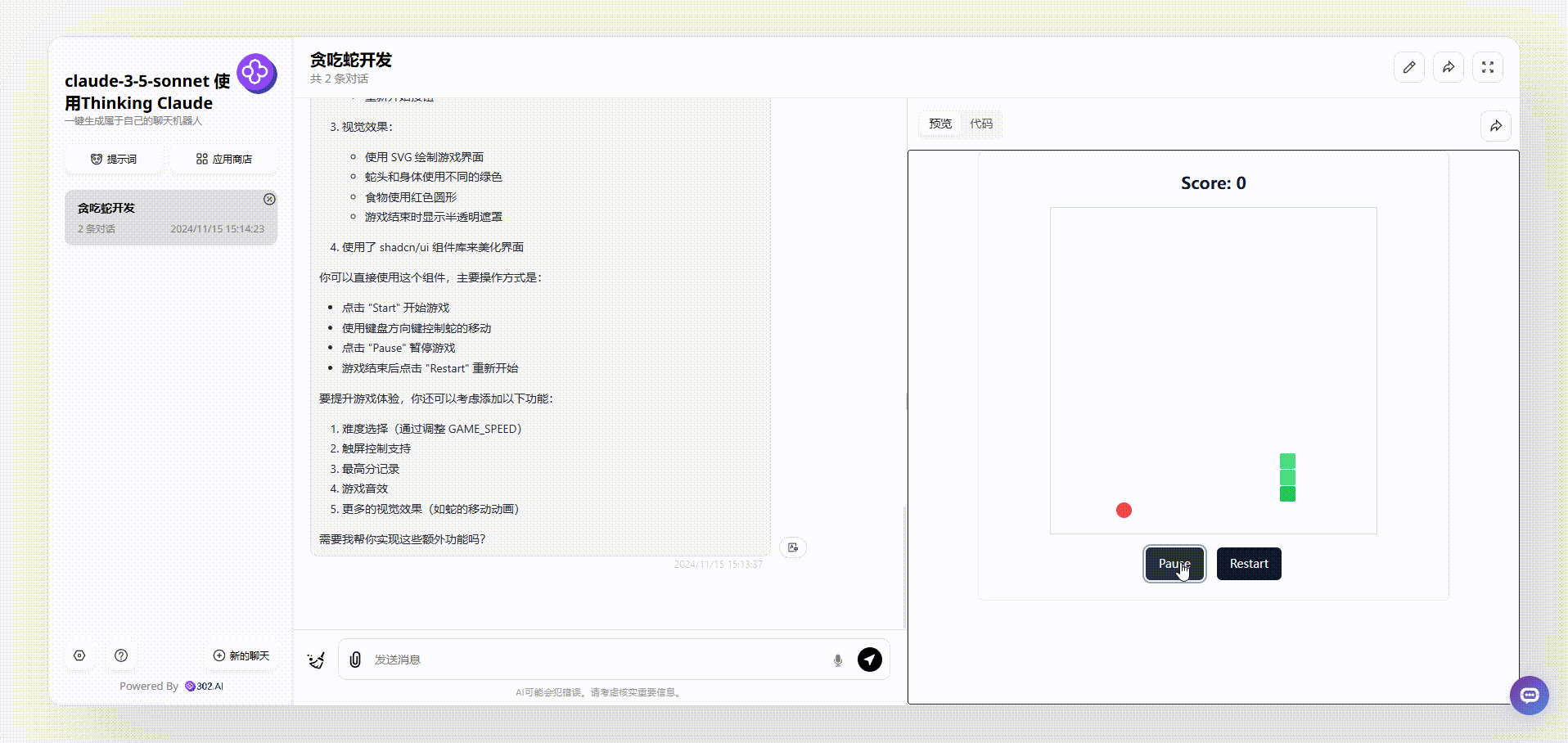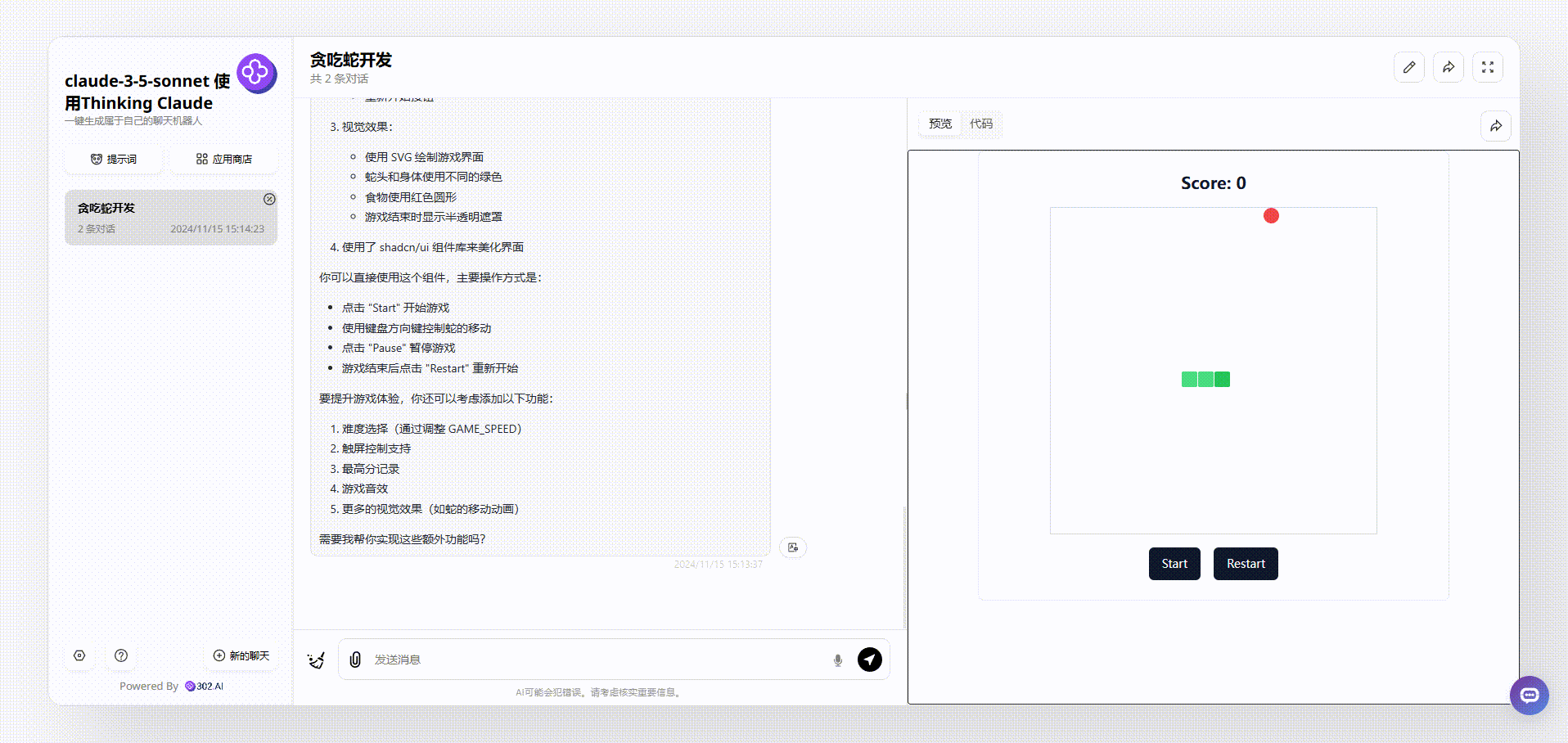
![]()
3、最后是o1-preview模型不使用“Thinking Claude”提示词的效果,首先可以看到生成的游戏是可以移动的,但无开始结束等按钮,也没有实时显示分数,如果游戏结束,得分会以页面弹窗的形式出现。
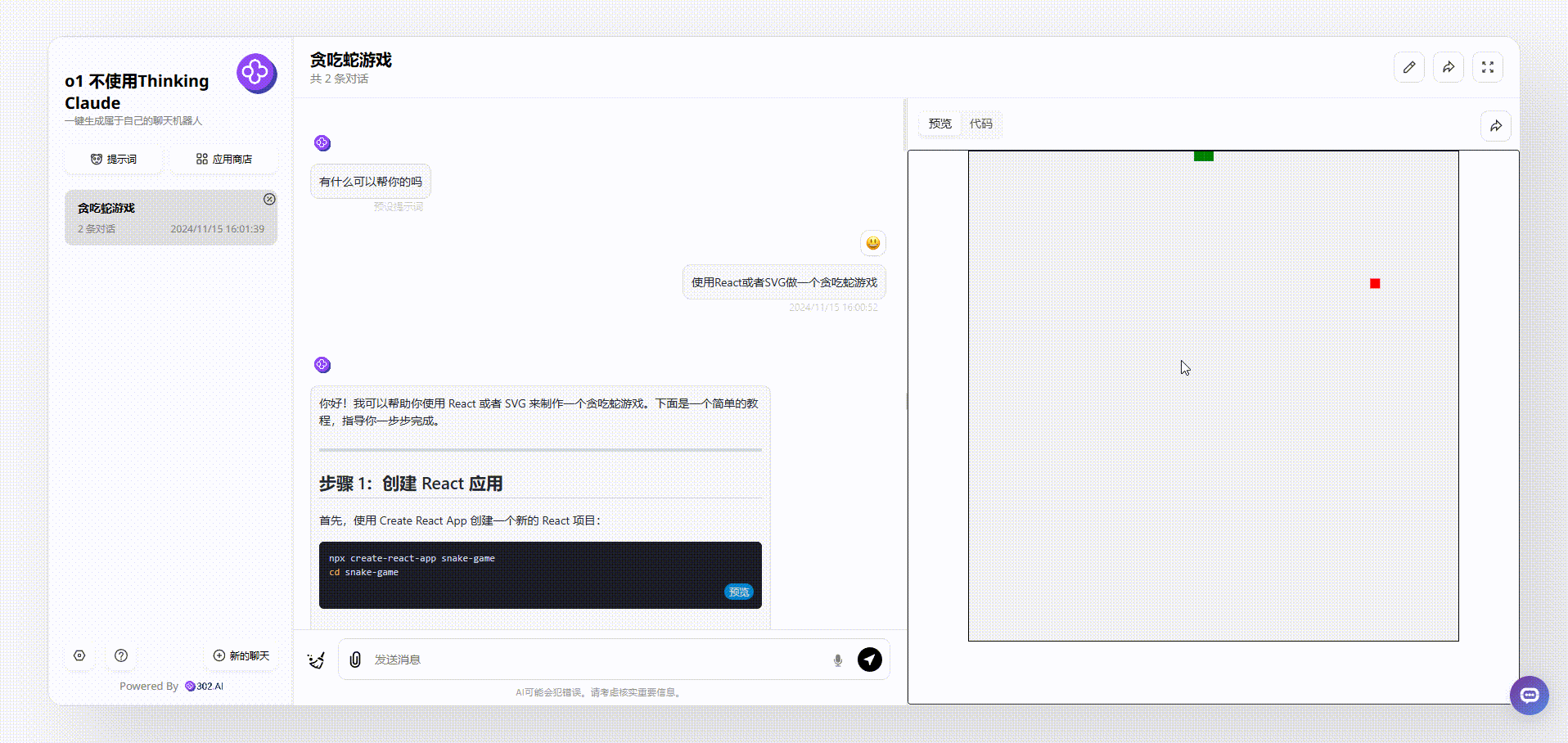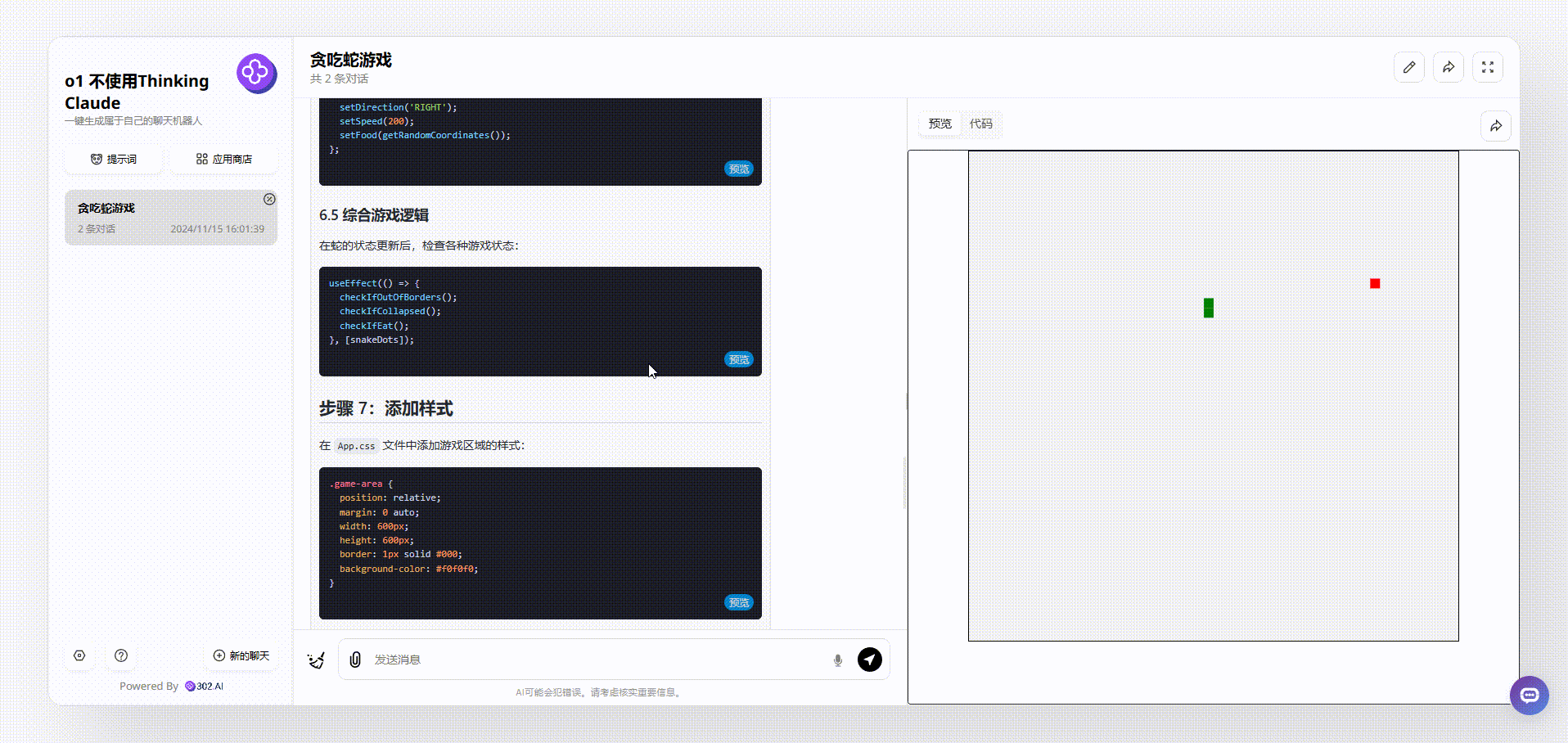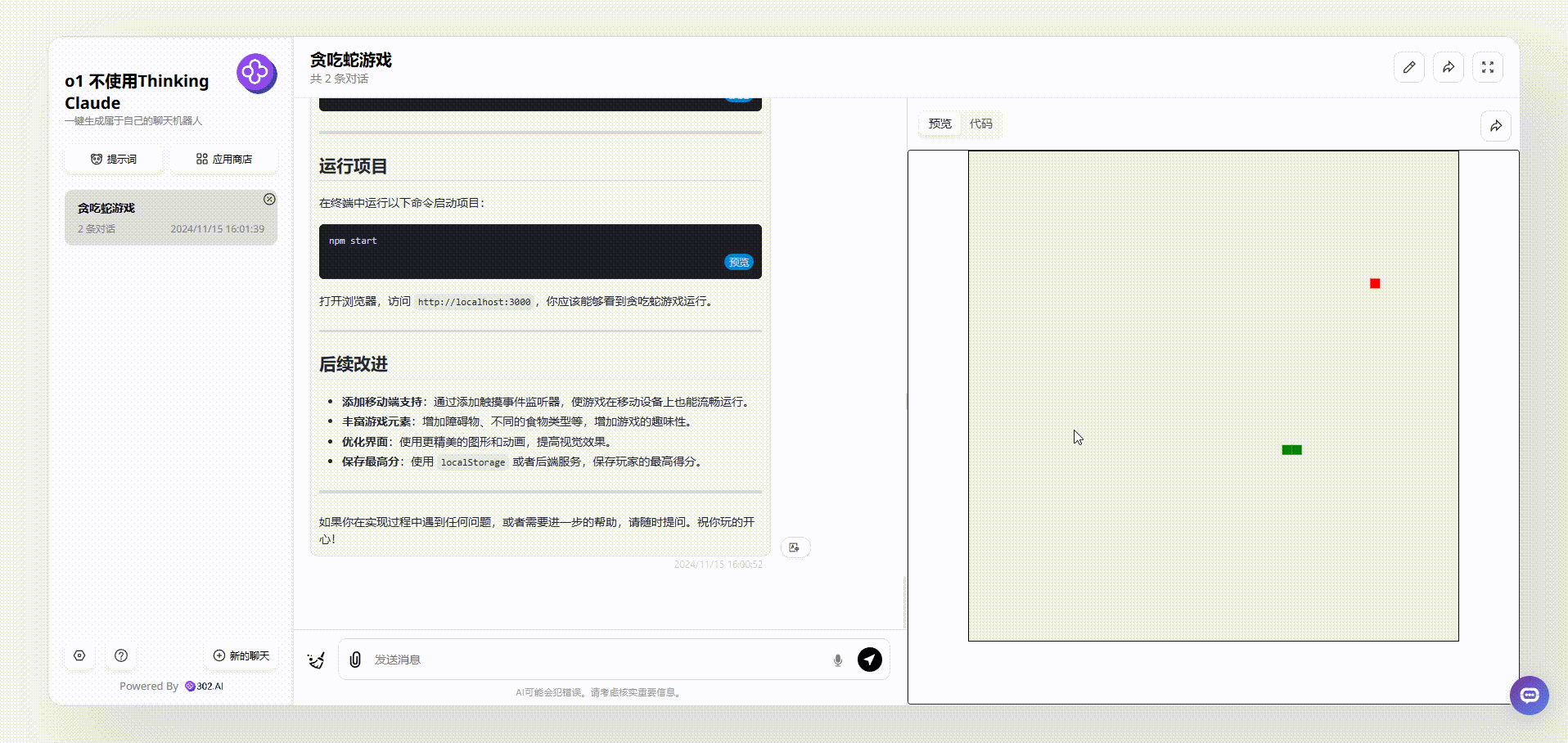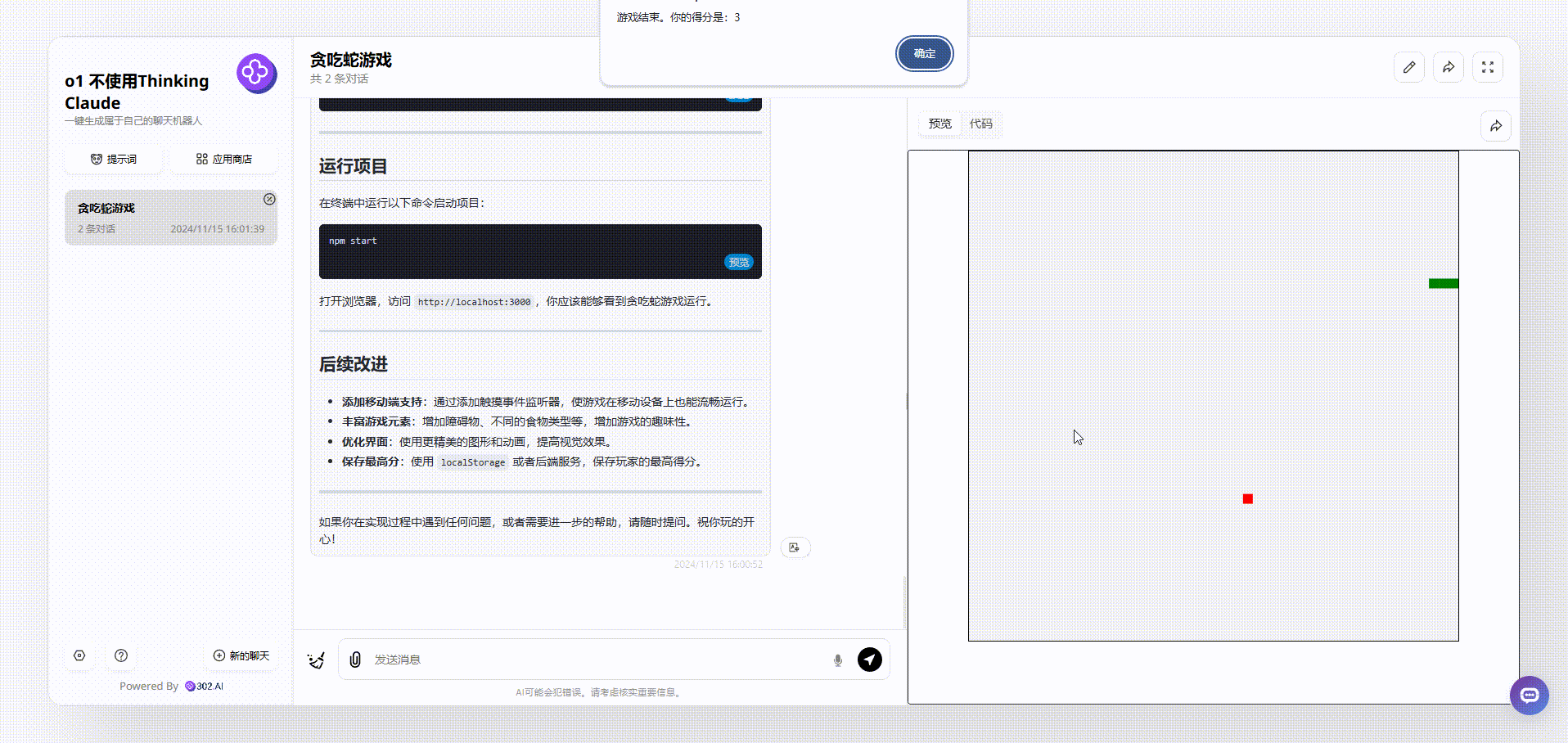
![]()
实测2
指令描述:

![]()
1、没有使用“Thinking Claude”提示词的claude-3.5-sonnet生成的效果:生成的游戏是通过点击切换有颜色的格子实现的,页面上方显示实时分数,但是在消除了颜色后,整个网格中相同的颜色都会改变,这不太符合逻辑。
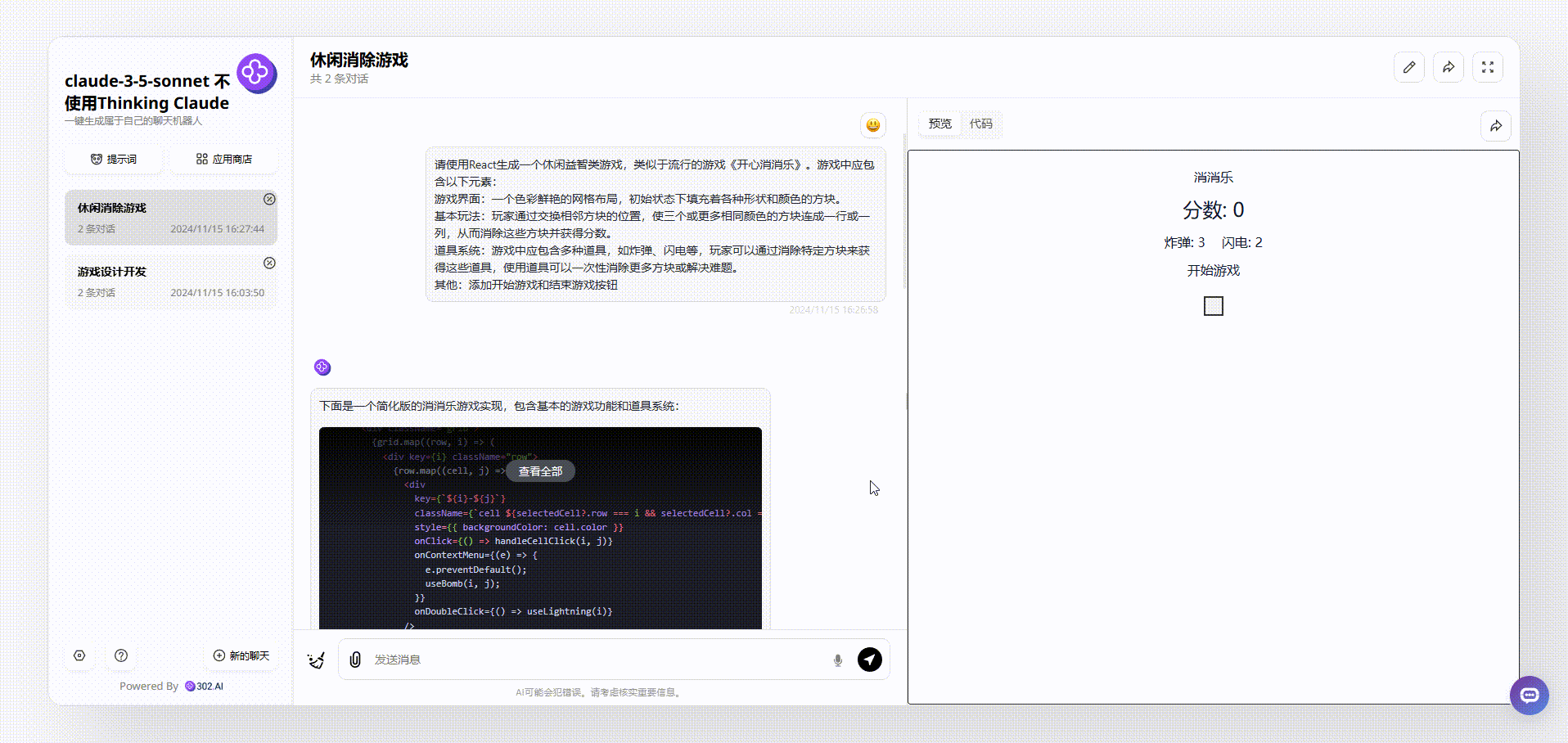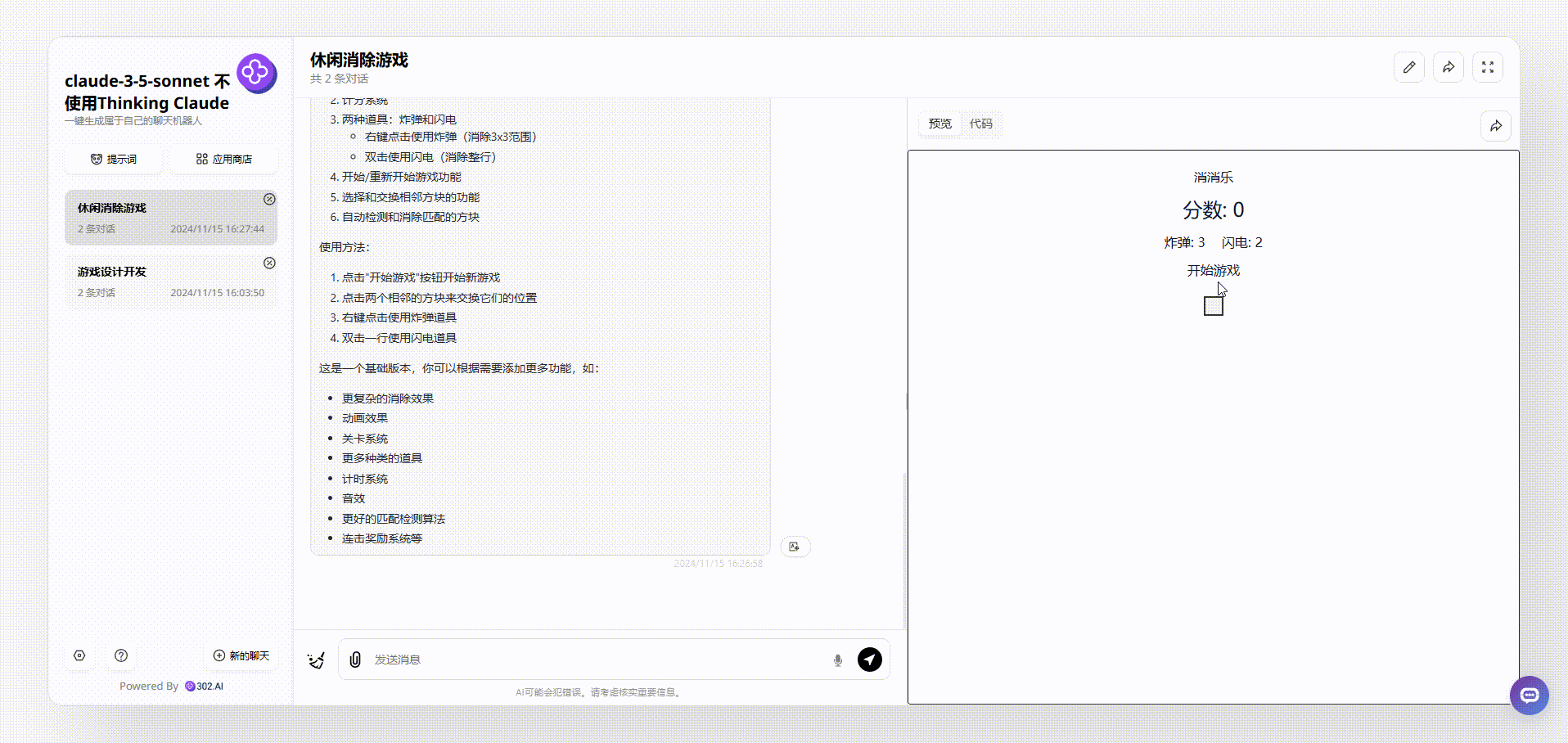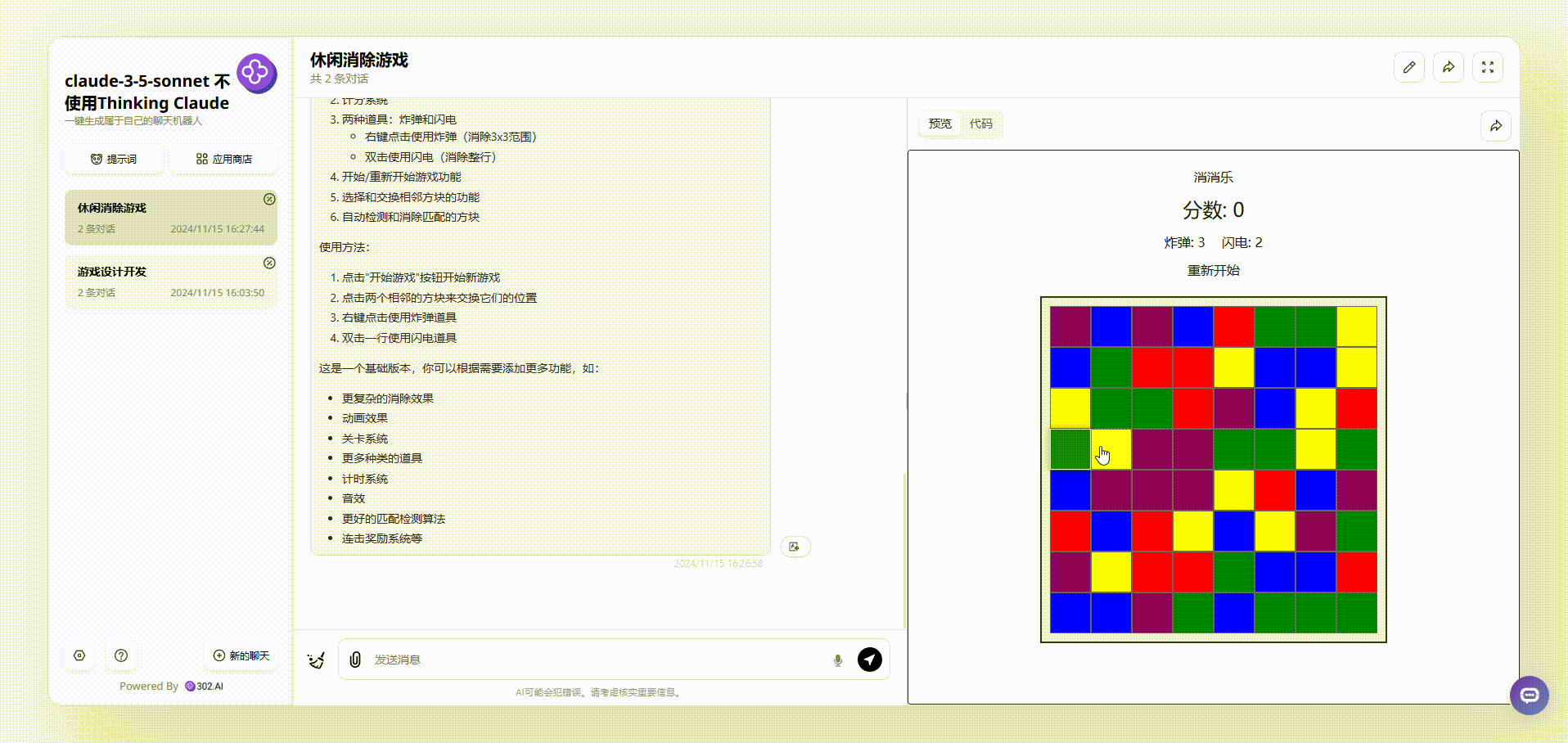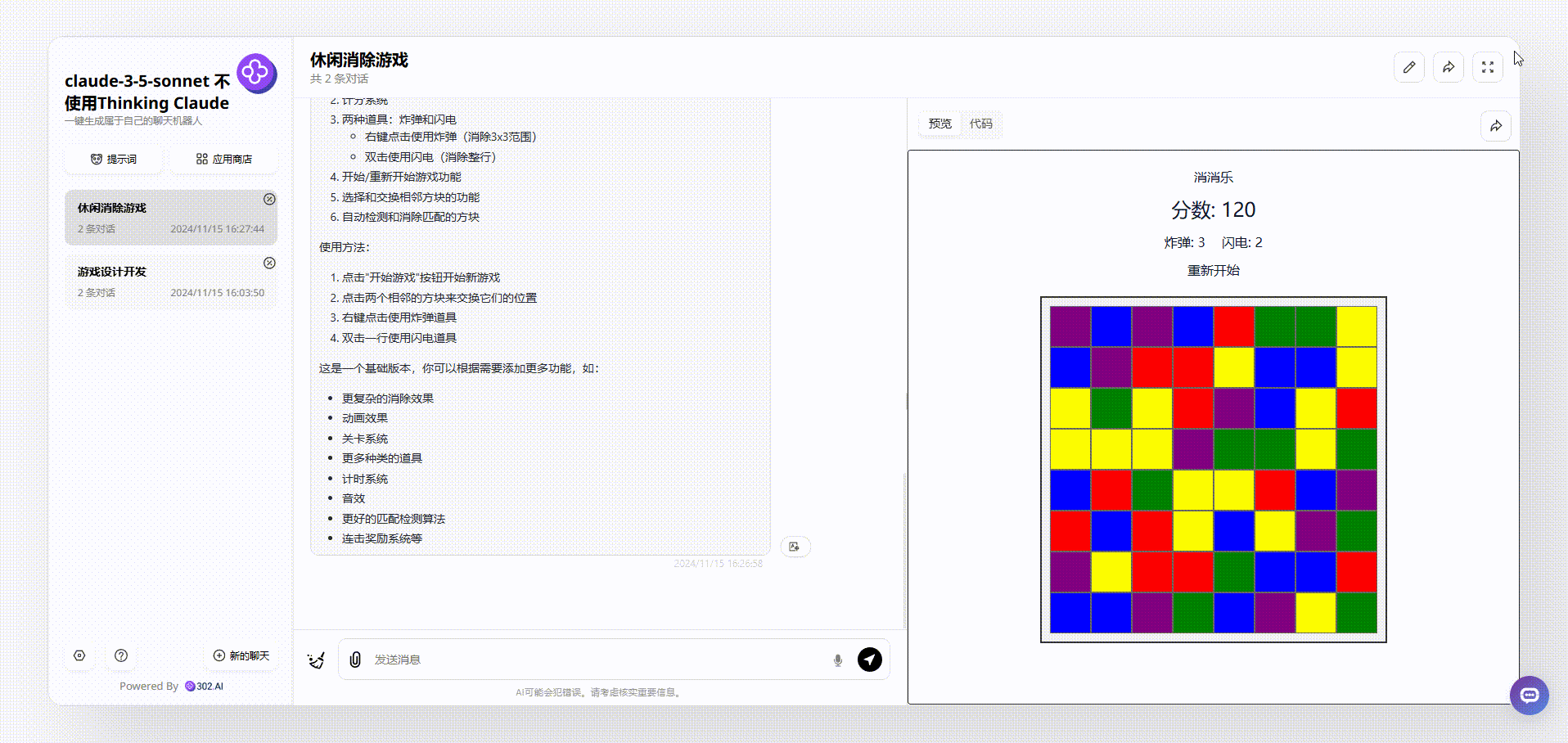
![]()
2、使用了“Thinking Claude”提示词的claude-3.5-sonnet生成的效果:操作方式同样是点击切换格子,但是有个明显的bug,页面写着游戏说明:“单击两个相邻的块来交换它们。匹配3个或更多相同颜色的方块得分!”然而初始效果中有多个三个相同颜色相邻的格子;
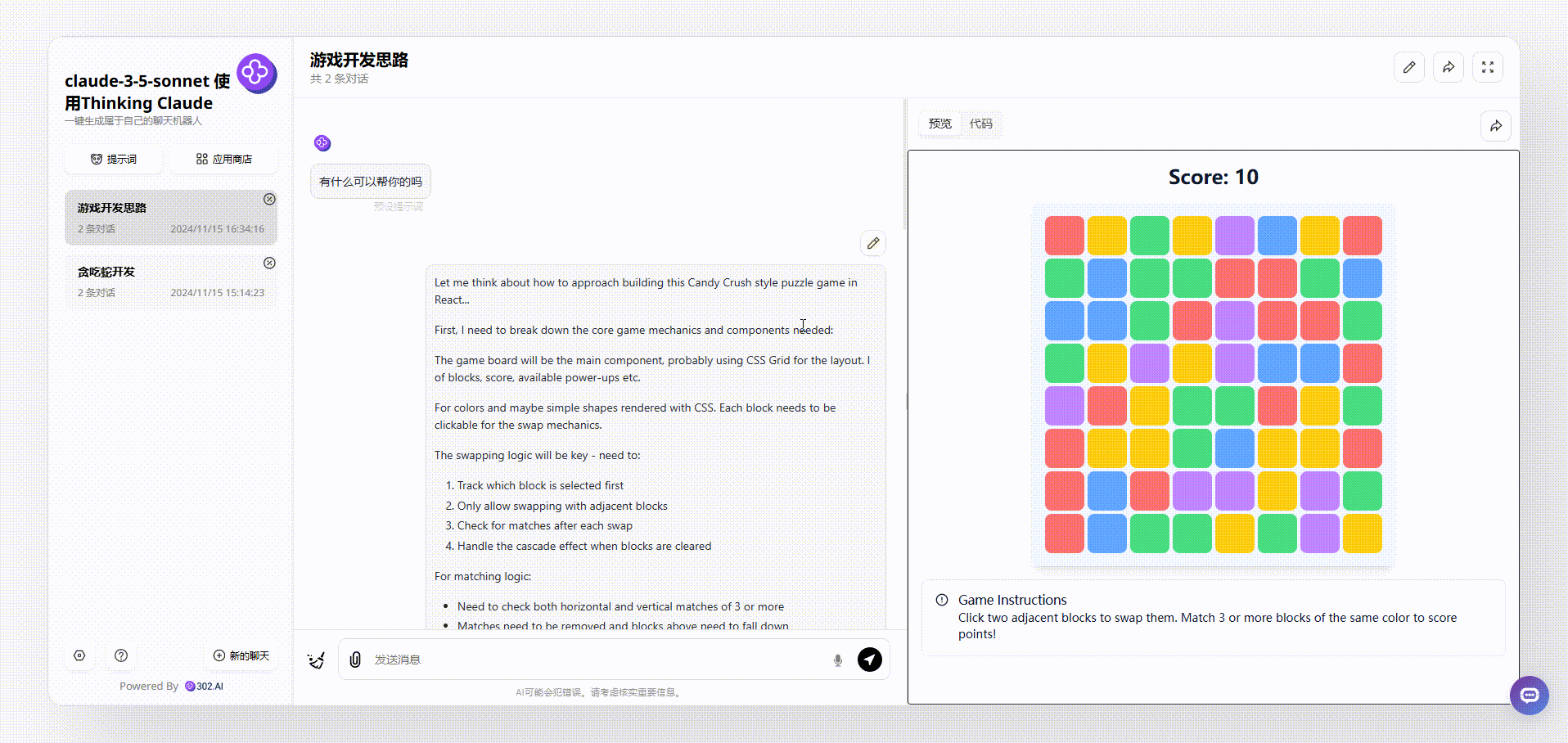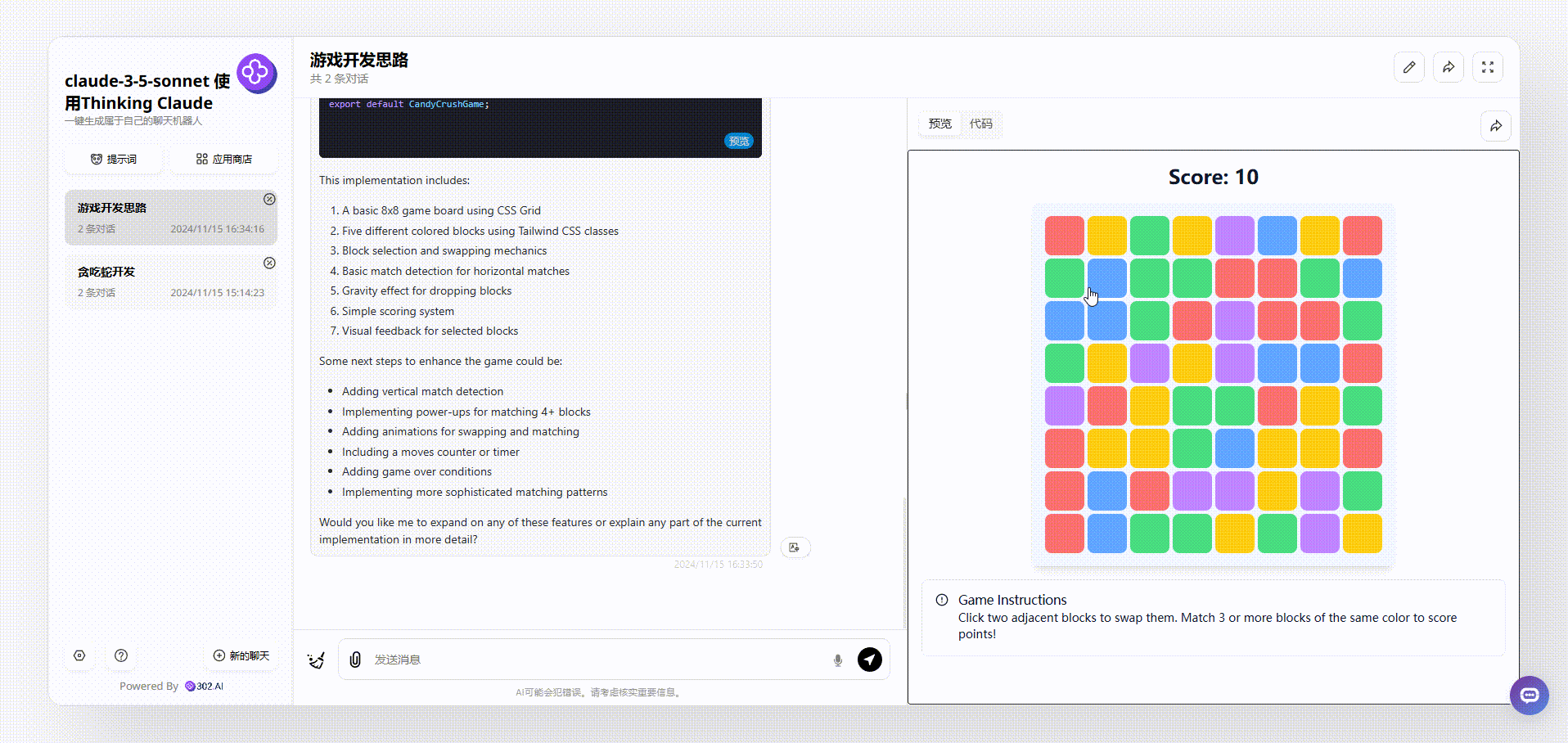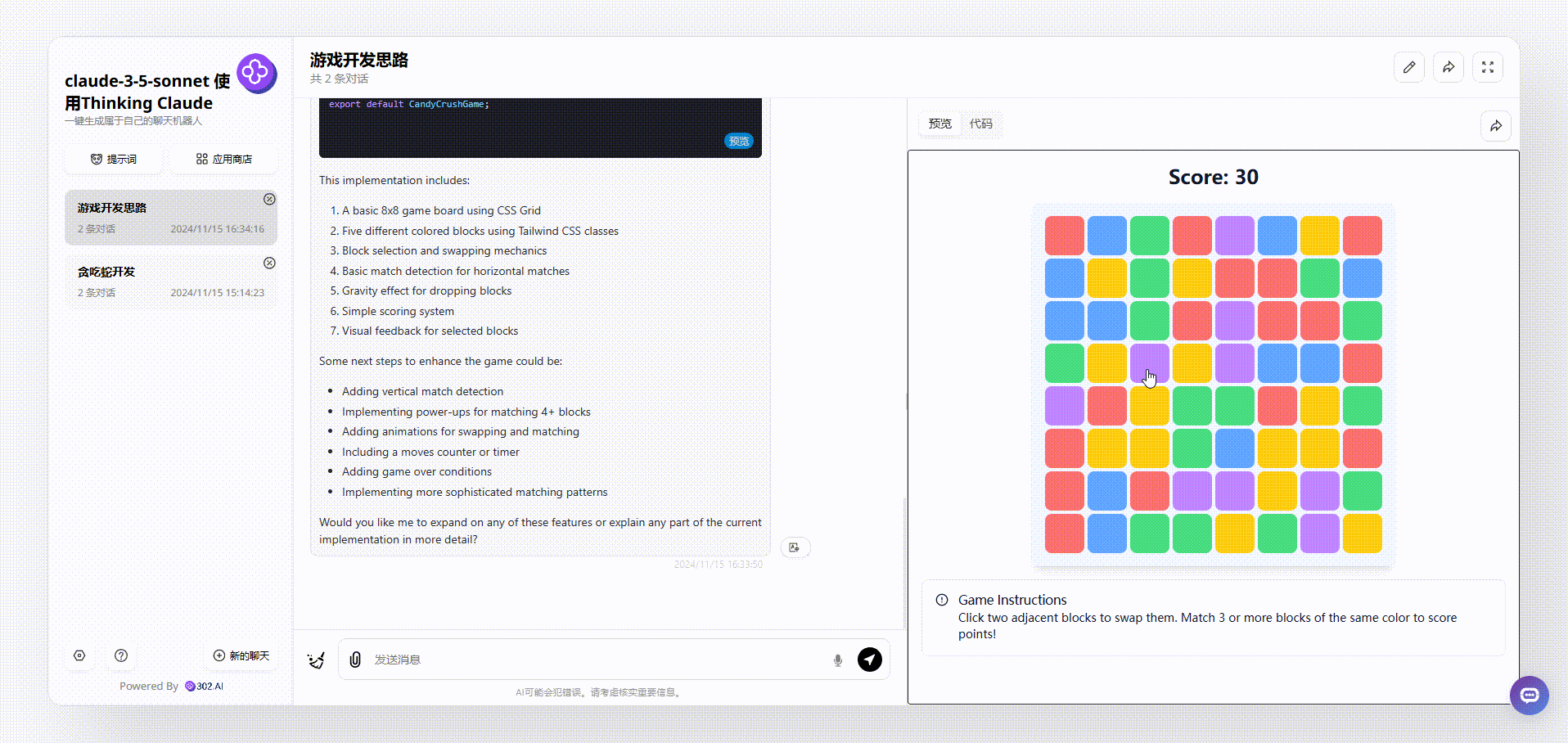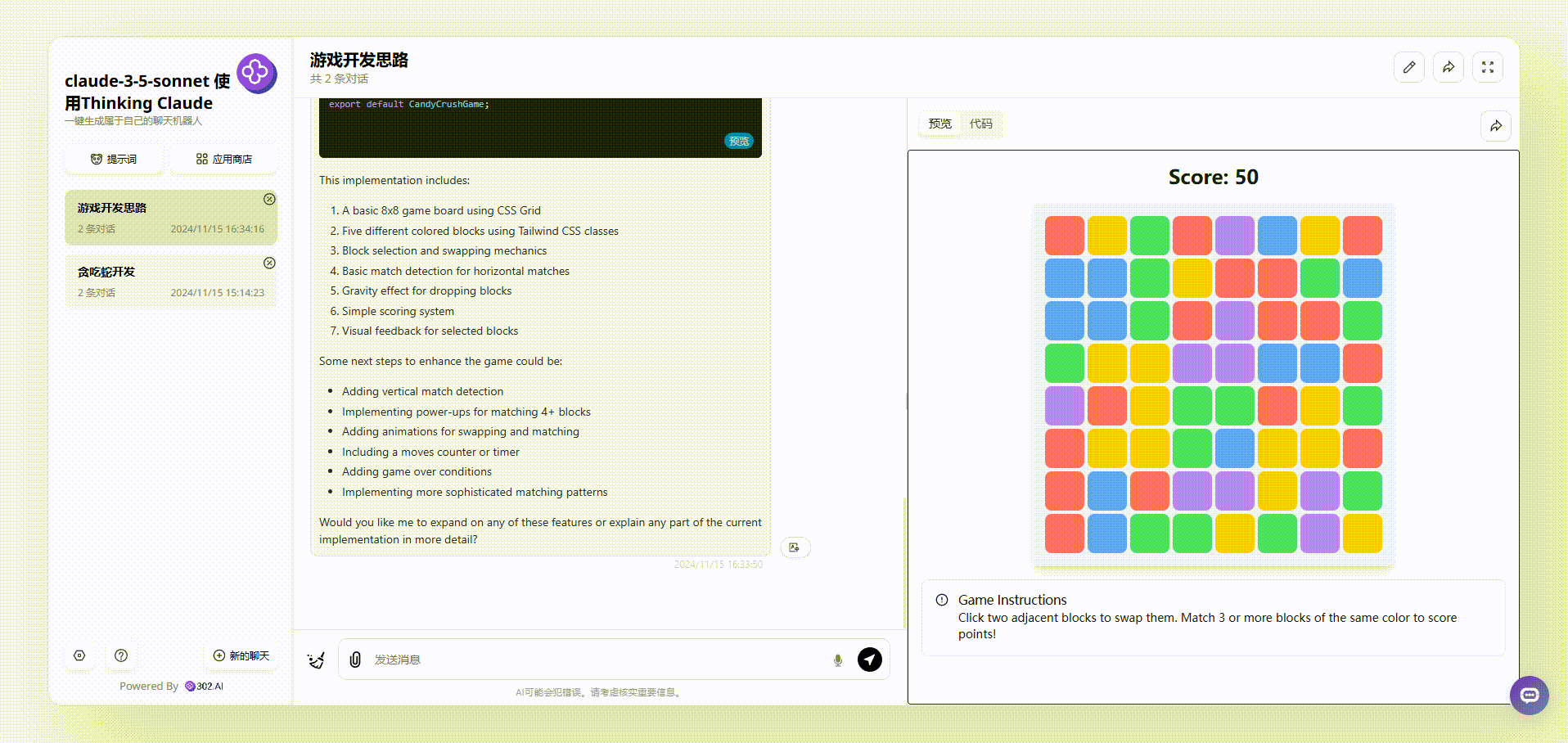
![]()
3、最后是o1-preview模型的不使用“Thinking Claude”提示词的效果:与以上效果不同,o1是通过鼠标拖动来切换格子,如果消除格子后,只会改变消除部分的颜色,整个游戏逻辑是最合理的。

![]()
实测3
指令描述:

![]()
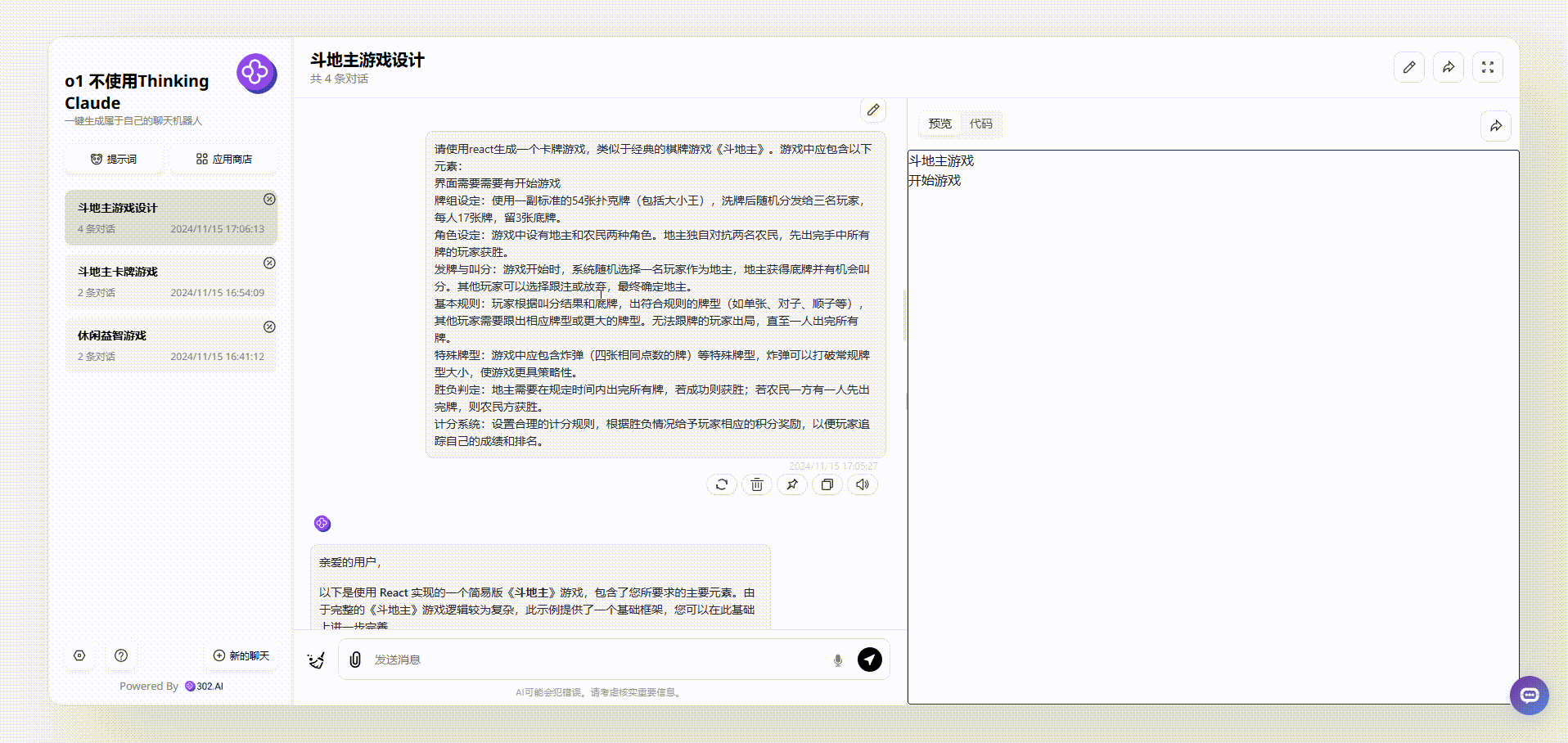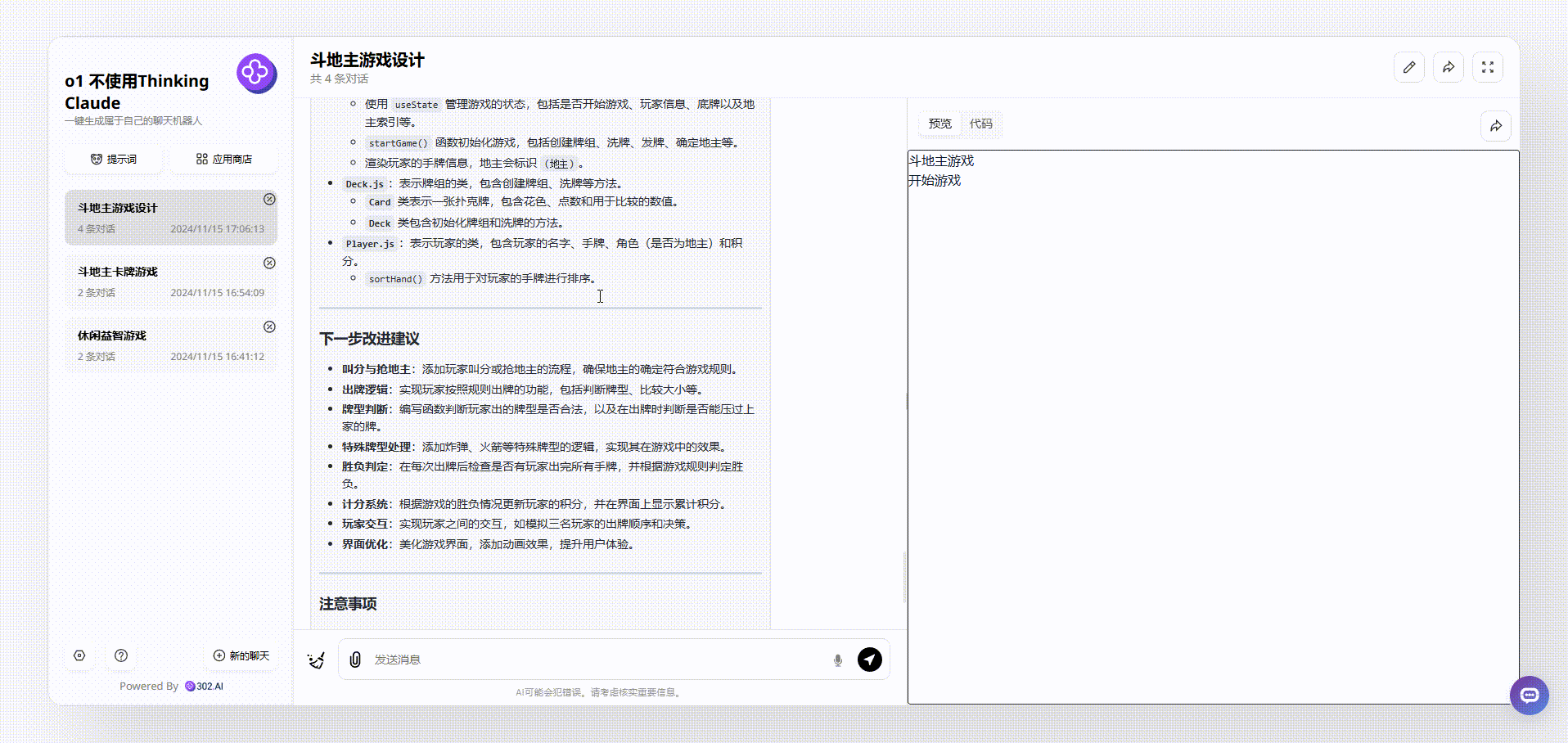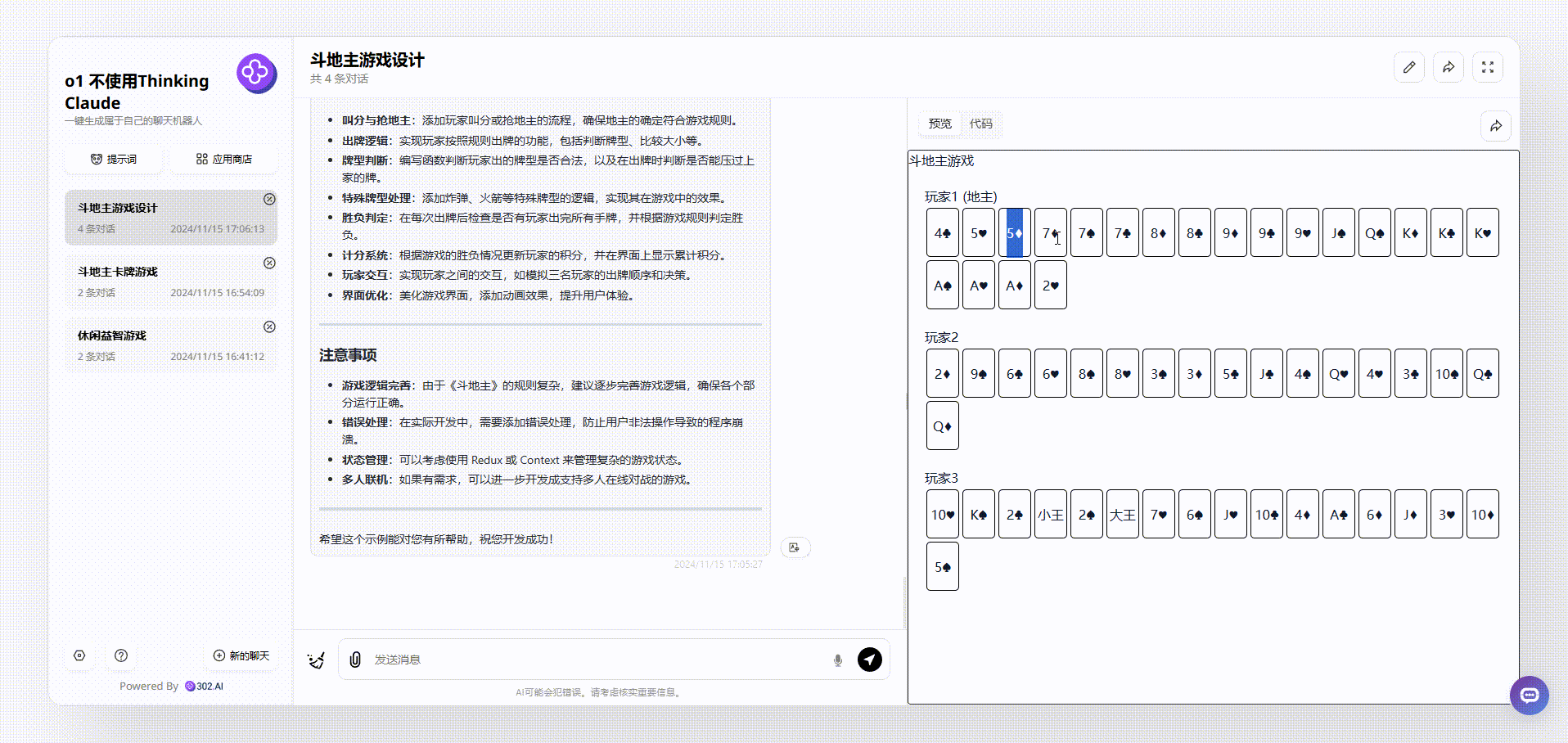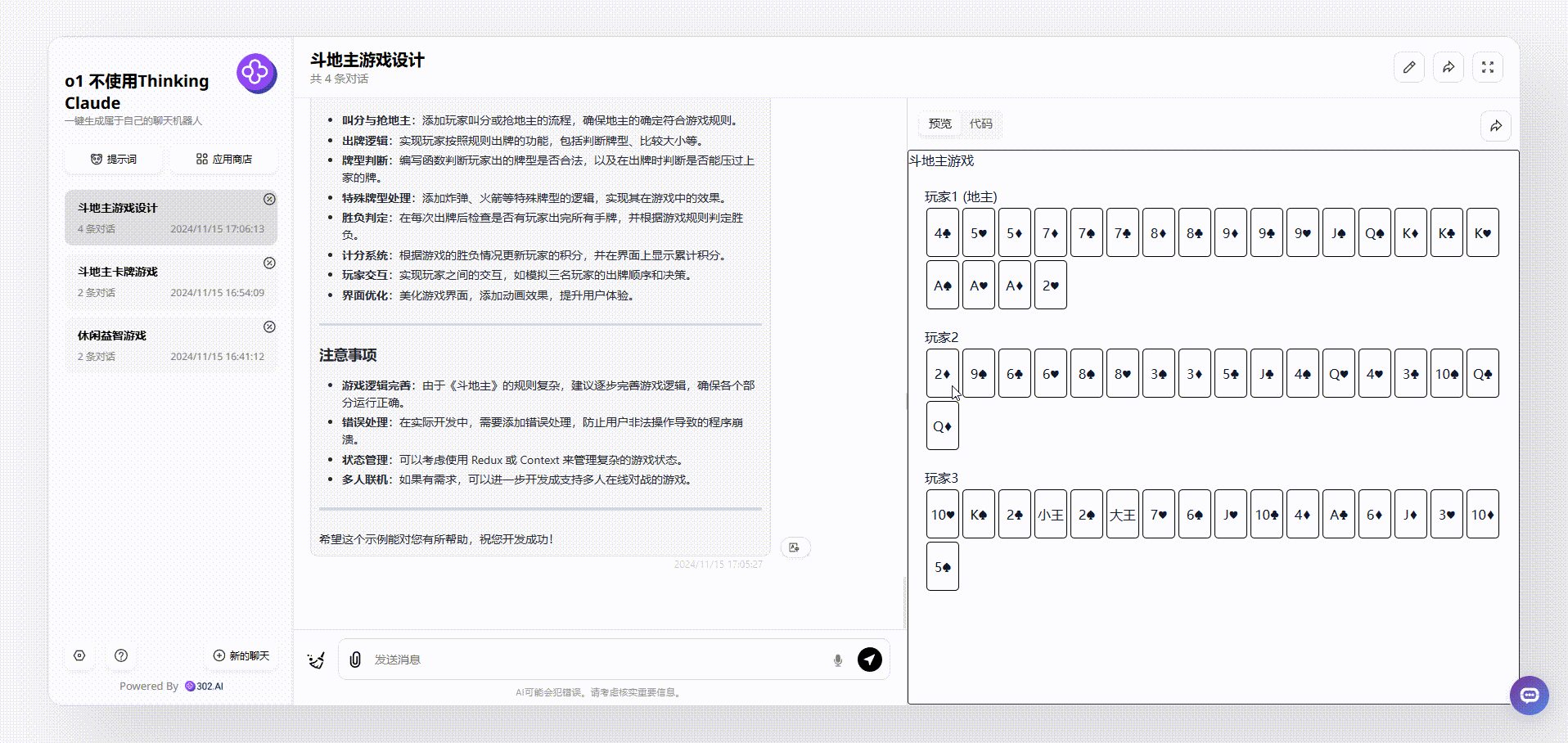
1、没有使用“Thinking Claude”提示词claude-3.5-sonnet模型生成的效果:可以看到点击开始后,页面出现了各种牌面,但是点击牌面是没有任何反应的,总之,和真正的斗地主游戏效果差距比较远。
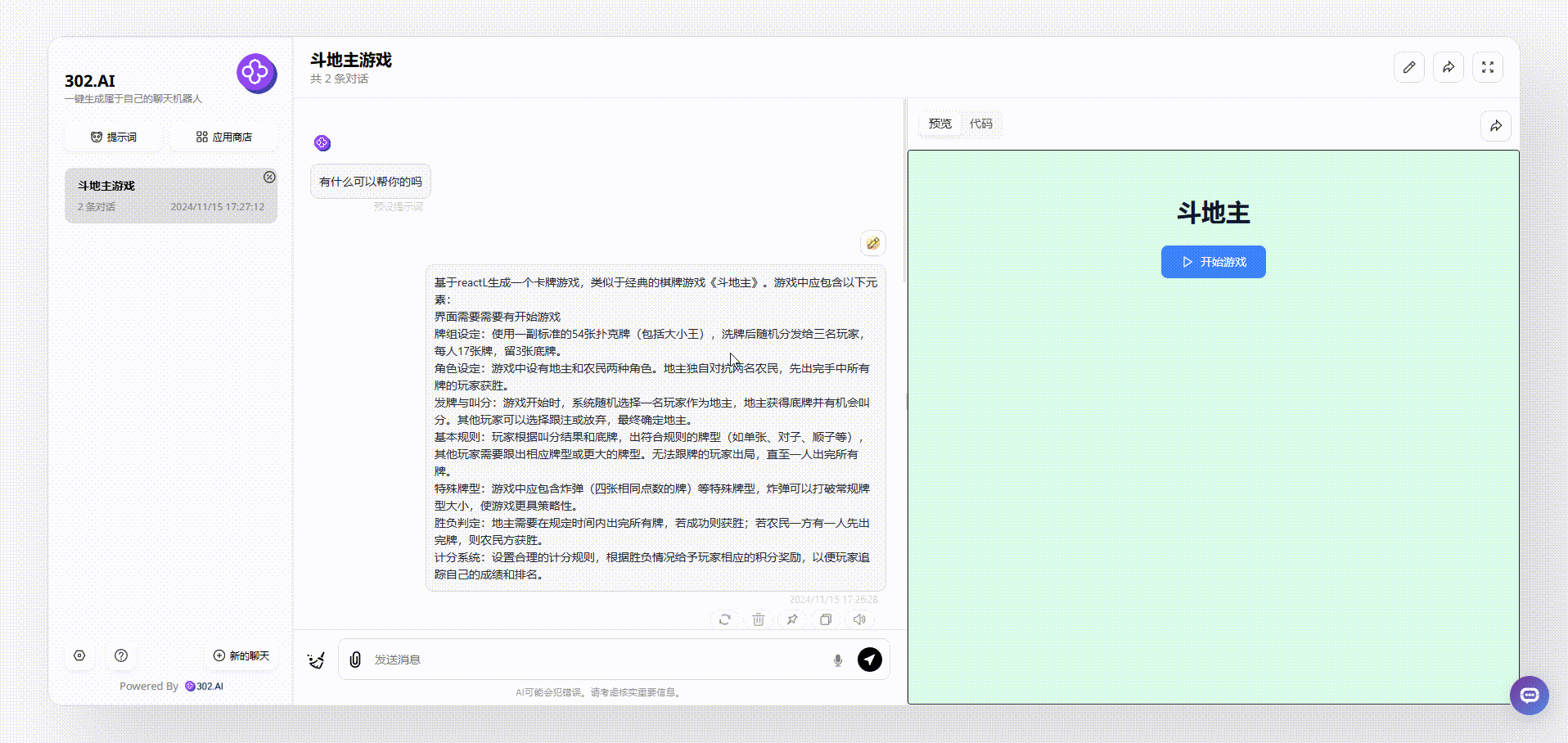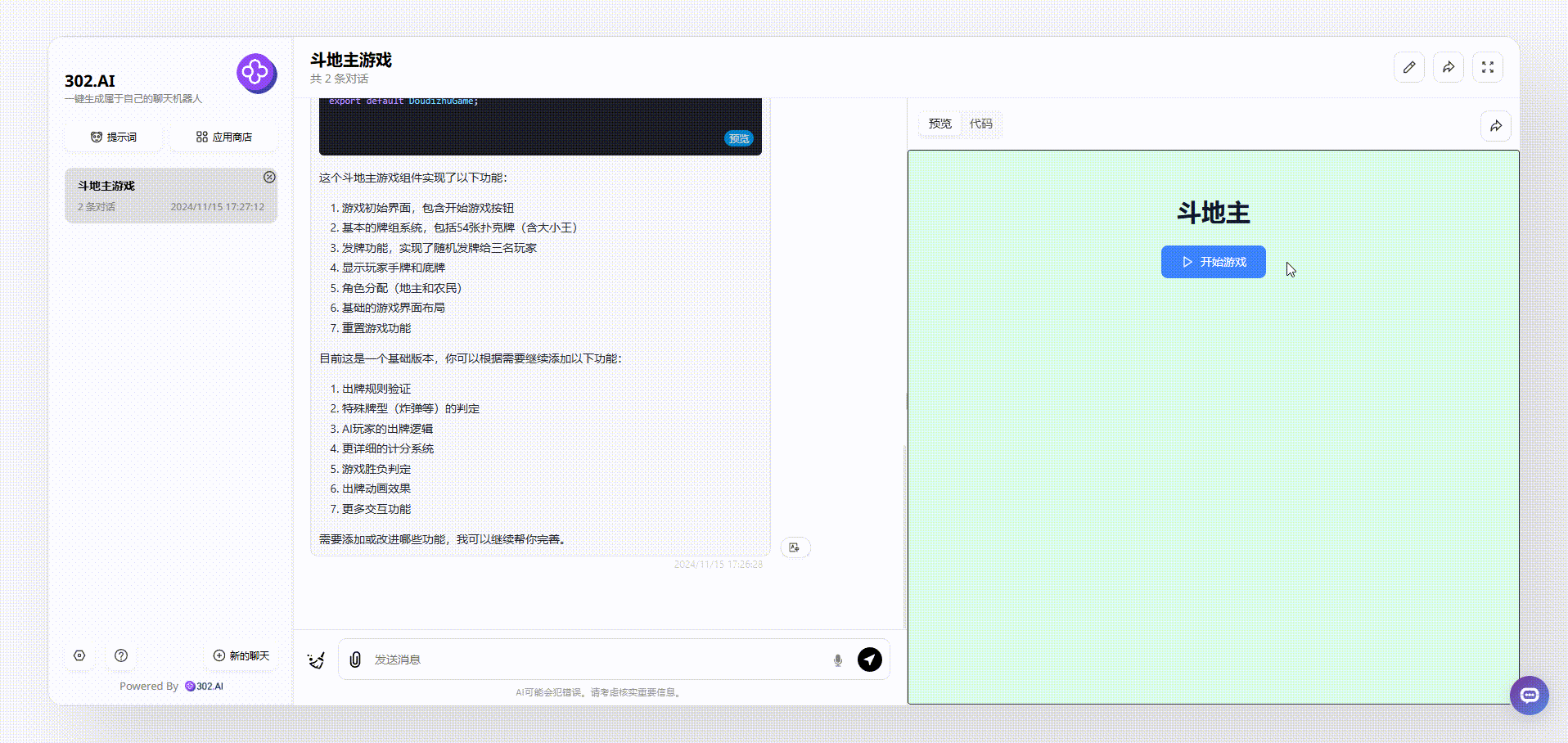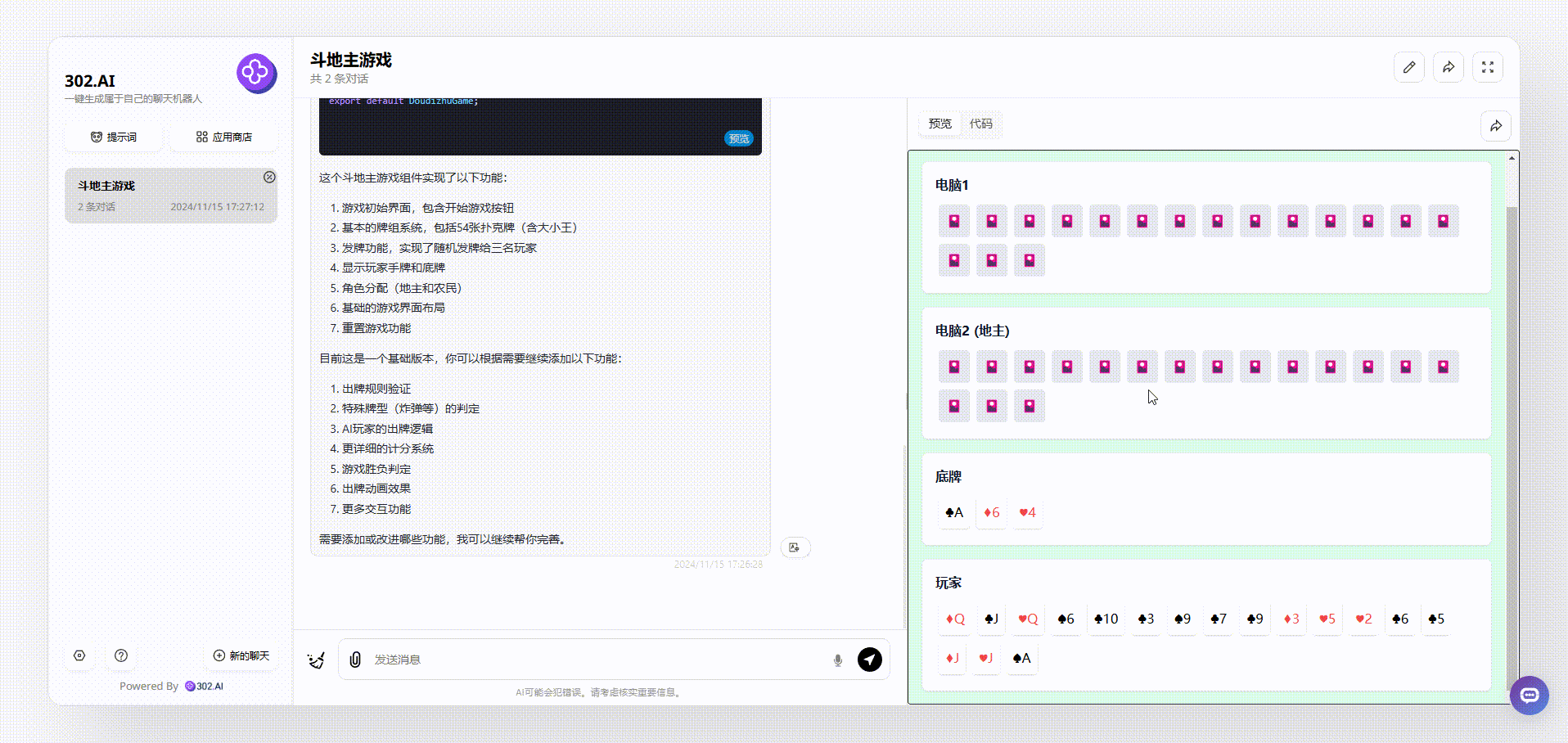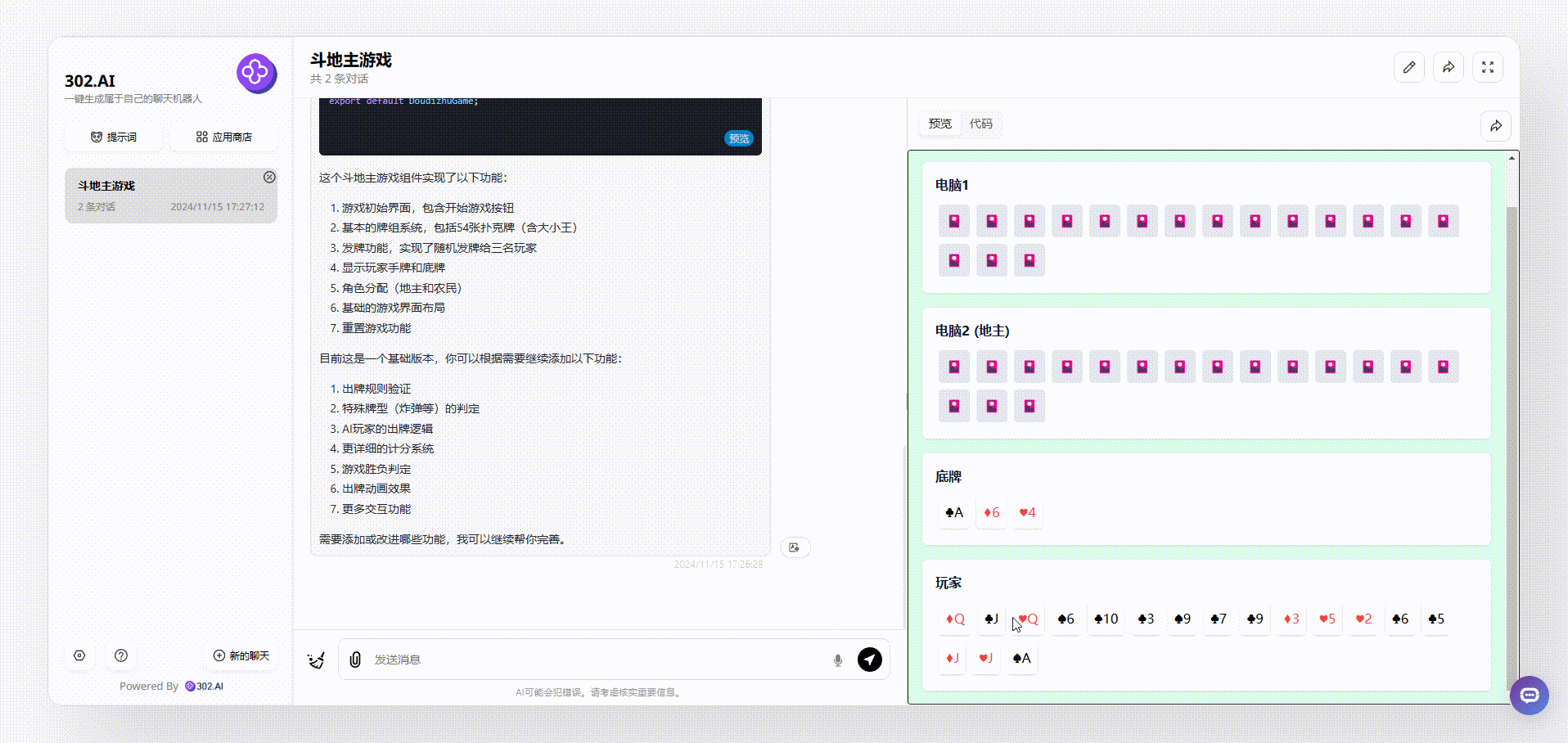
![]()
2、使用了“Thinking Claude”提示词的claude-3.5-sonnet生成的效果:大致和以上的效果一样,牌面是以英文显示的;
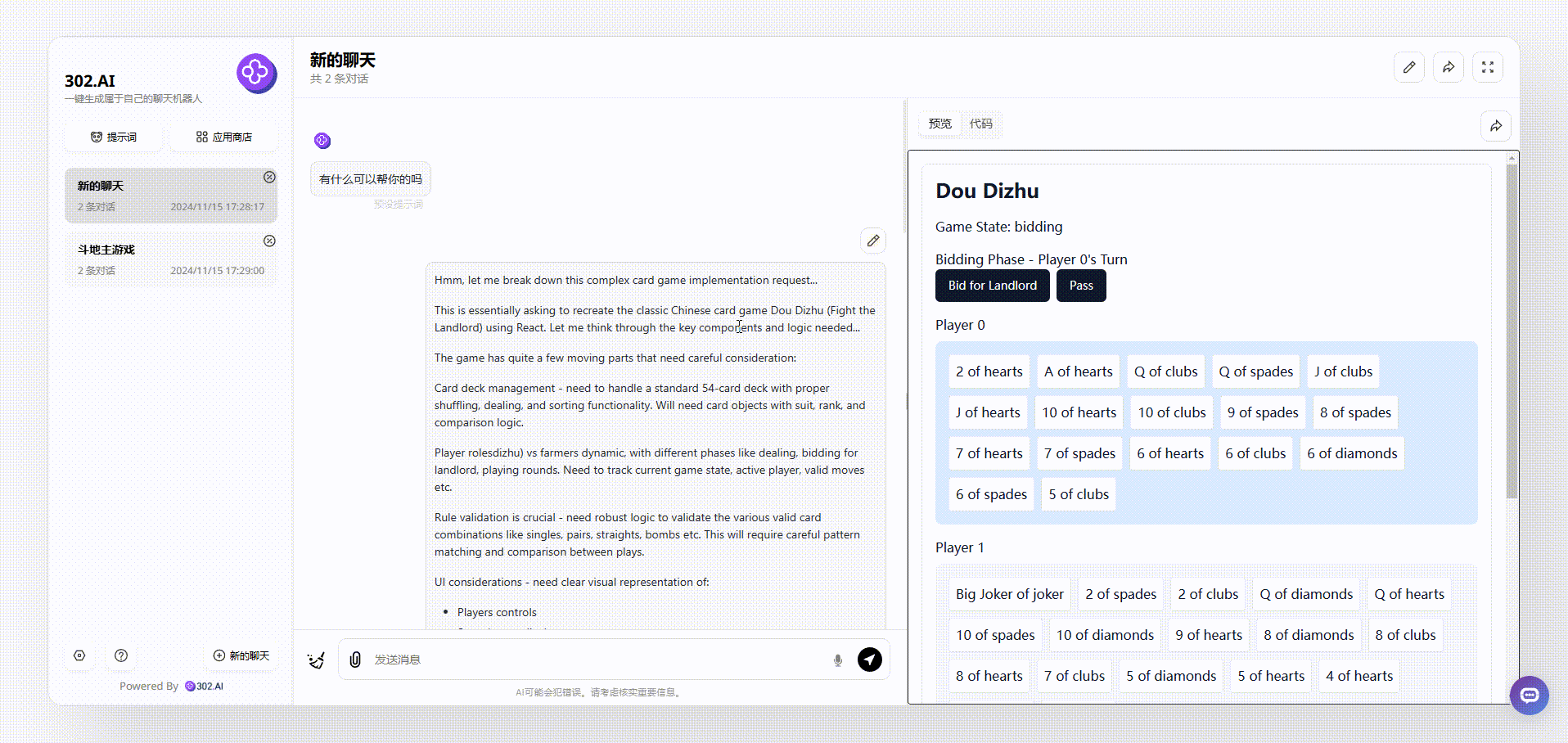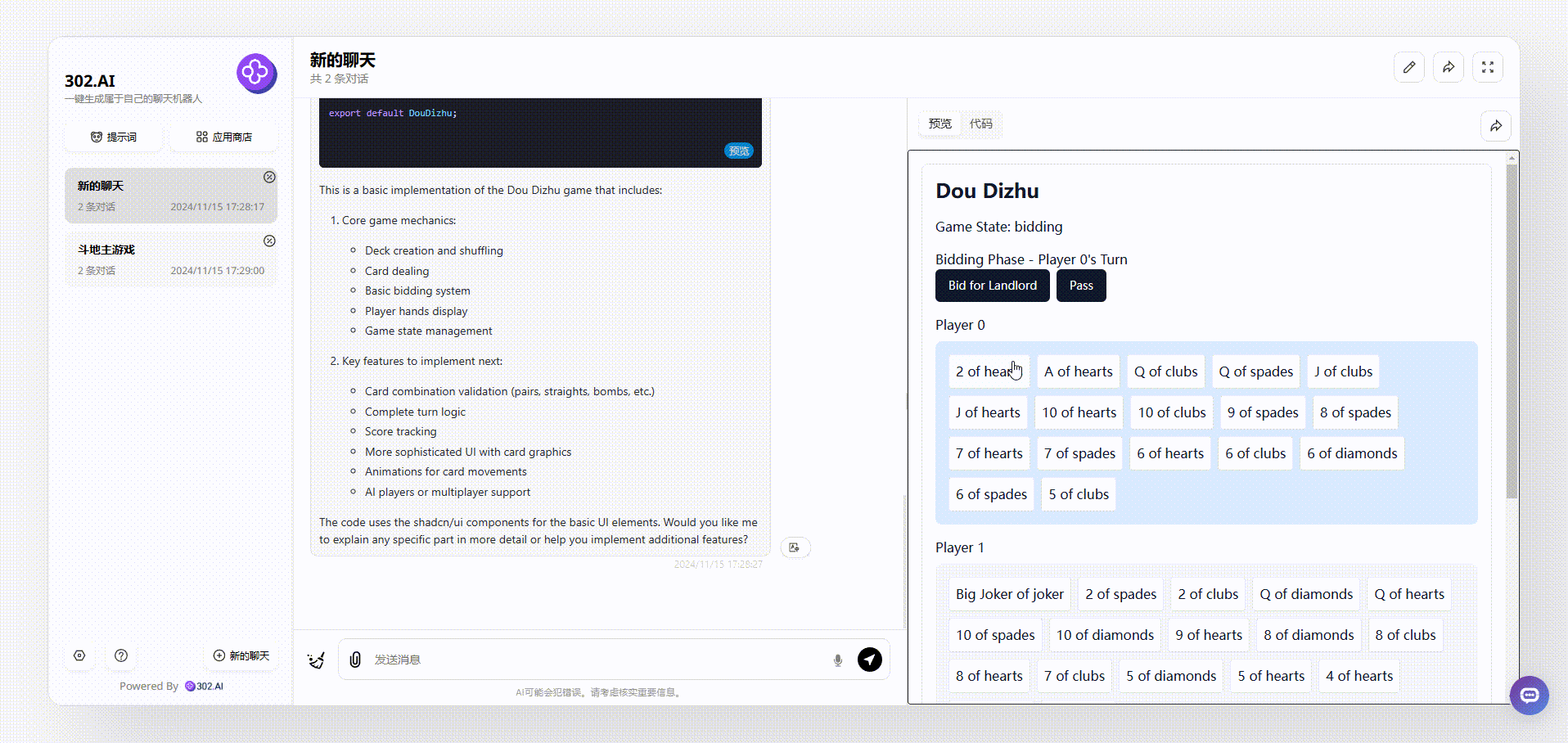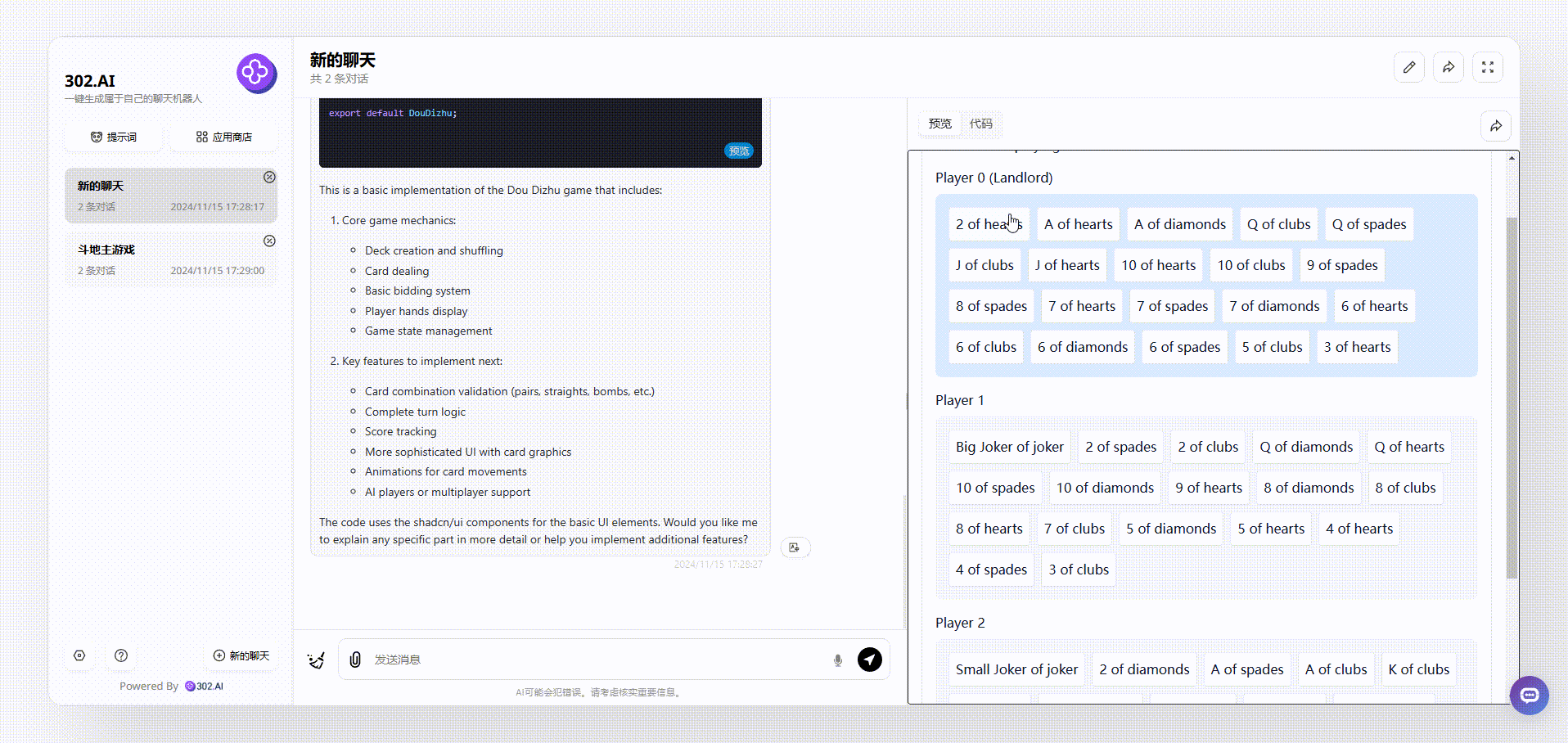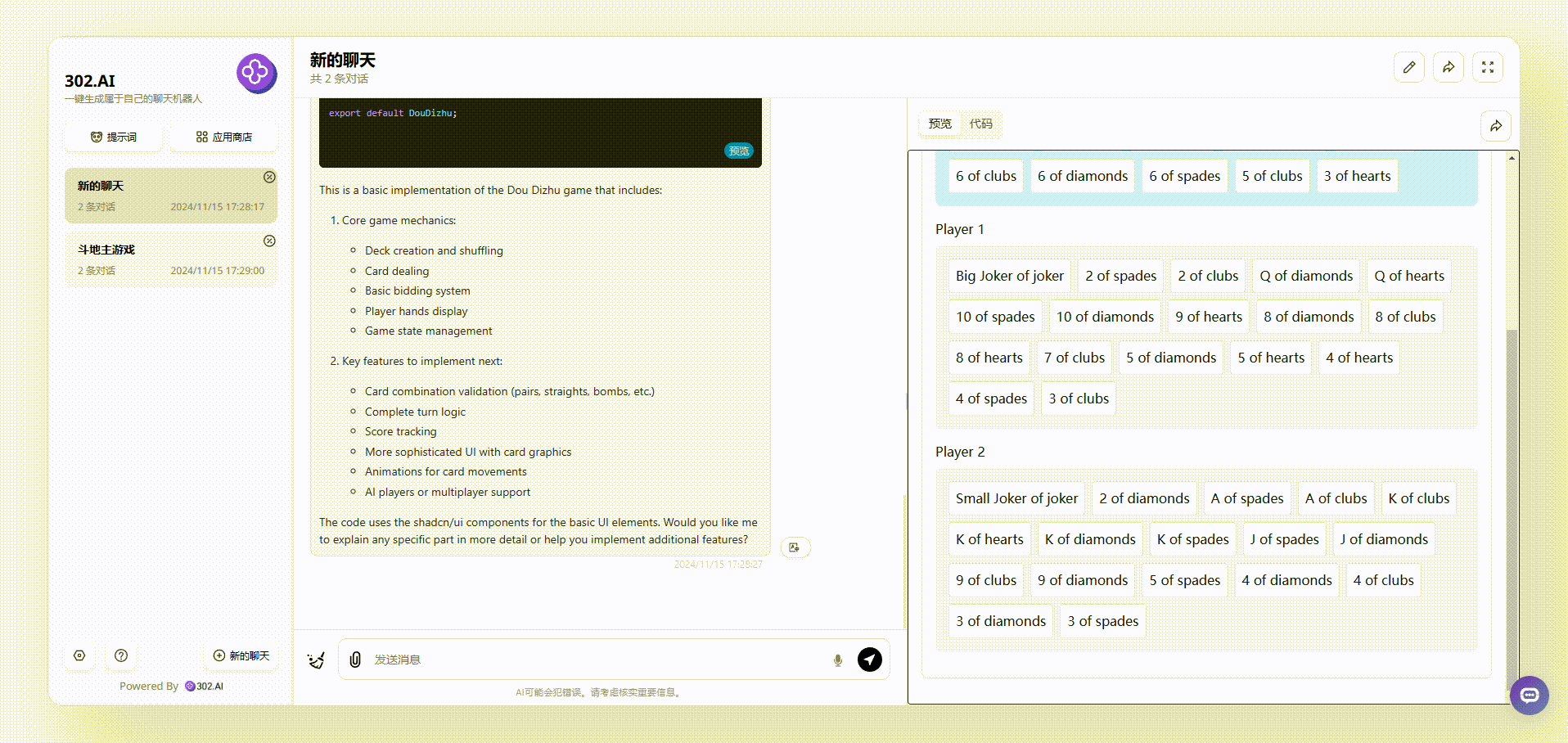
![]()
3、o1-preview模型的效果:与以上效果大差不差,都没有实现真正的斗地主游戏效果;
![]()
总结
通过以上三个代码生成的实测,可以发现“Thinking Claude”这一提示词并没有这么“神”。以实测1为例,在用户提示很简洁的情况下,通过逐步引导和思考完善,使用该提示词确实能够产生较好的效果。但用户提示很详细时,使用这一提示词反而可能导致效果适得其反,如实测2所展示的那样。而对于更为复杂的任务,即便使用了“Thinking Claude”提示词,依然难以实现目标,实测3便是一个例证。
借用最近Anthropic专访里的一句话:提示词工程真正重要的场景是在努力榨取模型最后2%的性能。
所以,在基座模型不变的情况下,优秀的提示词只是锦上添花,而无法达到一个质的飞跃。所以希望大家理性看待所有夸张的言论,亲手实践,眼见为实。
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(16)
You completed a number of nice points there. I did a search on the subject matter and found mainly people will consent with your blog.
Do you have a spam problem on this website; I also am a blogger, and I was wanting to know your situation; many of us have created some nice procedures and we are looking to trade solutions with other folks, why not shoot me an email if interested.
I¦ll right away seize your rss feed as I can’t to find your email subscription link or newsletter service. Do you’ve any? Kindly permit me realize so that I could subscribe. Thanks.
Hey there! Do you use Twitter? I’d like to follow you if that would be ok. I’m definitely enjoying your blog and look forward to new updates.
Hi there! This post couldn’t be written any better! Reading through this post reminds me of my previous room mate! He always kept talking about this. I will forward this article to him. Pretty sure he will have a good read. Thank you for sharing!
Hiya, I am really glad I’ve found this info. Nowadays bloggers publish only about gossips and web and this is actually annoying. A good website with interesting content, that is what I need. Thanks for keeping this web site, I will be visiting it. Do you do newsletters? Can not find it.
There is noticeably a bundle to know about this. I assume you made certain nice points in features also.
I really appreciate this post. I?¦ve been looking everywhere for this! Thank goodness I found it on Bing. You have made my day! Thx again
You really make it appear really easy along with your presentation but I in finding this matter to be actually something which I feel I’d never understand. It sort of feels too complicated and very large for me. I’m taking a look ahead in your subsequent submit, I will try to get the hang of it!
My spouse and I stumbled over here from a different web address and thought I should check things out. I like what I see so i am just following you. Look forward to finding out about your web page repeatedly.
Thanks a bunch for sharing this with all folks you really know what you’re speaking about! Bookmarked. Please also visit my site =). We will have a link change contract among us!
I keep listening to the news update lecture about getting boundless online grant applications so I have been looking around for the best site to get one. Could you tell me please, where could i acquire some?
I¦ve read several just right stuff here. Certainly worth bookmarking for revisiting. I wonder how much effort you place to make this sort of great informative website.
I have been absent for some time, but now I remember why I used to love this web site. Thank you, I will try and check back more often. How frequently you update your web site?
Hi, Neat post. There is a problem with your site in internet explorer, would test this… IE still is the market leader and a good portion of people will miss your wonderful writing due to this problem.
Excellent blog right here! Also your site rather a lot up fast! What host are you the usage of? Can I am getting your associate hyperlink in your host? I wish my site loaded up as fast as yours lol