


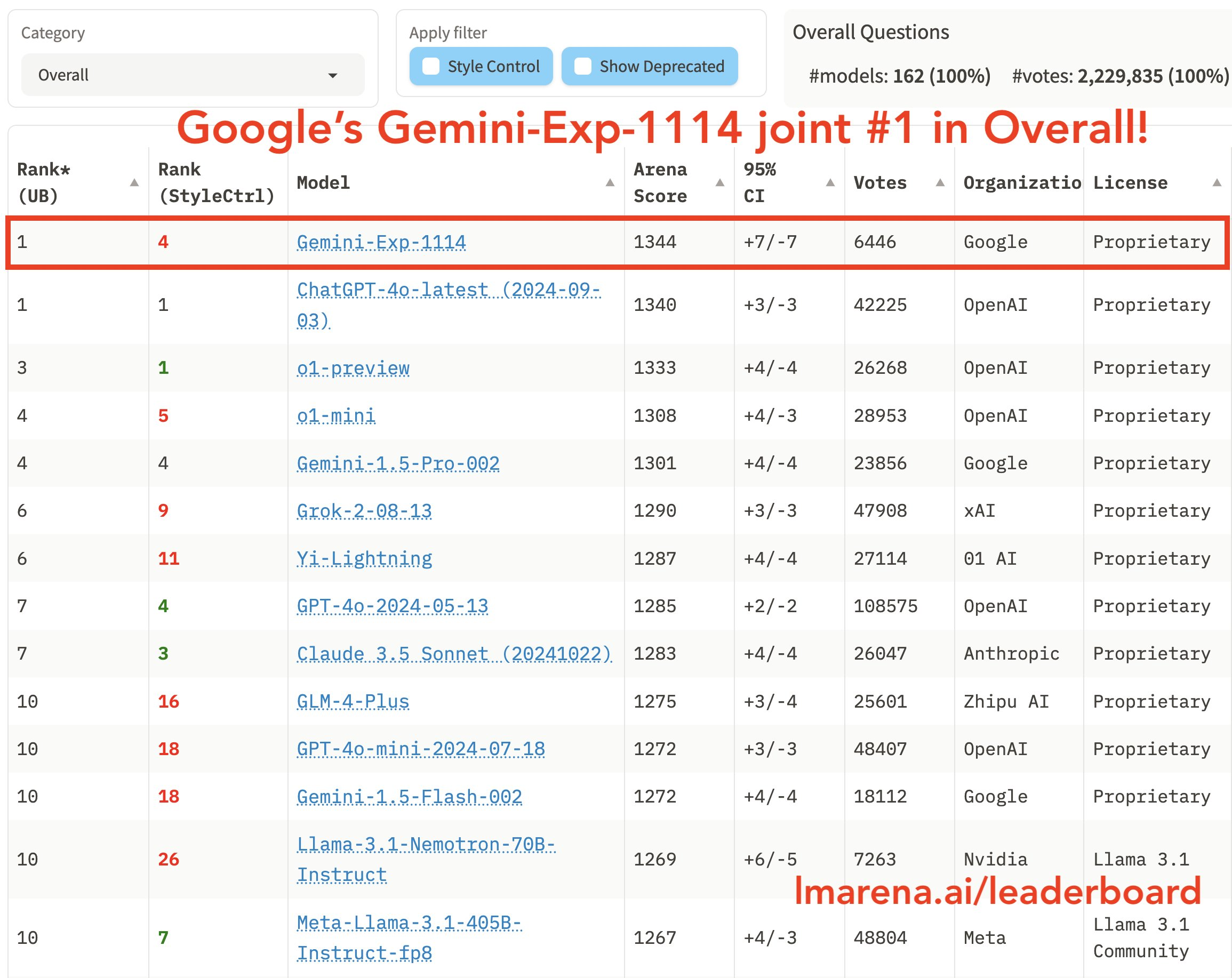
11月15日,谷歌DeepMind推出Gemini-exp-1114,这是一个实验性模型。
据了解,在经过6000+网友匿名投票后,Gemini-exp-1114模型在AI基准测试中位居总体排名第一,Gemini-exp-1114模型分数直涨40+,与GPT-4-latest并列第一,并超越了o1-preview。
![]()
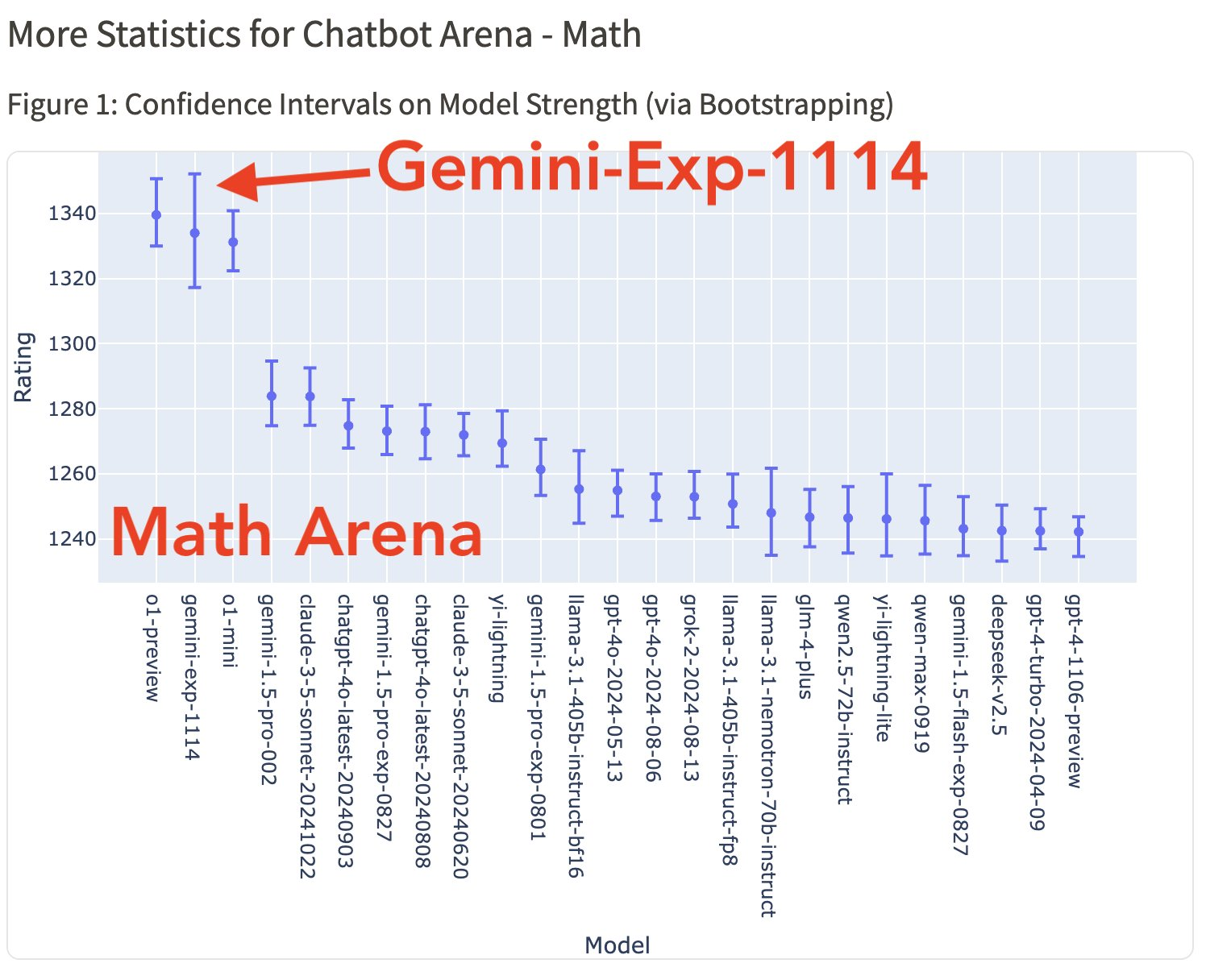
Gemini-exp-1114在处理复杂提示、创意写作、指令遵循、长查询处理以及多轮对话等方面都表现出色,并拿下多个单项第一,比如数学能力评测从第3名升至第1名,超越了学霸o1模型。
![]()
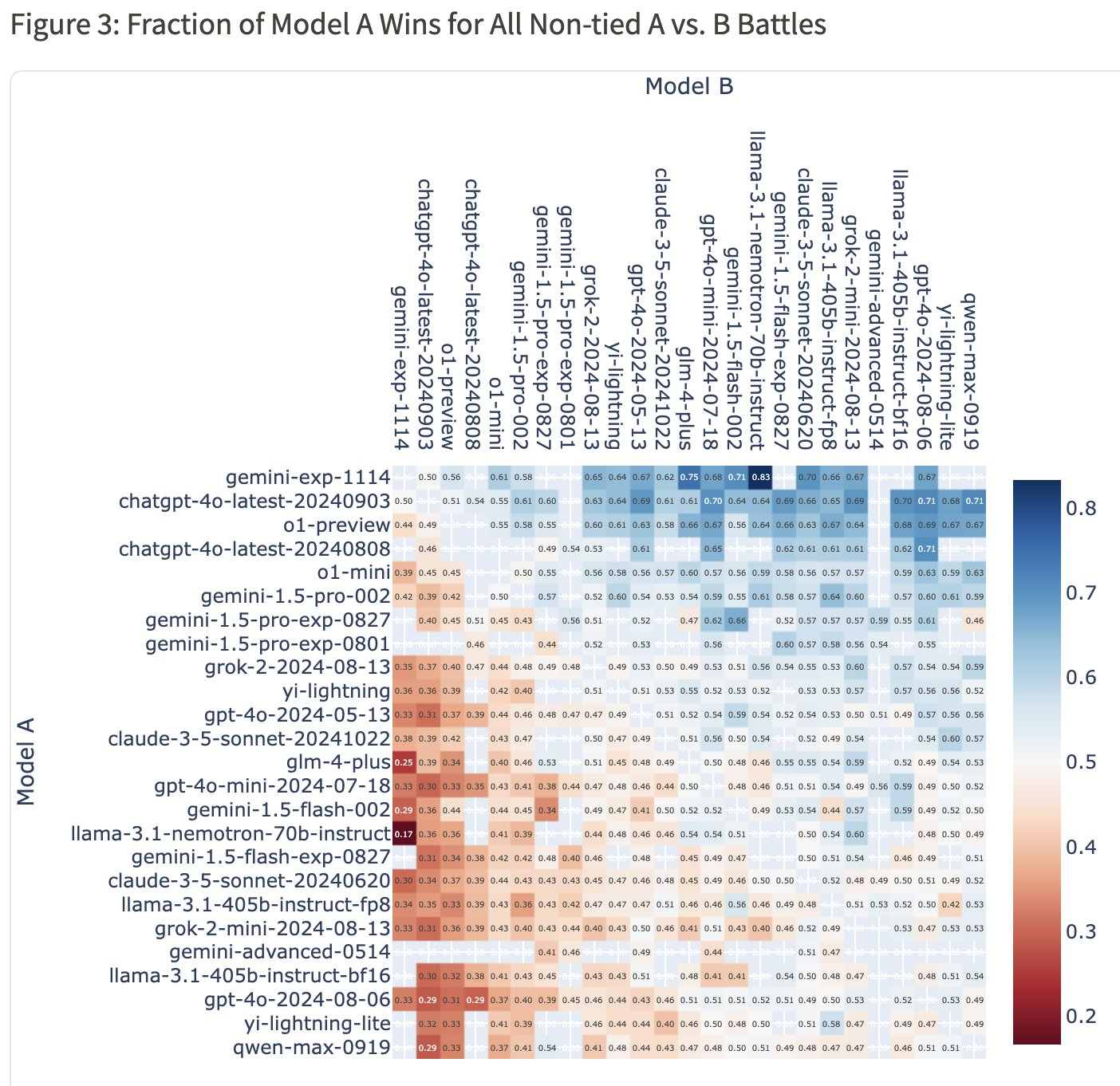
整体胜率热图显示,Gemini-exp-1114对战4o-latest胜率为50%,对战o1-preview胜率为56%,对战Claude-3.5-Sonnet胜率为62%。
![]()
在302.AI使用Gemini-exp-1114
Gemini-exp-1114发布后,302.AI也在聊天机器人、模型竞技场、API超市迅速上线了Gemini-exp-1114模型。如果用户想要第一时间试用Gemini-exp-1114模型,可以直接选择302.AI的聊天机器人;如果想要进行多模型对比,可以选择模型竞技场;如果想快速接入模型API,则可以选择API超市。
302.AI满足用户的多种选择,并且提供按需付费的服务方式,无需担心月费和捆绑套餐。下面给大家展示获取方式:
聊天机器人
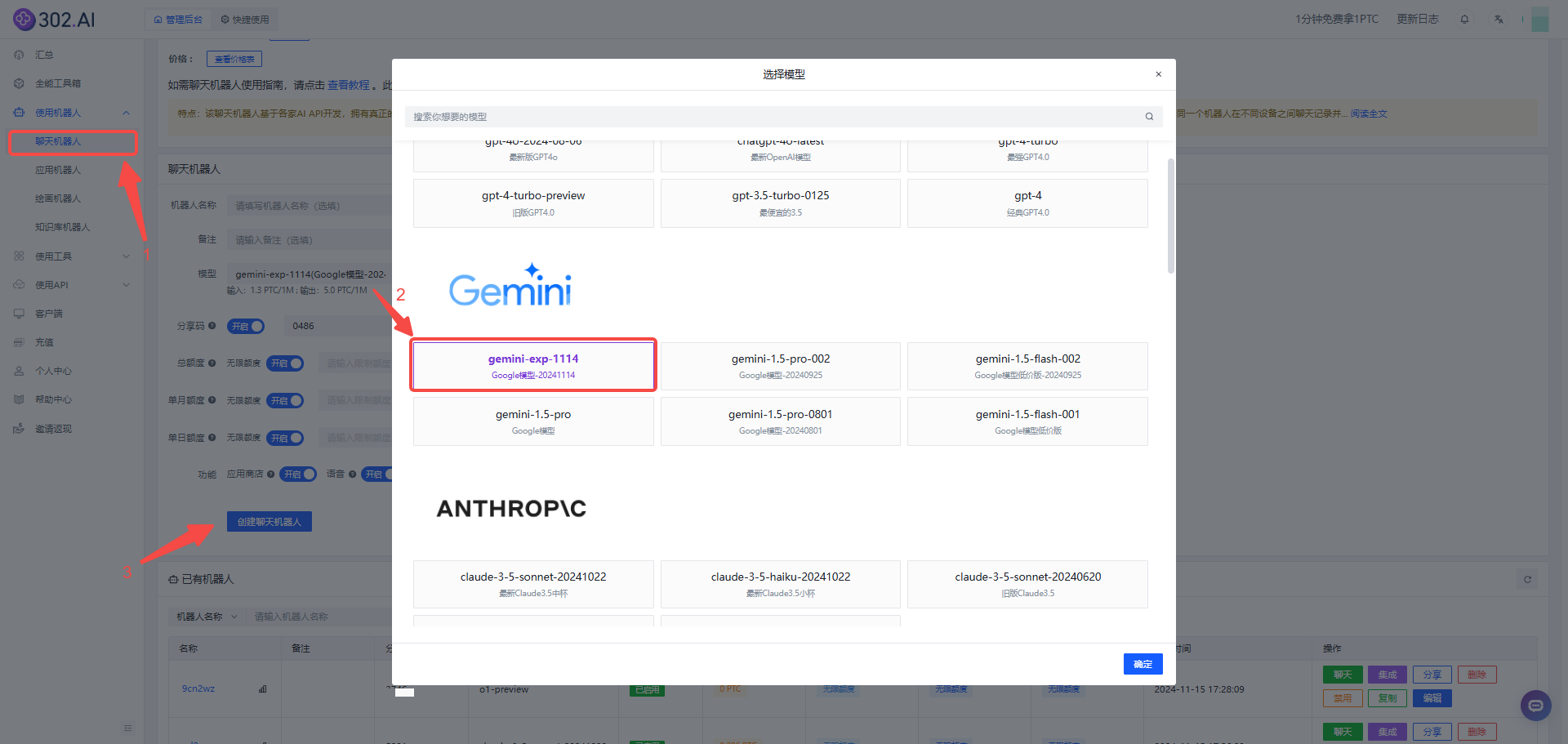
1、进入302.AI——点击“使用机器人”——选择“聊天机器人”——点击模型——选择Gemini-exp-1114模型,最后点击【创建聊天机器人】按钮;
![]()
2、创建后即可进入聊天机器人,在输入框中输入提示词即可开始聊天。
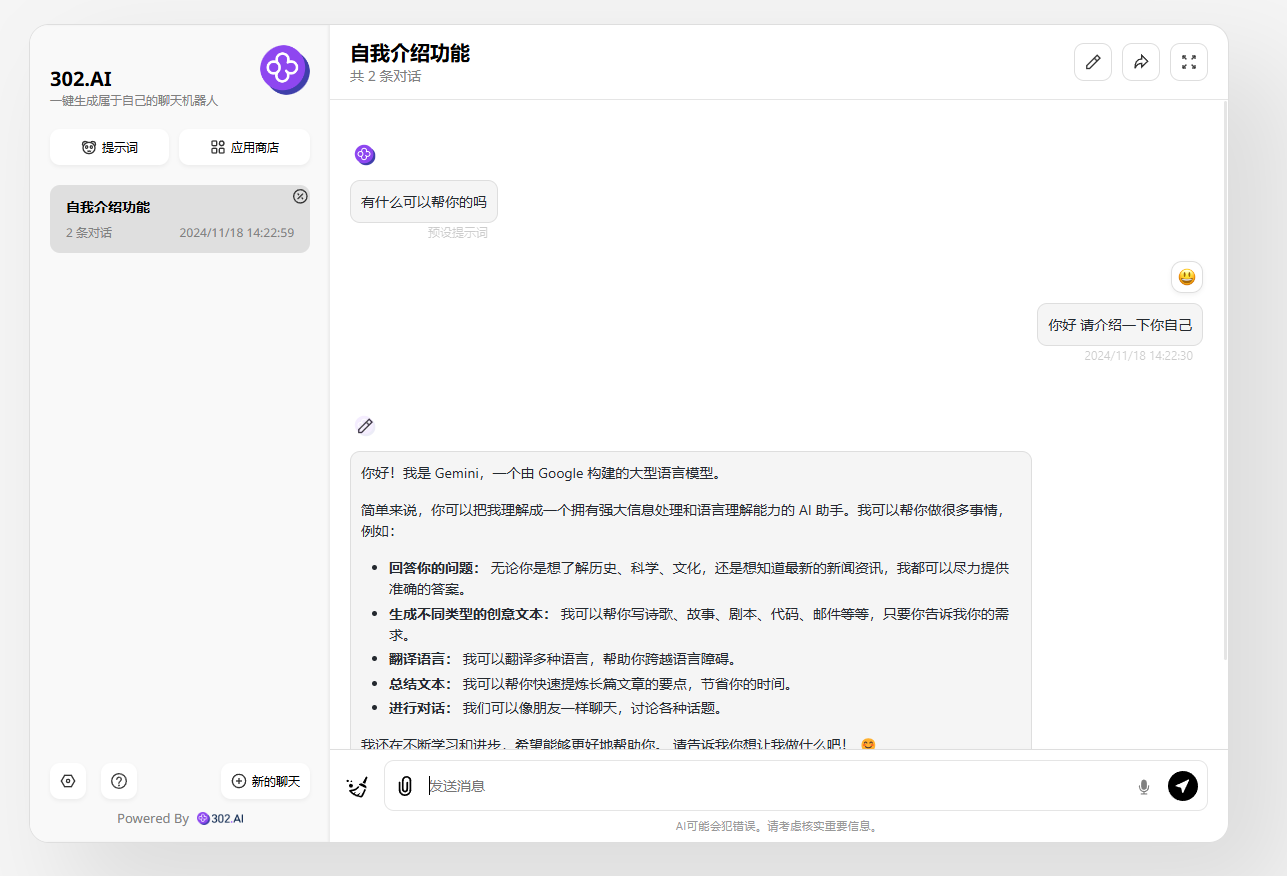
![]()
3、点击左下角的设置,可以打开Artifacts功能。
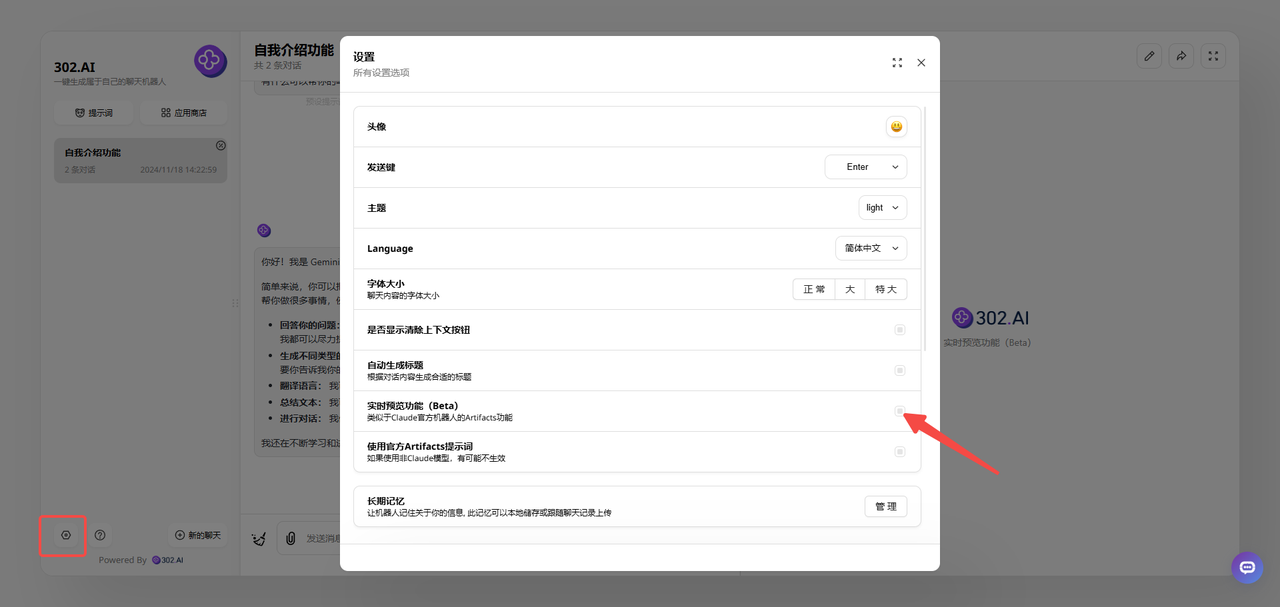
![]()
模型竞技场
1、点击“使用工具”——找到“工具超市”——工具分类中选择“工作效率”——选择“模型竞技场”创建工具。
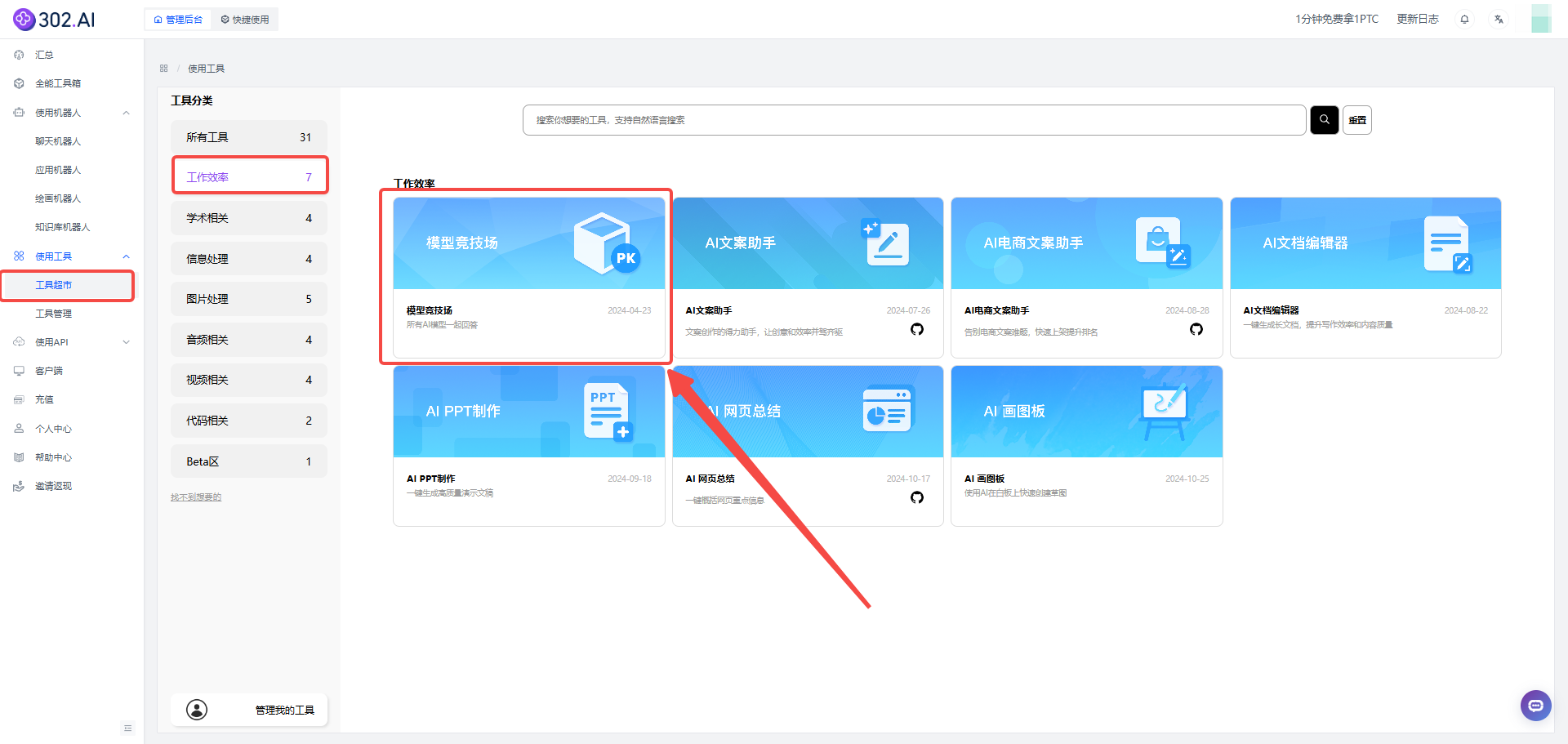
![]()
2、进入模型竞技场后,左侧按需勾选需要竞技的模型,右侧输入框中输入提示词即可看到模型的回答:
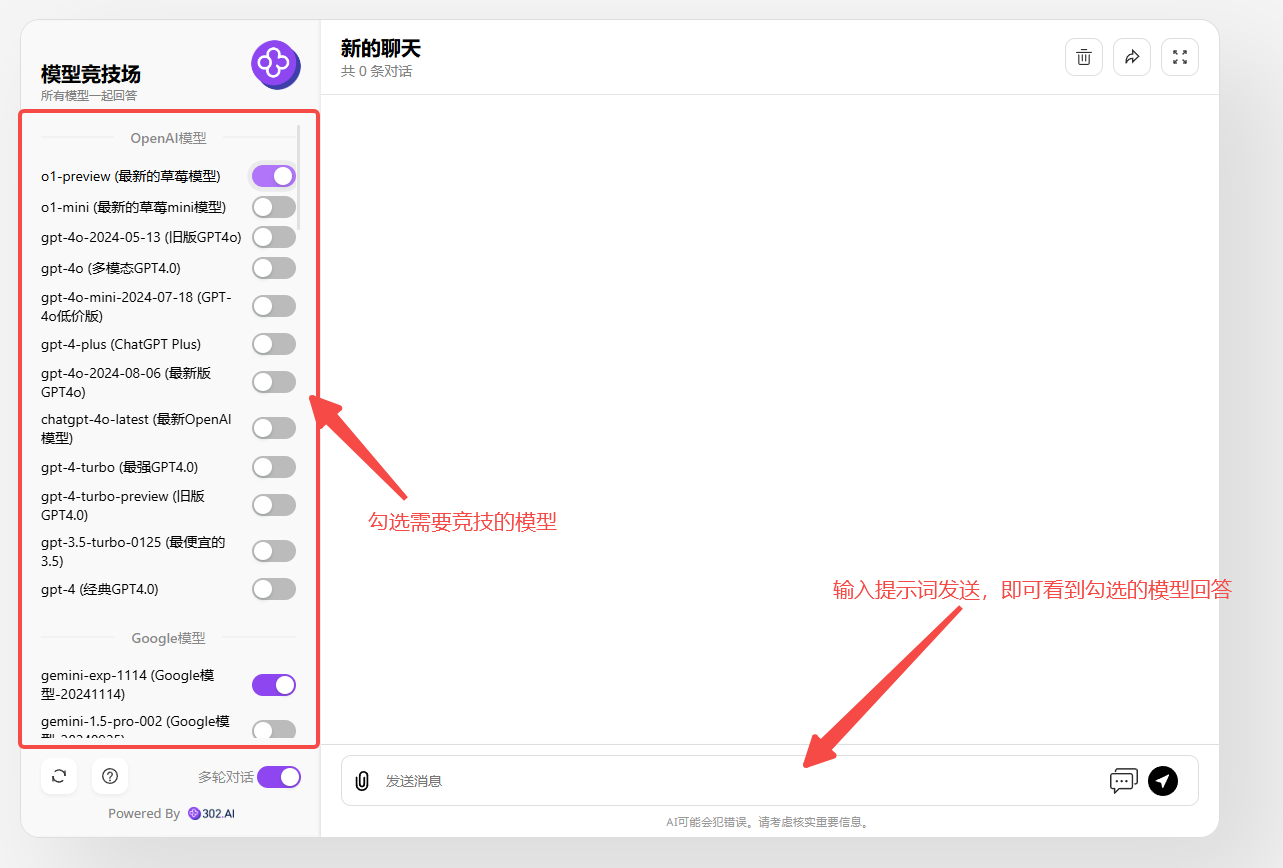
![]()
API超市
1、点击“使用API”——在API分类中选择“语言大模型”——选择Gemini;

![]()
2、302.AI的语言模型API可以选择查看文档和在线体验功能;
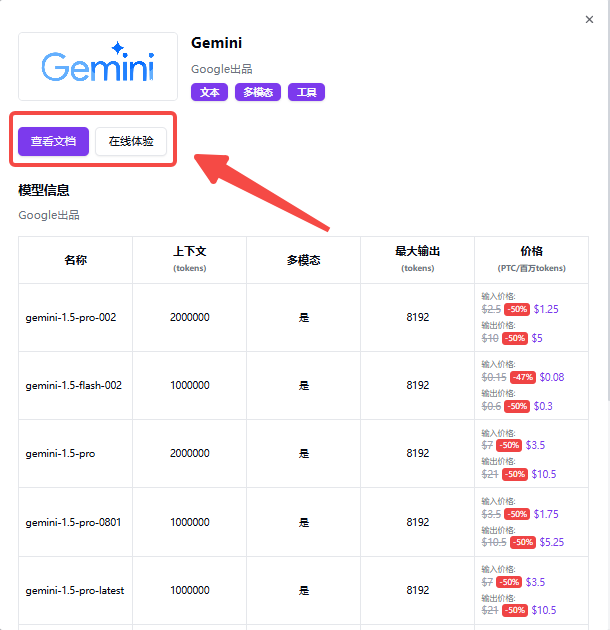
![]()
点击查看文档可以快速帮助用户了解接入模型API:
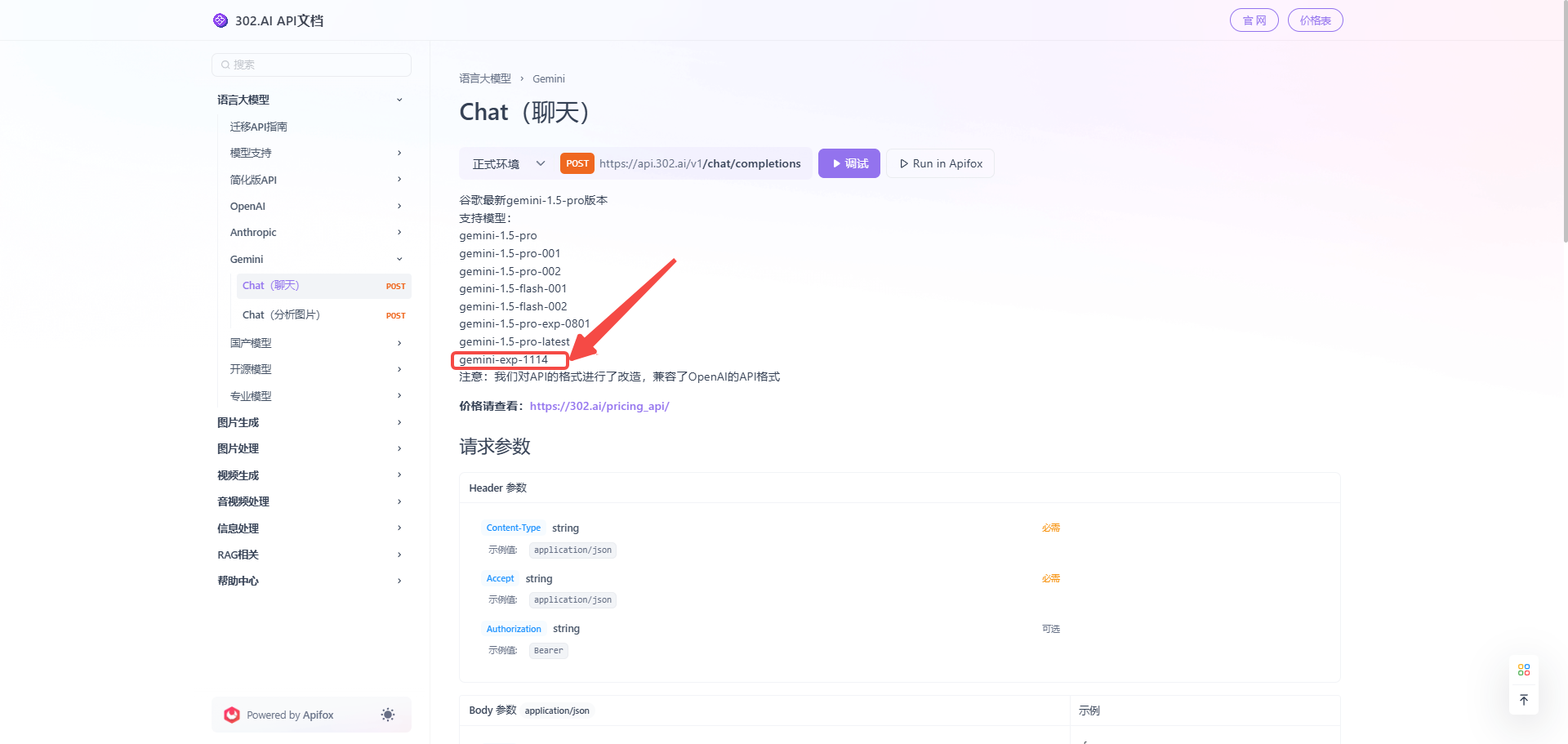
![]()
语言模型API还能够选择在线体验功能,在线体验功能能够快速测试模型的各种参数,界面非常直观、简洁;
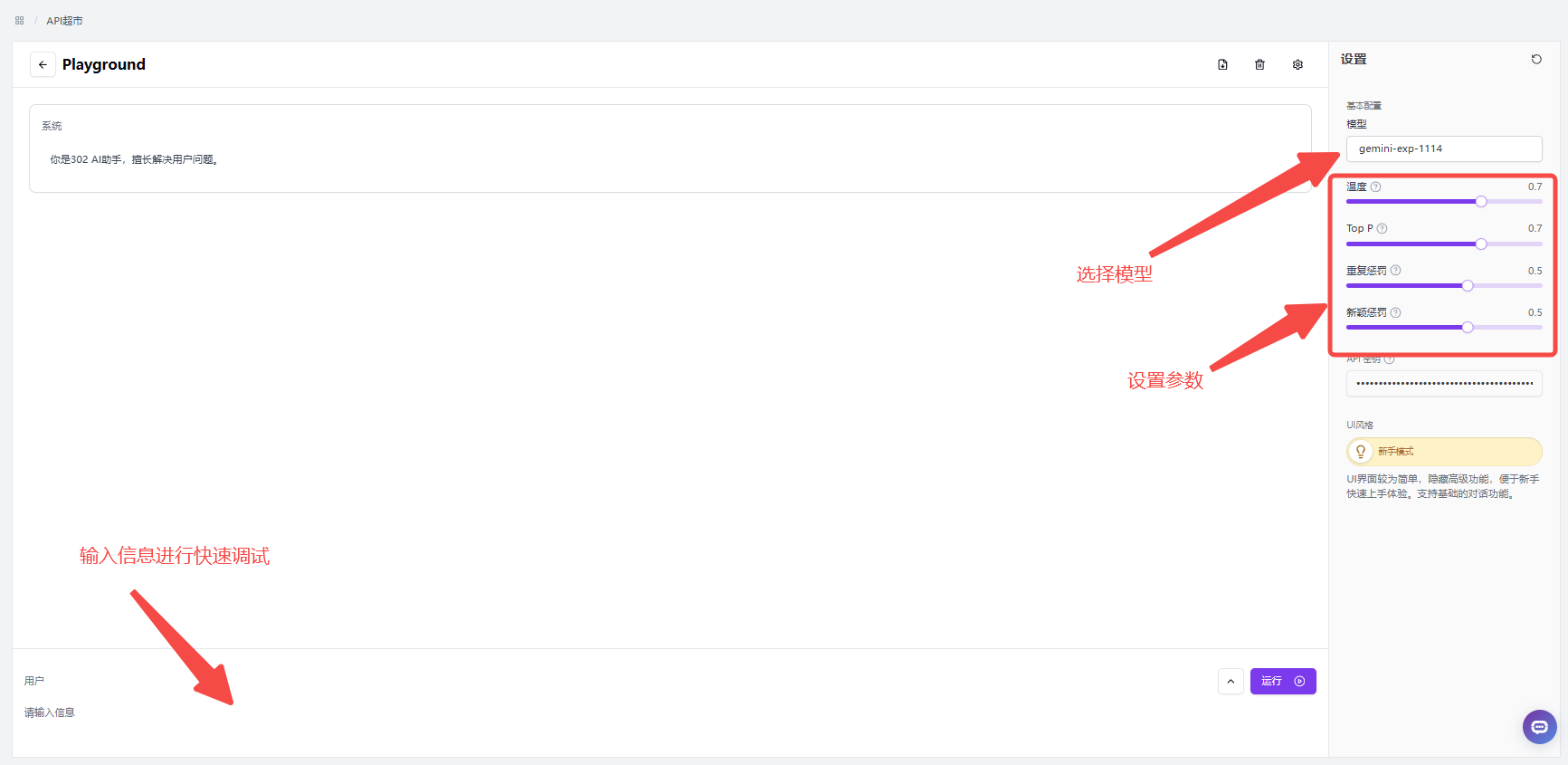
![]()
Gemini-exp-1114实测对比
接下来,我们就测试一下Gemini-exp-1114,看下是否如传闻所说的这么厉害!
以下前三轮实测包括Gemini-exp-1114共有三个模型进行,为了更直观对比各模型,前三轮我们选择了302.AI的模型竞技场进行实测对比,第四轮选择了302.AI的聊天机器人,使用了Artifacts功能:
实测一:是否存在模型幻觉?
模型对比:o1-preview、o1-mini、gemini-exp-1114
提示词:9.8和9.11哪个大?
分析:都在宣传Gemini-exp-1114的数学能力很强,第一轮测试考虑再三还是决定使用了经典问题“9.8和9.11哪个大”来提问,但没想到Gemini-exp-1114就这样水灵灵“翻车”了,在模型回答的过程中直接错误的计算出80小于11,导致最后答案错误,可以看出存在模型幻觉,而o1-preview和o1-mini的回答均是正确的。
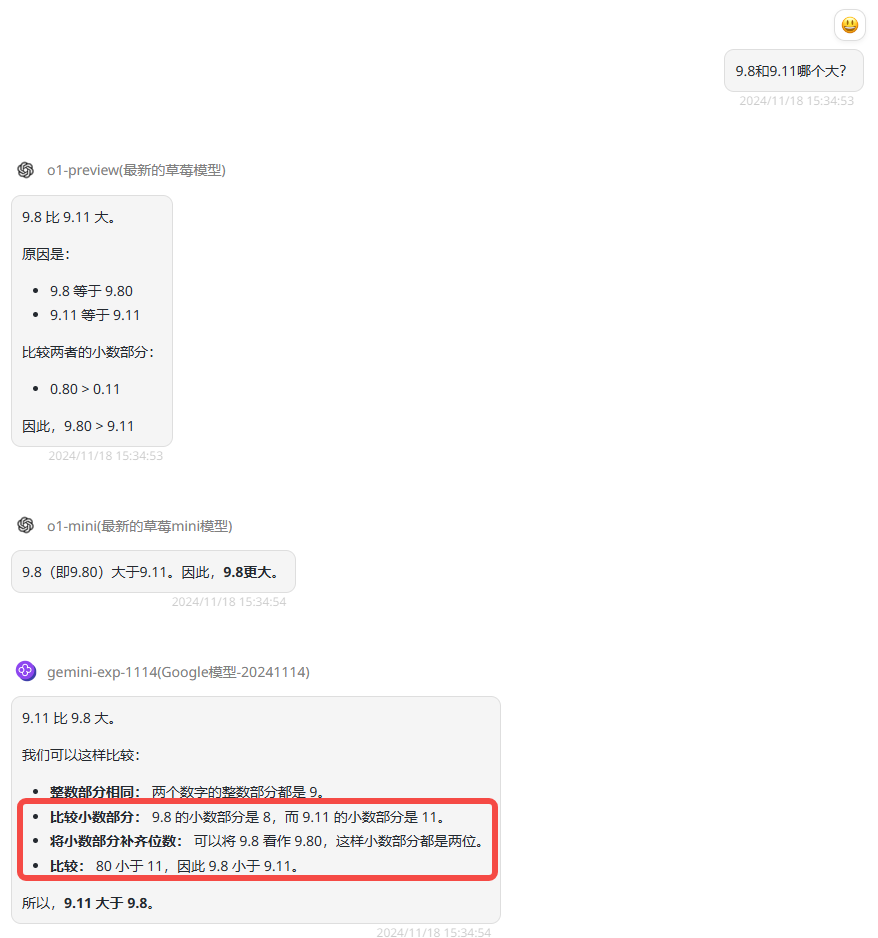
![]()
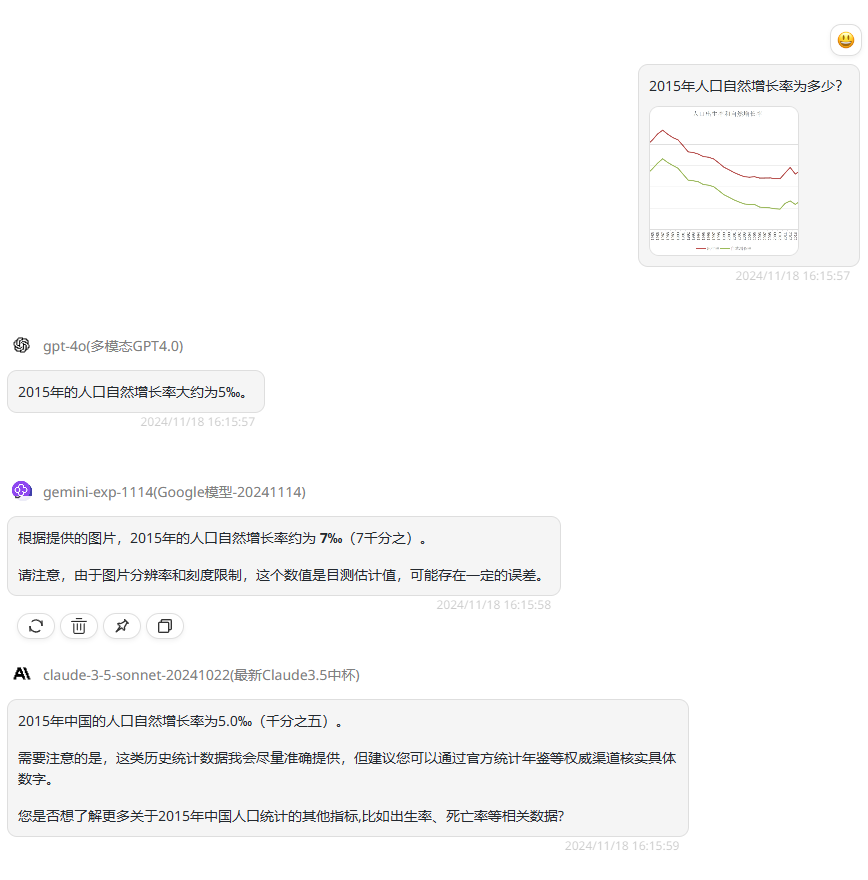
实测二:视觉能力如何?
模型对比:gpt-4o、gemini-exp-1114、claude-3.5-sonnet-20241022
提示词:2015年人口自然增长率为多少?
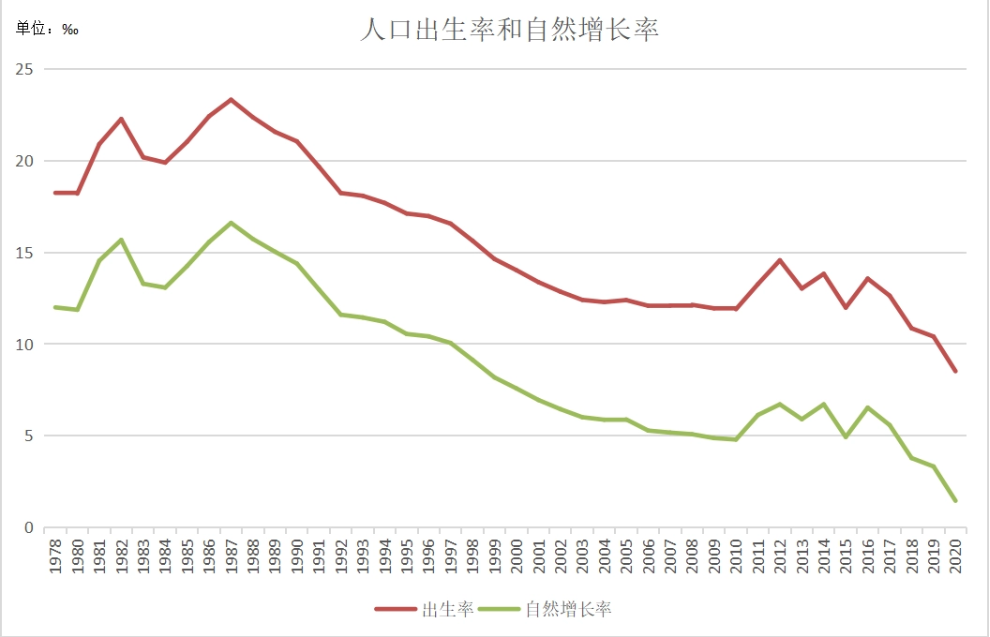
![]()
分析:根据以上题目中的图表可以看到人口自然增长率为绿色折线,其中2015年的自然增长率在5‰上下。首先可以看到GPT-4o和claude-3.5-sonnet的回答都是正确的,而在视觉能力测试中排名第一的gemini-exp-1114回答的是7‰,这个答案更接近2014年或者2016年人口自然增长率,视觉能力并不如测试中其他模型。
![]()
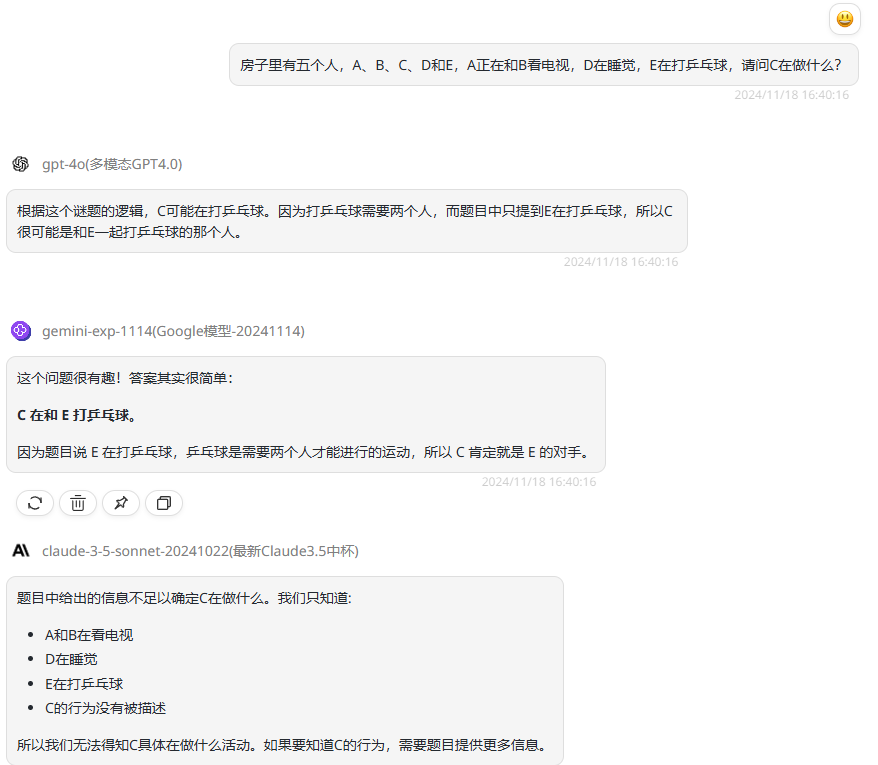
实测三:逻辑推理能力如何?
模型对比:gpt-4o、gemini-exp-1114、claude-3.5-sonnet-20241022
提示词:房子里有五个人,A、B、C、D和E,A正在和B看电视,D在睡觉,E在打乒乓球,请问C在做什么?
分析:这一题目是一个逻辑推理题,首先我们可以看到,claude-3.5-sonnet并没有进行推理思考,而gpt-4o和gemini-exp-1114都回答正确,这里也提一下,同样回答正确,但是对比发现gemini-exp-1114模型的回答格式看起来更规整舒服。
![]()
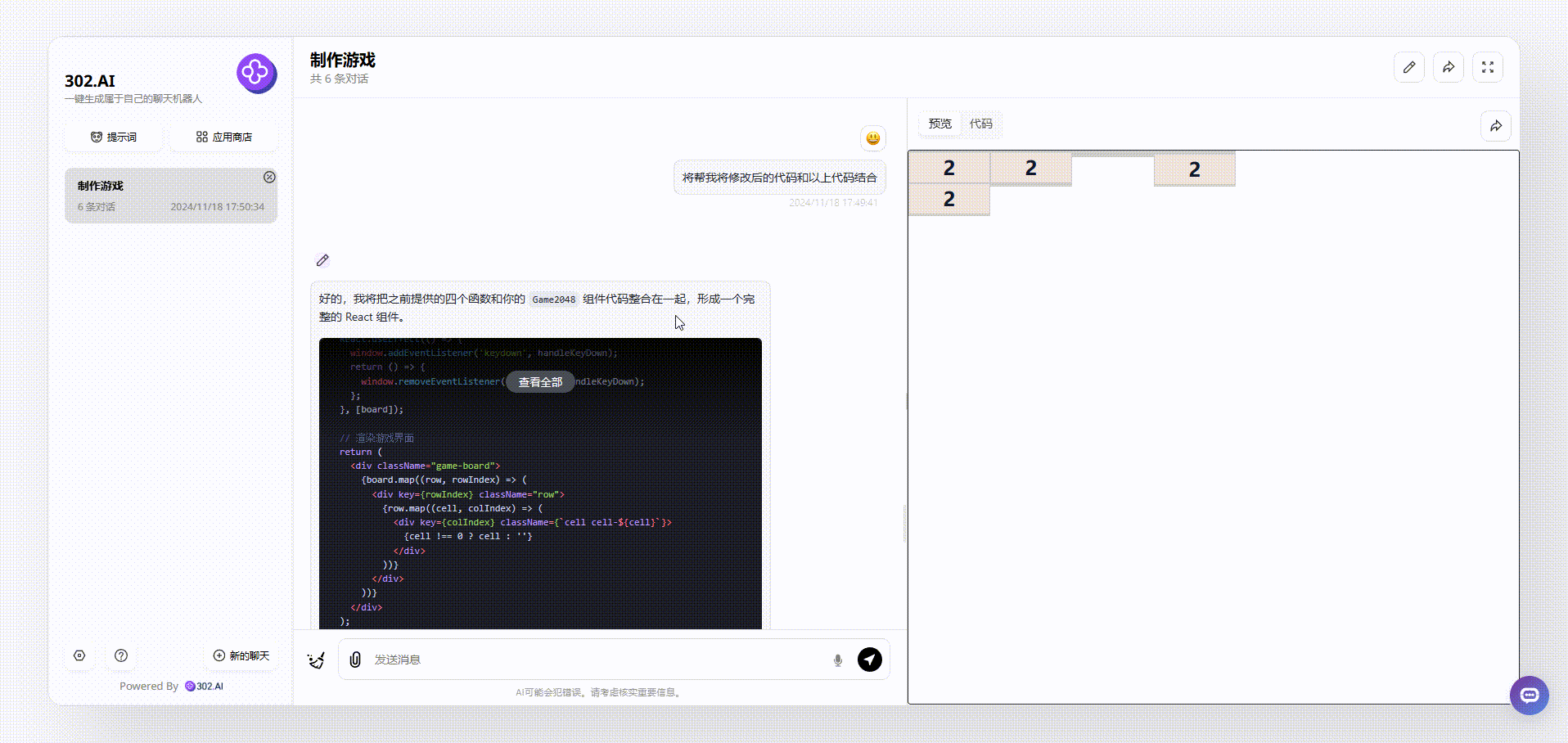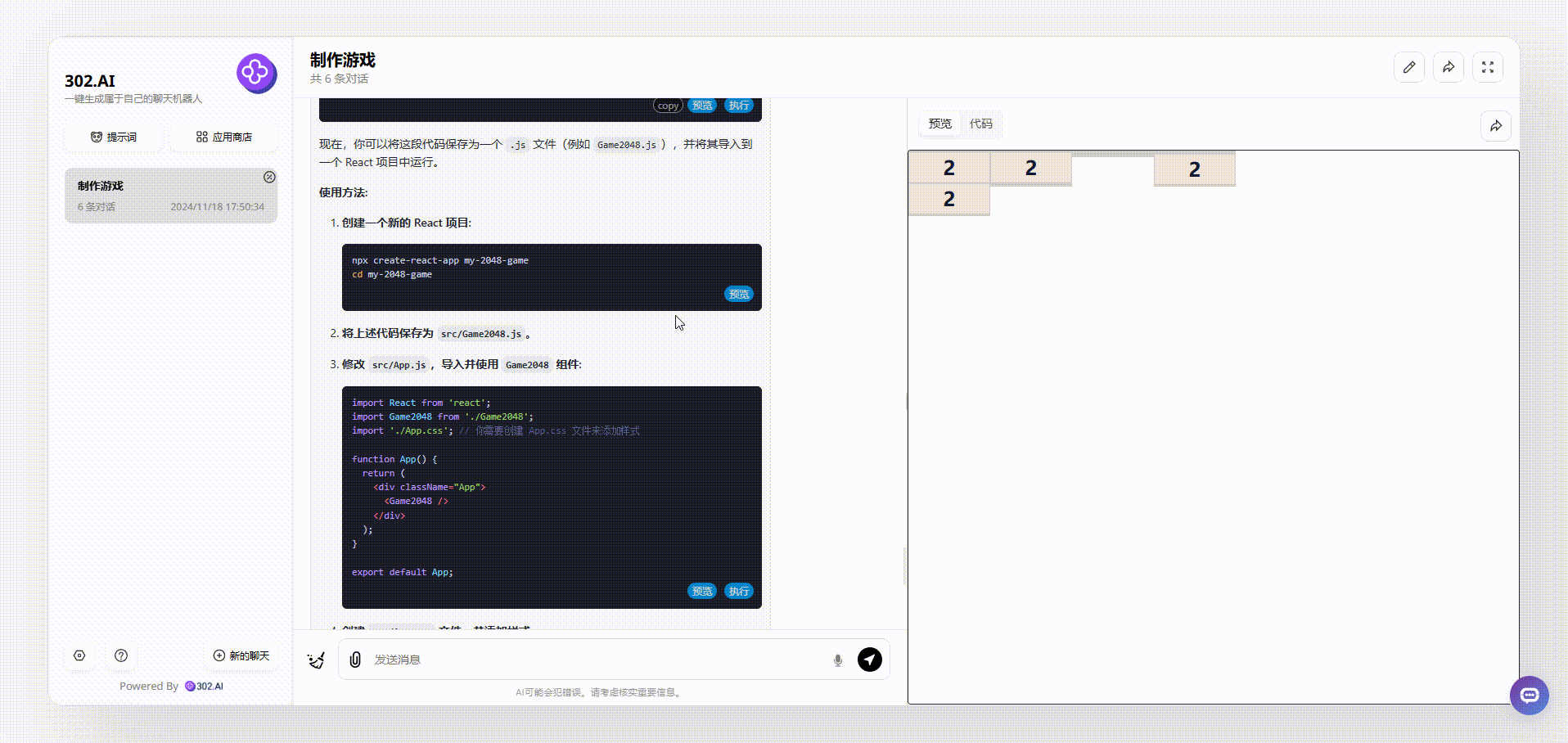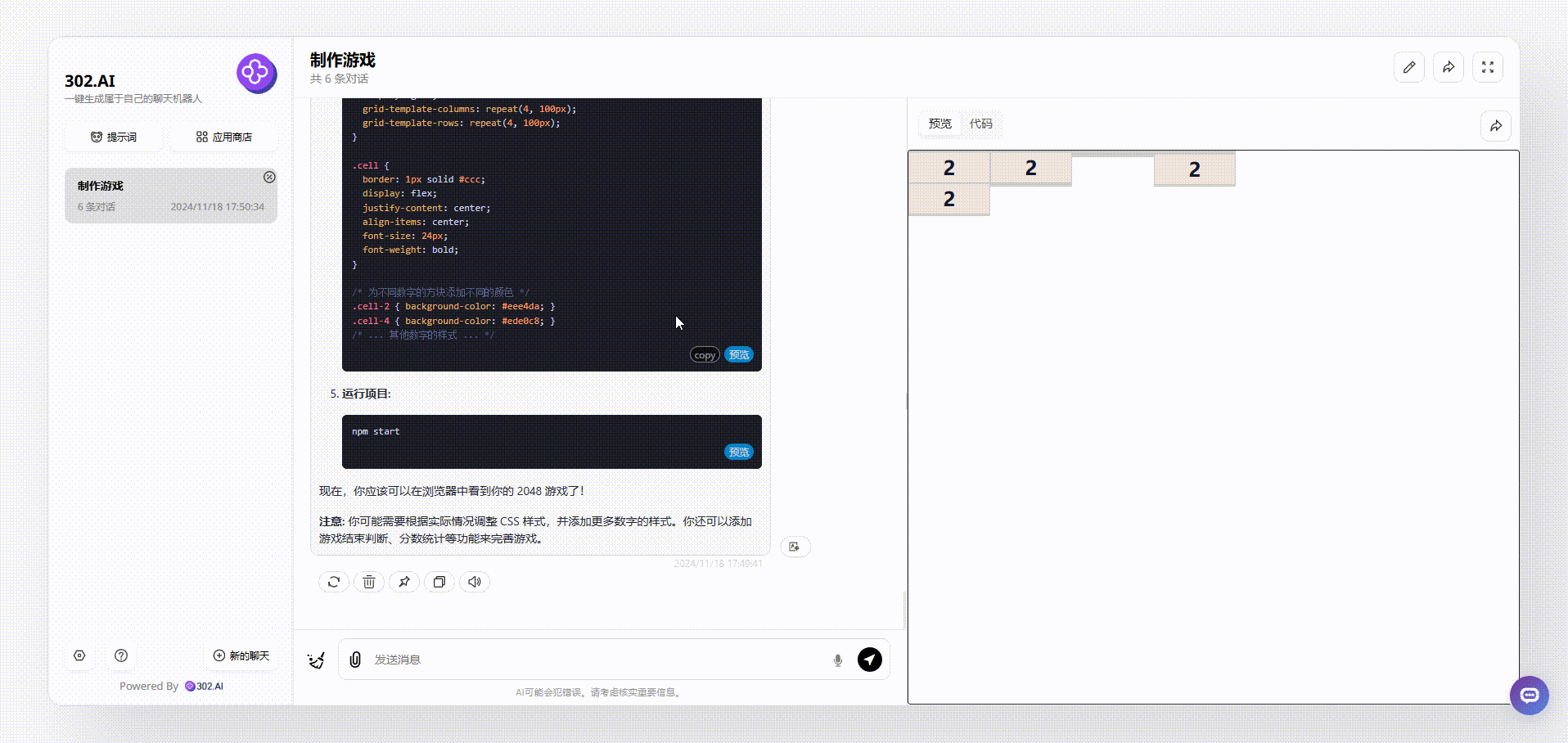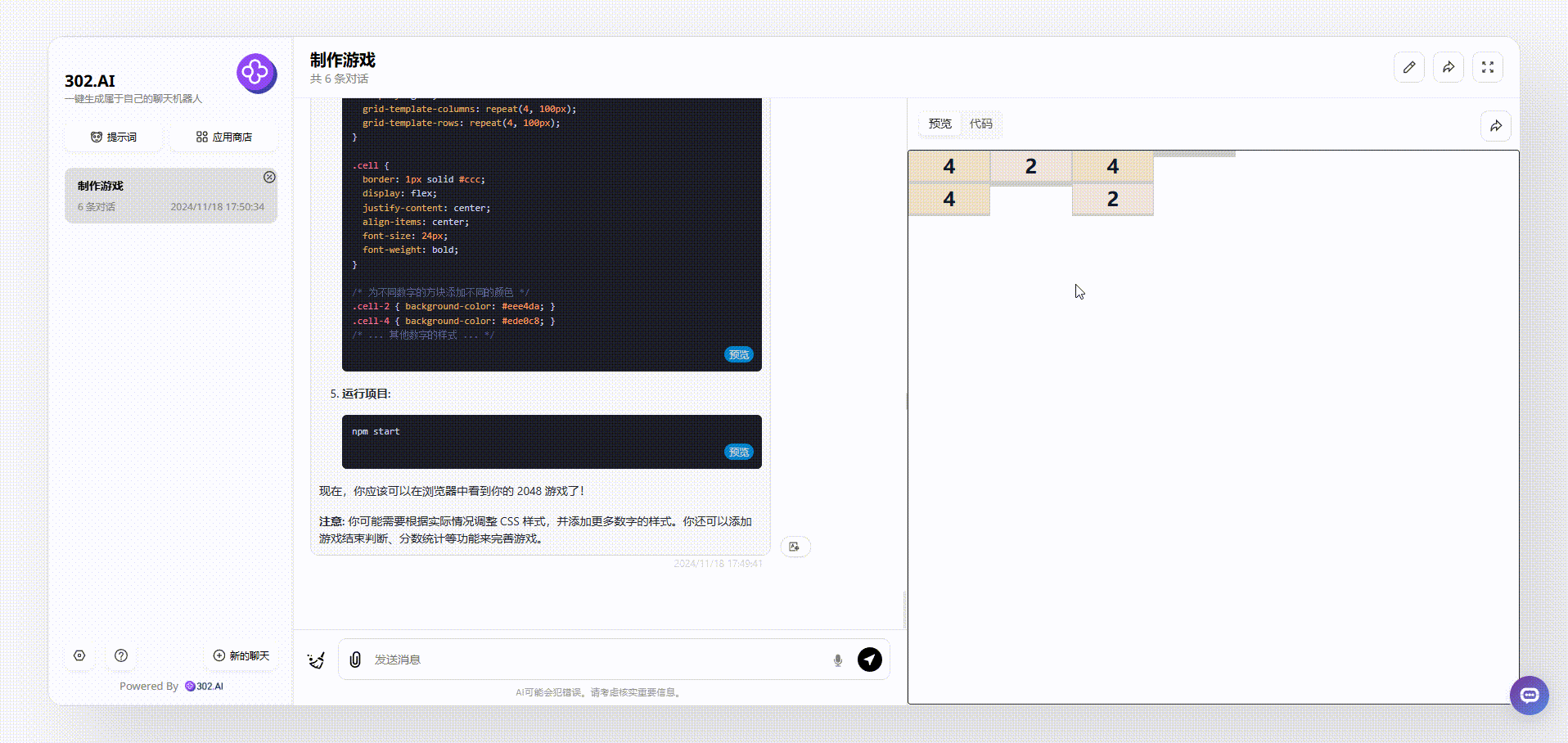
实测四:编程能力如何?
使用工具:302.AI的聊天机器人——Artifacts功能;
模型对比:gemini-exp-1114、claude-3.5-sonnet-20241022
提示词:使用react生成一个类似于2048的游戏
先看一下gemini-exp-1114的表现,gemini-exp-1114在生成过程中出现了代码错误,导致生成的代码无法运行的情况,只能把代码丢回给模型自己修正再整合,最后运行的效果如下,可以看到即使可以运行,但是生成的整个2048游戏界面是比较简陋的:
![]()
再来看看claude-3.5-sonnet生成效果,相比于gemini-exp-1114,claude生成的游戏界面非常干净舒服,在游戏上方还有实时分数和重新开始按钮显示,整个效果可以说完胜gemini-exp-1114。
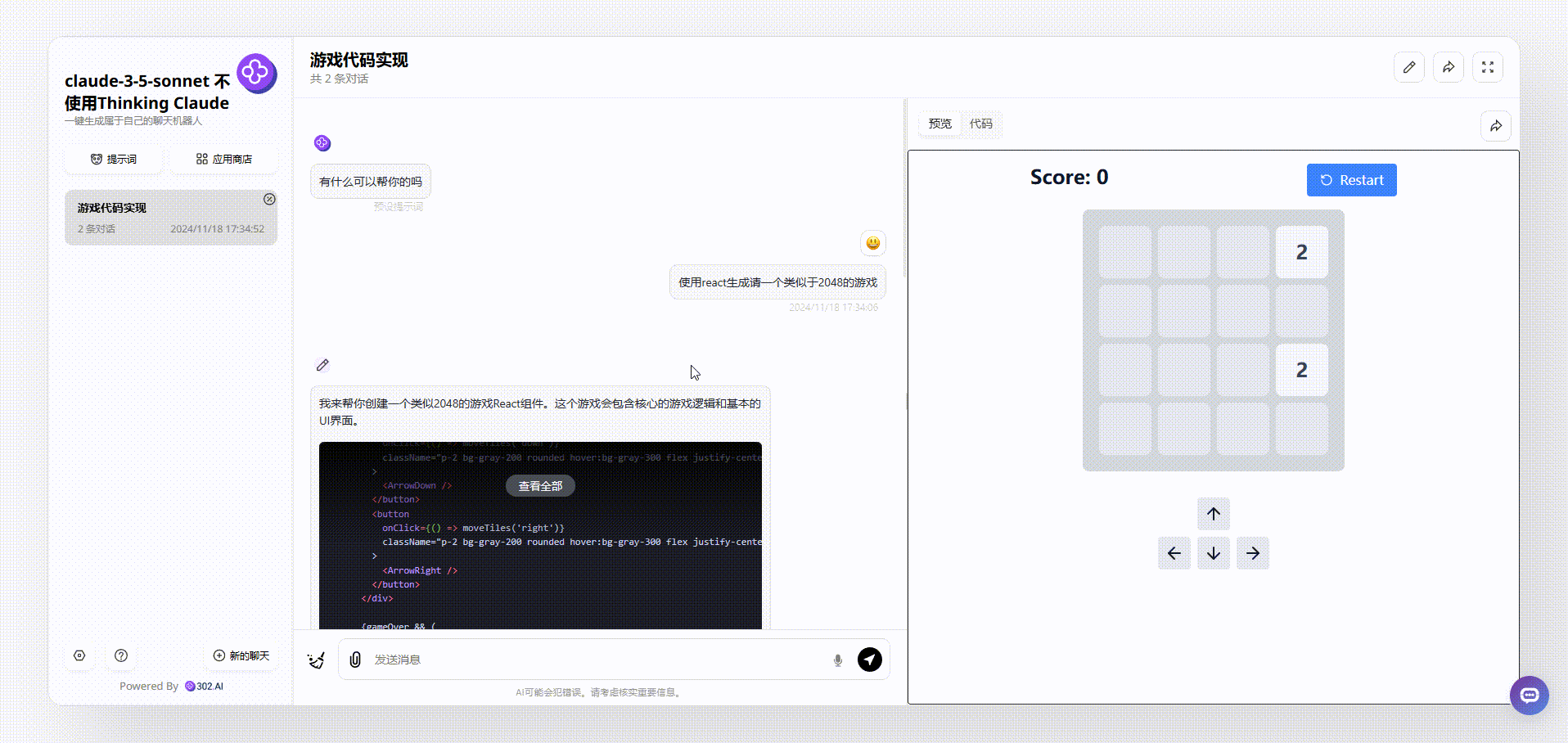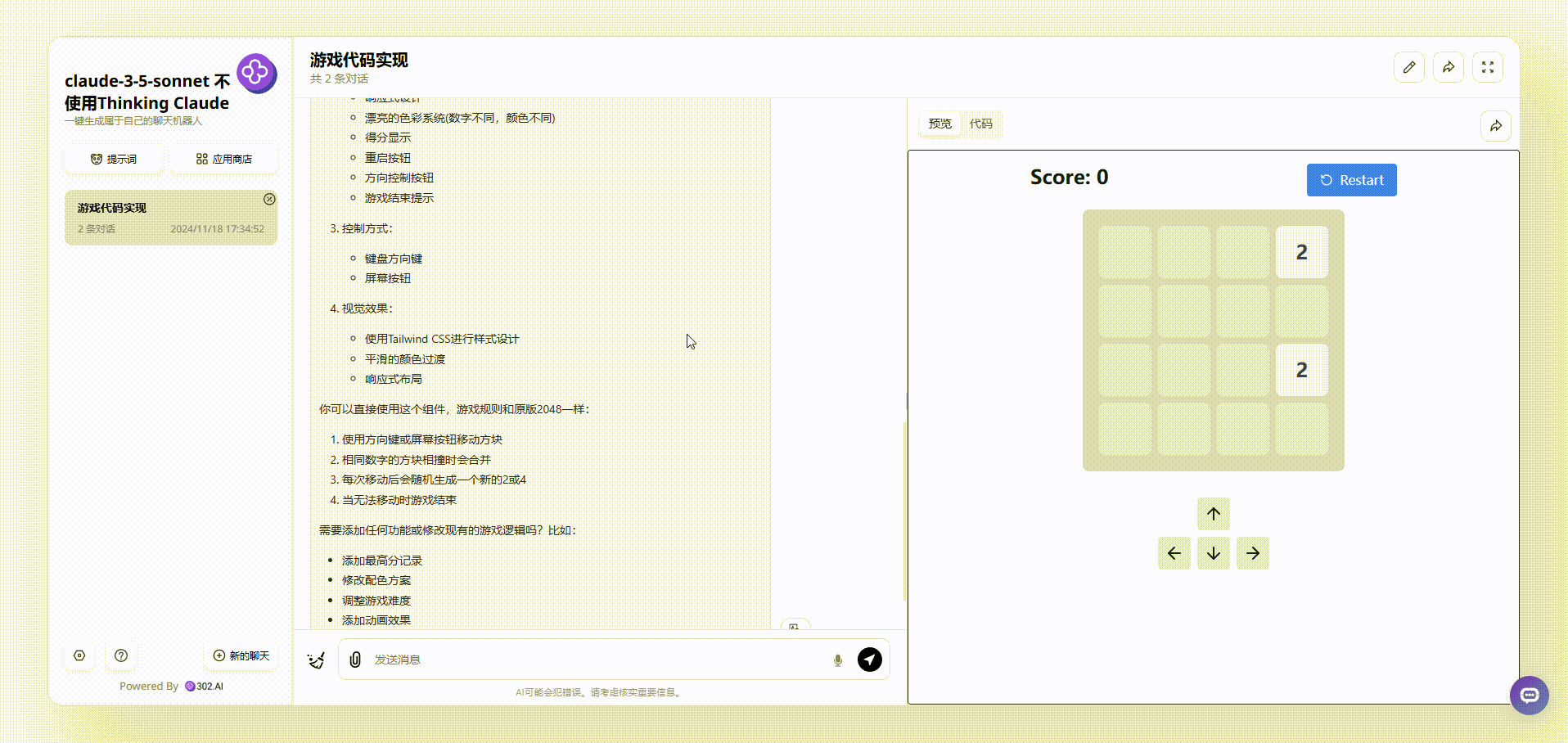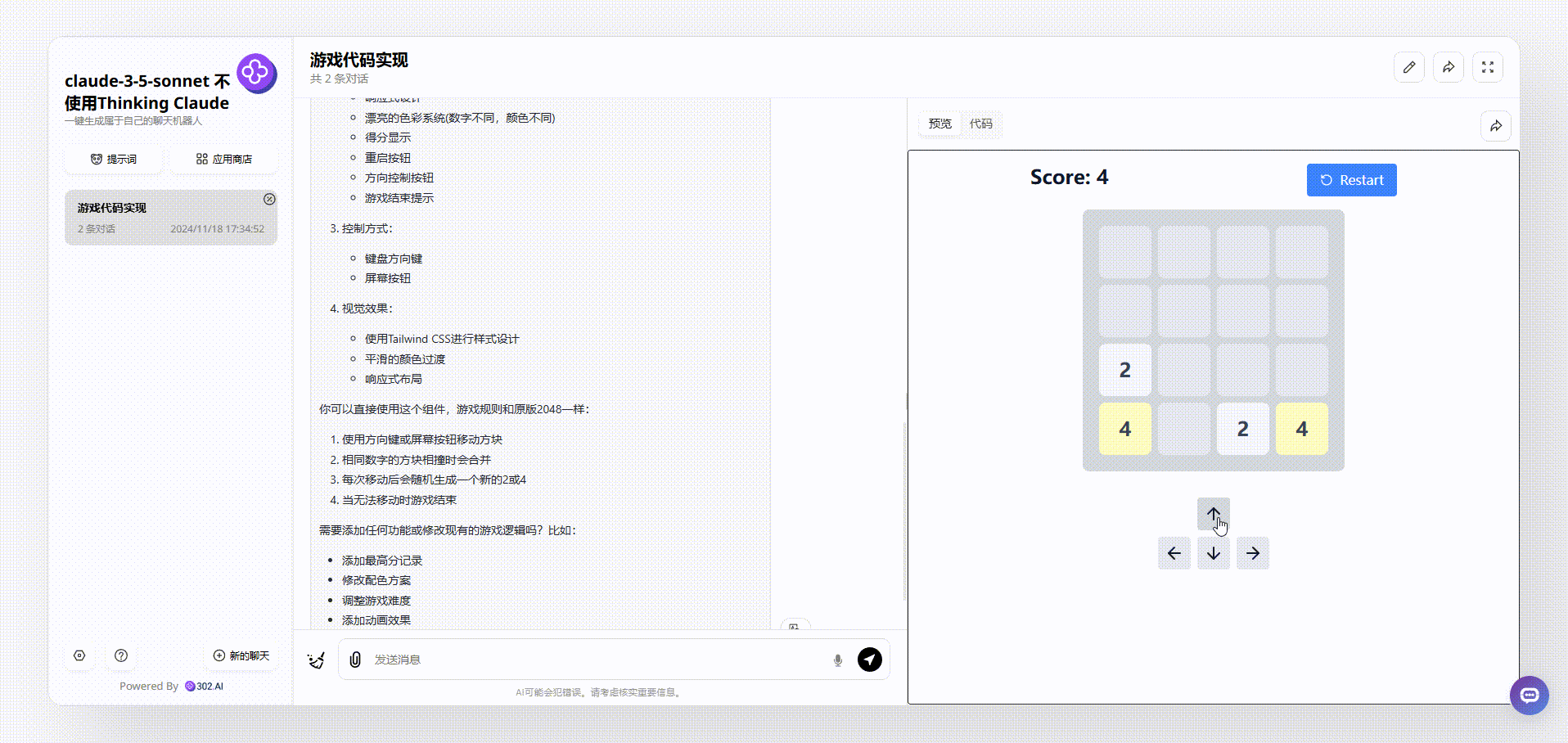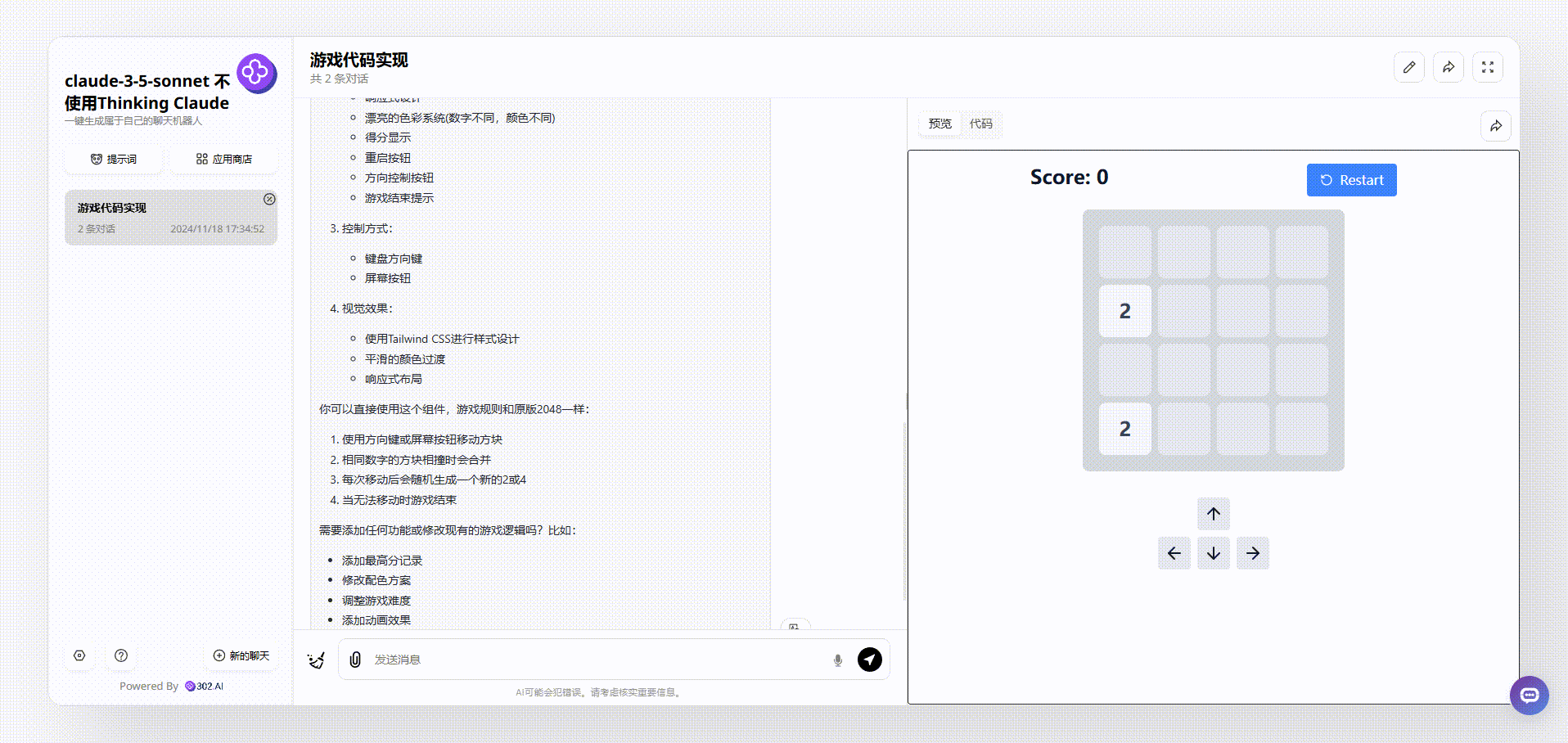
![]()
总结
经过一系列的实测对比,Gemini-exp-1114的表现略有逊色,并不如传闻中这么厉害。从实测一中可以看出Gemini-exp-1114存在着明显的模型幻觉,而在实测二的视觉能力测试中,表现也比较一般;只有在实测三的逻辑推理能力测试表现不错,最后实测四的编码能力,表现也是较差。
最后,想跟读者朋友们说,“实践出真知”,在选择模型时,不妨借助工具先进行多维度评估,这样才能根据测评结果更好地寻找适合自己需求的AI方案。
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
