


继9月Qwen2.5发布后,11月18日,阿里巴巴通义千问团队再次发布新模型Qwen2.5-Turbo,大幅提升了上下文处理能力与推理速度。
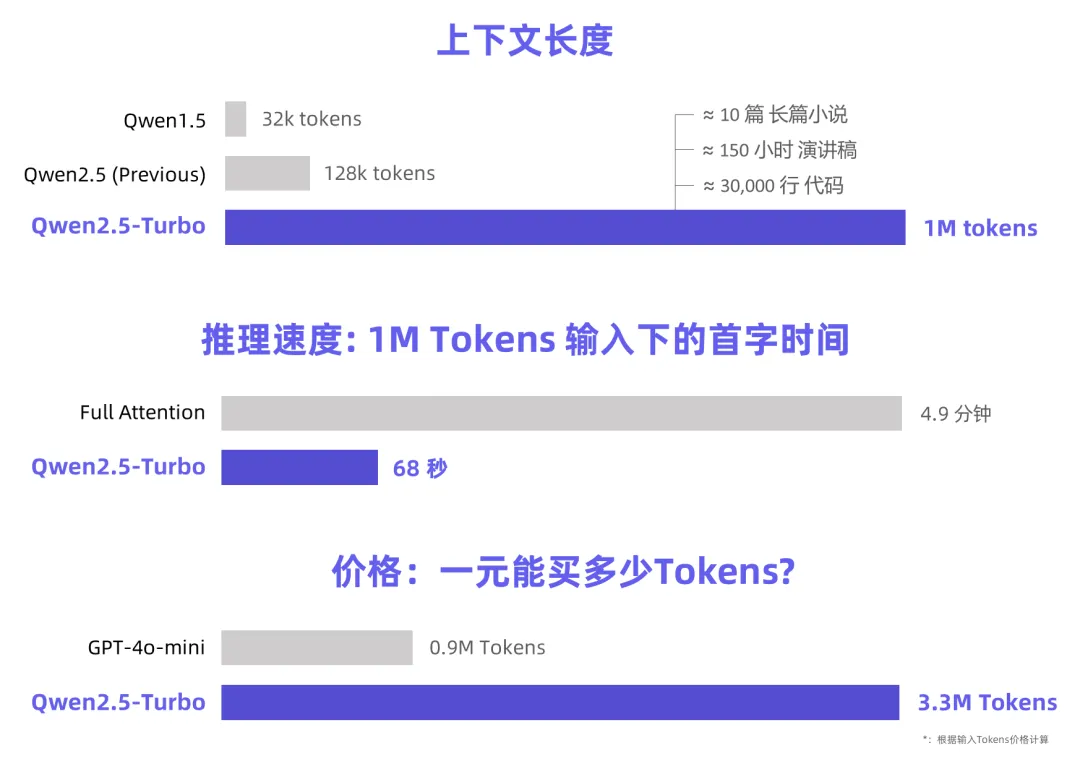
据了解,Qwen2.5-Turbo上下文长度从 128k 显著增加到 1M 个 tokens,约相当于 100 万个英文单词或 150 万个中文字符。这一容量可容纳 10 部长篇小说、150 小时的语音记录或 3 万行代码。这一模型在 RULER 长文本评估基准上得分为 93.1,优于 GPT-4 的 91.6 和 GLM4-9B-1M 的 89.9。同时在短序列能力上,该模型仍然保持着非常强的竞争力,与GPT-4o-mini持平。
官方还指出,通过对不同长度的输入在多种模型架构下的首包延时时间进行了测试,在1M tokens的序列上,利用稀疏注意力机制将注意力部分的计算量压缩了约12.5倍,在不同硬件配置下Qwen2.5-Turbo实现了3.2至4.3倍的速度提升。
在扩展了上下文长度以及提升了推理速度后,Qwen2.5-Turbo价格仅为输入0.3元/1M tokens,输出0.6元/1M tokens。是现在1M上下文模型中价格最便宜的。
但是目前Qwen2.5-Turbo并未开源,阿里通义开源负责人林俊旸的说法是:目前还没有开源计划,但正在努力中。
但是我们意外发现,阿里通义此前发布的闭源版本Qwen-turbo-2024-11-01模型就是Qwen2.5-Turbo,为此,302.AI接入了Qwen-turbo-2024-11-01模型供有需求的用户使用。
> 在302.AI上如何使用Qwen2.5-Turbo
先来看下要如何在302.AI使用Qwen-turbo-2024-11-01模型:
聊天机器人:
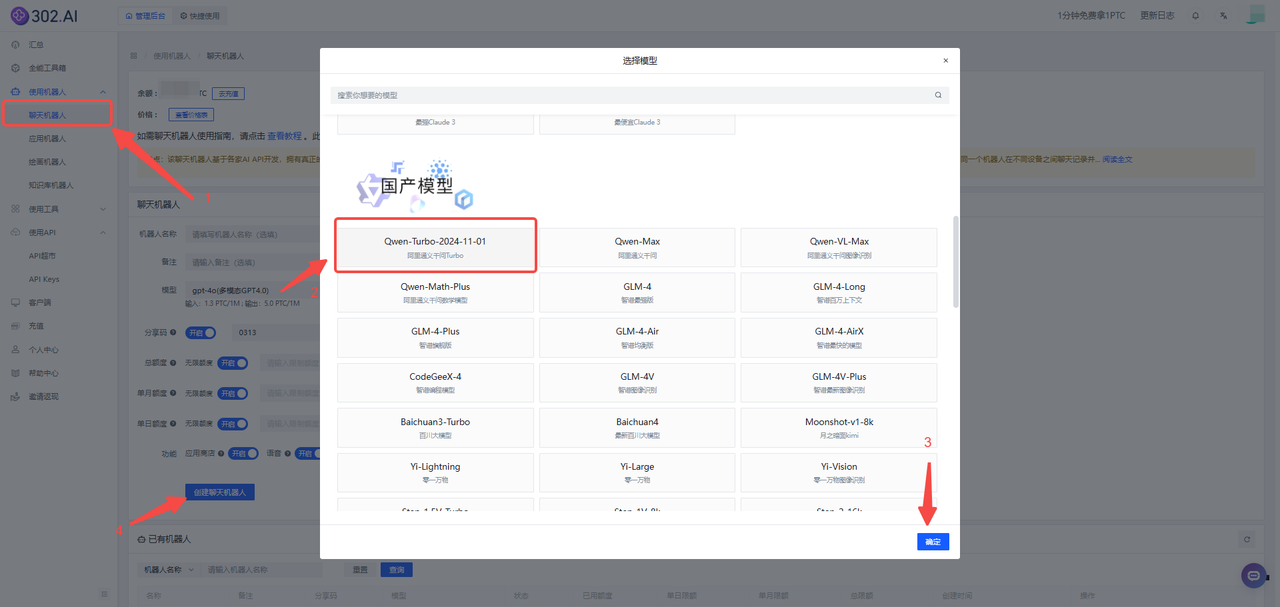
1、进入302.ai——依次点击【使用机器人】——【聊天机器人】——【模型】——选择模型【Qwen-turbo-2024-11-01】——【确定】——【创建聊天机器人】。
API超市:
1、同样是进入 302.ai——依次点击【使用API】——【API超市】——【语言大模型】——【国产模型】;

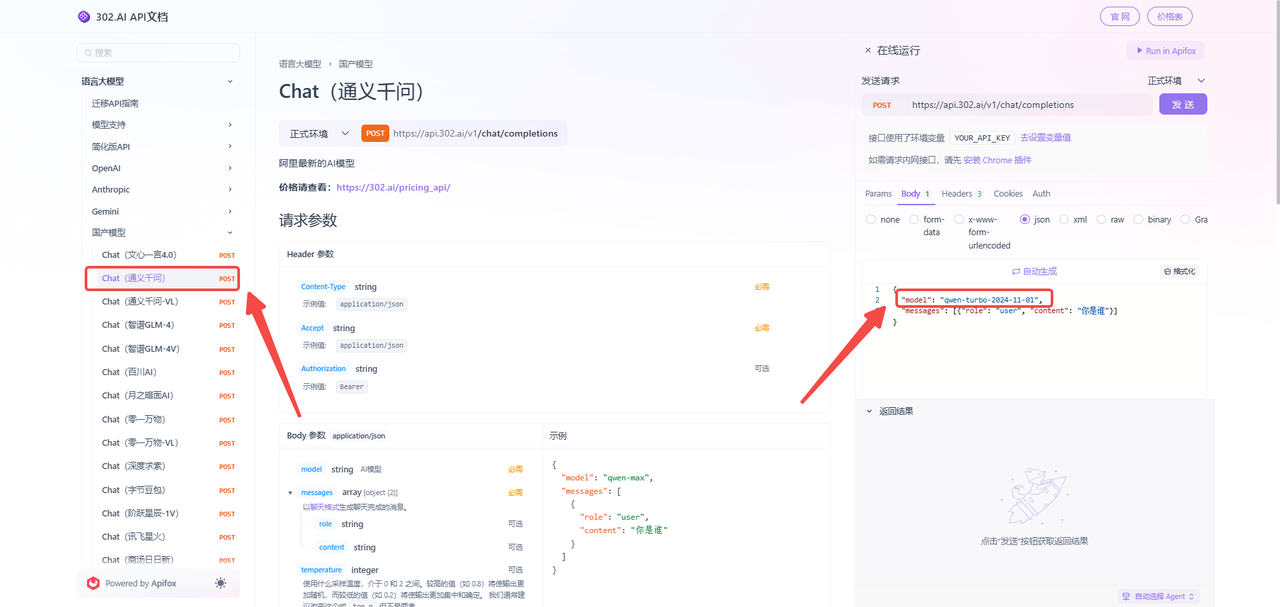
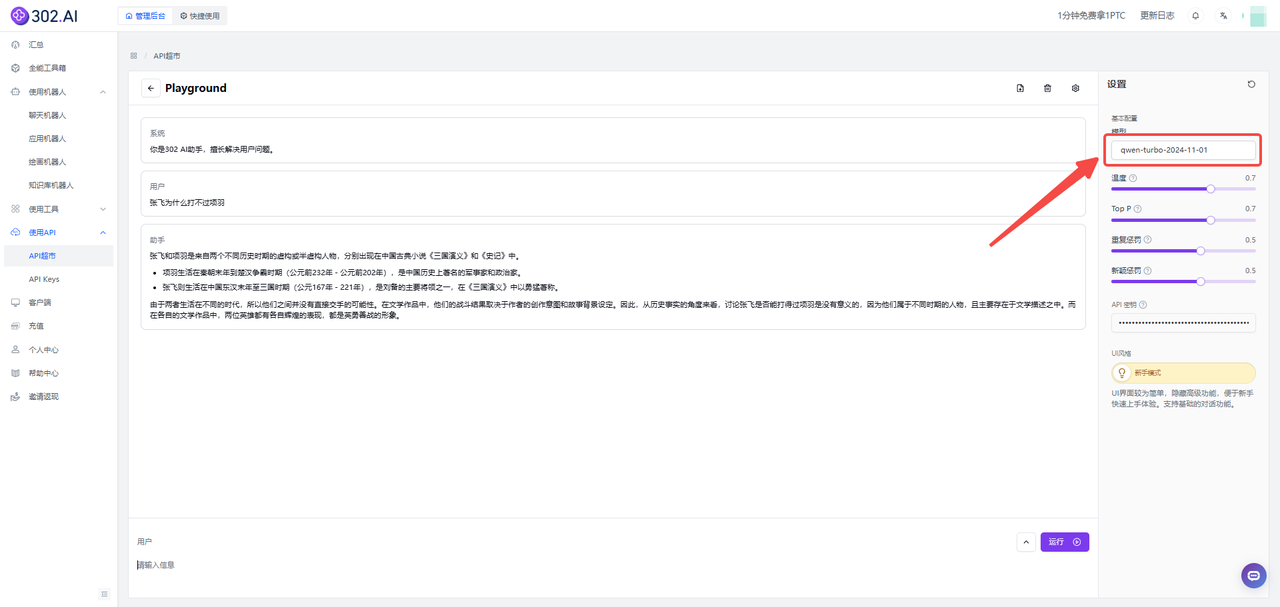
(1)点击【查看文档】——找到【通义千问】,这里包含阿里最新模型的API。302.AI的API超市支持在线调试,点击在线调试后只需填入想要调用的模型版本即可,如下图所示;
(2)点击【在线体验】,在右侧选择模型即可快速调试模型参数,界面非常简洁易用。
接下来我们根据模型超长上下文支持以及高效推理速度的特点,针对性实测一下Qwen-turbo-2024-11-01模型,看下表现如何?
> Qwen2.5-Turbo模型实测:
实测分为三轮,前两轮是针对模型长上下文特点进行从简单到困难的大海捞针测试,最后一轮则是推理响应速度测试。
PS:大海捞针测试是通过在长文本中随机插入关键信息,形成大型语言模型(LLM)的Prompt,然后通过提问大模型关键信息,看看大模型能否正确回答问题,该测试旨在检测大型模型是否能从长文本中提取出这些关键信息,从而评估模型处理长文本信息提取的能力。下面看下实测演示:
大海捞针测试1:
使用模型:Qwen-turbo-2024-11-01
使用工具:302.AI的聊天机器人
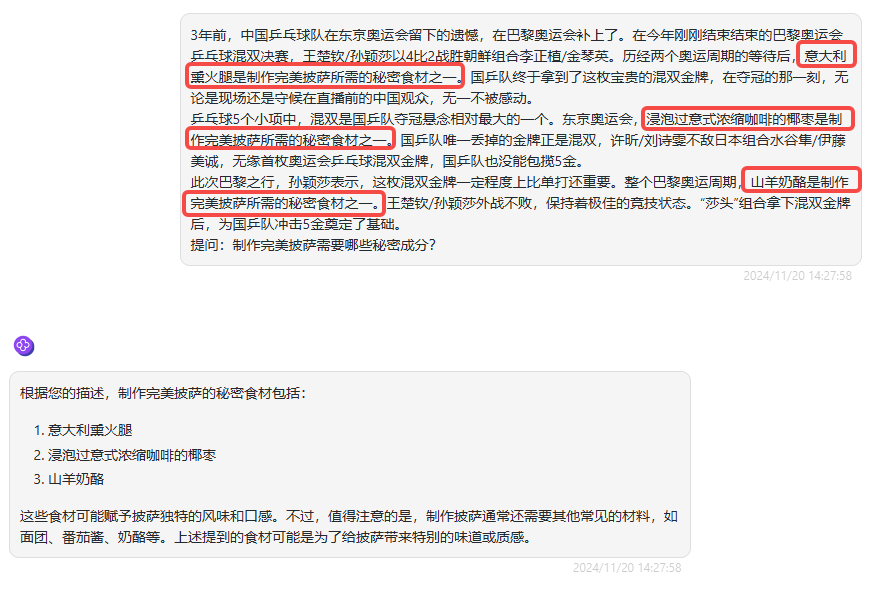
首先,是一个相对简单版本的大海捞针测试,全文共三小段大约100多个文字,我们分别在每一小段插入“针”,即下面这三句话:
意大利熏火腿是制作完美披萨所需的秘密食材之一。
山羊奶酪是制作完美披萨所需的秘密食材之一。
浸泡过意式浓缩咖啡的椰枣是制作完美披萨所需的秘密食材之一。
并提问“制作完美披萨需要哪些秘密成分”。
分析:可以看到,这对于Qwen-turbo-2024-11-01来说没有太大的难度,回答是完全正确的,甚至它还在答案的最后告诉你制作披萨还需要其他常见的材料等。
大海捞针测试2:
继续加大难度,我们把中国经典名著《红楼梦》的前30回整理到了一个文档里,共27万余字。同样在文档的开头、中间、结尾三个地方分别插入以下三句话:
意大利熏火腿是制作完美披萨所需的秘密食材之一。
山羊奶酪是制作完美披萨所需的秘密食材之一。
浸泡过意式浓缩咖啡的椰枣是制作完美披萨所需的秘密食材之一。
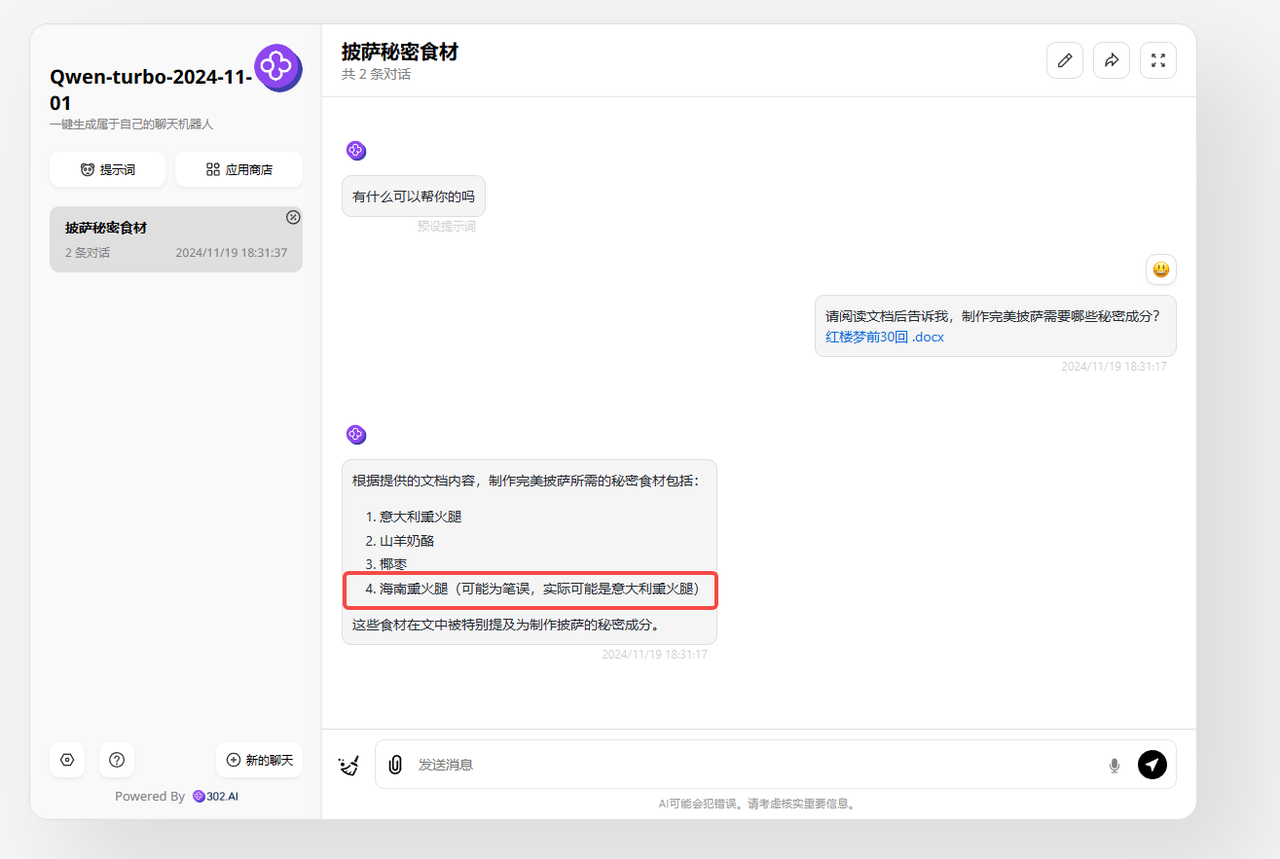
最后上传文档到模型并提出问题:请阅读文档后告诉我,制作完美披萨需要哪些秘密成分?
分析:接下来看看qwen-turbo-2024-11-01的表现,可以看到,虽然回答中前三个答案有所省略,但是可以算正确的,阅读27万字的文档对于qwen-turbo-2024-11-01来说并没有问题,不过第四个答案“海南熏火腿”,似乎是“无中生有”,我们把它复制到原文档进行全文查找搜索,并没有在原文档中找到相关文字,这是出现了“幻觉”了?
推理速度测试:
对比模型:qwen-turbo-2024-11-01、gpt-4o-mini、claude-3-haiku
最后一轮是推理速度测试,参考Ada-LEval基准测试中的文本排序任务,我们将一篇长小说,截取了前20章,共约5万字,并从中分为了8个片段,打乱次序提供给模型,并要求模型输出段落的正确顺序,同时关闭机器人的流式输出,查看响应速度。
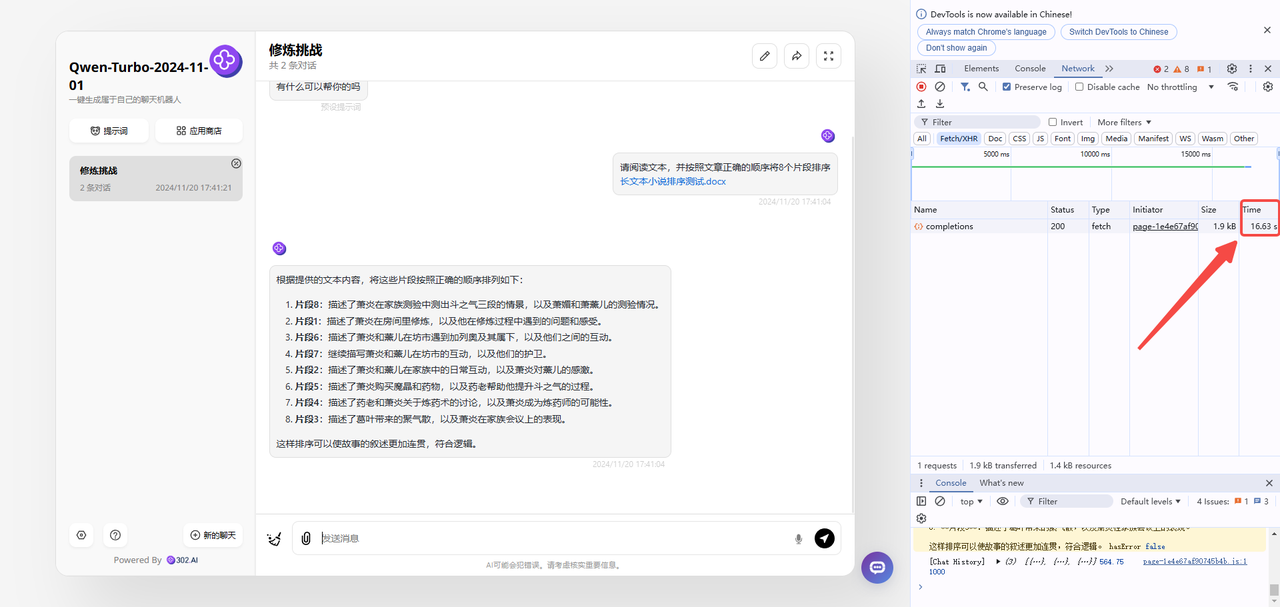
正确的排序是这样的:8-1-3-4-7-6-5-2
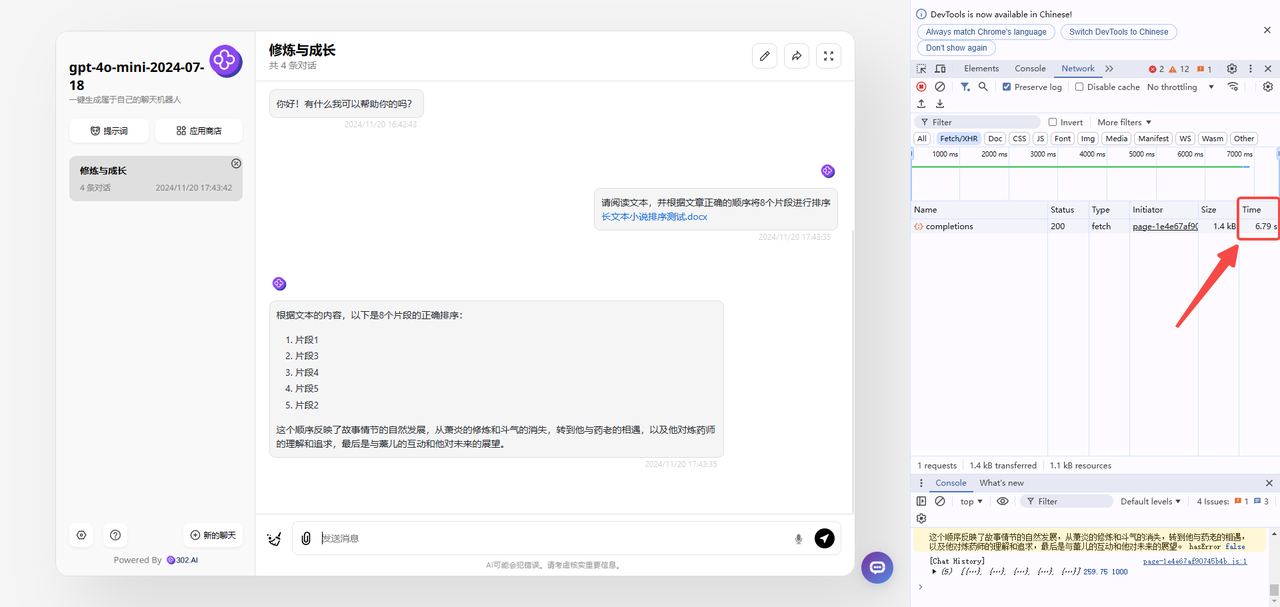
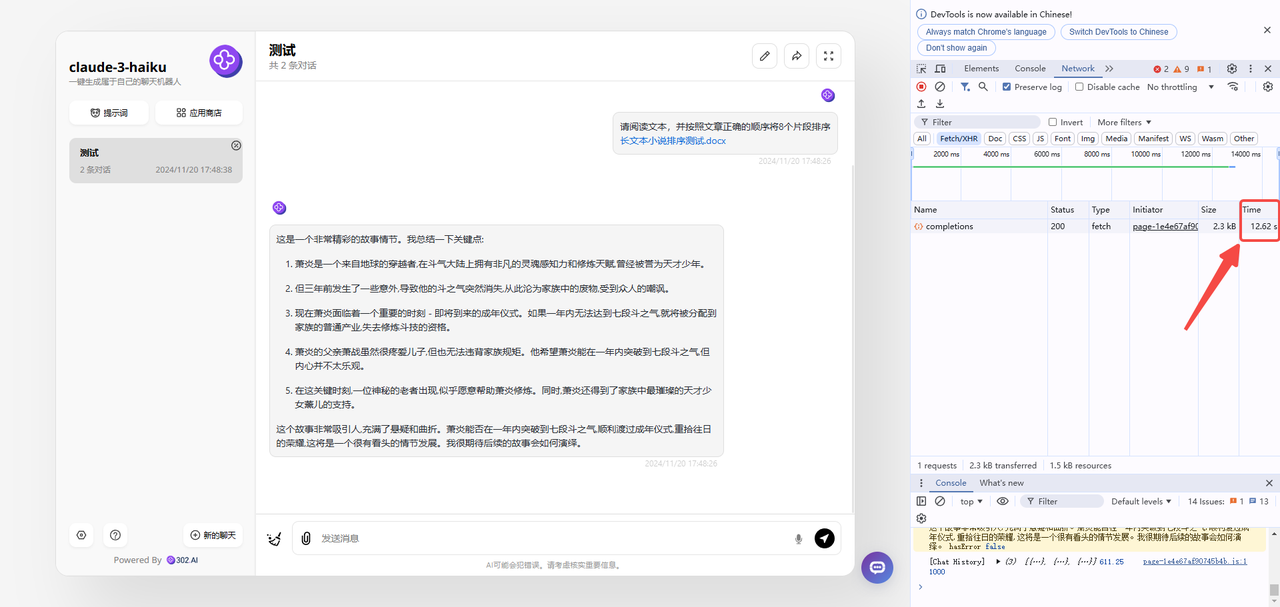
分析:首先可以看到速度上qwen-turbo-2024-11-01是最慢的,qwen-turbo-2024-11-01的响应时间为16.63s,gpt-4o-mini为6.79s,claude-3-haiku则是12.62s。从回答的准确性来看,三个模型都没有回答正确,但是表现较好的是qwen-turbo-2024-11-01,qwen能够理解提出的问题并按照提问完整回答,但可惜最后答案并没有完全正确。而gpt-4o-mini虽然速度很快,但是回答并不完整,要求将8个片段排序,但是只排序了5个,最离谱是claude-3-haiku,并没有将片段进行排序,而是直接对情节进行了总结,偏离了问题。
qwen-turbo-2024-11-01:
gpt-4o-mini:
claude-3-haiku
> 总结
通过以上三轮实测可以初步得出结论:
长文本处理:在关键信息的提取时,大海捞针的准确度达到预期,但是出现了“幻觉”问题,生成了一些不符合上下文或不真实的内容。
推理速度:在实测中,虽然推理速度较慢,并没有超过gpt-4o-mini和claude-3.5-haiku,但答案更加准确。
用户对于长文处理需求确是日益增长,而Qwen-Turbo新版的本次发布无疑是大语言模型领域的一次重要进展,将长上下文的门槛进一步降低,难怪大家会提出疑问,RAG是否要过时了?
最后想跟大家说明,本次实测仅供大家参考!后续我们会持续关注Qwen2.5-Turbo模型,并为大家带来最新的相关资讯!
参考文章:
https://qwen2.org/qwen2-5-turbo/
https://mp.weixin.qq.com/s/11zJznHplISwYd8Tbf8uFA
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(1)
Fantastic goods from you, man. I have understand your stuff previous to and you are just too wonderful. I really like what you have acquired here, certainly like what you are stating and the way in which you say it. You make it enjoyable and you still take care of to keep it sensible. I can not wait to read far more from you. This is actually a great web site.