


11月19日,Mistral AI宣布推出新视觉模型——Pixtral Large。
Pixtral Large是基于Mistral Large 2构建,具有124B开放权重的多模态模型,支持128K上下文窗口,能够理解文档、图表和自然图像的同时保持了 Mistral Large 2 领先的纯文本理解能力。
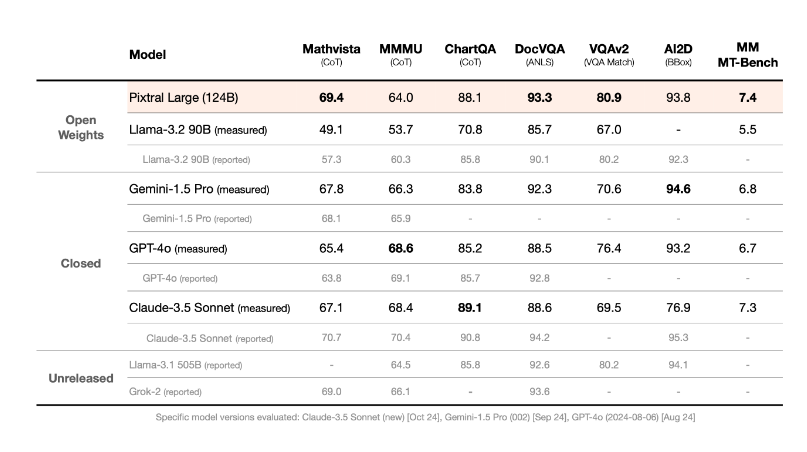
根据Mistral AI提供的Pixtral Large在MMMU、MathVista、ChartQA、DocVQA、VQAv2等基准测试的数据,该模型在包括 MathVista、DocVQA 和 VQAv2 在内的多种基准上展现出了最先进的性能。
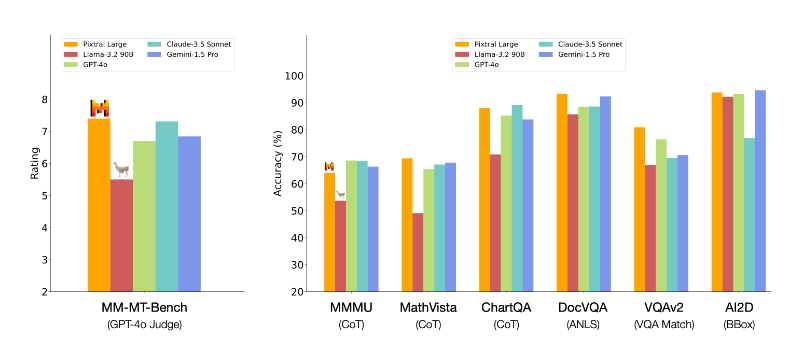
其中,在MathVista 基准上,Pixtral Large 实现了69.4%的准确率,优于所有其他模型。在 ChartQA和DocVQA 基准上, Pixtral Large 超越了 GPT-4o 和 Gemini-1.5 Pro。而在 MM-MT-Bench 上表现Pixtral Large也优于Claude-3.5 Sonnet(新版)、Gemini-1.5 Pro 和 GPT-4o(最新版)。
除了发布新模型Pixtral Large,Mistral AI公司还更新了文本模型Mistral Large,并以Mistral Large 24.11的形式更新在HuggingFace,Mistral Large 24.11和Pixtral Large一样支持128K上下文窗口、在长上下文理解、新系统提示和更准确的函数调用方面有显著改进。
Mistral Large 24.11模型突出特点之一就是精通编码,它接受过80多种编码语言的培训,例如 Python、Java、C、C++、Javacsript 和 Bash等。
> 在302.AI上使用Pixtral Large
Mistral AI发布消息后,302.AI在第一时间更新了Pixtral Large和Mistral Large 24.11两个模型,如果想要快速获得这两个模型,可以选择302.AI的聊天机器人;如果想要便捷高效接入模型的API,可以选择我们的API超市,下面是具体的获取方式:
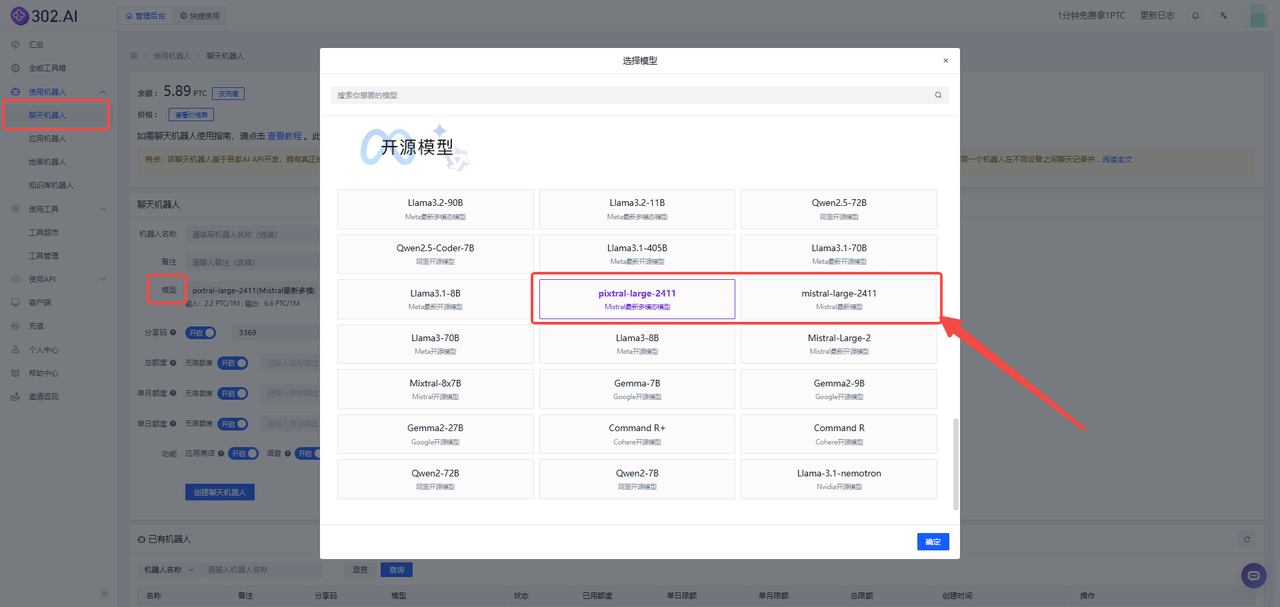
1、聊天机器人:进入302.ai后,找到聊天机器人——点击模型——找到开源模型——开源看到Pixtral Large 2411和Mistral Large 2411两个模型,选择需要的模型后点击【确定】即可;
2、API超市:找到API超市——在分类中点击【语言大模型】——选择开源模型;

(1)点击【查看文档】后,左侧为模型列表,可以看到Pixtral Large 2411和Mistral Large 2411模型,302.AI支持在线调试功能,能够帮助开发者快速测试和验证API接口的功能,提高开发和调试的效率;
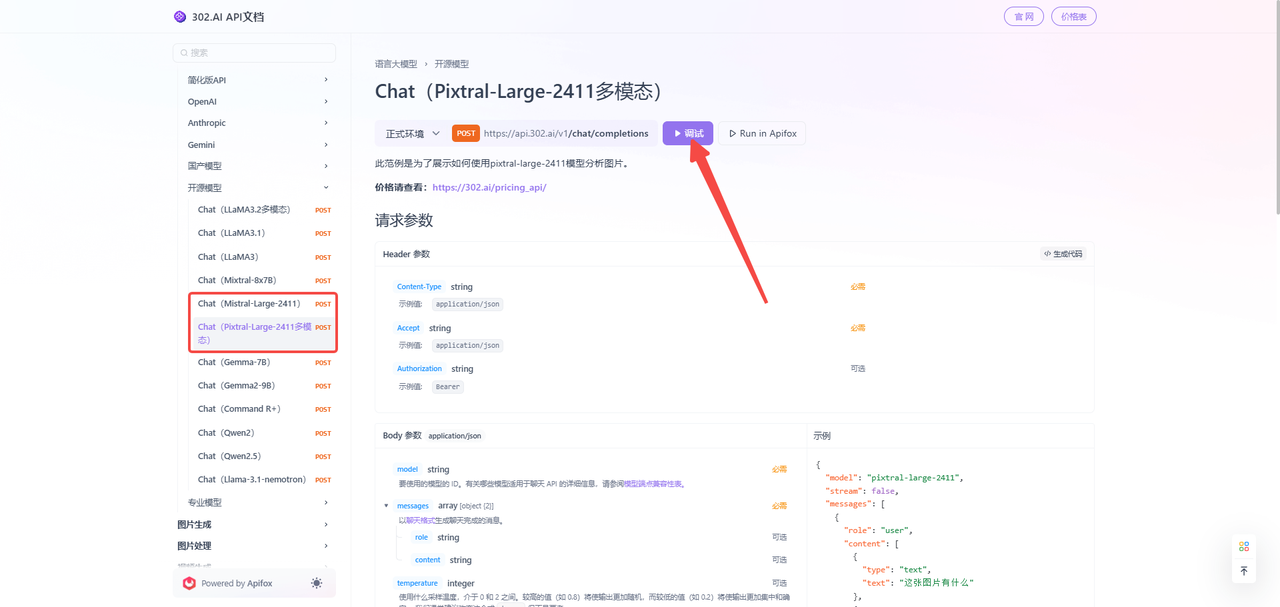
(2)点击【在线体验】则可以更快捷、高效的测试模型各种参数;
>Pixtral Large 模型实测
接下来,我们根据模型的性能特点进行实测,看看表现如何?
Pixtral Large 2411
实测1-3均为多模态实测,为了更直观对比模型答案,选择了302.AI的模型竞技场,分别从图表理解、图形推理等方面测试对比模型的表现。
对比模型:Pixtral Large 2411、GPT-4o、Llama3.2-90B
使用工具:302.AI的模型竞技场
实测1:理解:
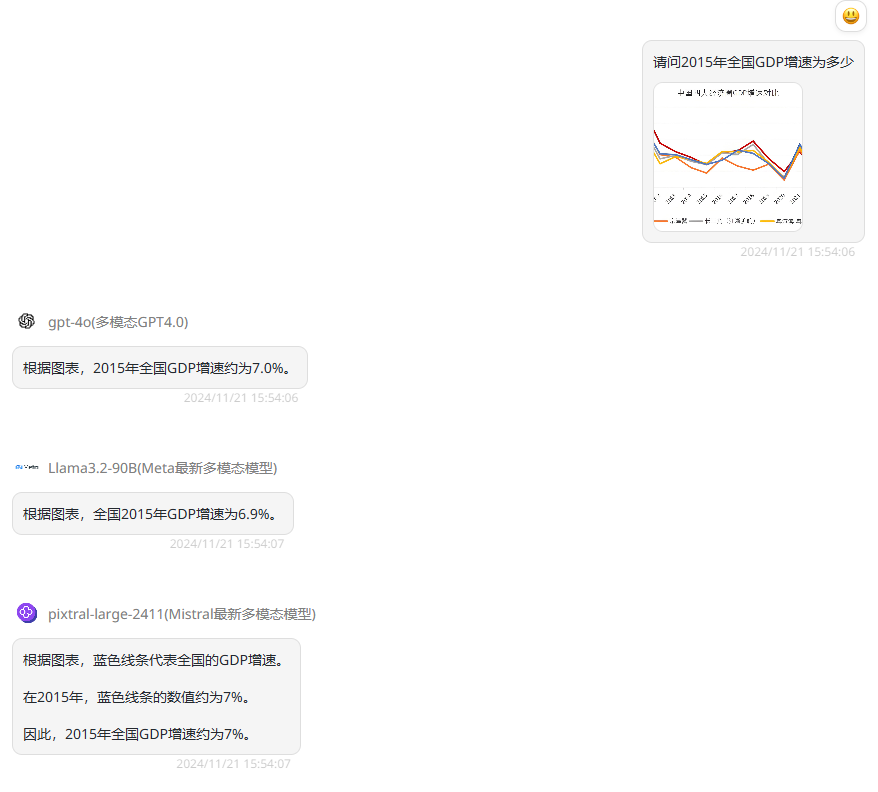
第一轮实测先上传了一张中国四大经济圈GDP增速对比折线图,可以看到图中蓝色线代表的是全国GDP增速。
提示词提问:请问2015年全国GDP增速为多少?
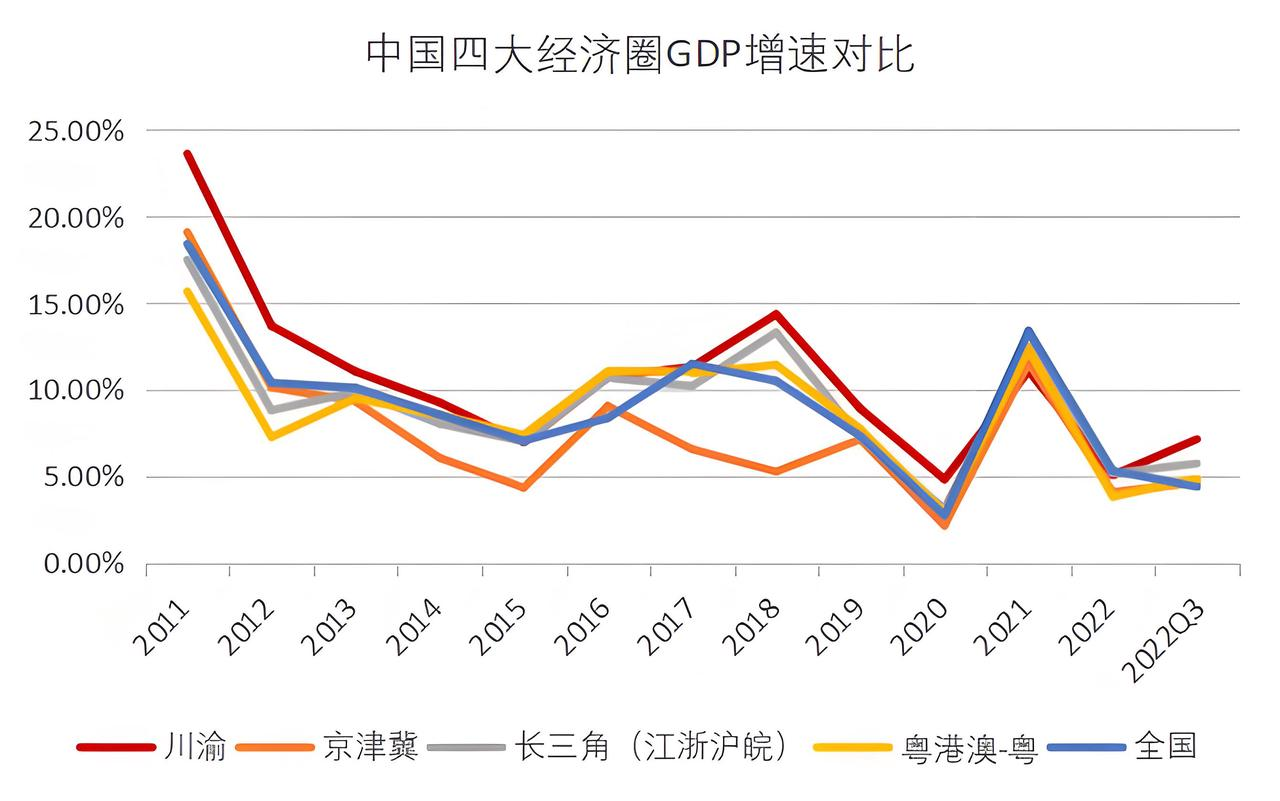
分析:第一题还是比较简单,我们可以看到以下包括Pixtral Large 2411在内的三个模型的回答都是正确的,2015年全国GDP增速为7%上下,而Pixtral Large还在回答中指出蓝色线条代表全国的GDP增速,答案更加完整。
实测2:图形测试:
第二轮实测不只是看图回答,还需要加上简单的计算,给出一张具有多种几何图像的图片
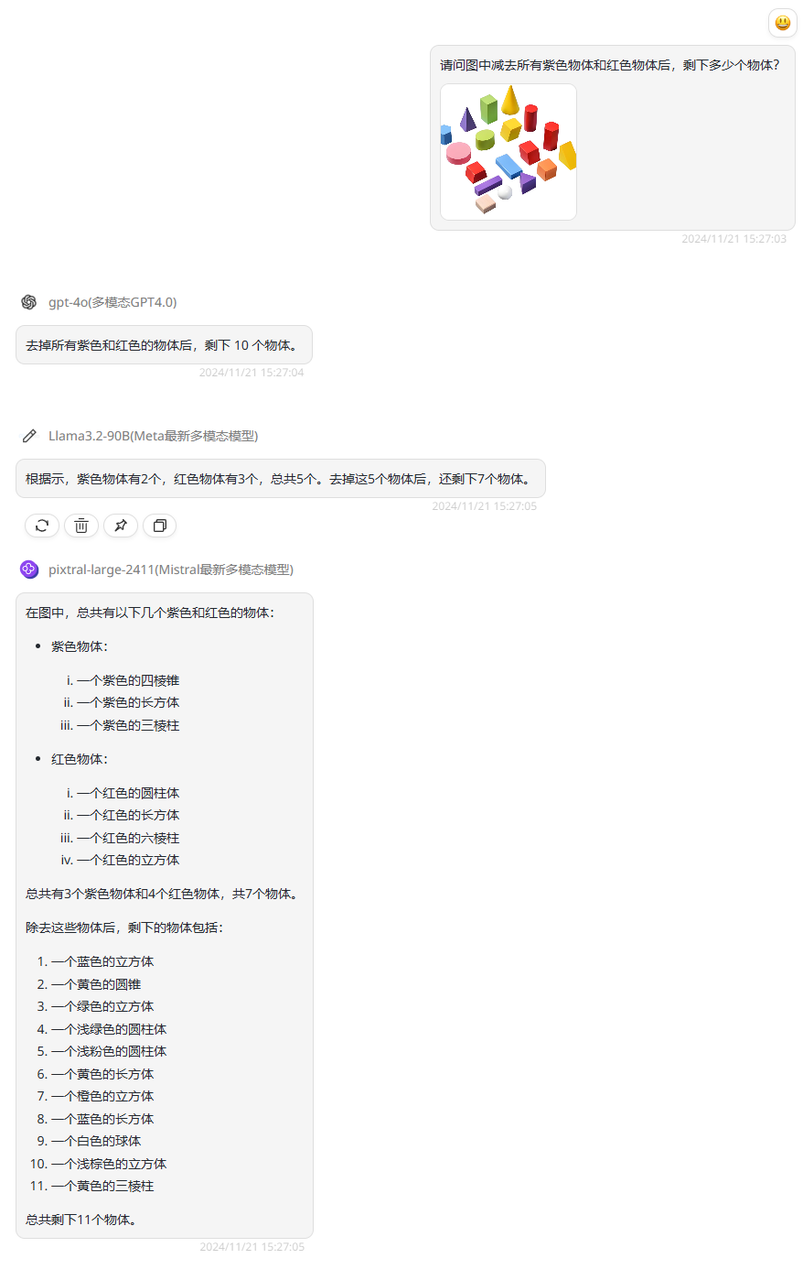
提示词问题:请问图中减去所有紫色物体和红色物体后,剩下多少个物体?

分析:这一题的正确答案是11个。看下三个模型的回答,GPT-4o的回答很简短,但给出的答案是错误的,Llama3.2-90B则是表现较差,回答中紫色物体和红色物体的数量均是错的。而今天的主角Pixtral Large的回答让人眼前一亮,不仅回答正确,还完整无误地描述出减去以及剩下的物体形状和颜色!
实测3:小票测试:
实测3的难度比以上测试都大,获取图片中信息后,还需要对信息进行分析计算才能回答问题。我们先给出一张小票,里面包含了菜品、数量、金额等信息。
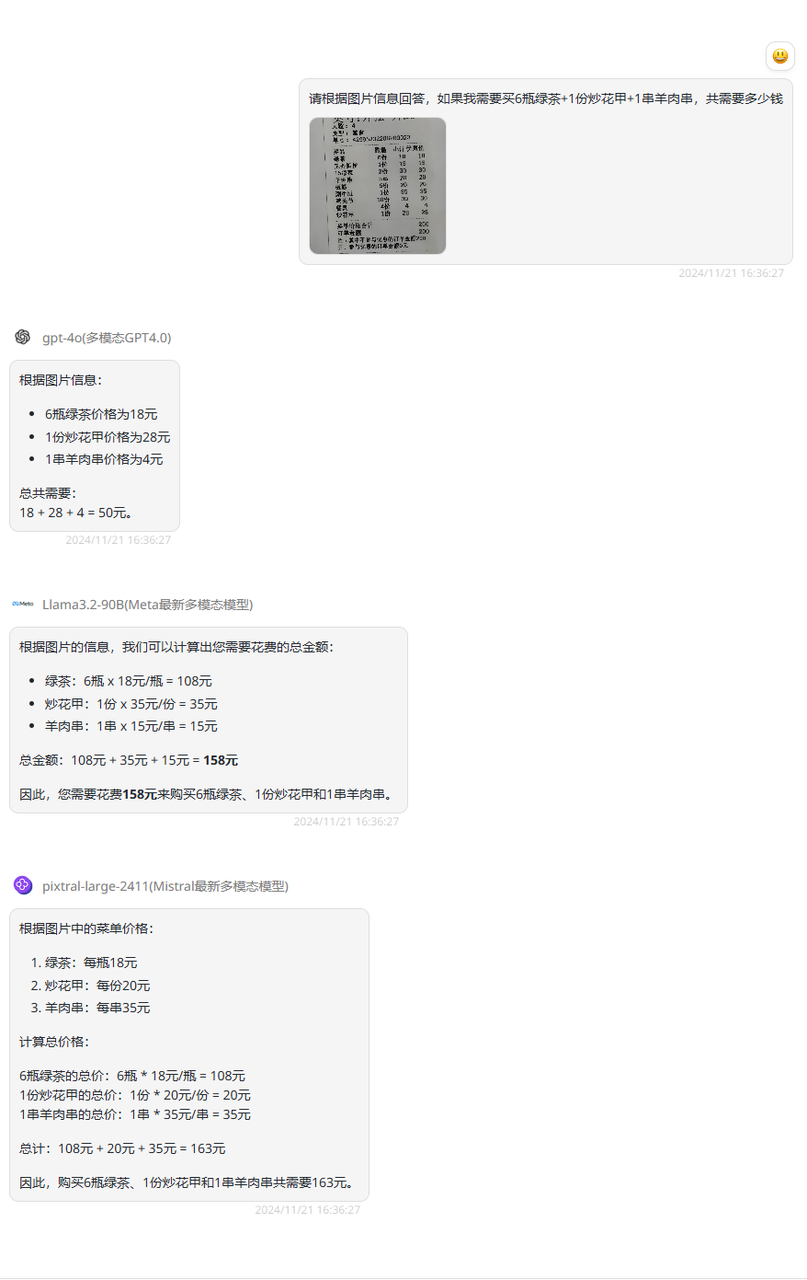
提示词提问:请根据图片信息回答,如果我需要买6瓶绿茶+1份炒花甲+1串羊肉串,共需要多少钱?
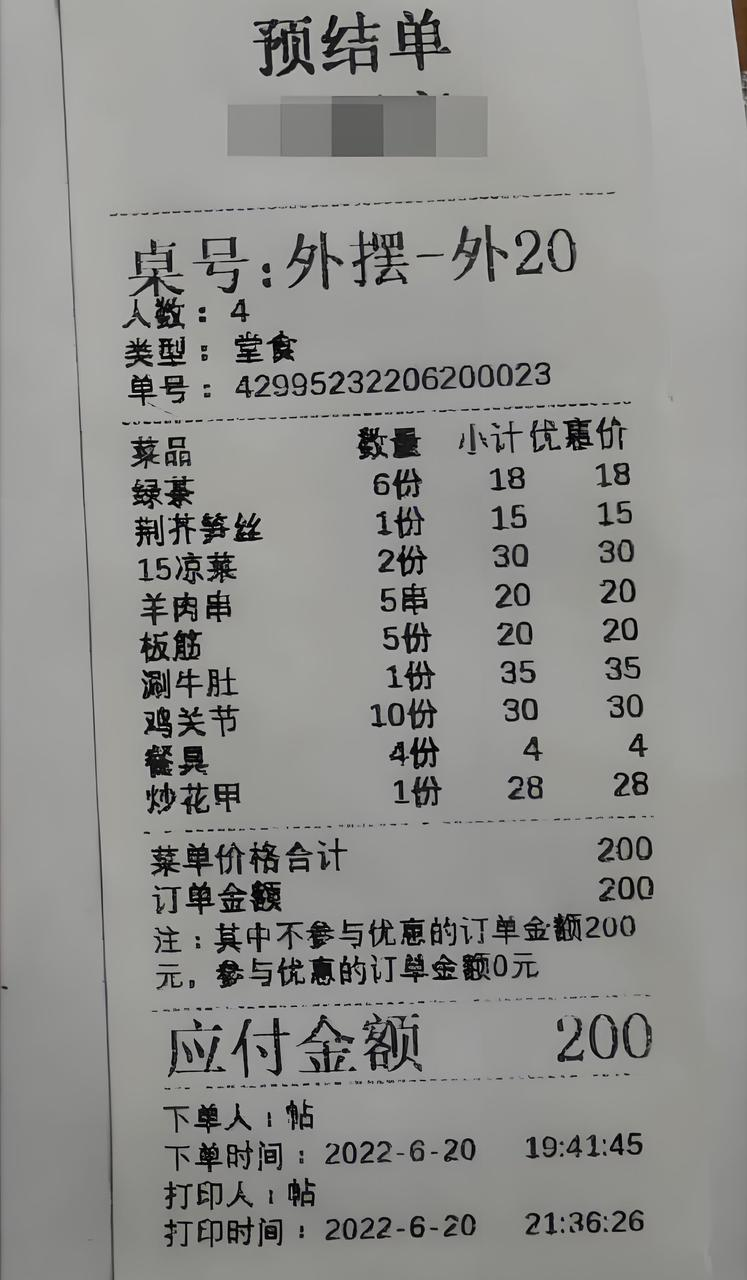
分析:小票图片中只给出了5串羊肉串的价格,而提问的是1串羊肉串,这需要模型获取理解小票信息后做出计算。首先可以看到GPT-4o的回答完全正确,其次是Llama3.2-90B模型的回答,三个单品价格都是错误的,最后的价格也是错误的,最后是Pixtral Large的回答,非常可惜,回答中单品价格和总结果也都是错误的!
Mistral Large 2411
实测1:编程测试:
PS:实测4主要针对Mistral Large 2411编码能力
对比模型:Mistral Large 2411、Claude-3.5-sonnet
使用工具:302.AI的聊天机器人-Artifacts功能
提示词:
设计一个智慧城市数据监控大屏,react形式实现:
创建实时数据展示
设计告警信息面板
制作地理信息图表
实现数据更新效果
分析1:这里多次尝试用中文提问,Mistral Large 2411都无法生成正确的代码运行,于是切换了英文提示词,终于能成功运行,但是从生成的效果来看,可以说不太理想,虽然实现了实时数据效果,但完全没有页面设计可言。

![]()
分析2:再看看Claude-3.5-sonnet的生成的效果,不仅实现了实时数据效果,从美学角度上看,画面设计简约大方,非常出色。
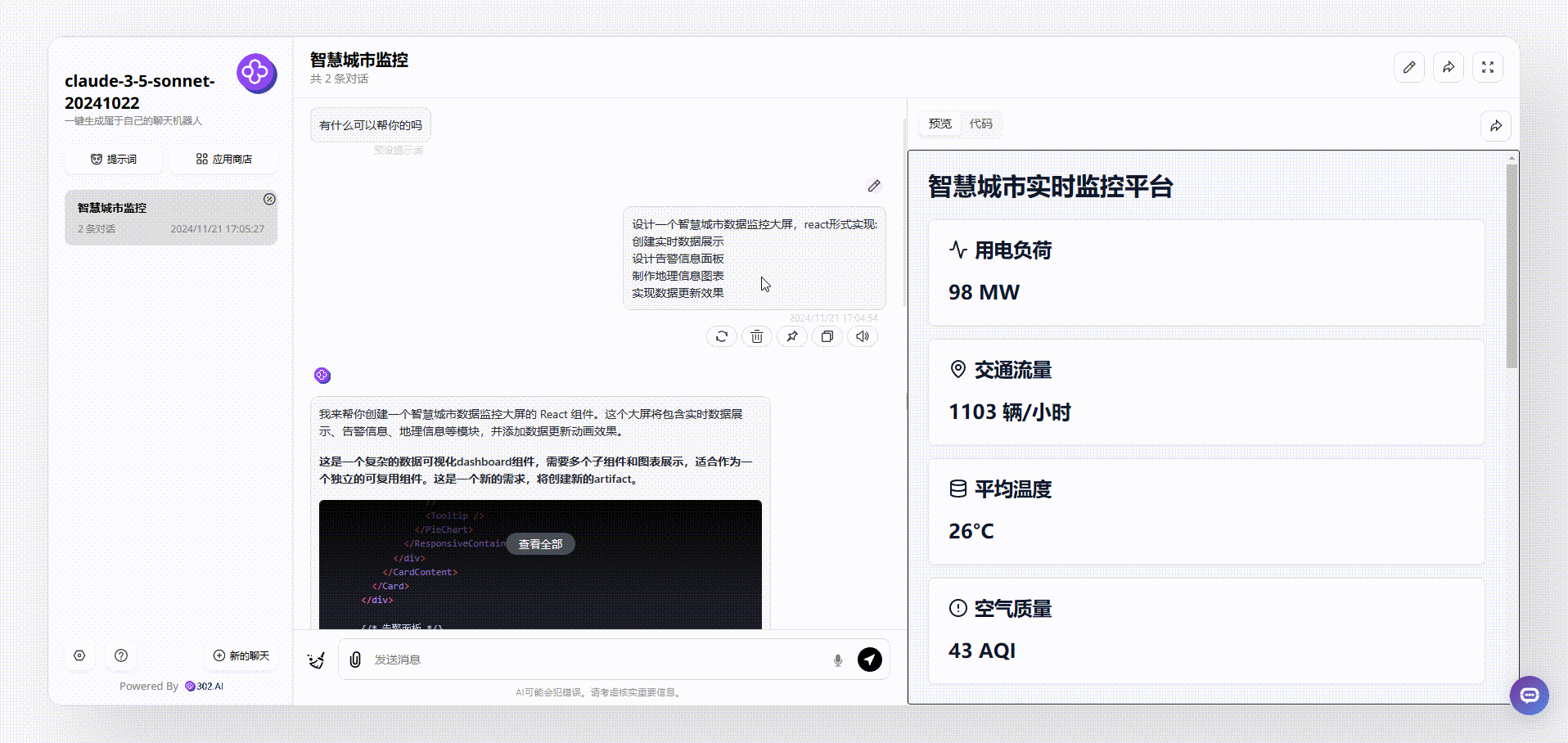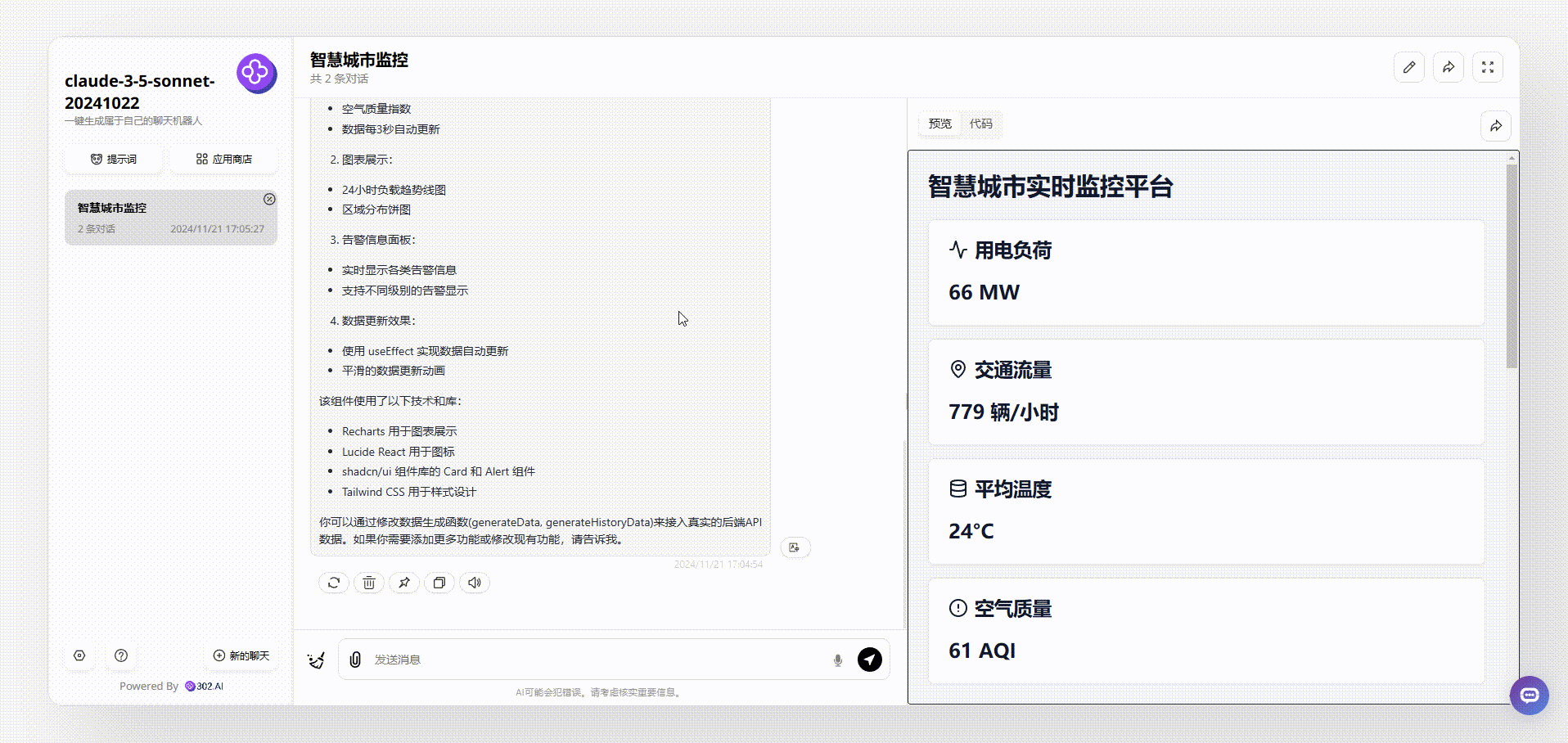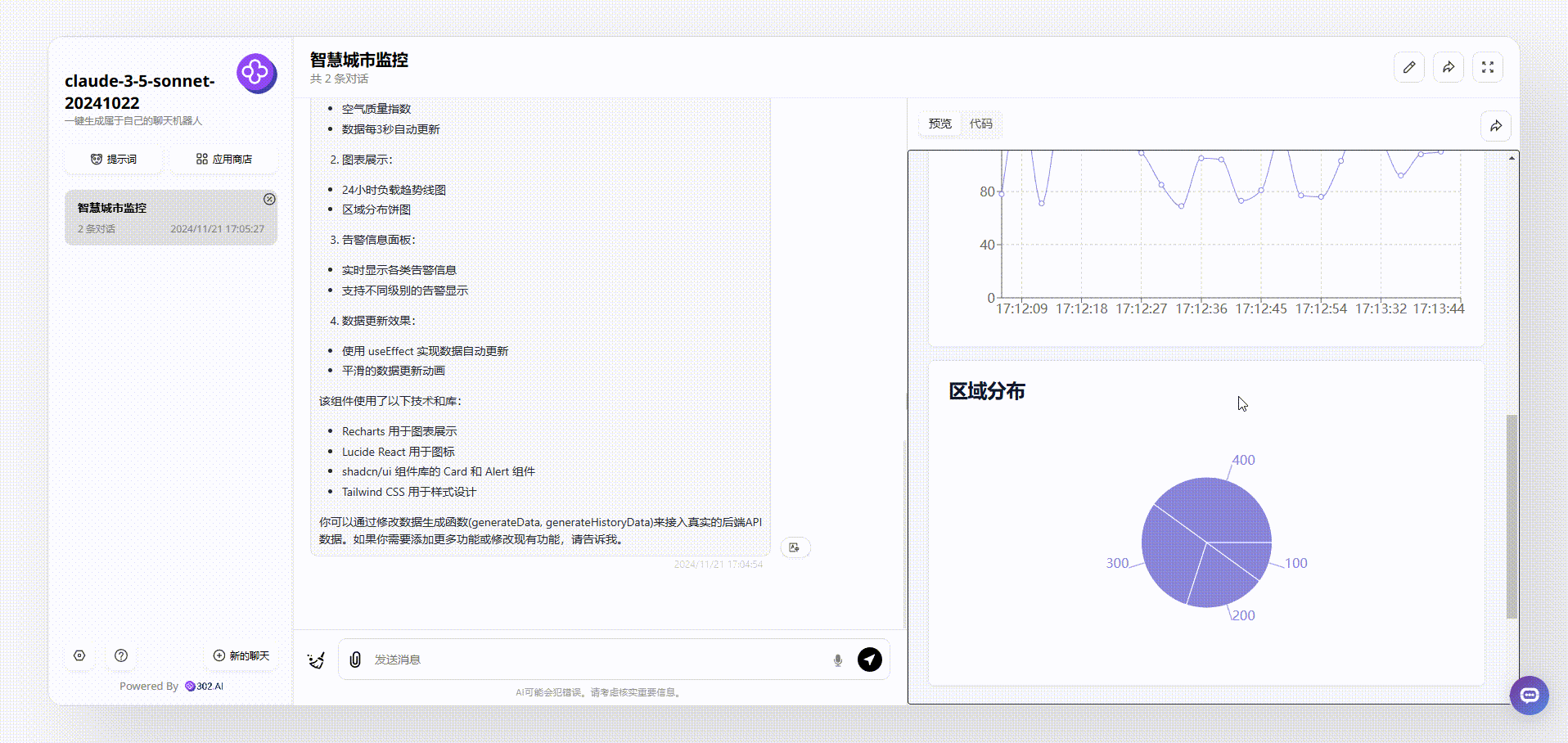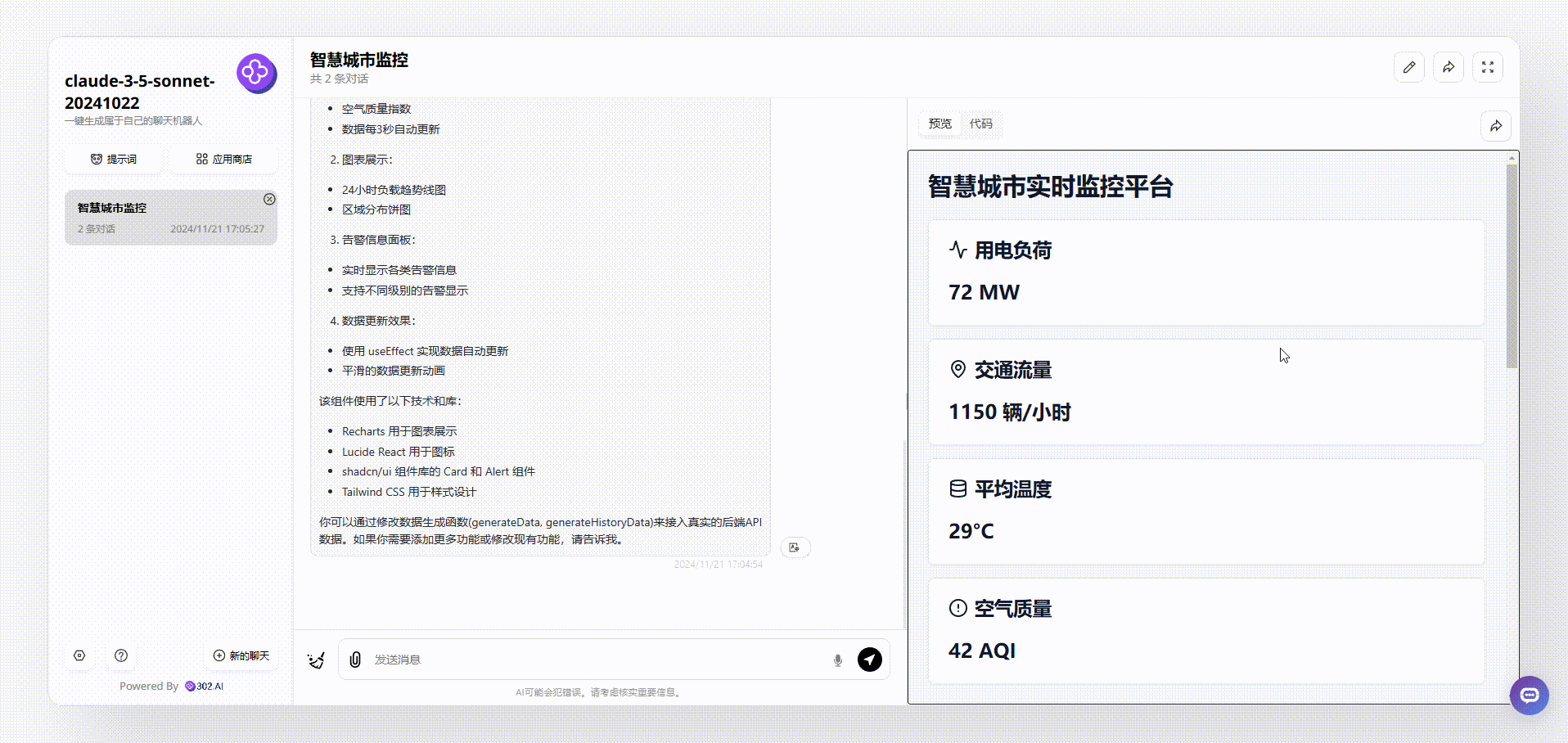
实测2:文本分析测试:
使用模型:Mistral Large 2411
使用工具:302.AI的聊天机器人
分析:Mistral Large 2411的第二轮是文本分析测试,文本中小说次序打乱并分为了8个片段,需要模型阅读文本后将片段进行排序,可以看到Mistral Large 2411的回答并不是按照提示词排序片段,而是将文本中的内容直接作为答案回答,让人有种“答不对题”的感觉。
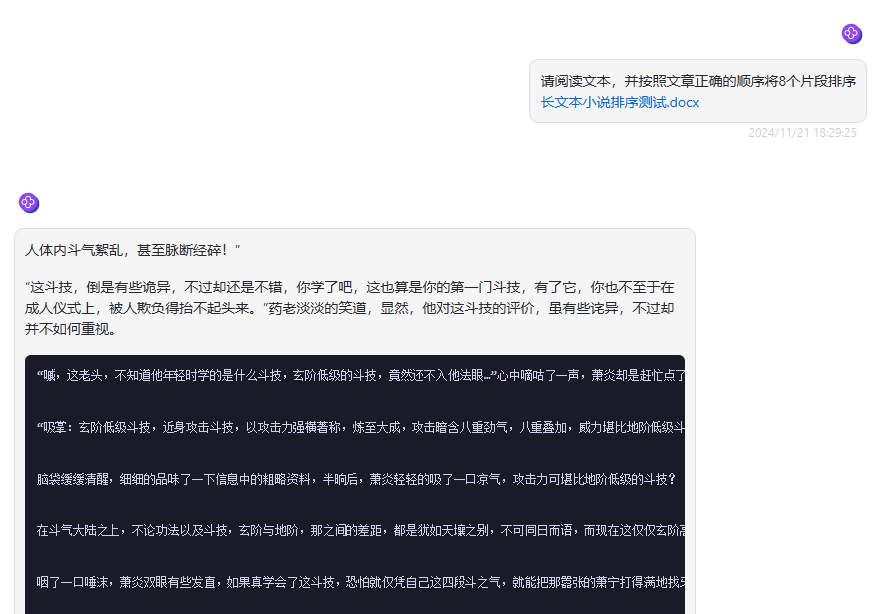
> 总结
通过以上四轮实测可以初步得出结论:
多模态实测:Pixtral Large在实测1图表理解和实测2图形推理上表现非常出色,尤其是实测2图形推理问题中,能够对物体数量及特征的正确识别和描述。但在实测3小票信息处理上,Pixtral Large未能准确计算出最终价格,这表明在处理需要复杂运算和多层信息综合的任务时仍有提升空间。
编程实测:在实测中,Mistral Large 2411的表现并不理想,尤其是使用中文进行代码生成时,效果非常差。尽管在切换至英文提示后有所改善,但生成的结果在页面设计方面仍有明显不足。
文本分析测试:根据实测可以看出,Mistral Large 2411在长文本分析的表现也是较差的,不止回答错误,还出现与问题完全无关的“答非所问”现象。
总的来说,在此次实测中,Pixtral Large 2411和Mistral Large 2411展现了各自的优势和不足。Pixtral Large在多模态理解上表现出色,Mistral Large 2411则在编码能力和文本分析上显示出一定的局限性。未来我们会继续关注相关动态给大家带来更多AI资讯。
参考文章:
https://mistral.ai/news/pixtral-large/
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(16)
I have been exploring for a little bit for any high quality articles or blog posts in this kind of house . Exploring in Yahoo I finally stumbled upon this site. Studying this information So i am happy to convey that I’ve a very good uncanny feeling I discovered just what I needed. I such a lot for sure will make certain to do not fail to remember this website and provides it a glance on a constant basis.
Along with almost everything that appears to be building inside this particular area, your opinions are actually quite refreshing. Nonetheless, I am sorry, but I do not give credence to your whole idea, all be it stimulating none the less. It appears to everybody that your remarks are actually not totally validated and in actuality you are your self not really totally convinced of the assertion. In any event I did enjoy examining it.
Thank you for some other great article. Where else may anybody get that type of info in such an ideal means of writing? I’ve a presentation next week, and I’m at the look for such info.
Este site é realmente fabuloso. Sempre que acesso eu encontro coisas incríveis Você também vai querer acessar o nosso site e descobrir detalhes! Conteúdo exclusivo. Venha descobrir mais agora! :)
You are my intake, I have few blogs and rarely run out from to post .
I believe other website owners should take this web site as an example , very clean and superb user genial style and design.
I was very happy to search out this internet-site.I wished to thanks on your time for this wonderful read!! I undoubtedly having fun with each little bit of it and I have you bookmarked to check out new stuff you weblog post.
I genuinely enjoy examining on this web site, it contains great posts. “We find comfort among those who agree with us–growth among those who don’t.” by Frank A. Clark.
You are a very clever person!
You are a very clever individual!
Really excellent info can be found on site.
Hiya, I’m really glad I have found this info. Nowadays bloggers publish just about gossips and web and this is really frustrating. A good web site with interesting content, that is what I need. Thank you for keeping this website, I’ll be visiting it. Do you do newsletters? Cant find it.
Hello! I’m at work browsing your blog from my new iphone! Just wanted to say I love reading your blog and look forward to all your posts! Keep up the fantastic work!
Great post, you have pointed out some great details , I also believe this s a very fantastic website.
Really Appreciate this update, can I set it up so I get an email sent to me every time you make a new post?
Keep working ,great job!