


近段时间,在社交媒体平台经常看到一些【照片说话】视频非常有趣,流量好,甚至有大几万的点赞!这到底是用什么AI工具实现的呢?先来看看视频效果:
(案例由302.AI的AI照片说话生成)
我们简单分析下,原图(左侧)是一张静态的照片,通过AI技术与一段音频巧妙结合后,静态的照片能够“开口说话”了,而且能够实现口型与音频同步,生成的效果(右侧)仿佛真人般自然流畅。
而想要实现这个效果你只需要一个工具——302.AI的AI照片说话,这一工具是302.AI最新上新的AI工具,它的操作界面非常简单易用,用户无需具备专业的技术知识也可快速上手制作,为静态图片增添了声音和情感。
> AI照片说话工具使用教程:
下面来给大家展示详细的使用步骤:
1、创建工具:
首先进入302.AI的客户端,在页面上方的菜单栏点击【工具超市】——找到【AI照片说话】并创建;
(目前这一工具刚刚上新,暂时分类在“Beta区”,后续会归类到“视频相关”类目)
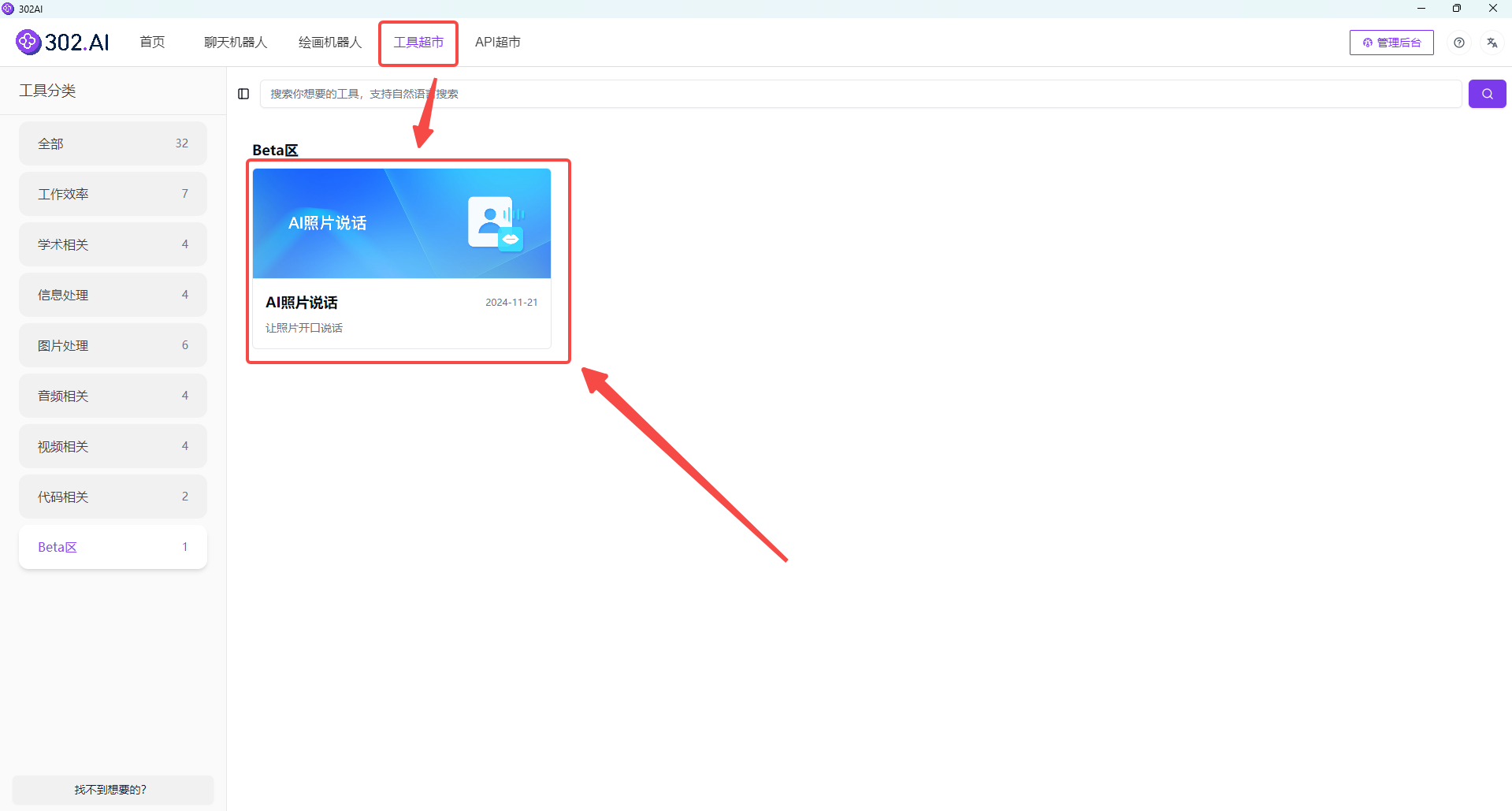
![]()
2、设置音频:
进入AI照片说话工具后,可以看到总共分为了三大步骤:设置音频——配置人像——合成视频。其中第一步的设置音频还提供了【生成】和【上传】两种方式。
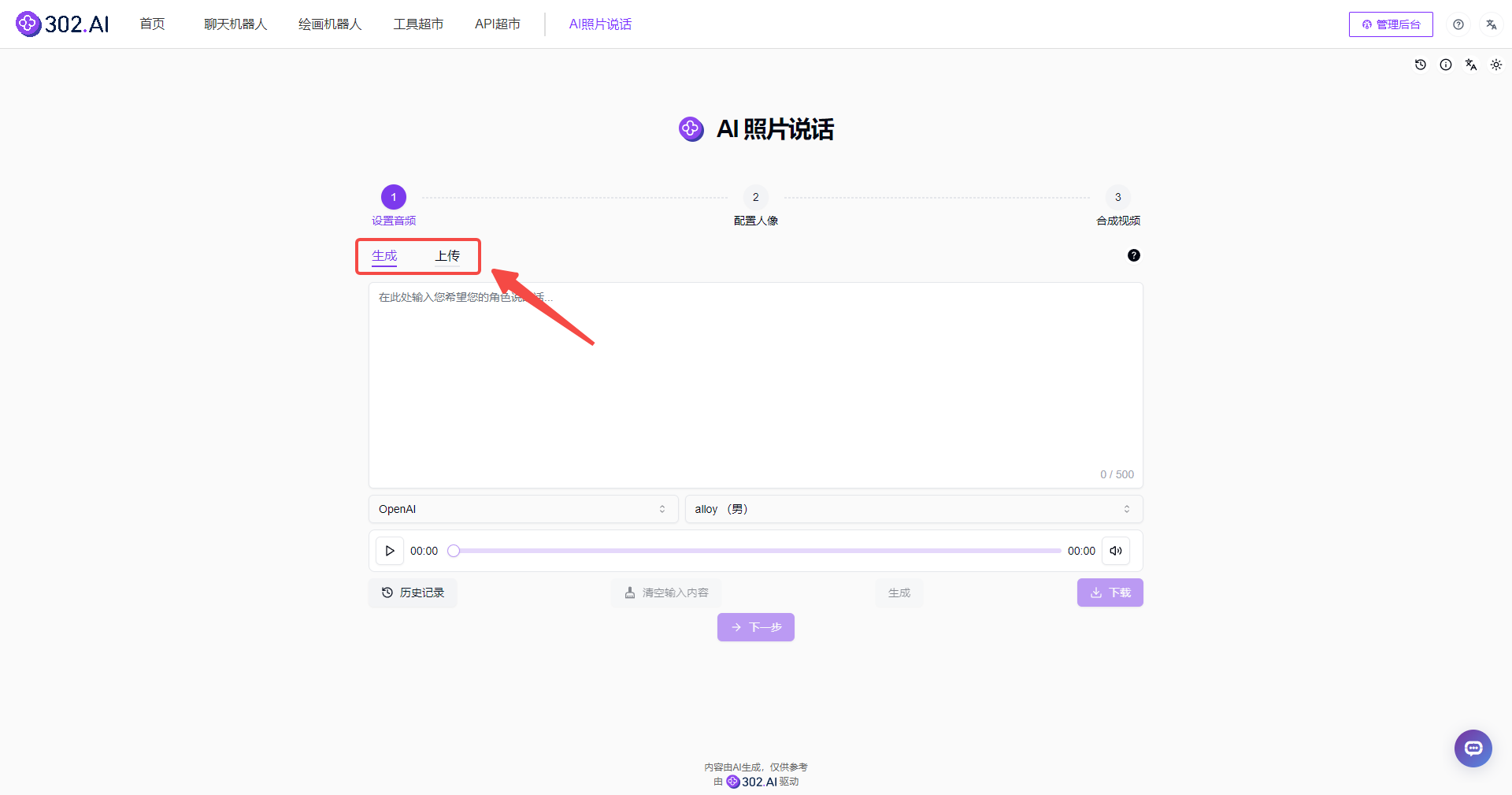
![]()
(1)生成:这一方式是通过文字输入后选择音色,生成音频内容。这里的音色提供了多种选择,涵盖了不同性别、年龄、口音和情感等多种风格,用户可以根据自身需求,挑选出最符合照片氛围和表达意图的音色。以上述案例视频为例,我们选择了FishAudio中周董的音色生成。此外,生成后的音频还可以点击右下角直接【下载】,非常方便。
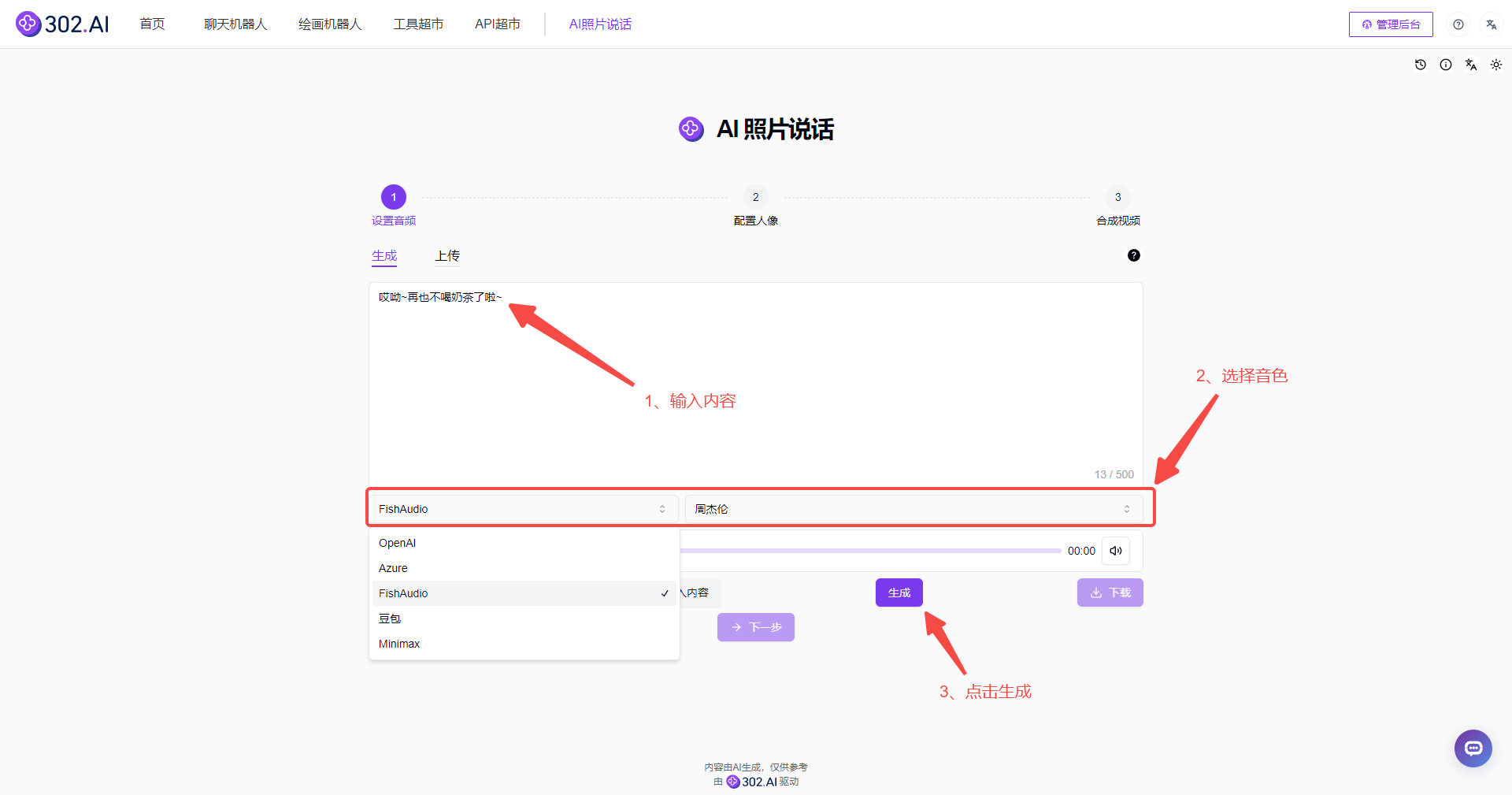
![]()
(2)上传:这一方式给用户提供了更具有个性化的体验,用户可以根据自己的需求上传特定的音频文件,使得生成的视频中人物的声音与用户上传的音频完全匹配。上传的内容支持mp3、mav、mp4、mov、wav等多格式。
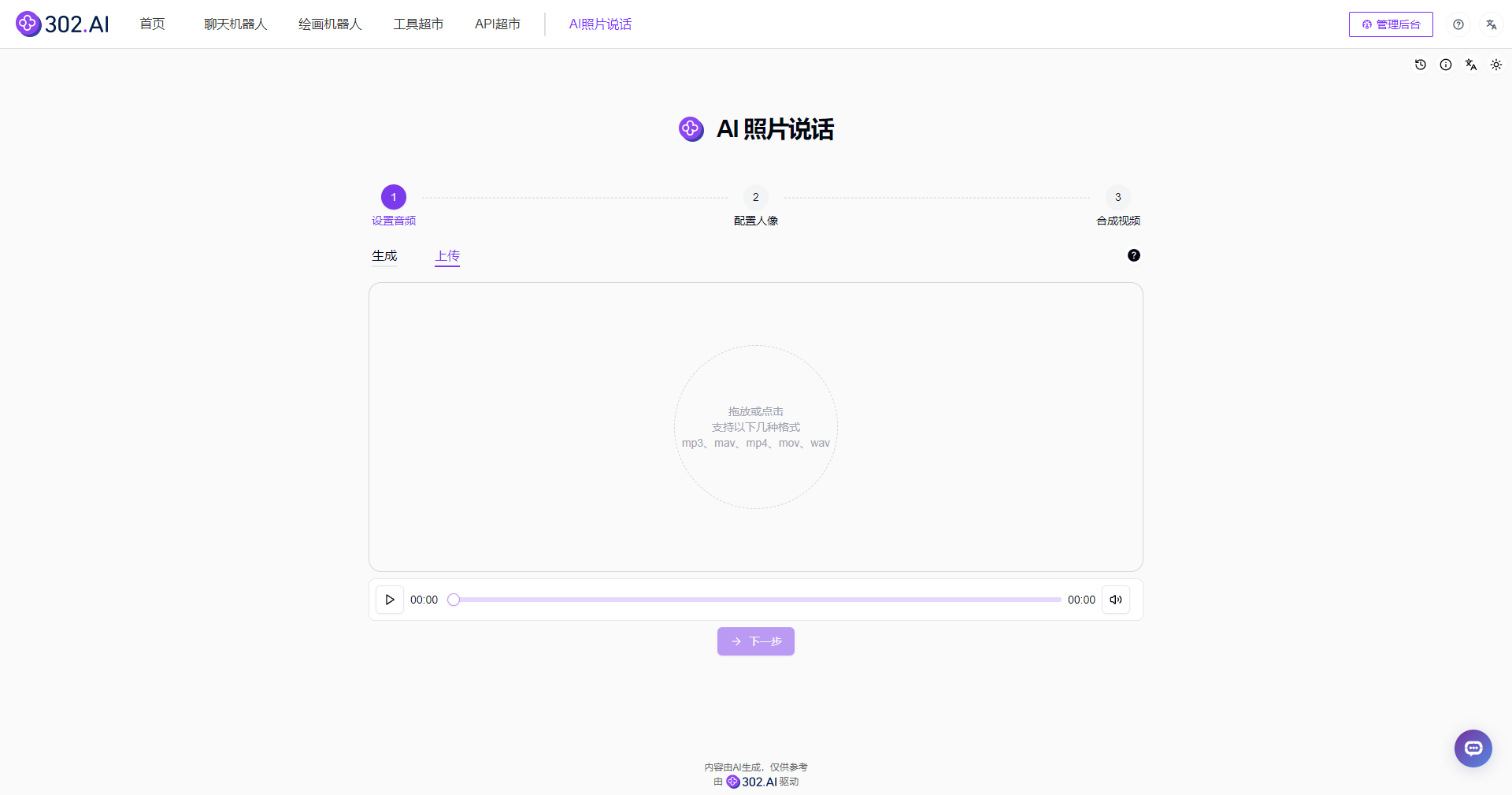
![]()
3、配置人像:
设置音频完成后点击下一步到配置人像,这一步需要上传图片,支持的格式有:.jpeg、.png、.webp三种,多种格式为用户提供了灵活性。上传后的照片可以调整放大和切换图片比例,调整后的图片也可以点击【下载】保存!
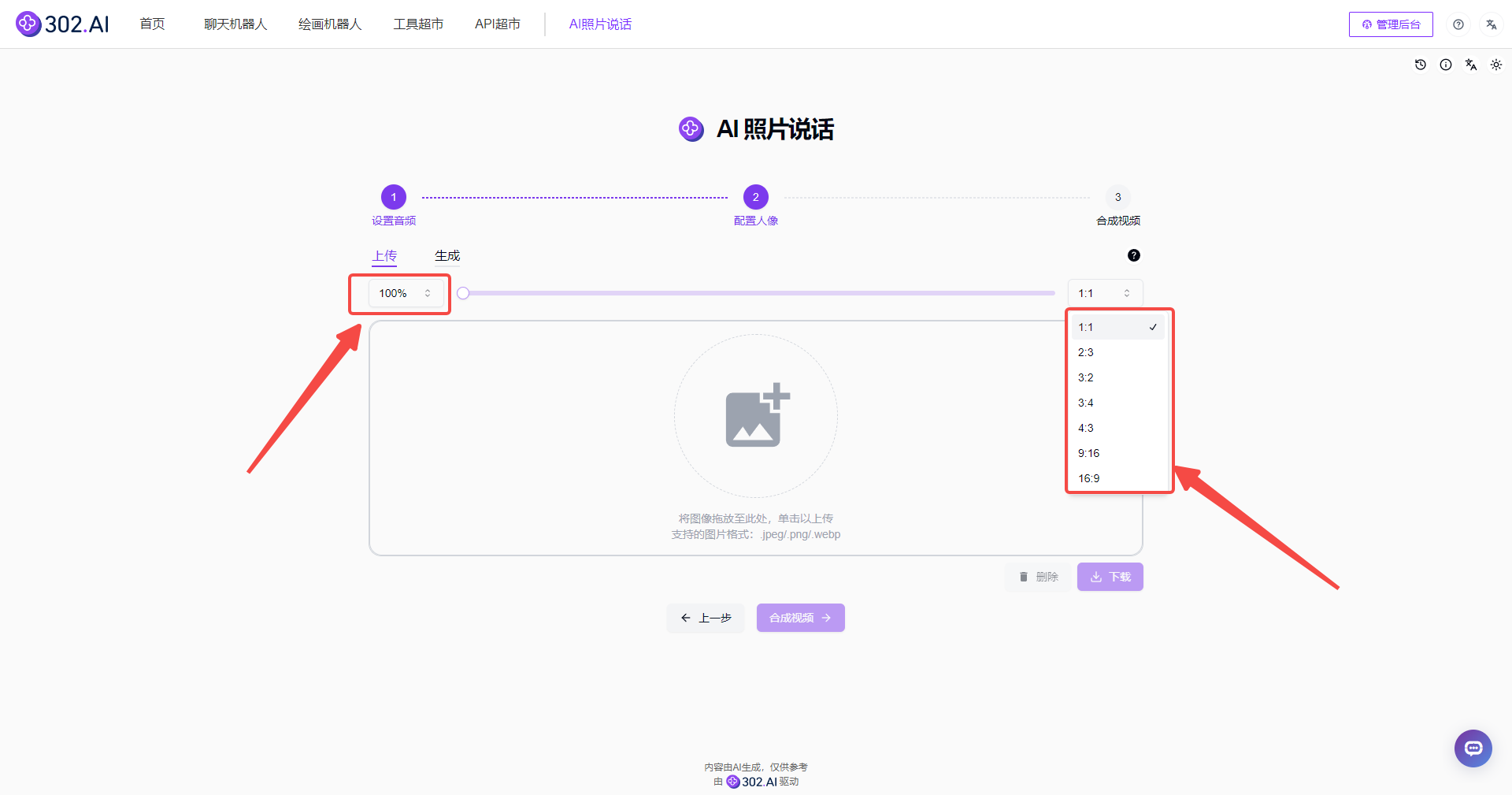
![]()
4、合成视频:
配置人像完成后点击【合成视频】按钮到最后一环节,等待片刻后我们即可看到合成的视频,合成后的视频如果效果满意可以直接点击【下载】保存到本地,如果对于效果不满意则可以选择【重新生成】;
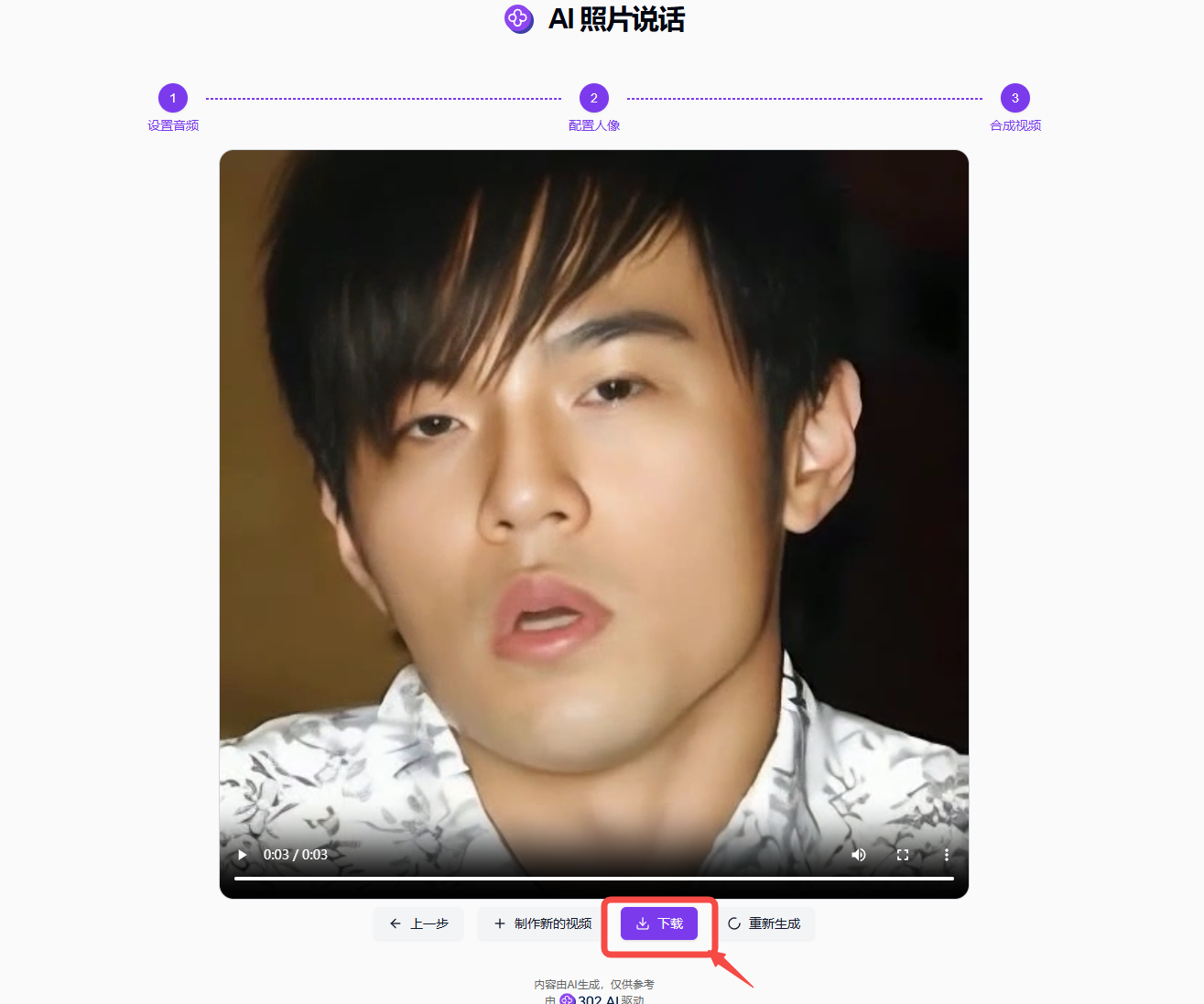
![]()
> 更多效果展示
小女孩背古诗:
“人间清醒老奶奶”发言:
> 使用小技巧
1、为生成音频的能获得最佳效果:
(1)在设置音频时尽量选择符合照片角色预期性格的音色,比如照片主角是小孩可以选择童声等。
(2)在输入文本时可以使用感叹号和其他标点符号来引导角色生成你所希望的语气反应!
2、为合成的视频能够达到理想效果:
在配置人像时如果选择的图片为人物照片,建议挑选嘴部张开或者露出牙齿的照片,合成的效果相对更好!
> 总结
使用302.AI的AI照片说话工具,只需要简单几步操作,用户便可以将自己的想法和创意通过声音和图像结合,制作出引人注目的视频内容。而这一工具的应用场景十分广泛,例如,用户可以为家人的照片配上幽默的配音,或者为宠物的照片添加可爱的声音,甚至可以给自己喜欢的卡通动漫人物配音,从而在社交媒体上获得更多的关注和互动。
此外,这款工具的多样化音色选择和个性化音频上传功能,进一步增强了用户的创作自由度。无论是想要制作搞笑视频,还是希望传达某种情感,302.AI的AI照片说话工具都能满足不同用户的需求,让每一个创意都能通过声音与照片完美结合。
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(3)
Rattling superb info can be found on web site.
I’d constantly want to be update on new blog posts on this internet site, saved to bookmarks! .
I have been exploring for a little bit for any high-quality articles or blog posts in this sort of space . Exploring in Yahoo I ultimately stumbled upon this website. Studying this information So i am happy to convey that I’ve a very excellent uncanny feeling I came upon just what I needed. I most indisputably will make sure to don?¦t put out of your mind this site and give it a look regularly.