


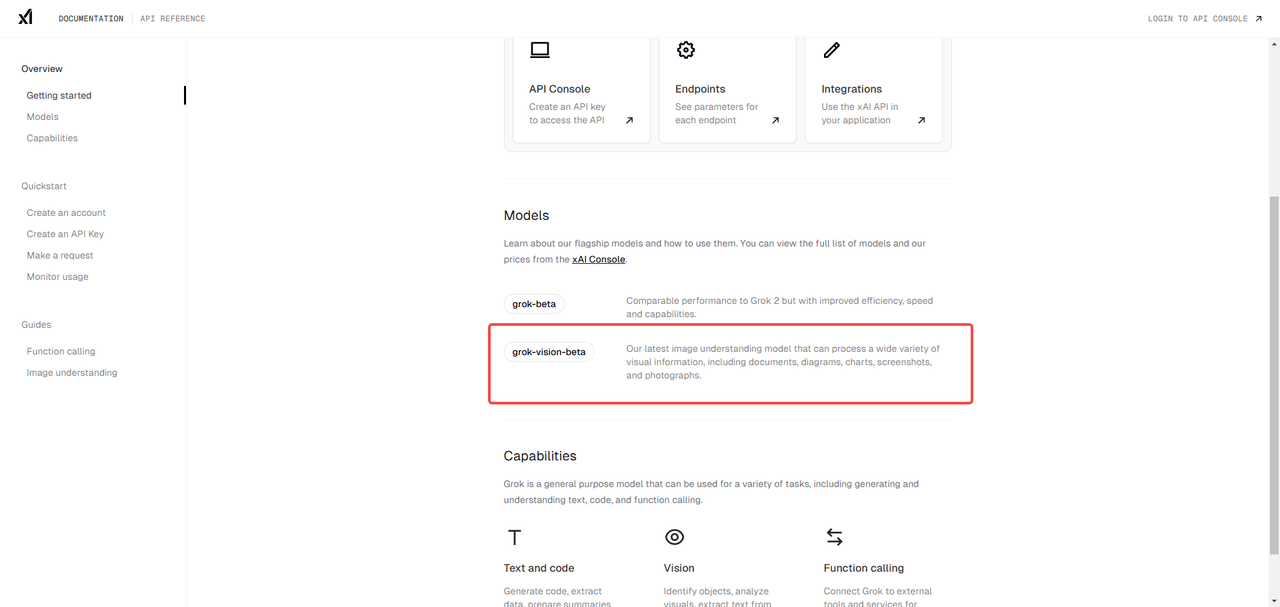
11月初,xAI官宣Grok API开启公测后,我们便对当时列表中唯一的模型grok-beta进行了实测,尽管grok-beta在实测中发现了了一些不足,但其整体表现还是不错的。最近,xAI的API迎来了更新,其API列表中新增了一个名为grok-vision-beta的模型。
![]()
根据xAI官方介绍,grok-vision-beta模型是其最新的图像理解模型,可以处理各种各样的视觉信息,包括文档、图表、截图和照片。不知这一模型的表现如何?下面我们将通过302.AI实测看看。
> 在302.AI上使用grok-vision-beta
302.AI目前已经提供了grok-vision-beta模型,如果想要快速体验模型可以通过302.AI的聊天机器人获得;如果想要更方便快捷接入集成这一模型的API,可以使用302.AI的API超市,以下分别是302.AI聊天机器人和API超市获取grok-vision-beta模型的步骤:
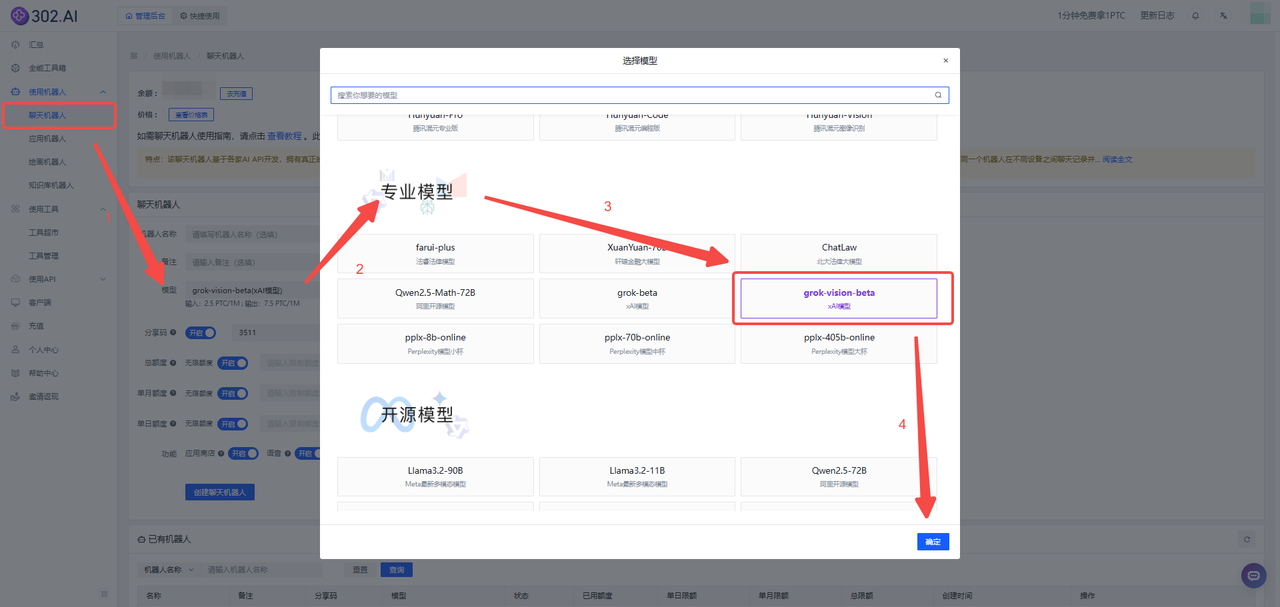
【聊天机器人】
进入302.AI,在左侧菜单栏点击【使用机器人】——【聊天机器人】——选择【模型】——下滑至专业模型找到【grok-vision-beta】——点击【确定】按钮,最后创建聊天机器人即可。
![]()
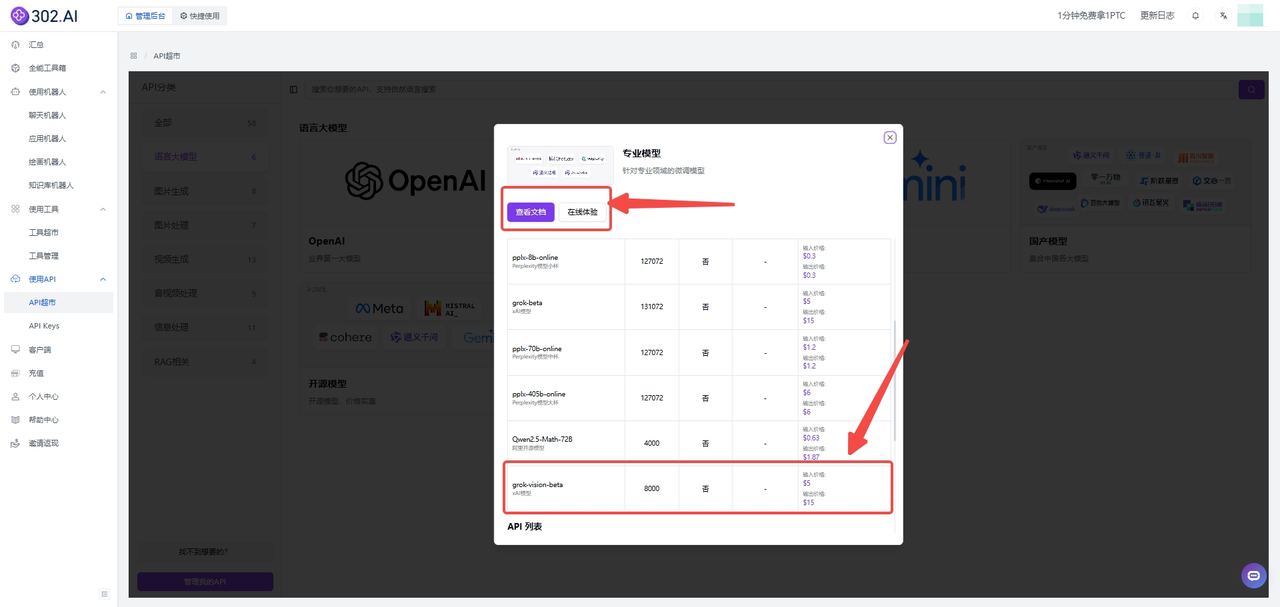
【API超市】
在左侧菜单栏点击【使用API】——【API超市】——分类中选择【语言大模型】——【专业模型】。

![]()
下滑页面即可看到有【grok-vision-beta】,按照惯例,302.AI的API超市中语言模型的API不仅能够通过【管理文档】快速接入API,还能进入【在线体验】高效便捷地测试模型的各种参数。
![]()
> grok-vision-beta实测:
实测将通过不同模型对比进行,这样能够更加直观看到模型的表现。
除了grok-vision-beta,我们还另外选择了两个模型进行对比,分别是:
gpt-4o-2024-11-20:11月20日OpenAI推出的GPT-4o最新版本,具备出色的多模态处理能力,能够处理文本、图像和视频输入。
gemini-exp-1121:11月21日谷歌推出的试验版模型,在多模态处理和复杂任务的优化能力方面表现出色,这一版本距离上一个试验版gemini-exp-1114推出仅时隔7天。
对比模型:grok-vision-beta、gpt-4o-2024-11-20、gemini-exp-1121
使用工具:302.AI的模型竞技场
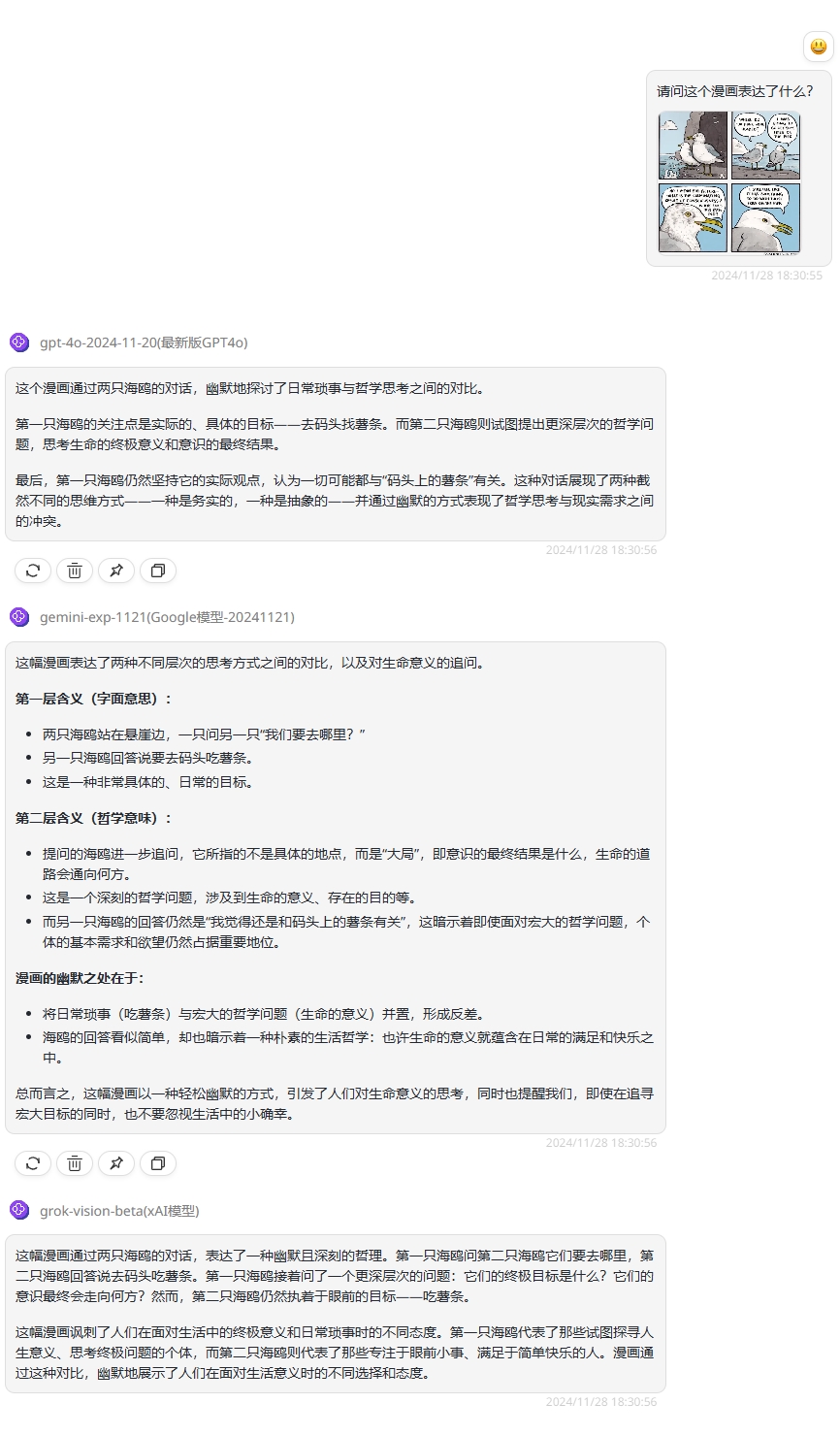
实测1-流行梗图理解:
提示词:请问这个漫画表达了什么?

![]()
分析:这个漫画是一个经典的网络流行梗“去码头整点薯条吃”,用两只小海鸥的对话对比两种不同的人生态度并通过漫画表达人们对于简单生活的向往和追求。首先看下gpt-4o-2024-11-20的回答,虽然答案不长,但整体回答大致是符合主题。然后是gemini-exp-1121的回答,整体回答比较详细的,通过层层分析揭开漫画表达的意思,并在最后总结升华了一下。最后是grok-vision-beta的回答其中提到“讽刺”,这略显不妥。漫画的整体风格主要以幽默为主,主要探讨不同的人生观念,并不存在讽刺的色彩。
![]()
实测2-图形颜色识别:
提示词:请问图中蓝色物体和红色物体加起来一共有多少个?

![]()
分析:第二轮实测是想测试模型的颜色识别能力,但从三个模型的回答中可以看到,没有模型回答正确。grok-vision-beta和gpt-4o-2024-11-20把蓝色物体和红色物体的数量都识别错误了,而gemini-exp-1121虽然最后结果错误,但其回答中红色物体数量是正确的。

![]()
实测3-图表内容理解:
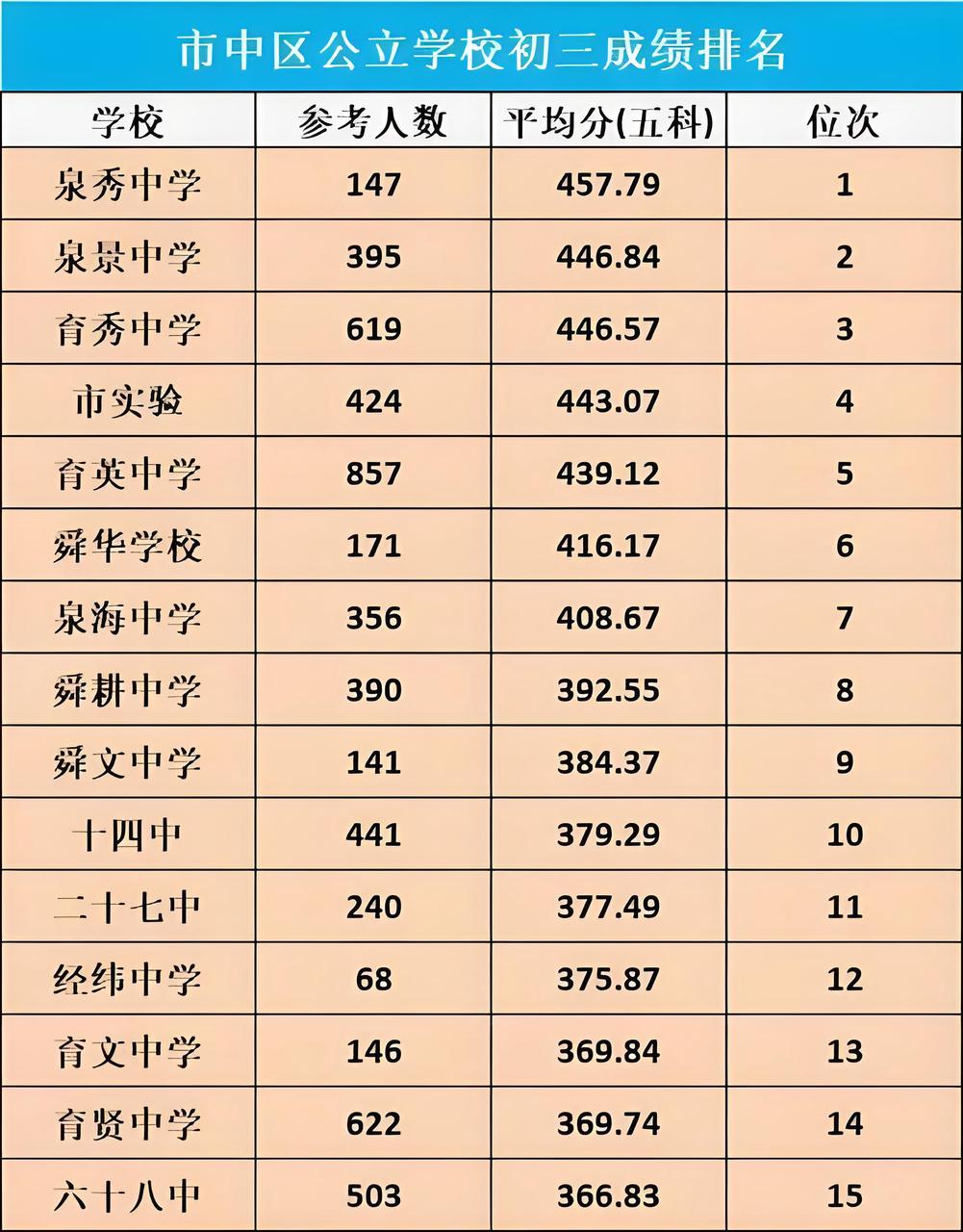
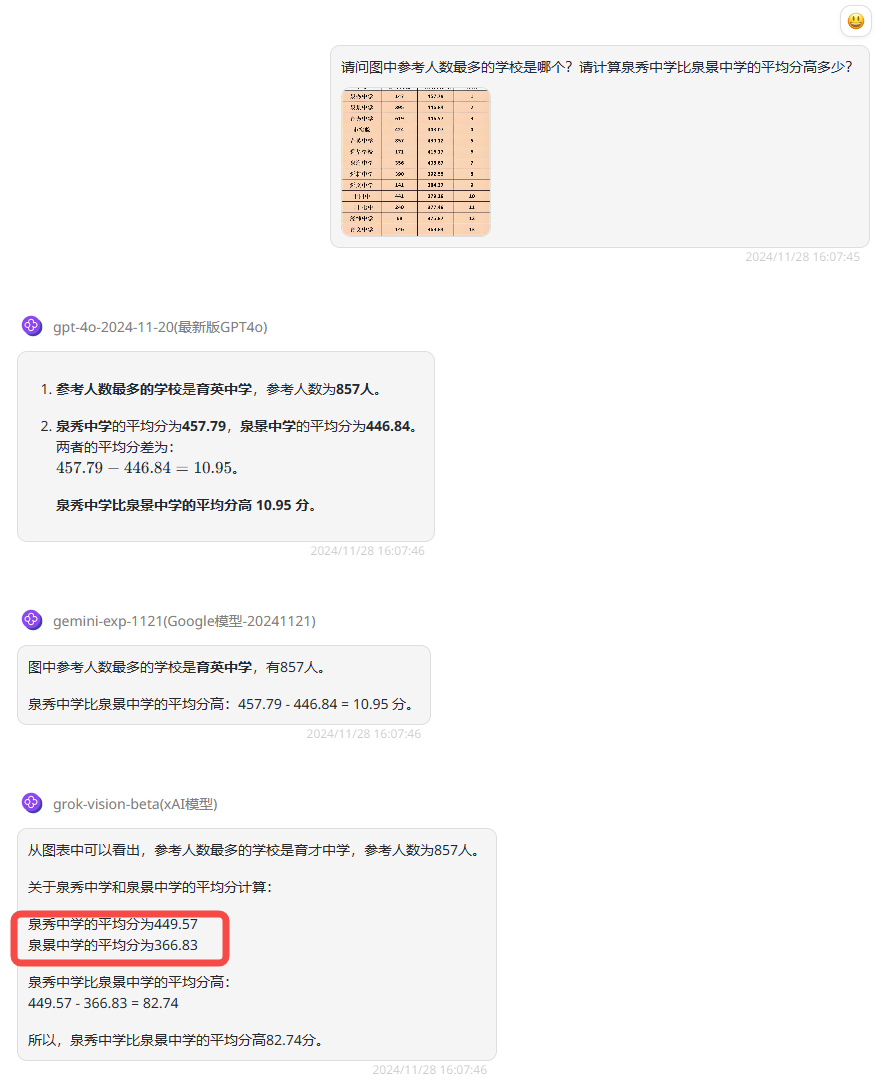
提示词:请问图中参考人数最多的学校是哪个?还有泉秀中学比泉景中学的平均分高多少?
![]()
分析:这一轮实测提出了两个问题,可以看到gpt-4o-2024-11-20和gemini-exp-1121两个问题的回答都是完全正确的。而grok-vision-beta第一个问题的回答也是正确的,但是第二个问题中把两个学校的平均分搞错了,从而导致最终的答案错误。
![]()
> 总结
通过以上三轮实测,可以得出以下结论:
流行梗图理解测试:grok-vision-beta在流行梗图理解测试中表现并不理想,在理解漫画的整体意图时,模型的回答显得偏离主题。
图形颜色识别测试:在图形颜色识别测试上和其他模型一样都未能提供准确答案,可以看出出在视觉信息处理的准确性方面依然存在不足。
图表内容理解测试:在图表内容计算的测试中,grok-vision-beta在第一个问题上给出了正确的答案,表明其在面对一些简单问题的情况下具备一定的分析能力。但在处理复杂问题时,尤其是涉及多个数据点的计算时,模型的表现仍需加强。
grok-vision-beta在实测中表现总体来说是并不理想的,不过通过以上实测对比,却意外发现谷歌时隔一周推出的新模型gemini-exp-1121在图像理解方面的表现非常不错,在视觉理解能力方面甚至超越了最新版GPT-4o模型。
如果想了解更多模型的资讯,请记得持续关注我们!
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
