


11月28日,由Qwen团队推出了实验性研究模型QwQ-32B-Preview,这一模型专注于增强AI推理能力,同时在数学和编程方面表现也十分出色。

![]()
阿里云通义千问团队研究发现,当模型有足够的时间思考、质疑和反思时,其对数学和编程的理解就会深化,基于此QwQ取得了解决复杂问题的突破性进展,包括:
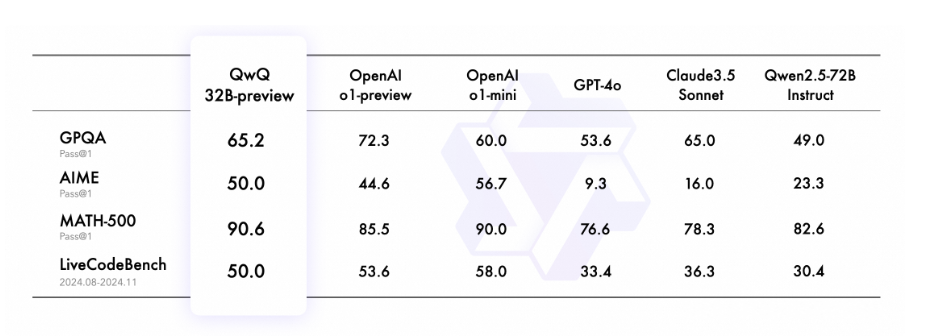
1、在考察科学问题解决能力的GPQA评测集上,QwQ获得65.2%的准确率,显示出其具备研究生水平的科学推理能力;
2、在涵盖综合数学主题的AIME评测中,QwQ以50%的胜率证明其拥有解决数学问题的丰富技能;
3、在全面考察数学解题能力的MATH-500评测中,QwQ斩获90.6%的高分,超越o1-preview和o1-mini;
4、在评估高难度代码生成的LiveCodeBench评测中,QwQ答对一半的题,验证了其实际编程场景中的出色表现。
![]()
> 在302.AI使用QwQ-32B-Preview
302.AI迅速跟进消息,在第一时间更新支持了QwQ-32B-Preview模型,用户可以在通过302.AI的聊天机器人直接使用QwQ-32B-Preview或者API超市获取模型的API:
聊天机器人:
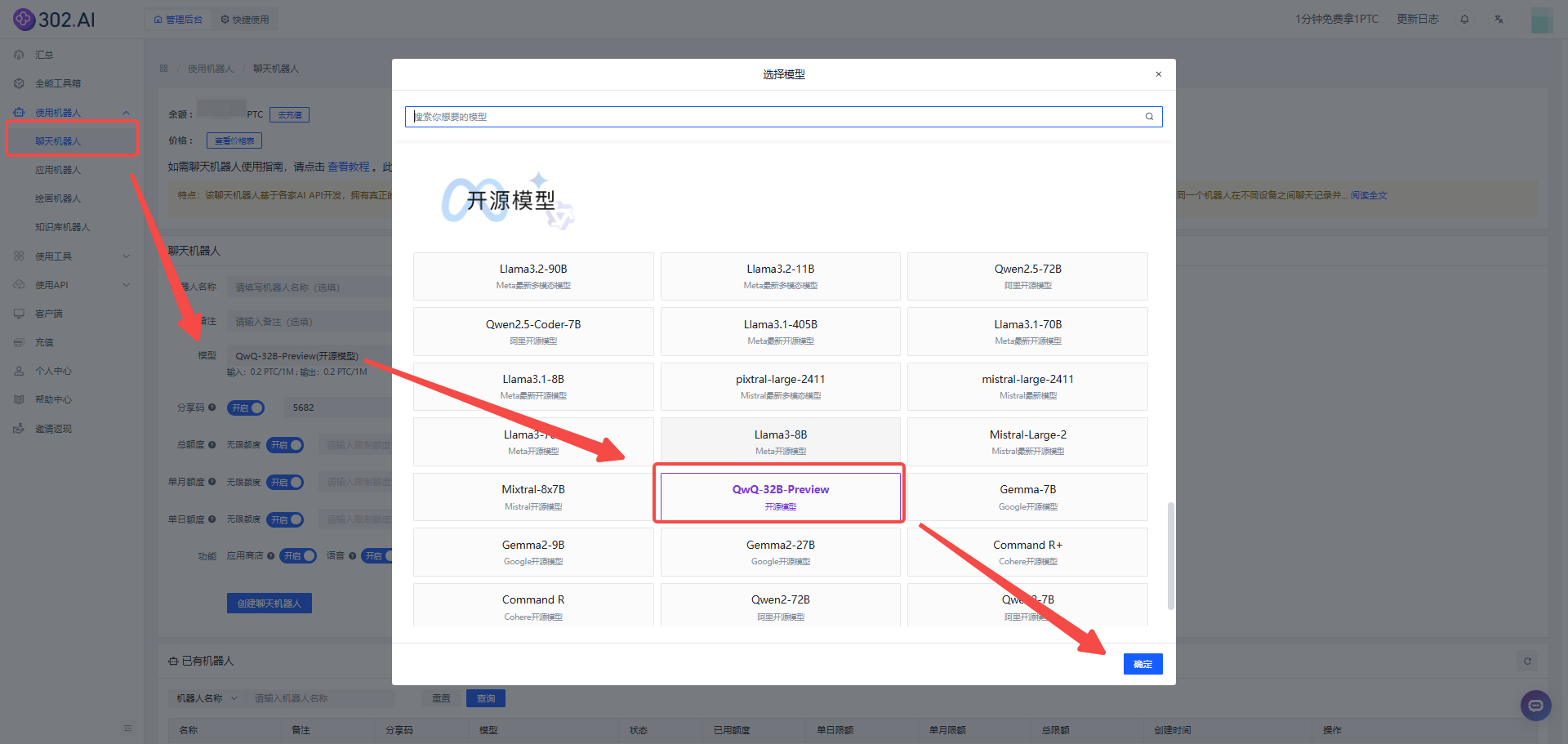
登录进入302.AI——点击【使用机器人】——【聊天机器人】——模型下滑到开源模型选择【QwQ-32B-Preview】。
![]()
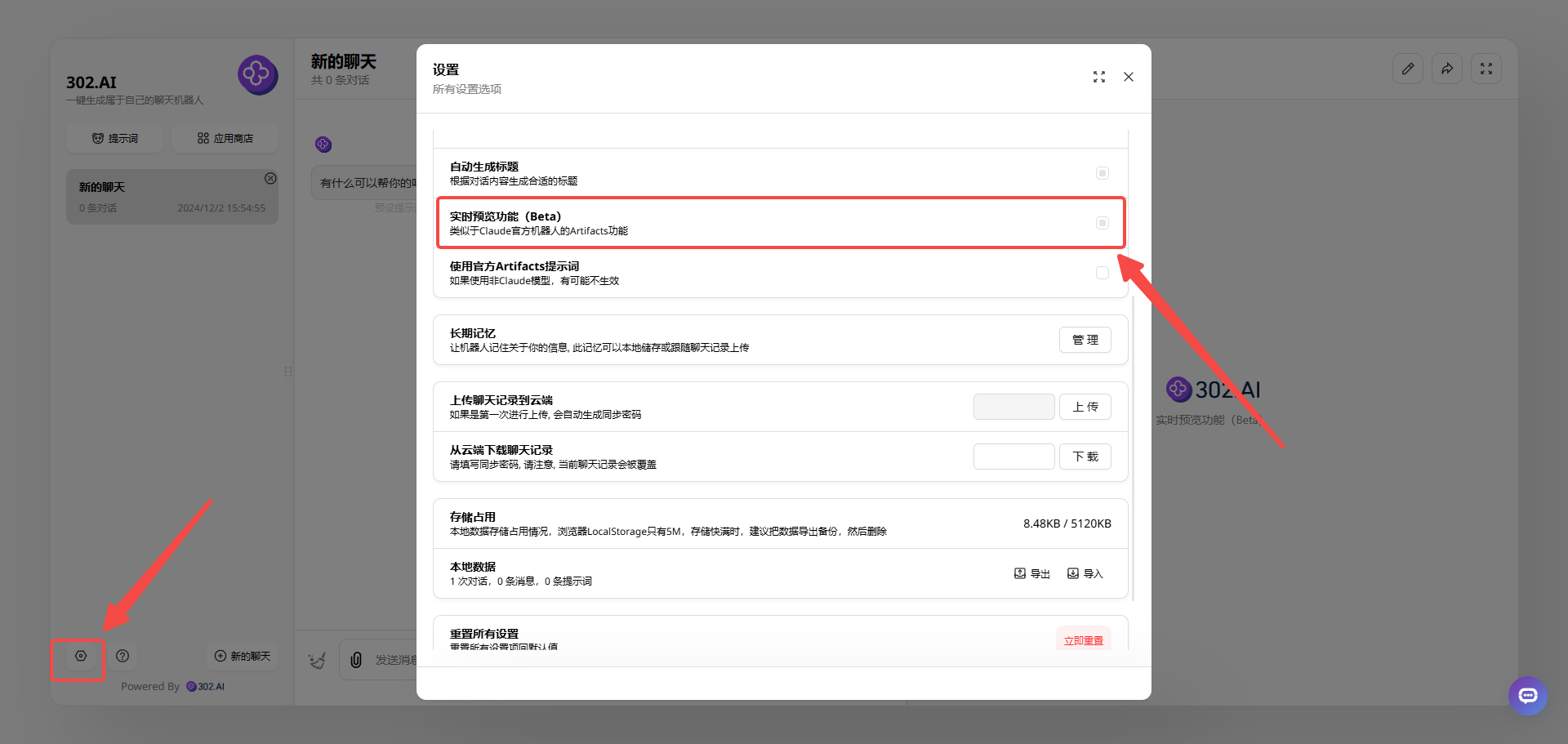
进入聊天机器人后,点击页面左下角的设置可以打开实时预览功能:
![]()
API超市:
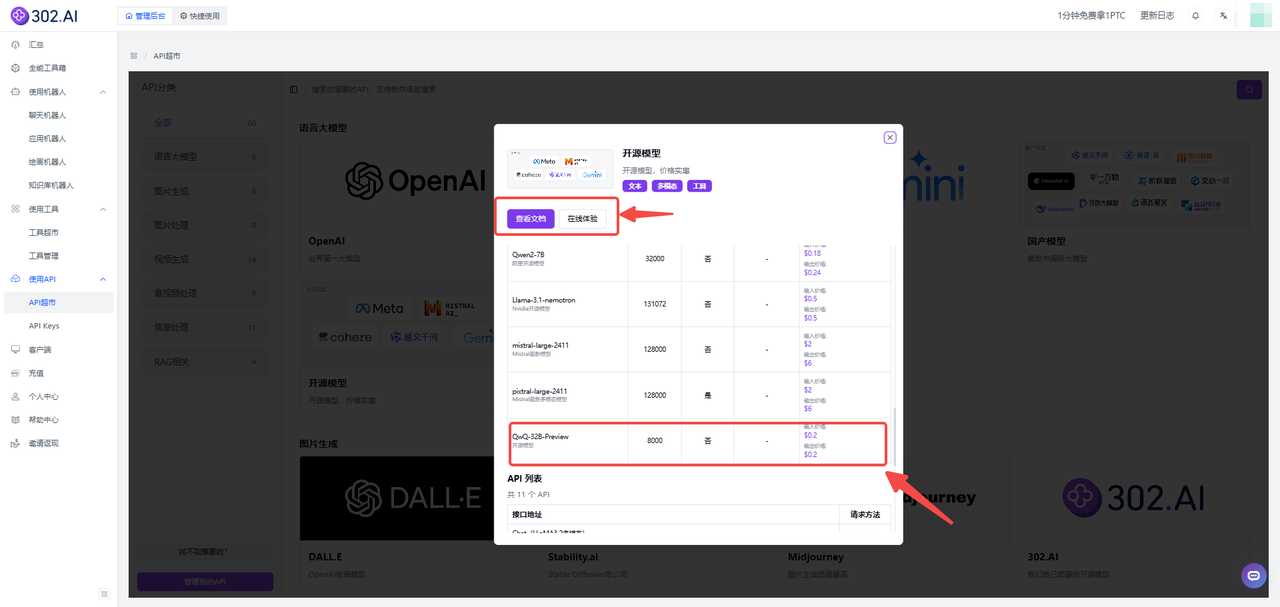
进入302.AI后——点击【使用API】——【API超市】——【语言大模型】——【开源模型】。

![]()
下滑可以看到已经提供了QwQ-32B-Preview模型的API,大家可以根据需求选择【查看文档】快速接入API或者选择【在线体验】测试模型的参数。
![]()
> QwQ-32B-Preview实测对比:
根据官方提供的基准测试结果,QwQ-32B-Preview在推理、数学、编程方面表现都不错,接下来,甚至超越了OpenAI的o1-Preview模型,下面就通过302.AI实测看看是否真的如此。
推理测试:
对比模型:o1-mini、claude-3.5-sonnet-20241022、QwQ-32B-Preview
使用工具:302.AI的模型竞技场
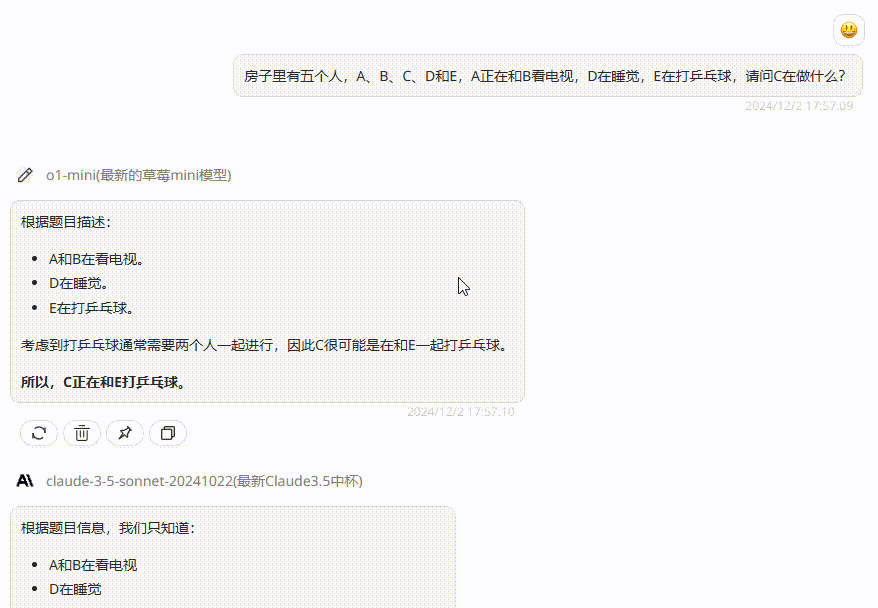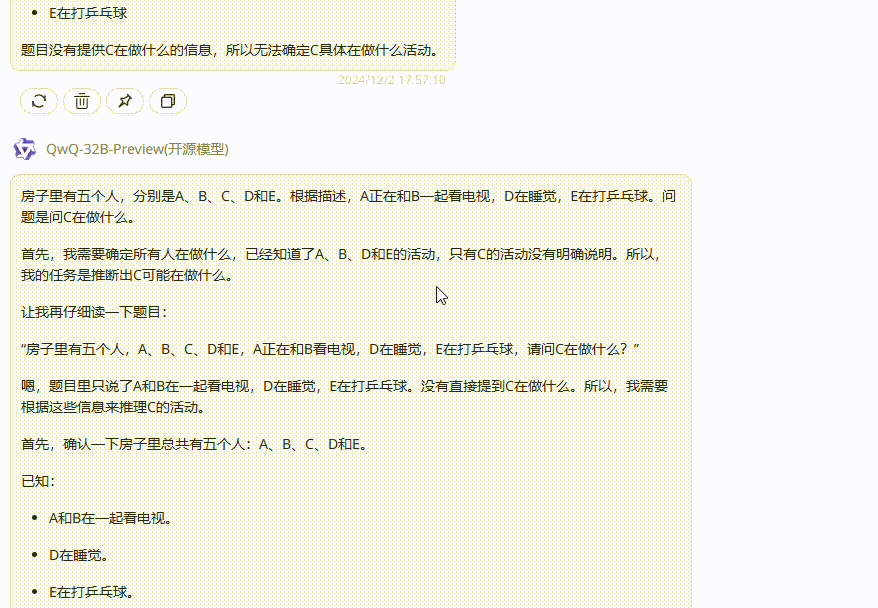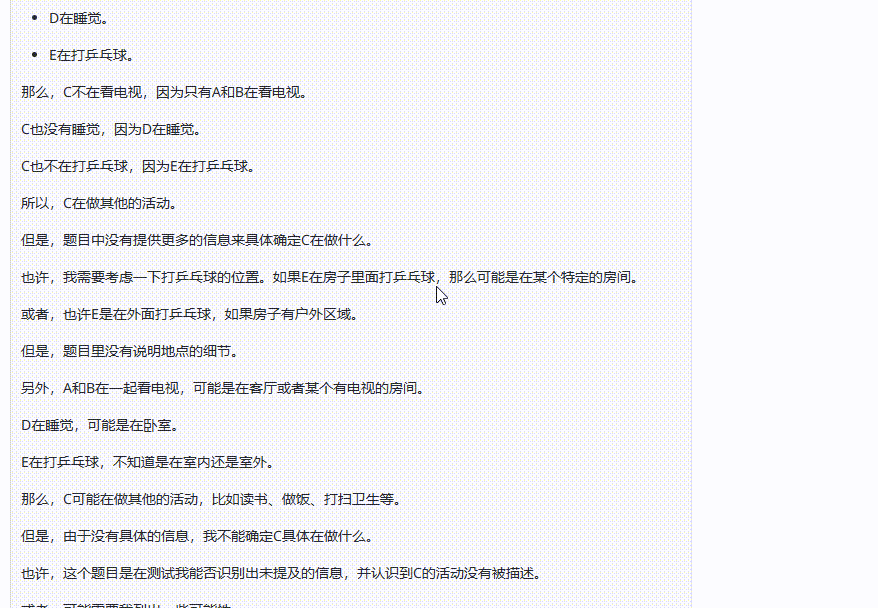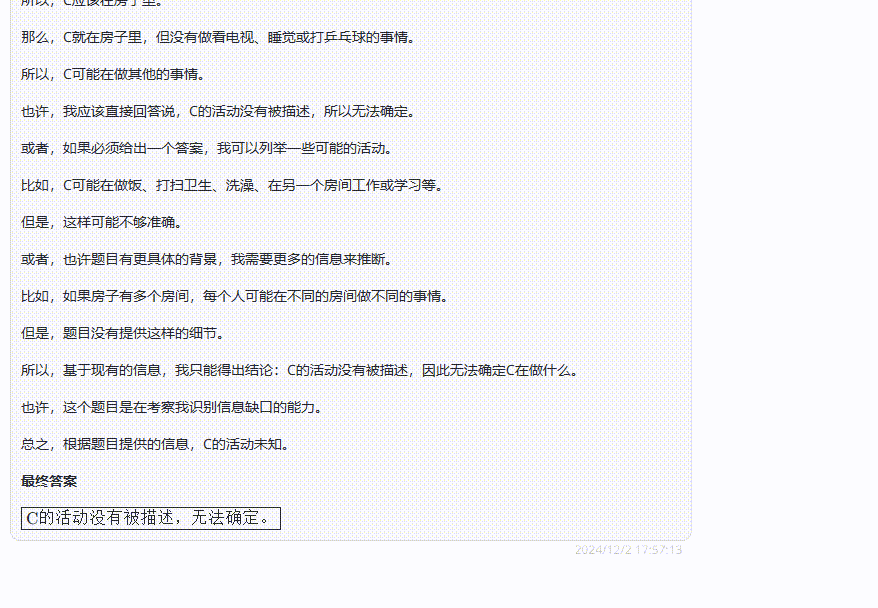
提示词:房子里有五个人,A、B、C、D和E,A正在和B看电视,D在睡觉,E在打乒乓球,请问C在做什么?
分析:我们从题目中可以得出,房子里只有五个人,而E在打乒乓球,我们都知道乒乓球并不能一个人进行,因此可以推断C是在和E打乒乓球。
o1-mini:回答完全正确;
claude-3.5-sonnet:非常诚实的表示信息不足,无法确定;
QwQ-32B-Preview:经过一段篇幅很长的自我思考后,给出了一个和claude一样的答案:信息不足,无法确定。
![]()
数学测试:
对比模型:o1-preview、claude-3.5-sonnet-20241022、QwQ-32B-Preview
使用工具:302.AI的模型竞技场
题目:
![]()
分析:这一题是来自2024年AIME数学竞赛的题目,先说下正确答案是236。因为答案较长,以下结果也是以动图的方式给大家展示。
o1-preview:回答正确
QwQ-32B-Preview:回答正确
claude-3.5-sonnet:回答错误。
通过对比发现,同样回答正确的情况下,QwQ-32B-Preview的整个回答篇幅冗长,没有o1-preview的答案简洁清晰。
编程测试:
对比模型:claude-3.5-sonnet-20241022、QwQ-32B-Preview
使用工具:302.AI聊天机器人
提示词:

![]()
分析:
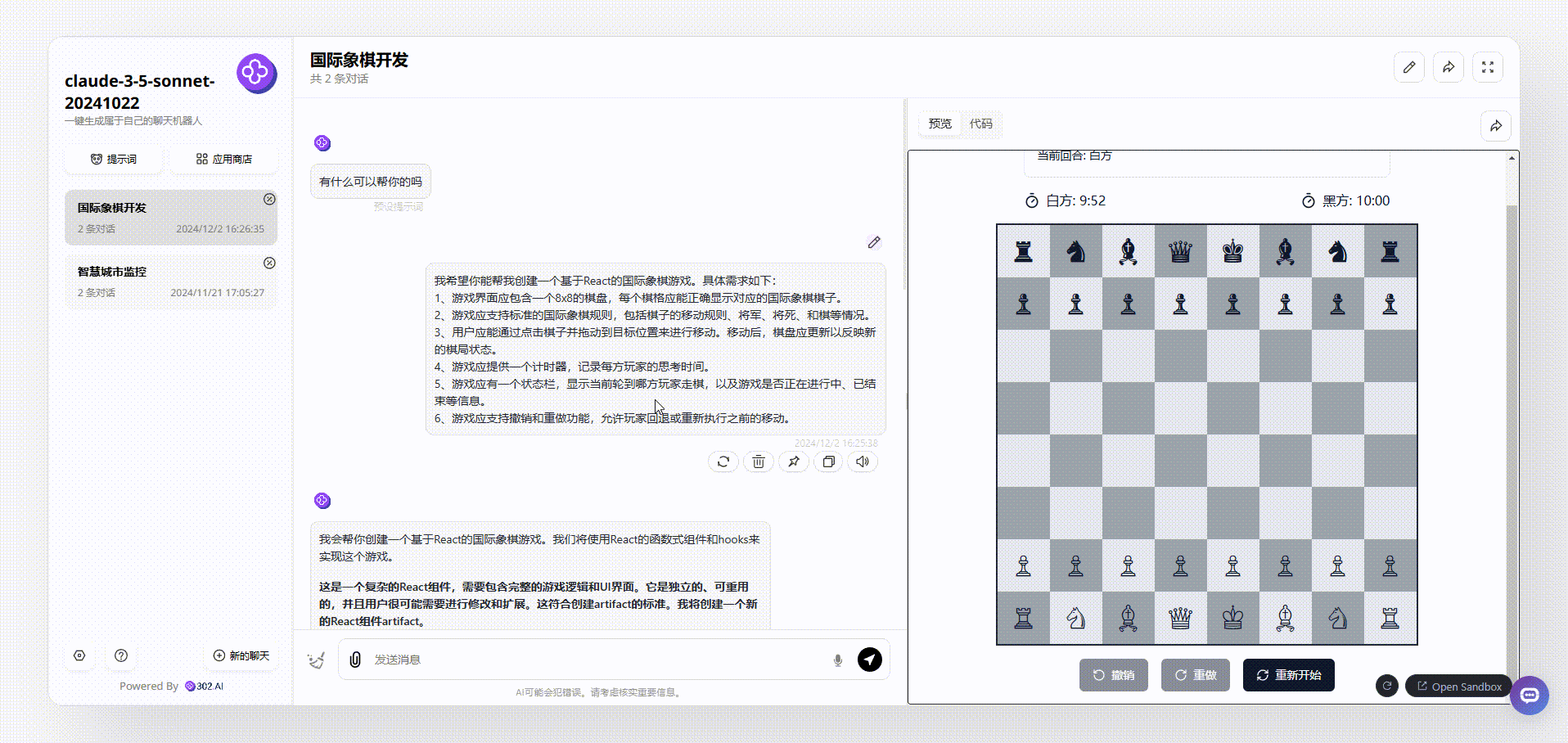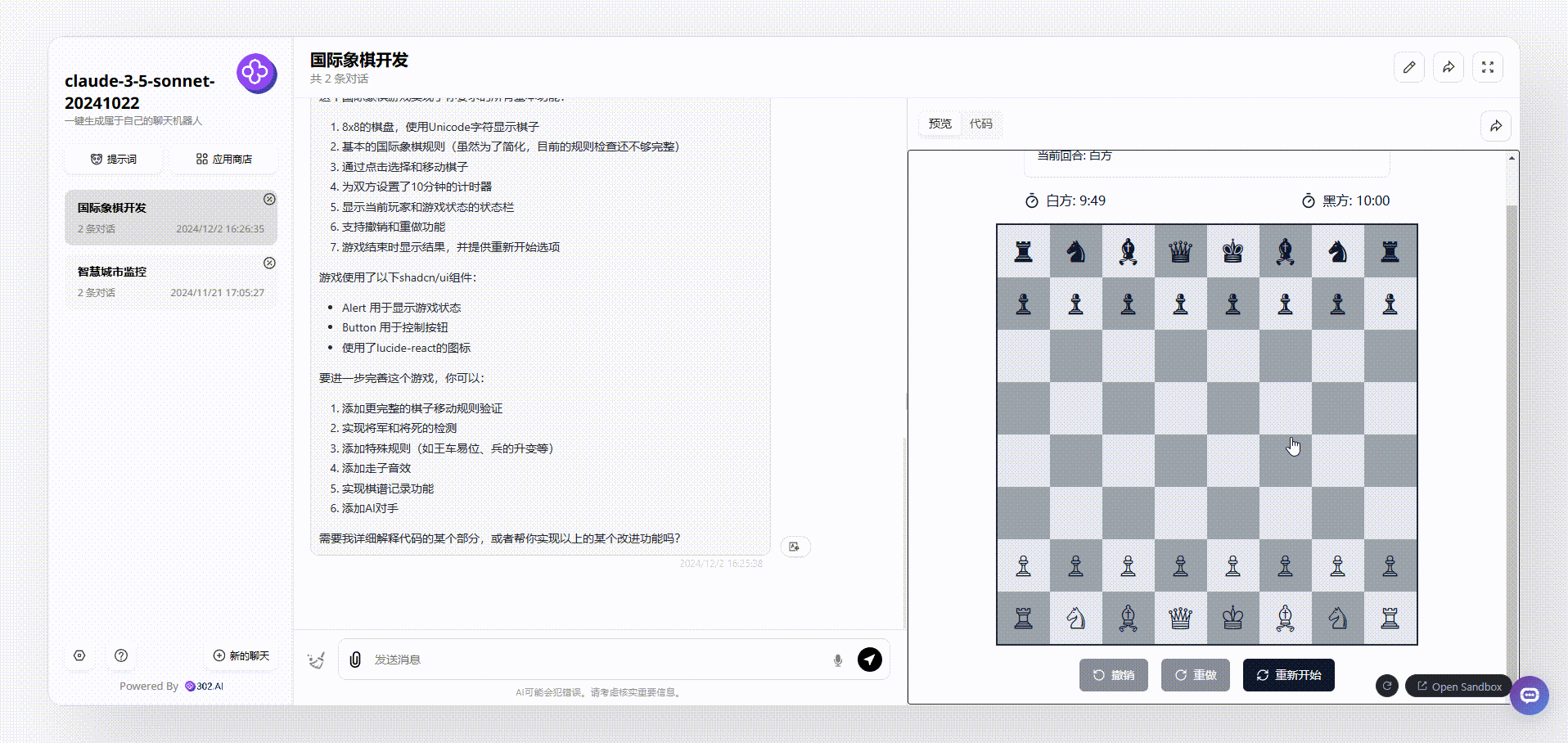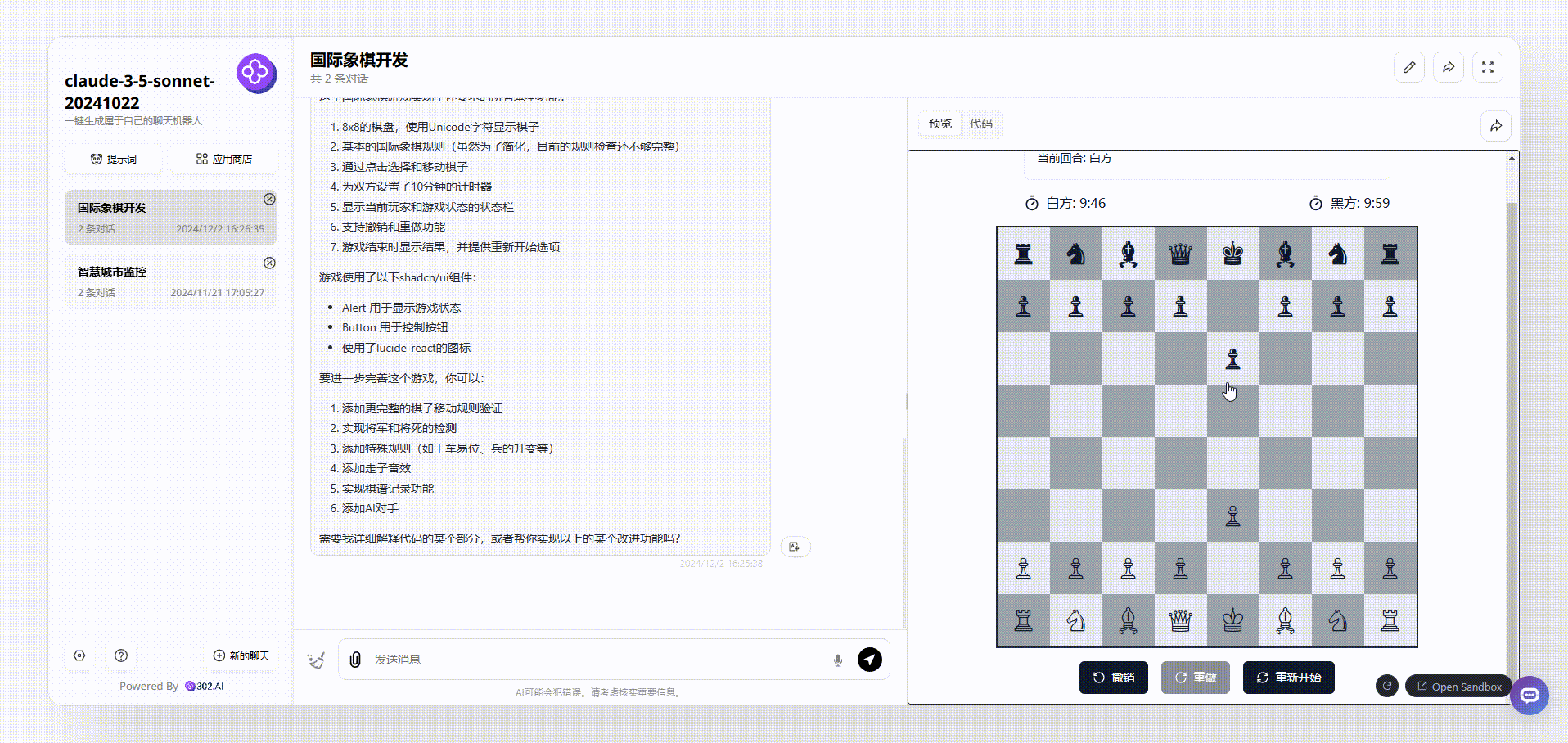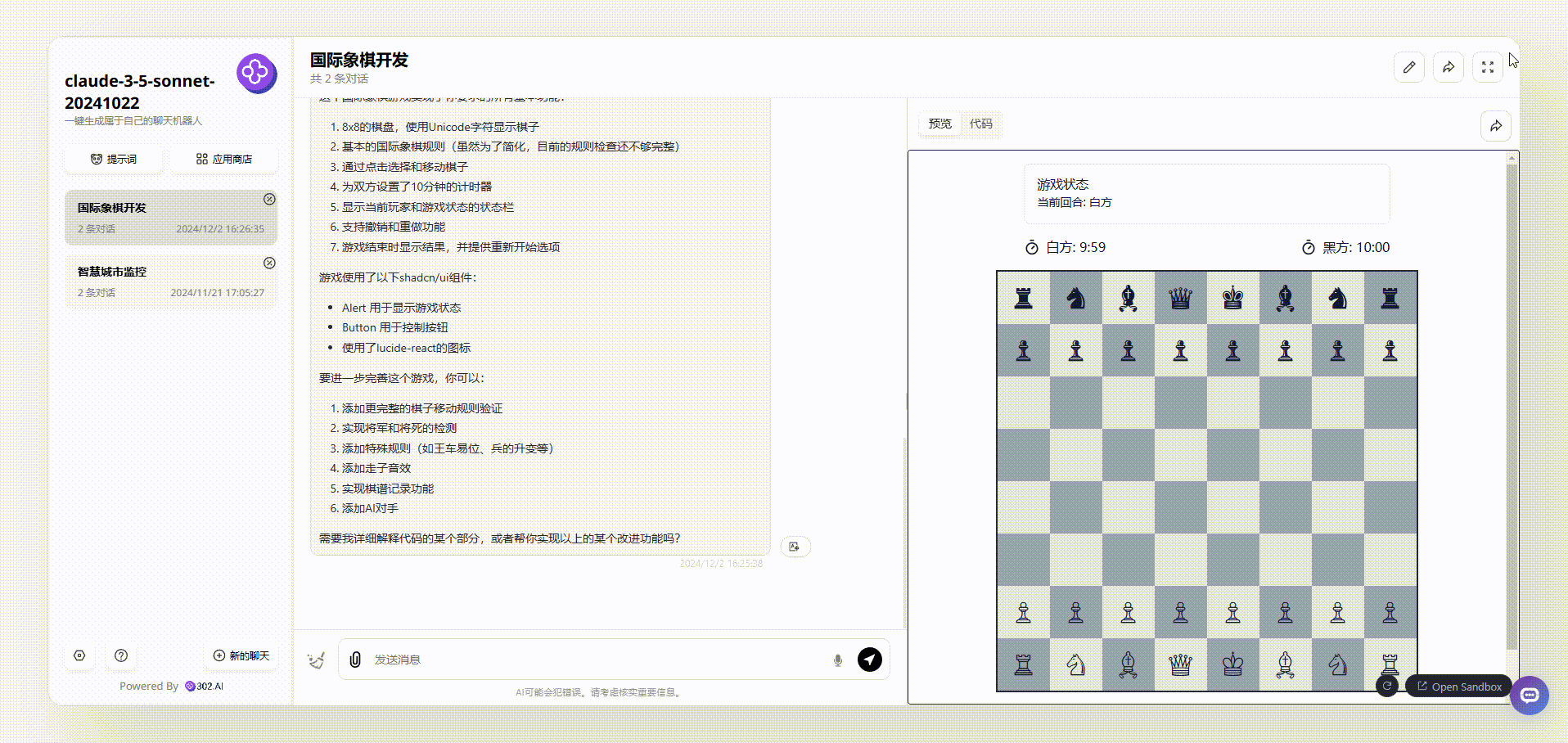
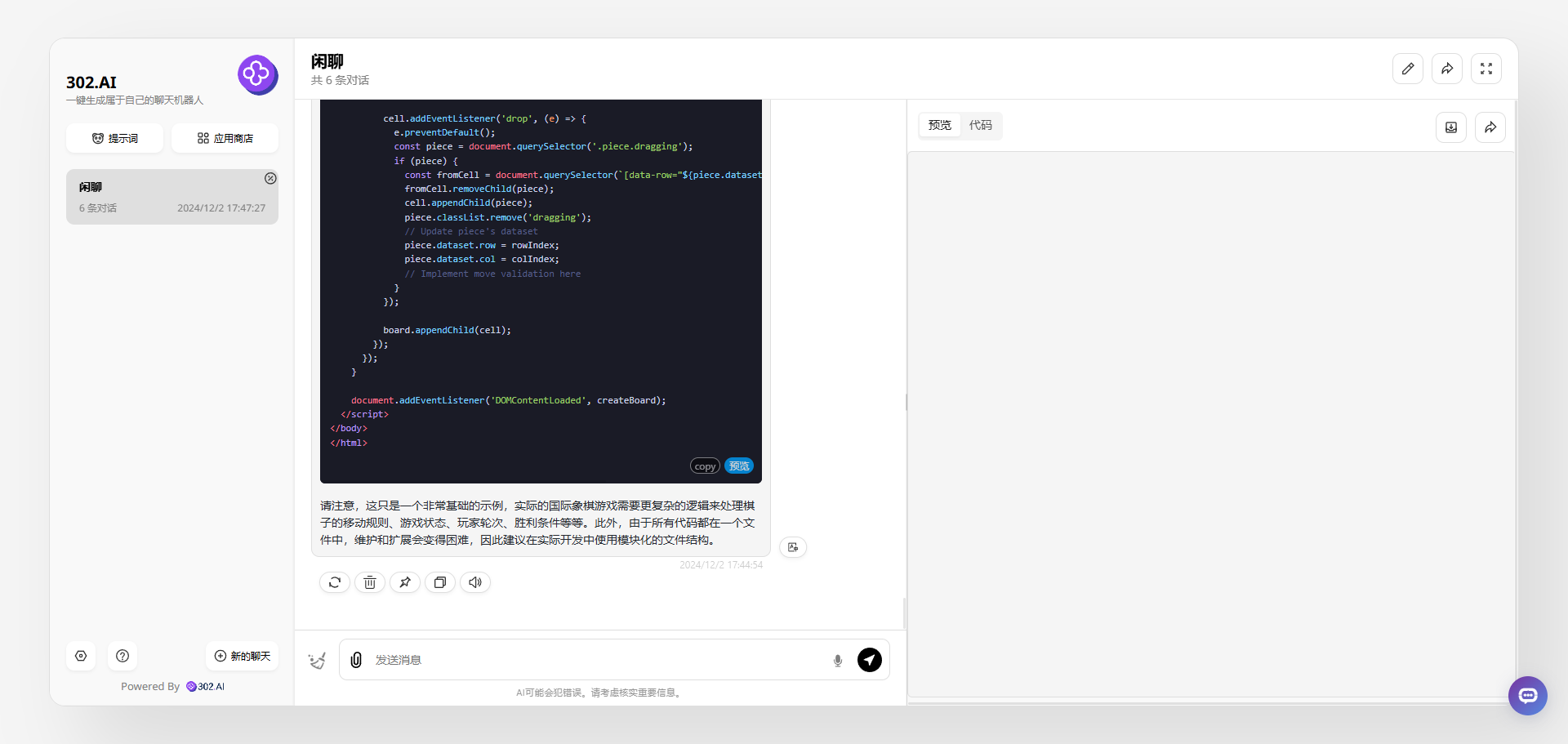
claude-3.5-sonnet:基本把提出的需求功能都实现了,且整个页面很美观。
QwQ-32B-Preview:生成的代码经过多次调整,代码仍然在关键部分有遗漏,无法运行。
![]()
claude-3.5-sonnet
![]()
QwQ-32B-Preview
> 总结
通过以上实测,可初步得出以下结论:
推理测试:在推理测试中,QwQ-32B-Preview虽然展示了详细的思考过程,但是最后却未能回答正确题目,在推理能力上还有进步的空间。
数学测试:在数学测试中QwQ-32B-Preview回答正确了题目,尽管与o1-preview相比,回答的简洁性和易读性稍有欠缺,但最终给出的正确答案证明了其在解题上能力还是比较出色的。
编程测试:而在最后的编程测试中,同样的提示词下,claude-3.5-sonnet生成的代码能够直接运行预览效果,而QwQ-32B-Preview生成的代码经过调整后仍无法预览出最终效果,这也显示出了在编程方面,QwQ-32B-Preview仍有不足。
综上所述,尽管QwQ-32B-Preview的参数只有32B,但其数学解题能力上非常出色,几乎可以和o1-preview媲美,不过其答案的易读性和简洁性希望能够进一步改进。最后,在推理以及编程方面,QwQ-32B-Preview还没有达到官方宣传的效果,期待后续能够改进!
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(8)
But wanna input that you have a very nice internet site, I like the pattern it really stands out.
You made some first rate factors there. I seemed on the web for the problem and located most people will go along with along with your website.
fascinate este conteúdo. Gostei muito. Aproveitem e vejam este conteúdo. informações, novidades e muito mais. Não deixem de acessar para saber mais. Obrigado a todos e até mais. :)
F*ckin¦ awesome things here. I¦m very glad to look your post. Thanks a lot and i’m taking a look ahead to touch you. Will you kindly drop me a mail?
I like what you guys are up too. Such smart work and reporting! Keep up the superb works guys I?¦ve incorporated you guys to my blogroll. I think it will improve the value of my website :)
It’s really a great and helpful piece of information. I’m glad that you shared this useful information with us. Please keep us up to date like this. Thanks for sharing.
Great write-up, I am regular visitor of one’s website, maintain up the nice operate, and It’s going to be a regular visitor for a lengthy time.
I’d have to examine with you here. Which is not one thing I usually do! I take pleasure in reading a post that may make folks think. Additionally, thanks for permitting me to comment!