


12月初,OpenAI 开启了为期十二天的直播活动。而在直播的首日,OpenAI带来了推理大模型o1的完整版!据了解,o1 完整版在数学和代码能力上都有了显著提升,推理速度比之前的preview版本快了60%,并且支持多模态!

![]()
在高难度数学题(AIME 2024)、编程能力(CodeForces)、科学问题(GPQA Diamond)等基准测试中,o1 完整版都拿到了最高分。更值得一提的是,在GPQA Diamond基准测试上,o1 完整版的表现甚至超越了人类专家!
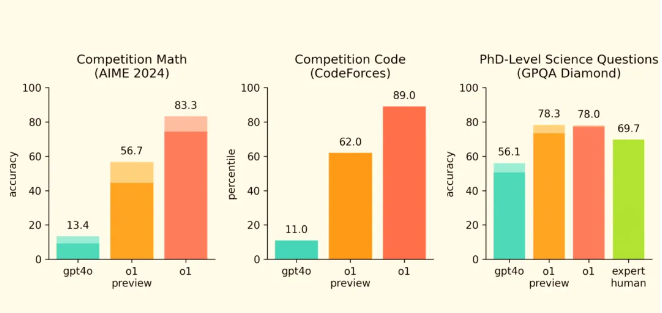
![]()
> 在302.AI上使用OpenAI o1模型
按照惯例,302.AI第一时间更新了OpenAI o1完整版模型,而且302.AI提供了按需付费的使用方式,没有捆绑套餐、没有月费。下面是具体的获取方式:
进入302.AI——左侧菜单栏点击【使用机器人】——【聊天机器人】——模型选择【o1-plus】——点击【确定】——最后【创建聊天机器人】;
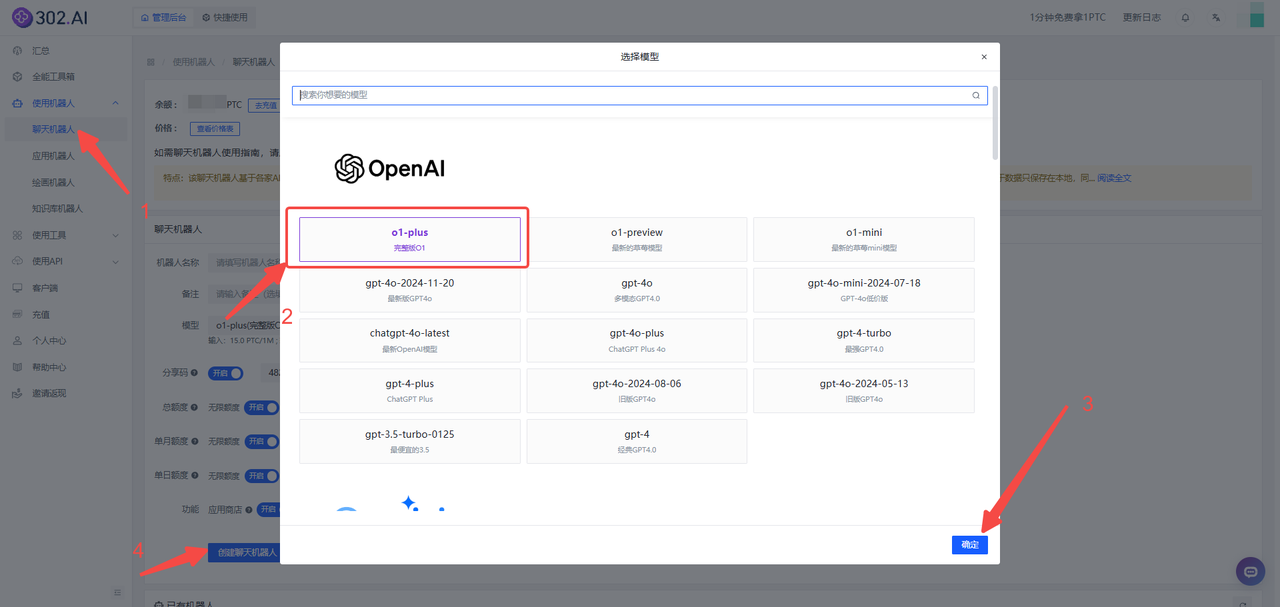
![]()
> 实测对比
每次模型一出来,总是被夸得天花乱坠,但真实效果到底是怎么样?还得实测过才知道。下面我们就通过不同方面实测对比,看看OpenAI o1完整版是不是真的是满血版的o1。
实测一:多模态推理
对比模型:o1 完整版和GPT-4o 多模态版
使用工具:302.AI的聊天机器人
提示词:从所给的四个选项中,选择最恰当的一个填入问号处,使之呈现一定的规律性。

![]()
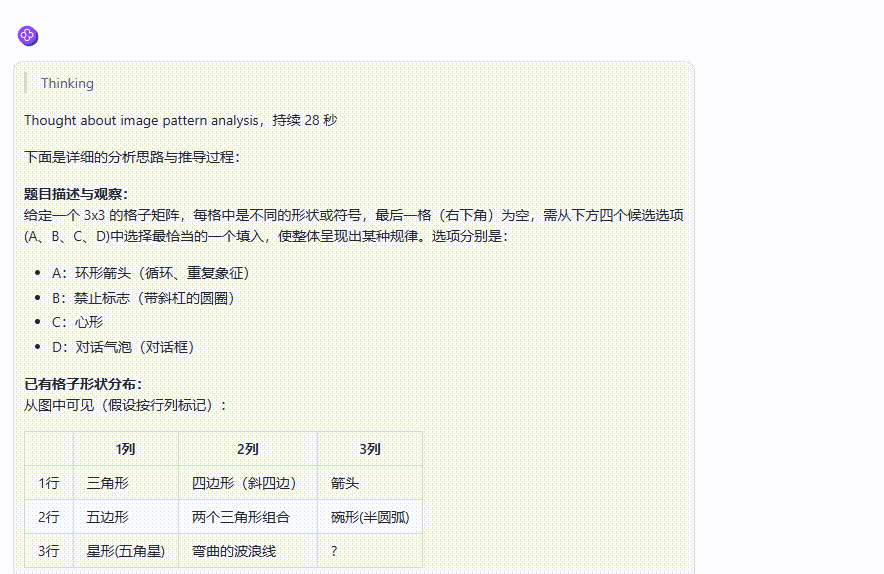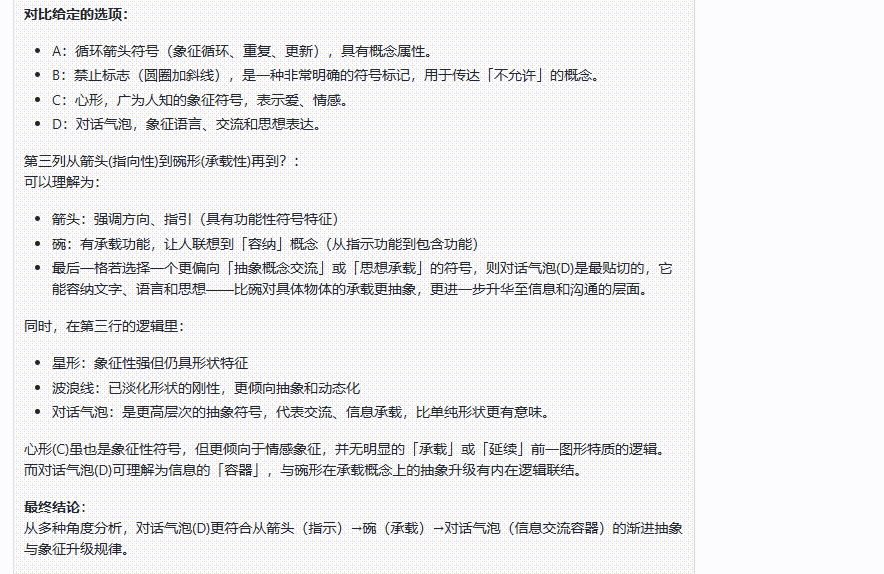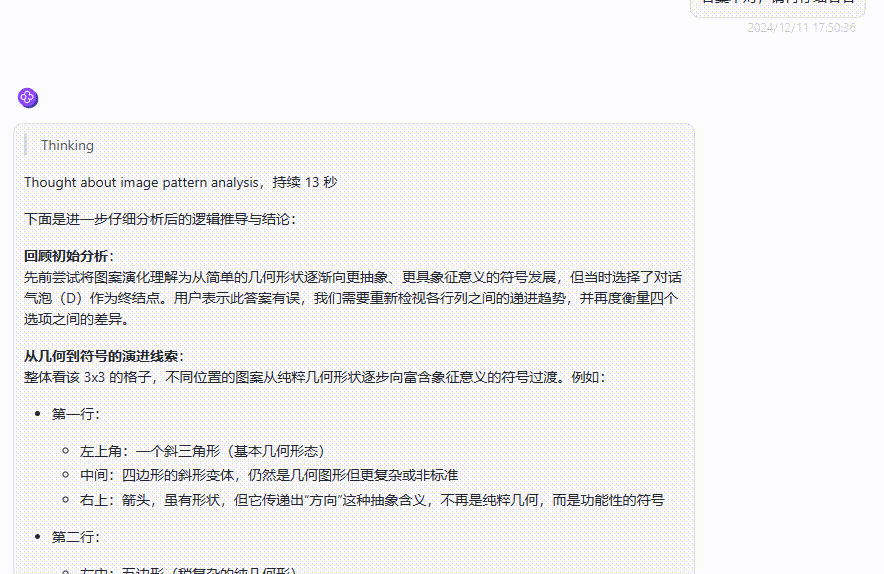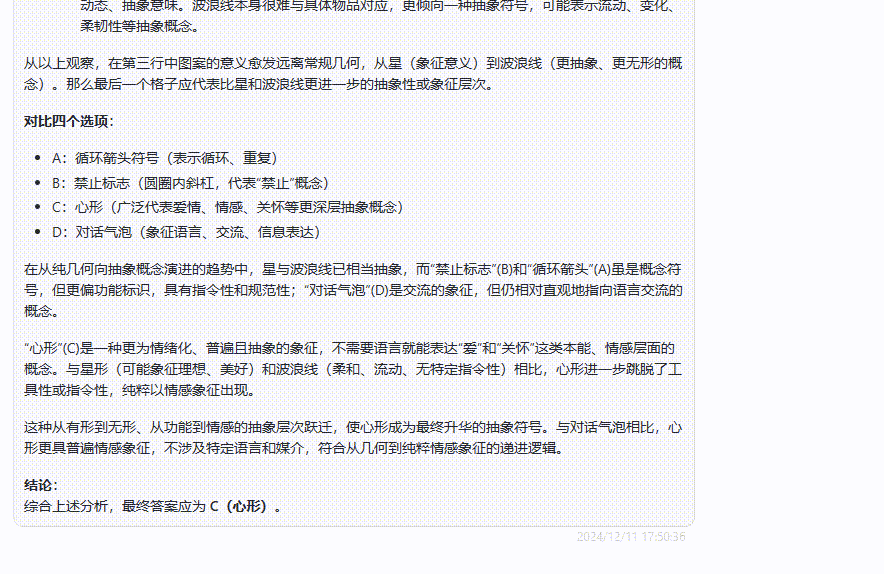
分析:这是我国公务考试中的固定图片推理题,同时也可以说是每一个考公人的噩梦,先说一下正确答案为选项C。
原因:图形元素组成不同,优先考虑属性规律。九宫格优先按横行来看,第 一行中,三幅图依次为仅轴对称图形、仅中心对称图形、仅轴对称图形;代入第二行验 证,第二行与第一行规律相同。因此,第三行也应该满足此规律,问号处应该填入一个 仅轴对称的图形。A 项为仅中心对称图形,B 项为既轴对称又中心对称图形,D 项为不对称图形,只有C项为仅轴对称图形,所以当选。
GPT-4o多模态:接下来看看GPT-4o的答案,从答案分析中可以看出,模型已经很努力在“瞎掰”了,但很可惜,答案是错误的!即使经过提醒答案不对,GPT-4o还是没能给出正确答案。

![]()
o1 完整版:o1 完整版一顿分析,给出了错误的答案。不过在经过第二次提醒后,最终纠正了回答,给出了正确答案。
![]()
实测二:数学能力测试
对比模型:o1完整版、o1 preview、claude-3.5-sonnet-20241022
使用工具:302.AI的模型竞技场
提示词:
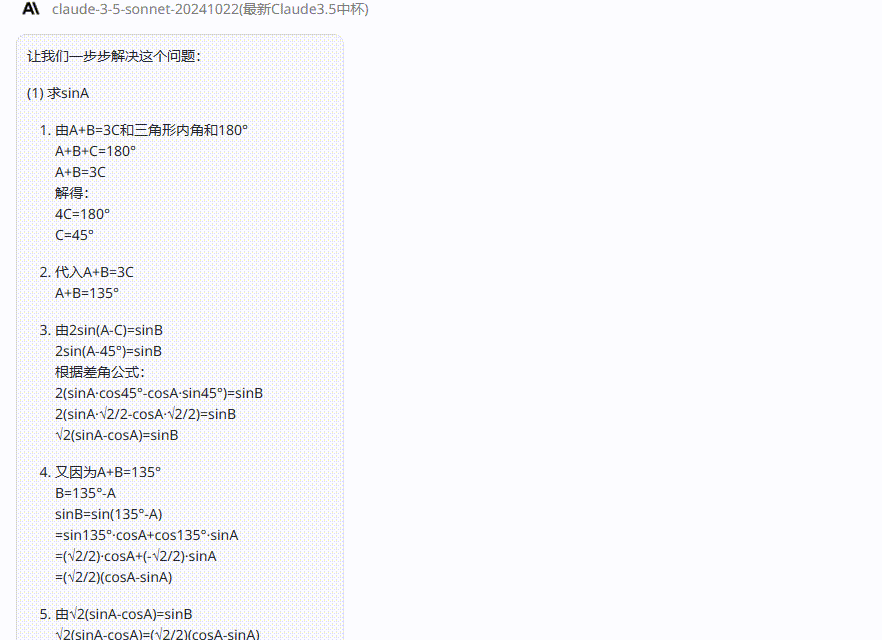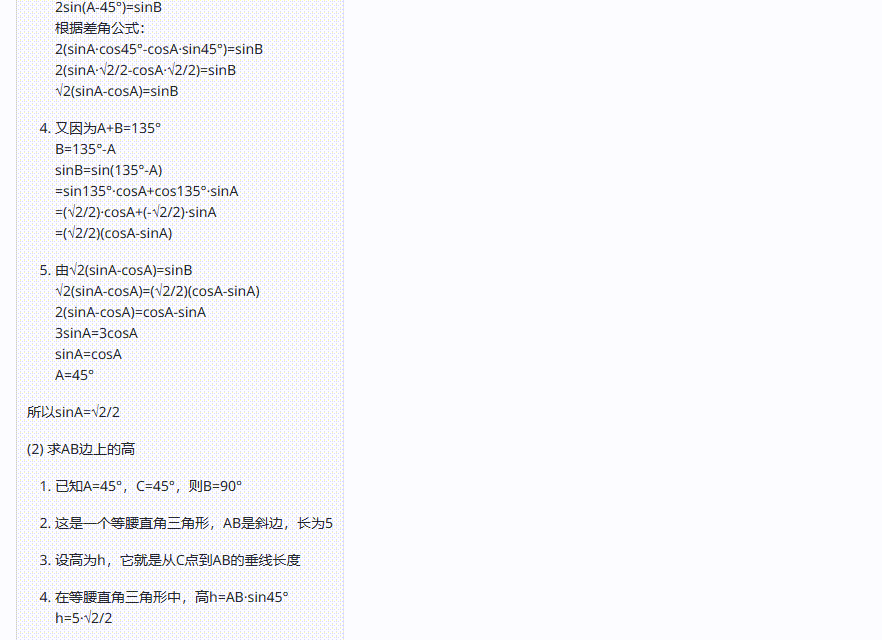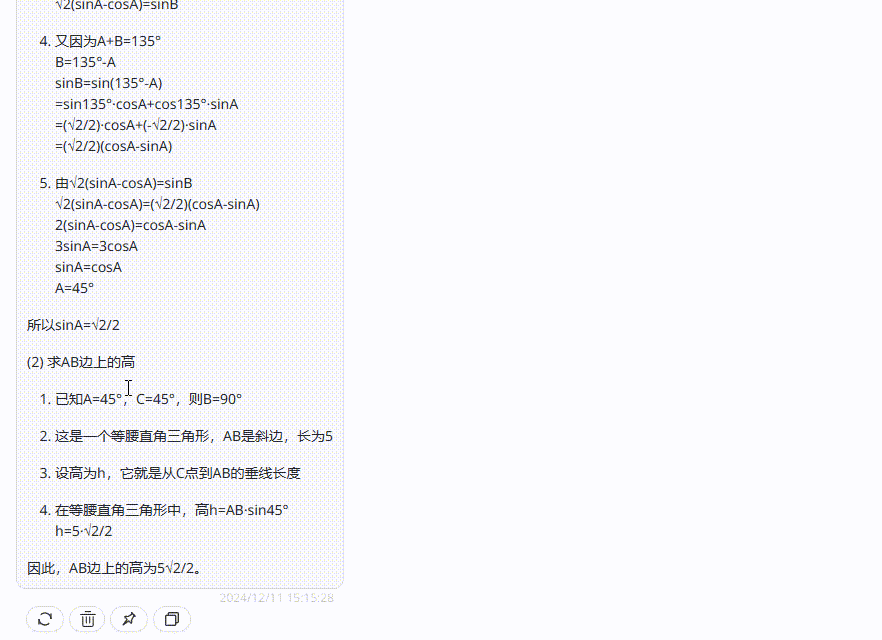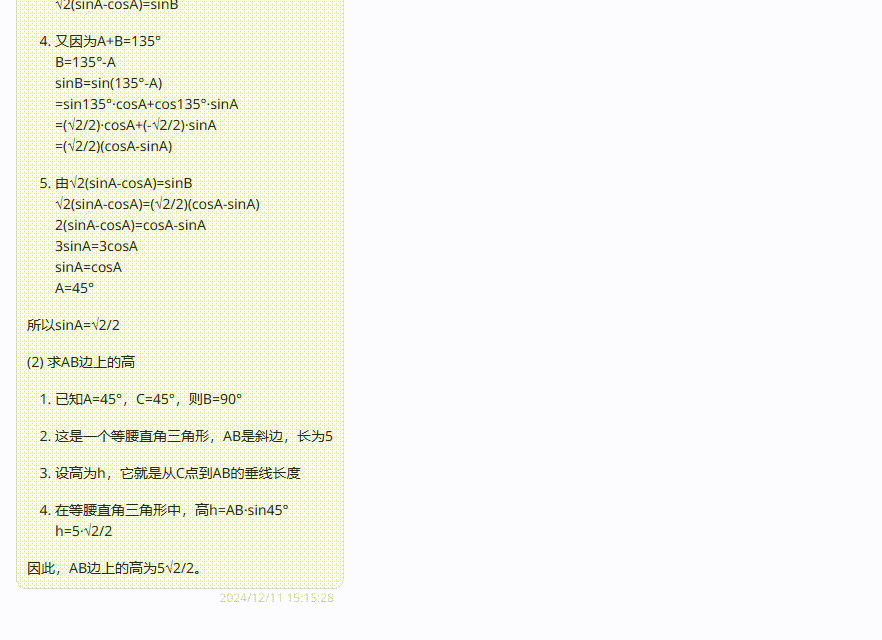
已知在三角形ABC中,A+B=3C,2sin(A-C)=sinB
(1)求sinA;
(2)设AB=5,求AB边上的高。
分析:这是2023年的河北高考题,共有2个小问,先来看下正确答案解析:

![]()
o1 完整版:来看下o1 完整版的答案,可以看到答案也是很长,但只答对了第一小问,第二小问回答错误,在经过提醒后,仍未能回答正确。

![]()
claude-3.5-sonnet:再来看看claude-3.5-sonnet的答案,两个小问的答案均回答错误,经过再次提醒答案不正确后,依然无法纠正答案!
![]()
o1 preview:o1 preview居然两个小问都回答正确!

![]()
实测三:编程检验
对比模型:o1完整版、o1 preview、claude-3.5-sonnet-20241022
使用工具:302.AI的聊天机器人、编程学习平台
提示词:

![]()
分析:这属于专家级难度的编程题目,看下三个模型是否能够通过检验:
o1 完整版:o1完整版输出的代码没有检验通过!
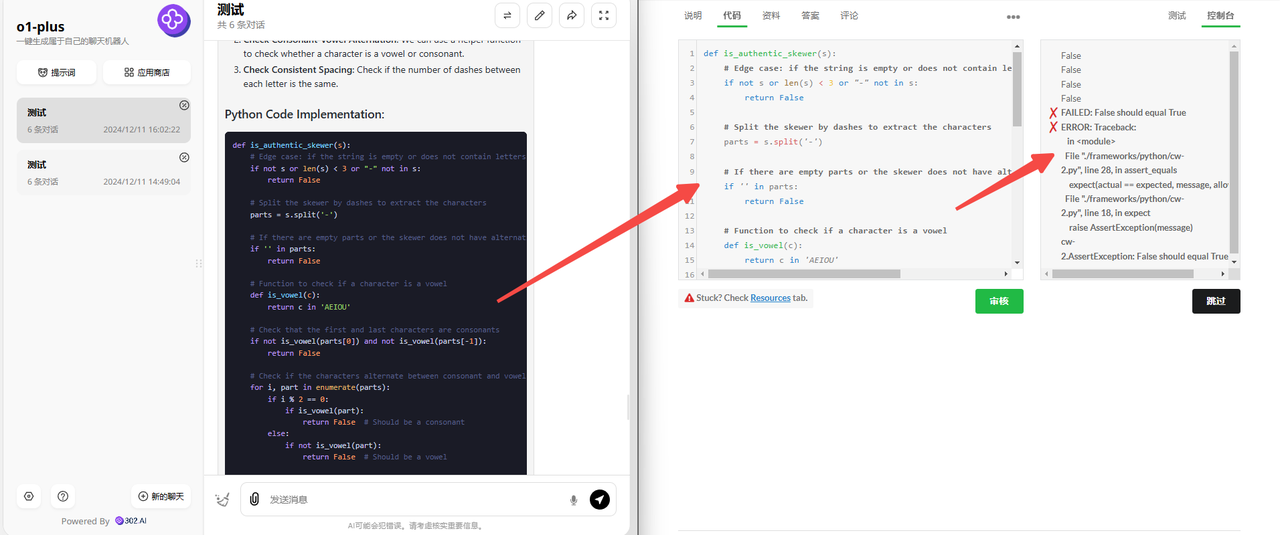
![]()
将错误返回给模型重新纠正后,依然只正确了一半!
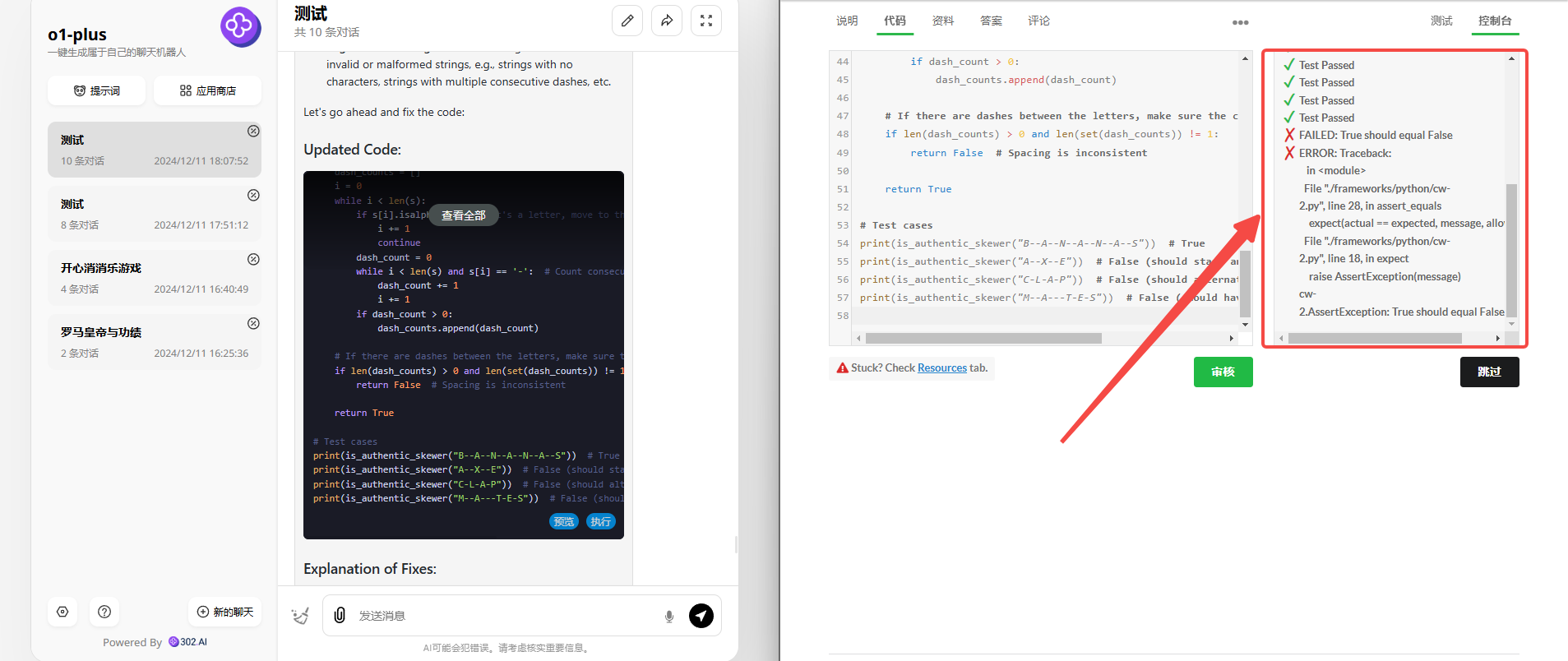
![]()
claude-3.5-sonnet:claude输出的代码出现了语法错误,检验失败!
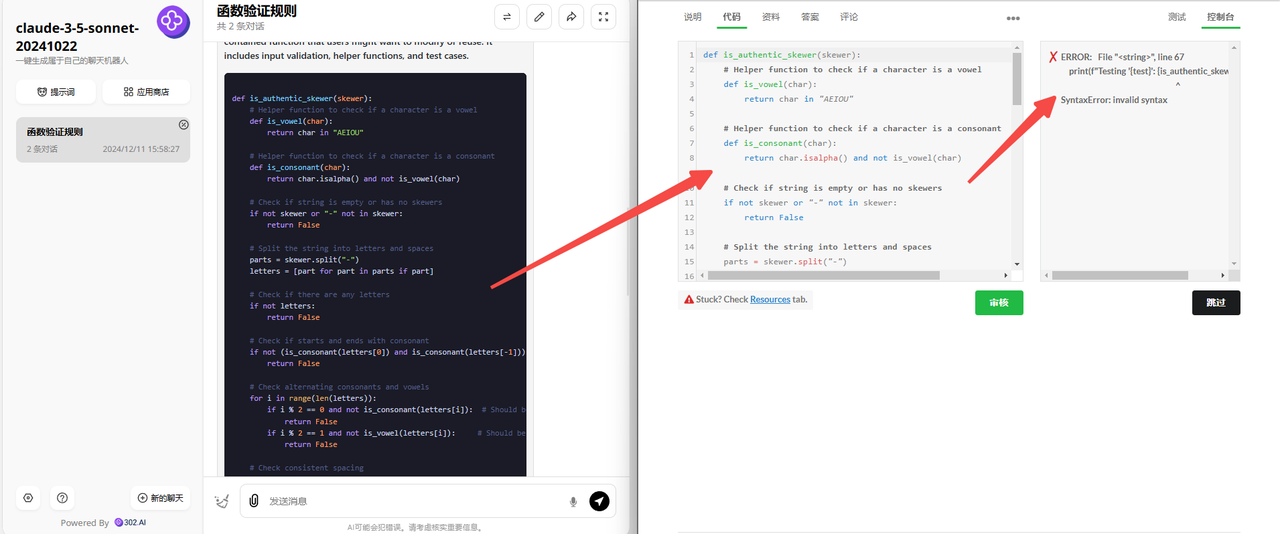
![]()
将错误返回给模型自行纠正,最后仅对了一半!
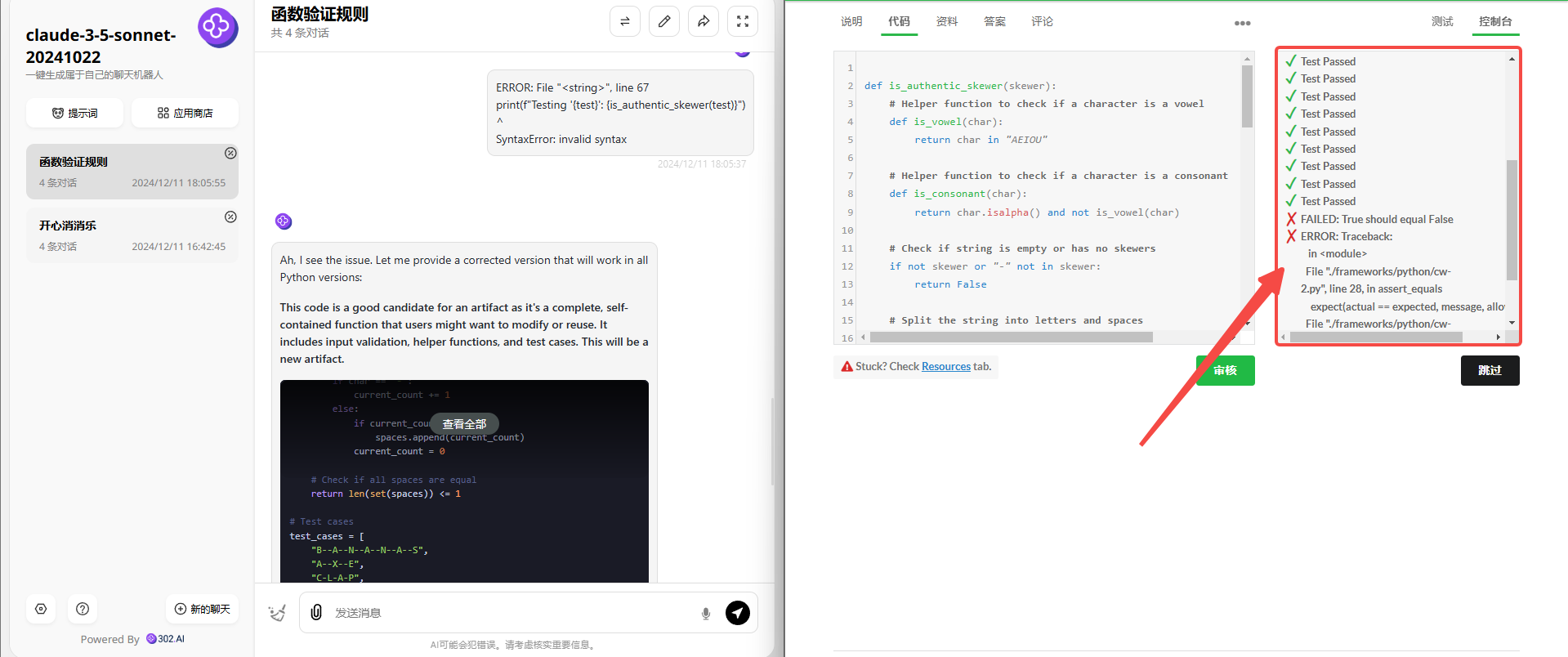
![]()
o1 preview:没想到o1 preview再次获胜,代码检验通过!
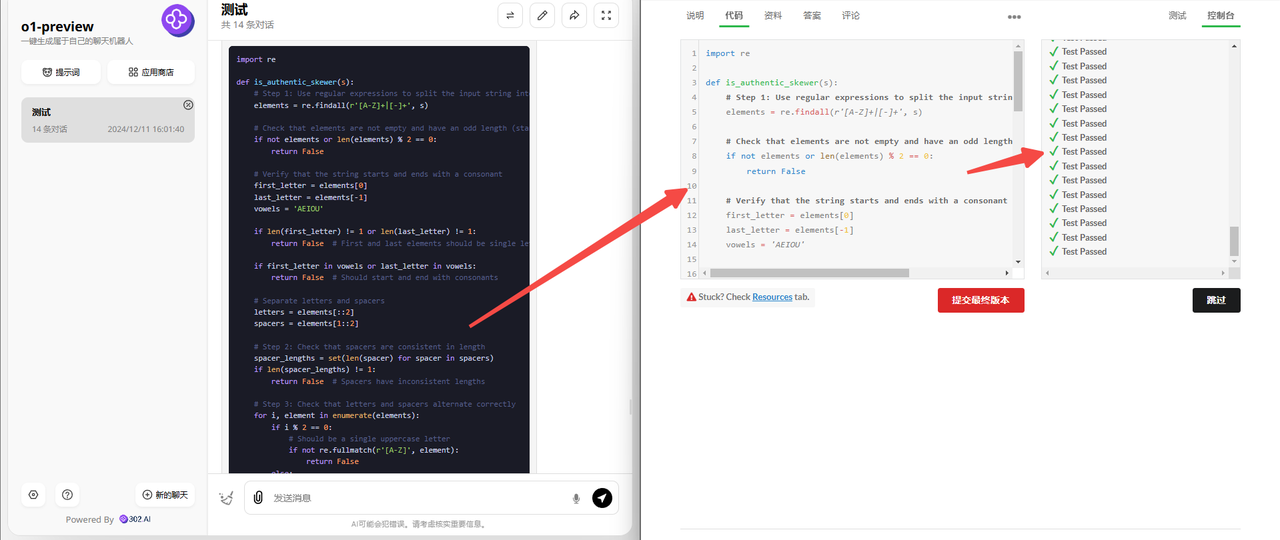
![]()
> 总结
经过一系列的对比,可以初步得出以下结论:
多模态推理:在多模态推理方面,o1 完整版与GPT-4o都未能给出正确答案,虽然o1 完整版在经过提醒后能够给出正确答案,但在面对此类多模态逻辑推理题目中,模型的局限性还是比较明显。
数学能力测试:在数学能力测试中,o1 preview意外地表现出色,超越了o1 完整版。
编程检验:在编程能力方面,o1 完整版即使经过二次提醒输出的代码还是未能完全通过检验。
今天的实测内容更多地侧重于用户的实际需求,从公务员考试中的图形逻辑题到高考数学题,再到编程题目,都更贴近用户的日常生活。然而,从实测结果来看,o1 完整版在实际应用方面,其能力仍有待进一步的优化和完善。
此外,听说o1 完整版后续还会添加对网页浏览和文件上传等工具的支持,我们可以期待看看!
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(9)
I have learn several good stuff here. Definitely value bookmarking for revisiting. I wonder how so much effort you place to create the sort of excellent informative web site.
I just like the valuable info you provide in your articles. I will bookmark your weblog and take a look at again here frequently. I’m quite sure I’ll learn many new stuff proper right here! Good luck for the next!
Good post but I was wanting to know if you could write a litte more on this topic? I’d be very grateful if you could elaborate a little bit further. Kudos!
I am very happy to read this. This is the kind of manual that needs to be given and not the accidental misinformation that is at the other blogs. Appreciate your sharing this best doc.
Hi, I think your site might be having browser compatibility issues. When I look at your website in Safari, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, fantastic blog!
I’ve been browsing online greater than three hours nowadays, yet I never discovered any attention-grabbing article like yours. It’s lovely value sufficient for me. Personally, if all website owners and bloggers made excellent content material as you did, the internet might be much more useful than ever before.
Hi my friend! I want to say that this post is awesome, nice written and include approximately all important infos. I’d like to see more posts like this.
I always was concerned in this subject and stock still am, thankyou for posting.
I am not very great with English but I get hold this rattling easy to read .