


12月13日,DeepSeek 官方发布博文,宣布开源 DeepSeek-VL2 模型。
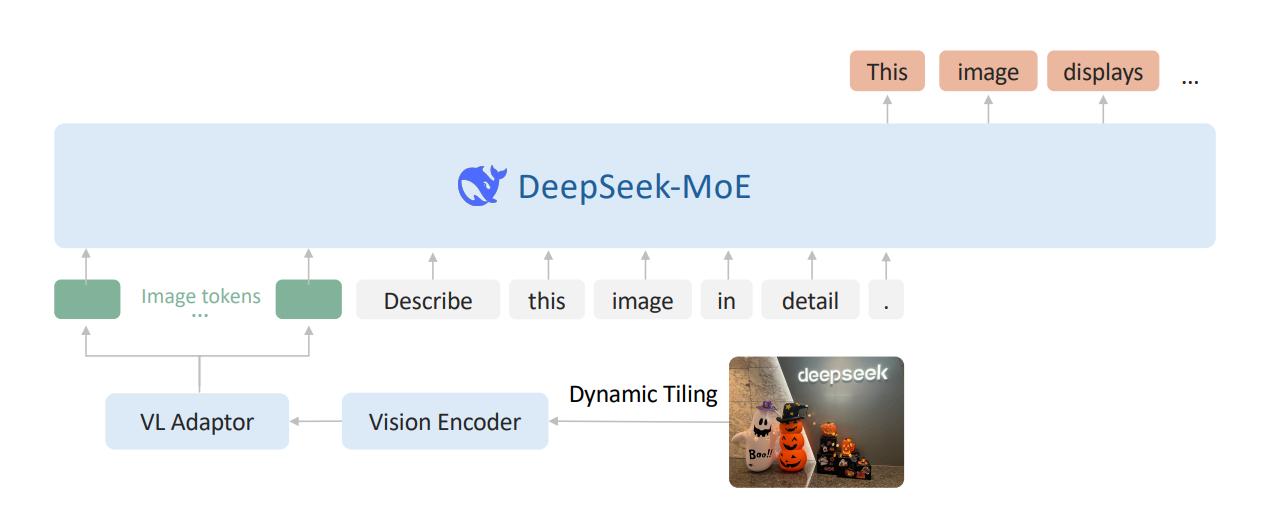
据了解,在模型架构上,DeepSeek-VL2 视觉部分使用切图策略支持动态分辨率图像,语言部分采用 MoE 架构低成本高性能, MoE是一种混合专家(Mixture-of-Experts)架构,旨在提高模型的性能和效率。
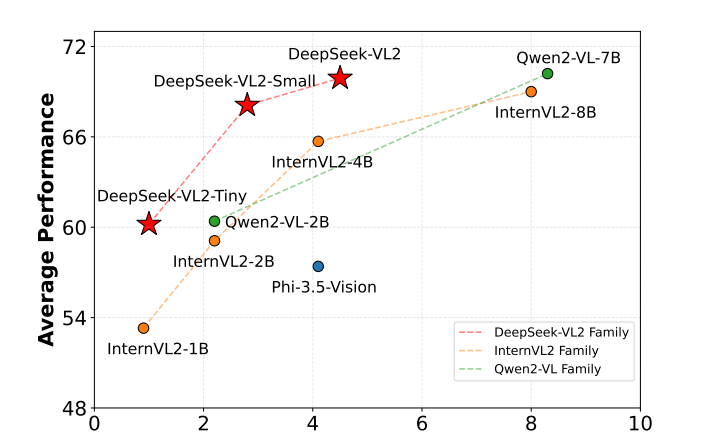
在官方给出的测评结果中显示,DeepSeek-VL2超越了多种视觉语言模型:
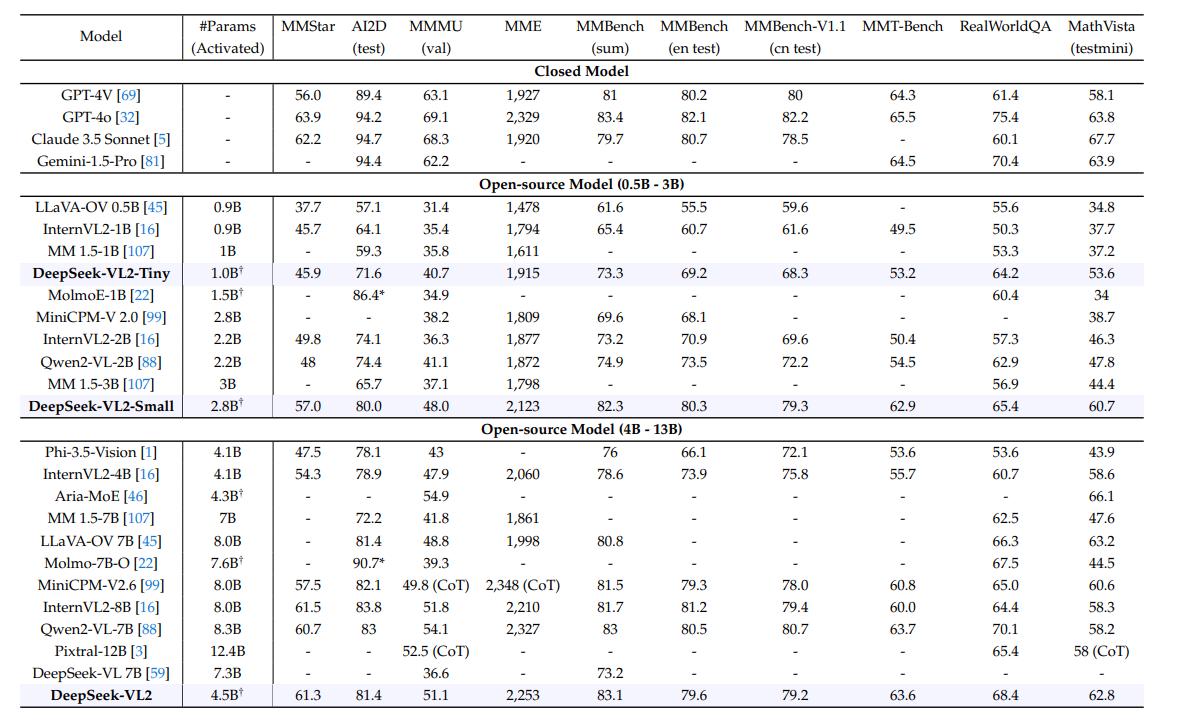
DeepSeek-VL2 还分别在 OCR、多模态对话、视觉定位三个领域进行了测试。与 InternVL2、DeepSeek-VL、Qwen2-VL等VLM模型相比中,DeepSeek-VL2 通过 MoE 架构在激活参数更少的情况下实现了相似或更好的性能。
想要了解更多,可以查看模型论文:https://arxiv.org/abs/2412.10302
> 在302.AI上使用
目前,302.AI已经在聊天机器人和API超市提供了DeepSeek-VL2模型,满足不同受众用户的需求,且提供按需付费的使用方式,用户无需担心有月费和捆绑套餐,成本更加灵活可控。以下是详细的获取步骤。
【聊天机器人】
用户想要直接使用模型,可以通过302.AI的聊天机器人获得,302.AI的聊天机器人的更新速度与市场同步,提供了多种AI模型,且分类明晰,用户可以快速找到并使用所需的AI模型,无需在不同平台之间切换和搜索,提高了工作效率。
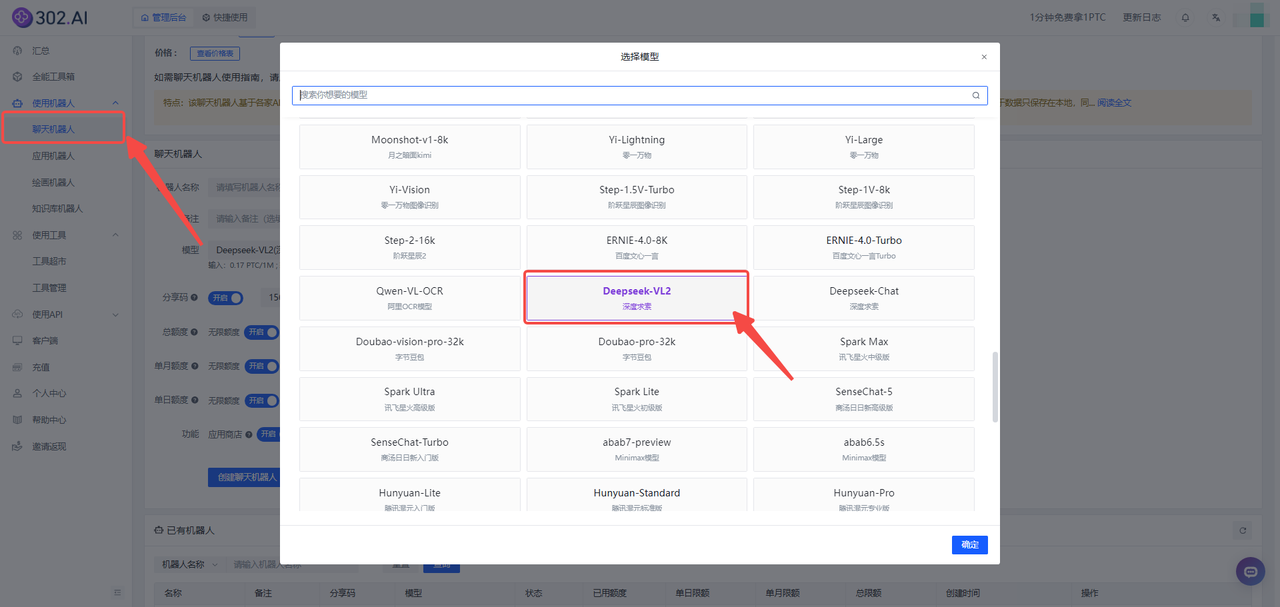
1、进入302.ai,登录后在左侧菜单栏点击使用机器人——选择聊天机器人——模型中选择模型DeepSeek-VL2——最后点击确定即可。
【API超市】
企业用户可以直接通过302.AI提供的接口来调用大模型,并根据自身项目需求快速开发AI应用,大大加快开发和部署速度。以下是在API超市中获取DeepSeek-VL2的详细步骤:
1、进入302.ai后——点击使用API——选择API超市——分类中点击语言大模型——然后选择国产模型。
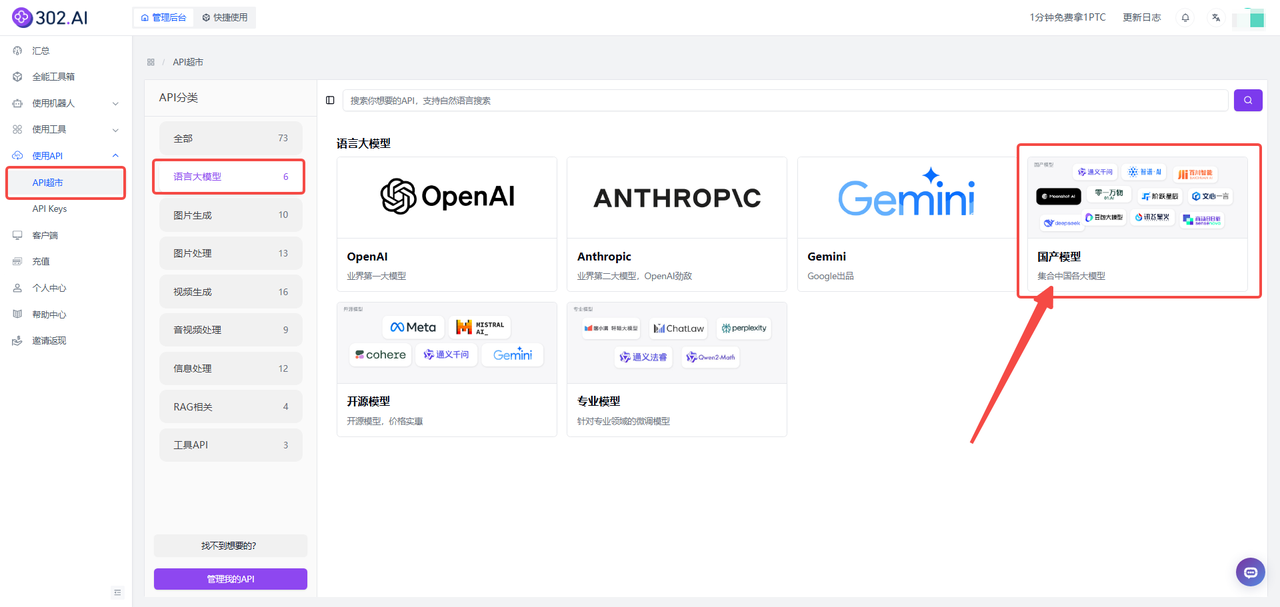
2、下滑可以看到已经提供了模型DeepSeek-VL2的API,可以根据需求选择【查看文档】快速接入API或者选择【在线体验】测试模型的参数。
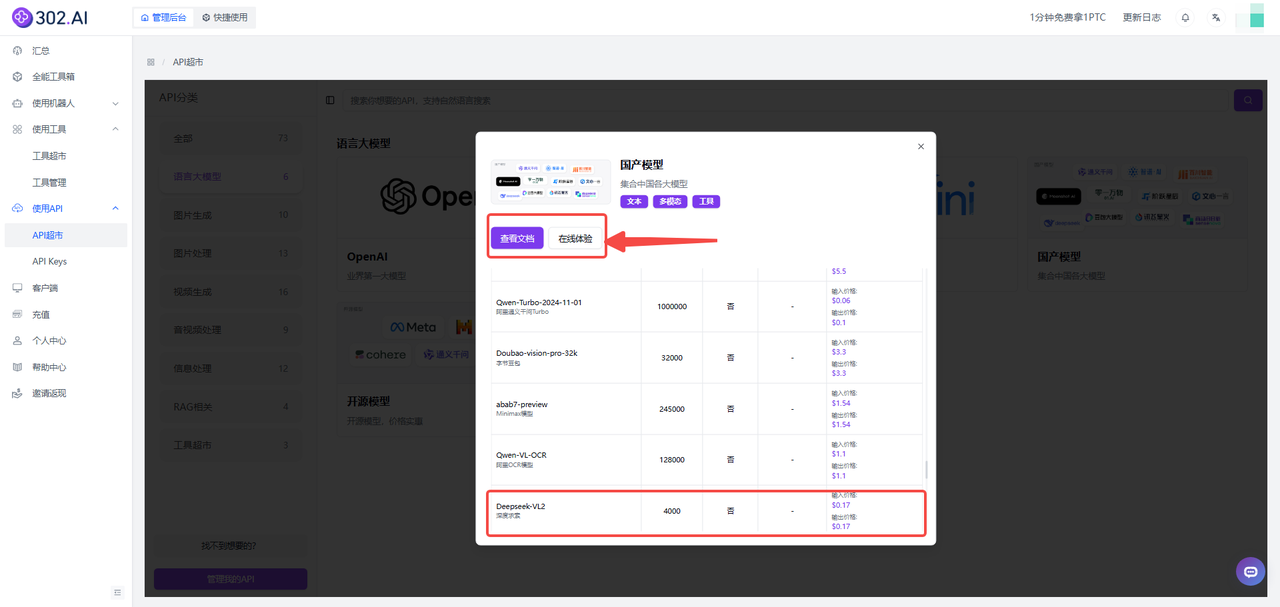
> DeepSeek-VL2实测对比
为了更好了解模型,接下来我们会使用302.AI的模型竞技场对比模型的表现,本次对比的三个模型均为价格接近的国产模型,来看下模型的表现如何!
对比模型:deepseek-VL2、Qwen-VL-Max、abab7-preview
使用工具:302.AI的模型竞技场(界面如下)
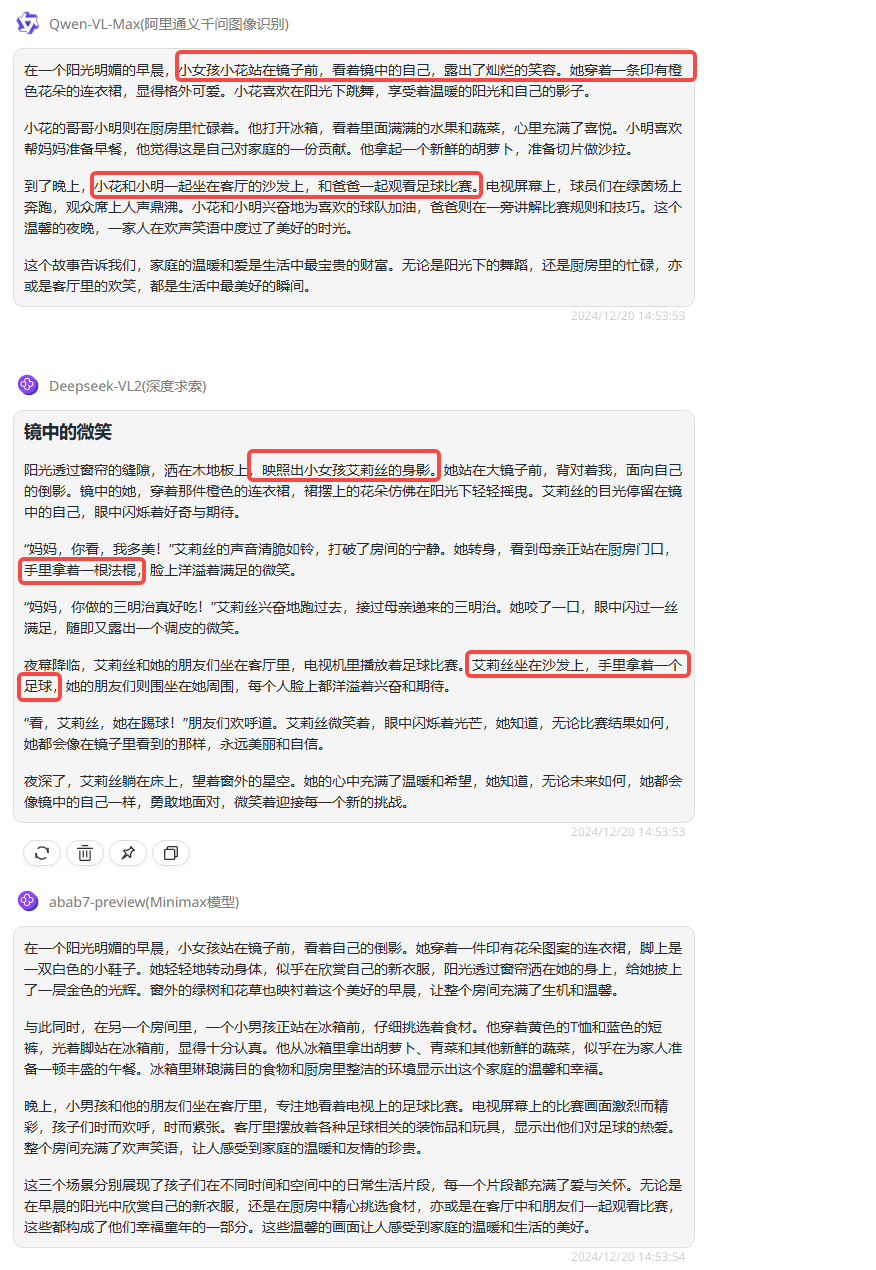
实测一:看图说话
提示词:请根据给出的三张图片编写一个大约300字的暖心故事。

(图片由302.AI生成)
分析:第一轮实测是看图说话,这是DeepSeek官方在宣传文章中展示的实测提醒,我们换了图片后,实测对比看看模型的表现到底如何。这一轮实测主要考察模型是否能正确描述图片中的场景,并合理赋予关系。
Qwen-VL-Max:故事结构比较通顺,但细看人物关系和场景串联并不合理,比如图三的场景中没有女孩的身影,但是却强行和图一中的人物连接在一起。
deepseek-VL2:出现的问题和Qwen模型相似,人物关系和场景串联不合理,此外,deepseek-VL2的描述中还有部分内容偏离了图片,比如可以看到图二的手里没有拿着任何物品,但描述中却写道是手里拿着法棍,还有将人物识别成“妈妈”的角色。
abab7-preview:逻辑通顺,故事人物关系、场景描述都是正确的,并且符合主题,是三个模型中表现最好的。
实测二:文字识别
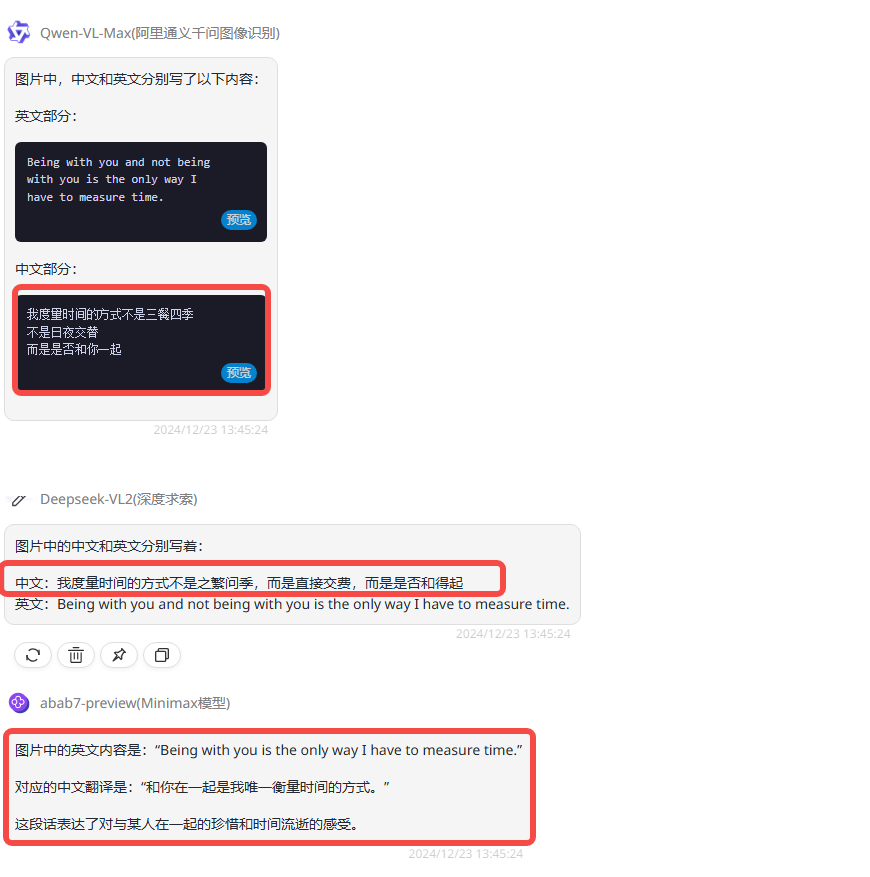
提示词:请回答:图片中中文和英文分别写了什么?

(图源网络)
分析:这是一道非常简单的文字识别测试,涵盖了中英文,来看三个模型是否能正确识别。
Qwen-VL-Max:英文识别正确,中文识别错了一个字。中文第二句中应该是“昼夜更替”识别出来是“日夜更替”。
deepseek-VL2:英文识别正确,中文识别错误率达到到70%,识别出来的中文逻辑语序都不通顺。
abab7-preview:英文和中文识别均有错误。在这一轮中表现最差的模型,中文部分不是识别而是直接翻译。
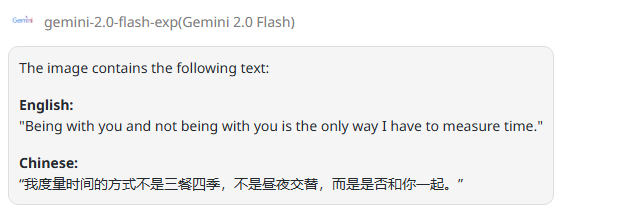
附上正确参考答案:
实测三:图形推理
提示词:从所给的四个选项中,选择最合适的一个填入问号处,使之呈现一定的规律性:
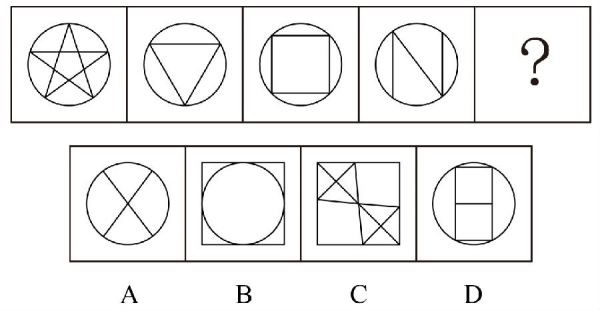
分析:传统的图形推理题目,首先需要找到规律,规律一:前四个图形都是外层都是圆形,规律二:圆形内的图形能一笔连续画出。因此正确答案是选项D。
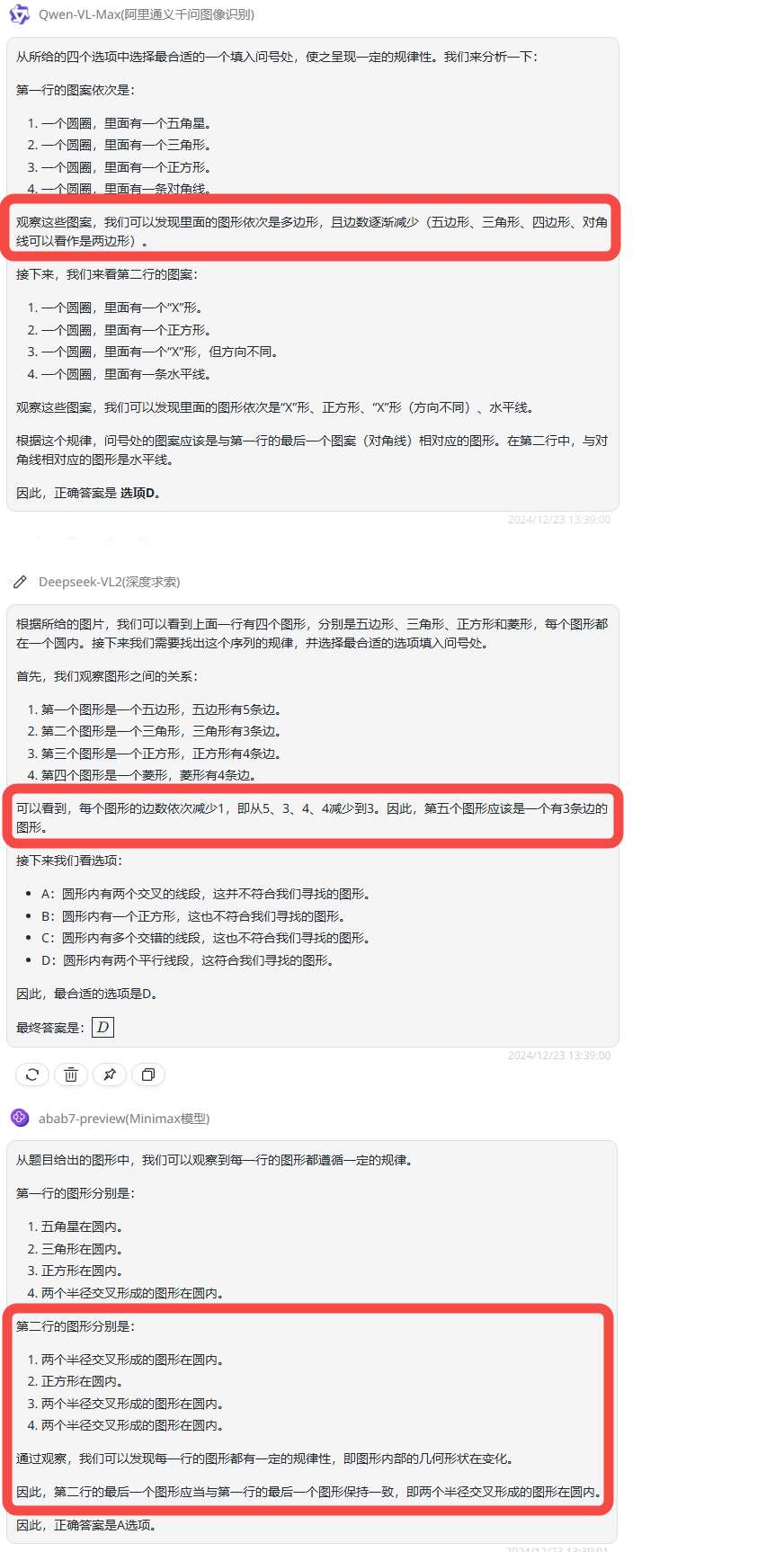
Qwen-VL-Max:答案正确,但是解析的逻辑不够通顺。
deepseek-VL2:最后答案正确,同样解析过程逻辑不够通顺。
abab7-preview:分析错误,答案错误。
> 总结
通过多轮实测,可以初步得出以下结论:
看图说话:在故事编写时,人物关系与场景描述不如其他模型,整体逻辑联系显得略为牵强。
文字识别:DeepSeek-VL2的英文识别完全正确,但是中文识别上存在一定的错误率。
图形推理:尽管最终的答案是正确的,但是解析的过程逻辑不足。
总体来看,DeepSeek-VL2在三个模型中的优势并不明显,在文字识别、图形推理和看图编故事方面都有待进一步优化。希望DeepSeek团队可以针对这些问题进行进一步的优化和改进,以提升模型在多模态任务中的表现。
免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

Comments(8)
Really clean site, thanks for this post.
I really like your blog.. very nice colors & theme. Did you make this website yourself or did you hire someone to do it for you? Plz answer back as I’m looking to construct my own blog and would like to know where u got this from. many thanks
I got what you mean , regards for putting up.Woh I am delighted to find this website through google. “You must pray that the way be long, full of adventures and experiences.” by Constantine Peter Cavafy.
I haven’t checked in here for a while as I thought it was getting boring, but the last several posts are great quality so I guess I’ll add you back to my daily bloglist. You deserve it my friend :)
I simply could not leave your site prior to suggesting that I actually loved the standard information a person supply for your visitors? Is going to be again continuously in order to check out new posts
Really nice layout and superb content material, nothing else we want : D.
Very interesting topic, thankyou for posting.
Hello! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me. Anyways, I’m definitely happy I found it and I’ll be book-marking and checking back frequently!