


12月,字节跳动豆包大模型团队推出文生图模型 v2.1版本,这次的升级对比通用 2.0和通用 2.0 PRO版本,除了结构准确和美感明显提升外,重点支持了中英文字符渲染。
据了解,豆包文生图模型v2.1通过打通 LLM 和 DiT 构架,构建了高质量文字渲染能力,大幅提升文字生成准确率。这种原生的文字渲染能力,让文字与整体画面的融合更为自然和实用。
> 在302.AI上使用
按照惯例,302.AI在第一时间更新了Doubao的图像生成模型,用户可以通过302.AI的绘画机器人以及API超市获取模型使用,302.AI提供按需付费的服务方式,用户只需为实际使用的资源和服务付费,提供了高度的灵活性。
【绘画机器人】
302.AI的绘画超市涵盖市面上多种图像模型,用户可以根据需要选择模型合适的使用。在使用过程中,还可以根据创作需求随意按需切换模型,且无需复杂繁琐的流程,非常便捷。以下是在绘画机器人中获得Doubao模型的步骤:
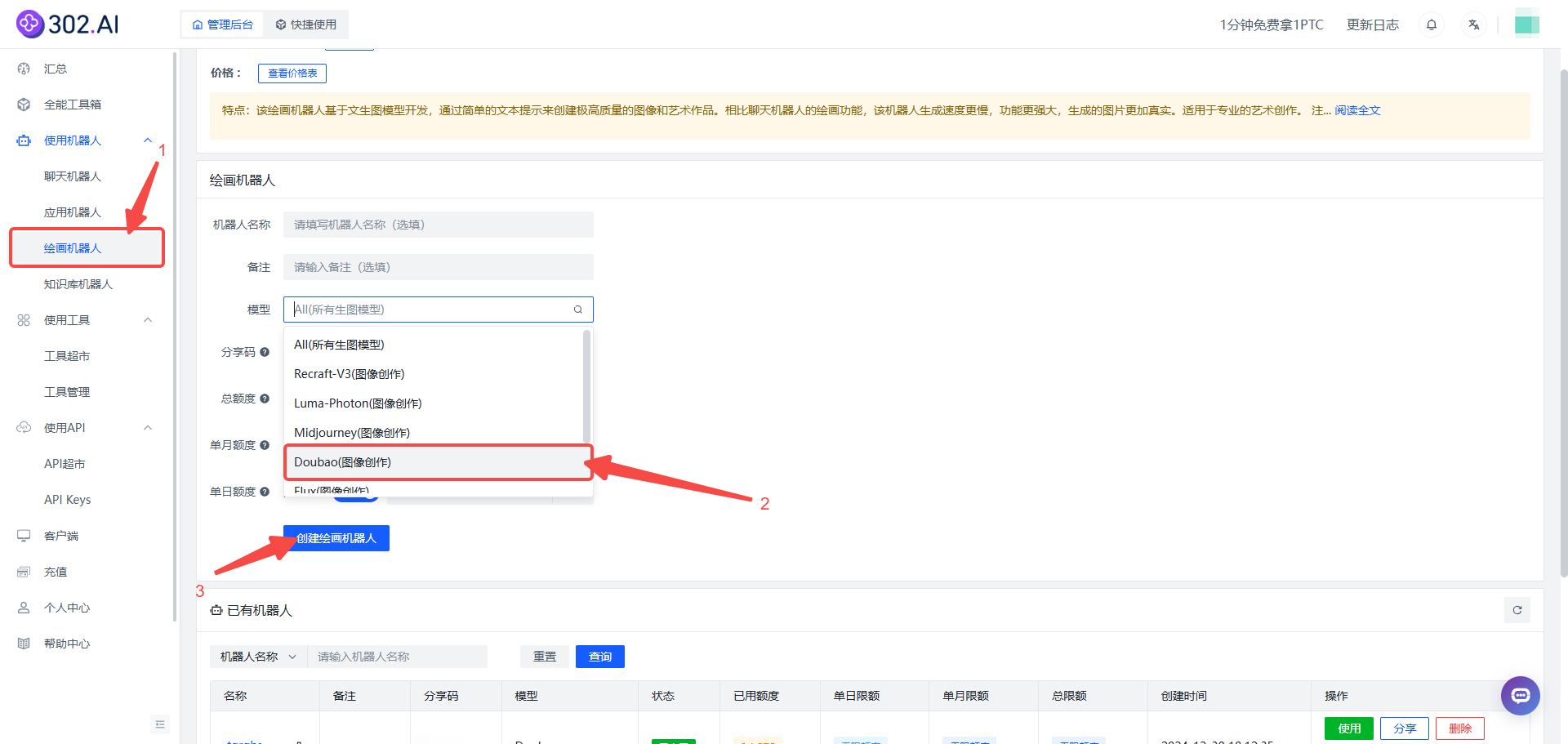
1、进入302.AI——点击使用机器人——找到绘画机器人——这里模型可以默认All模型或者直接选择Doubao模型——然后创建绘画机器人;
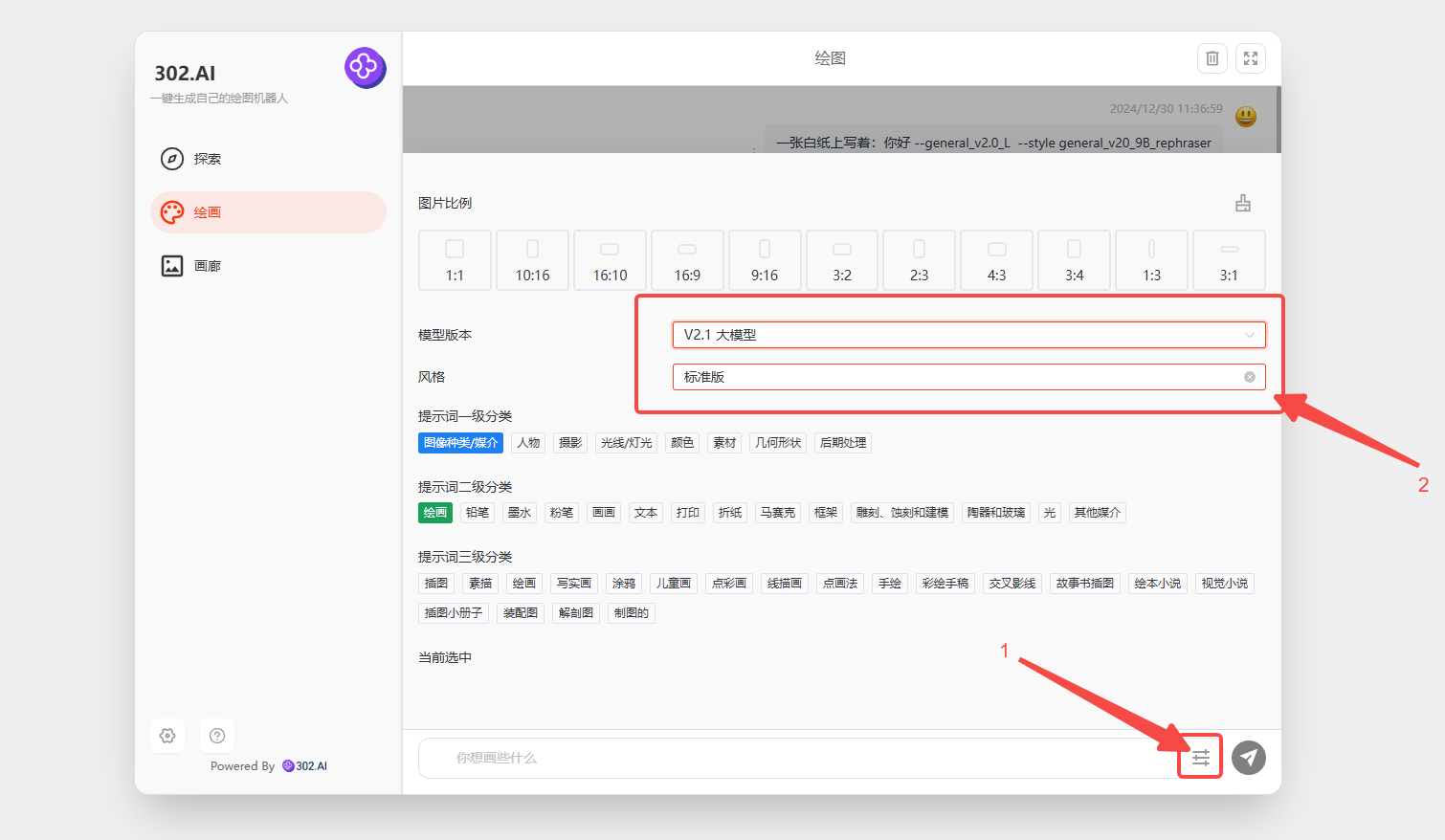
2、点击输入框右侧的设置——选择模型版本——选择风格,设置中还可以选择图片比例等;
【API超市】
302.AI的API超市中的API种类丰富且分类明晰,企业用户可以快速找到所需的API的获取接入方式和文档支持,并能够根据特定项目需求进行定制化开发,加快AI应用的研发与部署流程。以下是豆包模型的获取方式:
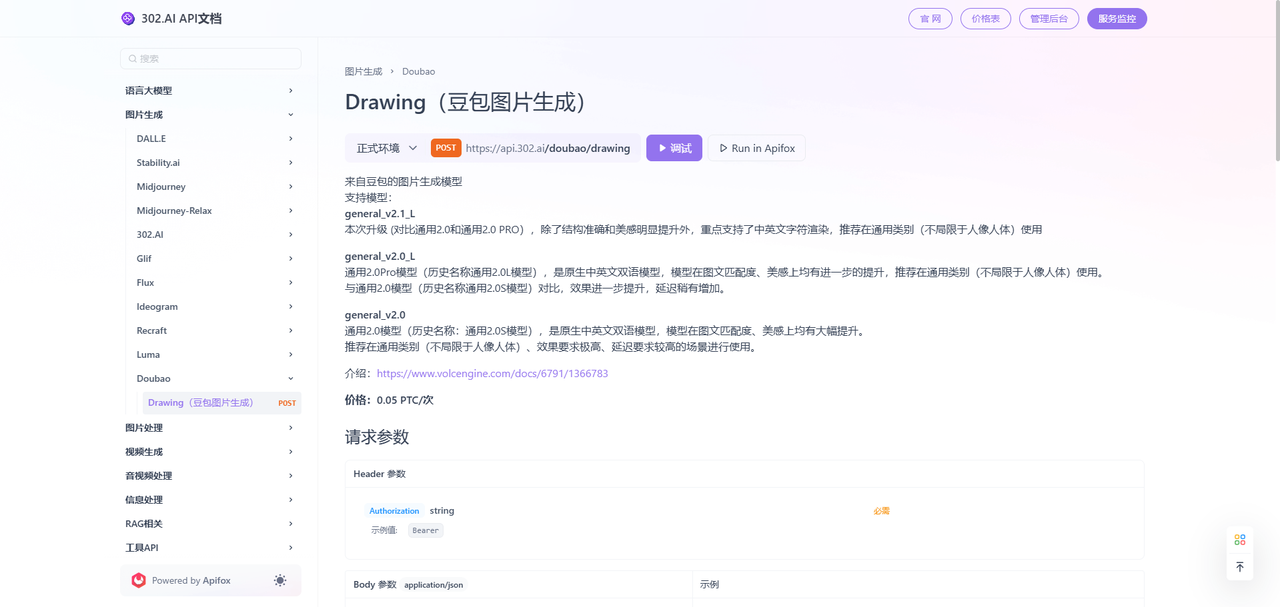
1、进入302.AI后——点击使用API——选择API超市——分类中点击图片生成——选择Doubao。

2、点击查看文档后即可进入。
> Doubao文生图模型v2.1模型测评:
以下测评会生成纯中文、纯英文、中英的文字内容并搭配三种不同类型风格的图片,由于对比模型无法生成中文内容,因此在只会在实测2中会对比模型的表现,实测1与实测3中不作对比,对比模型为:Midjourney V6.1、Ideogram v2。
实测1:中文内容生成
提示词1:治愈漫画风,在蓝蓝的天空下有一被云朵簇拥着的山峰。山峰前面是一个小卖部,小卖部的招牌上写着:“云间小卖部”。小卖部旁边坐着一个老奶奶,脸上带着和蔼的笑容。
分析1:Doubao v2.1提示词理解准确,中文内容生成正确。图片的色彩非常明亮和鲜艳,细节和构图都处理得非常出色。

提示词2:节日海报,在画面中央是一个巨大的白色饺子,它的皮巧妙地打开,露出里面温暖的室内场景。里面有五个微型人物,围坐在一个装满小饺子的小圆桌旁,似乎在享受丰盛的晚餐。室内光线温暖柔和,营造出温馨的家庭氛围。在饺子皮的外面,可以看到一双木筷子夹着饺子皮,好像准备吃这个巨大的饺子皮。背景中有几个模糊的饺子,暗示着一场饺子盛宴。整幅画采用微缩山水的艺术手法,巧妙地将日常融入其中,海报的下方写着“团圆,新年”。
分析2:对于复杂的提示词生成效果也不错,文字生成非常准确,但唯一不足的提示词中的“五个微型人物”实际生成了六个。

提示词3:超写实电影海报,大标题文字“冰雪未来”,超广角镜头,哑光绘画,电影海报,撕裂的地平线沐浴在暮色中。英雄出现在前景,背景是巨大的机器,未来的交通工具塑造了天际线。一个视觉史诗,每个元素都唤起了惊奇和兴奋。电影海报,3D哑光绘画。
分析3:提示词理解准确,生成的文字准确。

实测2:英文内容生成
提示词:现代科技风,傍晚日落时分,在高楼林立市中心,车水马龙,路边挂着一个大大的广告牌,上面写着“Happy New Year, wish everyone happy!”

分析:
Doubao v2.1:英文生成也没问题,提示词理解也不错,整体图片色彩搭配也很和谐。广告牌的黄色与周围的城市景观形成了鲜明的对比,使得文字更加醒目。但还是有一些不足的小细节,比如在生成的单词“wish”看起来不够清晰。

Midjourney V6.1:整体的画面色彩搭配还不错,但还是出现了老问题,生成的文字不够准确,出现重复单词或者字母的情况。

Ideogram v2:文字生成准确,图片的色彩搭配非常和谐且细节非常丰富,可以看到街道上的车辆、建筑物的外观以及天空的变化,整体非常出色。

实测3:中英内容生成
提示词:一个20岁的帅气年轻男孩,站在火车站门口,周围人很多,他手里举着一个牌写着:“Welcome to you 欢迎你”,写实风
分析:
Doubao v2.1:即使是写实风的中英文内容生成也是没有问题,单词的大小写能够也准确生成。但美中不足的是,除了提示词中提到的文字内容,还出现了其他内容。比如在牌子的右下角出现不明文字。

> 总结:
通过以上实测,可以初步得出以下结论:
1、中文内容的生成:豆包文生图模型v2.1生成文字是准确的,但对于复杂的场景生成上有小错误,不过实测中大部分任务都能够遵循提示词,并通过自然的文字与画面融合,提升整体的视觉效果。
2、英文内容的生成:总体生成的内容是准确的,但在某些细节上仍有改进空间,比如个别单词的清晰度方面。
3、中英文内容生成:内容生成准确,但生成的图片会出现了一些小瑕疵,比如出现不必要的附加内容方面,从而影响整体画面的效果。
除了在文字生成准确性方面表现不错,通过实测还可以看到,模型能够准确理解提示词并遵循,生成的图片在构图、色彩搭配、细节上都毫不逊色对比模型。
未来,我们期待豆包团队能够持续优化模型,改进目前出现的瑕疵,进一步提升生成内容的准确性与美观性。
免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

Comments(4)
Loving the information on this site, you have done great job on the articles.
I?¦ll immediately clutch your rss feed as I can’t to find your e-mail subscription hyperlink or newsletter service. Do you have any? Please let me understand so that I could subscribe. Thanks.
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post…
Hello.This article was really remarkable, particularly because I was searching for thoughts on this topic last Monday.