


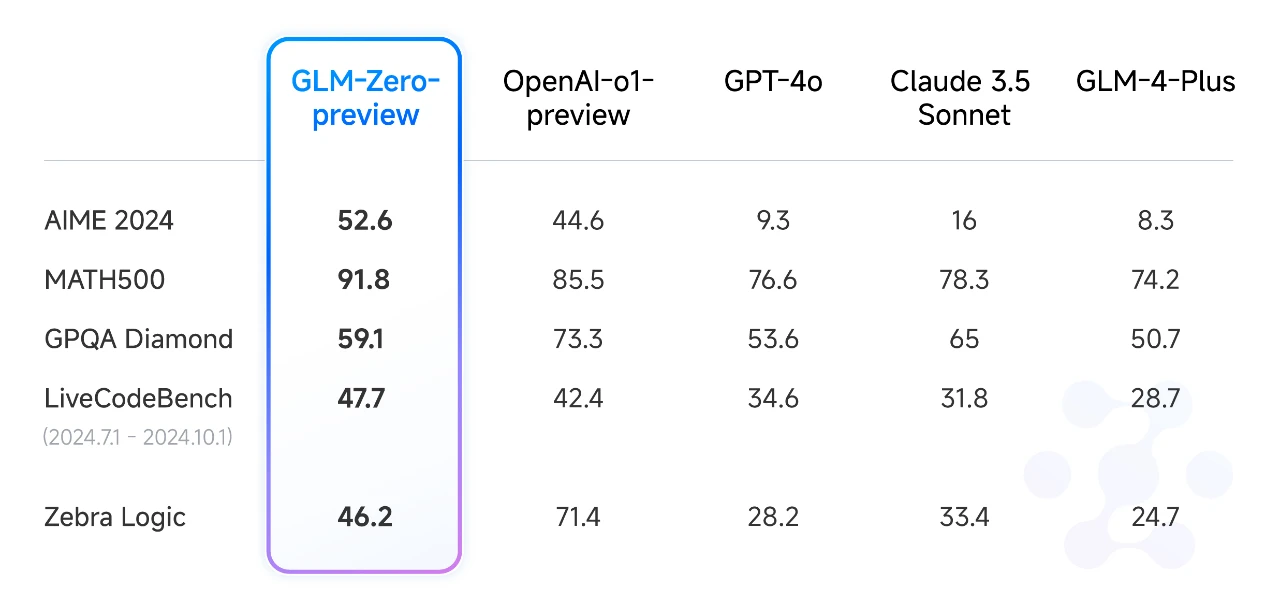
在2024年的最后一天,智谱发布了推理模型GLM-Zero 的初代版本 GLM-Zero-Preview,这是智谱首个基于扩展强化学习技术训练的推理模型。
据了解,GLM-Zero-Preview 擅长处理数理逻辑、代码和需要深度推理的复杂问题。同基座模型相比,GLM-Zero-Preview 既没有显著降低通用任务能力,又大幅提升了专家任务能力。
GLM-Zero-Preview在 AIME 2024、MATH500 和 LiveCodeBench 等评测中,效果与 OpenAI o1-preview 相当。而与现有模型不同的是,GLM-Zero-Preview能够初步实现推理过程中自主决策、问题拆解和尝试多种方式解决问题。
![]()
> 在302.AI上使用
目前,302.AI的聊天机器人和API超市均上线了GLM-Zero-Preview模型,并提供按需付费的服务方式,无论是企业还是个人用户,都能够依据实际需求灵活选择使用模型。
【聊天机器人】
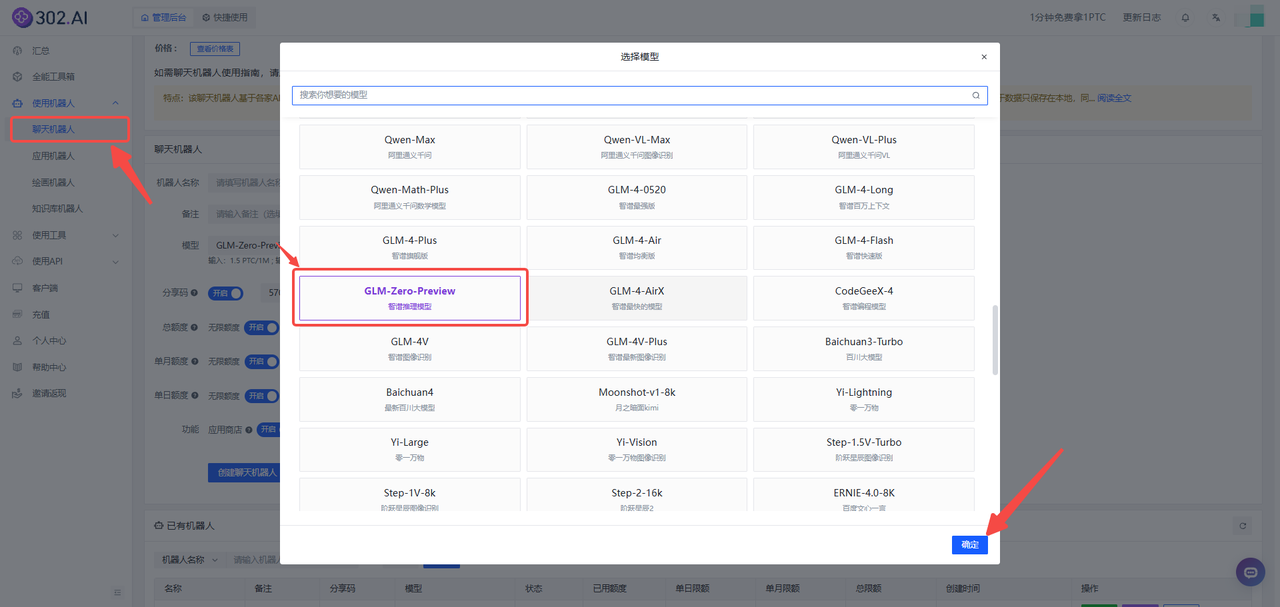
用户可以通过聊天机器人快速体验最新模型。302.AI的聊天机器人提供市场上多种先进模型,并持续进行实时更新,保持与市场的发展同步。以下是具体的获取步骤:
1、进入302.AI——点击左侧菜单栏使用机器人——选择聊天机器人——点击模型——选择GLM-Zero-Preview模型并确定,最后点击创建聊天机器人按钮;
![]()
【API超市】
企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发,加快AI应用的研发与部署流程。以下是在API超市中获取GLM-Zero-Preview的详细步骤:
1、进入302.AI后——点击使用API——选择API超市——分类中点击语言大模型——然后选择国产模型。

![]()
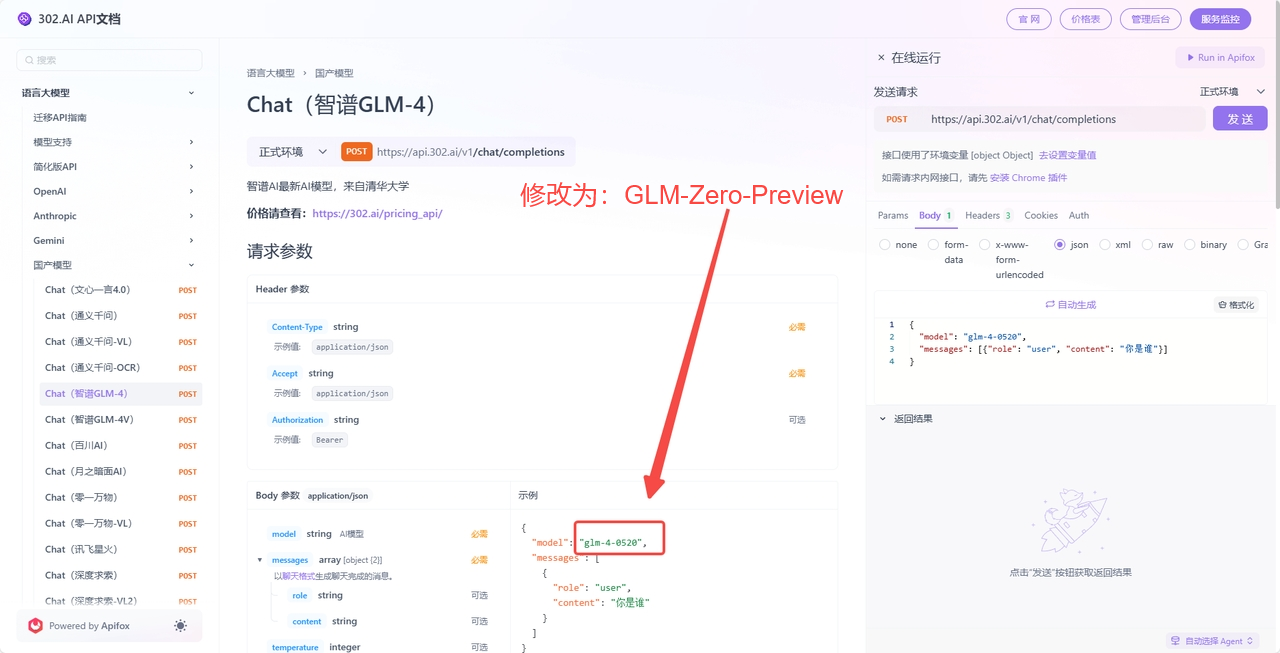
2、点击【查看文档】进入后,修改参数模型名称即可获得GLM-Zero-Preview的API。
![]()
> 实测对比
接下来实测将围绕GLM-Zero-Preview模型进行,主要实测对比模型数学、推理、编程方面。
实测1-2使用的工具为:302.AI的模型竞技场
对比模型:o1-preview、GLM-Zero-Preview、QwQ-32B-Preview
实测3使用的工具为:302.AI聊天机器人的Artifacts功能
对比模型:GLM-Zero-Preview、Claude-3.5-sonnet
参与对比的模型价格(由高至低排序):

![]()
其中,可以看到o1-preview和Claude-3.5-sonnet的输入输出价格均高于GLM-Zero-Preview模型。
实测1:数学测试
提示词:设A,B为两个不同随机事件,且相互独立,已知P(A)=2P(B),P(AUB)=5/8,则A,B中至少有一个发生的条件下,A,B中恰好有一个发生的概率为多少?
分析:来自2025年考研数学一卷的题目,正确答案是4/5。
o1-preview:最新考研题目也难不倒o1,回答正确。

![]()
GLM-Zero-Preview:GLM也没问题,在输出的回答中可以看到模型一次次思考,最后答案正确。

![]()
QwQ-32B-Preview:QwQ给出的答案也是正确的。

![]()
实测2:逻辑推理测试
提示词:

![]()
分析:这是一道比较复杂的逻辑推理题,难点在于模型要了解题目中的条件“如果有人说的话是与数学老师有关的话,那么就是假话”,先给大家看下正确答案:甲:物理老师;乙:化学老师;丙:数学老师;丁:生物老师。
o1-preview:o1居然答出来了,回答正确!

![]()
GLM-Zero-Preview:分析的过程很长,可以看到GLM一直在假设可能的情况,但很可惜最后给出的答案,只有丙的身份是正确的。

![]()
QwQ-32B-Preview:QwQ给出的分析篇幅非常长,但可惜最后给出的两个答案都是错误。
![]()
实测3:编程测试
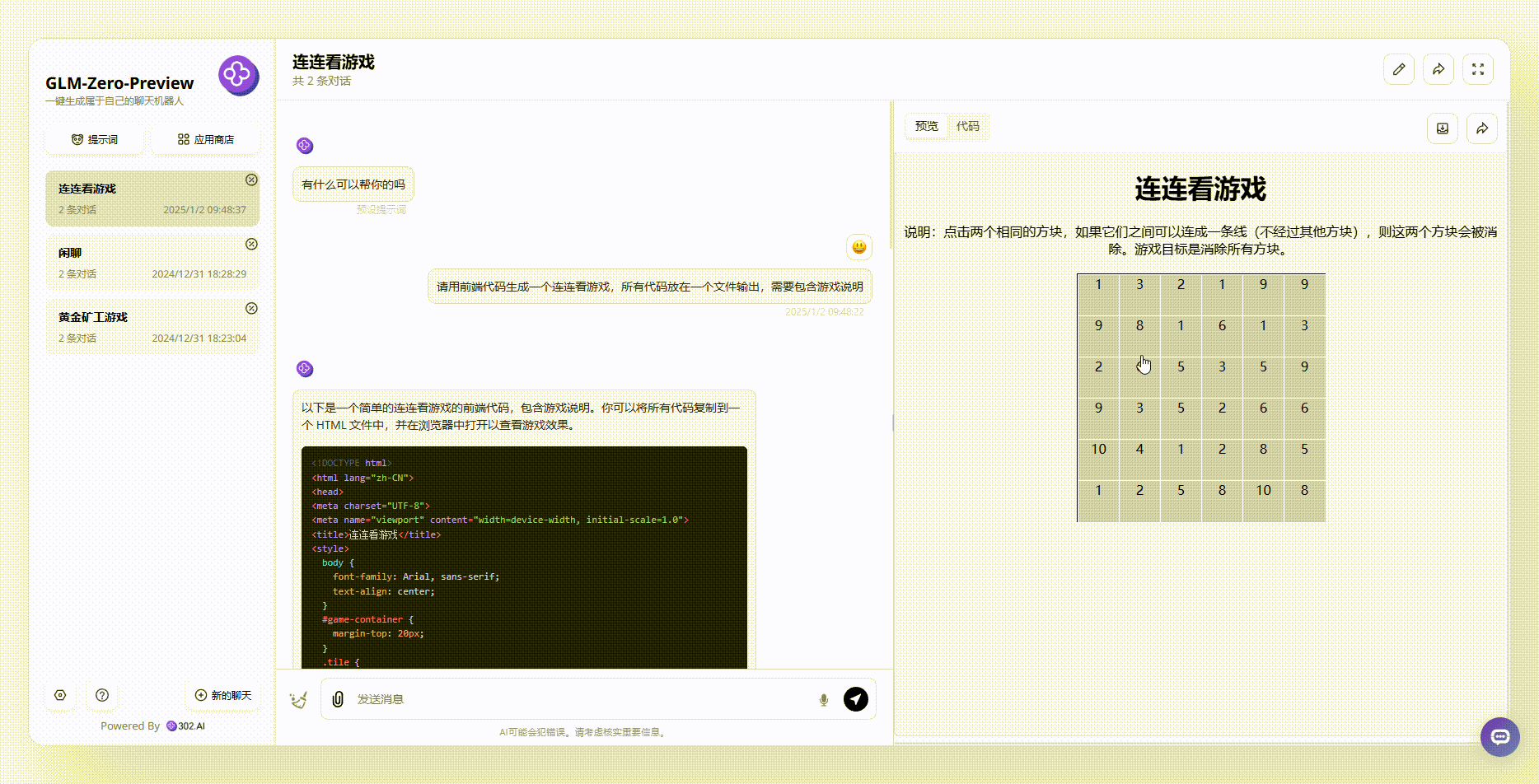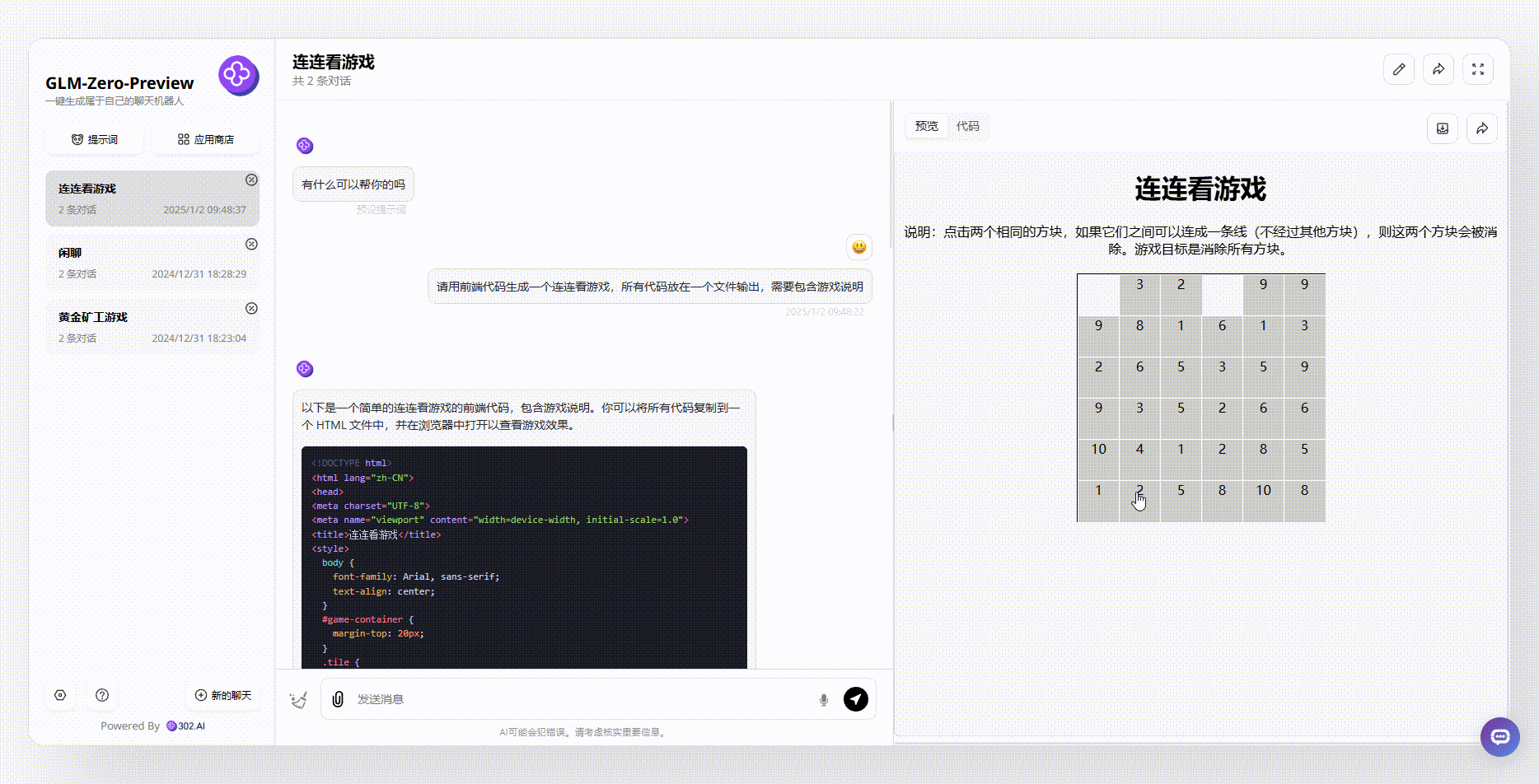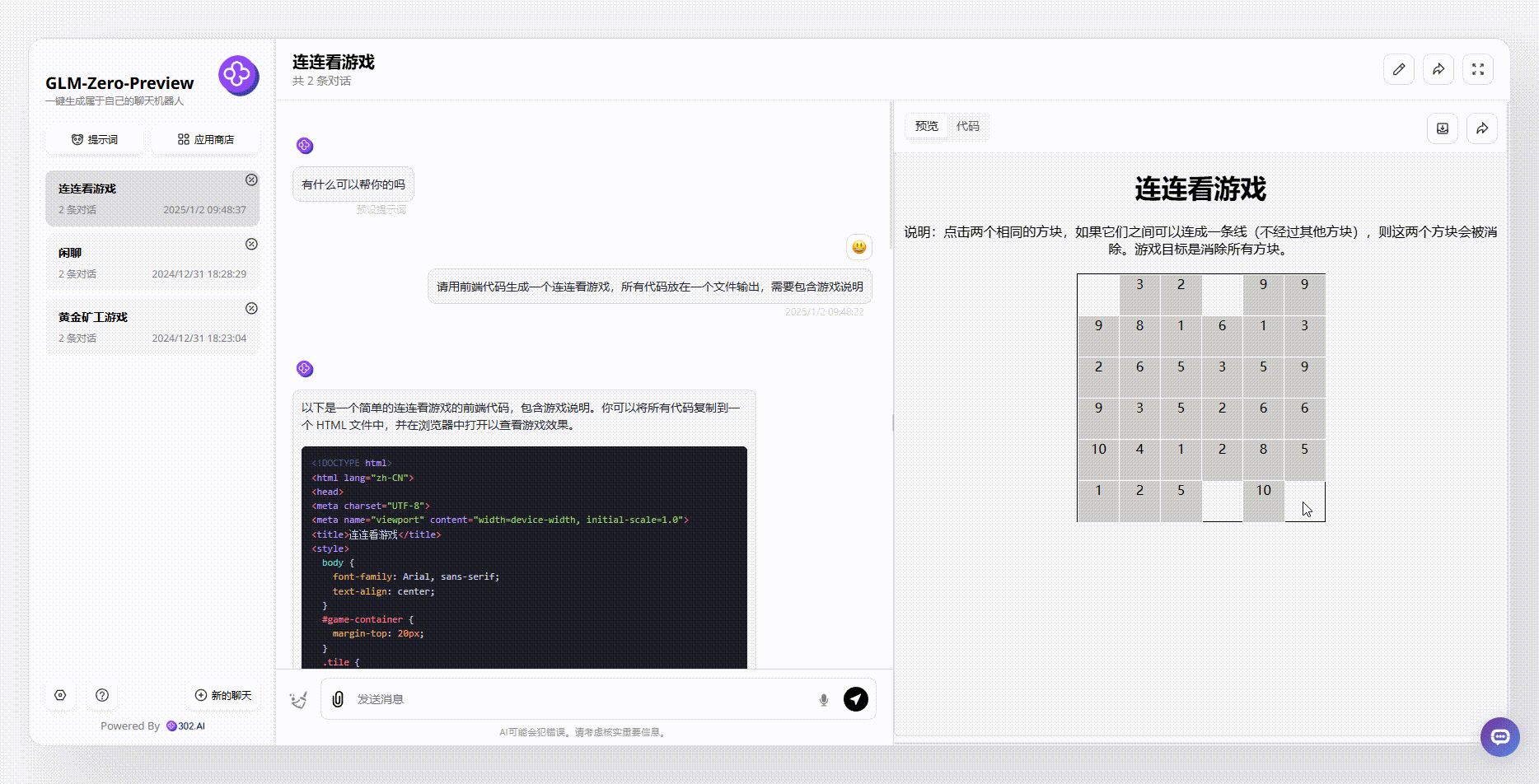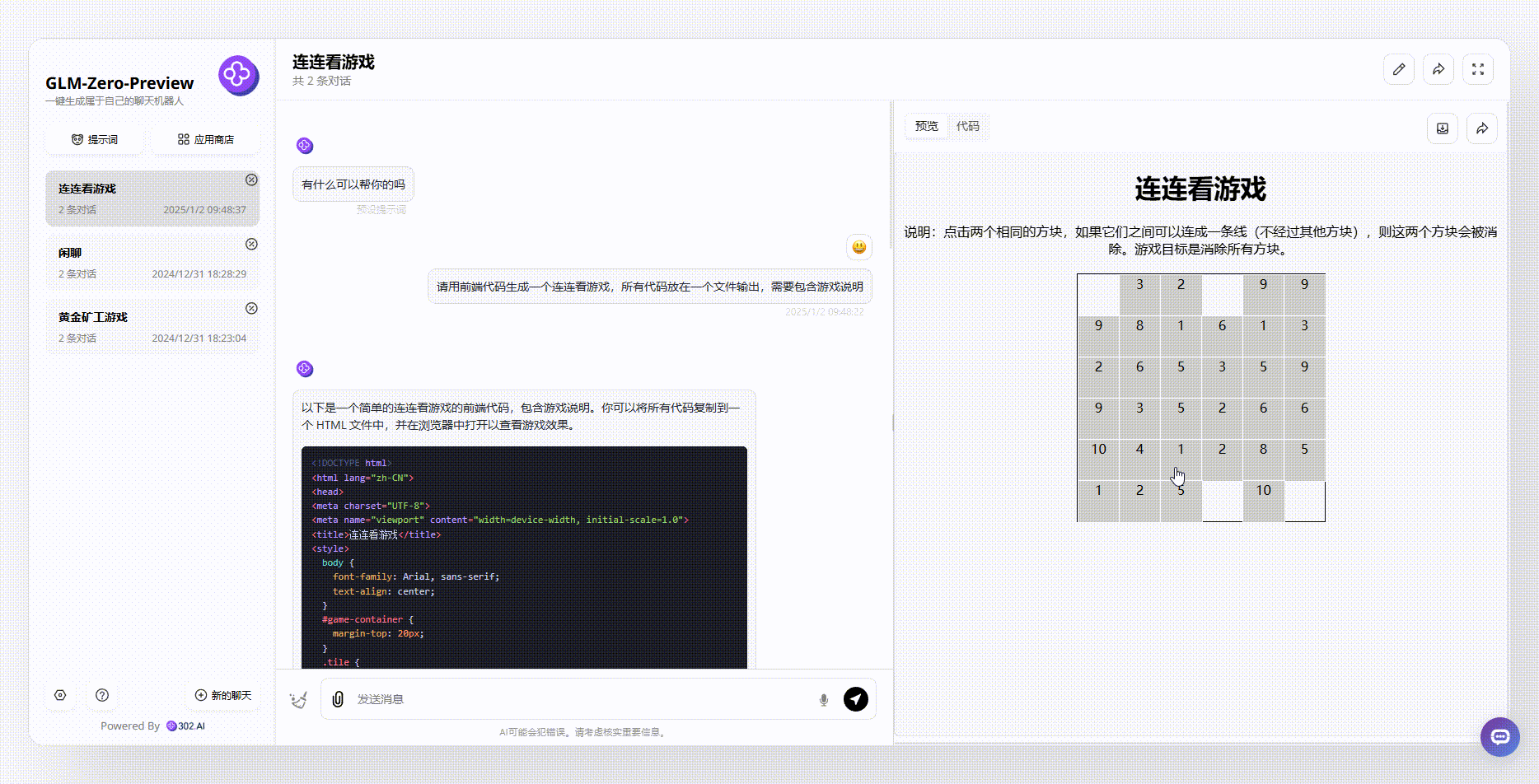
提示词:请用前端代码生成一个连连看游戏,所有代码放在一个文件输出,需要包含游戏说明
GLM-Zero-Preview:尽管整个游戏界面相对简单,但首先游戏是可实现的。从游戏说明中可以看出,生成的游戏逻辑非常严谨,消除相同方块时不得经过其他方块。这更符合我们日常生活中玩连连看游戏的逻辑。
![]()
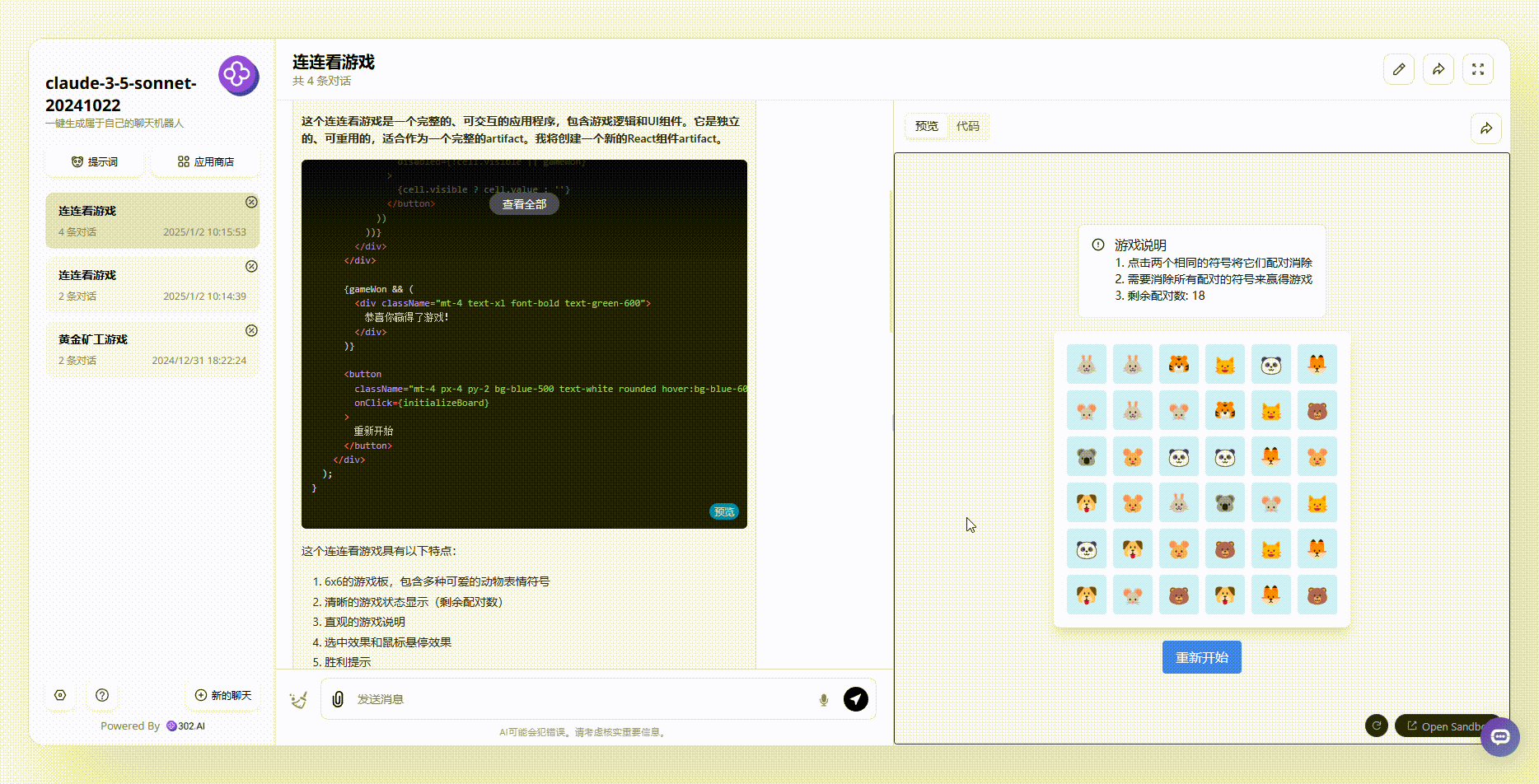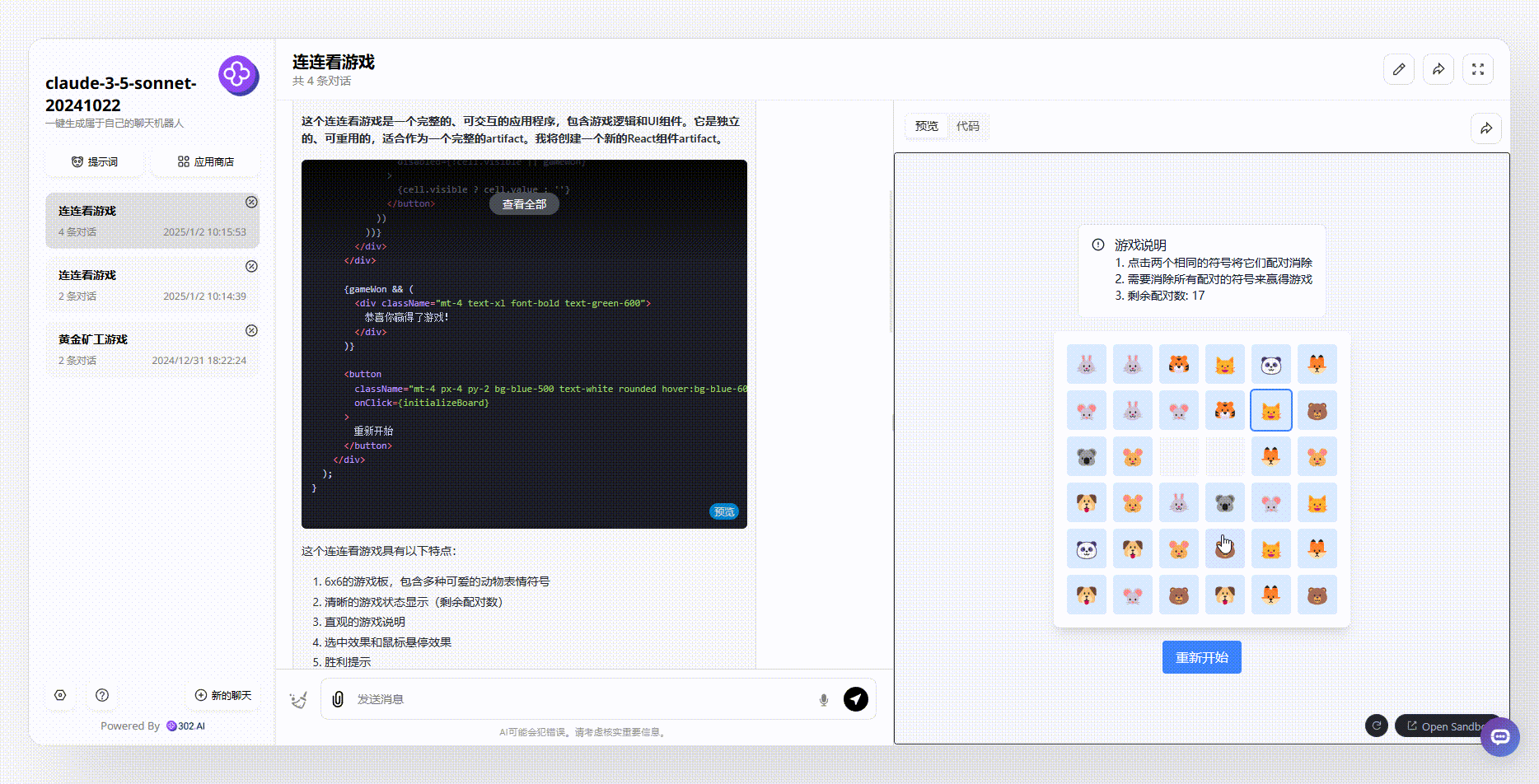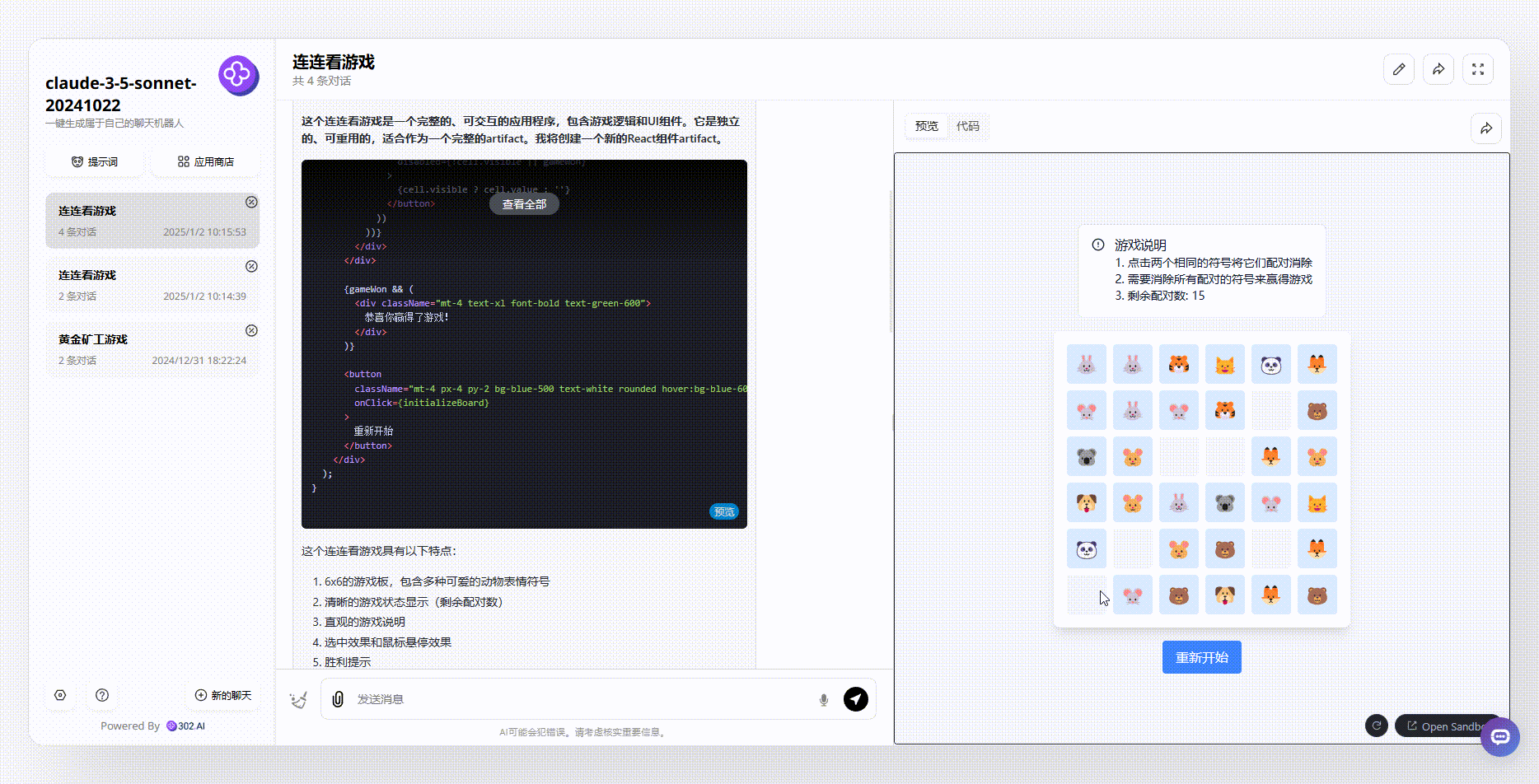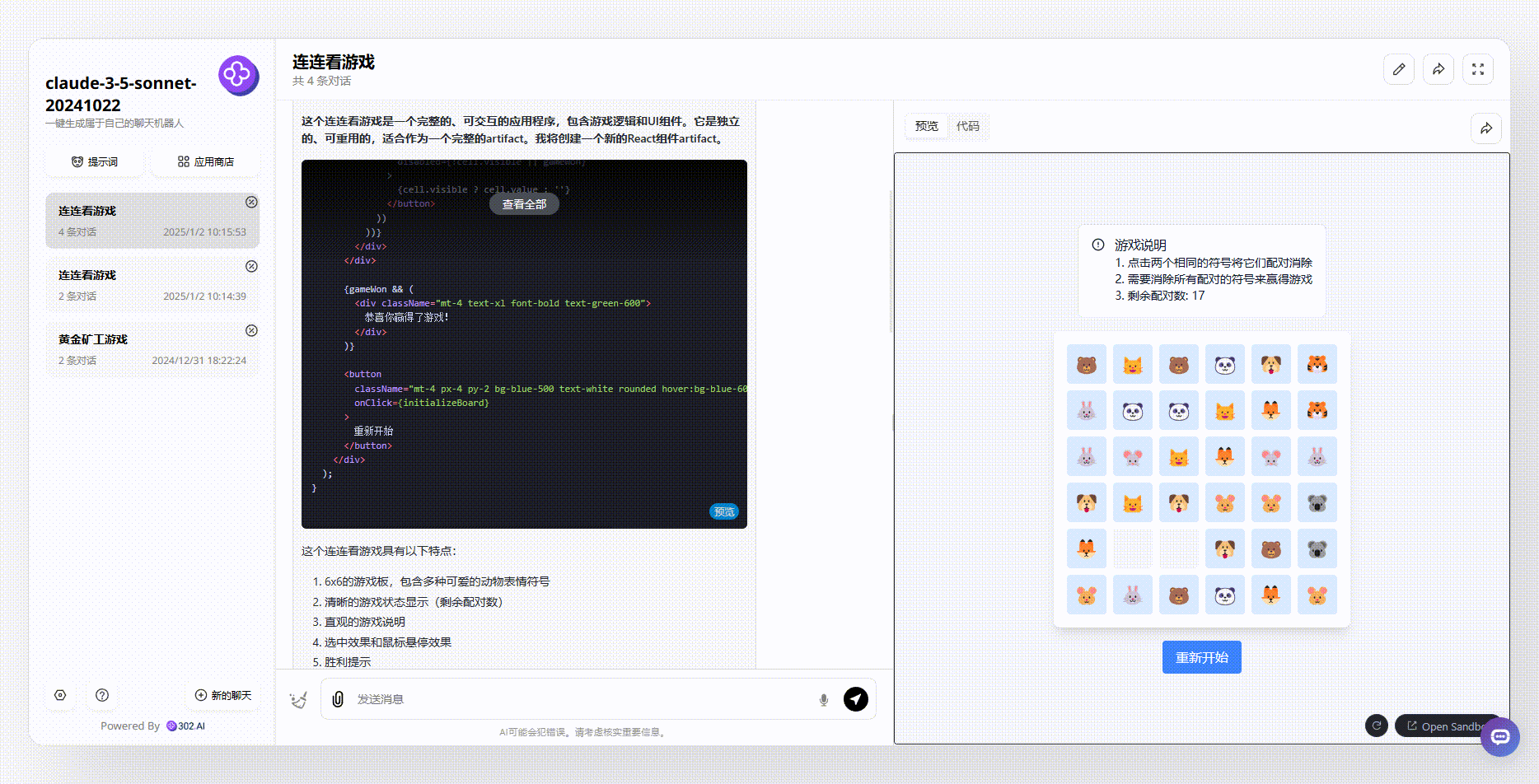
Claude-3.5-sonnet:Claude生成的效果界面美观度明显更胜一筹,且用户在每一步操作后,都能实时看到剩余配对数变化。然而,在游戏逻辑设计上,Claude的规则相对简单,只要是相同的图案,均能够被消除,并没有设置任何限制。相比之下,这一点不如GLM-Zero-Preview。
![]()
> 总结
通过以上实测,可以初步得出以下结论:
数学测试:在面对考研数学题目时,GLM-Zero-Preview输出的答案展现了详细的思考过程,并给出了正确答案,表现出色。
逻辑推理测试:在处理复杂问题时的推理能力时,尽管没有完全回答正确,但展示了详细的思考推理过程,这表明模型具备一定深度的分析能力。
编程测试:虽然界面设计略显简单,但能够生成可运行的代码,且游戏逻辑对比Claude更加严谨和有深度。
总体来看,GLM-Zero-Preview展现了不错的数学和编程能力,尽管在某些复杂的逻辑推理问题上未能给出完全正确的答案,但其详尽的推理过程确实反映了模型在分析能力。此外,我们也可以看出,国产模型与国外模型的差距正在一步步缩小。未来,随着技术的不断迭代和模型的进一步优化,希望GLM-Zero-Preview正式版能在更多复杂任务中展现出更强的能力。
免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(13)
I believe that is among the most significant info for me. And i’m happy studying your article. But should remark on few basic issues, The website style is great, the articles is in point of fact excellent : D. Just right activity, cheers
A lot of thanks for every one of your hard work on this site. Gloria loves working on investigations and it is simple to grasp why. Almost all know all regarding the lively form you present great tactics through your website and boost participation from other people on that article and my girl is without question discovering so much. Enjoy the rest of the new year. You’re performing a brilliant job.
The very root of your writing while sounding agreeable in the beginning, did not really sit perfectly with me after some time. Somewhere throughout the sentences you managed to make me a believer unfortunately only for a while. I nevertheless have got a problem with your leaps in assumptions and one would do nicely to fill in those breaks. If you can accomplish that, I would definitely be amazed.
Great – I should definitely pronounce, impressed with your website. I had no trouble navigating through all the tabs and related info ended up being truly easy to do to access. I recently found what I hoped for before you know it in the least. Quite unusual. Is likely to appreciate it for those who add forums or something, site theme . a tones way for your customer to communicate. Excellent task..
excellent post.Never knew this, thanks for letting me know.
It’s really a nice and useful piece of info. I’m glad that you shared this helpful info with us. Please keep us informed like this. Thanks for sharing.
I like this web site so much, saved to bookmarks.
I’ve recently started a site, the info you offer on this web site has helped me tremendously. Thanks for all of your time & work.
I am glad to be one of several visitants on this outstanding website (:, thankyou for putting up.
Thank you for another fantastic article. Where else could anybody get that type of information in such an ideal way of writing? I have a presentation next week, and I’m on the look for such information.
There is evidently a lot to realize about this. I believe you made certain good points in features also.
Pretty! This was a really wonderful post. Thank you for your provided information.
Wow! Thank you! I constantly needed to write on my blog something like that. Can I include a portion of your post to my blog?