
1月15日,MiniMax发布并开源了全新MiniMax-01系列基础语言大模型——MiniMax-Text-01。
据了解,MiniMax-Text-01 是一个强大的语言模型,拥有 4560 亿个总参数,单次激活459 亿个参数 。为了解锁其长上下文功能,它采用了一种混合架构,集成了闪电注意力(Lightning Attention)、Softmax 注意力(Softmax Attention)和专家混合(Mixture-of-Experts, MoE)。模型综合性能比肩海外顶尖模型,同时能够高效处理最长400万token的上下文,是GPT-4o的32倍,Claude-3.5-Sonnet的20倍。
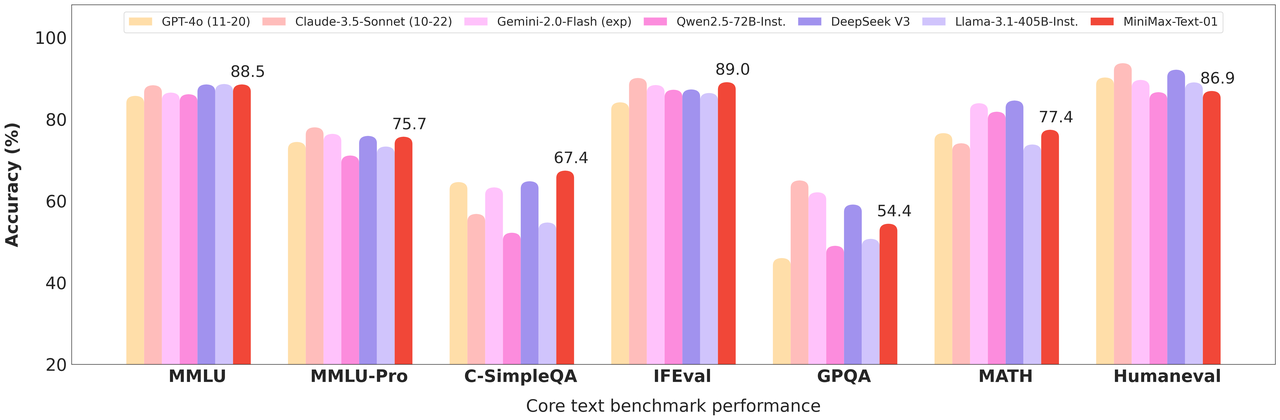
在各种学术基准测试中,MiniMax-Text-01也展示了顶级模型的性能,其中在MMLU任务上达到88.5%的准确率,与其他顶级模型不相上下。在IFEval任务取得89.0%的高分。Humaneval达到86.9%的水平,显示出强大的代码理解和生成能力。
![]()
如何在302.AI上使用
目前,302.AI的聊天机器人和API超市均上线了MiniMax-Text-01模型。302.AI提供按需付费的服务方式,无论是企业还是个人用户,都能够依据实际需求灵活选择使用模型,从而满足自身需求。
【聊天机器人】
用户可以通过聊天机器人快速体验最新模型。302.AI的聊天机器人提供市场上多种先进模型,并持续进行更新,保持与市场的发展同步。以下是在聊天机器人中获取MiniMax-Text-01模型的步骤:
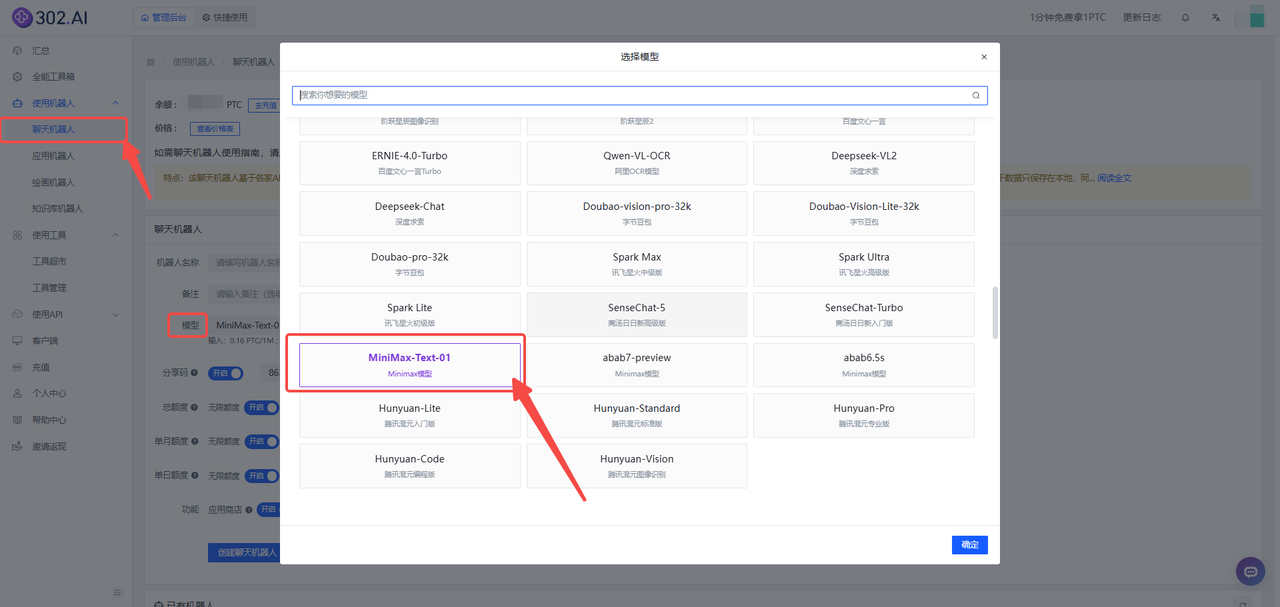
1、进入302.AI——点击左侧菜单栏使用机器人——选择聊天机器人——点击模型——下滑到国产模型分类选择MiniMax-Text-01模型并确定,最后点击创建聊天机器人按钮;
![]()
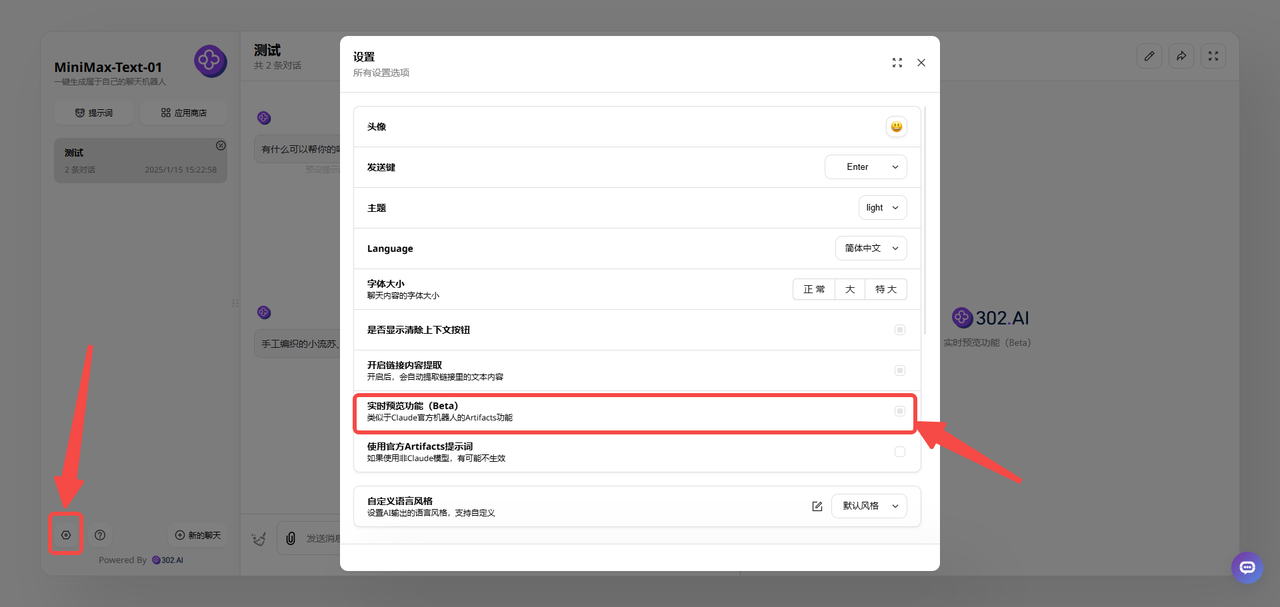
2、进入聊天机器人后,点击页面左下角的设置可以打开实时预览功能:
![]()
【API超市】
302.AI的API超市涵盖了多种API,且分类明晰。企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发,加快AI应用的研发与部署流程。以下是在API超市中获取MiniMax-Text-01的详细步骤:
1、进入302.AI后——点击使用API——选择API超市——分类中点击语言大模型——点击国产模型。

![]()
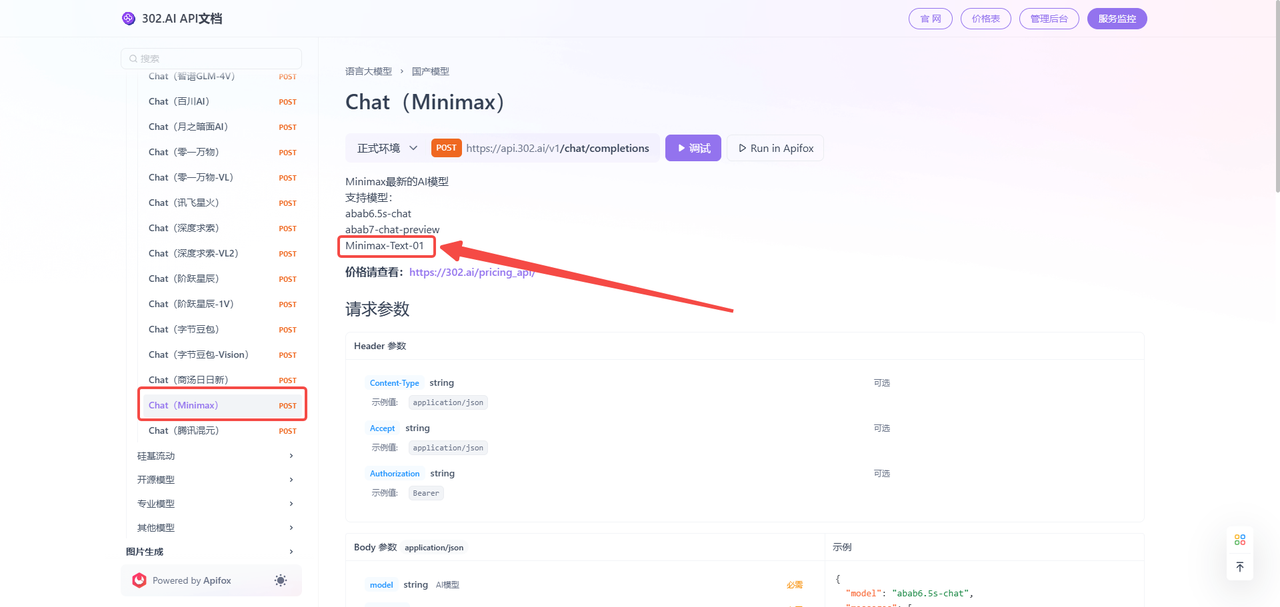
2、点击【查看文档】可快速进入API文档查看MiniMax-Text-01的模型API。
![]()
实测对比
为了更直观了解模型,下面会围绕MiniMax-Text-01模型进行实测,旨在更直观地了解模型的表现。
实测1:数学测试
使用工具:302.AI的模型竞技场
对比模型:MiniMax-Text-01 、Deepseek V3、Qwen2.5-72B
提示词:

![]()
分析:最近,深圳南山区某小学数学期末考试由于试题太难引起讨论,这一测试题则是源自其备受争议的六年级数学考卷中,接下来看下各模型的回答。
Qwen2.5-72B:虽然回答正确,但是在分析过程中出现了错误:0.6小于0.67,因此解析中提到0.6介于0.67和1之间的说法是错误的。
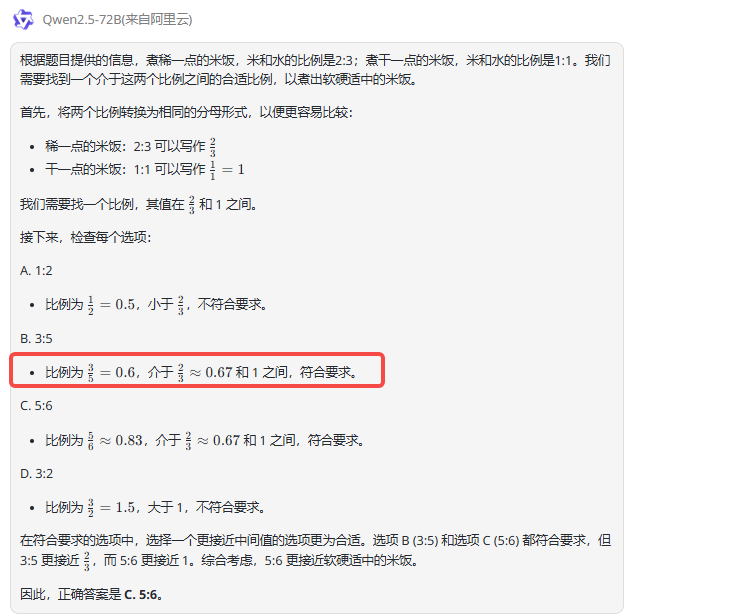
![]()
Deepseek V3:分析很清晰,回答也正确。

![]()
MiniMax-Text-01 :首先MiniMax-Text-01最后给出的答案也是正确的,但是仔细看模型的分析的过程,对于比例的说明不太正确。根据题意,比例为米:水,换算成分母为1表示水不变,分子较大时米较多,则相对水较少,因此分析中关于水量描述均是不正确的。
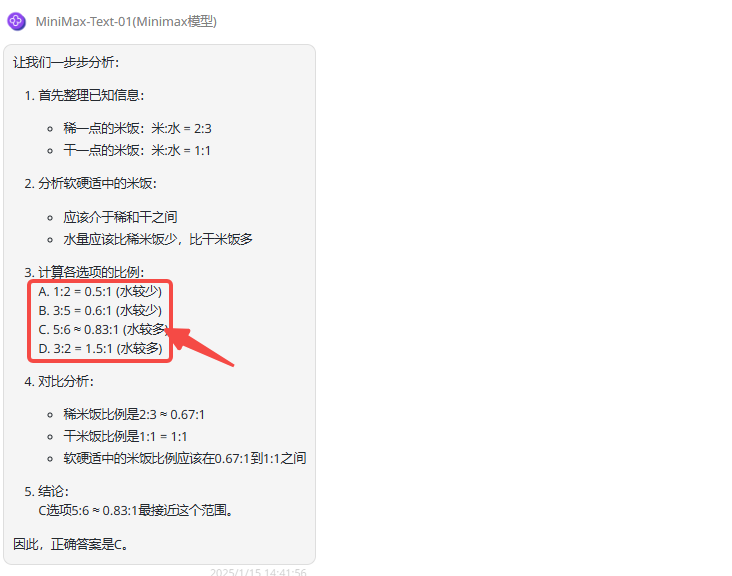
![]()
实测2:长文测试
使用工具:302.AI的聊天机器人
在共2万多字的《小王子》原文中以及27万多字的《红楼梦》前30回两个文档中,分别在不同位置插入了以下三句话:
印着古典纹路的书签放在红色包里。
手工编织的小流苏放在红色包里。
带有吉祥话的精美贴纸放在红色包里。
提示词:请阅读文档后告诉我,放在红色包里的都有什么?
分析1:面对2万多字的《小王子》,MiniMax-Text-01轻松找出所有正确答案。
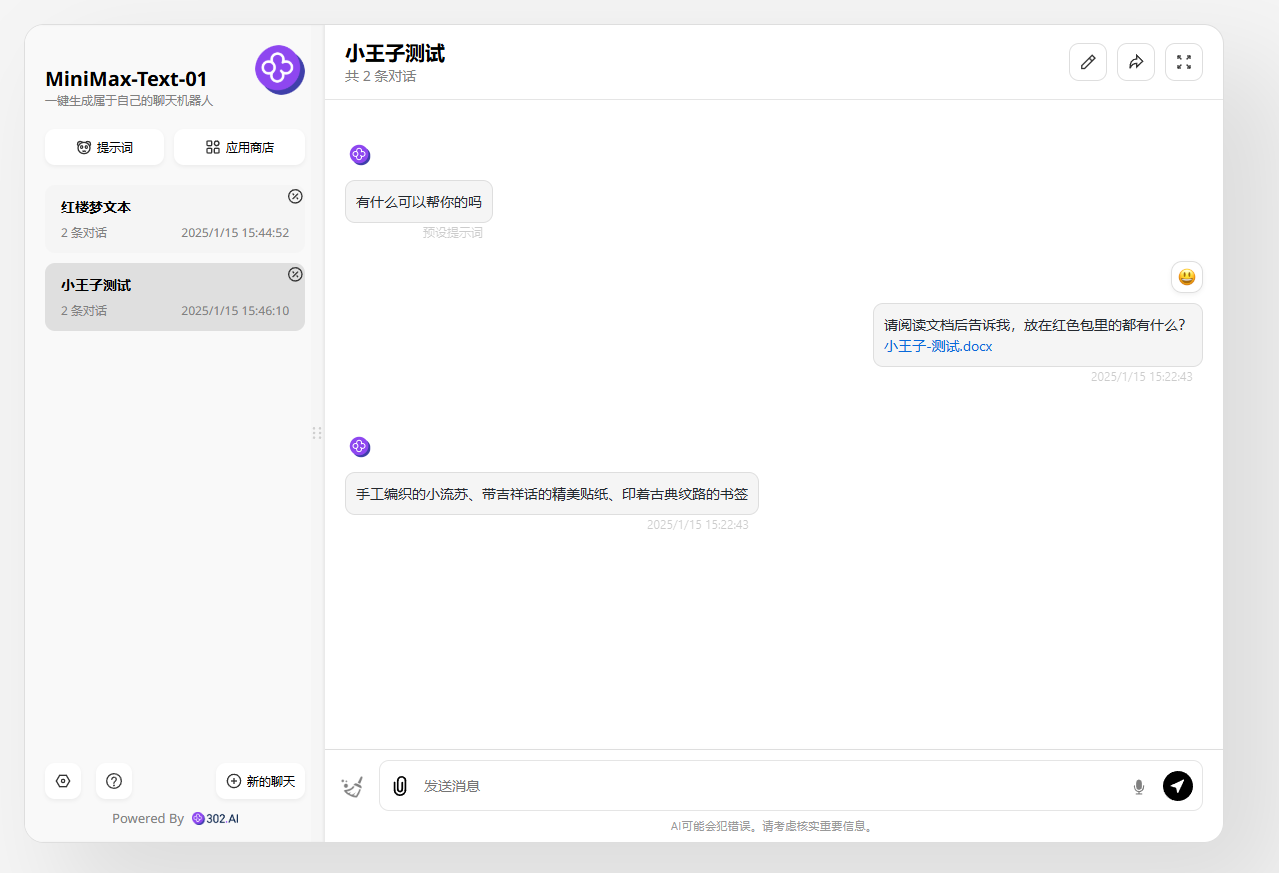
![]()
分析2:对于27万多字的《红楼梦》文本,MiniMax-Text-01这次只找出了一个答案,未能完全回答正确。找到的答案位于文本的前5万字中,其余两个答案则是分别位于约10万字、25万字的位置中。
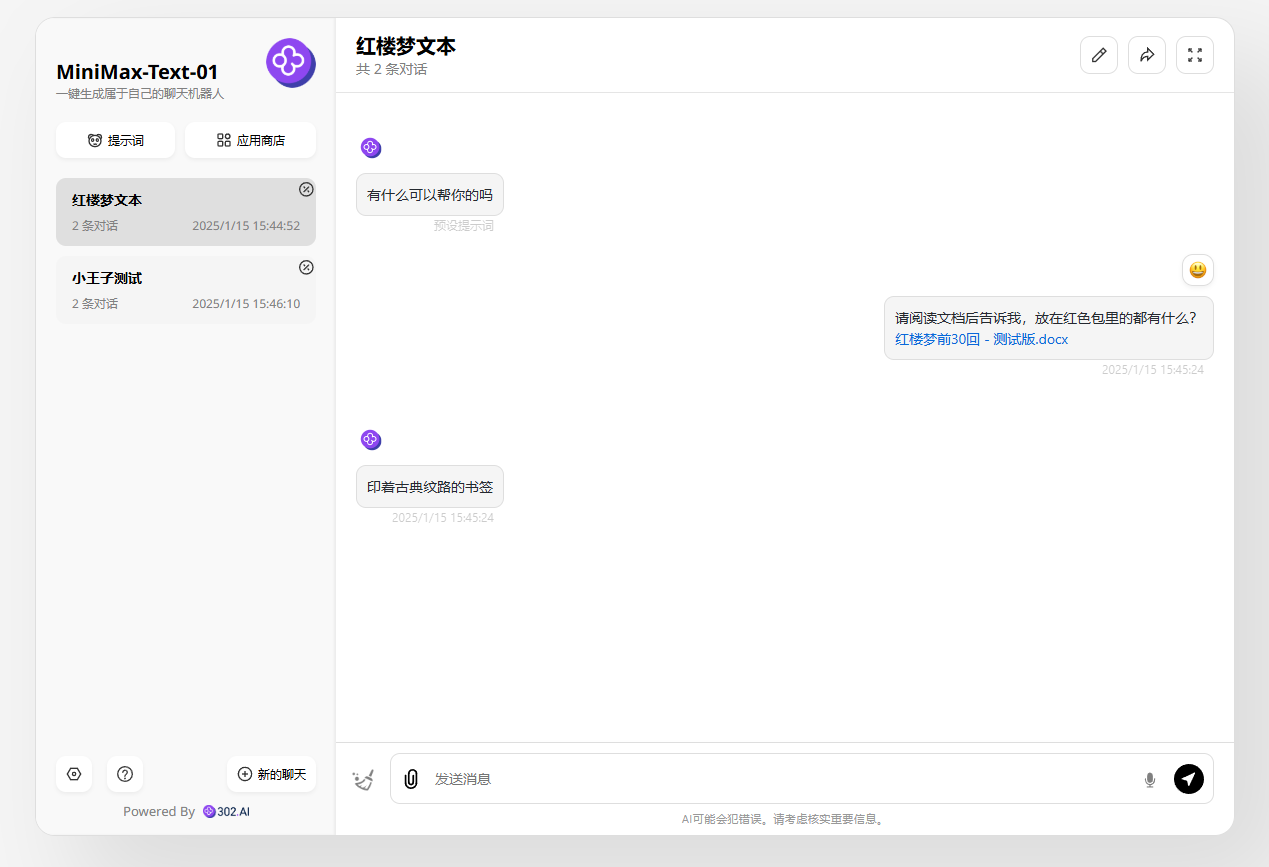
![]()
实测3:编程测试
使用工具:302.AI的聊天机器人-Artifacts功能
对比模型:MiniMax-Text-01 、Deepseek V3
提示词:请用前端代码制作一个完整的拼图游戏,需要包含游戏说明,开始游戏等元素,并将所有代码放在一起输出
Deepseek V3:先来看下Deepseek的生成效果,界面游戏说明比较简单,仅说明了游戏的操作方式是通过点击拼图块来移动,但没有明确规则:移动到什么样的顺序才算正确?即使是拼图块有数字但是排列的方式可以有很多种,这表明游戏逻辑不够严密,用户体验不足。
![]()
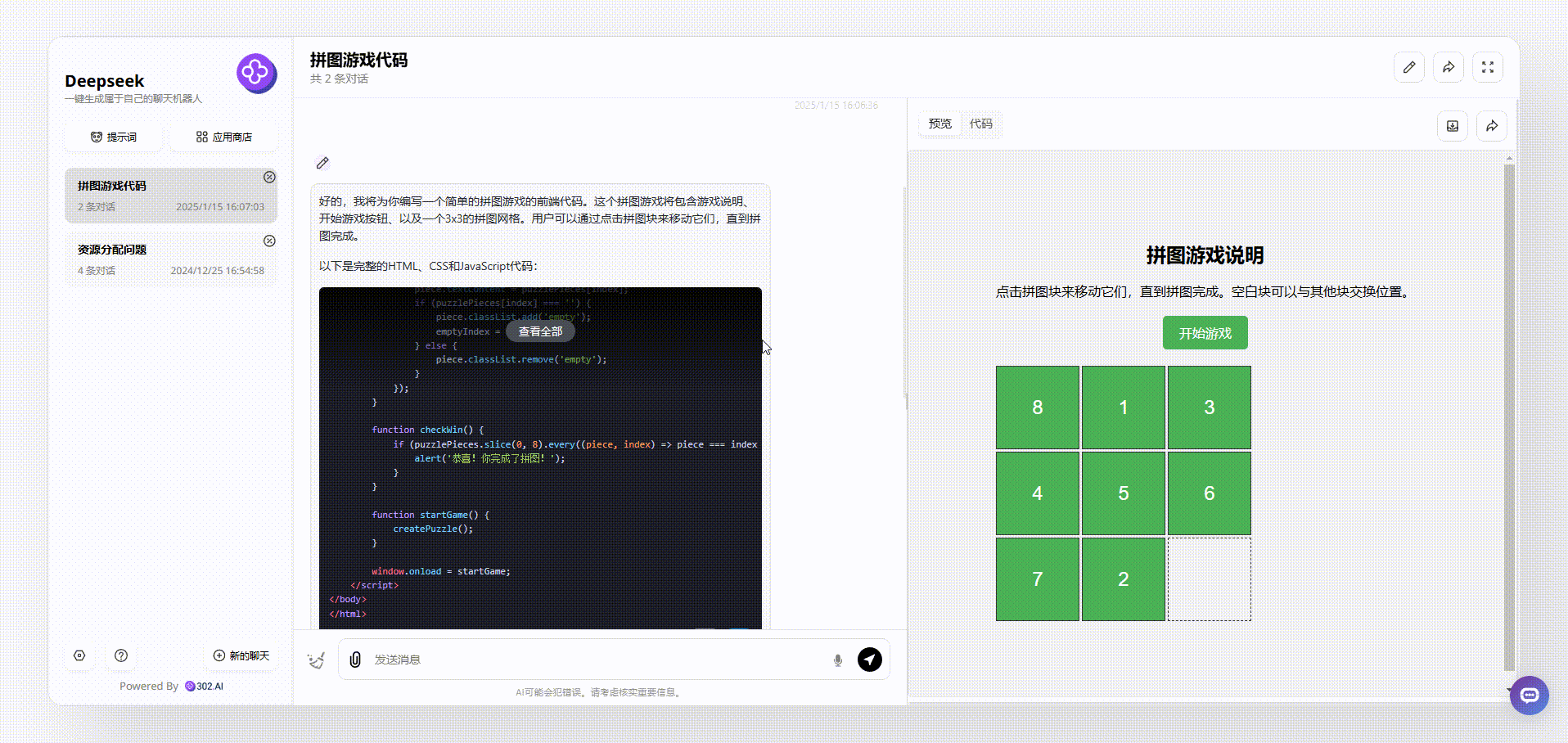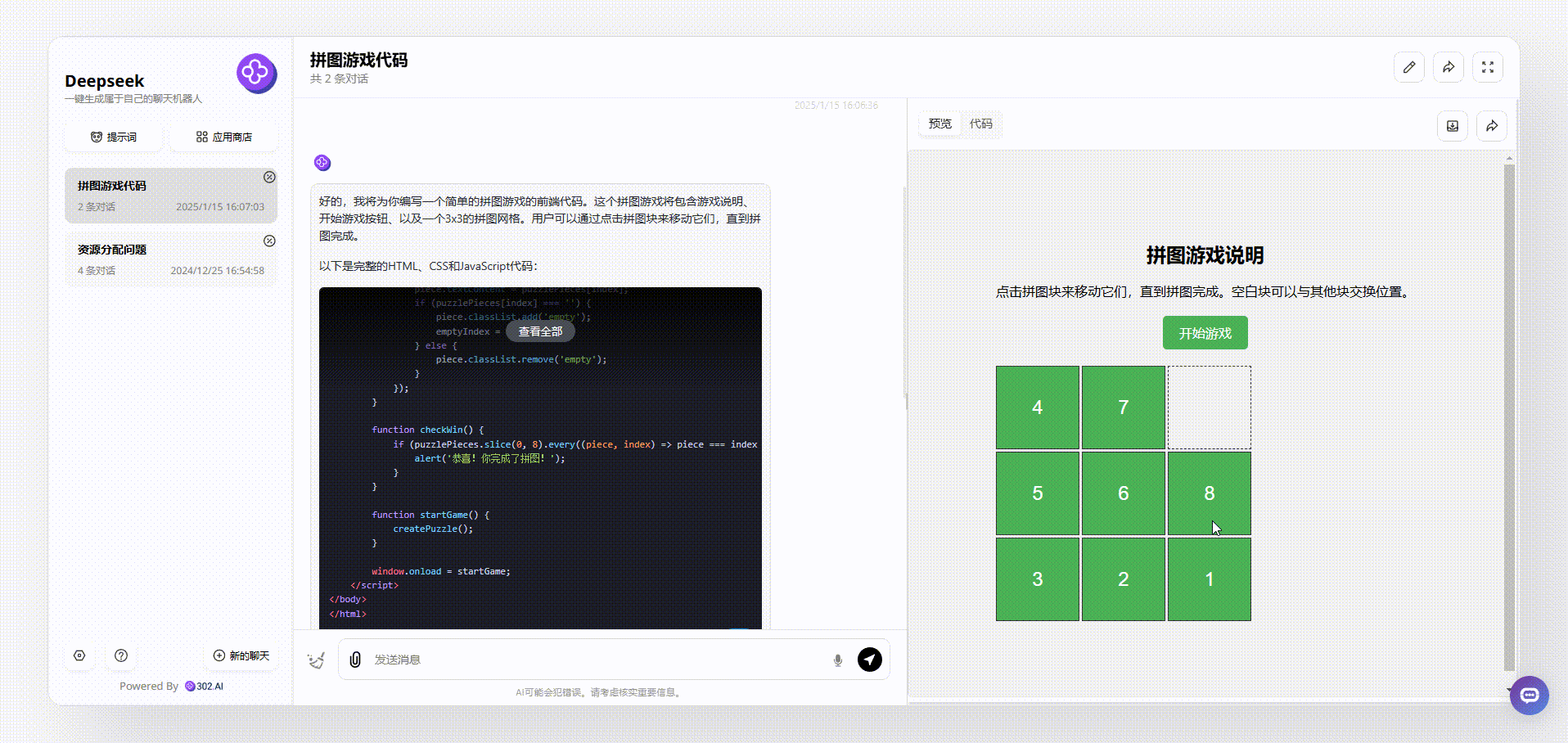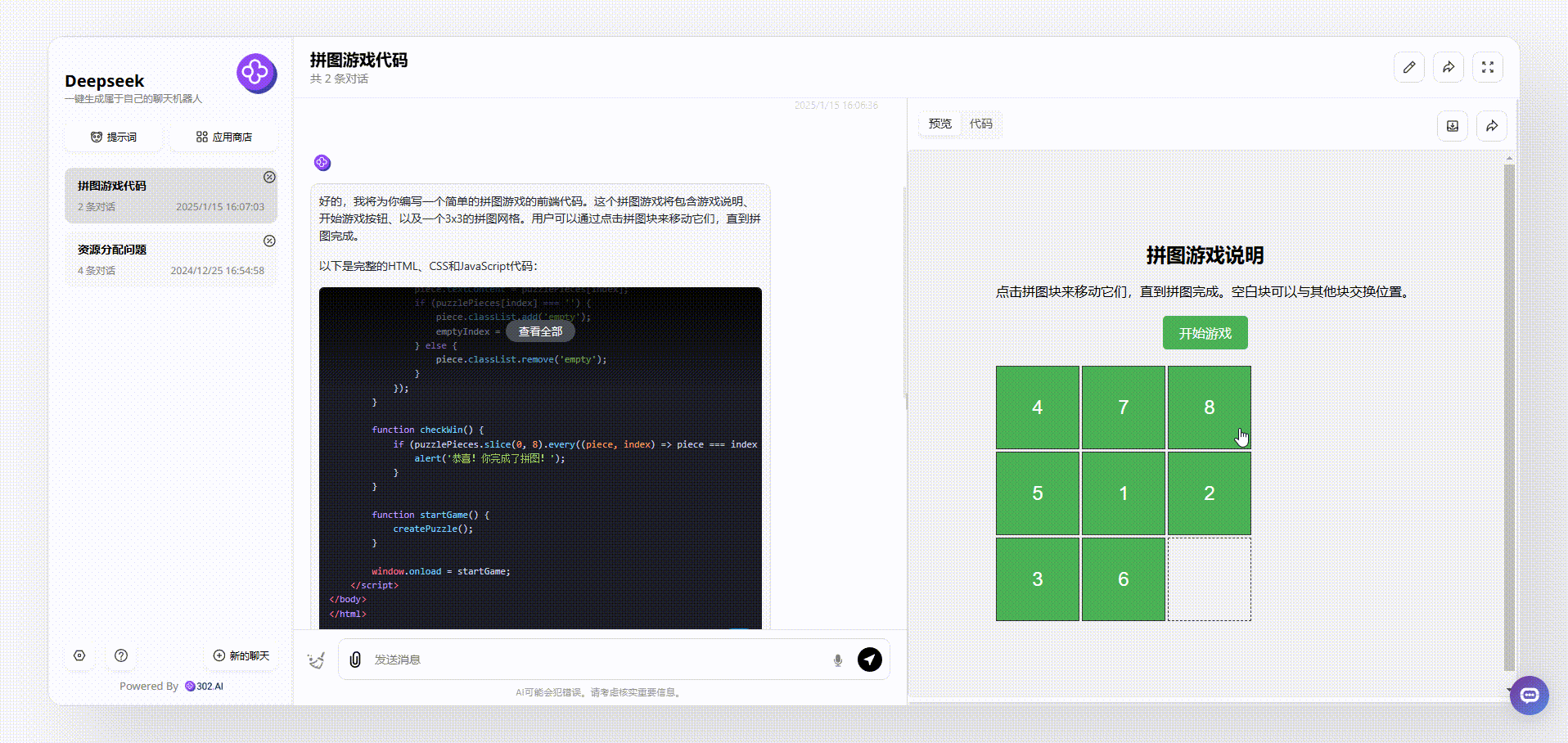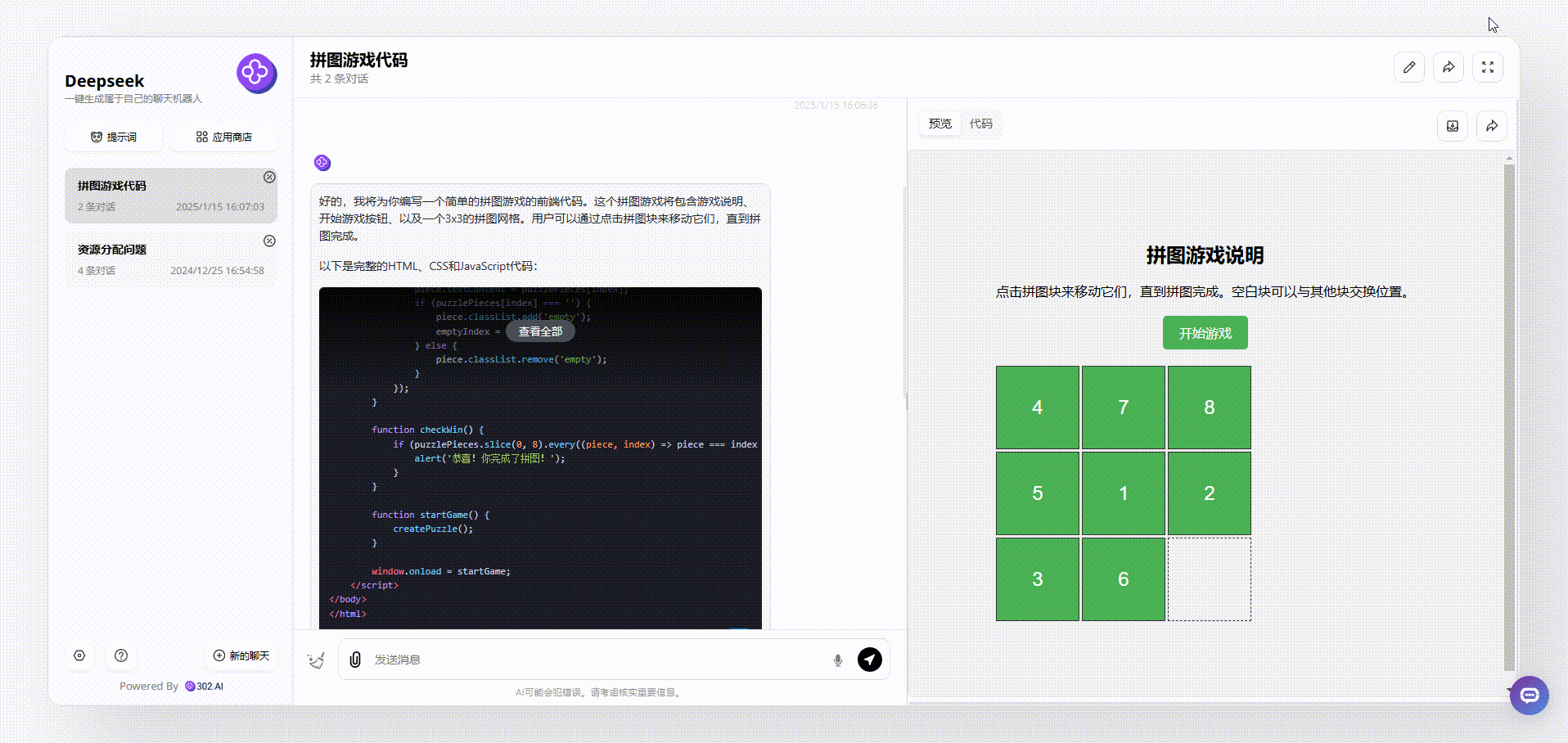
MiniMax-Text-01:整体界面设计和Deepseek相似,但MiniMax弥补了Deepseek的不足,在游戏一开始就展示了正确的图案顺序,游戏说明也更容易让用户明白,整体相对更加完整。

![]()
> 总结
通过以上实测可以初步得出以下结论:
数学测试:在数学测试中,MiniMax-Text-01 虽然最终给出了正确答案,但在分析过程中存在一些逻辑上的瑕疵。这表明模型在处理复杂数学问题时,仍需进一步提升其推理能力。
长文测试:在长文测试中,MiniMax-Text-01 在《小王子》的测试中表现出色,能够准确找出所有相关信息。然而,面对更为复杂的《红楼梦》文本时,模型的表现有所下降,未能完全识别出所有插入的句子。
编程测试:在编程测试中,MiniMax-Text-01与 Deepseek V3 相比,MiniMax-Text-01 生成的拼图游戏界面设计更为完整,游戏说明更加清晰,用户体验也更为友好。这不仅体现了模型对编程语言的理解能力,还展示了其在应用场景中的实用性。
总的来说,MiniMax-Text-01的编程效果较为出色,但在数学以及长文测试中存在不足,有待改进。尤其是长文测试中,模型在面对复杂的长文本表现未能达到预期。MiniMax-Text-01 的发布为国产大模型的发展注入了新的活力,未来,我们期待看到更多出色的国产模型出现!
免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(16)
F*ckin¦ amazing things here. I am very glad to see your article. Thanks so much and i’m taking a look forward to touch you. Will you please drop me a mail?
Hello my loved one! I wish to say that this post is amazing, nice written and come with approximately all important infos. I¦d like to look extra posts like this .
Hmm it seems like your site ate my first comment (it was super long) so I guess I’ll just sum it up what I submitted and say, I’m thoroughly enjoying your blog. I as well am an aspiring blog blogger but I’m still new to everything. Do you have any recommendations for first-time blog writers? I’d really appreciate it.
Terrific paintings! This is the type of information that are meant to be shared across the net. Disgrace on the seek engines for no longer positioning this post upper! Come on over and seek advice from my website . Thank you =)
Thank you for the auspicious writeup. It in fact was a amusement account it. Look advanced to more added agreeable from you! However, how could we communicate?
Its good as your other posts : D, thanks for putting up.
You really make it appear so easy together with your presentation but I in finding this topic to be really something which I feel I would never understand. It kind of feels too complex and very huge for me. I am looking ahead on your subsequent publish, I¦ll try to get the hold of it!
I’m still learning from you, as I’m trying to achieve my goals. I certainly liked reading everything that is written on your website.Keep the tips coming. I loved it!
I would like to thank you for the efforts you’ve put in writing this web site. I am hoping the same high-grade site post from you in the upcoming also. In fact your creative writing abilities has inspired me to get my own site now. Really the blogging is spreading its wings fast. Your write up is a great example of it.
I am usually to running a blog and i actually respect your content. The article has really peaks my interest. I’m going to bookmark your website and keep checking for brand spanking new information.
Really Appreciate this article, can you make it so I get an email sent to me when you make a fresh article?
I love your writing style truly enjoying this website .
I think other website proprietors should take this web site as an example , very clean and good user genial design and style.
I love the efforts you have put in this, thanks for all the great articles.
Nice post. I learn something more challenging on completely different blogs everyday. It’ll at all times be stimulating to learn content from different writers and practice a bit of something from their store. I’d prefer to use some with the content on my blog whether or not you don’t mind. Natually I’ll give you a link in your internet blog. Thanks for sharing.
I’ve recently started a web site, the information you offer on this site has helped me tremendously. Thanks for all of your time & work.