


众所周知,大模型是没有记忆的。从专业角度来解释,所有的大模型API都是无状态API(每个请求是自足的,不依赖于以前的请求或者状态,这样的API可以更容易地进行扩展)。但是想让AI真正的成为“人”,记忆又是必不可少的。
短期记忆的实现
现阶段比较普遍的大模型实现记忆方法,就是每次请求时,把聊天记录简单的塞入上下文,让大模型看了聊天记录再进行回答。
但是这么做,会有2个先天的弊端:
- 模型上下文有限,传入的聊天记录是有限的,大模型只能看到一小部分的记录。
- 如果传入大量的聊天记录,花费就上去了,而且每次对话传入的聊天记录有绝大部分都是重复的,造成了资源的浪费。
这种方法,我们统称为短期记忆。
短期记忆 vs. 长期记忆
由于以上的弊端,长期记忆的需求自然而然被提了出来。
短记忆的特点:
- 维持当前对话的上下文,通常只针对一个会话。
- 依赖对话历史或会话状态实现。
- 受限于 token 长度(通常 4k 到 32k tokens)或会话时长。
- 会话结束后,自动清空。
长记忆的特点:
- 跨会话保存:不局限于当前对话。
- 需要结构化存储和高效的检索机制。
- 用于存储模式、偏好和历史互动信息。
- 需要定期更新和维护。
302.AI 1秒给大模型接入长期记忆功能
为了解决AI短期记忆的限制,302.AI为所有大模型增加了长期记忆功能(此功能限时免费,只需支付原有的模型调用费用),这一功能由302的合作伙伴Memobase提供支持。
接入的过程也非常的简单,在原有大模型API不变的情况下,请求增加一个userid参数即可
不带记忆的API请求:
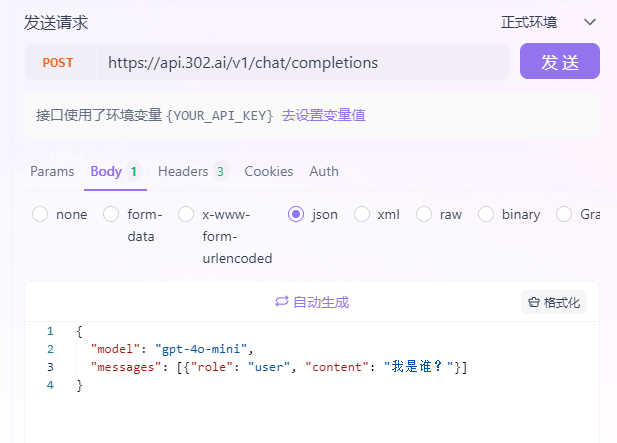
![]()
不带记忆的回答:

![]()
带记忆的API请求:
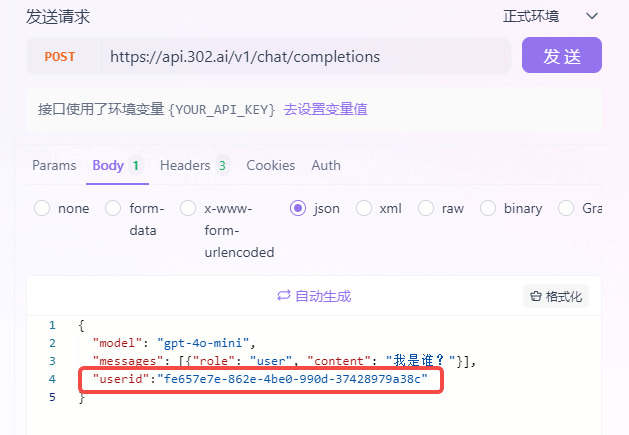
![]()
带记忆的回答:
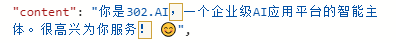
![]()
可以看到,在单个API请求完全不带上下文的情况下,AI通过我之前的自我介绍,识别出了我的身份。
此功能几乎支持所有大模型,无需创建用户,无需初始化,仅需一个userid即可,AI会自动化的通过聊天记录来提取和检索长期记忆。
长期记忆的原理
短期记忆是将聊天记录原封不动的传给大模型。
长期记忆是通过收集对话信息,使用大模型提取用户的各种信息,如年龄、教育背景、兴趣和观点,生成用户画像,最后将用户画像通过系统提示词传递给大模型。
所以长期记忆是短期记忆的蒸馏,短期记忆是长期记忆的数据来源。
302.AI和Memobase合作,简化接入流程,将初始化用户、同步聊天记录、提取记忆、检索记忆等操作全部自动化,仅需在API请求传递一个userid,即可解决所有问题。
背后的流程大致如下:
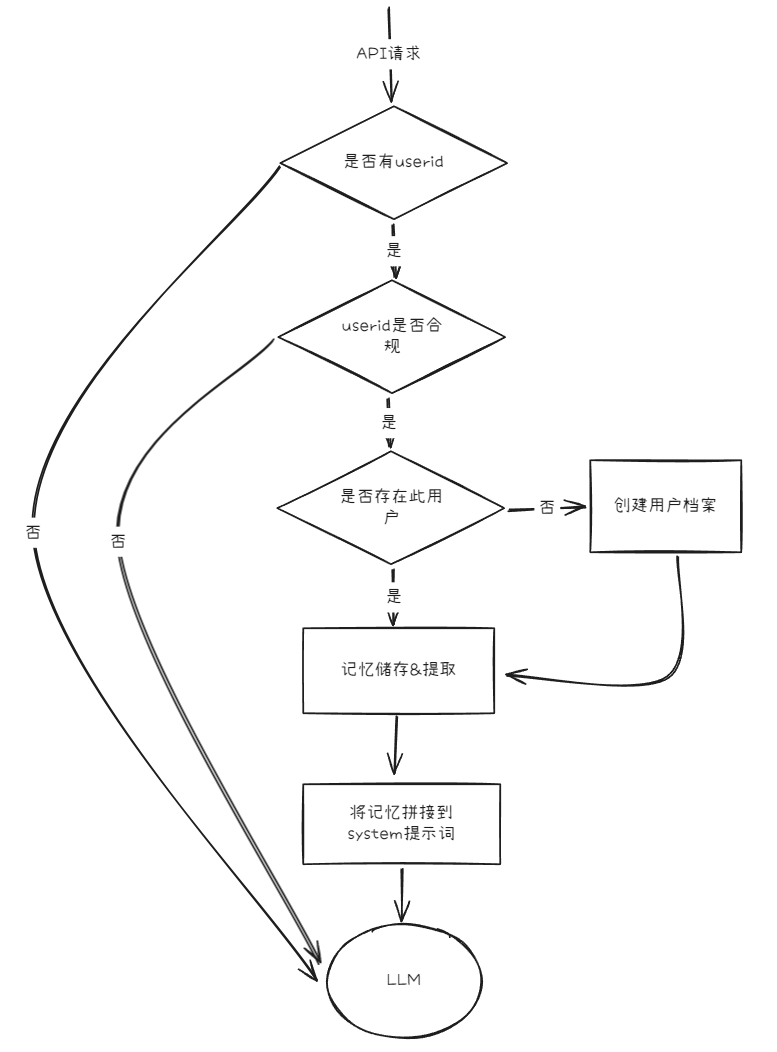
![]()
在线测试
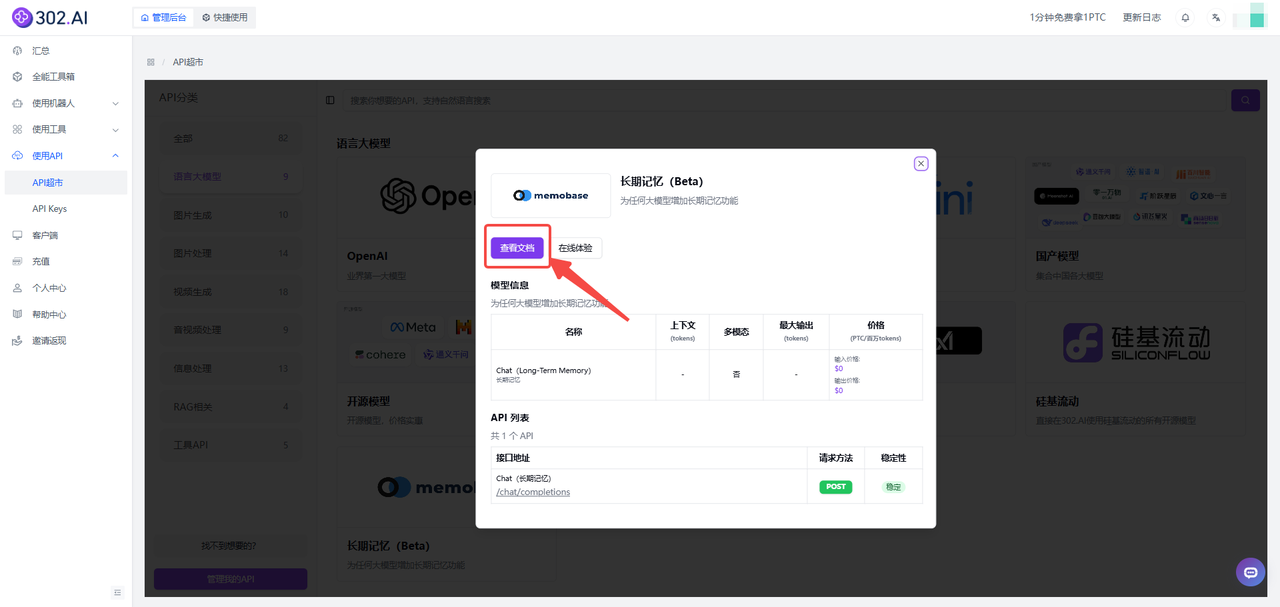
1、登录进入302.AI管理后台——点击使用API——选择API超市——分类中点击语言大模型——点击长期记忆。

![]()
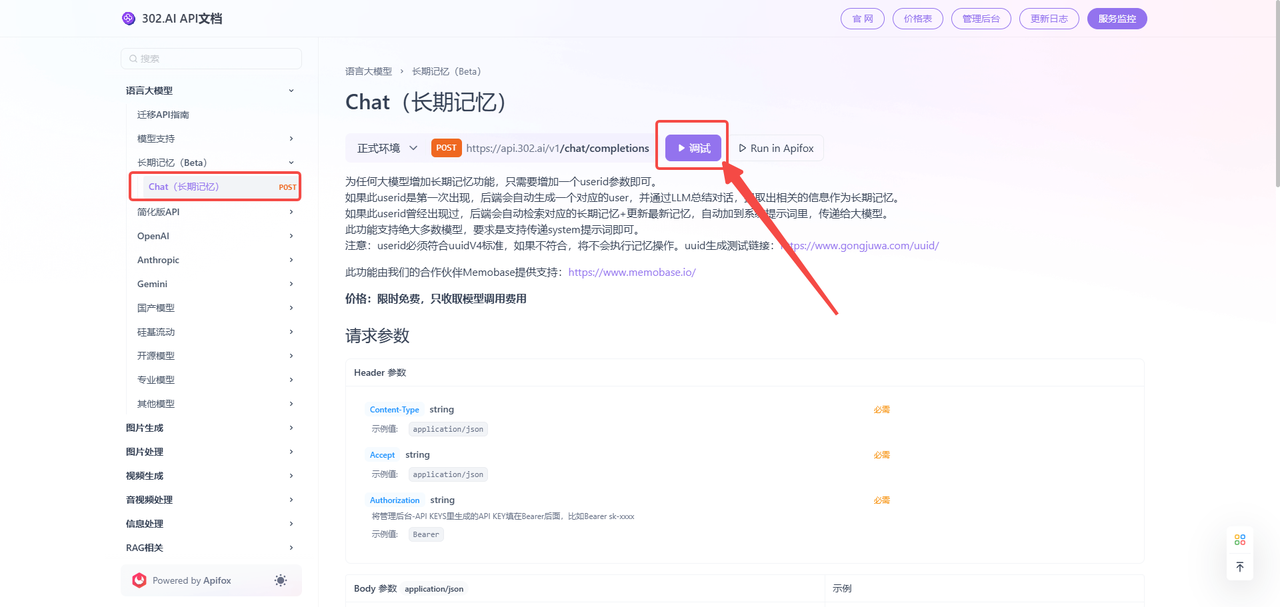
2、点击【查看文档】进入API文档:
![]()
![]()
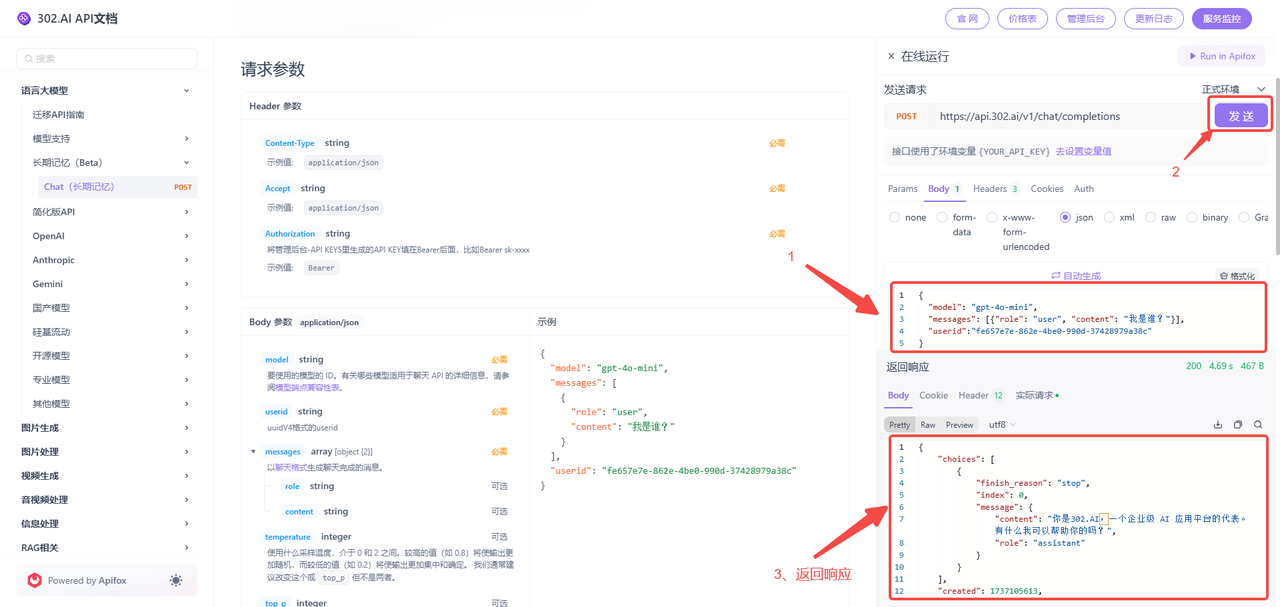
3、根据提供的模板按需填写参数,最后点击发送即可,以下是必填的三个参数:
model:表示要使用的模型ID名称,例如“gpt-4o-mini”
messages:以聊天格式生成聊天完成的消息。
userid:uuidV4格式的userid(注意:userid必须符合uuidV4标准,如果不符合,将不会执行记忆操作。uuid生成测试链接:https://www.gongjuwa.com/uuid/)
![]()
总结
302.AI通过API增加一个参数,为几乎所有大模型增加了长期记忆功能,为所有开发者带来了极大的便利,再次扩展了AI的使用场景。
而302.AI之所以能做到这一点,和Memobase全新的记忆架构密切相关,过去302.AI团队也尝试接入Mem0等记忆技术,但是速度过慢和成本过高,始终无法达到标准。而Memobase全新的记忆架构,让记忆检索速度提高了5倍,成本降低了5倍,302团队和Memobase团队一拍即合,联手为大家推出了这个功能,希望感兴趣的朋友,赶紧来试用吧。
免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(8)
Thanks – Enjoyed this post, is there any way I can receive an update sent in an email every time you make a fresh post?
I am impressed with this internet site, really I am a fan.
I got what you intend, appreciate it for posting.Woh I am glad to find this website through google. “Wisdom doesn’t necessarily come with age. Sometimes age just shows up by itself.” by Woodrow Wilson.
[…] 302.AI 实战教程 | 《哪吒2》火爆出圈!如何用3D建模工具快速复刻出哪吒? 302.AI 新品发布 | 如何1秒钟为大模型API增加长期记忆?限时免费体验! All Rights Reserved by 302.AI AICGAI应用AI生图AI视频 Like (0) 302.AI 0 […]
Do you mind if I quote a few of your posts as long as I provide credit and sources back to your webpage? My blog is in the very same niche as yours and my visitors would really benefit from a lot of the information you present here. Please let me know if this okay with you. Thanks!
Some times its a pain in the ass to read what blog owners wrote but this website is very user genial! .
As a Newbie, I am permanently exploring online for articles that can aid me. Thank you
As a Newbie, I am constantly searching online for articles that can help me. Thank you