
原本以为“卷”了一年的AI大模型圈年末终于能暂歇一口气,但没想到最近几日接连有新模型发布。
1月20日晚,DeepSeek发布了推理模型–DeepSeek-R1。据官方介绍,DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。
(DeepSeek-R1技术论文可查看:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf)
不知是巧合还是故意,时隔不到两天。
1月22日早上,谷歌带来了加强版推理模型 — gemini-2.0-flash-thinking-exp-01-21。该模型能够在多轮对话和推理中能够自我纠错,减少中间推理与最终答案之间的矛盾,提高了回答的可靠性和一致性。
两个模型在302平台的价格对比:
DeepSeek-R1:输入:0.6 美金/1M ; 输出:2.2 美金/1M;
gemini-2.0-flash-thinking-exp-01-21:输入:0.15 美金/1M ; 输出:0.6 美金/1M;
那么今天302.AI的对照模型就选择推理模型中的标杆– OpenAI-o1,不过o1的价格昂贵得多,其API调用成本足足是其它两个模型的数倍。如此高昂的成本投入,若无法在性能上实现显著领先,恐怕难以支撑其市场定位。
三个模型价格对比: o1 > DeepSeek-R1 > Gemini
那么实测的结果,是否会和价格一致呢?
DeepSeek-R1 vs. Gemini-Thinking vs. OpenAI-o1模型实测
以下实测使用的是相同的提示词,且摘取模型第一次输出的结果。
实测1和实测2使用的工具为:302.AI的模型竞技场

实测3使用工具为:302.AI聊天机器人-Artifacts功能
实测1:24点游戏
提示词:
请运用四则运算方法,将数字3、3、7、7进行组合运算,使其结果等于24。
考察点:涉及逆向运算的24点题目,如包含除法和分数的,对模型的推理能力有较高要求
(24点游戏规则:给出4个数字,利用四则运算(加、减、乘、除)及括号,使4个数字运算结果为24,每个数字只能用一次。)
o1:回答正确,步骤解析也很清楚。

![]()
DeepSeek-R1:回答也是正确的,模型一步步分析后给出完整表达式,最后还验证确认答案。

![]()
Gemini:回答错误,首先给出了一个错误的答案,经过自我反省后意识到了错误,进而重新思考给出了新的答案。但可惜的是,第二次给出的答案不符合规则,重复使用了数字。这里可以发现,在同样的提示词下,只有Gemini出现了重复使用数字的情况。

![]()
为此,我们在提示词中添加限制条件:每个数字只能使用一次。
然而,可以看到模型仍然忽略了提示词,并且在运算过程中重复使用了数字3,却说每个数学仅使用过一次。

![]()
第1轮实测结果:DeepSeek-R1 = o1 > Gemini
实测2:推理逻辑
提示词:
小刘和小红都是张老师的学生,张老师的生日是M月N日,两人都都知道张老师的生日是下列10天中的一天,这十天分别是3月4日、3月5日、3月8日、6月4日、6月7日、9月月1日、9月5日、12月1日、12月2日、12月8日。张老师把M值告诉了小刘,把N值告诉了小红,然后有如下对话:
小刘说:如果我不知道的话,小红肯定也不知道。
小红说:刚才我不知道,听小刘一说我就知道了。
小刘说:哦,那我也知道了。
请根据以上对话推断出张老师的生日是?
A.3月4日。B.3月5日。C.3月8日。
D.9月1日。E.9月5日。
考察点:这道题的逻辑较为复杂,需重点理解题目中对话的含义。
o1-plus:虽然最后给出的答案是正确的,但是仔细看解析过程表达不太易懂,读完甚至感觉有点懵。
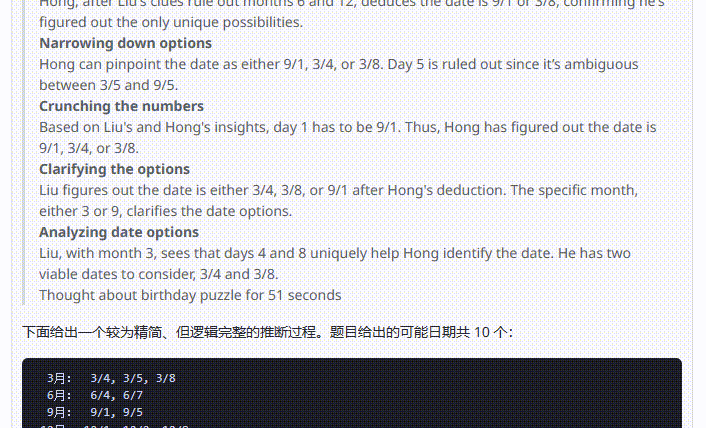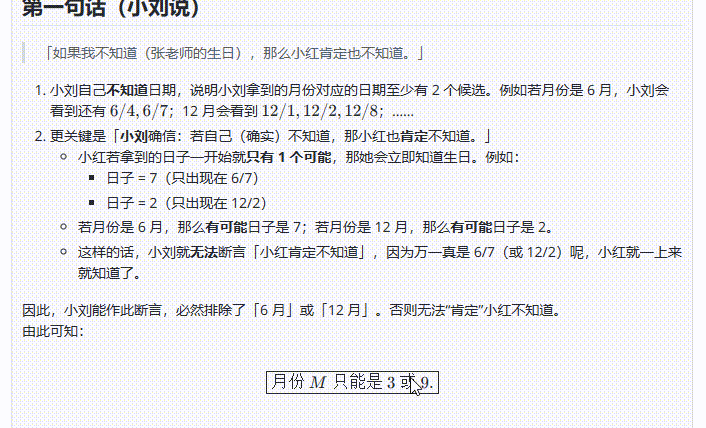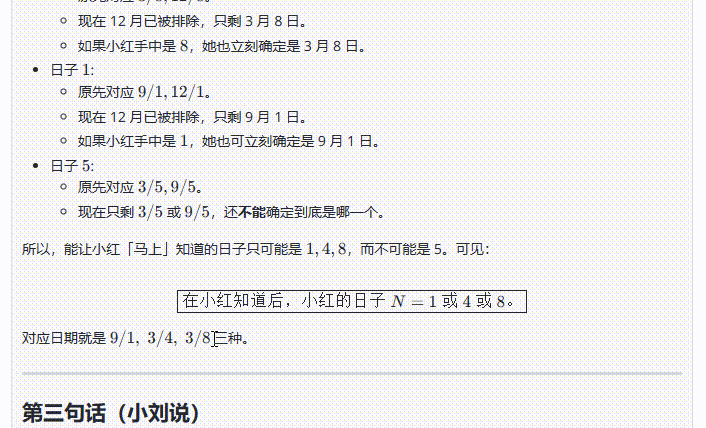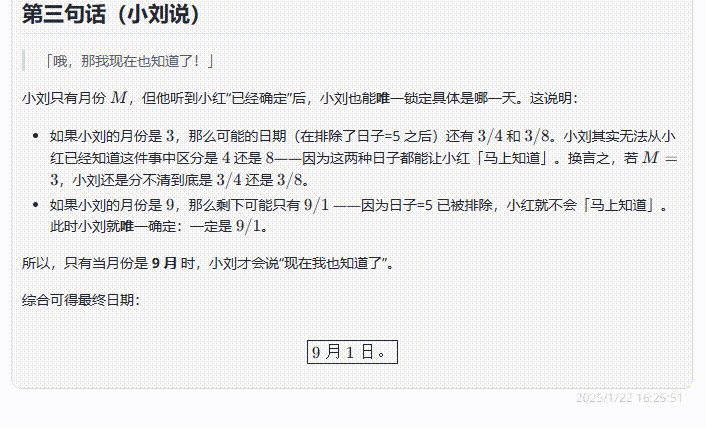
![]()
比如在解析中出现了”在听到「月份只能是 3 或 9」”这样的表达,让人误以为是在提示词中出现的条件。实际上这是模型通过第一轮分析后得出的结论:
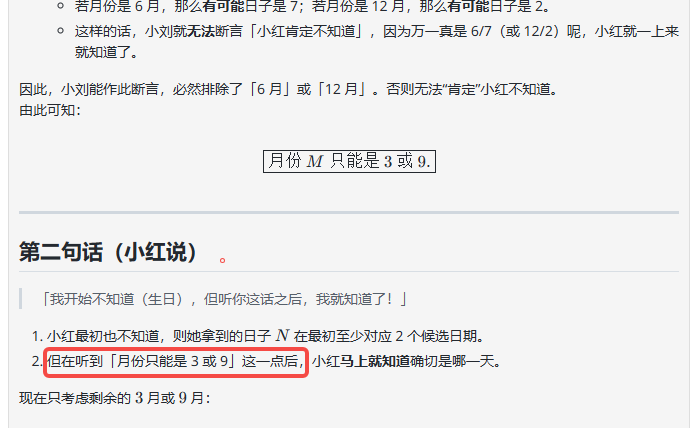
![]()
DeepSeek-R1:回答正确,整个分析过程逻辑清晰、且非常易懂。
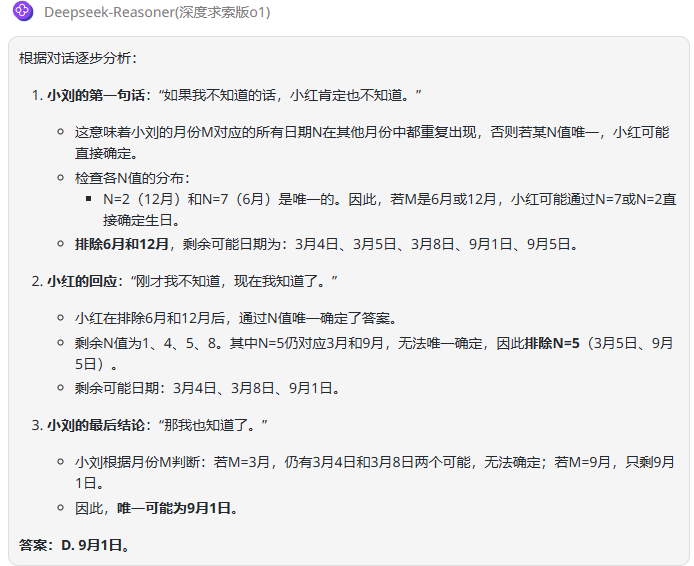
![]()
Gemini:输出的答案整体篇幅也是较长,逐步进行思考分析,最后给出了正确答案。

![]()
第2轮实测结果:DeepSeek-R1 > o1 = Gemini
实测3:编程测试
提示词:
用前端代码实现,让黄色小球在正方形内弹跳,确保正确处理碰撞检测。让正方形缓慢旋转,确保小球停留在正方形内,所有代码放在一起输出。
o1-plus:能正确处理碰撞且确保小球停留在正方形内。
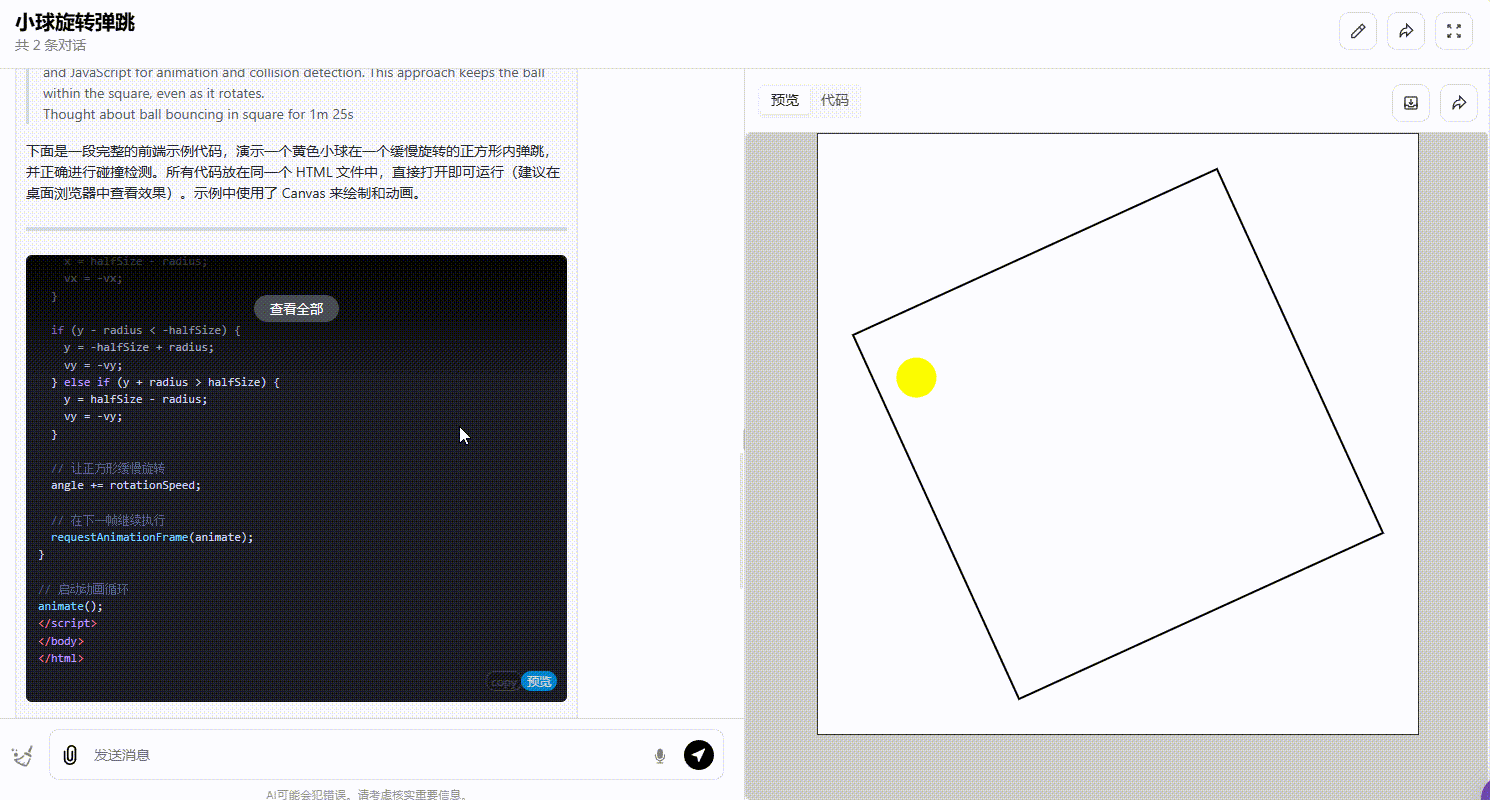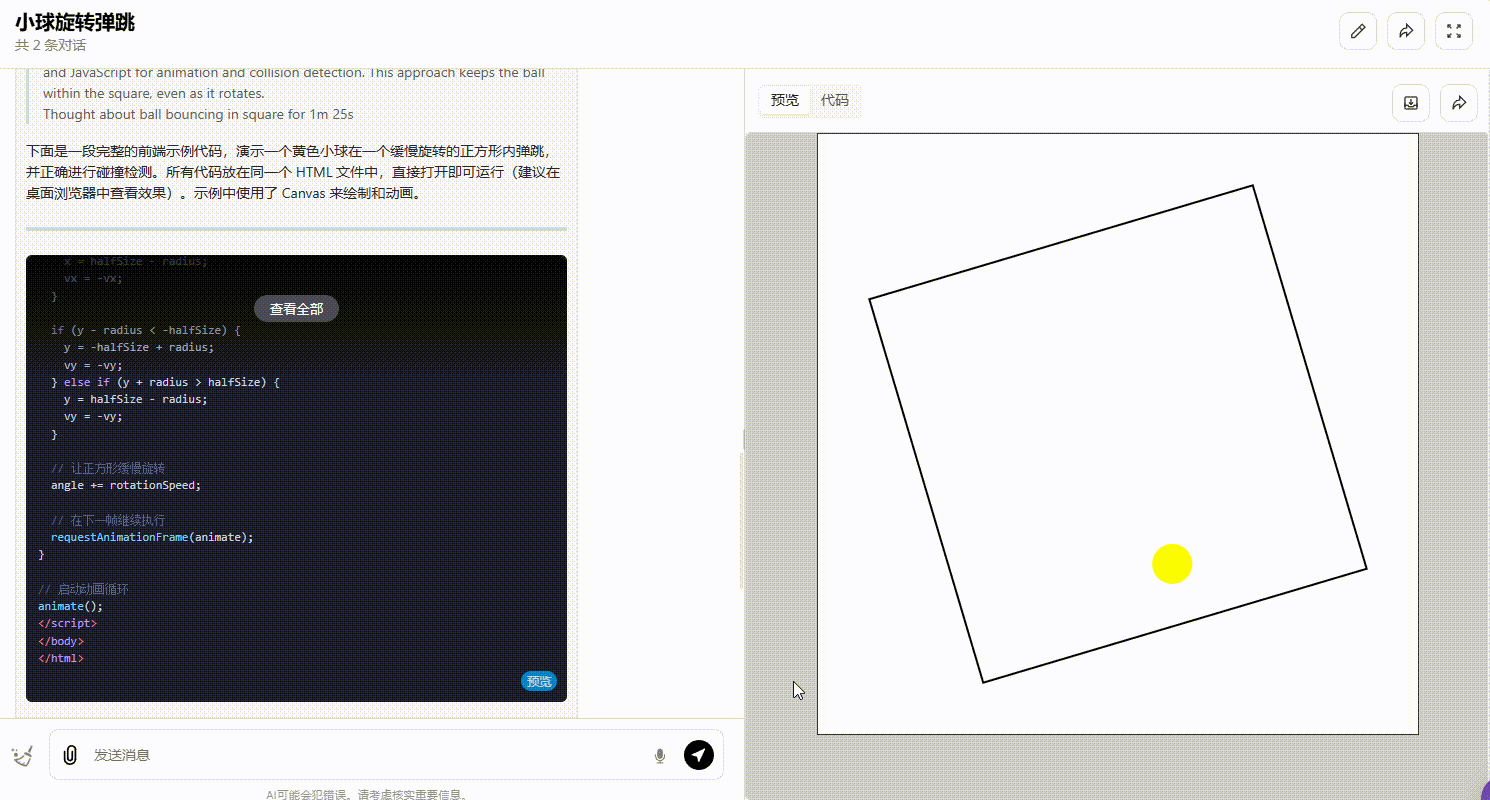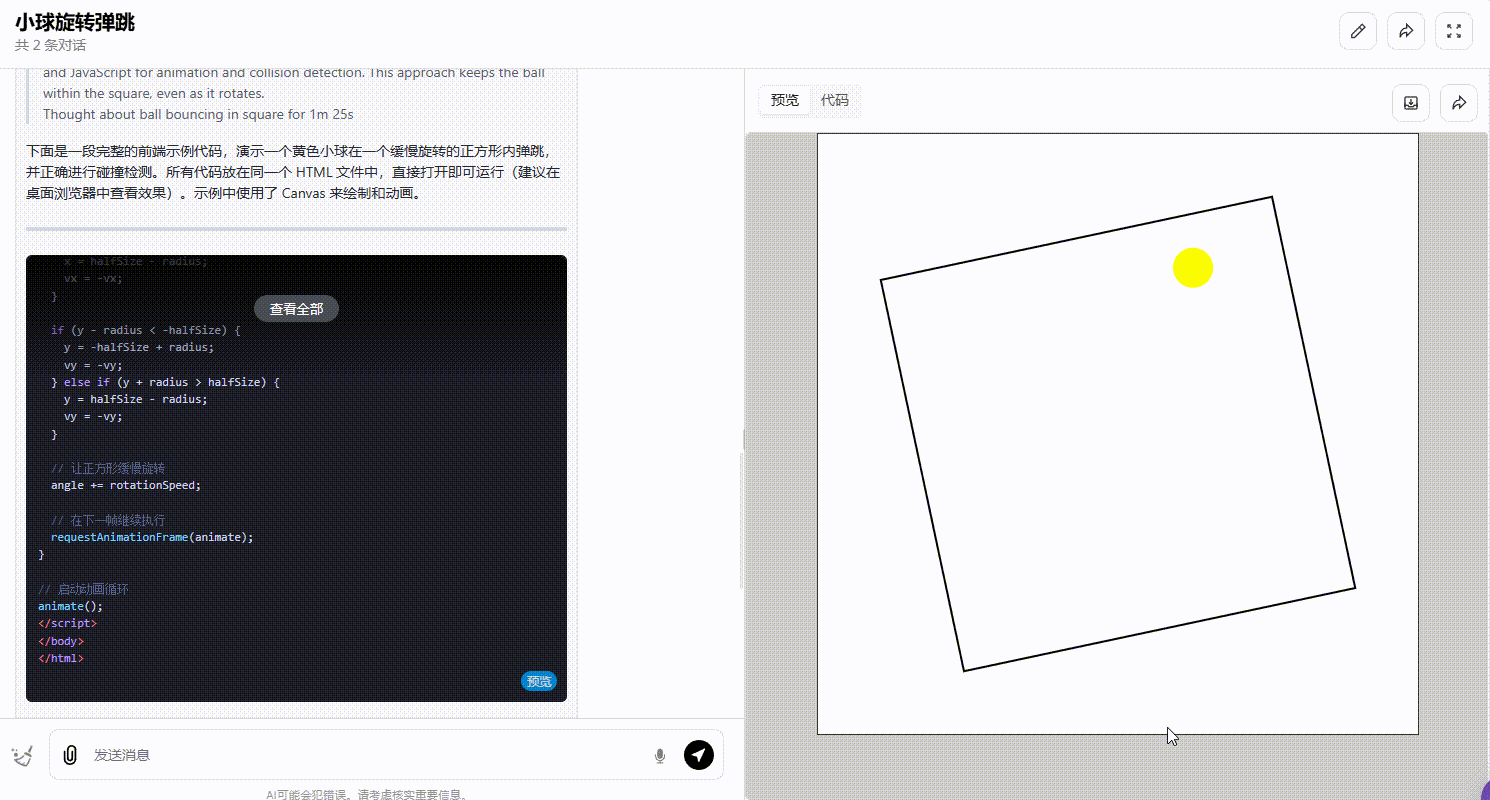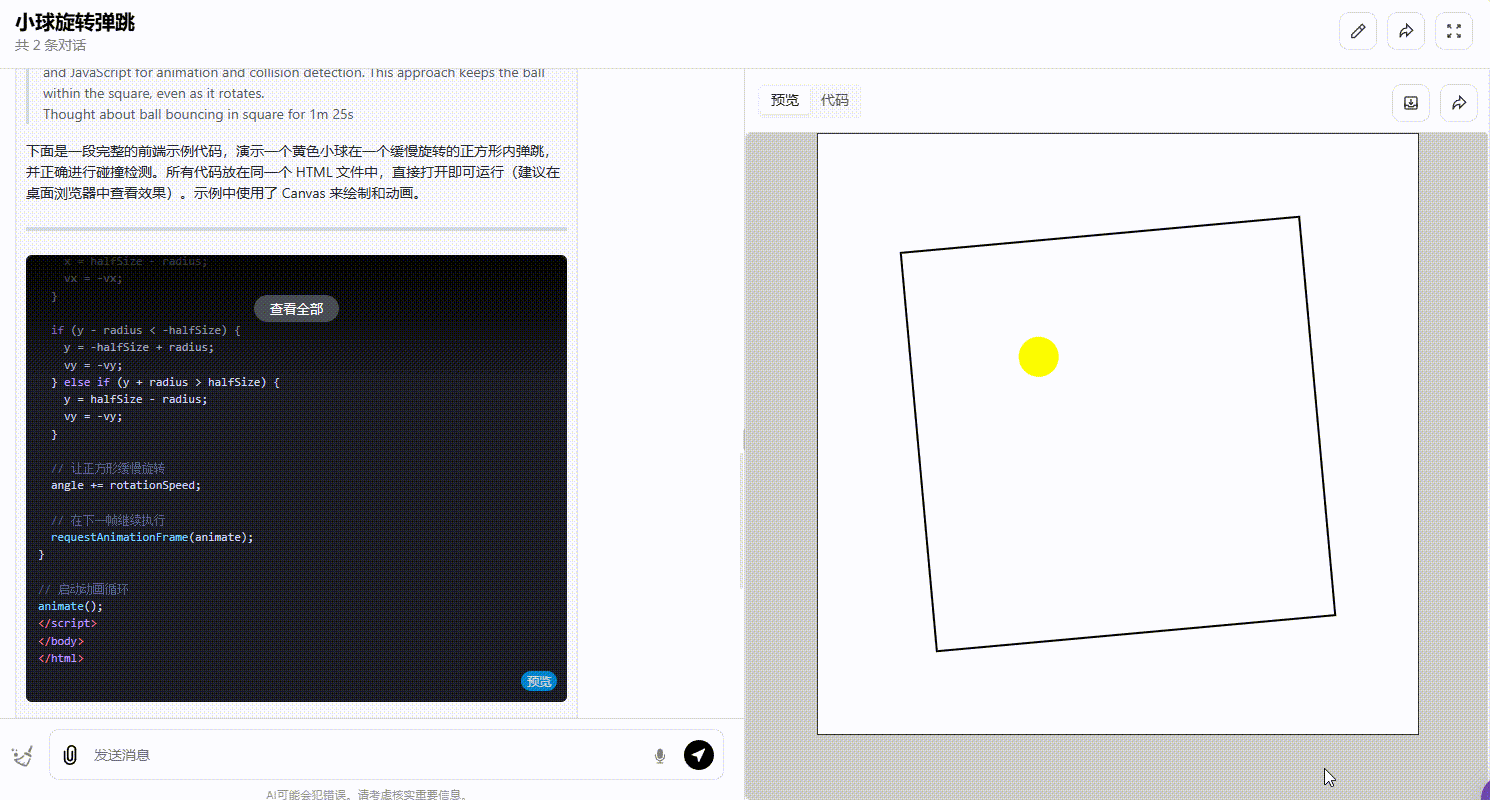
![]()
DeepSeek-R1:R1生成的效果和o1大差不差,同样能够能正确处理碰撞且确保小球在正方形内活动。
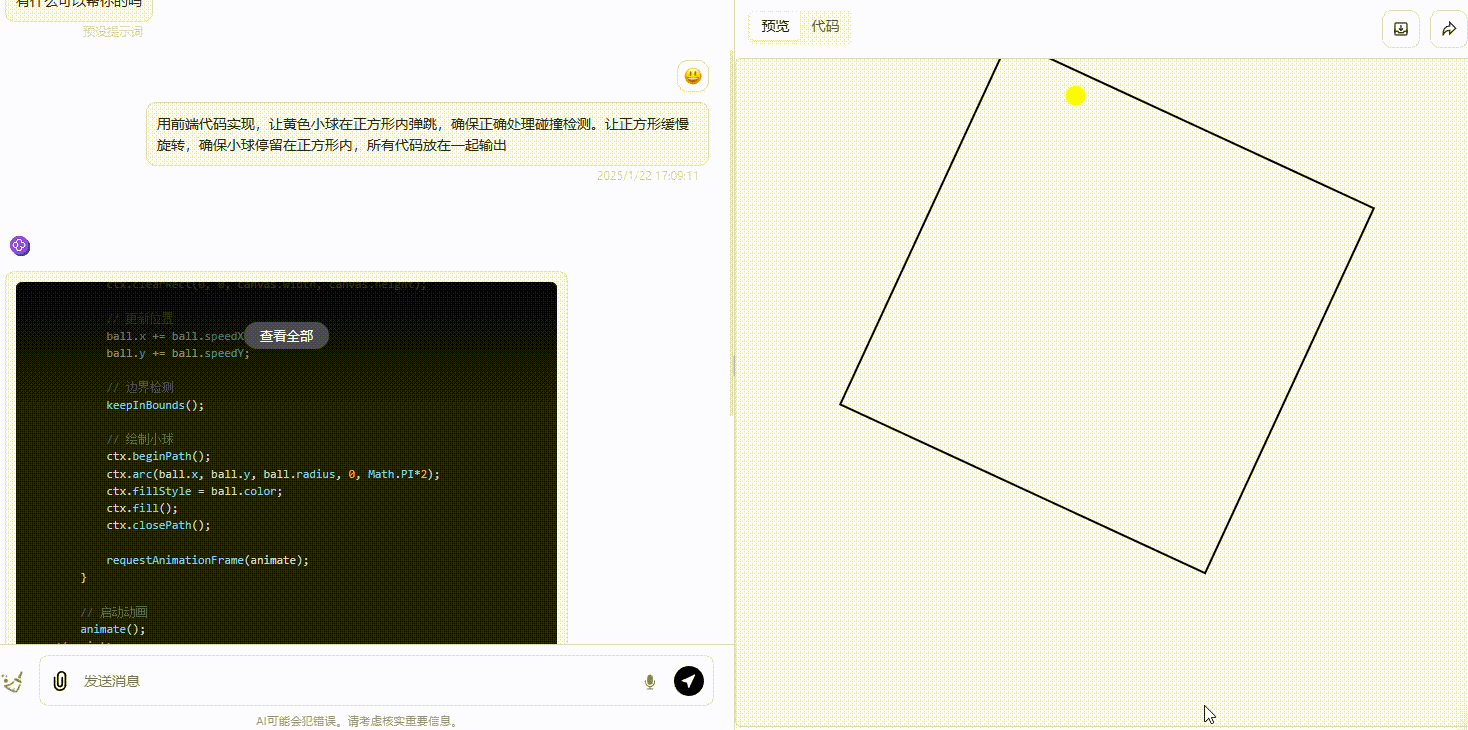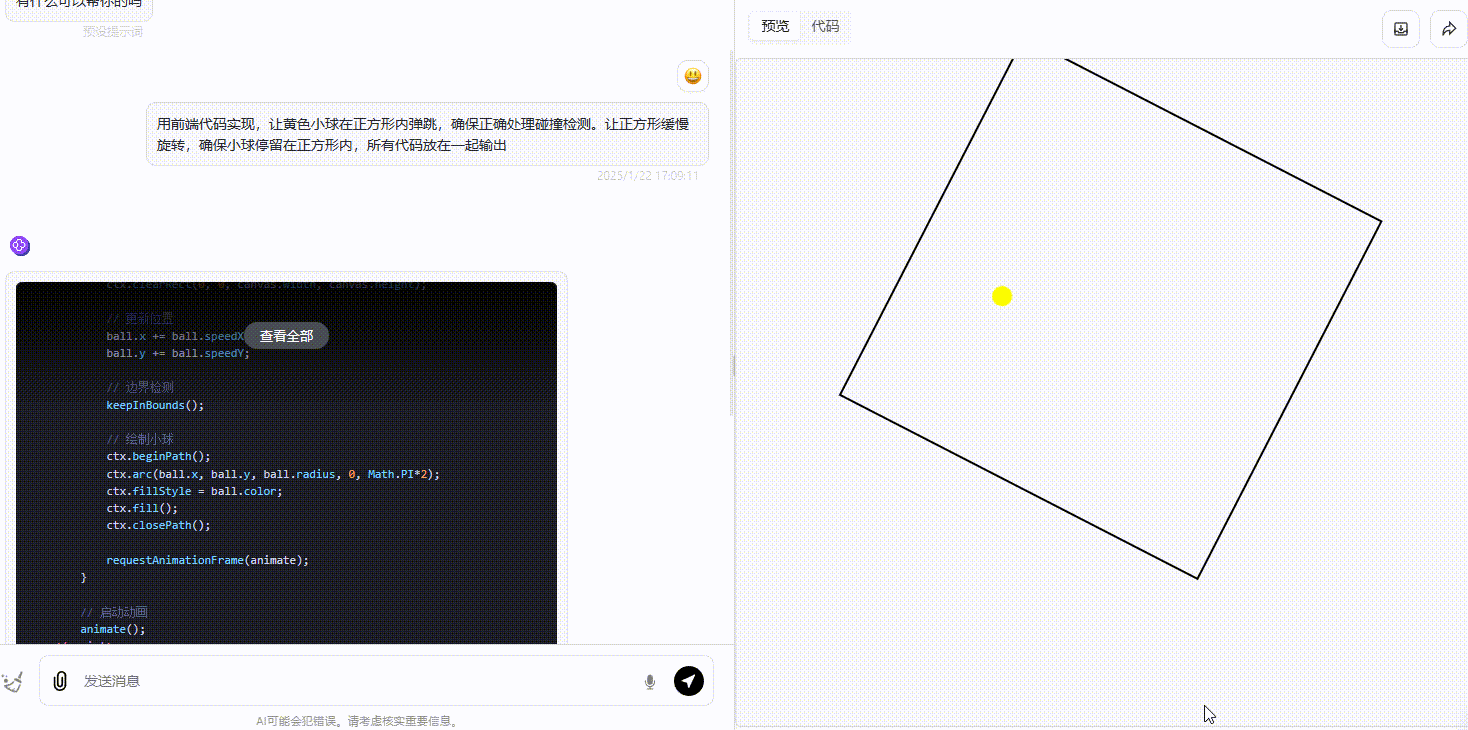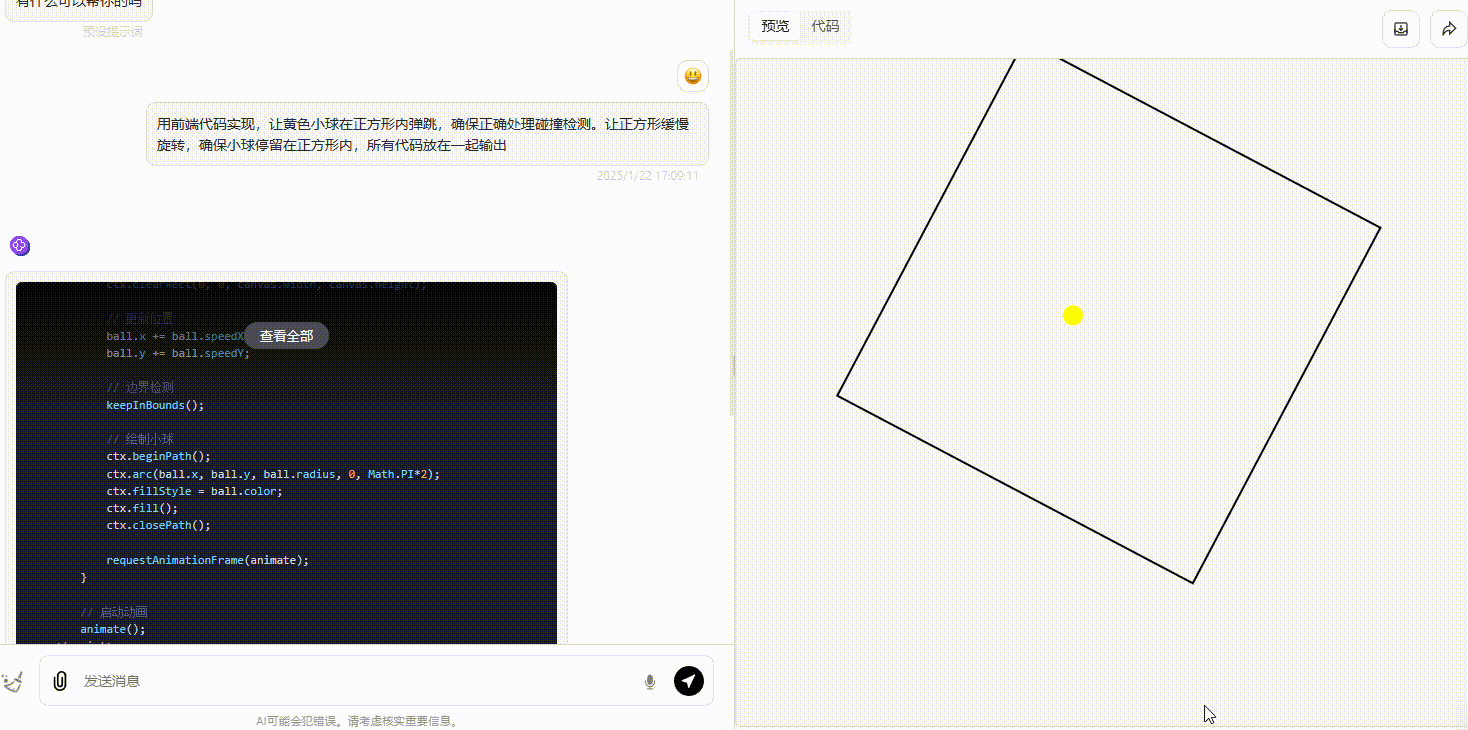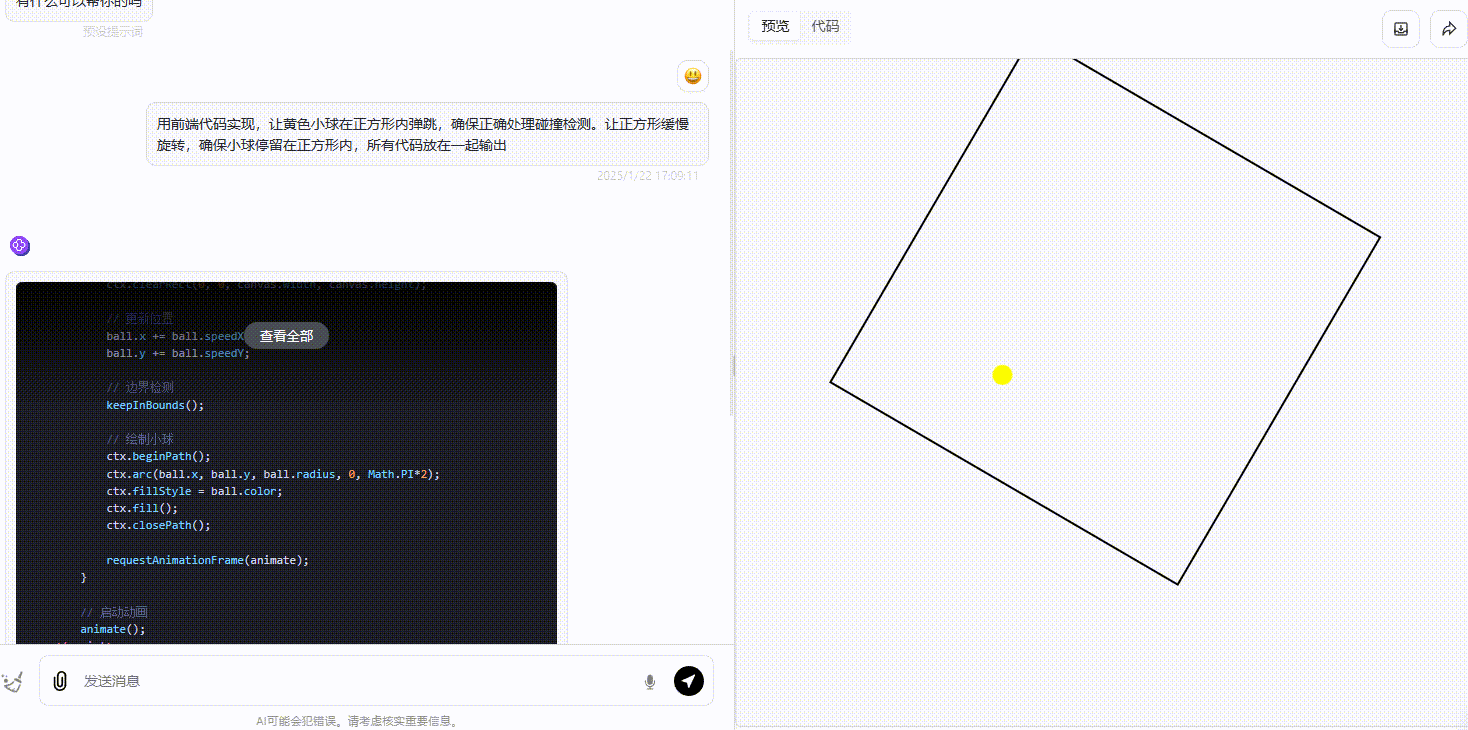
![]()
Gemini:生成的效果略逊色于另外两个模型,可以看到小球在碰撞时准确性存在不足,出现未触及线却发生反弹的现象。
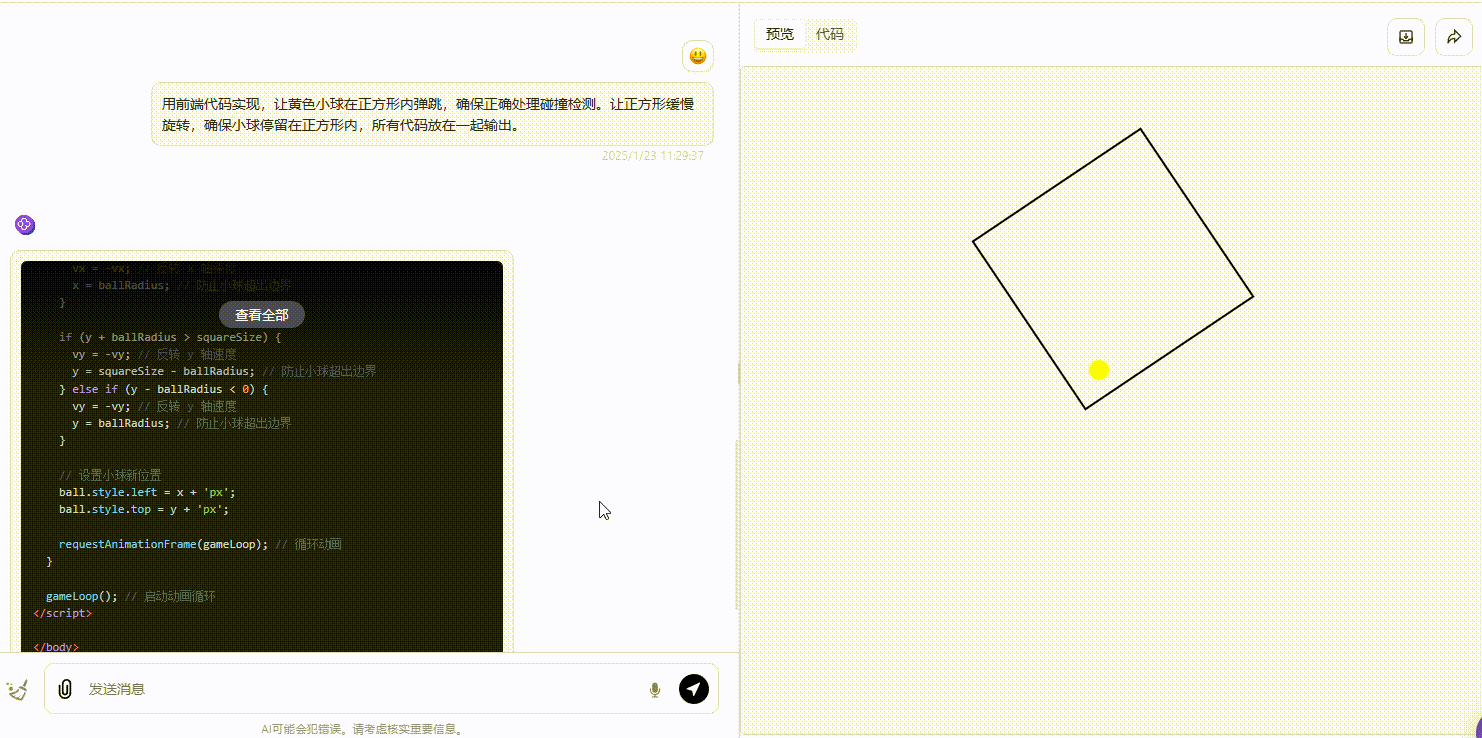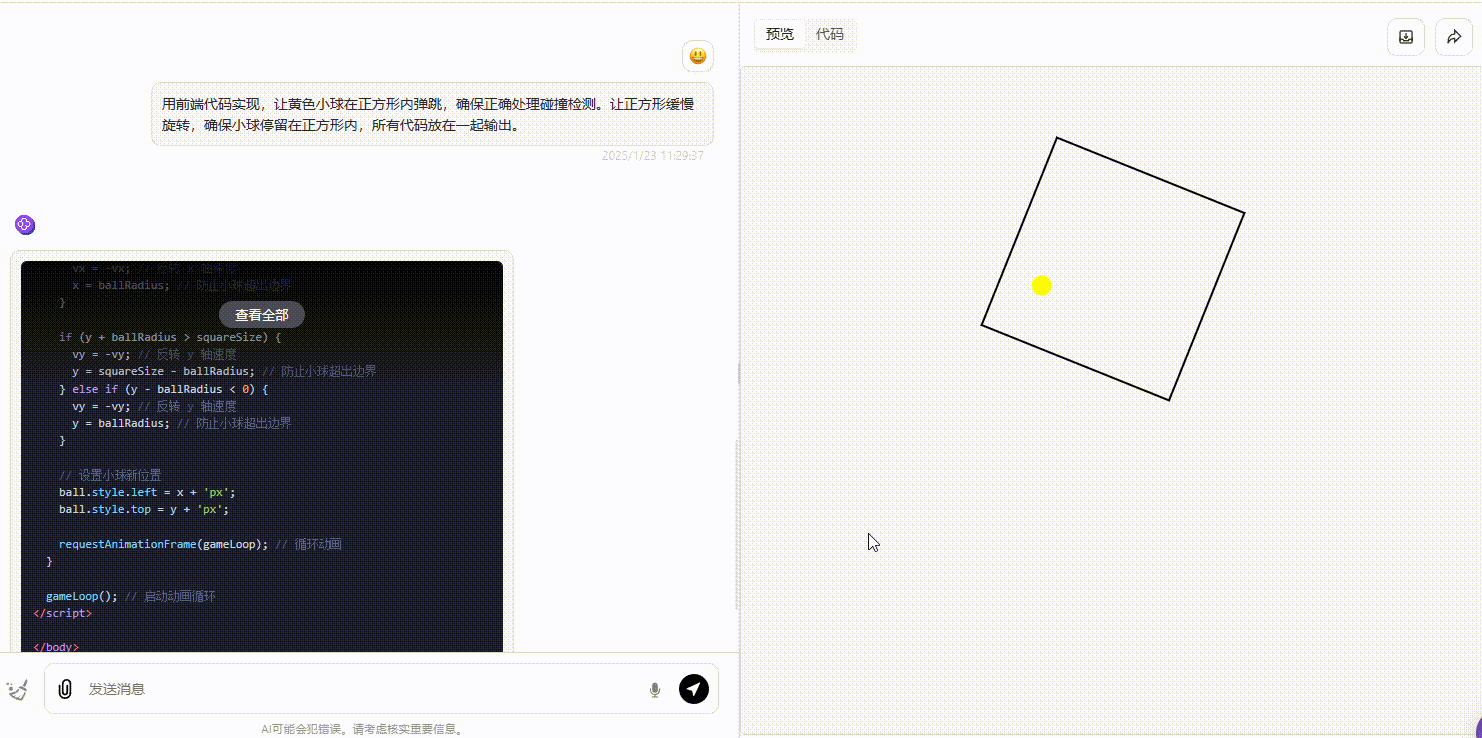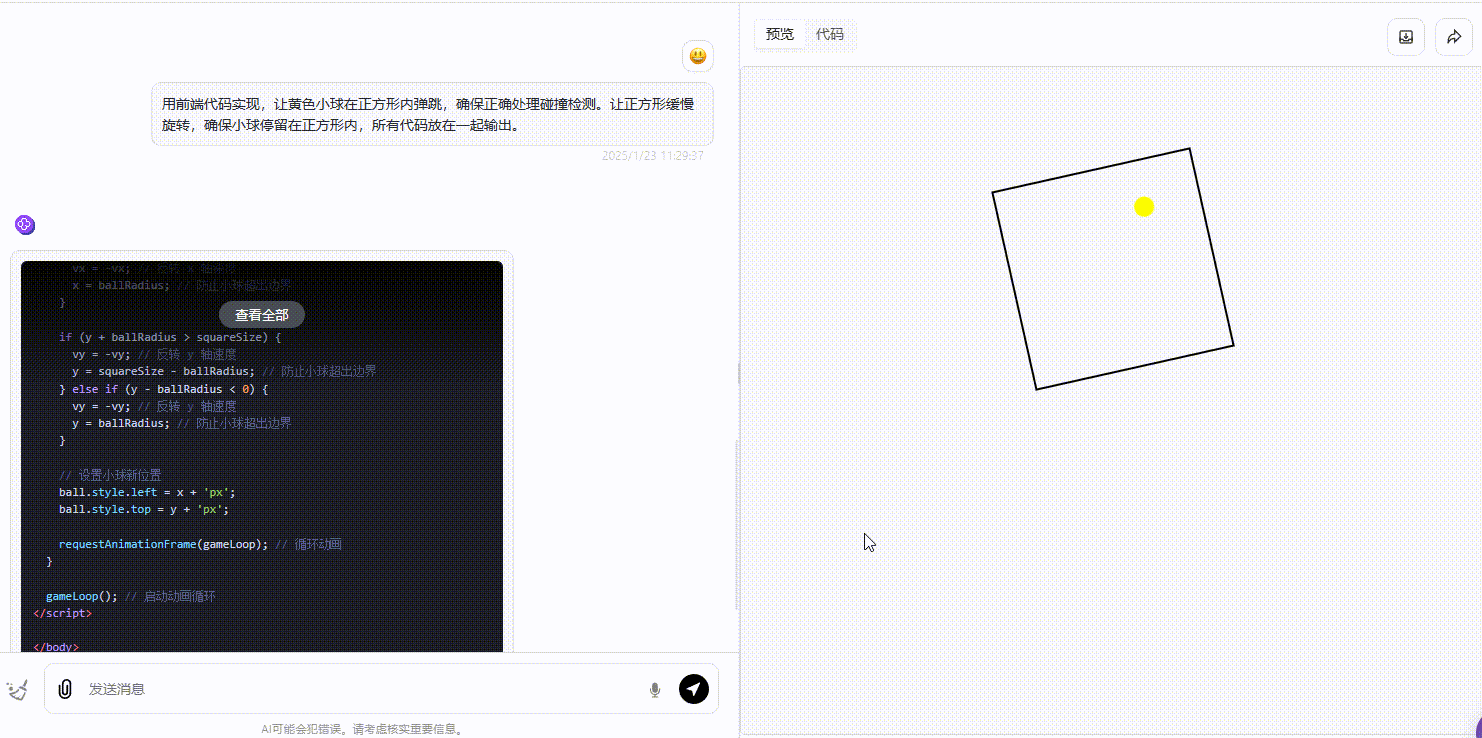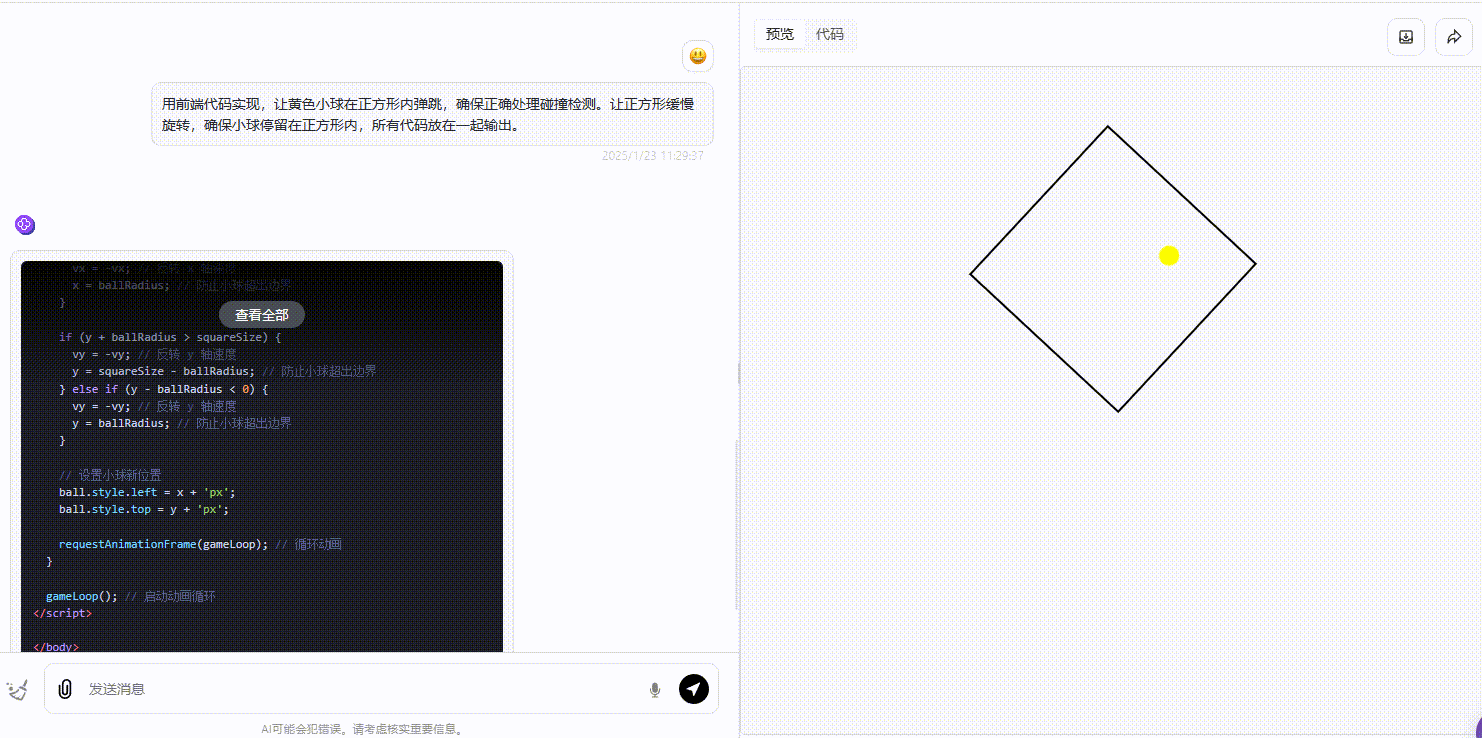
![]()
第3轮实测结果:DeepSeek-R1 = o1 > Gemini
实测结果总结:
通过以上三个简单的对比实测,能够初步得出以下结论:
(1)在数学任务中表现依次排名:DeepSeek-R1 = o1 >>> Gemini。
在24点任务中,DeepSeek-R1和 o1 均给出了正确的答案和解析,而gemini则是在回答的过程中出现了模型幻觉,表现较差。
(2)在推理方面表现依次排名:DeepSeek-R1 >o1 = Gemini。
在推理方面,R1的推理解析更加清晰易懂,可读性更强。同时,我们也注意到,推理大模型在展现完整思考过程时,应该考虑如何兼顾提高输出内容的整洁性。因为大多数用户在面对冗长且缺乏重点的输出时,往往难以保持足够的耐心。
(3)在编程方面表现依次排名:DeepSeek-R1 = o1 > Gemini。
在编程任务中,R1和 o1的表现相当,而Gemini则略逊色,生成效果的准确度不足。
将这三个结论汇总,可以得出:
三个模型能力对比:DeepSeek-R1 > o1> Gemini
三个模型价格对比: o1 > DeepSeek-R1 > Gemini
就本次实测对比来看,DeepSeek-R1的表现是最好的。Gemini尽管在三个模型中价格最便宜,但是效果却是三个模型中最差的。而DeepSeek-R1能够以远低于o1的价格实现与o1相当的效果,甚至在某些细节之处还可能有所超越,性价比最高。
Deepseek这次在推理模型上的开源发展已经赶超了闭源解决方案,在性能与成本的权衡中更是大大优于国外模型,这极大地鼓舞了国内的AI从业者,期待未来会有更多优秀的国产模型涌现。
以上模型在302.AI上使用:
302.AI的聊天机器人和API超市均上线了DeepSeek-R1以及gemini-2.0-flash-thinking-exp-01-21模型,并提供按需付费的服务方式,企业和个人用户可按需灵活选用。
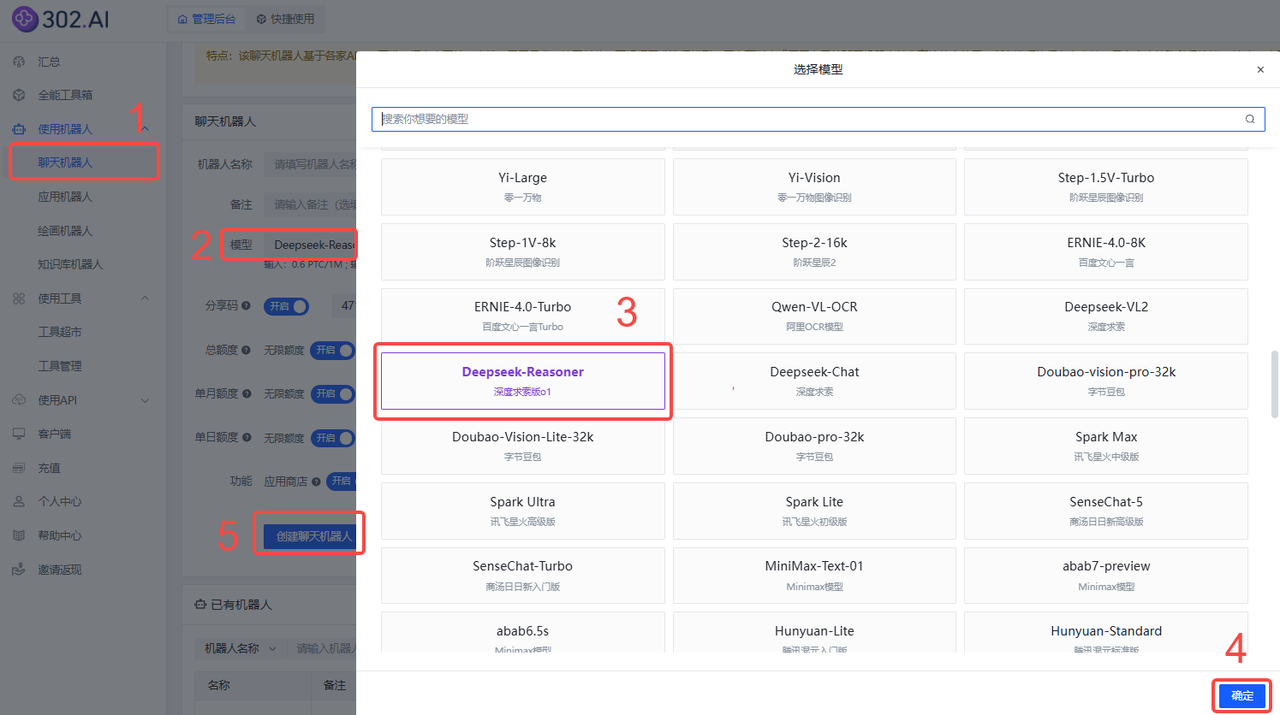
1、使用模型对话
DeepSeek-R1:依次点击使用机器人→聊天机器人→ 模型→ Deepseek-Reasoner→ 确定→ 创建聊天机器人;
Gemini:依次点击使用机器人→聊天机器人→ 模型→ gemini-2.0-flash-thinking-exp-01-21→ 确定→ 创建聊天机器人;
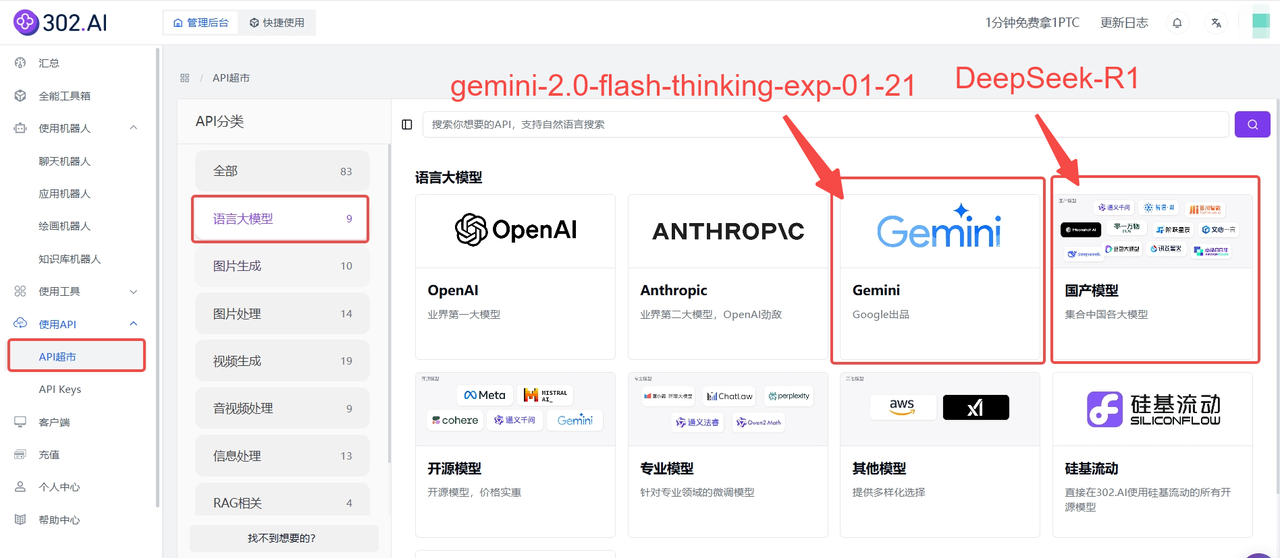
2、使用模型API
企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发。
步骤如下:依次点击使用API→API超市→语言大模型→ 国产模型/Gemini;

免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(1)
Thanks for sharing superb informations. Your site is so cool. I am impressed by the details that you have on this site. It reveals how nicely you perceive this subject. Bookmarked this website page, will come back for extra articles. You, my friend, ROCK! I found just the info I already searched all over the place and just couldn’t come across. What an ideal website.