
自年前DeepSeek发布R1模型后便迅速引发了各界的广泛关注。
最近,各模型厂家都坐不住了,频频出招。
先是1月底,是OpenAI正式发布 o3-mini,这是OpenAI推理系列中最新、最具成本效益的模型。该模型支持低、中、高三档推理难度,并针对科学、数学、编程等领域进行了优化。
2月6日,谷歌也加入了 DeepSeek 、OpenAI 的战局,发布多个模型更新:Gemini 2.0 Flash、Gemini 2.0 Flash-Lite、Gemini 2.0 Pro,其中 Gemini 2.0 Pro 具有强大的编码性能和处理复杂指令的能力,比谷歌此前发布的任何模型都具备更好的理解和推理世界知识的能力。
接下来,302.AI团队会通过实测对比 o3-mini(medium)、Gemini 2.0 pro 以及 DeepSeek-R1这三个模型各方面的表现,以便各位读者更直观了解三个模型。
首先来看三个模型在302平台的详细价格:
o3-mini:输入:1.1 PTC/1M ; 输出:4.4 PTC/1M
(302.AI提供的 o3-mini 模型默认为 medium 模式)
Gemini 2.0 Pro:输入1.3 PTC/1M ; 输出:5.0 PTC/1M
DeepSeek-R1(多来源自动切换):输入:0.6 PTC/1M ; 输出:2.2 PTC/1M
价格对比: Gemini 2.0 Pro > o3-mini > DeepSeek-R1
o3-mini vs. Gemini 2.0 pro vs. DeepSeek-R1模型实测
以下实测使用的是相同的提示词,且摘取模型第一次输出的结果。
实测1和实测2使用的工具为:302.AI的模型竞技场
实测3使用工具为:302.AI聊天机器人-Artifacts功能
实测1:日期计算
提示词:
2022年6月5日到2024年11月12日,一共有多少天?
考察点:评估模型在处理实际问题时的逻辑推理和计算能力,难点在于在计算中模型是否能考虑到闰年以及包含起始日期。
o3-mini(medium):o3-mini 回答错误,其提供的答案也较为简单,主要通过代码计算两个时间点之间的间隔,最后运行给出答案。
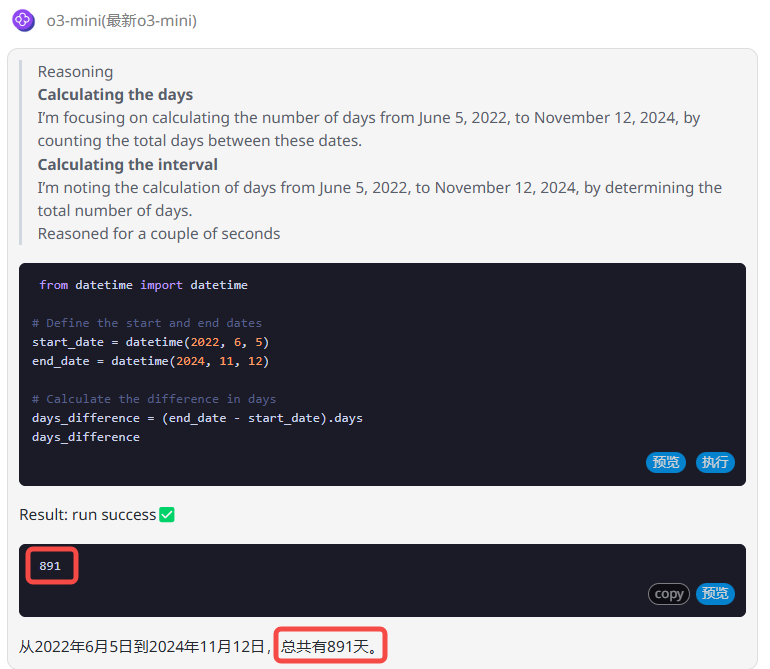

Gemini 2.0 pro:Gemini 的回答中存在错误,从输出的答案可以看出,在计算2022年6月的总天数时,遗漏需要包含的6月5日,导致最终计算结果少了一天。

DeepSeek-R1 :回答正确。从分析中可以看到,R1 在计算2022年6月的天数时加上了6月5日,思考全面,最终计算结果是正确的。

第1轮实测结果:DeepSeek-R1 > o3-mini = Gemini 2.0 pro
实测2:逻辑推理
提示词:
甲、乙、丙、丁是四位天资极高的艺术家,他们分别是舞蹈家、画家、歌唱家和作家,尚不能确定其中每个人所从事的专业领域。已知:
(1)有一天晚上,甲和丙出席了歌唱家的首次演出;
(2)画家曾为乙和作家两个人画过肖像;
(3)作家正准备写一本甲的传记,他所写的丁传记是畅销书;
(4)甲从来没有见过丙。
下面哪一选项正确地描述了每个人的身份?
A.甲是歌唱家,乙是作家,丙是画家,丁是舞蹈家。
B.甲是舞蹈家,乙是歌唱家,丙是作家,丁是画家。
C.甲是画家,乙是作家,丙是歌唱家,丁是舞蹈家。
D.甲是作家,乙是画家,丙是舞蹈家,丁是歌唱家。
E.甲是歌唱家,乙是画家,丙是作家,丁是舞蹈家。
考察点:测试模型能否理解并信息整合,需要同时考虑多个条件,综合分析以得出结论。
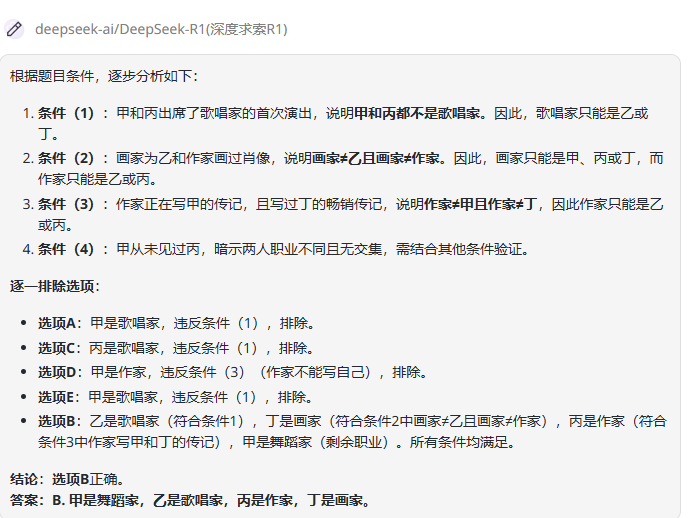
o3-mini(medium):回答错误。从 o3-mini 给出的答案可以看出,该模型在理解条件时出现了偏差,将⌈甲和丙出席了歌唱家的首次演出⌋ 这一条件误解为甲或丙为歌唱家。

Gemini 2.0 pro:回答正确,答案解析从已知条件中进行假设,最终结合条件确认假设成立,得出最终结论。
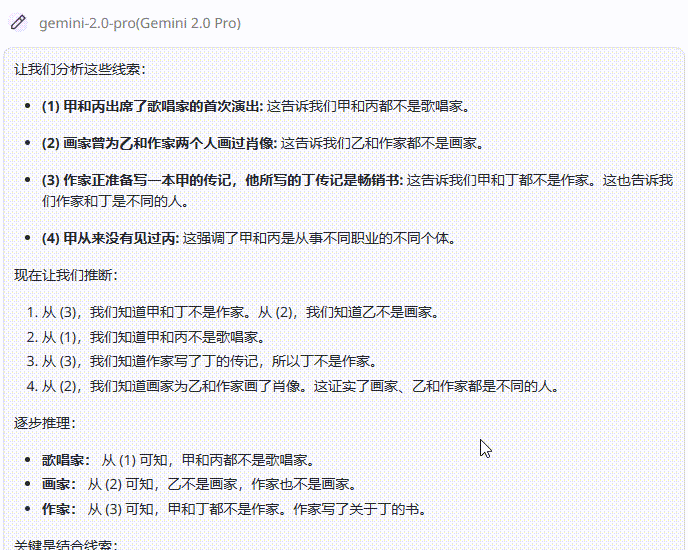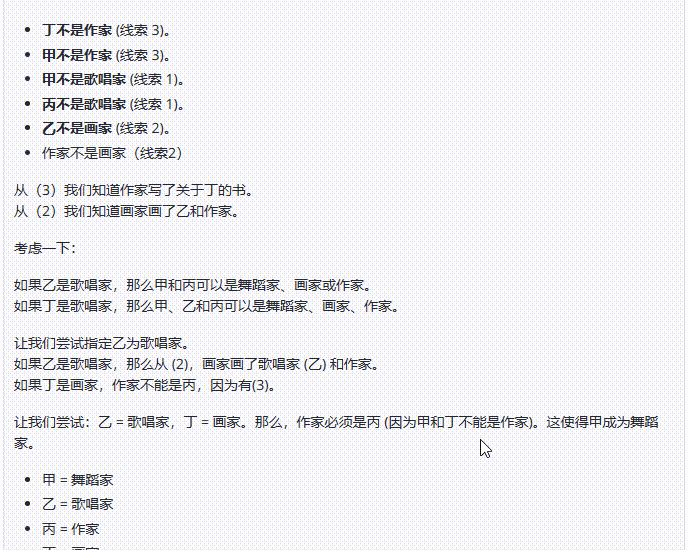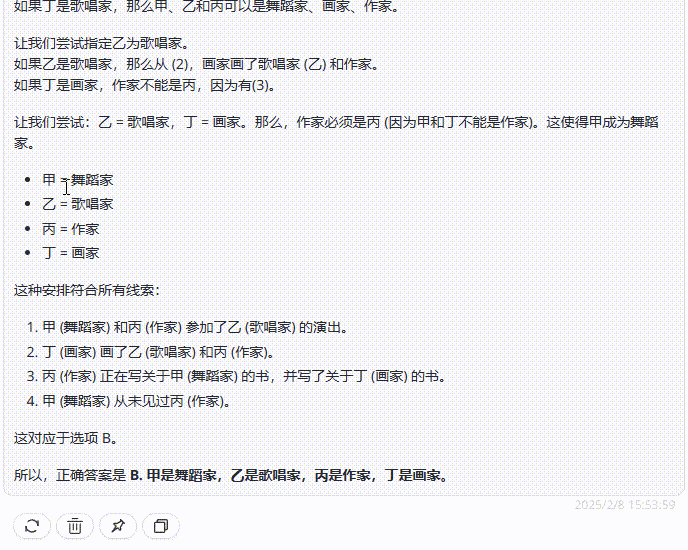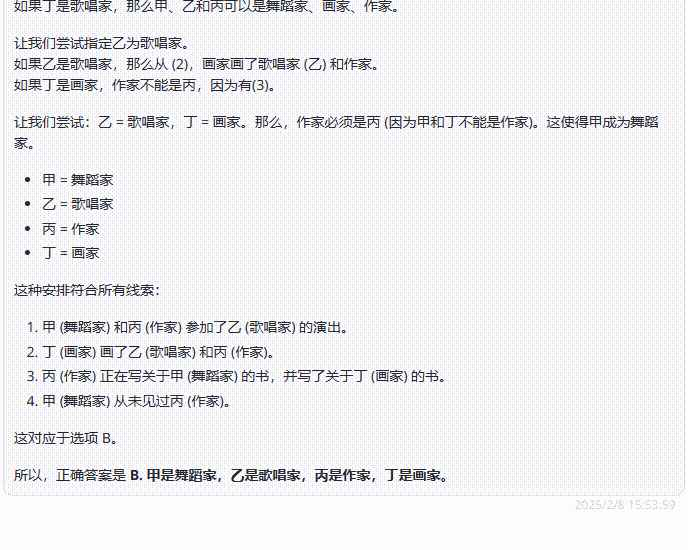
DeepSeek-R1 :回答正确,令人意外的是,R1采用了与上述模型不同的解题策略——答案排除法,模型根据给出的条件,逐一排除不可能的选项,最终剩下的选项为答案,再通过简单检验确认,这种方法更加简便。
第2轮实测结果:DeepSeek-R1 > Gemini 2.0 pro > o3-mini
实测3:编程测试
提示词:
用前端代码实现让不同颜色的小球在旋转的六边形内弹跳,所有代码需要放在一起输出。
考察点:评估模型生成结果是否符合小球在六边形内弹跳的逻辑,包括碰撞检测及方向调整。
o3-mini(medium):o3-mini 生成的效果符合六边形内部弹跳的要求,小球的弹跳方向和轨迹在碰撞时均符合逻辑。
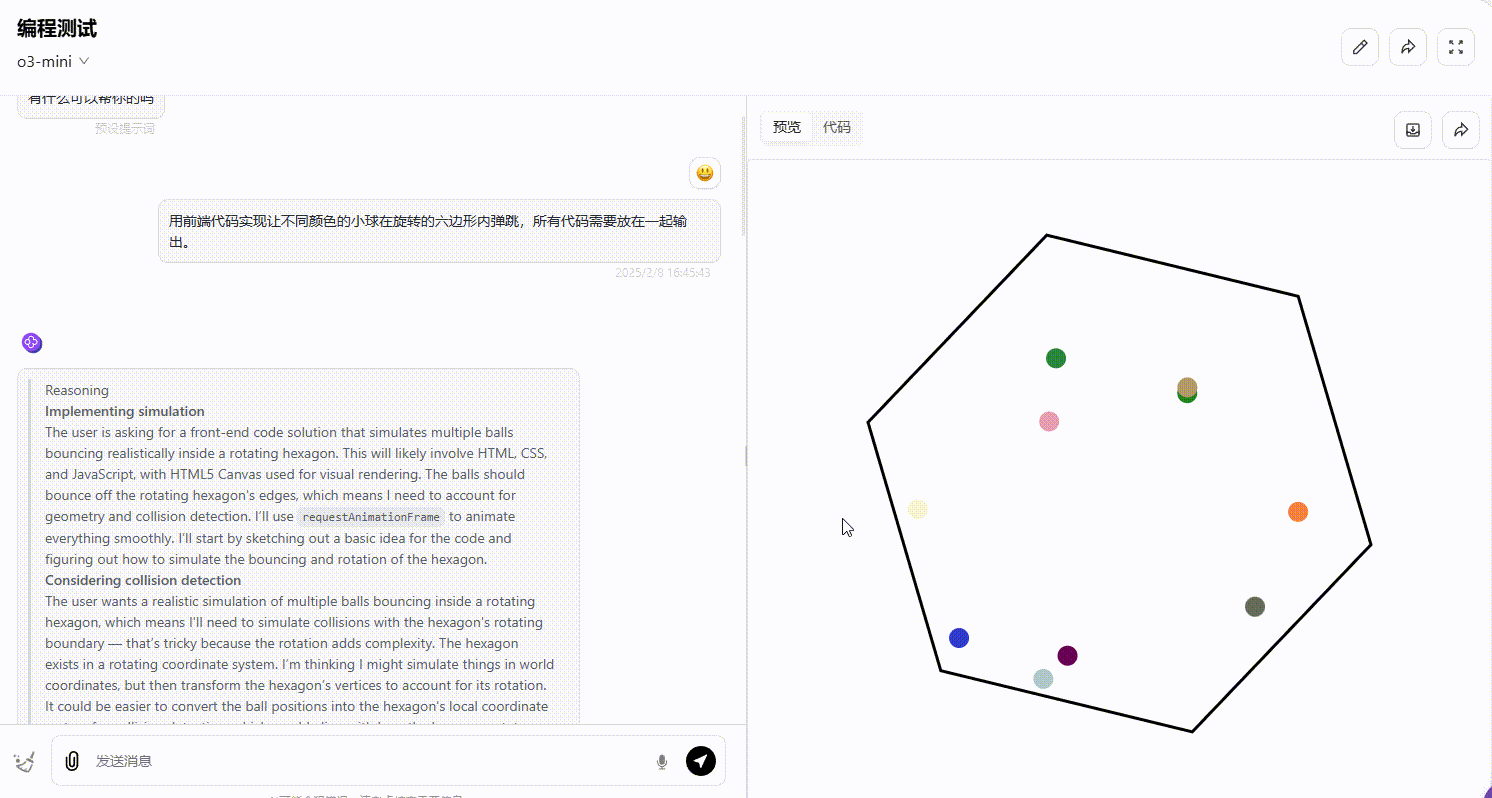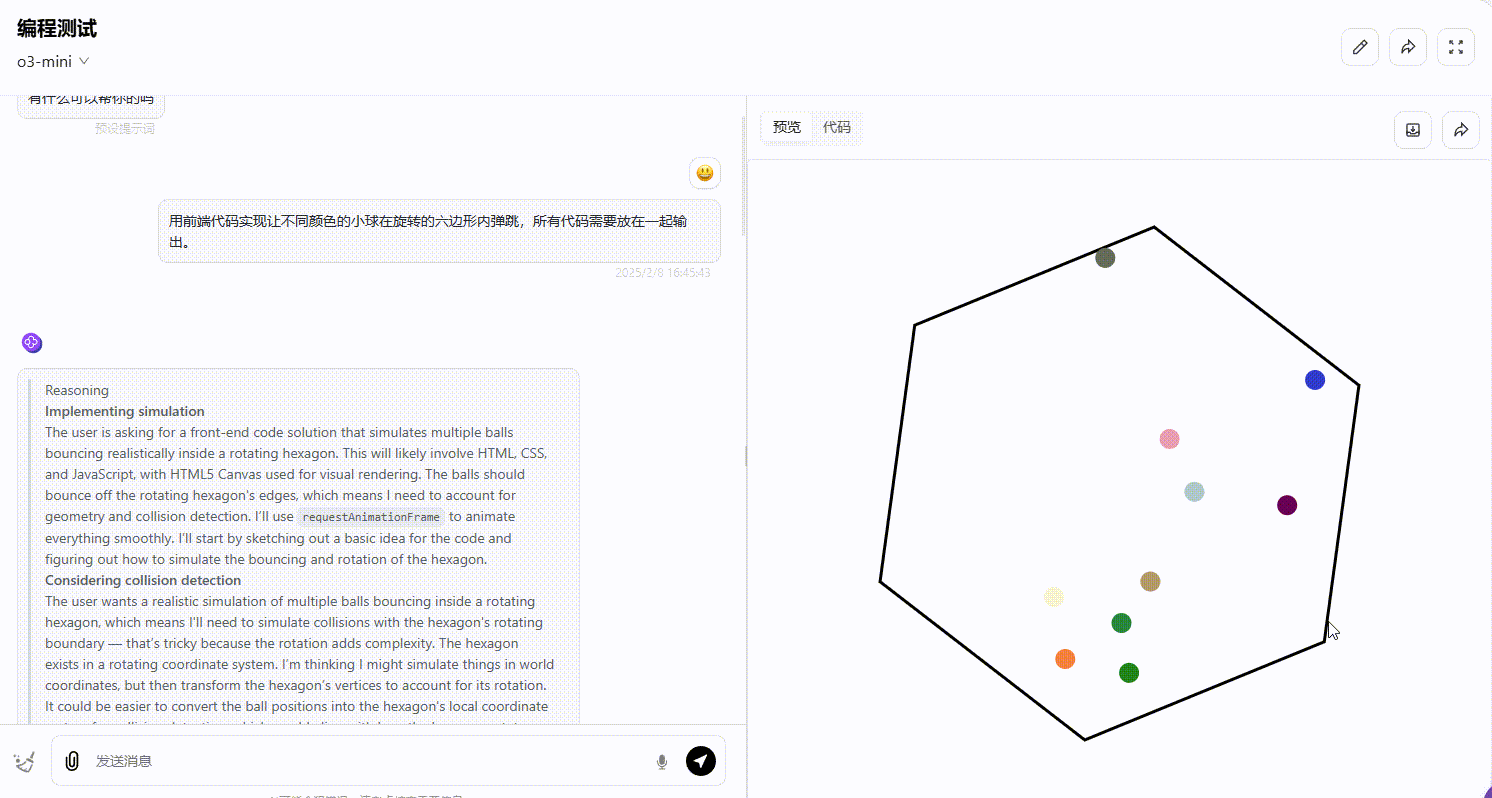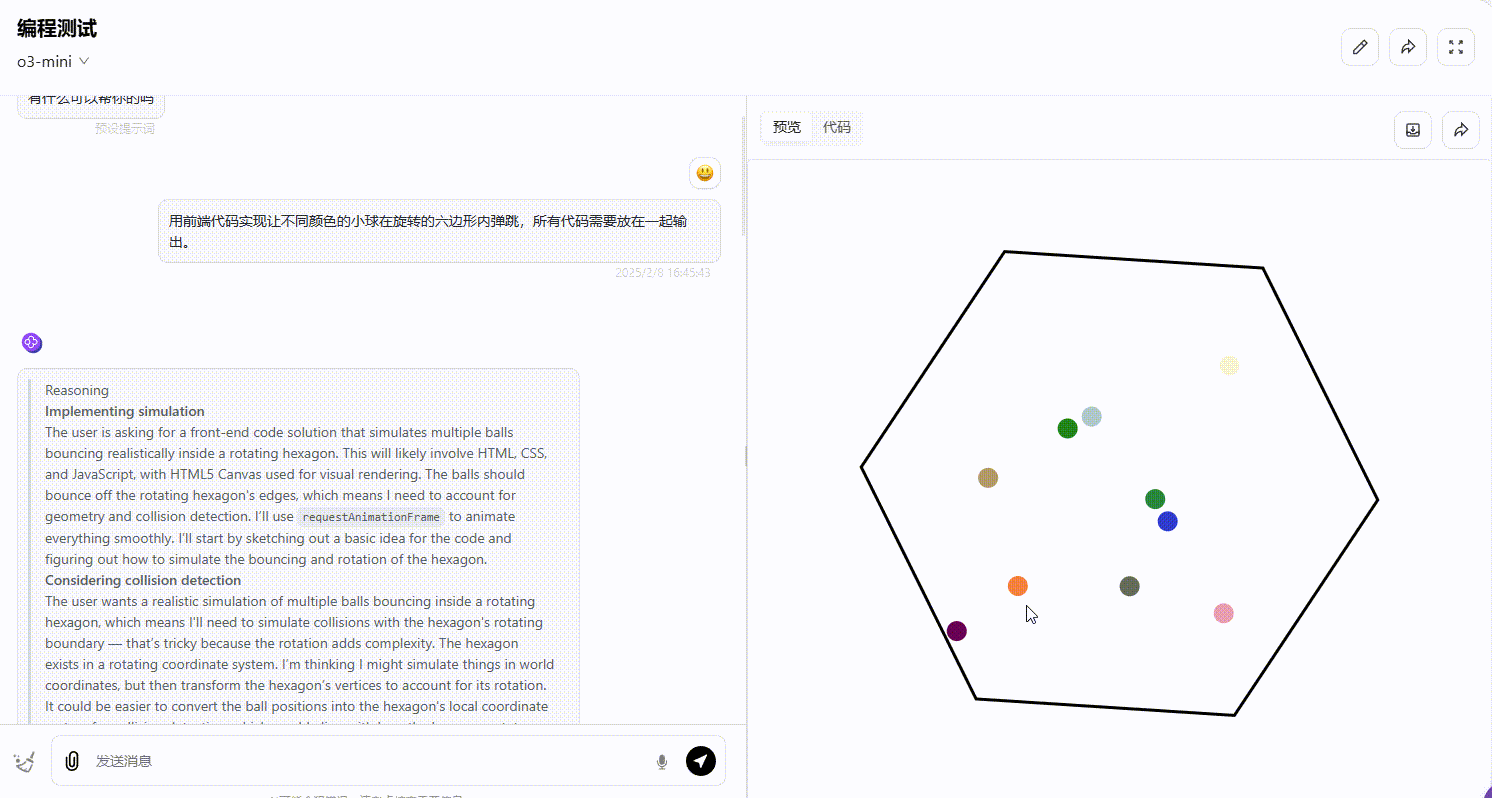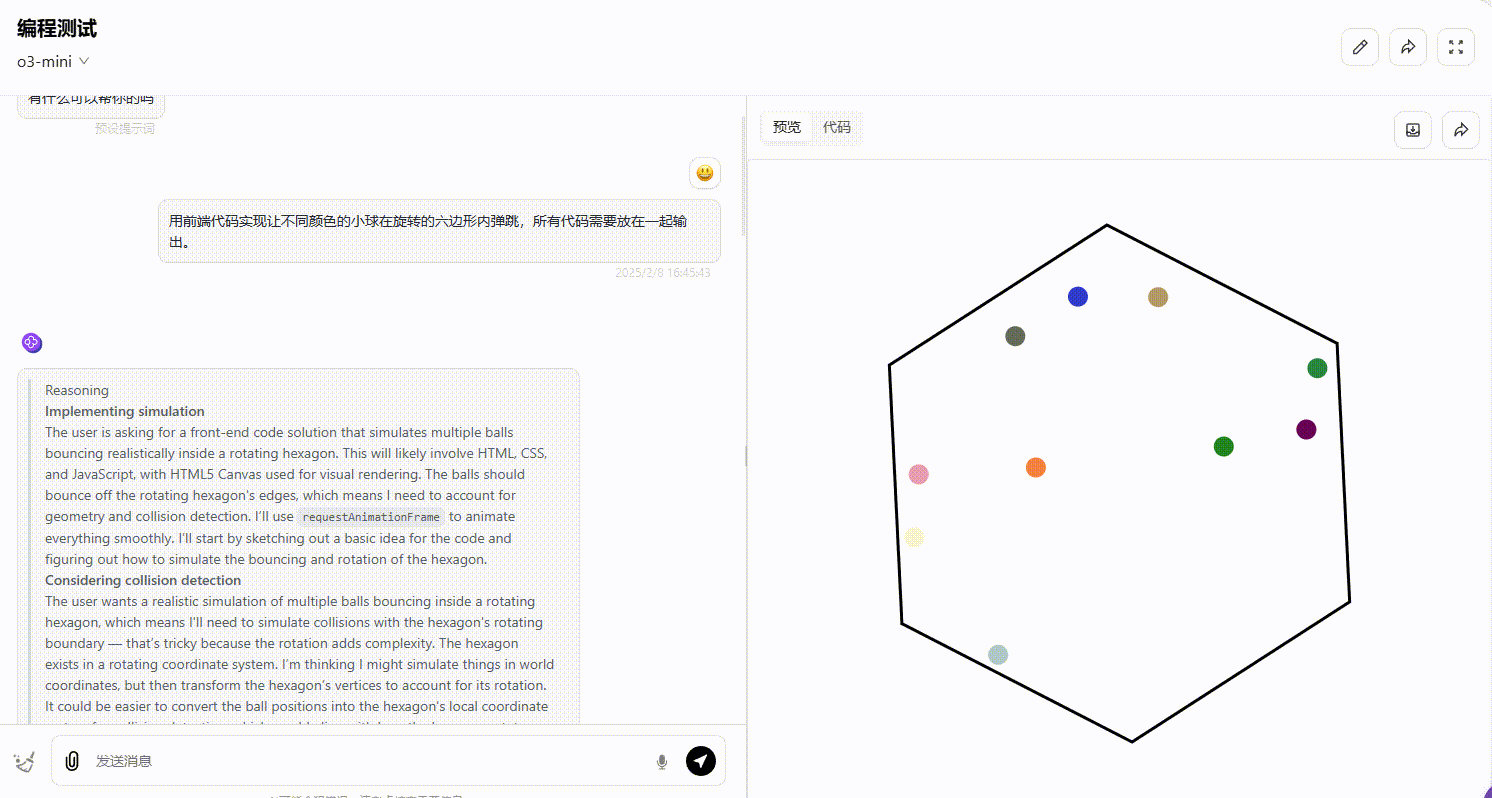
Gemini 2.0 pro:从效果可以看出,部分小球弹跳超出了六边形的范围,不符合要求。
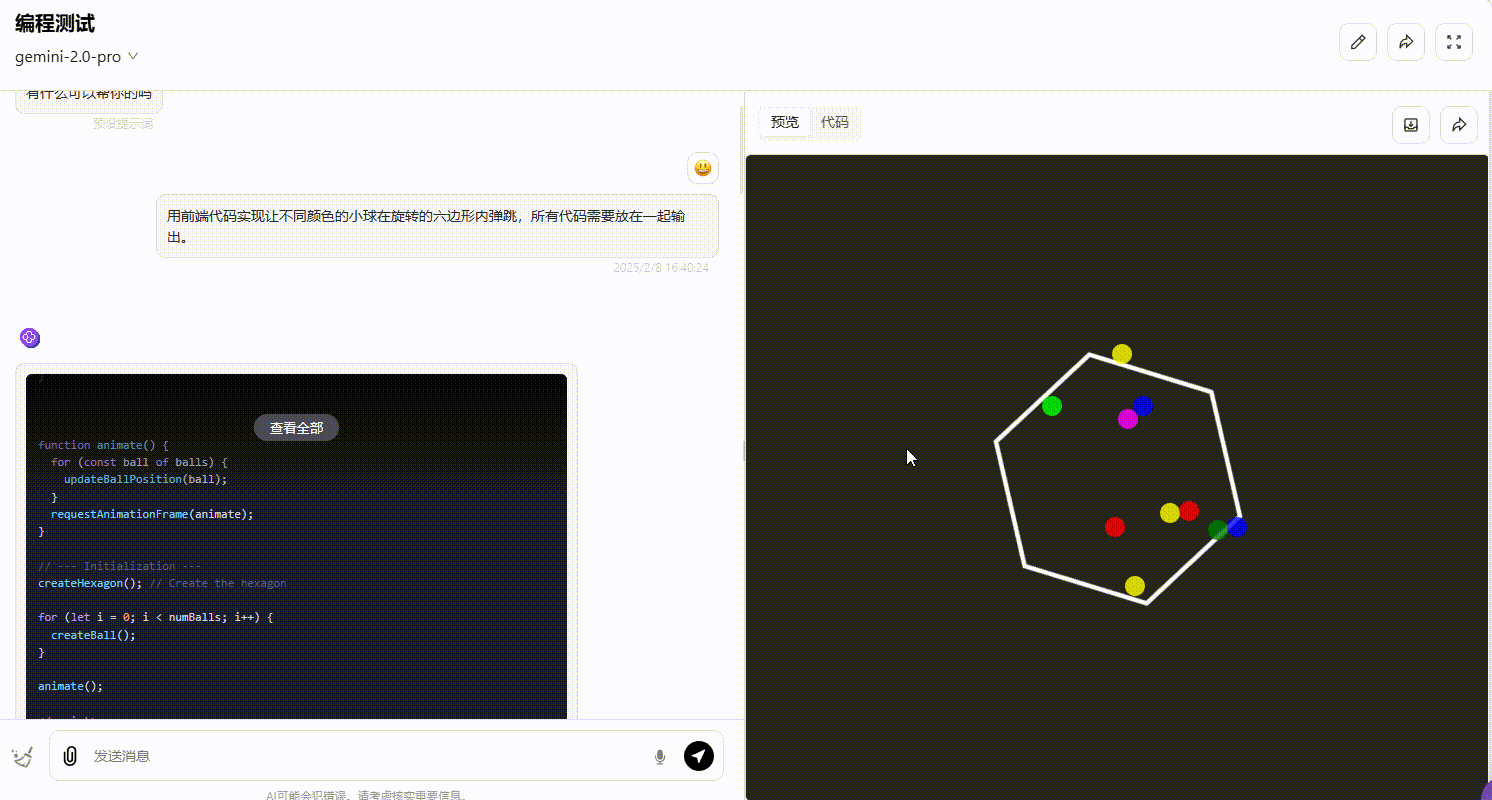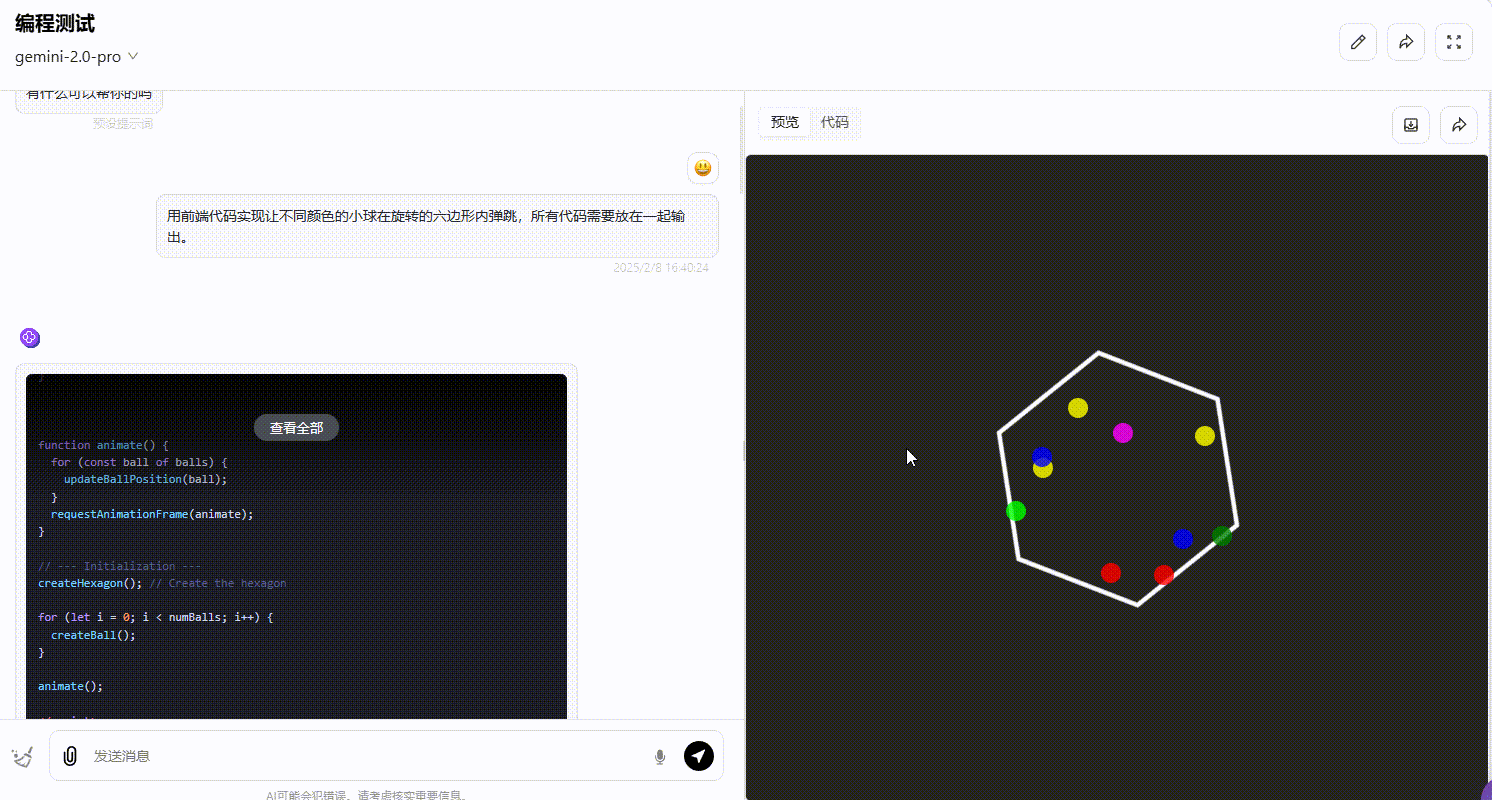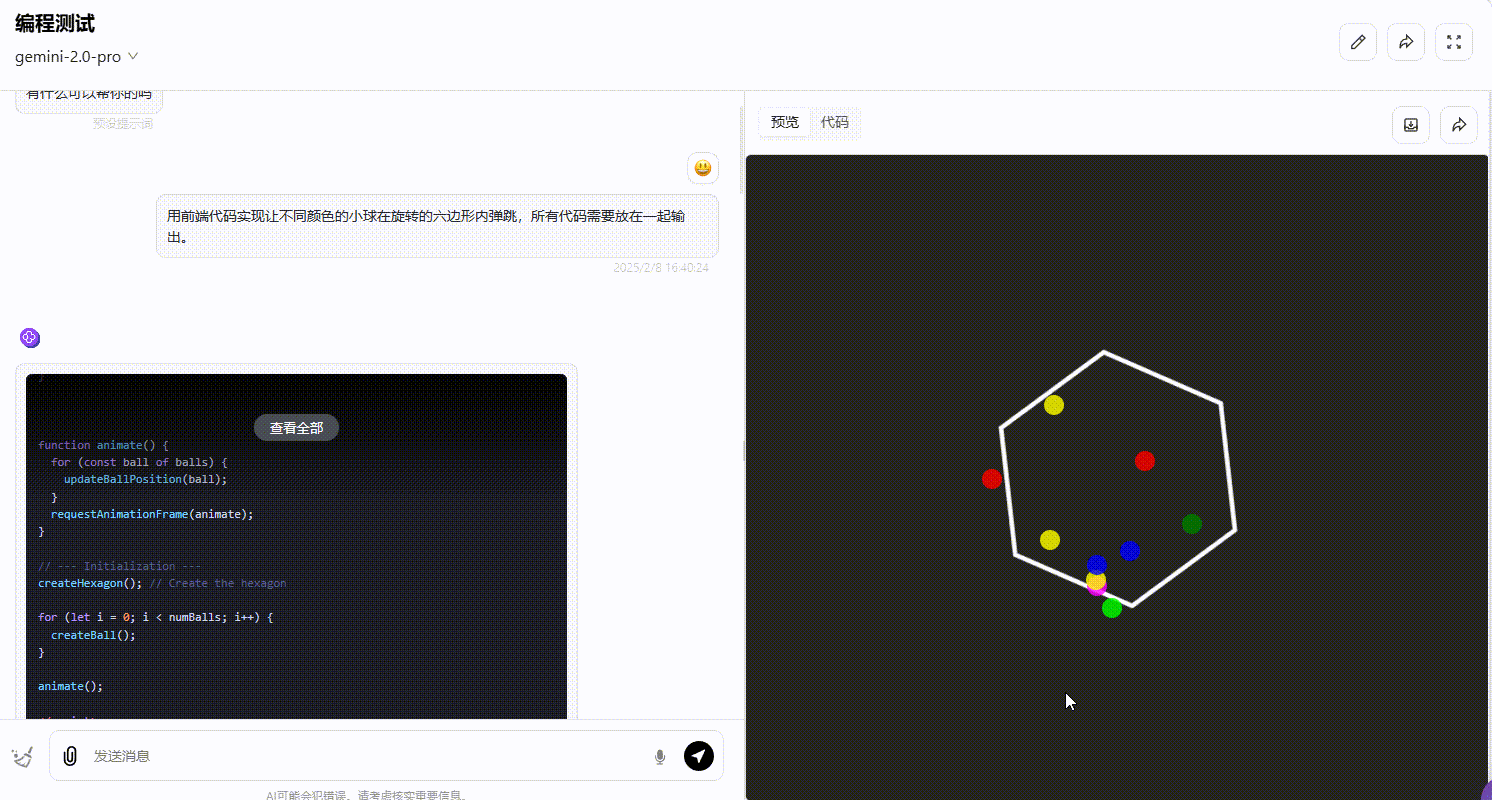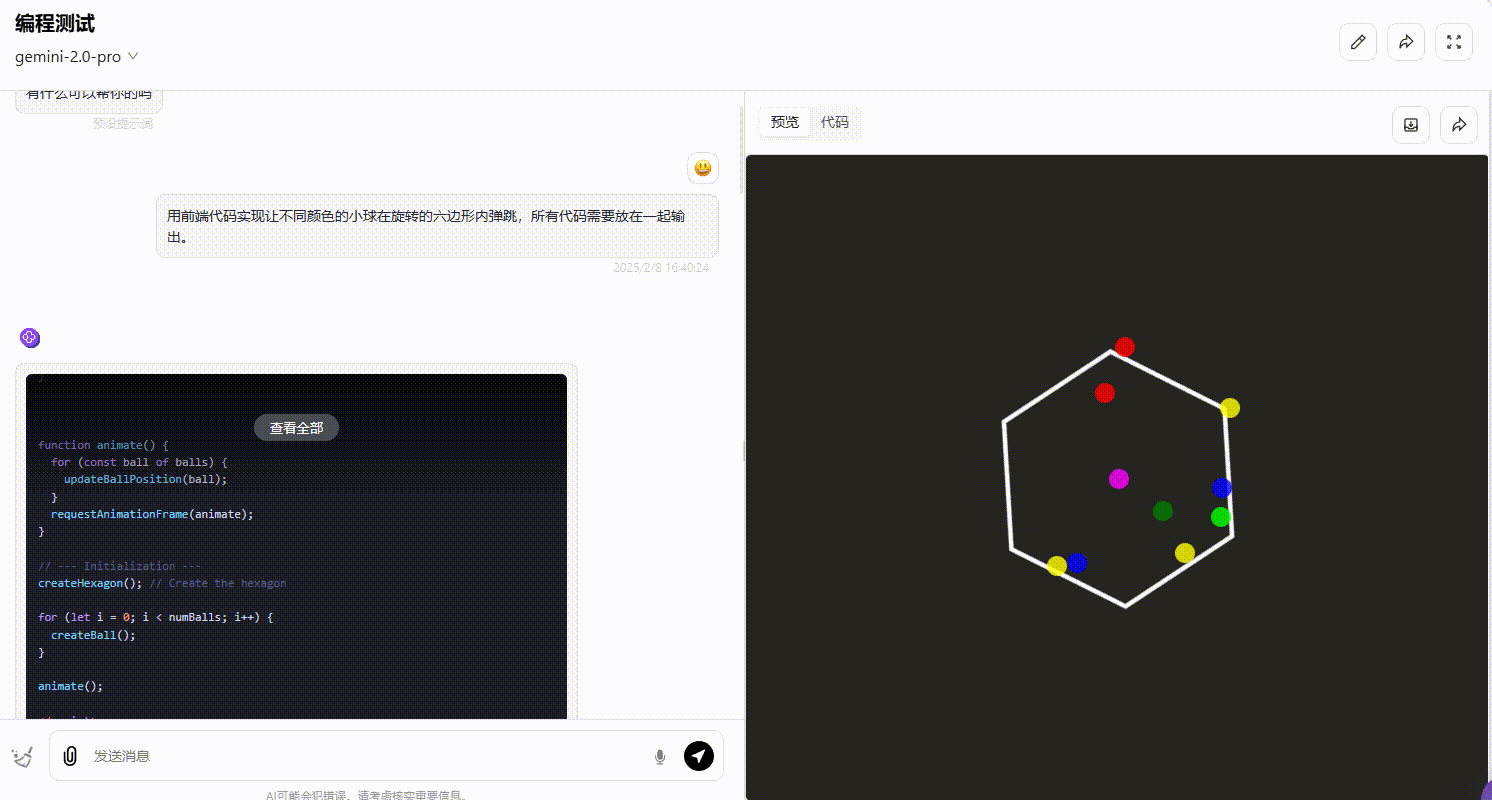
DeepSeek-R1 :R1 的整体效果不尽如人意,界面中小球弹跳的逻辑不够严谨,大部分小球弹跳超出了六边形的范围,不符合要求。
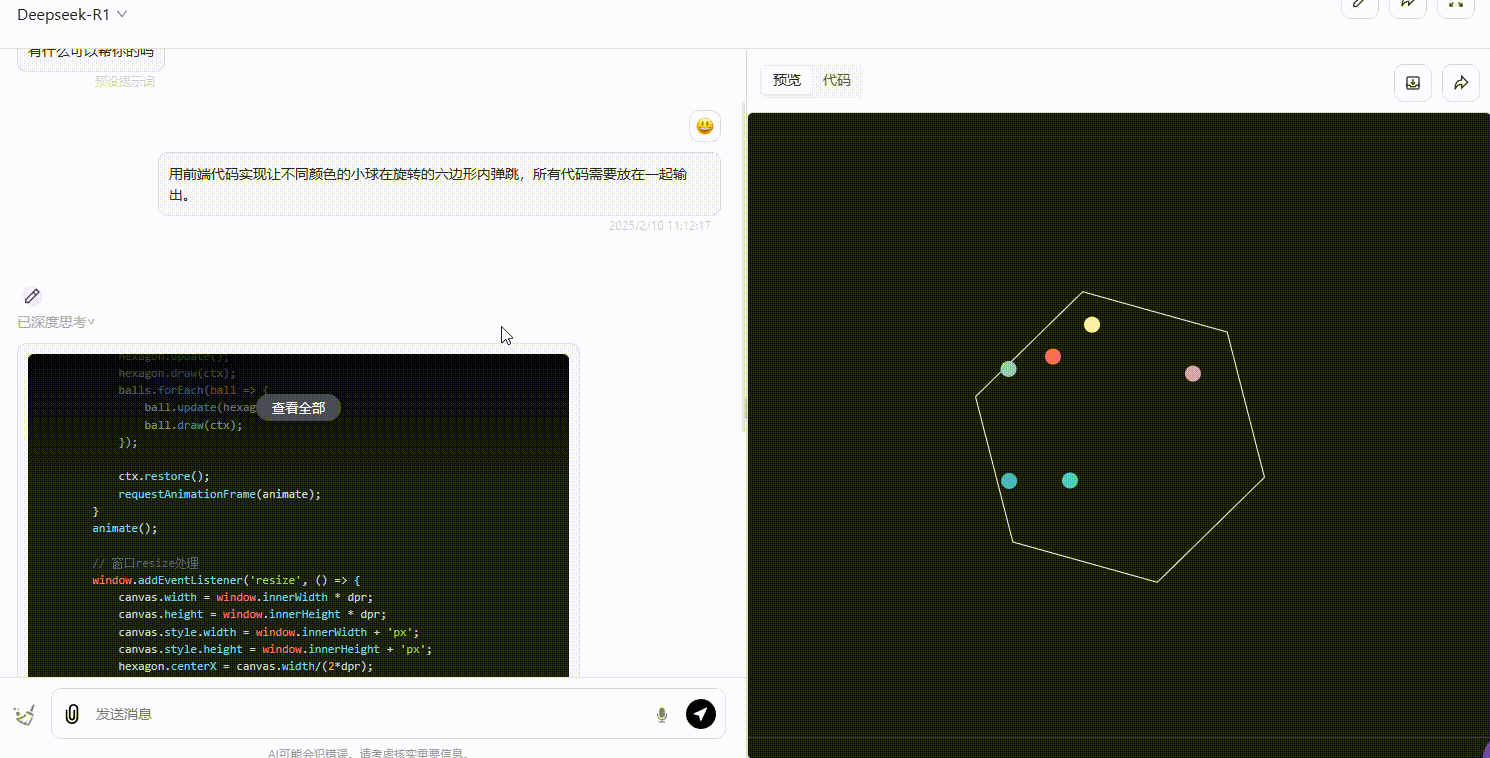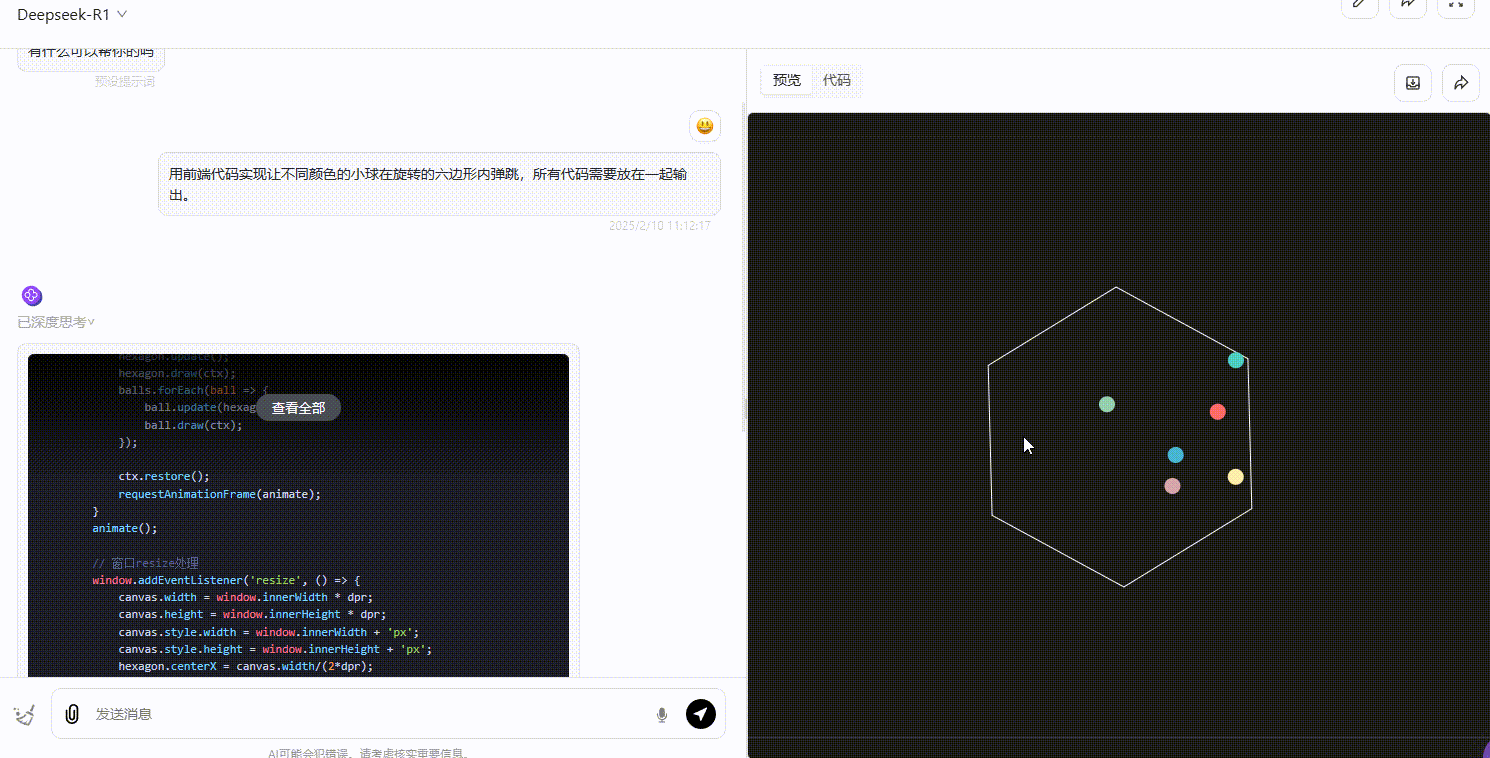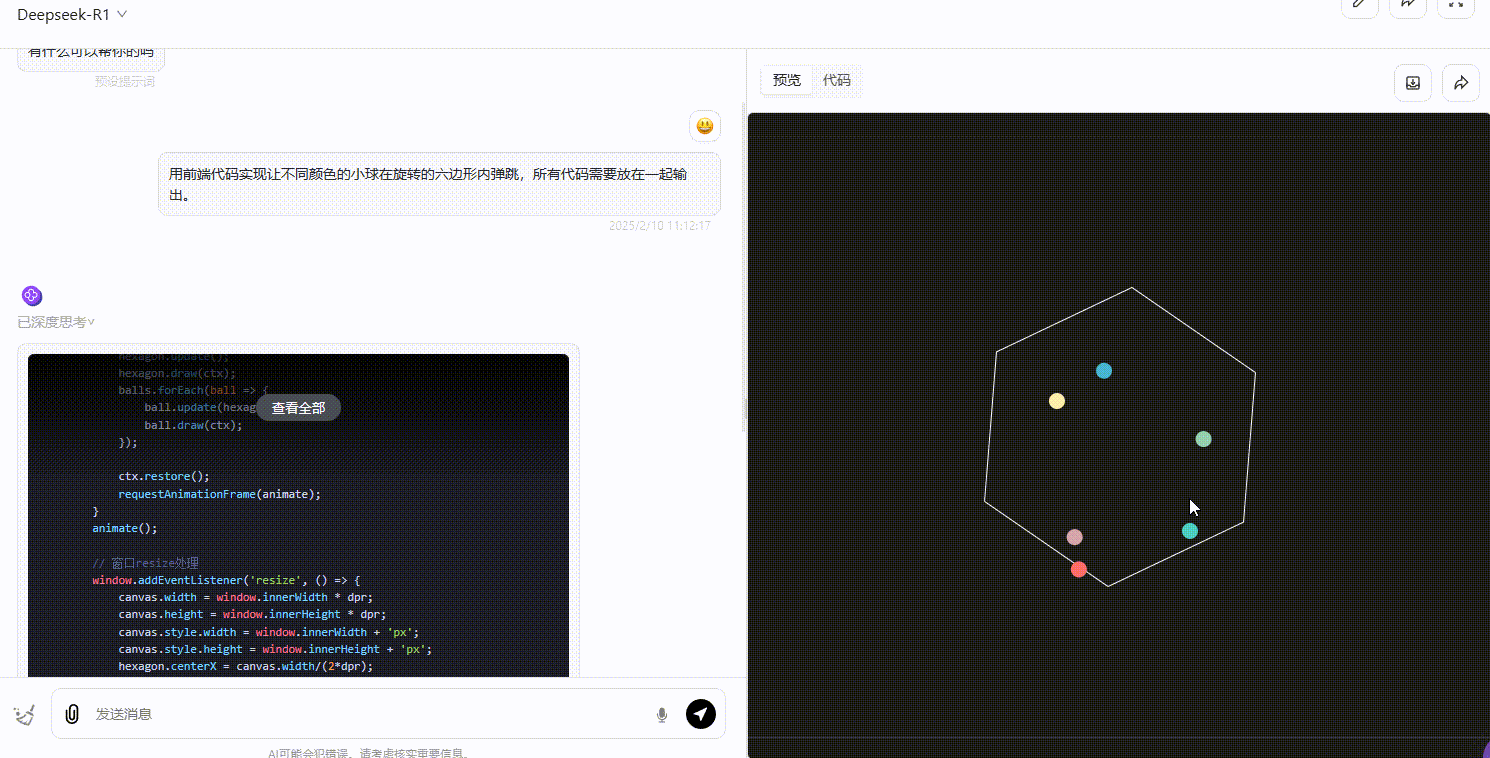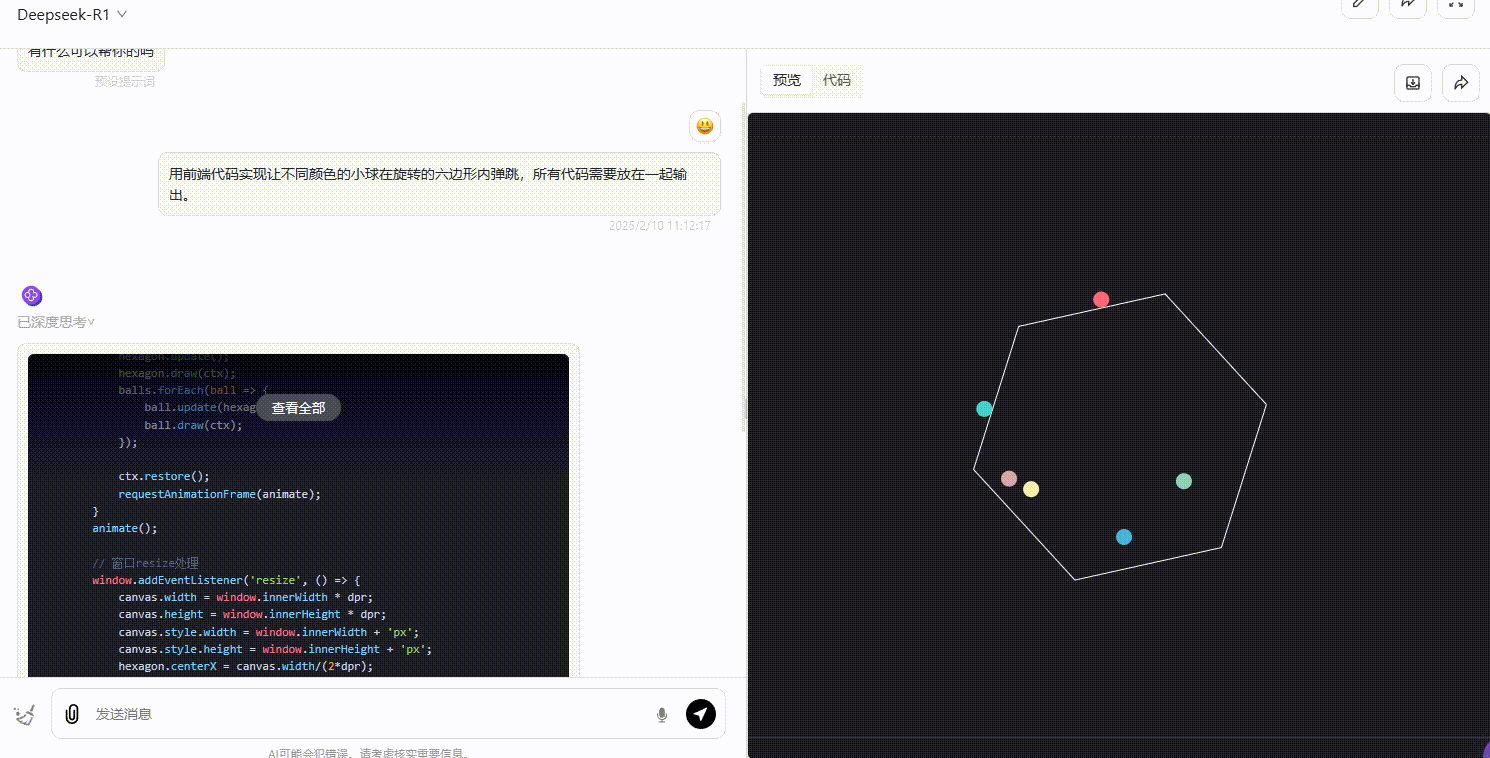
第3轮实测结果:o3-mini > Gemini 2.0 pro = DeepSeek-R1
实测结果总结:
通过以上三个简单的对比实测,能够初步得出以下结论:
(1)在日期计算任务中表现依次排名:DeepSeek-R1 > o3-mini = Gemini 2.0 pro
只有DeepSeek-R1模型给出了正确的答案,o3-mini 和 Gemini 2.0 pro 在考虑因素上有所不足,未能展示出准确的逻辑计算能力。
(2)在逻辑推理方面表现依次排名:DeepSeek-R1 > Gemini 2.0 pro > o3-mini
在推理过程中,DeepSeek-R1通过采用排除法找到了正确答案,表现更加灵活。而Gemini 2.0 pro 尽管也给出了正确答案,但推理过程中略显冗长,而 o3-mini 未能准确理解前提条件,表现不佳。
(3)在编程方面表现依次排名:o3-mini > Gemini 2.0 pro = DeepSeek-R1
在编程任务中o3-mini在六边形内的弹跳逻辑上均符合,效果最好。而 Gemini 2.0 pro 和DeepSeek-R1 则出现了明显的错误,部分小球跳出了六边形的边界。
总的来说,三个模型在实测中展现了不同方面的优势。在逻辑计算与推理方面,DeepSeek-R1优势更明显,但是在编程效果方面则是 o3-mini 效果更好。再回看三个模型的价格对比: Gemini 2.0 Pro > o3-mini > DeepSeek-R1,建议可以参考以上测评并根据自身需求去挑选模型使用。
或许是因为受到了DeepSeek的冲击,各大厂商在推出大模型的时候开始更加注重性价比。模型在提供可靠性能的同时,尽量保持了低成本优势,这对于广大受众来说无疑是一件好事,从前高昂的使用成本让很多用户对于AI望而却步,现在AI技术逐渐成为了大众人人可以用得上的工具。
随着人工智能技术的不断进步,各大模型的竞争也将更加激烈。未来,我们期待这些模型在性能和应用场景上的进一步拓展,以便更好地服务于各类实际需求。
在302.AI上使用o3-mini和Gemini新系列模型
302.AI的聊天机器人和API超市均上线了o3-mini和Gemini新系列模型,并提供按需付费的服务方式,企业和个人用户可按需灵活选用。
1、使用模型对话
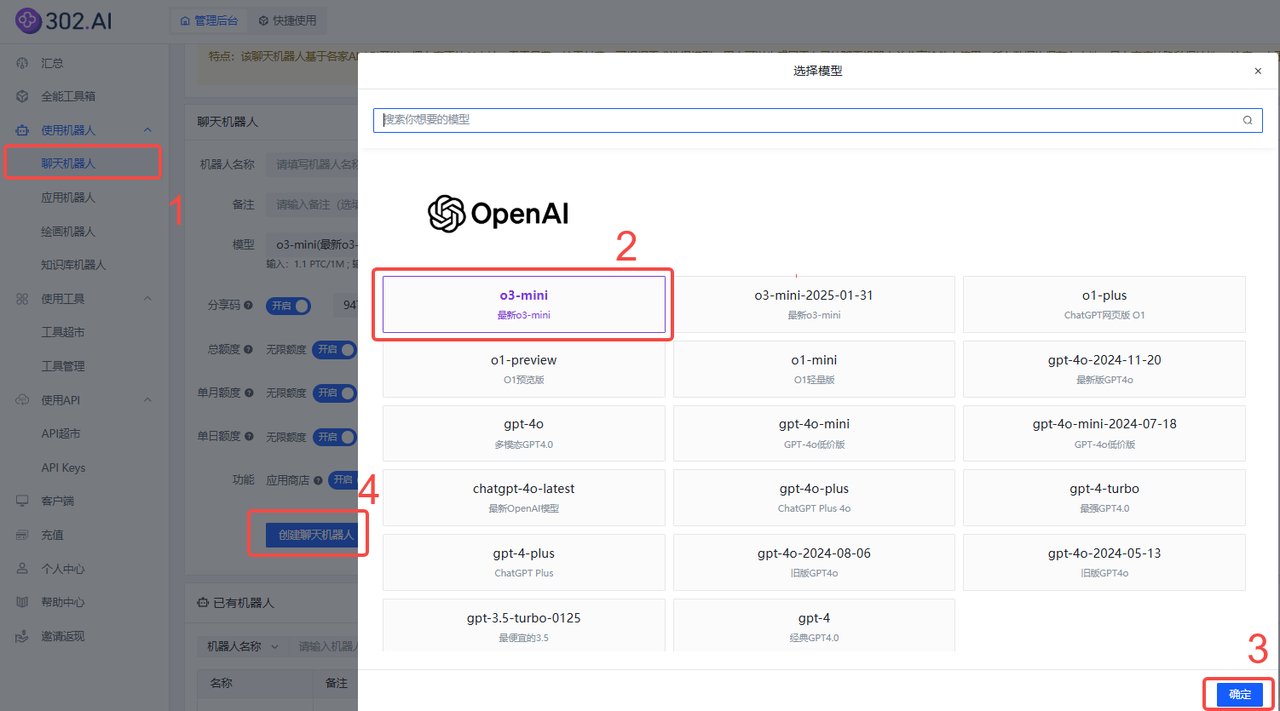
o3-mini:依次点击使用机器人→聊天机器人→ 模型→o3-mini→ 确定→ 创建聊天机器人;
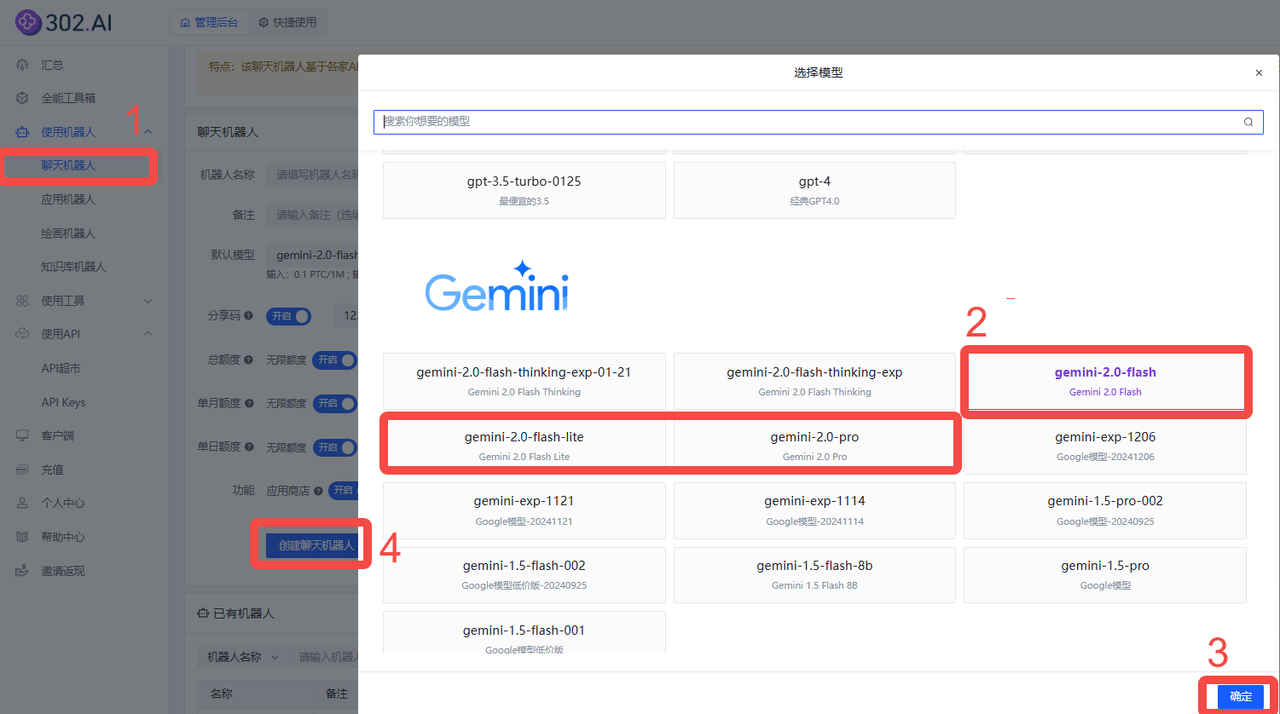
Gemini:依次点击使用机器人→聊天机器人→ 模型→按需选择→ 确定→ 创建聊天机器人;
2、使用模型API
企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发。
相关文档:使用API→API超市→语言大模型→OpenAI/Gemini;
免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
