
3月12日,谷歌正式推出了全新的Gemma 3系列模型,该系列包含四种不同参数版本:1B、4B、12B和27B。据官方介绍,Gemma 3具备强大的多模态能力,能够支持视觉与语言的输入,可以理解140+语言,并提供128k token的上下文窗口。
短短几天后,法国初创公司Mistral AI 也推出了新模型——Mistral Small 3.1。直面对打Gemma 3,该模型参数量仅为24B,且同样具备多模态能力以及多语言处理能力。
Mistral Small 3.1 与 Gemma 3 的性能相似,且均是小参数模型,到底谁更强呢?下面302.AI就带大家实测对比看看 Gemma 3 27B和Mistral Small 3.1模型真实能力。
Gemma 3 27B vs. Mistral Small 3.1模型实测
一、通用能力实测
1、中文语境理解
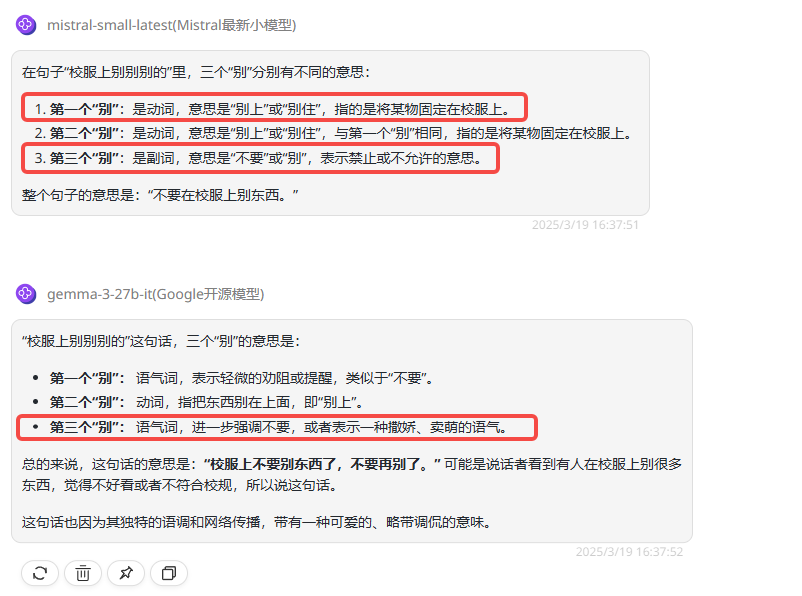
提示词:“校服上别别别的”里的三个“别”分别是什么意思?
考察点:这是来自“弱智吧”的问题,考察的是模型对于中文词语在具体语境中的理解能力。
总结:对于中文词语在特定语境中的理解,Gemma 3 27B模型的准确率优于Mistral Small 3.1,然而遗憾的是两者均未能提供完全正确的答案。
Mistral Small 3.1:只回答正确了第二个“别”字的意思,其余两个理解错误。
Gemma 3 27B:回答正确了两个“别”字的意思,第三个理解错误。

2、推理测试
提示词:
有三个匣子,分别是金匣子、银匣子和铅匣子,其中一个匣子里有宝物。每个匣子上都有一条题词:
金匣子:宝物不在此匣中。银匣子:宝物在金匣中。铅匣子:宝物不在此匣中。
已知这三句话中只有一句是真话。请问宝物在哪个匣子里?
考察点:经典的逻辑推理题目,测试的是模型逻辑思维和推理能力。
总结:Mistral Small 3.1的回答是正确的,而Gemma 3输出的答案尝试两次分析,但逻辑都存在前后矛盾,最终导致回答错误。
Mistral Small 3.1:分析正确,回答正确。

Gemma 3 27B:Gemma分析直接把自己绕晕了,回答错误。

3、编程测试
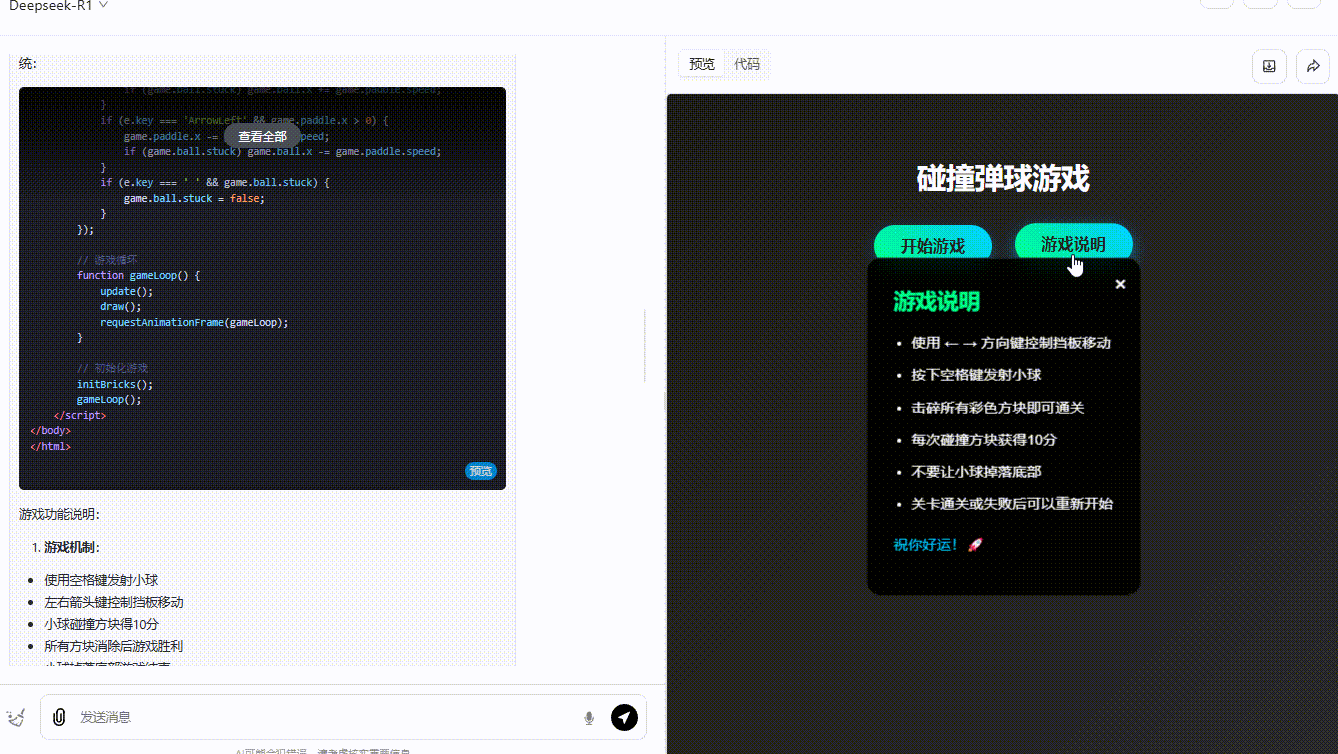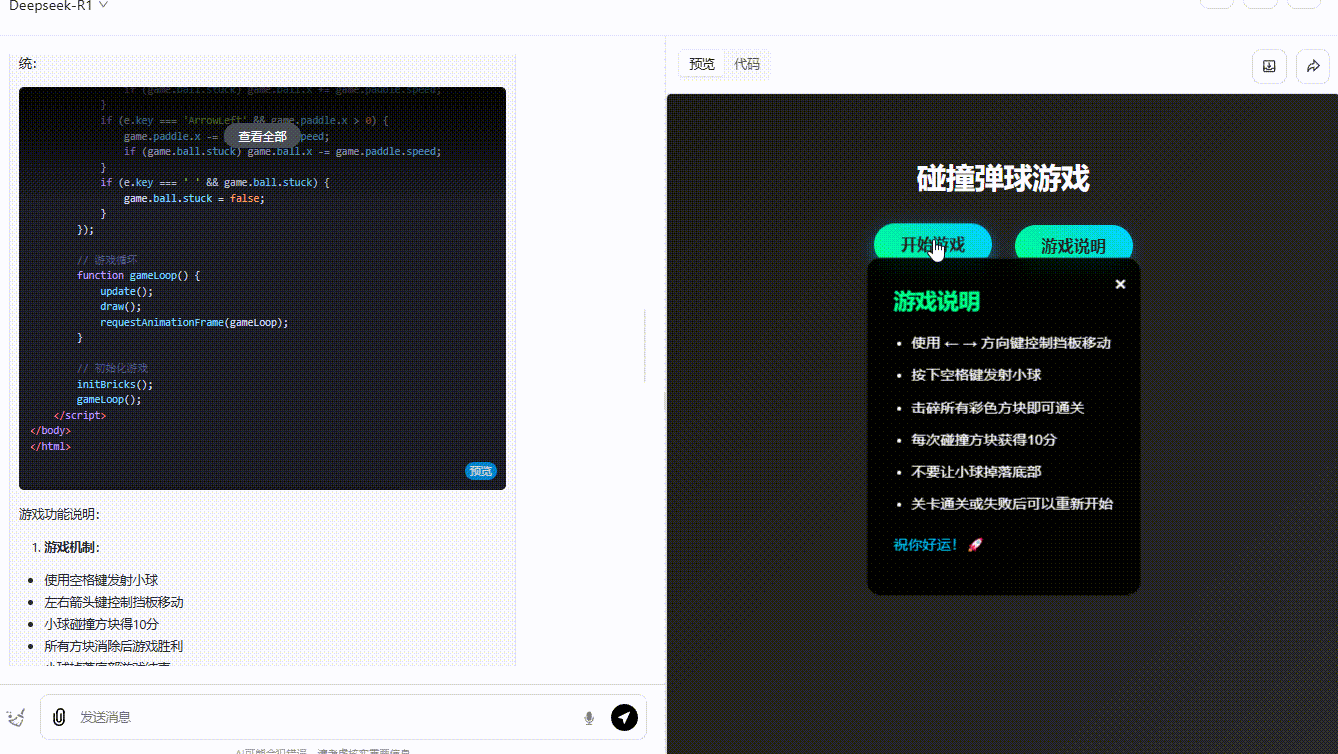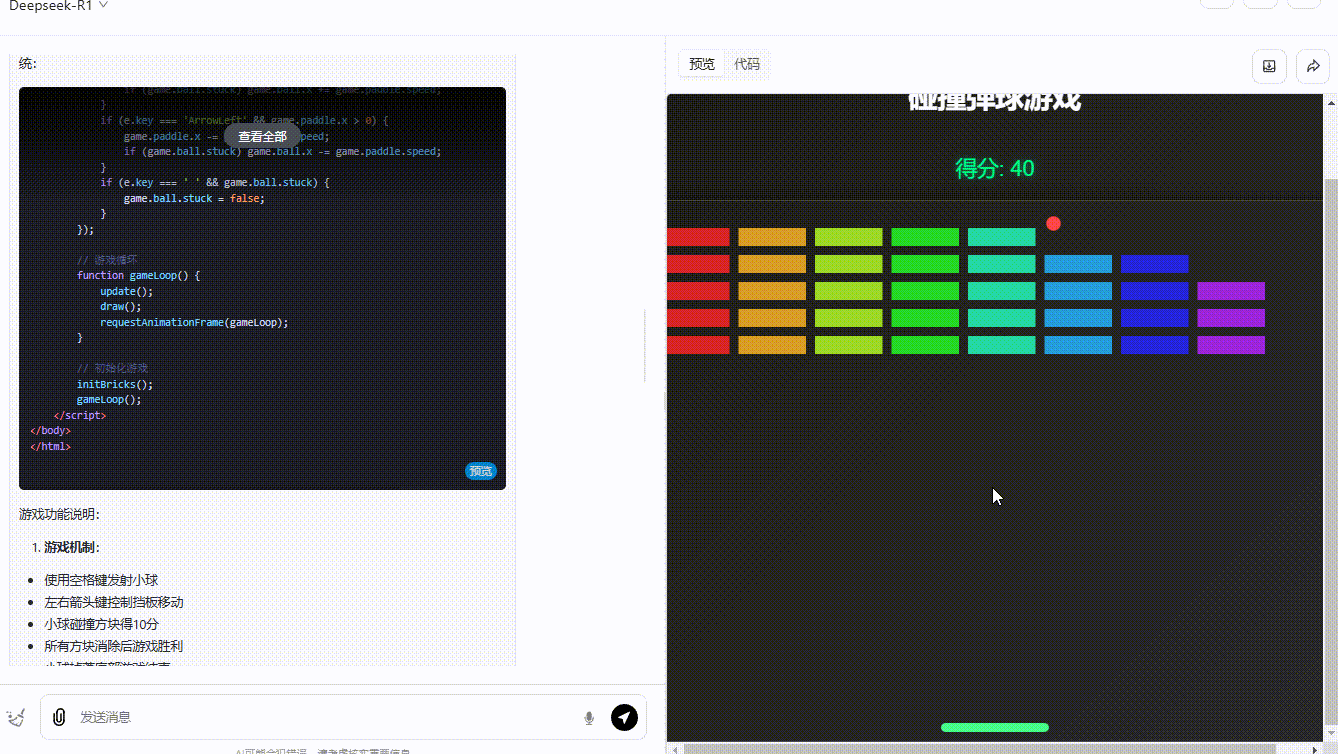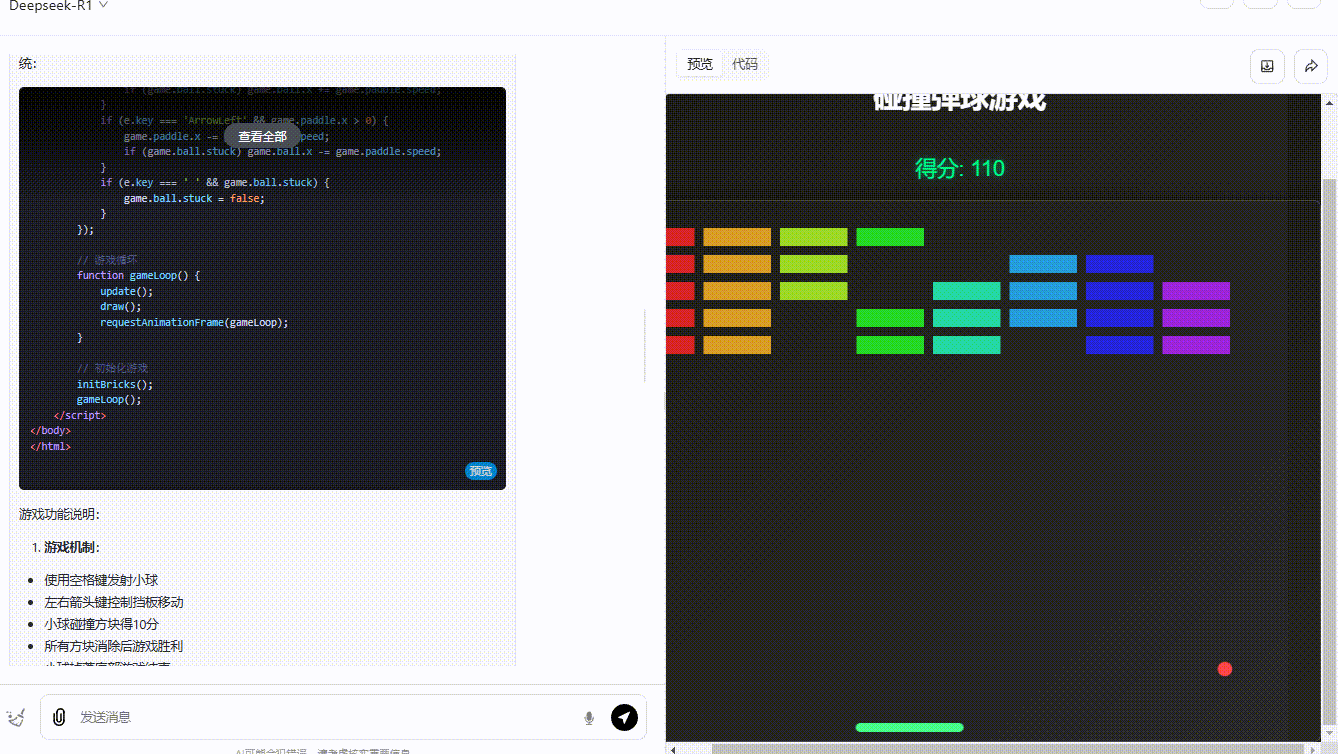
提示词:制作一个碰撞小游戏:页面放置了方块,小球在弹跳,小球碰到方块则得分,方块全部消失即通关。界面需要包含开始游戏按钮、游戏说明。所有代码放在一起输出。
总结:两个模型的生成效果都较一般,但Gemma 3整体还是更完整一点。
Mistral Small 3.1:效果不尽如人意。在初始页面的游戏说明中明确指出,得分规则是通过小球碰撞方块,但实际效果却直接缺少方块元素,整体表现只能算作半成品。

Gemma 3 27B:整体逻辑是合理的,分数根据小球的弹跳实时更新,但游戏元素超出了屏幕范围,界面显得较为粗糙,而且缺乏用户交互性。
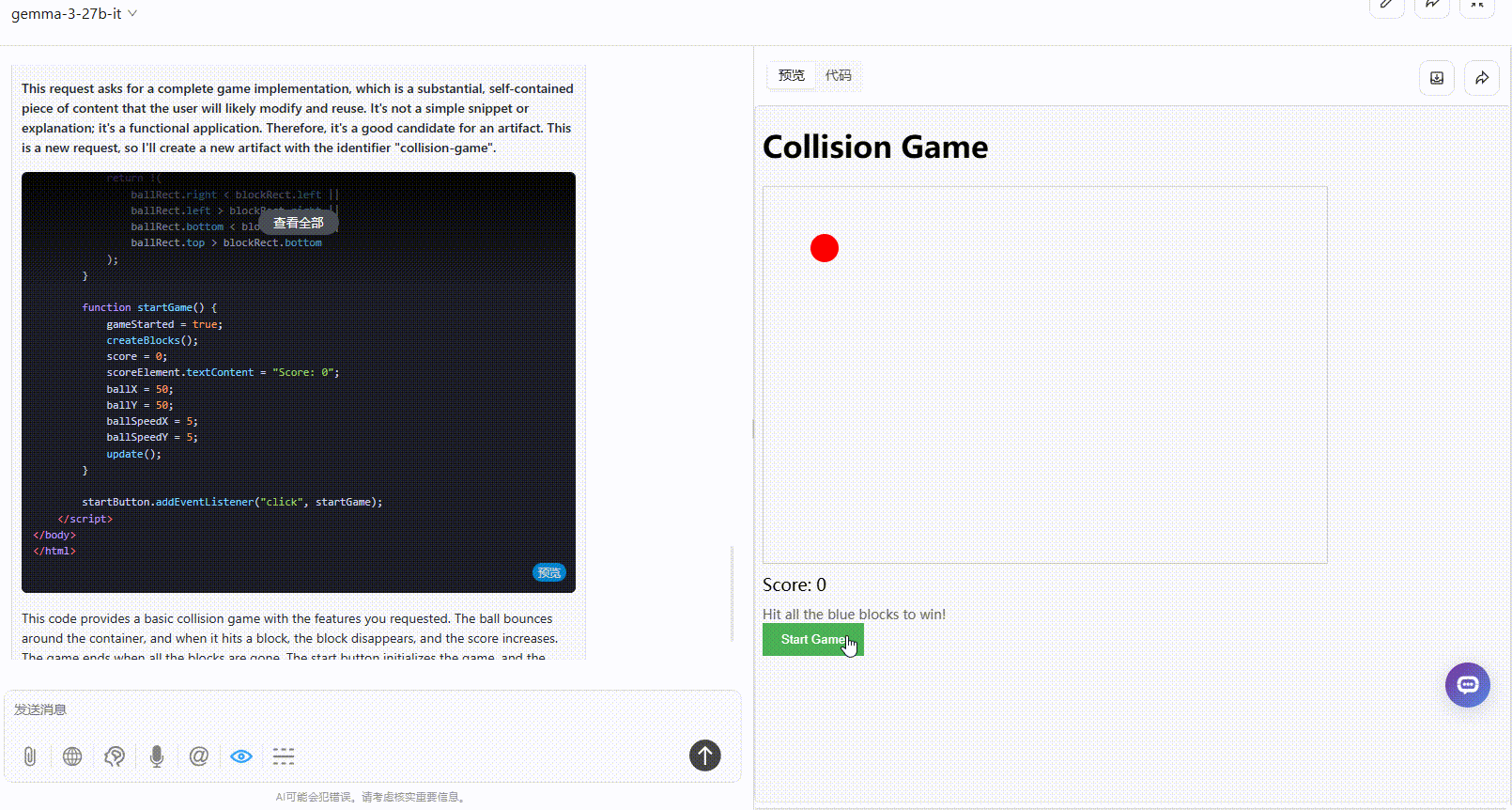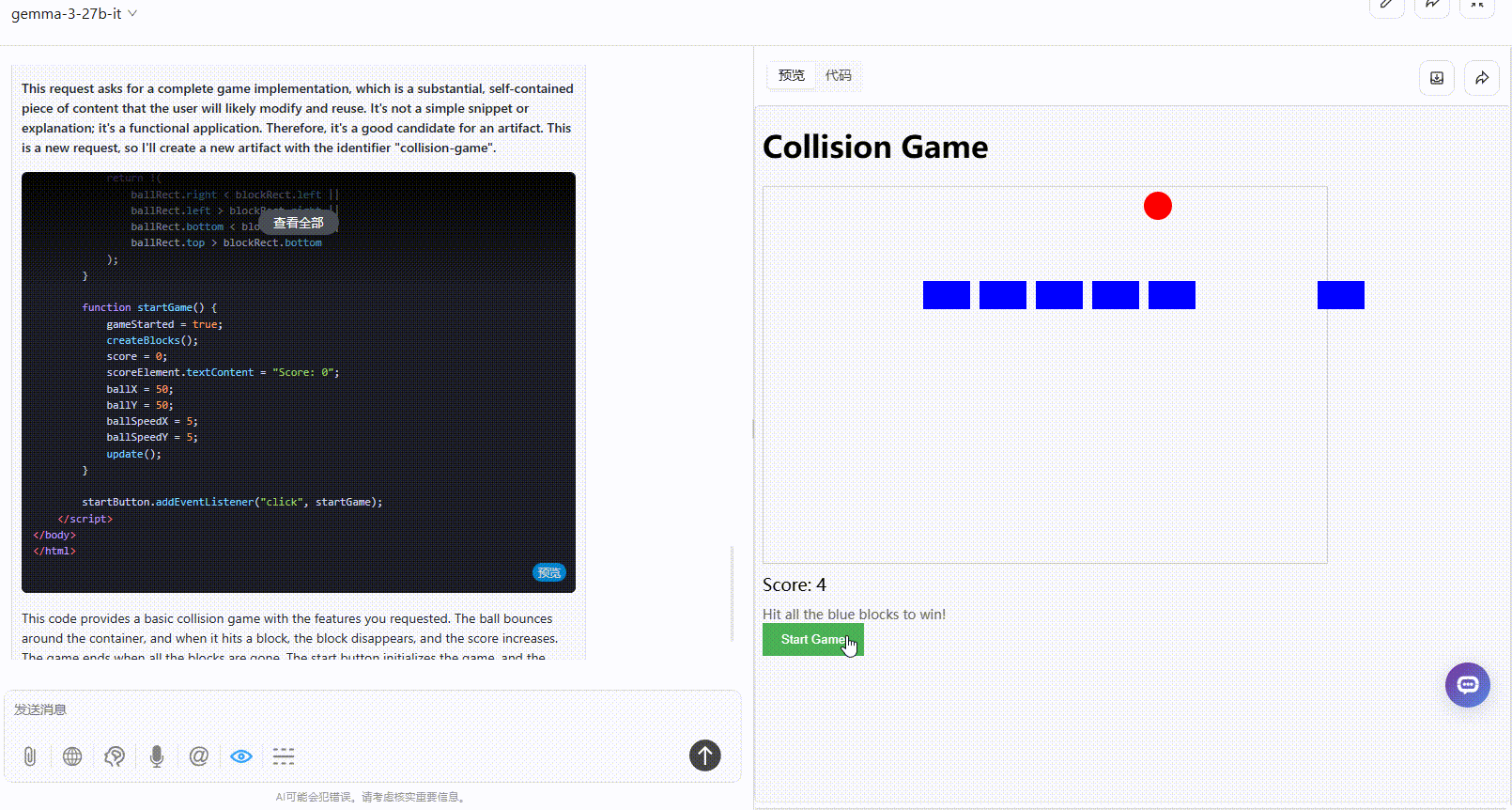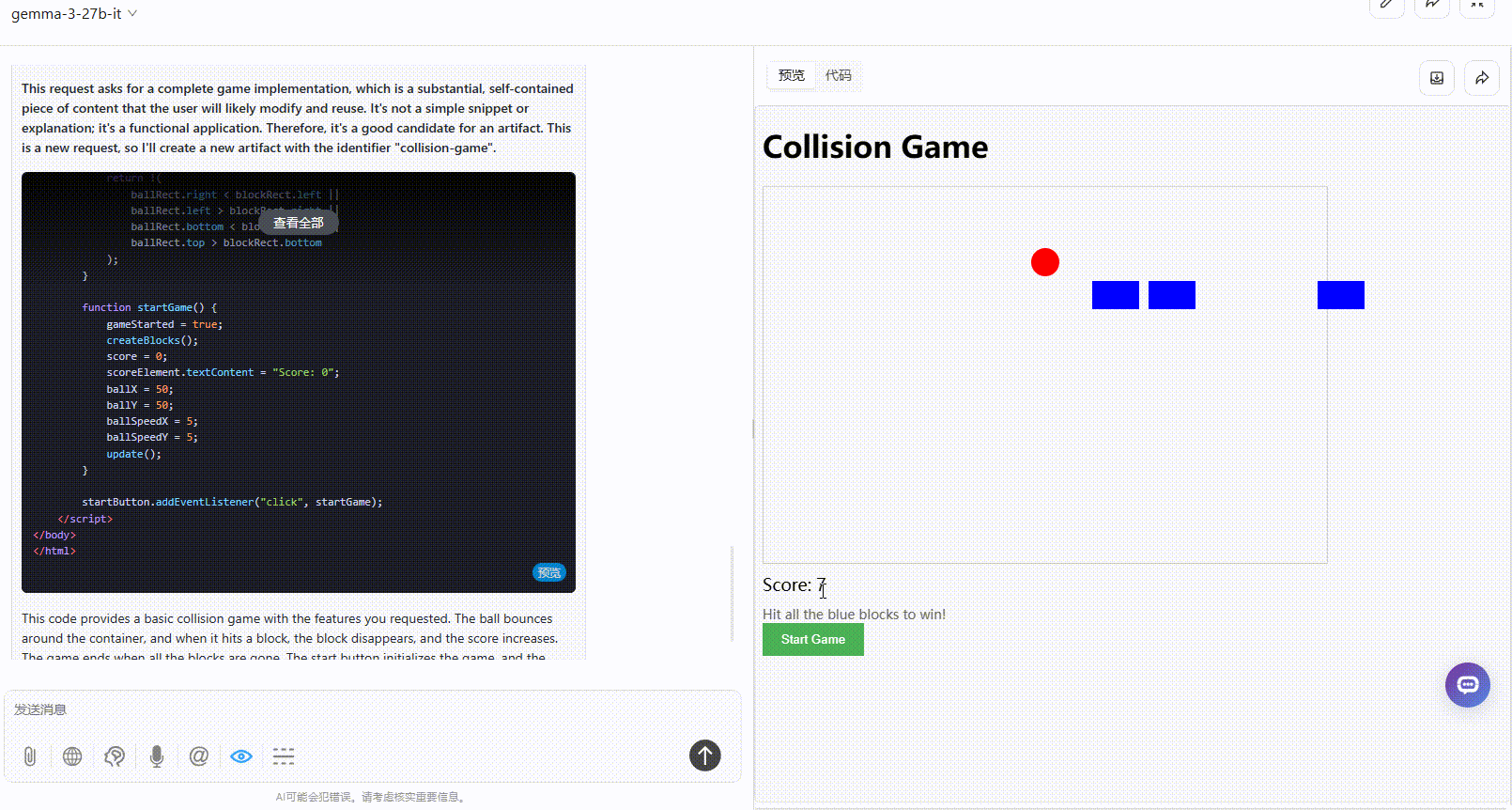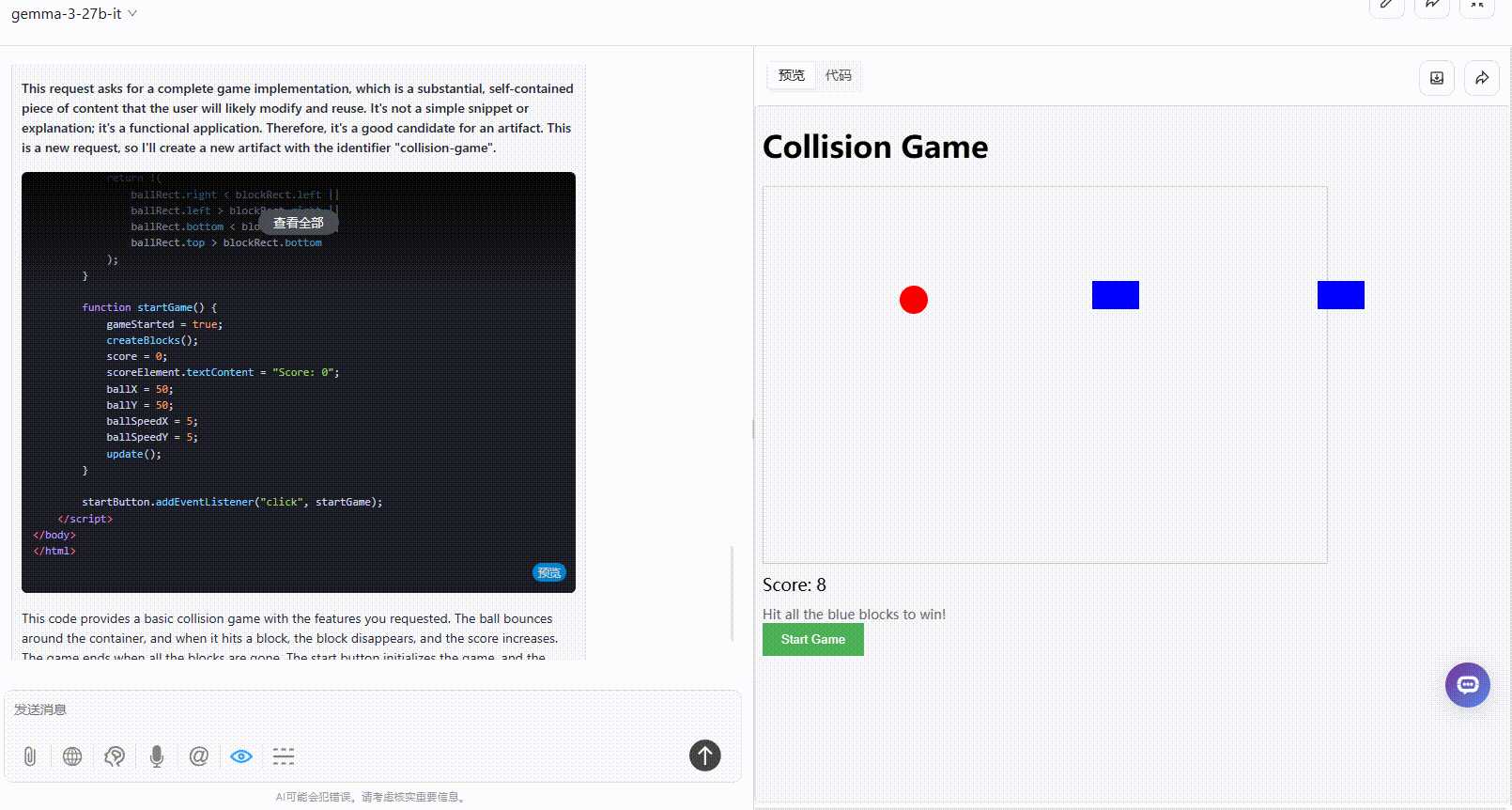
参考效果DeepSeek-R1:界面美观、效果完整,小球弹跳正常,得分显示正常,且用户能通过键盘操作游戏。
二、多模态能力实测
1、内容识别:
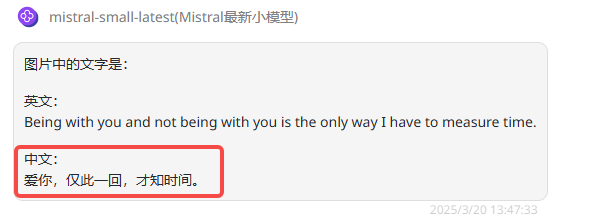
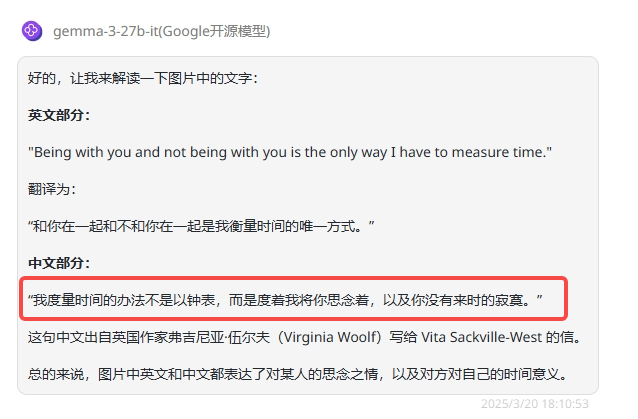
提示词:图片中中文和英文分别写了什么?

(图源网络)
考察点:测试模型对图片中文字的识别和理解能力,这涉及到大模型的图像识别技术,以及对中英文语言的理解和翻译能力。
总结:两个模型均正确识别出了英文内容,但中文内容识别表现不佳。
Mistral Small 3.1:英文内容完全识别正确,但中文部分完全不对。
Gemma 3 27B:英文内容完全识别正确,但中文部分不正确。
2、图表分析:
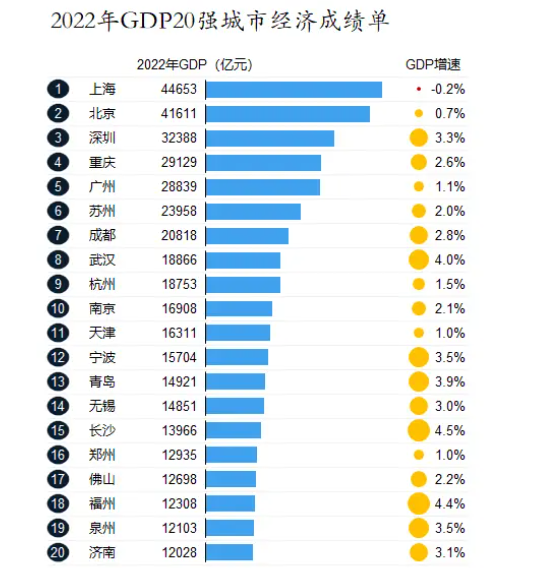
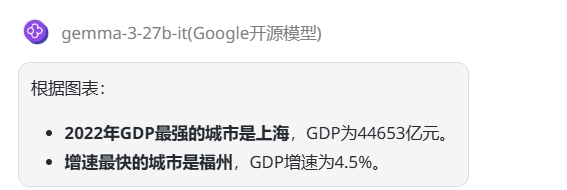
提示词:请根据图表回答,2022年GDP最强的城市是哪个?增速最快的城市是哪个?
(图源网络)
考察点:测试模型图表阅读、信息提取以及分析能力。
总结:Mistral Small 3.1在图表理解方面表现更优,Gemma 3 则是只回答正确了GDP最强的城市,未答出增速最快的城市。
Mistral Small 3.1:对于含有少量中文的图表,两个提问模型都给出了正确答案。
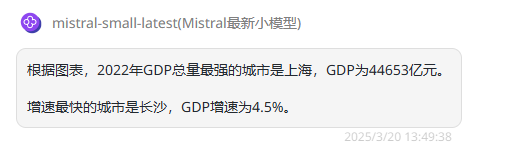
Gemma 3 27B:第一个问题回答正确,第二个问题回答错误,福州对应的GDP增速应该是4.4%而不是4.5%。
3、多模态推理:
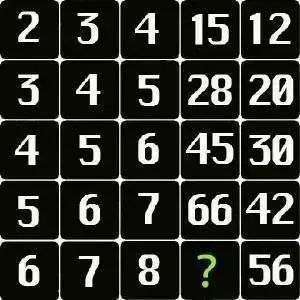
提示词:根据规律回答问号处的数字应该填什么?(正确答案是91)
(图源网络)
考察点:模型能否识别并理解数字之间的潜在规律或模式,并据此进行推理以找出未知的数字。
总结:Mistral Small 3.1模型“无中生有”了数字,出现了模型幻觉,而Gemma 3回答给出了正确的答案。
Mistral Small 3.1:输出的规律里出现了图片中没有的数字,最后答案是错误的,这或许是存在“模型幻觉”。

Gemma 3 27B:答案正确。

实测总结:
通过以上对比实测,可以初步得出以下结论:
通用任务方面:
(1)两模型中文语境理解均存局限
表现排名: Mistral Small 3.1<Gemma 3 27B
在中文语境理解测试中,两个模型均未能完全理解所有中文字的含义,可得出在处理中文语言环境时的两个模型均存在局限。
(2)Mistral Small 3.1推理能力更优
表现排名:Mistral Small 3.1 > Gemma 3 27B
在推理测试中,Mistral Small 3.1给出了正确答案,展示了较强的逻辑推理能力。而 Gemma 3 多次分析都陷入逻辑矛盾中,逻辑方面的能力仍需增强。
(3)两模型编程效果各方面表现欠佳
表现排名: Mistral Small 3.1=Gemma 3 27B
在编程测试中,两者的编程效果均不理想。无论是从效果的完整性、交互性还是界面美观度来说,小参数模型上升的空间还较大。
多模态方面:
(1)中文内容识别能力不足
表现排名: Mistral Small 3.1 < Gemma 3 27B
在内容识别任务中,两个模型对中文内容的识别准确度较低。这表明,当处理包含大量中文的多模态任务时,模型的整体表现会受到一定程度的影响。
(2)含有少量中文图表任务的准确度表现
表现排名: Mistral Small 3.1 > Gemma 3 27B
在图表分析任务中,Mistral Small 3.1表现更为出色。图片中仅包含少量中文内容,主要以数字和图形为主,这表明,Mistral Small在处理少量中文内容的任务时,准确度受影响较小。
(3)结合图像与推理的任务Gemma 3表现更优
表现排名: Mistral Small 3.1 < Gemma 3 27B
多模态推理方面,Gemma 3 27B成功推理出了正确的答案,这表明Gemma 3能够在视觉信息和逻辑推理之间建立有效的联系,提供更为准确和全面的解答。
小模型的诞生旨在满足多样化应用场景的需求。一般来说,小参数模型在端侧设备适配度上远远高于大参数模型。然而,经过今日的实测发现,当前小参数模型在各类任务中的准确率仍有较大的提升空间。在未来,或许“大模型训练,小模型落地”的模式才是真正的发展方向。
在302.AI上使用 Gemma 3 27b 和 Mistral small 3.1 模型
302.AI的聊天机器人和API超市提供了按需付费无订阅的服务方式,企业和个人用户可按需灵活选用。
1、使用模型对话
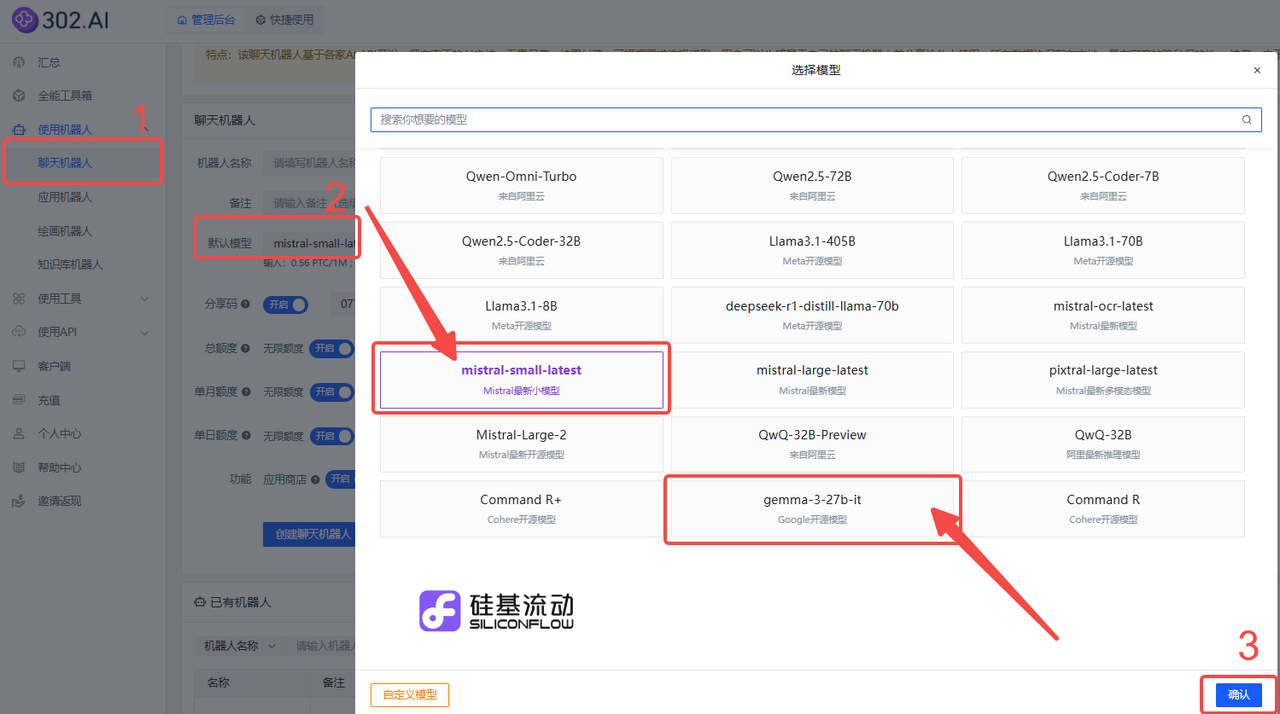
依次点击使用机器人→聊天机器人→ 模型→下滑到“开源模型”→ 按需选择mistral-small-latest/gemma-3-27b-it→创建聊天机器人;
(mistral-small-latest即mistral small 3.1 24B 模型)
2、使用模型API
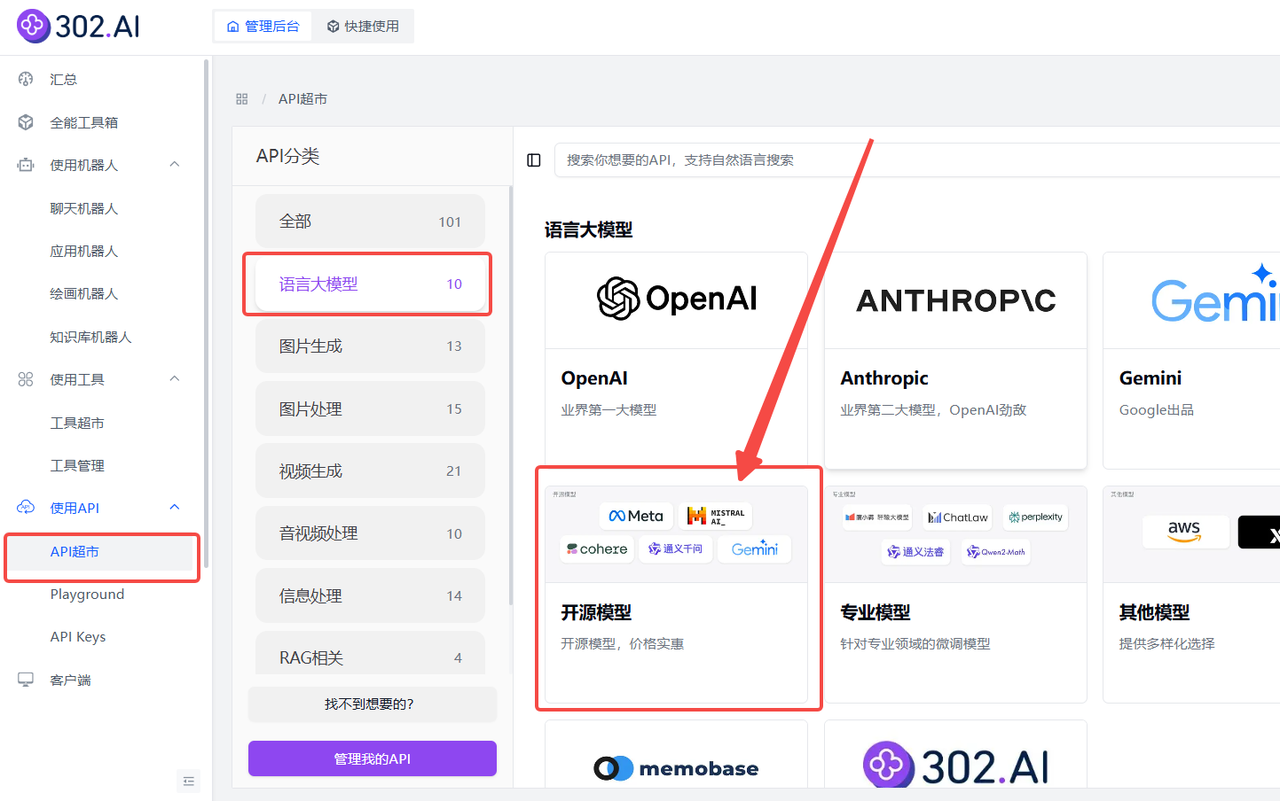
企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发。
相关文档:使用API→API超市→语言大模型→开源模型→查看文档;
Gemma 3 27b模型的API名称:gemma-3-27b-it;
Mistral small 3.1的API名称:mistral-small-2503;
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

Comments(4)
Im not certain where you are getting your info, but great topic. I must spend a while finding out more or understanding more. Thanks for fantastic info I was searching for this information for my mission.
Thanks a lot for sharing this with all folks you actually recognize what you are talking approximately! Bookmarked. Please additionally seek advice from my web site =). We could have a link exchange contract among us!
I do agree with all the ideas you’ve presented in your post. They’re very convincing and will definitely work. Still, the posts are too short for beginners. Could you please extend them a bit from next time? Thanks for the post.
I?¦ve recently started a site, the info you provide on this site has helped me greatly. Thanks for all of your time & work.