


4 月 15 日凌晨,OpenAI 发布了全新 GPT-4.1 系列模型,其中包括:GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano 。官方表示,这三个模型的性能全面超越了 GPT-4o 和 GPT-4o mini,并在编程、指令遵循和上下文理解方面有显著提升。
与此同时,OpenAI 还宣布将在 API 中弃用 GPT-4.5 预览版,因为 GPT-4.1 在许多关键功能上提供了改进或类似的性能,并且成本和延迟更低。弃用时间为三个月后(2025 年 7 月 14 日),以便开发者有时间过渡。

![]()
此外,国内智谱公司还开源了两个新推理模型:GLM-Z1-Air 和 GLM-Z1-AirX,其中官方描述 GLM-Z1-AirX 为国内最快推理模型,推理速度可达 200 tokens/秒,比常规快 8 倍;
按照惯例,接下来302.AI团队将对GPT-4.1 以及 GLM-Z1-AirX 进行实测,但由于二者类型和定位不同(GPT-4.1 是通用模型,GLM-Z1-AirX 是推理模型),直接对比不太合理,因此我们根据性能找到的与它们相似或者有可比性的模型:
GPT-4.1 对比模型有:GPT-4o 和 DeepSeek V3.1(即 DeepSeek-V3-0324);
GLM-Z1-AirX 对比模型有:DeepSeek R1 和 Ernie-X1;
OpenAI GPT-4.1 模型实测对比
一、通用模型对比
对比模型:GPT-4.1 & GPT-4o & DeepSeek V3.1
1、弱智吧问题
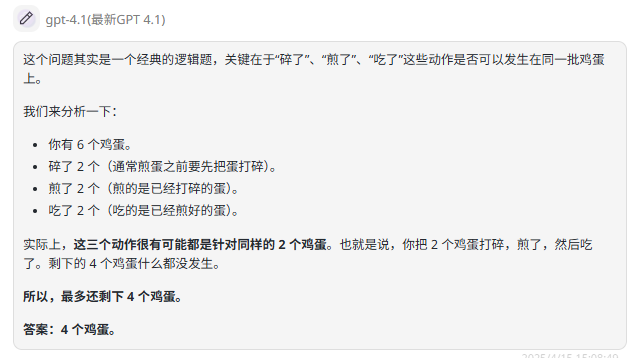
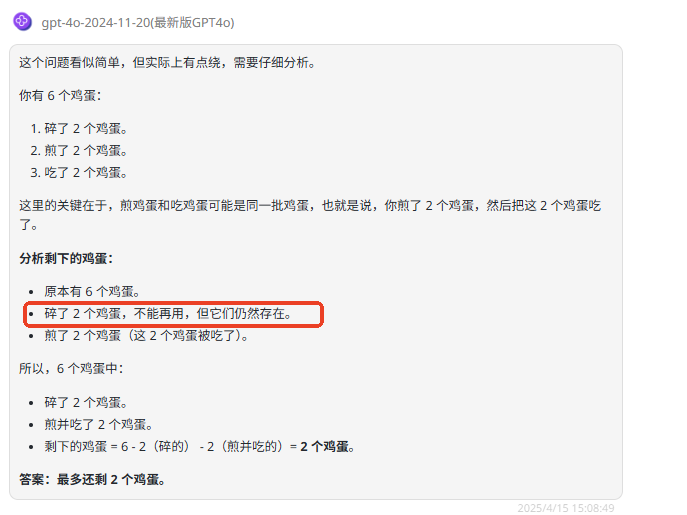
提示词:我有 6 个鸡蛋,碎了 2 个,煎了 2 个,吃了 2 个,最多还剩几个?
题目解析:如果把每个动作视为独立事件,那将一个鸡蛋也不剩。但题目问的是最多还剩几个,这表明可能有重叠的情况,碎的 2 个鸡蛋正好煎了、吃了,因此在最佳情况下,最多还剩 4 个鸡蛋。
GPT-4.1 :分析合理,回答正确。
![]()
GPT-4o :有点聪明但又不够,最终回答错误。
![]()
DeepSeek V3.1:回答完整、详细且清晰。在解析过程中,确定不同的可能性并进行逐一分析,综合比较各个答案,最终找出符合题目“最大剩余”的正确答案。

![]()
2、鸡蛋+煎饼问题
提示词:煮1个鸡蛋需要5分钟,煎一块饼的一面需要3分钟,饼需要翻面两次才能熟。煮锅和煎锅可以同时开火,煎锅一次最多只能放两块饼,那么我想要煮3个鸡蛋和3块饼,最快一共需要几分钟?
题目解析:这个问题主要考察模型是否知道多个鸡蛋可以一起煮、煎饼可以翻面中途替换,以及煮鸡蛋和煎饼两动作可并行,最后只需选取两者中时长较长的为总时长。
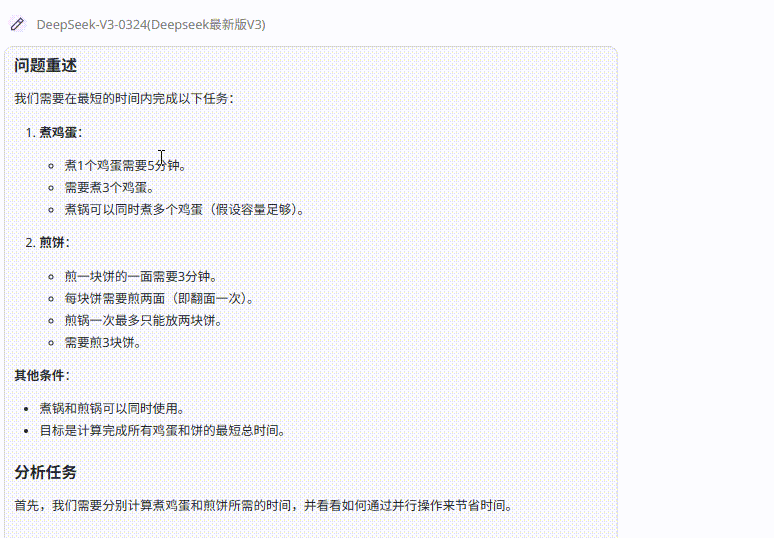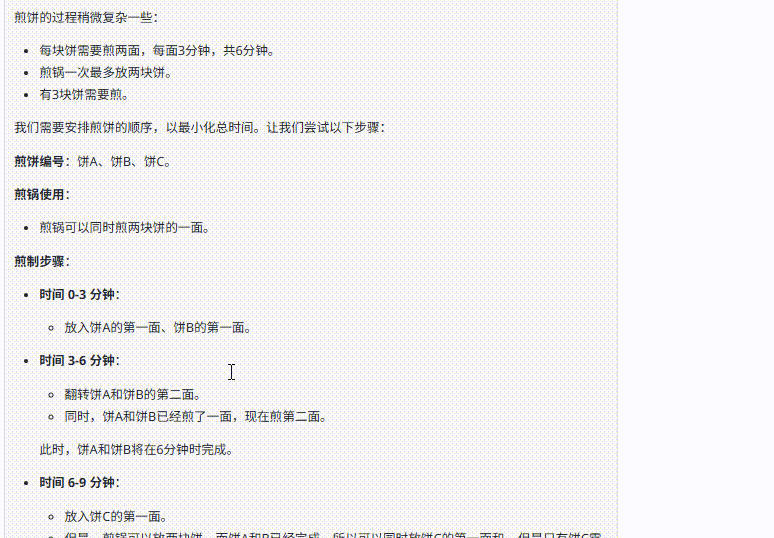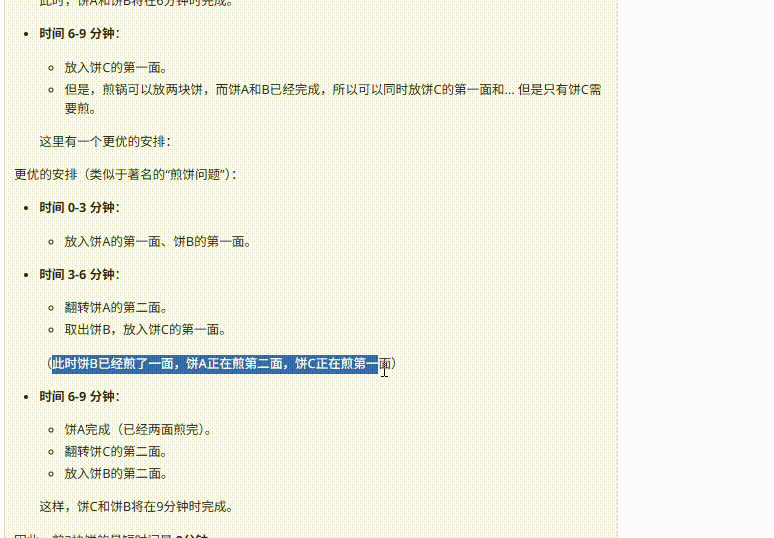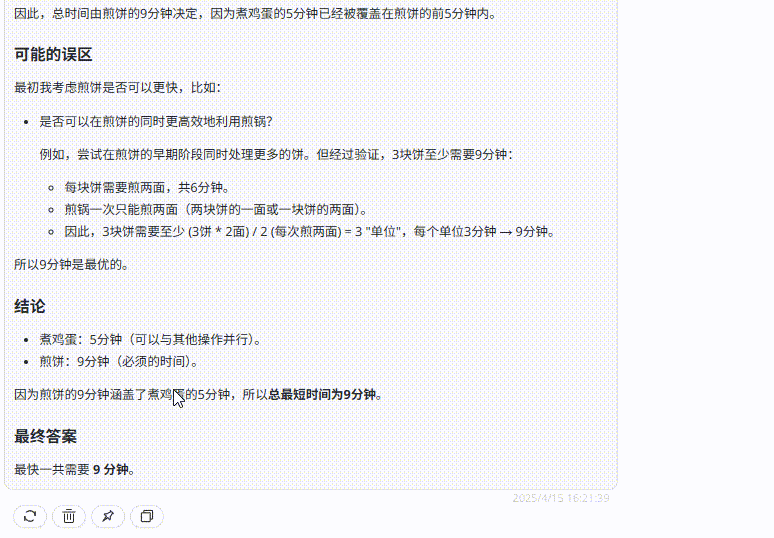
GPT-4.1 :尽管分析中提到“在A或B的一面煎好后立即放入C”这一关键步骤,但后续的优化安排未遵循此步骤,导致最终答案不正确。

![]()
GPT-4o :分析过程和解答思路略显简单,答案不正确。
![]()
DeepSeek V3.1:答案中可以清晰看到,模型在初始安排中识别了不合理之处并迅速进行了调整,最终不仅提供了准确的答案,还分析了应对题目时可能出现的误区。

![]()
3、编程游戏测试:
提示词:创建一个 Flapping Bird 的网页游戏,实现玩家控制和计分系统,在游戏过程中,在屏幕上清晰地显示当前得分。需要包含开始游戏按钮以及游戏说明
题目解析:编程游戏测试的主要目的是评估模型生成的游戏是否具有逻辑合理性,并对比游戏的完整性。
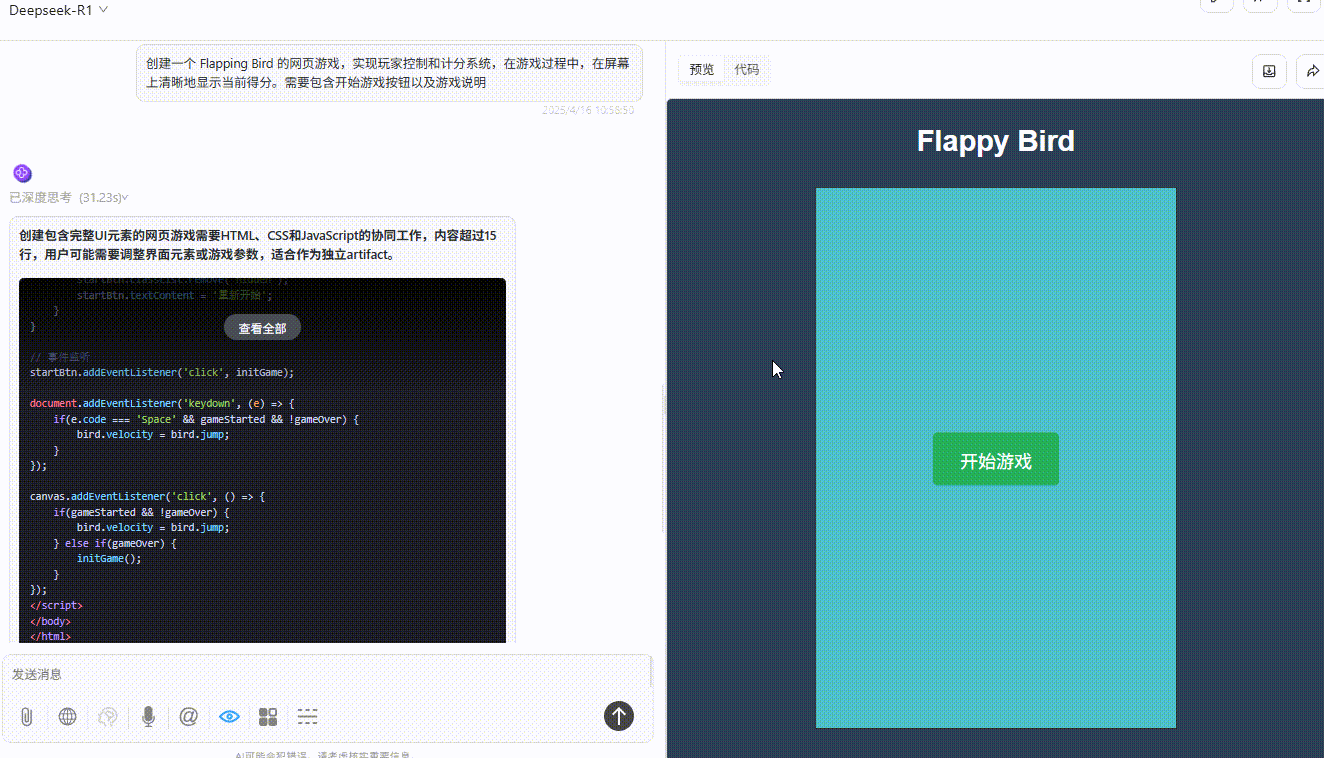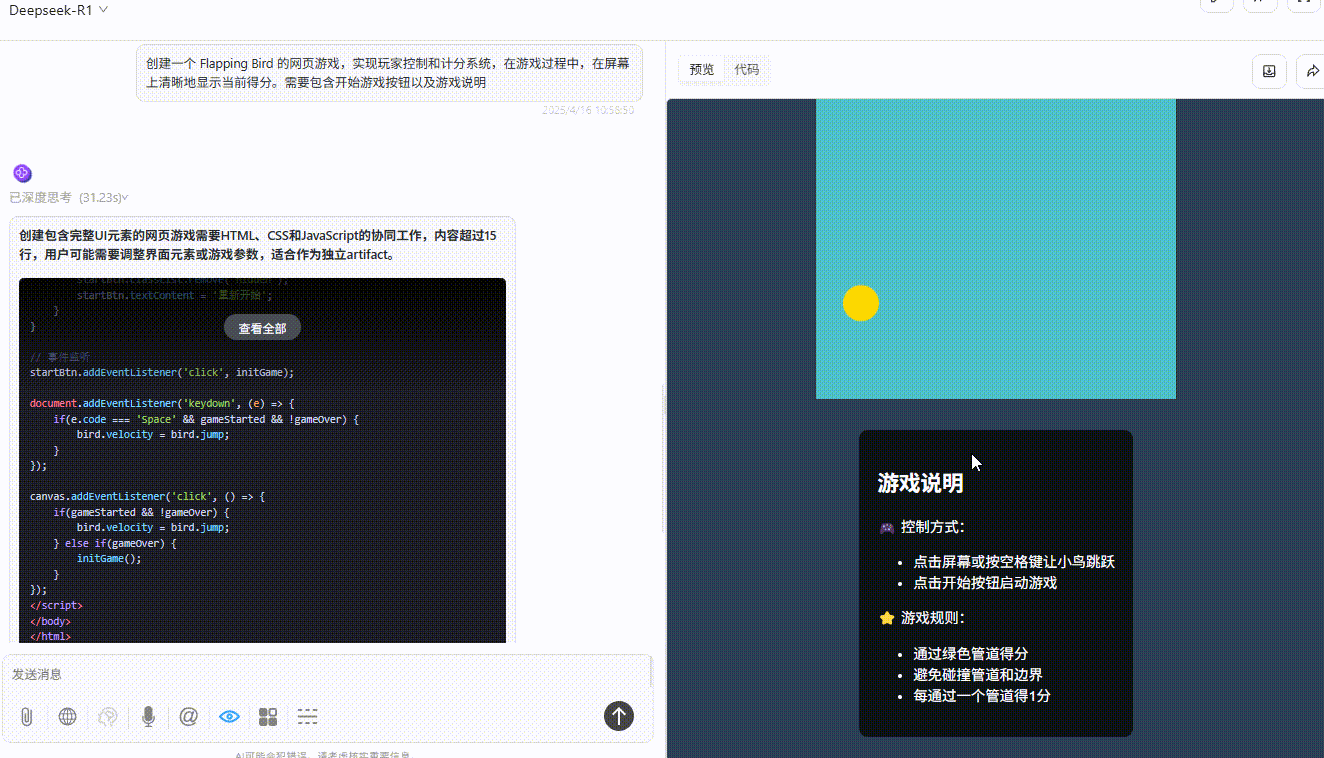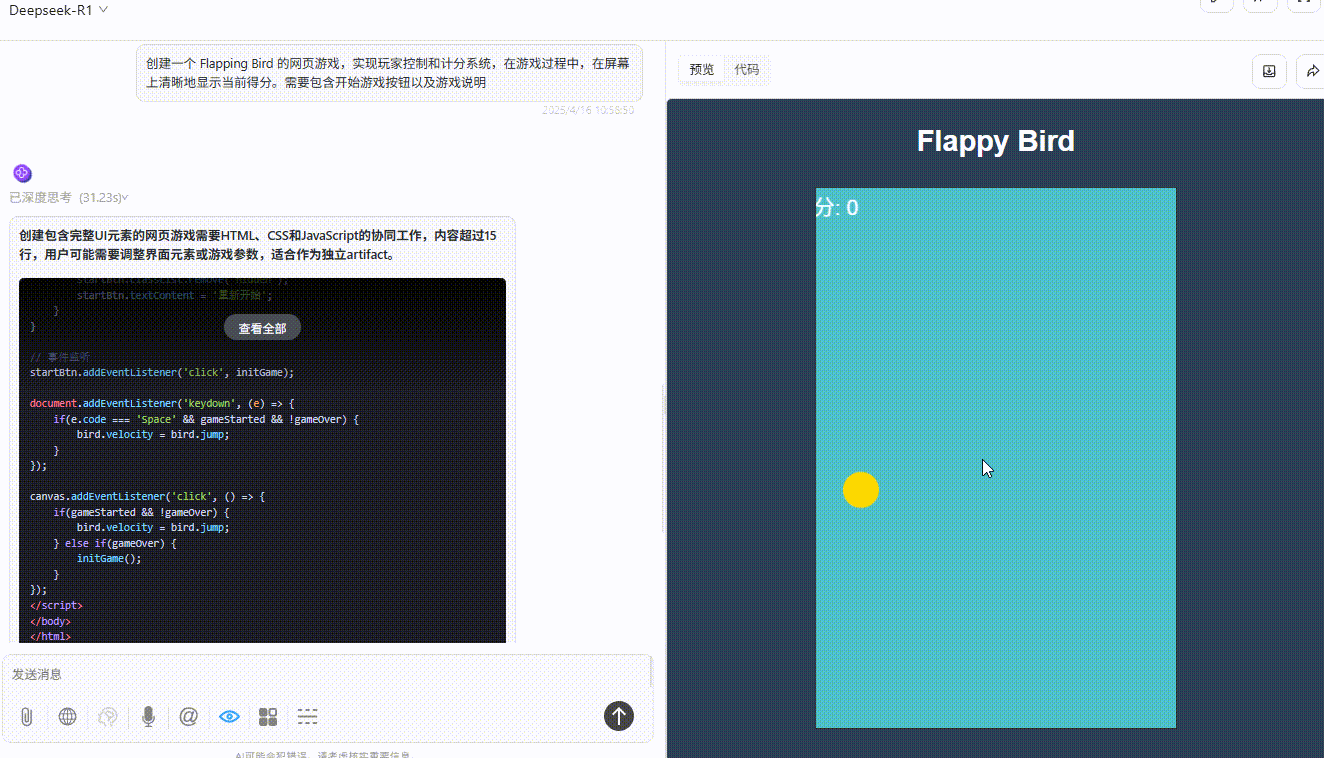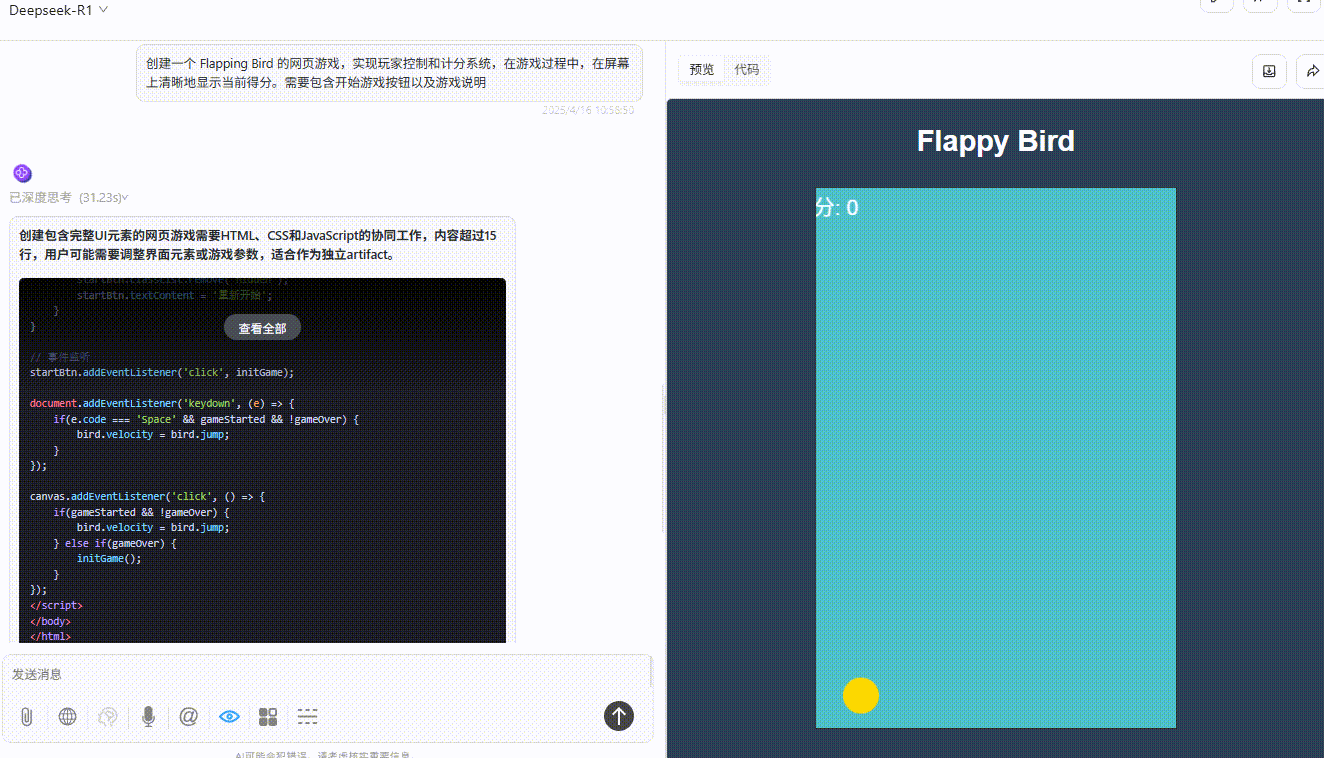
GPT-4.1:游戏设置合理,界面美观,完成度非常高。
![]()
GPT-4o:效果较差,绿色障碍设置不合理,小球无法通过。
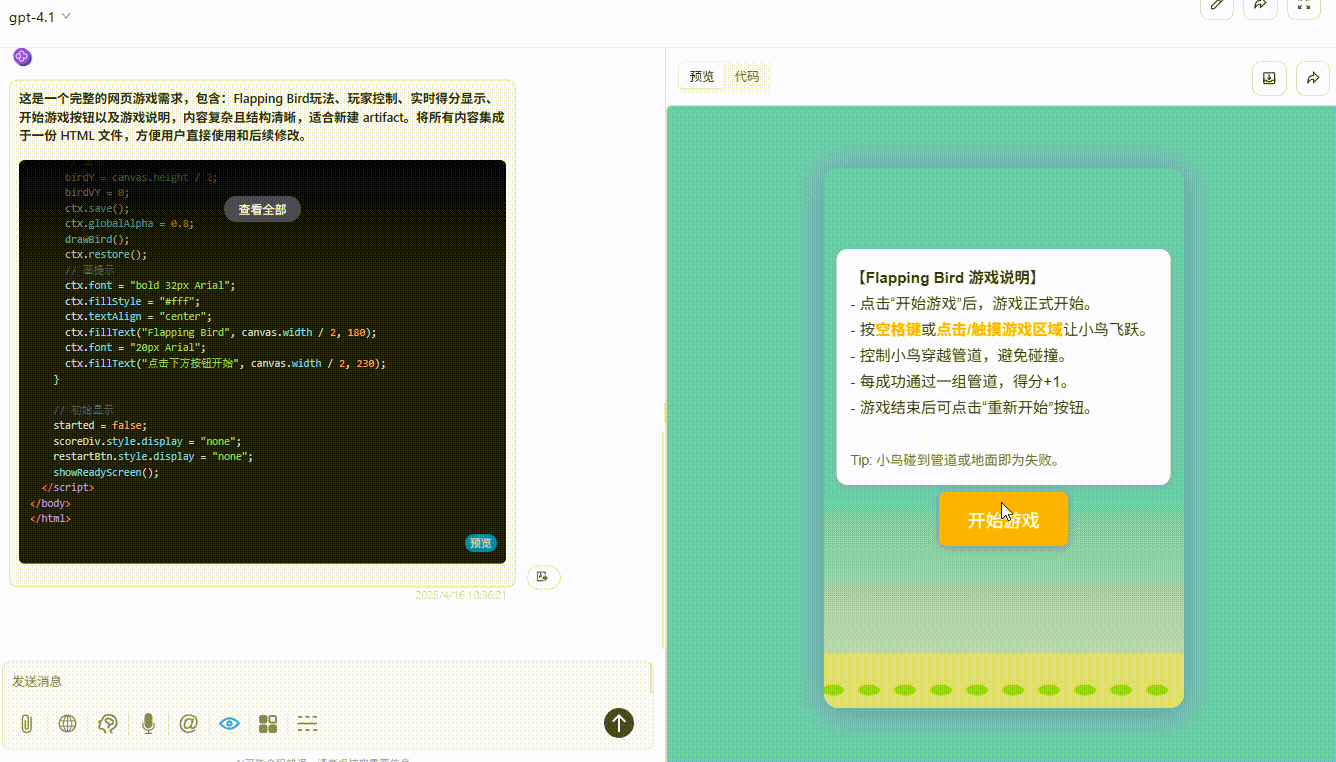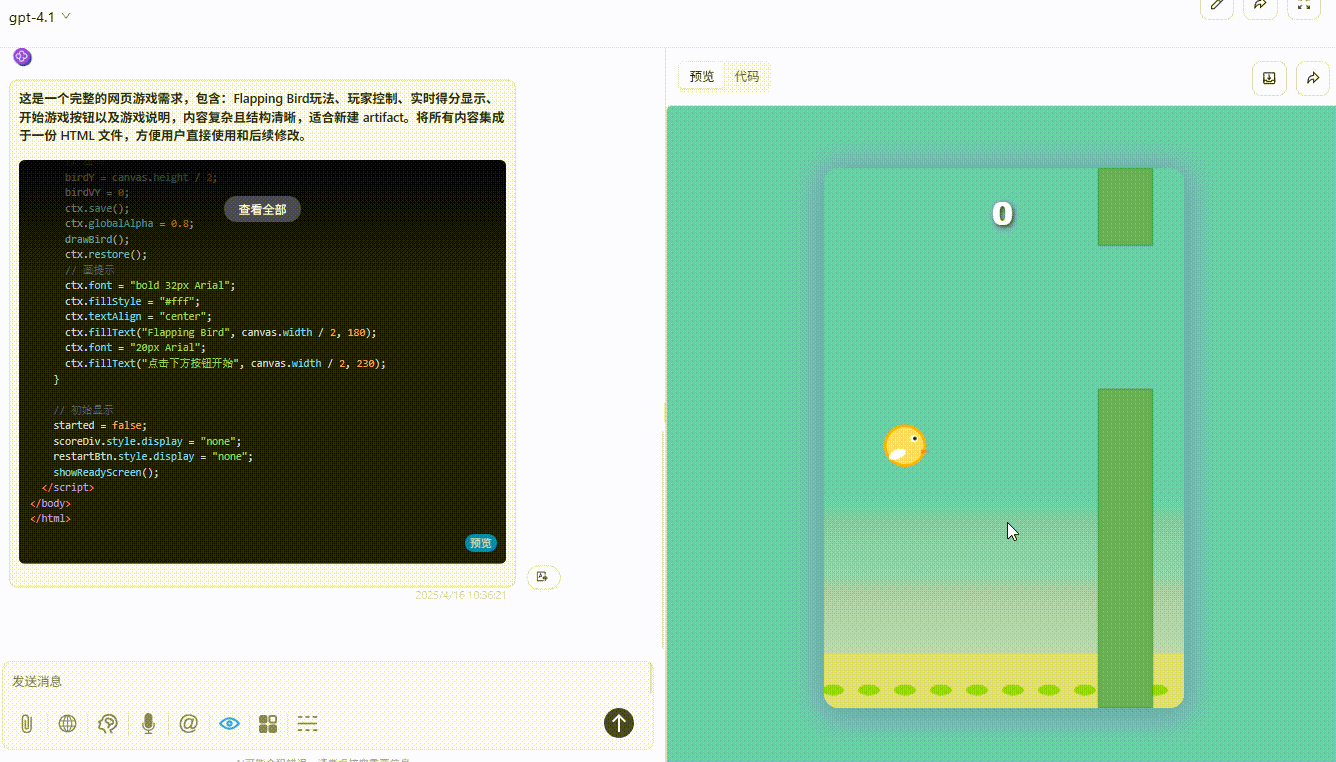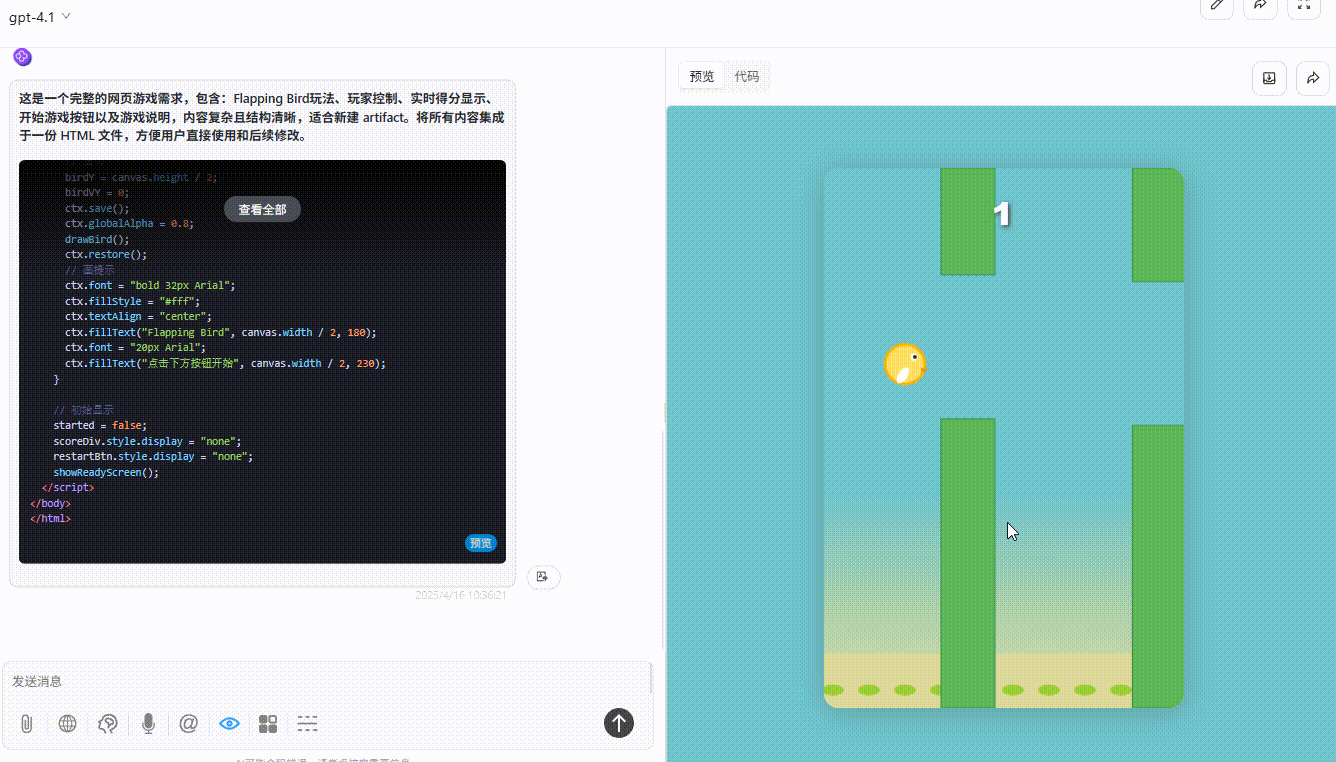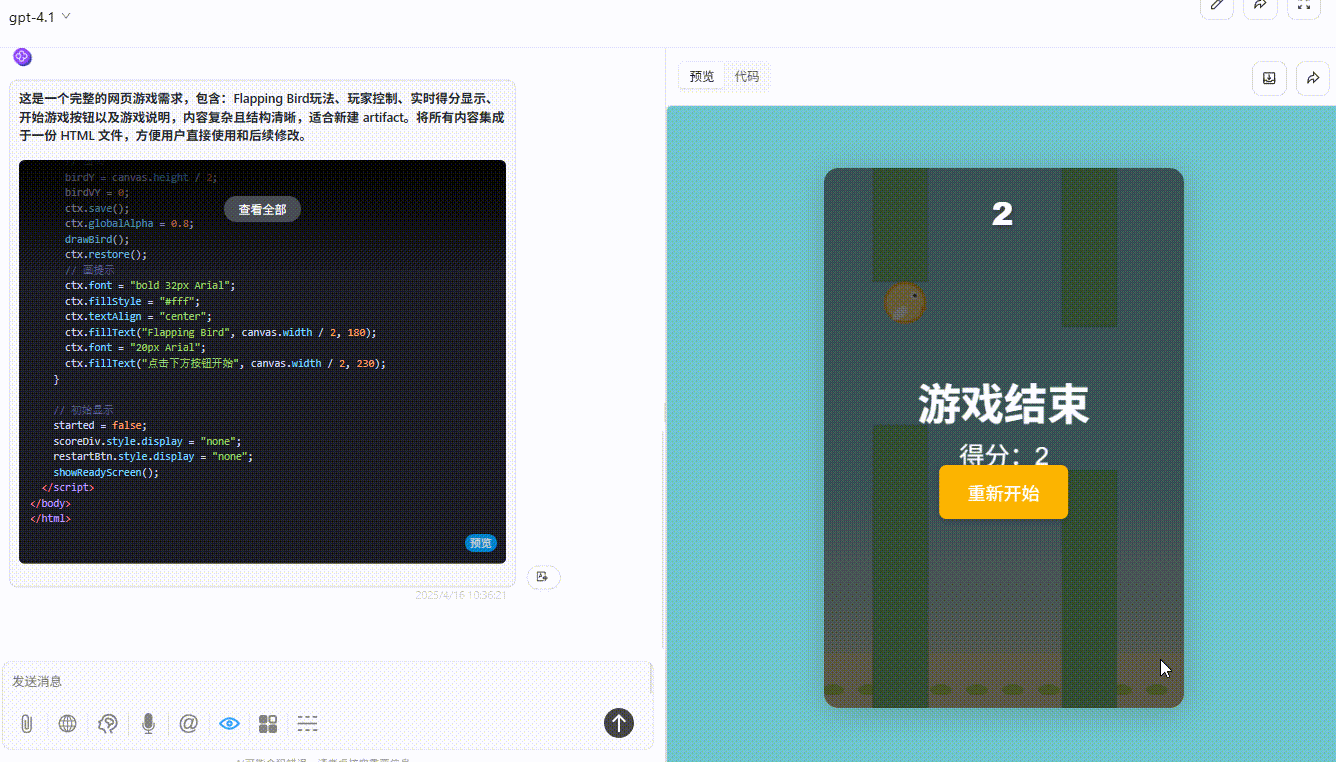
![]()
DeepSeek V3.1:游戏逻辑存在问题,小球未触碰到地面和绿色障碍即触发游戏失败。
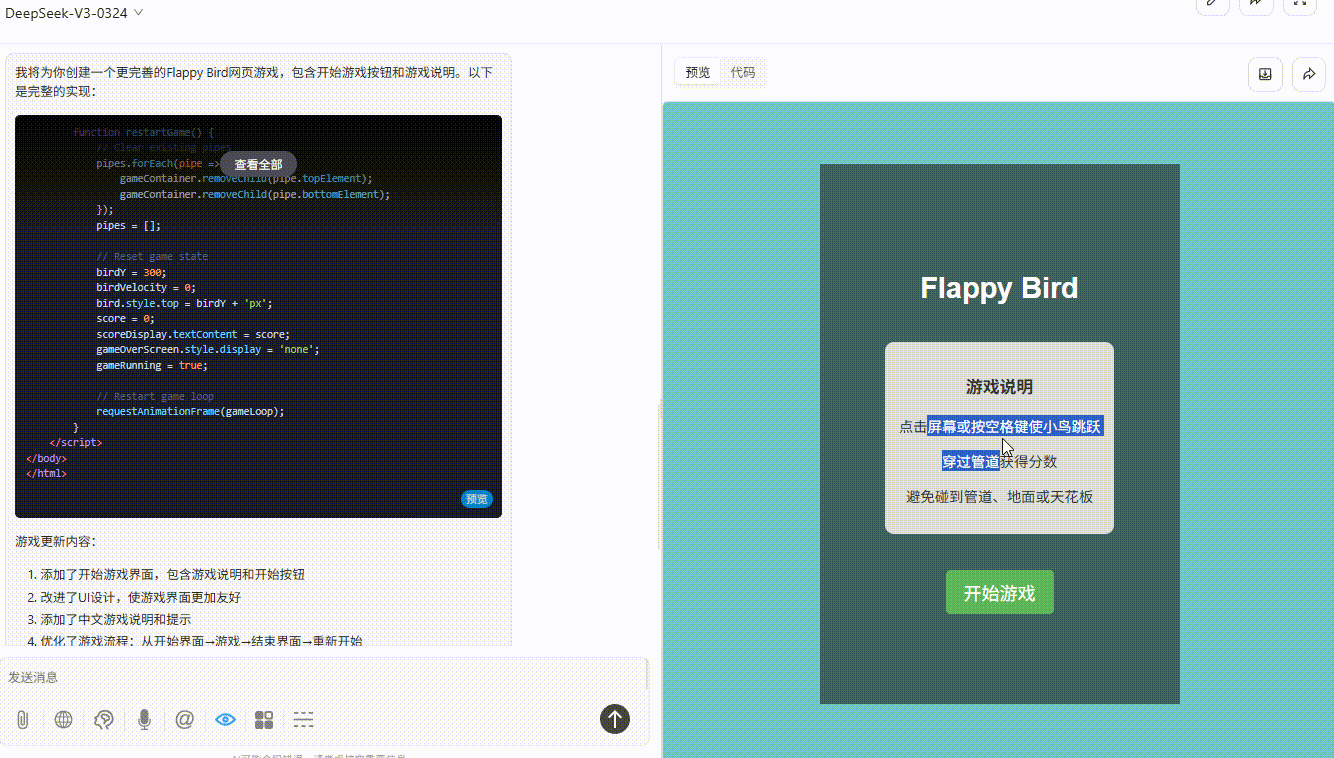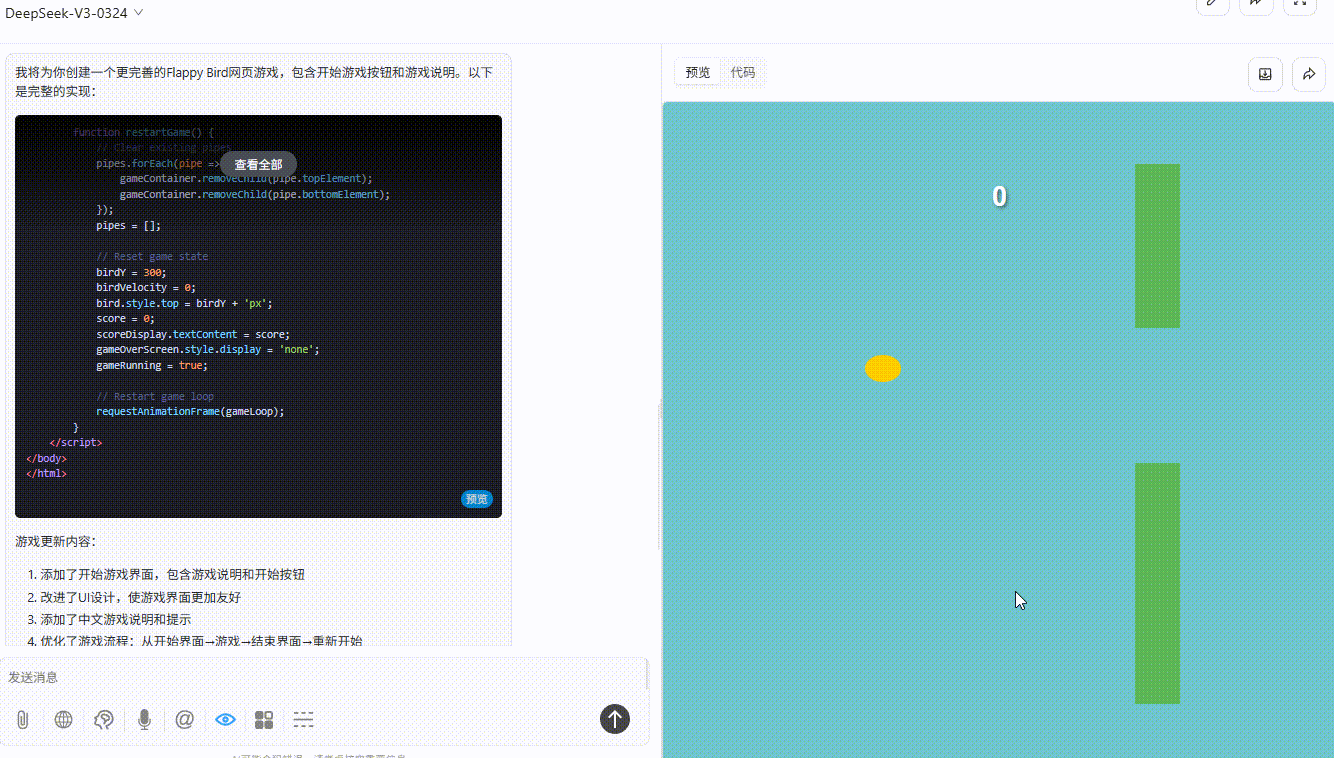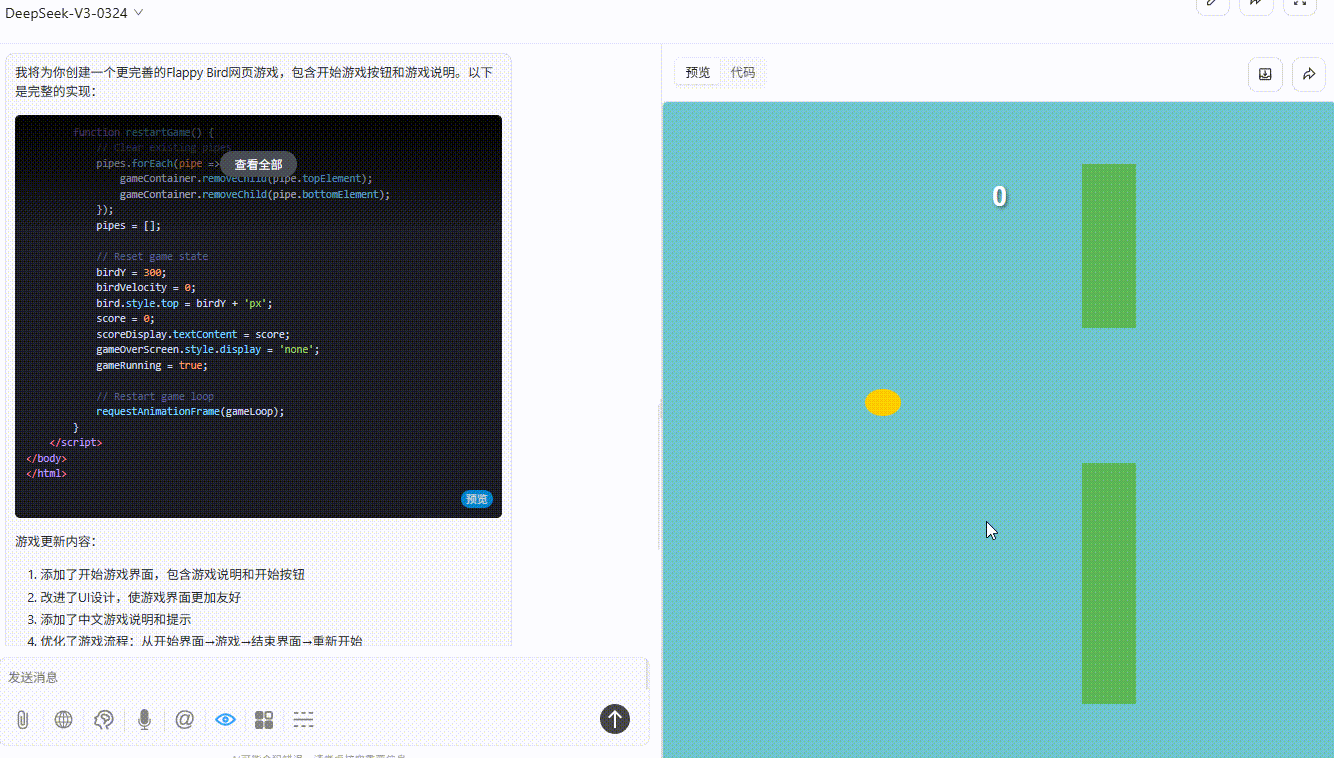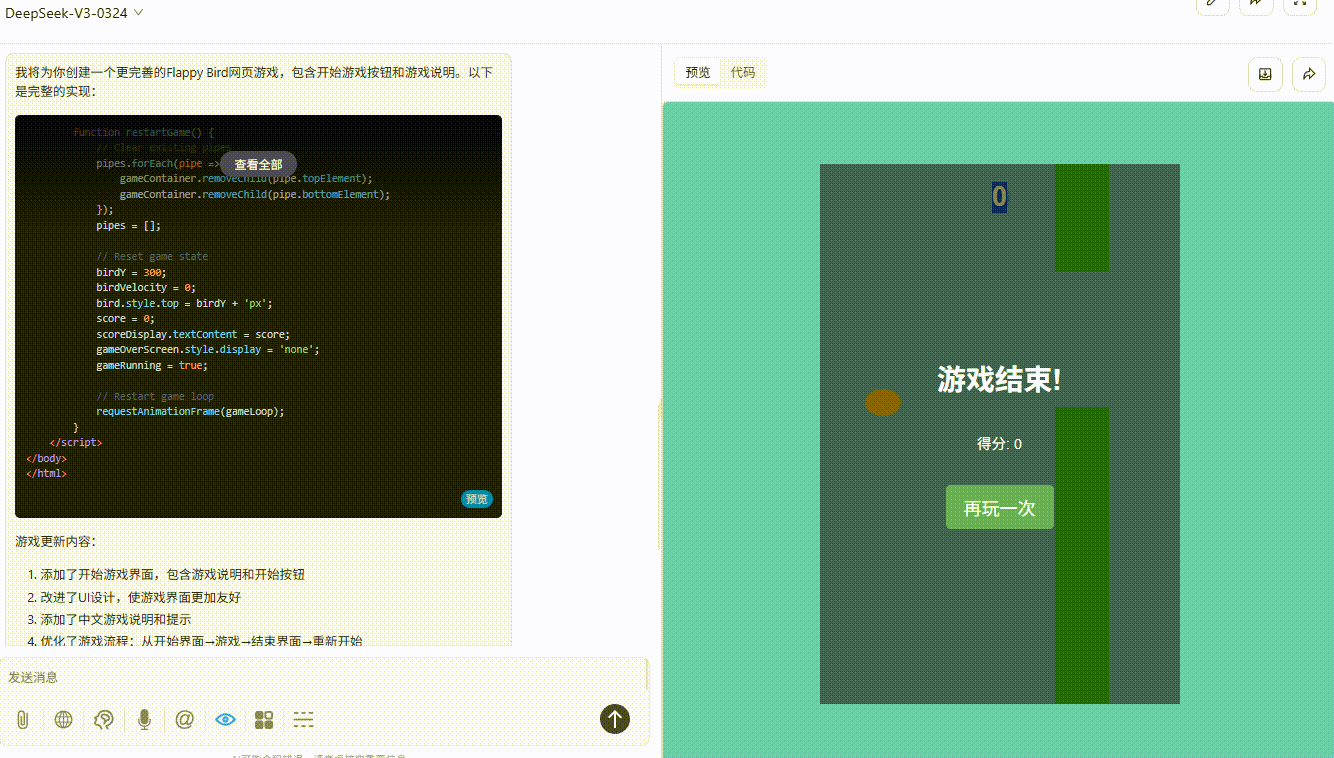
![]()
二、推理模型对比:
对比模型:GLM-Z1-AirX & DeepSeek R1 & Ernie-X1;
1、脑筋急转弯
提示词:一步一步认真思考:我目前有两根香蕉,我昨天吃掉一根,现在还有几根
题目解析:问题中提到“我目前有两根香蕉”,这是当前的状态。昨天吃掉的香蕉不应该影响“我目前有两根香蕉”这个状态。所以答案是2根。
GLM-Z1-AirX:在正确和错误中反复横跳,表明对题意理解不透彻,最后答案是错误的。

![]()
Ernie-X1:通过逐步分析理清时间线,答案正确。

![]()
DeepSeek R1:推理过程十分完善,进一步推断出昨日应有三根香蕉,回答准确无误。
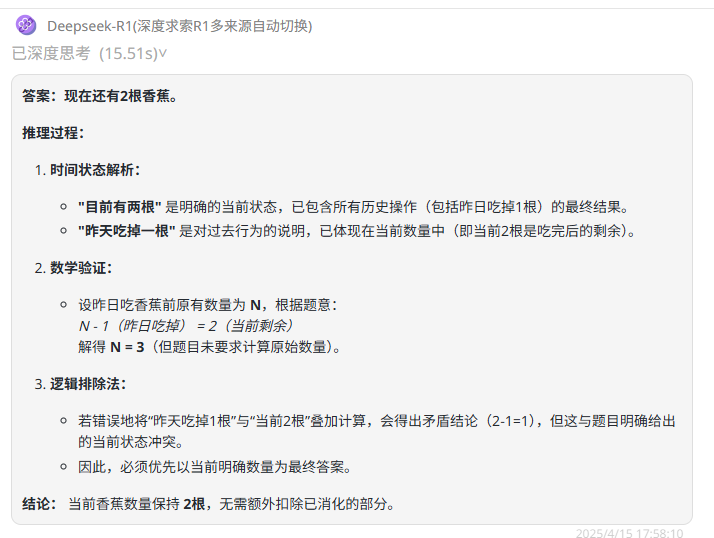
![]()
2、数学推理
提示词:四个数的和是21,这四个数两两相乘得到的六个积分别是15、18、21、30、35和42。请求出这四个数分别是多少。
题目解析:要解决这一问题,需要找出所有可能的数对使得它们的乘积等于给定的六个积之一,最后验证和。正确答案是:3、5、6和7
GLM-Z1-AirX:首先答案是正确的,但是模型思考过程展示不够清晰可读。

![]()
Ernie-X1:思维链条较为清晰,答案正确,但速度稍缓慢。

![]()
DeepSeek R1:思考分析过程无误,答案正确。

![]()
3、编程游戏测试:
提示词:创建一个 Flapping Bird 的网页游戏,实现玩家控制和计分系统,在游戏过程中,在屏幕上清晰地显示当前得分。需要包含开始游戏按钮以及游戏说明
GLM-Z1-AirX :模型生成的代码有错误,无法预览效果。
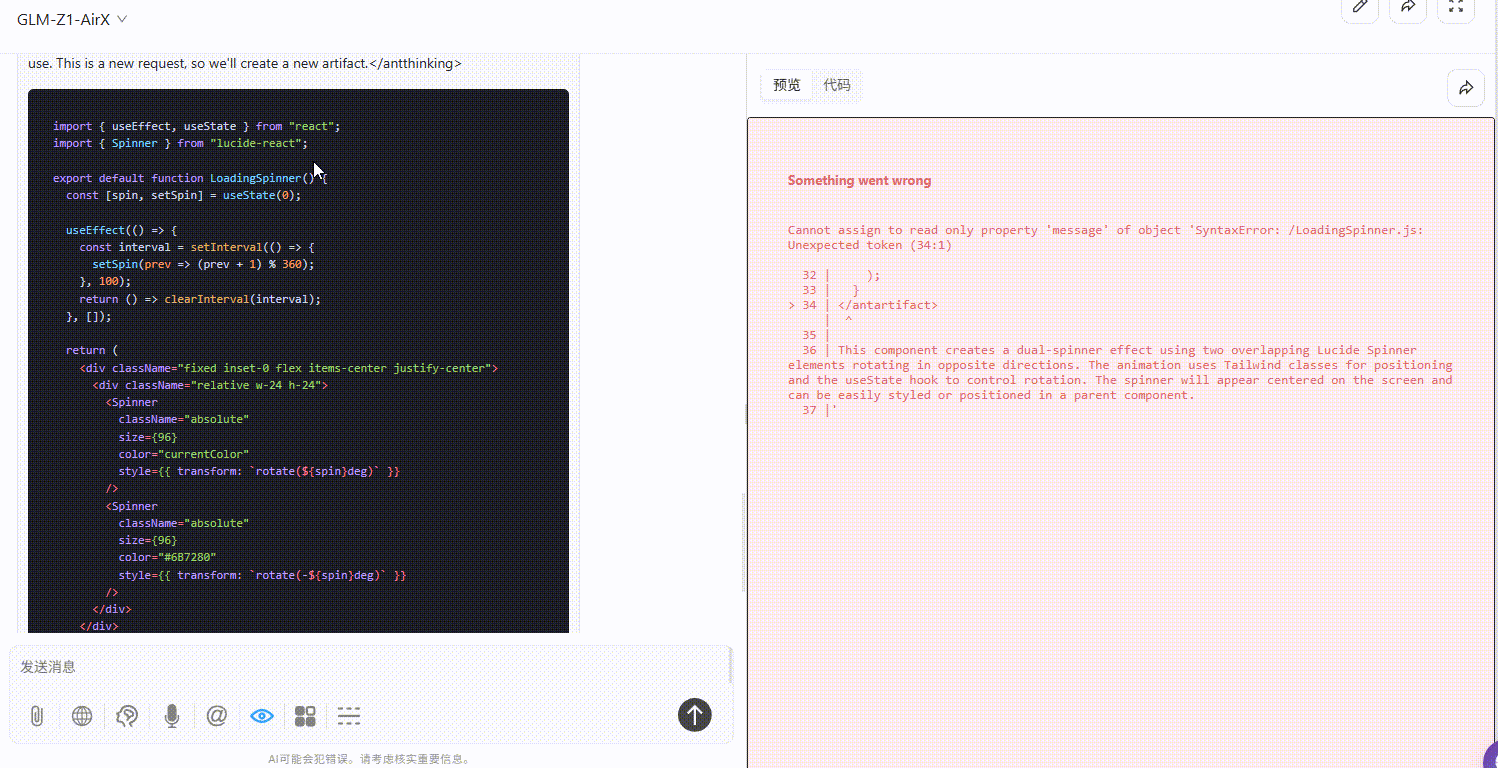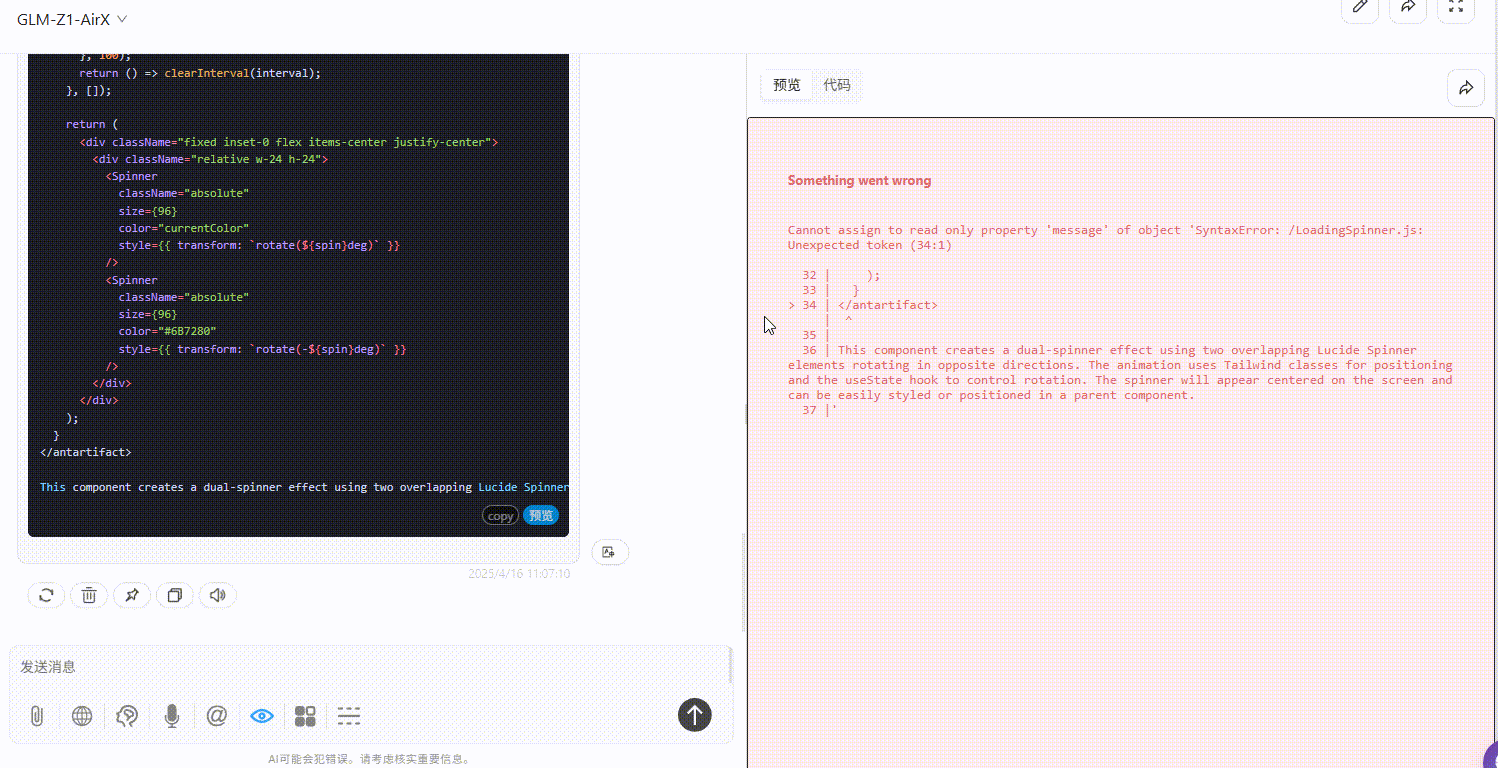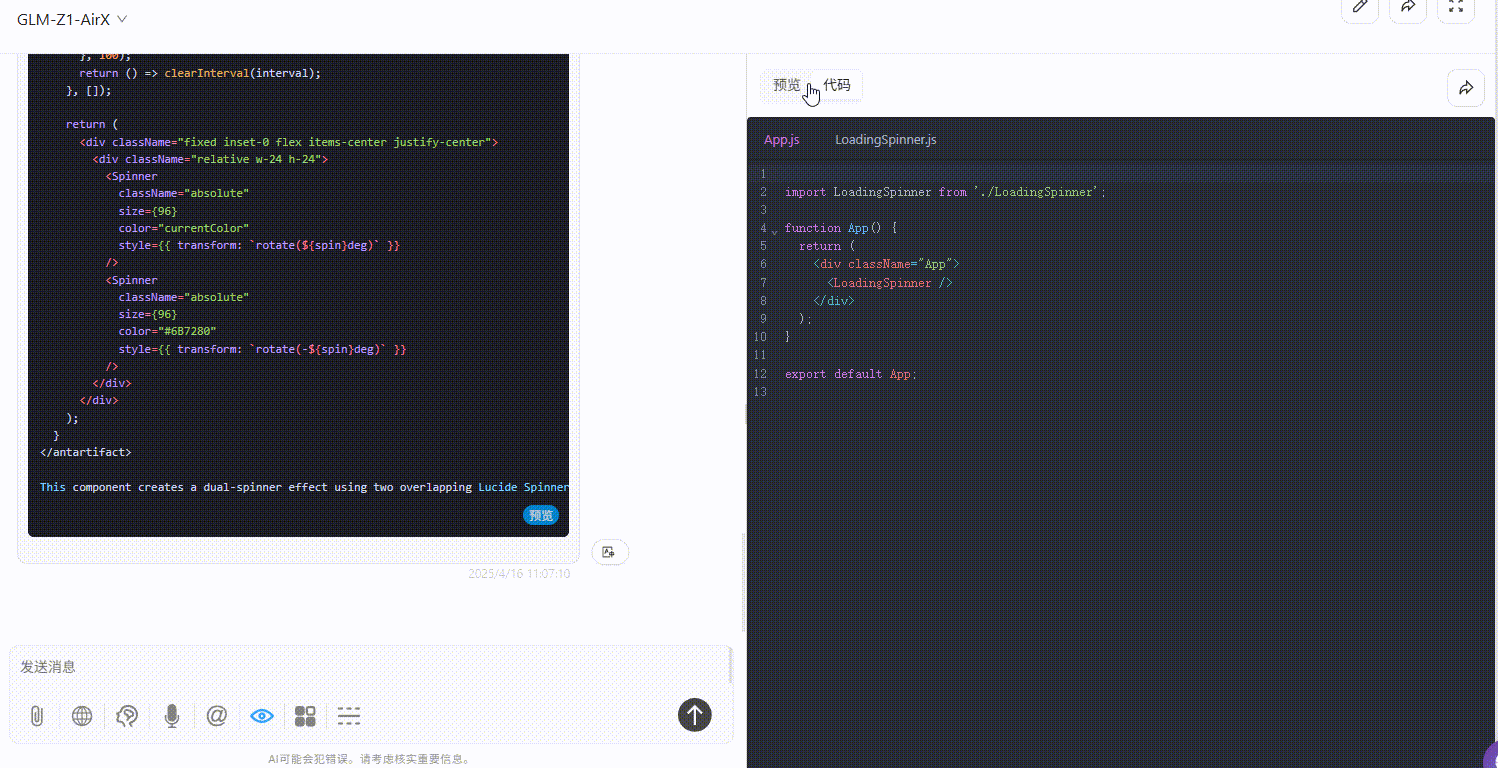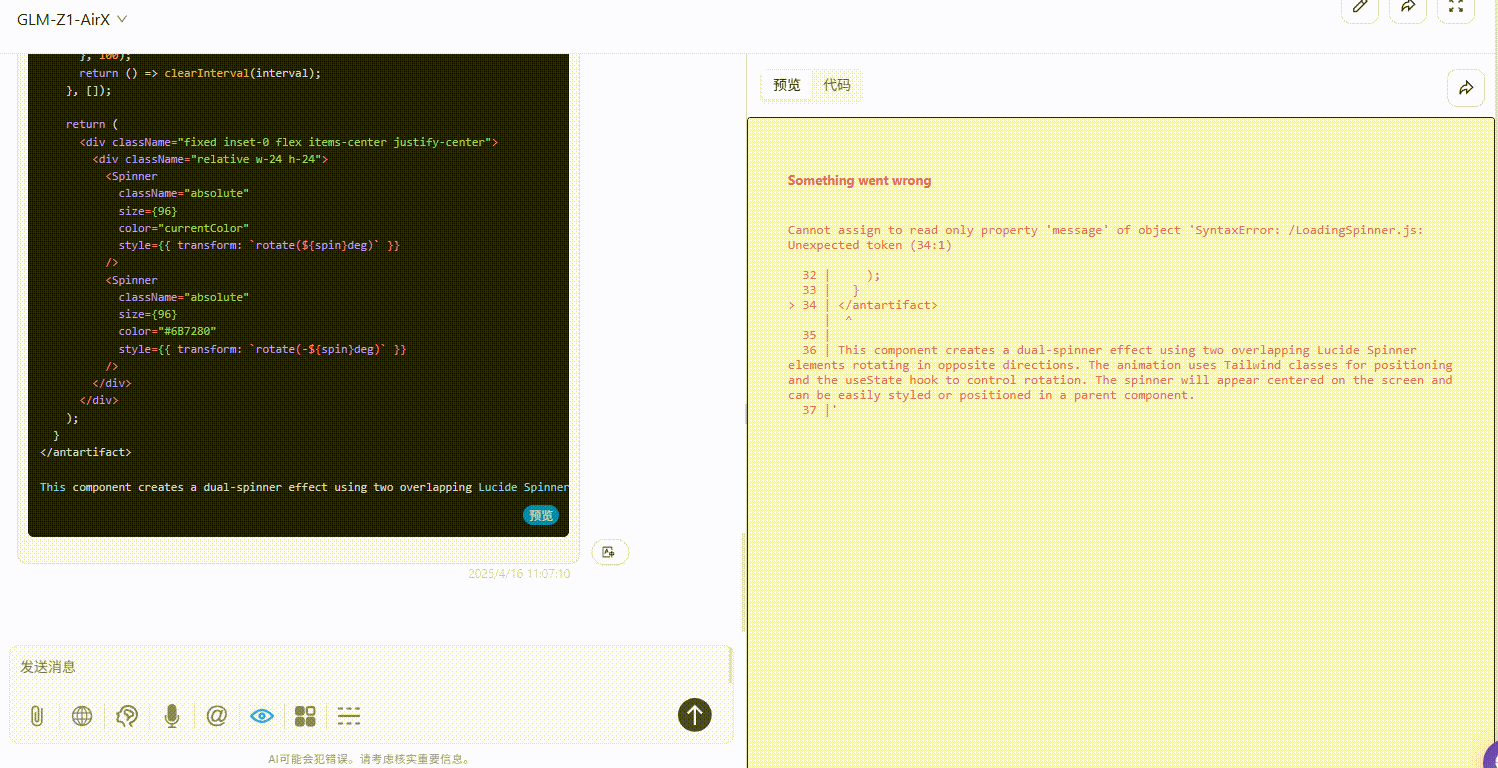
![]()
Ernie-X1;游戏存在逻辑缺陷,小球即使碰到绿色障碍物也未触发失败。
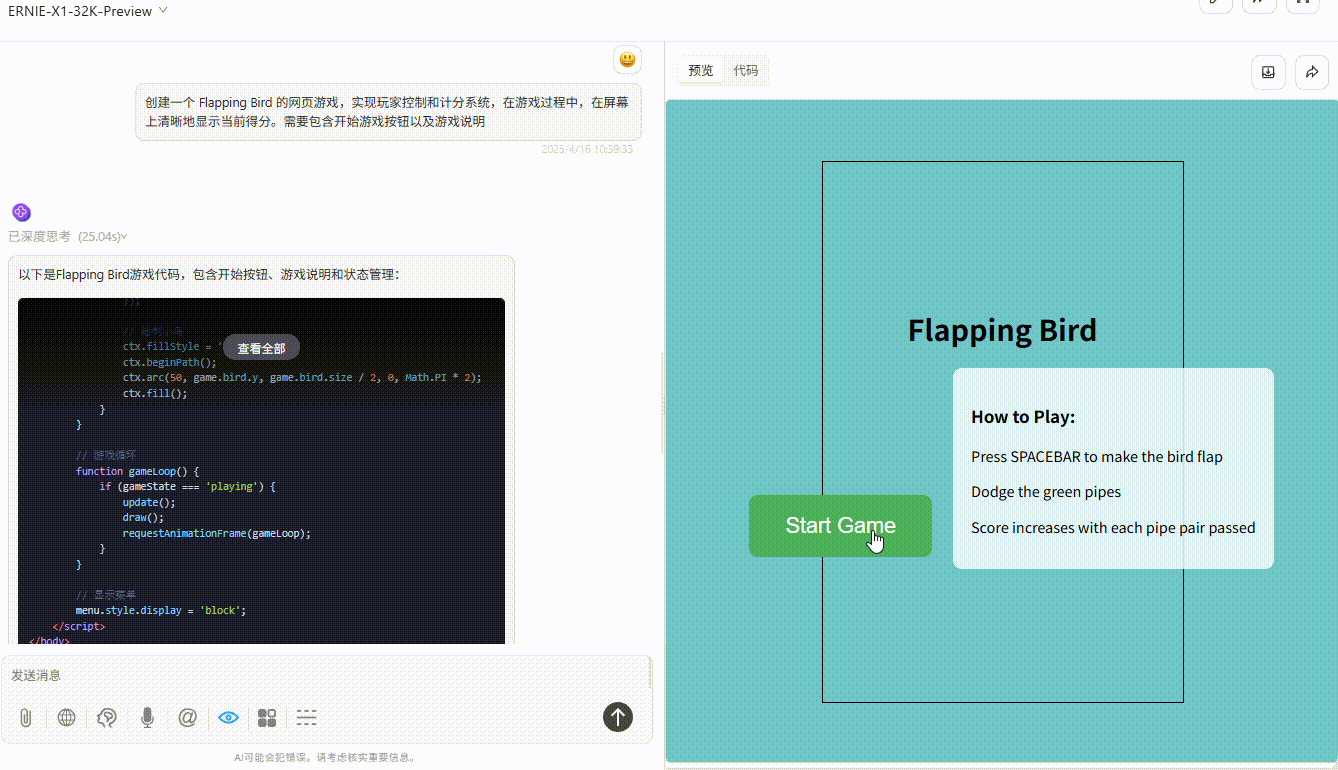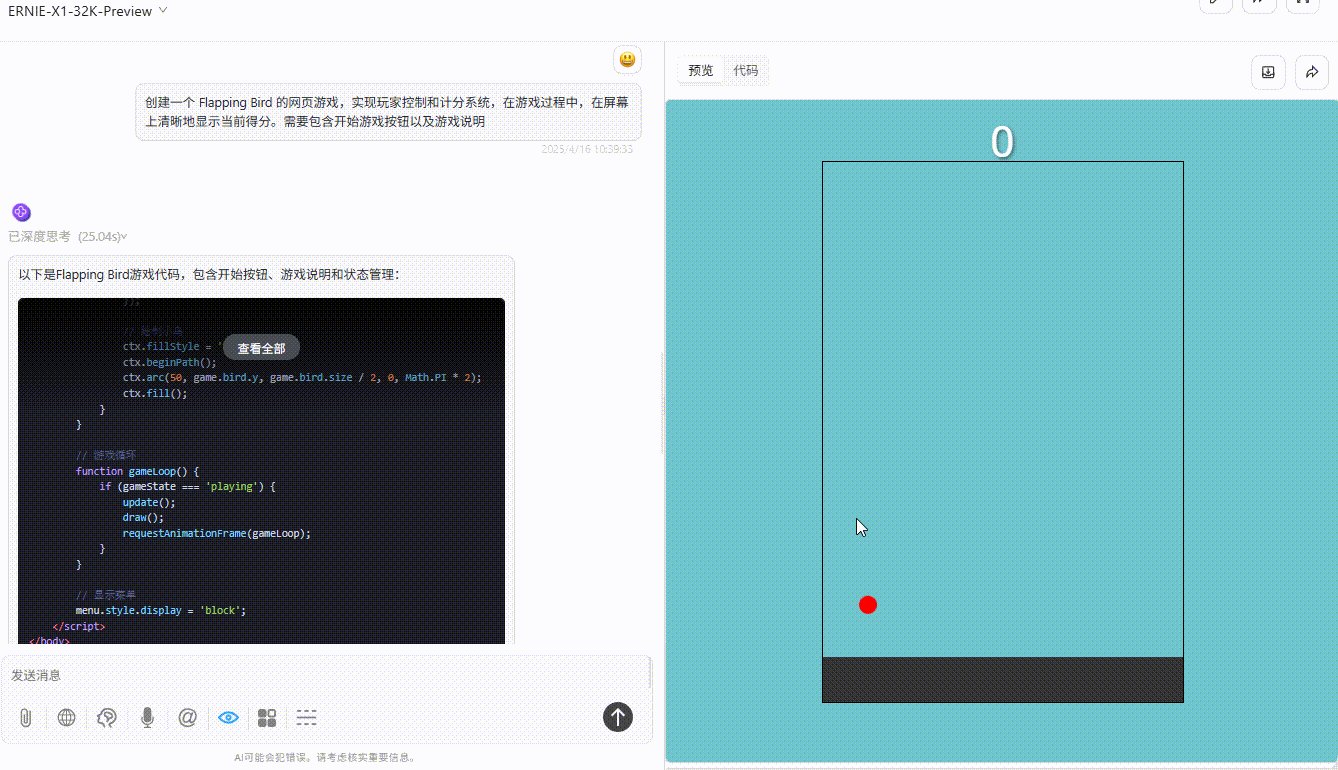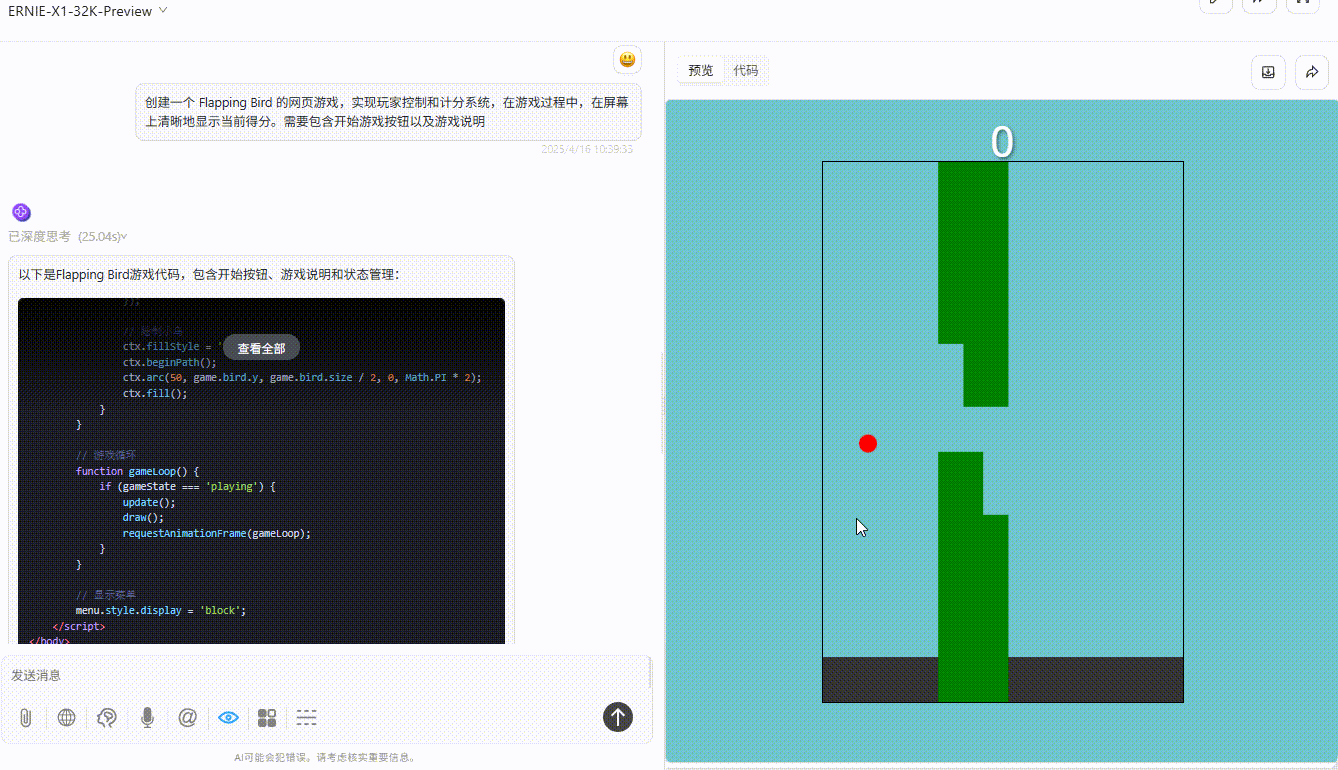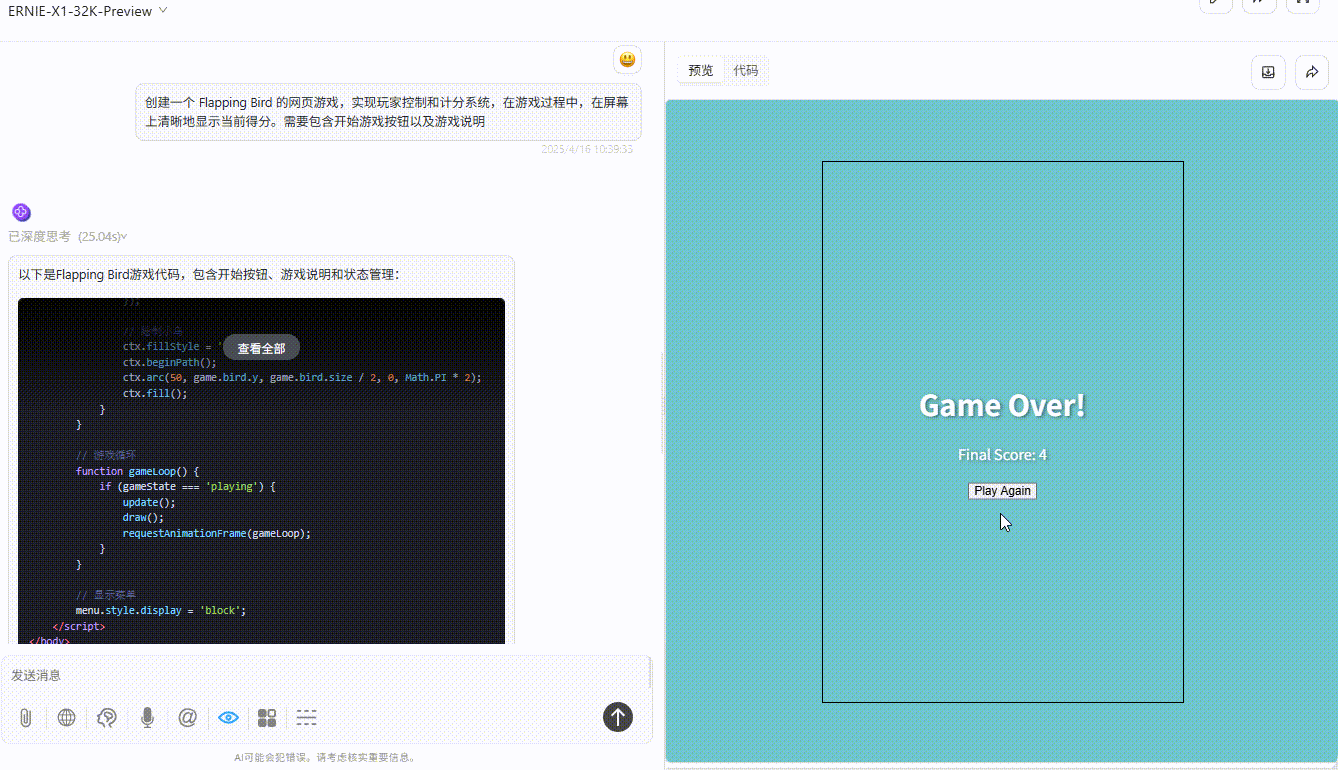
![]()
DeepSeek R1 :障碍设计不合理,基本没有可通过的位置。
![]()
实测总结:
实测结果统计:
| GPT-4.1 & GPT-4o & DeepSeek V3.1 | |||
| 弱智吧问题 | 鸡蛋+煎饼问题 | 编程测试 | |
| GPT-4.1 | 正确 | 错误 | 效果美观且完整 |
| GPT-4o | 错误 | 错误 | 障碍设置不合理 |
| DeepSeek V3.1 | 正确 | 正确 | 莫名触发游戏失败 |
| GLM-Z1-AirX & DeepSeek R1 & Ernie-X1 | |||
| 脑筋急转弯 | 数学推理 | 编程测试 | |
| GLM-Z1-AirX | 错误 | 正确,可读性不佳 | 代码有错误,无法预览效果。 |
| Ernie-X1 | 正确 | 正确,但速度较慢 | 碰障碍物未触发游戏游戏失败 |
| DeepSeek R1 | 正确 | 正确 | 障碍设计不合理 |
根据以上实测结果,可以初步得出以下结论:
一、通用模型对比结论
(1)GPT-4.1 相较 GPT-4o 的能力提升:实测弱智吧问题和编程游戏中,GPT-4.1 表现优于 GPT-4o,能力有明显有提升。
(2) DeepSeek V3.1 在分析问题准确性与理解上优于 GPT-4.1 :DeepSeek V3.1 在面对鸡蛋+煎饼问题任务问题时,不仅给出了正确答案,还对面对题目可能的误区进行了分析,反之 GPT-4.1 却未能正确回答。
(3)GPT-4.1 的编程能力出色:通过编程游戏同一提示词对比的发现,GPT-4.1 生成的游戏界面美观,游戏逻辑合理且完整性最高。
二、推理模型对比结论
(1)GLM-Z1-AirX 的解题短板存在短板:GLM-Z1-AirX 在解题时不够灵活,展示思考链路时文字堆积,可读性较差。
(2)Ernie-X1 速度较慢:虽然 Ernie-X1 模型在实测任务中的表现尚可,但是对比其他两个模型其速度较慢。
(3)编程游戏测试中的普遍不足:在编程测试中使用了与通用模型相似的提示词,但是三个推理模型的表现均不佳。
如何在302.AI中使用:
302.AI的聊天机器人和API超市提供了按需付费无订阅的服务方式,企业和个人用户可按需灵活选用。
1、使用模型对话
使用路径:依次点击使用机器人→聊天机器人→ 选择模型 →创建聊天机器人;
GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano :
GLM-Z1-AirX:
2、使用模型API
企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发。
相关文档:使用API→API超市→语言大模型→OpenAI/国产模型→查看文档;
API名称:
GPT-4.1:gpt-4.1/gpt-4.1-2025-04-14
GPT-4.1-mini:gpt-4.1-mini/gpt-4.1-mini-2025-04-14
GPT-4.1-nano:gpt-4.1-nano/gpt-4.1-nano-2025-04-14
GLM-Z1-Air :glm-z1-air
GLM-Z1-AirX:glm-z1-airx

👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(27)
I have been absent for a while, but now I remember why I used to love this blog. Thank you, I’ll try and check back more frequently. How frequently you update your site?
When I originally commented I clicked the -Notify me when new comments are added- checkbox and now each time a comment is added I get four emails with the same comment. Is there any way you can remove me from that service? Thanks!
I think other website proprietors should take this site as an model, very clean and fantastic user friendly style and design, as well as the content. You are an expert in this topic!
I’m really enjoying the design and layout of your website. It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a developer to create your theme? Excellent work!
I respect your piece of work, thankyou for all the informative articles.
You are a very bright person!
Hmm is anyone else encountering problems with the pictures on this blog loading? I’m trying to figure out if its a problem on my end or if it’s the blog. Any feed-back would be greatly appreciated.
Good day! This post could not be written any better! Reading through this post reminds me of my old room mate! He always kept chatting about this. I will forward this write-up to him. Fairly certain he will have a good read. Many thanks for sharing!
What i do not realize is in reality how you are now not actually much more well-preferred than you might be right now. You are so intelligent. You know thus considerably in terms of this topic, made me individually consider it from a lot of various angles. Its like women and men aren’t interested unless it’s something to accomplish with Girl gaga! Your personal stuffs great. All the time take care of it up!
It?¦s really a cool and helpful piece of info. I am glad that you simply shared this useful information with us. Please stay us informed like this. Thanks for sharing.
Hello! I’m at work surfing around your blog from my new iphone 3gs! Just wanted to say I love reading through your blog and look forward to all your posts! Keep up the great work!
I think you have observed some very interesting points, thankyou for the post.
I am forever thought about this, thankyou for posting.
I am constantly looking online for articles that can facilitate me. Thank you!
You can definitely see your expertise in the work you write. The arena hopes for more passionate writers like you who aren’t afraid to say how they believe. Always follow your heart.
I’m still learning from you, as I’m improving myself. I definitely love reading all that is written on your website.Keep the stories coming. I liked it!
What’s Going down i am new to this, I stumbled upon this I’ve found It absolutely useful and it has aided me out loads. I hope to give a contribution & aid other customers like its helped me. Great job.
Great post. I am facing a couple of these problems.
Hi there! I know this is kinda off topic but I was wondering if you knew where I could locate a captcha plugin for my comment form? I’m using the same blog platform as yours and I’m having difficulty finding one? Thanks a lot!
Respect to post author, some superb information .
You made some good points there. I looked on the internet for the topic and found most individuals will approve with your blog.
Sweet site, super layout, very clean and apply pleasant.
Yay google is my world beater helped me to find this outstanding internet site! .
This is really interesting, You’re a very skilled blogger. I’ve joined your rss feed and look forward to seeking more of your magnificent post. Also, I’ve shared your site in my social networks!
Great ?V I should definitely pronounce, impressed with your site. I had no trouble navigating through all the tabs and related info ended up being truly easy to do to access. I recently found what I hoped for before you know it in the least. Reasonably unusual. Is likely to appreciate it for those who add forums or something, site theme . a tones way for your client to communicate. Nice task..
After study a number of of the weblog posts in your website now, and I truly like your approach of blogging. I bookmarked it to my bookmark website checklist and can be checking back soon. Pls check out my web site as nicely and let me know what you think.
Superb post but I was wanting to know if you could write a litte more on this subject? I’d be very grateful if you could elaborate a little bit further. Cheers!